Embed Size (px)
Citation preview

UNGIS Modul “OpenGIS® und verteilte Geoinformationsverarbeitung” Autor: Dr. Martin Huber Lektion 14: IT-Architekturen
Lektion 14: IT-Architekturen
1. Ziele
Interoperabilität ist kein neues Thema, es verlagert sich nur. Früher beschränkten sich die Fragen der Interoperabilität auf das Zusammenspiel von Applikationen auf einer Workstation und zwischen einer Client-Applikation und dem Daten-bankserver. Heute geht es um das Zusammenspiel von Web-Diensten und Applikationsprogrammen, die permanent über Breitbandverbindungen mit dem Internet verbunden sind. Als Einstieg in die Thematik der technischen Umsetzung von offenen GIS-Standards lohnt sich daher zuerst ein Blick auf die Inter-operabilitätslösungen, die im Datenbankbereich schon seit bald 20 Jahren funktionieren.
Am Ende dieser Lektion haben Sie eine Geodatenbank für eine Baukoordinationsanwendung definiert und dabei herausgefunden, was das Datenbankmanagementsystem bereitstellt, damit es mit Clients zusammenarbeiten kann. Sie können darlegen, wieso nicht jedes x-beliebige Büro, das Web-Seiten gestaltet, auch interaktive Web-GIS-Anwendungen liefern kann. Sie können begründen, wie das Internet dynamisch wird.
Der Aufbau einer IT-Lösungsarchitektur ist für GIS-Experten die wohl schwierigste Aufgabe, um die GIS-IT-Integration voranztreiben, denn IT-Architektur hat überhaupt nichts mit dem zu tun, was man in den klassischen GIS-affinen Disziplinen wie Geografie, Geologie, Statistik oder Biologie gelehrt wird. Ziel ist, die für eine IT-Lösung mit GIS nötigen Komponenten und Schnittstellen zu definieren. Bevor man selber nach Lösungen für eine verteilte GIS-Architektur macht, lohnt sich ein Blick auf die Architektur eines Datenbankmanage-mentsystems (DBMS), denn scheinbar neue Lösungen sind oftmals nur Adaptationen alter Lösungen. DBMS funktionieren schon seit vielen Jahren in verteilten Mehrbenutzerumgebungen.
2. Datenverwaltung und Transaktionen
Es gibt mehrere Sichten auf eine Datenbank. In der Datenmodellierung wurde mit dem ER-Diagramm die konzeptuelle Sicht erstellt, mit dem relationalen Datenbankschema die logische Sicht. Die Anwendersicht(-en) steht oberhalb der konzeptuellen Sicht, während innerhalb des DBMS unterhalb der logischen Sicht die interne oder physische Sicht der konkreten Abspeicherung der Daten auf Datenträgern steht.
Ein relationales Datenbankschema wird mit der Datendefinitionssprache des Datenbankmanagementsystems (DBMS) in der Datenbank angelegt. Bei einem DBMS mit einer SQL-Schnittstelle geschieht dies über den „CREATE TABLE“ Befehl. Bei objekt-relationalen DBMS, die auch geografische Daten verwalten, werden für die geometrischen Eigenschaften Attribute mit den entsprechenden geografischen Datentypen angelegt. Die Verwaltung der Datengefässe, also der
© Copyright 2005 – 2008, alle Rechte vorbehalten 14.11.2008 1 / 21

UNGIS Modul “OpenGIS® und verteilte Geoinformationsverarbeitung” Autor: Dr. Martin Huber Lektion 14: IT-Architekturen
Harddisks auf denen die Tabellendaten abgelegt werden, sieht der Endbenutzer nicht. Nur der Datenbankadministrator hat mit diesen physischen Ressourcen des Systems zu tun.
Nun ist die Datenbank bereit um Daten aufzunehmen. SQL bietet dazu den „INSERT“ Befehl, zum Ändern den „UPDATE“ Befehl und zum Löschen den „DELETE“ Befehl. „INSERT“, „UPDATE“ und „DELETE“ werden im Rahmen von Datenbanktransaktionen eingesetzt.
Eine Transaktion ist ein Auftrag an ein Datenbanksystem, der den Datenbestand verändert und dabei die Datenbank von einem konsistenten Zustand in einen nächsten konsistenten Zustand überführt.
Damit die Konsistenz gewahrt werden kann, muss eine Transaktion vollständig ausgeführt werden. Ist diese nicht möglich, dann müssen bereits ausgeführte Teile der Transaktion rückgängig gemacht werden (Rollback). Das Transaktionskonzept ist vor allem bei Datenbanken wichtig, die von mehreren Personen gleichzeitig bearbeitet werden. Genau diese Anforderung besteht auch bei den über das Internet verteilten Geodateninfrastrukturen. Im einfachsten Fall ist eine einzelne „INSERT“ Anweisung eine Transaktion und das DBMS wird dafür sorgen, dass der neue Datensatz für die anderen Benutzer erst freigegeben wird, wenn die „INSERT“ Operation abgeschlossen ist. Vielfach müssen aber für eine Transaktion mehrere Datenveränderungen auf verschiedenen Tabellen vorgenommen werden, was man sich leicht an einem Bestellsystem mit Lagerverwaltung und Fakturierung vergegenwärtigen kann. Eine einzelne neue Bestellung verlangt unter Umständen, dass ein neuer Kunde eingetragen wird, dass die bestellten Artikel aus dem Lager ausgebucht werden und dass eine neue Rechnung angelegt wird. Die Logik einer Transaktion wird vom Geschäftsfall bestimmt, der abgebildet werden soll und teilweise auch von der Struktur des Datenbankschemas (vor allem bei verteilten Datenbanken oder wenn nicht vollständig normalisiert wurde).
Das Transaktionskonzept stellt sicher, dass zu jeder Zeit alle Datenbankabfragen korrekte Resultate im Sinne des modellierten Gegenstands liefern, bei der Bestellapplikation also z.B. immer den korrekten Lagerbestand und die richtige Gesamtsumme aller offenen Rechnungen. Die Abfragen („SELECT“ Statements im SQL) können jederzeit ausgeführt werden, ohne Rücksicht auf laufende Transaktionen nehmen zu müssen. Die Resultate sind in diesem dynamischen Umfeld aber nur gerade zu dem Zeitpunkt gültig, zu dem sie ausgeführt werden.
3. Aufbau des Datenbankmanagementsystems
Nun interessiert natürlich, wie ein Datenbankmanagementsystem aufgebaut ist und wie es die Interoperabilitätsprobleme löst. Die folgende Abbildung zeigt die wichtigsten Elemente eines DBMS.
© Copyright 2005 – 2008, alle Rechte vorbehalten 14.11.2008 2 / 21

UNGIS Modul “OpenGIS® und verteilte Geoinformationsverarbeitung” Autor: Dr. Martin Huber Lektion 14: IT-Architekturen
Abbildung 1: Aufbau eines relationalen Datenbankmanagementsystems mit SQL-Abfragesprache (stark vereinfacht) (Entwurf M. Huber 2006)
Als erstes baut ein Client eine Sitzung über eine Netzwerkverbindung zum Server auf. Dafür sendet er die so genannten Credentials, das sind die Angaben zur Identifizierung und Authentifizierung des Benutzers (z.B. Benutzername und Passwort oder Benutzername und Zertifikat etc.). Die Eingangspforte zum Server ist ein Socket-Service, zu Deutsch ein „Stecker“, wo die ankommende Anfrage entgegengenommen wird. Der Socket-Service verifiziert die Credentials und eröffnet eine Sitzung (Session), d.h. eine dedizierte Eingangstüre für den angemeldeten Client. Dies funktioniert natürlich nur, weil gewisse Konventionen festgelegt wurden. Z.B. muss der Client wissen, welche Netzwerkprotokolle der Server unterstützt und an welcher Adresse der Server zu finden ist. Versucht ein Client über eine „Named Pipe“ einen Server anzusprechen, der nur TCP/IP unterstützt, kommt keine Verbindung zustande. Nur wenn der Client auch TCP/IP verwendet und die richtige IP-Adresse des Servers inkl. Port-Nummer des Datenbankdienstes kennt, kann er eine Verbindung aufbauen. Ursprünglich mussten diese Angaben an jedem Client bei jedem Verbindungsaufbau manuell eingegeben werden. Heute gibt es Verzeichnisdienste, die Server-Adressen auf Anfrage bereitstellen. Ein Client kann sich dort zur Laufzeit Informationen zu den verfügbaren Datenbanken und ihren Verbindungsparametern holen.
Aufgrund der Benutzereingaben formuliert der Client einen SQL-Befehl. Der Client sendet diesen über die Netzwerk-Verbindung zum Datenbankserver. Der Socket-Service identifiziert diesen als SQL-Befehl und leitet ihn dementsprechend an den SQL-Parser weiter. Gewisse DBMS erlauben neben den SQL-Befehlen auch Systemmanagement-Befehle über den Socket-Service, die dann natürlich nicht an den SQL-Parser, sondern an ein Systemmanagement-Modul geschickt werden.
Der SQL-Parser liest den SQL-Befehl und kontrolliert, ob dieser korrekt formuliert ist. Dazu benutzt er unter anderem den Data Dictionary, wo die Struktur der Datenbank beschrieben ist, also alle Tabellen, Attribute, Beziehungen usw. Er kann dort nachschauen, ob die in einem SQL-Befehl referenzierte Tabelle in der Datenbank auch wirklich existiert. Der Parser zerlegt einen korrekten SQL-Befehl in seine Einzelteile, die anschließend an den SQL-
© Copyright 2005 – 2008, alle Rechte vorbehalten 14.11.2008 3 / 21

