Embed Size (px)
Citation preview

Parallele und Verteilte Simulationbei der Steuerung komplexer
Produktionssysteme
Dissertation
zur Erlangung des akademischen Gradeseines Doktors der Wirtschaftswissenschaften
(Dr. rer. pol.).Eingereicht an der Fakultät für Wirtschaftswissenschaften
der Technischen Universität Ilmenau
vorgelegt von
Dipl.-Wirtsch.-Inf. Roland Schulz
Eingereicht: Ilmenau, 15.03.2002
Verteidigt: Ilmenau, 08.11.2002
Gutachter:
Prof. Dr.-Ing. habil. Peter Gmilkowsky, TU Ilmenau
PD Dr.-Ing. habil. Thomas Schulze,Otto-von-Guericke Universität Magdeburg
Prof. Dr. habil. Dirk Stelzer, TU Ilmenau

Inhaltsverzeichnis
Seite 2
Inhaltsverzeichnis
Abbildungsverzeichnis _______________________________________ 8
Tabellenverzeichnis_________________________________________ 12
Formelverzeichnis __________________________________________ 13
Symbolverzeichnis _________________________________________ 14
Abkürzungsverzeichnis______________________________________ 19
1 Einleitung ___________________________________________ 211.1 Motivation und Zielsetzung ___________________________________________211.2 Aufbau der Arbeit___________________________________________________23
2 Einsatz der Parallelen und Verteilten Simulation zurFertigungssteuerung komplexer Produktionssysteme ______ 262.1 Begriff, Aufgaben, Vorteile und Probleme der simulationsbasierten
Fertigungssteuerung ________________________________________________262.1.1 Anliegen der simulationsbasierten Fertigungssteuerung _________________262.1.2 Aufgaben und Ziele der Fertigungssteuerung _________________________272.1.3 Probleme der Fertigungssteuerung _________________________________282.1.4 Einsatz von Heuristiken zur Lösung von Reihenfolgeproblemen __________312.1.5 Aufgaben und Probleme der simulationsbasierten Fertigungssteuerung_____32
2.2 Simulation - Sequentielle Simulation, Parallele Simulation, VerteilteSimulation - Begriffe, Aufgaben, Abgrenzung____________________________332.2.1 Grundlagen der Simulation _______________________________________33
2.2.1.1 Begriff und Vorteile der Simulation _______________________________ 332.2.1.2 Prinzipielle Bestandteile und Funktionsprinzipien von
Simulationssoftware____________________________________________ 352.2.1.3 Problem des hohen Zeitbedarfs für die Ausführung der Simulation als
Motiv für die Parallelisierung ____________________________________ 362.2.2 Abgrenzung zwischen Sequentieller, Paralleler und Verteilter Simulation __39
2.2.2.1 Abgrenzung zwischen Sequentieller Simulation und Paralleler bzw.Verteilter Simulation ___________________________________________ 39
2.2.2.2 Abgrenzung zwischen Paralleler und Verteilter Simulation _____________ 412.2.3 Ziele des Einsatzes der Parallelen und Verteilten Simulation_____________42
2.3 Aufgaben der Parallelen und Verteilten Simulation beim Einsatz in derFertigungssteuerung ________________________________________________432.3.1 Erstellung des Simulationsmodells - Problem der Modellbildung _________432.3.2 Modelle von Produktionssystemen als Abbildungsgegenstand der
Fertigungssteuerung - eine Komplexitätsbetrachtung___________________442.3.2.1 Komplexität der Modelle von Produktionssystemen___________________ 452.3.2.2 Bestandteile der Modelle von Produktionssystemen ___________________ 462.3.2.3 Komplexe Bedingungen bei der Modellierung von Produktionssystemen __ 53
2.3.3 Lösung weiterer allgemeiner simulationstechnischer Probleme ___________572.3.4 Spezielle Aufgaben und Probleme der Parallelen und Verteilten Simulation_59
2.4 Resümee der Anforderungen__________________________________________63

Inhaltsverzeichnis
Seite 3
2.4.1 Zusammenfassung der Aufgaben und Probleme der simulationsbasiertenFertigungssteuerung ____________________________________________ 63
2.4.2 Anforderungen an einen Lösungsansatz zum Einsatz der Parallelen bzw.Verteilten Simulation für die Simulation von komplexenProduktionssystemen ___________________________________________ 65
3 Internationaler Wissensstand auf dem Gebiet der Parallelenund Verteilten Simulation ______________________________673.1 Aufgaben bei Einsatz der Parallelen und Verteilten Simulation _____________ 67
3.1.1 Partitionierung_________________________________________________ 673.1.1.1 Begriff, Aufgaben und Ziele der Partitionierung ______________________673.1.1.2 Verfahren zur Partitionierung von Simulationsmodellen ________________673.1.1.3 Probleme der Partitionierung _____________________________________683.1.1.4 Anforderungen an Partitionierungsverfahren _________________________70
3.1.2 Kommunikation________________________________________________ 713.1.2.1 Begriff, Aufgaben und Ziele der Kommunikation _____________________713.1.2.2 Verfahren zur Kommunikation____________________________________723.1.2.3 Probleme der Kommunikation ____________________________________723.1.2.4 Anforderungen an Kommunikationsstrukturen und -verfahren ___________74
3.1.3 Synchronisation________________________________________________ 753.1.3.1 Begriff, Aufgaben und Ziele der Synchronisation _____________________753.1.3.2 Überblick über Verfahren zur Synchronisation von Simulationsmodellen __753.1.3.3 Konservative Synchronisationsverfahren ____________________________763.1.3.4 Optimistische Synchronisationsverfahren ___________________________793.1.3.5 Hybride Synchronisationsverfahren ________________________________813.1.3.6 Probleme der Synchronisation ____________________________________823.1.3.7 Anforderungen an Synchronisationsverfahren ________________________88
3.1.4 Mapping, Scheduling und Load-Balancing __________________________ 883.1.4.1 Begriffe, Aufgaben und Ziele des Load-Balancing ____________________883.1.4.2 Verfahren zum Load-Balancing ___________________________________893.1.4.3 Probleme des Load-Balancing ____________________________________913.1.4.4 Anforderungen an Verfahren zum Load-Balancing ____________________92
3.1.5 Kombination der Aufgaben der Parallelen und Verteilten Simulation ______ 933.2 Softwaretechnische Realisierungen der Parallelen und Verteilten Simulation __ 94
3.2.1 Überblick über Konzepte zur Realisierung der Parallelen und VerteiltenSimulation____________________________________________________ 94
3.2.2 Einordnung der Implementationsansätze ____________________________ 953.2.2.1 Überblick und Einordnung _______________________________________953.2.2.2 Message Passing-Ansätze________________________________________973.2.2.3 Simulationsbibliotheken _________________________________________973.2.2.4 Erweiterung von Standard-Simulations-Tools um Komponenten der
Parallelen und Verteilten Simulation _______________________________983.2.2.5 Erweiterungen von Verteilungsansätzen um Simulationskomponenten_____983.2.2.6 Tools mit Ziel auf andere Anwendungsgebiete _______________________983.2.2.7 Die High Level Architecture (HLA) als Beispiel für Integrationsansätze ___983.2.2.8 Spezielle Tools der Parallelen und Verteilten Simulation ______________100
3.2.3 Bisherige Anwendungsgebiete der Parallelen und Verteilten Simulation __ 1023.2.4 Kritik an den softwaretechnischen Realisierungen der Parallelen und
Verteilten Simulation __________________________________________ 1053.3 Anforderungen an die Parallele und Verteilte Simulation von
Produktionssystemen_______________________________________________ 106

Inhaltsverzeichnis
Seite 4
3.3.1 Defizite der bisherigen Ansätze der Parallelen und Verteilten Simulationzur Simulation von komplexen Produktionssystemen _________________106
3.3.2 Anforderungen an einen Implementationsansatz aus Sicht der Parallelenund Verteilten Simulation _______________________________________108
3.3.3 Vergleich der Anforderungen an die Simulation komplexerProduktionssysteme mit bisherigen Lösungsansätzen im Gebiet derParallelen und Verteilten Simulation ______________________________110
4 Lösungskonzept zum Einsatz der Parallelen und VerteiltenSimulation zur Steuerung von komplexenProduktionssystemen ________________________________ 1124.1 Überblick über die Bestandteile des Lösungskonzeptes ____________________1124.2 Ein Unterstützungssystem zur Durchführung von Simulationsstudien - Das
Framework zur simulationsbasierten Fertigungssteuerung ________________1134.2.1 Notwendigkeit eines Unterstützungssystems zur Durchführung von
Simulationsstudien ____________________________________________1144.2.2 Begriff des Frameworks_________________________________________1174.2.3 Konzeption des Frameworks zur simulationsbasierten Fertigungssteuerung 119
4.2.3.1 Aufgaben und Umfang des Frameworks ___________________________ 1194.2.3.2 Übersicht über die Architektur des Frameworks _____________________ 1204.2.3.3 Zusammenfassung des Exkurses „Framework zur simulationsbasierten
Fertigungssteuerung“ __________________________________________ 124
4.3 Grundprinzipien einer Parallelen bzw. Verteilten Simulation vonProduktionssystemen _______________________________________________1254.3.1 In das Simulationsmodell einzubeziehende Komplexität von
Produktionssystemen___________________________________________1254.3.1.1 Im Simulationsmodell abzubildende Daten und Bedingungen von
Modellen von Produktionssystemen ______________________________ 1254.3.1.2 Anforderungen an Modellstrukturen zur Abbildung spezifischer
Prozeßbedingungen komplexer Produktionssysteme__________________ 1264.3.1.3 Anforderungen an Modellstrukturen zur Abbildung der Steuerung
komplexer Produktionssysteme aus Sicht komplexerProzeßführungsstrategien_______________________________________ 127
4.3.2 Diskussion von Lösungsmöglichkeiten der Abbildung von Elementen desProduktionssystems im Simulationsmodell einer Parallelen und VerteiltenSimulation ___________________________________________________128
4.3.3 Diskussion von Lösungsmöglichkeiten für die Partitionierung desSimulationsmodells eines Produktionssystems für die Parallele undVerteilte Simulation ___________________________________________129
4.3.4 Identifikation von Einflußfaktoren auf die Performance der Parallelen undVerteilten Simulation im Kontext der Simulation von Produktionssystemen1314.3.4.1 Einflußfaktoren auf die Performance der Parallelen und Verteilten
Simulation aus Sicht der Partitionierung des Simulationsmodells und derKommunikation der Teilmodelle _________________________________ 131
4.3.4.2 Einflußfaktoren auf die Performance der Parallelen und VerteiltenSimulation aus Sicht der Synchronisationsverfahren__________________ 137
4.4 Synchronisation von Simulationsmodellen von Produktionssystemen ________1414.5 Partitionierung von Simulationsmodellen von Produktionssystemen_________144
4.5.1 Vorstellung der Verfahrensidee___________________________________144

Inhaltsverzeichnis
Seite 5
4.5.2 Ziele der Partitionierung ________________________________________ 1464.5.3 Vorstellung der Basisgrößen des Partitionierungsansatzes______________ 1474.5.4 Während des Simulationslaufes zu erfassende Meßgrößen _____________ 1484.5.5 Erfassung der Meßgrößen im Simulationsmodell_____________________ 1494.5.6 Auf Basis der erfaßten Meßgrößen berechenbare Größen ______________ 1494.5.7 Regelwerk zur Partitionierung ___________________________________ 1524.5.8 Ansatz zur Partitionierung von Simulationsmodellen von
Produktionssystemen auf Basis der vorgestellten Meßgrößen und Regeln _ 1584.5.8.1 Übersicht über den Algorithmus zur Partitionierung __________________1594.5.8.2 Schritt 1 - Aufbau eines aktualisierten Produktionssystemgraphen _______1594.5.8.3 Schritt 2a - Partitionsmeßdaten an den Knoten und Kanten des
Produktionssystemgraphen eintragen ______________________________1604.5.8.4 Schritt 2b - Anwendung der Partitionierungsregeln auf die Kanten des
Produktionssystemgraphen zur Ermittlung eines Bewertungsfaktors fürjede Kante ___________________________________________________162
4.5.8.5 Schritt 2c - Eröffnungsverfahren: Ermittlung der positiv bewertetenKanten zur Erstellung einer Startpartitionierung _____________________163
4.5.8.6 Schritt 2d - Auswahlverfahren: Bildung von zulässigen und günstigenPartitionierungsvarianten auf Basis der bewerteten Kanten _____________166
4.5.8.7 Schritt 2e - Bewertung der verbleibenden Varianten gemäß derZielkriterien der Partitionierung und Auswahl der anzuwendendenPartitionierungsvariante ________________________________________171
4.5.8.8 Schritt 3 - Bildung der Partitionen ________________________________172
4.6 Alternative Lösung mittels eines verteilten Experimentiersystems ___________ 1734.6.1 Motivation zum Einsatz eines verteilten Experimentiersystems _________ 1734.6.2 Einordnung des verteilten Experimentiersystems in das integrierte
Unterstützungssystem__________________________________________ 1754.6.3 Prinzipieller Lösungsansatz für ein verteiltes Experimentiersystem ______ 175
4.7 Zusammenfassung der Anforderungen an einen Lösungsansatz zur Parallelenund Verteilten Simulation von komplexen Produktionssystemen____________ 178
5 Implementation eines Prototypen zur simulationsbasiertenFertigungssteuerung komplexer Produktionssysteme mitHilfe der Parallelen Simulation _________________________1805.1 Implementation des Frameworks zur simulationsbasierten
Fertigungssteuerung als Unterstützungssystem zur Durchführung vonSimulationsstudien ________________________________________________ 1815.1.1 Überblick über die Komponenten des Frameworks ___________________ 1815.1.2 Das Framework aus Implementations-Sicht _________________________ 182
5.1.2.1 Grafische Benutzeroberfläche ___________________________________1825.1.2.2 Modellverwaltung und Verwaltungsdatenbank ______________________1835.1.2.3 Metadatenverwaltung und Metadatenbank__________________________1845.1.2.4 Modelldatenverwaltung ________________________________________1855.1.2.5 Datenimport-Komponente ______________________________________1855.1.2.6 Datenpflege-Komponente_______________________________________1865.1.2.7 Modelldatenbank _____________________________________________1865.1.2.8 Experimentplanungs-Komponente ________________________________1885.1.2.9 Experimentplandatenbank ______________________________________1905.1.2.10 Experimentdurchführungs-Komponente __________________________1915.1.2.11 Simulationsexperimentsteuerung ________________________________1935.1.2.12 Generator-Komponente _______________________________________195

Inhaltsverzeichnis
Seite 6
5.1.2.13 Simulationslaufsteuerung______________________________________ 1955.1.2.14 Simulationsausführungs-Komponente____________________________ 1965.1.2.15 Ergebnisaufbereitungs-Komponente _____________________________ 1975.1.2.16 Simulationsergebnisdateien ____________________________________ 1985.1.2.17 Laufergebnisdatenbank _______________________________________ 1995.1.2.18 Ergebnisaggregations-Komponente______________________________ 1995.1.2.19 Ergebnisdatenbank___________________________________________ 2005.1.2.20 Auswertungs-Komponente ____________________________________ 2015.1.2.21 Ergebnisübernahme-Komponente _______________________________ 201
5.1.3 Das Framework als Ausgangsbasis der simulationsbasiertenFertigungssteuerung komplexer Produktionssysteme__________________201
5.2 Entwicklung einer Simulationssoftware zur Parallelen Simulation vonkomplexen Produktionssystemen _____________________________________2025.2.1 Auswahl eines Implementationsansatzes____________________________2025.2.2 Das Tool ParSimONY als Ausgangsbasis ___________________________203
5.2.2.1 Grundlagen von ParSimONY ___________________________________ 2035.2.2.2 Wesentliche Bestandteile der Architektur von ParSimONY ____________ 2045.2.2.3 Funktionsprinzipien von ParSimONY_____________________________ 2115.2.2.4 Notwendige Anpassungen und Erweiterungen des Tools ParSimONY zu
ParSimONY-ProdSys _________________________________________ 2145.2.3 Dokumentation der Erweiterungen von ParSimONY zum Parallelen
Simulator für komplexe Produktionssysteme (ParSimONY-ProdSys)_____2155.2.3.1 Einbringung zusätzlicher Daten für die Simulation von
Produktionssystemen __________________________________________ 2155.2.3.2 Transfer der dynamischen Elemente des Bedienungssystems zwischen den
Logischen Prozessen __________________________________________ 2175.2.3.3 Kreierung einfacher benutzbarer Modellelemente____________________ 2185.2.3.4 Beachtung komplexer Prozeßbedingungen in den Modellelementen _____ 2205.2.3.5 Unterstützung der Erfassung und Aufbereitung von Ergebnisgrößen _____ 2215.2.3.6 Schaffung der Einsatzmöglichkeiten für verschiedenartigste
Reihenfolgeplanungsansätze ____________________________________ 2215.2.3.7 Lösung spezieller simulationstechnischer Probleme __________________ 226
5.3 Entwicklung eines integrierten Unterstützungssystem für dieFertigungssteuerung komplexer Produktionssysteme mittels Paralleler undVerteilter Simulation _______________________________________________2275.3.1 Ansatz zur Schaffung eines integrierten Unterstützungssystems für die
simulationsbasierte Fertigungssteuerung komplexer Produktionssysteme __2275.3.2 Integration des Simulators ParSimONY-ProdSys in das Framework zur
simulationsbasierten Fertigungssteuerung __________________________2295.3.3 Integration des Partitionierungsverfahrens für Produktionssysteme in den
Simulator ParSimONY-ProdSys __________________________________2325.3.4 Integration des Partitionierungsverfahrens für Produktionssysteme in das
Framework zur simulationsbasierten Fertigungssteuerung______________2335.3.5 Erweiterung des Simulations-Frameworks um den Aspekt einer verteilten
Experimentierumgebung ________________________________________2345.4 Ausblick auf Erweiterungen der prototypischen Lösung___________________238
5.4.1 Diskussion von Erweiterungen des Frameworks______________________2385.4.2 Ausblick auf Erweiterungen des Parallelen Simulators ParSimONY-
ProdSys _____________________________________________________239

Inhaltsverzeichnis
Seite 7
6 Empirische Untersuchung der Parallelen Simulation vonProduktionssystemen ________________________________2406.1 Performanceungewißheit als Motivationsfaktor für die empirische
Untersuchung ____________________________________________________ 2406.2 Einteilung der Modelle in Modellklassen ______________________________ 2416.3 Ergebnisse der empirischen Untersuchung _____________________________ 244
6.3.1 Überblick über die Testumgebungen ______________________________ 2446.3.2 Überblick über die Testmodelle __________________________________ 2446.3.3 Überblick über verwendeten Simulatoren und Synchronisationsverfahren _ 2456.3.4 Ergebnisse der Experimente mit dem Modell ModPerformance _________ 2456.3.5 Ergebnisse der Experimente mit dem Modell Mod11M________________ 2476.3.6 Ergebnisse der Experimente mit dem Modell ModKlein _______________ 2506.3.7 Ergebnisse der Experimente mit dem Modell ModKleineKetten_________ 2556.3.8 Ergebnisse der Experimente mit dem Modell KomplexMod ____________ 2576.3.9 Ergebnisse der Experimente mit dem Modell LinienMod ______________ 259
6.4 Diskussion der Ergebnisse der empirischen Untersuchung ________________ 263
7 Zusammenfassung ___________________________________2667.1 Überblick über die erreichten Ergebnisse ______________________________ 2667.2 Ausblick _________________________________________________________ 267
Anhang ______________________________________________271
Quellenverzeichnis ________________________________________301
Stichwortverzeichnis _______________________________________315

Abbildungsverzeichnis
Seite 8
Abbildungverzeichnis
Alle Abbildungen ohne explizite Quellenangabe sind durch den Autorselbst erstellte Abbildungen.
Abbildung 1 Regelkreis der Fertigungssteuerung ...................................................................... 27Abbildung 2 Das Reihenfolgeplanungsproblem an einem Beispiel............................................ 29Abbildung 3 Übersicht über elementare Planungsverfahren der Fertigungssteuerung ............. 30Abbildung 4 Bestandteile einer Prozeßführungsstrategie (Beispiel) .......................................... 30Abbildung 5 Ablauf einer Simulationsstudie ............................................................................... 33Abbildung 6 Elemente einer Simulation...................................................................................... 36Abbildung 7 Berechnung des Zeitbedarfs für eine Simulationsstudie........................................ 38Abbildung 8 Bestandteile einer Sequentiellen Simulation .......................................................... 40Abbildung 9 Verteilte Sequentielle Simulation - paralleles Experimentieren.............................. 41Abbildung 10 Bestandteile einer Parallelen bzw. Verteilten Simulation ....................................... 41Abbildung 11 Modellelemente eines Produktionssystems ........................................................... 46Abbildung 12 Statische Modellelemente....................................................................................... 47Abbildung 13 Dynamische Modellelemente ................................................................................. 48Abbildung 14 Semantische Darstellung der Elemente des Modells eines Produktions-
systems................................................................................................................... 49Abbildung 15 Semantische Darstellung der Beziehungen der dynamischen Elemente
Produkt, Auftrag, Los und Werkstück ..................................................................... 49Abbildung 16 Semantische Darstellung der Beziehungen zwischen den Elementen
Produkt, Arbeitsplan und Stückliste........................................................................ 49Abbildung 17 Semantische Darstellung der Zuordnung der für einen Arbeitsgang
benötigten Ressourcen........................................................................................... 50Abbildung 18 Semantische Darstellung der Zustände von Werkstücken .................................... 50Abbildung 19 Semantische Darstellung der Verbindungen des Elements der Maschinen-
gruppe..................................................................................................................... 51Abbildung 20 Semantische Darstellung der Transportelemente .................................................. 51Abbildung 21 Semantische Darstellung der Beziehungen der Werkerelemente ......................... 52Abbildung 22 Klassifikation der komplexen Prozeßbedingungen ................................................ 54Abbildung 23 Parallelisierung grobgranularer Aufgaben am Beispiel des verteilten Experi-
mentierens .............................................................................................................. 60Abbildung 24 Parallelisierung feingranularer Aufgaben am Beispiel der Parallelen und
Verteilten Simulation............................................................................................... 60Abbildung 25 Logischer Prozeß als Black-Box............................................................................. 71Abbildung 26 Beispiel einer Kommunikationstopologie zwischen Logischen Prozessen ............ 71Abbildung 27 Einteilung eines Logischen Prozesses in nebenläufige Substrukturen aus
Sicht der Kommunikation........................................................................................ 74Abbildung 28 Vorgehen bei konservativer Synchronisation ......................................................... 77Abbildung 29 Verbesserung der Performance konservativer Synchronisationsverfahren
durch Null-Messages .............................................................................................. 78Abbildung 30 Optimistisches Voranschreiten ............................................................................... 79Abbildung 31 Versenden von Anti-Messages............................................................................... 81Abbildung 32 Deadlock in einer zyklischen Topologie ................................................................. 83Abbildung 33 Beispiel eines Verfahrens zum Deadlock-Recovery .............................................. 84Abbildung 34 Berechnung der Global Virtual Time (GVT)............................................................ 86Abbildung 35 Entwicklungsstufen von Parallelisierungsprinzipien und Verteilungsansätzen ..... 96Abbildung 36 Entwicklungsstufen von Simulationsanwendungen................................................ 96

Abbildungsverzeichnis
Seite 9
Abbildung 37 Entwicklungsstufen der Implementationsansätze zur Parallelen undVerteilten Simulation............................................................................................... 96
Abbildung 38 Kategorien von Ansätzen der Parallelen und Verteilten Simulation....................... 97Abbildung 39 Einbettung des Frameworks in bestehende Informations- und Kommunika-
tionssysteme......................................................................................................... 119Abbildung 40 Architektur des Frameworks zur simulationsbasierten Fertigungssteuerung ...... 121Abbildung 41 Aufbau eines Experimentplans............................................................................. 121Abbildung 42 Prinzipieller Ablauf der Experimentdurchführung................................................. 123Abbildung 43 Änderungen in der Komponentenstruktur des Frameworks für die prototyp-
ische Lösung mittels Paralleler und Verteilter Simulation .................................... 125Abbildung 44 Beispiel der Topologie eines Fertigungssystems aus bedienungstheore-
tischer Sicht .......................................................................................................... 132Abbildung 45 Zusammenfassung von Quellen und Senken mit vor- bzw. nachgelagerten
Stationen zur Senkung des Kommunikationsaufwandes..................................... 133Abbildung 46 Abschätzung des minimalen Kommunikationsbedarfs aus der Topologie des
Fertigungssystems und dem Einsteuerungsvektor .............................................. 134Abbildung 47 Schematische Darstellung der Struktur und der Prozesse in einer Maschi-
nengruppe............................................................................................................. 135Abbildung 48 Schematische Darstellung der Zusammenhänge zwischen Ereignissen und
Berechnungslast in einem Modellelement „Maschinengruppe“ ........................... 136Abbildung 49 Lebensfadendiagramm der Logischen Prozesse einer Simulation...................... 138Abbildung 50 Parameter und Teilverfahren zur Lösung des Synchronisationsproblems .......... 142Abbildung 51 Vorgehen zur ex-post-Analyse eines Simulationslaufes zur Verbesserung
der Partitionierung ................................................................................................ 145Abbildung 52 Blockierungssituation an einer Station aufgrund noch ausstehender Nach-
richten ................................................................................................................... 149Abbildung 53 Hierarchie der Regeln zur Partitionierung ............................................................ 153Abbildung 54 Programmablaufplan zur Erstellung des aktualisierten Produktionssystem-
graphen................................................................................................................. 160Abbildung 55 Programmablaufplan zur Vervollständigung des Produktionssystemgraphen
mit den Meßdaten der Partitionierung .................................................................. 161Abbildung 56 Programmablaufplan zur Anwendung der Partitionierungsregeln auf die
Kanten des Produktionssystemgraphen............................................................... 162Abbildung 57 Prinzipskizze zur Verdeutlichung des Clusterings auf Basis der
Verbindungen des Produktionssystemgraphen ................................................... 164Abbildung 58 Programmablaufplan zur Ermittlung einer Startpartitionierung, Teil A -
Clustering gemäß der Verbindungskanten des Produktionssystemgraphen....... 164Abbildung 59 Programmablaufplan zur Ermittlung einer Startpartitionierung, Teil B -
Zusammenfassung der Cluster ............................................................................ 165Abbildung 60 Prinzipskizze zur Verdeutlichung der Zusammenfassung von Clustern auf
Basis von Verbindungskanten.............................................................................. 166Abbildung 61 Übersicht über die Teile des Algorithmus zur Aufstellung der
Partitionierungsvarianten...................................................................................... 167Abbildung 62 Teil A des Algorithmus zur Aufstellung der Partitionierungsvarianten -
Bildung der Variantenliste auf Basis positiv bewerteter Kanten........................... 168Abbildung 63 Prinzipskizze zum Aufbau der Partitionierungsvariantenliste .............................. 169Abbildung 64 Teil B des Algorithmus zur Aufstellung der Partitionierungsvarianten - Redu-
zierung der Variantenliste auf Basis negativ bewerteter Kanten ......................... 169Abbildung 65 Teil C des Algorithmus zur Aufstellung der Partitionierungsvarianten -
Vervollständigung der Varianten der Variantenliste mit bisher keinem Clusterzugeordneten Knoten ........................................................................................... 170
Abbildung 66 Programmablaufplan zur Bewertung der Partitionierungsvarianten undErmittlung der günstigsten Variante ..................................................................... 171
Abbildung 67 Prinzipielle Struktur eines verteilten Experimentiersystems................................. 174

Abbildungsverzeichnis
Seite 10
Abbildung 68 Lebensfadendiagramm zur parallelen Ausführung mehrerer Simulations-experimente auf mehreren Rechnern................................................................... 174
Abbildung 69 Entity-Relationship-Model der Bestandteile einer Simulationsstudie ................... 176Abbildung 70 Zuordnung der Funktionalitäten des verteilten Experimentiersystems zum
zentralen Steuerrechner bzw. den Simulationsausführungsrechnern ................. 177Abbildung 71 Detaillierte Struktur des Frameworks ................................................................... 182Abbildung 72 In die Benutzeroberfläche der Simulations-Shell eingebundene Kompo-
nenten ................................................................................................................... 183Abbildung 73 Entity-Relationship-Model der Metadatenbank .................................................... 184Abbildung 74 Die Komponente der Modelldatenverwaltung ...................................................... 185Abbildung 75 Die Datenimport-Komponente .............................................................................. 185Abbildung 76 Die Datenpflege-Komponente .............................................................................. 186Abbildung 77 Semantische Darstellung der Beziehungen der Tabellen der Modelldaten-
bank ...................................................................................................................... 187Abbildung 78 Übersicht über die Datenobjekte der Datenzugriffs-Komponente der Modell-
datenbank ............................................................................................................. 188Abbildung 79 Die Experimentplanungs-Komponente................................................................. 189Abbildung 80 Zusammenhänge der Daten in der Experimentplanung....................................... 189Abbildung 81 Semantische Darstellung der Beziehungen der Tabellen der Experiment-
plandatenbank ...................................................................................................... 191Abbildung 82 Aufbau der Experimentdurchführungs-Komponente ............................................ 191Abbildung 83 Aufbau der Experimentplandurchführungs-Komponente ..................................... 192Abbildung 84 Programmablaufplan der Experimentdurchführungs-Komponente...................... 193Abbildung 85 Programmablaufplan der Simulationsexperimentsteuerung ................................ 194Abbildung 86 Die Generator-Komponente ................................................................................. 195Abbildung 87 Programmablaufplan der Simulationslaufsteuerung ............................................ 196Abbildung 88 Die Simulationsausführungs-Komponente ........................................................... 196Abbildung 89 Die Ergebnisaufbereitungs-Komponente ............................................................. 197Abbildung 90 Detaillierter Aufbau der Ergebnisaufbereitungs-Komponente.............................. 198Abbildung 91 Die Ergebnisaggregations-Komponente .............................................................. 200Abbildung 92 Datenflüsse zwischen der Laufergebnisdatenbank und der Ergebnisdaten-
bank während der Ergebnisaggregation .............................................................. 200Abbildung 93 Die Auswertungs-Komponente............................................................................. 201Abbildung 94 Die Ergebnisübernahme-Komponente ................................................................. 201Abbildung 95 ParSimONY-Grundarchitektur .............................................................................. 205Abbildung 96 Grundbestandteile eines ParSimONY-Modells .................................................... 206Abbildung 97 Übersicht über die Modellelemente in ParSimONY ............................................. 208Abbildung 98 Beispiel eines Bedienungsnetzwerks mit ParSimONY-Grundelementen ............ 210Abbildung 99 Arbeitsweise der Channels in ParSimONY .......................................................... 210Abbildung 100 UML-Interaktionsdiagramm zur Arbeitsweise eines Channels in ParSimONY.... 211Abbildung 101 UML-Interaktionsdiagramm für ein Beispiel der Ereignismechanismen .............. 212Abbildung 102 UML-Interaktionsdiagramm eines Beispiels für Nachrichten und Ereignis-
mechanismen in ParSimONY............................................................................... 213Abbildung 103 Stufenweise Erweiterung von ParSimONY .......................................................... 214Abbildung 104 Darstellung der semantischen Beziehungen zwischen den Klassen, Teil 1 ........ 215Abbildung 105 Darstellung der semantischen Beziehungen zwischen den Klassen, Teil 2 ........ 216Abbildung 106 Darstellung der semantischen Beziehungen zwischen den Klassen, Teil 3 ........ 216Abbildung 107 Zusätzliche Modellelemente ................................................................................. 218Abbildung 108 Beispiel eines Bedienungssystems unter Verwendung der ParSimONY-
Zusatzelemente .................................................................................................... 219Abbildung 109 Das Modellelement „StationsKette“ zur Abbildung von Partitionen von
Bedienstationen .................................................................................................... 220

Abbildungsverzeichnis
Seite 11
Abbildung 110 Das Modellelement „Werkstatt“ zur Abbildung von Partitionen von Bedien-stationen ............................................................................................................... 220
Abbildung 111 Semantischen Beziehungen zwischen den Klassen zur Priorisierung undReihenfolgeplanung, Übersicht ............................................................................ 222
Abbildung 112 Semantische Beziehungen zwischen den Java-Klassen zur Priorisierungund Reihenfolgeplanung, Priorisierung der Lose ................................................. 223
Abbildung 113 Semantische Beziehungen zwischen den Klassen zur Priorisierung undReihenfolgeplanung, Zusammenhang zwischen Los und Batch ......................... 224
Abbildung 114 Semantische Beziehungen zwischen den Klassen zur Priorisierung undReihenfolgeplanung, Zusammenfassung der Lose zu Batchs............................. 225
Abbildung 115 Semantische Beziehungen zwischen den Klassen zur Priorisierung undReihenfolgeplanung, Zuordnung von Batchs zu Maschinen................................ 226
Abbildung 116 Verknüpfung von Simulationsprogrammgenerator und Partitionierungsver-fahren für den Parallelen Simulator ParSimONY-ProdSys im Framework zursimulationsbasierten Fertigungssteuerung........................................................... 228
Abbildung 117 Struktur des ParSimONY-Simulationsmodell-Generators.................................... 231Abbildung 118 Integration des Partitionierungsverfahrens in die Generator-Komponente des
Frameworks .......................................................................................................... 234Abbildung 119 Ergänzung des Frameworks um zusätzliche Komponenten zur Erweiterung
des Frameworks zu einem verteilten Experimentiersystem................................. 236Abbildung 120 Erweiterung des Frameworks um zusätzliche Komponenten .............................. 238Abbildung 121 Ausprägungen der Parametergruppen zur Beschreibung der Modellkomple-
xität (Region A hervorgehoben)............................................................................ 243Abbildung 122 Übersicht über die verwendeten Synchronisationsverfahren............................... 245Abbildung 123 Struktur des Modells Mod11M.............................................................................. 248Abbildung 124 Einteilung des Modells Mod11M in Logische Prozesse ....................................... 248Abbildung 125 Struktur des Beispielmodells ModKlein ................................................................ 251Abbildung 126 Einteilung des Modells ModKlein in Partitionen ................................................... 251Abbildung 127 Auswirkung des Zeitbedarfs für den Reihenfolgeplanungsansatz auf die
Ausführungsdauer der Simulation des Modells Mod11M..................................... 255Abbildung 128 Partitionierungsvarianten des Modells ModKleineKetten..................................... 256Abbildung 129 Vereinfachte Struktur des Modells KomplexMod ................................................. 258Abbildung 130 Struktur des Modells LinienMod ........................................................................... 260Abbildung 131 Einteilung des Modells LinienMod in Logische Prozesse .................................... 261Abbildung 132 Abarbeitungsdauer des Beispielmodells LinienMod in Abhängigkeit von
Simulationsdauer und Partitionierung .................................................................. 262Abbildung 133 Abarbeitungsdauer des Beispielmodells LinienMod in Abhängigkeit von
Simulationsdauer und Einlastung......................................................................... 262Abbildung 134 Abarbeitungsdauer des Beispielmodells LinienMod in Abhängigkeit von der
Berechnungsdauer des Reihenfolgeplanungsansatzes und der Partitionie-rung....................................................................................................................... 263
Abbildung 135 Übersicht über Verteilungsfunktionen in ParSimONY.......................................... 276Abbildung 136 Beispiel eines ParSimONY-Simulationsmodells, Teil 1 ....................................... 279Abbildung 137 Beispiel eines ParSimONY-Simulationsmodells, Teil 2 ....................................... 280Abbildung 138 Beispiel eines ParSimONY-Simulationsmodells, Teil 3 ....................................... 281Abbildung 139 Zusammenhänge der Datenbanken im Framework............................................. 283

Tabellenverzeichnis
Seite 12
Tabellenverzeichnis
Alle Tabellen ohne explizite Quellenangabe sind durch den Autor selbsterstellte Tabellen.
Tabelle 1 Sequentielle versus Parallele / Verteilte Simulation ............................................... 39Tabelle 2 An einer Maschinengruppe auftretende Ereignisse ............................................. 135Tabelle 3 Prioritätsklassen von Ereignissen......................................................................... 227Tabelle 4 Abarbeitungsplattformen....................................................................................... 244Tabelle 5 Abarbeitungsgeschwindigkeit [in Simulationsereignissen je Millisekunde] des
Modells ModPerformance auf verschiedenen Plattformen .................................. 246Tabelle 6 Abarbeitungsgeschwindigkeit [in Simulationsereignissen je Millisekunde] des
Modells ModPerformance in einem Rechnernetz ................................................ 247Tabelle 7 Arbeitspläne und Bearbeitungszeiten [in Minuten] der Produkte im Modell
Mod11M................................................................................................................ 248Tabelle 8 Ausführungszeit [in Sekunden] des Modells Mod11M ......................................... 249Tabelle 9 Arbeitspläne im Beispielmodell ModKlein............................................................. 251Tabelle 10 Abarbeitungsdauer [in Sekunden] des Modells ModKlein.................................... 252Tabelle 11 Abhängigkeit des Speedups von der Simulationsdauer....................................... 252Tabelle 12 Abhängigkeit des Speedups von der Einsteuerung ............................................. 252Tabelle 13 Abhängigkeit des Speedups von der Einsteuerung bei der Ausführung auf
dem Computeserver ............................................................................................. 253Tabelle 14 Abhängigkeit des Speedups von den Bearbeitungszeiten................................... 254Tabelle 15 Abhängigkeit des Speedups von der Berechnungsdauer des verwendeten
Reihenfolgeplanungsansatzes ............................................................................. 254Tabelle 16 Vergleich der Speedups bei unterschiedlicher Partitionierung des
Beispielmodells ModKleineKetten ........................................................................ 256Tabelle 17 Abarbeitungsdauer des Beispielmodells KomplexMod mit niedriger Ein-
lastung auf dem Mehrprozessorrechner............................................................... 259Tabelle 18 Abarbeitungsdauer des Beispielmodells KomplexMod mit hoher Einlastung
auf dem Mehrprozessorrechner ........................................................................... 259Tabelle 19 In ParSimONY vorhandene Statistik-Objektklassen ............................................ 278Tabelle 20 In ParSimONY vorhandene Ereignislistentypen................................................... 279Tabelle 21 Übersicht über die benutzerdefinierten Datentypen, Teil 1 .................................. 282Tabelle 22 Übersicht über die benutzerdefinierten Datentypen, Teil 2 .................................. 283Tabelle 23 Tabelle „Modell“ der Verwaltungsdatenbank........................................................ 284Tabelle 24 Tabelle „Strategien“ der Metadatenbank.............................................................. 284Tabelle 25 Tabelle „Strategie_Parameter“ der Metadatenbank ............................................. 284Tabelle 26 Tabelle „Strategie_Parameter_Bereich“ der Metadatenbank............................... 284Tabelle 27 Tabelle „Strategie_Parameter _Tabelle“ der Metadatenbank .............................. 285Tabelle 28 Tabelle „Verteilungen“ der Metadatenbank .......................................................... 285Tabelle 29 Tabelle „Verteilungs_Parameter“ der Metadatenbank ......................................... 285Tabelle 30 Tabelle „Grundparameter“ der Modelldatenbank ................................................. 285Tabelle 31 Tabelle „Produkttyp“ der Modelldatenbank .......................................................... 286Tabelle 32 Tabelle „Arbeitsplan“ der Modelldatenbank.......................................................... 286Tabelle 33 Tabelle „Auftrag“ der Modelldatenbank ................................................................ 286Tabelle 34 Tabelle „Los“ der Modelldatenbank ...................................................................... 287Tabelle 35 Tabelle „Maschinengruppe“ der Modelldatenbank............................................... 287Tabelle 36 Tabelle „Maschine“ der Modelldatenbank ............................................................ 287Tabelle 37 Tabelle „Uebergangszeit“ der Modelldatenbank .................................................. 288Tabelle 38 Tabelle „BearbMoeglichkeit“ der Modelldatenbank.............................................. 288

Tabellenverzeichnis
Seite 13
Tabelle 39 Tabelle „Setupgruppen“ der Modelldatenbank..................................................... 288Tabelle 40 Tabelle „Ruestzeiten_zwischen_Gruppen“ der Modelldatenbank ....................... 288Tabelle 41 Tabelle „Ruestzeit_in_Gruppe“ der Modelldatenbank.......................................... 288Tabelle 42 Tabelle „Anfangsbelegung_Auftrag“ der Modelldatenbank.................................. 288Tabelle 43 Tabelle „Anfangsbelegung_Los“ der Modelldatenbank........................................ 289Tabelle 44 Tabelle „Anfangsbelegung_Wartend“ der Modelldatenbank................................ 289Tabelle 45 Tabelle „Anfangsbelegung_Arbeitend“ der Modelldatenbank.............................. 289Tabelle 46 Tabelle „Versuchsplan“ der Experimentplandatenbank ....................................... 289Tabelle 47 Tabelle „Versuchsreihe“ der Experimentplandatenbank...................................... 290Tabelle 48 Tabelle „Plan_zu_Reihe“ der Experimentplandatenbank..................................... 290Tabelle 49 Tabelle „Versuch“ der Experimentplandatenbank................................................ 290Tabelle 50 Tabelle „Einsteuerungsvarianten“ der Experimentplandatenbank ....................... 290Tabelle 51 Tabelle „Einsteuerungsreihe“ der Experimentplandatenbank.............................. 290Tabelle 52 Tabelle „Gesamt_Einsteuerung_Variation“ der Experimentplandatenbank......... 291Tabelle 53 Tabelle „Gesamt_Einst_Produktverteilung“ der Experimentplandatenbank ........ 291Tabelle 54 Tabelle „Produktvektor_Einst_Variation“ der Experimentplandatenbank ............ 291Tabelle 55 Tabelle „Strategievarianten“ der Experimentplandatenbank................................ 291Tabelle 56 Datei „Lauf_Los“ der Simulationsergebnisdateien ............................................... 292Tabelle 57 Datei „Lauf_Auftrag“ der Simulationsergebnisdateien ......................................... 292Tabelle 58 Datei „Lauf_Produkttyp“ der Simulationsergebnisdateien.................................... 292Tabelle 59 Datei „Lauf_Maschinen“ der Simulationsergebnisdateien.................................... 293Tabelle 60 Datei „Lauf_Maschinengruppen“ der Simulationsergebnisdateien ...................... 293Tabelle 61 Tabelle „Lauf_Los“ der Laufergebnisdatenbank .................................................. 294Tabelle 62 Tabelle „Lauf_Auftrag“ der Laufergebnisdatenbank............................................. 294Tabelle 63 Tabelle „Lauf_Produkttyp“ der Laufergebnisdatenbank....................................... 294Tabelle 64 Tabelle „Lauf_Maschinen“ der Laufergebnisdatenbank....................................... 295Tabelle 65 Tabelle „Lauf_Maschinengruppen“ der Laufergebnisdatenbank ......................... 295Tabelle 66 Tabelle „Erg_Los“ der Ergebnisdatenbank, Teil 1................................................ 295Tabelle 67 Tabelle „Erg_Los“ der Ergebnisdatenbank, Teil 2................................................ 296Tabelle 68 Tabelle „Erg_Auftrag“ der Ergebnisdatenbank..................................................... 296Tabelle 69 Tabelle „Erg_Produkttyp“ der Ergebnisdatenbank ............................................... 297Tabelle 70 Tabelle „Erg_Alle_Lose“ der Ergebnisdatenbank ................................................ 298Tabelle 71 Tabelle „Erg_Maschine“ der Ergebnisdatenbank................................................. 299Tabelle 72 Tabelle „Erg_Maschinengruppen“ der Ergebnisdatenbank ................................. 299Tabelle 73 Tabelle „Erg_Alle_Maschinen“ der Ergebnisdatenbank....................................... 300
Formelverzeichnis
Formel 1 Das Speedup als Maß der beschleunigten Simulationsausführung ...................... 43Formel 2 Verhältnis zwischen Kommunikationsdauer und Berechnungsaufwand ............... 69Formel 3 Verhältnis zwischen partitionsinternen und partitionsexternen Ereignissen .......... 70

Symbolverzeichnis
Seite 14
Symbolverzeichnis
α Bestimmtheitsfaktor einer Regel, α ∈ [ ; ]0 1
ε Schwellwert für das Verhältnis zwischen Kommunikationsdauer und Berech-nungsaufwand, siehe Formel 2 auf Seite 69
λ Ankunftsrate von Forderungen in einem Bedienungssystem
µ Bedienrate eines Bedienungssystems
ρ Anzahl der Prozessoren bzw. Computer, auf denen das Simulationsmodell ab-gearbeitet werden soll
ABS j Anzahl der Situationen, in denen die Station sj aufgrund nicht vorhandener
Nachrichten blockierte
ABSij Anzahl der Situationen, in denen die Station sj aufgrund nicht vorhandener
Nachrichten von der Station si blockierte
AES j Anzahl der Entscheidungssituationen an der Stationen sj
AES AGS ABSj j j= +
AGS Gesamtanzahl der Garantiesituationen
AGS AGS jj
N
==
∑1
AGS j Anzahl der Situationen, in denen Garantien der vorgelagerten Stationen an der
Station sj vorlagen
BG Beladegröße einer Batch-Maschine
BH j Blockierungshäufigkeit an der Station sj [%]
( )BHABS
AESGH BHj
j
jj
i
N
ijMAX= = − ==
11
BHij Blockierungshäufigkeit an der Station sj aus Richtung der Station si [%]
BHABS
ABSij
ij
j
=
BLx Berechnungslast durch das Ereignis x ausgelöst wird
BLAnk Berechnungslast durch das Ereignis Ankunft eines Auftrages an einer Station
BLBB Berechnungslast durch das Ereignis Beginn der Bearbeitung
BLBE Berechnungslast durch das Ereignis Ende der Bearbeitung
BLDB Berechnungslast durch das Ereignis Beginn eines Defektes
BLDE Berechnungslast durch das Ereignis Ende eines Defektes
BLRB Berechnungslast durch das Ereignis Beginn des Umrüstens
BLRE Berechnungslast durch das Ereignis Ende des Umrüstens
BLRF Berechnungslast durch das Ereignis Auswahl des als nächstes durch die Stationzu bearbeitenden Auftrages (Reihenfolgeentscheidung)
DX(x) Standardabweichung der Größe x

Symbolverzeichnis
Seite 15
DX2(x) Streuung der Größe x
E Menge der Experimente einer Simulationsstudie, E:={e1,e2,...}
ei i-tes Experiment der Experimentmenge E
Ex Ereignis x
Eintern(pi) Menge der partitionsinternen Ereignisse der Partition pi
Eextern(pi) Menge der partitionsexternen Ereignisse der Partition pi
EM durchschnittliche Anzahl von Nachrichten, die eine Station empfängt
EMEM
W
ii
N
= =∑
1
EM j Anzahl der Nachrichten, die von der Station sj empfangen wurden
(Empfangsmenge)
EM KMj ijA
i
N
==∑
1
EX(x) Erwartungswert der Größe x
fan_inj Anzahl der Eingänge der Station sj
fan in wj iji
N
_ ==∑
1
fan_outj Anzahl der Ausgänge der Station sj
fan out wj jii
N
_ ==∑
1
GES Gesamtanzahl an Entscheidungssituationen, Anzahl der Ereignisse im gesam-ten Modell bei Ausführung des Modells
GES AES jj
N
==
∑1
GH j Garantiehäufigkeit an der Station sj [%]
( )GHAGS
AES
AES ABS
AESBH GHj
j
j
j j
jj
i
J
ijMIN= =−
= − ==
11
GHij Garantiehäufigkeit an der Station sj aus Richtung der Station si [%]
GHAES ABS
AESij
j ij
j
=−
GKM Gesamtkommunikationsmenge, ist äquivalent zu KMA wenn die StationsmengeS der Menge der Maschinengruppen MG entspricht
( )GKM KM
EM SMijA
j
L
i
L j jj
L
= =+
==
=∑∑ ∑11
1
2
GR Garantierate [%]
GRAGS
AES=
GVT Global Virtual Time, siehe Punkt 3.1.3.6, Seite 86

Symbolverzeichnis
Seite 16
KDij mittlerer Zeitabstand zwischen der Übertragung von Nachrichten zwischen denStationen si und sj (Kommunikationsdauer)
KM A Kommunikationsmenge des gesamten Modells (Gesamtanzahl der übertrage-nen Nachrichten)
( )KM KM
EM SMA
ijA
j
N
i
N j jj
N
= =+
==
=∑∑∑
11
1
2
KM B Kommunikationsmenge des gesamten Modells (Gesamtmenge in Bytes)
KM KMBijB
j
N
i
N=
== ∑∑ 11
KMijA Anzahl der Nachrichten im Austausch zwischen den Stationen si und sj
(Kommunikationsmenge)
KM i jijA = =0 (keine Kommunikation mit sich selbst)
KMijB Menge der Bytes im Austausch zwischen den Stationen si und sj
(Kommunikationsmenge)
KM i jijB = =0 (keine Kommunikation mit sich selbst)
KM ijB
durchschnittliche Menge der Bytes im Austausch zwischen den Stationen si
und sj
KMKM
KMi jij
B ijB
ijA= ≠
KM i jijB = =0
L Anzahl der Maschinengruppen im Simulationsmodell, L= |MG|
LPx Logischer Prozeß x
M Anzahl der Partitionen, M= |P|
MG Menge der Maschinengruppen, MG={mg1,mg2...mgL}
N die Anzahl der Stationen, N= |S|
ni Anzahl der Wiederholungen des Experimentes ei
OSGH Schrankenwert zur Beurteilung der Garantiehäufigkeit (GH) als hoch
OSGR Schrankenwert zur Beurteilung der Garantierate (GR) als hoch
OSREM Schrankenwert zur Beurteilung der Relativen Empfangsmenge (REM) als hoch
P Menge der Partitionen, P={p1,p2...pM}
pi Partition i
REMij relativer Anteil [%] der Kommunikation von der Station si zur Station sj an der
Gesamtanzahl der Nachrichten für Station sj
REMKM
EMij
ijA
j
=
RKM resultierende Kommunikationsmenge (nur die Kommunikation zwischen denPartitionen)
RKM KMijA
j
N
i
N=== ∑∑ 11
| ( ) ( ) ( )s p s p p pi a j b a b∈ ∧ ∈ ∧ ≠

Symbolverzeichnis
Seite 17
RSMij relativer Anteil [%] der Kommunikation von der Station si zur Station sj an der
Gesamtanzahl der Nachrichten von Station si
RSMKM
SMij
ijA
i
=
S Menge der Stationen, S={s1,s2...sN}
SAB Speedup durch die Ausführung des Simulationsmodell mit dem Simulator Astatt mit dem Simulator B
ABA
BS Z
Z=
SD Simulationsdauer in Simulationszeiteinheiten
SM durchschnittliche Anzahl von Nachrichten, die eine Arbeitsstation sendet
SMSM
W
ii
N
= =∑
1
SM j Anzahl der Nachrichten, die von der Station sj gesendet wurden (Sendemenge)
SM KMj jiA
i
N
==∑
1
t aktueller Zeitpunkt
Takt aktueller Zeitpunkt
TB Bearbeitungszeit
TD Defektzeit
Tglobal globale Zeit im Simulationsmodell
TL Leerzeit
Tlokal lokale Zeit eines Logischen Prozesses
TR Rüstzeit
TReal Realzeit
TSIM Simulationszeit
TW Wartezeit
TA mittlerer Teilaufwand einer Station
TA
TA
M
jj
M
= =∑
1
TAj Teilaufwand an der Station sj [%]
TAAES
GESj
j=
USGH Schrankenwert zur Beurteilung der Garantiehäufigkeit (GH) als niedrig
USGR Schrankenwert zur Beurteilung der Garantierate (GR) als niedrig
USREM Schrankenwert zur Beurteilung der Relativen Empfangsmenge (REM) als nied-rig

Symbolverzeichnis
Seite 18
VG Der Vernetzungsgrad gibt an, in welchem Maße die Stationen miteinander ver-netzt sind. Bei N Stationen sind prinzipiell N2 Wege möglich, diese werden je-doch nicht alle benutzt.
VGW
N= 2
W Anzahl der benutzten Kommunikationswege
W wijj
N
i
N
===
∑∑11
; ];1[ 2NNW −∈ mit
w i jij = =0
w KMij ijA= >1 0
w KMij ijA= =0 0
Zx Zeit für die Ausführung mit dem Simulator x
ZB(x) Zeitbedarf für die Ausführung von x
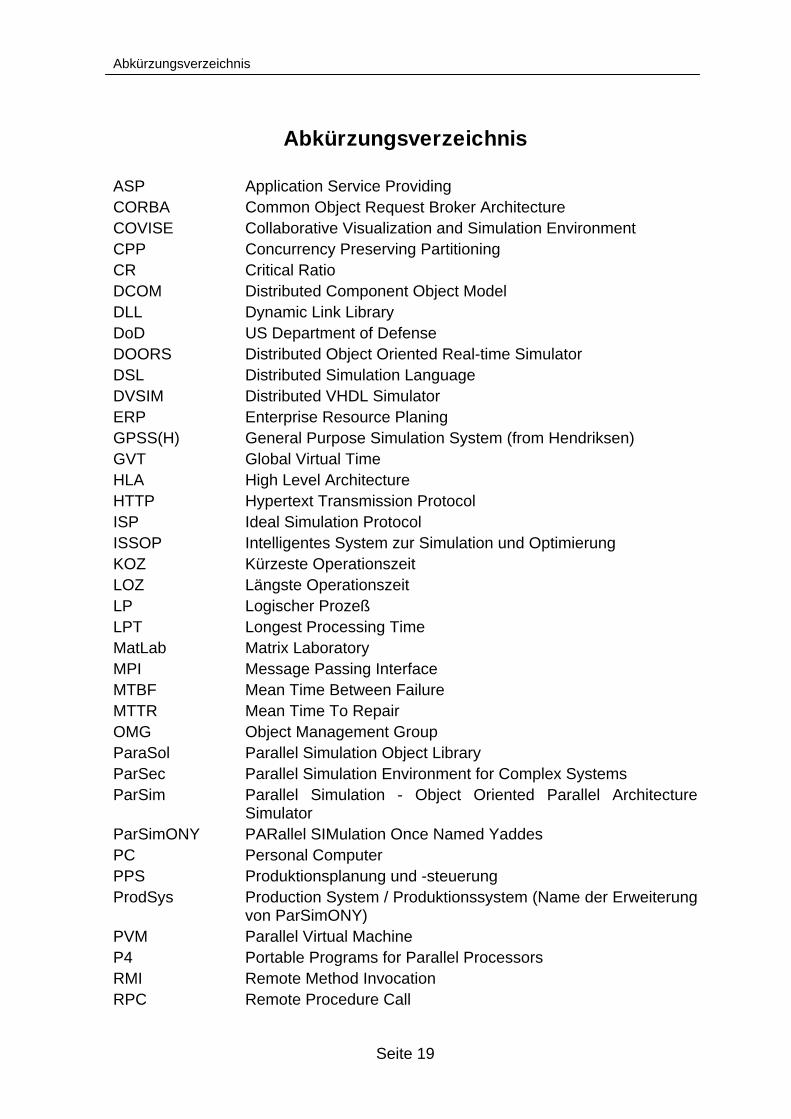
Abkürzungsverzeichnis
Seite 19
Abkürzungsverzeichnis
ASP Application Service ProvidingCORBA Common Object Request Broker ArchitectureCOVISE Collaborative Visualization and Simulation EnvironmentCPP Concurrency Preserving PartitioningCR Critical RatioDCOM Distributed Component Object ModelDLL Dynamic Link LibraryDoD US Department of DefenseDOORS Distributed Object Oriented Real-time SimulatorDSL Distributed Simulation LanguageDVSIM Distributed VHDL SimulatorERP Enterprise Resource PlaningGPSS(H) General Purpose Simulation System (from Hendriksen)GVT Global Virtual TimeHLA High Level ArchitectureHTTP Hypertext Transmission ProtocolISP Ideal Simulation ProtocolISSOP Intelligentes System zur Simulation und OptimierungKOZ Kürzeste OperationszeitLOZ Längste OperationszeitLP Logischer ProzeßLPT Longest Processing TimeMatLab Matrix LaboratoryMPI Message Passing InterfaceMTBF Mean Time Between FailureMTTR Mean Time To RepairOMG Object Management GroupParaSol Parallel Simulation Object LibraryParSec Parallel Simulation Environment for Complex SystemsParSim Parallel Simulation - Object Oriented Parallel Architecture
SimulatorParSimONY PARallel SIMulation Once Named YaddesPC Personal ComputerPPS Produktionsplanung und -steuerungProdSys Production System / Produktionssystem (Name der Erweiterung
von ParSimONY)PVM Parallel Virtual MachineP4 Portable Programs for Parallel ProcessorsRMI Remote Method InvocationRPC Remote Procedure Call

Abkürzungsverzeichnis
Seite 20
RTI Runtime InterfaceR/3 Realtime, Release 3SAP Systeme, Anwendungen und Produkte in der DatenverarbeitungSimBa Simulation Backplane for Heterogeneous SystemsSLX Simulation Language with eXtensibilitiesSPEEDES Synchronous Parallel Environment for Emulation and Discrete
Event SimulationSPT Shortest Processing TimeUS, USA United States of AmericaVHDL VHSIC Hardware Description LanguageVHSIC Very High Speed Integrated CircuitsVRML Virtual Reality Modeling LanguageXML Extensible Markup LanguageYADDES Yet Another Distributed Discrete Event SimulatorZB ZeitbedarfZE Zeiteinheit

Kapitel 1 Einleitung
Seite 21
1 Einleitung
1.1 Motivation und ZielsetzungHeutige Unternehmen leben in einem dynamischen Umfeld. Die Fertigungssteuerung siehtsich einer immer schwieriger lösbaren Aufgabe gegenüber [Adam 1992, S. 317f]:
„Zunehmend gesättigte Märkte führten in den letzten Jahren verstärkt zu einer kunden-orientierten Auftragsproduktion mit einer Vielzahl von Produkten und Varianten. Gleich-zeitig fragten die Kunden häufig komplette Problemlösungen nach. Diese strukturellenEntwicklungen führen die Produktion zu drei eng miteinander verknüpften Entwicklungen,welche die Produktionssteuerung komplexer werden lassen.
• Starke Zunahme der mengenmäßig und zeitlich zu koordinierenden Rohstoffe undBauteile für die Fertigung;
• zunehmend vernetzte Produktionsstrukturen;• produktionstechnologische Veränderungen (flexible Fertigungssysteme).“
Diese Trends verstärken sich bis heute noch. Von den Unternehmen wird mehr Flexibilitätin Bezug auf die Reaktion auf Kundenwünsche sowie die Abstimmung eines wachsenden,stark schwankenden Produktionsprogramms gemäß ökonomischer Aspekte erwartet. D.h.,die Aufgabe der Fertigungssteuerung1 wird immer komplizierter. Verschärft wird diesesProblem dadurch, daß bislang kein praktikables exaktes Lösungsverfahren für die Reihen-folgeplanung existiert. Die in der Praxis eingesetzten Heuristiken zur Lösung des Reihen-folgeproblems - insbesondere Prioritätsregeln - bilden jedoch die Gegebenheiten der mo-dernen Produktionssysteme nur unzureichend ab. Heutige Produktionssysteme sind viel-mals durch das Auftreten spezieller Prozeßbedingungen2 wie Parallelbearbeitung, Rüst-und Beladeproblematiken, Liegezeitbegrenzungen u.v.a.m. gekennzeichnet. Prioritäts-regeln sind i.d.R. nicht in der Lage, situationsbezogen - unter Beachtung der auftretendenProzeßbedingungen - zu reagieren. An dieser Stelle ist es erforderlich, genauere, detail-liertere Modelle und Steuerungsansätze zu entwerfen und einzusetzen [Fowler, Phillips,Hogg 1992], [Gurnani, Anupindi, Akella 1992], [Holthaus, Ziegler 1993]. Dies erhöhtnochmals die Komplexität des Lösungsverfahrens [Page 1991, S. 22], [Smith 1999].Um die entworfenen Verfahren zu testen, bestehen zwei Möglichkeiten: Zum Einen wäreder Einsatz im Realsystem möglich. Problematisch daran ist, daß die Auswirkungen einerEntscheidung erst ex-post festgestellt werden können, diese Art von Test sehr langwierigund teuer und deshalb nicht praktikabel ist [Seelbach 1975, S. 150], [Kosturiak, Gregor1995, S. 16-17]. Die andere Möglichkeit ist ein simulativer Test der entworfenen Ver-fahren. Anhand eines Ersatzsystems - des Simulationsmodells - kann man im Voraus Maß-nahmen zur Behebung zukünftiger Mißstände testen. D.h., das Werkzeug Simulation wirdals Prognosemethode eingesetzt [Mehl 1994, S. 1], [Kosturiak, Gregor 1995, S. 15]. Dochauch für diese Vorgehensweise bestehen Probleme. Um an einem Simulationsmodell zuhinreichend genauen Aussagen über das modellierte Realsystem zu kommen, ist es not-wendig, die Realität im Modell adäquat abzubilden [VDI 3633], [Page 1991, S. 22], [Smith1999]. Dieser Prozeß der Modellerstellung ist sehr aufwendig und erfordert i.d.R. einenSimulationsexperten [Page 1991, S. 145-156], [Kosturiak, Gregor 1995, S. 65], [Kobylka,Gäse, Wirth 2000]. Anschließend sind die zu testenden Reihenfolgeplanungsansätze imSimulationsmodell zu implementieren. Als letztes Problem verbleibt, daß Simulations- 1 Siehe dazu Punkt 2.1.2.2 Siehe dazu Punkt 2.3.2.3.

Kapitel 1 Einleitung
Seite 22
modelle für heutige Produktionssysteme sehr komplex sind, demzufolge einen hohen nu-merischen Aufwand für ihre Abarbeitung erfordern und deshalb eine hohe Laufzeit besit-zen [Fujimoto 1999], [Smith 1999]. Erschwerend kommt hinzu, daß Simulation lediglichprognostiziert, wie sich das Realsystem unter den momentanen Umständen und dem gege-benen Reihenfolgeplanungsansatz verhalten wird. Eine optimale Steuerungsstrategie fürdas Produktionssystem kann jedoch nicht durch einen einzelnen Simulationslauf gefundenwerden. Zur Ermittlung der optimalen Steuerungsstrategie ist die Kopplung der Simulationmit einem Suchverfahren notwendig. D.h., durch das Suchverfahren werden Parameter zurSteuerung des Produktionssystems variiert und die Auswirkung der veränderten Parame-tereinstellungen der Steuerungsstrategie werden simulativ getestet. Dies bedingt eine Viel-zahl von Simulationsläufen, der Zeitbedarf für die Ermittlung der optimalen Steuerungs-strategie wächst [Page 1991, S. 9], [Kosturiak, Gregor 1995, S. 70]. Primär ergibt sich da-her für den Einsatz der Simulation im Gebiet der Fertigungssteuerung ein Zeitproblem[Krug, Wiedemann 2000].
Dies führt dazu, Ansätze zur Parallelisierung bzw. verteilten Abarbeitung von Programmenfür den Einsatz in der Simulation zu hinterfragen. Modelle von Produktionssystemen sindgekennzeichnet durch eine Vielzahl von parallel stattfindenden Aktivitäten - zur Abarb-eitung dieser Simulationsmodelle erfolgt bisher jedoch eine Sequentialisierung3. Ein Lö-sungsansatz ist hier der Einsatz der Parallelen und Verteilten Simulation zur beschleunig-ten Ausführung der Simulation [Unger 1988], [Nicol 1988], [Mehl 1994], [Holthaus, Ro-senberg, Ziegler 1996]. Bisher wird die Methodik der Parallelen und Verteilten Simulationerfolgreich bei der Simulation von logischen Schaltungen oder auch im militärischen Be-reich eingesetzt [Feldmann 1992], [Sporrer 1995], [Fröhlich, Schlagenhaft, Fleischmann1997], [HLA], [Dahmann, Fujimoto, Weatherly 1998]. Eine Anwendung zur Simulationvon Produktionssystemen - insbesondere im Kontext der Fertigungssteuerung - ist abernoch nicht erfolgt4.
Daher soll die vorliegende Arbeit die Basis für den Einsatz der Parallelen und VerteiltenSimulation zur simulationsbasierten Fertigungssteuerung schaffen. Hierbei soll der Fokusauf der Simulation komplexer Produktionssysteme liegen, einerseits um den wachsendenKomplexitätsanforderungen heutiger Produktionssysteme zu begegnen, andererseits istgerade bei komplexen Produktionssystemen ein hoher Geschwindigkeitsvorteil durch denEinsatz der Parallelen und Verteilten Simulation zu erwarten. Weiterhin soll der Nachweisder prinzipiellen Eignung der Parallelen und Verteilten Simulation bei Einsatz neuer, kom-plexer Reihenfolgeplanungsverfahren erbracht werden. Zu beachten ist hierbei, daß dieseneuen Reihenfolgeplanungsverfahren einen wesentlich höheren Berechnungsaufwand alsz.B. Prioritätsregeln erfordern. Hier ist die Vereinbarkeit dieser Fertigungssteuerungs-ansätze mit der Parallelen und Verteilten Simulation aufzuzeigen.Ziel der Arbeit ist es hierbei nicht, neue Lösungsansätze für das Reihenfolgeproblem inkomplexen Produktionssystemen zu entwickeln, sondern eine beschleunigte Abarbeitungder Simulation durch Parallelisierung bzw. Verteilung zu erreichen. Im weiteren Sinn istdarunter nicht ausschließlich die beschleunigte Abarbeitung eines einzelnen Laufs des Si-mulationsmodells zu verstehen, sondern die umfassende Unterstützung des Anwenderswährend der Durchführung einer gesamten Simulationsstudie5. D.h., der aufwendige ma-nuelle Prozeß der Modellerstellung soll beschleunigt und der Anwenders soll bei derDurchführung und Auswertung aller Simulationsexperimente einer Studie unterstützt wer-den, um insgesamt eine Simulationsstudie in wesentlich kürzerer Zeit abzuschließen. 3 Siehe „Ablaufsteuerung der Simulation“, Punkt 2.2.1.2.4 Vergleiche Punkt 3.2.3.5 Siehe dazu Punkt 4.2.1.

Kapitel 1 Einleitung
Seite 23
1.2 Aufbau der ArbeitUm den angesprochenen Methoden wie Fertigungssteuerung, Simulation und Parallelisie-rung sowie deren Problemen zu begegnen, ist die Arbeit wie folgt aufgebaut:
Das Kapitel 2 befaßt sich mit den Grundlagen der simulationsbasierten Fertigungssteue-rung. Im Unterkapitel 2.1 werden ausgehend vom Anliegen der simulationsbasierten Ferti-gungssteuerung, die Probleme der simulationsbasierten Fertigungssteuerung herausge-arbeitet. Hauptanliegen in der Arbeit ist die Lösung des Problems der langen Simulations-laufzeit. Ein potentielles Lösungsverfahren dafür ist die Parallele und Verteilte Simulation.Dazu werden im Unterkapitel 2.2 die Begrifflichkeiten und Voraussetzungen für die Simu-lation geklärt. Weiterer Inhalt dieses Unterkapitels ist die Abgrenzung der verschiedenen‘Spielarten’ der Simulation - die Sequentielle (oder herkömmliche) Simulation, die Paral-lele Simulation und die Verteilte Simulation. Inhalt des Unterkapitels 2.3 ist dann die Auf-stellung der bei der Verknüpfung von simulationsbasierter Fertigungssteuerung und Paral-leler bzw. Verteilter Simulation prinzipiell zu lösenden Teilaufgaben, um den Umfang derzu lösenden Aufgabe zu verdeutlichen. Das Unterkapitel 2.4 faßt daraufhin die auf-gestellten Anforderungen an eine Lösung zusammen.
Das Kapitel 3 gibt anschließend einen Einstieg in die Thematik der Parallelen und Ver-teilten Simulation. Zu jeder der Teilaufgaben der Parallelen und Verteilten Simulationwerden Ziele, Aufgaben, Verfahren und Probleme erläutert (Unterkapitel 3.1). Im Unter-kapitel 3.2 wird ein Überblick über Software und Tools gegeben, mit deren Hilfe der Ein-satz der Parallelen und Verteilten Simulation prinzipiell möglich ist. Daran schließt sich imUnterkapitel 3.3 eine kritische Wertung der bisher vorhandenen Verfahren an, woraufhinAnforderungen an eine Lösung herausgearbeitet werden.
Kapitel 4 stellt das Konzept zum Einsatz der Parallelen und Verteilten Simulation zurFertigungssteuerung komplexer Produktionssysteme vor. Im Unterkapitel 4.1 wird der zurealisierende Umfang der Lösung skizziert. Das Unterkapitel 4.2 befaßt sich mit dem Ent-wurf eines Unterstützungssystems zur Durchführung von Simulationsstudien - dem Frame-work zur simulationsbasierten Fertigungssteuerung. Im Kapitel 2 wird mehrfach auf Pro-bleme und Defizite bei der Anwendung des Hilfsmittels „Simulation“ hingewiesen. Diesist Motivation für die Schaffung des Frameworks zur simulationsbasierten Fertigungs-steuerung, welches die angesprochenen Defizite beseitigen helfen soll. Andererseits ist dieExistenz des Frameworks zwingende Voraussetzung für die Erstellung umfangreicherTestmodelle der Parallelen und Verteilten Simulation (siehe Kapitel 6). Simulations-modelle komplexer Produktionssysteme sind bereits sehr aufwendig zu erstellen, für dieungleich komplizierteren Modelle der Parallelen und Verteilten Simulation vervielfachtsich dieser manuelle Aufwand. Zudem ist bedingt durch eine hohe Zahl von Freiheits-graden der Partitionierungs- und Synchronisationsverfahren der Parallelen und VerteiltenSimulation ein hoher Repetierfaktor der Modellerstellung notwendig. D.h., die Unter-stützung des manuellen Simulationsmodellerstellungsprozesses durch eine Software istunumgänglich.Das Unterkapitel 4.3 analysiert den Anwendungskontext der simulationsbasierten Ferti-gungssteuerung komplexer Produktionssysteme für die Anwendung der Parallelen undVerteilten Simulation. Einerseits wird hierbei die Komplexität von Modellen von Produk-tionssystemen näher beleuchtet, andererseits wird auf Einflußfaktoren auf die Performanceder Parallelen und Verteilten Simulation näher eingegangen. Diese Betrachtungen sindnotwendig, um Unterschiede des neuen Anwendungskontextes der Parallelen und Ver-teilten Simulation - die Fertigungssteuerung von Produktionssystemen - im Vergleich zuden bisherigen Anwendungsgebieten der Parallelen und Verteilten Simulation zu beleuch-ten.

Kapitel 1 Einleitung
Seite 24
Im Unterkapitel 4.4 erfolgt dann ein Vorschlag für die Lösung der Aufgabe der Synchro-nisation der Teilmodelle. Hierbei soll kein neues Synchronisationsverfahren entworfenwerden, sondern es soll eine Auswahl und Parameterisierung vorhandener Verfahren erfol-gen, denn es existieren bereits genügend spezialisierte Synchronisationsverfahren (siehePunkt 3.1.3.2-3.1.3.5), welche nur noch an die Simulation von Produktionssystemen ange-paßt werden müssen.Das Kapitel 4.5 enthält einen Vorschlag für ein Verfahren zur Partitionierung, welchesspeziell an die Belange der Simulation von Produktionssystemen angepaßt ist. Mit Hilfedieses Verfahrens ist es möglich, nach einer einmaligen Ausführung eines Simulations-modells automatisch dieses Simulationsmodell auf Basis der erfaßten Meßgrößen (siehePunkt 4.5.4) zu partitionieren. Dabei kann das Partitionierungsverfahren auch iterativ an-gewendet werden, um die Partitionierung des Modells weiter zu verbessern.Das Unterkapitel 4.6 zielt auf eine alternative Lösungsvariante mittels eines verteilten Ex-perimentiersystems. In bisherigen Untersuchungen [Bley, Wuttke 1997], [Arndt 2000],[Gehlsen, Page 2000], [Schneider, Reinhardt 2000] konnte eine hohe Beschleunigung derSimulationsausführung durch verteilte Experimentierumgebungen verzeichnet werden. Dasverteilte Experimentiersystem soll deshalb als Vergleichsbasis zur Parallelen und Verteil-ten Simulation dienen.Auf Basis der erläuterten Konzepte ist es möglich, ein integriertes Unterstützungssystemfür die Fertigungssteuerung komplexer Produktionssysteme mittels Paralleler und Ver-teilter Simulation zu erstellen.
Das Kapitel 5 befaßt sich mit dem realisierten Prototypen. Im Unterkapitel 5.1 erfolgt einedetaillierte Erläuterung der Architektur des Frameworks zur simulationsbasierten Ferti-gungssteuerung als dem Unterstützungssystem zur Durchführung von Simulationsstudien.Mit Hilfe dieses Werkzeugs ist es möglich, auf Basis der durch den Anwender ange-gebenen Daten des Produktionssystems und eines Experimentplans automatisch die ausdem Experimentplan resultierenden Simulationsexperimente abzuarbeiten. Dazu wirddurch das Framework für jedes Experiment automatisch ein vollständiges Simulations-modell erstellt und abgearbeitet. Weiterhin werden ebenfalls automatisch die Ergebnissedieses Experimentes ausgewertet und aufbereitet. Durch dieses Unterstützungssystem wirdder Anwender von einer Vielzahl manueller Tätigkeiten entlastet und der Zeitbedarf für dieDurchführung aller Experimente entscheidend verringert.Um die Abarbeitung eines Simulationsmodells zu beschleunigen, wird Parallele Simula-tion eingesetzt (Unterkapitel 5.2). Es bestand die Wahl ein völlig eigenständiges Tool zuentwerfen oder einen vorhandenen Implementierungsansatz an den Anwendungskontextder simulationsbasierten Fertigungssteuerung komplexer Produktionssysteme anzupassen.Die Entwicklung eines eigenständigen Tools konnte aus Aufwandsgründen nicht in Be-tracht gezogen werden. Außerdem existieren bereits genügend spezialisierte Synchronisa-tionsverfahren (siehe Punkt 3.1.3.2-3.1.3.5). Deshalb wird im Punkt 5.2.1 die Auswahleines geeigneten Implementierungsansatzes anhand der aufgestellten Anforderungen (siehePunkt 3.3 und Punkt 4.3.4 ) beschrieben. An diese Entscheidung schließt sich die Beschrei-bung der Architektur und der Funktionsprinzipien des ausgewählten Tools an (Punkt5.2.2). Anschließend werden die realisierten Erweiterungen des ausgewählten Tools be-schrieben (Punkt 5.2.3).Das Unterkapitel 5.3 befaßt sich mit der Zusammenführung des geschaffenen Tools zurParallelen Simulation von Produktionssystemen mit dem Framework zur simulations-basierten Fertigungssteuerung und dem im Punkt 4.5 beschriebenen Partitionierungs-verfahren zu einem integrierten Unterstützungssystem. Durch das dann letztendlich ent-stehende System ist es möglich, umfangreiche Modelle komplexer Produktionssysteme

Kapitel 1 Einleitung
Seite 25
automatisch zu erstellen und zu partitionieren. Andernfalls wäre eine Untersuchung derPerformance verschiedener Modelle und Modellvarianten nicht in vertretbarer Zeit durch-führbar.Abschließend führt das Unterkapitel 5.4 mögliche Erweiterungen der prototypischen Lö-sung auf.
Das Kapitel 6 zeigt anschließend Ergebnisse von Experimenten mit dem entworfenen Si-mulationstool anhand von exemplarischen Beispielmodellen auf. Als Erstes wird eineEinteilung von Modellen von Produktionssystemen in mehrere Untersuchungsbereichevorgenommen. Für jede dieser Modellklassen werden typische Beispielmodelle entworfenund es werden die Abarbeitungsergebnisse dieser Beispielmodelle auf fünf unterschied-lichen Rechnerplattformen ausgewiesen. Am Schluß dieses Kapitels erfolgt eine Diskus-sion der erzielten Ergebnisse und eine Analyse von Performanceeinflußfaktoren.
Das Kapitel 7 faßt die erreichten Ergebnisse zusammen und gibt einen Ausblick auf jetztmögliche Erweiterungen des Lösungsansatzes. Weiterhin wird der durch die vorliegendeArbeit geschaffene Wissenszuwachs resümiert und es werden Empfehlungen für weiter-führende Forschungsarbeiten gegeben.

Kapitel 2 Einsatz der Parallelen und Verteilten Simulation zur Fertigungssteuerung komplexerProduktionssysteme
Seite 26
2 Einsatz der Parallelen und Verteilten Simulation zurFertigungssteuerung komplexer Produktionssysteme
Ziel des Kapitels ist es, das Fertigungssteuerungsproblem für komplexe Produktions-systeme zu charakterisieren, die dabei auftretenden Probleme zu umreißen und Aufgabenfür einen Lösungsansatz abzuleiten. In einem ersten Unterpunkt wird auf die Aufgaben,Ziele und Probleme der simulationsbasierten Fertigungssteuerung eingegangen. Haupt-problem ist der sehr hohe Zeitbedarf für die Ausführung der Simulation. Die Lösungsideebesteht hier im Einsatz der Parallelen und Verteilten Simulation. Der zweite Unterpunktcharakterisiert die Methodik der Simulation - als ein Bestandteil des Lösungsansatzes zurFertigungssteuerung komplexer Produktionssysteme. Weiterhin wird eine Abgrenzungzwischen der herkömmlichen Art der Simulation und der Parallelen und Verteilten Simula-tion gezogen. Ziel des dritten Unterpunktes ist es, die Aufgaben an einen Lösungsansatzzur Parallelen und Verteilten Simulation zur Fertigungssteuerung komplexer Produktions-systeme herauszuarbeiten und Anforderungen an eine Lösung aufzustellen.
2.1 Begriff, Aufgaben, Vorteile und Probleme der simulationsba-sierten Fertigungssteuerung
2.1.1 Anliegen der simulationsbasierten Fertigungssteuerung
Simulation6 kann als Methode der Prognose benutzt werden, um am Modell eines Produk-tionssystems7 das Verhalten des abgebildeten Realsystems zu untersuchen und Handlungs-alternativen zur Behebung zukünftiger Mängel ex-ante zu testen (siehe Abbildung 1) [Page1991, S. 7], [Mehl 1994, S. 1], [Kosturiak, Gregor 1995, S. 15].
Das Simulationsmodell wird als Abbild des realen Produktionssystems erstellt und in einenRegelkreis eingebettet (siehe Abbildung 1). Dieses Simulationsmodell dient dann dazu, aufBasis der aktuellen Zustandsdaten der Fertigung und einer gegebenen Prozeßführungs-strategie den zukünftigen Zustand des Produktionssystems zu prognostizieren und damitdie Eignung der jeweiligen Prozeßführungsstrategie anhand von Zielgrößen wie Kapazi-tätsauslastung, Termineinhaltung usw. zu beurteilen. Auf diese Weise kann eine Vielzahlvon Prozeßführungsstrategien bzw. deren Parametereinstellungen (Handlungsalternativen)simulativ getestet werden, um im Voraus die in der aktuellen Situation effektivste Prozeß-führungsstrategie zu ermitteln und für die Umsetzung im realen Fertigungssystem vorzu-geben.Unter Prozeßführungsstrategie ist dabei ein Satz von (Prioritäts-)Regeln, Parametern undSteuerungsanweisungen für alle Maschinen des Produktionssystems (Teilstrategien derMaschinen) sowie zusätzlich ein Satz globaler Parameter und Handlungsanweisungen zuverstehen (siehe Punkt 2.1.3 und Punkt 2.1.4, insbesondere Abbildung 4, Seite 30).
6 Siehe Punkt 2.2.1.1.7 Siehe Punkt 2.3.2.

Kapitel 2 Einsatz der Parallelen und Verteilten Simulation zur Fertigungssteuerung komplexerProduktionssysteme
Seite 27
reales Produktionssystemals Regelstrecke
Modell der Regelstrecke= Simulationsmodell
Regler(Fertigungssteuerer)
Führungsgrößen(Zielgrößen)
Übergabe derRegelgrößen
Vorgabe derStellgrößen
Simulation
Optimierung
bewerteteStrategie
Strategie-vorschlag
Übergabe der Zustandsparameter
Abbildung 1 Regelkreis der Fertigungssteuerung8
Zur Suche nach der optimalen Prozeßführungsstrategie sind jedoch mehrere Simulations-experimente mit unterschiedlichen Einstellungen für die Handlungsalternativen notwendig(siehe Abbildung 1). Simulation erlaubt mit der Prognose der Zielwirkung einer Hand-lungsalternative lediglich die Bestimmung der Güte eines Punktes im Lösungsraum. Dieoptimale Lösung kann so aber nicht gefunden werden. D.h., der Einsatz von Suchverfahrenist notwendig, um durch eine Menge von Simulationsexperimenten die optimale Lösung zuermitteln [Page 1991, S. 9], [Kosturiak, Gregor 1995, S. 70]. In der Praxis geschieht dieSuche nach der optimalen Lösung meist durch manuelle Eingriffe des Disponenten / Ferti-gungssteuerers. Dieser gibt eine Auswahl zielträchtig erscheinender Handlungsalternativenvor, die simulativ zu untersuchen sind (siehe Abbildung 1).Durch den Einsatz der Methode der Simulation ist es dem Fertigungssteuerer - trotz derhohen Komplexität des Sachverhaltes und des Fehlens analytischer Verfahren - erstmalsmöglich, anhand eines Modells des Produktionssystems zu experimentieren und die Ziel-wirkung von Aktionen simulativ zu erproben. Somit kann die für eine gegebene Situationgünstigste Prozeßführungsstrategie9 entdeckt werden.
2.1.2 Aufgaben und Ziele der Fertigungssteuerung
Bei der Fertigungssteuerung handelt es sich um eine Teilaufgabe der Produktionsplanungund -steuerung (PPS).
Die Produktionsplanung und -steuerung umfaßt folgende Aufgaben (siehe u.a. [Jung 1998,S. 494ff]):
Produktionsplanung:
• Primärbedarfsplanung (Prognose, Grobplanung)• Mengenplanung (Materialbedarfsermittlung, Auftragsplanung)• Terminplanung (Arbeitsplanauflösung, Durchlaufterminierung)
8 Siehe dazu auch [Thiel, Schulz, Gmilkowsky 1998a], vergleiche „Zustandregelkreis“ [Kahlert, Frank 1993,
S. 121f, S. 139, S. 168f], [Wiendahl, Pritschow, Milberg 1993].9 Als Maß für die „Günstigkeit“ einer Prozeßführungsstrategie dienen die im Punkt 2.1.2 beschriebenen
Ziele der Fertigungssteuerung. Vergleiche auch [Kosturiak, Gregor 1995, S. 94ff].

Kapitel 2 Einsatz der Parallelen und Verteilten Simulation zur Fertigungssteuerung komplexerProduktionssysteme
Seite 28
• Kapazitätsplanung (Kapazitätsbedarfsrechnung, Kapazitätsterminierung)
Produktionssteuerung (synonym als Fertigungssteuerung bezeichnet):
• Auftragsfreigabe (Verfügbarkeitsprüfung, Reihenfolgeplanung)• Steuerung und Kontrolle der Abläufe (Kapazitäts- und Auftragsüberwachung,
kurzfristige Eingriffe in den laufenden Prozeß)
Die Fertigungssteuerung besteht somit aus zwei Aufgabenkomplexen. Einer Planungsauf-gabe (Auftragsfreigabe und Reihenfolgeplanung) und einer Steuerungs- und Kontrollauf-gabe (Überwachung der Abläufe, Rückkopplung zur Planungsaufgabe).
Die Aufgabe der Fertigungssteuerung ist als ein duales Problem zu sehen:• Die Auftragsfreigabe prüft die prinzipielle Durchführbarkeit von Aufträgen und
steuert ggf. diese Aufträge ein.• Die Reihenfolgeplanung hat für eine gegebene Menge von eingelasteten Aufträgen
die Abarbeitungsreihenfolge dieser Aufträge auf allen Maschinen des Produktions-systems festzulegen.
Dabei hat die Fertigungssteuerung die Oberziele der Produktionsplanung und -steuerung -eine kostengünstige Produktion und einen gewinnbringenden Absatz - zu verfolgen [Friedl1994, S. 446 f.], [Jung 1998, S. 463f, S. 489]. Da diese Ziele aber schwer operationalisier-bar sind, bedient man sich leichter meßbarer technizitärer Ersatzziele. Die verfolgten Zieleverhalten sich aber teilweise konträr (Dilemma der Ablaufplanung) [Adam 1993, S. 37ff,404f], [Zäpfel 1994, S. 721], [Schierenbeck 1995, S. 209]:
• Minimierung der Durchlaufzeiten• Maximierung der Kapazitätsauslastung• Minimierung der Lieferterminabweichungen• Minimierung der Bestände
D.h., im Rahmen der Auftragsfreigabe sind die Aufträge zur Fertigung freizugeben, derenFertigung prinzipiell möglich ist (Verfügbarkeitsprüfung der Materialien und sonstigenRessourcen), die in der gegebenen Zeit gefertigt werden können (Beachtung von Kapazi-tätsrestriktionen) und die dabei einen möglichst hohen Deckungsbeitrag (Rückkopplungzur Produktionsplanung) besitzen.Aufgabe der Reihenfolgeplanung ist es dann, für die von der Auftragsfreigabe festgelegteMenge von Aufträgen einen Fertigungsablauf zu planen, bei dem alle eingesteuerten Auf-träge zur rechten Zeit (Beachtung von Terminrestriktionen und dem Ziel der Minimierungder Bestände) fertiggestellt werden und der die gegebenen Kapazitätsrestriktionen beach-tet. Für nicht in Anspruch genommenes Kapazitätsangebot können eventuell weitere Auf-träge eingesteuert werden (Ziel der Durchsatzmaximierung). Zur Erfüllung des geplantenFertigungsablaufes wird eine Prozeßführungsstrategie festgelegt. Diese Prozeßführungs-strategie ist als eine Vielzahl organisatorischer Regelungen zur Steuerung der Fertigunganzusehen.

Kapitel 2 Einsatz der Parallelen und Verteilten Simulation zur Fertigungssteuerung komplexerProduktionssysteme
Seite 29
2.1.3 Probleme der Fertigungssteuerung
In der Literatur wird die Fertigungssteuerung weitgehend auf die Reihenfolgeplanung re-duziert. Die Aufgabe der Auftragsfreigabe und -einsteuerung wird dabei als bereits gelöstangesehen10 (siehe auch [Adam 1990, S. 806 f.], [Zäpfel 1994, S. 723], [Jung 1998, S.488f]).
Das Reihenfolgeplanungsproblem kann wie folgt charakterisiert werden:
Abstrakt betrachtet, bestehen Produktionssysteme aus Maschinen, zwischen denen sichAufträge gemäß ihrer Arbeitspläne bewegen (siehe Abbildung 2). An jeder Maschinekann es zum Aufbau von Auftragswarteschlangen und damit zu Konfliktsituationenkommen - es entstehen Reihenfolgeprobleme. Gesucht ist nun die optimale Abarb-eitungsreihenfolge der Aufträge über alle Maschinen.
Einsteuerungvon Aufträgen
des Typs A
Warteschlange 1Maschine 1
AussteuerungerledigterAufträge
Warteschlange 2Maschine 2
Warteschlange 3Maschine 3
Einsteuerungvon Aufträgen
des Typs B
Abbildung 2 Das Reihenfolgeplanungsproblem an einem Beispiel
Die Reihenfolgeplanung gehört zu den NP-schweren Problemen. Die Lösung kann nicht inpolynomialer Zeit gefunden werden11. Für die Reihenfolgeplanung ist kein praktikablesLösungsverfahren bekannt. Über eine vollständige Enumeration ist das Problem zwar prin-zipiell lösbar, durch die kombinatorische Explosion kann die Lösung aber nicht in ver-nünftiger Zeit erreicht werden. Die bekannten Näherungsverfahren scheitern an der nichttolerierbaren Vernachlässigung von Nebenbedingungen oder der gefundenen „Güte“12 derLösung [Blackstone, Phillips, Hogg 1982, S. 29].
Abbildung 3 zeigt eine Übersicht über wesentliche Verfahren zur Fertigungssteuerung13.
In Ermangelung praktikabler analytischer, optimierender Verfahren wurden eine Mengevon Heuristiken entworfen. Diese lassen sich grob in global und lokal orientierte Ansätzegliedern.Globale orientierte Ansätze - wie z.B. Genetische Algorithmen - geben eine Prozeß-führungsstrategie vor, welche einen möglichst optimalen Fluß aller Aufträge durch dasgesamte Produktionssystem zu erzielen beabsichtigt. Problematisch daran ist die oft man-gelnde Transparenz14 und Robustheit der Lösung15.
10 Hierzu werden in der Regel Verfahren wie z.B. BOA - Belastungsorientierte Auftragsfreigabe [Wiendahl
1992] eingesetzt.11 Für n Aufträge in einer Warteschlange bestehen n! mögliche Abarbeitungsreihenfolgen. Für die Festlegung
der Reihenfolge auf m Maschinen potenziert sich dies zu (n!)m. Für 5 Aufträge und 10 Maschinen existie-ren bereits 5!10 = 12010 = 6,19*1020 mögliche Abarbeitungsreihenfolgen (kombinatorische Explosion).
12 Oftmals kann die durch das Verfahren gefundene Lösung durch eine erfahrene Person auf einfache Weiseverbessert werden.
13 Vergleiche [Daub 1994, S. 123 ff], [Kramer 1994, S. 85 ff], [Zäpfel 1982, S. 261 ff].14 Unter Transparenz soll die Einsichtigkeit / Nachvollziehbarkeit der Lösung verstanden werden.15 Robustheit der Lösung bedeutet, daß die Güte der Lösung sich nicht wesentlich ändert, wenn Randbedin-
gungen des Problem verändert werden (z.B. Störung im Maschinensystem).