UNGIS Modul “OpenGIS® und verteilte Geoinformationsverarbeitung” Autor: Dr. Martin Huber Lektion 14: IT-Architekturen
oder Query-Optimizer weitergeleitet werden.
Der SQL-Optimizer erkennt, auf welche physischen Objekte in welcher Art zugegriffen werden muss. Dabei spielt es eine Rolle, ob aus einer Tabelle nur ganz wenige oder alle Zeilen geholt werden müssen. Der Query-Optimizer soll wenn möglich die Anzahl der physischen Zugriffe minimieren. Aufgrund von Statistiken über Datenmengen und Zugriffszeiten sowie mittels Heuristiken, die u.a. auch die verfügbaren Datenbankindizes einbeziehen, erstellt der Query-Optimizer einen Plan, wie er die physische Abfrage am besten ausführt. Ein SQL-Optimizer kann mehrere Zugriffsvarianten durchrechnen und wird dann die Variante mit dem geringsten Aufwand zur Ausführung bringen. Dafür setzt er die entsprechenden Datenzugriffsbefehle an die Speicherverwaltung ab.
Bis zu diesem Punkt ist noch alles abstrakt und ohne Kontakt zu den Daten erfolgt. Der Speichermanager übersetzt nun diese abstrakte Sicht in konkrete physische Dateizugriffe. Eine Datenbank kann über mehrere Dateien, Harddisks oder gar Rechnersysteme verteilt sein. Auch einzelne Tabellen und gar einzelne Datensätze können verteilt vorliegen. Der Speichermanager weiß, wo welche physischen Teile der Datenbank zu finden sind und greift i.d.R. mit Befehlen des Betriebssystems auf diese zu. Die Resultate werden dann wieder gemäß der logischen Sicht zusammengebaut und via Server-Socket zum Client übermittelt.
4. Datenbank-Standards und -Interoperabilität
Weshalb funktioniert die Datenbankabfrage in Abertausenden von Applikationen? Ganz einfach: weil sich Standards etabliert haben, wie Datenbanken modelliert und abgefragt werden sollen. SQL ist bestimmt nicht die einzig mögliche Datenbankabfragesprache und vielleicht auch nicht die beste, aber dadurch, dass sich viele DBMS- und Applikationshersteller auf diese Sprache geeinigt haben, ermöglicht sie heute die reibungslose Interoperabilität. Entscheidend für den Client-Server-Betrieb sind das Netzwerkprotokoll für den Transport und die Abfragesprache für den Inhalt. Alle die verschiedenen Datenbankzugriffstechnologien wie SQL over TCP/IP, ODBC, JDBC, OLEDB, ADO.Net oder JDO ermöglichen immer das eine, nämlich, dass eine Verbindung zwischen Client und Server aufgebaut wird, über die SQL-Befehle und Resultate dieser SQL-Befehle transportiert werden. Alles andere, was dahinter abläuft, um die Resultate zu erzeugen, interessiert den Client überhaupt nicht. Er kann sich also um seine Aufgabe kümmern, nämlich dem Benutzer eine schöne Oberfläche für die Datenerfassung und -abfrage bereitzustellen. Den Rest erledigt das DBMS hinter den Kulissen.
Neben diesem Grundprinzip „Transport“ und „Aufruf“ (im Fachbegriff ein Call Level Interface) sind im DBMS noch weitere Prinzipien zu beobachten, die für die Interoperabilität wichtig sind: Verzeichnisdienste und Benutzerrechteverwaltung.
Der Verzeichnisdienst beschreibt das Angebot eines Dienstes. Bei der Datenbank ist dies der Data Dictionary. Im Data Dictionary stehen die Metadaten des DBMS. Es handelt sich dabei um eine sehr technische Beschreibung der Daten-strukturen (Tabellen, Attribute), Ressourcen und weiterer Artefakte (Indizes, Constraints usw.), die für die Ausführung der Datenbankoperationen benötigt werden (s. Abbildung 2).
© Copyright 2005 – 2008, alle Rechte vorbehalten 14.11.2008 4 / 21

UNGIS Modul “OpenGIS® und verteilte Geoinformationsverarbeitung” Autor: Dr. Martin Huber Lektion 14: IT-Architekturen
Abbildung 2: Ausschnitt aus dem Data Dictionary des DBMS Oracle. In der „Tabellen-Tabelle“ stehen die Informationen zu den verfügbaren Tabellen, in der „Spalten-Tabelle“ die Informationen zu allen Tabellen-Spalten. Hier kann jedes Anwendungsprogramm nachschauen, wie aktuell die Struktur des Datenbankschemas aussieht. Die datenbankeigenen Werkzeuge konsultieren ebenfalls den Data Dictionary, denn sie sind generisch aufgebaut und wissen nicht von vornherein, welche Tabellen ein Administrator in der Datenbank anlegt. (Quelle: http://www.databaseanswers.org/data_models/oracle_data_dictionary/index.htm)
Im klassischen Data Dictionary fehlt die Beschreibung der verfügbaren Befehle, weil diese durch SQL vorgegeben sind. Wenn jedoch das Funktionsangebot vielfältiger wird, dann müssen die erweiterten Aufrufe, die ein Datenbank-managementsystem entgegennimmt, ebenfalls im Verzeichnisdienst doku-mentiert werden. Objekt-relationale Datenbanken erweitern dazu den Data Dictionary um Listen der verfügbaren Operationen, die durch spezifische Objekterweiterungen dynamisch vergrößert werden kann. Bei einer geografi-schen Erweiterung gemäß dem OpenGIS® Simple Features Standard wird dort z.B. eingetragen, dass auf den Datentyp „Polygon“ die Funktion „Area()“ ange-wendet werden kann und dass dieser eine Wert vom Typ „float“ zurückliefert.
Die Benutzerrechteverwaltung auf der anderen Seite schützt die Daten vor unberechtigtem Zugriff. Ursprünglich musste das DBMS die Benutzerverwaltung selber abdecken. Danach wurde die Benutzerverwaltung mit dem Betriebssystem geteilt (single sign-on) und inzwischen gibt es auch spezifische Dienste, die auf Benutzer- und Rechteverwaltung spezialisiert sind. Die wesentlichen Aufgaben sind die „3 As“ Authentifizierung, Autorisierung und Accounting (übliche Abkürzung: AAA, siehe Lektion 10). Die Authentifizierung stellt sicher, dass ein Benutzer eindeutig identifiziert werden kann. Die Autorisierung liefert die Beschreibung der Rechte des Benutzers in Bezug auf Daten, Befehle und Ressourcen, die er benutzen möchte. Im Accounting wird die Nutzung des Systems durch einen Anwender festgehalten, um Nachverfolgbarkeit und Abrechnung sicherzustellen.
© Copyright 2005 – 2008, alle Rechte vorbehalten 14.11.2008 5 / 21

UNGIS Modul “OpenGIS® und verteilte Geoinformationsverarbeitung” Autor: Dr. Martin Huber Lektion 14: IT-Architekturen
5. Geo-DBMS
Relationale Datenbankmanagementsysteme (rDBMS) sind für numerische und alphanumerische Datentypen optimiert. Die geografische Datenverwaltung stellt zusätzliche Anforderungen an die Datenverwaltung und Abfrage:
• Geometrische Datentypen.
• Georeferenzierung.
• Mehrdimensionale Indexierung.
• Größere Datenmenge je Datenelement.
• Geometrische Abfragebedingungen (z.B. Flächeninhalt).
• Topologische Abfragebedingungen (z.B. Nachbarschaft).
• Geometrische Berechnungsoperationen (z.B. Puffer, Distanz, Richtung).
• Grafische Ein- und Ausgabe.
Die nachfolgende Abbildung stellt die wesentlichen Erweiterungen eines rDBMS für die geografische Datenverwaltung dar.
Abbildung 3: Erweiterung eines relationalen Datenbankmanagementsystems für die geografische Datenverwaltung (Entwurf M. Huber 2003).
6. Lehren aus der DBMS-Architektur für die GIS-Interoperabilität
Die DBMS-Technologie zeigt eindrücklich, wie Interoperabilität in verteilten Umgebungen sichergestellt werden kann. Für die offene GIS-Interoperabilität können die folgenden Prinzipien übernommen werden:
• Einrichtung eines Verzeichnisdiensts zur Beschreibung der vorhandenen Datenstrukturen und Funktionen (Data Dictionary). Dadurch kann das System beliebig im Daten- und Funktionsumfang erweitert werden.
• Einrichtung eines Verzeichnisdiensts für Benutzerauthentifizierung, - auto-risierung und –abrechnung (AAA). Damit können die Berechtigungen ebenso flexibel gehandhabt werden wie die Daten- und Funktionserweiterungen.
• Der Datentransport soll unabhängig vom Inhalt (Befehle und Daten) erfolgen
© Copyright 2005 – 2008, alle Rechte vorbehalten 14.11.2008 6 / 21