Kapitel 2 Einsatz der Parallelen und Verteilten Simulation zur Fertigungssteuerung komplexerProduktionssysteme
Seite 30
Elementare Planungsverfahren derFertigungssteuerung
OptimierendePlanungsverfahren
NichtoptimierendePlanungsverfahren
- Enumerationsverfahren- Lineare Programmierung- Branch-and-Bound-Verfahren
Konventionelle PlanungsverfahrenPlanungsverfahren der Künstlichen
Intelligenz (KI)
Prioritäts-regeln
KonventionelleHeuristiken
- Statische Prioritätsregeln- Dynamische Prioritätsregeln
- Entscheidungs- theorie-Ansatz- Tabu-Search- Verfahren- Genetische Algorithmen- sonstige konventio- nelle Heuristiken
Expertensystem-ansätze
sonstigeKI-Ansätze
- Regelbasierte Planungsverfahren- Nonmonotone Inferenzkonzepte- Constraint- directed-Search- Planung mit Planskeletten- Opportunistische Terminierung- Planung durch Umplanung
- Simulated Annealing- Verteilte Planungs- verfahren- Multi-Agenten- Systeme
Lokal orientierte Verfahrenwurden durch Kursivstellung
kenntlich gemacht.
Abbildung 3 Übersicht über elementare Planungsverfahren der Fertigungs-steuerung16
Lokal orientierte Ansätze (Prioritätsregeln und regelbasierte Planungsverfahren, sieheAbbildung 3) dagegen zerlegen das Reihenfolgeplanungsproblem in besser operationali-sierbare Teilprobleme. Jedes Teilproblem befaßt sich mit der Lösung der an einer Maschi-ne auftretenden Reihenfolgekonflikte (siehe Punkt 2.1.4). Die gesuchte Prozeßführungs-strategie, setzt sich dann aus Teilstrategien für jede Maschine zusammen (siehe Abbildung4).
Einsteuerungvon Aufträgen
des Typs A
Warteschlange 1Maschine 1
AussteuerungerledigterAufträgeWarteschlange 2
Maschine 2
Warteschlange 3Maschine 3
Einsteuerungvon Aufträgen
des Typs B
Prozeßführungsstrategie := [Teilstrategie 1; Teilstrategie 2; Teilstrategie 3]
Teilstrategie 1 (z.B. Prioritätsregel SPT)
Teilstrategie 2 (z.B. Prioritätsregel FIFO)
Teilstrategie 3 (z.B. Prioritätsregel CR)
Abbildung 4 Bestandteile einer Prozeßführungsstrategie (Beispiel)17
Unter diesen Einschränkungen können zwar „gute“ lokale Lösungen der Teilprobleme ge-funden werden, eine Ausrichtung aller lokalen Teilsysteme zum global „guten“ Ergebnis -zur optimalen Steuerung aller Aufträge durch das gesamte Produktionssystem - unterbleibtjedoch.
16 Siehe [Weigelt 1994, S. 25].17 Für gewöhnlich sind die eingesetzten Teilstrategien Prioritätsregeln (siehe Punkt 2.1.4). Eine Übersicht
über Prioritätsregeln ist [Blackstone, Philips, Hogg 1982, S. 27 ff.], [Paulik 1984, S. 50f, S. 53f.], [Biendl1984, S. 73 ff.], [Haupt 1989, S. 7], [Dulger 1993, S. 114ff., S. 183 ff., S. 191 ff.], [Holthaus, Ziegler 1993,S. 159], [Holthaus, Ziegler, Rosenberg 1993, S. 8], [Kleeberg 1993, S. 138ff], [Lu, Ramaswamy, Kumar1994, S. 374 ff.] und [Weidner 1995, S. 17] zu entnehmen.

Kapitel 2 Einsatz der Parallelen und Verteilten Simulation zur Fertigungssteuerung komplexerProduktionssysteme
Seite 31
Da die optimale Lösung des Reihenfolgeplanungsproblems nicht bekannt ist, ist eine Reihevon Heuristiken auf ihre Eignung für ein gegebenes Produktionssystem zu testen, um dieHeuristik mit der höchsten Lösungsgüte zu ermitteln.Im Produktionssystem kann durch Experimentieren mit möglichen Teilstrategien (siehedazu Punkt 2.1.4) die Suche nach der optimalen Prozeßführungsstrategie durchgeführtwerden. Dies ist jedoch ein langwieriger und kostenintensiver Prozeß. Wenn man bemerkt,daß Probleme auftreten (z.B. Verschiebung von Engpässen, Verletzung von Terminrestrik-tionen), kann man nicht mehr handelnd eingreifen. Der Test der Prozeßführungsstrategienim Realsystem ist demzufolge nicht praktikabel.
Simulation bietet die Möglichkeit diesen Suchprozeß gebührend zu unterstützen, ist aberzur Lösung des Problems allein nicht geeignet (siehe dazu Punkt 2.1.1).
2.1.4 Einsatz von Heuristiken zur Lösung von Reihenfolgeproblemen
In der Praxis werden im Allgemeinen Prioritätsregeln zum Treffen einer Reihenfolge-entscheidung benutzt. Prioritätsregeln erfordern nur wenig Rechenaufwand, um eine Lö-sung zu bestimmen und liefern oft - verglichen mit zeitaufwendigen analytischen Verfah-ren - gute und robuste Lösungen. Diese Lösungen sind zudem plausibel. Bei Anwendungvon z.B. Genetischen Algorithmen ist die Auswahlentscheidung dagegen nicht nachvoll-ziehbar.
Es existieren einfache, zusammengesetzte, statische und dynamische Prioritätsregeln. Ein-fache Prioritätsregeln basieren auf lediglich einem Entscheidungskriterium (z.B. der Dauerder nächsten Bearbeitungsoperation, der Anzahl der verbleibenden Arbeitsgänge usw.)während zusammengesetzte Prioritätsregeln eine spezielle Kombination mehrerer Kriterien(z.B. Critical Ratio: Fertigstellungszeitpunkt minus aktuellen Zeitpunkt bezogen auf dieSumme der verbleibenden Bearbeitungszeiten) darstellen. Im Gegensatz zu statischen Prio-ritätsregeln besitzen dynamische Prioritätsregeln einen Zeitbezug, d.h. eines der Kriterienist von der aktuellen Zeit abhängig (z.B. Schlupfzeitregel: Fertigstellungszeitpunkt minusaktuellen Zeitpunkt).
Die gute Operationalität der Prioritätsregeln ist durch den Einbezug nur weniger Kriteriengegeben - es kann operativ in kurzer Zeit eine ansprechende Lösung gefunden werden.
Es existiert jedoch keine universelle Prioritätsregel, sondern eine Reihe von in der Praxisbewährten, an einen ausgewählten Anwendungskontext angepaßten Prioritätsregeln18.
Das Hauptproblem der Prioritätsregeln liegt in ihrer Wirkungsweise. Eine Prioritätsregelist fest anzuwenden, auch wenn die momentane Situation eigentlich die Anwendung ver-bieten würde - es mangelt an jeglichem Situationsbezug. In diesem Fall muß eine Erweite-rung des Ansatzes vorgenommen werden. Sind z.B. mehrere verschiedene Prioritätsregelnfür unterschiedliche Situationen geeignet, so ist über Produktionsregeln anzugeben, in wel-cher Situation welche der Prioritätsregeln angewendet werden soll. Durch den Einsatz sol-cher Regelsysteme können Prioritätsregeln situationsbezogen eingesetzt werden.
Ein weiteres Problem resultiert daraus, daß Prioritätsregeln i.d.R. völlig von den an denMaschinen anliegenden Prozeßbedingungen abstrahieren. Selbst durch Einbezug weitererPrioritätsregelteile wie z.B. Belade- oder Rüstregeln19 lassen sich nicht alle Prozeßbedin-
18 Eine Übersicht über Prioritätsregeln kann [Blackstone, Philips, Hogg 1982, S. 27 ff.], [Paulik 1984, S. 50f,
S. 53f.], [Biendl 1984, S. 73 ff.], [Haupt 1989, S. 7], [Dulger 1993, S. 114ff., S. 183 ff., S. 191 ff.],[Holthaus, Ziegler 1993, S. 159], [Holthaus, Ziegler, Rosenberg 1993, S. 8], [Kleeberg 1993, S. 138ff],[Lu, Ramaswamy, Kumar 1994, S. 374 ff.] und [Weidner 1995, S. 17] entnommen werden.
19 Siehe dazu [ManSim 1997, S. 45-48].

Kapitel 2 Einsatz der Parallelen und Verteilten Simulation zur Fertigungssteuerung komplexerProduktionssysteme
Seite 32
gungen erfassen (z.B. technologisch bedingte Liegezeiten zwischen zwei Maschinen, ver-gleiche dazu Punkt 2.3.2.3). Die Lösung des Reihenfolgeproblems muß aber unter Beach-tung der an der Maschine anliegenden Situation und den dort vorhandenen speziellen Pro-zeßbedingungen erfolgen [Richter u.a. 1998], [Thiel, Schulz, Gmilkowsky 1998a], [Thiel,Schulz, Gmilkowsky 1998b].
Weiterhin nachteilig an Prioritätsregeln ist, daß sie lediglich lokal einen Zielbezug her-stellen können. D.h., lokal an den einzelnen Maschinen können durch speziell angepaßtePrioritätsregeln sehr gute Auftragsreihenfolgen ermittelt werden. Jedoch ergibt eine Reihelokaler Optima nicht zwangsläufig die global optimale Lösung. D.h., zusätzlich hat eineKoordination der ermittelten lokalen Lösungen zu einer global guten Lösung zu erfolgen.
Die Probleme der Prioritätsregeln versucht man u.a. durch Prioritätsregeln mit einer Kom-bination spezieller Kriterien mit Situationsbezug (Kombination zu Regelsystemen) unddurch den Einsatz von Interaktionsregeln zu beheben.
Interaktionsregeln haben das Ziel, den momentanen und künftigen Zustand an technolo-gisch vor- bzw. nachgelagerten Maschinen in die Reihenfolgeentscheidung mit einzu-beziehen. Bekannteste Vertreter der Interaktionsregeln sind die Vorausschauende Auf-tragsnachfrage (VANF) und der Vorausschauende Auftragsfortschritt (VAFS) [Holthaus,Ziegler 1993, S. 52 ff., S. 161f.], [Holthaus, Rosenberg, Ziegler 1993, S. 6 ff., S. 11f.],[Weidner 1995, S. 21 ff., S. 71 ff.]. Man versucht nur Aufträge zur Bearbeitung auszu-wählen, die im nächsten Arbeitsgang nicht warten müssen (VAFS) bzw. Aufträge zur Be-arbeitung vorzuziehen, um die Kapazitätsauslastung von Maschinen zu erhöhen (VANF).Man unterscheidet ferner passive und aktive Interaktionsansätze. Passive Interaktions-ansätze sind dadurch gekennzeichnet, daß lediglich Informationen über den Zustand derumgebenden Maschinen in die lokale Reihenfolgeentscheidung einbezogen werden. Beiaktiven Interaktionsansätzen wird dagegen die Reihenfolgeentscheidung der umgebendenMaschinen aktiv beeinflußt [Thiel, Schulz 2000a].Auch Interaktionsansätze haben keine globale Zielausrichtung, sondern verbessern ledig-lich lokale Optima in Richtung des globalen Optimums.
Global orientierte Ansätze scheitern in der praktischen Anwendung wegen der Vernach-lässigung von Restriktionen und dem enormen Zeitbedarf für die Lösung des Reihenfolge-problems.
2.1.5 Aufgaben und Probleme der simulationsbasierten Fertigungssteuerung
Die Aufgabe der Fertigungssteuerung in der Reihenfolgeplanung ist es, unter den gegebe-nen Zielen (siehe Punkt 2.1.2) für das betrachtete Produktionssystem zeitlich effizient einerobuste Steuerungslösung von hoher Lösungsgüte finden.Die Forderungen der zeitlichen Effizienz und Robustheit werden erhärtet durch die wieder-holte Durchführung dieser Planungsaufgabe. In zyklischen Abständen ist die Reihenfolge-planung unter veränderten Gegebenheiten (Freigabe neuer Aufträge, Änderungen der Si-tuation im Maschinensystem usw.) zu wiederholen.Für die Ermittlung einer Lösung mit hoher Güte ist es entscheidend, daß die tatsächlich imrealen Produktionssystem auftretenden Bedingungen im Planungsmodell Niederschlaggefunden haben. Denn ein Lösungsverfahren ist nur so gut, wie das zu Grunde liegendePlanungsmodell. Dieses Modellierungsproblem wird im Abschnitt 2.3.1 näher beleuchtet.In der Regel vernachlässigen alle genannten Reihenfolgeplanungsansätze (siehe Punkt2.1.4) das Auftreten komplexer Prozeßbedingungen (siehe dazu Punkt 2.3.2.3). Infolge-dessen haben sie natürlich auch nur eine eingeschränkte Gültigkeit bei Auftreten solcherProzeßbedingungen. Aus diesem Grund wurden zusätzlich zu Prioritätsregeln noch Bela-

Kapitel 2 Einsatz der Parallelen und Verteilten Simulation zur Fertigungssteuerung komplexerProduktionssysteme
Seite 33
de- und Rüstregeln20 entworfen, die diesen Prozeßbedingungen Rechnung tragen. Einebloße Verknüpfung der Regelarten scheitert jedoch in der Praxis. An dieser Stelle sindintegrierte Ansätze zur Reihenfolgeplanung unter komplexen Prozeßbedingungen notwen-dig [Richter u.a. 1998], [Thiel, Schulz, Gmilkowsky 1998b], [Thiel 2001, S. 40, S. 45-80].Der Einsatz solcher komplexen Reihenfolgeplanungsansätze erfordert aufgrund des höhe-ren Berechnungsaufwands jedoch einen höheren Zeitbedarf für die Ausführung der Simu-lation, was eines der Motive für den Einsatz der Parallelen und Verteilten Simulation zurbeschleunigten Ausführung des Simulationsmodells ist.Bei der Lösung der Reihenfolgeplanungsaufgabe erfolgt eine Suche nach der effektivstenProzeßführungsstrategie. Während dieses Suchprozesses sind eine Vielzahl von heuristi-schen Teillösungen (siehe Punkt 2.1.4) zu testen. Durch die veränderliche Zusammen-setzung der Prozeßführungsstrategie drückt sich die Variabilität des Steuerungsansatzes alseine Ausprägung der Flexibilität des Unternehmens aus, auf veränderte Umfeldbedingun-gen angepaßt zu reagieren.Die Durchführung des Suchprozesses nach der effektivsten Prozeßführungsstrategie ist imRealsystem nicht praktikabel, weswegen diese Suche anhand des Planungsmodells durch-zuführen ist. Simulation bietet die Möglichkeit, diesen Suchprozeß gebührend zu unter-stützen (siehe Punkt 2.2.1.1), bedingt jedoch ein adäquates Abbild des realen Produktions-systems. Aus diesem Grund sind Zusammensetzung und Umfang der Modelle von Produk-tionssystemen nachfolgend näher zu untersuchen (siehe Punkt 2.3.2).
2.2 Simulation - Sequentielle Simulation, Parallele Simulation,Verteilte Simulation - Begriffe, Aufgaben, Abgrenzung
2.2.1 Grundlagen der Simulation
2.2.1.1 Begriff und Vorteile der Simulation
„Simulation ist das Nachbilden eines dynamischen Prozesses in einem System mit Hilfeeines experimentierfähigen Modells, um zu Erkenntnissen zu gelangen, die auf die Wirk-lichkeit übertragbar sind. Im weiteren Sinne wird unter Simulation das Vorbereiten,Durchführen und Auswerten gezielter Experimente mit einem Simulationsmodell ver-standen.“ [VDI 3633]
Die Durchführung einer Simulationsstudie besitzt einen festen Ablauf (siehe Abbildung 5):
formale Ergebnisse
Schlußfolgerungenfür das reale System
reales Systemkonzeptionelles
Modell
Simulationsmodell
ÜbertragungInterpretation
Durchführung vonExperimenten
ImplementationUmsetzung ModellierungAbstraktion
Abbildung 5 Ablauf einer Simulationsstudie21
Der erste Schritt ist die Abstraktion eines real vorhandenen oder gedanklich konzipiertenSystems zu einem Modell (Modellierungsprozeß). Für eine gedankliche Betrachtung einesumfangreichen realen Systems ist es notwendig, die Komplexität des Realsystems für die
20 Siehe dazu u.a. [ManSim 1997, S. 45-48].21 Vergleiche dazu [Kosturiak, Gregor 1995, S. 6], [Page 1991, S.11].

Kapitel 2 Einsatz der Parallelen und Verteilten Simulation zur Fertigungssteuerung komplexerProduktionssysteme
Seite 34
Betrachtung zu verringern und den gesamten Sachverhalt einfacher faßbar zu machen.D.h., durch Abstraktion, Vereinfachung, Vernachlässigung und Formalisierung von Teilendes Sachverhaltes soll eine einfachere Beschreibung des realen Systems erzielt werden[VDI 3633, Blatt 1], [Page 1991, S. 13-14].Das Modell - als vereinfachte Abbildung des Realsystems - ist Gegenstand für Unter-suchungen und Experimente [Kosturiak, Gregor 1995, S. 6]. Entscheidend ist hierbei, daßdas Modell die essentiellen Eigenschaften und das essentielle Verhalten des Realsystemskorrekt wiedergeben muß [Page 1991, S. 8], [Smith 1999], [Blazejewski 2000, S. 66],[Fishman 2001, S. 25]. Diese adäquate Abbildung ist zwingende Voraussetzung dafür, daßsich Modell und Realsystem ähnlich verhalten. Das Modell muß die wesentlichen Aspektedes Realsystems für die Planungsaufgabe widerspiegeln, denn die Qualität der Ergebnissedes Planungsverfahrens ist direkt von der Qualität des der Planung zu Grunde liegendenModells abhängig. Auf Basis eines die Wirklichkeit adäquat abbildenden Modells ist esmöglich, anhand von Experimenten mit dem Modell valide Rückschlüsse auf das model-lierte Realsystem zu ziehen [VDI 3633, Blatt 1], [Page 1991, S. 22], [Smith 1999],[Blazejewski 2000, S. 66].Dieses konzeptionelle Modell ist für die Durchführung auf einem Computer zu formalisie-ren - es entsteht das Simulationsmodell.Alle nachfolgenden Betrachtungen und Experimente werden dann am Simulationsmodellausgeführt [Kosturiak, Gregor 1995, S. 15]. Zum Einen kann der Grund dafür sein, daßnoch kein System in der Realität vorhanden ist (System wird noch konzipiert). Zum Ande-ren sind die durchzuführenden Betrachtungen am Realsystem nicht möglich oder sie wärenzu teuer bzw. mit einem zu hohen Zeitaufwand verbunden [Seelbach 1975, S. 150],[Kosturiak, Gregor 1995, S. 16-17], [Fishman 2001, S. 23].D.h., man benutzt Simulation, um Erklärungs- und Verhaltensmodelle herzustellen oderum Systeme anhand von Modellen zu konstruieren und zu dimensionieren [Kosturiak,Gregor 1995, S. 59].Simulation übernimmt die Funktion der Prognose des zukünftigen Zustandes und des zu-künftigen Verhaltens des modellierten Systems [Mehl 1994, S. 1]. Man kann am Simula-tionsmodell experimentieren, wie sich Änderungen von Parametern am Realsystem aus-wirken würden und so ex-ante Maßnahmen zur Behebung möglicher zukünftiger Problemetreffen [Kosturiak, Gregor 1995, S. 15]. Im Prozeß des Experimentierens an dem Simula-tionsmodell gelangt man so zu Erkenntnissen, die man für die Konstruktion des Real-systems benötigt oder die zur Erklärung der zukünftigen Reaktion des Realsystems aufeinen gegebenen momentanen Zustand notwendig sind. Ziel ist es dabei, die gewonnenenErkenntnisse zur sukzessiven Verbesserung des modellierten Systems zu nutzen.
Ein weiterer Vorteil ist, daß Simulationsmodelle für Systeme eingesetzt werden können,die eine sehr komplexe Struktur aufweisen, durch dynamische Prozesse gekennzeichnetsind und deren Verhalten sich nicht oder nur unzureichend durch analytische Modelle be-schreiben läßt [Page 1991, S. 8], [Mehl 1994, S. 1], [Kosturiak, Gregor 1995, S. 5, S. 13, S.83], [Fishman 2001, S. 24].Produktionssysteme sind hierfür ein typisches Beispiel [Blazejewski 2000, S. 68]. Analyti-sche Modelle können nur einfach strukturierte Produktionssysteme, die zudem durch eineReihe in der Praxis nicht haltbarer Restriktionen gekennzeichnet sein müssen (siehe Punkt2.3.2.3), hinreichend genau beschreiben [Kosturiak, Gregor 1995, S. 15-16]. Für jedenpraktisch relevanten Fall versagen die analytischen Modelle jedoch. Simulationstechnikensind dagegen mit Erfolg zur Beschreibung und Erklärung des Verhaltens von Produktions-systemen eingesetzt worden [Seelbach 1975, S. 150], [Reiche 1990], [Page 1991, S. 19],[Kosturiak, Gregor 1995, S. 87].

Kapitel 2 Einsatz der Parallelen und Verteilten Simulation zur Fertigungssteuerung komplexerProduktionssysteme
Seite 35
Doch der Einsatz der Simulation ist auch mit Problemen verbunden. Im Gegensatz zuanalytischen Verfahren (wie der linearen Programmierung oder anderen Optimierungs-verfahren) ist bei der Simulation das Auffinden der optimalen Lösung nicht sichergestellt[Page 1991, S. 9], [Kosturiak, Gregor 1995, S. 70], [Fishman 2001, S. 24]. D.h., eineKopplung der Simulation mit einem Optimierungsverfahren ist notwendig (siehe dazuauch Punkt 2.1.1).Ein zweites wesentliches Problem ist die Frage nach der optimalen Abbildungsgenauigkeit[Fishman 2001, S. 25]. Voraussetzung für die Simulation ist, daß das Simulationsmodelldie wesentlichen Eigenschaften und das wesentliche Verhalten des Realsystems abbildet[Page 1991, S. 8], [Smith 1999], [Blazejewski 2000, S. 66]. Abstrahiert man zu stark, sokann das Modell nicht zur Erklärung des Verhaltens des Realsystems herangezogen wer-den [Page 1991, S. 22]. Zum Anderen verursacht aber die detaillierte Abbildung des Real-systems einen immensen Aufwand. Ziel ist es demzufolge, die relevanten Eigenschaftenund Reaktionsmuster zu identifizieren und im Simulationsmodell umzusetzen [VDI 3633,Blatt 1].Oft ist jedoch eine detaillierte Abbildung des Realsystems im Modell notwendig, wodurchumfangreiche und komplexe Modelle entstehen [Page 1991, S. 22], [Smith 1999], [Blaze-jewski 2000, S. 66], [Fishman 2001, S. 26]. Das Experimentieren mit umfangreichen,komplexen Modellen verursacht naturgemäß einen wesentlich höheren numerischen Be-rechnungsaufwand, wodurch der Zeitbedarf für die Ausführung der notwendigen Experi-mente steigt (siehe Punkt 2.2.1.3). Die Zeit für die Ausführung der Simulation ist aber alskritischer Faktor anzusehen [Krug, Wiedemann 2000]. Zum Einen darf die Konstruktioneines neuen Systems nicht durch zu lange Experimente hinausgezögert werden und zumAnderen ist zum Zeitpunkt der Entscheidung auf Basis des momentanen Zustandes desSystems bei Benutzung der Simulation als Prognosemethode für das zukünftige VerhaltenEchtzeitnähe gefordert [Fujimoto 1999], [Smith 1999].
Nachfolgend soll kurz auf die Kategorisierung von Simulationsansätzen, wesentlichen Ab-arbeitungsprinzipien der Simulation und allgemeine Probleme der Simulation eingegangenwerden. Dies ist u.a. Basis für die späteren Ausführungen zur Parallelen und VerteiltenSimulation in Kapitel 3 und den Erläuterungen der Prototypischen Implementierung inKapitel 5.
2.2.1.2 Prinzipielle Bestandteile und Funktionsprinzipien von Simulationssoftware
Elemente einer Simulation:
Jede Simulation - im Sinne eines auf einem Computer abarbeitbaren Programms - umfaßtzwei Teile:
(a) den Simulator und(b) das Simulationsmodell.
Der Simulator enthält die Mechanismen zur Ausführung des Simulationsmodells und dasSimulationsmodell gibt vor, was zu simulieren ist, d.h. die Objekte und das Verhalten desbetrachteten Systems. Abbildung 6 zeigt die prinzipiellen Bestandteile einer Simulation(vergleiche [Page 1991, S. 33f], [Mehl 1994, S. 6]):

Kapitel 2 Einsatz der Parallelen und Verteilten Simulation zur Fertigungssteuerung komplexerProduktionssysteme
Seite 36
Objekte mitZustandsvariablen
Datenverwaltungs-mechanismus
Prozesse als Folgevon Ereignissen
Ereignisroutinen
Ereignislisten SimulationsuhrAblaufsteuerung
Simulationsmodell
Simulator
Simulation
Mechanismen zurFührung vonStatistiken
Statistiken vonErgebnisgrößen
Abbildung 6 - Elemente einer Simulation
Das Simulationsmodell besteht aus der Beschreibung von Objekten und deren Zustands-variablen, aus Anweisungen zur Führung von Statistiken zu den zu betrachtenden Ergeb-nisgrößen, der Definition des Verhaltens der Objekte als Folge von Ereignissen und denEreignisroutinen zur Reaktion auf diese Ereignisse.Der Simulator besteht dagegen aus Mechanismen zur Verwaltung der Objekte und Zu-standsvariablen, aus Mechanismen zur Führung der Statistiken für die Ergebnisgrößen, ausEreignislisten zur Verwaltung der auftretenden Simulationsereignisse, der Simulationsuhrund der Ablaufsteuerung.
Ablaufsteuerung einer Simulation:
Die typische Ablaufsteuerung einer Simulation (DES) funktioniert wie folgt (vergleiche[Page 1991, S. 35f], [Cassandras 1993, S. 505], [Fishman 2001, S. 39-40, S. 47]):
1. Die Simulationsuhr wird auf Null gesetzt.2. Bei der Modellinitialisierung werden erste Ereignisse eingeplant.3. Die Ablaufsteuerung sucht das Ereignis / die Ereignisse mit dem niedrigsten Ereig-
niszeitpunkt heraus.4. Die Simulationsuhr wird auf diesen niedrigsten Zeitpunkt gesetzt.5. Alle Ereignisse dieses Zeitpunktes werden der Reihe nach prozessiert.6. Bei der Ausführung eines Ereignisses wird dessen Ereignisroutine ausgeführt. So
kann das Ereignis dazu führen, daß sich Zustandsvariablen von Objekten ändern oderdaß neue Ereignisse einzuplanen sind.
7. Wurden alle Ereignisse des aktuellen Zeitpunktes ausgeführt, so wird der nächst-höhere Ereigniszeitpunkt bestimmt (Schritt 3). Überschreitet dieser neue Ereignis-zeitpunkt eine gesetzte Schranke, so endet die Simulation oder aber es werden wie-derum alle Ereignisse dieses Zeitpunktes prozessiert (Schritte 4-6).
Für eine Parallele bzw. Verteilte Simulation ist dies ungleich komplizierter. Da nicht alleim Modell auftretenden Ereignisse auf ein und dem selben Rechner abgearbeitet werden,müssen diese Ereignisse zwischen den Rechnern verteilt und die Simulationsuhren dereinzelnen Computer aufeinander abgestimmt werden. Hierbei ist es Aufgabe eines Syn-chronisationsverfahrens (siehe Punkt 3.1.3) sicherzustellen, daß auf jedem an der Simula-tion beteiligten Computer alle Ereignisse gemäß steigender Simulationszeit ausgeführtwerden.

Kapitel 2 Einsatz der Parallelen und Verteilten Simulation zur Fertigungssteuerung komplexerProduktionssysteme
Seite 37
2.2.1.3 Problem des hohen Zeitbedarfs für die Ausführung der Simulation als Motivfür die Parallelisierung
Der numerische Aufwand für die Modelldurchführung ist in den letzten Jahren gestiegen[Bagrodia 1996]. Zum Einen bestehen heutige Simulationsmodelle aus immer mehr Ele-menten und es wird ein immer komplexeres Verhalten modelliert. Zum Anderen werdenSysteme modelliert, die eine hohe Last aufweisen, d.h. in denen viele Elemente und Pro-zesse existieren, die parallel Aktivitäten durchführen. Dies äußert sich in einem steigendenRechenzeitbedarf [Mehl 1994, S. 2], [Fujimoto 1999], [Smith 1999], [Blazejewski 2000, S.66].
Einfluß auf die Länge der Simulationslaufzeit haben mehrere Faktoren:
a) Immer komplexere Modelle bedingen immer längere Laufzeiten der Simulation.b) In einem Simulationslauf wird oft das Verhalten des Realsystems über einen länge-
ren Zeitraum am Modell getestet - die benötigte Simulationslaufzeit wächst dement-sprechend an.
c) Zur statistischen Absicherung der Ergebnisse aufgrund von Stochastiken im Simula-tionsmodell ist ein hinreichend großer Stichprobenumfang an Simulationsläufen not-wendig22 [Page 1991, S. 121-143], [Kelton, Sadowski, Sadowski 1998, S. 8].
d) Zum Experimentieren mit dem Modell gehört eine ganze Reihe von Experimenten,in denen Parameter des Realsystems variiert werden. So ist eine Vielzahl von Experi-menten notwendig, um eine im Sinne des gegebenen Zielsystems optimale Parame-terkombination zu finden. D.h., Simulation und Optimierung sind getrennt zu be-trachten [Page 1991, S. 9], [Kosturiak, Gregor 1995, S. 70]. Simulation kann ledig-lich für ein gegebenes System und eine gegebene Situation das Verhalten des Sy-stems prognostizieren. Aufgabe des Optimierungsverfahrens ist es jedoch, die simu-lativ zu untersuchenden Situationen vorzugeben.
Für jedes Experiment besteht pro Simulationslauf bereits ein hoher Zeitbedarf (siehe An-striche (a) und (b) ) und zur Absicherung der statistischen Sicherheit multipliziert sich derBedarf (siehe Anstrich (c) ). Zur Ermittlung der im Sinne des Zielsystems der Fertigungs-steuerung optimalen Parameterkombination ist eine Vielzahl von Experimenten notwendig.Die benötigte Simulationszeit vervielfacht sich also erneut (siehe Abbildung 7).
Der resultierende Zeitbedarf zur Durchführung aller Simulationsläufe kann demzufolgesehr hoch werden [Bagrodia 1996]. Dies ist besonders kritisch, da Simulation u.a. zur echt-zeitnahen Entscheidungsunterstützung verwendet wird [Fujimoto 1999], [Smith 1999]. Beider Optimierung von Systemen mit Hilfe der Simulation - wie z.B. im Anwendungsfall dersimulationsbasierten Fertigungssteuerung - steht deswegen die Geschwindigkeit der Simu-lationsberechnungen im Vordergrund [Krug, Wiedemann 2000].
22 Durch den Einsatz von Verfahren wie z.B. der Varianzreduktion (siehe u.a. [Page 1991, S. 138f], [Exner
2000, S. 15ff]) kann die Anzahl der notwendigen Simulationsläufe zwar gesenkt werden, jedoch sind im-mer noch Dutzende oder gar Hunderte von Simulationsläufen notwendig.

Kapitel 2 Einsatz der Parallelen und Verteilten Simulation zur Fertigungssteuerung komplexerProduktionssysteme
Seite 38
};...;;{: 21 neeeE = Menge der im Rahmen der Simulationsstudie durch-zuführenden Experimente
];1[};...;;{: 21 nillle imiii ∈= Für ein Experiment ei sind aufgrund von Stochastiken im Modell m Replikationen durchzuführen. Ein Experi-ment setzt sich demzufolge aus einer Menge von Läufen zusammen.
∑=
=m
jiji lZBeZB
1
)()( Der Zeitbedarf für die Ausführung eines Experimentes ei ist die Summe der Zeitbedarfe für die Ausführung aller Läufe lij des Experiments.
∑=
=n
iieZBEZB
1
)()( = ∑∑= =
n
i
m
jijlZB
1 1
)( Der Zeitbedarf für die Ausführung der Simulations-studie E ist die Summe der Zeitbedarfe für die Aus-führung aller Experimente ei der Studie.
Abbildung 7 Berechnung des Zeitbedarfs für eine Simulationsstudie
Dem hohen Zeitbedarf zur Ausführung mehrerer Simulationsläufe bemühen sich verschie-dene Ansätze entgegenzuwirken:
• Ein trivialer Ansatz ist, die verschiedenen Experimente gleichzeitig auf mehrerenRechnern durchzuführen. Dies senkt die benötigte Zeit bereits enorm [Bley, Wuttke1997], [Arndt 2000], [Gehlsen, Page 2000], [Schneider, Reinhardt 2000].
• Jedoch verbleibt für jeden Simulationslauf noch ein hoher Bedarf an Rechenzeit zurSimulation eines komplexen Modells. Parallele und Verteilte Simulation bieten hierdie Möglichkeit, diesen Verbrauch an Rechenzeit nochmals drastisch zu verringern[Unger 1988], [Nicol 1988], [Mehl 1994], [Holthaus, Rosenberg, Ziegler 1996],[Bagrodia 1996], [Fujimoto 1999].
• Ein dritter Weg ist die Reduktion der Modellkomplexität (Modellreduktion)23. Zielist hier, wenig relevante Teile des Modells durch gröbere Strukturen abzubilden, dieeinen kleineren numerischen Aufwand erfordern. Das Problem besteht darin, einenKompromiß zwischen dem in Kauf zu nehmenden numerischen Aufwand und dernotwendigen Komplexität zur Abbildung relevanter Eigenschaften und des relevan-ten Verhaltens zu finden.
Für den Anwendungskontext der simulationsbasierten Fertigungssteuerung ist die Reduzie-rung des Zeitbedarfs für die Ausführung einer Simulationsstudie von vordringlicher Be-deutung. Hier ist eine Vielzahl von Experimenten durchzuführen, die Modelle besitzenstochastische Elemente und der Replikationsfaktor ist dementsprechend hoch. Die Benut-zung mehrerer Rechner zur parallelen Ausführung der Simulationsläufe ist gut geeignetden Zeitbedarf für die Ausführung einer Simulationsstudie zu verringern. Der Zeitbedarffür die Ausführung eines einzelnen Simulationslaufes ist aber immer noch sehr hoch, hierkann Parallele oder Verteilte Simulation eingesetzt werden, um auch diesen Zeitbedarf zureduzieren24.
Das Verfahren der Modellreduktion ist nicht Gegenstand der vorliegenden Arbeit, sondernes wird davon ausgegangen, daß der Modellierer nur dringend notwendige Eigenschaftenund erforderliches Verhalten im Simulationsmodell abbildet und daß eine Reduktion dieserElemente mit einer wesentlich geringeren Abbildungsgenauigkeit einhergeht.Dagegen soll auf die Möglichkeiten des verteilten Experimentierens (siehe Punkt 4.6,Punkt 5.3.5) und die Parallele und Verteilte Simulation (Kapitel 3, Kapitel 4) näher einge-gangen werden.
23 Siehe dazu [Völker, Munkelt, Gmilkowsky 2000].24 Einzelne Arbeiten wiesen eine Beschleunigung der Simulationsausführung um den Faktor 40 nach (siehe
[Luksch 1995]).

Kapitel 2 Einsatz der Parallelen und Verteilten Simulation zur Fertigungssteuerung komplexerProduktionssysteme
Seite 39
2.2.2 Abgrenzung zwischen Sequentieller, Paralleler und Verteilter Simulation
2.2.2.1 Abgrenzung zwischen Sequentieller Simulation und Paralleler bzw. Verteil-ter Simulation
Bei der Abbildung eines dynamischen Prozesses in der Simulation werden im Realsystemgleichzeitig stattfindende Aktionen sequentiell auf einem Computer ausgeführt25. Diessichert die prinzipielle Abbildbarkeit dieser zeitparallelen Prozesse auf dem Computer alseine sequentiell arbeitende Maschine. Hier liegt jedoch auch ein großes Manko. Besserwäre es, diese zeitparallel im Modell stattfindenden Aktivitäten auch in der Simulationparallel durchzuführen. Jedoch ist die parallele Durchführung dieser Aktivitäten im Simu-lationsmodell auf mehreren Computern nicht trivial lösbar. So vergingen seit der Ent-wicklung der Simulation ca. 20 Jahre bis Algorithmen zur Lösung der auftretenden Syn-chronisationsprobleme verfügbar waren. Dadurch, daß gleichzeitig auf mehreren Prozesso-ren bzw. Computern Berechnungen stattfinden, existieren mehrere lokale Zeiten (dieDurchführung der einzelnen im Modell zeitparallel stattfindenden Prozesse geschieht na-turgemäß unterschiedlich schnell), d.h. das Erreichen der Interaktionspunkte der parallelstattfindenden Prozesse erfolgt zu unterschiedlichen Realzeiten. Die Lösung dieses Pro-blems obliegt sogenannten Synchronisationsverfahren (siehe Punkt 3.1.3).
Grundsätzlich unterscheidet man zwischen Sequentieller Simulation und Paralleler bzw.Verteilter Simulation. Der wesentliche Unterschied liegt in der Art und Weise der Abarbei-tung des Simulationsmodells [Bagrodia u.a. 1998].
Tabelle 1 zeigt hier die Einteilung der Simulationsarten gemäß zweier Kriterien - der Ab-arbeitungsart und der Abarbeitungsplattform.
Tabelle 1 Sequentielle versus Parallele / Verteilte Simulation
Abarbeitungsart:
Abarbeitungs-plattform:
sequentielle Abarbeitung einesGesamtmodells (DES)
parallele Abarbeitung vonTeilmodellen (PDES)
lokale Abarbeitung lokale Sequentielle Simulation Parallele Simulation
verteilte Abarbeitung verteilte Sequentielle Simulation(verteiltes Experimentieren)
Parallele Simulation,Verteilte Simulation
Die herkömmliche Art der Simulation (DES - Discrete Event Simulation) besteht in dersequentiellen Abarbeitung von Ereignissen eines monolithischen Gesamtsimulations-modells. Die parallel im Modell stattfindenden Aktivitäten werden sequentiell nachein-ander auf einem Computer abgearbeitet (siehe „Ablaufsteuerung“ im Punkt 2.2.1.2). Hierwird von der im modellierten System vorhandenen Parallelität der Ereignisse bei derDurchführung der Simulation kein Gebrauch gemacht.
Bei der Parallelen bzw. Verteilten Simulation (PDES - Parallel Discrete Event Simulation)werden dagegen im Modell parallel stattfindenden Aktivitäten zum Teil auf mehrerenComputern bzw. Prozessoren zeitgleich abgearbeitet. Die prinzipiell zeitparallel abarbeit-baren Teile eines Simulationsmodell sind zu identifizieren und als Teilmodelle auszu-drücken. Diese Teilmodelle können dann durch Teilsimulatoren zeitgleich ausgeführt wer-den - eine schnellere Abarbeitung des Simulationsmodells ist möglich.
25 Vergleiche „Ablaufsteuerung“, Punkt 2.2.1.2.

Kapitel 2 Einsatz der Parallelen und Verteilten Simulation zur Fertigungssteuerung komplexerProduktionssysteme
Seite 40
Das Kriterium der Abarbeitungsplattform dient dazu weiter zu differenzieren [Fujimoto1999]:
• Lokale Abarbeitung bedeutet, daß die Teilaufgaben der Simulationsstudie auf einemComputer ausgeführt werden. Dabei ist es ohne Belang, ob es sich bei diesem Computerum einen Ein-Prozessor- oder einen Mehrprozessorrechner (Parallelrechner, Trans-puter) handelt.
• Verteilte Abarbeitung bedeutet dagegen, daß die Teilaufgaben der Simulationsstudie aufmehrere Computer eines Computernetzwerks (oder des Internets) verteilt sind und zeit-parallel ausgeführt werden.
Vorteil der lokalen Abarbeitung sind die wesentlich geringeren Übertragungszeiten fürNachrichten. Vorteile der verteilten Abarbeitung sind die geringeren Hardwarekosten unddie Möglichkeit den oft enormen Speicherbedarf auf mehrere Rechner zu verteilen [Mehl1994, S. 11].
Auf Basis dieser Unterscheidungsmerkmale ergeben sich vier Fälle.
Unter einer lokalen Sequentiellen Simulation ist die herkömmliche Art und Weise der Si-mulation zu verstehen (DES): ein monolithisches Simulationsmodell, welches in einemzusammenhängenden Simulationsprogramm beschrieben ist, wird durch einen Simulatorauf einem Computer ausgeführt.
Ausführender Computer
Sequentieller Simulator
monolithischesSimulationsmodell
Modelldaten
Abbildung 8 Bestandteile einer Sequentiellen Simulation
In einer verteilten Sequentiellen Simulation werden mehrere Computer eingesetzt, auf de-nen jeweils ein Teil der Simulationsstudie parallel ausgeführt werden. So besteht eine Si-mulationsstudie aus einer Vielzahl von Experimenten zur Ermittlung einer optimalen Pa-rameterkombination. Diese Experimente wiederum bestehen aus mehreren Simulations-läufen, damit aufgrund der Stochastik im Simulationsmodell statistisch gesicherte Aussa-gen getroffen werden können (vergleiche Punkt 2.3.3). So können für eine verteilte Se-quentielle Simulation die notwendigen Simulationsexperimente auf mehrere Rechner ver-teilt werden, welche dann die Simulationsläufe parallel ausführen. Weiterhin wäre denk-bar, die Läufe eines Experiments auf mehrere Rechner zu verteilen. Somit würde in praxiein verteiltes Experimentieren stattfinden.Diese Variante wird oft auch als Parallele bzw. Verteilte Simulation bezeichnet [Bley,Wuttke 1997], [Arndt 2000], [Schneider, Reinhardt 2000]. Es handelt sich aber de factoum eine Sequentielle Simulation, weil während des Simulationslaufes zwischen den ein-zelnen Computern keine Synchronisation notwendig ist.26
26 Zur Begriffsbildung Sequentielle Simulation und Parallele Simulation siehe [Unger 1988], [Bagrodia u.a.
1998].

Kapitel 2 Einsatz der Parallelen und Verteilten Simulation zur Fertigungssteuerung komplexerProduktionssysteme
Seite 41
Experiment 1 Experiment i Experiment n
Rechner A Rechner B Rechner Z
Abbildung 9 Verteilte Sequentielle Simulation - paralleles Experimentieren
In einer Parallelen bzw. Verteilten Simulation (PDES) wird dagegen das Simulations-modell in mehrere Teile - die sogenannten Partitionen oder Logischen Prozesse - zerlegt.Jeder dieser Logischen Prozesse stellt einen abgeschlossenen Teil des Simulationsmodellsdar, der in einem separaten (Teil-)Simulator abgearbeitet wird [Unger 1988], [Mehl 1994,S. 8], [Bagrodia u.a. 1998], [Fujimoto 1999]. So können prinzipiell eine Menge von Logi-schen Prozessen parallel abgearbeitet werden. Zu jedem Logischen Prozeß ist weiterhineine Kommunikationsschnittstelle fixiert, d.h., es ist festgelegt, welche Nachrichten derLogische Prozeß empfangen kann und welche Nachrichten er sendet. Über diese Kommu-nikation drückt sich die Abhängigkeit der Logischen Prozesse untereinander aus27. ZurWahrung der kausal richtigen Reihenfolge der Abarbeitung auftretender Ereignisse imGesamtmodell über alle parallel abgearbeiteten Logischen Prozesse ist ein globaler Syn-chronisationsmechanismus notwendig [Chandy, Misra 1978], [Nicol 1988]. Die Notwen-digkeit dieses Synchronisationsmechanismus stellt den wesentlichen Unterschied im Ver-gleich zur Sequentiellen Simulation dar.
globalerSynchronisations-
mechanismus
...
logischer Prozeß 1
Teil des Simulations-programms (Partition)
lokale Zuordnungder benötigtenModelldaten
(Teil-)Simulator
logischer Prozeß n
Teil des Simulations-programms (Partition)
lokale Zuordnungder benötigtenModelldaten
(Teil-)Simulator
Nachrichtenaustausch
Abbildung 10 Bestandteile einer Parallelen bzw. Verteilten Simulation
Die vorliegende Arbeit konzentriert sich auf die Nutzbarmachung der Parallelen und Ver-teilten Simulation für den Anwendungskontext der Simulation und Fertigungssteuerungvon Produktionssystemen.
2.2.2.2 Abgrenzung zwischen Paralleler und Verteilter Simulation
Während die Abgrenzung zwischen Sequentieller Simulation und Paralleler bzw. VerteilterSimulation leicht fällt, gestaltet sich die Abgrenzung zwischen Paralleler Simulation undVerteilter Simulation wesentlich schwieriger. Auch in der Literatur herrscht keine Einig-keit.
27 Ein Logischer Prozeß ist um so unabhängiger - und damit um so besser parallelisierbar - je weniger er
kommuniziert. Wobei der Grad der Kommunikation hier einen mengenmäßigen Aspekt (Anzahl der ein-und ausgehenden Nachrichten) und einen typmäßigen Aspekt (Anzahl der unterschiedlichen Nachrichten-typen) besitzt (siehe auch Punkt 3.1.3.3) [Preiss, Loucks 1990].

Kapitel 2 Einsatz der Parallelen und Verteilten Simulation zur Fertigungssteuerung komplexerProduktionssysteme
Seite 42
Häufige Unterscheidungskriterien sind die in Tabelle 1 dargestellten Faktoren der Abarb-eitungsplattform und der Abarbeitungsart [Unger 1988], [Bagrodia u.a. 1998], [Fujimoto1999].
Ein Simulationsmodell einer Verteilten Simulation besteht aus mehreren Teilmodellen, diezeitparallel auf mehreren Computern eines Computernetzwerks ausgeführt werden [Mehl1994, S. 11], [Bagrodia u.a. 1998], [Fujimoto 1999], [Smith 1999]. Die Besonderheit isthierbei, daß das Simulationsmodell aus mehreren disjunkten Teilmodellen besteht, dieauch physisch getrennt vorliegen. Hierzu hat der Ersteller entweder das Simulationsmodellexplizit in mehrere Teilmodelle zu zerlegen oder mehrere getrennt vorliegende Simula-tionsmodelle werden über eine gemeinsame Infrastruktur zu einem Gesamtsimulations-modell verbunden. Die Teilmodelle werden auf verschiedenen Computern gestartet undgleichzeitig abgearbeitet. Um die Dependenzen der Teilmodelle zu wahren, kommunizie-ren diese innerhalb des Computernetzwerks untereinander.
Ein Simulationsmodell der Parallelen Simulation besteht dagegen aus einem physisch ein-heitlich vorliegenden Simulationsmodell. Der Modellierer beschreibt hier explizit die par-allel ausführbaren Teile des Simulationsmodells. Man benutzt dazu Möglichkeiten der par-allelen Programmierung (Threads o.ä.), welche durch die Programmumgebung (Softwaredes Parallelen Simulators, Laufzeitumgebung der Programmiersprache, Betriebssystemoder Hardware [Bagrodia 1996]) zur Verarbeitung den einzelnen Prozessoren bzw. Com-putern zugewiesen werden. Die Kommunikation der Teilmodelle erfolgt hier über einengemeinsamen Speicher (Mehrprozessorrechner) oder ein Computernetzwerk [Mehl 1994,S. 11], [Bagrodia u.a. 1998], [Fujimoto 1999].
2.2.3 Ziele des Einsatzes der Parallelen und Verteilten Simulation
Es lassen sich zwei Hauptziele unterscheiden [Fujimoto 1999], die sich konträr zueinanderverhalten:
A) LaufzeitbeschleunigungB) Einbindung vorhandener, verteilt vorliegender Komponenten.
Der Fokus der Arbeit liegt hier auf dem Ziel A - der Laufzeitbeschleunigung (siehe Punkt2.2.1.3). Hauptziel der Simulation von Produktionssystemen und der Fertigungssteuerungist die Erhöhung der Performance der Simulation: eine Vielzahl von Simulationsläufen mitveränderten Parametern ist in kürzester Zeit abschließen.
Mit der Verfolgung des Ziels B befaßt sich z.B. die Interactive Simulation [Straßburger2001, S. 18]. Ziel der Interactive Simulation ist es u.a., eine verteilte Trainingsumgebungoder CyberSpace-Erlebniswelten aufzubauen, in denen verschiedene menschliche Benutzeruntereinander oder mit simulierten Komponenten des betrachteten Realsystems inter-agieren können. Die Hauptanwendungen der Interactive Simulation lassen sich im militäri-schen Bereich finden [HLA], [Hollenbach, Alexander 1997], [Dahmann, Fujimoto,Weatherly 1998], [Davis, Moeller 1999], [Smith 1999].
Das Speedup als Maß für die beschleunigte Simulationsausführung:
An vielen Stellen in der Literatur, u.a. in [Nicol 1988], [Unger 1988], [Mehl 1994, S. 41],[Page, Moose, Griffin 1997], [Bagrodia u.a. 1998], findet sich die Definition eines Ver-gleichsmaßes für die Rechengeschwindigkeit von Simulatoren - das Speedup.Das Speedup gibt an, in welchem Maße ein Simulator A gegenüber einem Simulator B dasselbe Simulationsmodell in kürzerer Zeit ausführen kann. Es wird die Ausführungs-geschwindigkeit eines speziellen untersuchten Simulators der Ausführungszeit der Sequen-tiellen Simulation gegenübergestellt. Hat der untersuchte Simulator eine kürzere Laufzeitals die Sequentielle Simulation, so spricht man von einem Speedup; ist dagegen die Lauf-

Kapitel 2 Einsatz der Parallelen und Verteilten Simulation zur Fertigungssteuerung komplexerProduktionssysteme
Seite 43
zeit des untersuchten Simulators größer als die Laufzeit der Sequentiellen Simulation, sospricht man von einem Slowdown.
Das Speedup SAB ist als Maß für die beschleunigte Ausführung des gleichen Simulations-modells durch einen Simulator B gegenüber einem Simulator A wie folgt definiert:
SAB = ZA / ZB
Formel 1 Das Speedup als Maß der beschleunigten Simulations-ausführung
Das Speedup gibt damit Auskunft, welcher Simulator zur Simulation des ausgewähltenSimulationsmodells in welchem Maße performanter ist.
2.3 Aufgaben der Parallelen und Verteilten Simulation beim Ein-satz in der Fertigungssteuerung
Um Parallele und Verteilte Simulation zur Fertigungssteuerung komplexer Produktions-systeme einsetzen zu können, müssen eine Reihe von Aufgaben gelöst werden. Ein erstesProblem besteht in der Erstellung des Simulationsmodells (Punkt 2.3.1). Hier ist ins-besondere der Umfang und die Komplexität für die abzubildenden komplexen Produk-tionssysteme zu betrachten (Punkt 2.3.2). Um dann das erstellte Simulationsmodell parallelbzw. verteilt zu simulieren, muß dieses Simulationsmodell partitioniert und synchronisiertwerden. Weitere dabei zu lösende Probleme sind die Kommunikation und der Lastaus-gleich zwischen der Berechnungshardware (Punkt 2.3.4).
2.3.1 Erstellung des Simulationsmodells - Problem der Modellbildung
Zur Erstellung eines Simulationsmodells ist:
a) ein Simulationsexperte notwendig, der die notwendigen Spezialkenntnisse zur Erstel-lung von Simulationsmodellen besitzt [Kosturiak, Gregor 1995, S. 65], [Blazejewski2000, S. 69 ff.] und
b) es ist ein hoher Aufwand mit dem Prozeß der Modellerstellung und -validierung ver-bunden [Page 1991, S. 24], [Kosturiak, Gregor 1995, S. 66], [Kobylka, Gäse, Wirth2000].
Abgesehen von der Notwendigkeit des Einsatzes eines Simulationsspezialisten besteht einhoher zeitlicher und personeller Aufwand zur Modellerstellung. Zur Erstellung eines Mo-dells des zu betrachtenden Systems sind die relevanten Objekte und das relevante Verhal-ten dieser Objekte des Systems zu identifizieren, zu analysieren und im Modell abzubilden[VDI 3633, Blatt 1], [Page 1991, S. 8, S. 13-14, S. 22], [Smith 1999], [Blazejewski 2000,S. 66].
Ein erstes Problem ist die Entscheidung: Was ist relevant? Hierzu ist eine Analyse desSystems durchzuführen, wesentliche Objekte im System sind zu identifizieren und zu be-schreiben (siehe Punkt 2.3.2). Eine Datenerhebung muß durchgeführt werden, um die kon-kreten Ausprägungen von Eigenschaften und das konkrete Verhalten des Systems festzu-stellen. Der Prozeß der Abstraktion - insbesondere die Relevanzentscheidung - ist schwie-rig und erfordert einen geübten Modellierer. Als Ergebnis steht eine detaillierte Beschrei-bung des zu modellierenden Systems.
Als Zweites sind zur Erstellung des Modells exakte Daten aus der Realität notwendig.Dies erfordert einen hohen Datenerfassungs-, Modellierungs- und Zeitaufwand [Blaze-jewski 2000, S. 69 ff.]. Diese hohen Datenmengen sollten in Datenbanken gespeichertwerden [Kosturiak, Gregor 1995, S. 158], [Blazejewski 2000, S. 70].

Kapitel 2 Einsatz der Parallelen und Verteilten Simulation zur Fertigungssteuerung komplexerProduktionssysteme
Seite 44
Als Drittes muß eine Beschreibung der Objekte und ihres Verhaltens im Simulations-system erfolgen. Dies ist üblicherweise eine Aufgabe der Programmierung in einer spezi-ellen Simulationssprache und kann nur von einem Simulationsexperten durchgeführt wer-den. Es existieren Simulationstools auf unterschiedlichen Abstraktionsebenen und mit un-terschiedlichen Fähigkeiten [Page 1991, S. 157ff], [Kosturiak, Gregor 1995, S. 154]. ImMinimalfall sind lediglich höhere Programmiersprachen mit speziellen Anweisungen zurBeeinflussung der Ablaufsteuerung der Simulation vorhanden. Günstiger sind Simulations-sprachen. Beide stellen einen unteren Level der Modellierung dar. Die Besonderheit ist dieAnwendungsunabhängigkeit. Mit Hilfe dieser Tools kann jedes betrachtete System model-liert werden, aber oft nur mit hohen Aufwand. Auf der oberen Abstraktionsebene der Si-mulationstools existieren bausteinorientierte Simulationssysteme. Diese erlauben eine ein-fachere Modellierung und erfordern nicht unbedingt einen Simulationsexperten, auch eingeübter Modellierer kann mit diesen Systemen umgehen [Simul8 1999, S. 17]. Es sindBausteine vorhanden, die häufige Elemente der Simulationsmodelle abbilden und das Mo-dell kann auf Basis dieser Bausteine graphisch konstruiert werden [Fishman 2001, S. 31].Nachteilig an den bausteinorientierten Simulationssystemen ist aber, daß die vorhandenenBausteine auf einen konkreten Anwendungskontext ausgerichtet sind und sich nicht fürbeliebige Aufgabenstellungen eignen. Soll ein Sachverhalt abgebildet werden, der bei derSchaffung der Bausteine nicht bedacht wurde, so ist die Modellierung des Systems mitdem bausteinorientierten Simulator u.U. gar nicht möglich oder aber es muß mit Hilfe ei-ner Simulationssprache erst ein neuer Baustein geschaffen werden.
Als Viertes ist die Modellvalidierung notwendig [Page 1991, S. 24, S. 145-156], [Kostu-riak, Gregor 1995, S. 66], [Kobylka, Gäse, Wirth 2000] - die Fertigstellung eines syntak-tisch korrekten Simulationsprogrammes mit analogem Verhalten wie das modellierte Sy-stem. Während der Modellvalidierung ist die nachträgliche Änderung und Anpassung desSimulationsmodells durchzuführen, um die Ergebnisse und Aussagen des Simulations-modells mit den Ergebnissen des modellierten Systems in Einklang zu bringen. Hierbeihandelt es sich um einen langwierigen, manuellen Prozeß. So sind z.B. Faktoren, die ineiner ersten Version des Simulationsmodells nicht berücksichtigt wurden, weil sie zur Mo-dellierung des Systems nicht relevant erschienen oder nicht bekannt waren, nachträglich indas Simulationsmodell einzubeziehen, um die mit dem Simulationsmodell erzielbarenAussagen mit den Ergebnissen im betrachteten System in Übereinstimmung zu bringen.Die Modellvalidierung ist nur eingeschränkt möglich, wenn zu dem Realsystem keineVergangenheitsdaten verfügbar sind, die Ausgangssituationen und das Verhalten des Sy-stems in den Situationen beschreiben.
Zusammenfassend kann man sagen, daß ein sehr hoher Aufwand zur Erstellung eineskorrekt abbildenden Simulationsmodells notwendig ist.
Der Aufwand zur Modellerstellung kann jedoch durch Simulationsprogrammgeneratorenin gewissem Maße gemildert werden [Kobylka, Gäse, Wirth 2000], [Gäse, Günther, Wirth2000], [Wiedemann 2000], [Eversheim, Intra, Abels 2000]. Dies ist einer der Beweggründezur Schaffung eines Frameworks zur Simulation von Produktionssystemen - näheres dazusiehe Kapitel 4.2.
2.3.2 Modelle von Produktionssystemen als Abbildungsgegenstand der Ferti-gungssteuerung - eine Komplexitätsbetrachtung
Die nachfolgenden Ausführungen über Komplexität und Bestandteile von Modellen vonProduktionssystemen sind notwendig, um die Inhalte der Simulationsmodelle von Produk-tionssystemen zu charakterisieren. All die vorgestellten Elemente müssen in einem Ansatzzur Parallelen bzw. Verteilten Simulation von Produktionssystemen ebenfalls zur Verfü-

Kapitel 2 Einsatz der Parallelen und Verteilten Simulation zur Fertigungssteuerung komplexerProduktionssysteme
Seite 45
gung stehen. Da jedoch kein direkt zur Simulation von Produktionssystemen geeignetesTool der Parallelen und Verteilten Simulation vorhanden ist (siehe dazu Punkt 3.2.2.8 undPunkt 3.2.3), muß diese Komplexität erst im gewählten Implementationsansatz ergänztwerden. Es muß also eine Implementation von Modellelementen respektive Modell-bausteinen28 für diesen Zweck durchgeführt werden. Deswegen sollen nachfolgend diewesentlichen Charakteristika herausgearbeitet werden.
2.3.2.1 Komplexität der Modelle von Produktionssystemen
Nachfolgend dient der Begriff der Komplexität als ein Maß für den Umfang und die Kom-pliziertheit von Modellen. Anhand der Komplexität kann der numerische Aufwand fürBerechnungen am Modell eingeschätzt werden.
Die Komplexität von Modellen von Produktionssystemen setzt sich aus fünf wesentlichenTeilaspekten zusammen:
1. dem Umfang an Elementen im Produktionssystem,
2. dem Organisationsgrad des Produktionssystems,
3. dem Belastungszustand des Produktionssystems,
4. dem Vorhandensein komplexer Prozeßbedingungen und
5. den eingesetzten Verfahren zur Fertigungssteuerung.
Der Umfang an Elementen gibt an, wieviel - und wieviel verschiedenartige - Elemente imModell des Produktionssystem existieren. Zu diesen Elementen gehören Maschinen, Ma-schinengruppen, Werkstätten, Lager, Stellplätze, Transportwege, Verteil- und Zusammen-führungspunkte, Fördermittel und Transporteinrichtungen, Produkte, Aufträge, Lose,Werkstücke, Transportbehälter, Werkzeuge, Werker etc. Je mehr Arten von Modell-elementen und Beziehungen zwischen diesen Modellelementen vorhanden sind, destokomplizierter wird das Modell. Der Punkt 2.3.2.2 beschreibt anschließend die in Modellenvon Produktionssystemen auftretenden Elementarten sowie die Daten und Zusammen-hänge dieser Modellelemente.
Der Organisationsgrad des Produktionssystems gibt an, wie die Elemente des Produk-tionssystems untereinander durch den technologischen Fluß verbunden sind. D.h., er be-schreibt die Anordnung der statischen Elemente und welche Wege zwischen diesen stati-schen Elementen von den dynamischen Elementen in Anspruch genommen werden29. Hiersind u.a. die Arbeitspläne und Stücklisten einzuordnen, welche den technologischen Flußder dynamischen Elemente definieren. Die Beschreibung dieser Daten und Zusammen-hänge erfolgt im Punkt 2.3.2.2. Weiterhin ist unter dem Organisationsgrad des Produk-tionssystems die Anordnungs- und Ablaufstruktur zu verstehen. Ein Produktionssystemkann z.B. eine Linienstruktur aufweisen oder aus einem Netz von Werkstätten bestehen.Man unterscheidet u.a. Fließ- und Werkstattfertigung [Jung 1998, S. 464-468]. Der letzt-lich resultierende Vernetzungsgrad des Produktionssystems ist Ausdruck für die Kompli-ziertheit des Modells.
Der Belastungszustand des Fertigungssystems definiert sich durch die Anzahl unter-schiedlicher Produkttypen im Produktionssystem (Produktspektrum) und die Anzahl derim System befindlichen Produkte, Aufträge, Lose, Werkstücke und Materialien (System-last). Hierzu ist einerseits die Kenntnis des aktuellen Belastungszustandes des Produktions-
28 Die Bereitstellung von typischen Simulationsmodellbestandteilen in sogenannten Modellelementen bzw.
Modellbausteinen ist eine wesentliche Forderung zur Erleichterung der Modellformulierung [Hirsch u.a.2000], [Fishman 2001, S. 31-33]. Siehe dazu auch Punkt 3.3.1.
29 Zur Einteilung der Elemente siehe Punkt 2.3.2.2.

Kapitel 2 Einsatz der Parallelen und Verteilten Simulation zur Fertigungssteuerung komplexerProduktionssysteme
Seite 46
systems notwendig (momentan in Bearbeitung befindliche bzw. auf Bearbeitung wartendeProdukte, Aufträge, Lose, Werkstücke usw.). Außerdem ist die Kenntnis der Einsteuerungnotwendig (Kopplung zur Auftragsfreigabe). D.h., welche Produkte, Aufträge, Lose,Werkstücke zu welchem Zeitpunkt, in welcher Menge das Produktionssystem betreten undbis wann diese fertiggestellt sein sollen (Fertigungsziele).
Abstrakt betrachtet kann man ein Produktionssystem bereits so charakterisieren, daß es ausMaschinen und Aufträgen besteht, wobei sich die Aufträge gemäß ihrer Arbeitspläne zwi-schen den Maschinen bewegen. Jedoch können an den Maschinen spezifische Bedin-gungen vorliegen, die im Modell beachtet werden müssen. Diese spezifischen Prozeß-bedingungen sind besondere Bestimmungen zur Behandlung von Aufträgen bzw. Werk-stücken oder Restriktionen der Arbeitsweise von Maschinen. Die Charakterisierung spe-zifischer Prozeßbedingungen wird ausführlich im Punkt 2.3.2.3 vorgenommen. Die Ein-beziehung von im Realsystem vorhandenen spezifischen Prozeßbedingungen führt zu einerhöheren Abbildungsgenauigkeit der Realität im Modell. Die Lösungsqualität der auf demModell basierenden Verfahren verbessert sich.
Als letztes haben die im Produktionssystem verwendeten Verfahren zur Fertigungs-steuerung Einfluß auf die Komplexität des Modells des Produktionssystems. Diese Ver-fahren erfordern unterschiedliche Daten für ihre Berechnungen und verursachen einen un-terschiedlichen numerischen Aufwand. Die Daten und Parameter sowie die Berechnungs-regeln des Verfahrens sind selbst wieder Bestandteil des Modells. Auf die Einbindung derVerfahren in das Modell wird im Punkt 2.3.2.2 näher eingegangen.
2.3.2.2 Bestandteile der Modelle von Produktionssystemen
2.3.2.2.1 Arten von Modellelementen
Kosturiak und Gregor [Kosturiak, Gregor 1995, S. 71-81] unterscheiden drei Gruppen vonElementen von Produktionssystemen:
• dynamische Elemente,• stationäre oder statische Elemente und• Schnittstellenelemente.
Modellelemente
dynamische Elemente statische ElementeSchnittstellen-
elemente
Bearbeitungsobjekte
Bearbeitungselemente
Materialflußelemente
Informationselemente
Bearbeitungselemente
Materialflußelemente
Informationselemente
Eintrittspunkte - Quellen
Austrittspunkte - Senken
Abbildung 11 Modellelemente eines Produktionssystems30
30 Siehe [Kosturiak, Gregor 1995, S. 72].

Kapitel 2 Einsatz der Parallelen und Verteilten Simulation zur Fertigungssteuerung komplexerProduktionssysteme
Seite 47
Die statischen Elemente (Abbildung 12) können in Bearbeitungselemente, Materialflußele-mente und Informationselemente unterteilt werden [Kosturiak, Gregor 1995, S. 76]. Zu denBearbeitungselementen gehören Maschinen, Maschinengruppen und Werkstätten. DenMaterialflußelementen sind Lager, Stellplätze, Transportwege, Verteil- und Zusammenfüh-rungspunkte und stetige Fördermittel zuzurechnen. Zu den Informationselementen gehörenAngaben über Arbeitszeitregelungen und Wartungspläne, Angaben über globale und lokaleSteuerungen. So wird der Arbeitsplan eines Produktes als Durchlaufsteuerung (stationäresInformationselement) angesehen. Die Steuerungsregel zum Abbau der Warteschlange derMaschinengruppe ist dagegen als Informationselement der lokalen Steuerung anzusehen.
statische Elemente
Bearbeitungselemente
Materialflußelemente
Informationselemente
Lager, Stellplätze
stetige Fördermittel,Transporteinrichtungen
Transportwege
Bearbeitungsstation(Maschine, Maschinengruppe)
Verteil- undZusammenführungspunkte
Arbeitszeit- und Wartungspläne
lokale Steuerungen
globale Steuerungen
Abbildung 12 Statische Modellelemente31
Die dynamischen Elemente (siehe Abbildung 13) sind weiter in Bearbeitungsobjekte, Be-arbeitungselemente, Transportelemente und Informationselemente zu unterteilen[Kosturiak, Gregor 1995, S. 73]. Zu den Bearbeitungsobjekten gehören Produkte, Aufträ-ge, Lose, Werkstücke und sonstige Materialien. Als Bearbeitungselemente sind Werker,Werkzeuge und Fertigungshilfsmittel anzusehen. Zu den Transportelementen zählenTransportbehälter, Transporteinrichtungen und Förderhilfsmittel. Zu den Informations-elementen gehören Nachrichten oder Daten, welche mit den beweglichen Elementen wei-tergereicht werden (z.B. Arbeitsplankarten).
31 Siehe [Kosturiak, Gregor 1995, S. 76].

Kapitel 2 Einsatz der Parallelen und Verteilten Simulation zur Fertigungssteuerung komplexerProduktionssysteme
Seite 48
dynamische Elemente
Bearbeitungsobjekte
Bearbeitungselemente
Materialflußelemente
Informationselemente
Produkte, Aufträge,Lose, Werkstücke
Werker
Fertigungshilfsmittel
beweglicheFördermittel
Förderhilfsmittel
Abbildung 13 Dynamische Modellelemente32
Die Schnittstellenelemente [Kosturiak, Gregor 1995, S. 81] stellen eine Analogie zu denForderungsquellen und -senken der Bedienungstheorie dar. Quellenelemente geben an, fürwelches Produkt, in welchen zeitlichen Abständen, in welcher Menge Aufträge bzw. Loseeinzusteuern sind. Sie geben damit Aufschluß über die zukünftige Last des Produktions-systems. Die Senkenelemente dienen dagegen zur Erfassung der ausgesteuerten Aufträgebzw. Lose.
Für die physische Repräsentation des Modells erfolgt die Aufteilung dieser Modellbestand-teile in Datenobjekte sowie Operations- und Steuerobjekte [Herzog 1999]33:
• Datenobjekte sind Bestandteile des Modells, die sich vollständig durch Daten cha-rakterisieren lassen. Sie sind näher im Punkt 2.3.2.2 beschrieben.34
• Operations- und Steuerobjekte sind dagegen Bestandteile des Modells mit funktiona-lem Charakter, wie z.B. Steuerungsregeln. Sie sind näher ab Seite 52 beschrieben.
Prozeßbedingungen geben Restriktionen in Aufbau und Ablauf von Vorgängen im Modellan. Einige der spezifischen Prozeßbedingungen benötigen sowohl Daten- als auch Operati-ons- und Steuerobjekte (z.B. Rüstzeittabelle plus Rüstregel). Im Punkt 2.3.2.3 erfolgt einenähere Beschreibung ausgewählter spezifischer Prozeßbedingungen.
2.3.2.2.2 Abbildung der Daten der Modellelemente
Die nachfolgenden Abbildungen (Abbildung 14 - Abbildung 21) stellen die benötigtenDaten- und Informationselemente sowie ihre Beziehungen untereinander dar.
32 Siehe [Kosturiak, Gregor 1995, S. 73].33 Man unterscheidet generell zwischen Daten- oder Speicherobjekten sowie Operations- und Steuerobjekten
[Herzog 1999]. Daten- bzw. Speicherobjekte dienen zur Aufbewahrung und Speicherung von Informatio-nen. Operationsobjekte fassen Algorithmen zur Manipulation von Datenobjekten zusammen. Steuerobjekteerlauben die Angabe von Bedingungen für die Anwendung von Operationsobjekten auf Datenobjekte. Die-se Trennung ist inspiriert von der Trennung zwischen Funktionalität und Oberfläche. Siehe dazu „DesignPattern“ [Gamma u.a. 1995].
34 Siehe dazu auch Begriff des „Entities“ [Fishman 2001, S. 38].

Kapitel 2 Einsatz der Parallelen und Verteilten Simulation zur Fertigungssteuerung komplexerProduktionssysteme
Seite 49
Produkt
beziehensich auf
Fertigungs-auftrag
Einsteuerungs-strategie
möglicheEinsteuerungs-
strategien
ist eine
Produktionssystem
hat kann mehrereherstellen
MaschinengruppeTransportmittel-
gruppeWerkergruppe
Werkzeug
Lager
hatmehrere
hatmehrere
hatmehrere
hatmehrere
hatmehrere
Maschinen
hat mehrere
Transportmittel
hat mehrere
Werker
hat mehrere
werdeneingesteuert
Abbildung 14 Semantische Darstellung der Elemente des Modells einesProduktionssystems35
In einem Produktionssystem können mehrere Produkte hergestellt werden. Das Produkti-onssystem besitzt eine Einsteuerungsstrategie, welche Fertigungsaufträge für die Produkteeinsteuert. Zur Abarbeitung der Fertigungsaufträge besitzt das Produktionssystem mehrereMaschinengruppen, Transportmittel, Lager, Werker und Werkzeuge.
Produkt Loskann
mehrerebesitzen
Fertigungs-auftrag
Werkstückkann ausmehrerenbestehen
kann ausmehrerenbestehen
Abbildung 15 Semantische Darstellung der Beziehungen der dynamischenElemente Produkt, Auftrag, Los und Werkstück
Gemäß der erfolgten Einsteuerung können im Produktionssystem zu einem Produkt mehre-re Fertigungsaufträge vorhanden sein. Ein Fertigungsauftrag kann wiederum aus mehrerenLosen bestehen. Ein Los kann aus mehreren Werkstücken bestehen. Das Los ist dabei alskleinste, durch das Produktionssystem transportierbare Einheit anzusehen. Das Werkstückbildet dagegen das Bearbeitungsobjekt (siehe Punkt 2.3.2.2.1).
Produkt Arbeitsplan Arbeitsgang
Stückliste Material
besitztbesteht
aus
besitzt
listetauf
bestehtaus
ist erforderlich für
Abbildung 16 Semantische Darstellung der Beziehungen zwischen denElementen Produkt, Arbeitsplan und Stückliste
35 Zur Erläuterung der Darstellungsform: Das Semantikdiagramm ist an die Darstellungsform der Seman-
tischen Netze angelehnt. Es gibt die Beziehungen respektive Zusammenhänge zwischen verschiedenenEntitäten eines Sachverhaltes wieder. Jede Entität wird durch ein Kästchen symbolisiert. Entitäten sind mitObjekten im Problemraum vergleichbar. Jede Entität besitzt Daten, die aus Gründen der Übersichtlichkeitjedoch nicht im Semantikdiagramm ausgedrückt werden. Im Gegensatz zu der Darstellung Entity-Relationship-Models, welche hohe Ähnlichkeit aufweist - geben die Pfeile im Semantikdiagramm die Le-serichtung für eine benannte Beziehung an. Kardinalitäten werden nicht über die Pfeile ausgedrückt, son-dern sind ggf. in der Benennung anzugeben. Semantikdiagramme sind ideal zur Beschreibung des struktu-rellen Aufbaus komplexer Sachverhalte. Leider ist die Darstellungsform der Semantikdiagramme nicht ge-normt.

Kapitel 2 Einsatz der Parallelen und Verteilten Simulation zur Fertigungssteuerung komplexerProduktionssysteme
Seite 50
Jedes im Produktionssystem vorhandene Produkt besitzt einen Arbeitsplan und eine Stück-liste. Der Arbeitsplan ist als geordnete Folge von Arbeitsgängen definiert. Die Stücklistelistet die zur Herstellung des Produktes notwendigen Materialien auf. Ein Material (z.B.eine Baugruppe) kann selbst wieder aus mehreren anderen Materialien bestehen. DieStückliste gibt dabei an, welche Materialien in welchem Arbeitsgang erforderlich sind.
Bearbeitungszeitgibt an
Arbeitsgang
Maschinengruppe
WerkerWerkzeug
erfordert
Rüstzustand
gibt an
wirdausgeführt
auf
erfordert
erfordert
Bearbeitungs-anforderung
Abbildung 17 Semantische Darstellung der Zuordnung der für einen Ar-beitsgang benötigten Ressourcen
Um die zur Ausführung eines Arbeitsganges notwendigen Ressourcen zu beschreiben, er-folgt im Arbeitsgang die Angabe einer Bearbeitungsanforderung. In den Daten der Bearb-eitungsanforderung ist vermerkt, auf welcher Maschinengruppe dieser Arbeitsgang auszu-führen ist, welcher Rüstzustand dazu auf einer der Maschinen der Maschinengruppe not-wendig ist, ob Werker für die Bearbeitung notwendig sind und ob ggf. ein oder mehrereWerkzeuge notwendig sind. Weiterhin ist die erforderliche Bearbeitungszeit vermerkt.
Maschine
Werkstück Transportmittel
Warteschlange(auf Transport)
Transportbehälter
MaterialLager
ist ein
lagert in
wirdbearbeitet
aufwartet in
wirdtransportiert
in
wirdtransportiert
mit
Warteschlange(vor Bearbeitung)
wartet in
Abbildung 18 Semantische Darstellung der Zustände von Werkstücken
Die Werkstücke als Bearbeitungsobjekte können sich in verschiedenen Zuständen be-finden. Ein Werkstück ist als ein Material anzusehen. Materialien können in Lagern ge-lagert werden. Ein Werkstück kann sich weiterhin in einer Warteschlange befinden und aufBearbeitung oder Transport warten. Oder das Werkstück befindet sich auf einer Maschinein Bearbeitung oder das Werkstück wird in einem Transportbehälter mit einem Trans-portmittel transportiert. Ein Werkstück kann sich folglich in den Zuständen „lagert“,„wartet auf Bearbeitung“, „wird bearbeitet“, „wartet auf Transport“ und „wird transpor-tiert“ befinden.
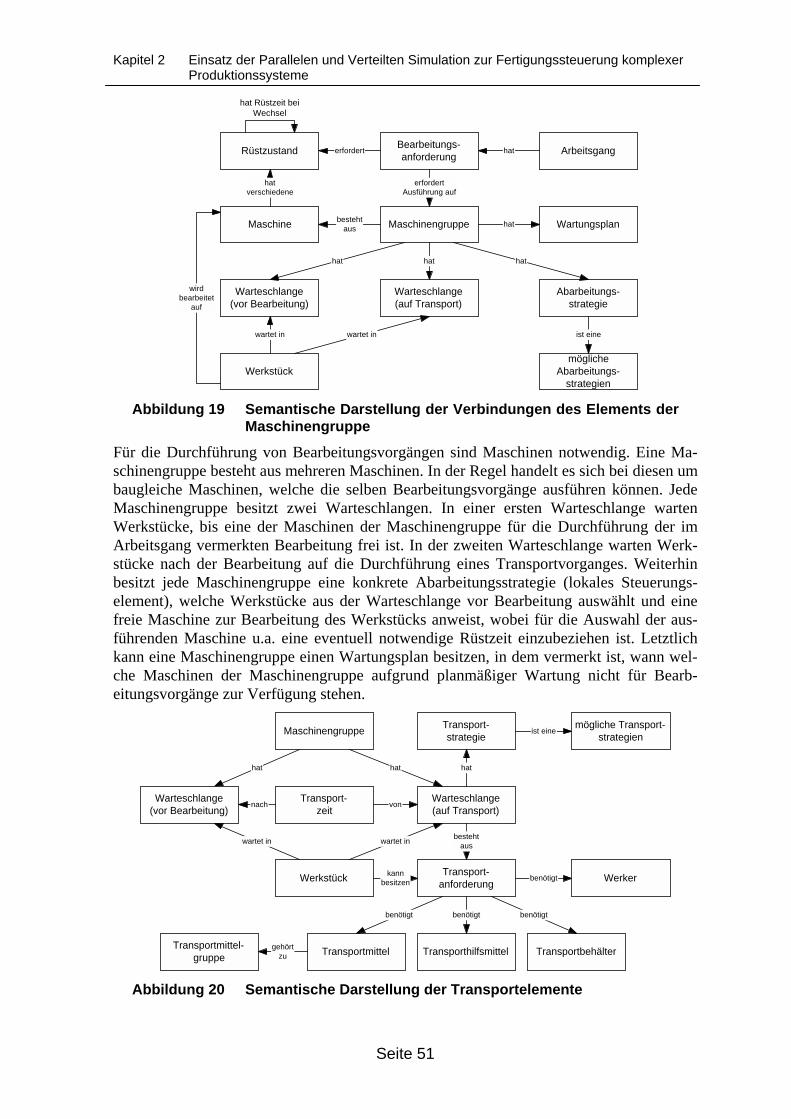
Kapitel 2 Einsatz der Parallelen und Verteilten Simulation zur Fertigungssteuerung komplexerProduktionssysteme
Seite 51
Arbeitsgang
Maschine Maschinengruppe
Werkstück
Wartungsplan
Rüstzustand
Abarbeitungs-strategie
Warteschlange(vor Bearbeitung)
möglicheAbarbeitungs-
strategien
Warteschlange(auf Transport)
wartet in
bestehtaus
hat
hat
ist eine
hathat
hatverschiedene
Bearbeitungs-anforderung
erfordertAusführung auf
erfordert hat
hat Rüstzeit beiWechsel
wartet in
wirdbearbeitet
auf
Abbildung 19 Semantische Darstellung der Verbindungen des Elements derMaschinengruppe
Für die Durchführung von Bearbeitungsvorgängen sind Maschinen notwendig. Eine Ma-schinengruppe besteht aus mehreren Maschinen. In der Regel handelt es sich bei diesen umbaugleiche Maschinen, welche die selben Bearbeitungsvorgänge ausführen können. JedeMaschinengruppe besitzt zwei Warteschlangen. In einer ersten Warteschlange wartenWerkstücke, bis eine der Maschinen der Maschinengruppe für die Durchführung der imArbeitsgang vermerkten Bearbeitung frei ist. In der zweiten Warteschlange warten Werk-stücke nach der Bearbeitung auf die Durchführung eines Transportvorganges. Weiterhinbesitzt jede Maschinengruppe eine konkrete Abarbeitungsstrategie (lokales Steuerungs-element), welche Werkstücke aus der Warteschlange vor Bearbeitung auswählt und einefreie Maschine zur Bearbeitung des Werkstücks anweist, wobei für die Auswahl der aus-führenden Maschine u.a. eine eventuell notwendige Rüstzeit einzubeziehen ist. Letztlichkann eine Maschinengruppe einen Wartungsplan besitzen, in dem vermerkt ist, wann wel-che Maschinen der Maschinengruppe aufgrund planmäßiger Wartung nicht für Bearb-eitungsvorgänge zur Verfügung stehen.
Maschinengruppe
Transportmittel Transportbehälter
Transport-strategie
mögliche Transport-strategien
TransporthilfsmittelTransportmittel-
gruppe
hat
Werkstück
Warteschlange(vor Bearbeitung)
Warteschlange(auf Transport)
wartet in wartet in
hat hat
ist eine
bestehtaus
Transport-anforderung
benötigtbenötigt benötigt
gehörtzu
kannbesitzen Werkerbenötigt
Transport-zeit
vonnach
Abbildung 20 Semantische Darstellung der Transportelemente

Kapitel 2 Einsatz der Parallelen und Verteilten Simulation zur Fertigungssteuerung komplexerProduktionssysteme
Seite 52
Außer Bearbeitungsvorgängen können auch Transportvorgänge stattfinden. Zu einer Ma-schinengruppe gehört eine Warteschlange auf Transport. Diese Warteschlange besteht ausTransportanforderungen der in ihr wartenden Werkstücke. In den Daten der Transport-anforderung ist vermerkt, ob und welches Transportbehältnis, welche Transportmittel,Transporthilfsmittel und Werker benötigt werden. Für die Durchführung eines Transport-vorganges von einer Warteschlange auf Transport einer Maschinengruppe A zu der Warte-schlange auf Bearbeitung einer Maschinengruppe B wird eine festgelegte Transportzeitbenötigt. Letztlich kann eine konkrete Transportstrategie angegeben werden, welche eineReihenfolge für Transportvorgänge festlegt.
Werker Werkergruppegehörtzu Arbeitszeitplanbesitzt
Bearbeitungs-anforderung
Transport-anforderung
erfordert erfordert
Abbildung 21 Semantische Darstellung der Beziehungen der Werker-elemente
Werker werden bei der Durchführung von Bearbeitungs- und Transportvorgängen benö-tigt. In den Daten der Bearbeitungs- oder Transportanforderung ist vermerkt, wieviel Wer-ker welcher Qualifikation notwendig sind. Die Werker selbst gehören zu einer Werker-gruppe. Jede Werkergruppe besitzt einen Arbeitszeitplan, mehrere Werkergruppen könnenden selben Arbeitszeitplan besitzen. Der Arbeitszeitplan definiert die Arbeits- und Pausen-zeiten der Werker, sowie die im Betriebskalender festgelegten Arbeits- und Feiertage.
2.3.2.2.3 Abbildung organisatorischer Regelungen im Modell
Die im vorangegangenen Punkt genannten Entitäten36 beziehen sich in der Regel auf Da-ten. Das Modell des Produktionssystems enthält aber außer Daten, welche konkrete Aus-prägungen von Eigenschaften angeben, auch Verhalten. Dieser funktionale Aspekt desVerhaltens wird im Modell in Operations- und Steuerobjekten37 ausgedrückt, um z.B. or-ganisatorische Regelungen abzubilden.In Abbildung 14, Abbildung 19 und Abbildung 20 waren bereits die wesentlichen Operati-ons- und Steuerobjekte zu sehen. Man unterscheidet Einsteuerungs-, Abarbeitungs- undTransportstrategien. Die in [Kosturiak, Gregor 1995, S. 76-77] genannten Informations-elemente wie Operationsdauer-, Transformations- und Durchlaufsteuerungen zählen dage-gen nicht zu den Operations- und Steuerobjekten, da sie vollständig über Daten beschreib-bar sind.
Einsteuerungsstrategien sind zweigeteilt zu sehen. Zum Einen ist eine Strategie not-wendig, die angibt, wann welche Einsteuerung erfolgen soll. Diese Funktion ist mit derAufgabe der Auftragsfreigabe (vergleiche Punkt 2.1.2) gleichzusetzen und soll nach-folgend nicht weiter betrachtet werden. Zum Zweiten lassen sich die Ergebnisse der Ein-steuerung vollständig als Daten ausdrücken. Für die Reihenfolgeplanung (vergleiche Punkt2.1.3, Punkt 2.1.4) sind Angaben über Aufträge bzw. Lose mit konkretem Einsteuerungs-termin, der Einsteuerungsmenge, einem Plantermin (Fertigungsziel) und ggf. mit einer vor-gegebenen Priorität als gegeben anzunehmen (siehe Anhang C).
36 Zum Begriff des „Entities“ siehe [Fishman 2001, S. 38].37 Siehe dazu [Herzog 1999], [Gamma u.a. 1995].

Kapitel 2 Einsatz der Parallelen und Verteilten Simulation zur Fertigungssteuerung komplexerProduktionssysteme
Seite 53
Unter Abarbeitungsstrategie ist die einer Maschinengruppe zugeordnete Teilstrategie einerProzeßführungsstrategie (siehe Abbildung 4, Seite 30) zu verstehen. Hierbei ist jede Teil-strategie als die Festlegung einer definierten Steuerungsregel und der zugehörigen Regel-parameter anzusehen. Aufgabe der Abarbeitungsstrategie ist es, aus mehreren in der War-teschlange wartenden Werkstücken, eines davon zur Bearbeitung auszuwählen und einerfreien Maschine der Maschinengruppe zuzuweisen. Dabei sind eventuell anfallende Bear-beitungs- und Rüstzeiten zu beachten (siehe Abbildung 19). Die potentiell möglichenSteuerungsregeln wurden bereits im Punkt 2.1.4 genannt. In der Regel handelt es sich da-bei um zusammengesetzte Prioritätsregeln. Eventuell werden dabei auch Kombinationenmit Interaktionsregeln benutzt (siehe Punkt 2.1.4).
Unter Transportstrategie ist eine Strategie der Vergabe und Belegung von Transportmittelzu verstehen. Da für gewöhnlich weniger Transportmittel als Werkstücke zur Verfügungstehen, müssen die Werkstücke im Falle einer Transportanforderung um die Transport-mittel konkurrieren. Für die Lösung dieser Konfliktsituationen sind die Transportstrategienzuständig. In der Regel wird hier FIFO angewendet - die erste Transportanforderung wirdzuerst bedient. Weiterhin wäre der Einsatz von Prioritäten oder eine Abarbeitung gemäßTerminsituation denkbar. Außerdem ist eine Wegeoptimierung sinnvoll, um die Summeder anfallenden Transportzeiten zu minimieren. In der Regel erfolgt eine globale Vorgabeeiner anzuwendenden Transportstrategie als ein Bestandteil der Prozeßführungsstrategie.
2.3.2.3 Komplexe Bedingungen bei der Modellierung von Produktionssystemen
2.3.2.3.1 Motivation zur Einbeziehung komplexer Prozeßbedingungen
Im den vorangegangenen Punkten und im Anhang C wurde die prinzipielle Struktur undKomplexität von Modellen von Produktionssystemen beschrieben. Ein das reale Produkti-onssystem adäquat abbildendes Modell muß diese beschriebenen Strukturen aufweisen. Inder Praxis werden jedoch zahlreiche Einschränkungen und Vereinfachungen getroffen.
Eine erste Abstraktion betrifft das Vorhandensein von Werkern. Aufgrund der schwierigenAbbildbarkeit im Modell wird für gewöhnlich auf die Modellierung des Vorhandenseinsvon Werkern verzichtet [Schmidt 1999], [Smith 1999].
Eine zweite wesentliche Abstraktion betrifft das Transportsystem. Üblicherweise wird vonTransportvorgängen abstrahiert. Prinzipiell lassen sich Transportvorgänge auch als Bear-beitungsvorgänge auffassen. Transportmittel und Transporthilfsmittel können analog alsMaschinen und Werkzeuge aufgefaßt werden. Durch diese Annahmen vereinfacht sich dasModell des Produktionssystems wesentlich38 und es entsteht ein einfacher handhabbaresModell des Produktionssystems, welches bereits die Abarbeitung von Planungsverfahrenerlaubt.
Ziel der Modellierung ist es jedoch, wesentliche Eigenschaften und wesentliches Verhaltenim Modell abzubilden. Dazu gehört aber auch, sich von bisherigen Restriktionen in derAbbildung zu lösen und näher am Realsystem zu modellieren. Bisher wurden Restriktio-nen, die aus dem Lagersystem, dem Transportsystem und durch die Werker resultieren,vernachlässigt. Ebenso wurden bei der Bearbeitung Möglichkeiten der Parallelbearbeitungund Rüstproblematiken vernachlässigt. In realen Produktionssystemen treten aber diese
38 Gründe für diese Vereinfachungen sind, daß die Planungsverfahren nicht mit den komplexen Daten der im
Punkt 2.3.2.2 und im Anhang C beschriebenen Elemente umgehen können und/oder daß die Daten nicht(vollständig) zur Verfügung stehen (sie sind nicht bekannt oder die Erhebung der Daten wäre zu aufwen-dig).

Kapitel 2 Einsatz der Parallelen und Verteilten Simulation zur Fertigungssteuerung komplexerProduktionssysteme
Seite 54
Prozeßbedingungen auf39. Um die Funktion des Produktionssystem korrekt abzubilden,wäre es notwendig, auch diese Aspekte im Modell zu hinterlegen. Ein auf diesen neuenModellen basierendes Planungsverfahren erzielt dann eine bessere Lösungsgüte.Ebenso ist zu bemerken, daß ein grobes Modell für Extremsituationen im Realsystem40
sinnfrei ist, da die Aussagen eines Planungsverfahrens auf Basis des groben Modells weitvon der Realität entfernt sind. Durch die Vernachlässigung von Restriktionen fehlt dieMöglichkeit, das konkrete Verhalten des Systems durch das Modell hinreichend zu be-schreiben, d.h. das Verhalten des Realsystems erscheint chaotisch und das Modell ist nichtin der Lage, die Zusammenhänge im Realsystem erklären zu helfen.Aus diesem Grund sollen nachfolgend komplexe Prozeßbedingungen im Realsystem fürdie Modellierung erfaßt werden.
2.3.2.3.2 Klassifikation und Beschreibung der komplexen Prozeßbedingungen
Man kann komplexe Prozeßbedingungen in fünf Kategorien einteilen:
der Werkstücke und Produkte
korrekte Abbildung des Routings
detailliertere Abbildungder Priorisierung
Begrenzungen der Liegezeitzwischen Bearbeitungsvorgängen
detailliertere Abbildung derphysischen Eigenschaften
der Funktionsweisevon Maschinen
komplexe Prozeßbedingungender parallelen Bearbeitung
Maschinengruppen
Routing auf Maschinen-gruppenebene
gemeinsame Bearbeitungin Batchs
Rüstproblematiken
Umrüstprozesse
Rüstgruppen
Sequenzabhängige Rüstzeiten
Beachtung von Ausfallsituationen
Einbeziehung der Möglichkeitvon Maschinenausfällen
Backupproblematik
detailliertere Abbildung derphysischen Eigenschaften
Einbezug komplexer Prozeßbedingungenzur genaueren Abbildung
des Transportsystems
Beachtung des Vorhandenseinsvon Transportvorgängen
Abbildung vonTransporteinrichtungen
Abbildung von (teil)auto-matisierten Transportsystemen
des Verhaltens von Menschenim Produktionssystem
Abbildung von Werkern imFertigungssystem als Ressourcen
Abbildung von Verhaltenund Strategien der Werker
von Steuerungslogikim Produktionssystem
Mechanismen zur Priorisierungbei Reihenfolgeentscheidungen
Abbildung physischerSteuerungslogik
Abbildung von menschlichenEntscheidungen
Abbildung 22 Klassifikation der komplexen Prozeßbedingungen
Detailliertere Abbildung der Eigenschaften von Werkstücken und Produkten:
Als Erstes ist es zur korrekten Abbildung des Routings der Produkte durch das Produk-tionssystem unumgänglich, Wissen über vorhandene und eingesteuerte Produkte sowie
39 Siehe z.B. [Gurnani, Anupindi, Akella 1992, S. 319 ff.], [Fowler, Phillips, Hogg 1992, S. 153 ff.],
[Bobrowski, Kim 1994], [Jordan, Drexl 1995], [ManSim 1997, S. 77 ff.], [Richter u.a. 1998], [Paprotny,Fowler 2001].
40 Solche Extremsituationen sind eine totale Überlastung des Produktionssystems oder eine wesentlich zuniedrige Auslastung. Siehe dazu [Kosturiak, Gregor 1995, S. 81-87, insbesondere S. 84].

Kapitel 2 Einsatz der Parallelen und Verteilten Simulation zur Fertigungssteuerung komplexerProduktionssysteme
Seite 55
Wissen über die Arbeitspläne der Produkte einzusetzen. Das Routing von Produkten be-schreibt, welchen Weg die Werkstücke bzw. Produkte durch das Fertigungssystem neh-men. So ist z.B. oft ein Routing auf Maschinengruppenebene anzutreffen, d.h. im Arbeits-plan ist nicht mehr eine konkrete Maschine für die Bearbeitung im aktuellen Arbeitsgangvorgesehen, sondern es wird eine Maschinengruppe - als Zusammenstellung baugleicheroder bearbeitungsidentischer Maschinen - angegeben (siehe Abbildung 19, Seite 51).Als Zweites gehört zur detaillierteren Abbildung der Priorisierung von Produkten dieAnalyse und Hinterlegung von Prioritätsanteilen wie Kundenboni, Produktboni, Fertig-stellungsgradboni, Auftragsboni u.v.a.m.Als Drittes ist es u.U. zur detaillierteren Abbildung der physischen Eigenschaften derWerkstücke und Produkte notwendig, auf physikalische Eigenschaften wie Abmessungen,Gewicht, oder z.B. Transportanforderungen (Palette, Gabelstapler, Transportarbeiter) odersonstige Ressourcenanforderungen (Vorhandensein von Werkern, Werkzeugen, Hilfs-stoffen etc.) im Simulationsmodell zu beachten.Zur detaillierten Abbildung von Werkstücken zählen auch Bedingungen wie technologischbedingte Liegezeiten. Eine Liegezeit gibt an, wie lange ein Werkstück nach Abschluß einerBearbeitung minimal warten muß (Begrenzung der minimalen Liegezeit) oder maximalwarten darf (Begrenzung der maximalen Liegezeit), bis eine andere Bearbeitung begonnenwird bzw. beendet ist. Ein Beispiel hierfür ist das Aufbringen von umgebungsreaktivenSubstanzen [Thiel, Schulz 2000b].
Detailliertere Abbildung der Arbeitsweise von Maschinen:
Bei den komplexen Prozeßbedingungen der parallelen Bearbeitung wäre als erste Prozeß-bedingung das Vorhandensein von Maschinengruppen zu beachten. Eine Maschinengruppestellt eine Zusammenfassung einer Menge baugleicher Maschinen oder von Maschinen,welche die selben Bearbeitungen durchführen können, dar. Dies ist meist auch mit demRouting auf Maschinengruppenebene gekoppelt. D.h., im Arbeitsplan ist für den Arbeits-gang nur die Maschinengruppe vermerkt. Auf welcher konkreten Maschine der Gruppe dieBearbeitung stattfindet, ist irrelevant. Alle Maschinen einer Gruppe werden somit aus einergemeinsamen Warteschlange gespeist.Ein viel größeres Problem stellt die Beachtung der gemeinsamen Bearbeitung dar. So kön-nen mehrere Aufträge temporär für eine gemeinsame Bearbeitung als ein Batch zusam-mengefaßt werden. Die maximale Größe eines Batchs ist entweder durch die Beladegrößeder Maschine in Stück oder durch die Anzahl der Aufträge pro Batch begrenzt. Dieser Fakthat starken Einfluß auf die Modellierung der Bearbeitungszeit. Da ein Batch gemeinsambearbeitet wird, ist es für die resultierende Bearbeitungszeit nicht von Belang, wievielStück bzw. Aufträge sich im Batch befinden. Aus Steuerungssicht ist es aber von hohemInteresse, daß möglichst viel Stück bzw. Aufträge gemeinsam in einem Batch bearbeitetwerden. Zur zeitlichen Auslastung der Maschine kommt hier einen zweiter Auslastungs-aspekt hinzu - die quantitative Auslastung.Nachfolgend soll unter einer Maschinengruppe eine Zusammenfassung von Maschinenverstanden werden, welche die selben Bearbeitungsvorgänge mit den selben Parametern(Menge und Zeit) ausführen können. Andernfalls wäre eine Steuerungslogik notwendig,welche unter mehreren freien Maschinen der Maschinengruppe die Maschine auswählt,welche die Bearbeitung mit der höchsten Qualität oder in der kürzesten Zeit oder mit derhöchsten quantitativen Auslastung ausführen kann.Das Auftreten von Rüstproblematiken äußert sich dadurch, daß eine Maschine verschie-dene Bearbeitungsvorgänge ausführen kann, die Umstellung zwischen den Bearbeitungs-zuständen jedoch eine gewisse Zeitspanne dauert. Es ist notwendig, die beim Wechsel zwi-schen zwei Bearbeitungsvorgängen auf einer Maschine anfallende Rüstzeit im Simula-

Kapitel 2 Einsatz der Parallelen und Verteilten Simulation zur Fertigungssteuerung komplexerProduktionssysteme
Seite 56
tionsmodell zu berücksichtigen. Hierfür wären die auf den Maschinen bzw. Maschinen-gruppen möglichen Bearbeitungsvorgänge zu erfassen und Tabellen mit den Rüstzeiten fürden Wechsel zwischen zwei unterschiedlichen Bearbeitungszuständen sind zu hinterlegen.Weiterhin können sich die auf einer Maschine möglichen Bearbeitungsvorgänge in denBearbeitungsanforderungen so stark unterscheiden, daß die Rüstzeit zwischen allen auf derMaschine möglichen Bearbeitungszuständen nicht konstant ist, sondern daß sich Gruppenvon Bearbeitungszuständen finden lassen, für welche die Rüstzeiten zu anderen Bearb-eitungszuständen ähnlich hoch sind. In einem solchen Fall spricht man von Rüstgruppen.Üblicherweise ist für einen Rüstwechsel innerhalb einer Rüstgruppe nur eine kurze, wenigZeit verbrauchende Umstellung der Maschine notwendig, während für den Wechsel zwi-schen Bearbeitungszuständen unterschiedlicher Rüstgruppen intensive, zeitverbrauchendeProzesse notwendig sind.Zusätzlich ist es möglich, daß die Rüstzeiten sequenzabhängig sind. D.h., daß der Wechselzwischen zwei Rüstzuständen unterschiedlich lange dauert, je nachdem in welche Rich-tung der Wechsel stattfindet. Dies ist typisch bei Farbumstellungen oder Temperaturpro-zessen (das Heizen auf eine höhere Temperatur geht schnell, aber die Maschinen besitzenkein Aggregat zum Kühlen, wodurch die Abkühlzeit größer ist).Die Abbildung der genannten Prozeßbedingungen erfordert in jedem Fall eine zusätzlicheSteuerungslogik (z.B. Beachtung der quantitativen Auslastung von Batchs, Beachtung desZiels der Minimierung der Rüstzeit).Ein weiterer Problemkreis komplexer Prozeßbedingungen aus der Kategorie der detaillier-teren Abbildung der Maschinen ist die Beachtung von Ausfallsituationen. In vielen Mo-dellen wurde die Möglichkeit eines Maschinendefektes vernachlässigt, wodurch naturge-mäß für das Produktionssystem ein höherer Durchsatz vorausgesagt wird. Durch die Ein-beziehung von potentiell möglichen Maschinenausfällen nähert sich die Aussage des Mo-dells der Realität an. Natürlich handelt es sich bei den Maschinenausfällen um ein stocha-stisches Element, eine exakte Replikation eines Simulationslaufes ist somit nur einge-schränkt möglich.In Zusammenhang mit Maschinenausfällen steht die Backupproblematik. Hierunter ist zuverstehen, daß bei Ausfall einer Maschine oder Maschinengruppe eine andere Maschineoder Maschinengruppe die Bearbeitung übernehmen kann. Zum Einen ist festzulegen, wel-che Maschinen(gruppen) füreinander als Backup eingesetzt werden dürfen, zum Anderenist die Auswahlreihenfolge der Backupmaschinen(gruppen) entscheidend. So können z.B.für eine ausgefallene Maschine zwei weitere Maschinen die selbe Bearbeitung durchfüh-ren, jedoch kann eine der Maschinen dies nur mit Qualitätseinbußen und die andere Ma-schine würde z.B. doppelt so lange benötigen. Auch hierfür ist es wieder notwendig, Lö-sungsstrategien zu entwickeln und im Modell zu hinterlegen.
Detailliertere Abbildung von Transportprozessen:
In vielen Modellen von Produktionssystemen werden Transportprozesse völlig vernach-lässigt. Man postuliert Transportzeiten der Höhe Null oder setzt unbegrenzte Transport-ressourcen voraus. Die Beachtung des Vorhandenseins von Transportvorgängen erfordertaber zum Einen das Ansetzen einer Transportzeit größer Null und zum Anderen sind Res-sourcen (Werker, Fahrzeuge, Behälter etc.) notwendig, um den Transport durchzuführen(siehe Abbildung 20, Seite 51). Problematisch ist die Höhe der Transportzeit. Für nichtautomatisierte Systeme handelt es sich um eine höchst stochastische Größe. In (teil)auto-matisierten Transportsystemen kann dagegen eine Fließbandgeschwindigkeit oder ähnli-ches ermittelt werden. Auch hier sind wieder Strategien (Wege- und Ressourcennutzungs-minimierung) notwendig, die im Modell hinterlegt werden müssen.

Kapitel 2 Einsatz der Parallelen und Verteilten Simulation zur Fertigungssteuerung komplexerProduktionssysteme
Seite 57
Detailliertere Abbildung von Menschen im Produktionssystem:
Für die Abbildung des Verhaltens von Menschen im Produktionssystem ist es zumindestnotwendig, die Werker im Fertigungssystem als Ressourcen abzubilden. Die Abbildungvon Verhalten und Strategien der Werker stellt sich dagegen als schwierig und höchstkompliziert dar. [Smith 1999], [Schmidt 1999], [VDI 3633, Blatt 6]
Detailliertere Abbildung von Strategien zur Lösung von Problemen:
In vielen Fällen wurde bereits die Notwendigkeit der Hinterlegung von Strategien zur Lö-sung von Problemen in Zusammenhang mit komplexen Prozeßbedingungen angesprochen.So ist es für Reihenfolgeentscheidungen jeder Art (Auswahl aus der Warteschlange, Um-rüsten, Zusammenfassen zu einem Batch, Transportmittel und -weg usw.) notwendig, dieProblemlösungsstrategien des Realsystems im Modell abzubilden, da diese signifikantenEinfluß auf Zustand und Verhalten des modellierten Systems besitzen. Oft ist genau diesder Einsatzzweck des Modells. Es werden Problemlösungsstrategien konzipiert, im Modellimplementiert und dann z.B. simulativ auf ihre Eignung getestet. Die Validierung der kon-zipierten Strategien erfolgt oft mit Hilfe der Simulation, weil ein empirischer Test im Real-system nicht möglich, zu aufwendig oder zu teuer wäre oder zu lange dauern würde[Seelbach 1975, S. 150], [Kosturiak, Gregor 1995, S. 15-17].
Zusammenfassung:
Es wird deutlich, daß es einer genauen Analyse der konkreten Elemente und Abläufe desrealen Produktionssystems bedarf, um die notwendigen Daten für das Modell des Produk-tionssystems zusammenzustellen und aufzubereiten. So sind bei Auftreten komplexer Pro-zeßbedingungen weiteres Wissen und weitere Daten für die Implementation des Modellszu erfassen.Ein für jedes Produktionssystem passendes Modell kann leider nicht aufgestellt werden.Unter Einbeziehung einer Reihe der in Punkt 2.3.2.3 genannten komplexen Prozeßbedin-gungen ist es jedoch möglich, ein allgemeiner gehaltenes Modell zu kreieren und in künf-tigen Simulationsmodellen einzubeziehen. Somit ist es möglich, Modelle höherer Abbil-dungsgenauigkeit zu entwickeln und die Lösungsgüte der auf diese Modelle angewendetenPlanungsverfahren zu verbessern.
Hinzu kommt, daß die dargelegten Spezifika auch in Simulationsmodellen der Parallelenund Verteilten Simulation manifestiert werden müssen. Hierbei haben sie Einfluß auf diePartitionierung des Modells und den Synchronisationsbedarf der Partitionen.
2.3.3 Lösung weiterer allgemeiner simulationstechnischer Probleme
Simulation ist mit einer Reihe „technischer“ Probleme verbunden, die einerseits durch Ab-bildungsfehler bei der Abstraktion des Realsystems und andererseits durch die Algo-rithmen der Ablaufsteuerung entstehen. Bei Einsatz der Simulation ist für jedes dieser Pro-bleme eine Lösung anzustreben. Zu diesen Problemen gehören u.a.:
• anwendungsunspezifische Probleme der Simulation:• Stochastiken im abgebildeten System• die Vorgabe eines initialen Zustandes des Simulationsmodells
• Probleme bei der Simulation von Produktionssystemen:• die Erfassung von Ergebnisgrößen zur statistischen Auswertung• Probleme beim Ereignisscheduling

Kapitel 2 Einsatz der Parallelen und Verteilten Simulation zur Fertigungssteuerung komplexerProduktionssysteme
Seite 58
Maßnahmen zur Wahrung der statistischen Sicherheit aufgrund von Stochastiken imabgebildeten System:
Wenn im Simulationsmodell die im betrachteten System vorhandenen Stochastiken be-rücksichtigt wurden, so liefert jeder Simulationslauf andere Ergebnisse. D.h., es ist jetztnotwendig, zur Wahrung der statistischen Sicherheit einen genügend großen Stichproben-umfang an Simulationsläufen durchzuführen [Page 1991, S. 121-143], [Kelton, Sadowski,Sadowski 1998, S. 8].
Problem der Vorgabe eines initialen Zustandes des Simulationsmodells:
Einige Simulationstools erlauben es nicht, einen initialen Zustand des modellierten Sy-stems vorzugeben. Als Folge dessen ist zu Beginn der Simulation das modellierte Systemleer. Ein leeres System verhält sich jedoch völlig anders als ein System unter Last [Page1991, S. 24, S. 122ff], . Das betrachtete Realsystem wird i.d.R. nie leer sein, d.h. das Si-mulationsmodell weist einen Abbildungsfehler auf.
Strategien, diesen Abbildungsfehler zu kompensieren, sind:
a) die Vorgabe eines initialen Zustandes41 undb) die Nichtbetrachtung des anfänglichen Verhaltens im Simulationsmodell bis sich
das modellierte System auf einen stabilen Zustand eingeschwungen hat42.
Die Vorgabe eines initialen Zustandes wäre zu präferieren, jedoch verfügt nicht jeder Si-mulator über diese Möglichkeit.
Geht man davon aus, daß man ein anfänglich leeres System betrachtet, so vergeht einegewisse Zeitspanne, bis dieses System einen Lastzustand erreicht, unter dem es sich stabilverhält. Für die Betrachtung des Systems bedeutet dies jedoch, daß sich während dieserEinschwingphase ein mehr oder minder starker Abbildungsfehler ereignet und dieser Zeit-raum nicht zur Gewinnung von Aussagen herangezogen werden darf [Welch 1983], [Page1991, S. 122]. Das zusätzliche Ansetzen eines Zeitraumes - der Einschwingphase - erhöhtjedoch die Simulationszeit in signifikanten Maße.
Erfassung von Ergebnisgrößen zur statistischen Auswertung:
Um Aussagen auf Basis von Experimenten mit einem Simulationsmodell treffen zu kön-nen, ist es notwendig, bestimmte Ergebnisgrößen zu betrachten. Solche Größen sind beider Simulation von Produktionssystemen beispielsweise die Auslastung von Maschinen,die mittlere Warteschlangenlänge vor einer Maschine oder die mittlere Durchlaufzeit vonAufträgen. Ferner werden zu diesen Ergebnisgrößen statistische Größen wie Anzahl,Summe, Mittelwert, Standardabweichung, Streuung, Minimum und Maximum benötigt.Das Simulationssystem hat demzufolge Mechanismen bereitzustellen, die es erlauben, diegewünschten Größen zu beobachten und statistisch aufzubereiten [Kosturiak, Gregor 1995,S. 156-158].Problematisch ist, daß i.d.R. nicht alle der gewünschten Ergebnisgrößen automatisch durchdas Simulationssystem erfaßt werden43, daß die vom Simulator vorgegebenen Möglich-keiten zur statistischen Auswertung von Ergebnisgrößen u.U. nicht ausreichend sind, daß
41 Für gewöhnlich muß ein Simulationsexperte dazu Anweisungen im Simulationsmodell hinterlegen, die
beschreiben in welchen Zustand sich die stationären Elemente befinden und wo im System die dynami-schen Elemente zu plazieren sind. Einige Simulatoren erlauben auch die direkte Angabe des Initialzustan-des [ManSim 1997, S. 246-247, S. 23].
42 Siehe dazu u.a. [Welch 1983], [Langendörfer 1992].43 Blazejewski [Blazejewski 2000, S. 66] nennt als Problem, daß Simulatoren nicht nur Standardgrößen zur
Auswertung anbieten dürfen, sondern flexibel hinsichtlich der Auswertungswünsche des Benutzers seinmüssen.

Kapitel 2 Einsatz der Parallelen und Verteilten Simulation zur Fertigungssteuerung komplexerProduktionssysteme
Seite 59
die Erfassung zusätzlicher Ergebnisgrößen und deren statistische Aufbereitung schwierigzu realisieren sind und nicht zuletzt, daß es sich bei den betrachteten Größen um einenhohen Datenumfang handelt.Es ist folglich im Voraus zu untersuchen, ob die vom Simulationssystem bereitgestelltenMechanismen für die Erfassung von Ergebnisgrößen und deren statistische Aufbereitungausreichen.
Probleme beim Ereignisscheduling:
Im Allgemeinen kann die Abarbeitungsreihenfolge von n Ereignissen, die den selben Er-eigniszeitpunkt tx besitzen, beliebig sein44.Bei einigen Typen von Simulationsmodellen ist dem jedoch nicht so [Scriber, Brunner1998], [Jha, Bagrodia 2000], [Fishman 2001, S. 52]. Ein typisches Beispiel hierfür sindModelle von Produktionssystemen.
Man stelle sich folgende Situation vor:
Zum Zeitpunkt tx liegen an einer Maschine zwei Ereignisse vor. Bei dem Ereignis E1
handelt es sich um die Ankunft eines weiteren Auftrages an der Maschine. DasEreignis E2 löst die Auswahl des höchstpriorisierten Auftrags aus der Warteschlangezur nächsten Bearbeitung aus.Hier ist es jetzt zwingend notwendig, das Ereignis E1 vor dem Ereignis E2 auszu-führen, damit der zum Zeitpunkt tx in die Warteschlange zu stellende Auftragkorrekterweise in die Reihenfolgeentscheidung im Ereignis E2 einbezogen wird.
In einigen Simulatoren ist ein solcher Fakt jedoch außer acht gelassen worden, so daß mitdiesen Simulatoren abgearbeitete Simulationsmodelle das modellierte System fehlerhaftabbilden [Scriber, Brunner 1998].
2.3.4 Spezielle Aufgaben und Probleme der Parallelen und Verteilten Simulation
Die bisher genannten Aufgaben und Probleme treten bereits beim Einsatz der herkömmli-chen Sequentiellen Simulation auf. Die Parallele und Verteilte Simulation ist jedoch durcheine Reihe weiterer Aufgaben gekennzeichnet, welche die Modellbildung und Modell-abarbeitung noch schwieriger gestalten.
Parallelisierung von Programmen als Ansatzpunkt für die Parallele und VerteilteSimulation:
Die Grundidee der Parallelisierung ist: Eine Aufgabe wird in Teilaufgaben zerlegt, umdiese Teilaufgaben zeitparallel lösen zu können (siehe Abbildung 23). Damit sinkt derZeitbedarf für die Lösung der Gesamtaufgabe. Die Parallelisierung der ursprünglichenAufgabe kann also zu einer schnelleren Berechnung führen. Für die Simulation gilt dies inanaloger Weise. Das Hauptproblem der Simulation ist der hohe Zeitbedarf für die Ausfüh-rung eines Simulationslaufes (siehe Punkt 2.2.1.3) - hier bietet es sich an, Parallelisie-rungsansätze eingehender zu betrachten und zur Laufzeitbeschleunigung einzusetzen. ZurParallelisierung einer Aufgabe ist diese in Teile zu zerlegen und diese Teile sind separatabzuarbeiten. Anschließend können die Ergebnisse der Teilaufgaben zur Gesamtlösungzusammengefaßt werden.
44 Vergleiche Arbeitsweise der Ablaufsteuerung der Simulation (Punkt 2.2.1.2).

Kapitel 2 Einsatz der Parallelen und Verteilten Simulation zur Fertigungssteuerung komplexerProduktionssysteme
Seite 60
Zeit
Aufgabe
Ergebnis
Steuer-rechner
Aufgabe
Ergebnis
Aufgabe
Aufgabe
Rechner1
Rechner2
Abbildung 23 Parallelisierung grobgranularer Aufgaben am Beispiel desverteilten Experimentierens
Für die Parallele und Verteilte Simulation ist dies jedoch schwieriger. Durch die Ordnungvon Bruchteilen der Teilaufgaben auf einer zeitlichen Skala entsteht eine enge Verzahnungder Teilaufgaben (siehe Abbildung 24). Innerhalb aller Teilaufgaben muß die korrektezeitliche Abfolge gewahrt bleiben. Dies ist ein schwierigeres Problem als die herkömm-liche Programmparallelisierung.
Nachricht
LP1 LP2 LP3
Nachricht
Nachricht
Nachricht
Realz
eit
Sim
ula
tionsz
eit
für
LP
1
Sim
ula
tionsz
eit
für
LP
2
Sim
ula
tionsz
eit
für
LP
3
Abbildung 24 Parallelisierung feingranularer Aufgaben am Beispiel der Par-allelen und Verteilten Simulation
Innerhalb der Parallelen und Verteilten Simulation sind zwei Hauptaufgaben und zweiHilfsaufgaben zu lösen:
• Hauptaufgaben:• Partitionierung• Synchronisation

Kapitel 2 Einsatz der Parallelen und Verteilten Simulation zur Fertigungssteuerung komplexerProduktionssysteme
Seite 61
• Hilfsaufgaben:
• Kommunikation• Load-Balancing
Partitionierung:
Als ein erstes Problem ist ein Simulationsmodell der Parallelen und Verteilten Simulationin möglichst unabhängige Teilmodelle - die sogenannten Partitionen oder Logischen Pro-zesse - zu zerlegen. Diese Aufgabe nennt man Partitionierung .Die Zerlegung des Simulationsmodells in mehrere, möglichst unabhängige Teilmodelle hatden Hintergrund, den Berechnungsaufwand des Gesamtmodells auf mehrere Prozessorenbzw. Rechner zu verteilen [Mehl 1994, S. 10], [Bagrodia 1996].Je stärker das Simulationsmodell partitioniert wird, desto mehr Teilmodelle entstehen unddesto besser kann der Berechnungsaufwand verteilt werden. Jedoch schafft die Existenzvieler Teilmodelle - die ja untereinander Dependenzen besitzen - einen erhöhten Kommu-nikations- und Synchronisationsbedarf und verschärft die Probleme der anderen Aufgabender Parallelen und Verteilten Simulation.Diese Aufgabe der Partitionierung ist zudem lösungsdefekt45. Es existiert kein (all-gemeines) Verfahren zur Partitionierung von Simulationsmodellen. Die Möglichkeiten zurPartitionierung sind modellabhängig. Ebenso ist die Zweckmäßigkeit einer Partitionierungvon den konkreten Gegebenheiten und Parametern des Modells abhängig. Bisher erfolgtdie Partitionierung eines Modells manuell im trial-and-error-Verfahren [Mehl 1994, S. 10-11], [Bagrodia 1996], [Smith 1999].
Kommunikation:
Die Kommunikation ist als eine Hilfsaufgabe zwischen Partitionierung und Synchro-nisation zu sehen. Unter Kommunikation ist der Austausch von Nachrichten zwischen denLogischen Prozessen zu verstehen. Über diese Kommunikation drückt sich die Abhängig-keit der Logischen Prozesse untereinander aus. Mittels dieser Nachrichten informieren sichdie Logischen Prozesse untereinander über das Eintreten von Ereignissen im sendendenLogischem Prozeß, auf die der empfangende Logische Prozeß reagieren muß.Ziel ist hier, eine Kommunikationsinfrastruktur anzubieten, welche dem Kommunikations-bedarf und -profil der Logischen Prozesse entspricht. Die Kommunikation ist so schnellund effizient wie nur möglich abzuarbeiten, da sie - im Gegensatz zur Sequentiellen Si-mulation - einen zusätzlichen zeitlichen Aufwand erfordert. Arbeiten zeigten [Loucks,Preiss 1990], [Mehl 1994, S. 142f], [Bagrodia 1996], [Holthaus, Rosenberg, Ziegler 1996],daß u.U. ein Kommunikationsoverhead entstehen kann - ein hoher Bedarf und Aufwand anund zur Kommunikation.Die Lösung der Aufgabe der Kommunikation ist von der vorgegebenen Partitionierungabhängig. Je mehr Partitionen existieren, desto mehr Kommunikationswege existieren unddesto mehr Informationen müssen ausgetauscht werden. D.h., die Minimierung des Kom-munikationsbedarfs und des Kommunikationsaufwands sind vordringliches Ziel.Außer der Partitionierung hat aber auch das verwendete Synchronisationsverfahren Einflußauf die Kommunikation. Denn einige Synchronisationsverfahren erfordert zusätzlichenNachrichtenverkehr.
Synchronisation:
Durch die Partitionierung ist eine definierte Menge von Logischen Prozessen entstanden,die parallel abgearbeitet werden. Dadurch, daß die Logischen Prozesse gleichzeitig Be-
45 Zur Definition der Defekte siehe [Heinen 1990, S. 345 f.], [Corsten, May 1994, S. 3].

Kapitel 2 Einsatz der Parallelen und Verteilten Simulation zur Fertigungssteuerung komplexerProduktionssysteme
Seite 62
rechnungen durchführen, werden i.d.R. die lokalen Zeiten der einzelnen Logischen Prozes-se voneinander abweichen, da diese unterschiedlich oft Berechnungen durchführen müssenund sie diese Berechnungen unterschiedlich schnell absolvieren. Zur Wahrung der Kausa-lität ist es aber erforderlich, daß alle Ereignisse eines Logischen Prozesses nach monotonsteigender Simulationszeit abgearbeitet werden. Der Empfang von zukünftig relevantenNachrichten ist unproblematisch, aber Nachrichten, welche in der Vergangenheit des Logi-schen Prozesses liegen, können die kausale Ordnung verletzt haben. Unter Umständen istein ungültiger Zustand erreicht worden.Aufgabe der Synchronisation ist es daher, sicherzustellen, daß die kausale Ordnung derEreignisabfolge über alle Logischen Prozesse gewahrt bleibt [Chandy, Misra 1978],[Jefferson, Sowizral 1985], [Jefferson u.a. 1987], [Nicol 1988].Es existieren eine Reihe unterschiedlicher Synchronisationsverfahren und Verfahrens-varianten. Es gibt jedoch kein universell geeignetes Synchronisationsverfahren, vielmehrexistieren eine Reihe modellabhängiger Parameter mit hohem Einfluß auf das Synchro-nisationsverfahren. Dies geht sogar so weit, daß durch Änderung eines Modellparametersein anderes Synchronisationsverfahren besser geeignet ist. Das geeignetste Synchronisa-tionsverfahren kann demzufolge nur durch Testen herausgefunden werden [Fujimoto1988b], [Preiss 1990], [Fujimoto 1990], [Bagrodia 1996], [Fujimoto 1999], [Smith 1999].
Load Balancing:
Unter Load-Balancing im weiteren Sinne werden drei Teilprobleme zusammengefaßt:
• die Verteilung von Logischen Prozessen auf Prozessoren (das Mapping),• die Zuteilung von Rechenzeit des Prozessors an mehrere dem Prozessor zugewiesene
Logische Prozesse (das Scheduling) und• die dynamische Zuordnung von Logischen Prozessen auf Prozessoren (Load-
Balancing im engeren Sinne).
Gemeinsam ist die Aufgabe, Logische Prozesse (dynamisch) den Prozessoren zur Abarb-eitung zuzuweisen. Diese Aufgabe entsteht dadurch, daß i.d.R. die Anzahl der LogischenProzesse größer als die Anzahl der verfügbaren Prozessoren ist. Bei der Lösung dieserAufgabe wird das Ziel verfolgt, die vorhandenen Prozessoren möglichst gleich auszulasten(Load-Balance) [Sporrer 1995, S. 35], [Bagrodia 1996], [Paprotny, Fowler 2001].Hintergrund des Strebens nach gleicher Lastverteilung (Load-Balance) ist die Gefahr derVerklemmung von Logischen Prozessen (siehe Punkt 3.1.3.6) [Sporrer 1995, S. 35f, S.110], [Bagrodia 1996].Das Problem des Load-Balancings entsteht durch ein Ungleichgewicht zwischen der ent-worfenen Struktur des Gesamtsimulationsmodells in Partitionen und der tatsächlich zurVerfügung stehenden Berechnungshardware. Andererseits wird aufgrund des Lösungs-defektes der Partitionierungsaufgabe ein Teil des Problems nicht gelöst - es wird eine hoheMenge atomarer, parallel abarbeitbarer Modellteile abgespalten und zur parallelen Aus-führung auf der Berechnungshardware angewiesen. Die Lösung des Problems einer Viel-zahl um die Ressourcen Prozessor und Rechenzeit konkurrierender Tasks ähnelt den in derBetriebssystemtheorie behandelten Mapping- und Schedulingproblemen. D.h., man obläßtden in Hardware oder Betriebssystem implementierten Verfahren die Aufgabe diese Kon-kurrenzsituation wohlgefällig zu lösen.
Das Polylemma der Parallelen und Verteilten Simulation:
Es findet eine „Gratwanderung“ zwischen Partitionierung und Synchronisation statt. Jestärker ein Simulationsmodell partitioniert wird, desto höher wird der Kommunikations-und Synchronisationsaufwand, aber der Berechnungsaufwand ist besser verteilbar und dieBerechnungen erfolgen potentiell schneller. Unternimmt man Maßnahmen zur Senkung

Kapitel 2 Einsatz der Parallelen und Verteilten Simulation zur Fertigungssteuerung komplexerProduktionssysteme
Seite 63
des Kommunikationsaufwandes oder zur Senkung des Synchronisationsaufwandes, so er-fordert dies i.d.R. eine Senkung der Partitionsanzahl, wodurch der Grad der potentiellschnelleren Berechnung sinkt. Außerdem besteht sowohl für die Aufgabe der Partitionie-rung als auch für die Aufgabe der Synchronisation ein Lösungsdefekt - es existiert keinpraktikables Lösungsverfahren. Die Partitionierung obliegt mehr oder weniger dem„Gefühl“ des Modellierers [Smith 1999], [Fujimoto 1999] und die verschiedenen Synchro-nisationsverfahren sind je nach Modellparametern unterschiedlich geeignet [Bagrodia1996], [Fujimoto 1999]. Ein praktikables Lösungsverfahren existiert nicht. Zur Ungewiß-heit über die verwendbaren Verfahren kommt noch die Ungewißheit über die Performance.Es existieren Untersuchungen, die zeigen, daß ein Speedup von Faktor 40 resultiert oderdaß ein Slowdown von Faktor 10 entsteht [Meister 1993], [Luksch 1995], [Vee, Hsu1999].
2.4 Resümee der Anforderungen
2.4.1 Zusammenfassung der Aufgaben und Probleme der simulationsbasiertenFertigungssteuerung
Probleme und Anforderungen aus Sicht der Simulation:
Probleme beim Einsatz der Simulation bestehen u.a. in der Schaffung eines die Realitätadäquat abbildenden Modells des Produktionssystems [Page 1991, S. 8], [Smith 1999],[Blazejewski 2000, S. 66] (siehe Punkt 2.3.1). Zum Einen ist der hohe Zeitaufwand zurSchaffung des Modells zu nennen, zum Anderen ist ggf. ein Simulationsexperte not-wendig, um das Simulationsmodell zu erstellen [Blazejewski 2000, S. 69 ff.].Zu beachten ist, daß das Simulationsmodell die wesentlichen Eigenschaften und das we-sentliche Verhalten des modellierten Produktionssystems aufweisen muß, damit man anHand des Simulationsmodells Aussagen treffen kann, die auf die Wirklichkeit übertragbarsind [Page 1991, S. 24, S. 145-156], [Kosturiak, Gregor 1995, S. 66]. Dies führt dazu, daßdie Modellkomplexität anwächst. Die im Modell erforderlichen Strukturen sind im Punkt2.3.2.2 näher beschrieben. Der nach der Modellvalidierung erreichte Umfang des Simula-tionsmodell stellt den erforderlichen Komplexitätsgrad des Modells dar. Der durch dieseKomplexität bedingte numerische Aufwand kann nicht ohne Inkaufnahme von Abbil-dungsfehlern reduziert werden und ist hinzunehmen.
Probleme und Anforderungen aus Sicht der Fertigungssteuerung komplexer Produk-tionssysteme:
In den Punkten 2.1.3 und 2.1.4 wurden bereits Probleme der Fertigungssteuerung und derin der Praxis eingesetzten Lösungsverfahren diskutiert.Einer der Mängel war das Unvermögen der verwendeten Verfahren situationsabhängig zureagieren. Dies ist aber eine zwingende Anforderung an neuere Ansätze [Blazejewski2000, S. 66]. Weiterhin war ausgeführt worden, daß in der Regel alle genannten Reihen-folgeplanungsansätze (siehe Punkt 2.1.4) das Auftreten komplexer Prozeßbedingungen(siehe Punkt 2.3.2.3) vernachlässigen. Infolgedessen haben sie natürlich auch nur eine ein-geschränkte Gültigkeit bei Auftreten solcher Prozeßbedingungen. Deswegen steht die For-derung, komplexe Prozeßbedingungen in den Modellen zu berücksichtigen [Blazejewski2000, S. 66].Ein dadurch entstehendes Problem ist der bisherige Mangel an einem Lösungsverfahrenbei Auftreten komplexer Prozeßbedingungen. Aus diesem Grund wurden in der Vergan-genheit zusätzlich zu Prioritätsregeln noch Belade- und Rüstregeln46 entworfen, die einzel- 46 Siehe dazu [ManSim 1997, S. 45-48].

Kapitel 2 Einsatz der Parallelen und Verteilten Simulation zur Fertigungssteuerung komplexerProduktionssysteme
Seite 64
nen der Prozeßbedingungen Rechnung tragen. Eine bloße Verknüpfung der Regelartenscheitert jedoch in der Praxis.Dadurch entsteht die Forderung, integrierte Ansätze zur Reihenfolgeplanung unter komple-xen Prozeßbedingungen zu entwickeln und einzusetzen [Richter u.a. 1998], [Thiel u.a.1998], [Thiel 2001].Der Entwurf und Test solcher komplexer Reihenfolgeplanungsansätze ist aber nicht Ge-genstand der vorliegenden Arbeit. Ziel ist es, einen für komplexe Produktionssysteme ad-äquaten Steuerungsansatz im Simulationsmodell abbilden zu können und dieses umfang-reiche Simulationsmodell durch den Einsatz der Parallelen und Verteilten Simulationschneller auszuführen.
Probleme aus Sicht der Suche nach der optimalen Prozeßführungsstrategie:Im Gegensatz zu analytischen Verfahren ist bei der Simulation das Auffinden der opti-malen Lösung nicht sichergestellt [Page 1991, S. 9], [Kosturiak, Gregor 1995, S. 70]. D.h.,eine Kopplung der Simulation mit Optimierungsverfahren ist notwendig (siehe auch 2.1.1).In der Praxis erfolgt meist ein simulativer Test verschiedener, zielträchtig erscheinenderHandlungsalternativen. D.h., ein Mensch - der Disponent des Fertigungssystems - erstellteinen Experimentplan, um die zu untersuchenden Handlungsalternativen vorzugeben. Indiesem Experimentplan sind eine Reihe von Simulationsexperimenten festgelegt, um dieunter den gegebenen Umständen geeignetste Handlungsalternative zu bestimmen (ver-gleiche Punkt 2.1.1).Ein weiteres Problem resultiert daraus, daß die Simulation die gleichen Optimierungs-ansätze und Lösungsverfahren verwenden muß wie die Steuerungssysteme des Real-systems [Blazejewski 2000, S. 66ff.]. Dies ist für eine korrekte Abbildung des Realsystemsnotwendig, zum Anderen soll gerade ein simulativer Test dieser Steuerungssysteme durch-geführt werden.
Fehlende Integration des Werkzeugs Simulation in bestehende Planungs- und Infor-mationssysteme:Der Integrationsaspekt ist zweigeteilt zu sehen. Zum Ersten sind viele Simulationswerk-zeuge selbst wenig integriert und erfüllen nicht alle Anforderungen an ein modernes Simu-lationswerkzeug [Kosturiak, Gregor 1995, S. 156-160], [Blazejewski 2000, S. 66ff]. ZumZweiten fehlt es an der Integration der Simulation als Methode der Prognose in bestehendePlanungs- und Informationssysteme - wie z.B. vorhandene PPS- oder Werkstattsteuerungs-systeme [Blazejewski 2000, S. 92f]. So fehlen für gewöhnlich Schnittstellen, die es er-lauben, die aktuellen Zustandsdaten aus vorhandenen Informationssystemen für die Erstel-lung des Simulationsmodells zu übernehmen [Blazejewski 2000, S. 66]. Das Vorhanden-sein dieser Daten ist aber wiederum Basis für Ansätze zur automatischen Erzeugung vonSimulationsmodellen [Schulz 1996], [Kobylka, Gäse, Wirth 2000], [Gäse, Günther, Wirth2000], [Wiedemann 2000], [Eversheim, Intra, Abels 2000], als eine Möglichkeit den Auf-wand zur Modellerstellung drastisch zu verringern. Basis für solche Simulationsmodell-generatoren ist die Verwendung eines Referenzmodells. So sind Modelle nicht nur für einekonkrete Aufgabenstellung zu entwickeln, sondern für viele Benutzer und Aufgaben ver-wendbar zu machen [Blazejewski 2000, S. 66], [Wiedemann 2000].Ein letzter Schritt zu einer integrierten Lösung wäre, eine Methodendatenbank zu erstellen,um dem Anwender verschiedene Planungsmethoden zur Verfügung zu stellen [Blaze-jewski 2000, S. 66].
Probleme durch den Zeitbedarf für die Durchführung einer Simulationsstudie:Der hohe Zeitbedarf für die Durchführung einer Simulationsstudie, welche aus vielen Si-mulationsexperimenten besteht, erweist sich als Problem (siehe Punkt 2.2.1.3). Der Zeit-

Kapitel 2 Einsatz der Parallelen und Verteilten Simulation zur Fertigungssteuerung komplexerProduktionssysteme
Seite 65
bedarf für die Ausführung eines komplexen Simulationsmodells ist bereits sehr hoch[Kosturiak, Gregor 1995, S. 70], erhöht sich aber durch das Vorhandensein stochastischerModelle und die Vielzahl durchzuführender Simulationsexperimente, die zur Bestimmungder geeignetsten Handlungsalternative notwendig sind, nochmals um mehrere Größen-ordnungen (vergleiche Abbildung 7 auf Seite 38). Bei der Optimierung von Systemen mitHilfe der Simulation steht deswegen die Geschwindigkeit der Simulationsberechnungen imVordergrund [Krug, Wiedemann 2000], [Blazejewski 2000, S. 66].
Probleme beim Einsatz der Parallelen und Verteilten Simulation:
Es existiert kein Lösungsverfahren für die Aufgabe der Partitionierung und diese Aufgabewird bisher manuell im trial-and-error-Verfahren durchgeführt. Für die Aufgabe der Syn-chronisation existiert eine Reihe parametersensitiver Verfahren. Im Voraus besteht keineMöglichkeit, die Performance der Ausführung eines Modells mittels Paralleler und Ver-teilter Simulation zu prognostizieren - es herrscht eine hohe Performanceungewißheit.Potentiell ist ein Nutzen der Anwendung der Parallelen und Verteilten Simulation auf dieFertigungssteuerung komplexer Produktionssysteme wahrscheinlich, es existiert jedochnoch keine Vergleichsbasis. Ziel ist es deshalb, die Einsatzmöglichkeiten der Parallelenund Verteilten Simulation zu untersuchen und diese Wissensdefizite zu beseitigen.
2.4.2 Anforderungen an einen Lösungsansatz zur Parallelen bzw. Verteilten Si-mulation komplexer Produktionssysteme
Die im vorangegangenen Punkt genannten Anforderungen zeigen insbesondere fünf Pro-bleme auf:
1. die adäquate Abbildung des Realsystems im Simulationsmodell,2. einen aufwendigen Prozeß der Modellerstellung,3. die mangelnde Unterstützung des Anwenders bei der Durchführung von Simula-
tionsstudien,4. einen hohen Zeitbedarf für die Abarbeitung von Simulationsstudien und5. eine hohe Parameterisierbarkeit der Verfahren der Parallelen und Verteilten Simu-
lation welche zu einer Ungewißheit über die Performance der Parallelen undVerteilten Simulation für ein gegebenes Simulationsmodell führen.
Die Unterstützung des bisher manuell ausgeführten Modellbildungs- und Experimentier-prozesses (Anstriche 1 bis 3) soll softwaregestützt durch das Framework zur simulations-basierten Fertigungssteuerung erfolgen (siehe Kapitel 4.2). Somit kann der Zeitbedarf fürden Prozeß zur Erstellung eines adäquaten Simulationsmodells entscheidend verringertwerden.
Die Verringerung des Zeitbedarfes für die Ausführung der Simulationsstudie (vergleicheAbbildung 7 auf Seite 38) kann auf drei Wegen erreicht werden:
♦ Verringerung des Zeitbedarfes für ein einzelnes Experiment:
• durch Reduktion des numerischen Aufwandes des Simulationsmodells,• durch den Einsatz der Parallelen und Verteilten Simulation zur schnelleren Ab-
arbeitung des Simulationsmodells
♦ Verringerung des Zeitbedarfes für eine Reihe von Experimenten:
• durch parallele Abarbeitung der unabhängigen Experimente auf mehrerenRechnern (verteiltes Experimentiersystem)
Die Reduktion des numerischen Aufwandes des Simulationsmodells steht im Konflikt mitder adäquaten Abbildung des realen Produktionssystems im Simulationsmodell. Es ist sehrschwierig, reduzierbare Anteile des Simulationsmodells zu identifizieren und das Simula-

Kapitel 2 Einsatz der Parallelen und Verteilten Simulation zur Fertigungssteuerung komplexerProduktionssysteme
Seite 66
tionsmodell so zu reduzieren, daß die mit dem reduzierten Simulationsmodell erzieltenAussagen nicht wesentlich vom Verhalten des Realsystems abweichen.
Durch den Einsatz der Parallelen und Verteilten Simulation kann dagegen eine paral-lele Abarbeitung von mehreren Teilen eines Simulationsmodells stattfinden, was letztlichzu einer schnelleren Abarbeitung des Simulationsmodells führt. Die Methode der Paral-lelen und Verteilten Simulation wird bereits mit großem Erfolg in der Logiksimulation(Simulation des Verhaltens elektronischer Schaltungen) angewandt. Bisher fehlen jedochAnwendungen auf dem Gebiet der Simulation von Produktionssystemen oder der Ferti-gungssteuerung. Bei der Vorstellung der Modellelemente von Produktionssystemen (siehePunkt 2.3.2.2) wurde bereits eine Vielzahl parallel aktiver Elemente ersichtlich. Ziel ist esjetzt, mit Hilfe der Parallelen und Verteilten Simulation diese parallel aktiven Elementeauch zeitparallel auf mehreren Prozessoren respektive Computern abzuarbeiten, um so einebeschleunigte Ausführung der Simulation zu erreichen. Das Kapitel 3 befaßt sich mit denGrundlagen der Parallelen und Verteilten Simulation, im Kapitel 4 wird ein konkreter Vor-schlag zur Parallelen und Verteilten Simulation von Produktionssystemen unterbreitet.Hierbei sind die beiden Hauptaufgaben der Partitionierung und der Synchronisation ange-paßt an den Kontext der simulationsbasierten Fertigungssteuerung komplexer Produk-tionssysteme zu lösen.
Der dritte Weg - die Schaffung eines verteilten Experimentiersystems - erlaubt die zeit-gleiche Abarbeitung von unabhängigen Experimenten des gleichen Simulationsmodells aufmehreren Rechnern eines Computernetzwerks. Dadurch kann eine wesentliche Beschleuni-gung der Abarbeitung einer Simulationsstudie erreicht werden. Das verteilte Experimen-tiersystem kann zudem noch mit den beiden anderen Lösungswegen kombiniert werden.47
Näheres zu dieser Lösung ist im Punkt 4.6 und im Punkt 5.3.5 ausgeführt.
Das Problem 5, die hohe Parameterisierbarkeit der Verfahren der Parallelen und Ver-teilten Simulation und die Ungewißheit über die Performance für ein gegebenes Simu-lationsmodell, erfordert eine Vielzahl von Tests und Testmodellen. Die Erstellung einesSimulationsmodells ist aber eine sehr aufwendige Aufgabe (Problem 2). Der hohe Wieder-holungsgrad der Simulationsmodellerstellung macht es demzufolge unumgänglich, denModellerstellungsprozeß zu automatisieren - was mit dem Framework zur simulations-basierten Fertigungssteuerung geschehen soll. Notwendig für diesen Modellerstellungs-prozeß ist aber auch der Einbezug der Lösung der Teilaufgaben der Parallelen und Ver-teilten Simulation wie die Partitionierung und die Synchronisation. D.h., in den Modell-erstellungsprozeß ist ein Partitionierungsverfahren zu integrieren, um automatisch partitio-nierte Simulationsmodelle zu erzeugen. Für die Aufgabe der Partitionierung erfolgt deswe-gen im Punkt 4.5 der Entwurf eines speziell an die Belange der Simulation von Produk-tionssystemen angepaßten Partitionierungsverfahrens. Weiterhin sind die für die Simula-tionsmodellabarbeitung zu verwendenden Synchronisationsverfahren anders zu parameter-isieren (siehe Punkt 4.4).
47 Dies entspricht der Verteilten Sequentiellen Simulation, siehe Punkt 2.2.2.1.

Kapitel 3 Internationaler Wissensstand auf dem Gebiet der Parallelen undVerteilten Simulation
Seite 67
3 Internationaler Wissensstand auf dem Gebiet der Par-allelen und Verteilten Simulation
Dieses Kapitel enthält die State of the Art-Analyse zu Aufgaben, Problemen, Verfahrenund Tools zur Parallelen und Verteilten Simulation. Im ersten Unterkapitel wird auf dieTeilaufgaben der Partitionierung, der Kommunikation, der Synchronisation und des Load-Balancing näher eingegangen. Zu jeder der Aufgaben werden Verfahren genannt und Pro-bleme erläutert. Das zweite Unterkapitel stellt die Ergebnisse einer Recherche über poten-tiell geeignete Implementationsansätze zur Parallelen und Verteilten Simulation dar. ZumAbschluß des Kapitels erfolgt aus den genannten Kritikpunkten die Ableitung von Anfor-derungen an einen Lösungsansatz.
3.1 Aufgaben bei Einsatz der Parallelen und Verteilten SimulationIm Rahmen der Parallelen bzw. Verteilten Simulation sind folgende Aufgaben zu lösen[Unger 1988], [Mehl 1994, S. 8-13], [Bagrodia 1996]:
• die Partitionierung des Simulationsmodells in Teilmodelle,• die Kommunikation zwischen den Teilmodellen,• die Synchronisation der Teilmodelle,• die Zuweisung von Teilmodellen zu Prozessoren (Mapping),• das Scheduling zwischen mehreren Teilmodellen auf einen Prozessor und• das Load-Balancing zwischen den Prozessoren bzw. Rechnern.
3.1.1 Partitionierung
3.1.1.1 Begriff, Aufgaben und Ziele der Partitionierung
Die Partitionierung bestimmt die Zerlegung des Simulationsmodells in mehrere, möglichstunabhängige Teilmodelle, um so den Berechnungsaufwand auf mehrere Prozessoren bzw.Rechner verteilen zu können. Die Aufgabe der Partitionierung ist gleichzeitig unter derRestriktion der Minimierung des Kommunikationsaufwandes zu lösen [Mehl 1994, S. 10],[Bagrodia 1996].D.h., prinzipiell parallel abarbeitbare Teile des Simulationsmodells sind zu identifizierenund so auf Partitionen aufzuteilen, daß der Kommunikationsbedarf zwischen den Partitio-nen minimal ist, aber die potentiell erreichbare Parallelität durch die Partitionierung maxi-mal ist.Diese Aufgabe ist lösungsdefekt48.
3.1.1.2 Verfahren zur Partitionierung von Simulationsmodellen
Je nach Anwendungsgebiet der Parallelen und Verteilten Simulation existiert eine unter-schiedliche Anzahl von Partitionierungsverfahren. Ein allgemeines, anwendungsgebiets-übergreifendes Verfahren existiert jedoch nicht:
• In der militärischen Simulation werden i.d.R. die einzelnen Truppenverbände als Parti-tionen modelliert [Dahmann, Fujimoto, Weatherly 1998], [Davis, Moeller 1999].
• Für die Logiksimulation (Simulation elektronischer Bauteile) existieren eine Reihe vonanwendungsspezifischen Verfahren [Feldmann u.a. 1992], [Riess, Doll, Johannes 1994],[Kleis u.a. 1994], [Sporrer 1995], [Fröhlich, Schlagenhaft, Fleischmann 1997].
48 Zur Definition der Defekte siehe [Heinen 1990, S. 345 f.], [Corsten, May 1994, S. 3].

Kapitel 3 Internationaler Wissensstand auf dem Gebiet der Parallelen undVerteilten Simulation
Seite 68
• In der Simulation biologischer Systeme werden Partitionen meist als Parzellen des Ge-samtsystems abgebildet [Hotovy, Shen, Zollweg 1995].
• Bei der Simulation von Warteschlangennetzen oder Produktionssystemen werden ofteinzelne Maschinen oder Gruppen von Maschinen als Partitionen aufgefaßt. KonkreteVerfahren zur Partitionierung existieren jedoch nicht [Nandy, Loucks 1993].
Meist werden Ansätze aus der Graphentheorie benutzt [Kernighan, Lin 1970], [Schweikert,Kernighan 1972], [Fiduccia, Mattheyses 1982], [Krishnamurthy 1984], [Vijayan 1989],[Vijayan 1991], eng interdependierende Teile zusammen in einer Partition abzubilden unddie Verbindungen zwischen wenig oder nicht interdependierenden Teilen als Trennliniezwischen den Partitionen festzustellen. Diese graphentheoretischen Ansätze sind jedochmit Kriterien verbunden, die je nach Anwendungsfeld variieren.
In der Regel legt der Anwender jedoch selbst fest, welche Elemente des zu modellierendenSystems in Partitionen zusammengefaßt werden sollen (siehe u.a. [Mehl 1994, S. 10],[Smith 1999]). Es wird ein iteratives Vorgehen angewandt. Man testet eine Partitionierung,findet dabei Problemstellen, nimmt Maßnahmen zur Behebung der Probleme vor und ver-ändert daraufhin die Partitionierung.
Ein anderer Ansatz setzt eine Anpassung des Simulators an ein festgelegtes Anwendungs-gebiet voraus. Für ein ausgewähltes Anwendungsgebiet ist bekannt, welche Gruppen vonElementen sich typischerweise in dem zu modellierenden System befinden. Oft sind fürdiese Elementtypen im Simulator bereits Modellbausteine vorhanden. Diese Bausteinebilden die wesentlichen Eigenschaften und das typische Verhalten dieser Elemente ab.Zugleich stellen die Modellbausteine die Logischen Prozesse dar [Holthaus, Ziegler, Ro-senberg 1996]. Für den Anwender ist dieses Vorgehen am einfachsten, da es seiner natürli-chen Sicht am nächsten kommt. Er identifiziert die typischen Elemente des zu modellie-renden Systems und ordnet diesen dann die vorhandene Modellbausteine zu (Grund-partitionierung). Das Simulationsmodell setzt sich somit aus parameterisierten Modell-bausteinen (den Partitionen) und einer Beschreibung der Verknüpfung zwischen den Mo-dellbausteinen (Kommunikationskanälen zwischen den Partitionen) zusammen. Auf dieseWeise erhält man alle parallel im System agierenden Elemente. Das Ziel der maximalenParallelität wurde erreicht. Jedoch ist der Kommunikationsaufwand zwischen den so gebil-deten Logischen Prozessen oft erheblich. Später versucht man dieses Problem durch einegemeinsame Zuordnung eng kommunizierender Logischer Prozesse auf einen Prozessor zumildern. D.h., ein Teil der Aufgabe der Partitionierung wird auf das Mapping abgewälzt(vergleiche Punkt 3.1.4.3).
3.1.1.3 Probleme der Partitionierung
Lösungsdefekt:
Es existiert kein allgemeines Verfahren. Vorschläge für Partitionierungsverfahren sindimmer auf ein konkretes Anwendungsgebiet beschränkt.
Es existieren nur einige Grundregeln (vergleiche [Kvasnicka 1995, S. 49f]):
1. Jedes System setzt sich aus Subsystemen und Elementen zusammen. Diese Sub-systeme bzw. Elemente sollten als erster Ansatz zur Partitionierung genutztwerden.49
2. Stark interdependente Teilsysteme sollten in eine Partition eingeordnet werden.3. Wenig interdependente Teilsysteme sollten in unterschiedliche Partitionen ein-
geordnet werden.
49 Siehe auch [Dahmann, Fujimoto, Weatherly 1998] - System-in-the-System-View.

Kapitel 3 Internationaler Wissensstand auf dem Gebiet der Parallelen undVerteilten Simulation
Seite 69
4. Teilsysteme, welche nur in eine Richtung Dependenzen besitzen, können in un-terschiedliche Partitionen eingeordnet werden.
5. Teilsysteme zwischen denen viel kommuniziert wird (oft oder mengenmäßig),sollten in eine Partition eingeordnet werden [Mehl 1994, S. 10-12], [Bagrodia1996], [Xiao u.a. 1999].
6. Teilsysteme zwischen denen nicht kommuniziert wird, sollten in unter-schiedliche Partitionen eingeordnet werden [Loucks, Preiss 1990].
7. Teilsysteme zwischen denen wenig kommuniziert wird, können in unter-schiedliche Partitionen eingeordnet werden [Loucks, Preiss 1990].
8. Teilsysteme, welche nur Nachrichten produzieren, aber keine Nachrichten er-halten, sollten mit den ihnen nachgelagerten Teilsystemen in einer Partition zu-sammengefaßt werden, um den Kommunikationsaufwand zu senken.
9. Teilsysteme, welche nur Nachrichten empfangen, aber keine Nachrichten pro-duzieren, sollten mit den ihnen vorgelagerten Teilsystemen in einer Partition zu-sammengefaßt werden, um den Kommunikationsaufwand zu senken.
10. Teilsysteme mit hoher Berechnungslast sollten möglichst als einzelne Partitionabgebildet werden [Sporrer 1995, S. 35f].
11. Mehrere Teilsystemen mit geringer Berechnungslast können in einer Partitionzusammengefaßt werden [Sporrer 1995, S. 35f].
D.h., als Einflußfaktoren bestehen:
• die Topologie des Systems,• der Berechnungsaufwand in einem Teilsystem,• die Dependenz der Aufgabe(n) eines Teilsystems von den Aufgaben anderer Teil-
systeme,• uni- oder bidirektionale Kommunikation zwischen Teilsystemen und• der Kommunikationsbedarf und -aufwand eines Teilsystems (Häufigkeit der Kom-
munikation und Menge der Kommunikation).
Zielstellung ist, den Berechnungsaufwand in einem Teilsystem zu minimieren sowie dieKommunikation zwischen den Teilsystemen zu minimieren. Als Restriktionen bestehendie Dependenz zwischen den Teilsystemen und der daraus resultierende Bedarf an Kom-munikation sowie eine Untergrenze für das Verhältnis zwischen Berechnungsaufwand ineinem Teilsystem im Vergleich zur Kommunikationsdauer zwischen benachbarten Teil-systemen (siehe Punkt Formel 2) [Nicol 1988], [Mehl 1994, S. 142f], [Sporrer 1995, S. 35-36], [Bagrodia 1996].
≤ εEX( Transferzeit von Nachrichten zwischen logischen Prozessen )
EX( resultierender Berechnungsaufwand durch eingetroffene Nachrichten )
Formel 2 Verhältnis zwischen Kommunikationsdauer und Berech-nungsaufwand50
50 Die Formel weist Ähnlichkeiten zur Verkehrsgleichung der Bedienungstheorie auf: λ / µ ≤ 1
D.h., die Ankunftsrate λ muß kleiner oder gleich der Bedienrate µ sein. Andernfalls kann das System dieankommenden Forderungen nicht mehr bedienen - die Warteschlangenlänge wächst gegen unendlich.Hier jedoch ist die Bedienrate (des Netzwerkes) das Reziproke der mittleren Zeitdauer für die Übertragungeiner Nachricht. Die Ankunftsrate dagegen ist das Reziproke der mittleren Zeitdauer für die Durchführungder mit einem Ereignis verbundenen Aktionen und somit die mittlere Zeitdauer für die Generierung neuer,zu übertragender Nachrichten.

Kapitel 3 Internationaler Wissensstand auf dem Gebiet der Parallelen undVerteilten Simulation
Seite 70
Wird diese Untergrenze ε überschritten51, so überwiegt der Kommunikationsaufwand diepotentiell erreichbare Laufzeitverbesserung durch parallele Berechnung, da eintreffendeNachrichten in kürzerer Zeit verarbeitet werden können, als es möglich ist Nachrichten zutransferieren. Das System kommuniziert nur noch (Kommunikationsoverhead). Je nachAnwendungsgebiet variiert dieser Einflußfaktor jedoch.Diese Formel kann auch zu nachfolgendem Verhältnis adaptiert werden:
|Eintern(pi)| ≥ |Eextern(pi)| | ∀ pi
Formel 3 Verhältnis zwischen partitionsinternen und partitionsexternenEreignissen
Die Anzahl der partitionsinternen Ereignisse (|Eintern(pi)|) muß für jede Partition pi größergleich der Anzahl der partitionsexternen Ereignisse (|Eextern(pi)|) sein. Ansonsten ist dieBerechnungslast in der Partition im Verhältnis zum Kommunikationsaufwand zu gering.Die Parallelisierung in diese Partition pi würde keinen Nutzen erbringen.
Statische versus dynamische Partitionierung:
Der Prozeß der Partitionierung kann nicht als statisch angesehen werden. Für jedes neueSimulationsmodell oder gar bei Änderung einiger Parameter im Simulationsmodell isteventuell eine andere Partitionierung sinnvoll oder gar notwendig, da sich ein anderer Gradder Dependenz der Teilsysteme oder ein anderer Kommunikationsbedarf ergibt.So kann sich z.B. bei der Simulation von Produktionssystemen durch die Verschiebung desProduktmixes zugunsten eines Produktes eine völlig andere Häufigkeit der Benutzung vonWegen zwischen den Maschinen ergeben und es ergibt sich somit ein im Vergleich zu ei-nem anderen Produktmix unterschiedliches Kommunikationsprofil und damit andereKommunikationsbedarfe. So ist jetzt u.U. günstiger, eine andere Partitionierung zu wählen.
3.1.1.4 Anforderungen an Partitionierungsverfahren
Für ein gegebenes Simulationsmodell kann nicht starr eine Partitionierungsvorschrift ange-wendet werden. Bei Änderung von Parametern im Simulationsmodell ist eine verändertePartitionierung sinnvoll. Deswegen ist eine dynamische Partitionierung notwendig. Dieskann partiell durch eine höhere Grundpartitionierung des Simulationsmodells (viele kleine-re Partitionen mit teilweise engen Zusammenhängen) erreicht werden. Diese kleinen Parti-tionen können dann im Rahmen des Mappings (siehe Punkt 3.1.4) dynamisch auf gleicheoder unterschiedliche Rechner zugewiesen werden. Über die höhere Grundpartitionierungwird so eine maximal sinnvolle Unterteilung des Simulationsmodells - und damit eine ma-ximal erreichbare Parallelität - vorgegeben.Dieser maximal sinnvollen Unterteilung des Simulationsmodells steht die Restriktion desVerhältnisses zwischen Berechnungsaufwand in einer Partition im Vergleich zur Kommu-nikationsdauer zwischen Partitionen gegenüber (Formel 2). Hier muß der lokal in einerPartition erforderliche Berechnungsaufwand die mittlere Zeitdauer für eine Nachrichten-übermittlung zwischen den Partitionen übersteigen. Andernfalls blockiert das System, danur noch auf eintreffende Nachrichten gewartet werden muß.
51 Ein konkreter Wert für ε kann nicht angegeben werden, da dieser Grenzwert modellabhängig ist. Allge-
mein gilt ε < 1, jedoch ist in seltenen Fällen auch ε > 1 möglich.

Kapitel 3 Internationaler Wissensstand auf dem Gebiet der Parallelen undVerteilten Simulation
Seite 71
3.1.2 Kommunikation
3.1.2.1 Begriff, Aufgaben und Ziele der Kommunikation
Kommunikation ist der Austausch von Nachrichten zwischen den Logischen Prozessen.Über diese Kommunikation drückt sich die Abhängigkeit der Logischen Prozesse unter-einander aus.Die Art und Weise der Kommunikation muß für eine verteilte Abarbeitung innerhalb einesComputernetzwerkes und eine lokale Abarbeitung auf einem Mehrprozessorrechner unter-schieden werden. Während bei einer lokalen Abarbeitung die Kommunikation der unter-schiedlichen Prozesse über einen gemeinsamen Speicher gelöst wird, erfolgt bei einer ver-teilten Abarbeitung ein Versand von Nachrichten im Netzwerk. Der Nachrichtenaustauschüber einen gemeinsamen Speicher ist hierbei um Größenordnungen performanter, aller-dings ist in Computernetzwerken eine bessere Skalierbarkeit52 gegeben.
Wesentlich für den Aufwand zur Kommunikation ist die Notwendigkeit der LogischenProzesse Nachrichten auszutauschen. Faßt man einen Logischen Prozeß als Black-Box auf,so läßt sich zu ihm eine Input- und eine Output-Schnittstelle fixieren. D.h., welche Nach-richten der Logischer Prozeß empfängt und welche er sendet.
LogischerProzeßIn
put
Output
Abbildung 25 Logischer Prozeß als Black-Box
Aufgrund der Dependenzen zwischen den Logischen Prozessen kann eine Topologie desKommunikationsnetzwerks zwischen den Logischen Prozessen aufgestellt werden.
LogischerProzeß 2In
put
Output
LogischerProzeß 3In
put
Output
LogischerProzeß 4In
put
Output
LogischerProzeß 5In
put
Output
LogischerProzeß 6In
put
Output
LogischerProzeß 1In
put
Output
Abbildung 26 Beispiel einer Kommunikationstopologie zwischen LogischenProzessen
Ziel ist hier, eine Kommunikationsinfrastruktur anzubieten, die dieser Topologie ent-spricht. D.h., die Etablierung von gerichteter Kommunikation zwischen den LogischenProzessen ist notwendig (Vermeidung von Broadcasting).Weiteres Ziel ist eine Kommunikationsinfrastruktur anzubieten, welche den Transfer dernotwendigen Nachrichten möglichst schnell erledigt. Dies ist erforderlich, denn Arbeitenzeigten [Loucks, Preiss 1990], [Mehl 1994, S. 142f], [Bagrodia 1996], [Holthaus, Rosen-berg, Ziegler 1996], daß u.U. ein Kommunikationsoverhead entstehen kann (hoher Bedarf
52 Ein Mehrprozessorrechner besitzt eine feste Anzahl von Prozessoren, die sich nicht ändern läßt. Werden
mehr Prozessoren benötigt, so werden bei einer verteilten Abarbeitung einfach weitere Computer demNetzwerk hinzugefügt.

Kapitel 3 Internationaler Wissensstand auf dem Gebiet der Parallelen undVerteilten Simulation
Seite 72
und Aufwand an Kommunikation). In einem solchen Falle ist es zwingend notwendig,Nachrichten schnell zu transferieren.Die Lösung der Aufgabe der Kommunikation ist von der vorgegebenen Partitionierungabhängig. Beide Aufgaben können nicht losgelöst voneinander betrachtet werden.
3.1.2.2 Verfahren zur Kommunikation
Plattformabhängige Faktoren der Kommunikation:
Die Art und Weise der Kommunikation ist von der verwendeten Rechnerplattform abhän-gig.Bei einer Abarbeitung der Logischen Prozesse auf einem Mehrprozessorrechner kann dieKommunikation über einen gemeinsamen Speicher erfolgen. Dies ist die effektivste Artder Kommunikation.Bei der Abarbeitung der Logischen Prozesse auf Rechnern in einem Computernetzwerk istdie Art der Kommunikation von der Hardware und den im Netzwerk verwendeten Proto-kollen abhängig. In der Regel wird im Netzwerk die Hardware verwendet, welche diehöchste Übertragungsrate bietet. Dieser Faktor kann also nicht beeinflußt werden. AlsProtokoll wird für gewöhnlich TCP/IP eingesetzt, da dieses Protokoll zur Kommunikationim Internet verwendet wird und nahezu universal verfügbar ist. In geschirmten Computer-netzwerken (siehe Punkt 3.1.2.3, „Abhängigkeit der Kommunikationsdauer von der Inan-spruchnahme der Kommunikationshardware“) können jedoch auch Spezialprotokolle zumEinsatz kommen. Das Hauptproblem der Kommunikation zwischen räumlich verteiltenRechnern ist, daß die zu transferierenden Nachrichten eine gewisse Laufzeit haben, die -verglichen mit der Kommunikation über einen gemeinsamen Speicher - um mehrere Grö-ßenordnungen höher liegt.
Empfängerbezogene Unterscheidung der Kommunikationsarten:
Man unterschiedet zwischen Unicast und Broadcast. Ein Unicast besitzt nur genau einenEmpfänger (gerichtete Kommunikation). Ein Broadcast dagegen besitzt eine Gruppe vonEmpfängern oder wird an alle erreichbaren Empfänger gesendet.Muß ein und die selbe Nachricht an viele Empfänger gesendet werden, so ist ein Broadcastvorteilhafter. Nachteilig an einem Broadcast ist aber, daß jeder potentielle Empfänger dieNachricht erhält. Denn dies verursacht eine hohe Netzlast, was zur Folge hat, daß diemittlere Übertragungsgeschwindigkeit im Netzwerk sinkt.
3.1.2.3 Probleme der Kommunikation
Problem der verteilten Abarbeitung:
Bei einer verteilten Abarbeitung in einem Computernetzwerk muß die Kommunikationzwischen den einzelnen Logischen Prozessen über das Computernetzwerk erfolgen. Be-dingt durch technische Restriktionen ist diese Zeit des Transfers von Nachrichten als einkritischer Zeitfaktor zu betrachten, da in dieser Zeit lokal zahlreiche weitere Berechnungendurchgeführt werden können53. Der Transfer der Nachrichten über das Computernetzwerkerweist sich hier als Bremse für eine verteilte Abarbeitung (vergleiche [Mehl 1994,S. 143], [Bagrodia 1996], [Smith 1999]).Bei einer Abarbeitung auf einem Mehrprozessorrechner kann dagegen die Kommunikationüber einen gemeinsamen Speicher erfolgen. Dies ist um Größenordnungen schneller.
53 Die Übertragung der Nachrichten im Netzwerk erwies sich in Tests als Flaschenhals. Siehe dazu Punkt 6.3.
Vergleiche auch Formel 2 auf Seite 69.

Kapitel 3 Internationaler Wissensstand auf dem Gebiet der Parallelen undVerteilten Simulation
Seite 73
Gefahr eines Kommunikationsoverheads:
Bedingt durch eine mangelhafte Partitionierung54 ist ein hoher Grad an Kommunikationerforderlich. Durch das Synchronisationsverfahren kann dieser Kommunikationsbedarfweiter steigen (z.B. Null-Messages, Garantien, Anti-Messages usw., siehe Punkt 3.1.3.3und Punkt 3.1.3.4). Es kann nun dazu kommen, daß der Hauptaufwand für die Durch-führung der Parallelen und Verteilten Simulation auf den Aufwand zur Kommunikationentfällt. In einem solchen Fall spricht man von einem Kommunikationsoverhead. Erfah-rungen zeigen [Loucks, Preiss 1990], [Mehl 1994, S. 142f], [Bagrodia 1996], [Holthaus,Rosenberg, Ziegler 1996] eine sehr nachteilige Auswirkung auf die Performance.
Gefahr eines Kommunikationsdeadlocks:
Bedingt durch einen Kommunikationsoverhead oder sehr lange Übertragungszeiten vonNachrichten kann zusätzlich an einzelnen Logischen Prozessen ein Deadlock eintreten.D.h., diese Prozesse sind nur noch mit Senden oder Empfangen von Nachrichten befaßtund führen für eine gewisse Zeit keine Berechnungen mehr durch. Andere Logische Pro-zesse warten aber vielleicht gerade auf die Ergebnisse dieser Berechnungen und könnenselbst nicht aktiv werden, diese Prozesse sind verklemmt. Unter Umständen kann es sogarso weit kommen, daß alle Prozesse verklemmt sind, in einem solchen Fall ist ein Deadlockaufgetreten - die Simulation terminiert nicht mehr.
Abhängigkeit der Kommunikationsdauer von der Kommunikationshardware:
Bedingt durch die physische Verkabelung der einzelnen Rechner des Netzwerkes ergebensich Einflußfaktoren auf die Geschwindigkeit der Übertragung und die Art und Weise derÜbertragung. Im Normalfall wird die Verkabelungstopologie des Computernetzwerks nichtmit der Kommunikationstopologie der Logischen Prozesse übereinstimmen. Dadurch er-geben sich für die eigentlich gerichtet gedachte Kommunikation Überschneidungen in derVerkabelung. Es entsteht zusätzliche Last an einigen Stellen des Computernetzwerks, dieunerwartete Effekte auf die Übertragungszeit der gerichteten Kommunikation zwischenzwei Logischen Prozessen haben kann. Dieser Faktor ist jedoch nicht beeinflußbar undmuß hingenommen werden.
Abhängigkeit der Kommunikationsdauer von der Inanspruchnahme der Kommuni-kationshardware:
In einem Computernetzwerk haben üblicherweise mehrere Nutzer Zugang und werdeni.d.R. diesen Zugang auch gleichzeitig nutzen. D.h., für die verteilte Abarbeitung ist be-dingt durch andere Nutzer im Computernetzwerk eine Hintergrundlast im Netzwerk vor-handen. Ist als alleinige Anwendung in dem Computernetz die Durchführung der Simulati-on erlaubt und besitzt dieses Computernetz keine Verbindung zu anderen Rechnern oderNetzen, so spricht man von einem geschirmten Netz. In einem solchen Netz ist die Hinter-grundlast wesentlich niedriger. Die Hintergrundlast kann - bedingt durch Kommunika-tionsprozesse des Betriebssystems der Rechner des Netzwerkes - nicht Null sein, in ge-schirmten Netzen aber Null nahe kommen.Ein weiterer Einflußfaktor resultiert aus dem Profil der Kommunikation. Für die mittlereÜbertragungsdauer ist die mittlere Anzahl von zu übertragenden Paketen wesentlich. Sobelasten viele kleine Nachrichten das Netzwerk stärker als eine große Nachricht, auchwenn das Übertragungsvolumen in beiden Fällen gleich ist, da die Verwaltungssoftwaredes Netzwerkes stärker beansprucht wird. Die Kommunikation im Rahmen der Parallelenund Verteilten Simulation besteht ausschließlich aus vielen aber kleinen Nachrichten, wasdie verfügbare Übertragungskapazität besonders beansprucht. 54 D.h., zwischen einzelnen oder allen Partitionen wird zu viel kommuniziert.

Kapitel 3 Internationaler Wissensstand auf dem Gebiet der Parallelen undVerteilten Simulation
Seite 74
Nebenläufigkeit:
Ein Logischer Prozeß muß gleichzeitig Berechnungen durchführen können, Nachrichtenempfangen können und Nachrichten senden können. Dies bedingt eine Nebenläufigkeit desEingangs und Ausgangs von Nachrichten, ansonsten wäre der Prozeß durch die Bereit-schaft zum Empfang von Nachrichten oder durch den Versand von Nachrichten blok-kiert55.
3.1.2.4 Anforderungen an Kommunikationsstrukturen und -verfahren
Als Anforderungen aus Sicht von Strukturen und Verfahren des Kommunikation wärenaufzustellen:
• • • • Realisierung der Nebenläufigkeit von Empfang und Versand von Nachrichten:
Ein Logischer Prozeß muß in der Lage sein, gleichzeitig Nachrichten zu empfangen,Berechnungen durchzuführen und Nachrichten zu versenden. Dies bedingt eine Neben-läufigkeit dieser drei Aufgaben:
Empfangs-einheit
Sendeeinheit
Verarbeitung
logischer Prozeß
Nachrichten-puffer
Nachrichten-puffer
Abbildung 27 Einteilung eines Logischen Prozesses in nebenläufige Sub-strukturen aus Sicht der Kommunikation
• • • • Verwendung gerichteter Kommunikation:
Durch die Verwendung gerichteter Kommunikation kann die Last im Netzwerk geringergehalten werden, bedingt dadurch sind die Übertragungszeiten somit kürzer.
• • • • Ausnutzung des topologischen Verbindungswissens der Logischen Prozesse:
Die Synchronisationsverfahren (insbesondere konservative) profitieren von der Ausnut-zung des Topologiewissens. Dadurch muß nicht auf Prozesse gewartet werden, die kei-ne Verbindung zum aktuell betrachteten Prozeß besitzen. Dies entspricht dem Einfluß-faktor des fan-in bzw. fan-out [Preiss, Loucks 1990], [Bagrodia 1996].
• • • • Verwendung effektiver Kommunikationshard- und -software:
Dieser Fakt ist selten beeinflußbar. Wenn möglich, sollte die Verwendung eines Rech-ners mit mehreren Prozessoren und gemeinsamen Speicher stattfinden, weil dies die ef-fizienteste Art der Kommunikation und Abarbeitung ist56. Dem stehen allerdings diehohen Kosten solcher Hardware und der hohe Speicherbedarf der Logischen Prozessegegenüber. Bei einer verteilten Abarbeitung kann der Speicherbedarf zwar auf dieRechner im Netzwerk aufgeteilt werden, die Übertragungsdauer der Nachrichten wird
55 In Ansätzen wie MPI ist dies z.T. wirklich so. Es gibt Funktionen zum Versenden (bzw. Empfangen) von
Nachrichten, die den Programmablauf blockieren.56 Mehl [Mehl 1994, S. 43] verweist z.B. darauf, daß unter sonst gleichen Bedingungen eine Parallele Simu-
lation auf einem Mehrprozessorrechner als obere Schranke für die Performance der Verteilten Simulationangesehen werden kann.

Kapitel 3 Internationaler Wissensstand auf dem Gebiet der Parallelen undVerteilten Simulation
Seite 75
aber um ein Vielfaches höher. Die für das gegebene Problem effektivste Hardware kannnur durch Testen gefunden werden [Smith 1999].
• • • • Variabilität des Kommunikationsverfahrens:
Bei einer verteilten Abarbeitung auf mehreren Rechnern kommt es in der Regel vor, daßmehrere Logische Prozesse dem Rechner zugewiesen sind (siehe „Mapping“, Punkt3.1.4.1). Da diese Logischen Prozesse z.T. untereinander kommunizieren, ist es not-wendig, daß das Kommunikationsverfahren flexibel hinsichtlich des Transfers derNachrichten ist. Für eine lokale Übertragung (zwischen Logischen Prozessen auf einemRechner) ist es nicht notwendig, die zu sendende Nachricht über das Netzwerk zu über-tragen. In einem solchen Fall kann - wie bei einer lokalen Abarbeitung auf einem Mehr-prozessorrechner - ein Austausch der Nachricht über einen gemeinsamen Speicher statt-finden. Durch diese Flexibilität kann die Last auf dem Netzwerk verringert werden unddie Übertragung von Nachrichten findet im Mittel schneller statt.
3.1.3 Synchronisation
3.1.3.1 Begriff, Aufgaben und Ziele der Synchronisation
Durch die Partitionierung ist eine definierte Menge von Logischen Prozessen entstanden.Diese Logischen Prozesse sind parallel abarbeitbar. Da die Logischen Prozesse aber kei-neswegs völlig voneinander unabhängig sind, ist zwischen ihnen Kommunikation notwen-dig um Informationen auszutauschen. Durch die gleichzeitige parallele Ausführung derLogischen Prozesse kann die kausale Ordnung verletzt werden. Aufgabe der Synchronisa-tion ist es daher, sicherzustellen, daß die kausale Ordnung der Ereignisabfolge über alleLogischen Prozesse gewahrt bleibt [Chandy, Misra 1978], [Jefferson, Sowizral 1985],[Jefferson u.a. 1987], [Nicol 1988].Dadurch, daß die Logischen Prozesse gleichzeitig Berechnungen durchführen, können dielokalen Zeiten der einzelnen Logischen Prozesse voneinander abweichen, da diese unter-schiedlich oft Berechnungen durchführen müssen und sie diese Berechnungen unterschied-lich schnell absolvieren. Zur Wahrung der Kausalität ist es aber erforderlich, daß alle Erei-gnisse eines Logischen Prozesses nach monoton steigender Simulationszeit abgearbeitetwerden. Ein Logischer Prozeß wird im Normalfall Nachrichten erhalten, die - im Vergleichmit seiner lokalen Zeit - in seiner Vergangenheit oder Zukunft liegen. Da durch das Ein-treffen von Nachrichten Ereignisse ausgelöst werden, kann die kausal richtige Abarbei-tungsreihenfolge von Ereignissen gefährdet sein. Der Empfang von zukünftig relevantenNachrichten ist unproblematisch, aber Nachrichten, welche in der Vergangenheit des Logi-schen Prozesses liegen, können die kausale Ordnung verletzt haben. Unter Umständen istein ungültiger Zustand erreicht worden.Zur Wahrung der kausalen Ordnung bzw. zur Behebung von Verletzungen selbiger hat dasverwendete Synchronisationsverfahren Lösungsmechanismen bereitzustellen [Chandy,Misra 1978], [Jefferson u.a. 1987], [Jha, Bagrodia 1994], [Bagrodia 1996].
3.1.3.2 Überblick über Verfahren zur Synchronisation von Simulationsmodellen
Es existieren eine Reihe von Synchronisationsverfahren, die sich in vier Gruppen einteilenlassen (vergleiche [Unger 1988], [Mehl 1994, S. 15ff], [Jha, Bagrodia 1994], [Sporrer1995, S. 27ff], [Bagrodia 1996], [Kvasnicka 1995, S.33f], [Fujimoto 1999]):
• konservative Verfahren [Chandy, Misra 1978], [Bryant 1979], [Misra 1986], [Chandy,Sherman 1989a], [Jha, Bagrodia 1993], [Xiao u.a. 1999]:
Konservative Synchronisationsverfahren zeichnen sich dadurch aus, daß in jedem Falldie kausal richtige Reihenfolge der Ereignisabarbeitung gewahrt bleibt. Ggf. muß ein

Kapitel 3 Internationaler Wissensstand auf dem Gebiet der Parallelen undVerteilten Simulation
Seite 76
Logischer Prozeß so lange warten, bis sichergestellt werden kann, daß keine Nach-richten mit einem früheren Zeitpunkt als die lokale Zeit eintreffen können. Dadurchwird aber der potentielle Grad an Parallelisierbarkeit eingeschränkt.57 58
• optimistische Verfahren [Jefferson, Sowizral 1985], [Jefferson u.a. 1987], [Steinman1993], [Carothers, Perumalla, Fujimoto 1999]:
Optimistische Synchronisationsverfahren dagegen führen in den Logischen Prozessenalle vorhandenen Ereignisse aus (optimistisches Voranschreiten). Somit müssen dieProzesse nicht unnötigerweise auf das Eintreffen weiterer Nachrichten warten. Trifftnun doch eine Nachricht eines anderen Logischen Prozesses mit einem Zeitpunkt früherals die lokale Zeit ein („unangebrachter Optimismus“), so wird der Zustand des Logi-schen Prozesses auf den Zustand zur Simulationszeit vor dieser Nachricht zurückgesetzt- ein sogenannter Rollback wird ausgeführt. Die Verletzung der kausalen Abfolge derEreignisse wird also nachträglich behoben.
• hybride Verfahren [Mehl 1994], [Jha, Bagrodia 1994]:
Hybride Synchronisationsverfahren versuchen die Vorteile konservativer und optimisti-scher Verfahren zu kombinieren.
So wird z.B. bei der Spekulativen Verteilten Simulation nach Mehl [Mehl 1994, S. 106-144] ein optimistisches Voranschreiten nur ausgeführt, wenn eine Reihe von Bedingun-gen zutrifft. So wird versucht zu erkennen, ob ein optimistisches Voranschreiten imaktuellen Fall zu einem Rollback führen wird. Dadurch können potentielle Kausalitäts-verletzungen im Voraus erkannt und somit vermieden werden. Die Anzahl der auf-tretenden Rollbacks kann so deutlich verringert werden - eine beschleunige Ausführungder Simulation ist die Folge [Mehl 1994, S. 125-129].
• Das Ideal Simulation Protocol (ISP) [Bagrodia, Jha 1996]:
Dieses Synchronisationsverfahren stellt einen nicht praxisrelevanten Spezialfall dar.Hintergrund ist hier die Frage: Wie kann man das maximal mögliche Speedup einergegebenen Partitionierung bestimmen, um so verschiedene Synchronisationsverfahrenbewerten zu können? Die Idee ist hier, einen Simulationslauf mit einem konservativenVerfahren durchzuführen und zu vermerken, an welcher Stelle das konservative Ver-halten notwendig war und an welcher Stelle nicht. Damit besteht für den nächsten Si-mulationslauf unter sonst gleichen Bedingungen ex-ante das Wissen, ob die Ausführungeines Ereignisses zu einem Rollback führen wird. Damit kann das maximal möglicheSpeedup der vorgegebenen Partitionierung ermittelt werden. Somit ist für die anderenSynchronisationsverfahren die obere Schranke des Speedups bekannt und beliebigeSynchronisationsverfahren können daran gemessen werden.
57 Die Einschränkung der potentiell möglichen Parallelität durch konservative Verfahren entsteht durch das
Warten auf weitere Nachrichten, die einen kleineren Zeitstempel als die lokale Zeit haben, weil in derWartezeit vom lokalen Prozessor weitere Berechnungen ausgeführt werden könnten. Bestünde keine Not-wendigkeit zu warten, so würde der logische Prozeß schneller ausgeführt.
58 Wurden dem Prozessor mehrere Logische Prozesse zur Bearbeitung zugewiesen (Aufgabe des Mappings,siehe Punkt 3.1.4.1), so muß das Warten eines logischen Prozesses keinen Nachteil darstellen, weil derProzessor den nächsten, nicht durch Warten blockierten Logischen Prozeß zur Abarbeitung bringen kann.

Kapitel 3 Internationaler Wissensstand auf dem Gebiet der Parallelen undVerteilten Simulation
Seite 77
3.1.3.3 Konservative Synchronisationsverfahren
Konservative Verfahren zeichnen sich dadurch aus, in jedem Fall die kausale Ordnung derAbarbeitung der Ereignisse zu wahren.Die Grundidee ist hier: Ein Logischer Prozeß hat Kenntnis von den Logischen Prozessen,welche Nachrichten an ihn senden können, und er hat Kenntnis davon, mit welchen Zeit-stempel die letzten eingetroffenen Nachrichten versehen sind. Der Logische Prozeß kannnun alle lokal vorliegenden Ereignisse mit einem Zeitstempel kleiner als seine lokale Zeitabarbeiten. Der Logische Prozeß kann seine lokale Simulationszeit erst dann erhöhen,wenn sichergestellt ist, daß keine Nachrichten mit einem Zeitstempel kleiner als die zu-künftige lokale Zeit mehr eintreffen können. Gegebenenfalls wird der Logische Prozeßsolange blockiert, bis von allen Eingängen Nachrichten mit einem Zeitstempel größer alsdie lokale Zeit vorliegen.
Bereits von anderen logischenProzessen empfangene
Nachrichten.
lokale Zeit von LPi = 15
Logischer Prozeß LP i
LPCLPA LPB
t=0
t=20
t=25
t=0
t=5
t=5
t=10
t=40
t=0
t=20
ausführbare Ereignisse
nicht ausführbare Ereignisse
Nicht möglich:lokale Zeit := 20
Max: 40 25 5
Da LPC möglicherweise erst beiSimulationszeit = 5 angekommen istund bis Simulationszeit = 15 weitereNachrichten senden könnte !
> 15 ?
Abbildung 28 Vorgehen bei konservativer Synchronisation
Dieses Vorgehen ist jedoch mit Problemen behaftet:
So kann es vorkommen, daß fast alle Logischen Prozesse auf eine Nachricht des LogischenProzesses LPk warten - die Simulation hat sich verklemmt.Schlimmer noch, es kann Situationen geben, in denen alle Prozesse warten (z.B. bei zykli-schen Topologien) - ein Deadlock ist aufgetreten. Die Simulation terminiert nicht59. Siehedazu Punkt 3.1.3.6.
D.h., das Synchronisationsverfahren muß Mechanismen besitzen, die Deadlock- und Ver-klemmungssituationen im Voraus erkennen oder aber zumindest in der Lage sind, dieseprekären Situationen aufzulösen (siehe Punkt 3.1.3.6).
In der Beschreibung der Grundidee sind bereits Ansatzpunkte für eine Verbesserung vor-handen:
Durch die Kenntnis der Verbindungen zwischen den Logischen Prozessen kann die Listeder Logischen Prozesse, auf die noch gewartet werden muß, erheblich eingeschränkt wer-den. D.h., die Nutzung des Topologiewissens ist dringend zu empfehlen60.
59 Vergleiche [Chandy, Misra 1981], [Mehl 1994, S. 32].60 Besteht das Simulationsmodell aus 100 Partitionen, so müßte ein Logischer Prozeß so lange warten, bis die
anderen 99 Prozesse eine lokale Zeit größer gleich seiner lokalen Zeit erreicht haben. Ist über das Topolo-giewissen bekannt, daß der betrachtete Logische Prozeß lediglich von zwei anderen logischen ProzessenNachrichten erhalten kann, so muß nur auf diese beiden logischen Prozesse gewartet werden. D.h., der Lo-gische Prozeß hat gegenüber den anderen 97 Prozessen einen Lookahead von ∞.

Kapitel 3 Internationaler Wissensstand auf dem Gebiet der Parallelen undVerteilten Simulation
Seite 78
Zum Anderen richtet sich das Weiterschalten der lokalen Zeit eines Logischen Prozessesnach dem kleinsten Zeitstempel der zeitlich letzten von anderen Prozessen eingetroffenenNachrichten. Der Zeitstempel der letzten eingetroffenen Nachricht sagt aber nichts über diejetzige lokale Zeit dieses Prozesses aus. Ein Logischer Prozeß kann also vor Aufnahmevon Berechnungen zur Erstellung seines Outputs an Nachrichten vorab eine Nachricht anseine topologischen Nachfolger senden, daß er die lokale Zeit tx erreicht hat und noch aktivist. Eine solche Nachricht heißt Null-Message (da sie außer dem Zeitstempel leer ist).
Bereits von anderen logischenProzessen empfangene
Nachrichten.
lokale Zeit von LPi = 15
Logischer Prozeß LP i
LPCLPA LPB
t=0
t=20
t=25
t=0
t=5
t=5
t=10
t=40
t=0
t=20
ausführbare Ereignisse
nicht ausführbare Ereignisse
Durch die Null-Message von LPC istes jetzt möglich, die lokale Zeit auf 20zu erhöhen, da alle Eingänge weiterals die lokale Zeit vorangeschrittensind und keine Nachrichten miteinem Zeitstempel kleiner als 15mehr senden können.
Max: 40 25 20
> 15 ?
t=20
t=20 Null-Message
Abbildung 29 Verbesserung der Performance konservativer Synchronisa-tionsverfahren durch Null-Messages61
Eine Erweiterung des Gedankens der Null-Messages sind Garantien oder Garantie-Nach-richten. Mit einer Garantie gibt ein Logischer Prozeß an seine topologischen Nachfolgerdie Gewähr, daß er keine Nachrichten mehr senden wird, die vor dem Garantiezeitpunktliegen [Mehl 1994, S. 19-28]. Problematisch hieran ist natürlich die Berechnung des Ga-rantiezeitpunktes.
Als weiterer Verfahrensparameter ist der Lookahead oder Vorausschauhorizont von sehrhoher Bedeutung. Der Lookahead eines Logischen Prozesses definiert dessen Möglichkeitin einer gegebenen Situation das eigene Verhalten (und damit die zu sendenden Nach-richten) für einen gewissen Zeithorizont vorhersagen zu können. Je größer der Lookaheadist, desto schneller kann ein Logischer Prozeß voranschreiten. Die Höhe des Lookaheadshat somit signifikanten Einfluß auf die Geschwindigkeit der Simulation [Chandy, Misra1978], [Fujimoto 1988a], [Loucks, Preiss 1990], [Preiss, Loucks 1990], [Bagrodia 1993],[Bagrodia 1994], [Mehl 1994, S. 26], [Sporrer 1995, S. 34], [Bagrodia 1996].Der Parameter Lookahead ist insbesondere für das Versenden von Garantien von Interesse.Besitzt ein Logischer Prozeß LPi zum Simulationszeitpunkt ti einen Lookahead von Lj, sokann er an seinen topologischen Nachfolger LPj eine Garantie von ti+Lj geben. Es gelingtsomit besser, die Logischen Prozesse zu entkoppeln und die Simulationsausführung zubeschleunigen.
Bekannteste Vertreter der konservativen Synchronisationsverfahren sind das Verfahrennach Chandy und Misra [Chandy, Misra 1978], dessen Erweiterungen nach Bryant [Bryant1979] und Misra [1986]. Das Verfahren ist auch unter dem Namen CMB-Verfahren -Chandy, Misra and Bryant - bekannt.
61 Vergleiche Abbildung 28, Seite 77.