UNGIS Modul “OpenGIS® und verteilte Geoinformationsverarbeitung” Autor: Dr. Martin Huber Lektion 14: IT-Architekturen
(Transportprotokolle).
• Der Befehlsumfang soll minimal für die gestellte Aufgabe definiert werden. Eine schlanke, aber eindeutige Schnittstelle verringert den Implementierungsaufwand und die Fehleranfälligkeit.
• Die Datenstrukturen für den Austausch müssen eindeutig definiert und damit für alle Beteiligten einfach zu interpretieren sein.
• Optimierung des Datenflusses: Reduktion des Datenumfangs so nahe bei der Datenquelle wie immer möglich.
• Räumlicher Datenzugriff: Schaffen eines gemeinsamen Bezugsrahmens für alle beteiligten Komponenten, Ausnutzen der Raumdimension zur Optimierung: Der nächste Zugriff erfolgt mit höchster Wahrscheinlichkeit auf Objekte in der Nähe des vorangehenden Zugriffs, was mit räumlicher Indexierung beschleunigt werden kann.
7. Funktionsweise des dynamischen Webs
Vor 15 Jahren war es noch einfach zu erklären, wie das Internet funktioniert. Es gab E-Mail-Dienste, Telnet und einige sehr hackermässige Tools zum Herumwerkeln auf fremden Computern und fremden Harddisks. Dann kamen das Hypertext Transfer Protocol (HTTP) und die Hypertext Markup Language (HTML) und veränderten die Art und Weise, wie die Leute ihren Computer und die Welt drum herum betrachteten. Zuerst war alles noch statisch und es ging primär um Dokumente. Ein HTTP-Server (Web-Server) verfügte über eine Dokumentenablage und wenn ein Benutzer ein Dokument wollte und wusste, unter welchem Namen es zu finden ist, dann lieferte ihm der Web-Server dieses aus. Weil das Dokument in der Regel in HTML codiert war, konnte es der Browser darstellen: Titel fett, Abschnitte im Fliesstext, Tabellen und einzelne Bilder. Abbildung 4 zeigt diesen Vorgang.
Abbildung 4: Klassischer Ablauf einer Anfrage über das HTTP-Protokoll: 1. GET-Befehl mit Angabe der URL vom Client an den Server; 2: Web-Server holt das Dokument aus seinem Speicher; 3. Web-Server liefert das Dokument auf das Netz aus; 4. Web-Browser stellt das Dokument gemäß den HTML-Auszeichnungen dar (Entwurf M. Huber).
Kaum hatte man die Möglichkeiten der statischen Webseiten erkannt, kam der Wunsch nach dynamisch aufbereiteten Inhalten. Lange nicht jeder Betreiber einer Webseite war Redakteur und Herausgeber, deren Aufgabe die permanente Versorgung der Gesellschaft mit Text- und Bildinhalten ist. Eine viel größere Gruppe hatte den Bedarf, mit Menschen über das Web interaktiv zu
© Copyright 2005 – 2008, alle Rechte vorbehalten 14.11.2008 7 / 21

UNGIS Modul “OpenGIS® und verteilte Geoinformationsverarbeitung” Autor: Dr. Martin Huber Lektion 14: IT-Architekturen
kommunizieren und dynamisch Inhalte nicht nur aus Textspeichern, sondern auch aus Datenbanken und anderen Anwendungen bereitzustellen. Die Frage war nur, wie ein Webbenutzer an diese Inhalte herankommt. Abbildung 5 stellt humorvoll die Problematik der Distanz zwischen den potentiell weltweit verstreuten Anwendern und der Server-Infrastruktur eines Webbetreibers dar:
Abbildung 5: Problematik der Interaktion mit einer dynamischen Applikation auf dem Internet.
Die grundlegende Schwierigkeit war und ist es heute noch, dass die Interaktion mit einer dynamischen Applikation, die bisweilen auf mehrere Maschinen an unterschiedlichen Standorten zugreifen muss, sehr viel variantenreicher ist, als das Dokumentenmodell von HTML. Das einzige, was auf einer HTML-Seite angestoßen werden kann, ist ein Hyperlink. Dieser wiederum holt - mittels http-get-Befehl - nur ein nächstes Dokument.
Die Darstellung von Karten erfolgt im dokumentenorientierten Browsermodell als fertiges Bild in einer HTML-Seite. Für die Interaktion mit Bildern bietet HTML die Hinterlegung eines Hyperlinks oder alternativ die Überlagerung mit einer so genannten Image-Map, eines einfachen Vektor-Layers, in dem jedem Polygon ein Hyperlink hinterlegt ist.
Eine erste Dynamisierung kann durch serverseitig parametrisierte URLs erfolgen. Was muss man sich darunter vorstellen? Grundsätzlich bleibt das Seitenlayout stabil, z.B. mit einer Karte in der Mitte der Seite und acht Pfeilen am Rand für das Verschieben der Karte (s. Abbildung 6). Je nach dem dargestellten Kartenausschnitt ist hinter jedem Pan-Pfeil ein anderer Link, so dass immer das unmittelbar anschließende Kartenstück gefunden wird. Wird solch eine Applikation statisch vorbereitet, heißt das, dass für jeden Kartenausschnitt acht Hyperlinks individuell eingegeben werden müssen - eine sehr fehleranfällige und mühsame Angelegenheit. Der dynamische Mechanismus läuft folgendermaßen: Der Server hat nun nicht mehr einfach fertige Dokumente, sondern Dokumentmuster mit kleinen Programmen drin. Diese Programme werden auf dem Server ausgeführt, bevor die Web-Seite an den Client ausgeliefert wird. Die Resultate werden direkt in die Web-Seite hinein geschrieben, z.B. als Image-Link mit der Angabe der neuen Position der Karte, die eingestellt werden muss, falls auf den Link geklickt wird.
© Copyright 2005 – 2008, alle Rechte vorbehalten 14.11.2008 8 / 21

UNGIS Modul “OpenGIS® und verteilte Geoinformationsverarbeitung” Autor: Dr. Martin Huber Lektion 14: IT-Architekturen
Abbildung 6: Typisches Seitenlayout für die Interaktion mit einer dynamischen Kartenapplikation (Entwurf M. Huber 2006).
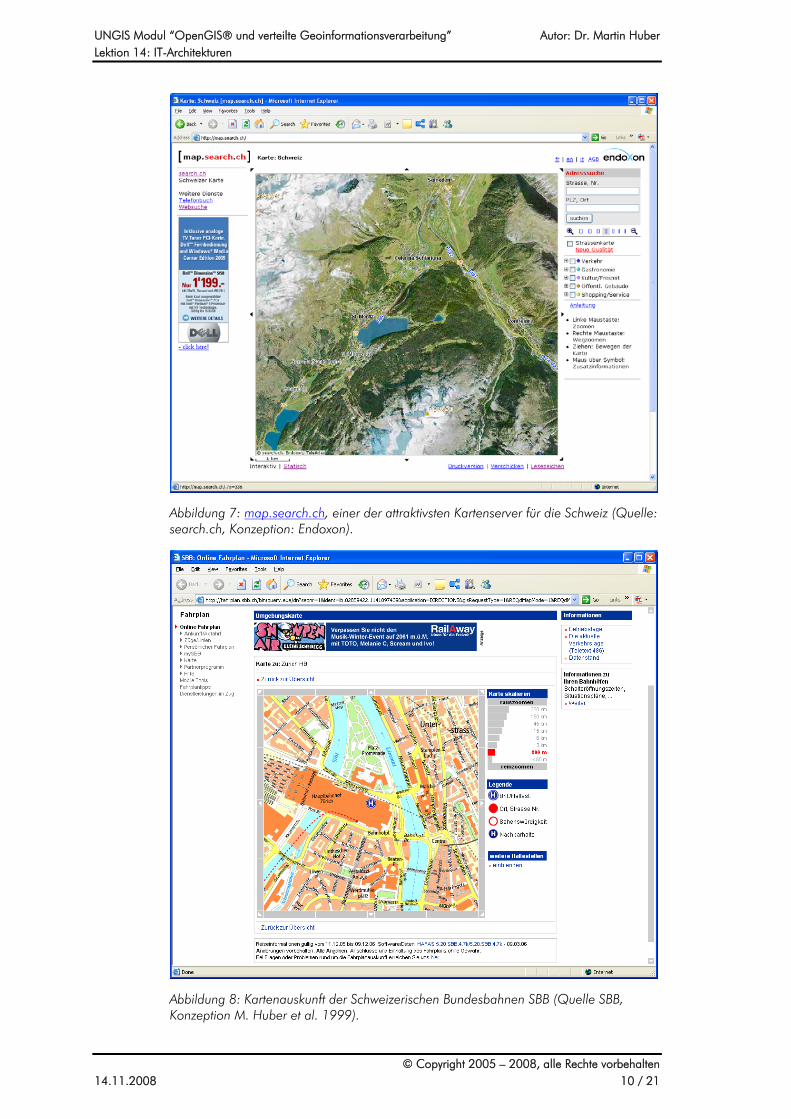
Nehmen wir an, ein Web-Benutzer ist in der Kartenapplikation aus Abbildung 6 beim rechteckig umrandeten Kartenausschnitt angelangt. Um diesen Kartenausschnitt zu erhalten mussten bereits die Eckkoordinaten an den Server geschickt werden. Dieser konnte nun einerseits den richtigen Kartenausschnitt als Rasterbild erzeugen. Andererseits konnten die Parameter für die Links hinter den acht Navigationspfeilen errechnet und in die HTML-Seite „hineingeschrieben“ werden. Hinter dem Pfeil unten links könnte z.B. der Kartenaufruf mit einer um eine halbe Kartenausdehnung nach Westen und eine halbe Kartenausdehnung nach Süden verschobenen Bounding Box abgelegt sein. Zudem könnte über den sichtbaren Kartenausschnitt eine Image-Map in Form eines Gitters gelegt sein. Hinter jeder Gitterzelle wäre der Link gelegt, der einen auf die Gitterzelle zentrierten Kartenausschnitt abfragt. Ein gutes Beispiel zu diesem Verfahren findet man auf http://map.search.ch (s. Abbildung 7). Wenn Sie in dieser Anwendung auf dem Internet die Maus auf die Pfeile am Rand der Karte halten, sehen Sie die entsprechenden Parameter in der Statuszeile des Browsers. Sie können beobachten, dass diese Parameter sich nach jedem Aufruf eines neuen Kartenausschnitts ändern. Ebenso werden die Links hinter der Zoom-Leiste am rechten Rand bei jedem Kartenausschnitt neu berechnet. Ein ähnliches Verfahren verwendet auch die Kartenapplikation der Schweizerischen Bundesbahnen (www.sbb.ch, Abbildung 8). Vergleicht man die Aufrufparameter der beiden Applikationen, dann fällt auf, dass diese nichts gemeinsam haben. Beide Lösungen sind also proprietär implementiert.
© Copyright 2005 – 2008, alle Rechte vorbehalten 14.11.2008 9 / 21
UNGIS Modul “OpenGIS® und verteilte Geoinformationsverarbeitung” Autor: Dr. Martin Huber Lektion 14: IT-Architekturen
Abbildung 7: map.search.ch, einer der attraktivsten Kartenserver für die Schweiz (Quelle: search.ch, Konzeption: Endoxon).
Abbildung 8: Kartenauskunft der Schweizerischen Bundesbahnen SBB (Quelle SBB, Konzeption M. Huber et al. 1999).
© Copyright 2005 – 2008, alle Rechte vorbehalten 14.11.2008 10 / 21