Kapitel 3 Internationaler Wissensstand auf dem Gebiet der Parallelen undVerteilten Simulation
Seite 79
Eine wesentliche Erweiterung dieses Verfahrens stellt der conditional event Ansatz nachChandy und Sherman [Chandy, Sherman 1989a] dar.Jha und Bagrodia stellen in [Jha, Bagrodia 1993] eine Kombination von Null-Message-basierten Ansätzen und dem conditional event-Ansatz vor. Ziel ist hier die Vorteile derAnsätze zu verbinden, um eine schnellere Abarbeitung der Simulation zu erzielen.Das Critical Channel Traversing [Xiao u.a. 1999] ist eine weitere Adaption des CMB-Verfahrens. Ziel ist es hier, das Scheduling zwischen aktiven und inaktiven Prozessen zuverbessern. So sollen insbesondere die Logischen Prozesse bevorzugt abgearbeitet werden,welche mit größter Wahrscheinlichkeit einen Deadlock verursachen können.Weitere Erweiterungen konservativer Synchronisationsverfahren werden in [Preiss 1989],[Leung u.a. 1989], [Lin, Lazowska, Baer 1990], [Loucks, Preiss 1990], [Preiss, Loucks,McIntyre 1991] und [Nandy, Loucks 1993] beschrieben.
3.1.3.4 Optimistische Synchronisationsverfahren
Im Gegensatz zu konservativen Verfahren arbeiten optimistische Verfahren alle lokalenEreignisse ab, ohne dabei auf potentielle Verletzungen der kausalen Ordnung zu achten.Die Grundidee ist hier, vor der Ausführung von Ereignissen den momentanen Zustand desLogischen Prozesses zu speichern. Trifft zu einem späteren Zeitpunkt eine Nachricht miteinem kleineren Zeitstempel als die lokale Zeit ein - liegt also eine Kausalitätsverletzungvor, so wird der Logischen Prozeß auf einen vor diesem Zeitpunkt gesicherten Zustandzurückgesetzt und die Abarbeitung von Ereignissen wird teilweise wiederholt. Diese Zu-standsrücksetzung nennt man Rollback. Im Gegensatz zum Rollback erfolgt ein Commit(eine Bestätigung), wenn der Zustand erreicht wird, daß von allen Eingängen Nachrichtenmit einem größeren Zeitstempel als die lokale Zeit eingetroffen sind. Ab diesem Zeitpunktkönnen als Ereignisse als sicher betrachtet werden und es kann konservativ vorange-schritten werden. Alle bisherigen Zustandsspeicherungen werden dann nicht mehr be-nötigt. Der verwendete Mechanismus mit Commit und Rollback ist eine Analogie zu denTransaktionsmechanismen aus der Datenbanktheorie.
Logischer Prozeß LP i
t=0
t=20
sicher ausführbareEreignisse
unsichere Ereignisse
von anderen logischen Prozessenempfangene Nachrichten:
LPCLPA LPB
t=0
t=20
t=25
t=0
t=5
t=5
t=10
t=40 t=12 Rollback auslösendes Ereignis
t=0
t=0
t=5
t=5
t=10
Zustands-speicherungvon LPi bei
t=10
t=20 t=25Rollbackauf t=10
t=12 t=20
Reihenfolge der Abarbeitung der Ereignisse des Logischen Prozesses LP i
Zustands-speicherungvon LPi bei
t=20
Zustands-speicherungvon LPi bei
t=25
Zustands-speicherungvon LPi bei
t=12
lokale Zeit von LP i = 25
Abbildung 30 Optimistisches Voranschreiten62
62 Vergleiche Abbildung 28, Seite 77.

Kapitel 3 Internationaler Wissensstand auf dem Gebiet der Parallelen undVerteilten Simulation
Seite 80
Die verschiedenen Synchronisationsverfahren unterscheiden sich hinsichtlich der Mecha-nismen der Zustandsspeicherung und Behebung von Kausalitätsverletzungen. Verfahrens-parameter für die optimistischen Synchronisationsverfahren sind:
• die Häufigkeit der Zustandsspeicherung,• der Umfang der Zustandsspeicherung,• das Vorgehen bei Erkennung eines Rollbacks sowie• die Methodik zur Berechnung der Global Virtual Time (GVT).
Zum Einen kann vor der Ausführung jedes Ereignisses eine Zustandsspeicherung erfolgen.Der Nachteil ist jedoch der enorme Speicherbedarf für die Sicherung der Zustände. ZumAnderen kann die Sicherung des Zustandes des Logischen Prozesses vor dem Ausführenvon z.B. jedem zehnten Ereignis stattfinden. Hier verringert sich der Speicherbedarf, aberbei einem Rollback auf einen Zeitpunkt, zu dem keine Zustandssicherung vorhanden ist,müssen im ungünstigsten Fall die letzten (im Beispiel neun) Ereignisse nochmals ausge-führt werden [Lin, Lazowska, 1990a].Im Umfang der Zustandsspeicherung ist hier zwischen der Zustandssicherung durch Ko-pieren der Zustandsdaten des Logischen Prozesses und einer inkrementellen Zustands-sicherung zu unterscheiden [Gomes 1996, S. 36-51].Die Sicherung des kompletten Prozeßzustands hat den höchsten Speicherbedarf, kann je-doch oft in kürzerer Zeit realisiert werden.Bei einer inkrementellen Zustandssicherung werden nur die seit dem letzten Ereignis ver-änderten Zustandsvariablen gesichert. Der Speicherbedarf sinkt hier, jedoch dauert dasVergleichen zweier umfangreicher Prozeßzustände auf Änderungen oft länger als das Ko-pieren. Weiterhin ist im Falle eines Rollbacks auf eine Reihe inkrementeller Sicherungenzuzugreifen, um den gewünschten Prozeßzustand zu restaurieren. Die alleinige Anwen-dung einer inkrementellen Zustandssicherung ist daher nicht sinnvoll63 [Mehl 1994, S. 54],[Gomes 1996, S. 54-87].Einen ganz anderen Weg geht reverse computing [Carothers, Perumalla, Fujimoto 1999].Bei der Erkennung einer Kausalitätsverletzung werden die bereits ausgeführten Simula-tionsereignisse in umgekehrter Reihenfolge rückwärts ausgeführt (rückgängig gemacht).Eine Zustandssicherung ist nicht notwendig, lediglich die ausgeführten Simulations-ereignisse müssen gesichert werden.Die Lösung des ersten Problems - die Restauration des lokalen Zustandes des LogischenProzesses - ist relativ einfach, jedoch kann der Logische Prozeß in der Zwischenzeit Nach-richten versendet haben. Um diese an andere Logische Prozesse versandten Nachrichtenaufzuheben, werden sogenannte Anti-Messages versendet. Eine Anti-Message gibt an,welche der bereits empfangenen Nachrichten gestrichen werden soll.
63 Mit zunehmender Zeit steigt der Aufwand zur Rekonstruktion des gewünschten Prozeßzustandes drastisch
an. Zur Rekonstruktion des Prozeßzustandes wird eine immer höhere Anzahl an inkrementellen Zustands-sicherungen benötigt. Insbesondere bei einem großen Datenumfang eines Logischen Prozesses ist die Aus-führung der notwendigen Ereignisse oft schneller als die Rekonstruktion des Prozeßzustandes aus den in-krementellen Sicherungen.
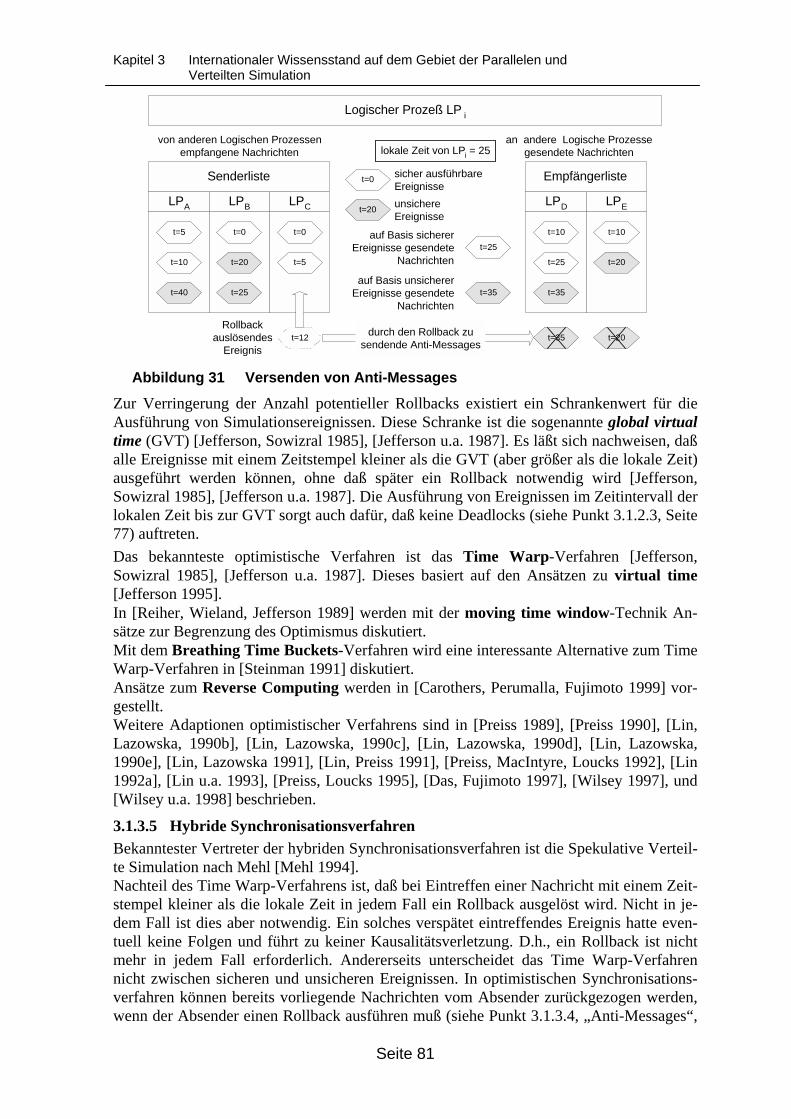
Kapitel 3 Internationaler Wissensstand auf dem Gebiet der Parallelen undVerteilten Simulation
Seite 81
Logischer Prozeß LP i
t=0
t=20
sicher ausführbareEreignisse
unsichereEreignisse
von anderen Logischen Prozessenempfangene Nachrichten
LPCLPA LPB
t=0
t=20
t=25
t=0
t=5
Senderliste
t=5
t=10
t=40
t=12
Rollbackauslösendes
Ereignis
t=25
t=35
an andere Logische Prozessegesendete Nachrichten
LPD LPE
t=10
t=25
t=35
t=10
t=20
Empfängerliste
auf Basis sichererEreignisse gesendete
Nachrichten
auf Basis unsichererEreignisse gesendete
Nachrichten
t=35 t=20durch den Rollback zu
sendende Anti-Messages
lokale Zeit von LPi = 25
Abbildung 31 Versenden von Anti-Messages
Zur Verringerung der Anzahl potentieller Rollbacks existiert ein Schrankenwert für dieAusführung von Simulationsereignissen. Diese Schranke ist die sogenannte global virtualtime (GVT) [Jefferson, Sowizral 1985], [Jefferson u.a. 1987]. Es läßt sich nachweisen, daßalle Ereignisse mit einem Zeitstempel kleiner als die GVT (aber größer als die lokale Zeit)ausgeführt werden können, ohne daß später ein Rollback notwendig wird [Jefferson,Sowizral 1985], [Jefferson u.a. 1987]. Die Ausführung von Ereignissen im Zeitintervall derlokalen Zeit bis zur GVT sorgt auch dafür, daß keine Deadlocks (siehe Punkt 3.1.2.3, Seite77) auftreten.
Das bekannteste optimistische Verfahren ist das Time Warp-Verfahren [Jefferson,Sowizral 1985], [Jefferson u.a. 1987]. Dieses basiert auf den Ansätzen zu virtual time[Jefferson 1995].In [Reiher, Wieland, Jefferson 1989] werden mit der moving time window-Technik An-sätze zur Begrenzung des Optimismus diskutiert.Mit dem Breathing Time Buckets-Verfahren wird eine interessante Alternative zum TimeWarp-Verfahren in [Steinman 1991] diskutiert.Ansätze zum Reverse Computing werden in [Carothers, Perumalla, Fujimoto 1999] vor-gestellt.Weitere Adaptionen optimistischer Verfahrens sind in [Preiss 1989], [Preiss 1990], [Lin,Lazowska, 1990b], [Lin, Lazowska, 1990c], [Lin, Lazowska, 1990d], [Lin, Lazowska,1990e], [Lin, Lazowska 1991], [Lin, Preiss 1991], [Preiss, MacIntyre, Loucks 1992], [Lin1992a], [Lin u.a. 1993], [Preiss, Loucks 1995], [Das, Fujimoto 1997], [Wilsey 1997], und[Wilsey u.a. 1998] beschrieben.
3.1.3.5 Hybride Synchronisationsverfahren
Bekanntester Vertreter der hybriden Synchronisationsverfahren ist die Spekulative Verteil-te Simulation nach Mehl [Mehl 1994].Nachteil des Time Warp-Verfahrens ist, daß bei Eintreffen einer Nachricht mit einem Zeit-stempel kleiner als die lokale Zeit in jedem Fall ein Rollback ausgelöst wird. Nicht in je-dem Fall ist dies aber notwendig. Ein solches verspätet eintreffendes Ereignis hatte even-tuell keine Folgen und führt zu keiner Kausalitätsverletzung. D.h., ein Rollback ist nichtmehr in jedem Fall erforderlich. Andererseits unterscheidet das Time Warp-Verfahrennicht zwischen sicheren und unsicheren Ereignissen. In optimistischen Synchronisations-verfahren können bereits vorliegende Nachrichten vom Absender zurückgezogen werden,wenn der Absender einen Rollback ausführen muß (siehe Punkt 3.1.3.4, „Anti-Messages“,

Kapitel 3 Internationaler Wissensstand auf dem Gebiet der Parallelen undVerteilten Simulation
Seite 82
Seite 80). Mehl beschreibt Tests [Mehl 1994, S. 117-123], um zwischen sicheren und unsi-cheren Ereignissen zu unterscheiden. Sichere Ereignisse können problemlos ausgeführtwerden. Die Wahrscheinlichkeit eines Rollbacks ist hier gering. Die unsicheren Ereignissedagegen führen mit hoher Wahrscheinlichkeit zu einem Rollback und werden deshalb nichtsofort ausgeführt.Ein weiterer hybrider Ansatz ist in [Jha, Bagrodia 1994] beschrieben. Hier können ver-schiedene Teile des Simulationsmodells mit unterschiedlichen Synchronisationsmethodensimuliert werden, wobei sogar ein dynamischer Wechsel des Synchronisationsprotokollsmöglich ist.
3.1.3.6 Probleme der Synchronisation
Hoher Synchronisationsaufwand:
Zwischen Partitionierung und Synchronisation besteht ein enger Zusammenhang. Einestarke Partitionierung garantiert eine schnelle Berechnung der Teilmodelle, weil die Be-rechnungslast auf immer mehr Prozessoren bzw. Rechner verteilt werden kann, anderer-seits verursacht die starke Partitionierung einen steigenden Kommunikations- und Syn-chronisationsaufwand [Mehl 1994, S. 10], [Bagrodia 1996], [Holthaus, Rosenberg, Ziegler1996].Erfahrungen zeigen, daß dieser Aufwand so extrem steigen kann, daß die Vorteile derschnelleren verteilten Berechnung kompensiert werden und daß eine Sequentielle Simula-tion eine kürzere Laufzeit als die Parallele oder Verteilte Simulation aufweist [Loucks,Preiss 1990], [Bagrodia 1996], [Fujimoto 1999].
Verfahrensbedingte Probleme:
Als Probleme konservativer Verfahren wären die Notwendigkeit des Vorhandenseins vonLookahead im Simulationsmodell und die Notwendigkeit von Deadlock-Recovery im Syn-chronisationsverfahren zu nennen.
Der Lookahead eines Logischen Prozesses drückt dessen Möglichkeit zur „Vorausschau“in seine Zukunft aus. Durch die Kenntnis der Nachrichten, die ein Logischer Prozeß in dernächsten Zeit produzieren wird, ist es möglich, diese Nachrichten vorzeitig zu versenden.Dadurch, daß andere Logische Prozesse diese Nachrichten früher erhalten, gelingt es, dieseProzesse zeitlich zu entkoppeln, da die Logischen Prozesse jetzt nicht mehr durch dasWarten auf eben diese Nachrichten blockiert werden. Als Folge dessen verkürzt sich dieLaufzeit der Simulation. Die Performance konservativer Verfahren ist demzufolge sehrstark von der Größe des Lookaheads der Logischen Prozesse abhängig [Chandy, Misra1978], [Nicol 1988], [Fujimoto 1988a], [Loucks, Preiss 1990], [Preiss, Loucks 1990],[Bagrodia 1993], [Bagrodia 1994], [Sporrer 1995, S. 34], [Bagrodia 1996].Problematisch ist aber die exakte Festlegung der Größe des Lookaheads. In den meistenArbeiten wurde ein konstanter Lookahead angesetzt64. Die Natur dieser Größe ist aber dy-namisch [Preiss, Loucks 1990], [Bagrodia 1996]. Es ist sehr schwer, Einflußgrößen auf denLookahead zu identifizieren oder gar diese zu dynamisieren [Bagrodia 1996], [Loucks,Preiss 1990]. Oft ist der angesetzte Wert des Lookaheads unreal hoch und kann in der Pra-xis nicht nachvollzogen werden (vergleiche [Nicol 1988]). In einigen Simulationsmodellenist der real ansetzbare Lookahead dagegen sogar Null [Loucks, Preiss 1990]. Einige derkonservativen Verfahren fordern aber einen Lookahead größer Null und sind daher in einersolchen Situation nicht einsetzbar [Misra 1986], [Chandy, Sherman 1989].
64 Vergleiche [HLA], [Fujimoto 1998], [Paprotny, Fowler 2001].

Kapitel 3 Internationaler Wissensstand auf dem Gebiet der Parallelen undVerteilten Simulation
Seite 83
Weiterhin sind die konservativen Synchronisationsverfahren mit Deadlock-Recovery aus-zustatten, da die nachfolgende Situation auftreten kann und behoben werden muß [Chandy,Misra 1978], [Mehl 1994, S. 18 u. S. 34], [Sporrer 1995, S. 28]:
Es existieren drei Logische Prozesse LPi, LPj und LPk. LPi wartet auf eine Nachrichtvon LPk, LPk wartet auf eine Nachricht von LPj und LPj wartet auf eine Nachrichtvon LPi. Keiner der Logischen Prozesse kann in seiner lokalen Zeit voranschreiten,die Simulation ist in einen Deadlock geraten.
Logischer Prozeß LP it=8
Logischer Prozeß LP j
Logischer Prozeß LP k
lokale Zeit = 15
lokale Zeit = 12
lokale Zeit = 10
t=8
t=10
>10?
>15? >12?
Abbildung 32 Deadlock in einer zyklischen Topologie65
D.h., das Synchronisationsverfahren muß Mechanismen besitzen, die (a) eine solche Si-tuation vermeiden (Deadlock-Avoidance) oder (b) in der Lage sind eine solche Situationzu beheben (Deadlock-Recovery).Analog zur GVT-Berechnung66 optimistischer Verfahren besitzen einige konservative Ver-fahren einen zusätzlichen Logischen Prozeß, dessen Aufgabe es ist, festzustellen ob eineVerklemmung (oder ein Deadlock) aufgetreten ist, und den auslösenden Logischen Prozeßzu ermitteln [Preiss, McIntyre 1991], [Bagrodia, Jha 1994].
Auf das obige Beispiel übertragen bedeutet dies:
LPi ist mit einer lokalen Zeit von 10 der blockierende Prozeß. Ein Verfahren zur Be-hebung des Deadlocks könnte nun wie nachfolgend beschrieben funktionieren. LPi
fordert von seinen topologischen Vorgängern - also LPk - eine Garantie an. In diesemFall würde LPk an LPi eine Garantie mit dem Zeitstempel 12 senden. Zusätzlich for-dert jetzt LPk von seinem topologischen Nachfolger - LPj - eine Garantie an. LPj ver-sendet daraufhin an LPk eine Garantie mit dem Zeitstempel 15. LPj fordert dann vonLPi eine Garantie, die dieser mit 10 (oder 12) beantwortet. LPj bleibt weiterhin blok-kiert, aber LPk kann seine lokale Zeit auf 15 weiterbewegen und wieder aktiv wer-den. Ebenso kann LPi seine lokale Zeit auf 12 erhöhen und wieder aktiv werden.
65 Deadlocks können nicht nur in zyklischen Topologien auftreten, an dieser Stelle wurde lediglich eine zy-
klische Topologie als Erklärungsbeispiel benutzt.66 Die Analogie besteht darin, daß die GVT-Berechnung als ein Nebenprodukt den zeitlich am weitesten
zurückliegenden Prozeß identifiziert. Das Finden dieses Prozesses ist hier der Ansatz zur Lösung.

Kapitel 3 Internationaler Wissensstand auf dem Gebiet der Parallelen undVerteilten Simulation
Seite 84
Logischer Prozeß LP i
Logischer Prozeß LP j
Logischer Prozeß LP k
lokale Zeit = 15
lokale Zeit = 12
lokale Zeit = 10
Garantie-anforderung
Garantie-anforderung
Garantie: t=12
Garantie: t=15
Garantie-anforderung
Garantie: t=10
neue lokale Zeit := 15
neue lokale Zeit := 12
Abbildung 33 Beispiel eines Verfahrens zum Deadlock-Recovery
Durch die Mechanismen zur Deadlock-Vermeidung (Deadlock-Avoidance) bzw. -Behe-bung (Deadlock-Recovery) entsteht ein zusätzlicher Aufwand, der jedoch zur korrektenAbarbeitung der Simulation notwendig ist. Andernfalls terminiert die Simulation nicht(Deadlock).
Als Probleme optimistischer Verfahren sind zu nennen:
A) der hohe Speicherbedarf für die Zustandssicherungen,B) der Aufwand zur Wiederherstellung eines Prozeßzustandes,C) der Aufwand zur Zurücknahme voreilig gesendeter Nachrichten,D) die Methodik zur Berechnung der Global Virtual Time (GVT) undE) Rollbackkaskaden.
Der Speicherbedarf für die Zustandssicherungen kann sehr hoch werden [Preiss, Mac-Intyre, Loucks 1992], [Mehl 1994, S. 53ff], [Bagrodia 1996], [Fujimoto 1999]. So mußeventuell vor jedem auszuführenden Simulationsereignis der Zustand des Logischen Pro-zesses gespeichert werden. Die Daten der Zustandsvariablen können aber einen enormenUmfang annehmen (mehrere hundert Kilobyte bis sogar mehrere Megabyte). Diese Zu-standsdaten müssen über einen größeren Zeitraum aufbewahrt werden. So vergehen mit-unter Hunderte von Simulationsereignissen bis bemerkt wird, daß ein Rollback notwendigwird oder daß durch eine Neuberechnung der GVT alle Zustandsspeicherungen älter alsdie GVT hinfällig sind und freigegeben werden können. Der Speicherbedarf zur Aufbe-wahrung dieser Zustandsdaten kann sehr leicht die Grenzen des physischen Arbeits-speichers sprengen67. Deswegen unterscheiden sich die Synchronisationsverfahren in Maß-nahmen zur Eindämmung des Speicherbedarfs [Lin, Lazowska 1991]. So kann z.B. statteiner Kopie des Prozeßzustandes ein inkrementelles Speichern der Änderungen erfolgen[Lin, Lazowska, 1990a], [Lin, Preiss 1991], [Preiss, MacIntyre, Loucks 1992], [Steinman1991], [Mehl 1994, S. 54f], [Bagrodia 1996]. Hier ist zwar der Speicheraufwand geringer,jedoch wird zusätzliche Berechnungslast dadurch erzeugt, durch zur Feststellung von Zu-standsänderungen ein Vergleich stattfinden muß. Bei einem sehr hohem Datenvolumen desProzeßzustands ist der Zeitverbrauch für das Feststellen der Änderungen eventuell sohoch68, daß der Vorteil der schnelleren Abarbeitung des Simulationsmodells durch die op-timistische Synchronisation kompensiert wird und es zu einem Slowdown kommt.
67 Reicht der physische Arbeitsspeicher nicht aus, um alle Zustandsdaten zu speichern, so bricht die Simulati-
on ab oder der wesentlich langsamere virtuelle Arbeitsspeicher muß genutzt werden. In einem solchen Fallwird die Abarbeitung so stark verzögert, daß i.d.R. ein Slowdown resultiert.
68 Es läßt sich leicht nachweisen, daß es länger dauert, den aktuellen Zustandsraum auf Änderungen im Ver-gleich zu einer Zustandssicherung zu überprüfen, als eine Kopie des aktuellen Zustandsraumes zu erzeu-gen. Der Vergleich ist nur schneller, wenn alle Daten des Zustandsraumes und der Zustandssicherung line-

Kapitel 3 Internationaler Wissensstand auf dem Gebiet der Parallelen undVerteilten Simulation
Seite 85
Einen Ausweg bietet die verteilte Abarbeitung. Hier hat jeder Computer einen eigenenArbeitsspeicher und der Speicherbedarf verteilt sich somit auf die einzelnen Rechner. Aberauch hier sind physische Grenzen gesetzt und zudem treten andere Probleme auf (siehePunkt 3.1.2.3 „Probleme der Kommunikation“).
Der Aufwand zur Wiederherstellung des Prozeßzustandes im Falle eines Rollbacks hathohen Einfluß auf die Simulationslaufzeit [Jefferson u.a. 1987], [Lin, Lazowska 1991],[Preiss, MacIntyre, Loucks 1992], [Mehl 1994, S. 46ff], [Sporrer 1995, S. 29], [Bagrodia1996].
Prinzipiell bestehen drei Möglichkeiten:
a) Vor Ausführung von Ereignissen wird der Zustand des Logischen Prozesses ge-speichert und bei einem Rollback wird dieser gespeicherte Zustand wieder akti-viert [Jefferson u.a. 1987], [Steinman 1993], [Jha, Bagrodia 1994]. Hier ist ledig-lich ein Laden des gespeicherten Zustandes und Überschreiben der Zustands-variablen notwendig - der Aufwand ist minimal.
b) Es findet eine inkrementelle Zustandsspeicherung statt und bei einem Rollbackmuß der Prozeßzustand aus mehreren Zustandsspeicherungen rekonstruiert wer-den [Lin, Lazowska, 1990a], [Lin, Preiss 1991], [Preiss, MacIntyre, Loucks1992]. Unter Umständen müssen dabei viele inkrementelle Zustandsspeicherun-gen zur Rekonstruktion des Prozeßzustands herangezogen werden. Eine alleinigeVerwendung inkrementeller Zustandsspeicherungen ist deswegen nicht sinnvoll.Zwar sinkt der Speicherbedarf, aber der Aufwand zur Rekonstruktion des Prozeß-zustandes steigt mit wachsender Simulationszeit an. Eine Kombination beider Zu-standssicherungsverfahren wäre ratsam [Palaniswamy, Wilsey 1993], [Lin u.a.1993].
c) Es wird reverse computing angewendet. Bereits ausgeführte Ereignisse werden inumgekehrter Reihenfolge rückgängig gemacht [Carothers, Perumalla, Fujimoto1999]. Dieses Verfahren kommt ohne Zustandsspeicherungen aus, es müssen le-diglich die ausgeführten Ereignisse gespeichert werden, damit sie später für dieretrograde Berechnung zur Verfügung stehen. Das reverse computing benötigtden höchsten Berechnungsaufwand zur Rekonstruktion des Prozeßzustandes. Zu-dem ist eine entgegengesetzte Ereignisausführung nicht in jedem Anwendungsge-biet der Simulation möglich. Kann jedoch eine Umkehrfunktion für die Ereignis-ausführung gefunden werden und ist der Datenumfang eines Prozeßzustandes imGegensatz zum Datenumfang der zu speichernden Ereignisse hoch, so bietet dasreverse computing eine interessante Alternative.
Die optimistischen Synchronisationsverfahren unterscheiden sich in der Art und Weise derBehebung einer Kausalitätsverletzung. Außer der Durchführung eines Rollbacks ist dieZurücknahme bereits versendeter Nachrichten (Cancellation) notwendig. Hier unter-scheidet man zwischen:
• aggressive cancellation,• lazy cancellation,• direct cancellation und• adaptive cancellation.
Im Falle eines Rollbacks müssen Nachrichten, die durch die Verarbeitung von Ereignissenin der optimistischen Phase versendet wurden, storniert werden. Dies erfolgt durch Anti-
ar im Speicher des Computers angeordnet sind. In der Praxis ist handelt es sich aber um komplexe, überPointer verlinkte Strukturen.

Kapitel 3 Internationaler Wissensstand auf dem Gebiet der Parallelen undVerteilten Simulation
Seite 86
Messages. Für jede voreilig versandte Nachricht muß eine Anti-Message versendet werden(vergleiche Abbildung 31, Seite 81).Bei aggressive cancellation werden sofort nach der Ausführung des Rollbacks für alle inder optimistischen Phase versendeten Nachrichten die betreffenden Anti-Messages ge-sendet [Jefferson, Sowizral 1985], [Jefferson u.a. 1988].Bei lazy cancellation [Gafni 1988] erfolgt direkt nach dem Rollback keine Zurücknahmevon Nachrichten. Es wird zuerst weiter simuliert und dabei festgestellt, ob sich durch dasden Rollback auslösende Ereignis die bisherige Reihenfolge der Abarbeitung von Ereignis-sen überhaupt verschiebt und damit andere zu sendende Nachrichten entstehen. Erst wennbemerkt wird, daß eine in der optimistischen Phase versendete Nachricht definitiv falschwar, wird die betreffende Anti-Message versendet. Somit werden in der Summe wenigerAnti-Messages gesendet, es besteht aber ein hoher Speicher- und Berechnungsaufwand zurDetektion des veränderten Nachrichtensendeschemas.Bei adaptive cancellation erfolgt zur Laufzeit - je nach den aktuellen Gegebenheiten - eindynamischer Wechsel zwischen den beiden anderen Zurücknahmeschemata [Rajan, Wilsey1995], [Wilsey 1997], [Wilsey u.a. 1998].Bei direct cancellation [Fujimoto 1989] wird eine Speicherstruktur mit Pointern benutzt,um zu kennzeichnen, welche Ereignisse welche Nachrichten auslösten. Somit entfällt derAufwand zur Identifikation der rückgängig zu machenden Nachrichten.In [Lin, Lazowska 1991], [Lin, Preiss 1991] und [Lin 1992a] werden Adaptionen undKombinationen der Verfahren lazy und direct cancellation besprochen.
Die optimistischen Synchronisationsverfahren unterscheiden sich außerdem in der Metho-dik zur Berechnung der Global Virtual Time (GVT). Die GVT gibt die Zeit an, bis zuder alle lokalen Ereignisse ohne die Gefahr einer zukünftig auftretenden Kausalitätsver-letzung verarbeitet werden können. Problematisch daran ist, daß zur Berechnung der GVTInformationen aus allen Logischen Prozessen notwendig sind. D.h., es ist ein zusätzlicherLogischer Prozeß notwendig, der in zyklischen Zeitabständen69 alle Logischen Prozessenach ihrer momentanen lokalen Simulationszeit und dem frühsten zukünftigen Ereignisbefragt [Lin, Lazowska, 1990d]. Aus diesen Größen kann dann die GVT mittels folgenderFormel berechnet werden [Jefferson, Sowizral 1985], [Mehl 1994, S. 21f, S. 63f]:
mit:
Nexti(τ) = kleinster Zeitstempel eines Ereignisses in der Ereignisliste des logischen Prozesses LPi
zum Zeitpunkt τ=∞ falls die Ereignisliste leer ist und keine Nachrichten anderer LP’s ausstehen
Uhri(τ) = Uhrzeit des logischen Prozesses LPi zum Zeitpunkt τ
= min{ ∞, Zeitstempel aller Ereignisse von LPi, die zum zum Zeitpunkt τ bereits erzeugt,aber noch nicht in der Ereignisliste LPi, von eingefügt wurden
iTin_transit
Nexti(τ) | sonst
Uhri(τ) | LPi führt zum Zeitpunkt τ ein Ereignis aus{=Tlokali
GVT(τ) = min{ Tlokal (τ), Tin_transit (τ) }i
LPii
Abbildung 34 Berechnung der Global Virtual Time (GVT)70
Das Problem besteht darin, daß zusätzliche Kommunikation zur Ermittlung der Berech-nungsgrundlagen notwendig ist und daß die Logischen Prozesse in ihren Berechnungengestört werden [Mehl 1994, S. 61-66]. Positiver Nebeneffekt der GVT ist aber, daß alle
69 Eine konkrete Empfehlung für diese Zykluszeit kann nicht gegeben werden. Sie ist modellabhängig. Ver-
gleiche dazu [Mehl 1994, S. 64-65].70 Siehe [Mehl 1994, S. 63f].

Kapitel 3 Internationaler Wissensstand auf dem Gebiet der Parallelen undVerteilten Simulation
Seite 87
Zustandssicherungen mit einem Zeitstempel kleiner gleich der GVT nicht mehr benötigtwerden, weil die Ereignisse, die zur Zustandssicherung führten, sich als sicher erwiesenhaben (erfolgreicher Optimismus).
Ein weiteres Problem optimistischer Synchronisationsverfahren ist das Auftreten von Roll-backkaskaden [Mehl 1994, S. 67-71 u. S. 101f]. Unter einer Rollbackkaskade ist zu ver-stehen, daß ein Logischer Prozeß aufgrund einer Kausalitätsverletzung einen Rollbackauslösen muß. Verbunden mit dem Rollback ist aber auch, daß bereits gesendete Nach-richten storniert werden müssen (siehe Punkt 3.1.3.4, „Anti-Messages“, Seite 80). Durchdas Versenden der dazu notwendigen Anti-Messages kann an einem oder mehreren ande-ren Logischen Prozessen ein weiterer Rollback dadurch ausgelöst werden, daß eine bereitsverarbeitete Nachricht storniert werden muß (die zur Anti-Message gehörige Nachrichtwurde bereits verarbeitet). Der andere Logische Prozeß hatte demzufolge ein Ereignis ver-arbeitet, welches de facto nie bei ihm angekommen wäre (Kausalitätsverletzung). Er mußeinen Rollback auslösen und selbst Anti-Messages versenden. Eventuell werden dadurchbei zahlreichen weiteren Logischen Prozessen Rollbacks ausgelöst - es kommt zu einerKaskade von Rollbacks. Insbesondere in zyklischen Topologien kann es dazu kommen,daß nahezu ständig Rollbacks ausgeführt werden müssen (vergleiche [Mehl 1994, S. 68]).
Lösungsdefekt:
Es existiert kein allgemeines Verfahren zur Synchronisation von Teilen eines Systems. Jenach Anwendungsfall sind die Synchronisationsverfahren unterschiedlich geeignet. Solassen sich Fälle konstruieren, in denen konservative Verfahren einen höheren Speedupbieten als optimistische Verfahren und umgekehrt [Fujimoto 1988b], [Preiss 1990], [Fuji-moto 1990], [Bagrodia 1996], [Fujimoto 1999]. Welches Synchronisationsverfahren - mitwelchen Parametern - am besten geeignet ist, kann im konkreten Fall also nur durch Testenherausgefunden werden [Smith 1999].Dies geht sogar so weit, daß bei Änderung von Parametern im Simulationsmodell ein an-deres Synchronisationsverfahren besser geeignet ist [Fujimoto 1988b], [Leung u.a. 1989],[Fujimoto 1990] weil durch diese Parameteränderung sich Dependenzen zwischen Logi-schen Prozessen geändert haben. Dadurch kann es dazu kommen, daß ein Logischer Pro-zeß jetzt Garantien versenden kann (Verbesserung eines konservativen Verfahrens durchLockerung von Dependenzen) oder daß in einem anderen Logischen Prozeß jetzt vermehrtKausalitätsverletzungen auftreten und somit mehr Rollbacks notwendig sind(Verschlechterung eines optimistischen Verfahrens durch Verschärfung von Dependen-zen).Eine einfache Vermischung zwischen konservativen und optimistischen Verhalten für ein-zelne Regionen des Simulationsmodell [Fujimoto 1998] gelingt jedoch selten (die Syn-chronisation betrifft die Dependenzen zwischen den Logischen Prozessen und nicht dieLogischen Prozesse selbst)71. Zudem verhält sich ein nicht dependenter Logischer Prozeß(z.B. eine Forderungsquelle eines Bedienungssystems) in einer konservativen und eineroptimistischen Synchronisation identisch. Als kritisch betrachtet werden muß dagegen derVersand von Nachrichten durch die optimistisch synchronisierten Prozesse an konservativsynchronisierte Prozesse. Wenn z.B. ein Logischer Prozeß sich optimistisch verhält, alleanderen Prozesse dagegen konservativ synchronisiert werden, so besteht eigentlich einVerbot an den optimistischen Prozeß, die durch unsichere Ereignisse erzeugten Nach-richten zu versenden. Der Grund dafür ist, daß die konservativen Prozesse nicht über Me-
71 Es ist in der HLA möglich Federates mit konservativem und optimistischen Verhalten in einer Simulation
zu verbinden. Physisch erfolgt jedoch eine optimistische Synchronisation über die RTI. Dies ist jedoch fürdie konservativen Federates intransparent.

Kapitel 3 Internationaler Wissensstand auf dem Gebiet der Parallelen undVerteilten Simulation
Seite 88
chanismen zur Behebung von Kausalitätsverletzungen - die durch solche Nachrichten ent-stehen können - verfügen. Eine Lösung dieses Dilemmas wird immer auf eine fast voll-ständige Anwendung eines optimistischen Synchronisationsverfahrens hinauslaufen [Jha,Bagrodia 1994].
3.1.3.7 Anforderungen an Synchronisationsverfahren
Es sollte möglich sein, mehrere verschiedene Synchronisationsverfahren einsetzen zu kön-nen, um das in der jeweiligen Situation performanteste Synchronisationsverfahren aus-wählen zu können (vergleiche [Smith 1999]).Dies bedingt jedoch, daß der Anwender nicht gezwungen ist, Anweisungen zur Realisie-rung und Steuerung des Synchronisationsverfahrens im Simulationsmodell (und damit inden Logischen Prozessen) selbst zu hinterlegen. Vielmehr besteht die Forderung, das Si-mulationsmodell nicht mit dem Synchronisationsverfahren zu mischen. Andernfalls ist derAnwender gezwungen, um ein anderes Synchronisationsverfahren auf seine Performancezu testen, das Simulationsmodell zu ändern72.Des Weiteren sollte die Möglichkeit bestehen, hybride Synchronisationsverfahren einzu-setzen. Diese verbinden die Vorteile konservativen und optimistischen Vorgehens. Mehl[Mehl 1994, S. 125-126] zeigte, daß durch Einsatz der Spekulativen Verteilten Simulationes möglich ist, Rollbackkaskaden zu vermeiden und durch die Trennung in sichere undunsichere Ereignisse den Nutzen des optimistischen Vorgehens deutlich zu verbessern.Außerdem lassen sich im konkreten Anwendungsgebiet Möglichkeiten finden, die GrößeLookahead positiv zu beeinflussen und somit insbesondere konservative Synchronisations-verfahren zu beschleunigen. So kann z.B. bei einer Anwendung zur Simulation von Pro-duktionssystemen bei Auftreten eines Maschinendefekts (Ereignis) die Mean Time to Re-pair (MTTR) als der Lookahead identifiziert werden, denn der Logische Prozeß der Ma-schine kann frühestens nach der Reparatur neue Nachrichten senden, die Logischen Pro-zesse der anderen Maschinen würden aber auf Nachrichten dieser Maschine warten. DurchVersenden einer Garantie bei Auftreten des Defekts wird verhindert, daß andere LogischeProzesse warten (Verklemmung wird verhindert). Die Durchmusterung des Anwen-dungskontextes auf weitere solche Beispiele ist somit dringend zu empfehlen [Loucks,Preiss 1990], [Preiss, Loucks 1990], [Bagrodia 1996].
3.1.4 Mapping, Scheduling und Load-Balancing
3.1.4.1 Begriffe, Aufgaben und Ziele des Load-Balancing
Unter Load-Balancing im weiteren Sinne werden drei Teilprobleme zusammengefaßt:
• die Verteilung von Logischen Prozessen auf Prozessoren (das Mapping),• die Zuteilung von Rechenzeit des Prozessors an mehrere dem Prozessor zugewiesene
Logische Prozesse (das Scheduling) und• die dynamische Zuordnung von Logischen Prozessen auf Prozessoren (Load-
Balancing im engeren Sinne).
Gemeinsam ist die Aufgabe, Logische Prozesse (dynamisch) den Prozessoren zur Abarb-eitung zuzuweisen. Diese Aufgabe entsteht dadurch, daß i.d.R. die Anzahl der LogischenProzesse größer als die Anzahl der verfügbaren Prozessoren ist. Bei der Lösung dieserAufgabe wird das Ziel verfolgt, die vorhandenen Prozessoren möglichst gleich auszulasten(Load-Balance) [Sporrer 1995, S. 35], [Bagrodia 1996], [Paprotny, Fowler 2001]. Dazukann es nötig sein, berechnungsintensive Logische Prozesse separaten Prozessoren zuzu-orden und dafür andere Logische Prozesse gemeinsam auf einen Prozessor zuzuweisen.
72 Vergleiche auch [Mehl 1994, S. 41], [Fujimoto 1998].

Kapitel 3 Internationaler Wissensstand auf dem Gebiet der Parallelen undVerteilten Simulation
Seite 89
Hintergrund des Strebens nach gleicher Lastverteilung (Load-Balance) ist die Gefahr derVerklemmung von Logischen Prozessen (siehe Punkt 3.1.4.3 „Probleme des Load-Balancing“) [Sporrer 1995, S. 35f, S. 110], [Bagrodia 1996].
Die Aufgabe des Mappings besteht darin, n Logische Prozesse auf ρ Prozessoren zur Ab-arbeitung zuzuweisen (n ≥ p). Im Idealfall kann jedem der ρ Prozessoren genau ein Logi-scher Prozeß zugewiesen werden. Im Normalfall jedoch ist n sehr viel größer als ρ, dem-zufolge werden den Prozessoren mehrere Logische Prozesse zur Abarbeitung zugewiesen.Ziel der Verteilung der Logischen Prozesse ist es, die Prozessoren möglichst gleich aus-zulasten. Problematisch daran ist, daß oftmals im Voraus keine Aussage darüber getroffenwerden kann, welche Berechnungslast durch einen Logischen Prozeß entsteht. Man kannoft nur qualitativ unterscheiden (hohe Berechnungslast ! geringe Berechnungslast). DieGrundstrategie ist daher, jedem Logischen Prozeß mit einer hohen zu erwartenden Berech-nungslast allein einen Prozessor zuzuweisen und mehrere Logische Prozesse mit geringerzu erwartender Berechnungslast gemeinsam einem Prozessor zuzuordnen.Eine weitere Aufgabe des Mappings ist in Zusammenhang mit der Partitionierung zu se-hen. Wurde nur eine Grundpartitionierung in viele kleinere Logische Prozesse vorge-nommen (siehe Seite 68), so entsteht ein hoher Kommunikationsbedarf. Dieser kann da-durch reduziert werden, daß oft miteinander kommunizierende Logische Prozesse demgleichen Prozessor zugewiesen werden. In einer verteilten Abarbeitung befinden sich dieseinterdependenten Logischen Prozesse dann auf dem gleichen Rechner und können ihreKommunikation in kürzerer Zeit abwickeln (siehe Punkt 3.1.2.3). D.h., die Aufgabe derPartitionierung wird z.T. dem Mapping überlassen.
Aufgabe des Schedulings ist es, aus mehreren dem Prozessor zugewiesen Logischen Pro-zessen den Prozeß auszuwählen, der als nächstes Rechenzeit erhalten soll. Zum Einen wä-ren berechnungsintensivere Logische Prozesse zu bevorzugen. Zum Anderen sollte derLogische Prozeß, dessen lokale Simulationszeit am weitesten zurückliegt, bevorzugt be-dient werden, weil er eine Verklemmung der Simulation auslösen kann („Penalty-Throttling“, vergleiche Punkt 3.1.3.6, Seite 77). Die Aufgabe des Schedulings bleibt meistdem Betriebssystem überlassen73.
Aufgabe des Load-Balancing (im engeren Sinne) ist es, dynamisch die Berechnungslastder Logischen Prozesse auf die Prozessoren zu verteilen. D.h., Überlastung oder Unter-lastung von Prozessoren durch die Berechnungen Logischer Prozesse zu erkennen undgegebenenfalls einzelne Logische Prozesse auf andere Prozessoren zu verlagern. Hierzu istes notwendig, die momentane und zukünftige Auslastung eines Prozessors zu erkennen,um abschätzen zu können, welcher Logische Prozeß auf welchen niedrig ausgelastetenProzessor verlagert werden soll. Im Falle einer lokalen Abarbeitung auf einem Mehrpro-zessorsystem übernimmt das Betriebssystem zum Teil diese Aufgabe. Bei einer verteiltenAbarbeitung in einem Rechnernetz wird diese Aufgabe - aufgrund ihres fraglichen Nutzensim Vergleich zum Aufwand für ihre Lösung - meist nicht gelöst (siehe Punkt 3.1.4.3).
3.1.4.2 Verfahren zum Load-Balancing
Statisches versus dynamisches Load-Balancing:
Man unterscheidet zwischen statischem und dynamischen Load-Balancing [Mehl 1994,S. 10-12], [Bagrodia 1996].
73 In den Betriebsystemen für Mehrprozessorrechner sind für gewöhnlich bereits Scheduling-Mechanismen
vorhanden. Eine redundante Implementierung von Scheduling-Mechanismen im Lösungsansatz wäre eineVerschwendung von Rechenzeit.

Kapitel 3 Internationaler Wissensstand auf dem Gebiet der Parallelen undVerteilten Simulation
Seite 90
Beim statischen Load-Balancing wird vor der Ausführung der Simulation bestimmt, wel-che Logischen Prozesse auf welchen Prozessoren abgearbeitet werden sollen. Dies ent-spricht der Aufgabe des Mappings. Zur Laufzeit der Simulation bleibt diese Zuweisungunveränderlich.Das dynamische Load-Balancing berücksichtigt dagegen den Fakt, daß die durch einenLogischen Prozeß erzeugte Berechnungslast nicht gleichmäßig über die gesamte Simula-tionslaufzeit verteilt sein muß. Über das Mapping wird eine Startzuordnung der LogischenProzesse zu den Prozessoren erzeugt. Wenn während der Simulation festgestellt wird, daßdie momentane oder zukünftig zu erwartende Berechnungslast auf einem Prozessor zuhoch ist, so werden diesem Prozessor zugewiesene Logische Prozesse zu anderen Prozes-soren transferiert und dort abgearbeitet. D.h., man versucht die Berechnungslast zwischenden Prozessoren dynamisch auszugleichen (Load-Balancing im engeren Sinn) [Bagrodia1996].
Verfahren zur Lösung der Aufgabe des Mappings:
Die Aufgabe des Mappings ist wie die Aufgabe der Partitionierung lösungsdefekt.Aufgrund der Probleme zur Quantifizierung der Berechnungslast eines Logischen Prozes-ses wird für das Mapping meist das Round-Robin-Prinzip [Rotithor 1994], [Preis, Wan1999] angewandt. D.h., die Logischen Prozesse werden der Reihe nach auf die verfügbarenProzessoren verteilt. Ist die Anzahl der Logischen Prozesse größer als die Anzahl der Pro-zessoren, so wird wieder von vorn begonnen.Oft wird auch manuell, nach dem trial-and-error-Prinzip, vorgegangen [Mehl 1994, S. 11],[Smith 1999]. D.h., man gibt manuell ein Mapping vor, welches dann getestet und dessenWirkung dann mit der Wirkung anderer Mappings verglichen wird.
Verfahren zur Lösung der Aufgabe des Schedulings:
Für das Scheduling stellt sich die Problemstellung ähnlich wie für das Mapping dar. I.d.R.verläßt man sich auf die in Betriebssystem oder Hardware implementierten Scheduling-Mechanismen. D.h., die Logischen Prozesse werden der Reihe nach durch das Multi-tasking bedient.Nur selten existiert ein Kontrollprozeß, der bestimmt, welcher Logische Prozeß als näch-stes Rechenzeit erhalten soll. Aufgabe dieser Kontrollprozesses ist es dann, den LogischenProzeß zu ermitteln, der zeitlich am weitesten zurückliegt, und diesen Prozeß für die vor-rangige Abarbeitung durch den Prozessor auszuwählen [Lin, Lazowska, 1990d].
Verfahren zur Lösung der Aufgabe des dynamischen Load-Balancing:
Für die Abarbeitung auf einem Mehrprozessorrechner wird diese Aufgabe z.T. durch dasBetriebssystem übernommen. Das Betriebssystem versucht alle gleichzeitig auszu-führenden Programme (in dem Fall alle nicht blockierten Logischen Prozesse) so auf dievorhandenen Prozessoren zu verteilen, daß die Prozessoren in etwa gleich ausgelastet sind[Dahlin 1998].Für eine verteilte Abarbeitung in einem Rechnernetzwerk existieren Ansätze [Schlagenhaftu.a. 1995], [Schlagenhaft 1999a], [Schlagenhaft 1999b], in denen ein auf jedem Rechnerlokal laufender Kontrollprozeß die zu transferierenden Logischen Prozesse auswählt undanderen Prozessoren zur Berechnung zuweist [Lin, Lazowska, 1990d]. Jedoch benötigtdieser Kontrollprozeß selbst Rechenzeit und die Kontrollprozesse müssen untereinanderkommunizieren, um den am wenigsten ausgelasteten Prozessor zu finden. Das Haupt-problem ist aber, daß bei einem Transfer eines Logischen Prozesses die kompletten Zu-standsdaten des Prozesses - bei einer optimistischen Synchronisation sogar noch zusätzlichalle Zustandsspeicherungen - über das Netzwerk zu einem anderen Rechner übertragenwerden müssen. Bedingt durch den Umfang der Daten und die hohe Übertragungszeit kann

Kapitel 3 Internationaler Wissensstand auf dem Gebiet der Parallelen undVerteilten Simulation
Seite 91
es vorkommen, daß der zu entlastende Prozessor innerhalb der Übertragungszeit dieÜberlastsituation überwunden hat und bei einer Verarbeitung des verlagerten Prozesses nureine normale Auslastung erreichen würde. D.h., der Nutzen des Load-Balancings bleibtfraglich. Der softwaretechnische Aufwand zur Lösung dieses Problems ist jedoch enorm.Aus diesem Grund werden Verfahren zum dynamischen Lastausgleich in Rechnernetzennur selten angewendet.
3.1.4.3 Probleme des Load-Balancing
Load-Balancing und Kommunikation:
Bei der Zuordnung von Logischen Prozessen zur Berechnungshardware ist die notwendigeKommunikation zwischen den Logischen Prozessen zu bedenken. Eng kommunizierendeProzesse sollten z.B. im Rechnernetzwerk eng beieinander liegen (kürzere Kommu-nikationszeiten) oder ggf. auf dem gleichen Prozessor bzw. Rechner plaziert werden bzw.als ein Logischer Prozeß zusammengefaßt werden [Mehl 1994, S. 10-12], [Bagrodia 1996],[Xiao u.a. 1999].Andererseits wird vielmals ein Teil der Aufgabe der Partitionierung zur Lösung auf dasMapping übertragen. Hierunter ist zu verstehen, daß die Partitionierung viele kleine Logi-sche Prozesse erzeugt (siehe Seite 68) und es dem Mapping überläßt, den Kommunika-tionsaufwand zu minimieren. Das Mapping versucht dann, stark miteinander kommu-nizierende Prozesse auf den selben Prozessor bzw. Rechner zur Berechnung zuzuweisen.D.h., der Lösungsdefekt der Partitionierung überträgt sich auf das Mapping.
Gefahr der Verklemmung:
Dieses Problem entsteht dadurch, daß i.d.R. auf einem Prozessor mehrere Logische Pro-zesse Berechnungen durchführen und um die Ressource Rechenzeit konkurrieren. Es kannnun dazu kommen, daß ein Logischer Prozeß keine Berechnungen durchführen kann, weilfür ihn momentan keine Rechenzeit zur Verfügung steht, das Fehlen der Ergebnisse diesesLogischen Prozesses jedoch die gesamte Simulationszeit unnötig in die Länge zieht. Da-durch daß ein Logischer Prozeß A keine Rechenzeit zugeteilt bekommt - und somit keinenOutput produziert - können andere Logische Prozesse aufgrund ihrer Abhängigkeit von Aggf. ihre Arbeit nicht fortsetzen. Dies ist analog zu den Deadlocks der konservativen Syn-chronisationsverfahren (siehe Punkt 3.1.3.6, Seite 77).Daher ist es Aufgabe des Schedulings, während der Ausführung der Simulation festzu-stellen, welcher Logische Prozeß - von mehreren möglichen Logischen Prozessen - alsnächstes auf dem Prozessor ausgeführt werden sollte [Lin, Lazowska, 1990d]. Das Sche-duling muß hier erkennen, ob der Entzug von Rechenzeit einen Prozeß dazu bringt, diegesamte Simulation zu verklemmen. Üblicherweise werden jedoch keine Scheduling-Mechanismen angewandt.
Load-Balance als Forderung für optimistische Synchronisationsverfahren:
Es empfiehlt sich - um die potentielle Anzahl von Kausalitätsverletzungen und somit anRollbacks niedrig zu halten - Partitionen zu bilden, die eine etwa gleiche Berechnungslastverursachen oder die Logischen Prozesse so den Prozessoren zuzuordnen, daß die Berech-nungslast gleich verteilt ist [Sporrer 1995, S. 35, S. 110], [Bagrodia 1996]. Ursache fürdiese Forderung ist, daß Logische Prozesse mit wenig Berechnungslast schnell in ihrerAbarbeitung voranschreiten. Es besteht also in erhöhtem Maße die Gefahr von Rollbacks.Sind dagegen alle Logischen Prozesse in ihrer Berechnungslast etwa gleich, so kann i.d.R.kein Logischer Prozeß „vorauseilen“.

Kapitel 3 Internationaler Wissensstand auf dem Gebiet der Parallelen undVerteilten Simulation
Seite 92
Statisches versus dynamisches Load-Balancing:
Meist wird statisches Load-Balancing aufgrund des geringeren Implementationsaufwandsbevorzugt. Dynamisches Load-Balancing kann jedoch - aufgrund der Beachtung des dy-namischen Charakters der Logischen Prozesse - zu besseren Ergebnissen (schnellere Aus-führung der Simulation) führen [Schlagenhaft 1999b]. Kritisch für den Erfolg des dynami-schen Load-Balancing sind insbesondere zwei Faktoren:
• Speichervolumen bei Transfer eines Logischen Prozesses und• zusätzlicher Berechnungsaufwand für das Erkennen der Notwendigkeit des Trans-
fers.
Einerseits ist ein zusätzlicher Berechnungsaufwand (zusätzlicher Kontrollprozeß, Erweite-rung des Schedulings) notwendig, um zu erkennen, daß eine Verklemmung droht oder be-reits besteht, daß also ein Transfer eines oder mehrerer Logischer Prozesse zu anderenProzessoren vorteilhaft oder notwendig ist. Dieser zusätzliche Berechnungsaufwand kannden Vorteil der schnelleren Abarbeitung unter Umständen bereits kompensieren [Mehl1994, S. 144], [Bagrodia 1996].Andererseits darf der Zeitbedarf für den Transfer des Logischen Prozesses nicht unter-schätzt werden. Da ein kompletter Logischer Prozeß mit seinen gesamten Daten zu einemanderen Prozessor oder gar über das Rechnernetzwerk zu einem anderem Rechner transfe-riert werden muß, fällt hier das notwendige Speichervolumen des Prozesses für denTransfer negativ ins Gewicht. So kann z.B. bei einem optimistischen Synchronisations-verfahren zusätzlich ein Transfer aller bisherigen Zustandspeicherungen notwendig sein.Bedenkt man dieses Datenvolumen (oft mehrere Megabyte) und die z.T. hohe Übertra-gungszeit im Netzwerk74, so ist es fraglich, ob sich durch das dynamische Load-Balancingüberhaupt ein Nutzen einstellt.Dagegen wird bei einer lokalen Abarbeitung auf einem Mehrprozessorrechner i.d.R. durchdas Betriebssystem ein dynamisches Load-Balancing ausgeführt. Sind einem bereits ausge-lasteten Prozessor weitere Aufgaben zur Berechnung zugewiesen, so verlagert das Be-triebssystem diese weiteren Aufgabe zu anderen, freien Prozessoren. Die Übertragungs-zeiten fallen hier durch die Nutzung eines gemeinsamen Speichers nicht ins Gewicht.
Vergleichbarkeit von Simulationsläufen:
Mit dem Load-Balancing ist ein weiteres Problem verbunden - die Vergleichbarkeit vonSimulationsläufen [Mehl 1994, S. 145ff]. So haben z.B. die Last im Rechnernetz (rechner-und netzseitig), die Reihenfolge des Eintreffens von Nachrichten75 als natürlich auch dieStochastik im Simulationsmodell starken Einfluß auf die Dauer der Simulation. Es kannsomit nicht oder nur schwer sichergestellt werden, daß zwei Simulationsläufe unter exaktden selben Bedingungen durchgeführt werden. Dies erschwert z.B. die Validierung undFehlersuche im Simulationsmodell, sowie den Vergleich von Ergebnissen erheblich.
3.1.4.4 Anforderungen an Verfahren zum Load-Balancing
Zumindest die Aufgabe des Mappings ist zu unterstützen. Somit kann die Berechnungslastgleichmäßiger auf die Prozessoren bzw. Rechner verteilt werden. Dies hat positive Effekteauf die Durchführungsgeschwindigkeit der Simulation. Verklemmungen drohen wenigeroft und optimistische Synchronisationsverfahren werden weniger oft von Kausalitäts-verletzungen betroffen.
74 Für einen Prozeß mit ca. 10 MB an Daten kann der Transfer bis zu 20 Sekunden dauern. Verglichen mit
einer Gesamtsimulationsdauer im Minutenbereich, ist dies wesentlich zu hoch.75 Durch eine andere Ankunftsreihenfolge von Nachrichten kann eine Kausalitätsverletzung auftreten und ein
Rollback ist notwendig.

Kapitel 3 Internationaler Wissensstand auf dem Gebiet der Parallelen undVerteilten Simulation
Seite 93
Für eine lokale Abarbeitung auf einem Mehrprozessorrechner sollte ein Betriebssystem ge-wählt werden, dessen Scheduling-Mechanismen durch eine dynamische Änderung derTaskpriorität der Logischen Prozesse beeinflußt werden können. Zugleich ist darauf zuachten, daß dieses Betriebssystem ein Load-Balancing zwischen den Prozessoren anbietet.Somit können bereits im Betriebssystem verankerte Strategien benutzt werden76.
Weiterhin besteht das Problem, daß ex-ante eine Vorhersage, welche Ausführungsplatt-form für das gewählte Simulationsmodell und Synchronisationsverfahren am geeignetstenist, nicht möglich ist. Daher sollte der zu verwendende Lösungsansatz verschiedene Rech-nerplattformen unterstützen.
3.1.5 Kombination der Aufgaben der Parallelen und Verteilten Simulation
Die Aufgaben einer Parallelen und Verteilten Simulation: Partitionierung, Kommunika-tion, Synchronisation und Load-Balancing können nicht losgelöst voneinander betrachtetwerden. Vielmehr besteht zwischen ihnen ein enger Zusammenhang.Die Partitionierung schafft prinzipiell parallel abarbeitbare Teilmodelle, die jedoch unter-einander kommunizieren und untereinander zu synchronisieren sind. Mit zunehmenderPartitionierung steigt zwar der Grad der potentiellen Parallelität, jedoch nimmt der Kom-munikations- und Synchronisationsaufwand ebenfalls zu - oft sogar überproportional, da -bedingt durch das Synchronisationsverfahren - weitere Kommunikation notwendig ist (z.B.durch den Versand von Null-Messages, von Garantien, von Rollback-Benachrichtigungen,von Anti-Messages) [Loucks, Preiss 1990], [Preiss, Loucks 1990], [Mehl 1994, S. 142f],[Bagrodia 1996], [Holthaus, Rosenberg, Ziegler 1996]. Ebenso kann eine Einteilung inviele Partitionen beim Load-Balancing eher negative Effekte herbeiführen, da immer mehrLogische Prozesse gemeinsam einem Prozessor zugeordnet sind. Der Verwaltungsaufwandfür die verschiedenen Logischen Prozesse je Prozessor steigt [Mehl 1994, S. 11f], [Bag-rodia 1996], [Perumalla, Fujimoto 1998]. In einigen Anwendungen der Parallelen undVerteilten Simulation ist zudem das Verhältnis zwischen dem Aufwand zur Ereignisaus-wertung (durch ein Ereignis ausgelöster Berechnungsaufwand) zum Kommunikations-aufwand sehr ungünstig [Nicol 1988], [Mehl 1994, S. 142f], [Sporrer 1995, S. 35-36],[Bagrodia 1996]. Einem kleinen Berechnungsaufwand steht ein großer Kommunikations-aufwand gegenüber (siehe Formel 2, Seite 69). Dies hat negative Effekte auf den zu erwar-tenden Speedup77. Sporrer [Sporrer 1995, S. 36, S. 110] fordert deswegen größere Parti-tionen mit mehr Berechnungsaufwand, um das Verhältnis zwischen Berechnungsaufwandund Kommunikationsaufwand zu verbessern.D.h., bei genauerer Betrachtung findet eigentlich zwischen Partitionierung und Synchro-nisation eine „Gratwanderung“ statt. Dies ist auch der Grund warum kein allgemeinesVerfahren zur Partitionierung bzw. Synchronisation existiert. Für jeden Typus von Simula-tionsmodell ist eine andere Art von Partitionierung respektive Synchronisation besser ge-eignet. Es lassen sich Simulationsmodelle konstruieren, an denen sich zeigen läßt, daßdurch Änderung eines oder weniger Parameter ein anderes Partitionierungs- bzw. Synchro-
76 Ein Betriebssystem sollte folgende Möglichkeiten bieten: (1) Load-Balancing zwischen mehreren Prozes-
soren, (2) Scheduling-Mechanismen für mehrere einem Prozessor zugewiesene Tasks, (3) eine Unterschei-dung zwischen blockierten und in ihrer Abarbeitung unterbrochenen Tasks und (4) die Möglichkeit zurLaufzeit die Priorität einer Task zu verändern. Leider erfüllt keines der Betriebssysteme all diese Merkma-le. Solaris von Sun IRIX von Silicon Graphics decken jedoch die Merkmale 1;2 und 4 ab. Microsoft Win-dows NT / 2000/XP deckt die Merkmale 1 und 3 ab. Linux realisiert die Merkmale 1; 3 und 4.
77 Bei einer verteilten Abarbeitung hat dies einen sehr starken Einfluß. Hier stehen hohen Transferzeiten vonNachrichten im Computernetzwerk sehr kleine Aufwände zur Ereignisauswertung gegenüber. Bei Aus-tausch der Nachrichten über einen gemeinsamen Speicher sinkt zwar der Zeitbedarf für die Kommunikati-on, jedoch auch hier ist dieses Verhältnis ein Indikator über die Performance.

Kapitel 3 Internationaler Wissensstand auf dem Gebiet der Parallelen undVerteilten Simulation
Seite 94
nisationsverfahren besser geeignet ist (die Simulation in einer kürzeren Zeit ausführt)[Fujimoto 1988a], [Leung u.a. 1989], [Fujimoto 1990], [Bagrodia 1996]. D.h., es ist imKontext der Simulationsaufgabe zu prüfen, welche Partitionierung und welches Synchro-nisationsverfahren am besten für den jeweiligen Anwendungsfall geeignet sind [Smith1999]. Das bedeutet, daß der letztendliche Lösungsansatz flexibel für den Einsatz unter-schiedlicher Synchronisationsverfahren und Partitionierungsansätze sein muß.
3.2 Softwaretechnische Realisierungen der Parallelen und Ver-teilten Simulation
3.2.1 Überblick über Konzepte zur Realisierung der Parallelen und Verteilten Si-mulation
Recherchiert man über vorhandene und potentiell anwendbare softwaretechnische Ansätzezur Parallelen und Verteilten Simulation, so läßt sich eine Vielzahl unterschiedlicher Kon-zepte und Tools feststellen (innerhalb der Gruppen in alphabetischer Reihenfolge):78
♦ ♦ ♦ ♦ Ausschließlich zur Verteilten Simulation geeignete Ansätze:
• DOORS (Distributed Object Oriented Real-time Simulator) [DOORS]• HLA (High Level Architecture), [HLA], [Dahmann, Fujimoto, Weatherly 1998]• ParSim (Parallel Simulation - Object Oriented Parallel Architecture Simulator)
[ParSim]• SimJAVA [Kreutzer, Hopkins, van Mierlo 1997], [Page, Moose, Griffin 1997]• SPEEDES (Synchronous Parallel Environment for Emulation and Discrete Event
Simulation) [SPEEDES], [Steinman 1991 und 1992], [Steinman, Wieland 1994]
♦ ♦ ♦ ♦ Ausschließlich zur Parallelen Simulation geeignete Ansätze:
• ParaSol (Parallel Simulation Object Library) [ParaSol]
♦ ♦ ♦ ♦ Zur Parallelen und Verteilten Simulation geeignete Ansätze:
• Message-Passing und darauf aufbauende Ansätze:
− COVISE (Collaborative Visualization and Simulation Environment) [COVISE]− MPI (Message Passing Interface), [Snir 1996], [Gropp, Lusk 1994]− PVM (Parallel Virtual Machine), [Beguelin u.a. 1991]− P4 (Portable Programs for Parallel Processors), [P4]− SimBa (Simulation Backplane for Heterogeneous Systems), [SimBa]− Warped (Time-Warp-Bibliothek für MPI) [Warped]
• andere Ansätze:
− DSL (Distributed Simulation Language) [Mehl 1994, S. 75-87]− DVSIM (Distributed VHDL Simulator, VHDL= VHSIC Hardware Description Lan-
guage, VHSIC = Very High Speed Integrated Circuits) [DVSIM], [Meister 1996]− Maisie [Maisie], [Bagrodia, Liao 1990], [Bagrodia, Liao 1994]− MOOSE [Waldorf 1992], [Waldorf, Bagrodia 1994]− ParSec (Parallel Simulation Environment for Complex Systems) [ParSec],
[Bagrodia u.a. 1998]− ParSimONY (PARallel SIMulation Once Named Yaddes, YADDES= Yet An-
other Distributed Discrete Event Simulator) [Preiss, Wan 1999]
78 Die Aufzählung nennt exemplarisch wesentliche Ansätze. Sie erhebt keinen Anspruch auf Vollständigkeit.
Siehe auch [Low u.a. 1999], [Vee, Hsu 1999], [Gomes 2001].

Kapitel 3 Internationaler Wissensstand auf dem Gebiet der Parallelen undVerteilten Simulation
Seite 95
− VHDL (VHSIC Hardware Description Language, VHSIC = Very High SpeedIntegrated Circuits) [VHDL], [GM-VHDL]
− YADDES (Yet Another Distributed Discrete Event Simulator) [Preiss 1989]
♦ ♦ ♦ ♦ Prinzipiell zur Parallelen oder Verteilten Simulation geeignete Ansätze(Vorstufen):
• Anwendungsunspezifische Verteilungsansätze, die sich zur Parallelen und VerteiltenSimulation erweitern lassen:
• CORBA (Common Object Request Broker Architecture) [OMG]• DCOM (Distributed Component Object Model) [DCOM]• RMI (Remote Method Invocation) [RMI]
• Visualisierungskonzepte mit Verteilungsbezug:
• VRML (Virtual Reality Modeling Language) [VRML]
Die aufgeführten Ansätze lassen sich unterschiedlichen Niveaustufen zuordnen und zielenauf unterschiedliche Anwendungsgebiete. Nachfolgend soll deswegen eine Einteilung derAnsätze in verschiedene Kategorien erfolgen.
3.2.2 Einordnung der Implementationsansätze
3.2.2.1 Überblick und Einordnung
Die genannten Ansätze unterscheiden sich hinsichtlich ihres Niveaus und ihrer Eignungzur Parallelen und Verteilten Simulation von Produktionssystemen z.T. erheblich.Dies ist jedoch historisch bedingt. Für einen Ansatz zur Parallelen und Verteilten Simula-tion sind einerseits Kommunikationskonzepte, Parallelisierungsprinzipien und Verteilungs-ansätze notwendig (siehe Abbildung 35). Andererseits werden Simulationskomponentenund Synchronisationsverfahren benötigt (siehe Abbildung 36). All diese Komponentenhaben sich jedoch getrennt voneinander und zeitlich parallel entwickelt. Abbildung 37zeigt die spätere Zusammenführung dieser beiden Entwicklungslinien.
Begonnen hat die Entwicklung von Parallelisierungsprinzipien und Verteilungsan-sätzen mit Kommunikationsmechanismen. Diese stellen Möglichkeiten bereit, zwischenProgrammen Informationen auszutauschen. Hierbei ist es notwendig, Schutzmechanismenfür den gemeinsamen Zugriff auf Daten (Semaphore) und zur Interprozeßsynchronisation(asynchroner Nachrichtenaustausch) zur Verfügung zu haben. Voraussetzung für z.B. In-terprozeßkommunikation auf einem Rechner ist die Fähigkeit des Multitaskings. Eine Taskwiederum kann aus mehreren Threads bestehen. So fungiert z.B. ein Thread als Sender, einanderer Thread als Empfänger und ein dritter Thread erledigt die Verarbeitung der Infor-mationen (vergleiche Abbildung 27, Seite 74). Diese Unterteilung ist notwendig, umgleichzeitig Informationen verarbeiten und Nachrichten empfangen zu können. All dieseMechanismen müssen als hochsprachliche Mechanismen zur Verfügung stehen. Dies istheute in allen höheren Programmiersprachen gegeben (z.B. C++, Java). Zur Entwicklungverteilter Anwendungen sind eine Reihe weiterer Dienste notwendig (siehe [OMG]). EineTeilmenge dieser Dienste wird benötigt, um Objekte verteilen zu können (siehe [RMI]).
Die Entwicklung bei den Simulationsanwendungen begann mit der Schaffung von Simu-lationskernen. Diese enthalten die Grundfunktionalitäten für die Ausführung einer Simula-tion (siehe Punkt 2.2.1.2), wie z.B. Simulationsuhr, Ereignislisten, Verwaltung von Zu-standsvariablen und eine Ablaufsteuerung. Auf Basis eines solchen Simulationskerns istbereits die Erstellung von sequentiellen Simulationsanwendungen möglich. Um Simula-tionsmodelle verteilt oder parallel abarbeiten zu können, ist einerseits die Partitionierung

Kapitel 3 Internationaler Wissensstand auf dem Gebiet der Parallelen undVerteilten Simulation
Seite 96
des Gesamtsimulationsmodells in Logische Prozesse und andererseits die Synchronisationdieser Logischen Prozesse notwendig. Dazu mußten insbesondere Synchronisationsverfah-ren entwickelt werden. Ein Verteilter bzw. Paralleler Simulator umfaßt dann sowohl dieFunktionalitäten eines Simulationskerns als auch die Funktionalität eines oder mehrererSynchronisationsverfahren.
Kommunikationsmechanismen(gemeinsamer Speicher, Sockets)
Interprozeßsynchronisation(Semaphore)
Multitasking, Multithreading
hochsprachliche Möglichkeiten derEntwicklung verteilter Anwendungen
Niv
eau
verteilte Anwendungen
Verteilung von Objekten
Abbildung 35 Entwicklungsstufen von Parallelisierungsprinzipien und Ver-teilungsansätzen 79
Niv
eau
Simulationskern(z.B. Abarbeitung von Ereignislisten)
Partitionierung undSynchronisationsverfahren
Anwendungen der Parallelenund Verteilten Simulation
Anwendungen derSequentiellen Simulation
Abbildung 36 Entwicklungsstufen von Simulationsanwendungen
Für eine Anwendung der Parallelen und Verteilten Simulation war eine Zusammen-führung der beiden Entwicklungslinien notwendig (siehe Abbildung 37).
niedrig
mittel
hoch
Ent
wic
klun
gsst
ufen
der
Ver
teilu
ngsa
nsät
ze
Parallelisierungs undVerteilungskonzepte
Anwendungen der Parallelenund Verteilten Simulation
Kommunikations- undSynchronisationsprimitive
Simulationsgrundlagen
Synchronisationsverfahren
Entw
icklungsstufen der
Sim
ulationsansätzeN
iveau
Abbildung 37 Entwicklungsstufen der Implementationsansätze zur Paralle-len und Verteilten Simulation
Bedenkt man die Möglichkeiten der Kombination von Ansätzen dieser verschiedenen Ni-veaustufen, so kann nachfolgende Kategorisierung vorgenommen werden:
1. Message Passing-Ansätze (bis Stufe Interprozeßsynchronisation in Abbildung 35)
2. Simulationsbibliotheken (enthalten Synchronisationsverfahren, siehe Abbildung36)
79 In Abbildung 35 bis Abbildung 38 gibt die vertikale Anordnung das Niveau der Dienste an. Parallele Ent-
wicklungen des selben Niveaus sind nebeneinander angeordnet. Überlappungen weisen auf gemeinsambenutzte Funktionalitäten hin.

Kapitel 3 Internationaler Wissensstand auf dem Gebiet der Parallelen undVerteilten Simulation
Seite 97
3. Erweiterung von Standard-Simulationstools um Komponenten der Parallelenund Verteilten Simulation (Ergänzung eines „Simulationskerns“ um Synchronisa-tionsverfahren, siehe Abbildung 36)
4. Erweiterungen von Verteilungsansätzen um Simulationskomponenten (Erweite-rung von hochsprachlichen Möglichkeiten der verteilten Anwendungsentwicklung(siehe Abbildung 35) auf den Kontext der Simulation)
5. Spezialtools für andere Anwendungsgebiete (parallele oder verteilte Programm-umgebungen mit anderen Einsatzzielen)
6. Integrationsansätze (Zusammenführung von Simulationskomponenten, Synchro-nisationsverfahren und verteilten Anwendungen)
7. Tools zur Parallelen und Verteilten Simulation (Kombination von Simulatorenmit Synchronisationsverfahren als parallele/verteilte Anwendung realisiert mit einerzusätzlichen Simulationsmodellkomponente)
Erweiterung vonVerteilungskonzepten
Message PassingErweiterung
Sequentieller Simulatoren
Simulationsbibliotheken mitSynchronisationsverfahren
* Tools zur Parallelen und Verteilten Simulation* Integrationsansätze* Spezialtools für andere Anwendungsgebiete
Abbildung 38 Kategorien von Ansätzen der Parallelen und Verteilten Simu-lation (vergleiche Abbildung 37)
3.2.2.2 Message Passing-Ansätze
Die Ansätze des Message Passing (MPI, PVM, P4) beschränken sich auf Funktionen zumAustausch von Nachrichten in einem Computernetzwerk inklusive der dazu notwendigenSynchronisationsprimitive wie blockierendes Versenden und Empfangen von Nachrichten.Message Passing-Ansätzen fehlen Mechanismen zur Simulation (Ereignislisten, Zeit-steuerung, Erfassung von Ergebnisgrößen) und zur Synchronisation (Synchronisations-verfahren). Die Implementation der fehlenden Mechanismen kann aber nur mit hohem per-sonellen und zeitlichen Aufwand realisiert werden. Erfolgreiche Realisierungen solchermehrjähriger Projekte existieren jedoch [Skjellum, Lusk, Gropp 1994], [Hotovy, Shen,Zollweg 1995].Der Vorteil der Message Passing-Ansätze liegt in ihrer unschlagbaren Performance.
3.2.2.3 Simulationsbibliotheken
Unter Simulationsbibliotheken80 (ParaSol, ParSim, Simba, Warped) ist an dieser Stelle dieErweiterung von Message Passing-Ansätzen um Funktionen für Synchronisationsverfahrenin Form einer Programmbibliothek zu verstehen. In der Regel wird ein ausgewähltes Syn-chronisationsverfahren umgesetzt und in der Programmbibliothek als Liste von Funktionen
80 Anmerkung zur Begriffsbildung: Die Hersteller dieser Ansätze verwenden selbst den Begriff „simulation
library“. Gemeint ist damit die Realisierung von Synchronisationsverfahren für eine Parallele oder VerteilteSimulation in Form einer Fortran- oder C-Funktionsbibliothek. Diese „Simulationsbibliotheken“ beinhaltenaber i.d.R. keine Funktionalitäten der Simulation wie Ereignislisten, Zeitsteuerung oder Erfassung von Be-obachtungsgrößen.

Kapitel 3 Internationaler Wissensstand auf dem Gebiet der Parallelen undVerteilten Simulation
Seite 98
angeboten. Damit ist es möglich, unabhängig von der zu modellierenden Gegebenheit einspezielles Synchronisationsverfahren anzuwenden.Auch dieser Gruppe von Ansätzen fehlen wieder Mechanismen zur Simulation wie Zeit-steuerung, Ereignislisten oder die Erfassung von Beobachtungsgrößen.
3.2.2.4 Erweiterung von Standard-Simulations-Tools um Komponenten der Paral-lelen und Verteilten Simulation
Auf Basis der Simulationsbibliotheken ist es möglich, herkömmliche Standardsimulatorenum die in den Simulationsbibliotheken enthaltenen Synchronisationsverfahren zu erwei-tern. Positiv hieran ist, daß der Nutzer auf die im Standardsimulator angebotene Funktio-nalität zurückgreifen kann (Ereignislisten, Zeitsteuerung, Erfassung von Ergebnisgrößen).Negativ ist aber, daß der Benutzer allein dafür verantwortlich ist, die richtigen Funktionender Simulationsbibliothek in der korrekten Reihenfolge in seinem Simulationsmodell zuimplementieren. Die Simulationsbibliotheken geben oftmals nur eine syntaktische Be-schreibung der enthaltenen Funktionen, die Anwendungsreihenfolge der Funktionen unddie Semantik der Parameter der Funktionen sind dagegen oft nicht angegeben. Dies er-schwert die Umsetzung erheblich und macht sie fehleranfällig.Durch die Kopplung mehrerer Instanzen eines Standardsimulators über eine Simulations-bibliothek ist es möglich eine Verteilte Simulation durchzuführen.
3.2.2.5 Erweiterungen von Verteilungsansätzen um Simulationskomponenten
Es besteht auch die Möglichkeit, auf Basis von Verteilungsansätzen wie RMI (RemoteMethod Invocation), DCOM (Distributed Component Object Model) und CORBA (Com-mon Request Broker Architecture) herkömmliche Standardsimulatoren zu koppeln.Diese Verteilungsansätze konzentrieren sich in der Regel auf die Verteilung von Anwen-dungen in einem Netzwerk und den Austausch von Objekten. Dies hat insbesondere positi-ve Effekte für den dynamischen Transfer von Aufgaben innerhalb der Verteilungsarchi-tektur. Somit ist prinzipiell eine Parallele oder Verteilte Simulation mit dynamischen Lo-ad-Balancing möglich.Auch für diesen Ansatz gilt wieder, daß Mechanismen zur Synchronisation und/oder zurSimulation fehlen und deshalb noch zu implementieren wären.
3.2.2.6 Tools mit Ziel auf andere Anwendungsgebiete
Einige der aufgeführten Tools besitzen neben ihren Simulationskomponenten eine starkeAusrichtung auf völlig konträre Anwendungsgebiete wie z.B. den Schaltkreisentwurf. Diesbetrifft beispielsweise VHDL (Very high speed integrated circuit Hardware DescriptionLanguage) und deren Erweiterung: DVSIM (Distributed VHDL Simulator) oder auchVRML (Virtual Reality Modeling Language). Die Anpaßbarkeit dieser Ansätze zur Paral-lelen und Verteilten Simulation von Produktionssystemen ist fraglich und soll deswegennicht näher untersucht werden.
3.2.2.7 Die High Level Architecture (HLA) als Beispiel für Integrationsansätze
Eine Erweiterung der vorangehend genannten Konzepte sind Integrationsansätze. Dieseversuchen Standardsimulatoren über eine gemeinsame Plattform zu koppeln. BekanntestesBeispiel ist die High Level Architecture des US Department of Defense (DoD) [HLA].Die HLA ist ein Integrationsansatz mit Ausrichtung auf die Verteilte Simulation. Sie er-möglicht unterschiedlichen Simulationskomponenten (den sogenannten „federates“) In-formationen austauschen und an einer gemeinsamen Simulation (der „federation“) teilzu-nehmen. Positiv ist, daß der Nutzer auf die gewohnte, im Standardsimulator angeboteneFunktionalität zurückgreifen kann. Negativ ist aber auch hier, daß der Benutzer allein dafür

Kapitel 3 Internationaler Wissensstand auf dem Gebiet der Parallelen undVerteilten Simulation
Seite 99
verantwortlich ist, die richtigen Funktionen der HLA-Bibliothek in der richtigen Reihen-folge in seinem Simulationsmodell zu implementieren.Die HLA ist gut geeignet zur Kopplung heterogener Komponenten (diverser Simulatoren,Animatoren und interaktiver Trainingsumgebungen). Sie weist jedoch Mängel auf (sieheauch [Dahmann, Fujimoto, Weatherly 1998], [Davis, Moeller 1999], [Pixius u.a. 2000]):
• die Verflechtung von Modell und Simulator,• die Nichtverfügbarkeit von übergreifenden Synchronisationsverfahren,• teilweise zentrale Datenhaltung,• unzureichende Kommunikationsmechanismen,• die Unmöglichkeit hierarchische Strukturen abzubilden und• sie weist nur eine geringe Performance auf.
So sind die Anweisungen zur Implementation und Steuerung der Synchronisationsver-fahren jeweils eigenständig durch den Anwender in den Teilmodellen zu hinterlegen. Eswerden dazu lediglich atomare Bausteine in Form von Funktionen in einer Programm-bibliothek mitgeliefert. D.h., durch diese Nichtverfügbarkeit von übergreifenden Synchro-nisationsverfahren sind Teile des Simulators durch den Nutzer im Simulationsmodellselbst zu implementieren. Bei einem Wechsel des Synchronisationsverfahren muß somiteine Änderung des Modells erfolgen.Zum Anderen besitzt das Runtime Interface (RTI) der HLA Kenntnis von allen zwischenden Logischen Prozessen auszutauschenden Nachrichtentypen. Werden nun Nachrichtenversendet, so werden die Daten dieser Nachrichten zentral im Runtime Interface gespei-chert. D.h., jeder Logische Prozeß sendet seine Nachrichten zu einem zentralen Rechner,auf dem das Runtime Interface läuft. Das RTI speichert die Nachricht und gibt diese an daseigentliche Ziel weiter. Alle Nachrichten laufen also auf einem Rechner zusammen. Wei-terhin besteht die Möglichkeit von gemeinsam durch alle Logischen Prozesse nutzbarenVariablen. Solche Variablen dienen zum globalen Informationsaustausch. Das Datenvolu-men der Nachrichten und von gemeinsam durch alle Prozesse genutzten Daten kann aberz.T. erhebliche Ausmaße annehmen. Eine Dezentralisierung dieser Funktionen und derRTI wäre ratsam.Außerdem besitzt die HLA nur unzureichende Kommunikationsmechanismen. So bestehtdie Möglichkeit Typen für Nachrichten zu definieren und einzelne Logische Prozesse kön-nen die Absicht erklären, Nachrichten dieses Typs senden oder empfangen zu wollen.Wollen jedoch eine Vielzahl von Logischen Prozessen Nachrichten des gleichen Typsempfangen, so werden all diesen Prozessen diese Nachrichten per Broadcast überbracht.Der Empfänger muß dann noch feststellen, ob die empfangene Nachricht überhaupt an ihnadressiert war. Diese Vorgehensweise hat sehr negative Auswirkungen auf die Perfor-mance. Umgekehrt ist es aber auch nicht sinnvoll, für jede mögliche Verbindung zwischenSender und Empfänger einen eigenen Nachrichtentyp zu definieren.Zudem ist die HLA nicht in der Lage hierarchische Strukturen abzubilden. Dies ist durchdie zweischichtige Architektur - Runtime Interface und Federates - bedingt. Auf dieseWeise können z.B. militärische Kommandostrukturen nur äußerst schwer abgebildet wer-den [Davis, Moeller 1999].Hauptziele der HLA sind Interoperabilität und die Unterstützung der Interactive Simula-tion [Fujimoto 1998], [Schulze u.a. 1998], [Fujimoto 1999]. Ziel der Interactive Simulationist es, in einem verteilten Umfeld unterschiedliche Komponenten - u.a. auch den Menschenin interaktiven Trainingsumgebungen - zu verbinden.Hauptziel der Simulation von Produktionssystemen im Kontext der Fertigungssteuerung istaber die Erhöhung der Performance der Simulation (Vielzahl von Simulationsläufen mit

Kapitel 3 Internationaler Wissensstand auf dem Gebiet der Parallelen undVerteilten Simulation
Seite 100
veränderten Parametern in kürzester Zeit abschließen). Diese beiden Ziele verhalten sichkonträr.
3.2.2.8 Spezielle Tools der Parallelen und Verteilten Simulation
Neben den bisher vorgestellten Ansätzen gibt es aber auch Ansätze, die direkt für die Par-allele und Verteilte Simulation konzipiert worden sind. Diese sollen nachfolgend detail-lierter vorgestellt werden. Simulationstools zur Parallelen und Verteilten Simulation aufhohem Niveau wären (nach Entstehungsjahr geordnet):
• YADDES (1989),• Maisie (1990),• SPEEDES (1991),• DSL (1994),• MOOSE (1994),• ParSec (1998) und• ParSimONY (1999).
In diesen Tools stehen für die Abarbeitung eines Simulationsmodells i.d.R. mehrere Syn-chronisationsverfahren zur Auswahl. Die Tools sind zudem allgemein gehalten und fokus-sieren nicht auf einem speziellen Anwendungsgebiet. Des Weiteren lassen sich in der Lite-ratur sowohl zahlreiche Artikel als auch Anwendungen finden81. Bisher sind diese Toolsaber nicht auf dem Gebiet der Simulation von Produktionssystemen eingesetzt worden.
YADDES:Bei YADDES (Yet Another Distributed Discrete Event Simulator) handelt es sich um eine1989 von B. R. Preiss [YADDES] vorgestellte Simulationssprache. Die Syntax erinnert anC, die Programmiersprache C ist auch Basis für die Implementation von YADDES. YAD-DES ist dadurch plattformunabhängig. YADDES ist zwar anwendungsunspezifisch konzi-piert, Hauptanwendungsgebiet ist aber die Simulation von Bedienungsnetzen. Die Model-lierung mit YADDES ist aufgrund von Konstrukten einer Simulationshochsprache einfach.
Maisie:Maisie ist eine 1990 von R. L. Bagrodia und Wentoh Liao vorgestellte Simulationssprache[Bagrodia, Liao 1990], [Maisie]. Maisie basiert ebenfalls auf der Programmiersprache Cund ist auch plattformunabhängig. Maisie ist ein Allzwecksimulator, Hauptanwendungs-gebiet ist aber die Simulation von Computernetzwerken. Die Modellierung mit der Simula-tionssprache Maisie ist einfach.
SPEEDES:Bei SPEEDES (Synchronous Parallel Environment for Emulation and Discrete EventSimulation) handelt es sich um ein 1991 von Jeff Steinman vorgestellte Simulations-software zur Verteilten Simulation [Steinman 1991], [SPEEDES].SPEEDES selbst stellt eine Reihe von Funktionen sowohl zur Simulation (Führen von Er-eignislisten, Zeitsteuerung) als auch zur Synchronisation bereit. SPEEDES geht damit weitüber den in Simulationsbibliotheken üblichen Umfang hinaus.Die Basis für SPEEDES war die Programmiersprache C, in der neusten Version ist es dieProgrammiersprache C++. SPEEDES ist plattformunabhängig.
81 Die obige Aufzählung ist nicht erschöpfend, das Vorhandensein weiterer Tools ist nicht ausgeschlossen.
Jedoch wurde mit der Aufzählung gemäß der Kriterien (Artikel und Anwendungen vorhanden) das Zielverfolgt, über das Stadium theoretischer Ansätze hinausgehende Lösungen zu finden. Zum Anderen ließensich trotz wiederholter Recherchen keine weiteren dieser Kategorie zuordenbaren Ansätze finden.

Kapitel 3 Internationaler Wissensstand auf dem Gebiet der Parallelen undVerteilten Simulation
Seite 101
In SPEEDES besteht prinzipiell die Möglichkeit zwischen mehreren Synchronisations-verfahren zu wählen. Hauptausrichtung von SPEEDES ist aber die optimistische Synchro-nisation mittels Time Warp-Verfahren (siehe Punkt 3.1.3.4). Allerdings besteht in SPEE-DES keine vollständige Trennung zwischen Simulationsmodell und Synchronisations-verfahren. Der Anwender ist gezwungen, die notwendigen Funktionen zur Synchronisationinnerhalb seines Simulationsmodells aufzurufen.Die Modellierung in SPEEDES ist schwierig, es existieren außerdem keine Modellbau-steine. SPEEDES selbst besitzt zur Anwendung in der Simulation von Produktions-systemen zu wenig Grundlagen und ist für Änderungen zu unflexibel. Bisheriges Anwen-dungsgebiet von SPEEDES ist die Logiksimulation und die Militärische Simulation. EineSchnittstelle zur HLA ist vorhanden.
DSL:Bei DSL (Distributed Simulation Language) handelt es sich um eine selbständige Simula-tionssprache. DSL wurde 1994 von Horst Mehl [Mehl 1994, S. 75-87] entworfen. DSLerlaubt die Kopplung ein und des selben Modells mit mehreren Synchronisationsverfahren.Genaue Angaben zu dieser Simulationssoftware macht der Autor leider nicht und die Si-mulationssoftware ist der Allgemeinheit auch nicht zugänglich.
MOOSE:Bei MOOSE (Maisie Object-Orientated Simulation Environment) handelt es sich um eine1992 erschienene Weiterentwicklung von Maisie [Waldorf 1992], [Waldorf, Bagrodia1994]. Zusätzlich zu den Eigenschaften von Maisie besteht jetzt die Möglichkeit, objekt-orientierte Mechanismen wie Objekte (entity) und Vererbung zu benutzen. MOOSE ver-einfacht somit die Implementierung von Maisie-Simulationsprogrammen. Dazu verwendetMOOSE einen Precompiler um Maisie-Code zu erzeugen.
ParSec:Bei ParSec (Parallel Simulation Environment for Complex Systems) handelt es sich umeine 1998 erschienene Weiterentwicklung von Maisie [ParSec], [Bagrodia u.a. 1998]. ImGegensatz zu Maisie basiert ParSec auf C++. ParSec ist auf die Simulation von Computer-netzwerken ausgerichtet und besitzt dafür sogar eine graphische Oberfläche zur Modellie-rung (Pave = ParSec Visual Environment). Dem Anwender werden Bausteine zur Model-lierung von Computernetzwerken zur Verfügung gestellt. Die Modellierungssprache isteinfach, aber wegen der graphischen Oberfläche Einschränkungen unterworfen.
ParSimONY:Bei dem 1999 erschienen ParSimONY (PARallel SIMulator Once Named Yaddes) [Preiss,Wan 1999] handelt es sich um eine Weiterentwicklung von YADDES. ParSimONY setztauf der Basis von Java und RMI (Remote Method Invocation) auf und erweitert diese umSimulationskomponenten und Synchronisationsverfahren. Ziel der Entwicklung von Par-SimONY war es, einen Ansatz zu schaffen, mit dem es möglich ist, die Performance unter-schiedlicher Synchronisationsverfahren auf unterschiedlichen Rechnerplattformen zu eva-luieren. Positiv an ParSimONY hervorzuheben ist die strikte Trennung zwischen Synchro-nisationsverfahren und Simulationsmodell. Zur Laufzeit kann der Anwender über eine gra-phische Oberfläche entscheiden, welches Simulationsmodell mit welchem der eingebautenSynchronisationsverfahren ausgeführt werden soll. Für die Ausführung des Modells ist esdabei ohne Belang, ob dies auf einem Rechner (PC), einer Mehrprozessormaschine oder ineinem Computernetzwerk erfolgt. Der Anwender muß in ParSimONY lediglich das Simu-lationsmodell mittels Java-Anweisungen definieren und kann dabei bereitgestellte Ele-mente eines Bedienungssystems benutzen. Die Modellierung mit ParSimONY ist daher

Kapitel 3 Internationaler Wissensstand auf dem Gebiet der Parallelen undVerteilten Simulation
Seite 102
einfach. ParSimONY bietet zwar die Möglichkeit Bedienungsnetzwerke zu simulieren, füreine Anwendung zur Simulation von Produktionssystemen ist es aber nicht direkt geeignet.
Zusammenfassend läßt sich sagen, dem Anwender steht bisher kein Tool zur Verfügung,um Produktionssysteme direkt parallel oder verteilt simulieren zu können. Dies gilt insbe-sondere im Hinblick auf die Anwendung in der Fertigungssteuerung. Für dieses Anwen-dungsgebiet lassen sich keine erfolgten Anwendungen finden.
3.2.3 Bisherige Anwendungsgebiete der Parallelen und Verteilten Simulation
Im Gegensatz zu der breiten Palette an potentiell geeigneten Softwareansätzen zur Paral-lelen und Verteilten Simulation ist die Breite der Anwendungsgebiete begrenzt. Im nach-folgenden Abschnitt erfolgt eine kurze Vorstellung der Anwendungsgebiete der Parallelenund Verteilten Simulation, die Herausarbeitung charakteristischer Unterschiede der An-wendungsgebiete und es sollen Gründe für die bisherige Nichtanwendung der Parallelenund Verteilten Simulation zur Simulation von Produktionssystemen aufgezeigt werden.
Bisher ist die Parallele und Verteilte Simulation auf folgende Anwendungsgebiete ausge-richtet:82
1. Simulation biologischer Systeme:
• „NAMMU – Groundwater Modeling for Continuous Media“ [Skjellum, Lusk,Gropp 1994, S. 13f]
• „ZELIG - Forest Growth Simulation“ [Hotovy, Shen, Zollweg 1995]
2. Simulation von chemischen oder physikalischen Prozessen:
• „Many-body Methods for Light Nuclei“ [Skjellum, Lusk, Gropp 1994, S. 9f]• „Volume Visualization“ [Skjellum, Lusk, Gropp 1994, S. 15]• [Iotov u.a. 1995]
3. Parallele Lösung von Gleichungssystemen:
• „Solution of Unsteady Incompressible Viscous Flows“ [Skjellum, Lusk, Gropp1994, S. 10]
• „PDF2DV, 2-D Turbulent Reactive Flow Simulation“ [Hotovy, Shen, Zollweg1995]
4. Militärische Simulation:
• [HLA]• [Hollenbach, Alexander 1997]• [Dahmann, Fujimoto, Weatherly 1998]• [Davis, Moeller 1999]• [Pixius u.a. 2000]
5. Logiksimulation:
• [Feldmann u.a. 1992]• [Kleis u.a. 1994]• [Riess, Doll, Johannes 1994]• [Bauer 1994]• [Sporrer 1995]• [Fröhlich, Schlagenhaft, Fleischmann 1997]
82 Die nachfolgende Nennung von Quellen versteht sich als exemplarische Aufzählung von Anwendungen.
Sie erhebt keinerlei Anspruch auf Vollständigkeit.

Kapitel 3 Internationaler Wissensstand auf dem Gebiet der Parallelen undVerteilten Simulation
Seite 103
6. Simulation von Computernetzen:
• [Harju, Salmi 1993]• [Porras, Harju, Ikonen 1995]• [Meyer, Bagrodia 1998]• [Waheed, Yan 1998]• [Tree 1999]
7. Simulation von Verkehrssystemen:
• „PARMICS-MP - Microscopic Traffic Simulation“ [Skjellum, Lusk, Gropp1994, S. 14]
• [Kosonen 1996]• [Klein u.a. 1998]• [Pursula 1999]
8. Simulation von Bedienungsnetzwerken:
• [Nicol 1988]• [Loucks, Preiss 1990]• [Preiss, Loucks 1990]• [Holthaus, Rosenberg, Ziegler 1996]• [Kreutzer, Hopkins, van Mierlo 1997]
9. Simulation von Produktions- und Logistiksystemen:
• [Bley, Wuttke 1997]• [Schulze u.a. 1998]• [Arndt 2000]• [Gehlsen, Page 2000]• [Schneider, Reinhardt 2000]
Die Simulation biologischer Systeme, chemischer oder physikalischer Prozesse undvon Gleichungssystemen soll an dieser Stelle ausgeklammert werden, da die vorliegendeArbeit auf die diskrete, ereignisorientierte Simulation (PDES - Parallel Discrete EventSimulation) fokussiert, die genannten Simulationen aber durch stetige Prozesse gekenn-zeichnet sind oder auf Differentialgleichungen beruhen.
Im Bereich der militärischen Simulation wird meist zwangsweise83 die HLA eingesetzt,um historisch gewachsene, heterogene Simulationssysteme zu verbinden [Davis, Moeller1999], [Pixius u.a. 2000].
Bei der Logiksimulation handelt es sich um die diskrete Simulation des Schaltungsver-haltens elektronischer Bauteile. Die Logiksimulation unterscheidet sich insofern von derSimulation von Produktions- und Logistiksystemen, daß:
a) wesentlich größere Topologien betrachtet werden (Logiksimulation: mehrere TausendBauelemente; Simulation von Produktionssystemen: weniger als 100 Maschinen),
b) die dynamischen Elemente eine geringere Komplexität aufweisen (Logiksimulation:nicht unterscheidbare, völlig gleichartige Informationen, binäre Signale; Simulationvon Produktionssystemen: konkrete, attributierte Auftragsobjekte)
83 Das US-Verteidigungsministerium schreibt für militärische Simulationsanwendungen eine Schnittstelle zur
HLA vor und innerhalb der NATO existiert diese Vorschrift ebenfalls.

Kapitel 3 Internationaler Wissensstand auf dem Gebiet der Parallelen undVerteilten Simulation
Seite 104
c) die Last im Simulationsmodell höher ist (Logiksimulation: viele Signale gleichzeitigunterwegs; Simulation von Produktionssystemen: wenige Aufträge gleichzeitig zwi-schen den Maschinen zu transferieren) und
d) der Umfang an Berechnungen, der durch das Eintreffen eines Ereignisses ausgelöstwird, größer ist (Logiksimulation: geringer bis mittlerer Aufwand zur Berechnung desOutputs eines Bauelements; Simulation von Produktionssystemen: sehr geringer bisgeringer Berechnungsaufwand zur Reaktion auf Ereignisse).
Aufgrund dieser Charakteristika ergeben sich signifikante Unterschiede bei der Anwen-dung von Verfahren der Parallelen und Verteilten Simulation.
In der Simulation von Computernetzen werden große Netzwerke von Computern z.T. bisauf Protokollebene abgebildet und simuliert. Die Simulation von Computernetzen weistAnalogien zur Logiksimulation auf.
Bei der Simulation von Verkehrssystemen werden beispielsweise Straßen- und Bahn-netze größerer Städte parallel simuliert. Hier sind Analogien zur Simulation von Bedien-ungsnetzwerken erkennbar. Der Berechnungsaufwand bei Ankunft eines Ereignisses isthier i.d.R. minimal. Der Kommunikationsaufwand dagegen ist oft sehr groß.
Die Simulation von Bedienungsnetzwerken unterscheidet sich von der Simulation vonProduktionssystemen u.a. dadurch, daß:a) im Allgemeinen geschlossene Bedienungssysteme betrachtet werden,b) die dynamischen Elemente des Bedienungssystems als nicht voneinander unterscheid-
bar gelten (homogen sind) und keine Attribute besitzen,c) das Verhalten des betrachteten Systems über Wahrscheinlichkeitsverteilungen fest-
gelegt ist (da Attribute der dynamischen Elemente nicht betrachtet werden),d) für gewöhnlich keine Strategien zur Abarbeitung von Warteschlangen an den Maschi-
nen eingesetzt werden (es wird FIFO - First In First Out - verwendet)e) von speziellen, im realen Produktionssystem auftretenden Prozeßbedingungen wird
abstrahiert (siehe dazu Punkt 2.3.2.3).
So werden in den Bedienungsnetzwerken nur Kenntnisse über aggregierte Größen wieEinsteuerungsverteilungen, Übergangswahrscheinlichkeiten zwischen Netzknoten undBedienzeitverteilungen eingesetzt. Von konkreten Aufträgen, Arbeitsplänen und von Bear-beitungszeiten wird abstrahiert. Die mit solchen Modellen gewinnbaren Erkenntnisse las-sen sich jedoch mit lokalen Simulatoren auf simple Weise mit wesentlich geringeremAufwand gewinnen - die Anwendung der Parallelen oder Verteilten Simulation bringthierfür wenig oder keinen Nutzen.
Die Parallele und Verteilte Simulation wird bisher nicht zur Simulation in Produktionund Logistik eingesetzt. Insbesondere auf dem Gebiet der Fertigungssteuerung fehlenAnwendungen bislang völlig. Die bisher unter dem Anwendungsgebiet Parallele und Ver-teilte Simulation von Produktionssystemen eingeordneten Ansätze müssen bei näherer Be-trachtung in andere Gebiete eingeordnet werden. Bei den in [Bley, Wuttke 1997], [Arndt2000], [Gehlsen, Page 2000], [Schneider, Reinhardt 2000] vorgestellten Ansätzen handeltes sich de facto um eine verteilte Sequentielle Simulation (parallele Experimente). Der in[Schulze u.a. 1998] vorgestellte Ansatz ist dagegen eine Kopplung eines SequentiellenSimulators, einer Animationssoftware und eines Leitstandes über die HLA. Das Fehlenvon Ansätzen zur Parallelen und Verteilten Simulation von Produktionssystemen liegt u.a.begründet in:

Kapitel 3 Internationaler Wissensstand auf dem Gebiet der Parallelen undVerteilten Simulation
Seite 105
a) der höheren Komplexität in diesem Anwendungsfall84,b) der Unwahrscheinlichkeit größerer Speedups85 undc) im Fehlen geeigneter Simulationstools.
Der zur Beseitigung dieser Defizite notwendige personelle, zeitliche und finanzielle Auf-wand stellt hier den Hinderungsgrund dar.
3.2.4 Kritik an den softwaretechnischen Realisierungen der Parallelen und Ver-teilten Simulation
Die meisten der vorgestellten softwaretechnischen Realisierungen befassen sich nur miteinem oder wenigen Aspekten der Parallelen und Verteilten Simulation. So sind aber umeine Parallele oder Verteilte Simulation ausführen zu können, folgende Funktionalitätennotwendig:
• Formulierung des Simulationsmodells:
Hierbei muß der Benutzer die Möglichkeit haben, auf die gewohnten Funktionalitä-ten einer Programmiersprache und eines Simulators zuzugreifen. Er muß auf ein-fache Art und Weise Datenstrukturen und Algorithmen formulieren können und ermuß die Möglichkeit haben, in die Zeitsteuerung einzugreifen und Ereignisse erzeu-gen und einplanen zu können. Viele der untersuchten Ansätze vernachlässigen diesenAspekt.Während diese Forderung bereits für Sequentielle Simulatoren gilt, ist sie für dieParallele und Verteilte Simulation in verschärfter Form zu sehen. Simulations-modelle der Parallelen und Verteilten Simulation sind komplex und schwierig zuhandhaben, so daß die Einfachheit der Formulierung des Simulationsmodells an Be-deutung gewinnt [Chen, Jha, Bagrodia 1995], [Paprotny, Fowler 2001].
• Partitionierung des Simulationsmodells in Teilmodelle:
Es muß möglich sein, die parallel auszuführenden Teile des Simulationsmodells an-zugeben. Bedingt durch den Lösungsdefekt für die Aufgabe der Partitionierung exi-stiert kein allgemeingültiges Lösungsverfahren. Als Resultat bleibt dem Anwenderdiese Aufgabe völlig überlassen. Lediglich zwei Tools (ParSec und ParSimONY)geben durch das Vorhandensein von Modellbausteinen eine Grundpartitionierungvor, die sich noch ändern läßt.
• Kommunikation zwischen den Teilmodellen:
Einige der aufgeführten Ansätze fokussieren ausschließlich auf diesen Aspekt. Faktist aber auch, das Arbeiten zeigten [Loucks, Preiss 1990], [Mehl 1994, S. 142f],[Bagrodia 1996], [Holthaus, Rosenberg, Ziegler 1996], daß u.U. ein Kommunika-
84 Bisher werden meist nur die statischen Elemente eines Bedienungssystems (Maschinen usw.) betrachtet,
dynamische Elemente (Aufträge) werden als nicht existent angenommen. Von einem Innenleben der stati-schen Elemente wird abstrahiert, diese sind aber durch spezielle Eigenschaften und Verhaltensregeln ge-kennzeichnet. Dadurch ergibt sich eine Uniformität der statischen Elemente, die in der Realität nicht gege-ben ist. In der Realität müssen beispielsweise spezifische Prozeßbedingungen (z.B. Parallelbearbeitung,Rüstproblematiken) beachtet werden. Des Weiteren sind insbesondere Strategien zum Abbau von Warte-schlangen von Interesse, werden bisher aber nicht betrachtet.
85 Der Lookahead innerhalb von Produktionssystemen ist minimal [Nicol 1988], [Loucks, Preis 1990],[Preiss, Loucks 1990], [Jha, Bagrodia 1993]. Annahmen zur Verbesserung des Lookaheads lassen sich inder Praxis nicht durchsetzen. Z.B. werden gerade in der Fertigungssteuerung andere Abarbeitungs-strategien für Warteschlangen als FIFO betrachtet. Die Höhe des Lookaheads hat aber signifikanten Ein-fluß auf das erzielbare Speedup. Mehl [Mehl 1994, S. 43, S. 72] verweist auf einige Projekte, in denen trotzdes Einsatzes einer hohen Rechner- bzw. Prozessorenanzahl nur ein bescheidener Speedup erreicht wurde.

Kapitel 3 Internationaler Wissensstand auf dem Gebiet der Parallelen undVerteilten Simulation
Seite 106
tionsoverhead entstehen kann. Es ist demzufolge Broadcasting zu vermeiden undstatt dessen gerichtete Kommunikation zu verwenden.
• Synchronisation der Teilmodelle:
Viele der vorgestellten Ansätze fokussieren auf die Implementation eines ausge-wählten Synchronisationsverfahrens und vernachlässigen die anderen Aspekte. EinProblem der Parallelen und Verteilten Simulation ist aber die Ungewißheit über diePerformance des Synchronisationsverfahrens. Durch Änderung weniger Parameterist ggf. ein anderes Synchronisationsverfahren performanter [Fujimoto 1988a],[Preiss 1990], [Fujimoto 1990], [Smith 1999]. Dadurch macht die Festlegung auf ge-nau ein spezielles Verfahren wenig Sinn. Andererseits ist bei Fehlen von Synchro-nisationsverfahren ein Ansatz nicht der Parallelen und Verteilten Simulation zuor-denbar.
Die wenigsten der vorgestellten Ansätze decken all diese Aspekte ab. So ist der Anwendermeist gezwungen, die zusätzlich notwendige Funktionalität selbst zu implementieren. Derhohe zeitliche und personelle Aufwand für diese Arbeiten stellt - insbesondere im Ver-gleich zu den z.T. mageren Ergebnissen verschiedener Studien [Fujimoto 1990], [Preiss,Loucks 1990], [Luksch 1995], [Fujimoto 1999], [Paprotny, Fowler 2001] - den Haupt-hinderungsgrund für den Einsatz der Parallelen und Verteilten Simulation dar.Der Lösungsdefekt für die Partitionierung und die Synchronisation und der dadurch be-dingte Mangel an einem Lösungsverfahren in Verbindung mit der hohen Parametrisier-barkeit der Verfahren erschweren die Entwicklung eines anwendungsgebietübergreifendenAnsatzes zur Parallelen und Verteilten Simulation. Zudem sind die unter Punkt 3.2.3 auf-geführten Unterschiede der Anwendungsgebiete oft unüberbrückbares Hindernis für eineAdaption eines vorhandenen Tools.
Zusammenfassend läßt sich sagen, dem Anwender steht kein Tool zur Verfügung, um Pro-duktionssysteme - insbesondere im Hinblick auf die Anwendung in der Fertigungs-steuerung - parallel oder verteilt simulieren zu können.
3.3 Anforderungen an die Parallele und Verteilte Simulation vonProduktionssystemen
Nachfolgend sollen Anforderungen an einen Implementationsansatz herausgearbeitet wer-den. Diese Anforderungen sind dann Basis für einen Vergleich der verschiedenen Imple-mentationsansätze im Punkt 3.3.3.
3.3.1 Defizite der bisherigen Ansätze der Parallelen und Verteilten Simulation zurSimulation von komplexen Produktionssystemen
Als Erstes sollen Anforderungen an eine softwaretechnische Realisierung der Parallelenund Verteilten Simulation aus der Sicht der Simulation von Produktionssystemen näherbetrachtet werden86.Um Produktionssysteme modellieren zu können, ist es notwendig, die in diesen Systemenvorhandenen Elemente in Daten und Funktionen ausdrücken zu können. Modelle von Pro-duktionssystemen sind üblicherweise durch eine Vielfalt von Daten, sowohl in strukturel-ler wie auch mengenmäßiger Sicht, gekennzeichnet (siehe Punkt 2.3.2). Dies sind z.B.Daten über Ressourcen wie Maschinen, Transporter, Lagerplätze und Fertigungspersonalsowie Daten über Produkte, Arbeitspläne, Stücklisten, Aufträge und Lose. Der Implemen-tationsansatz muß dem Rechnung tragen. Hierzu sind dem Benutzer entweder Modell-
86 Vergleiche [Kosturiak, Gregor 1995, S. 156-166] zu Anforderungen an moderne Simulationssysteme.

Kapitel 3 Internationaler Wissensstand auf dem Gebiet der Parallelen undVerteilten Simulation
Seite 107
bausteine87 zur Abbildung von z.B. Arbeitsplänen zur Verfügung zu stellen oder der Be-nutzer muß die Möglichkeit besitzen, die benötigten Datenstrukturen in einer höheren Pro-grammiersprache selbst zu formulieren. D.h., es müssen Strukturen zur Verfügung stehen,die in der Lage sind, die benötigten Daten aufzunehmen, und die große Mengen dieserDaten auf einfache Art und Weise handhaben können.Eine weitere Forderung ist die Einfachheit der Modellformulierung. Aufgrund der hohenKomplexität des zu modellierenden Systems muß man mit Hilfe des Implementations-ansatzes in der Lage sein, einfach und übersichtlich ein Modell zu formulieren. Andern-falls sind komplexe Strukturen nicht oder nur sehr schwer handhabbar - die Fehleranfällig-keit bei der Modellformulierung steigt. Außerdem soll ggf. ein Nicht-Simulationsexpertein der Lage sein, die Modelle zu formulieren oder aber zumindest die formulierten Modellelesen zu können [Hirsch u.a. 2000].Des Weiteren ist der Vorrat an typischen Elementen von Produktionssystemen begrenzt,wodurch es eigentlich möglich ist, Modellbausteine für diese Elemente wie z.B. Maschi-nen und Lager zur Verfügung zu stellen. Dies würde die Modellbildung wesentlich erleich-tern und den Aufwand senken [Hirsch u.a. 2000], [Fishman 2001, S. 31-33]. Problematischbleibt allerdings, daß diese allgemeinen Elemente sich in einigen Eigenschaften unter-scheiden. Entweder muß dem Anwender die Möglichkeit geboten werden - analog zur ob-jektorientierten Programmierung - auf Basis vorhandener Bausteine eigene Bausteine an-zulegen und zu verändern, oder dem Anwender sind Möglichkeiten zur Konfiguration derBausteine zu bieten. Der zweite Weg ist jedoch wesentlich inflexibler.Ein weiteres Problem ist die Herkunft der Daten. Die Daten von Modellen von Produkti-onssystemen sind meist bereits in Datenbanken operativer Systeme vorhanden (z.B. in ei-nem Produktionsplanungs- und -steuerungssystem (PPS-System) oder einem Werkstatt-steuerungssystem). Es bietet sich somit an, statt einer manuellen Erfassung dieser Datenund der anschließenden Modellerstellung, diese Daten aus den vorhandenen Daten-speichern der operativen Systeme automatisiert zu übernehmen (siehe Punkt 2.4.1, Punkt4.2.1). D.h., ein Implementationsansatz muß Schnittstellen zur Kopplung mit bestehendenoperativen Systemen bieten88. Diese Schnittstellen sind auch für die rückwärtige Über-nahme von Ergebnissen der Experimente mit dem Modell des Produktionssystems in dasoperative System interessant [Hirsch u.a. 2000] (vergleiche Punkt 2.4.1, Punkt 4.2.1).Der Implementationsansatz muß weiterhin Möglichkeiten bieten, im Produktionssystemvorhandene spezifische Prozeßbedingungen abzubilden. Dies ist eine zwingende Voraus-setzung für die korrekte Modellierung des Produktionssystems, um wesentliche Eigen-schaften und wesentliches Verhalten abzubilden [Thiel, Schulz, Gmilkowsky 1998b],[Richter u.a. 1998]. D.h., eventuell vorhandene Modellbausteine und Mechanismen müs-sen anpaßbar sein oder nach eigenem Ermessen umdefiniert werden können.Für den Einsatz in der Fertigungssteuerung ist es weiterhin notwendig, in einzelne derElemente steuernd einzugreifen. D.h., zur Festlegung der konkreten Reihenfolge der Abar-beitung einer Warteschlange an einer Maschine muß es möglich sein, beliebige Steue-rungsansätze einsetzen zu können. Dazu sollte der Implementationsansatz bereits über eineAuswahl von verschiedenen Ansätzen zur Reihenfolgeplanung, wie z.B. einfache undkombinierte Prioritätsregeln, verfügen. Andernfalls wären diese Reihenfolgeregeln nochmit zusätzlichem Aufwand zu implementieren. Ebenso muß die Möglichkeit geboten wer-
87 Siehe u.a. [Eversheim, Intra, Abels 2000], [Fishman 2001, S. 30-31].88 Oder es muß zumindest die Möglichkeit bestehen, diese Schnittstellen noch zu implementieren. Ansätze,
die sich ausschließlich auf eine interaktive Modellerstellung mittels Bausteinen (Point&Click) verlassen,sind für solche Zwecke nicht geeignet.

Kapitel 3 Internationaler Wissensstand auf dem Gebiet der Parallelen undVerteilten Simulation
Seite 108
den, komplexere Reihenfolgeplanungsansätze algorithmisch formulieren zu können. Auchhier ist es wieder von Vorteil, wenn man eine höhere Programmiersprache benutzen kann.Für die Suche nach der optimalen Steuerungsstrategie für ein Produktionssystemen ist esweiterhin notwendig, eine hohe Anzahl von Simulationsexperimenten mit veränderten Pa-rametern durchzuführen. Hier ist die Kopplung zu Optimierungstools oder Suchverfahrenhilfreich (siehe Punkt 2.4.1).Im Zuge des Experimentierens mit dem Modell muß der Anwender dahingehend unter-stützt werden, daß eine Änderung von Einstellungen oder Parametern von Modellelemen-ten nicht zur Neuprogrammierung des Modells führen darf. D.h., das Modell sollte para-metrisierbar sein, um direkte Änderungen am Modell oder gar an den Modellelementenvermeiden zu können. Der notwendige Aufwand für solche im Rahmen des Experimentie-rens notwendige Änderungen des Modells sollte so gering wie möglich gehalten werden[Hirsch u.a. 2000], [Wiedemann 2000]. Dies gilt ebenso für das Verhindern von ständigenmanuellen Änderungen des Simulationsmodells im Hinblick auf die Integration von ver-schiedenen Synchronisationsverfahren bei Änderung von Parametern des Simulations-experimentes.Weiterhin werden flexible Auswertemöglichkeiten gefordert. Der zu verwendende Ansatzmuß in der Lage sein, auf Wunsch des Anwenders eine beliebige Kombination von Krite-rien oder gar zusätzliche Kriterien zur Ergebnisbewertung eines Experimentes anwendenzu können (benutzerdefinierte Reports) (siehe Punkt 2.4.1).
Keine der vorgestellten Lösungen bietet all diese Möglichkeiten. D.h., man ist gezwungen,selbst die notwendigen Datenstrukturen und Algorithmen zu implementieren. Selbst diesist jedoch nicht mit allen der vorgestellten Ansätze möglich, so das die Flexibilität des An-satzes (Möglichkeit zum Hinterlegen benutzerdefinierter Inhalte) wesentlich an Bedeutunggewinnt.
3.3.2 Anforderungen an einen Implementationsansatz aus Sicht der Parallelenund Verteilten Simulation
Die Ausführungen der vorangegangenen Kapitel haben gezeigt, daß auch in den Ansätzenzur Parallelen und Verteilten Simulation noch Defizite bestehen. Deshalb sind an einesoftwaretechnische Realisierung der Parallelen und Verteilten Simulation nachstehendeAnforderungen aufzustellen.
Einfachheit der Modellformulierung:
Eine wesentliche Forderung ist die Einfachheit der Modellformulierung. Aufgrund derhohen Komplexität des zu modellierenden Systems muß man mit Hilfe des Tools in derLage sein, einfach und übersichtlich ein Modell zu formulieren. Andernfalls sind komplexeStrukturen nicht oder nur sehr schwer handhabbar. Aus diesem Grund sollte das Tool be-reits über eine größere Auswahl von Modellbausteinen verfügen, mit denen es möglich ist,häufige Elemente von Produktionssystemen abbilden zu können. Dies würde die Modell-bildung wesentlich erleichtern [Hirsch u.a. 2000], [Mehl 1994, S. 227] (vergleiche Punkt3.3.1).
Trennung von Modell und Simulator bzw. Synchronisationsverfahren:
Dies ist notwendig, damit das Simulationsmodell mit mehreren Synchronisationsverfahrengetestet werden kann, da keine allgemeine Empfehlung gegeben werden kann, welchesSynchronisationsverfahren in welcher Situation am performantesten ist [Fujimoto 1988b],[Preiss 1990], [Fujimoto 1990], [Bagrodia 1996], [Fujimoto 1999], [Smith 1999] und ande-rerseits ist dem Anwender nicht zuzumuten, daß für jedes einzusetzende Synchronisations-verfahren ein speziell angepaßtes Simulationsmodell implementiert werden muß [Mehl

Kapitel 3 Internationaler Wissensstand auf dem Gebiet der Parallelen undVerteilten Simulation
Seite 109
1994, S. 41]. D.h., der Wechsel zwischen verschiedenen Synchronisationsverfahren mußeinfach möglich sein [Smith 1999] (vergleiche Punkt 3.1.3.6).
Effektive Kommunikationsmechanismen:
Arbeiten zeigen [Loucks, Preiss 1990], [Mehl 1994, S. 142f], [Bagrodia 1996], [Holthaus,Rosenberg, Ziegler 1996], daß u.U. ein Kommunikationsoverhead entstehen kann, was zueinem Slowdown führt, da nur noch auf das Eintreffen gesendeter Nachrichten gewartetwerden muß. Deshalb ist es notwendig, gerichtete Kommunikation einzusetzen und Nach-richten nicht per Broadcasting an alle zu senden, sondern die Nachrichten nur an die wirk-lich notwendigen Stellen zu transferieren (vergleiche Punkt 3.1.2.3).
Unabhängigkeit von einer speziellen Implementierungsumgebung:
Es muß gewährleistet sein, daß der Implementationsansatz und das Simulationsmodell oh-ne Konvertierungsaufwand auf andere Rechner, andere Rechnerplattformen und andereBetriebssysteme übertragbar sind. D.h. der Implementationsansatz und das Simulations-modell müssen ohne Änderungsaufwand sowohl innerhalb eines Computernetzwerks (ver-teilte Abarbeitung) als auch auf einem Mehrprozessorrechner (lokale Abarbeitung) ein-setzbar sein (vergleiche Punkt 3.1.3.6). Dies resultiert aus dem Problem, daß nicht vorher-gesagt werden kann, welche Plattform besser zur Abarbeitung eines gegebenen Simula-tionsmodells geeignet ist [Bagrodia 1996], [Smith 1999].
Flexibilität:
Da nicht im Voraus absehbar ist, welche Spezifika im Modell manifestiert werden müssenund ob die Abbildung dieser Spezifika mit den bisher im Implementationsansatz vorhan-denen Mechanismen möglich ist, muß der Implementationsansatz eine offene Struktur be-sitzen und flexibel erweiterbar sein.
Es besteht daher die Anforderung, zusätzliche Algorithmen leicht integrieren zu können.Dies ist z.B. wesentlich für:
• die Abbildung von im Produktionssystem vorhandenen spezifischen Prozeßbedin-gungen, was wiederum eine zwingende Voraussetzung für die korrekte Modellierungdes Produktionssystems ist [Thiel u.a. 1998], [Richter u.a. 1998] (vergl. Punkt 3.3.1),
• die Umsetzung eigener Reihenfolgeplanungsverfahren im Rahmen der Fertigungs-steuerung (vergleiche Punkt 3.3.1),
• oder um ein Feintuning an den integrierten Synchronisationsverfahren vornehmen zukönnen (vergleiche Punkt 3.1.3.6).
Als ein Problem für die Implementation zusätzlicher Algorithmen erweist sich oft, daßviele ereignisorientierte Simulatoren nur fest definierte Ereignisse besitzen, zu denen derBenutzer eine eigene Ereignisroutine hinterlegen kann. Wird während des Simulations-laufes das betreffende Ereignis ausgelöst, so wird die vom Benutzer hinterlegte Ereignis-routine aufgerufen.
Hier muß die Möglichkeit geboten werden:• frei weitere Ereignistypen abbilden zu können und• in den Ereignisroutinen muß man sowohl das zu lösende Problem auf hohem Niveau
formulieren können und man muß auch Zugriff auf alle (wesentlichen) Funktio-nalitäten des Simulationssystems haben.
Hohe Performance:
Die Abarbeitung eines Simulationsmodells mit dem Implementationsansatz sollte so per-formant wie möglich sein. Denn das Oberziel der Anwendung der Parallelen und Ver-

Kapitel 3 Internationaler Wissensstand auf dem Gebiet der Parallelen undVerteilten Simulation
Seite 110
teilten Simulation zur Simulation von Produktionssystemen ist die Beschleunigung derSimulationsausführung. Die Forderung der hohen Performance steht allerdings im Kontrastzur Forderung einer hohen Flexibilität.
3.3.3 Vergleich der Anforderungen mit bisherigen Lösungsansätzen im Gebiet derParallelen und Verteilten Simulation
Vergleicht man die Anforderungen an ein Tool zur Parallelen und Verteilten Simulation:
1. Modellierung auf hohem Niveau.2. Strikte Trennung zwischen Simulationsmodell und Synchronisationsverfahren.3. Effiziente Kommunikationsmechanismen.4. Hohe Performance.5. Unabhängigkeit von einer speziellen Implementationsumgebung.6. Flexibel erweiterbar.
mit den bisherigen softwaretechnischen Realisierungen aus Punkt 3.2, so ist folgendes zubemerken:
• Es existiert bisher kein Tool, welches die Parallele oder Verteilte Simulation von Pro-duktionssystemen direkt unterstützt.
• Es lassen sich nur sehr wenige Projekte finden, die sich mit der Parallelen und Verteil-ten Simulation auf dem Gebiet der Simulation von Produktionssystemen befassen.
• Die Möglichkeiten der meisten Tools sind sehr begrenzt.• Die Modellierung mit vielen der Ansätze ist sehr schwer, sehr zeitaufwendig, erfolgt
oftmals nach dem trial-and-error-Prinzip und ist mit hohem Änderungsaufwand ver-bunden.
• Die Anforderung (2) erweist sich als härteste Anforderung. Nur wenige Tools unter-stützen die Trennung von Simulationsmodell und Synchronisationsverfahren.
• Eine direkte Vergleichbarkeit der Performance der einzelnen Tools existiert nicht. Jedesder Tools hat oft ein spezielles Anwendungsgebiet in dem es besser geeignet ist. Zudemsind Realisierungen von aussagekräftigen Benchmarkmodellen in verschiedenen Simu-latoren sehr selten.
• Simulationssprachen bieten gegenüber den als Softwarepaketen vorliegenden Toolseindeutig Vorteile in puncto Flexibilität. Sie bieten die Möglichkeit zusätzliche Daten-strukturen und Algorithmen zur freien Benutzung durch den Anwender anlegen zu kön-nen.
• Es ist schwierig einen Ansatz zu finden, der hochflexibel ist, aber eine einfache Model-lierung unterstützt.
Prinzipiell könnte man auf Basis der aufgestellten Anforderungen ein eigenes Simulations-tool entwickeln. Jedoch beträgt allein der Aufwand zur Entwicklung und Implementationeiner Simulationshochsprache bereits mehrere Mannjahre. Zusätzlich wäre die Schaffungeiner Infrastruktur a lá HLA notwendig, was mit einem Aufwand von ca. 20 Mannjahrenanzusetzen wäre. Die Implementation eines eigenen Tools wäre vom Aufwand nicht ver-tretbar und soll deswegen nicht näher betrachtet werden. Auch die Kopplung von Toolswie z.B. CORBA als Infrastruktur und SLX als Simulationshochsprache würde auf dieselben, oben angesprochenen Probleme hinauslaufen und deswegen nur eine unbefriedi-gende Lösung darstellen. Ziel ist es deshalb, aus den vorhandenen Tools, die direkt zurParallelen und Verteilten Simulation entworfen wurden, das geeignetste Tool auszuwählenund für die Simulation von komplexen Produktionssystemen zu erweitern (siehe Punkt5.2.1).

Kapitel 3 Internationaler Wissensstand auf dem Gebiet der Parallelen undVerteilten Simulation
Seite 111
Bevor ein Implementationsansatz ausgewählt werden kann, müssen die Strukturen und Ab-läufe in einem Tool zur Parallelen und Verteilten Simulation komplexer Produktions-systeme näher analysiert werden. Deswegen erfolgt in Kapitel 4 eine Betrachtung vonPerformanceeinflußfaktoren (Punkt 4.3) und eine Auswahl und Parameterisierung einesgeeigneten Synchronisationsverfahrens (Punkt 4.4). Weiterhin erfolgt im Punkt 4.5 dieVorstellung eines speziell für Produktionssysteme geeigneten Partitionierungsverfahrens.Nach der Konkretisierung obiger Anforderungen in Kapitel 4 erfolgt im Punkt 5.2.1 dieAuswahl eines Implementationsansatzes für die Umsetzung der prototypischen Lösung.

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 112
4 Lösungskonzept zum Einsatz der Parallelen und Ver-teilten Simulation zur Steuerung von komplexen Pro-duktionssystemen
4.1 Überblick über die Bestandteile des LösungskonzeptesIn den Anforderungen im Punkt 2.4.2 wurde bereits festgehalten, daß es aufwendig ist einSimulationsmodell für ein größeres Produktionssystem zu erstellen. Im Kapitel 3 wurdegezeigt, daß die Erstellung von Modellen für die Parallele und Verteilte Simulation mitvielen Problemen behaftet ist und sehr schwierig ist (siehe Punkt 3.2.4). D.h., es ist unum-gänglich die Erstellung von Modellen zur Parallelen und Verteilten Simulation durch Soft-ware zu unterstützen (siehe Punkt 4.2). Des Weiteren wurde im Punkt 3.2.4 deutlich, daßnoch kein Simulationssystem existiert, welches direkt zur Parallelen und Verteilten Simu-lation von Produktionssystemen geeignet ist. Das Fehlen eines Tools und die Ungewißheitüber die Performance der Parallelen und Verteilten Simulation motivieren, ein solches Si-mulationssystem zu erstellen und damit Tests durchzuführen, um die Performanceunge-wißheit auszuräumen. Durch die Existenz eines solchen Simulationswerkzeugs bestehtdann die Möglichkeit, die Ausführung von Simulationsmodellen komplexer Produktions-systeme zu beschleunigen. D.h., es läßt sich beweisen, ob das Ziel - durch Parallelisierungdie Abarbeitung eines Simulationsmodells zu beschleunigen (siehe Punkt 1.1) - realisierbarist.
Bei der Durchführung der Parallelen und Verteilten Simulation sind insbesondere zweiAufgaben zu lösen:
• die Partitionierung (siehe Punkt 3.1.1) und• die Synchronisation (siehe Punkt 3.1.3).
Beide Aufgaben sind lösungsdefekt - es existieren keine praktikablen Lösungsverfahren.Für den Anwendungskontext der Simulation von Produktionssystemen lassen sich jedochSchlußfolgerungen für die Partitionierung ableiten (siehe Punkt 4.3). Die Synchronisationist dagegen durch eine hohe Zahl an Freiheitsgraden wie Teilverfahren und Parameter ge-kennzeichnet. Auch hier muß durch das Wissen aus dem Anwendungskontext eine Aus-wahl stattfinden (siehe Punkt 4.3). Letzten Endes muß eine Verknüpfung aller zu lösenderAspekte in einem integrierten System stattfinden. D.h., die Teilaufgaben wie:
• automatische Simulationsmodellerstellung,• Unterstützungssystem zur Durchführung von Simulationsstudien,• automatische Partitionierung des Simulationsmodells,• Abarbeitung des generierten und partitionierten Simulationsmodells sowie• die Experimentauswertung
müssen in einem Simulationswerkzeug - in einer Software - zusammengefaßt werden.Durch dieses integrierte Unterstützungssystem ist es einem Anwender möglich, einzelneSimulationsläufe und die gesamte Simulationsstudie einfacher und schneller auszuführen(siehe Punkt 1.1).
D.h., das integrierte Unterstützungssystem muß sich aus:
1. einem System zur Unterstützung von Simulationsstudien2. einem Partitionierungsverfahren3. einem Simulationsmodellgenerator

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 113
zusammensetzen und dabei
4. eine Simulationssoftware zur Ausführung der Parallelen und Verteilten Simulationmittels eines speziell parameterisierten Synchronisationsverfahren einbetten.
Die Lösung der Aufgaben (1) und (3) obliegt dabei dem Framework zur simulationsbasier-ten Fertigungssteuerung (siehe Punkt 4.2). Daran schließt sich die Untersuchung und Dis-kussion des Anwendungskontextes auf Einflußfaktoren, welche in der Parallelen und Ver-teilten Simulation berücksichtigt werden müssen, an (siehe Punkt 4.3). Die Beschreibungder Parameterisierung des einzusetzenden Synchronisationsverfahrens (Aufgabe 4) erfolgtim Punkt 4.4. Die Funktionsweise und die Algorithmen des Partitionierungsverfahrens(Aufgabe 2) sind im Punkt 4.5 beschrieben.Alternativ zum Einsatz der Parallelen und Verteilten Simulation kann und soll ein ver-teiltes Experimentiersystem eingesetzt werden. Eine solche verteilte Sequentielle Simu-lation ist bereits mit Erfolg zur beschleunigten Abarbeitung von Simulationsstudien einge-setzt worden [Bley, Wuttke 1997], [Arndt 2000], [Gehlsen, Page 2000], [Schneider, Rein-hardt 2000]. Im Punkt 4.6 wird deshalb ausgeführt, wie das verteilte Experimentiersystemin die Architektur des Frameworks zur simulationsbasierten Fertigungssteuerung zu inte-grieren ist.
4.2 Ein Unterstützungssystem zur Durchführung von Simula-tionsstudien - Das Framework zur simulationsbasierten Fer-tigungssteuerung
Es wurde bereits festgestellt, daß der Prozeß der Simulationsmodellerstellung der Paralle-len und Verteilten Simulation unbedingt durch Software zu unterstützen ist. Das in diesemUnterkapitel beschriebene Framework stellt das geforderte integrierte Unterstützungs-system für den Simulationsanwender dar. Ohne dieses Unterstützungssystem ist es nicht insinnvoller Zeit möglich, umfangreiche Simulationsmodelle komplexer Produktionssystemefür eine Parallele oder Verteilte Simulation zu erstellen.Verallgemeinernd ist zu bemerken, daß jeglicher Simulationsmodellerstellungsprozeßdurch Software unterstützt werden kann und muß. Nachfolgend soll deswegen das Frame-work zur simulationsbasierten Fertigungssteuerung als das dafür notwendige Unterstüt-zungssystem charakterisiert werden. Allein für den Einsatz der Parallelen und VerteiltenSimulation wäre nur eine Teilmenge der Funktionalitäten des Frameworks notwendig, umden Prozeß der Partitionierung und Modellerstellung eines parallelisierten Simulations-modells zu unterstützen. Das Framework stellt jedoch eine Generalisierung dar, welcheviel mehr leisten kann. Nachfolgend sollen deswegen der Umfang und die Möglichkeitendes Frameworks als Unterstützungssystem aufgezeigt werden. An zweckmäßigen Stelleninnerhalb dieses ‘Exkurses’ wird dabei immer wieder eine Eingrenzung auf die im Rahmender vorliegenden Arbeit für die Lösung der Parallelen und Verteilten Simulation notwen-digen Teilaufgaben vorgenommen. Ziel ist es jedoch, die Universalität des Gedankens desFrameworks dem Leser verständlich zu machen, wenn auch im Rahmen der Arbeit nur einTeil dieser Idee umgesetzt werden kann. Der vollständige Ausbau des skizzierten Gedan-ken des Frameworks als universelles Unterstützungssystem der simulationsbasierten Ferti-gungssteuerung ist jedoch ein lohnendes Ziel weiterführender Arbeiten89.
89 Siehe auch [Thiel u.a. 2001].

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 114
4.2.1 Notwendigkeit eines Unterstützungssystems zur Durchführung von Simula-tionsstudien
Herkömmliche Systeme zur Fertigungssteuerung sind dadurch gekennzeichnet, daß das derPlanung zugrunde liegende Modell nur ein unzureichendes Abbild des realen Produktions-systems darstellt. Es wird zum Einen nur ein begrenzter Ausschnitt betrachtet und zumAnderen werden auftretende Restriktionen des Produktionssystems sowie bestehende In-terdependenzen zu benachbarten Teilsystemen vernachlässigt [Page 1991, S. 8], [Mehl1994, S. 1], [Kosturiak, Gregor 1995, S. 5, S. 13, S. 83]. Bedingt durch das unzureichendeModell der Planung lassen sich keine vollständig zufriedenstellenden Planungsergebnisseerzielen. Die als Ergebnis der Planung ermittelten Maßnahmen lassen sich somit nur be-dingt auf das Realsystem übertragen [Page 1991, S. 22], [Smith 1999], [Blazejewski 2000,S. 66].Einen Ausweg verspricht der Einsatz der Simulation. Die Simulation bietet die Möglich-keit, einen mehrstufigen Produktionsprozeß in einem Modell abzubilden und das dynami-sche Verhalten von Durchlaufzeiten, Durchsatz, Kapazitätsauslastung usw. hinreichendgenau zu prognostizieren [Blazejewski 2000, S. 68]. Durch den Einsatz der Simulationkann man aufzeigen, wie sich die Wahl einer Steuerungsstrategie (siehe Punkt 2.1.4) aufdie Ziele der Fertigungssteuerung (siehe 2.1.2) auswirken würde. Somit lassen sich ver-schiedene Handlungsalternativen auf ihren Zielerreichungsgrad hin untersuchen, um die inder aktuellen Situation günstigste Handlungsalternative zu bestimmen [Kosturiak, Gregor1995, S. 15]. Die adäquate Abbildung des Produktionssystems im Simulationsmodell istdabei die notwendige Voraussetzung, um beim Experimentieren mit dem Simulations-modell zu Erkenntnissen zu gelangen, die auf die Realität übertragbar sind (Ziel der Si-mulation, siehe Punkt 2.2.1.1) [Page 1991, S. 8], [Smith 1999].
Bei der Anwendung der Simulation als Methode der Prognose im Kontext der Fertigungs-steuerung (vergleiche Punkt 2.1.1) treten allerdings mehrere Probleme auf:
• Es ist ein hoher Aufwand zur Modellerstellung notwendig (siehe auch Punkt 2.3.1)[Page 1991, S. 24], [Kosturiak, Gregor 1995, S. 66], [Kobylka, Gäse, Wirth 2000].
• Während des Experimentierens mangelt es dem Anwender an Unterstützung[Kosturiak, Gregor 1995, S. 155-161], [Blazejewski 2000, S. 66ff.].
• Bei der Auswertung der Ergebnisse der Simulationsexperimente wird der Anwendernur unzureichend unterstützt [Kosturiak, Gregor 1995, S. 155-161], [Blazejewski2000, S. 66ff.].
• Es fehlt an einer Kopplung des Werkzeugs „Simulation“ mit bestehenden Planungs-und Informationssystemen [Kosturiak, Gregor 1995, S. 87], [Blazejewski 2000, S.66ff.].
• Es fehlt die Integration von Komponenten zur Durchführung der in ihrer Gesamtheitnotwendigen Teilaufgaben und Prozesse einer Simulationsstudie in einem Werkzeug(als Software).
Das Problem der Modellerstellung äußert sich darin, daß ein Simulationsexperte manuellein Simulationsmodell aufbauen muß, bevor Experimente mit dem Simulationsmodelldurchgeführt werden können. Der Abstraktionsprozeß zur Erstellung des Modells ist mitzwei Problemen behaftet. Erstens ist jeder Abstraktionsprozeß schwierig und bedarf eineserfahrenen Bearbeiters und Zweitens ist der Abstraktionsprozeß mit einem hohen zeit-lichen Aufwand verbunden (siehe Punkt 2.3.1). Um anhand von Experimenten an einemModell zu Aussagen zu gelangen, die auf die Wirklichkeit übertragbar sind (Ziel der Si-mulation, siehe 2.2.1.1), ist eine adäquate Abbildung der wesentlichen Elemente und deswesentlichen Verhaltens des Produktionssystems sowie der im Produktionssystem auf-

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 115
tretenden Restriktionen im Simulationsmodell zwingend notwendig (vergleiche 2.2.1.1)[Page 1991, S.13-14], [Smith 1999], [Blazejewski 2000, S. 66]. Es existiert jedoch keinallgemein für jedes Produktionssystem anwendbares Simulationsmodell. D.h., für jedesProduktionssystem ist ein spezielles Simulationsmodell zu entwickeln [Blazejewski 2000,S. 66], [Wiedemann 2000]. Da die Realsysteme verschieden sind, muß immer wieder einneues, das betrachtete Realsystem adäquat abbildendes Modell geschaffen werden. So be-steht unter Umständen die Notwendigkeit, verschiedene Prozeßbedingungen (siehe 2.3.2.3)und damit verbundene Steuerungsansätze im Modell zu implementieren, um eine wirklich-keitsnahe Abbildung zu erhalten. Die zu erstellenden Simulationsmodelle weisen zwargroße Ähnlichkeiten auf, unterscheiden sich aber in den Details. Die Aufgabe eines Simu-lationsspezialisten besteht u.a. darin, ein vorhandenes Grundmodell zu finden und diesesgemäß des zu betrachtenden Produktionssystems abzuändern oder anzupassen. Der Prozeßder manuellen Erstellung und manuellen Pflege von Simulationsmodellen ist aufgrund derKomplexität realer Produktionssysteme sehr zeitintensiv [Page 1991, S. 24], [Kosturiak,Gregor 1995, S. 66], [Kobylka, Gäse, Wirth 2000]. Die Reduktion der Komplexität desSimulationsmodells zur Verringerung des Modellierungsaufwandes ist aber nicht ohneVerlust an Abbildungsgenauigkeit - und damit durch von der Realität abweichende Aussa-gen der Experimente - möglich. Zur Modellierung ist ferner ein Simulationsexperte not-wendig, der in langwieriger Kleinarbeit auf Basis seiner Erfahrungen die notwendigen Im-plementationen bzw. Anpassungen am Simulationsmodell vornimmt [Kosturiak, Gregor1995, S. 65], [Blazejewski 2000, S. 69 ff.], [Wiedemann 2000]. Die fehlende Kopplung zuden bestehenden Planungs- und Informationssystemen verhindert außerdem eine automati-sche Übernahme der aktuellen Zustandsdaten aus dem Produktionssystem für die Modell-erstellung und -validierung (vergleiche Punkt 2.3.3., Vorgabe eines initialen Systemzu-standes) [Blazejewski 2000, S. 66, S. 92f]. D.h., der Anwender ist gezwungen, die notwen-digen Daten selbst zu ermitteln und für die Simulation in geeigneter Form bereitzustellen.Der manuelle Prozeß der Modellerstellung läßt sich durch Modellgeneratoren aber in star-kem Maße unterstützen [Schulz 1996], [Kobylka, Gäse, Wirth 2000], [Gäse, Günther,Wirth 2000], [Wiedemann 2000], [Eversheim, Intra, Abels 2000].
Ein weiteres wesentliches Problem ist die mangelnde Unterstützung des Anwenders bei derDurchführung von Simulationsexperimenten und bei deren Auswertung. Der Ablauf einerSimulationsstudie gestaltet sich prinzipiell wie folgt:
1. Ein Simulationsexperte erstellt ein das reale Produktionssystems adäquat abbilden-des Simulationsmodell.
2. Der Anwender macht für einen ersten Simulationslauf die Experimentvorgaben. Z.B.welche konkreten Verfahren zur Festlegung der Auftragsreihenfolge an den jeweili-gen Maschinengruppen einzusetzen sind.
3. Im dritten Schritt startet der Anwender den Simulator und wartet bis dieser den Si-mulationslauf abgeschlossen hat.
4. Dann muß der Anwender die Simulationsergebnisse sichern, weil durch einen neuenSimulationslauf die letzten Ergebnisdateien in der Regel überschrieben werden.
5. Dieser Prozeß wiederholt sich solange, bis der Anwender sämtliche zu unter-suchenden Varianten90 simuliert hat.
6. Danach werden die Ergebnisse durch den Anwender ausgewertet.7. Dies kann auch dazu führen, daß der Anwender den Prozeß des Experimentierens
weiterführt.
90 Simulation ist eine Methode der Prognose, sie kann nicht direkt zur Optimierung verwendet werden. Siehe
dazu Punkt 2.1.1, 2.2.1.1.

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 116
Primär ist hierbei der Tatbestand, daß der Anwender eine Vielzahl manueller Tätigkeitenausführt, welche den Prozeß des Experimentierens aufwendig gestalten, die sich aber ande-rerseits automatisieren lassen91.
Ein Problem bei der Anwendung der Simulation besteht darin, daß die meisten Tools dieSimulationsergebnisse in einer für den Anwender ungeeigneten Form präsentieren bzw.daß sich die Auswertung auf Standardgrößen beschränkt (wie z.B. auf die Durchlaufzeitender Aufträge oder auf die Kapazitätsauslastung der einzelnen Maschinen) [Blazejewski2000, S. 66], welche eine detaillierte Untersuchung des Systemverhaltens verhindert (z.B.Analyse wie sich die Kapazitätsauslastung über die Zeit verteilt). Die vom Simulator aus-gegebenen Ergebnisse müssen demzufolge nachträglich manuell oder mit Hilfe zusätzlichgeschaffener Werkzeuge aufbereitet werden. Weiterhin archivieren die Simulationswerk-zeuge die Ergebnisse nicht - diese Archivierung ist aber eine notwendige Voraussetzungfür die vergleichende Gegenüberstellung der verschiedenen simulativ untersuchten Maß-nahmen, um die effizienteste Maßnahme auszuwählen. Das bedeutet, daß ein Lösungs-ansatz benutzerdefinierbare Auswertemöglichkeiten über alle charakteristischen Einfluß-größen anbieten muß und die Ergebnisse aller Experimente für eine abschließende Gegen-überstellung aufzubewahren hat.
Ein weiteres Problem der Simulation besteht darin, daß eine Kopplung der Simulations-werkzeuge zu bestehenden Planungs- und Informationssystemen bisher fehlt. So wird z.B.eine automatische Übernahme der aktuellen Zustandsdaten aus dem Produktionssystem fürdie Modellerstellung und -validierung verhindert [Hirsch u.a. 2000]. D.h., der Anwenderist zu Beginn der Simulationsstudie gezwungen, die notwendigen Daten selbst zu ermittelnund für die Simulation in geeigneter Form bereitzustellen. Das Problem der fehlendenKopplung besteht auch bei der Rückführung der durch den Anwender aufgrund der Simu-lationsergebnisse ausgewählten Handlungsalternative als Vorgabegröße an bestehendePlanungs- und Informationssysteme. Diese Rückführung muß bisher manuell durch denAnwender erfolgen.
Außerdem stellt die fehlende Integration der Komponenten zur Durchführung der in ihrerGesamtheit notwendigen Teilaufgaben und Prozesse einer Simulationsstudie in einemWerkzeug - als eine Software - ein großes Problem dar (vergleiche Punkt 2.4.2). Bisherexistieren für fast jede der Teilaufgaben vom Anwender selbstgeschaffene Teillösungen,die nicht in anderen Simulationsprojekten wiederverwendet werden können. D.h., jedeSimulationsanwendung ist völlig losgelöst von anderen Simulationsanwendungen. Es wirdDoppelarbeit geleistet, anstatt vorhandene Bausteine, Daten, Methoden und Vorgehens-weisen wiederzuverwenden (vergleiche Punkt 4.2.2, Wiederverwendbarkeit als Ziel einesFrameworks) [Wiedemann 2000].
Aus den dargestellten Problemen ergibt sich das Fazit, daß die Simulation bisher nicht be-triebsbegleitend eingesetzt werden kann. Letzteres ist allerdings für einen effizienten Ein-satz der Simulation im Rahmen der Fertigungssteuerung notwendig (siehe Punkt 2.4.2).
Aus den Problemen lassen sich Anforderungen an eine zukünftige Lösung ableiten:
• Es besteht die Notwendigkeit, die Simulationssysteme mit den bestehenden Planungs-und Informationssystemen zu koppeln, um eine Erstellung und Validierung von Simula-tionsmodellen, eine Extraktion des aktuellen Zustandes des Produktionssystems und ei-
91 Bereits [Kosturiak, Gregor 1995, S. 150-161], [Blazejewski 2000, S. 66ff] weisen auf die Wohlstrukturiert-
heit dieser Aufgaben, aber die mangelnde Unterstützung des Anwenders hin.

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 117
ne Rückführung der Steuerungsanweisungen und Ergebnissen in das Produktionssystemautomatisch vornehmen zu können.
• Simulationsmodelle müssen mit geringem Aufwand, in kurzer Zeit und ohne Spezial-kenntnisse erstellt werden können. Das Simulationsmodell soll ferner automatisch - oh-ne Eingriff des Anwenders und ohne Einsatz eines Simulationsexpertens - erstellt wer-den (siehe 5.1.2.12, „Die Generator-Komponente“).
• Eine Unterstützung des bisher manuellen Experimentierens und der Ergebnisauswer-tung ist dringend notwendig. Hierzu muß das Framework Vorgehensmodelle enthalten,welche helfen, die bisher manuell durchgeführten Prozesse zu automatisieren.
• Eine Lösung hat die Hauptfunktionalitäten bei der Anwendung der Simulation - dieExtraktion der aktuellen Zustandsdaten aus dem Produktionssystem, die Modell-erstellung und -validierung, die Experimentplanung, die Experimentdurchführung, dieErgebnisauswertung und die Rückführung von Vorgabegrößen in das Produktions-system - in einen geschlossenen Modellansatz zu integrieren.
• Das System soll die Möglichkeit eröffnen, in den Ergebnisdaten verborgenes zusätz-liches Steuerungswissens zu entdecken.
• Das zu schaffende System muß einfach bedienbar, flexibel erweiterbar und offen sein(nicht allein für spezielles System konzipiert), austauschbare und wiederverwendbareKomponenten besitzen und eine prinzipiell verteilbare Architektur92 aufweisen.
• Für den Einsatz der Parallelen und Verteilten Simulation ergibt sich zusätzlich die Not-wendigkeit, die bisher manuell im trial-and-error Verfahren durchgeführte Aufgabe derPartitionierung ebenfalls zu automatisieren und mit der automatischen Simulations-modellerstellung zu koppeln.
Ziel des Simulations-Framework zur Fertigungssteuerung ist es, dem Anwender ein Instru-mentarium in die Hand zu geben, welches ihn befähigt:
a) auf Basis der aktuellen Zustandsdaten des Produktionssystems simulativ Maßnahmenzu testen,
b) die in der aktuellen Situation effektivste Maßnahme zu finden undc) diese Maßnahme sowie die damit verbundenen Größen dem Produktionssystem vor-
zugeben,d) ohne dabei Kenntnisse über Aufbau und Funktionsweise des „Werkzeuges Simulation“
zu besitzen.
4.2.2 Begriff des Frameworks
Die Spannweite der Definitionen des Begriffs Framework ist relativ groß [Brunkhorst2001]:
A Framework, in object-oriented systems, is a set of classes that embodies an ab-stract design for solutions to a number of related problems. [wombat]
A semifinished software architecture that can be adapted to specific need by apply-ing object-oriented programming concepts. [Pree 1995]
A framework is a collection of abstract and concrete classes and the interface be-tween them. [Chen, Chen 1994]
92 Siehe 4.6 - Aufbau eines verteilten Experimentiersystems zur schnelleren Abarbeitung einer Vielzahl von
Experimenten einer Simulationsstudie.

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 118
A framework is a set of cooperating classes that make up a reusable design for a spe-cific class of software. The framework dictates the architecture of your application.[Helm, Gamma 1994]
Ein Framework besteht aus einer Menge von Objekten, die eine generische Lösungfür eine Reihe verwandter Probleme implementieren. [Eggenschwiler u.a. 1995]
Ein Framework definiert eine bestimmte Architektur für eine Familie von Systemen.[Reißing 1998]
Ein Framework definiert die Stellen, an denen Anpassungen für das konkrete Systemgemacht werden sollen. [Reißing 1998]
Ein Framework besteht aus einer Menge von zusammenarbeitenden Klassen, die ei-nen wiederverwendbaren Entwurf mit einer wiederverwendbaren Implementierungdarstellen. [Appelrath 1998]
Ein Framework bestimmt die Softwarearchitektur der Anwendung: Es definiert dieStruktur ,,im Großen'', seine Unterteilung in Klassen und Objekte, die jeweiligenzentralen Zuständigkeiten, die Zusammenarbeit der Klassen, sowie den Kontrollfluß.[Appelrath 1998]
Ein Framework enthält die Entwurfsentscheidungen, die in seinem Anwendungs-bereich allgemein anzufinden sind (Entwurfswiederverwendung). [Appelrath 1998]
Gemeinsam sind somit folgende Merkmale:
• Frameworks definieren in ihrem Anwendungsbereich die Architektur eines Sy-stems.
• Frameworks enthalten wiederverwendbare, im Sinne einer Anwendung noch unfer-tige Softwarebausteine (Komponenten).
• Frameworks definieren die Regeln, nach denen sie zur vollständigen Anwendungweiterentwickelt werden.
• Frameworks enthalten eine wiederverwendbare, allgemeingültige und durch dasZusammenspiel einzelner Objekte des Frameworks vordefinierte Verarbeitungs-logik.
• Frameworks sind oft objektorientiert implementiert.
Berten [Berten 1997] schreibt: „Frameworks bestehen aus mehreren interagierenden Soft-warekomponenten. Dies sind vornehmlich die Klassen der objektorientierten Program-mierung. Einige dieser Klassen sind dabei noch abstrakt gehalten und müssen mit Hilfe derobjektorientierten Methoden vom Entwerfer vervollständigt werden. Der Software-entwickler implementiert die erforderliche Funktionalität der abstrakten Klassen und er-stellt somit das gewünschte Teilsystem. Ein Framework stellt eine Art vordefiniertenRahmen dar, indem anwendungspezifische Details integriert werden. Dabei stellt ein Fra-mework die Infrastrukturen und Konzepte eines bestimmten Anwendungsbereichs zurVerfügung.“
Genau dies ist der Ansatzpunkt für ein Simulations-Framework zur Fertigungssteuerung.Zukünftig kann der Bearbeiter eines Simulationsthemas auf Komponenten des Frameworkszurückgreifen und so bereits nach kurzer Zeit erste Simulationsmodelle präsentieren. DieKomponenten des Frameworks sollen hierbei den Anwender aktiv bei seiner Arbeit unter-stützen und bereits die Grundfunktionalitäten der Anwendung der Simulation anbieten.
Das Simulations-Framework zur Fertigungssteuerung besteht dabei aus zwei Hauptkompo-nenten: der Shell und den Generatoren.

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 119
• Die Shell kapselt die Verwaltung der Daten des Produktionssystems und die Auf-bereitung der Ergebnisse der Simulationsläufe.
• Ein Generator dagegen hat die Aufgabe, basierend auf den Daten des Produktions-systems, ein Simulationsmodell zu generieren, mit welchem die Simulation durch-führbar ist.
4.2.3 Konzeption des Frameworks zur simulationsbasierten Fertigungssteuerung
4.2.3.1 Aufgaben und Umfang des Frameworks
Das Framework zur simulationsbasierten Fertigungssteuerung definiert eine Spezifikationzur Implementation eines Werkzeuges, das den Disponenten eines Produktionssystems indie Lage versetzt (siehe Abbildung 39), Simulation als Methode der Prognose im Kontextder Fertigungssteuerung einzusetzen (siehe Punkt 2.1.1, insbesondere Abbildung 1).Die Simulations-Shell „SimFab“93 stellt die prototypische Realisierung der Spezifikationendes Frameworks als Software dar (siehe Punkt 5.1).
Das Framework integriert die Hauptfunktionalitäten bei der Anwendung der Simulation inder Fertigungssteuerung in einen geschlossenen Modellansatz:
• die Extraktion der aktuellen Zustandsdaten,• die Modellerstellung und -validierung,• die Experimentplanung,• die Durchführung der Simulationsexperimente,• die Ergebnisauswertung und• die Rückführung von Vorgabegrößen in das Produktionssystem.• Für die Parallele und Verteilte Simulation ergibt sich zusätzlich, daß die Modell-
erstellung automatisch ein partitioniertes Simulationsmodell erstellt.• Die Aufgabe der Synchronisation dagegen ist als Bestandteil der externen Simula-
tionssoftware anzusehen.
externe Simulationssoftware
Simulations-Shell
Anwender (Disponent)
Enterprise Ressource Planning System
Fertigungssystem
Betriebsdatenerfassung
Abbildung 39 Einbettung des Frameworks in bestehende Informations- undKommunikationssysteme
Durch die Simulations-Shell wird der Anwender umfassend bei diesen Prozessen unter-stützt. Bisher manuell ablaufende Prozesse werden (teil)automatisiert. Der Anwender mußjetzt keine Kenntnisse von Aufbau und Funktionsweise des „Werkzeugs Simulation“ mehrbesitzen.
93 SimFab - Simulator für Fabriken

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 120
Das Framework besitzt eine modulare, flexible, offene und erweiterbare Struktur. Es be-steht dadurch die Möglichkeit, Komponenten auszutauschen oder zusätzliche Kompo-nenten einzubringen, um das Framework an andere externe Systeme oder andere externeSimulatoren anzupassen.
4.2.3.2 Übersicht über die Architektur des Frameworks
In diesem Abschnitt wird beschrieben, aus welchen grundsätzlichen Komponenten dasFramework zur simulationsbasierten Fertigungssteuerung besteht und welche grundsätz-lichen Abläufe im Framework existieren. Dies soll das prinzipielle Verständnis des Auf-baus und der Funktion des Frameworks ermöglichen. Im Punkt 5.1 erfolgt dann eine de-taillierte Erläuterung der Funktionsweise der Komponenten des Frameworks.
Zur Erfüllung seiner Aufgaben weist das Framework die in Abbildung 40 dargestellteStruktur auf.
Die Simulations-Shell stellt über eine graphische Oberfläche die Hauptfunktionalitätenbei der Anwendung der Simulation bereit (siehe Abbildung 40):
• die Extraktion der aktuellen Zustandsdaten aus dem Produktionssystem (Daten-import-Komponente, siehe Punkt 5.1.2.5),
• die Modellerstellung und -validierung (Komponente der Modellgenerierung, siehePunkt 5.1.2.12),
• die Experimentplanung (Komponente der Experimentplanung, siehe Punkt 5.1.2.8),• die Experimentdurchführung (Komponente der Experimentdurchführung, siehe
Punkt 5.1.2.10),• die Ergebnisauswertung (Komponenten der Ergebnisaufbereitung und Auswertung,
siehe Punkte 5.1.2.15 bis 5.1.2.20) und• die Rückführung von Vorgabegrößen in das Produktionssystem (Ergebnisüber-
nahme-Komponente, siehe Punkt 5.1.2.21)
Die Datenimport-Komponente hat die Aufgabe, die Daten des zu modellierenden Pro-duktionssystems - und später die aktuellen Zustandsdaten dieses Produktionssystems - auseinem bestehenden Planungs- und Informationssystem herauszuziehen und in der Modell-datenbank zu speichern. Hierbei existiert eine Spezifikation über den Funktionsumfangeiner Datenimport-Komponente. Für jedes Planungs- und Informationssystem, welches mitder Simulations-Shell gekoppelt werden soll, wird eine eigene Datenimport-Komponentegemäß der Spezifikation benötigt.
Die Datenimport-Komponente legt die Daten des zu modellierenden Produktionssystemsin der Modelldatenbank ab. Hier werden Informationen über die statischen Elemente desProduktionssystems (die Maschinen, die Maschinengruppen, die Lagerplätze und dieTransportmöglichkeiten) und die dynamischen Elemente des Produktionssystems (Pro-dukte, Arbeitspläne, Bearbeitungsanweisungen, Aufträge und Lose) gespeichert. Die Mo-delldatenbank ist hierbei in der Lage, mehrere Modelle von Produktionssystemen odermehrere Varianten eines Modells aufzunehmen und zu verwalten.Die Ablage der Daten des Produktionssystems in der Modelldatenbank ermöglicht es, dasFramework unabhängig von konkreten verwendeten externen Informationssystemen zubetreiben. Damit besteht auch die Möglichkeit, daß die Anwender vorhandene Modelle inihren Ausprägungen variieren können, um so verschiedene Szenarien des Realsystems zuanalysieren.
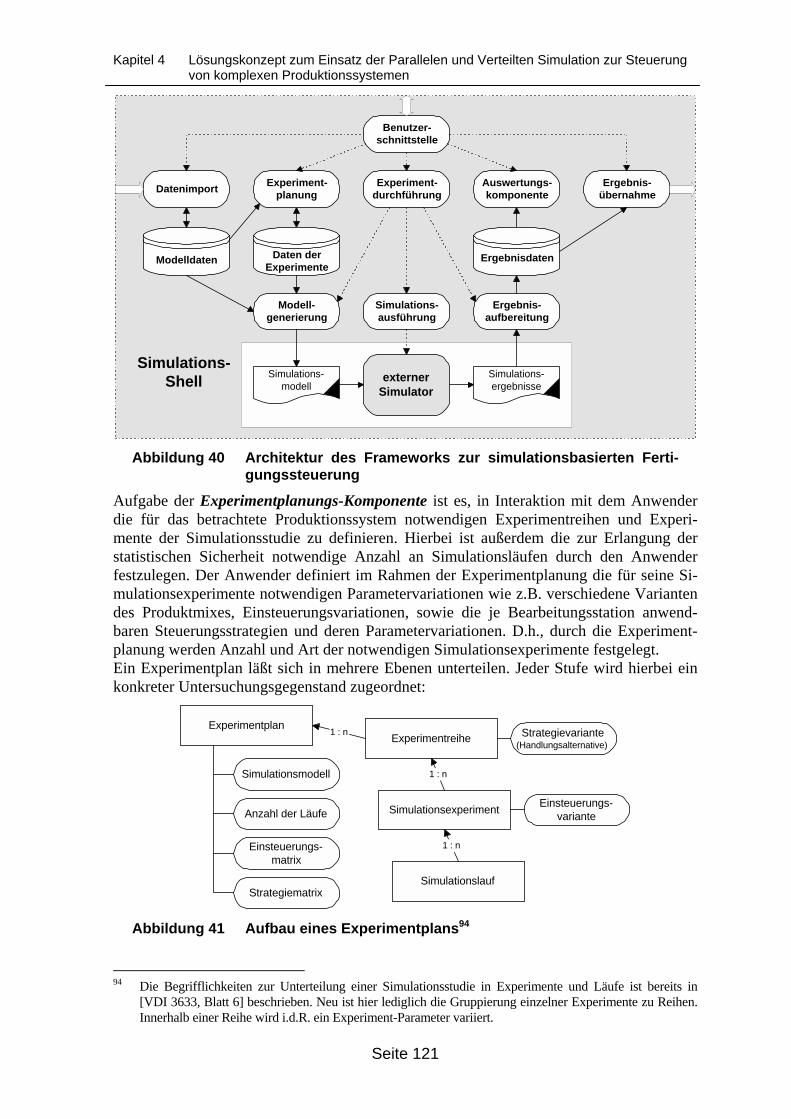
Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 121
Simulations-Shell
Modelldaten
Modell-generierung
Simulations-modell
Ergebnis-aufbereitung
Auswertungs-komponente
Benutzer-schnittstelle
Daten derExperimente
Experiment-planung
Ergebnisdaten
Ergebnis-übernahme
Experiment-durchführung
externerSimulator
Simulations-ausführung
Datenimport
Simulations-ergebnisse
Abbildung 40 Architektur des Frameworks zur simulationsbasierten Ferti-gungssteuerung
Aufgabe der Experimentplanungs-Komponente ist es, in Interaktion mit dem Anwenderdie für das betrachtete Produktionssystem notwendigen Experimentreihen und Experi-mente der Simulationsstudie zu definieren. Hierbei ist außerdem die zur Erlangung derstatistischen Sicherheit notwendige Anzahl an Simulationsläufen durch den Anwenderfestzulegen. Der Anwender definiert im Rahmen der Experimentplanung die für seine Si-mulationsexperimente notwendigen Parametervariationen wie z.B. verschiedene Variantendes Produktmixes, Einsteuerungsvariationen, sowie die je Bearbeitungsstation anwend-baren Steuerungsstrategien und deren Parametervariationen. D.h., durch die Experiment-planung werden Anzahl und Art der notwendigen Simulationsexperimente festgelegt.Ein Experimentplan läßt sich in mehrere Ebenen unterteilen. Jeder Stufe wird hierbei einkonkreter Untersuchungsgegenstand zugeordnet:
ExperimentplanExperimentreihe
Simulationsexperiment
1 : n
Simulationslauf
1 : n
1 : n
Einsteuerungs-matrix
Strategiematrix
Simulationsmodell
Anzahl der Läufe
Strategievariante(Handlungsalternative)
Einsteuerungs-variante
Abbildung 41 Aufbau eines Experimentplans94
94 Die Begrifflichkeiten zur Unterteilung einer Simulationsstudie in Experimente und Läufe ist bereits in
[VDI 3633, Blatt 6] beschrieben. Neu ist hier lediglich die Gruppierung einzelner Experimente zu Reihen.Innerhalb einer Reihe wird i.d.R. ein Experiment-Parameter variiert.

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 122
Die Ebene des Experimentplans umfaßt eine Enumeration sämtlicher zu variierender Mo-dellparameter. Dem Experimentplan ist die Ebene der Experimentreihe untergeordnet. EineExperimentreihe bezieht sich auf die Untersuchung einer Strategievariante über einen fest-gelegten Einsteuerungsbereich. Die Zahl der Experimentreihen eines Experimentplans be-stimmt sich aus der Anzahl der definierten Strategievarianten. Eine Experimentreihe be-steht wiederum aus mehreren Experimenten. Das Simulationsexperiment spezifiziert nebender Strategievariante eine konkrete Einsteuerungsvariante. Die Zahl der Simulations-experimente zu einer Experimentreihe leitet sich aus den Grenzen des Einsteuerungs-bereiches und der Schrittweite der Erhöhung der Einsteuerungszahl ab. Der Simulations-lauf bildet die unterste Ebene. Die Anzahl der Simulationsläufe pro Simulationsexperimentist durch den Parameter “Anzahl der Läufe“ des Experimentplans festgelegt.
Die während der Experimentplanung erstellten Daten werden in der Datenbank der Expe-rimentpläne gespeichert. Es ist möglich, je Modell der Modelldatenbank eine Reihe vonExperimentplänen zu hinterlegen.
Aufgabe der Komponente der Experimentdurchführung ist es, für den ausgewählten Ex-perimentplan die in der Experimentplan-Datenbank definierten Simulationsexperimenteautomatisch auszuführen und deren Ergebnisse aufzubereiten. Hierzu wird für jedes imExperimentplan definierte Simulationsexperiment folgendes ausgeführt (Abbildung 42,siehe auch Punkt 5.1.2.10):
1. Über die Komponente der Modellgenerierung (siehe Punkt 5.1.2.12) wird aus denDaten des Modells des Produktionssystems (welche in der Modelldatenbank gespei-chert sind) und den Daten des aktuellen Simulationsexperiments (dessen Daten in derExperimentplan-Datenbank gespeichert sind) das notwendige Simulationsprogrammautomatisch gemäß der aktuellen Gegebenheiten des Simulationsexperiments erzeugt,der Anwender ist somit nicht mehr gezwungen, das Simulationsmodell manuell zu er-stellen oder bei Änderung von Parametern das Modell manuell abzuändern.Für den Einsatz der Parallelen und Verteilten Simulation ist diese Komponente zusätz-lich um die automatische Partitionierung des Simulationsmodells bei der Generierungzu ergänzen.
2. Die Komponente der Simulatorsteuerung (siehe Punkt 5.1.2.13) hat die Aufgabe, ei-nen Simulationslauf mit dem automatisch generierten Modell auszuführen. Hierzu wirdein externer Simulator mit der erzeugten Simulationsmodelldatei gestartet und nachBeendigung des Laufes des externen Simulators werden die Ergebnisse dieses Simula-tionslaufes aufbereitet. Die Simulatorsteuerung hat diese Prozedur für die notwendigeAnzahl von Simulationsläufen zu wiederholen.
Die Komponente der Ergebnisaufbereitung hat zwei Aufgaben. Erstens müssen nach derAusführung eines Simulationslaufes die vom externen Simulator erzeugten Ergebnis-dateien aufbereitet werden (siehe Punkt 5.1.2.15). Diese Ergebnisse werden in einer tem-porären Datenbank gespeichert. Als zweite Aufgabe steht, nach der Ausführung aller Si-mulationsläufe des Simulationsexperiments, die in der temporären Datenbank gespeicher-ten Ergebnisse der einzelnen Simulationsläufe zu aggregieren (siehe Punkt 5.1.2.18). Dieseaggregierten Ergebnisse eines Simulationsexperiments werden abschließend in der Ergeb-nisdatenbank gespeichert.

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 123
Modelldaten
Generator
Simulations-modell
Ergebnis-aufbereitung
Experimentplan Ergebnisdatenaller Experimente
Simulations-experiment-steuerung
externerSimulator
Simulations-ausführung
Datendateien(optional)
(definiertesFormat)
Simulations-ergebnisse
Ergebnisse einesExperimentes
Simulations-laufsteuerung
Ergebnis-aggregation
Experiment-durchführung
Abbildung 42 Prinzipieller Ablauf der Experimentdurchführung
Das Framework gibt jeweils die Funktionalität der Komponenten vor. Für jeden mit derSimulations-Shell zu koppelnden externen Simulator ist es notwendig, einen anderen Si-mulationsmodell-Generator einzubinden und eine andere Parametrisierung der Simula-tionsausführungs-Komponente vorzunehmen. Eine Änderung der Ergebnisaufbereitungs-Komponente ist dagegen nicht notwendig, solange der externe Simulator in der Lage ist,die als standardisierte Schnittstelle durch das Framework vorgegebenen Simulations-ergebnisdateien (siehe Punkt 5.1.2.16) zu erzeugen.
In der Ergebnisdatenbank (siehe Punkt 5.1.2.19) werden die Ergebnisse aller Simulations-experimente des Experimentplans des betrachteten Simulationsmodells gespeichert. Zujeder Ergebnisgröße werden Summe, Anzahl, Mittelwert, Streuung, Minimum und Maxi-mum festgehalten. Als Ergebnisdaten werden z.B. für die Bearbeitungsstationen gespei-chert: die Summe der Bearbeitungs-, Leer- und Rüstzeiten, die Anzahl der bearbeitetenAufträge und die Auslastung. Als Ergebnisgrößen für die Produkte und Aufträge werdenz.B. gespeichert: Durchlaufzeit, Lieferterminabweichung, Anzahl eingesteuerter und aus-gesteuerter Aufträge. Durch die Speicherung der Ergebnisdaten in einer Datenbank ist dieVoraussetzung für die spätere vergleichende Bewertung der Simulationsergebnisse dieserExperimente gegeben.
Aufgabe der Auswertungs-Komponente (siehe Punkt 5.1.2.20) ist es dann, die in der Er-gebnisdatenbank gespeicherten Ergebnisse der Simulationsstudie dem Anwender in geeig-neter Form zu präsentieren. Hier ist sowohl eine tabellarische als auch eine grafische An-zeige möglich. Mit Hilfe der Auswertungs-Komponente wird der Anwender in die Lageversetzt, die unter den getesteten Umständen beste Handlungsalternative auszuwählen.
Schließlich ist es die Aufgabe der Ergebnisübernahme-Komponente (siehe Punkt5.1.2.21), die vom Anwender ausgewählte Handlungsalternative und die zu dieser Hand-

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 124
lungsalternative im Experimentplan festgehaltenen Parameter an das externe Planungs-und Informationssystem vorzugeben. Für jedes unterschiedliche Planungs- und Informa-tionssystem, welches mit der Simulations-Shell gekoppelt werden soll, wird eine eigeneErgebnisübernahme-Komponente benötigt.
4.2.3.3 Zusammenfassung des Exkurses „Framework zur simulationsbasierten Fer-tigungssteuerung“
Durch das beschriebene Framework kann der Prozeß der Simulationsmodellerstellung ent-scheidend vereinfacht und verkürzt werden. Ebenso leistet das Framework unverzichtbareHilfe bei der Durchführung und Auswertung von Experimenten mit dem Simulations-modell.Somit kann nicht nur eine Parallele und Verteilte Simulation durch das Framework zursimulationsbasierten Fertigungssteuerung unterstützt werden, sondern das Frameworkstellt ein Unterstützungssystem für jegliche Simulationsanwendung zur Optimierung vonProduktionssystemen dar.Durch die Implementation einer prototypischen Lösung dieses Frameworks kann der sehraufwendige Modellerstellungsprozeß der Parallelen und Verteilten Simulation vereinfachtwerden und es ist möglich, in kurzer Zeit umfangreiche Simulationsmodelle für die Paral-lele und Verteilte Simulation zu erstellen und somit Tests mit diesen Modellen durchzu-führen. Dies ist eine notwendige Voraussetzung, um die für ein gegebenes Modell perfor-manteste Parameterkombination der Synchronisations- und Partitionierungsverfahren he-rauszufinden (Ungewißheit über die Performance, Lösungsdefekt, siehe Punkt 3.3.2).Der zur Durchführung der Parallelen und Verteilten Simulation notwendige Teil des Fra-meworks (siehe Abbildung 43) beschränkt sich auf die Modelldatenbank und eine zugehö-rige Datenpflege-Komponente, eine exemplarische Lösung der Experimentplanungs-Komponente, die Experimentdurchführungs-Komponente, hierbei insbesondere die Mo-dellgenerierungs-Komponente mit eingebetteten Partitionierungsverfahren und eine rudi-mentäre Auswertungskomponente. Die Kopplungskomponenten des Frameworks (ver-gleiche Abbildung 40) werden dagegen nicht benötigt, da es in der vorliegenden Arbeit umdie Durchführung der Parallelen und Verteilten Simulation geht und der Entwurf einerSteuerungslösung für ein konkretes Produktionssystem hier nicht von Interesse ist. Ausden selben Gründen kann sich der Prototyp auf eine rudimentäre Auswertungskomponentebeschränken, da es Ziel der Arbeit ist, ein Simulationsmodell mit eingebetteter Fertigungs-steuerungslösung durch den Einsatz der Parallelen und Verteilten Simulation beschleunigtabzuarbeiten, anstatt eine qualitativ bessere Fertigungssteuerungslösung zu entwerfen, fürdie eine vollständig ausgeführte Auswertungskomponente unverzichtbar wäre.

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 125
Modelldaten
Modell-generierung
inc.Partitionierung
partitioniertesSimulationsmodell
Ergebnis-aufbereitung
Auswertungs-komponente
Benutzer-schnittstelle
Daten derExperimente
Experiment-planung
Ergebnisdaten
Experiment-durchführung
externerSimulator
Datenpflege
Simulations-ergebnisse
Daten derPartitionierung
Abbildung 43 Änderungen in der Komponentenstruktur des Frameworks fürdie prototypische Lösung mittels Paralleler und Verteilter Si-mulation
4.3 Grundprinzipien einer Parallelen bzw. Verteilten Simulationvon Produktionssystemen
Nachfolgend müssen einige grundlegende Fragen geklärt werden. Zum Einen ist eine Ent-scheidung über die tatsächliche Modellkomplexität zu treffen. Weiterhin steht die Frage,welche Elemente des Produktionssystems wie im Simulationsmodell abgebildet werdensollen. Dies hat starken Einfluß auf die Partitionierung des Modells und die Synchro-nisation der Modellteile, welche wiederum Einflußfaktoren auf die Parallele und VerteilteSimulation von Produktionssystemen sind.
4.3.1 In das Simulationsmodell einzubeziehende Komplexität von Produktions-systemen
4.3.1.1 Im Simulationsmodell abzubildende Daten und Bedingungen von Modellenvon Produktionssystemen
Prinzipiell enthalten Modelle von Produktionssystemen Daten über Ressourcen und Auf-träge. Es müssen Angaben über Maschinen, Werker, Transporteinrichtungen, Werkzeugeusw. vorhanden sein. Ebenso sind Daten über bereits im Fertigungssystem befindlicheAufträge, die Einsteuerung von weiteren Aufträgen, die Arbeitspläne, Arbeitsgangdaten,Rüstzeit- und Übergangszeittabellen usw. notwendig. Der Punkt 2.3.2.2 (vergleiche An-hang C) enthält eine Auflistung der notwendigen Daten. Wesentlich ist hier, daß das Si-mulationsmodell das reale Fertigungssystem adäquat abbilden muß (vergleiche 2.2.1.1,2.4.1).
Für eine Lösung wird nachfolgende Eingrenzung vorgenommen:
• Es erfolgt eine Konzentration auf Stückgutprozesse. D.h., alle vorliegenden Werkstückeund Produkte werden in diskreten Einheiten von Stück gemessen. Von chemischen Pro-dukten o.ä. in stetigen Mengen wird abgesehen.

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 126
• Es wird kein Bedienermodell verwendet. Von dem Vorhandensein von Werkern wirdabstrahiert. Es wird angenommen, daß zu jeder Maschine ein Bediener vorhanden sei,der ständig verfügbar ist.
• Transportprozesse werden nicht gesondert betrachtet. Prinzipiell kann nach jedem Be-arbeitungsvorgang ein Transport zu einem anderen Bearbeitungsort stattfinden. In dennachfolgenden Modellen werden jedoch weder ortsfeste noch bewegliche Transport-einrichtungen betrachtet. Lediglich die Angabe einer festen oder gemäß einer ange-gebenen Verteilung entsprechenden Transportzeit ist möglich. Transportvorgänge, dienicht auf diese Weise vereinfacht werden können, sind als Bearbeitungsvorgänge abzu-bilden.
• Weiterhin erfolgt die Einschränkung, daß von Montageprozessen, für die Stücklistennotwendig wären, abgesehen wird. Dagegen können Arbeitspläne eine nahezu beliebigeLänge erreichen und auch Zyklen aufweisen (gleiche oder ähnliche Folgen von Arbeits-gängen).
• Es wird davon ausgegangen, daß sich die im Fertigungssystem befindlichen Fertigungs-aufträge in mehrere Lose unterteilen können und daß diese Lose eine unteilbare Einheitdarstellen und das Fertigungssystem geschlossen durchlaufen.
Auf Basis der im Punkt 2.3.2.2 diskutierten Strukturen und diesen einschränkenden An-nahmen können Modelle von Produktionssystemen gebildet werden, die einer typischenFließ- oder Werkstattfertigung im Maschinenbau entsprechen. Ebenso können Modellegebildet werden, die eine komplexe Fertigung wie z.B. in der Halbleiterindustrie abbilden.Die vorgenommenen Einschränkungen sind somit wesentlich weiter gefaßt als Annahmenin bisherigen Betrachtungen in der Literatur [Nicol 1988], [Preiss, Loucks 1990], [Jha,Bagrodia 1993], [Holthaus, Ziegler, Rosenberg 1996], [Greenberg, Lubachevsky 1996],[Preiss, Wan 1999]. Zusätzlich geht der Punkt 4.3.1.2 auf weitere einzubeziehende Sach-verhalte ein, die in bisherigen Lösungen vernachlässigt wurden.
4.3.1.2 Anforderungen an Modellstrukturen zur Abbildung spezifischer Prozeßbe-dingungen komplexer Produktionssysteme
Motivation zur Einbeziehung spezifischer Prozeßbedingungen:
Heutige Produktionssysteme werden immer komplexer, sie bestehen aus mehr und ver-schiedenartigeren Maschinen und werden von einer immer größeren Anzahl an unter-schiedlichen Aufträgen in immer kleineren Stückzahlen durchlaufen. Zur Vorhersage desVerhaltens solcher komplexer Systeme bietet sich der Einsatz der Simulation an. Auf dieseWeise können bereits im Voraus Maßnahmen zur Behebung künftiger Mißstände getestetwerden. Die zur adäquaten Abbildung des Produktionssystems notwendigen komplexenSimulationsmodelle benötigen aber einen immer höheren numerischen Aufwand für ihreAbarbeitung. Aus diesem Grund soll der Einsatz der Parallelen Simulation erfolgen, umparallel Berechnungen durchführen zu können und die Simulation in kürzerer Zeit abzu-schließen. Der Einsatz der Parallelen Simulation lohnt sich aber nur, wenn die Modelleeinen gewissen Komplexitätsgrad aufweisen, da ansonsten eine rein Sequentielle Simula-tion performanter ist.
Einzubeziehende spezifische Prozeßbedingungen:
Zusätzlich zu den bisher betrachteten einfachen Modellen sollen häufig auftretende kom-plexe Prozeßbedingungen Beachtung finden. Dies wären u.a.:

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 127
• parallele Anlagen:
Es sind Maschinengruppen vorhanden. Alle Maschinen einer Gruppe können diegleichen Bearbeitungen ausführen und sind alternativ einsetzbar. Das Routing derAufträge findet auf Maschinengruppenebene statt. In den Arbeitsplänen wird ver-merkt, welcher Arbeitsgang auf welcher Maschinengruppe zu fertigen ist. Auf wel-cher konkreten Maschine der Gruppe die Bearbeitung stattfindet, ist von der momen-tanen Belegungssituation der Maschinengruppe abhängig (siehe Punkt 2.3.2.3).
• parallele Bearbeitung (Batching):
Einige Bearbeitungsprozesse können statt auf einzelne Werkstücke auf eine be-grenzte Menge von Werkstücken angewandt werden. Typischer Fall sind hier Tem-peraturprozesse oder chemische Bäder. So kann z.B. eine über die Beladegröße derkonkreten Maschine begrenzte Menge von Werkstücken gleichzeitig in einen Ofenzu einer Temperaturbehandlung geladen werden (siehe Punkt 2.3.2.3).
Bei einem kombinierten Auftreten von parallelen Anlagen und paralleler Bearb-eitung wird davon ausgegangen, daß alle Maschinen einer Maschinengruppe in allenBearbeitungsparametern - also auch in ihrer Fähigkeit zur parallelen Bearbeitung undder Beladegröße - übereinstimmen.
• Rüstproblematiken:
Oft können die selben Maschinen mehrere verschiedene Bearbeitungen durchführen.Unter Umständen ist jedoch vor dem Beginn einer andersartigen Bearbeitung eineUmstellung der Maschine notwendig - die Maschine ist umzurüsten. Zur besserenUnterscheidung der einzelnen Bearbeitungen werden die auf der Maschine durch-führbaren Bearbeitungsvorgänge als sogenannte Bearbeitungsmöglichkeiten benannt(siehe Punkt 2.3.2.2). Die im Rahmen eines konkreten Auftrages notwendige Ma-schineneinstellung ist im Arbeitsplan des Auftrages durch eine Bearbeitungs-anforderung gekennzeichnet. Stimmt die Bearbeitungsanforderung des als nächsteszu fertigenden Auftrages nicht mit der momentanen Bearbeitungsmöglichkeit derMaschine überein, so ist ein Umrüsten der Maschine erforderlich. Dazu ist eine Rüst-zeittabelle zu hinterlegen, der man entnehmen kann, wie lange das Umrüsten von ei-ner Bearbeitungsmöglichkeit auf eine andere Bearbeitungsmöglichkeit dauert.
Weiterhin können Rüstgruppen auftreten, d.h. der Wechsel zwischen Bearbeitungs-möglichkeiten einer Gruppe ist relativ kurz. Im Gegensatz dazu dauert der Wechselauf Bearbeitungsmöglichkeiten außerhalb der Gruppe wesentlich länger (siehe Punkt2.3.2.3).
Ebenso können die Rüstzeiten sequenzabhängig sein. D.h., die Höhe der Rüstzeit istabhängig von der Richtung des Umrüstprozesses. Typische Fälle hierfür sind Farb-folgen (siehe Punkt 2.3.2.3).
Weitere komplexe Prozeßbedingungen wie z.B. Liegezeitbegrenzungen (siehe 2.3.2.3)sollen aus Umfangsgründen nicht berücksichtigt werden.
4.3.1.3 Anforderungen an Modellstrukturen zur Abbildung der Steuerung komple-xer Produktionssysteme aus Sicht komplexer Prozeßführungsstrategien
In jedem Fall sind Reihenfolgeplanungsverfahren wie z.B. Prioritätsregeln (siehe Punkt2.1.4) zu unterstützen. Hierzu ist mitunter die Kenntnis zusätzlicher, z.T. berechneter Grö-ßen notwendig. So ist z.B. für die Berechnung der Priorität gemäß der Schlupfzeitregel dieKenntnis der Restbearbeitungszeit des Auftrages notwendig. D.h., es besteht die Notwen-digkeit zusätzliche Daten zu halten, die ausschließlich für die Prioritätsberechnung benö-tigt werden.