UNGIS Modul “OpenGIS® und verteilte Geoinformationsverarbeitung” Autor: Dr. Martin Huber Lektion 14: IT-Architekturen
Die serverseitige Verarbeitung hat den Vorteil, dass ohne Änderung am Dokumentenmodell festgehalten werden kann. Im Web-Browser befindet sich zu jeder Zeit nur eine HTML-Seite mit Links und trotzdem hat der Benutzer das Gefühl, grafisch-interaktiv auf der Karte zu navigieren. Der Browser muss nichts mehr können, als HTML-Seiten anzeigen und Hyperlinks aufrufen. Unschön ist dabei nur, dass die ganze Kartenseite bei jedem Klick neu aufgebaut wird, was bei kommerziellen Sites dazu verwendet wird, jeweils eine neue Werbung einzublenden (siehe SBB).
Die serverseitige Verarbeitung hat im Web mit CGI-Skripten begonnen (CGI: Common Gateway Interface). Eine der ersten mit CGI angetriebenen dynamischen Kartenapplikationen im Web war der Xerox PARC Map Viewer (http://pubweb.parc.xerox.com/), der im Juni 1993 aufgeschaltet wurde, inzwischen aber vom Netz entfernt wurde.
Abbildung 9: Xerox PARC Map Viewer: usa 37.30N 122.41W (409.1X)
Sein Präsentationsmodell (s. Abbildung 9), das dem Benutzer Interaktionsele-mente bereitstellte, deren Link zur Laufzeit vom Server generiert wurde, hat sich bis heute gehalten. Mit CGI wurden Skripts aufgerufen, die aus den Übergabeparametern den Inhalt der nächsten Web-Seite berechneten und das, was man sonst von Hand in HTML hätte schreiben müssen, in einen Datenstrom schrieben, der vom Web-Server an den Browser weitergereicht wurde.
Die CGI-Technologie ist heute in der Anwendungsentwicklung nicht mehr so verbreitet, respektive arbeitet versteckt im Hintergrund. An ihrer Stelle stehen heute verschiedene Web-Programmiermodelle, die alle ihre Anhängerschaft haben. Zwei große Blöcke bilden die Microsoft-Welt mit ASP.Net (ASP: Active Server Pages) und die Java Welt mit JSP und JSF (JSP: Java Server Pages; JSF: Java Server Faces). In beiden Welten können mit modernen Programmier-sprachen wie Java, C# oder Visual Basic dynamisch erzeugte Elemente beliebig in eine Webseite eingestreut werden. Durch den mächtigen Sprachumfang der gewählten Sprachen kann auch ohne weiteres auf eine Datenbank zugegriffen werden oder eine Kartenzeichnung dynamisch generiert werden. Parallel zu JSP und ASP hat sich eine größere Zahl von Web-Applikationsserver-Technologien entwickelt, die spezifische Skriptsprachen und Bibliotheken anbieten. Durch die hohe Spezialisierung auf das Server-Skripting können mit diesen Werkzeugen oftmals sehr komplexe aber für Web-Applikationen typische Aufgaben sehr elegant und ohne großen Programmieraufwand realisiert werden. Spitzenreiter ist hier PHP (PHP: ursprünglich Personal Homepage, heute sind verschiedene Namen gebräuchlich wie Professional Homepage oder Hypertext PreProcessor). PHP verwendet eine eigene Skriptsprache. Die PHP-Skripts werden direkt in HTML-Fragmente eingebunden. Die Sprache ähnelt den im Unix-Umfeld gebräuchlichen Skripting-Sprachen wie z.B. Perl.
© Copyright 2005 – 2008, alle Rechte vorbehalten 14.11.2008 11 / 21
UNGIS Modul “OpenGIS® und verteilte Geoinformationsverarbeitung” Autor: Dr. Martin Huber Lektion 14: IT-Architekturen
Ein aktuelles Beispiel einer vollständig auf dem Server dynamisierten Web-Mapping-Applikation ist der Basisviewer des Geoportals Bund (http://ims3.bkg.bund.de/navigator/basicviewer.jsp?MAP_NAME=map_one&RESET=true).
8. Aktivierung des Web-Browsers
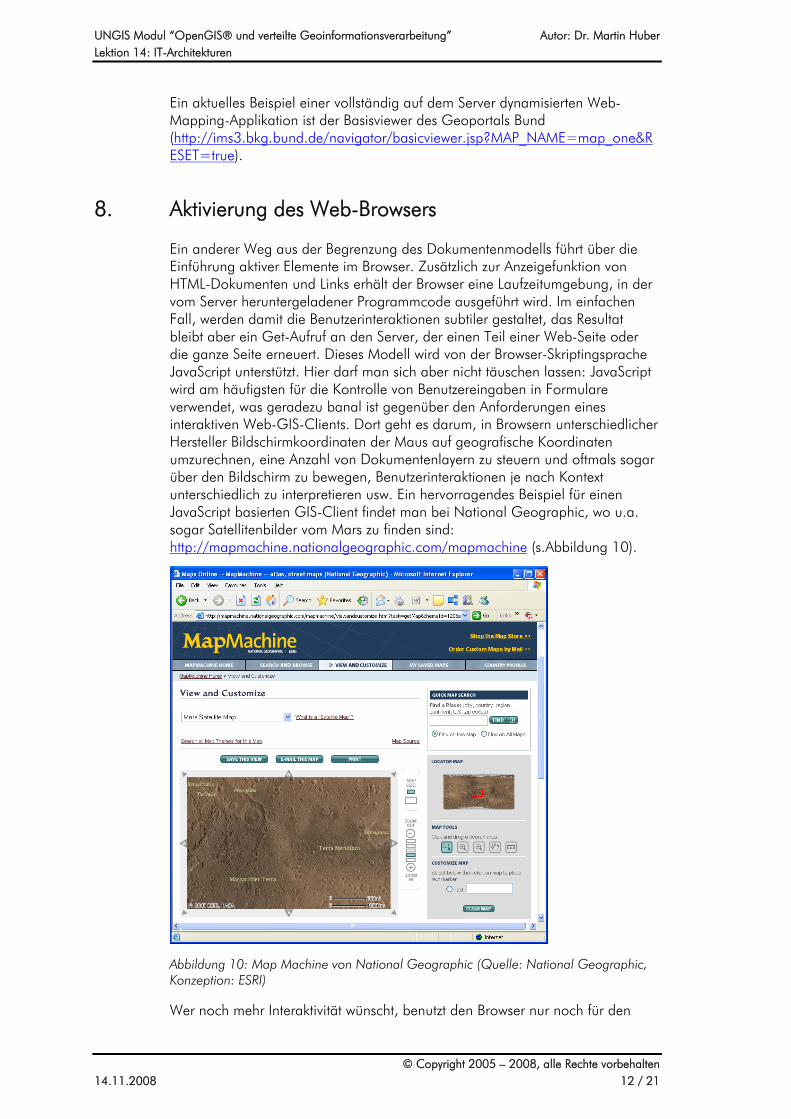
Ein anderer Weg aus der Begrenzung des Dokumentenmodells führt über die Einführung aktiver Elemente im Browser. Zusätzlich zur Anzeigefunktion von HTML-Dokumenten und Links erhält der Browser eine Laufzeitumgebung, in der vom Server heruntergeladener Programmcode ausgeführt wird. Im einfachen Fall, werden damit die Benutzerinteraktionen subtiler gestaltet, das Resultat bleibt aber ein Get-Aufruf an den Server, der einen Teil einer Web-Seite oder die ganze Seite erneuert. Dieses Modell wird von der Browser-Skriptingsprache JavaScript unterstützt. Hier darf man sich aber nicht täuschen lassen: JavaScript wird am häufigsten für die Kontrolle von Benutzereingaben in Formulare verwendet, was geradezu banal ist gegenüber den Anforderungen eines interaktiven Web-GIS-Clients. Dort geht es darum, in Browsern unterschiedlicher Hersteller Bildschirmkoordinaten der Maus auf geografische Koordinaten umzurechnen, eine Anzahl von Dokumentenlayern zu steuern und oftmals sogar über den Bildschirm zu bewegen, Benutzerinteraktionen je nach Kontext unterschiedlich zu interpretieren usw. Ein hervorragendes Beispiel für einen JavaScript basierten GIS-Client findet man bei National Geographic, wo u.a. sogar Satellitenbilder vom Mars zu finden sind: http://mapmachine.nationalgeographic.com/mapmachine (s.Abbildung 10).
Abbildung 10: Map Machine von National Geographic (Quelle: National Geographic, Konzeption: ESRI)
Wer noch mehr Interaktivität wünscht, benutzt den Browser nur noch für den
© Copyright 2005 – 2008, alle Rechte vorbehalten 14.11.2008 12 / 21