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 128
Weiterhin ist es bei Vorhandensein komplexer Prozeßbedingungen notwendig, diese zu-sätzlichen Bedingungen zu beachten und in die Steuerung einzubeziehen. So ist es z.B. beiVorhandensein von parallelen Maschinen und der Rüstproblematik erforderlich, daß Um-rüsten vieler Maschinen der Maschinengruppe auf die selbe Bearbeitungsmöglichkeit zuverhindern, um insgesamt gesehen die Summe der Rüstzeiten zu minimieren. Ebenso ver-langt die Möglichkeit der gleichzeitigen Bearbeitung mehrerer Werkstücke in einem Bear-beitungsvorgang eine spezielle Steuerung. Als einfache Ansätze existieren Rüst- und Bela-deregeln [ManSim 1997, S. 45-48], die zusätzlich noch mit den bereits vorhandenen Prio-ritätsregeln kombiniert werden können.Ferner können Bedingungen im Maschinensystem vorliegen, die es erforderlich machen,daß mehrere Maschinengruppen miteinander kooperieren (Abstimmung von Bearbeitungs-vorgängen). Hierfür sind weitere Steuerungsmechanismen wie z.B. Interaktionsregeln vor-gesehen [Holthaus, Ziegler 1993, S. 52 ff., S. 161f.], [Holthaus, Rosenberg, Ziegler 1993,S. 6 ff., S. 11f.], [Weidner 1995, S. 21 ff., S. 71 ff.].Jedoch kann nicht eine simple Kombination der Ansätze wie Prioritätsregeln, Rüstregeln,Beladeregeln und Interaktionsregeln als effektive Steuerungslösung angesehen werden[Thiel u.a. 1998]. Hierzu sind eigene, algorithmische Steuerungsansätze notwendig, derenTest und Einsatz im Simulationsmodell vorbereitet werden muß. D.h., die für den Einsatzvon Prioritätsregeln, Rüstregeln, Beladeregeln, Interaktionsregeln und eigenen Steuerungs-ansätzen notwendigen Daten müssen im Simulationsmodell vorgehalten werden. Dies be-trifft z.B. die Beladegröße von Maschinen, Rüstzeittabellen, Gruppen von Maschinen dieuntereinander interagieren, sowie Parameter für all diese Regeln [Thiel 2001, S. 42ff].
4.3.2 Diskussion von Lösungsmöglichkeiten der Abbildung von Elementen desProduktionssystems im Simulationsmodell einer Parallelen und VerteiltenSimulation
Für die Abbildung eines Produktionssystems im Simulationsmodell bestehen zwei prinzi-pielle Möglichkeiten. Zum Einen können Ressourcen wie Maschinen und Werker als stati-sche Elemente (in der Simulation ortsfeste Elemente) angesehen werden. Zwischen diesenstatischen Elementen bewegen sich die Aufträge als dynamische Elemente (wechselnderäumliche Zuordnung in der Simulation). Zum Zweiten wäre es möglich, Gruppen vonMaschinen und Aufträgen als statische Elemente anzusehen. Bearbeitungsanforderungenund Bearbeitungsangebote (bisher informationelle Objekte95) wären dann die dynamischenElemente.Für die Parallele und Verteilte Simulation ist die Auswahl eines der beiden Lösungswegevon entscheidender Bedeutung. Die Festlegung der Art und Weise der Abbildung der Ele-mente des Produktionssystems ist Basis für die Partitionierung des Simulationsmodells.Durch die Partitionierung entstehen mehrere Logische Prozesse, die untereinander kommu-nizieren. Je nach Abbildung der Elemente im Simulationsmodell ergibt sich ein völlig un-terschiedlicher Kommunikationsbedarf zwischen den Partitionen.Sieht man die Maschinen als statische Elemente und die Aufträge als dynamische Ele-mente an, so wäre als Kommunikation zwischen den Partitionen die Weiterleitung vonAufträgen an eine andere Maschine zu sehen. In einer Partition können alle Informationenzu Maschinen (Bearbeitungszustand etc.) und deren momentane Warteschlange (Liste zubearbeitender Aufträge) gehalten werden. Dies entspricht der natürlichen Sicht auf denSachverhalt. Bei Transfer der Aufträge ist lediglich zu beachten, daß der Arbeitsplan alsDatenobjekt96, welches eigentlich dem Auftrag zugeordnet ist, jeder Maschine im Voraus
95 Siehe dazu Seite 46ff.96 Zum Begriff der Datenobjekte siehe Punkt 2.3.2.2.

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 129
bekannt sein sollte, damit der Arbeitsplan - welcher eine große Menge an Daten darstellt -nicht bei jedem Transfer des Auftrages versendet werden muß (Verringerung des Kommu-nikationsbedarfes).Für eine Einteilung von Gruppen von Maschinen als eine Partition(sgruppe) und Gruppenvon Aufträgen als andere Partition(sgruppe)97 entsteht das Problem, daß diese Partitionenständig miteinander kommunizieren, daß andererseits die einzelnen Aufträge einer Parti-tion untereinander aber keine Informationen austauschen. In einer solchen Partition ent-steht demzufolge kaum Berechnungsaufwand. Andererseits würde ständig eine Kommu-nikation zwischen Partitionen der Maschinen und den Partitionen der Aufträge stattfinden,um nach erfolgter Bearbeitung einen Auftrag an die nächste Maschine weiterzuleiten. AusGründen der Minimierung des Kommunikationsaufwandes ist diese Art der Partitionierungrespektive der Abbildung der Elemente des Produktionssystems im Simulationsmodellabzulehnen (siehe Punkt 3.1.2.3).
Es ist daher sinnvoll, die Maschinen als statische Elemente und die Aufträge als dyna-mische Elemente aufzufassen. In diesem Fall besteht auch ein günstigeres Verhältnis zwi-schen partitionsinternen und -externen Ereignissen (siehe Formel 3, Punkt 3.1.1.3, Seite70). Der im Modell vorhandene numerische Aufwand wird bei geringerem Kommunika-tionsaufkommen besser verteilt - eine höhere Performance der Parallelen und VerteiltenSimulation ist die Folge.
4.3.3 Diskussion von Lösungsmöglichkeiten für die Partitionierung des Simula-tionsmodells eines Produktionssystems für die Parallele und Verteilte Si-mulation
Partitionierung und Kommunikation stehen in einem engen Zusammenhang. Die Partitio-nierung schafft Teilmodelle, die untereinander kommunizieren. Ziel der Partitionierung istes, die optimale Aufteilung des Simulationsmodells in Teilmodelle zu finden, d.h. einemöglichst hohe Anzahl von parallel abarbeitbaren Teilmodellen zu erhalten, die zudemuntereinander nur wenig kommunizieren (siehe Punkt 3.1.1.1).In bisherigen Arbeiten stellte sich die Menge der notwendigen Kommunikation oft alsFallstrick für die schnellere parallele Berechnung heraus [Loucks, Preiss 1990], [Mehl1994, S. 142f], [Bagrodia 1996], [Holthaus, Rosenberg, Ziegler 1996]. Aus diesem Grundgilt bei der Partitionierung der Verringerung des Kommunikationsbedarfs ein besondererAugenmerk.
Grundgedanke bei der Partitionierung ist es, lokales Wissen98 und lokale Kommunikationzu kapseln, um den globalen Kommunikationsaufwand zu senken.
Offen bleibt die Frage, wie die Partitionen zu bilden sind. Hier existieren drei prinzipielleMöglichkeiten:
A) es wird nicht partitioniert - das gesamte Modell wird als eine einzige Partition auf-gefaßt
B) man faßt jeden elementaren Bestandteil eines Produktionssystems als Partition aufC) Gruppen von Elementen des Produktionssystems werden als Partitionen zusam-
mengefaßt
Fall A - eine Partition:
Sehr kleine Modelle mit nur wenigen Elementen sollten nicht partitioniert werden, da hierder Aufwand für die Kommunikation zwischen den Partitionen den Nutzen durch die par- 97 Diese Form der Einteilung ist in Analogie zu einem Multiagentensystem zu sehen.98 Wissen kann als Datenbestand aufgefaßt werden, welcher selbst zum Kommunikationsgegenstand werden
kann. Ziel ist es also, durch die lokale Kapselung von Wissen unnötige Kommunikation zu vermeiden.

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 130
allele Abarbeitung bei weitem übersteigt99. Diese kleinen Modelle können in einer Se-quentiellen Simulation leichter und schneller abgearbeitet werden100. D.h., der Umfang desModells an Elementen kann als ein erster Einflußfaktor auf die Performance der Parallelenund Verteilten Simulation identifiziert werden. Ein exakter Grenzwert an Elementen kannjedoch nicht angegeben werden, da die Performance auch von der Gestaltung der Elementeund deren Interaktion abhängt (siehe dazu Punkt 4.3.4).
Fall B - elementare Bestandteile des Produktionssystems als Partitionen:
Dieses Vorgehen hat den Vorteil, daß ein solches Modell leicht verständlich ist, daß keinspezielles Partitionierungsverfahren durchgeführt werden muß und daß zwischen den Par-titionen eine maximal mögliche Parallelität erreicht wird. Allerdings entsteht durch diehohe Partitionenanzahl eventuell auch ein hoher Kommunikations- und Synchronisations-aufwand (vergleiche Punkt 3.1.1.3, Seite 68, siehe auch [Holthaus, Ziegler, Rosenberg1996]).Im Kontext der Kapselung lokaler Daten und lokaler Kommunikation in einem Elementkann die Maschinengruppe als kleinste sinnvolle - atomare - Einheit identifiziert werden.Die Partition der Maschinengruppe besteht aus der Warteschlange an Aufträgen und allenMaschinen der Maschinengruppe. Die Zustandsdaten dieser Subelemente werden zudemzwingend für die Steuerungsstrategie der Maschinengruppe benötigt. Maschinen einerGruppe tauschen sehr oft Nachrichten untereinander aus und arbeiten eng miteinander zu-sammen. Sie haben zum Teil sogar eine gemeinsame Datenbasis und sind daher durch einhohes Maß an Kommunikation miteinander verbunden. Die notwendigen Daten sowie dieSteuerungslogik - und damit eine hohe Komplexität - verbleiben in einer Partition. Dage-gen findet das Routing der Aufträge auf Maschinengruppenebene statt, d.h., zwischen denPartitionen der Maschinengruppen ist nur noch der Austausch von Routinginformationenund globalen Steuerungsanweisungen notwendig.Durch die Abbildung von Maschinengruppen als atomare Elemente ist es wesentlich ein-facher ein Simulationsmodell aufzustellen, da Modellelemente für unterschiedliche Artenvon Maschinengruppen gebildet werden können und da das Modell nur noch aus unter-schiedlich parameterisierten Modellelementen zusammengestellt werden muß (siehe Punkt3.3.1, Anforderung der Einfachheit der Modellierung).In Abhängigkeit von der Modellgröße erhält man bei der Zerlegung des Gesamtmodells ineine Partition für jede Maschinengruppe mitunter eine sehr hohe Anzahl von Partitionen.Der aus dieser Partitionierung resultierende Kommunikationsbedarf ist u.U. sehr hoch, derBerechnungsaufwand in den Partitionen dagegen relativ klein. Betrachtet man Formel 2(Kapitel 3.1.1.3, Seite 69) und die Aussagen von Mehl [Mehl 1994, S. 142f], Sporrer[Sporrer 1995, S. 35-36] und Bagrodia [Bagrodia 1996] so ist ein ungünstiges Verhältniszwischen Kommunikation und Berechnungsaufwand zu bemerken. Es ist jedoch ebensomöglich, daß diese Aufteilung des Modells in viele Partitionen bei sehr hoher Last im Pro-duktionssystem positive Effekte erbringt. Dies kann jedoch nur durch Tests mit dem kon-kreten Modell beantwortet werden.Ein weiteres Problem bei der Unterteilung des Modells in eine Partition für jede Maschi-nengruppe ist, daß der Aufwand zur Verwaltung einer hohen Anzahl an Partitionen undThreads sehr groß ist. Je nach verwendeten Betriebssystem und der Effektivität der in die-sem Betriebssystem implementierten Verwaltungsmechanismen kann der Aufwand zumWechsel zwischen den Threads den Nutzen der parallelen Berechnung kompensieren oder
99 Siehe dazu Punkt 3.1.2.3 - Auftreten eines Kommunikationsoverheads.100 Der Aufwand für die Erstellung eines Verteilten oder Parallelen Simulationsmodells wäre wesentlich höher
als der potentielle Nutzen durch eine geringfügig schnellere parallele Abarbeitung.

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 131
aber die Unterteilung in viele Threads erweist sich als günstig, da Prozesse, die momentanblockiert sind, die Kontrolle abgeben und das Betriebssystem den nächsten Thread zurAbarbeitung freigibt101 (siehe Punkt 3.1.4.3, 3.1.5, Performanceungewißheit der Abarbei-tungsplattform).
Fall C - Zusammenfassung von Elementen des Produktionssystems als Partitionen:
Ein Weg um den Kommunikationsaufwand zu senken besteht darin, mehrere Maschinen-gruppen aufgrund enger Kommunikationsbeziehungen oder wegen Abhängigkeiten imProduktionsdurchlauf zu Partitionen zusammenzufassen. Das können z.B. mehrere Ma-schinengruppen einer Fertigungslinie oder einer Werkstatt sein. Der Kommunikations-bedarf zwischen den Partitionen wird verringert und gleichzeitig wird die Berechnungslastin der Partition erhöht (Verbesserung des Performanceindikators partitionsinterne versus -externe Ereignisse, vergleiche Formel 3 aus Kapitel 3.1.1.3).Durch die Zusammenfassung atomarer Elemente in Partitionen geht aber potentiell Paral-lelität verloren und es ist außerdem explizit ein Partitionierungsverfahren zur Einteilungder Elemente in Partitionen notwendig. In Kapitel 3 (siehe Punkt 3.1.1.2) wurde bereits derMangel eines fehlenden, allgemein anwendbaren Partitionierungsverfahrens angesprochen.
Um einen Vorschlag zur Partitionierung von Simulationsmodellen von Produktionssyste-men unterbreiten zu können, ist es notwendig, die Kommunikationsstrukturen zwischenden Maschinengruppen und den Berechnungsaufwand in der Maschinengruppe näher zubetrachten. Dies ist Gegenstand des Punktes 4.3.4
4.3.4 Identifikation von Einflußfaktoren auf die Performance der Parallelen undVerteilten Simulation im Kontext der Simulation von Produktionssystemen
4.3.4.1 Einflußfaktoren auf die Performance der Parallelen und Verteilten Simula-tion aus Sicht der Partitionierung des Simulationsmodells und der Kommu-nikation der Teilmodelle
Die Verringerung des Kommunikationsbedarfs bei gleichzeitiger Maximierung der Paral-lelität der Teilmodelle ist erklärtes Ziel der Partitionierung.
Zur Verringerung des Kommunikationsbedarfes ist es u.a. notwendig, gerichtete Kommu-nikation einzusetzen. Durch die Vermeidung von Broadcasting und Strukturen in denenprinzipiell jeder mit jedem kommunizieren kann, kann die Menge der zu empfangenen undzu verarbeitenden Nachrichten drastisch reduziert werden. Hierzu kann z.B. das Topolo-giewissen [Mehl 1994, S. 24f] über Aufbau und Verbindungen der Stationen des Produkti-onssystems benutzt werden.Weiterhin ist es notwendig, so wenig wie möglich zu kommunizieren. Dazu sind eng inter-agierende Stationen den selben Partitionen zuzuordnen, um statt zwischen Partitionen zukommunizieren, diese Interaktionen durch Ereignisse innerhalb einer Partition abzu-arbeiten, was wesentlich effizienter ist (Verbesserung des Verhältnisses interner zu exter-nen Ereignissen, siehe Formel 3, Seite 70).Als letztes sollte für die nicht mehr vermeidbare Kommunikation ein Format auf möglichstgeringen Level verwendet werden, damit der Verwaltungsoverhead für die Übertragungder Nachricht gering gehalten wird102.
101 Die konkrete Implementation dieser Mechanismen ist von Betriebssystem zu Betriebssystem verschieden
und in der Regel auch nicht offengelegt. Man ist also gezwungen, das konkrete Verhalten des Betriebssy-stems durch Testen herauszufinden.
102 Übliche Kommunikationsstrukturen sind allgemein gehalten und unspezialisiert. Sie versuchen flexibel aufden jeweiligen Übertragungswunsch eines Anwendungsprogramms einzugehen. Diese Flexibilität ist hieraber nicht notwendig und stört durch ihren höheren Aufwand sogar.

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 132
Der Mangel eines fehlenden, allgemein anwendbaren Partitionierungsverfahrens führt zuder Notwendigkeit, die Kommunikationsstrukturen zwischen den Maschinengruppen undden Berechnungsaufwand in der Maschinengruppe näher zu betrachten.
Abschätzung des Kommunikationsbedarfs zwischen den Partitionen:
Es ist bekannt, welche Produkte im Produktionssystem hergestellt werden können und wiedie Arbeitspläne dieser Produkte beschaffen sind. In den Arbeitsplänen ist die Abfolge dereinzelnen Maschinen(gruppen) für den Durchlauf von Aufträgen des Produktes durch dasProduktionssystem festgelegt. Auf Basis dieser Angaben kann ermittelt werden, welcheMaschinen(gruppen) untereinander über den Materialfluß verbunden sind und demzufolgekommunizieren müssen (siehe Abbildung 44).
Station 1
Station 2
Station 5 Station 6
Station 3
Station 4
Station 7
Station 8
Station 9
Station 11
Station 10
Station 12
Station 13
F
E
A
B
C
A A
B
C
E
D
F
D, E E, F
A
A, B
C, D, C, D,
E, F
B B
C
Quelle A
Senke
Senke
Quelle B
Quelle C
Quelle D
Quelle E
Quelle F
D
F
Abbildung 44 Beispiel der Topologie eines Fertigungssystems aus bedie-nungstheoretischer Sicht
Durch die Topologie des Fertigungssystems sind bereits die Grundelemente (Maschinenbzw. Maschinengruppen) und die notwendigen Kommunikationswege gegeben.Als kleinste sinnvolle Einheiten wurden bereits die Maschinengruppen identifiziert. Diesesollen als Logische Prozesse abgebildet werden. Die Maschinengruppen kommunizierenuntereinander mindestens über den Materialfluß (Bewegung von Aufträgen zwischen denMaschinengruppen). Hier ist jedoch noch weitere Kommunikation denkbar. So könnensich die Maschinengruppen im Rahmen von Interaktionsverfahren (siehe Punkt 2.1.4) un-tereinander über zukünftige Bearbeitungen austauschen, um die Reihenfolgeplanung imglobalen Maßstab zu verbessern.Die Anzahl der notwendigen Verbindungen W kann dagegen durch die Kenntnis der Topo-logie des Fertigungssystems drastisch reduziert werden. So kommunizieren die inAbbildung 44 nicht verbundenen Stationen auch nicht miteinander. Im Gegensatz dazu istdie Anzahl der prinzipiell möglichen Verbindungen bei N Stationen gleich N2 Verbindun-gen (im Beispiel: N=21, N2=441, W=22, VG≈5%).
Als Zweites können aus bedienungstheoretischer Sicht die betrachteten Stationen in dreiTypen eingeteilt werden:
• Forderungsquellen: diese Stationen produzieren lediglich Nachrichten,konsumieren aber keine Nachrichten
• Forderungssenken: diese Stationen konsumieren lediglich Nachrichten,produzieren aber keine Nachrichten
• Arbeitsstationen: diese Stationen konsumieren und erzeugen Nachrichten
Diese Grundeinteilung hilft eine erste Zusammenfassung von Stationen zu betreiben.Quellen, die lediglich einen Ausgang besitzen, sollten immer mit der ihnen nachgelagerten

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 133
Station zusammengefaßt werden. Analog gilt dies für Senken mit nur einem Eingang.Besitzt die Quelle bzw. Senke mehrere Ausgänge bzw. Eingänge, so sollte die Quelle bzw.Senke mit dem Ausgang bzw. Eingang zusammengefaßt werden, mit dem sie imVerhältnis gesehen am häufigsten kommuniziert. Werden alle Eingänge bzw. Ausgängeetwa gleich benutzt, so sollte man alle beteiligten Stationen in einer Partition zusammen-fassen. Da Quellen keine externen Ereignisse besitzen, können sie unabhängig von anderenPartitionen ihre Ereignisse abarbeiten. Durch die Zusammenfassung der Quelle mitMaschinen wird der Anteil interner Ereignisse erhöht, die Partition gerät nicht mehr so oftin Blockierungssituationen.Durch die Einschränkung oder gar Vermeidung der Kommunikation von Quellen bzw.Senken mit den vor- bzw. nachgelagerten Arbeitsstationen kann der Kommunikations-aufwand reduziert werden (im Beispiel: N=13, W=14, VG≈3%, siehe Abbildung 45).
Station 1
Station 2
Station 5 Station 6
Station 3
Station 4
Station 7
Station 8
Station 9
Station 11
Station 10
Station 12
Station 13
F
E
A
B
C
A A
B
C
E
D
F
D, E E, F
A
A, B
C, D, C, D,
E, F
B B
C
Quelle A
Senke
Senke
Quelle B
Quelle C
Quelle D
Quelle E
Quelle F
D
F
Abbildung 45 Zusammenfassung von Quellen und Senken mit vor- bzw.nachgelagerten Stationen zur Senkung des Kommunikations-aufwandes
Als Drittes kann man Strecken von Stationen zusammenfassen. Bestimmte Maschinen-gruppen bilden von der Topologie her Ketten und sind stark voneinander abhängig. SolcheKetten von Maschinengruppen sollten zu Logischen Prozessen zusammengefaßt werden.Ebenso ist es im Zuge der Verringerung der Kommunikation ratsam, Maschinengruppen,die untereinander stark kommunizieren oder die Zyklen103 bilden, in Logischen Prozessenzusammenzufassen. So ist in Abbildung 45 ersichtlich, daß die Stationen 1, 5 und 6 eineKette bilden. Das Zusammenfassen dieser Stationen in einer Partition hat den Vorteil, daßdie Kommunikation zwischen diesen Stationen entfällt. Ein möglicher Nachteil entstehtjedoch, falls die Stationen fast immer gleichzeitig aktiv sind. Dann können die notwendi-gen Berechnungen immer nur sequentiell nacheinander ausgeführt werden - die Parallelitätleidet. Die Kenntnis über die Aktivitätsphasen der Stationen existiert jedoch erst nach derAusführung der Simulation. Bei der Zusammenfassung der Stationen in einer Partitionexistiert noch ein weiteres Problem. An manchen Punkten (z.B. Station 7) kann nicht imVoraus entschieden werden, wie zu partitionieren ist, da der resultierende Umfang anKommunikation noch nicht bekannt ist. Über die Kenntnis der Arbeitspläne und des Ein-steuerungsvektors kann man sich lediglich ein prinzipielles Bild vom Kommunikations-bedarf machen (siehe Abbildung 46).
103 Durch Kommunikationszyklen zwischen Partitionen wird die Gefahr von Verklemmungen erhöht. Befin-
det sich der Kommunikationszyklus innerhalb einer Partition, so entsteht durch gleichzeitige interne Erei-gnisse kein Verklemmungsproblem (vergleiche Punkt 3.1.3.6).

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 134
Station 1
Station 2
Station 5 Station 6
Station 3
Station 4
Station 7
Station 8
Station 9
Station 11
Station 10
Station 12
Station 13
F (150)E, F
A
B
C, D
A (100) A (100)
B (150)
C (100)
E (100)
D (200)
F (150)
D, E
E, F
A (100)
A, B
C, D, C, D,
E, F
100 Stück
150 Stück
100 Stück
200 Stück
150 Stück
100 Stück
B (150)B (150)
C (100)
(300)(550) (550)
(250)
Abbildung 46 Abschätzung des minimalen Kommunikationsbedarfs aus derTopologie des Fertigungssystems und dem Einsteuerungs-vektor
Zu welchen Zeiten die Kommunikation anfällt, kann nicht ohne die Ausführung des Mo-dells prognostiziert werden. Ebenso sind die angegebenen Zahlen als untere Schranke fürdie Kommunikation zu werten104.Abbildung 46 zeigt jedoch, daß Station 7 häufiger von Station 2 (mindestens 150 mal) alsvon Station 3 (mindestens 100 mal) Nachrichten erhält. Da dieser Unterschied nicht signi-fikant groß ist, kann nicht vorhergesagt werden, ob es günstiger ist, die Stationen 2 und 7oder die Stationen 3 und 7 in einer Partition zusammenzufassen. An dieser Stelle wäre dieKenntnis über die zeitliche Entkopplung der Berechnungen der drei Stationen notwendig.So kann es ohne Weiteres sinnvoll sein, Stationen die wenig miteinander kommunizierenin einer Partition zusammenzufassen, da diese zu unterschiedlichen Simulationszeitpunk-ten Berechnungen durchführen. Dieses Wissen ist aber ex-ante nicht vorhanden. Dazumüßte das Simulationsmodell mindestens einmal ausgeführt werden.
Als Hauptmanko kristallisiert sich heraus, daß ex-ante keine Kenntnis über die zeitlicheEntkopplung der Stationen - und damit der Partitionen - existiert, da nicht bekannt ist, zuwelchen Simulationszeitpunkten Berechnungen durchgeführt werden müssen. DieseKenntnisse können erst nach der erstmaligen Ausführung eines Simulationslaufs aus denErgebnissen dieses Laufs gewonnen werden.Als Prinzipielle Einflußfaktoren wurden aber die Anzahl der Ein- und Ausgänge der Parti-tionen105 sowie die Häufigkeit der Nutzung der Kommunikationswege identifiziert.
Qualitative Beurteilung der Berechnungslast einer Partition:
Berechnungslast entsteht durch die in einem Logischen Prozeß zu erzeugenden und zuverarbeitenden Ereignisse. Für eine Maschinengruppe sind dies die in Tabelle 2 darge-stellten Ereignisse.
104 Auf diese Art ist lediglich die für den Materialfluß notwendige Kommunikation ersichtlich. Bedingt durch
die Synchronisationsverfahren entsteht jedoch weitere Kommunikation.105 Diese als fan_in und fan_out bezeichneten Größen haben maßgeblichen Einfluß auf die Performance
[Preiss, Loucks 1990], [Mehl 1994, S. 4], [Bagrodia 1996].

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 135
Tabelle 2 An einer Maschinengruppe auftretende Ereignisse106
Ereignis BeschreibungE1 Ankunft eines Werkstücks in der Warteschlange der MaschinengruppeE2 Auswahl des als nächstes zu bearbeitenden Werkstücks auf einer Maschine
der MaschinengruppeE3 Beginn des Umrüstens einer Maschine der MaschinengruppeE4 Ende der Umrüstens einer Maschine der MaschinengruppeE5 Beginn der Bearbeitung eines Werkstücks auf einer Maschine der Maschi-
nengruppeE6 Ende der Bearbeitung eines Werkstücks auf einer Maschine der Maschinen-
gruppeE7 Beginn einer Defektsituation an einer Maschine der MaschinengruppeE8 Ende einer Defektsituation an einer Maschine der Maschinengruppe
Abbildung 47 zeigt den Zusammenhang zwischen der Struktur der Maschinengruppe undden stattfindenden Prozessen. In der Regel ist jeder dieser Prozesse durch ein Start- undein Ende-Ereignis gekennzeichnet.
Maschine 1
Maschine 2Warteschlange derMaschinengruppe
Ankunft vonWerkstücken
Maschine n
...
Auswahl desnächsten zufertigendenWerkstücks
(Reihenfolge-entscheidung)
Umrüsten vonMaschinen
Bearbeitung vonWerkstücken Weitergabe der
Werkstücke
Defektsituationan Maschinen
E1
E2
E3
E4
E5
E6
E7 E8
Abbildung 47 Schematische Darstellung der Struktur und der Prozesse ineiner Maschinengruppe
Die Werkstücke durchlaufen Zustände wie warten, umrüsten abwarten, in Bearbeitung.Dazu sind Zeitgrößen wie Wartezeit (TW), Rüstzeit (TR) und Bearbeitungszeit (TB) zu er-fassen.Die Maschinen können sich in den Zuständen leer, wartend, rüstet um, führt Bearbeitungaus und ist defekt befinden. Hier sind Zeitgrößen wie Leerzeit (TL), Rüstzeit (TR), Bear-beitungszeit (TB) und Defektzeit (TD) zu erfassen. Für die Maschinen sind zusätzlich Men-gengrößen wie die gleichzeitig zu bearbeitenden Werkstücke (Beladegröße), die Gesamt-zahl der bearbeiteten Werkstücke und die Gesamtzahl der durchgeführten Bearbeitungenzu erfassen107.Für die Warteschlange sind Mengengrößen wie die Gesamtzahl der angekommenen Werk-stücke und die Anzahl der momentan in der Warteschlange befindlichen Werkstücke zuerfassen. 106 Vergleiche dazu [Fishman 2001, S. 41-42].107 Parallel arbeitende Maschinen (siehe Punkt 2.3.2.3) können gleichzeitig mehrere Werkstücke bearbeiten.
Hier bekommt die Auslastung einen zweiten Aspekt. Man unterscheidet jetzt zwischen zeitlicher undquantitativer Auslastung.

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 136
Aus diesen Größen können am Ende Erkenntnisse zur Bewertung der Steuerungsstrategiean der Maschinengruppe gewonnen werden (vergleiche Punkt 2.3.2.2, Seite 52).
Auf Basis der Ereignisse und der daran angebundenen Prozesse kann man die damit ver-bundenen Berechnungslasten identifizieren (siehe Abbildung 48). Auf jedes Ereignis folgtein Prozeß, der durch eine Berechnungslast gekennzeichnet ist. An einigen Stellen kannnach Ablauf des Prozesses in Abhängigkeit einer Bedingung eine Verzweigung zu einemvon mehreren möglichen Folgeereignissen auftreten.
E1 E2 E3 E4 E5 E6
E7 E8
BLAnk BLRF BLRB BLRE BLBB BLBE
BLDB BLDE
Abbildung 48 Schematische Darstellung der Zusammenhänge zwischen Er-eignissen und Berechnungslast in einem Modellelement„Maschinengruppe“
In der Simulation müssen an folgenden Ereignissen Berechnungen anknüpft werden, umeinerseits das korrekte Verhalten des Modellelements sicherzustellen und andererseits umalle notwendigen Ergebnisgrößen zu erfassen:
• E1: Ankunft eines Werkstücks in der Warteschlange der Maschinengruppe: Das angekommene Werkstück ist in die Warteschlange zu stellen, falls alle
Maschinen der Maschinengruppe frei sind, ist das Ereignis E2 auszulösen. DieBerechnungslast BLAnk ist als sehr gering einzustufen.
• E2: Auswahl des als nächstes zu bearbeitenden Werkstücks auf dieser Maschine: Es ist für eine (oder mehrere) Maschinen festzustellen, welche Werkstücke als
nächstes zu bearbeiten sind. Dazu ist ein Reihenfolgeplanungsansatz abzu-arbeiten. Je nach den an dieser Maschinengruppe auftretenden spezifischenProzeßbedingungen sind die Werkstücke zu priorisieren, ggf. gemäß Rüst-eignung umzuordnen und ggf. zu einer gemeinsamen Bearbeitung als Batchzusammenzufassen. Die Berechnungslast BLRF ist je nach Reihenfolgepla-nungsansatz als gering bis hoch einzustufen.
• E3: Beginn des Umrüstens einer Maschine der Maschinengruppe: Es erfolgt lediglich eine Statusänderung an der Maschine und Ergebnisgrößen
müssen erfaßt werden. Weiterhin ist das Ereignis E4 einzuplanen. Die Berech-nungslast BLRB ist als sehr gering einzustufen.
• E4: Ende der Umrüstens einer Maschine der Maschinengruppe: Es erfolgt lediglich eine Statusänderung an der Maschine und Ergebnisgrößen
müssen erfaßt werden. Zusätzlich muß das Ereignis E5 ausgelöst werden. DasEreignis E4 bietet die Möglichkeit eine geplante Reihenfolge wieder außerKraft zu setzen. Die Berechnungslast BLRE ist als gering einzustufen.
• E5: Beginn der Bearbeitung eines Werkstücks auf einer Maschine: Es erfolgt lediglich eine Statusänderung an der Maschine und Ergebnisgrößen
müssen erfaßt werden. Zusätzlich muß das Ereignis E6 eingeplant werden. DieBerechnungslast BLBB ist als sehr gering einzustufen.

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 137
• E6: Ende der Bearbeitung eines Werkstücks auf einer Maschine: Es erfolgt lediglich eine Statusänderung an der Maschine und Ergebnisgrößen
müssen erfaßt werden. Weiterhin ist das Werkstück an die nächste Maschineweiterzusenden. Dann ist das Ereignis E2 auszulösen. Die BerechnungslastBLBE ist als gering einzustufen.
• E7: Beginn einer Defektsituation an einer Maschine der Maschinengruppe: Es erfolgt lediglich eine Statusänderung an der Maschine und Ergebnisgrößen
müssen erfaßt werden. Je nach Modellanforderungen ist mit ggf. in Bearbei-tung befindlichen Werkstücke anders zu verfahren108. Zusätzlich ist das Ereig-nis E8 einzuplanen. Die Berechnungslast BLDB ist als gering einzustufen.
• E8: Ende einer Defektsituation an einer Maschine der Maschinengruppe: Es erfolgt lediglich eine Statusänderung an der Maschine und Ergebnisgrößen
müssen erfaßt werden. Die Berechnungslast BLDE ist als sehr gering einzu-stufen.
Es wird deutlich, daß außer der Reihenfolgeentscheidung alle Ereignisse mit einer gerin-gen Berechnungslast verbunden sind. D.h., das Verhältnis zwischen Kommunikation undBerechnungslast ist gespannt (Formel 2, Seite 69).Unterteilt man die Ereignisse in für die Partition interne und externe Ereignisse, so ver-bleibt die Ankunft von Aufträgen in der Warteschlange (E1) als externes Ereignis. DasEreignis E6 - die Fertigstellung der Bearbeitung auf einer Maschine - stellt das Gegenstückfür das Ereignis E1 an den nachgelagerten Stationen dar.Außerdem ist ersichtlich, daß ein Logischer Prozeß blockiert, wenn die Warteschlange leerist, da er auf die Ankunft weiterer Werkstücke wartet. D.h. es wäre günstig, traditionellniedrig ausgelastete Maschinengruppen in einer Partition zusammenzufassen.
4.3.4.2 Einflußfaktoren auf die Performance der Parallelen und Verteilten Simulati-on aus Sicht der Synchronisationsverfahren
Bei den Betrachtungen zur Kommunikation und Partitionierung wurde schon ein wesentli-cher Faktor genannt - die Entkoppelbarkeit von Stationen.Aufgabe der Synchronisationsverfahren ist es, die kausal richtige Reihenfolge der Abarbei-tung von Ereignissen sicherzustellen (siehe Punkt 3.1.3.1).Die Ereignisse bilden aber - wie Abbildung 48 zeigte - Ketten109. Es ist daher sinnvoll,Partitionen zu bilden, in denen möglichst lange Ketten von Ereignissen bestehen, die zu-dem nur durch wenige externe Ereignisse angestoßen werden (vergleiche Formel 3, Seite70). Die Simulation von parallel stattfindenden Prozessen - wie z.B. Bearbeitungs-prozessen auf Maschinen in einem Produktionssystem - kann wie in Abbildung 49 gezeigtaufgefaßt werden.
108 Falls das Werkstück durch die Defektsituation der Maschine Schaden nimmt, so ist das Werkstück jetzt
entweder Ausschuß (ggf. Neueinsteuerung eines Auftrages für die beschädigten Werkstücke) oder aber dasWerkstück kann repariert werden. Dazu sind eventuell einige gesonderte Arbeitsgänge zu durchlaufen be-vor die Bearbeitung wiederholt werden kann.
109 Vergleiche conditional / unconditional events [Fishman 2001, S. 44].

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 138
Zeit
Nachricht
Nachricht
Nachricht
Nachricht
LP1 LP2 LP3
Abbildung 49 Lebensfadendiagramm der Logischen Prozesse einer Simula-tion
Zum Startzeitpunkt nehmen mehrere Logische Prozesse ihre Arbeit auf (symbolisiert durcheinen Balken). Dabei senden sie Nachrichten an andere Prozesse oder warten auf Nach-richten anderer Prozesse (Warten durch die unterbrochene Linie symbolisiert). Um diekorrekte kausale Abfolge der Ereignisabarbeitung zu gewährleisten, muß ein Synchronisa-tionsverfahren vor der Ausführung von Ereignissen prüfen, ob zeitlich frühere Ereignisse,welche die kausale Ordnung stören können, durch noch unbekannte Nachrichten ausstehen(diese Synchronisationspunkte sind durch die Kreise symbolisiert). Wird in einem solchenSynchronisationspunkt bemerkt, daß noch durch ausstehende Nachrichten weitere externeEreignisse eingeplant werden könnten, die zeitlich vor den nächsten bekannten Ereignissenliegen, so muß der Prozeß auf das Eintreffen dieser Nachrichten warten (konservativesVorgehen) - der Prozeß blockiert.Ziel ist es, die Logischen Prozesse so zu gestalten, daß sie möglichst selten - und dannauch nur kurz - blockieren. Dadurch können die vorhandenen Logischen Prozesse mög-lichst oft parallel arbeiten. Mißlingt diese Gestaltung der Logischen Prozesse, so ist derGrad der ausnutzbaren Parallelität gering und kann ggf. den Aufwand zur Synchronisationkompensieren. Aus diesem Grund ist es im Rahmen der Synchronisationsverfahren not-wendig, die Logischen Prozesse mit Informationen über die mit ihnen verbundenen ande-ren Logischen Prozesse zu versorgen, damit eine solche Blockierungssituation nicht oderzumindest nur selten eintritt. Allerdings entsteht durch diese Informationsversorgung zu-sätzliche Kommunikation.
Ein erster Weg ist die Untersuchung der zwischen den Partitionen zu versendenden Nach-richten, um Möglichkeiten zur weiteren Entkopplung der Prozesse durch zusätzliche Ga-rantien (siehe Punkt 3.1.3.6, „Lookahead“, Seite 78) zu entdecken.Wie im vorangegangenen Punkt gezeigt, erhält eine Partition Nachrichten darüber, welcherAuftrag zwischen den Stationen zu transferieren ist. Diese Nachricht wird durch einen Lo-gischen Prozeß nur dann weitergegeben, wenn der Auftrag das Ereignis Bearbeitungsende(E6) erreicht hat.
Hier existieren zwei Ansatzpunkte:

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 139
1. Senden von Nachrichten über das Erreichen eines Zeitpunktes,2. Identifikation von Lookahead im Kontext einer Maschinengruppe zur Versendung
von Garantien.
Der Ansatzpunkt 1 führt zum Senden zusätzlicher Nachrichten, die einen Logischen Pro-zeß lediglich über das Erreichen eines Zeitpunktes informieren. Eine solche Nachrichtheißt Null-Message (siehe Punkt 3.1.3.3).
So könnten beispielsweise Null-Messages versendet werden, wenn eine Maschine mit demUmrüsten beginnt oder eine Bearbeitung aufnimmt. Problematisch daran ist, daß so dieAnzahl der zu versendenden Nachrichten drastisch steigt. Außerdem nutzt das Versendendieser Nachricht nur wenig, da die Berechnungslasten nach diesen Ereignissen minimalsind und schon bald die eigentliche Nachricht versendet wird. Verbesserungen des Null-Message-Gedankens gehen immer mit einer zeitlichen Vorausschau - dem Lookahead -einher.
Der Lookahead (siehe Punkt 3.1.3.3) gibt die Möglichkeit eines Logischen Prozesses zudessen Vorausschau in seine Zukunft an. Die Identifikation dieser Größe im Anwendungs-kontext hat signifikanten Einfluß auf die Performance der Parallelen und Verteilten Simu-lation [Chandy, Misra 1978], [Fujimoto 1988a], [Loucks, Preiss 1990], [Preiss, Loucks1990], [Bagrodia 1993], [Bagrodia 1994], [Mehl 1994, S. 26], [Sporrer 1995, S. 34], [Bag-rodia 1996]. Der Lookahead ist eine situationsbezogene und keine konstante Größe, wiesie vereinfachend in einigen Verfahren und Tools [Preiss, Loucks 1990], [Bagrodia 1996],[Paprotny, Fowler 2001] angenommen wird.Der Prozeß einer Maschinengruppe besitzt Lookahead, wenn z.B. eine Maschine eine Be-arbeitung aufnimmt, denn bei Aufnahme der Bearbeitung ist die Bearbeitungsdauer be-kannt. Gleiches gilt für das Beginnen eines Rüstvorganges und die Rüstzeit. D.h., es wärejetzt möglich, bei Eintreten dieser Ereignisse eine Null-Message mit dem Zeitstempel desaktuellen Zeitpunktes plus die Bearbeitungszeit bzw. Rüstzeit zu versenden. Dieses Vor-gehen ist aber mit zwei Problemen behaftet. Zum Einen tritt hier wieder das schon fürNull-Messages beschriebene Problem auf. Zum Anderen hat hier die Null-Message nichtden Charakter einer Garantie, daß der Prozeß keine Nachricht mehr senden wird, die zeit-lich vor dem Zeitstempel der Null-Message liegt. Dies kommt daher, daß eine Maschinen-gruppe mehrere Maschinen umfaßt. Sendet nun eine Maschine eine Null-Message Takt +Lookahead, so sagt dies nicht aus, ob eine andere Maschine der Maschinengruppe eineNachricht innerhalb des Intervalls [ Takt; Takt+Lookahead ] senden wird. D.h., vor demSenden dieser Null-Message wäre zu prüfen, welche Zeit garantiert werden kann und es istggf. auf das Senden der Null-Message zu verzichten.Es gibt noch weitere Ansatzpunkte für den Lookahead. Tritt z.B. ein Defektereignis ein, sosteht fest, daß keine Auftragsnachricht für den Zeitraum des Defekts gesendet werdenkann. An dieser Stelle wäre es sinnvoll, die nachgelagerten Stationen über das Erreichendes aktuellen Zeitpunktes und den nächsten möglichen Zeitpunkt des Eintreffens von Auf-trägen zu informieren. Auch hier gilt wieder, daß vor Versenden dieser Nachricht geprüftwerden muß, ob nicht die anderen Maschinen der Maschinengruppe zu einem früherenZeitpunkt wieder aktiv werden.Eine weitere Möglichkeit des Lookahead resultiert aus den an der Maschinengruppe vor-liegenden spezifischen Prozeßbedingungen und dem zugehörigen Reihenfolgeplanungs-ansatz. Wird z.B. festgestellt, daß eine Bearbeitung von Aufträgen nicht sinnvoll wäre,weil ein eigentlich unnötiger Rüstvorgang ausgelöst würde, oder weil bedingt durch dieMöglichkeit zur parallelen Bearbeitung nicht genügend Aufträge vorhanden sind, um einwenigstens halbvolles Batch zu bilden, so wird für einen undefiniert langen Zeitraum die-

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 140
ser Logische Prozeß keine Auftragsnachrichten senden. Jetzt jedoch kann er seine Nach-folger wenigstens über das Erreichen dieses Entscheidungszeitpunktes in Kenntnis setzen.Verwendet man FIFO zur Regelung der Abarbeitungsreihenfolge der an der Maschinen-gruppe ankommenden Aufträge, so kann eine weitere Lookahead-Größe identifiziert wer-den: Durch die Kenntnis der Bearbeitungszeit und der Abarbeitungsreihenfolge ist bereitsfür einen ankommenden Auftrag bekannt, wann dieser seine Bearbeitung vollendet habenwird. So kann für einen Auftrag, der die Warteschlange betritt, dessen Fertigstellungszeit-punkt berechnet werden und der Auftrag kann sofort weitergesendet werden. Dies führt zueiner enormen Beschleunigung der Simulation [Nicol 1988], [Preiss, Loucks 1990],[Loucks, Preiss 1990], [Jha, Bagrodia 1993], [Greenberg, Lubachevsky 1996], [Paprotny,Fowler 2001]. In der Praxis ist eine solche Restriktion aber nicht haltbar. Zum Einen istder simulative Test verschiedener Ansätze zur Reihenfolgeplanung von Interesse und zumAnderen dürfen keine Defekte auftreten, da sonst die vorausberechnete Fertigstellungszeithinfällig ist.Topologieinformationen können als eine Art Lookahead aufgefaßt werden. Tauschen zweiLogische Prozesse keine Informationen aus, d.h. sie besitzen keine topologische Verbin-dung, so haben beide dem anderen gegenüber einen Lookahead von Unendlich.Auf Basis dieser Betrachtungen kann aber noch nicht entschieden werden, welches Syn-chronisationsverfahren besser zur Abarbeitung von Modellen von Produktionssystemengeeignet ist. Die Betrachtungen zeigen lediglich, daß sehr oft Synchronisationspunkteerreicht werden und daß die Berechnungslast zwischen diesen Synchronisationspunktengering ist. Bei einem konservativen Synchronisationsverfahren ist dies unkritisch, jedochbei einem optimistischen Synchronisationsverfahren muß an jedem der Synchronisations-punkte der Zustand des Logischen Prozesses gesichert werden, damit im Falle einer Kausa-litätsverletzung auf diesen gesicherten Prozeßzustand zurückgegriffen werden kann (Roll-back). Für eine Maschinengruppe ist der Speicherumfang des Prozeßzustandes aber sehrhoch. Zum Prozeßzustand gehören die Daten der Aufträge, die sich in der Warteschlangeoder momentan in Bearbeitung befinden, die Zustandsdaten der Maschinen sowie alle An-gaben zur Erfassung von Ergebnisgrößen für die Warteschlange und die Maschinenausla-stung. Weiterhin können noch Zustandsvariablen für den Reihenfolgeplanungsansatz an-fallen. Außerdem müssen für die Rollbackfähigkeit die gesendeten und empfangenenNachrichten (die Aufträge) gesichert werden, um die in der optimistischen Phase an andereMaschinen versendeten Aufträge wieder canceln zu können (siehe dazu Punkt 3.1.3.4).Kritischer Faktor ist hier die Länge einer optimistischen Phase (in Ereignissen gemessen).Beginnt ein Logischer Prozeß mit einer optimistischen Phase, so kann er alle bereits vor-handenen (und innerhalb der Phase noch eintreffenden) externen Ereignisse sowie alle in-ternen Ereignisse abarbeiten. Diese Abarbeitung geht recht schnell. Die optimistische Pha-se ist dann beendet, wenn eine Nachricht mit einem Zeitstempel kleiner als die lokale Zeiteintrifft. Bei einer solchen Kausalitätsverletzung muß ein Rollback auf den Prozeßzustand,der zuletzt vor dem eintreffenden Ereignis gesichert wurde, durchgeführt werden. Einezweite Möglichkeit die optimistische Phase zu beenden besteht darin, daß eine Garantie-situation eintritt und somit definitiv keine Nachrichten vor dem Garantiezeitpunkt mehrempfangen werden können. Im Falle eines Rollbacks müssen Anti-Nachrichten (siehePunkt 3.1.3.4, 3.1.3.6) gesendet werden, um die anderen Prozesse über die fehlerhaften,bereits gesendeten Nachrichten zu informieren. Unter Umständen wird dadurch bei diesenProzessen ein weiterer Rollback ausgelöst - eine Rollbackkaskade entsteht.Die optimistischen Verfahren unterscheiden sich nun darin, ob bei jedem auszuführendenEreignis der Prozeßzustand gesichert wird oder nur nach einer gewissen Anzahl von Er-eignissen. Ebenso dient das inkrementelle Zustandsspeichern zur Eindämmung des Spei-cherbedarfs (siehe Punkt 3.1.3.6, Seite 85). Tests zeigten (siehe Punkt 6.3.), daß der Spei-

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 141
cherbedarf bei der Ausführung eines Modells mit 23 Maschinengruppen bei einer vollstän-digen Zustandssicherung nach einer gewissen Simulationszeit 1 GB überschreitet. Ebensoergaben die Tests, daß bei sehr großen Prozeßzuständen das Vergleichen der Prozeßzu-stände zur Ermittlung der Änderungen zur inkrementellen Speicherung wesentlich längerdauert als das Speichern der Kopie des Prozeßzustandes.Für alle optimistischen Verfahrensarten gilt jedoch, daß die Partitionen in etwa eine glei-che Berechnungslast besitzen sollen, damit kein Logischer Prozeß vorauseilen kann, wo-durch später Rollbackkaskaden erzeugt werden [Mehl 1994, S. 67-71], [Sporrer 1995, S.30-36]. Die Tests (Punkt 6.3.) zeigten jedoch, daß nahezu ständig Rollbacks ausgelöstwerden (Rollbackkaskaden), wodurch die optimistisch synchronisierte Simulation nurlangsam voranschreitet. Ein Modell, daß in einer konservativen Synchronisation nach4 Minuten terminierte, benötigte bei optimistischer Synchronisation ca. 35 Minuten. Die-ses Mißverhältnis entsteht durch die geringe Berechnungslast der Ereignisse, wodurch dieLogischen Prozesse sehr schnell die vorhandenen Ereignisse abarbeiten und Nachrichtenversenden, die sie kurze Zeit später wieder zurücknehmen müssen110. Die durch Rollbacksbedingte zusätzliche Kommunikation erhöht den Kommunikationsaufwand jedoch be-trächtlich.Der Einsatz optimistischer Synchronisationsverfahren ist daher zur Simulation von Pro-duktionssystemen wenig geeignet.Es empfiehlt sich dagegen Erweiterungen des konservativen Standardverfahren nachChandy, Misra und Bryant [Chandy, Misra 1978], [Bryant 1979], [Misra 1986] einzusetzen(siehe Punkt 3.1.3.7). Zusätzlich kann das eingesetzte konservative Verfahren noch durchdas Versenden von Null-Messages in folgenden Lookahead-Situationen verbessert werden:bei Auftreten eines Defektes und bei Nichtbelegung von Maschinen bei einer Reihenfolge-entscheidung.
4.4 Synchronisation von Simulationsmodellen von Produktions-systemen
In den Unterkapiteln 3.1.3 und 4.3.4.2 wurden eine Vielzahl vorhandener Synchronisa-tionsverfahren aufgeführt und diskutiert. Diese Verfahren und -varianten sind inAbbildung 50 aufgeführt.Es kann jedoch keine Empfehlung gegeben werden, welches Synchronisationsverfahrenallgemein besser geeignet ist (siehe Punkt 3.1.3.6). Der Entwurf eines eigenen Synchro-nisationsverfahrens ist vor diesem Hintergrund fraglich. Aus diesem Grund sollen zuerst inbestehenden Tools implementierte Synchronisationsverfahren benutzt und getestet werden.Anschließend können diese Verfahren noch über Parameter angepaßt oder an die im An-wendungskontext der Simulation von Produktionssystemen veränderten Gegebenheitenadaptiert werden.Aus diesen Gründen wurden mit dem ausgewählten Tool ParSimONY (siehe Punkt 5.2.1)Tests durchgeführt. Diese Tests (Punkt 6.3.) zeigten eine sehr schlechte Performance vonoptimistischen Synchronisationsverfahren. Konservative Verfahren sind zur Simulationvon Produktionssystemen besser geeignet.111
110 [Preiss, Loucks 1990] und [Bagrodia 1996] bezeichnen diesen Effekt als „kritische Ereignispopulation“.
Sinkt die Anzahl der im Logischen Prozeß bereits bekannten Ereignisse (die Ereignispopulation) unter einekritische Schwelle, dann tritt der beschriebene Effekt auf. Optimistische Synchronisationsverfahren benöti-gen zwingend eine größere Ereignispopulation.
111 Mehl begründet dies u.a. damit, daß konservative Verfahren dann besser geeignet sind, wenn der Zustands-raum besonders groß ist [Mehl 1994, S. 73 u. S. 227].
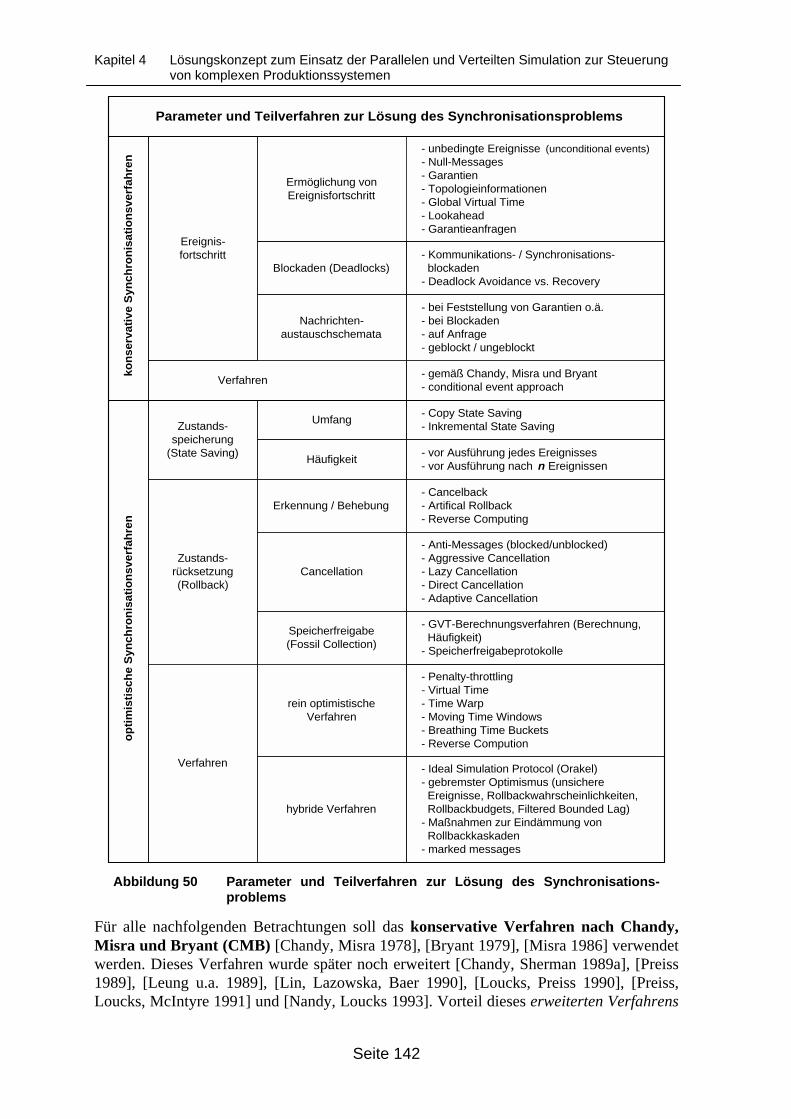
Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 142
Parameter und Teilverfahren zur Lösung des Synchronisationsproblemsko
nserv
ati
ve S
yn
ch
ron
isati
on
sverf
ah
ren
op
tim
isti
sch
e S
yn
ch
ron
isati
on
sverf
ah
ren
Ereignis-fortschritt
Verfahren- gemäß Chandy, Misra und Bryant- conditional event approach
- unbedingte Ereignisse (unconditional events)- Null-Messages- Garantien- Topologieinformationen- Global Virtual Time- Lookahead- Garantieanfragen
Ermöglichung vonEreignisfortschritt
Blockaden (Deadlocks)
Nachrichten-austauschschemata
- Kommunikations- / Synchronisations- blockaden- Deadlock Avoidance vs. Recovery
- bei Feststellung von Garantien o.ä.- bei Blockaden- auf Anfrage- geblockt / ungeblockt
Zustands-speicherung
(State Saving)
Zustands-rücksetzung(Rollback)
Verfahren
Umfang
Häufigkeit
- Copy State Saving- Inkremental State Saving
- vor Ausführung jedes Ereignisses- vor Ausführung nach n Ereignissen
Speicherfreigabe(Fossil Collection)
Erkennung / Behebung- Cancelback- Artifical Rollback- Reverse Computing
rein optimistischeVerfahren
hybride Verfahren
- Ideal Simulation Protocol (Orakel)- gebremster Optimismus (unsichere Ereignisse, Rollbackwahrscheinlichkeiten, Rollbackbudgets, Filtered Bounded Lag)- Maßnahmen zur Eindämmung von Rollbackkaskaden- marked messages
- Penalty-throttling- Virtual Time- Time Warp- Moving Time Windows- Breathing Time Buckets- Reverse Compution
- GVT-Berechnungsverfahren (Berechnung, Häufigkeit)- Speicherfreigabeprotokolle
Cancellation
- Anti-Messages (blocked/unblocked)- Aggressive Cancellation- Lazy Cancellation- Direct Cancellation- Adaptive Cancellation
Abbildung 50 Parameter und Teilverfahren zur Lösung des Synchronisations-problems
Für alle nachfolgenden Betrachtungen soll das konservative Verfahren nach Chandy,Misra und Bryant (CMB) [Chandy, Misra 1978], [Bryant 1979], [Misra 1986] verwendetwerden. Dieses Verfahren wurde später noch erweitert [Chandy, Sherman 1989a], [Preiss1989], [Leung u.a. 1989], [Lin, Lazowska, Baer 1990], [Loucks, Preiss 1990], [Preiss,Loucks, McIntyre 1991] und [Nandy, Loucks 1993]. Vorteil dieses erweiterten Verfahrens

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 143
ist, daß kein explizit ausgewiesener, konstanter Lookahead mehr vorausgesetzt werdenmuß. Viele Implementierungen konservativer Verfahren geraten in Deadlocksituationen,aus denen sie sich nicht mehr befreien können - die parallele Abarbeitung des Simulations-modells terminiert nicht [Chandy, Misra 1981], [Mehl 1994, S. 35], [Bagrodia 1996]. Umdies zu verhindern, wurde ein explizit ausgewiesener konstanter Lookahead verwendet.Zum Einen ist aber die Größe des Lookahead nicht konstant, zum Anderen kann in vielenModellen kein explizit ausweisbarer Lookahead entdeckt werden [Preiss, Loucks 1990].Durch die Erweiterungen des CMB-Verfahrens terminieren Simulationsmodelle auch ohnedas Vorhandensein von Lookahead ordnungsgemäß. Hierzu verwendet das Verfahren derArbeitsgruppe um Preiss [ParSimONY] einen separaten Prozeß zur Deadlockfeststellungund -behebung. Aufgabe dieses zusätzlichen Prozesses ist es, bei Feststellung eines Dead-locks eine Berechnung der Global Virtual Time (GVT) durchzuführen (Analogie zu opti-mistischen Synchronisationsverfahren) und die verklemmten Logischen Prozesse wiederzu starten (siehe Punkt 3.1.3.6, Seite 83).Ein wesentlicher Fakt bei der Anwendung von Synchronisationsverfahren ist, daß in Si-mulationsmodellen ein hoher Kommunikationsaufwand erforderlich ist. Bedingt durch dasSimulationsmodell und noch zusätzlich durch das Synchronisationsverfahren wird zwi-schen benachbarten Stationen eine Vielzahl von Nachrichten versendet. Um die Menge derzu übertragenden Nachrichten zu verkleinern, empfiehlt es sich, die Nachrichten gepuffertzu versenden [Fujimoto 1988b], [Mehl 1994, S. 34]. Oft sind zwischen zwei Stationen inkurzem Realzeitabstand zwei oder mehr aufeinanderfolgende Nachrichten zu versenden,welche nun als „Block“ versendet werden. Die Bytemenge der Nachrichten bleibt bei die-sem Vorgehen zwar gleich, jedoch sinkt die Anzahl der zu übertragenden Nachrichten. Beider verteilten Abarbeitung in einem Computernetzwerk würde sich somit eine signifikanteniedrigere Rate an Übertragungsanforderungen ergeben und das Computernetz könnte ein-gehende Übertragungsanforderungen wesentlich schneller abarbeiten - eine höhere Per-formance ist die Folge [Su, Seitz 1989], [Mehl 1994, S.34ff].
Durch die Verwendung bereits implementierter Synchronisationsverfahren kann die Auf-gabe der Synchronisation lediglich über Parameter beeinflußt werden. Der wesentlichsteVerfahrensparameter von Synchronisationsverfahren ist der Lookahead. Bei Modellen vonProduktionssystemen sind die beiden einzig sinnvollen Anwendungsmöglichkeiten vonLookahead (vergleiche 4.3.4.2): das Versenden von Garantien bei Auftreten eines Defektesund bei der Nichtbelegung von Maschinen durch eine Reihenfolgeentscheidung. Bei Auf-treten eines Defektes an einer Maschine kann diese Maschine bis zur Beendigung der Re-paratur (MTTR) keine anderen Nachrichten senden. Dies ist der einzige Fall eines hohenLookaheads in Modellen von Produktionssystemen. Weiterhin kann bei einer Reihenfolge-entscheidung unter komplexen Prozeßbedingungen die Entscheidung fallen, die Maschineleer zu lassen und keine Bearbeitung aufzunehmen. Dies kann z.B. zweckmäßig sein, umhäufige Rüstwechsel zu vermeiden oder um die quantitative Auslastung von Batchs zuerhöhen. In beiden Fällen ist jedoch zu beachten, daß das genannte Ereignis an einer Ma-schine auftritt, die Nachrichten aber zwischen Maschinengruppen ausgetauscht werden.D.h., vor dem Versenden der Garantie ist festzustellen, ob die zu übertragende Garantienicht durch Nachrichten der anderen Maschinen der Maschinengruppe hinfällig werdenkann. Die Nachricht darf nur gesendet werden, wenn dies nicht der Fall ist. Andernfallshätte diese Nachricht keinen Garantiecharakter.

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 144
Soll die Simulation mit einem optimistischen Synchronisationsverfahren112 durchge-führt werden, so ist das nachfolgend beschriebene Vorgehen zu empfehlen.Durch eine Analyse der während des Simulationslaufes auftretenden Rollbacks könnenLogische Prozesse identifiziert werden, die oft bzw. ständig Rollbacks auslösen. SolchenLogischen Prozessen sollte durch Setzen eines Flags verboten werden, sich weiterhin op-timistisch zu verhalten113. Der Teilsimulator für diesen Prozeß darf dann nur sichere Erei-gnisse verarbeiten und kann somit keine Rollbacks und Rollbackkaskaden auslösen. DiePerformance kann auf diese Weise verbessert werden.Der Umfang der Zustandsspeicherungen der Logischen Prozesse ist für Simulations-modelle von Produktionssystemen sehr groß. Weiterhin geschehen diese Zustandsspeiche-rungen sehr oft. Zu empfehlen wäre also, die Zustandspeicherungen nicht bei jedem zuprozessierenden unsicheren Ereignis durchzuführen, sondern nach z.B. jedem fünften Er-eignis. Als Methode zur Zustandsspeicherung sollte das Speichern des Zustandes durchKopieren angewendet werden, da für eine inkrementelle Zustandsspeicherung dieser zeitli-che Aufwand ebenfalls anfällt und das Vergleichen hoher Bytemengen sehr zeitaufwendigist.Kommt es doch zu einem Rollback, so sollte Lazy Cancellation verwendet werden. D.h.,bei Feststellung einer Kausalitätsverletzung und Auslösung eines Rollbacks werden dieAnti-Nachrichten nicht sofort gesendet, sondern erst, wenn festgestellt wird, daß eine inder optimistischen Phase gesendete Nachricht fehlerhaft ist. Durch die verzögerte Versen-dung der Anti-Nachrichten kann der Kommunikationsaufwand gesenkt werden und dasAusmaß und die Häufigkeit von Rollbackkaskaden kann verringert werden [Mehl 1994, S.48], [Bauer 1994, S. 34].
Interessant wäre auch der Vergleich mit hybriden Synchronisationsverfahren wie derSpekulativen Verteilten Simulation nach Mehl [Mehl 1994, S. 106-144]. Leider existiertjedoch keine zugängliche Implementation dieses Ansatzes (siehe Punkt 3.2.2.8).
4.5 Partitionierung von Simulationsmodellen von Produktions-systemen
4.5.1 Vorstellung der Verfahrensidee
Die Aufgabe der Partitionierung ist lösungsdefekt. Es mangelt an einem allgemein an-wendbaren Verfahren. Außer prinzipiellen Aussagen zu Zielen und einigen wenigenGrundregeln haben die Partitionierungsverfahren keine Gemeinsamkeiten. Alle vorhande-nen Partitionierungsverfahren sind lediglich Lösungsheuristiken ohne die Garantie eineroptimalen Lösung. Zudem sind die Partitionierungsverfahren auf jeweils ein speziellesAnwendungsgebiet ausgerichtet. Ein Partitionierungsverfahren für Modelle von Produkti-onssystemen fehlt bisher.Das Partitionieren eines Simulationsmodells ist ohne Kenntnis der Zeitpunkte, zu denenparallel Berechnungen stattfinden, nur unzureichend möglich. Die „günstigste“ Partitio-nierung kann nicht im Voraus bestimmt werden. Das dafür notwendige Wissen kann erstnach der Ausführung mindestens eines Simulationslaufs durch Analyse der Protokolle desSimulationslaufs gewonnen werden.
112 Das orginale Time Warp-Verfahren nach [Jefferson, Sowizral 1985], [Jefferson u.a. 1988] kann noch um
weitere Gedanken ergänzt werden. Diese Erweiterungen werden in [Preiss 1989], [Preiss 1990], [Lin, La-zowska, 1990b], [Lin, Lazowska, 1990c], [Lin, Lazowska, 1990d], [Lin, Lazowska, 1990e], [Lin, La-zowska 1991], [Lin, Preiss 1991], [Preiss, MacIntyre, Loucks 1992], [Lin 1992a], [Lin u.a. 1993], [Preiss,Loucks 1995], [Das, Fujimoto 1997], [Wilsey 1997], und [Wilsey u.a. 1998] diskutiert.
113 Jha und Bagrodia haben in [Jha, Bagrodia 1994] eine ähnliche Strategie beschrieben.

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 145
Jha und Bagrodia [Jha, Bagrodia 1996] verfolgen mit dem Ideal Simulation Protocol einenähnlichen Ansatz für Synchronisationsverfahren. Die Idee besteht darin, einen einfachen(sequentiellen) Simulationslauf durchzuführen, um für den nächsten Simulationslauf zujedem Ereigniszeitpunkt zu wissen, wann welche Kommunikation mit welchem Erfolgstattfindet.Analog dazu kann für die Partitionierung über eine ex-post-Analyse des Simulationslaufsfestgestellt werden (siehe Abbildung 51), welche Elemente des Produktionssystems ge-meinsam in eine Partition eingeordnet werden sollten. Während eines ersten Simulations-laufs wird gemessen, wie oft Nachrichten zwischen den Maschinengruppen transferiertwurden und wie oft diese Kommunikation nützte, d.h. Blockierungssituationen vermied.Dadurch können Gruppen von eng kooperierenden bzw. kommunizierenden Maschinen-gruppen gefunden werden. Richtwerte für die ermittelten Zahlen entscheiden über die Zu-sammenfassung von Maschinengruppen in einer Partition oder getrennte Abbildung derMaschinengruppen in unterschiedlichen Partitionen.
Simulationslauf
Meßdaten
Tuning desRegelwerks
Regeln zurPartitionierung
Neuziehen vonPartitionsgrenzen
Abbildung 51 Vorgehen zur ex-post-Analyse eines Simulationslaufes zurVerbesserung der Partitionierung
Die Meßdaten können während der Versuche mit dem Simulationsmodell ermittelt werdenund dann zur schrittweisen Verfeinerung der Partitionierung genutzt werden.Ebenso können diese Meßdaten benutzt werden, um das Regelwerk zur Partitionierung(z.B. Schwellwerte) iterativ zu verbessern.
Bei dieser Analyse treten aber folgende Probleme auf:
1. Es fallen sehr viele Meßdaten an.2. Es existiert nur ein grobes Regelwerk.3. Der Prozeß des Partitionierens bedingt eine Modelländerung und ist bisher manuell
vorzunehmen.4. Die Bildung der Partitionen ist sensitiv gegenüber Modellparametern.
Es ist eine Vielzahl von zu überwachenden Parametern und Meßgrößen notwendig, umSchlüsse für das Ziehen von Partitionsgrenzen abzuleiten. Dazu ist es erforderlich, im Si-mulationsmodell selbst Anweisungen zur Erfassung dieser Meßgrößen anzugeben. Diesvergrößert aber den numerischen Umfang des Simulationsmodells und führt zu einer ge-ringeren Performance. Zur effektiven Verwaltung der Meßgrößen ist es außerdem sinnvoll,diese in einer Datenbank aufzubewahren.Viel problematischer ist jedoch, daß nur ein grobes, unscharfes Regelwerk vorliegt. Vieleder Regeln sind zudem mit Schwellwerten versehen, die erst aus der Erfahrung heraus mitkonkreten Werten versehen werden können. Ebenso sind die Regeln z.T. widersprüchlich

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 146
und können erst nach längerer Zeit mit Bestimmtheitsfaktoren belegt werden. An dieserStelle zeigt sich wieder der Lösungsdefekt des Partitionierens.Außerdem bedingt eine Änderung der Partitionierung naturgemäß ein anders imple-mentiertes Simulationsmodell. Dazu sind die in den Partitionen benötigten Daten richtigzuzuordnen und die einzelnen Logischen Prozesse korrekt zu formulieren. Bisher wirddieser Prozeß ausschließlich manuell vorgenommen. Manuell ist dies aufgrund des hohenDaten- und Programmumfangs und des damit verbundenen hohen Aufwandes aber nurschwer durchführbar. Der Partitionierungsprozeß läßt sich aber - wie in Punkt 4.2.3 fürModellbildung im Allgemeinen gezeigt - durch Modellgeneratoren in hohem Maße unter-stützen (vergleiche dazu Punkt 5.3.2).
In einem ersten Ansatz soll davon ausgegangen werden, daß ein Logischer Prozeß aus ei-ner einzelnen Maschinengruppe besteht. Auf Basis der nachfolgend vorgestellten Meß-größen und Regeln soll dies sukzessive verändert werden. Auf diese Art entstehen nachmehreren Simulationsläufen größere Partitionen, die aus mehreren Maschinengruppen be-stehen.Nachdem man auf diese Weise eine effiziente Partitionierung des Modells erreicht hat,kann man die Anweisungen zur Erfassung der Partitionierungsmeßgrößen im Simulations-modell deaktivieren, wodurch der Performancenachteil, der durch diese zusätzlichen An-weisungen entstanden ist, wieder erlischt.
Dieses Verfahren stellt eine weitere Lösungsheuristik für das Partitionierungsproblem dar.Das Verfahren ist speziell für Modelle von Produktionssystemen geeignet, aber auch aufandere Anwendungsgebiete ausdehnbar. Neu daran ist insbesondere die Verfolgung desZiels der maximalen Gleichzeitigkeit, die ex-post-Analyse des Simulationslaufes zur Fest-stellung des Nutzens der Partitionierung und die automatische Anpassung des Simulations-modells an eine günstigere Partitionierung durch einen Simulationsmodellgenerator.
4.5.2 Ziele der Partitionierung
Das Oberziel der Partitionierung ist es, Partitionen so einzurichten, daß die durch die vor-handenen Partitionen erzielbare Parallelität maximal ausgenutzt werden kann. D.h., daßdas Modell in kürzerer Zeit abgearbeitet werden kann. Das bedeutet, daß man unter sonstgleichen Bedingungen den Erfolg einer Partitionierung am resultierenden Speedup messenkann. Je höher das Speedup, desto erfolgreicher ist die angewendete Partitionierung.Leider kann das Oberziel der Maximierung des Speedups während des Partitionierungs-prozesses nicht direkt verfolgt werden, da die exakten Wirkungsbeziehungen verschiede-ner Einflußfaktoren auf das Speedup nicht hinreichend bestimmbar sind. Man bedient sichdaher leichter faßbarer Ersatzziele.In der Literatur114 oft verwendete Ersatzziele sind das Minimum der Verbindungen zwi-schen den Partitionen (vergleiche [Kernighan, Lin 1970], [Schweikert, Kernighan 1972],[Fiduccia, Mattheyses 1982], [Krishnamurthy 1984], [Vijayan 1989], [Vijayan 1991]), dieAusgewogenheit der Größe der Partitionen (vergleiche [Wei, Cheng 1989], [Wei, Cheng1991], [Sporrer 1995, S. 11, S. 35], [Bagrodia 1996], [Kim, Jean 1996]) und ein minimalerKommunikationsaufwand (vergleiche [Smith u.a. 1987], [Manjikian, Loucks 1993], [Spor-rer, Bauer 1993], [Mehl 1994, S. 10, S142. f], [Sporrer 1995, S. 34f], [Bagrodia 1996]).Diese Ziele lassen sich jedoch auf zwei Ziele reduzieren: die Minimierung des Kommu-nikationsaufwandes und die Schaffung eines Lastausgleichs zwischen den Partitionen.
114 Einen Überblick über Verfahren zur Partitionierung geben u.a. [Smith u.a. 1987], [Lengauer 1990] und
[Luksch 1993].

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 147
Das Ziel des minimalen Kommunikationsaufwandes resultiert aus dem starken Perfor-manceeinfluß der Kommunikation. Dieser Einfluß entsteht zum Einen aus einem wesentli-chen zeitlichen Mehrverbrauch im Falle einer verteilten Abarbeitung, da hier über einComputernetzwerk kommuniziert werden muß (siehe Punkt 3.1.2.3). Zum Anderen hattenvergangene Arbeiten gezeigt [Loucks, Preiss 1990], [Mehl 1994, S. 142f], [Bagrodia1996], [Holthaus, Rosenberg, Ziegler 1996], daß ein Kommunikationsoverhead entstehenkann (siehe Punkt 3.1.2.3).Das Ziel des Lastausgleichs ist insbesondere für optimistische Synchronisationsverfahrenvon entscheidender Bedeutung. Bei annähernd gleicher Last kann keine Partition den ande-ren Partitionen vorauseilen (siehe Punkt 3.1.3.6) und sich somit in einer längeren optimisti-schen Phase befinden, wodurch die Wahrscheinlichkeit von Rollbacks und insbesonderevon Rollbackkaskaden wachsen würde (vergleiche [Mehl 1994, S. 67-71], [Sporrer 1995,S. 30-36, S. 110], [Kim, Jean 1996]).Bei alleiniger Verfolgung dieser beiden Ziele wurde jedoch das wesentlichste Ziel außerAcht gelassen: Es muß versucht werden, Partitionen zu bilden, die zu den selben Zeit-punkten aktiv sind, damit diese Partitionen überhaupt parallel Berechnungen ausführenkönnen. Dieses Ziel der Gleichzeitigkeit (concurrency) wird oft vernachlässigt (siehe[Briner 1990], [Luksch 1993, S. 144], [Kim, Jean 1996]).So beschränken sich graphentheoretische Verfahren auf die Schaffung von Partitionen mitminimalen Kommunikationsaufwand, indem sie Teilgraphen mit möglichst wenig Verbin-dungen identifizieren (siehe Min-Cut-Verfahren und dessen Erweiterungen [Kernighan,Lin 1970], [Schweikert, Kernighan 1972], [Fiduccia, Mattheyses 1982], [Krishnamurthy1984], [Vijayan 1989], [Vijayan 1991]). Die so entstehenden Partitionen haben aber zumTeil eine völlig unterschiedliche Größe und werden im Nachhinein zu Meta-Partitionenetwa gleichen Aufwandes kombiniert. Andere Verfahren bilden Cluster (siehe dazu [Hil-berg 1981], [Garbers u.a. 1990], [Cong, Smith 1993], [Manjikian 1992], [Saucier u.a.1993], [Sporrer, Bauer 1993], [Sporrer 1995, S. 43-80]), um eng zusammenhängende Teil-graphen zu identifizieren, die dann zu größeren Blöcken zusammengefaßt werden. EinePartitionierung mit einem minimalen Kommunikationsaufwand führt aber nicht zwangs-läufig zu gleichzeitig aktiven Partitionen und damit zu einer hohen Performance. LediglichKim und Jean [Kim, Jean 1996] beschreiben eine explizite Einbeziehung des Ziels derGleichzeitigkeit (concurrency).
Im vorliegenden Partitionierungsansatz (siehe Punkte 4.5.3 bis 4.5.8) werden deshalb dieseZiele verfolgt (gemäß Rang geordnet):
1. maximale Ausnutzung der Gleichzeitigkeit um Berechnungen parallel durch-führen zu können,
2. minimaler Kommunikationsaufwand,3. Ausgewogenheit der Partitionsgrößen,4. keine Replikation von Elementen in unterschiedlichen Partitionen115.
4.5.3 Vorstellung der Basisgrößen des Partitionierungsansatzes
Vorbemerkung:
Während des Partitionierungsprozesses wird das betrachtete Element als ‘Station’ bezeich-net. Eine Station kann dabei aus einer Maschinengruppe (am Anfang des Partitionierungs-
115 Die Simulation dieser replizierten Elemente verursacht in mehreren Partitionen einen Berechnungs-
aufwand. Außerdem wird die Kommunikationsmenge nicht geringer. Aus Gründen der Ressourcen-effizienz sollte auf die Replikation von Elementen verzichtet werden (vergleiche [Sporrer 1995, S. 5],[Ungerer 1997, S. 89].

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 148
prozesses) oder aus mehreren Maschinengruppen (gegen Ende des Partitionierungsprozes-ses) bestehen. Aufgabe des Partitionierens ist es, die Stationen den Partitionen zuzuordnen.
Größen:
− Es sei MG={mg1,mg2...mgL} die Menge der Maschinengruppen und ihre Elemente.L= |MG| sei die Anzahl der Elemente dieser Menge - die Anzahl der Maschinengrup-pen.
− Es sei S={s1,s2...sN} die Menge der Stationen und ihre Elemente. N= |S| sei die Anzahlder Elemente dieser Menge - die Anzahl der Stationen.
− Zu Beginn der Partitionierung sei S:=MG; s mg ii i= ∀ .
− Es sei P={p1,p2...pM} die Menge der Partitionen und ihre Elemente. M= |P| sei die An-zahl der Elemente dieser Menge - die Anzahl der Partitionen.
− Dann muß gelten: Spi ⊂ ; p p p P p P i ji j i j∩ = ∅ ∀ ∈ ∀ ∈ ≠| ; ; und |P| ≤ |S|.
− Weiterhin sei ρ als Anzahl der Prozessoren bzw. Computer, auf denen das Simulations-modell abgearbeitet werden soll, gegeben.
4.5.4 Während des Simulationslaufes zu erfassende Meßgrößen
KMijA Anzahl der Nachrichten im Austausch zwischen den Stationen si und sj
(Kommunikationsmenge)
KM i jijA = =0 (keine Kommunikation mit sich selbst)
KMijB Menge der Bytes im Austausch zwischen den Stationen si und sj
(Kommunikationsmenge)
KM i jijB = =0 (keine Kommunikation mit sich selbst)
KDij mittlerer Zeitabstand zwischen der Übertragung von Nachrichten zwischen denStationen si und sj (Kommunikationsdauer)
ABSij Anzahl der Situationen, in denen die Station sj aufgrund nicht vorhandener
Nachrichten von der Station si blockierte
ABS j Anzahl der Situationen, in denen die Station sj aufgrund nicht vorhandener
Nachrichten blockierte
AGS j Anzahl der Situationen, in denen Garantien der vorgelagerten Stationen an der
Station sj vorlagen
AES j Anzahl der Entscheidungssituationen an der Stationen sj
Die Berechnungslast BLj einer Arbeitsstation sj ist abhängig von AESj, kannaber nur schwer ermittelt werden.AES AGS ABSj j j= +
Auf die Betrachtung optimistischer Synchronisationsverfahren (und damit von Rollbacks)soll an dieser Stelle verzichtet werden. Tests (siehe Punkt 6.3) zeigten, daß optimistischeSynchronisationsverfahren für Modelle von Produktionssystemen eine drastische schlech-tere Laufzeit aufweisen.

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 149
4.5.5 Erfassung der Meßgrößen im Simulationsmodell
Einfach zu bestimmen sind die Größen der Kommunikationsmengen KMijA und KMij
B . Für
jede in einer Station si zu versendende Nachricht muß festgestellt werden, zu welcher an-deren Station sj die Nachricht gesendet werden soll. Daraufhin ist KMij
A um Eins zu erhö-
hen und KMijB ist um die Länge der Nachricht in Bytes zu erhöhen.
Für die Bestimmung der mittleren Kommunikationsdauer KDij ist durch den Sender(Station si ) einer Nachricht ein Zeitstempel zu setzen, der durch den Empfänger der Nach-richt (Station sj) auszuwerten ist. Der Empfänger hat über alle ermittelten Werte den Mit-telwert zu errechnen.
Das Bestimmen der Anzahl der Entscheidungssituationen (AESj) und der Anzahl der Blok-kierungssituationen (ABSj) ist ungleich komplizierter (siehe Abbildung 52). Für jeden Ein-gang einer Station sj ist zu vermerken, welchen Aktivierungszeitpunkt die nächste der ein-getroffenen Nachrichten (ini) für jeden der Eingänge der Stationen si hat. Die Station istblockiert, wenn es einen Eingang gibt, dessen Eingangszeit ini kleiner als die lokale Zeit(Tlokal) der Station ist und die Station keine internen Ereignisse mehr besitzt. In diesem Fallist die Anzahl der Blockierungssituationen ABSij um Eins zu erhöhen. Falls alle Eingängeder Station blockiert sind, so ist ABSj (die Anzahl der Situationen, in denen die Station sj
aufgrund nicht vorhandener Nachrichten blockierte) um Eins zu erhöhen. Falls es keinini < Tlokal gibt, ist die Anzahl der Garantiesituationen AGSj um Eins zu erhöhen. DieAnzahl der Entscheidungssituationen AES j ergibt sich dann als Summe aus ABS j und
AGS j .
t=17Eingang A
Tlokal=15
t=16 t=17
t=18Eingang B t=18
t=12Eingang C
inA
inB
inC
sj
Abbildung 52 Blockierungssituation an einer Station aufgrund noch aus-stehender Nachrichten
4.5.6 Auf Basis der erfaßten Meßgrößen berechenbare Größen116
KM ijB
durchschnittliche Menge der Bytes im Austausch zwischen den Stationen si
und sj
KMKM
KMi jij
B ijB
ijA= ≠
KM i jijB = =0
116 Ein Teil dieser Größen kann bereits auf Basis des Topologiewissens über das Produktionssystem berechnet
werden.

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 150
EM j Anzahl der Nachrichten, die von der Station sj empfangen wurden
(Empfangsmenge)
EM KMj ijA
i
N
==∑
1
Für jede der Größen die auf der Kommunikationsmenge KMijA beruht, kann eine gleich-
artige Größe für KMijB aufgestellt werden. Die auf der Anzahl der Nachrichten beruhenden
Größen sind aber i.d.R. aussagekräftiger. Außerdem ist die Bytegröße der Nachrichten inetwa gleich, weswegen die einfacher zu handhabende Größe der Anzahl der Nachrichtenbenutzt werden kann.
SM j Anzahl der Nachrichten, die von der Station sj gesendet wurden (Sendemenge)
SM KMj jiA
i
N
==∑
1
REMij relativer Anteil [%] der Kommunikation von der Station si zur Station sj an der
Gesamtanzahl der Nachrichten für Station sj
REMKM
EMij
ijA
j
=
RSMij relativer Anteil [%] der Kommunikation von der Station si zur Station sj an der
Gesamtanzahl der Nachrichten von Station si
RSMKM
SMij
ijA
i
=
KM A Kommunikationsmenge des gesamten Modells (Gesamtanzahl der übertrage-nen Nachrichten)
( )KM KM
EM SMA
ijA
j
N
i
N j jj
N
= =+
==
=∑∑∑
11
1
2
KM B Kommunikationsmenge des gesamten Modells (Gesamtmenge in Bytes)
KM KMBijB
j
N
i
N=
== ∑∑ 11
W Anzahl der benutzten Kommunikationswege
W wijj
N
i
N
===
∑∑11
; ];1[ 2NNW −∈ mit
w i jij = =0
w KMij ijA= >1 0
w KMij ijA= =0 0
fan_inj Anzahl der Eingänge der Station sj
fan in wj iji
N
_ ==∑
1
fan_outj Anzahl der Ausgänge der Station sj
fan out wj jii
N
_ ==∑
1

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 151
VG Der Vernetzungsgrad gibt an, in welchem Maße die Stationen miteinander ver-netzt sind. Bei N Stationen sind maximal N2 Wege möglich, diese werden je-doch nicht alle benutzt.
VGW
N= 2
EM durchschnittliche Anzahl von Nachrichten, die eine Arbeitsstation empfängt
EMEM
W
ii
N
= =∑
1
SM durchschnittliche Anzahl von Nachrichten, die eine Arbeitsstation sendet
SMSM
W
ii
N
= =∑
1
GES Gesamtanzahl an Entscheidungssituationen, Anzahl der Ereignisse im gesam-ten Modell bei Ausführung des Modells117
GES AES jj
N
==
∑1
TAj Teilaufwand an der Station sj [%]
TAAES
GESj
j=
TA mittlerer Teilaufwand einer Station
TA
TA
M
jj
M
= =∑
1
AGS Gesamtanzahl der Garantiesituationen
AGS AGS jj
N
==
∑1
GR Garantierate [%]
GRAGS
AES=
BH j Blockierungshäufigkeit an der Station sj [%]
( )BHABS
AESGH BHj
j
jj
i
N
ijMAX= = − ==
11
GH j Garantiehäufigkeit an der Station sj [%]
( )GHAGS
AES
AES ABS
AESBH GHj
j
j
j j
jj
i
J
ijMIN= =−
= − ==
11
117 Diese Größe wird in vielen Simulationstools als „moves“ bezeichnet.

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 152
BHij Blockierungshäufigkeit an der Station sj aus Richtung der Station si [%]
BHABS
ABSij
ij
j
=
GHij Garantiehäufigkeit an der Station sj aus Richtung der Station si [%]
GHAES ABS
AESij
j ij
j
=−
4.5.7 Regelwerk zur Partitionierung
Vorbemerkungen:
Auf Basis der vorgestellten Meßgrößen lassen sich Situationen beschreiben, in denen be-kannt ist, wie verfahren werden sollte. D.h., in welchem Fall Stationen in der selben Parti-tion zusammengefaßt werden sollen und in welchem Fall nicht. Die nachfolgenden Regelnbeschreiben diese Situationen. Diese Regeln sind in ihrer Gesamtheit nicht frei von Wider-sprüchen und sie stellen auch noch keinen vollständigen Ansatz zur Partitionierung dar.Dieser Ansatz wird erst im Punkt 4.5.8 vorgestellt.
Unsicherheit in den Regeln:
Nachfolgend sei α der Bestimmtheitsfaktor einer Regel. Dieser Bestimmtheitsfaktor be-sagt, in welchem Maße die Regel zutrifft. Es gelte: α ∈ [ ; ]0 1 . Man kann sieben Abstufun-
gen von α unterscheiden:• α =1.0 Die Aussage trifft mit Sicherheit zu.• α ∈ [ , ; ]0 81 Die Aussage trifft mit hoher Wahrscheinlichkeit zu.
• α ∈ [ , ; , ]0 6 0 8 Es ist wahrscheinlich, daß die Aussage zutrifft.
• α ∈ [ , ; , ]0 4 0 6 Die Aussage ist völlig unsicher.
• α ∈ [ , ; , ]0 2 0 4 Es ist wahrscheinlich, daß die Aussage nicht zutrifft.
• α ∈ [ ; , ]0 0 2 Die Aussage trifft mit hoher Wahrscheinlichkeit nicht zu.
• α =0.0 Die Aussage trifft mit Sicherheit nicht zu.
Regelwerk:
Für die nachfolgend beschriebenen Regeln läßt sich aufgrund ihrer Zielausrichtung die inAbbildung 53 gezeigte Hierarchie aufstellen.Prinzipiell werden die in Punkt 4.5.2 vorgestellten Zielgrößen verfolgt. Dabei lassen sichzu jeder der Meß- bzw. Berechnungsgrößen Regeln aufstellen.
Die Regelgruppe 1.1 (Regeln 1-4) zielt auf die Garantierate als ein Maß für die prinzipielleParallelisierbarkeit und erfolgte Parallelisierung des Simulationsmodells. Diese Kriteriendienen auch zur abschließenden Beurteilung der Güte einer Partitionierung.Die Regelgruppe 1.2 (Regeln 5-10) verfolgt dagegen das Ziel, für eine Station den Anteilder Garantiesituationen zu erhöhen. Die Garantiehäufigkeit kann hier als Maß für die ge-lungene Entkopplung zweier Stationen angesehen werden.Die Regelgruppe 2.1 (Regeln 11-14) zielt auf den mittleren Kommunikationsaufwand.Deutlich davon abweichende Stellen des Simulationsmodells bedürfen bei der Partitionie-rung einer erhöhten Aufmerksamkeit.Die Regeln der Gruppe 2.2 (Regeln 15-18) zielen auf die Verbindung der Stationen unter-einander. Sie sind Entscheidungshilfe für die Trennung bzw. Zusammenfassung von Sta-tionen in einer Partition.