UNGIS Modul “OpenGIS® und verteilte Geoinformationsverarbeitung” Autor: Dr. Martin Huber Lektion 14: IT-Architekturen
Aufbau der Verbindung und das Herunterladen des Applikationscodes eines Plug-ins oder eines Java-Applets. Die Kommunikation zwischen dem aktiven Client und dem Server erfolgt direkt und wird am Browser vorbeigeführt. Dabei besteht aber die Gefahr, dass die zwischen Client und Server verwendete Sprache proprietär wird und nur von einzelnen wenigen Produkten genutzt werden kann. Für eine offene und wieder verwendbare Infrastruktur ist bei dieser Technologie unbedingt auf die Verwendung von Standards zu bestehen.
Aktive Clients waren einige Zeit in Form von Plug-ins, d.h. Erweiterungen des Browsers, die auf dem Client-Betriebssystem laufen, weit verbreitet. Aufgrund des proprietären Ansatzes, der mühseligen Download- und Installationsprozedur (nicht alle Benutzer haben die nötigen Rechte für die Installation von Plug-ins) und der beschränkten Verfügbarkeit auf einigen wenigen Browsern auf ausgewählten Betriebssystemen sind die Plug-ins für GIS-Anwendungen weitgehend wieder verschwunden. Nach wie vor großer Beliebtheit erfreuen sich hingegen die Java-Applets. Ihr Code wird direkt mit der Web-Seite heruntergeladen und läuft dann in einer Java-Laufzeitumgebung, die auf den meisten Browsern und Betriebssytemen verfügbar ist.
Ein schlummerndes Potential besteht zudem in den inzwischen gegen einer Milliarde Mobiltelefonen und Personal Digital Assistants (PDA) mit einer Java Laufzeitumgebung. Auch auf all diesen Geräten muss nicht auf Kartenapplikationen verzichtet werden, wie die deutsche Firma Skylab demonstriert (http://www.skylab-mobilesystems.com/en/products/j2me_wms_client.html). Für die Java-Umgebung im Mobiltelefon wurde sogar spezifisch das Location API for J2ME für mobile GIS-Anwendungen definiert (Java Specification Request (JSR) 179, http://jcp.org/en/jsr/detail?id=179). Interessanterweise wurden diese Spezifikationen vorwiegend von den Handy-Herstellern gestaltet. Aus dem GIS-Umfeld waren nur ganz wenige Firmen beteiligt. Ist dies nun ein Erfolg des OGC bei der Verbreitung der GIS-Technologie in die ICT oder macht die ICT sowieso, was sie will, ungeachtet von OpenGIS?
Zurück zum Java-Applet: Java bietet sehr reichhaltige Programmierbibliotheken, die allesamt auf dem Browser vorhanden sind. Es ist nicht abwegig anzunehmen, dass sehr bald vollständige GIS-Produkte auf Java-Basis vernetzt zur Verfügung stehen.
Ein stark ausgereiftes OpenSource Projekt in diesem Bereich ist OpenJump (http://www.openjump.org/). Jump hat nicht nur einen WMS-Client, sondern auch umfangreiche Funktionalität für die Erfassung, Bereinigung, Darstellung und Analyse von Geodaten. Wenn nun solch reichhaltige Kost in den Browser geladen wird, entsteht natürlich auch ein Sicherheitsrisiko. Es wäre in Java ein-fach, Code mit verheerenden Konsequenzen für den Client-Rechner zu schrei-ben und über ein Applet einzuschleichen. Damit dies nicht geschieht, laufen die Java-Applets in einer stark eingeschränkten Umgebung, die den Zugriff auf lo-kale Ressourcen nur nach ausdrücklicher Erlaubnis durch den Benutzer erlaubt. Mit Herstellerzertifikaten versehen können sich Applets auch gleich zu Beginn einer Session einen Blankoscheck geben lassen. Zumindest einen kurzen Blick sollte man auf das Zertifikat werfen um zu schauen, wer hinter dem gerade ge-ladenen Applet steht und ob man dem traut. Im Zweifelsfalle ist es besser, das Zertifikat vorerst nicht zu akzeptieren und noch zusätzliche Abklärungen zu tätigen.
Ein interessantes Beispiel eines interaktiven Java-Clients findet sich wiederum auf
© Copyright 2005 – 2008, alle Rechte vorbehalten 14.11.2008 13 / 21

UNGIS Modul “OpenGIS® und verteilte Geoinformationsverarbeitung” Autor: Dr. Martin Huber Lektion 14: IT-Architekturen
dem GeoPortal Bund (http://ims3.bkg.bund.de/organizer?gid=TvKEx80oxzgRA6rXSwC43RqSUFq3lf4 oder http://www.geoportal.bund.de -> Expertenviewer). Wer es genau wissen möchte, kann in der Java Console die Serveraufrufe mitverfolgen. Besonders interessant sind natürlich die WMS-Aufrufe, die wir bereits selber interpretieren können.
Es wurde erwähnt, dass die Plug-ins für Web-GIS nicht mehr so relevant sind wie vor einigen Jahren. Hierzu gibt es eine Ausnahme, Scalable Vector Graphics (SVG). Zugegeben, SVG wurde nicht primär für GIS entwickelt, sondern ganz allgemein für die Grafikdarstellung in XML. Doch die GIS-Gemeinschaft nimmt alles, was grafisch-interaktiv im Web funktioniert, dankbar auf.
Die Geschichte der XML-Grafikformate wurde bereits erzählt. Hier sei noch ergänzt, dass u.a. Google Maps (maps.google.com) das VML-Format von Erzrivale Microsoft verwendet, um Vektorlayer mit Strassen und administrativen Grenzen über Rasterkarten zu legen.
Auch die dynamischen Präsentationsmöglichkeiten von SVG seien hier nochmals vorgeführt. Der Name SVG stimmt insofern nicht, als dass mit SVG nicht nur Vektor-, sondern auch Rasterdaten angezeigt werden können. SVG bietet eine sehr reichhaltige Palette an grafischen Auszeichnungsstilen, vergleichbar mit den Möglichkeiten von Adobe Illustrator oder Corel Draw vor ca. 4 Versionen. Damit können auch Kartendaten grafisch ansprechend aufbereitet werden. Mit dem passenden Browser-Plugin z.B. von Adobe (http://www.adobe.com/svg/viewer/install/main.html) kann in diesen Karten hinein- und herausgezoomt werden. Gegenüber echt dynamischen Web-Mapping-Anwendungen ist das lokale Zoom im SVG-Viewer jedoch nicht wirklich überzeugend, weil bei höherer Auflösung die grafische Darstellung zwar immer noch sehr scharf ist (Vektordarstellung), jedoch nicht automatisch neue Daten zur Verdichtung nachgeladen werden. Aber machen Sie sich doch gleich selber ein Bild. Hierzu ein paar interessante Links:
• Stadtplan von Stuttgart und der zur WM 2006 eingerichtete Stadionplan http://www.stuttgart2006.net/index.php
• Weltweite Statistikdaten der kanadischen Entwicklungsagentur http://www.canadiangeographic.ca/worldmap/cida/CIDAWorldMap.aspx?Language=EN&Resolution=1024x768
• Ansicht von Daten der amtlichen Vermessung http://www.bgrundviewer.de/demo/alk.svg
• Schweizerische Topografische Karte http://www.carto.net/papers/svg/tuerlersee/
• Diverse Beispiele aus Frankreich http://www.netagis.com (bitte beachten Sie, dass auf dieser Site auch die Menus in SVG sind, zoombar!)
9. OpenGIS®-Service-Architektur
Nach soviel Praxis sei das Ganze nun in einem theoretischen Konzept zusammengefasst. Die OpenGIS® Abstract Specification – Topic 12, ebenfalls bekannt unter dem ISO-Label „ISO 19119 – Geographic Information Services“
© Copyright 2005 – 2008, alle Rechte vorbehalten 14.11.2008 14 / 21