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 153
Regeln zur Beurteilung vonGarantie- und Blockierungs-
häufigkeit (GH,BH)
Regeln zur Beurteilung derGarantierate (GR)
Regeln zur Partitionierung
Ziel: Minimierung desKommunikationsaufwandes
Ziel: Maximierung derGleichzeitigkeit
Ziel: Gleichverteilung derBerechnungslast
1.1
1.2
Regeln zur Beurteilung derKommunikationsmenge (KM)
2.1
Regeln zur Beurteilung desNutzungsgrades von Kommu-nikationsverbindungen (REM)
2.2
Regeln zur Verbesserung desVerhältnisses zwischen internen
und externen Ereignissen2.3
Regeln zur Beurteilung desTeilaufwandes (TA)
3.1
Regeln zur Beurteilung desVernetzungsgrades (VG)
3.2
Abbildung 53 Hierarchie der Regeln zur Partitionierung
Die Regelgruppe 2.3 (Regeln 19-22) beabsichtigt, durch Zusammenfassung von Quellenund Senken mit Stationen die Anzahl der Kommunikationswege zu verringern und denAnteil interner Ereignisse zu erhöhen (vergleiche Formel 3, Seite 70).Die Regeln der Gruppe 3.1 (Regeln 23-24) versuchen eine gleichmäßige Verteilung derLast zwischen den Partitionen zu erreichen.Die Regelgruppe 3.2 (Regeln 25-26) kombiniert das Ziel des Lastausgleichs mit dem Zielder Senkung des Kommunikationsaufwandes.
Regeln:
(1) Wenn gilt GR = 100%,dann ist die Partitionierung optimal. Kein Logischer Prozeß pi blockiert zu irgend-einer Zeit einen anderen Logischen Prozeß pj. Die Menge P ist ideal.α=1.0
(2) Wenn gilt GR > OSGR,dann blockieren sich die Logischen Prozesse gegenseitig nur selten. Die Partitionie-rung ist gut.α=1.0
(3) Wenn gilt GR < USGR,118
dann blockieren sich die Logischen Prozesse gegenseitig sehr oft. Eine andere Parti-tionierung muß gefunden werden.α=1.0
(4) Wenn gilt GR = 0%,dann blockieren sich die Logischen Prozesse gegenseitig zu jedem Zeitpunkt. DiesePartitionierung ist der schlechtestmögliche Fall.α=1.0
Die Größe der Garantiehäufigkeit GHj sagt aus, wie oft ein Prozeß der Station sj durchKenntnis der ihm vorliegenden Nachrichten weiter prozessieren konnte. Diese Größe giltals Maß für die prinzipielle Entkoppelbarkeit des Prozesses der Station sj von den Prozes-sen der technologisch vorgelagerten Stationen.
118 Wenn die Garantierate GR zu niedrig wird, dann blockieren die Logischen Prozesse laufend (bei einer
konservativen Synchronisation) oder die Logischen Prozesse verhalten sich laufend optimistisch (bei eineroptimistischen Synchronisation) und provozieren dann später Rollbackkaskaden (siehe Punkt 3.1.3.6).

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 154
Die Blockierungshäufigkeit einer Station BHj ist das Gegenstück zur GarantiehäufigkeitGHj. Für BHj können ebenfalls Regeln aufgestellt werden, diese Regeln haben aber dieumgekehrten Aussagen: GHj + BHj =1.
(5) Wenn gilt GH j = 100%,
dann s p p Cj k k⊆ ∧ ∩ = ∅ mit { }C s wi ij:= =1 .
Ist die Garantiehäufigkeit an einer Station sj gleich 100% (d.h. die Station sj war nieblockiert), dann kann die Station sj separat zu all ihren Vorgängerstationen als einanderer Logischer Prozeß abgebildet werden.α=1.0
(6) Wenn gilt GH j > OSGH,
dann s p p Cj k k⊆ ∧ ∩ = ∅ mit { }C s wi ij:= =1 .
Ist die Garantiehäufigkeit an einer Station sj größer als eine obere Schranke, dannkann die Station sj separat zu ihren Vorgängerstationen als ein anderer LogischerProzeß abgebildet werden.α= GH j
(7) Wenn gilt GH j < USGH,
dann s p C pj k k∈ ∧ ⊂ mit { }C s wi ij:= =1 .
Ist die Garantiehäufigkeit an einer Station sj kleiner als eine untere Schranke, dannsollte die Station sj zusammen mit ihren Vorgängerstationen einen gemeinsamen Lo-gischen Prozeß bilden.α=1- GH j
(8) Wenn gilt GH j = 0%,
dann s p C pj k k∈ ∧ ⊂ mit { }C s wi ij:= =1 .
Ist die Garantiehäufigkeit an einer Station sj gleich 0% (d.h. die Blockierungshäufig-keit beträgt 100%), dann sollte die Station sj zusammen mit all ihren Vorgängersta-tionen einen gemeinsamen Logischen Prozeß bilden.α=1.0
(9) Wenn gilt BHij =100%,
dann { ; }s s pj i k⊆ .
Wenn alle Blockierungssituationen an der Station sj durch die Station si ausgelöstwurden, dann sollten beide Stationen in die gleiche Partition eingeordnet werden.α=1.0
(10) Wenn gilt GHij =100%,
dann s p s p k li k j l⊆ ∧ ⊆ ≠| .
Wenn die Station si an allen Garantiesituationen der Station sj beteiligt war, dannsollten beide Stationen in unterschiedliche Partitionen eingeordnet werden.119
α=0.9
119 Die Garantiehäufigkeit GHij gilt als Maß für die prinzipielle Entkoppelbarkeit zweier Prozesse. Je höher die
Garantiehäufigkeit auf der Verbindungskante zwischen den Prozessen ist, desto besser lassen sich die Pro-zesse entkoppeln und können somit parallel Berechnungen durchführen.

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 155
(11) Wenn gilt KMKM
WijB
B
>> ,
dann { ; }s s pj i k⊆ .
Wenn die zwischen zwei Stationen si und sj übertragene Menge an Bytes sehr vielgrößer als die insgesamt übertragene Menge an Bytes im gesamten Modell geteiltdurch die Anzahl der Wege ist, dann sollten die Stationen si und sj in einer Partitionzusammengefaßt werden.α=0.67
(12) Wenn gilt KMKM
WijB
B
<< ,
dann s p s p k li k j l⊆ ∧ ⊆ ≠| .
Wenn die zwischen zwei Stationen si und sj übertragene Menge an Bytes sehr vielkleiner als die insgesamt übertragene Menge an Bytes im gesamten Modell geteiltdurch die Anzahl der Wege ist, dann sollten die Stationen si und sj unterschiedlichenPartitionen zugeteilt werden.α=0.6
(13) Wenn gilt KMijA >> KM
A,
dann { ; }s s pj i k⊆ .
Wenn zwei Stationen si und sj wesentlich mehr kommunizieren als die durchschnitt-liche Kommunikationsmenge, dann sollten die Stationen si und sj in einer Partitionzusammengefaßt werden.α=0.67
(14) Wenn gilt KMijA << KM
A,
dann s p s p k li k j l⊆ ∧ ⊆ ≠| .
Wenn zwei Stationen si und sj wesentlich weniger kommunizieren als die durch-schnittliche Kommunikationsmenge, dann sollten die Stationen si und sj unter-schiedlichen Partitionen zugeteilt werden.α=0.67
(15) Wenn gilt REMij > OSREM,
dann{ ; }s s pj i k⊆ .
Wenn die Station si den überwiegenden Teil (OS - Obere Schranke) der Kommunika-tion der Station sj ausmacht, dann sollten die Stationen si und sj in einer Partition zu-sammengefaßt werden.α=0.7
(16) Wenn gilt REMij < USREM,
dann s p s p k li k j l⊆ ∧ ⊆ ≠| .
Wenn die Station si fast gar nicht (US - Untere Schranke) mit der Station sj kommu-niziert, dann sollten die Stationen si und sj unterschiedlichen Partitionen zugeteiltwerden.α=0.7

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 156
(17) Wenn gilt EM j >> EM ,
dann { }p s Ak j: ;= mit A s KMEM
fan ini ijA j
j
:_
= >
.
Wenn eine Station sj viel mehr Nachrichten empfängt als die durchschnittliche Men-ge an Nachrichten die eine Station erhält, dann sollte diese Station sj mit der/dentechnologisch vorgelagerten Stationen zusammengefaßt werden, mit denen sie ammeisten kommuniziert.α=0.6
(18) Wenn gilt EM j << EM ,
dann s p p Bj k k⊆ ∧ ∩ = ∅ mit B s KMEM
fan ini ijA j
j
:_
= <
.
Wenn eine Station sj viel weniger Nachrichten empfängt als die durchschnittlicheMenge an Nachrichten die eine Station erhält, dann sollte diese Station sj nicht mitder/den vorgelagerten Stationen zusammengefaßt werden, mit denen sie am wenig-sten kommuniziert.α=0.7
(19) Wenn gilt fan in j_ = 0 und fan out j_ =1,
dann { ; }s s pj i k⊆ mit ∃ =i wij| 1.
Station sj ist eine Quelle mit nur einem Ausgang und soll mit der ihr technologischnachgelagerten Station in einer Partition zusammengefaßt werden.α=1.0
(20) Wenn gilt fan out j_ = 0 und fan in j_ =1,
dann { ; }s s pj i k⊆ mit ∃ =i wij| 1.
Station sj ist eine Senke mit nur einem Eingang und soll mit der ihr technologischvorgelagerten Station in einer Partition zusammengefaßt werden.α=1.0
(21) Wenn gilt fan in j_ = 0 und fan out j_ >1,
dann { ; }s s pj i k⊆ mit ( )∃ ==
i w KMiji
N
jiAMAX| |1
1
.
Station sj ist eine Quelle mit mehreren Ausgängen und soll mit der ihr technologischnachgelagerten Station in einer Partition zusammengefaßt werden, mit der sie ammeisten kommuniziert.α=0.85
(22) Wenn gilt fan out j_ = 0 und fan in j_ >1,
dann { ; }s s pj i k⊆ mit ( )∃ ==
i w KMiji
N
ijAMAX| |1
1
.
Station sj ist eine Senke mit mehreren Eingängen und soll mit der ihr technologischvorgelagerten Station in einer Partition zusammengefaßt werden, mit der sie am mei-sten kommuniziert.α=0.85
(23) Wenn gilt TAj << TA ,
dann kj ps ⊂ | | |pk >1.

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 157
Wenn die Berechnungslast für die Station sj sehr gering ist, dann sollte diese Stationnicht eine separate Partition bilden, sondern mit anderen Stationen zusammengelegtwerden.120
α=0.9
(24) Wenn gilt TAj >> TA ,
dann p sk j= { } .
Wenn die Berechnungslast für die Station sj sehr hoch ist, dann sollte diese Stationeine separate Partition bilden.121
α=0.8
(25) Wenn gilt VG≈100%,
dann |P|:=ρ mit )(*%10)(;1TAEXTADXppSp jijik
M
k<∅=∩∀⊂∀ =
Wenn der Vernetzungsgrad der Stationen nahe 100% ist122, dann sollte für jedenProzessor/Computer eine Partition gebildet werden. Der Teilaufwand in den Partitio-nen sollte in etwa gleich sein.α=0.8
(26) Wenn gilt VG≈N
N
−12 ,
dann{ ; }s s pj i k⊆ .| KMij > 0 oder KM ji > 0 und TA TAj << und TA TAi << .
Wenn der Vernetzungsgrad der Stationen nahe dem Minimum N
N
−12 ist123, dann
sollten aufeinanderfolgende Stationen mit geringen Teilaufwänden eine Partition bil-den.α=0.65
Nachfolgend soll für alle Schrankenwerte vereinfachend angenommen werden, daß eineobere Schranke (OS) auf 80% festgelegt sei und daß eine untere Schranke (US) auf 20%festgelegt sei. Natürlich können diese Schrankenwerte je nach betrachteter Größe späterdifferenziert werden.
Im vorgestellten Regelwerk verbleiben Lücken. So können Situationen auftreten, in denenkeine Aussagen über die Zuordnung von zwei Stationen si und sj zu Partitionen getroffenwerden bzw. die Aussagen widersprechen sich. In einem solchen Fall sind manuell alleprinzipiellen Zuordnungsmöglichkeiten (si und sj in der selben oder in unterschiedlichenPartitionen) zu testen. Dies ist auch der Grund warum Mehl [Mehl 1994, S. 227] undSmith [Smith 1999] den Vorgang des Partitionierens mehr Kunst als Wissenschaft nennen.
120 Prozesse mit geringer Berechnungslast können schnell voranschreiten und blockieren deshalb oft. Es hat
wenig Sinn diese Prozesse zu separieren. Je geringer der Teilaufwand eines Logischen Prozesses ausfällt,desto weniger lohnt es sich, diesen Prozeß zu separieren.
121 Prozesse mit hoher Berechnungslast kommen in ihrer Abarbeitung nur langsam voran und blockierendeshalb andere Prozesse oft. Es wäre günstig, diese Prozesse zu separieren.
122 Der Vernetzungsgrad VG ist nahe 100% wenn fast jede Station mit jeder anderen Station verbunden ist.Dies ist typisch für Hypercubemodelle [Nicol 1988], [Loucks, Preiss 1990].
123 Das Minimum ist erreicht, wenn alle Stationen in einer Kette angeordnet sind. Dann existieren N Stationenund zwischen diesen Stationen N-1 Wege.Ist der Vernetzungsgrad VG nur unwesentlich größer als der Minimalwert, so existieren nur wenige Rück-kopplungsstellen in der Kette oder die Kette teilt sich an wenigen Stellen in Teilstränge.

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 158
4.5.8 Ansatz zur Partitionierung von Simulationsmodellen von Produktions-systemen auf Basis der vorgestellten Meßgrößen und Regeln
Die Maschinengruppen stellen die kleinste sinnvolle Einheit im Simulationsmodell dar,deshalb sollen sie für die Partitionierung als atomar angesehen werden (siehe Punkt 4.3.3).Ein Produktionssystem kann dann als ein gerichteter Graph aufgefaßt werden, dessenKnoten Maschinengruppen sind und dessen Kanten Materialflüsse darstellen. Aufgabe derPartitionierung ist es jetzt, diesen Graphen in mehrere, parallel abarbeitbare Teilgraphen zuzerlegen.Als Ausgangspunkt sei die Menge S der Stationen mit der Menge MG der Maschinen-gruppen identisch. D.h., jedes Element der Menge MG sei als Element sj der Menge S an-zusehen (S := MG).Nachfolgend bezeichnet eine Station nicht mehr eine einzelne Maschinengruppe, sondernauch eine Menge oder Folge von Maschinengruppen bzw. eine Partition. Der Grund dafürist, daß sonst alle angegebenen Formeln je nach Verwendungskontext mit verändertenFormelzeichen versehen werden müßten.
In einem ersten Schritt der Partitionierung müssen „Kristallisationskeime“ für Partitionengefunden werden. Dazu eignen sich die Quellen und Senken des Produktionssystems(Regeln 19-22).Ausgehend von diesen Kristallisationskeimen wird versucht, entlang des Materialflussesbenachbarte Stationen in die gleiche Partition einzuordnen (Regeln 5-18). Auf diese Weisebilden sich erste kurze Strecken von Stationen im Bedienungssystem.124
Da die Stationen jedoch nicht nur einen Ein- bzw. Ausgang besitzen, muß an Verzwei-gungsstellen entschieden werden, welche Station (bzw. welcher Weg im Materialfluß) zuraktuell betrachteten Partition hinzuzufügen ist. Dabei werden die Ziele der Minimierungdes Kommunikationsaufwandes (Regeln 11-18) und der Maximierung der Gleichzeitigkeit(Regeln 1-10) beachtet. Es können dabei aber auch Strecken von Stationen entstehen, diekeiner Quelle bzw. Senke zugeordnet sind.Man erhält eng interdependierende Stationsmengen, die gemeinsam in eine Partition einge-ordnet werden sollten. Zusätzlich ist in den Partitionen ein hoher Grad an Gleichzeitigkeiterreicht worden.Die erstellten Partitionen haben aber noch eine sehr unterschiedliche Größe (Anzahl anStationen |pj|). Deshalb gilt es, in Hinblick auf das Ziel des Lastausgleichs (Regeln 23-26),die Partitionierung nochmals zu verändern. Hierbei werden z.B. mehrere kleine Partitionenzu einer größeren Partition zusammengefaßt125.Zusätzlich ist bei der Zusammenfassung von Partitionen darauf zu achten, daß die Anzahlder letztendlich verbleibenden Partitionen (|P|) gegenüber der Anzahl der verfügbaren Pro-zessoren (ρ) nicht zu groß wird.Als Ergebnis entsteht eine Partitionierung, die für das gegebene Modell einen günstigenFall darstellt und einen Speedup bieten sollte. Die Optimalität dieser Partitionierung kannallerdings nicht garantiert werden126.
124 Vergleiche dazu auch [Agrawal 1986] und [Briner 1990], die ebenfalls Elementketten suchen.125 Die Materialflußgraphen dieser Partitionen weisen dabei meist keinen Schnittpunkt auf. Dies ist ein we-
sentlicher Unterschied zu den graphentheoretischen Verfahren.126 Das Problem der Partitionierung ist lösungsdefekt. Außer der totalen Enumeration existiert kein Verfahren
mit Optimalitätsgarantie. Aufgrund der kombinatorischen Explosion des Lösungsraumes ist die totaleEnumeration aber nicht praktikabel. Der vorgeschlagene Partitionierungsansatz stellt eine Lösungsheuristikdar. Durch seine spezielle Ausrichtung auf die Simulation von Produktionssystemen ist er besser als unspe-zifische, allgemeine Partitionierungsverfahren.

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 159
4.5.8.1 Übersicht über den Algorithmus zur Partitionierung
Der Algorithmus zur Partitionierung eines Modells eines Produktionssystems gliedert sichin drei Hauptschritte:
(1) Aufbau eines aktualisierten Produktionssystemgraphen
(2) Bildung von Clustern als potentiellen Partitionena) Partitionsmeßdaten an den Knoten und Kanten des Produktionssystemgraphen ein-
tragenb) Anwendung der Partitionierungsregeln auf jede Kante des Produktionssystem-
graphen zur Ermittlung eines Bewertungsfaktors für die Kantec) Ermittlung der positiv bewerteten Kanten zur Erstellung einer Startpartitionierungd) Bildung von zulässigen und günstigen Partitionierungsvarianten auf Basis der be-
werteten Kantene) Bewertung der verbleibenden Varianten gemäß der Zielkriterien und Auswahl der
anzuwendenden Partitionierungsvariante
(3) Zusammenfassung der Cluster zu Partitionen
Vor dem Start des Algorithmus müssen die Daten vorhanden sein, welche das betrachteteProduktionssystem charakterisieren, damit ein Produktionssystemgraph erstellt werdenkann. Weiterhin muß bereits mindestens ein Simulationslauf mit einem gemäß dieser Da-ten erzeugten Simulationsmodell ausgeführt worden sein, damit die für das Partitio-nierungsverfahren benutzten Partitionsmeßdaten (siehe Punkt 4.5.4 und Punkt 4.5.5) vor-handen sind.Durch die Ausführung des Algorithmus wird eine Liste erstellt, welche die Knoten desProduktionssystemgraphen (die Maschinengruppen) den Partitionen zuordnet. Diese Zu-ordnungsliste ist dann Basis für die Generierung des nächsten Simulationsmodells, um einbesser partitioniertes - und somit schneller ausführbares - Simulationsmodell zu erhalten.
Dieser Algorithmus ist partiell inspiriert durch den Partitionierungsansatz von Sporrer[Sporrer 1995, S. 43-80] und durch den Partitionierungsansatz Concurrency PreservingPartitioning (CPP) [Kim, Jean 1996].
4.5.8.2 Schritt 1 - Aufbau eines aktualisierten Produktionssystemgraphen
Ziel:
Ziel dieses Schritts ist das Bestimmen der auf Basis der aktuellen Einsteuerung beteiligtenArbeitsstationen (Knoten) und der benutzten Verbindungswege (Kanten) zwischen diesenArbeitsstationen.Mit Kenntnis der vorhandenen Produkte und der zugehörigen Arbeitspläne kann bereits einerster Produktionssystemgraph aufgestellt werden. Dieser zeigt die prinzipielle Verbin-dung der Arbeitsstationen über Materialflüsse auf.Unter Einbeziehung der aktuellen Einsteuerung erfolgt eine Reduzierung dieses Graphenauf die tatsächlich eingesteuerten Produkte und deren Materialflüsse.
Ergebnis:
Ergebnis ist eine Liste der Arbeitsstationen des Produktionssystems (Knoten), die auf Ba-sis der aktuellen Einsteuerung erreicht werden bzw. erreicht werden können. Für jede die-ser Arbeitsstationen ist je eine Liste mit den technologisch vorgelagerten Arbeitsstationenund den technologisch nachgelagerten Arbeitsstationen vorhanden. Auf diese Weise hatjedeStation Kenntnis von den Stationen von bzw. zu denen sie Verbindungen unterhält.

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 160
Zur einfacheren Handhabung ist zusätzlich eine Liste der Knoten des Produktionssystem-graphen (die Arbeitsstationen) und eine Liste der Kanten des Produktionssystemgraphen(die benutzten Wege zwischen den Arbeitsstationen) vorhanden.
Algorithmus:
lege einen Knoten für die Quelledes aktuellen Produktes an
Start
vermerke die Quelle als letztenbesuchten Knoten
erzeuge die Verbindungen des Knotens
lege für die Senke einen Knoten an,falls dieser noch nicht existiert
Ende
erzeuge einen Knoten für die Maschinen-gruppe des aktuellen Arbeitsganges falls
dieser Knoten noch nicht existiert
den aktuellen Knoten als Nachfolgerdes letzten Knotens vermerken
den letzten Knoten als Vorgängerdes aktuellen Knotens vermerken
eine neue Kante anlegen,die zwischen den beiden Knoten verläuft
vermerke den aktuellen Knoten alsletzten besuchten Knoten
erzeuge die Verbindungen des Knotens
Submodul:Verbindungen des Knotens erzeugen
Ende Submodul
ja
Für alle Arbeitsgänge des Arbeitsplansdes Produktes:
Für alle Produkte für dieeine Einsteuerung erfolgt:
Abbildung 54 Programmablaufplan zur Erstellung des aktualisierten Pro-duktionssystemgraphen
4.5.8.3 Schritt 2a - Partitionsmeßdaten an den Knoten und Kanten des Produktions-systemgraphen eintragen
Ziel:
Eines der Ergebnisse des Simulationslaufes ist eine Datei, welche die Meßdaten der Ergeb-nisse der Partitionierung enthält (siehe Punkt 5.3.3). Diese Meßdaten werden nun in derKnoten- bzw. Kantenliste eingetragen und es werden weitere Größen (siehe Punkt 4.5.6)auf Basis dieser Meßgrößen berechnet. Diese erfaßten bzw. berechneten Größen sind dannEntscheidungsbasis bei der Anwendung der Partitionierungsregeln (siehe Punkt 4.5.7) imnächsten Schritt.
Algorithmus:
• Die Erfassung der Partitionierungsmeßdaten ist in den Punkten 4.5.4 und 4.5.5 be-schrieben.
• Die Berechnung der weiteren Meßgrößen wird ausführlich im Punkt 4.5.6 erläutert.
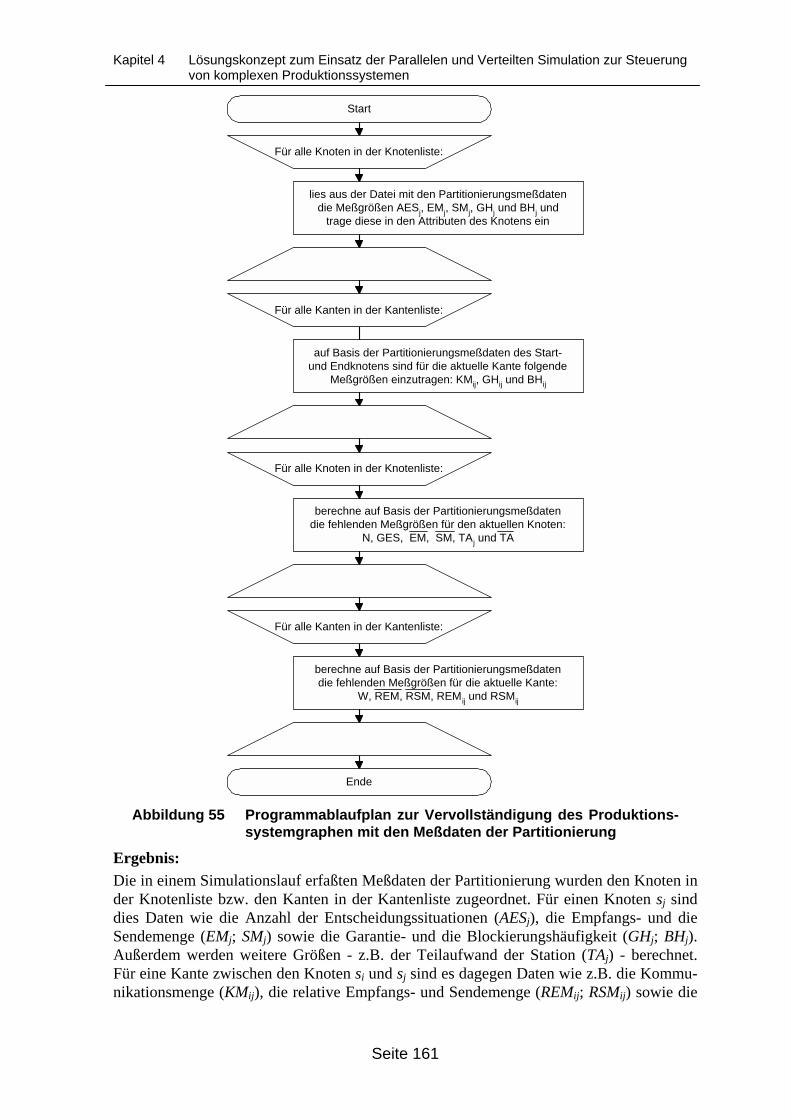
Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 161
lies aus der Datei mit den Partitionierungsmeßdatendie Meßgrößen AESj, EMj, SMj, GHj und BHj und
trage diese in den Attributen des Knotens ein
Start
auf Basis der Partitionierungsmeßdaten des Start-und Endknotens sind für die aktuelle Kante folgende
Meßgrößen einzutragen: KMij, GHij und BHij
Ende
berechne auf Basis der Partitionierungsmeßdatendie fehlenden Meßgrößen für den aktuellen Knoten:
N, GES, EM, SM, TAj und TA
berechne auf Basis der Partitionierungsmeßdatendie fehlenden Meßgrößen für die aktuelle Kante:
W, REM, RSM, REMij und RSMij
Für alle Knoten in der Knotenliste:
Für alle Kanten in der Kantenliste:
Für alle Knoten in der Knotenliste:
Für alle Kanten in der Kantenliste:
Abbildung 55 Programmablaufplan zur Vervollständigung des Produktions-systemgraphen mit den Meßdaten der Partitionierung
Ergebnis:
Die in einem Simulationslauf erfaßten Meßdaten der Partitionierung wurden den Knoten inder Knotenliste bzw. den Kanten in der Kantenliste zugeordnet. Für einen Knoten sj sinddies Daten wie die Anzahl der Entscheidungssituationen (AESj), die Empfangs- und dieSendemenge (EMj; SMj) sowie die Garantie- und die Blockierungshäufigkeit (GHj; BHj).Außerdem werden weitere Größen - z.B. der Teilaufwand der Station (TAj) - berechnet.Für eine Kante zwischen den Knoten si und sj sind es dagegen Daten wie z.B. die Kommu-nikationsmenge (KMij), die relative Empfangs- und Sendemenge (REMij; RSMij) sowie die

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 162
Garantie- und Blockierungshäufigkeit der Kante (GHij; BHij). Die genannten Größen wer-denanschließend in den Partitionierungsregeln im Schritt 2b verwendet.
4.5.8.4 Schritt 2b - Anwendung der Partitionierungsregeln auf die Kanten des Pro-duktionssystemgraphen zur Ermittlung eines Bewertungsfaktors für jedeKante
Ziel:
Die Kanten geben an, welche der Arbeitsstationen des Produktionssystems über den Mate-rialfluß verbunden sind. Im Simulationsmodell wirkt sich dies durch Interdependenzenzwischen den Arbeitsstationen aus. Durch die Anwendung der Partitionierungsregeln wer-den die Kanten mit einem Bewertungsfaktor versehen, der angibt, wie günstig oder ungün-stig das Zusammenfassen der durch die Kante betroffenen Arbeitsstationen (Knoten) ineiner Partition wäre.
Algorithmus:Start
addiere zu der Bewertung der Kanteden Bestimmtheitsfaktor der Regel
Ende
ja
trifft die aktuelle Regelauf die aktuelle Kante zu ?
nein
Für alle Kanten in der Kantenmenge:
Für alle Regeln in der Regelmenge:
Abbildung 56 Programmablaufplan zur Anwendung der Partitionierungs-regeln auf die Kanten des Produktionssystemgraphen
Anmerkung:
• Die in der Regelmenge festzuhaltenden Regeln wurden im Punkt 4.5.7 ausführlich be-schrieben.
• Wenn eine Regel gegen die Zusammenfassung von Stationen spricht, so ist deren Be-stimmtheitsfaktor mit einem negativen Vorzeichen zu versehen.
Ergebnis:
Für jede Kante des Produktionssystemgraphen wurde ein Bewertungsfaktor berechnet, derangibt wie sinnvoll die Zusammenfassung der durch die Kanten verbundenen Arbeits-stationen (Knoten) in einer Partition ist. Positiv bewertete Kanten geben an, daß die beidenbetroffenen Arbeitsstationen besser der gleichen Partition zugeordnet werden sollten. ImGegensatz dazu gibt eine negative Bewertung an, daß die durch die Kante verbundenen

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 163
Arbeitsstationen in unterschiedliche Partitionen plaziert werden sollten. Auf Basis der be-werteten Kanten ist es somit prinzipiell möglich, die Knoten des Produktionssystem-graphen den Partitionen zuordnen. Problematisch daran ist, daß sich durch verschiedeneKanten Widersprüchlichkeiten in der Zuordnung der Knoten zu den Partitionen ergebenkönnen. Die Lösung dieses Problems obliegt dem nächsten Schritt.
4.5.8.5 Schritt 2c - Eröffnungsverfahren: Ermittlung der positiv bewerteten Kantenzur Erstellung einer Startpartitionierung
Ziel:
Auf Basis der bewerteten Kanten könnte man alle Variationen der Zuordnung von Knotenzu Partitionen aufstellen und anschließend bewerten. Je größer das betrachtete Produk-tionssystem ist, desto höher wird allerdings der Aufwand dafür. Es tritt eine kombinatori-sche Explosion des zu untersuchenden Lösungsraumes auf. Eine totale Enumeration wärekein adäquates Lösungsmittel. Leider existiert jedoch auch kein direktes Lösungsverfahrenfür dieses Problem. Aus der Verfahrensklasse der Begrenzten Enumeration haben sich ins-besondere die Verfahren des Branch and Bound hervorgetan. Anhand unterschiedlichsterRegeln wird entschieden, ob es sich lohnt, eine Verzweigung im Suchbaum weiterzu-verfolgen. Auch hier kann immer noch ein enorm hoher Aufwand zum Auffinden der Lö-sung bestehen. Branch and Bound-Verfahren sind prinzipiell in der Lage, die optimaleLösung zu finden, in der Regel sind es jedoch Heuristiken, die eine gute Lösung in relativkurzer Zeit entdecken.Im Schritt 2c soll für das heuristische Branch and Bound-Verfahren im Schritt 2d eineStartlösung gefunden werden, die bereits auf Basis sicherer Erkenntnisse aus den Ergeb-nissen des ersten Simulationslaufes eine hohe Menge potentieller Lösungen geringer Güteausschließt und so die Lösungssuche entscheidend abkürzt. Dieses Verfahren ist von derArt her ein Eröffnungsverfahren.
Algorithmus:
Der Algorithmus zur Erstellung der Startpartitionierung besteht aus zwei größeren Teilen(siehe Abbildung 58 und Abbildung 59).Im Teil A (Abbildung 58) werden Cluster gebildet, die alle Umgebungsknoten für die imSchritt 2b (Abbildung 56) positiv bewerteten Kanten127 enthalten. Die Liste der positivbewerteten Kanten (pbK) ist gemäß der höchsten Bewertung zu sortieren. Damit ist sicher-gestellt, daß zuerst Cluster entstehen und zusammengefaßt werden, die Gruppierungen vonKnoten enthalten, die aufgrund sicher anwendbarer Partitionierungsregeln in einer Partiti-on plaziert werden sollen.Die im Teil A gebildeten Cluster enthalten aber z.T. die selben Knoten des Produktions-systemgraphen (siehe Abbildung 60). Der Teil B des Algorithmus (Abbildung 59) faßtdeshalb sich überlappende Cluster zusammen und verringert so die Anzahl der Cluster. DieGröße des verbleibenden, zu durchsuchenden Lösungsraumes für Partitionierungsvariantenkann dadurch stark eingeschränkt werden.Zum besseren Verständnis soll nachfolgende Abbildung aufzeigen, welcher Schritt desProgrammablaufplans in Abbildung 58 sich auf welche Art von Verbindung der Knotender aktuell betrachteten Kante bezieht.
127 Eine Kante gilt als positiv bewertet, wenn die Summe der Bewertungen der einzelnen Partitionierungs-
regeln für diese Kante einen festgelegten Schwellwert übersteigt. Da diese Summe der Summe der Be-stimmtheitsfaktoren der anwendbaren Regeln entspricht (siehe Abbildung 56), soll 1,2 als eine erste Mani-festation dieses Schwellwertes genügen. Dies würde bedeuten, daß es zur betrachteten Kante mindestenseine Regel gibt, deren Aussage mit Sicherheit zutrifft (siehe Bestimmtheitsfaktoren der Regeln, Punkt4.5.7).
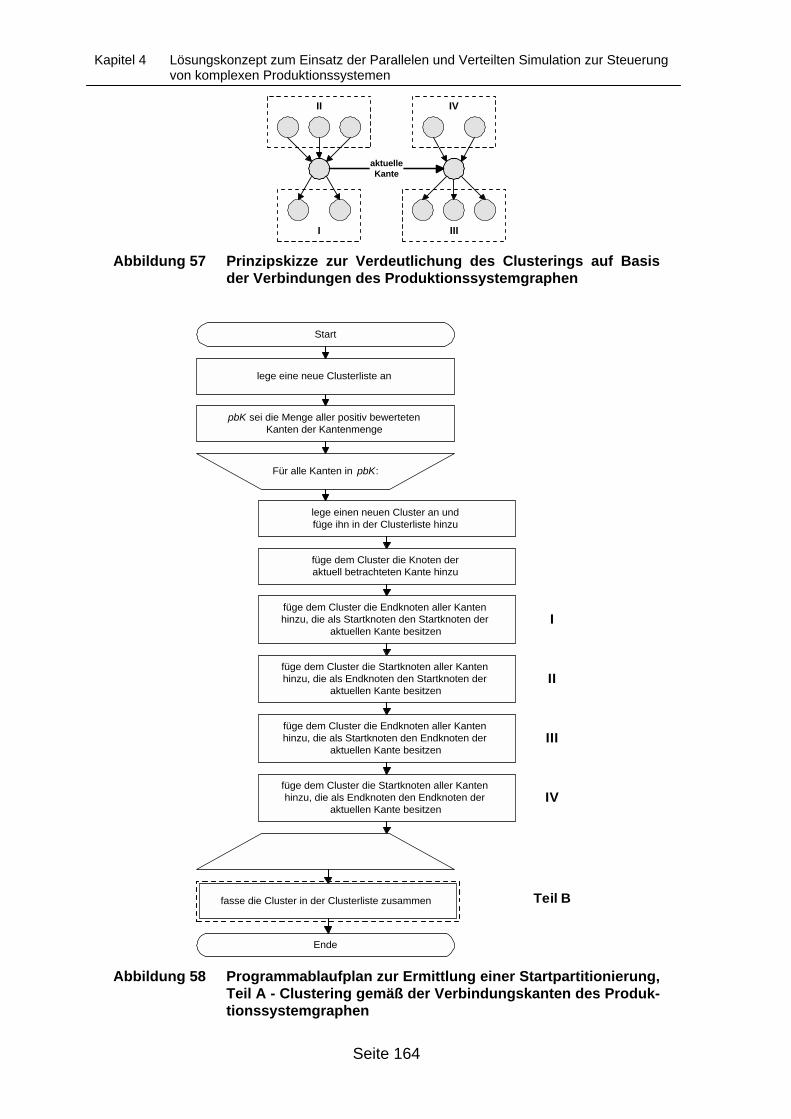
Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 164
aktuelleKante
II
IIII
IV
Abbildung 57 Prinzipskizze zur Verdeutlichung des Clusterings auf Basisder Verbindungen des Produktionssystemgraphen
Start
Ende
lege eine neue Clusterliste an
pbK sei die Menge aller positiv bewertetenKanten der Kantenmenge
lege einen neuen Cluster an undfüge ihn in der Clusterliste hinzu
füge dem Cluster die Knoten deraktuell betrachteten Kante hinzu
füge dem Cluster die Endknoten aller Kantenhinzu, die als Startknoten den Startknoten der
aktuellen Kante besitzen
füge dem Cluster die Startknoten aller Kantenhinzu, die als Endknoten den Startknoten der
aktuellen Kante besitzen
füge dem Cluster die Endknoten aller Kantenhinzu, die als Startknoten den Endknoten der
aktuellen Kante besitzen
füge dem Cluster die Startknoten aller Kantenhinzu, die als Endknoten den Endknoten der
aktuellen Kante besitzen
fasse die Cluster in der Clusterliste zusammen
I
II
III
IV
Teil B
ja
Für alle Kanten in pbK:
Abbildung 58 Programmablaufplan zur Ermittlung einer Startpartitionierung,Teil A - Clustering gemäß der Verbindungskanten des Produk-tionssystemgraphen
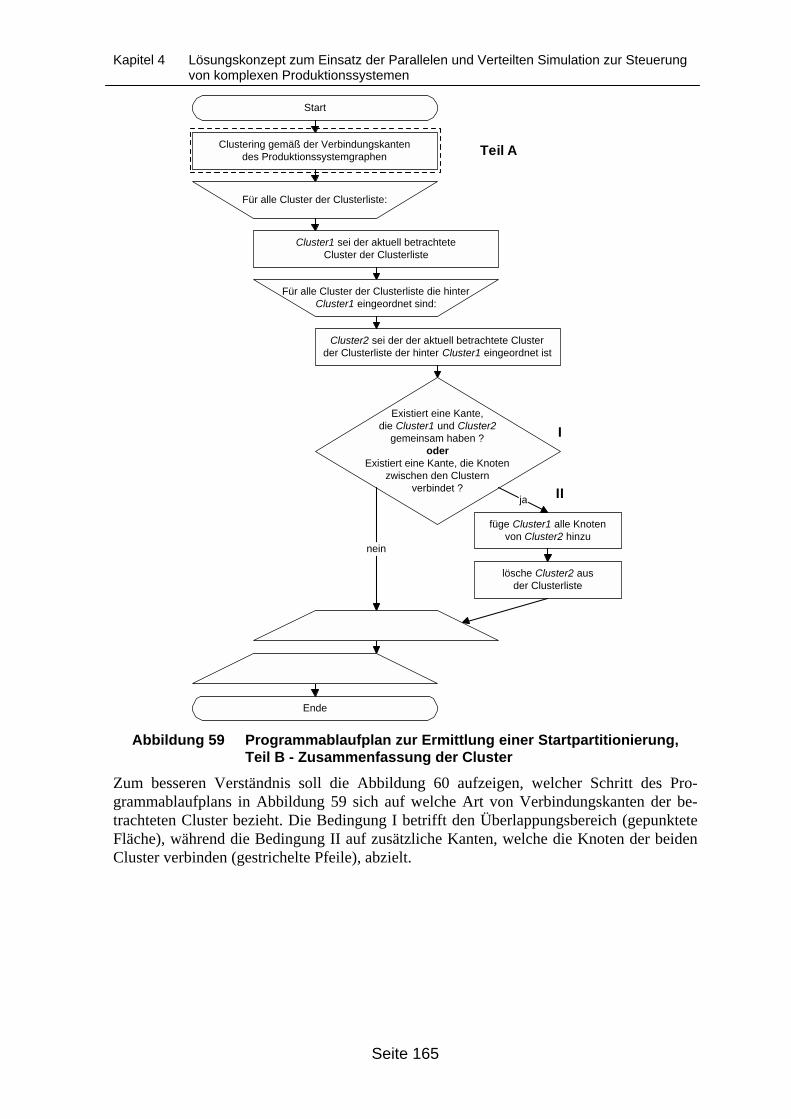
Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 165
Start
Ende
Cluster1 sei der aktuell betrachteteCluster der Clusterliste
Cluster2 sei der der aktuell betrachtete Clusterder Clusterliste der hinter Cluster1 eingeordnet ist
füge Cluster1 alle Knotenvon Cluster2 hinzu
lösche Cluster2 ausder Clusterliste
Clustering gemäß der Verbindungskantendes Produktionssystemgraphen Teil A
I
II
Existiert eine Kante,die Cluster1 und Cluster2
gemeinsam haben ?oder
Existiert eine Kante, die Knotenzwischen den Clustern
verbindet ?
nein
ja
Für alle Cluster der Clusterliste:
Für alle Cluster der Clusterliste die hinterCluster1 eingeordnet sind:
Abbildung 59 Programmablaufplan zur Ermittlung einer Startpartitionierung,Teil B - Zusammenfassung der Cluster
Zum besseren Verständnis soll die Abbildung 60 aufzeigen, welcher Schritt des Pro-grammablaufplans in Abbildung 59 sich auf welche Art von Verbindungskanten der be-trachteten Cluster bezieht. Die Bedingung I betrifft den Überlappungsbereich (gepunkteteFläche), während die Bedingung II auf zusätzliche Kanten, welche die Knoten der beidenCluster verbinden (gestrichelte Pfeile), abzielt.

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 166
Cluster 1 Cluster 2
Abbildung 60 Prinzipskizze zur Verdeutlichung der Zusammenfassung vonClustern auf Basis von Verbindungskanten
Ergebnis:
Sichere und unstrittig anwendbare Regeln zur Partitionierung des betrachteten Produk-tionssystems wurden bereits angewendet, um eine Startlösung für die Partitionierung zuerstellen. Diese Startlösung ist noch unvollständig und muß im nächsten Schritt ergänztwerden. Jedoch kürzt das Vorhandensein dieser Startlösung die Lösungssuche entschei-dend ab.
4.5.8.6 Schritt 2d - Auswahlverfahren: Bildung von zulässigen und günstigen Parti-tionierungsvarianten auf Basis der bewerteten Kanten
Ziel:
Auf Basis der ermittelten Startlösung (Clusterliste) und der bewerteten Kanten des Produk-tionssystemgraphen ist es möglich, eine Menge von Varianten der Partitionierung aufzu-stellen. Aufgabe des Lösungsschrittes (2d) ist es daher, Widersprüche in der Partitionie-rung von Varianten zu erkennen und solche Varianten zu verwerfen, um die Menge der zuprüfenden Varianten einzuschränken. Denn bei der Erstellung einer Variante erfolgt unterUmständen keine widerspruchsfreie Einordnung von Knoten in Partitionen, da bewerteteKanten existieren können, die eine widersprüchliche Zuordnung ergeben.
Algorithmus:
Bisher liegt eine Liste mit Clustern (Clusterliste) vor, die als potentielle Partitionen aufge-faßt werden können. Bei der Bildung dieser Cluster wurden die Knoten und Kanten zu-sammengefaßt, für die mindestens eine Partitionierungsregel (siehe Punkt 4.5.7) sicher an-wendbar war (Bestimmtheitsfaktor = 1,0). Im Schritt 2b (Seite 162) wurden jedoch alleKanten der Kantenmenge bewertet. Unter diesen Kanten sind noch solche, deren Bewer-tung zwar positiv ist, jedoch keine sichere Anwendung dieser Regeln erlaubt (Summe derBestimmtheitsfaktoren < 1,0). D.h., es bestehen hier zwei Alternativen: die Regel anzu-wenden oder die Regel zu ignorieren. Dies führt zu mehreren Varianten für die Partitionie-rung. Der Algorithmus sammelt all diese Varianten in einer Variantenliste. Unter den be-werteten Kanten sind außerdem auch solche, die eine negative Bewertung aufweisen, d.h.deren Knoten nicht zusammen in einer Partition eingeordnet werden sollten. Diese negativbewerteten Kanten werden im Algorithmus dazu benutzt, Varianten der Variantenliste vonder weiteren Untersuchung auszuschließen. Letzten Endes verbleiben u.U. einige Knotendes Produktionssystemgraphen, die bisher keiner Partition zugeordnet wurden, da für siedurch die Partitionierungsregeln keine oder nur widersprüchliche Aussagen getroffen wer-
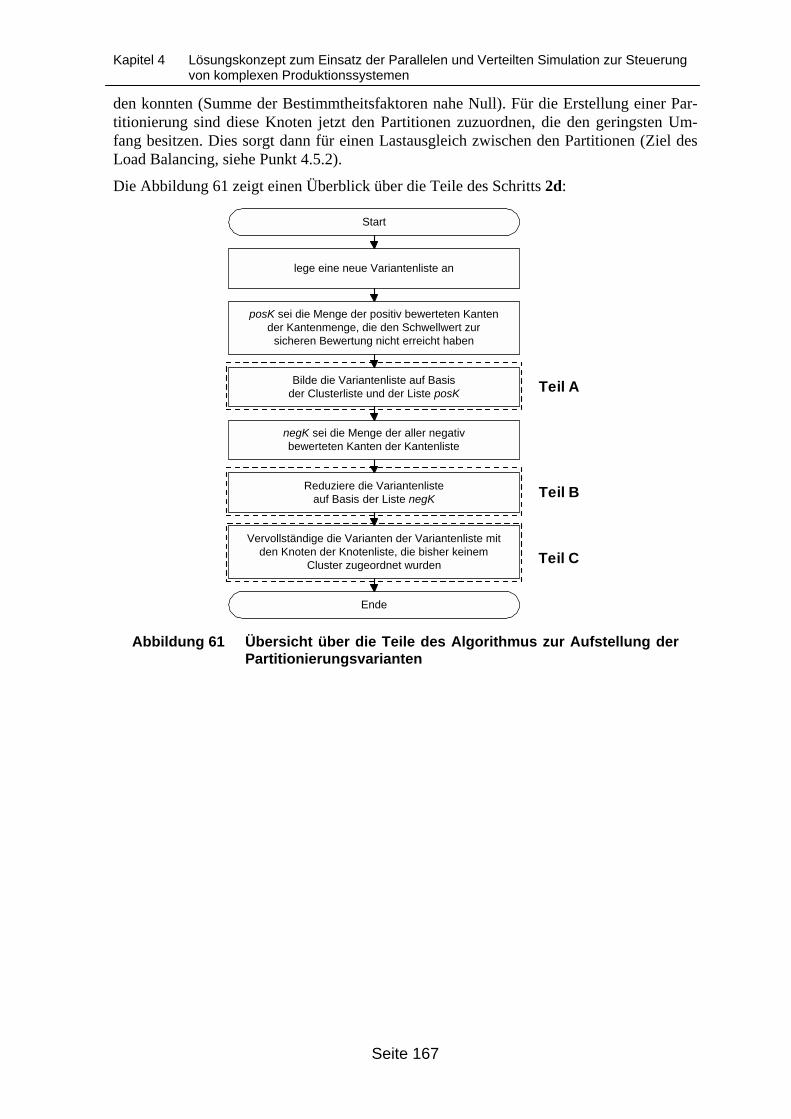
Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 167
den konnten (Summe der Bestimmtheitsfaktoren nahe Null). Für die Erstellung einer Par-titionierung sind diese Knoten jetzt den Partitionen zuzuordnen, die den geringsten Um-fang besitzen. Dies sorgt dann für einen Lastausgleich zwischen den Partitionen (Ziel desLoad Balancing, siehe Punkt 4.5.2).
Die Abbildung 61 zeigt einen Überblick über die Teile des Schritts 2d:
Start
Ende
lege eine neue Variantenliste an
posK sei die Menge der positiv bewerteten Kantender Kantenmenge, die den Schwellwert zur
sicheren Bewertung nicht erreicht haben
Bilde die Variantenliste auf Basisder Clusterliste und der Liste posK
negK sei die Menge der aller negativbewerteten Kanten der Kantenliste
Reduziere die Variantenlisteauf Basis der Liste negK
Vervollständige die Varianten der Variantenliste mitden Knoten der Knotenliste, die bisher keinem
Cluster zugeordnet wurden
Teil A
Teil B
Teil C
Abbildung 61 Übersicht über die Teile des Algorithmus zur Aufstellung derPartitionierungsvarianten
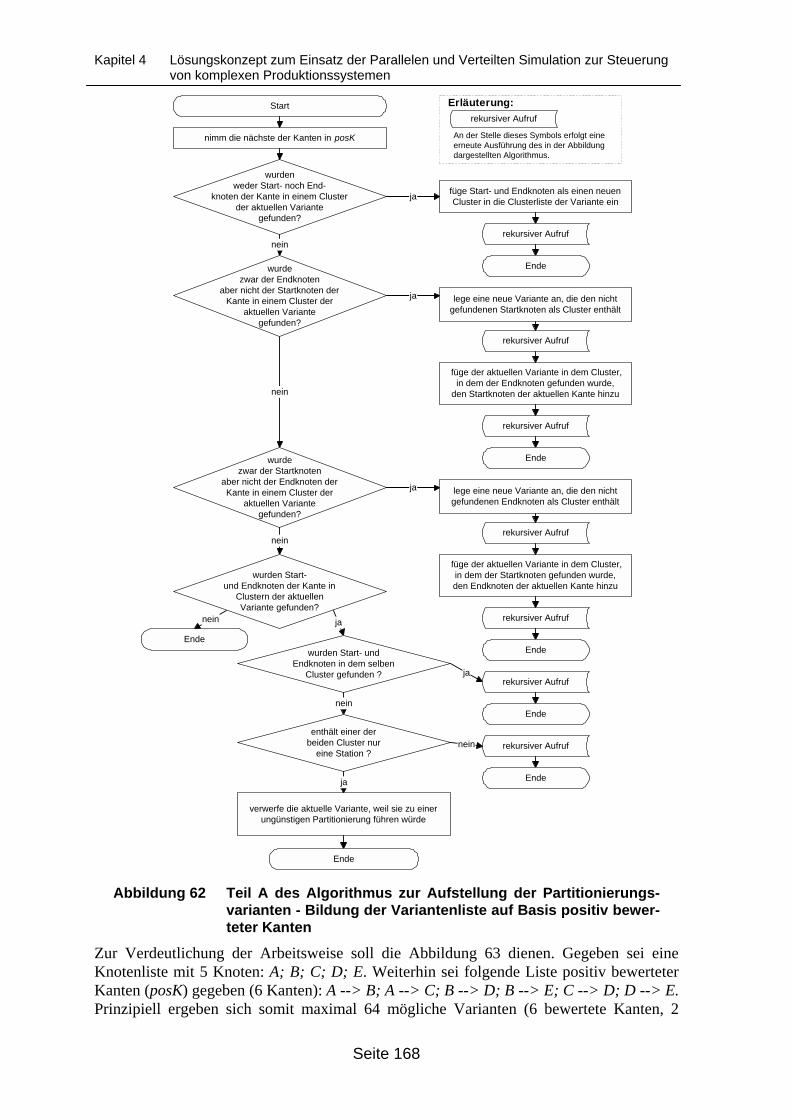
Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 168
Start
nimm die nächste der Kanten in posK
wurdenweder Start- noch End-
knoten der Kante in einem Clusterder aktuellen Variante
gefunden?
ja
nein
nein
jafüge Start- und Endknoten als einen neuenCluster in die Clusterliste der Variante ein
rekursiver Aufruf
wurdezwar der Endknoten
aber nicht der Startknoten derKante in einem Cluster der
aktuellen Variantegefunden?
lege eine neue Variante an, die den nichtgefundenen Startknoten als Cluster enthält
rekursiver Aufruf
füge der aktuellen Variante in dem Cluster,in dem der Endknoten gefunden wurde,
den Startknoten der aktuellen Kante hinzu
rekursiver Aufruf
wurdezwar der Startknoten
aber nicht der Endknoten derKante in einem Cluster der
aktuellen Variantegefunden?
nein
ja lege eine neue Variante an, die den nichtgefundenen Endknoten als Cluster enthält
rekursiver Aufruf
füge der aktuellen Variante in dem Cluster,in dem der Startknoten gefunden wurde,den Endknoten der aktuellen Kante hinzu
rekursiver Aufruf
wurden Start-und Endknoten der Kante in
Clustern der aktuellenVariante gefunden?
nein ja
wurden Start- undEndknoten in dem selben
Cluster gefunden ? ja
nein
rekursiver Aufruf
enthält einer derbeiden Cluster nur
eine Station ?nein
ja
verwerfe die aktuelle Variante, weil sie zu einerungünstigen Partitionierung führen würde
rekursiver Aufruf
Ende
Ende
Ende
Ende
Ende
Ende
Ende
rekursiver Aufruf
Erläuterung:
An der Stelle dieses Symbols erfolgt eineerneute Ausführung des in der Abbildungdargestellten Algorithmus.
Abbildung 62 Teil A des Algorithmus zur Aufstellung der Partitionierungs-varianten - Bildung der Variantenliste auf Basis positiv bewer-teter Kanten
Zur Verdeutlichung der Arbeitsweise soll die Abbildung 63 dienen. Gegeben sei eineKnotenliste mit 5 Knoten: A; B; C; D; E. Weiterhin sei folgende Liste positiv bewerteterKanten (posK) gegeben (6 Kanten): A --> B; A --> C; B --> D; B --> E; C --> D; D --> E.Prinzipiell ergeben sich somit maximal 64 mögliche Varianten (6 bewertete Kanten, 2
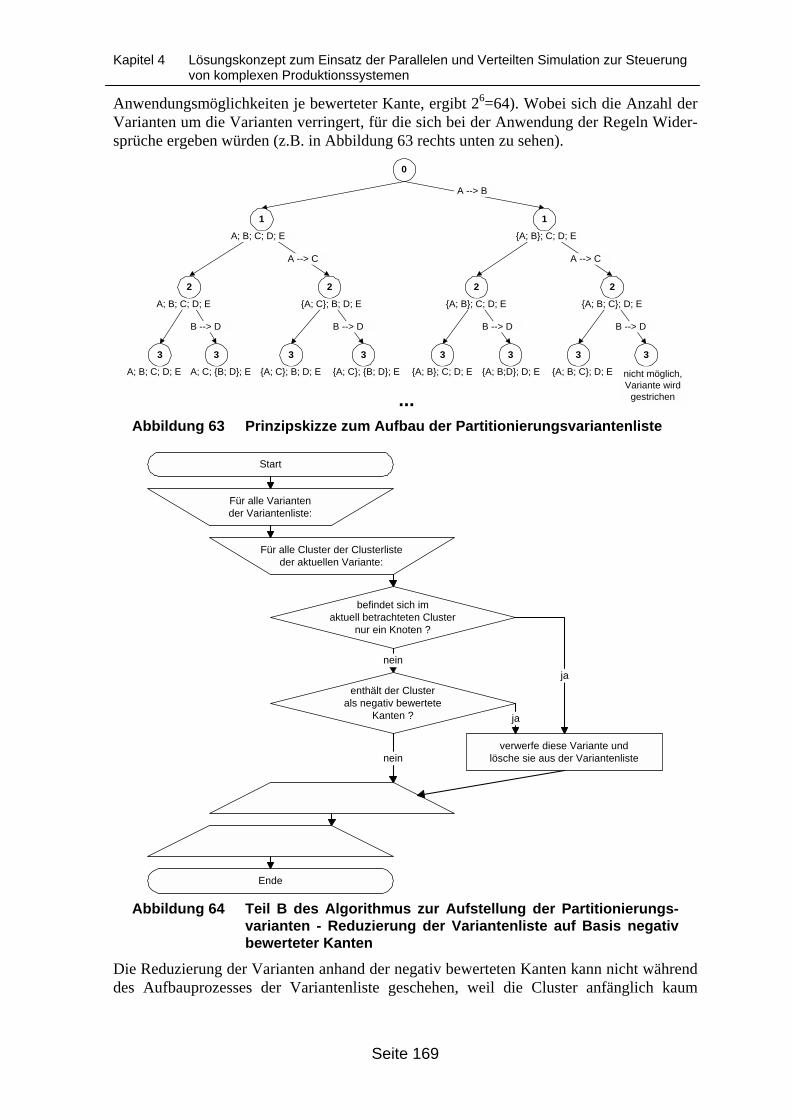
Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 169
Anwendungsmöglichkeiten je bewerteter Kante, ergibt 26=64). Wobei sich die Anzahl derVarianten um die Varianten verringert, für die sich bei der Anwendung der Regeln Wider-sprüche ergeben würden (z.B. in Abbildung 63 rechts unten zu sehen).
A --> B
0
1 1
{A; B}; C; D; EA; B; C; D; E
2 2
A --> C
A; B; C; D; E {A; C}; B; D; E
2 2
{A; B; C}; D; E{A; B}; C; D; E
A --> C
3 3
B --> D
A; B; C; D; E A; C; {B; D}; E
3 3
B --> D
{A; C}; {B; D}; E{A; C}; B; D; E
3 3
B --> D
{A; B}; C; D; E {A; B;D}; D; E
B --> D
3 3
{A; B; C}; D; E nicht möglich,Variante wird
gestrichen...Abbildung 63 Prinzipskizze zum Aufbau der Partitionierungsvariantenliste
Start
Ende
befindet sich imaktuell betrachteten Cluster
nur ein Knoten ?
nein
verwerfe diese Variante undlösche sie aus der Variantenliste
enthält der Clusterals negativ bewertete
Kanten ? ja
nein
ja
Für alle Variantender Variantenliste:
Für alle Cluster der Clusterlisteder aktuellen Variante:
Abbildung 64 Teil B des Algorithmus zur Aufstellung der Partitionierungs-varianten - Reduzierung der Variantenliste auf Basis negativbewerteter Kanten
Die Reduzierung der Varianten anhand der negativ bewerteten Kanten kann nicht währenddes Aufbauprozesses der Variantenliste geschehen, weil die Cluster anfänglich kaum
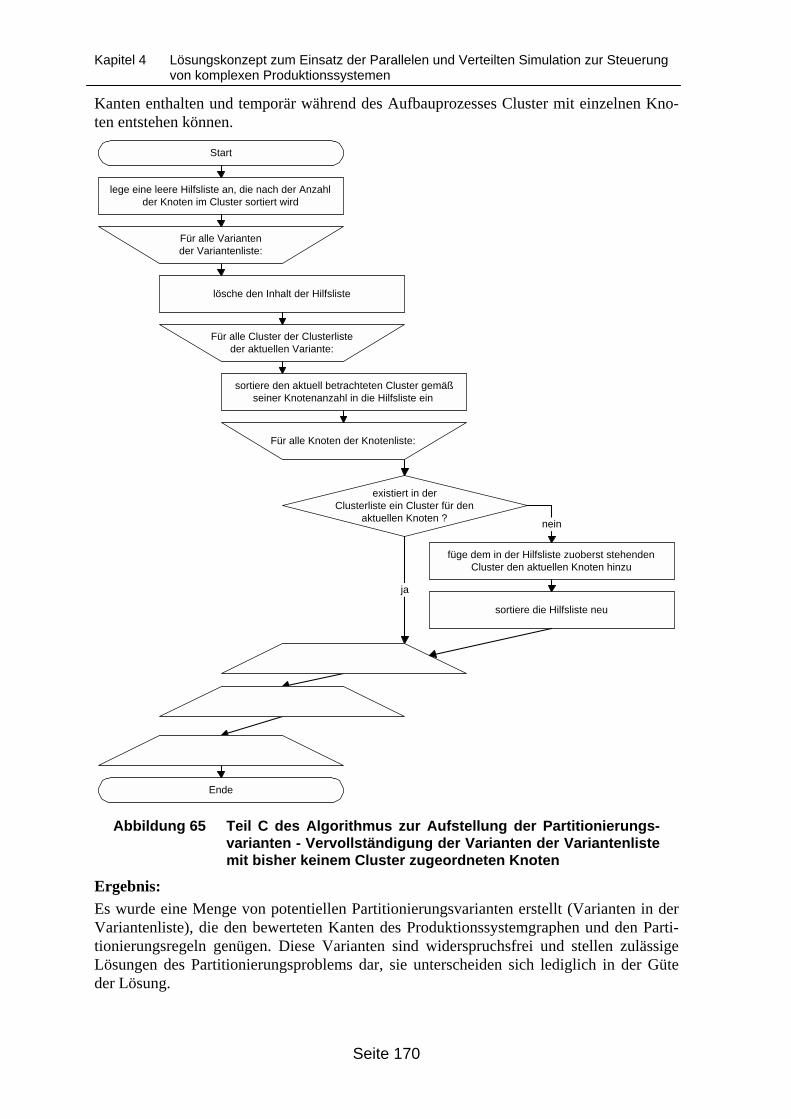
Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 170
Kanten enthalten und temporär während des Aufbauprozesses Cluster mit einzelnen Kno-ten entstehen können.
Start
Ende
existiert in derClusterliste ein Cluster für den
aktuellen Knoten ?
ja
lege eine leere Hilfsliste an, die nach der Anzahlder Knoten im Cluster sortiert wird
lösche den Inhalt der Hilfsliste
sortiere den aktuell betrachteten Cluster gemäßseiner Knotenanzahl in die Hilfsliste ein
füge dem in der Hilfsliste zuoberst stehendenCluster den aktuellen Knoten hinzu
nein
sortiere die Hilfsliste neu
Für alle Variantender Variantenliste:
Für alle Cluster der Clusterlisteder aktuellen Variante:
Für alle Knoten der Knotenliste:
Abbildung 65 Teil C des Algorithmus zur Aufstellung der Partitionierungs-varianten - Vervollständigung der Varianten der Variantenlistemit bisher keinem Cluster zugeordneten Knoten
Ergebnis:
Es wurde eine Menge von potentiellen Partitionierungsvarianten erstellt (Varianten in derVariantenliste), die den bewerteten Kanten des Produktionssystemgraphen und den Parti-tionierungsregeln genügen. Diese Varianten sind widerspruchsfrei und stellen zulässigeLösungen des Partitionierungsproblems dar, sie unterscheiden sich lediglich in der Güteder Lösung.

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 171
4.5.8.7 Schritt 2e - Bewertung der verbleibenden Varianten gemäß der Zielkriteriender Partitionierung und Auswahl der anzuwendenden Partitionierungs-variante
Ziel:
Jede der möglichen Partitionierungsvarianten ist hinsichtlich der Güte der Lösung zu be-werten. Dazu werden Kriterien wie das Ausmaß der Kommunikation zwischen den Parti-tionen, die gleichzeitige Aktivität der Partitionen als Möglichkeit zur parallelen Berech-nung und die Verteilung des Berechnungsaufwandes über die Partitionen herangezogen(siehe dazu Punkt 4.5.2). Abschließend wird die Partitionierungsvariante zur Umsetzungausgewählt, welche diese Ziele am besten erfüllt.
Algorithmus:Start
Ende
Zur Ermittlung der Gesamtkommunikationsmenge(GKM) summiere die Kommunikationsmenge über
alle Knoten der Knotenliste.
Zur Ermittlung der resultierenden Kommunikations-menge (RKM) summiere die Kommunikationsmengeüber alle Verbindungskanten zwischen den Clustern
der Clusterliste.
Berechne die Gesamtanzahl derEntscheidungssituationen (GES).
Bestimme die Anzahl der Entscheidungssituationen(AESj) über alle Knoten des Clusters.
Bestimme die Standardabweichung über die Anzahlder Entscheidungssituationen in den Clustern über
alle Cluster (DX(AESj)).
Die Bewertung der Variante sei:-RKM/GKM -DX(AESj)/GES
Wähle die Variante mit dermaximalen Bewertung aus.
Für alle Cluster der Clusterlisteder Variante:
Für alle Variantender Variantenliste:
Abbildung 66 Programmablaufplan zur Bewertung der Partitionierungs-varianten und Ermittlung der günstigsten Variante

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 172
Anmerkungen:
• Die Berechnung der Größen ist im Punkt 4.5.6 beschrieben.• Die Ziele der Partitionierung wurden in Punkt 4.5.2 erläutert. Der minimale Kommu-
nikationsaufwand wird durch das Verhältnis RKM/GKM präsentiert. Je höher diesesVerhältnis ist, desto ungünstiger wäre die Partitionierung gemäß dieser Variante. DasZiel der Ausgewogenheit der Partitionsgrößen (Balance) wird durch das Verhältnisvon DX(AESj)/GES repräsentiert. Auch hier gilt, je größer dieser Wert ist, desto un-günstiger wäre diese Partitionierung. Das Ziel der maximalen Ausnutzung derGleichzeitigkeit wird bereits bei der Bildung der Partitionierung durch die Anwen-dung der Regeln zur Partitionierung beachtet (Punkt 4.5.7, Regeln 5-10).
Ergebnis:
Als Ergebnis der Anwendung des vorgeschlagenen Partitionierungsverfahrens liegt eineEinteilung des Produktionssystemgraphen in Partitionen vor, in der die verbleibendeKommunikation zwischen den Partitionen niedrig ist, die Partitionen untereinander mög-lichst wenig Interdependenzen aufweisen und nach Möglichkeit zeitgleich aktiv sind undin denen der Berechnungsaufwand annähernd gleich auf die Partitionen verteilt ist (LoadBalance, siehe 4.5.2). Diese vorgeschlagene Partitionierung stellt für das betrachtete Pro-duktionssystem einen günstigen Fall dar. Die Optimalität dieser Lösung ist allerdings nichtgarantiert.
4.5.8.8 Schritt 3 - Bildung der Partitionen
Ziel:
Im letzten Schritt müssen die gebildeten potentiellen Partitionen - die Cluster - hinsichtlichder zur Verfügung stehenden Berechnungshardware128 gruppiert bzw. zusammengefaßtwerden. So sind Cluster mit geringem Aufwand zusammenzufassen, damit möglichst allePartitionen einen gleichen Aufwand besitzen und auch gleich schnell abgearbeitet werdenkönnen (siehe Ziel des Load Balancing in Punkt 4.5.2). Letzten Ende sollten so viele Par-titionen wie Berechnungseinheiten (Prozessoren) vorhanden sein.Dieser Schritt ist notwendig, weil durch die bisherige Verfahrensweise nicht garantiertwerden kann, daß genau soviel Partitionen (Cluster) gebildet werden, wie Prozessoren zurAbarbeitung zur Verfügung stehen. Ist die Anzahl der durch Schritt 2e vorgeschlagenenPartitionen jedoch kleiner oder gleich der Anzahl der Prozessoren, so ist das Partitionier-ungsverfahren bereits beendet.Bei einer Abarbeitung auf einem Parallelrechner ist das Partitionierungsverfahren ebenfallsbereits beendet. Jeder Cluster ist als Partition anzusehen. Bei der Ausführung auf einemParallelrechner bedient sich ein Prozessor, der eine Berechnungsaufgabe abgeschlossen hat(z.B. eine Partition ausgeführt hat, bis diese auf das Eintreffen von Nachrichten wartet),mit der nächsten zur Abarbeitung anstehenden Aufgabe (eine auf Abarbeitung wartendePartition). Hierzu besitzt das Betriebssystem des Parallelrechners bereits Zuteilungsstrate-gien zur Verteilung von Aufgaben auf Prozessoren (siehe Punkt 3.1.4.2). Es wäre unsinnig,zusätzlichen numerischen Aufwand zu investieren, um das selbe Problem doppelt zu lösen.D.h., die Anwendung des nachfolgend beschriebenen Algorithmus ist nur notwendig, wennes sich um eine verteilte Abarbeitung in einem Rechnernetz handelt und mehr potentiellePartitionen als Rechner vorhanden sind.
128 Berechnungshardware = Rechner innerhalb eines Computernetzes im Falle einer verteilten Abarbeitung
oder aber Prozessoren eines Parallelrechners

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 173
Algorithmus:
Bereits in der Betriebssystemtheorie wird dieses Zuteilungsproblem diskutiert. Dort wirdes als bin packing-Problem oder knapsack-Problem bezeichnet129. Die Frage ist, wie sollenn unterschiedlich aufwendige Aufgaben auf p Prozessoren/Rechner verteilt werden? Hier-bei handelt es sich wieder um ein NP-schweres Problem. In der Betriebssystemtheoriewerden zur Lösung des Problems zahlreiche Heuristiken diskutiert, nachfolgend soll diedort favorisierte Lösung gemäß der „offline-best-fit“-Heuristik130 für das Partitionierungs-verfahren Anwendung finden:
1. Ordne die Cluster nach ihrem Aufwand. Zur Beurteilung des Aufwandes dient die An-zahl der Entscheidungssituationen (AESj).
2. Ordne den größten, nicht zugeordneten Cluster dem Prozessor zu, dem bisher am we-nigsten zugewiesen wurde.
3. Wiederhole 2., bis alle Cluster zugeordnet sind.
Ergebnis:
Als Ergebnis dieses letzten Schrittes liegt eine Liste mit den Partitionen für das gegebeneProduktionssystem und die gegebenen Bedingungen vor, welche eine performante Abar-beitung des auf dieser Partitionierung basierenden Simulationsmodells erlaubt. Zu jederPartition ist dabei vermerkt, welche der Stationen des Produktionssystems in dieser Partiti-on zu plazieren sind.Die erstellten Partitionierungsdaten sind dann Basis für die automatisierte Erstellung desSimulationsmodells (siehe dazu Punkt 5.3.3).
Mit Hilfe des im Punkt 4.5 beschriebenen Partitionierungsverfahrens ist es möglich, für eingegebenes Modell eines Produktionssystems eine effiziente Partitionierung zu finden. Da-mit ist für das letzte der Teilprobleme der Parallelen und Verteilten Simulation (siehePunkt 3.3.3) eine Lösung vorhanden.
4.6 Alternative Lösung mittels eines verteilten Experimentier-systems
4.6.1 Motivation zum Einsatz eines verteilten Experimentiersystems
Eine der wesentlichen Anforderungen an eine Lösung zur Unterstützung der simulations-basierten Fertigungssteuerung ist die Beschleunigung der Abarbeitung einer Simulations-studie (siehe Punkt 2.4.2). Hier besteht außer der Anwendung der Parallelen und VerteiltenSimulation noch die Möglichkeit des Einsatzes eines verteilten Experimentiersystems.Im Rahmen einer Simulationsstudie sind eine Reihe von Simulationsexperimenten undSimulationsläufen durchzuführen. Hier ist es möglich, die voneinander unabhängigen Si-mulationsexperimente auf die Rechner eines Rechnernetzwerks zu verteilen und dort par-allel auszuführen (siehe Abbildung 67). Dies führt zu einer enormen Verringerung desZeitbedarfes für die Abarbeitung der Simulationsstudie (siehe u.a. [Bley, Wuttke 1997],[Arndt 2000], [Gehlsen, Page 2000], [Schneider, Reinhardt 2000]).
129 Eine Übersicht über die Verfahren zur Lösung des bin packing-Problems findet sich in [Coffman, Garey,
Johnson 1996].130 Zur Anwendung des bin packing auf Multiprozessorsysteme siehe [Coffman, Garey, Johnson 1978]. Ver-
gleiche auch [Domschke, Scholl, Voß 1997, S. 338-343, 351-354], [Brucker 1998, S. 101ff] zum Schedu-ling identischer, paralleler Maschinen.
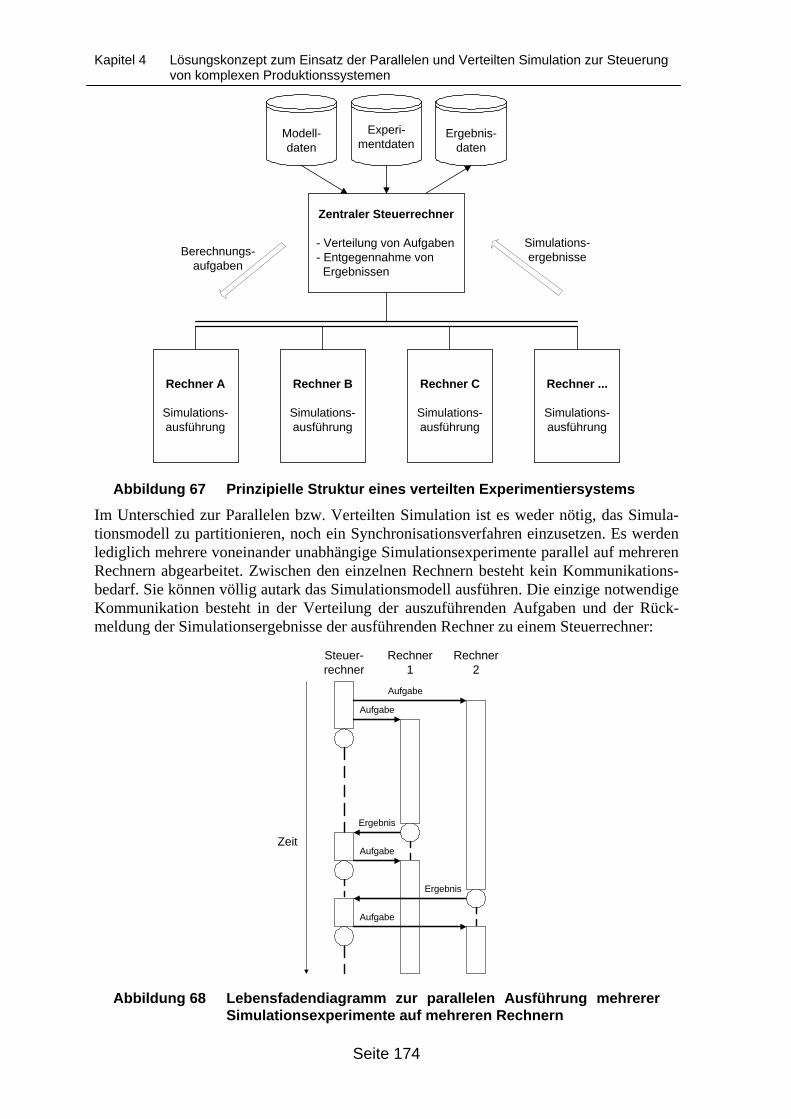
Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 174
Zentraler Steuerrechner
- Verteilung von Aufgaben - Entgegennahme von Ergebnissen
Rechner A
Simulations-ausführung
Rechner B
Simulations-ausführung
Rechner C
Simulations-ausführung
Rechner ...
Simulations-ausführung
Berechnungs-aufgaben
Simulations-ergebnisse
Modell-daten
Experi-mentdaten
Ergebnis-daten
Abbildung 67 Prinzipielle Struktur eines verteilten Experimentiersystems
Im Unterschied zur Parallelen bzw. Verteilten Simulation ist es weder nötig, das Simula-tionsmodell zu partitionieren, noch ein Synchronisationsverfahren einzusetzen. Es werdenlediglich mehrere voneinander unabhängige Simulationsexperimente parallel auf mehrerenRechnern abgearbeitet. Zwischen den einzelnen Rechnern besteht kein Kommunikations-bedarf. Sie können völlig autark das Simulationsmodell ausführen. Die einzige notwendigeKommunikation besteht in der Verteilung der auszuführenden Aufgaben und der Rück-meldung der Simulationsergebnisse der ausführenden Rechner zu einem Steuerrechner:
Zeit
Aufgabe
Ergebnis
Steuer-rechner
Aufgabe
Ergebnis
Aufgabe
Aufgabe
Rechner1
Rechner2
Abbildung 68 Lebensfadendiagramm zur parallelen Ausführung mehrererSimulationsexperimente auf mehreren Rechnern

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 175
Der Grad an Parallelität ist hier viel höher als innerhalb eines Simulationsmodells der Par-allelen und Verteilten Simulation131. Es kann somit durch diese Art der Parallelisierungeine höhere Laufzeitbeschleunigung erzielt werden (vergleiche dazu Abbildung 49, Seite138).Obwohl ein verteiltes Experimentiersystem partiell in der Literatur als Verteilte Simulationbezeichnet wird, handelt es sich de facto um eine verteilte Sequentielle Simulation (siehePunkt 2.2.2.1).
4.6.2 Einordnung des verteilten Experimentiersystems in das integrierte Unter-stützungssystem
Das verteilte Experimentiersystem versteht sich als integrativer Bestandteil des Frame-works zur simulationsbasierten Fertigungssteuerung. Es kann alternativ zu einer Parallelenoder Verteilten Simulation eingesetzt werden.Durch den Anwender des Frameworks wird eine Simulationsstudie als eine Vielzahl vonunabhängig ausführbaren Experimenten definiert. Für die Abarbeitung der Experimenteder Simulationsstudie bestehen drei Möglichkeiten:
A) lokale Abarbeitung aller Experimente der Studie,
B) entfernte Abarbeitung aller Experimente der Studie auf einem Computeserver,
C) verteilte Abarbeitung von Experimenten der Studie in einem Netzwerk von Rech-nern.
Die Varianten (A) und (B) laufen auf eine sequentielle Ausführung der Experimente hin-aus. In der Variante (A) erfolgt für ein Experiment eine Sequentielle Simulation des Si-mulationsmodells. Die einzelnen Experimente werden nacheinander ausgeführt. Die Vari-ante (B) ist ähnlich. Auch hier werden die einzelnen Experimente nacheinander auf demselben Rechner ausgeführt. Jedoch erfolgt die Abarbeitung der Experimente auf einemleistungsfähigen Mehrprozessorrechner. D.h., zu Beginn sind alle für die Ausführung einesExperimentes notwendigen Angaben zu diesem Rechner zu transferieren und nach Ab-schluß der Ausführung des Simulationslaufes werden die Simulationsergebnisse auf denRechner des Frameworks zurücktransferiert. In der Variante (C) werden dagegen zeit-gleich mehrere Experimente der Studie auf verschiedenen Rechnern ausgeführt. D.h., esstehen mehrere Rechner für die Ausführung der Experimente zur Verfügung und jeder die-ser Rechner arbeitet ein oder mehrere Experimente ab.Alternativ zur Anwendung einer Sequentiellen Simulation (A) oder einer Parallelen undVerteilten Simulation (B) kann demzufolge die verteilte Experimentierumgebung (C) ein-gesetzt werden.
4.6.3 Prinzipieller Lösungsansatz für ein verteiltes Experimentiersystem
Im verteilten Experimentiersystem soll eine parallele Ausführung von Simulationsexperi-menten stattfinden. Dazu ist eine Einteilung der Funktionalitäten in zentral und verteilt ab-arbeitbare Funktionen notwendig. Als Basis für das verteilte Experimentiersystem soll dasim Punkt 4.2 beschriebene Framework zur simulationsbasierten Fertigungssteuerung die-nen.Als eine erste Frage ist der Verteilungsgegenstand zu klären. Abbildung 69 zeigt den prin-zipiellen Aufbau einer Simulationsstudie. Einer Simulationsstudie ist ein Experimentplanzugeordnet, der beschreibt, welches Simulationsmodell mit welchen Änderungen wie oftsimuliert werden soll. Die Änderungen des Modells sind jeweils als Experimente angege-
131 Das Verhältnis zwischen Berechnungsaufwand und Kommunikationsdauer (siehe Formel 2, Seite 69) - als
Maß für die Parallelisierbarkeit - ist hier sehr entspannt. Einem sehr hohen Berechnungsaufwand steht einsehr geringer Kommunikationsbedarf gegenüber.

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 176
ben und werden in Experimentreihen gruppiert. Zu jedem Experiment ist konkret festge-legt, welche Änderungen am Simulationsmodell vorzunehmen sind. Aufgrund stochasti-scher Modelleinflüsse ist eine wiederholte Abarbeitung des Simulationsmodells eines Ex-perimentes notwendig, um letztlich statistisch gesicherte Aussagen treffen zu können(siehe Punkt 2.3.3).
ExperimentplanExperimentreihe
Simulationsexperiment
1 : n
Simulationslauf
1 : n
1 : n
Einsteuerungs-matrix
Strategiematrix
Simulationsmodell
Anzahl der Läufe
Strategievariante(Handlungsalternative)
Einsteuerungs-variante
Abbildung 69 Entity-Relationship-Model der Bestandteile einer Simulations-studie132
Aus Sicht des parallelen Experimentierens gilt das Simulationsmodell eines Experimentesals atomar. D.h., es werden keine Anstrengungen zur Parallelisierung dieses Simulations-modells unternommen. Für die verteilte Abarbeitung des Simulationsmodells in einemRechnernetzwerk bestehen folgende Möglichkeiten:
A) Man könnte jedem der verfügbaren Rechner die Abarbeitung einer Experimentreiheals Aufgabe geben. Jeder Rechner würde eventuell mehrere Experimentreihen zurAbarbeitung erhalten.
B) Man könnte jedem der verfügbaren Rechner die Abarbeitung eines Experiments alsAufgabe geben. Jeder Rechner würde eventuell mehrere Experimente zur Abarb-eitung erhalten.
C) Man könnte jedem der verfügbaren Rechner die Abarbeitung eines Laufs eines Ex-periments als Aufgabe geben. Jeder dieser Rechner würde jeweils einen oder meh-rere Läufe eines Experimentes zur Abarbeitung erhalten. Weiterhin ist es wahr-scheinlich, daß sich dies für mehrere Experimente wiederholt.
Da sich die Experimentreihen unter Umständen stark im Aufwand unterscheiden133, er-scheint es nicht sinnvoll, die Experimentreihen zum Verteilungsgegenstand zu machen.Ebenso ist eine Verteilung der Läufe nicht sinnvoll, da jedem beteiligten Rechner das be-treffende Simulationsmodell (eventuell sogar mehrfach) übermittelt werden müßte undabschließend die Übersendung der Ergebnisdaten der Läufe an eine zentrale Stelle erfolgenmuß, um die statistische Aufbereitung der Ergebnisse der verschiedenen Läufe ein und desselben Experiments stattfinden muß. Es kristallisiert sich also die Vorgehensweise (B) alsam attraktivsten heraus. Ein mathematisches Modell zur Begründung dieser Auswahl kannin [Elsäßer 2001, S. 13-26] nachgelesen werden.
132 Genaueres zu dieser Aufteilung kann Punkt 5.1.2.8 entnommen werden.133 Die Experimentreihen können eine unterschiedliche Anzahl an Experimenten enthalten und der numerische
Aufwand - und damit die Zeit zur Durchführung der Simulation - kann sich sehr stark unterscheiden. Zu-sätzlich wäre es also notwendig, die Experimentreihen so auf die verfügbaren Rechner zu verteilen, daßalle Rechner einen vergleichbar hohen numerischen Aufwand abarbeiten müssen. Andernfalls würde sichdie Gesamtdauer für die Abarbeitung der Simulationsstudie unnötig verlängern.
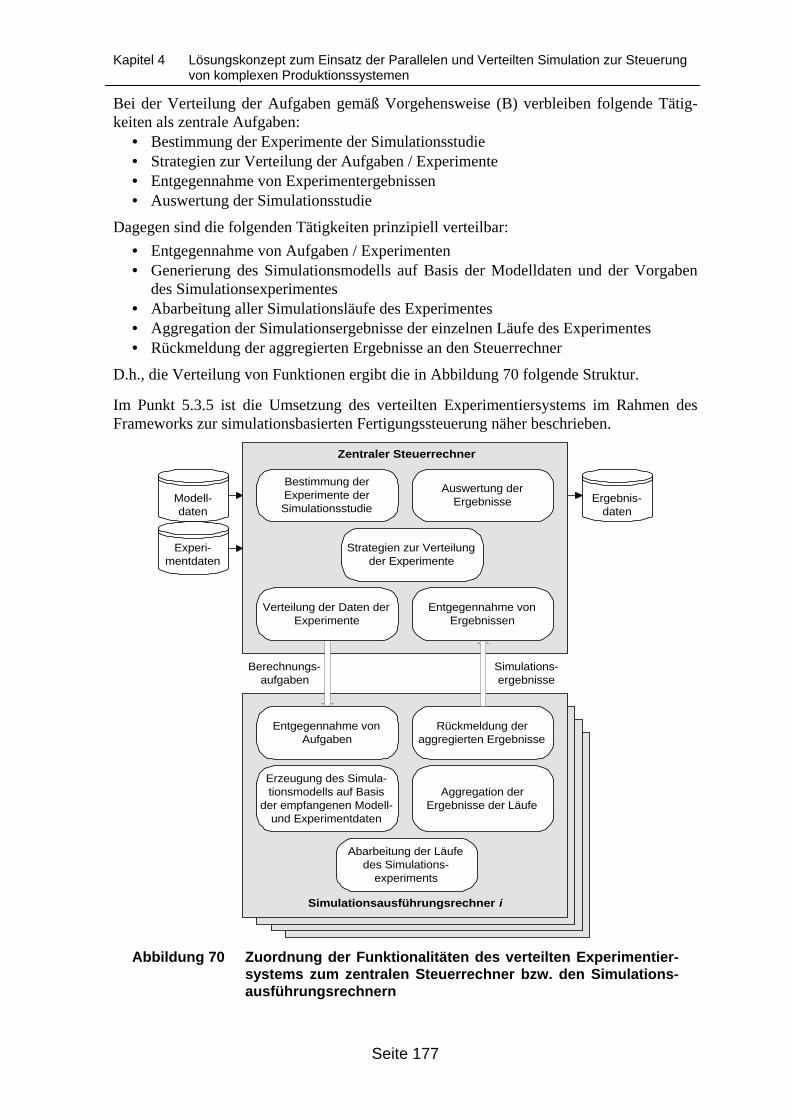
Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 177
Bei der Verteilung der Aufgaben gemäß Vorgehensweise (B) verbleiben folgende Tätig-keiten als zentrale Aufgaben:
• Bestimmung der Experimente der Simulationsstudie• Strategien zur Verteilung der Aufgaben / Experimente• Entgegennahme von Experimentergebnissen• Auswertung der Simulationsstudie
Dagegen sind die folgenden Tätigkeiten prinzipiell verteilbar:
• Entgegennahme von Aufgaben / Experimenten• Generierung des Simulationsmodells auf Basis der Modelldaten und der Vorgaben
des Simulationsexperimentes• Abarbeitung aller Simulationsläufe des Experimentes• Aggregation der Simulationsergebnisse der einzelnen Läufe des Experimentes• Rückmeldung der aggregierten Ergebnisse an den Steuerrechner
D.h., die Verteilung von Funktionen ergibt die in Abbildung 70 folgende Struktur.
Im Punkt 5.3.5 ist die Umsetzung des verteilten Experimentiersystems im Rahmen desFrameworks zur simulationsbasierten Fertigungssteuerung näher beschrieben.
Modell-daten
Experi-mentdaten
Zentraler Steuerrechner
Simulationsausführungsrechner i
Berechnungs-aufgaben
Simulations-ergebnisse
Ergebnis-daten
Bestimmung derExperimente derSimulationsstudie
Strategien zur Verteilungder Experimente
Verteilung der Daten derExperimente
Entgegennahme vonErgebnissen
Entgegennahme vonAufgaben
Erzeugung des Simula-tionsmodells auf Basis
der empfangenen Modell-und Experimentdaten
Abarbeitung der Läufedes Simulations-
experiments
Aggregation derErgebnisse der Läufe
Rückmeldung deraggregierten Ergebnisse
Auswertung derErgebnisse
Abbildung 70 Zuordnung der Funktionalitäten des verteilten Experimentier-systems zum zentralen Steuerrechner bzw. den Simulations-ausführungsrechnern

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 178
4.7 Zusammenfassung der Anforderungen an einen Lösungs-ansatz zur Parallelen und Verteilten Simulation von komple-xen Produktionssystemen
Bereits im Punkt 2.4.2 wurde gefordert, daß die verwendeten Simulationsmodelle die Pro-duktionssysteme adäquat abbilden müssen. D.h., es muß möglich sein, auf Basis der dasProduktionssystem beschreibenden Daten (siehe Punkt 2.3.2.2, Punkt 5.1.2.7, Anhang C)ein geeignetes Simulationsmodell zu erstellen. Die im Punkt 4.3.1 vorgenommenen Ein-schränkungen widersprechen dem nicht, sondern gehen noch über die Komplexität bisherin der Literatur betrachteter Simulationsanwendungen hinaus. Weiterhin sind im Modelldie im realen Produktionssystem auftretenden spezifischen Prozeßbedingungen zu berück-sichtigen (siehe Punkt 4.3.1.2), um eine adäquate Abbildung der Realität im Simulations-modell zu erreichen (siehe Anforderung aus Punkt 2.4.2). Als Letztes muß das Modell aufBasis des aktuellen Zustandes des Produktionssystems erstellt werden. Diesen Anforderun-gen wird zum Einen durch das Framework zur simulationsbasierten Fertigungssteuerung(siehe Punkt 4.2) Rechnung getragen. Zum Anderen sind diese Anforderungen bei der Er-stellung des Simulationsmodells für ein spezielles Simulationstool zu bedenken.Eine zweite Anforderung aus Punkt 2.4.2 ist die automatische Modellerstellung ohne Ein-griff eines Simulationsexperten. Dies wird bereits durch das Framework gewährleistet.Voraussetzung hierfür ist die Existenz einer Generator-Komponente für das Framework,welche das Simulationsmodell für eine Parallele oder Verteilte Simulation automatischerstellt (siehe dazu Punkt 5.3.2).Weiterhin wurde im Punkt 2.4.2 gefordert, daß der Experimentierprozeß zur Bestimmungder geeignetsten Handlungsalternative durch Software zu unterstützen ist. Dies wird durchdas Framework zur simulationsbasierten Fertigungssteuerung bereits realisiert.Eine letzte Anforderung aus Punkt 2.4.2 besteht darin, den Zeitbedarf für die Abarbeitungdes Simulationsmodells zu verkürzen. Hierzu wurde im Punkt 4.4 beschrieben, welchesSynchronisationsverfahren mit welchen Parametern und Einstellungen zu verwenden istund welche Möglichkeiten zur positiven Beeinflussung des performancekritischen FaktorsLookahead bestehen (siehe Punkt 4.3.4.2).Einen maßgeblichen Einfluß auf die Performance der Parallelen und Verteilten Simulationhat aber auch die Partitionierung des Modells [Schlagenhaft 1999a], [Schlagenhaft 1999b].Deswegen wurde im Punkt 4.5 beschrieben, wie Modelle von Produktionssystemen zu par-titionieren sind. Daraus erwächst jetzt die Forderung, daß dieses Partitionierungsverfahrenanzuwenden ist. Dies muß so geschehen, daß ein gegebenes Modell automatisch partitio-niert wird. D.h., bei der bereits automatisch erfolgenden Generierung des Simulations-modells ist jetzt zusätzlich das Partitionierungsverfahren automatisch anzuwenden.Als Problem verbleibt der Mangel an einer konkreten Software zur Parallelen und Verteil-ten Simulation für Produktionssysteme. Bereits in Punkt 3.2.4 wurde dieses Defizit aufge-zeigt. D.h., es ist jetzt notwendig, eine entsprechende Software herzustellen, welche deneben aufgezeigten Anforderungen (vergleiche Punkt 3.3) genügt. Das Kapitel 5 befaßt sichmit diesem Aspekt. Der dabei erstellte Simulator ist anschließend in das Framework zursimulationsbasierten Fertigungssteuerung zu integrieren (siehe vorherige Anforderungen). Ein wesentliches Problem der Parallelen und Verteilten Simulation ist die Ungewißheitüber die Performance des Modells. Leider existieren keine Kriterien, welche es erlauben,im Voraus die Modellperformance zu prognostizieren. Auch sind in der Literatur die ver-schiedenartigsten Angaben in Bezug auf das erzielte Speedup zu finden. D.h., es ist drin-gend notwendig, für unterschiedliche Arten von Modellen von Produktionssystemen diePerformance unter differierenden Gegebenheiten (verschiedene Synchronisationsver-

Kapitel 4 Lösungskonzept zum Einsatz der Parallelen und Verteilten Simulation zur Steuerungvon komplexen Produktionssystemen
Seite 179
fahren, verschiedene Abarbeitungsplattformen usw., vergleiche dazu 3.1.3.2, 5.2.2.1, 6.3.1)zu untersuchen. Dies ist Gegenstand von Kapitel 6.