UNGIS Modul “OpenGIS® und verteilte Geoinformationsverarbeitung” Autor: Dr. Martin Huber Lektion 14: IT-Architekturen
stellt die zentralen Design-Fragen der dienste-orientierten Architektur sehr kompakt und anschaulich dar und beeindruckt selbst Vollblutinformatiker.
Worum geht es?
• Welche Dienste werden benötigt, um eine Service-Architektur zu bauen?
• Wie werden Dienste hintereinander gehängt, damit daraus sinnvolle Arbeitsabläufe und Applikationen entstehen?
• Wie werden Dienste sinnvollerweise zu Modulen gruppiert unter Beachtung der Aspekte Performance und Wiederverwendbarkeit?
Die OpenGIS® Service Architecture schlägt folgende Dienste vor, die nicht nur für geografische Anwendungen, sondern ganz allgemein nützlich sind:
Abbildung 11: Gruppierung der Dienste in der OGC Service Architektur (Entwurf M. Huber 2004)
Die Frage, wie die Dienste zu sinnvollen Abläufen zusammengehängt werden, ist bei näherer Betrachtung nicht trivial. Formulieren wir es einmal so: Wenn das GIS in atomare Funktionen aufgeteilt wird, wie können diese Dienste wieder sinnvoll aneinandergereiht werden, dass a) der Benutzer das anstoßen kann, was er benötigt und b) die interessierenden Objekte durch die ganze Kette von möglicherweise auf verschiedenen Servern laufenden Diensten durchgereicht werden, so dass innerhalb einer vertretbaren Frist etwas Sinnvolles dabei herauskommt?
Es gibt verschiedene Ebenen, auf denen Interoperabilität erfolgen muss: zuerst die Ebene der Primitive, auf der semantisch und physisch festgelegt werden muss, was eine Zahl, ein Zeichen, eine Zeichenkette, eine Geometrie, ein Punkt, eine Linie etc. ist. Dann folgt die Ebene der Objekte, was im OGC-Umfeld Feature heißt. Hier werden Primitive für Attribute verwendet und zu Features zusammen gruppiert. Natürlich erhält nun jedes Element einen Namen, also jedes Attribut und auch jeder Feature-Typ. Ein Feature-Typ hat jedoch nur eine Bedeutung, wenn das Anwendungsgebiet, der so genannte Domain, bekannt ist. Eine „Strasse“ ist für eine Navigationsanwendung etwas anderes als für eine Anwendung im Straßenbau und -unterhalt. Diese domain-spezifische Semantik wird in Metadaten beschrieben. Nun wissen wir erst einmal, wie ein Feature aussieht und was es bedeutet. Dann kommt die Semantik der einzelnen Verarbeitungsfunktion: was kommt hinten heraus, wenn ich eine „Strasse“ im Sinne der Navigationsanwendung in eine Puffer-Funktion hinein gebe? Und kann ich das dabei resultierende Gebilde in eine Verschneideoperation mit
© Copyright 2005 – 2008, alle Rechte vorbehalten 14.11.2008 15 / 21

UNGIS Modul “OpenGIS® und verteilte Geoinformationsverarbeitung” Autor: Dr. Martin Huber Lektion 14: IT-Architekturen
einem Gewässer einspeisen? Was kommt dann heraus? Was bedeutet das resultierende Objekt und wie soll es interpretiert werden?
Es braucht also eine Instanz, die Auskunft gibt über die Objekte und ihre Bedeutung und wo festgelegt werden kann, was mit einem Objekt gemacht werden kann und was nicht. Bis dies über alle möglichen Domains hinweg automatisiert funktioniert, wird noch einige Arbeit zu leisten sein. Bis dahin müssen GIS-Spezialisten die Modellierung vom Domain-spezifischen Feature-Typen über alle dann explizit erlaubten Operationen hinweg bis zu den dabei resultierenden Feature-Typen manuell vornehmen.
Da die Spezifikation abstrakt ist, können einige dieser Fragen für konkrete Implementierungsspezifikationen aufgehoben werden. Auf der abstrakten Ebene liefert die Spezifikation aber eine interessante Sammlung von Konzepten zur Organisation des logischen Arbeitsablaufs, wovon zwei herausgegriffen werden sollen. Das erste Beispiel (s. Abbildung 12) zeigt eine Organisation, bei der ein hoch-interaktiver Client dem Benutzer das Diensteangebot präsentiert, der nun ad-hoc seine gewünschten Operationen zusammenstellen kann. Der Client ruft danach die gewünschten Dienste auf und präsentiert die Resultate. Damit dies funktioniert braucht es einen Catalogue Service, der ähnlich dem Data Dictionary einer Datenbank weiß, was an Diensten angeboten wird. Der Client muss diese Information über die Dienste auswerten und dem Benutzer in geeigneter Form präsentieren. Zudem muss er mit dieser Information die einzelnen Dienste parametrisiert aufrufen können.
Abbildung 12: Ad-hoc Zusammenstellung der Verarbeitungsdienste dank Dienstebeschreibung in einem Katalogdienst. (Quelle: OGC: The OpenGIS Service Architecture, Topic 12).
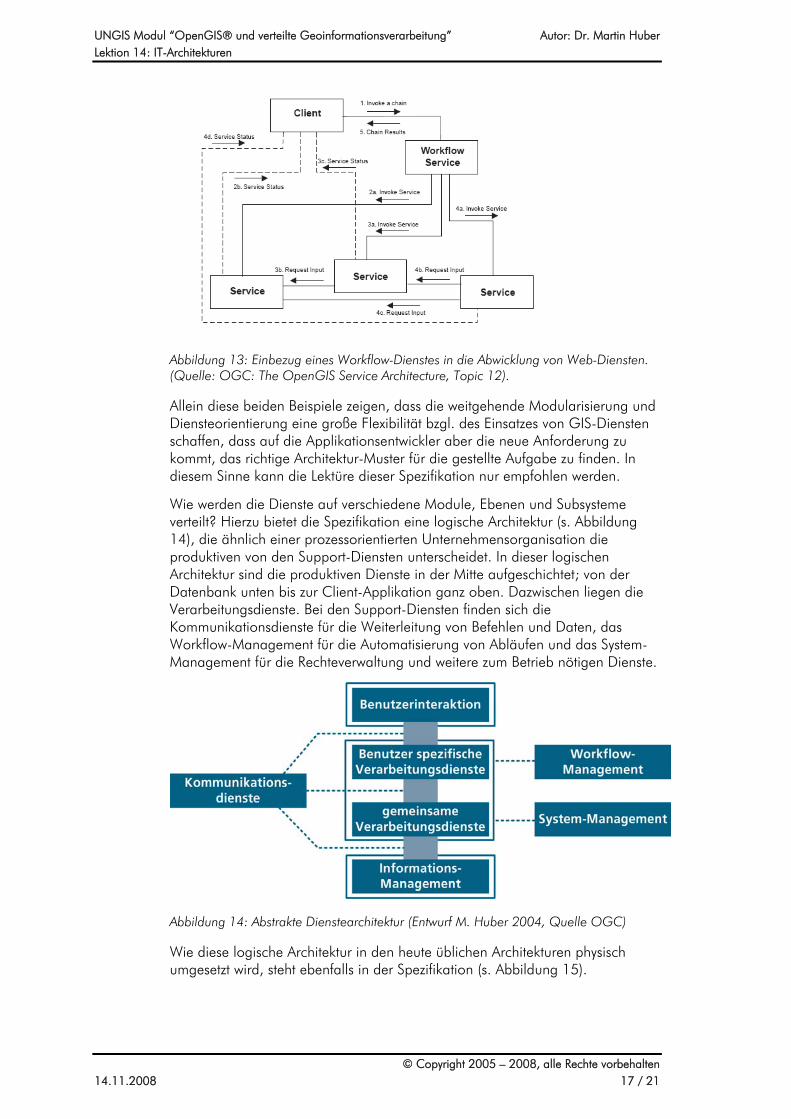
Das zweite Beispiel (s. Abbildung 13) zeigt eine Umgebung, in der Arbeitsabläufe durch einen Workflow Service vorgegeben sind. Die Arbeitsweise für den Endbenutzer unterscheidet sich sehr stark von der im ersten Beispiel. Nun stehen nicht einzelne Dienste zur Verfügung, sondern fertige Arbeitsabläufe. Diese werden angestoßen, dann kann der Status der Ausführung überwacht werden und am Schluss werden die Resultate der Ausführung präsentiert.
© Copyright 2005 – 2008, alle Rechte vorbehalten 14.11.2008 16 / 21
UNGIS Modul “OpenGIS® und verteilte Geoinformationsverarbeitung” Autor: Dr. Martin Huber Lektion 14: IT-Architekturen
Abbildung 13: Einbezug eines Workflow-Dienstes in die Abwicklung von Web-Diensten. (Quelle: OGC: The OpenGIS Service Architecture, Topic 12).
Allein diese beiden Beispiele zeigen, dass die weitgehende Modularisierung und Diensteorientierung eine große Flexibilität bzgl. des Einsatzes von GIS-Diensten schaffen, dass auf die Applikationsentwickler aber die neue Anforderung zu kommt, das richtige Architektur-Muster für die gestellte Aufgabe zu finden. In diesem Sinne kann die Lektüre dieser Spezifikation nur empfohlen werden.
Wie werden die Dienste auf verschiedene Module, Ebenen und Subsysteme verteilt? Hierzu bietet die Spezifikation eine logische Architektur (s. Abbildung 14), die ähnlich einer prozessorientierten Unternehmensorganisation die produktiven von den Support-Diensten unterscheidet. In dieser logischen Architektur sind die produktiven Dienste in der Mitte aufgeschichtet; von der Datenbank unten bis zur Client-Applikation ganz oben. Dazwischen liegen die Verarbeitungsdienste. Bei den Support-Diensten finden sich die Kommunikationsdienste für die Weiterleitung von Befehlen und Daten, das Workflow-Management für die Automatisierung von Abläufen und das System-Management für die Rechteverwaltung und weitere zum Betrieb nötigen Dienste.
Abbildung 14: Abstrakte Dienstearchitektur (Entwurf M. Huber 2004, Quelle OGC)
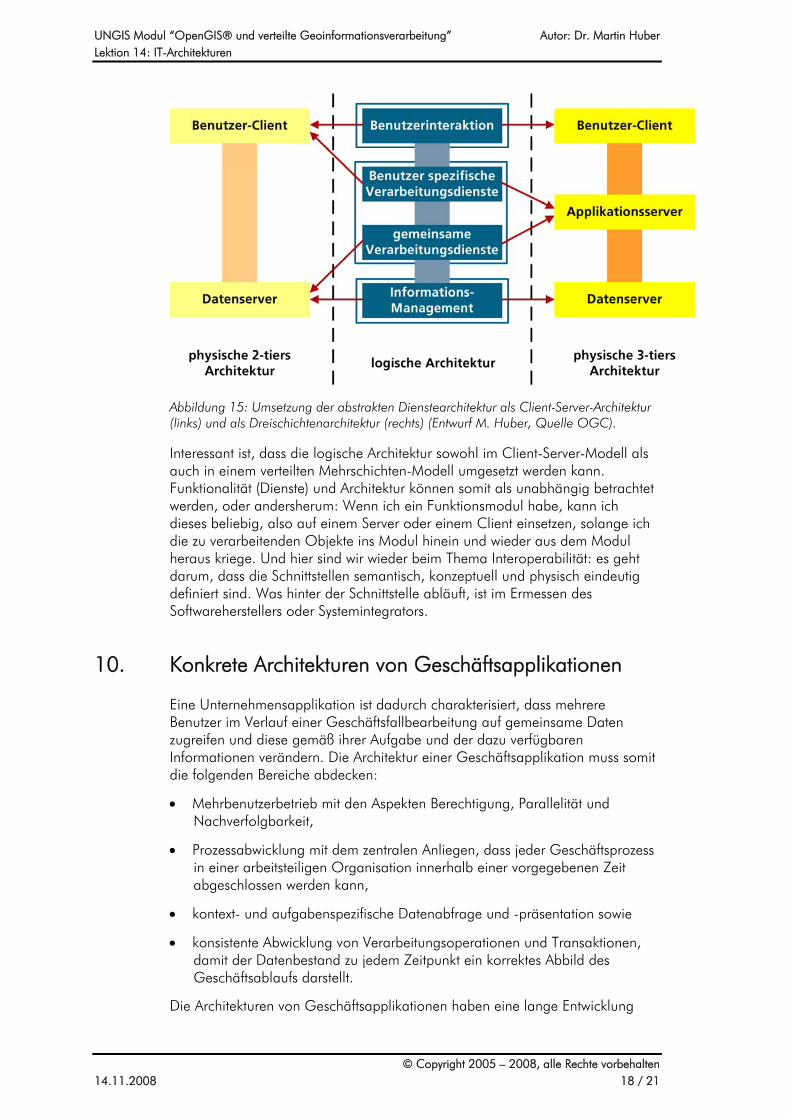
Wie diese logische Architektur in den heute üblichen Architekturen physisch umgesetzt wird, steht ebenfalls in der Spezifikation (s. Abbildung 15).
© Copyright 2005 – 2008, alle Rechte vorbehalten 14.11.2008 17 / 21
UNGIS Modul “OpenGIS® und verteilte Geoinformationsverarbeitung” Autor: Dr. Martin Huber Lektion 14: IT-Architekturen
Abbildung 15: Umsetzung der abstrakten Dienstearchitektur als Client-Server-Architektur (links) und als Dreischichtenarchitektur (rechts) (Entwurf M. Huber, Quelle OGC).
Interessant ist, dass die logische Architektur sowohl im Client-Server-Modell als auch in einem verteilten Mehrschichten-Modell umgesetzt werden kann. Funktionalität (Dienste) und Architektur können somit als unabhängig betrachtet werden, oder andersherum: Wenn ich ein Funktionsmodul habe, kann ich dieses beliebig, also auf einem Server oder einem Client einsetzen, solange ich die zu verarbeitenden Objekte ins Modul hinein und wieder aus dem Modul heraus kriege. Und hier sind wir wieder beim Thema Interoperabilität: es geht darum, dass die Schnittstellen semantisch, konzeptuell und physisch eindeutig definiert sind. Was hinter der Schnittstelle abläuft, ist im Ermessen des Softwareherstellers oder Systemintegrators.
10. Konkrete Architekturen von Geschäftsapplikationen
Eine Unternehmensapplikation ist dadurch charakterisiert, dass mehrere Benutzer im Verlauf einer Geschäftsfallbearbeitung auf gemeinsame Daten zugreifen und diese gemäß ihrer Aufgabe und der dazu verfügbaren Informationen verändern. Die Architektur einer Geschäftsapplikation muss somit die folgenden Bereiche abdecken:
• Mehrbenutzerbetrieb mit den Aspekten Berechtigung, Parallelität und Nachverfolgbarkeit,
• Prozessabwicklung mit dem zentralen Anliegen, dass jeder Geschäftsprozess in einer arbeitsteiligen Organisation innerhalb einer vorgegebenen Zeit abgeschlossen werden kann,
• kontext- und aufgabenspezifische Datenabfrage und -präsentation sowie
• konsistente Abwicklung von Verarbeitungsoperationen und Transaktionen, damit der Datenbestand zu jedem Zeitpunkt ein korrektes Abbild des Geschäftsablaufs darstellt.
Die Architekturen von Geschäftsapplikationen haben eine lange Entwicklung
© Copyright 2005 – 2008, alle Rechte vorbehalten 14.11.2008 18 / 21
UNGIS Modul “OpenGIS® und verteilte Geoinformationsverarbeitung” Autor: Dr. Martin Huber Lektion 14: IT-Architekturen
durchgemacht und befinden sich auch heute im laufenden Umbau. Entscheidend für die verteilte Geoinformationsverarbeitung ist, dass Doppelspurigkeiten vermieden werden. Das bedeutet, sich für die GIS-Funktionalitäten weitgehend der bereits vorhandenen architektonischen Komponenten bedienen und nur dort neue Elemente einführen, wo nichts Entsprechendes vorhanden ist.
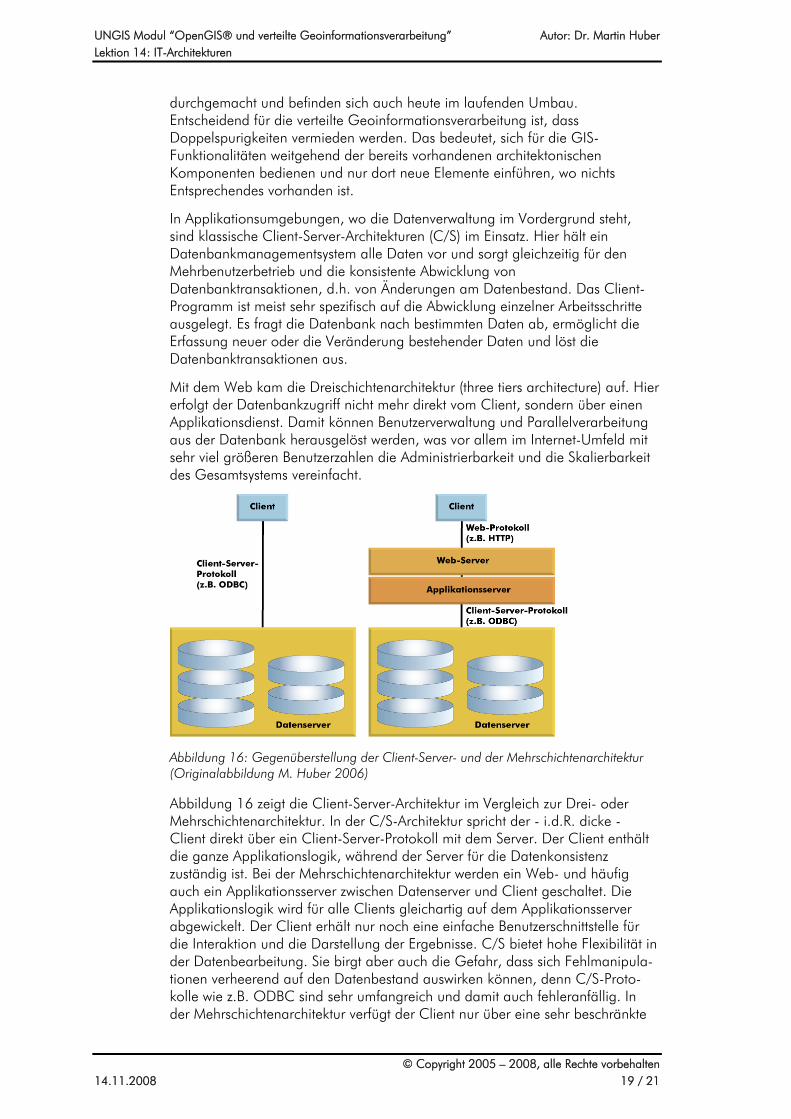
In Applikationsumgebungen, wo die Datenverwaltung im Vordergrund steht, sind klassische Client-Server-Architekturen (C/S) im Einsatz. Hier hält ein Datenbankmanagementsystem alle Daten vor und sorgt gleichzeitig für den Mehrbenutzerbetrieb und die konsistente Abwicklung von Datenbanktransaktionen, d.h. von Änderungen am Datenbestand. Das Client-Programm ist meist sehr spezifisch auf die Abwicklung einzelner Arbeitsschritte ausgelegt. Es fragt die Datenbank nach bestimmten Daten ab, ermöglicht die Erfassung neuer oder die Veränderung bestehender Daten und löst die Datenbanktransaktionen aus.
Mit dem Web kam die Dreischichtenarchitektur (three tiers architecture) auf. Hier erfolgt der Datenbankzugriff nicht mehr direkt vom Client, sondern über einen Applikationsdienst. Damit können Benutzerverwaltung und Parallelverarbeitung aus der Datenbank herausgelöst werden, was vor allem im Internet-Umfeld mit sehr viel größeren Benutzerzahlen die Administrierbarkeit und die Skalierbarkeit des Gesamtsystems vereinfacht.
Abbildung 16: Gegenüberstellung der Client-Server- und der Mehrschichtenarchitektur (Originalabbildung M. Huber 2006)
Abbildung 16 zeigt die Client-Server-Architektur im Vergleich zur Drei- oder Mehrschichtenarchitektur. In der C/S-Architektur spricht der - i.d.R. dicke - Client direkt über ein Client-Server-Protokoll mit dem Server. Der Client enthält die ganze Applikationslogik, während der Server für die Datenkonsistenz zuständig ist. Bei der Mehrschichtenarchitektur werden ein Web- und häufig auch ein Applikationsserver zwischen Datenserver und Client geschaltet. Die Applikationslogik wird für alle Clients gleichartig auf dem Applikationsserver abgewickelt. Der Client erhält nur noch eine einfache Benutzerschnittstelle für die Interaktion und die Darstellung der Ergebnisse. C/S bietet hohe Flexibilität in der Datenbearbeitung. Sie birgt aber auch die Gefahr, dass sich Fehlmanipula-tionen verheerend auf den Datenbestand auswirken können, denn C/S-Proto-kolle wie z.B. ODBC sind sehr umfangreich und damit auch fehleranfällig. In der Mehrschichtenarchitektur verfügt der Client nur über eine sehr beschränkte
© Copyright 2005 – 2008, alle Rechte vorbehalten 14.11.2008 19 / 21
UNGIS Modul “OpenGIS® und verteilte Geoinformationsverarbeitung” Autor: Dr. Martin Huber Lektion 14: IT-Architekturen
Einflussmöglichkeit auf den Datenbestand. Nur das, was der Web-Server oder der Applikationsserver explizit bereitstellen, kann benutzt werden.
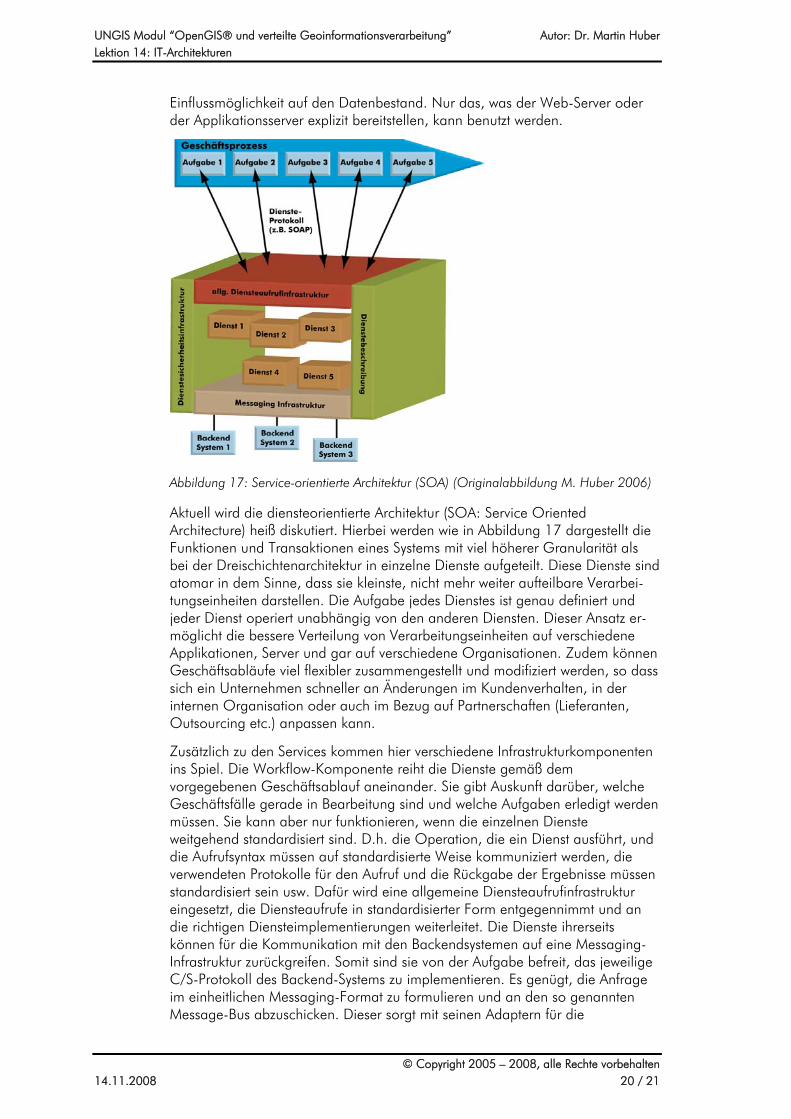
Abbildung 17: Service-orientierte Architektur (SOA) (Originalabbildung M. Huber 2006)
Aktuell wird die diensteorientierte Architektur (SOA: Service Oriented Architecture) heiß diskutiert. Hierbei werden wie in Abbildung 17 dargestellt die Funktionen und Transaktionen eines Systems mit viel höherer Granularität als bei der Dreischichtenarchitektur in einzelne Dienste aufgeteilt. Diese Dienste sind atomar in dem Sinne, dass sie kleinste, nicht mehr weiter aufteilbare Verarbei-tungseinheiten darstellen. Die Aufgabe jedes Dienstes ist genau definiert und jeder Dienst operiert unabhängig von den anderen Diensten. Dieser Ansatz er-möglicht die bessere Verteilung von Verarbeitungseinheiten auf verschiedene Applikationen, Server und gar auf verschiedene Organisationen. Zudem können Geschäftsabläufe viel flexibler zusammengestellt und modifiziert werden, so dass sich ein Unternehmen schneller an Änderungen im Kundenverhalten, in der internen Organisation oder auch im Bezug auf Partnerschaften (Lieferanten, Outsourcing etc.) anpassen kann.
Zusätzlich zu den Services kommen hier verschiedene Infrastrukturkomponenten ins Spiel. Die Workflow-Komponente reiht die Dienste gemäß dem vorgegebenen Geschäftsablauf aneinander. Sie gibt Auskunft darüber, welche Geschäftsfälle gerade in Bearbeitung sind und welche Aufgaben erledigt werden müssen. Sie kann aber nur funktionieren, wenn die einzelnen Dienste weitgehend standardisiert sind. D.h. die Operation, die ein Dienst ausführt, und die Aufrufsyntax müssen auf standardisierte Weise kommuniziert werden, die verwendeten Protokolle für den Aufruf und die Rückgabe der Ergebnisse müssen standardisiert sein usw. Dafür wird eine allgemeine Diensteaufrufinfrastruktur eingesetzt, die Diensteaufrufe in standardisierter Form entgegennimmt und an die richtigen Diensteimplementierungen weiterleitet. Die Dienste ihrerseits können für die Kommunikation mit den Backendsystemen auf eine Messaging-Infrastruktur zurückgreifen. Somit sind sie von der Aufgabe befreit, das jeweilige C/S-Protokoll des Backend-Systems zu implementieren. Es genügt, die Anfrage im einheitlichen Messaging-Format zu formulieren und an den so genannten Message-Bus abzuschicken. Dieser sorgt mit seinen Adaptern für die
© Copyright 2005 – 2008, alle Rechte vorbehalten 14.11.2008 20 / 21

UNGIS Modul “OpenGIS® und verteilte Geoinformationsverarbeitung” Autor: Dr. Martin Huber Lektion 14: IT-Architekturen
Weiterleitung und korrekte Übersetzung für das Backend-System. Die Sicherheitsinfrastruktur sorgt für alle Dienste eines Servers übergreifend für die korrekte Identifikation der Benutzer, die Einhaltung der Benutzerberechtigungen, die Sicherung der Verbindungsleitung zwischen Client und Service sowie für die Abwehr der leider üblichen und weit verbreiteten Hacker-Attacken (z.B. Denial-of-Service (DOS) Attacken, die einen Dienst mit Abertausenden von Anfragen überschütten und so zum Absturz bringen sollen). Eine standardisierte Dienstebeschreibung sorgt für flexible Ausbaubarkeit. Wird ein neuer Dienst bereitgestellt, dann genügt in der Regel ein entsprechender Eintrag im Diensteregister damit alle berechtigten Clients den Dienst nutzen können - ohne weitere Programmierung.
Zusammenfassend kann festgestellt werden, dass
• Unternehmensapplikationen die wesentlichen Bereiche Mehrbenutzerbetrieb, Prozessabwicklung, Präsentation/Interaktion und Transaktionen abdecken,
• integrierte GIS-Lösungen von diesen Infrastrukturen profitieren können, wenn sie sich an die entsprechenden Standards halten und
• GIS-Funktionalität und damit die GIS-Standards auf das konzentrieren können, was eben typisch geografisch ist und nicht bereits durch einen ICT Standard abgedeckt ist.
11. Zusammenfassung
In dieser Lektion wurde anhand der Datenbanktechnologie eine Einführung in die Interoperabilitätsarchitekturen gegeben. Zudem wurde die Funktionsweise eines Geo-DBMS erläutert. Die Lektion hat auch aufgezeigt, dass aufgrund der Funktionsweise der Hypertext Markup Language (HTML) im Web-Browser eine dynamische, grafische Interaktion mit GIS-Anwendungen nicht auf einfache Weise zu bewerkstelligen ist. Als Methoden für die Dynamisierung von Web-Inhalten wurden das URL-Rewriting, die serverseitige Dynamisierung mittels Common Gateway Interface (CGI), Java Server Pages (JSP), Java Server Faces (JSF) und Active Server Pages (ASP.Net) sowie die Clientseitige Dynamisierung mittels JavaScript, Plug-ins und Java Applets vorgestellt.
© Copyright 2005 – 2008, alle Rechte vorbehalten 14.11.2008 21 / 21
![Microservice-Architekturen Aspekte von Projektmanagement · Projektmanagement Aspekte von Microservice-Architekturen “ Organizations which design systems […] are constrained to](https://img.pdfslide.org/doc/110x75/5e0628b57ddc187340454729/microservice-architekturen-aspekte-von-projektmanagement-projektmanagement-aspekte.jpg)




