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 180
5 Implementation eines Prototypen zur simulations-basierten Fertigungssteuerung komplexer Produk-tionssysteme mit Hilfe der Parallelen Simulation
Die Parallele bzw. Verteilte Simulation komplexer Produktionssysteme ist durch eine Viel-zahl von Aufgaben und Problemen gekennzeichnet. Zur adäquaten Abbildung eines realenProduktionssystems muß ein Simulationstool verwendet werden, daß die dort vorliegendenkomplexen Prozeßbedingungen hinreichend genau im Simulationsmodell abzubilden ver-mag (siehe Anforderungen im Punkt 2.4.2). Weiterhin muß dieses Tool ein Simulations-modell ohne Änderungsaufwand mit verschiedenen Synchronisationsverfahren auf ver-schiedenen Rechnerplattformen ausführen können. Der Grund dafür ist die Performance-ungewißheit der Parallelen und Verteilten Simulation (siehe Punkt 3.3.2). Es mußte dem-zufolge ein passendes Tool ausgewählt werden (siehe Punkt 5.2.1). Mit ParSimONY wur-de ein Tool gefunden (siehe Punkt 5.2.2), welches sowohl die wiederverwendbare Ab-bildung komplexer Strukturen, als auch die Trennung von Modell und Simulationssteue-rung erfüllt. Damit war es prinzipiell möglich, eine Parallele Simulation komplexer Pro-duktionssysteme durchzuführen.Als Problem steht jedoch, daß Produktionssysteme im Allgemeinen und komplexe Produk-tionssysteme im Besonderen durch einen sehr hohen Datenumfang gekennzeichnet sind.Auf Basis dieser Datenmenge entsteht ein hoher Aufwand zur Erstellung eines Simula-tionsmodells (Manifestierung der notwendigen Daten im Simulationsmodell bzw. Berück-sichtigung von Daten für Steuerungsfunktionalität im Simulationsmodell). Die manuelleErstellung des ParSimONY-Simulationsmodells für ein umfangreiches, komplexes Pro-duktionssystem ist nicht sinnvoll. Bereits in Punkt 4.2.1 wurde aufgezeigt, daß die Erstel-lung eines Simulationsmodells durch das Framework zur simulationsbasierten Fertigungs-steuerung unterstützt werden kann und muß. Aus diesem Grund wurde ein Simulations-programmgenerator für ParSimONY geschaffen (siehe Punkt 5.1.2.12). Dieser Generatorist Bestandteil des Frameworks zur simulationsbasierten Fertigungssteuerung. Das Frame-work übernimmt dabei auch die Aufgaben der Definition und Pflege der Daten zur Be-schreibung des Produktionssystems. Zusätzlich stellt das Framework Funktionalitäten zumExperimentieren und zur Auswertung der Experimente bereit.Als ein starker Performanceeinflußfaktor auf die Parallele und Verteilte Simulation wurdedie Partitionierung des Modells identifiziert (siehe Punkt 4.3.4.1). D.h., bei der Erstellungeines ParSimONY-Simulationsmodells ist es notwendig, ein an die Partitionierung vonModellen von Produktionssystemen angepaßtes Partitionierungsverfahren zu verwenden.Dieses Partitionierungsverfahren benötigt für seine Ausführung Meßdaten zur Güte derPartitionierung (siehe Punkt 4.5.4). Diese Meßdaten sind während des Simulationslaufeszu erfassen. Die Erfassung der notwendigen Größen geschieht durch im Simulationsmodellimplementierte Funktionen. D.h., als Erstes war der Generator für ParSimONY-Simula-tionsmodelle an diesen Fakt anzupassen (siehe Punkt 5.3.2). Als Zweites muß bei der auto-matischen Generierung des Simulationsmodells durch das Framework das Partitionie-rungsverfahren für Modelle von Produktionssystemen eingesetzt werden. D.h., es war eineIntegration des Partitionierungsverfahrens in das Framework notwendig (Punkt 5.3.4).
Zur Darstellung der Dokumentation des Umfangs, der Architektur sowie der Funktions-prinzipien und Prozesse der prototypischen Lösung ist das Kapitel 5 wie folgt aufgebaut:

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 181
• Im Unterkapitel 5.1 erfolgt eine detaillierte Erläuterung der Architektur des Frame-works zur simulationsbasierten Fertigungssteuerung als dem Unterstützungssystem zurDurchführung von Simulationsstudien.
• Das Unterkapitel 5.2 enthält die Darstellung der Entwicklung und Implementation eines Parallelen Simulators für komplexe Produktionssysteme.• Inhalt des Unterkapitels 5.3 ist die Überführung der Teillösungen zu einem integrierten
Unterstützungssystem. D.h., es wird die Kopplung von Framework, Parallelem Simu-lator und dem Partitionierungsverfahren beschrieben.
• Das Unterkapitel 5.4 enthält die Beschreibung der alternativen Lösung mittels des ver-teilten Experimentiersystems. Hier wird beschrieben, welche Teile des integrierten Un-terstützungssystems auszutauschen sind. Ebenso sind Details der Implementation desverteilten Experimentiersystems mittels CORBA dargestellt.
• Abschließend enthält das Unterkapitel 5.5 einen Ausblick auf Erweiterungen der proto-typischen Lösung.
5.1 Implementation des Frameworks zur simulationsbasiertenFertigungssteuerung als Unterstützungssystem zur Durch-führung von Simulationsstudien
Wie bereits im Punkt 4.2 ausgeführt, dient das Framework zur simulationsbasierten Ferti-gungssteuerung als Unterstützungssystem zur Erstellung von Simulationsmodellen und zurDurchführung und Auswertung von Experimenten mit diesen Modellen.Von seiner Idee geht das Framework über die für einen Prototypen zur Durchführung derParallelen bzw. Verteilten Simulation benötigten Dienste hinaus. Jedoch in Anbetrachtkünftiger Erweiterungen soll bereits der Prototyp zur Durchführung einer Parallelen Simu-lation (siehe Punkt 5.2) in das Unterstützungssystem des Frameworks integriert werden.Durch die Verwendung exakt des selben Datenbestandes durch automatische Simulations-modellgeneratoren wird auch eine bessere Vergleichbarkeit der Sequentiellen mit der Par-allelen Simulation erreicht. Das Framework kann somit sowohl für eine herkömmlicheSequentielle Simulation, ein verteiltes Experimentieren als auch eine Parallele Simulationverwendet werden.
5.1.1 Überblick über die Komponenten des Frameworks
Die im Punkt 4.2 getroffenen Aussagen zu den Komponenten des Frameworks können innachfolgender Strukturabbildung zusammengefaßt werden.
Das Framework enthält die bereits aus dem Punkt 4.2 bekannten Datenbestände:• Modelldatenbank,• Experimentplandatenbank,• Laufergebnisdatenbank und• Ergebnisdatenbank.
Zur Kapselung der Datenbestände134 werden Datenzugriffs-Komponenten eingesetzt.
Weiterhin sind Komponenten für die Durchführung der Hauptaufgaben bei der Durch-führung einer Simulationsstudie vorhanden (vergleiche Punkt 4.2.1):
• Datenimport-Komponente,• Experimentplanungs-Komponente,
134 Durch den Einsatz der Datenzugriffs-Komponenten ist es möglich, die Implementierung von Algorithmen
von der Datenherkunft zu trennen. Somit kann das verwendete Datenbanksystem - und auch das Dateifor-mat - beliebig ausgetauscht werden.

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 182
• Modellerstellungs-Komponente (Generator),• Experimentplandurchführungs-Komponente,• Auswertungs-Komponente und• Ergebnisübernahmekomponente.
Die Abarbeitung eines Simulationsexperimentes gestaltet sich wie im Punkt 4.2.3.2 be-schrieben.
externes System(PPS-System)
(m verschiedene)
Shell(SimFab)
externeDatenquellen
Modelldaten
Konverter(m verschiedene)
Datenzugriffs-komponente
Datenpflege(optional)
Anwender
Generator(n verschiedene)
Simulations-modell
Ergebnis-konverter
Auswertungs-komponente
GUI
Datenzugriffs-komponente
Experiment-pläne
Experiment-planung
Ergebnisdaten
Datenzugriffs-komponente
Ergebnis-übernahme
Simulations-experiment-steuerung
externerSimulator
(n verschiedene)
Simulations-ausführung
(n verschiedene)
Datenimport
Modelldaten-verwaltung
Konverter(m verschiedene)
Datendateien(optional)
(definiertesFormat)
Simulations-ergebnisse
Laufergebnisse(temporär)
Simulations-laufsteuerung
Ergebnis-aggregation
Experimentplan-durchführung
Datenzugriffs-komponente
Abbildung 71 Detaillierte Struktur des Frameworks
5.1.2 Das Framework aus Implementations-Sicht
In diesem Abschnitt erfolgt eine detailliertere Beschreibung der Komponenten und Ab-läufe des Frameworks zur simulationsbasierten Fertigungssteuerung. Auf dieser Basis istes möglich, die prototypische Umsetzung nachzuvollziehen. Auf eine profunde Darstellungaller Einzelheiten der Implementation an dieser Stelle soll aus Umfangsgründen verzichtetwerden. Zur Verdeutlichung der Komplexität und des Umfangs dieser Module sei nur ge-nannt, daß der gesamte Quelltext des Frameworks sich auf 215 Dateien (Module) verteiltund ca. 28.000 Codezeilen umfaßt.
5.1.2.1 Grafische Benutzeroberfläche
Die grafische Benutzeroberfläche stellt die „Kommandozentrale“ der Simulations-Shell fürden Anwender dar. Sämtliche wesentlichen Funktionalitäten sind direkt über die Benutzer-oberfläche zu erreichen (siehe Abbildung 72).

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 183
Modell-verwaltungs-
daten
Metadaten(Verteilungen,Steuerungs-strategien)
grafische Benutzeroberfläche
Mo
dell-
verw
alt
un
g
Mo
delld
ate
n-
verw
alt
un
g
Meta
date
n-
verw
alt
un
g
Exp
eri
men
t-p
lan
un
g
Au
sw
ert
un
gs-
ko
mp
on
en
te
Erg
eb
nis
-ü
bern
ah
me
Exp
eri
men
tpla
n-
du
rch
füh
run
g
Abbildung 72 In die Benutzeroberfläche der Simulations-Shell einge-bundene Komponenten135
Aufgabe der Modellverwaltungs-Komponente (siehe Punkt 5.1.2.2) ist es, dem Benutzereine Auswahl aus mehreren in der Datenbank gespeicherten Modellen bzw. Modellvaria-tionen zu ermöglichen.Mit Hilfe der Metadatenverwaltung (siehe Punkt 5.1.2.3) kann der Benutzer (oder ein Ad-ministrator) dem Framework neue Steuerungsstrategien bekanntgeben. Diese Steuerungs-strategien stehen dem Benutzer dann innerhalb der Simulations-Shell zur Auswahl zurVerfügung. Weiterhin sind über die Metadatenverwaltung zusätzliche statistische Ver-teilungen integrierbar und die Aufrufparameter weiterer externer Simulatoren können kon-figuriert werden.Die Modelldatenverwaltung (siehe Punkt 5.1.2.4) faßt die Möglichkeit des Imports vonDaten aus Fremdsystemen (siehe Punkt 5.1.2.5) und die Pflege der konkreten Daten einesModells (siehe Punkt 5.1.2.6) zusammen.Über die Experimentplanungs-Komponente (siehe Punkt 5.1.2.8) kann der Benutzer einenvorhandenen Experimentplan für die simulative Untersuchung auswählen oder z.B. einenneuen Experimentplan anlegen.Die Experimentdurchführungs-Komponente (siehe Punkt 5.1.2.10) hat dann die Aufgabeden vom Benutzer ausgewählten Experimentplan automatisch abzuarbeiten und die Simu-lationsergebnisse für die Auswertungs-Komponente in der Datenbank abzulegen.Die Auswertungs-Komponente (siehe Punkt 5.1.2.20) erlaubt dann eine tabellarische undgrafische Anzeige der Simulationsergebnisse der einzelnen Experimente oder den Ver-gleich der Ergebnisse mehrerer Experimente des Experimentplans.Die Ergebnisübernahme-Komponente (siehe Punkt 5.1.2.21) ermöglicht es dem Benutzer,die Einstellungen eines ausgewählten Experimentes zur Umsetzung im Realsystem vorzu-geben und alle dazu notwendigen Daten in ein externes Informationssystem zu übergeben.
5.1.2.2 Modellverwaltung und VerwaltungsdatenbankDie Verwaltungsdatenbank enthält alle Angaben, die es der Simulations-Shell ermög-lichen, die Daten mehrerer Modelle von Produktionssystemen zu verwalten.In der Modellverwaltung werden z.B. alle in der Verwaltungsdatenbank vorhandenen Mo-delle als die im Rahmen der Simulations-Shell verfügbaren Modelle dem Benutzer zurAuswahl angeboten. Intern in der Simulations-Shell ist die in der gleichen Tabelle gespei-cherte Modellnummer von Interesse. Diese Modellnummer bestimmt, in welcher der Da-
135 Die fett markierten Komponenten werden in den folgenden Unterkapitel weiter untersetzt.

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 184
tenbankdateien der Modelldatenbank (siehe Punkt 5.1.2.7), der Experimentplandatenbank(siehe Punkt 5.1.2.9) und der Ergebnisdatenbank (siehe Punkt 5.1.2.19) sich die Daten desausgewählten Modells befinden.
5.1.2.3 Metadatenverwaltung und MetadatenbankIn der Metadatenbank sind Angaben gespeichert, die übergreifend für alle von der Simula-tions-Shell verwalteten Modelle gelten. Diese Angaben teilen sich in drei Gruppen:
• Angaben zu statistischen Verteilungen• Angaben zu Steuerungsstrategien• Angaben zu Vorhandensein, Aufruf und Parameterisierung von externen Simulatoren
Die Metadatenbank enthält Angaben zu den im Framework verfügbaren statistischen Ver-teilungen und den Steuerungsstrategien. Die Metadatenbank besitzt dazu die TabellenStrategie, Strategie_Parameter, Strategie_Parameter_Bereich, Strategie_Parameter_-Tabelle, Verteilungen und Verteilungs_Parameter (siehe Abbildung 73).
Parameter
ordinaler Parameter
Strategie
ist ein
Wertebereichs-Parameter
ParameterbereichAusprägungstabelle
hat
ist ein
Parameter-ausprägung
hat
hat
XOR
Parameter
Verteilung
hat hat
Abbildung 73 Entity-Relationship-Model der Metadatenbank
Eine Strategie kann Parameter besitzen. Jeder Parameter ist entweder ein ordinaler Para-meter oder ein Wertebereichsparameter. Im Falle eines ordinalen Parameters besitzt derParameter eine Ausprägungstabelle. In dieser Tabelle ist zu jeder Ausprägung der konkreteWert des Parameters und eine Erläuterung gespeichert. Im Falle eines Wertebereichs-parameter wird der Parameterbereich durch Unter- und Obergrenze des Bereichs sowieeine sinnvolle Schrittweite im Bereich angegeben.Für Verteilungen ist dies einfacher. Eine Verteilung kann Parameter besitzen. Der Werte-bereich dieser Parameter unterliegt keinen Einschränkungen.
Hintergrund der Speicherung dieser Angaben ist, daß alle Dialoge im Framework auf diein der Metadatenbank abgelegten Angaben zurückgreifen. Wird z.B. in der Metadatenbankeine neue Strategie samt Parametern und Parameterbedeutungen hinterlegt, so steht dieseStrategie in der Experimentplanung zur Definition einer Strategievariante (siehe Punkt5.1.2.8) zur Auswahl. In diesem Auswahldialog werden die für diese Strategie notwendi-gen Angaben über die Tabelle der Strategieparameter ermittelt und die Konsistenzprüfungder Parameter verwendet die gespeicherten Parameterausprägungen bzw. Bereichsangaben.

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 185
Die Angaben zu Vorhandensein, Aufruf und Parameterisierung von externen Simulatorenwerden nicht in der Metadatenbank gespeichert, sondern sind Bestandteil der Windows-Registrierdatenbank. Grund für dieses Vorgehen ist, daß sehr oft Zugriffe auf diese Datenerfolgen, die Daten jedoch nie geändert werden und die Registrierungsdatenbank ständigim Arbeitsspeicher liegt, wodurch der Zugriff auf diese Daten wesentlich beschleunigtwird. Zu jedem Simulator werden Name, Installationsverzeichnis, Programmdateinameund eine Zeichenkette mit den Aufrufparametern festgehalten. Die Pflege dieser Angabenerfolgt vollständig über den Menüpunkt Optionen \ Simulatoreinstellungen.
5.1.2.4 Modelldatenverwaltung
Die Modelldatenverwaltung umfaßt die Datenimport-Komponente (siehe Punkt 5.1.2.5)und die Komponente zur Pflege der Daten eines Modells (siehe Punkt 5.1.2.6).
Datenimport-komponente
Modelldaten
Konverter(m verschiedene)
Datenpflege(optional)
Datenzugriffs-komponente
Datenimport
Modelldaten-verwaltung
Abbildung 74 Die Komponente der Modelldatenverwaltung
5.1.2.5 Datenimport-Komponente
Aufgabe dieser Komponente ist es, die für die Modellerstellung notwendigen Angabenüber das Produktionssystem aus den Daten eines bereits bestehenden, externen Informati-onssystems herauszuziehen.Das Framework beschreibt den Aufbau und die Funktionsweise einer solchen Kompo-nente. Für jedes Informationssystem, welches mit dem Framework gekoppelt werden soll,ist nur ein eingeschränkter Teil - der Konverter - zu ersetzen (siehe Abbildung 75).
Datenimport-komponente
Modelldaten
Konverter(m verschiedene)
Datenzugriffs-komponente
Datenimport
Abbildung 75 Die Datenimport-Komponente
Im Prototyp der Simulations-Shell ist die Datenimport-Komponente nicht realisiert.

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 186
5.1.2.6 Datenpflege-Komponente
Die Komponente zur Pflege der Modelldaten stellt ein quasi eigenständiges Programm dar,um alle in der Modelldatenbank gespeicherten Daten zur Beschreibung des Produktions-systems einzusehen und zu verändern. Die Datenpflege-Komponente eröffnet die Möglich-keit, die Modelldaten über diese Schnittstelle manuell einzugeben. Wichtig sind dabei dieimplementierten Konsistenzprüfungen.
Modelldaten
Datenpflege(optional)
Datenzugriffs-komponente
Abbildung 76 Die Datenpflege-Komponente
Die Komponente zur Modelldatenpflege umfaßt Dialoge und Subdialoge zur Pflege von(vergleiche Datenbestände der Modelldatenbank, Punkt 5.1.2.7):
• Arbeitszeiteinstellungen,• Maschinengruppen- und Maschinendaten,• Transport- und Übergangszeitdaten,• Bearbeitungsmöglichkeit- und -gruppendaten,• Rüstzeitdaten,• Produktdaten,• Arbeitsplandaten,• Auftrags- und Losdaten sowie• Daten zur Beschreibung der aktuellen Situation im Produktionssystem.
5.1.2.7 Modelldatenbank
In der Modelldatenbank können die Daten mehrerer Modelle (bzw. Modellvarianten) vonProduktionssystemen gespeichert werden. Aus Gründen der Speichereffizienz und desperformanteren Zugriffs existiert für jedes in der Verwaltungsdatenbank aufgeführte Mo-dell eine separate Datei mit der Datenbank des jeweiligen Modells.Die Datenzugriffs-Komponente der Modelldatenbank hat die Aufgabe, eine definierteSchnittstelle zwischen der Modelldatenbank und Komponenten, die Daten aus dieser Da-tenbank benötigen, anzubieten. Somit werden alle lesenden und schreibenden Zugriffe aufden Datenbestand der Modelldatenbank gekapselt und von der konkreten Datenbank ge-trennt. Das verwendete Datenbankmanagementsystem oder das Format der Datenbankkann auf diese Weise beliebig ausgetauscht werden.
Die Modelldatenbank besteht aus den Tabellen Anfangsbelegung_Arbeitend, Anfangs-belegung_Auftrag, Anfangsbelegung_Los, Anfangsbelegung_Wartend, Arbeitsplan, Auf-trag, Bearbmoeglichkeit, Grundparameter, Los, Maschine, Maschinengruppe, Produkttyp,Ruestzeit_zwischen_Gruppen, Ruestzeit_in_Gruppe, Setupgruppen und Uebergangszeit(siehe Anhang C).

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 187
Die nachfolgende Abbildung stellt die Beziehungen der einzelnen Tabellen dar. Sie leitetsich aus dem ERM zur Darstellung der Daten und Objekte eines komplexen Produktions-systems (siehe Kapitel 2.3.2.2) ab.
Anfangsbelegungarbeitend
AnfangsbelegungAuftrag
AnfangsbelegungLos
Anfangsbelegungwartend
Arbeitsgang
Auftrag
Bearbeitungs-möglichkeit
Grundparameter
Los
MaschineMaschinengruppe
Produkttyp
Rüstzeit in Gruppe Rüstzeit zwischenGruppen
SetupgruppenÜbergangszeit
bestehtaus
kannmehrerebesitzen
hatmehrere
hat(mehrere)
verweist auf
kannsein
kannsein
XOR
verweistauf
hat bei Wechselzwischen zwei
bietet mehrere
hat bei Wechselzwischen zwei
hat
bezieht sich auf
gehörtzu
arbeitengemäß
kannhaben
hatmehrere
Abbildung 77 Semantische Darstellung der Beziehungen der Tabellen derModelldatenbank
Zu jedem Produkt existiert eine Tabelle mit allgemeinen Angaben (Tabelle Produkttyp).Jedes Produkt verfügt über einen Arbeitsplan, dessen Arbeitsgänge in der Tabelle Arbeits-gaenge gespeichert sind. In einem Arbeitsgang ist festgelegt, auf welcher Maschinen-gruppe er durchgeführt werden soll und welche Bearbeitungsanforderung an die aus-führende Maschine gestellt wird. Zu den Produkten können Aufträge eingesteuert werden,wobei ein Auftrag aus einem oder mehreren Losen besteht.Eine Maschinengruppe besteht aus einer Menge von Maschinen, welche die selben Bear-beitungen in der selben Zeit ausführen können. In der Tabelle Uebergangszeiten wird diemittlere Transportzeit zwischen zwei Maschinengruppen gespeichert. Zu jeder Maschinewird in der Tabelle Bearbeitungsmoeglichkeiten festgelegt, welche Bearbeitungsanfor-derungen die Maschine erfüllen kann und wie lange sie dazu benötigt. Wobei eine Maschi-ne mehrere Bearbeitungsmöglichkeiten bieten kann und die selbe Bearbeitungsmöglichkeitvon mehreren Maschinen - auch unterschiedlicher Maschinengruppen - angeboten werdenkann.Die Bearbeitungsmöglichkeiten können noch in Gruppen zusammengefaßt werden. Krite-rium für die Gruppierung sind die Umrüstzeiten zwischen den verschiedenen Bearbei-tungsmöglichkeiten. Die Besonderheit ist aber, daß die selben Bearbeitungsmöglichkeitenauf unterschiedlichen Maschinengruppen unterschiedlichen Gruppen angehören können.Die Rüstzeiten werden aus Gründen der Speicherkomplexität auf zwei Tabellen aufgeteilt.Zur Definition des aktuellen Zustandes des Produktionssystems können die bereits im Pro-duktionssystem befindlichen Aufträge (Tabelle Anfangsbelegung_Auftrag) und deren Zu-

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 188
sammensetzung aus Losen (Tabelle Anfangsbelegung_Los) angegeben werden. Zu jedemdieser Lose ist noch festzulegen, ob es sich in einer Warteschlange befindet und auf Bear-beitung wartet (Tabelle Anfangsbelegung_wartend) oder ob das Los momentan auf einerMaschine bearbeitet wird (Tabelle Anfangsbelegung_arbeitend)136.
TProdukttypRecListe
TProdukttypRec
TArbeitsgangRecListe
TDatenWrapper
hat
TArbeitsgangRec
TMaschinenGruppeRecListe
TMaschinenGruppeRec
TMaschineRecListeTBearbeitungs-
moeglichkeitenListeTRuestzeitenListe
TMaschineRec
TMaschineSetupListe
TBearbeitungsmoeglichkeit
TUebergangszeitenListe TAnfangsbelegungRecListe
TVersuchsDatenWrapper
TAnfangsbelegung
besteht aus
hat hat hat
hat
besteht aus
hat
besteht aus besteht aus
besteht aus
hat
besteht aus
hat
besteht aus
hat hat
Abbildung 78 Übersicht über die Datenobjekte der Datenzugriffs-Kompo-nente der Modelldatenbank
Ein wesentliches Modul ist die Datenzugriffs-Komponente der Modelldaten. In dieserwerden eine Vielzahl von - im objektorientierten Sinne angelegten - Klassen zusammen-gefaßt (siehe Abbildung 78). Im Prinzip existiert für jede Art von in der Datenbank gespei-chertem Datum ein Datenobjekt (Klasse) und eine Liste zur Verwaltung der Datenobjekte(Klasse). Es ergibt sich eine vernetzte Baumstruktur, in der alle Daten der Datenbank ge-mäß ihrer Zusammenhänge gespeichert werden können. Diese Baumstruktur wird dann ineiner zentralen Klasse - dem ModelldatenWrapper - zusammengefaßt. Dieser Modell-datenWrapper bietet dann universelle Methoden zum Zugriff auf die Modelldaten.Die je Experiment variierenden Daten (Angaben über alle an den Maschinen einzu-setzenden Reihenfolgeregeln und deren Parameter sowie die Einsteuerungsmenge und -zeiten für alle Produkte) sind dabei im VersuchsdatenWrapper zusammengefaßt. Dieser istTeil des ModelldatenWrappers (siehe Abbildung 78). Bei der Abarbeitung eines Experi-mentplanes brachen später also nur diese veränderlichen Daten ausgetauscht werden. EinLaden der gesamten Daten des Modells ist nicht notwendig.
5.1.2.8 Experimentplanungs-Komponente
Aufgabe der Experimentplanungs-Komponente ist es, dem Benutzer die Möglichkeit zubieten, für das Modell des Produktionssystems einen Plan aufzustellen, welche Experimen-
136 Vergleiche dazu 2.3.3, Problem der Vorgabe eines initialen Systemzustandes.

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 189
te simulativ durchgeführt werden sollen, um die Auswirkungen der Steuerungsanwei-sungen der Experimente simulativ zu untersuchen.137
Datenzugriffs-komponente
Daten derVersuchspläne
Experiment-planung
Modelldaten
Datenzugriffs-komponente
Abbildung 79 Die Experimentplanungs-Komponente
Bei der Definition von Experimenten durch den Anwender bedient sich die Experiment-planungs-Komponente u.a. der Daten des Modells des Produktionssystems (Maschinen-und Produktdaten). Die Daten der in der Experimentplanung definierten Experimente wer-den abschließend in der Experimentplandatenbank gespeichert.
Bei der Experimentplanung unterscheidet man zwischen dem Experimentplan, Experi-mentreihen, Experimenten und Läufen (siehe Abbildung 80).
ExperimentplanExperimentreihe
Simulationsexperiment
1 : n
Simulationslauf
1 : n
1 : n
Einsteuerungs-matrix
Strategiematrix
Simulationsmodell
Anzahl der Läufe
Strategievariante(Handlungsalternative)
Einsteuerungs-variante
Abbildung 80 Zusammenhänge der Daten in der Experimentplanung
Einem Simulationsmodell können mehrere Experimentpläne zugeordnet werden. Ein Ex-perimentplan legt die im Rahmen einer Simulationsstudie zu untersuchenden Handlungs-alternativen und die Untersuchungsbedingungen fest. Im Falle des Frameworks ergebensich die Handlungsalternativen aus unterschiedlichen, durch den Anwender (Disponent)vorzugebenden Steuerungsstrategien der Bedienstationen. Die Untersuchungsbedingungenergeben sich aus der aktuellen Situation im realen Produktionssystem (repräsentiert durchdie Daten in der Modelldatenbank) und möglichen zukünftigen Szenarien - welche durchunterschiedliche Einsteuerungsprofile angegeben werden. D.h., im Experimentplan werdenVarianten von Steuerungsstrategien (Strategiematrix) und Variationen des Einsteuerungs-profils (Einsteuerungsmatrix) angegeben. Die Experimentreihen stellen dann eine Unter-gliederung des Experimentplans nach konkreten Strategievarianten dar. Innerhalb einerExperimentreihe wird lediglich die Einsteuerung variiert. Das Simulationsexperiment istdie Untergliederung der Experimentreihe, es findet die Zuordnung einer konkretenEinsteuerung statt. Aufgrund von Stochastiken im Simulationsmodell ist eine replikative
137 Vergleiche zur Experimentplanung auch [VDI 3633, Blatt 3].

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 190
Ausführung des Simulationsmodells notwendig, um zu den Ergebnisgrößen im Simula-tionsmodell statistisch gesicherte Aussagen treffen zu können (siehe Punkt 2.3.3). Ein Si-mulationsexperiment wird deshalb mehrfach wiederholt und die Ergebnisgrößen werdenstatistisch aufbereitet.
5.1.2.9 Experimentplandatenbank
In der Experimentplandatenbank können die Daten mehrerer Experimentpläne gespeichertwerden. Aus Gründen der Speichereffizienz und des performanteren Zugriffs existiert fürjedes in der Verwaltungsdatenbank aufgeführte Modell eine separate Datei mit der Expe-rimentplandatenbank des jeweiligen Modells.Die Datenzugriffs-Komponente der Experimentplandatenbank hat die Aufgabe, eine defi-nierte Schnittstelle zwischen der Experimentplandatenbank und Komponenten, die Datenaus dieser Datenbank benötigen, anzubieten. Somit werden alle lesenden und schreibendenZugriffe auf den Datenbestand der Experimentplandatenbank gekapselt und von der kon-kreten Datenbank getrennt. Das verwendete Datenbankmanagementsystem oder das For-mat der Datenbank kann auf diese Weise beliebig ausgetauscht werden.
Die Experimentplandatenbank besteht aus den Tabellen Experimentplan, Experimentreihe,Plan_Zu_Reihe, Experiment, Einsteuerungsvariante, Einsteuerungsreihe, Gesamt_Ein-steuerung_Variation, Gesamt_Einst_Produktverteilung, Produktvektor_Einst_Variation,und Strategievarianten (siehe Abbildung 81, vergleiche Anhang C).In der Tabelle Experimentplan werden allgemeine Angaben, wie die Anzahl der Repli-kationen abgelegt. Aufgabe der Tabelle Plan_Zu_Reihe ist es, Experimentreihen den Expe-rimentplänen zuzuordnen. Diese Zwischentabelle ermöglicht es, bewährte Experiment-reihen in mehreren Experimentplänen zu nutzen. Die Experimentreihe legt die Verwen-dung einer konkreten Einsteuerungsreihe fest. Eine Einsteuerungsreihe ist entweder eineGesamteinsteuerung oder eine Produktvektoreinsteuerung. Für eine Gesamteinsteuerungwerden für jedes Produkt der prozentuale Anteil (Tabelle Gesamt_Einst_Produkt-verteilung) sowie minimale und maximale Einsteuerungsmenge (Tabelle Gesamt_-Einsteuerung_Variation) festgelegt. Für eine Produktvektoreinsteuerung ist für jedes Pro-dukt die minimale und maximale Einsteuerungsmenge (Tabelle Produktvektor_Einst_-Variation) festzulegen. Die Enumeration über die in diesen Tabellen festgelegten mini-malen und maximalen Einsteuerungsmengen anhand der festgelegten Schrittweite ergibtdann eine Menge von Einsteuerungsvarianten, die in der gleichnamigen Tabelle gespei-chert werden. Letztlich wird zu einem Simulationsexperiment festgelegt, welche Strategie-variante und welche Einsteuerungsvariante zu verwenden sind. Zu jeder der Strategie-varianten in der gleichnamigen Tabelle ist zu jeder Maschinengruppe des Produk-tionssystems festgelegt, welche Strategie mit welchen Parametern anzuwenden ist.
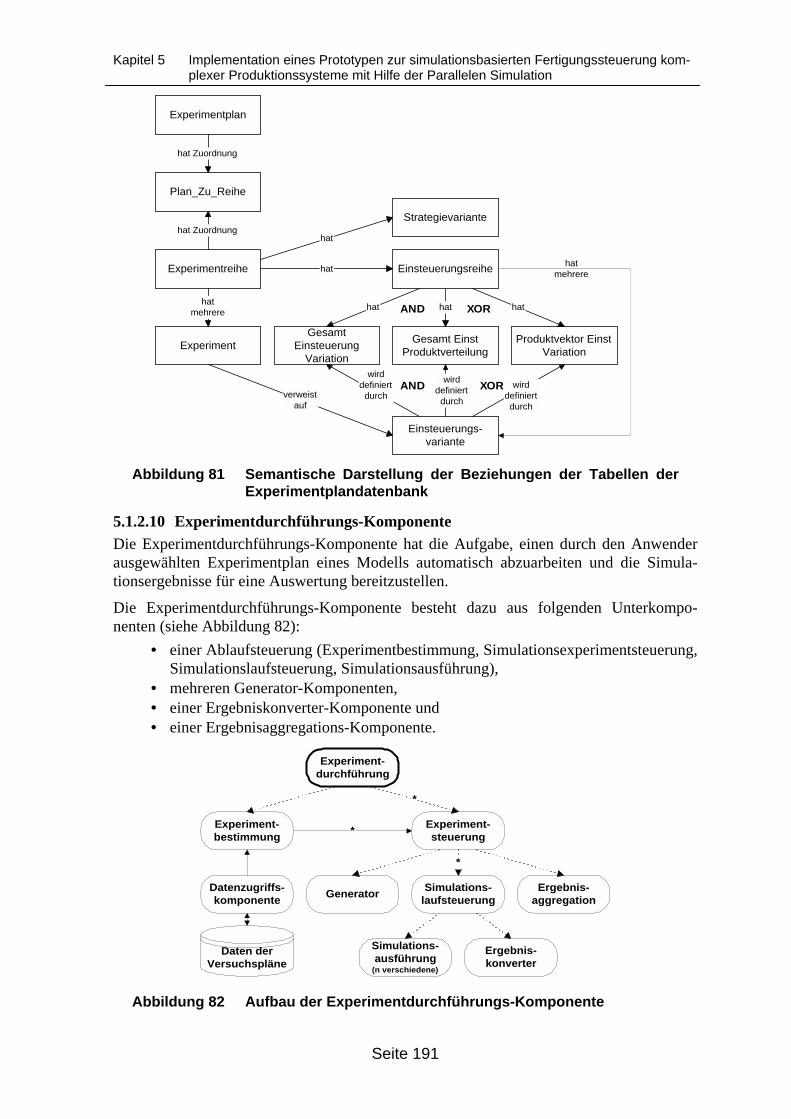
Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 191
Plan_Zu_Reihe
Experimentreihe
Gesamt EinstProduktverteilung
Experiment
Einsteuerungsreihe
Einsteuerungs-variante
Experimentplan
Strategievariante
Produktvektor EinstVariation
GesamtEinsteuerung
Variation
hatmehrere
hat Zuordnung
hat Zuordnung
verweistauf
wirddefiniertdurch
hat
hat hat hatAND XOR
wirddefiniert
durch
wirddefiniert
durch
AND XOR
hatmehrere
hat
Abbildung 81 Semantische Darstellung der Beziehungen der Tabellen derExperimentplandatenbank
5.1.2.10 Experimentdurchführungs-Komponente
Die Experimentdurchführungs-Komponente hat die Aufgabe, einen durch den Anwenderausgewählten Experimentplan eines Modells automatisch abzuarbeiten und die Simula-tionsergebnisse für eine Auswertung bereitzustellen.
Die Experimentdurchführungs-Komponente besteht dazu aus folgenden Unterkompo-nenten (siehe Abbildung 82):
• einer Ablaufsteuerung (Experimentbestimmung, Simulationsexperimentsteuerung,Simulationslaufsteuerung, Simulationsausführung),
• mehreren Generator-Komponenten,• einer Ergebniskonverter-Komponente und• einer Ergebnisaggregations-Komponente.
Experiment-durchführung
Datenzugriffs-komponente
Daten derVersuchspläne
Experiment-bestimmung
Experiment-steuerung
GeneratorSimulations-
laufsteuerung
Simulations-ausführung
(n verschiedene)
Ergebnis-konverter
Ergebnis-aggregation
*
*
*
Abbildung 82 Aufbau der Experimentdurchführungs-Komponente

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 192
Die Experimentbestimmungs-Komponente liest aus den Daten des ausgewählten Experi-mentplans, wieviel Experimente durchzuführen sind und wie diese Experimente charakte-risiert sind. Darauf hin wird für jedes der im Experimentplan festgehaltenen Experimentedie Simulationsexperimentsteuerung für das aktuell betrachtete Experiment aufgerufen.Die Simulationsexperimentsteuerung führt daraufhin die Generator-Komponente aus, wel-che unter Beachtung der Einstellungen des aktuellen Simulationsexperiments ein neuesSimulationsmodell erzeugt. Die Simulationslaufsteuerung hat dann die Aufgabe, den ge-wünschten Simulator mit dem eben erzeugten Simulationsmodell auszuführen und ans-chließend die Simulationsergebnisse durch die Ergebniskonverter-Komponente in eineDatenbank des Frameworks zurückzuführen. Die Simulationsexperimentsteuerung akti-viert die Simulationslaufsteuerung mehrfach, um durch die wiederholte Ausführung desSimulationsmodell stochastischen Einflüssen auf die Auswertung zu begegnen. Abschlie-ßend führt die Simulationsexperimentsteuerung die Ergebnisaggregations-Komponenteaus, um die Simulationsergebnisse aller Läufe eines Experiments statistisch aufzubereitenund in der Ergebnisdatenbank zu speichern.
Die Experimentdurchführungskomponente besteht aus folgenden Subkomponenten:
Modelldaten
Datenzugriffs-komponente
Generator(n verschiedene)
Simulations-modell
Ergebnis-konverter
Datenzugriffs-komponente
Daten derVersuchspläne Ergebnisdaten
Datenzugriffs-komponente
Simulations-experiment-steuerung
externerSimulator
(n verschiedene)
Simulations-ausführung
(n verschiedene)
Datendateien(optional)
(definiertesFormat)
Simulations-ergebnisse
Laufergebnisse(temporär)
Simulations-laufsteuerung
Ergebnis-aggregation
Experiment-durchführung
Datenzugriffs-komponente
Abbildung 83 Aufbau der Experimentplandurchführungs-Komponente
Die Abbildung 84 beleuchtet die Abläufe in der Experimentplandurchführungs-Kompo-nente näher. Die weitere Untergliederung der Subkomponenten (in Abbildung 84 durchfett markierte Rahmen angedeutet) erfolgt in der Abbildung 85 und der Abbildung 87.
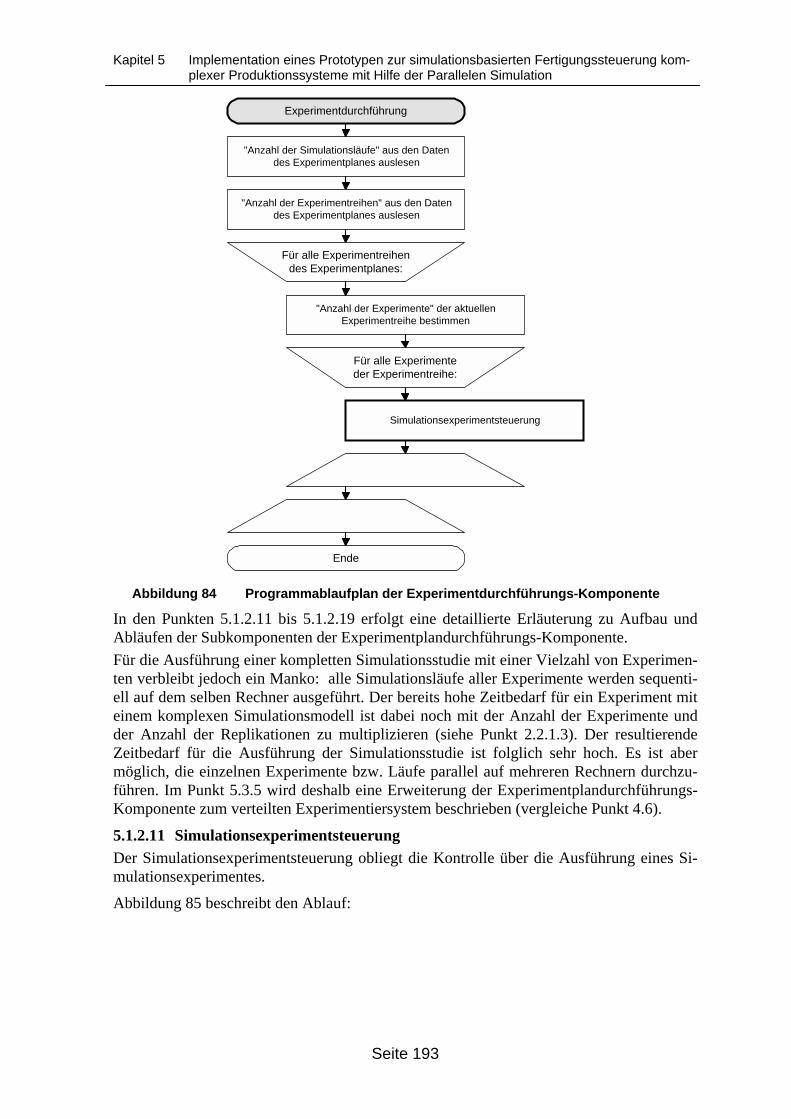
Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 193
"Anzahl der Simulationsläufe" aus den Datendes Experimentplanes auslesen
Experimentdurchführung
"Anzahl der Experimentreihen" aus den Datendes Experimentplanes auslesen
"Anzahl der Experimente" der aktuellenExperimentreihe bestimmen
Simulationsexperimentsteuerung
Ende
Für alle Experimentreihendes Experimentplanes:
Für alle Experimenteder Experimentreihe:
Abbildung 84 Programmablaufplan der Experimentdurchführungs-Komponente
In den Punkten 5.1.2.11 bis 5.1.2.19 erfolgt eine detaillierte Erläuterung zu Aufbau undAbläufen der Subkomponenten der Experimentplandurchführungs-Komponente.
Für die Ausführung einer kompletten Simulationsstudie mit einer Vielzahl von Experimen-ten verbleibt jedoch ein Manko: alle Simulationsläufe aller Experimente werden sequenti-ell auf dem selben Rechner ausgeführt. Der bereits hohe Zeitbedarf für ein Experiment miteinem komplexen Simulationsmodell ist dabei noch mit der Anzahl der Experimente undder Anzahl der Replikationen zu multiplizieren (siehe Punkt 2.2.1.3). Der resultierendeZeitbedarf für die Ausführung der Simulationsstudie ist folglich sehr hoch. Es ist abermöglich, die einzelnen Experimente bzw. Läufe parallel auf mehreren Rechnern durchzu-führen. Im Punkt 5.3.5 wird deshalb eine Erweiterung der Experimentplandurchführungs-Komponente zum verteilten Experimentiersystem beschrieben (vergleiche Punkt 4.6).
5.1.2.11 Simulationsexperimentsteuerung
Der Simulationsexperimentsteuerung obliegt die Kontrolle über die Ausführung eines Si-mulationsexperimentes.
Abbildung 85 beschreibt den Ablauf:
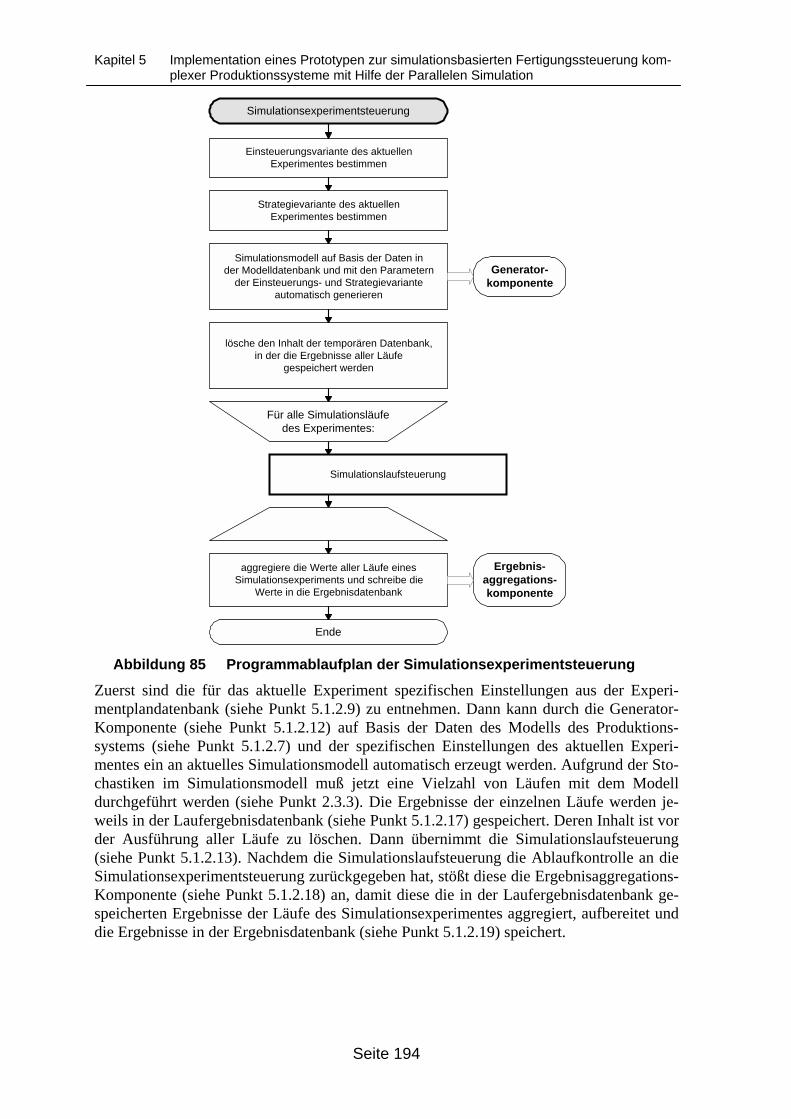
Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 194
Simulationsexperimentsteuerung
Einsteuerungsvariante des aktuellenExperimentes bestimmen
Strategievariante des aktuellenExperimentes bestimmen
Simulationsmodell auf Basis der Daten inder Modelldatenbank und mit den Parametern
der Einsteuerungs- und Strategievarianteautomatisch generieren
lösche den Inhalt der temporären Datenbank,in der die Ergebnisse aller Läufe
gespeichert werden
aggregiere die Werte aller Läufe einesSimulationsexperiments und schreibe die
Werte in die Ergebnisdatenbank
Simulationslaufsteuerung
Ende
Generator-komponente
Ergebnis-aggregations-komponente
Für alle Simulationsläufedes Experimentes:
Abbildung 85 Programmablaufplan der Simulationsexperimentsteuerung
Zuerst sind die für das aktuelle Experiment spezifischen Einstellungen aus der Experi-mentplandatenbank (siehe Punkt 5.1.2.9) zu entnehmen. Dann kann durch die Generator-Komponente (siehe Punkt 5.1.2.12) auf Basis der Daten des Modells des Produktions-systems (siehe Punkt 5.1.2.7) und der spezifischen Einstellungen des aktuellen Experi-mentes ein an aktuelles Simulationsmodell automatisch erzeugt werden. Aufgrund der Sto-chastiken im Simulationsmodell muß jetzt eine Vielzahl von Läufen mit dem Modelldurchgeführt werden (siehe Punkt 2.3.3). Die Ergebnisse der einzelnen Läufe werden je-weils in der Laufergebnisdatenbank (siehe Punkt 5.1.2.17) gespeichert. Deren Inhalt ist vorder Ausführung aller Läufe zu löschen. Dann übernimmt die Simulationslaufsteuerung(siehe Punkt 5.1.2.13). Nachdem die Simulationslaufsteuerung die Ablaufkontrolle an dieSimulationsexperimentsteuerung zurückgegeben hat, stößt diese die Ergebnisaggregations-Komponente (siehe Punkt 5.1.2.18) an, damit diese die in der Laufergebnisdatenbank ge-speicherten Ergebnisse der Läufe des Simulationsexperimentes aggregiert, aufbereitet unddie Ergebnisse in der Ergebnisdatenbank (siehe Punkt 5.1.2.19) speichert.

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 195
5.1.2.12 Generator-Komponente
Aufgabe der Generator-Komponente ist es, für das gegebene Modell eines Produktions-systems und die Einstellungen des aktuell betrachteten Experiments automatisch das kor-rekte Simulationsprogramm zu generieren138.
Das Framework enthält eine Schnittstelle für Simulationsprogramm-Generatoren. DieseSchnittstelle ist eine abstrakte Klasse, welche allen Generatoren zum Einen gemeinsameAttribute und Funktionalitäten und zum Anderen die Schnittstellen zu den anderen Kom-ponenten des Frameworks bereitstellt. Ein konkreter Generator ist dann als Subklasse die-ser abstrakten Basisklasse zu realisieren. Bei Aufruf eines konkreten Generators wird überdie in der Basisklasse definierte Schnittstelle (a) ein Objekt (der DatenWrapper, siehePunkt 5.1.2.7, Seite 188) übergeben, welches den Zugriff auf alle zum Generierungsprozeßnotwendigen Daten kapselt, sowie (b) der Pfad, in den die zu generierende(n) Datei(en)ausgegeben werden soll(en). Der Aufbau bzw. die Anzahl der zu erzeugenden Dateienkann je Simulator anders sein. Wesentlich ist nur, daß der externe Simulator über eine Si-mulationsprogrammdatei im ASCII-Format gesteuert werden kann.
DatenWrapperSimulations-
modell
Datendateien(optional)
ModelldatenDatenzugriffs-komponente
Datenzugriffs-komponente
Daten derVersuchspläne
Generator-komponente
AbstrakterGenerator
SLX-GeneratorParSimONY-
Generator
Abbildung 86 Die Generator-Komponente
Für das Framework wurden Generatoren für zwei sehr unterschiedliche Simulationstoolsgeschaffen. Es steht ein Generator für die Hochgeschwindigkeitssimulationssprache SLXund ein Generator für den parallelisiert anwendbaren Simulator ParSimONY zur Verfü-gung. Der SLX-Generator erzeugt hierbei lediglich die Datendateien für das in der prozeß-orientierten Simulationssprache SLX geschriebene vollständig datengetriebene Simula-tionsmodell. Der ParSimONY-Generator dagegen muß ein in Java geschriebenes, ereignis-orientiertes Simulationsmodell erzeugen Die Daten des Produktionssystem werden dabeials Java-Anweisungen im Simulationsmodell codiert (siehe Punkt 5.3.2). Bei der Erzeu-gung des Simulationsmodells wird zudem das in Punkt 4.4 beschriebene Partitionierungs-verfahren angewendet, welches das Simulationsmodell in mehrere Logische Prozesse teilt.
Zusätzlich könnte man einen Generator für z.B. Arena/Siman entwickeln, welcher die be-nötigten Simulationsdateien erzeugt.
5.1.2.13 Simulationslaufsteuerung
Die Simulationslaufsteuerung ist für alle in das Framework integrierbaren externen Simu-latoren gleich. Zuerst ist der externe Simulator mit dem generierten Simulationsmodell
138 Unter Generieren soll die Fähigkeit einer Software verstanden werden, auf Basis von Vorgaben des An-
wenders automatisch einen kompletten Programmquelltext zu erzeugen. Der Anwender muß dabei keineKenntnisse der Zielsprache besitzen.

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 196
auszuführen - dies ist Aufgabe der Simulationsausführungs-Komponente (Punkt 5.1.2.14).Danach müssen die Ergebnisse des Simulationslaufes aufbereitet und in die Laufergebnis-datenbank gesichert werden. Dies ist Aufgabe der Ergebniskonvertierungs-Komponente(siehe Punkt 5.1.2.15).
Simulationslaufsteuerung
Simulator mit dem erzeugtenSimulationsmodell starten
Ergebnisse aus den Ausgabedateien desSimulators auslesen und unter der Nummer
dieser Simulationslaufes in der Laufergebnis-Datenbank speichern
Ende
Simulations-ausführung
Ergebnis-konvertierungs-
komponente
Abbildung 87 Programmablaufplan der Simulationslaufsteuerung
5.1.2.14 Simulationsausführungs-Komponente
Im Gegensatz zur Generator-Komponente kann die Simulationsausführungs-Komponentedes Frameworks an einen anderen externen Simulator über Parameter angepaßt werden,eine Änderung der Implementation der Simulationsausführungs-Komponente ist nichtnotwendig.In Abhängigkeit der in den Optionen der Simulations-Shell (Optionen \ Simulatoren) ein-gestellten Parameter startet die Simulationsausführungs-Komponente die Programmdateides externen Simulators, übergibt dieser den Namen des generierten Simulationsmodellsund wartet das Ende des Programmlaufs des externen Simulators ab.
Simulations-modell externer
Simulator(n verschiedene)Datendateien
(optional)(definiertes
Format)
Simulations-ergebnisse
Simulations-ausführungs-komponente
Abbildung 88 Die Simulationsausführungs-Komponente
Nahezu jeder externe Simulator kann in das Framework eingebunden werden. Voraus-setzung ist zum Einen, daß der externe Simulator über eine Simulationsprogrammdatei imASCII-Format gesteuert werden kann, und zum Anderen, daß der externe Simulator er-laubt, die Simulationsergebnisse in ASCII-Dateien zu schreiben. Ob der Simulator dieseErgebnisdateien nach Konfiguration durch den Anwender selbst anlegt, oder ob im Simu-lationsmodell Anweisungen zur Ausgabe der Ergebnisgrößen in diese Dateien codiert wer-den müssen, ist dabei belanglos. Das Format der Ergebnisdateien ist festgelegt (siehePunkt 5.1.2.16), enthält aber eine einfache Struktur. Diese einfache Struktur kann in her-kömmlichen Simulationstools i.d.R. durch wenige Anweisungen zur Ausgabe der Ergeb-nisgrößen erreicht werden.

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 197
Im Prototyp des Frameworks können zwei Simulatoren verwendet werden. Der prozeß-orientierte Simulator SLX kann bei vorhandenem Modell im Batch-Modus139 ausgeführtwerden. Der ereignisorientierte Simulator ParSimONY benötigt für seinen Aufruf mehrAngaben. Zum Ersten sind alle durch den Generator erzeugten Dateien durch einen Aufrufdes Java-Compilers zu übersetzen. Anschließend ist die Java-Applikation ParSimONY-BatchRunner140 mit dem Namen des Simulationsmodells aufzurufen, um die eigentlicheSimulation durchzuführen. D.h., die genannten Aufrufe sind in einer Batch-Datei zusam-menzufassen und diese Batch-Datei ist durch die Simulationsausführungs-Komponente zustarten.
5.1.2.15 Ergebnisaufbereitungs-Komponente
Die Ergebnisaufbereitungs-Komponente muß die in ASCII-Dateien vorliegenden Ergeb-nisse der Simulationsausführung in die Datenbestände des Frameworks übernehmen (sieheAbbildung 89).Das Format der Ergebnisdateien ist festgelegt (siehe Punkt 5.1.2.16), enthält aber eine ein-fache Struktur, die im Simulationsmodell i.d.R. durch wenige Anweisungen zur Ausgabeder Ergebnisgrößen in ASCII-Dateien erreicht werden kann.Somit mußte im Gegensatz zur Generator-Komponente nur eine Ergebnisaufbereitungs-Komponente im Framework implementiert werden, statt für jeden externen Simulator An-passungen an der Ergebnisaufbereitungs-Komponente vorzunehmen.
Ergebnis-konverter
Laufergebnisse(temporär)
Datenzugriffs-komponente
(definiertesFormat)
Simulations-ergebnisse
Abbildung 89 Die Ergebnisaufbereitungs-Komponente
Die von den einzelnen Simulationstools erzeugten Ergebnisdateien weisen z.T. noch Un-terschiede auf. Zum Einen ist nicht jedes Simulationstool in der Lage, die Datenspalten inden Ergebnisdateien exakt auszurichten, d.h. für eine beständig gleiche Breite der Daten-spalten zu sorgen. Diese Ausrichtung ist aber Voraussetzung, um die Daten später aus denDateien einfach extrahieren zu können. Zum Zweiten unterscheiden sich die Zahlen-formate der Simulatoren in der Druckdarstellung. I.d.R. wird das Komma in den Simula-torausgaben durch einen Dezimalpunkt symbolisiert, in der Simulations-Shell werden je-doch die länderspezifischen Einstellungen von Windows benutzt, welche an dieser Stelleein Kommazeichen erwarten.
Abbildung 90 stellt die Abfolge der einzelnen Konvertierungsschritte dar. Zuerst findeteine Zahlenformatkonvertierung statt. Hierzu sind in jeder der Simulationsergebnisdateiendie Dezimalpunkte durch Kommazeichen zu ersetzen. In einem zweiten Schritt erfolgt fürjede der Simulationsergebnisdateien die Formataufbereitung. Zu diesem Zweck wird dasexterne Programm AWK141 aufgerufen. In der übergebenen AWK-Anweisung142 ist festge- 139 D.h., die Ausführung eines Simulationsmodell kann allein durch einen korrekt parameterisierten Pro-
grammaufruf erfolgen, Benutzereingaben sind dazu nicht erforderlich.140 Diese Java-Klasse stellt das Äquivalent zum Batch-Modus von SLX dar.141 Das Programm AWK ist eine ursprünglich für UNIX entwickelte Standardsoftware zur Manipulation von
ASCII-Dateien. AWK ermöglicht u.a. Druckaufbereitung und Zeichenausrichtung.142 Diese Anweisung wird in einer AWK-Programmdatei (*.AWK) gespeichert.

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 198
halten, welches Zielformat die Simulationsergebnisdatei nach der Behandlung mit AWKbesitzen soll. In einem letzten Schritt werden die aufbereiteten Simulationsergebnisdateiendurch in der Simulations-Shell implementierte Funktionen gelesen und in der Laufergeb-nisdatenbank gespeichert.
Simulations-ergebnisdateien
*.ergZahlenformat-konvertierung Simulations-
ergebnisdateien*.tmp
Simulations-ergebnisdateien
*.asc
Format-aufbereitung Laufergebnisse
(temporär)
Datenzugriffs-komponente
Daten einlesen
Ergebnisaufbereitungs-Komponente
Abbildung 90 Detaillierter Aufbau der Ergebnisaufbereitungs-Komponente
5.1.2.16 Simulationsergebnisdateien
Durch das mittels des externen Simulators ausgeführte Simulationsmodell sind fünf Simu-lationsergebnisdateien zu erzeugen:
• eine Datei mit den Ergebnissen der Maschinengruppen (LAUF_MASCHINEN-GRUPPEN.ERG),
• eine Datei mit den Ergebnissen der Maschinen (LAUF_MASCHINEN.ERG),• eine Datei mit den Ergebnissen der Lose (LAUF_LOS.ERG),• eine Datei mit den Ergebnissen der Aufträge (LAUF_AUFTRAG.ERG) und• eine Datei mit den Ergebnissen der Produkttypen (LAUF_PRODUKTTYP.ERG).
In der Ergebnisdatei der Maschinengruppen befinden sich Angaben über die mittlere undmaximale Warteschlangenlänge, die Anzahl der Lose und Stück, die an dieser Maschinen-gruppe auf Bearbeitung warteten und noch warten, sowie die Summe der Zeiten, die Loseauf Bearbeitung warten mußten. Weitere Ergebnisgrößen wie quantitative und zeitlicheAuslastung, Anzahl der bearbeiteten Lose und Stück usw. können aus den Ergebnissen derMaschinen der Maschinengruppe berechnet werden. Dies ist dann Aufgabe der Ergebnis-aggregations-Komponente (siehe Punkt 5.1.2.18).
Die Ergebnisdatei der Maschinen enthält Angaben über die zeitliche Summe der ausge-führten Bearbeitungen, die Summe der Ausfallzeiten, die Summe der Leerzeiten, die mitt-lere quantitative Auslastung, Anzahl und zeitliche Summe der Rüstvorgänge innerhalb derRüstgruppen und zwischen den Rüstgruppen, sowie die Anzahl der gefertigten Batchs,Lose und Stück. Diese Größen bilden dann die Berechnungsgrundlage für ihre Äquivalentefür die Maschinengruppen (Aggregation über alle Maschinen einer Maschinengruppe).
Die Ergebnisdatei der Lose enthält Angaben über den betroffenen Auftrag, das gewünschteProdukt, die Losgröße, die Ist-Durchlaufzeit des Loses, die Summe der Bearbeitungszei-ten, die Summe der ausgelösten Rüstzeiten, die Summe der Transportzeiten, die Summeder Wartezeit auf Bearbeitung, die Summe der Wartezeit auf Transport und die Liefer-terminabweichung des Loses. Während der Simulation sind nur die Lose in die Ergebnis-datei zu schreiben, die ausgesteuert werden.

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 199
Die Ergebnisdatei der Aufträge enthält Angaben über das Produkt des Auftrages, die Ge-samtanzahl der Lose und der Stück des Auftrages, die Anzahl der Lose und Stück desAuftrages, die eingesteuert wurden, und die Anzahl der Lose und Stück des Auftrages, diebereits ausgesteuert wurden. Die weiteren Ergebnisse wie Durchlaufzeiten, Terminein-haltung etc. werden später durch die Ergebnisaggregations-Komponente (siehe Punkt5.1.2.18) aus den Ergebnissen der Lose des Auftrages berechnet.
Die Ergebnisdatei der Produkttypen enthält Angaben über die Anzahl der eingesteuertenund fertiggestellten Aufträge, Lose und Stück. Weitere Angaben wie Durchlaufzeiten,Termineinhaltung usw. können später durch die Ergebnisaggregations-Komponente ausden Ergebnissen der Lose bzw. Aufträge berechnet werden.
5.1.2.17 Laufergebnisdatenbank
Die Laufergebnisdatenbank speichert die Simulationsergebnisse für mehrere Läufe einesSimulationsexperiments. Zu Beginn des Simulationsexperiments wird der Inhalt der Lauf-ergebnisdatenbank durch die Simulationsexperimentsteuerung (siehe Punkt 5.1.2.11) ge-löscht. Durch die Ergebnisaufbereitungs-Komponente (siehe Punkt 5.1.2.15) werden diekonkreten Simulationsergebnisse jeweils eines Laufes in die Laufergebnisdatenbank ge-schrieben. Die Strukturen der Tabellen der Laufergebnisdatenbank ähneln dem Aufbau derSimulationsergebnisdateien (siehe Punkt 5.1.2.16). Der wesentliche Unterschied ist, daßjede Tabelle der Laufergebnisdatenbank ein Feld „Laufnummer“ besitzt, welches Be-standteil des Primärschlüssels ist, um die Ergebnisse des selben Loses bzw. der selben Ma-schine usw. in der Datenbank ablegen zu können. Die Ergebnisaggregations-Komponentekann dann auf einfache Art und Weise die für die Auswertung interessanten Daten heraus-ziehen. Die Tabellenstrukturen der Laufergebnisdatenbank sind im Anhang C dargestellt.Die Aufteilung der Ergebnisse der Simulationsläufe (Laufergebnisdatenbank) und der ag-gregierten Ergebnisse (Ergebnisdatenbank) erfolgte aus dem Grund, daß der Datenumfangfür die Laufergebnisse bereits sehr hoch ist143. Würden für alle Experimente diese Daten ineiner gemeinsamen Datenbank gespeichert144, so wäre eine für den Anwender zumutbareAusführungsdauer der auszuführenden Prozesse nicht mehr zu garantieren. Andererseitswerden die Laufergebnisdaten eines Experiments nach der Aggregation nicht mehr benö-tigt - sie haben lediglich temporären Charakter.
5.1.2.18 Ergebnisaggregations-Komponente
Aufgabe der Ergebnisaggregations-Komponente ist es, die Simulationsergebnisse allerLäufe eines Simulationsexperimentes, die in der Laufergebnisdatenbank gespeichert wur-den, zu aggregieren und statistisch aufzubereiten. Für jede der Ergebnisgrößen werdenAnzahl des Auftretens, Summe, Mittelwert, Standardabweichung, Minimum und Maxi-mum ermittelt und in die Ergebnisdatenbank geschrieben.
143 Nimmt man z.B. an, es werden 500 Simulationsläufe ausgeführt und es sind im Modell 50 Maschinen und
1.000 Aufträge vorhanden, so ergibt sich pro Simulationsexperiment ein Datenumfang von 25.000 Daten-sätzen für Maschinen und 500.000 Datensätzen für Aufträge.
144 Sollen 100 Experimente durchgeführt werden, so ergäbe sich ein Datenumfang von 2,5 Mio. Datensätzenfür Maschinen und 50 Mio. Datensätze für Aufträge. Bei einem Platzbedarf von ca. 50 Byte pro Datensatzwären dies 2,625 GB Platzbedarf für die Datenbank.

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 200
Ergebnis-aggregation
Ergebnisdaten
Datenzugriffs-komponente
Laufergebnisse(temporär)
Datenzugriffs-komponente
Abbildung 91 Die Ergebnisaggregations-Komponente
Während dieser Aggregation sind zum Einen die Ergebnisse eines Betrachtungsgegen-standes (Los, Auftrag, Maschine usw.) über alle Simulationsläufe zusammenzufassen undzum Anderen sind für einige Betrachtungsgegenstände Größen aus anderen Betrachtungs-gegenständen zu berechnen (z.B. Aggregation der Auslastung der Maschinen für die Ma-schinengruppe).
Lauf_Maschinen-gruppen
Lauf_Maschinen
Lauf_LosLauf_AuftragLauf_Produkttyp
Erg_MaschinenErg_Maschinen-
gruppenErg_Produktions-
system
Erg_LosErg_AuftragErg_ProdukttypErg_Alle_Produkte
Abbildung 92 Datenflüsse zwischen der Laufergebnisdatenbank und derErgebnisdatenbank während der Ergebnisaggregation
5.1.2.19 Ergebnisdatenbank
Die Ergebnisdatenbank enthält für jede der Ergebnisgrößen Anzahl des Auftretens, Sum-me, Mittelwert, Standardabweichung, Minimum und Maximum. Die Tabellenstruktur äh-nelt der Laufergebnisdatenbank, jedoch werden die Berechnungsergebnisse der Ergebnis-aggregation auch in der Datenbank gespeichert. Dadurch wächst der Umfang der Tabellen-strukturen. Zusätzlich enthält die Ergebnisdatenbank noch zwei weitere Tabellen, die (a)Zusammenfassungen von Größen aller Maschinengruppen bzw. (b) Zusammenfassungenvon Größen aller Lose / Aufträge / Produkte beinhalten. Die Tabellenstrukturen der Ergeb-nisdatenbank sind im Anhang C dargestellt.Auch hier existiert wieder eine Datenzugriffs-Komponente, um eine definierte Schnittstellezwischen der Ergebnisdatenbank und Komponenten, die Daten aus dieser Datenbank be-nötigen, anzubieten. Somit werden alle lesenden und schreibenden Zugriffe auf den Daten-bestand der Ergebnisdatenbank gekapselt und von der konkreten Datenbank getrennt. Dasverwendete Datenbankmanagementsystem oder das Format der Datenbank kann auf dieseWeise beliebig ausgetauscht werden. Die Datenzugriffs-Komponente ermöglicht es wei-terhin, externen Programmen lesenden Zugriff auf die Ergebnisdaten der Simulationsstudiezu bieten, um eine Kopplung des Frameworks mit anderen Auswertungsprogrammen vor-zunehmen (siehe dazu Punkt 5.1.2.20).

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 201
5.1.2.20 Auswertungs-Komponente
Mit Hilfe der Auswertungs-Komponente kann der Benutzer nach der Experimentplan-durchführung (siehe Punkt 5.1.2.10) die Simulationsergebnisse der Experimente einsehen.Die Auswertungs-Komponente stellt dazu tabellarische und grafische Darstellungen derErgebnisgrößen zur Verfügung. Ebenso ist eine Anzeige von Gantt-Diagrammen möglich.Des Weiteren können externe Auswerteprogramme wie z.B. Microsoft Excel oder MatLabmit dem Framework gekoppelt werden. Dazu stellt die Datenzugriffs-Komponente derErgebnisdatenbank mittels einer DLL-Schnittstelle Funktionen zum Lesen der Ergebnis-daten zur Verfügung.
Ergebnisdaten
Datenzugriffs-komponente
Auswertungs-komponente externe
Auswertungs-programme
(optional)
Abbildung 93 Die Auswertungs-Komponente
Die Auswertungs-Komponente ist im Prototyp der Simulations-Shell nur rudimentär reali-siert.
5.1.2.21 Ergebnisübernahme-Komponente
Die Ergebnisübernahme-Komponente erlaubt es dem Anwender, die Einstellungen einesExperimentes für die Umsetzung im Realsystem vorzugeben. Dazu sind (a) die Einstellun-gen des Experimentes wie die Parameterisierung der verwendeten Steuerungsstrategie so-wie (b) Ergebnisse als Richtwerte aus den Datenbanken des Frameworks zu extrahierenund an ein externes Informationssystem weiterzugeben.Für jedes externe Informationssystem ist dazu eine andere Konvertierungs-Komponenteerforderlich.
Ergebnis-übernahme
Konverter(m verschiedene)
Datenexport-komponente
Ergebnisdaten
Datenzugriffs-komponente
Datenzugriffs-komponente
Daten derVersuchspläne
Abbildung 94 Die Ergebnisübernahme-Komponente
Die Ergebnisübernahme-Komponente ist im Prototyp der Simulations-Shell nicht realisiert.
5.1.3 Das Framework als Ausgangsbasis der simulationsbasierten Fertigungs-steuerung komplexer Produktionssysteme
Für einen abgegrenzten Anwendungsbereich ist auf Basis des Prototyps des entwickeltenFrameworks die Anwendung der Simulation als Hilfsmittel zur Fertigungssteuerung leich-ter möglich. Für die Erstellung eines das betrachtete Produktionssystem adäquat abbilden-

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 202
den Simulationsmodells müssen nicht mehr zeitraubend die Daten des Produktionssystemszusammengetragen und ein Simulationsprogramm durch Experten erstellt oder angepaßtwerden. Die Simulations-Shell „SimFab“ und damit der Simulationsmodellgenerator (siehePunkt 5.1.2.12, „Die Generator-Komponente“, siehe auch Punkt 5.3.2) verfügen bereitsüber die relevanten Daten und erstellen das Simulationsmodell automatisch und in kürze-ster Zeit. Die Simulations-Shell unterstützt den Anwender außerdem bei der Definition derExperimente (Punkt 5.1.2.8), die mit dem erstellten Simulationsmodell ausgeführt werdensollen. Die Abarbeitung der Experimente erfolgt dann automatisch durch die Simulations-Shell, ohne daß ein Eingriff des Anwenders notwendig wird (siehe Punkt 5.1.2.10). DerAnwender wird ergo von einer Vielzahl manueller Tätigkeiten bei der Experimentdurch-führung und -auswertung entlastet. Über die Auswertungs-Komponente (siehe Punkt5.1.2.20) kann der Anwender dann die Ergebnisse der einzelnen Experimente einsehen unddie unter den gegebenen Umständen beste Handlungsalternative auswählen.Der Anwender kann sich also auf seine eigentliche Aufgabe - die Fertigungssteuerung -konzentrieren und muß sich nicht mehr mit den Problemen bei der Anwendung seinesHilfsmittels - der Simulation - befassen. Mit dem Framework steht dem Anwender ein in-tegriertes Werkzeug zur Verfügung, welches ihn aktiv bei seinen Aufgaben unterstützt.Durch den Einsatz des Frameworks können bisher bestehende Probleme bei der Anwen-dung der Simulation zur Fertigungssteuerung weitgehend beseitigt werden. Der Anwenderwird umfassend beim Prozeß der Modellerstellung, des Experimentierens und der Ergeb-nisauswertung unterstützt.Das Framework besitzt zudem eine modulare, flexible, offene und erweiterbare Struktur.Das bedeutet, es besteht die Möglichkeit, Komponenten auszutauschen oder zusätzlicheKomponenten einzubringen, um das Framework an andere externe Systeme oder andereexterne Simulatoren anzupassen. Diese Komponenten sind zudem wiederverwendbar undkönnen in andere Systeme integriert werden. Somit kann man unterschiedliche Simula-toren und Animatoren einsetzen. Möglichkeiten zur Kopplung mit Optimierungstools wer-den erstmals geschaffen.
Das Framework erlaubt den Einsatz einer Sequentiellen oder einer Parallelen Simulationzur Abarbeitung des Simulationsmodells. Im Rahmen der vorliegenden Arbeit ist das Fra-mework lediglich als Unterstützungssystem zur Erstellung umfangreicher, partitionierterSimulationsmodelle der Parallelen Simulation zu sehen. Im Punkt 5.2 wird beschrieben,wie ein Paralleler Simulator für komplexe Produktionssysteme geschaffen wird. Im Punkt5.3 werden dann das Framework und der Parallele Simulator zu einer integrierten Lösungzusammengeführt.
5.2 Entwicklung einer Simulationssoftware zur Parallelen Simula-tion von komplexen Produktionssystemen
5.2.1 Auswahl eines Implementationsansatzes
Für die Implementation einer Parallelen oder Verteilten Simulation bietet es sich an, einenspeziell dafür geschaffenen Implementationsansatz zu benutzen. Von den im Punkt 3.2.2.8vorgestellten Lösungen sind insbesondere ParSec und ParSimONY geeignet. Beide er-lauben es, verschiedene Synchronisationsverfahren ohne Änderung des Simulationsmo-dells einzusetzen. Diese Simulatoren sind dabei sogar von der Ausführungsplattform (aufeinem Rechner, einer Mehrprozessormaschine oder in einem Computernetzwerk) unabhän-gig. Damit werden zwei der wesentlichen Anforderungen an ein Tool zur Parallelen undVerteilten Simulation erfüllt (siehe Punkt 3.3). Prinzipiell sind beide Tools anwendungs-gebietunabhängig, der bisherige Einsatz erfolgte aber für die Simulation von Computer-netzwerken (ParSec) bzw. Bedienungsnetzwerken (ParSimONY). Beide besitzen die Mög-

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 203
lichkeit, die Modellierung durch die Schaffung von Modellbausteinen zu erleichtern. BeideTools benutzen eine Modellierungssprache (basierend auf C++ bzw. Java) und ermögli-chen es somit auch komplexe, bisher in den Tools nicht berücksichtigte Probleme im Si-mulationsmodell zu formulieren. Damit ist durch diese Flexibilität eine weitere Anforde-rung an ein Tool zur Parallelen und Verteilten Simulation erfüllt (siehe Punkt 3.3.2).
ParSec konzentriert sich auf die Modellierung von Computernetzwerken und besitzt dazueine graphische Oberfläche. Die Modellierungssprache ist deswegen Einschränkungenunterworfen. Die Programmquellen zu ParSec sind nicht frei erhältlich. Falls die Notwen-digkeit bestehen sollte, direkt am Tool Anpassungen an die Simulation komplexer Produk-tionssysteme vorzunehmen, so ist dies mit ParSec nicht möglich.
ParSimONY ist auf die Simulation von Bedienungsnetzwerken ausgerichtet, welche einenTeilausschnitt aus der Simulation von Produktionssystemen darstellt (siehe Punkt 3.2.3).Der Anwender muß in ParSimONY das Simulationsmodell mittels Java-Anweisungen de-finieren und kann dabei bereitgestellte Elemente eines Bedienungssystems benutzen. DieModellierung mit ParSimONY ist daher einfach. ParSimONY bietet zwar die MöglichkeitBedienungsnetzwerke zu simulieren, für eine Anwendung zur Simulation von Produktions-systemen ist es aber nicht direkt geeignet. Dadurch das die Programmquellen zur Verfü-gung stehen, ist es hier jedoch möglich, Anpassungen direkt an ParSimONY vorzunehmen.
Aus diesen Gründen fiel die Entscheidung, den Parallelen Simulator ParSimONY zu nut-zen und an die Simulation komplexer Produktionssysteme anzupassen, weil ParSimONYeine Modellierung auf hohem Niveau ermöglicht und von allen betrachteten Tools am fle-xibelsten ist.
5.2.2 Das Tool ParSimONY als Ausgangsbasis
5.2.2.1 Grundlagen von ParSimONY
ParSimONY steht für Parallel Simulation Once Named YADDES [Preiss, Wan 1999], wo-bei YADDES für Yet Another Distributed Discrete Event Simulator steht [Preiss 1989].Bei ParSimONY handelt es sich um ein im Quelltext vorliegendes Java-Tool, das an derUniversity of Waterloo in Kanada entwickelt wurde. Acht Personen waren vier Jahre ineinem Forschungsprojekt [ParSimONY] beschäftigt, um ParSimONY zu entwickeln.Entwicklungsziel von ParSimONY war es, ein Tool für den Performance-Test von ver-schiedenen Synchronisationsverfahren zu schaffen. Daher stehen bei der Simulation mitParSimONY auch mehrere Synchronisationsverfahren zur Auswahl (siehe Punkt 5.2.2.2,Seite 205) [ParSimONY].Besonders positiv an ParSimONY hervorzuheben ist die strikte Trennung zwischen Syn-chronisationsverfahren (dem sogenannten Simulator) und Simulationsmodell (sieheAbbildung 95). Das Simulationsmodell ist sowohl von der Art der Abarbeitung, als auchvom verwendeten Synchronisationsverfahren unabhängig. Das Simulationsmodell ist somitfür (a) eine Abarbeitung auf einem Rechner, in einem Rechnernetzwerk oder auf einemParallelrechner und (b) für eine konservative oder optimistische Synchronisation iden-tisch145 [Preiss, Wan 1999].Der Anwender muß in ParSimONY nur noch das Simulationsmodell als Java-Programmdefinieren und kann dabei bereitgestellte Elemente eines Bedienungssystems benutzen. MitParSimONY besteht somit die Möglichkeit, auf einem hohen Niveau - ähnlich einer Simu-lationshochsprache - zu arbeiten [Preiss, Wan 1999].
145 Andernfalls (z.B. bei Einsatz der HLA) wären verschiedene Versionen des selben Modells notwendig, die
jeweils noch separat implementiert werden müssen - ein ungleich höherer Aufwand. Hinzu kommt, daß beiÄnderungen am Modell sonst alle Versionen anzupassen wären.

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 204
Es existieren aber auch Probleme bei der Verwendung von ParSimONY:
• Da es sich bei dem plattformunabhängigen Java um eine interpretierte Programmier-sprache handelt, ist eine schlechtere Performance als bei compilierten Programm-dateien zu erwarten.
• Es existiert keinerlei Dokumentation über Aufbau und Anwendung von ParSimONY.• Die Autoren von ParSimONY geben keine Unterstützung der Software, da das zuge-
hörige Forschungsprojekt bereits beendet ist und die Projektmitarbeiter nicht mehrgreifbar sind.
• Die in ParSimONY vorhandenen Elemente gehen für die Anwendung zur Simulationvon Produktionssystemen nicht weit genug. Der Umfang von ParSimONY ist hierfürzu erweitern. Näheres zu dieser Erweiterung ist in Punkt 5.2.2.4 aufgeführt.
5.2.2.2 Wesentliche Bestandteile der Architektur von ParSimONY
Vorbemerkungen:
Nachfolgend soll kurz die Architektur des Parallelen Simulators ParSimONY erläutertwerden. Leider ist zu ParSimONY keine Dokumentation verfügbar, lediglich einige weni-ge Artikel und technische Berichte [Preiss 1998a], [Preiss 1998b], [Preiss, Wan 1999],[Bishop, Hembruch, Trudeau 1999], [ParSimONY]146 beschreiben Grundzüge von ParSim-ONY. Deswegen soll in diesem Gliederungspunkt tiefer auf die Architektur und die Ab-läufe des Tools ParSimONY eingegangen werden, damit beim Leser ein prinzipielles Ver-ständnis der Wirkmechanismen geweckt wird, bevor in den Punkten 5.2.2.4 und 5.2.3 aufdie Erweiterung von ParSimONY eingegangen wird.
Die Komponentenstruktur von ParSimONY:
Das Tool ParSimONY besteht aus drei großen Komponenten (siehe Abbildung 95).
• Der Simulator ist für die Abarbeitung eines Modells verantwortlich. Er muß die Abar-beitung der im Modell auftretenden Ereignisse übernehmen und dabei die verschiede-nen Teile des Modells (die Partitionen) synchronisieren, d.h. er übernimmt die Auf-gaben der Zeitsteuerung und des Synchronisationsverfahrens (siehe Punkt 2.2.1.2 undPunkt 3.1.3.1). ParSimONY definiert eine Klasse AbstractSimulator, welche die ge-meinsamen Attribute und das gemeinsame Verhalten für jede Art von Simulator(globale Zeitsteuerung einer lokalen, Sequentiellen Simulation bis zur Verteilten Simu-lation innerhalb eines Rechnernetzes) beinhaltet. Eine Erläuterung der in ParSimONYvorhandenen Simulatoren ist auf Seite 205 aufgeführt.
• Das Modell dagegen spezifiziert den Aufbau und die Abläufe des zu simulierenden Sy-stems. Ein Modell kann dazu aus mehreren Typen von Modellelementen bestehen(siehe Seite 207), welche häufig genutzte Funktionalitäten eines Bedienungssystemswiederverwendbar bereitstellen. In den Modellelementen werden Ereignisse und Nach-richten benutzt, um das Verhalten des modellierten Systems abzubilden und um Infor-mationen zwischen den parallel abarbeitbaren Teilen des Simulationsmodells auszutau-schen (siehe Punkt 5.2.2.3). ParSimONY definiert eine abstrakte Klasse Abstract-Simulation, welche die gemeinsamen Attribute und das gemeinsame Verhalten für jedeArt von Simulationsmodell beinhaltet.
• Die dritte Komponente ist die Programmoberfläche. Mittels dieser kann der Benutzerzur Laufzeit entscheiden, welches Modell er mit welchem Simulator auf welchen Rech-nern ausführen möchte. In der grafischen Oberfläche sind später auch die Ergebnisse
146 Dies ist eine vollständige Aufzählung aller zu ParSimONY vorhandenen Literatur.

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 205
der Simulation in textueller Form zu sehen. Die Klasse App übernimmt dabei die Steue-rungsfunktionalität, während die Klasse GUI die visuell sichtbaren Komponenten derProgrammoberfläche beinhaltet.
Parsimony-Simulation(Parsimony.App)
Modell(Parsimony.AbstractSimulation)
Simulator(Parsimony.AbstractSimulator)
grafische Oberfläche(Parsimony.GUI)Synchronisations-
verfahrenElemente von Bedienungssystemen
(Parsimony.AbstractModel)
Kommunikationskanäle
Ereignis-abarbeitung
Abbildung 95 - ParSimONY-Grundarchitektur
ParSimONY-Simulatoren - Zeitsteuerung und Synchronisationsverfahren:
Durch die Auswahl eines Simulators wird festgelegt, welche Art von Simulation ausge-führt werden soll. So existieren Synchronisationsverfahren für eine Sequentielle Simula-tion und für konservativ und optimistisch synchronisierte Simulationen in einem Rechner-netzwerk oder auf einem Parallelrechner (Parallele Simulation).
Folgende Synchronisationsverfahren stehen in ParSimONY zur Verfügung:
• SequentialSimulator• MultiListSimulator• ThreadedMLSimulator• ThreadedCMBSimulator• ThreadedTWSimulator• DistributedMLSimulator• DistributedCMBSimulator• DistributedTWSimulator• RealTimeSimulator• DistributedRTSimulator
Bei dem SequentialSimulator handelt es sich um eine lokale Sequentielle Simulation.D.h., alle im Simulationsmodell auftretenden Ereignisse werden in einer globalen Ereig-nisliste plaziert und durch eine globale Zeitsteuerung verarbeitet. Dies entspricht der übli-chen Form der Simulation.Der MultiListSimulator ist die Erweiterung eines SequentialSimulator. Hier existierenmehrere Ereignislisten, die jedoch weiterhin über eine globale Zeitsteuerung verwaltetwerden. Der Vorteil ist hier, daß die Ereignislisten kürzer sind und sich somit Operationenüber den Ereignislisten schneller durchführen lassen (Parallelisierung von Hilfsfunktionender Simulation).Ein nächster Schritt ist der ThreadedMLSimulator. Hier existieren mehrere Threads, dieüber separate Ereignislisten verfügen. Dieser Simulator kann auf einem PC und auf einemParallelrechner eingesetzt werden.Ähnlich verhält es sich mit dem DistributedMLSimulator. Hier kann jede Partition aufeinem anderen Rechner eines Rechnernetzwerks ausgeführt werden. Jede Partition besitzteine eigene Ereignisliste, es existiert jedoch nur eine, global zugeordnete Zeitsteuerung.

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 206
Während dem ThreadedMLSimulator und dem DistributedMLSimulator noch die Synchro-nisationsmechanismen fehlen, besitzen ThreadedCMBSimulator, ThreadedTWSimulator,DistributedCMBSimulator und DistributedTWSimulator ein spezielles Synchronisations-verfahren.Bei einem ThreadedCMBSimulator handelt es sich um ein auf einem lokalen Rechneroder einer Mehrprozessormaschine ausführbare Parallele Simulation. Jede Partition besitzteine eigene lokale Ereignisliste und jede Partition wird mittels des konservativen Synchro-nisationsverfahrens nach Chandy, Misra und Bryant (CMB = Chandy, Misra and Bryant)synchronisiert [Chandy, Misra 1978], [Bryant 1979], [Misra 1986].Bei einem ThreadedTWSimulator handelt es sich um ein auf einem lokalen Rechner odereiner Mehrprozessormaschine ausführbare Parallele Simulation. Jede Partition besitzt eineeigene lokale Ereignisliste und jede Partition wird mittels des optimistischen Synchronisa-tionsverfahrens TimeWarp (TW = TimeWarp) synchronisiert [Jefferson, Sowizral 1985],[Jefferson u.a. 1987].Im Gegensatz zu ThreadedCMBSimulator und ThreadedTWSimulator stellen Distributed-CMBSimulator und DistributedTWSimulator Simulatoren dar, welche eine verteilte Ab-arbeitung in einem Rechnernetzwerk ermöglichen. Auch hier besitzt jede Partition eineeigene lokale Ereignisliste und jede Partition wird mittels der Verfahren CMB bzw. Ti-meWarp synchronisiert.Der Simulator RealTimeSimulator benutzt die aktuelle Systemzeit (Echtzeit) für die Zeit-steuerung. Ereignisse werden hier durch die Zeitsteuerung in einer globalen Ereignislisteverwaltet und gemäß dem Eintreten der gewünschten Echtzeit ausgelöst. Der RealTime-Simulator ermöglicht nur die Ausführung auf einem einzelnen PC.DistributedRTSimulator ist die Erweiterung von RealTimeSimulator zur Ausführung in-nerhalb eines Rechnernetzes. Hier existieren mehrere lokale Ereignislisten und die Syn-chronisation der Partitionen erfolgt konservativ, in Abhängigkeit von der aktuellen Sy-stemzeit.
Simulationsmodelle in ParSimONY:
Ein Simulationsmodell in ParSimONY ist unter Nutzung gegebener Elemente eines Bedie-nungssystems (nachfolgend Modellelemente genannt) in Java zu programmieren (AnhangB enthält ein kommentiertes Beispiel eines ParSimONY-Simulationsmodells). Hierbeisetzt sich ein Modell aus Modellelementen und zusätzlich den sogenannten Channels - denVerbindungskanälen zwischen diesen Modellelementen - zusammen.Ein Simulationsmodell muß von der Basisklasse AbstractSimulation abgeleitet werden undmehrere Modellelemente (abgeleitet von der Klasse AbstractModel), mehrere LogischeProzesse (abgeleitet von der Klasse AbstractProcess) und Kommunikationskanäle (Instan-zen der Klasse Channel) enthalten.
AbstractSimulation
AbstractModel AbstractProcess
n n
Channel
k
Abbildung 96 - Grundbestandteile eines ParSimONY-Modells
Die in der Abbildung aufgezeigte Kardinalität der Bestandteile ist per Definition in ParSi-mONY festgelegt. Zu jedem AbstractModel muß es genau einen AbstractProcess geben.

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 207
Während AbstractModel die modellnahen Funktionalitäten definiert, übernimmt Abstract-Process die Kopplung des Modellelements zu den Simulatoren (zu Zeitsteuerung und Syn-chronisationsverfahren). Durch diese Unterteilung ist es möglich, Modellelemente zu ent-wickeln, die vollkommen unabhängig davon sind, welcher Simulator - und damit welchesSynchronisationsverfahren - und welche Rechnerarchitektur verwendet werden. Dies be-gründet den wesentlichen Vorteil von ParSimONY.
Ein Modellelement bildet ein statisches Element eines Bedienungssystems - wie Quelle,Warteschlange, Bedieneinrichtung oder Senke ab.147 Jedes Modellelement muß von derKlasse AbstractModel abgeleitet werden. Die Anzahl der in einem konkreten Modell-element verwendeten Eingangs- und Ausgangskanäle (Channels) ist ebenfalls festgelegt,kann aber für jeden Typ von Modellelement unterschiedlich sein.
Die Steuerungsfunktionalität eines Logischen Prozesses ist in der Klasse AbstractProcessenthalten. AbstractProcess stellt die Verbindung eines Modellelements mit dem Simulatorund damit mit dem Synchronisationsverfahren her. Einem AbstractProcess wird genau einAbstractModell als prinzipiell parallel abarbeitbarer Teil des Gesamtsimulationsmodellszugewiesen. Gemäß des verwendeten Simulators werden die im Simulationsmodell ent-haltenen Logischen Prozesse auf dem gleichen Rechner bzw. Prozessor ausgeführt oderauf unterschiedlichen Rechnern oder Prozessoren. Das konkret verwendete Synchronisa-tionsverfahren ist ebenfalls vom ausgewählten Simulator abhängig. Im Gegensatz zu denModellelementen muß der Anwender keine eigene Klasse für die verschiedenen logischenProzesse definieren, sondern er nutzt die Methode createProcess() des Simulationsmodells(von AbstractSimulation geerbt).
Ein Channel verbindet genau zwei Modellelemente miteinander (unidirektional). Es istAufgabe des Channels die Implementation der Verbindung von der Verbindungsschnitt-stelle für das Modellelement zu trennen. Ein Modellelement benutzt nur die über dieSchnittstelle des Channels bereitgestellten Methoden. Dabei ist es nicht von Belang, ob derChannel lediglich eine Datenstruktur zum Austausch von Daten zwischen zwei Threadsdes gleichen Rechners oder ein per RMI148 verteiltes Objekt auf zwei physisch getrenntenRechnern darstellt.
Die Modellelemente des Simulationsmodells:
Der Grundumfang der Modellelemente von ParSimONY umfaßt einfache Elemente einesBedienungssystems wie Quelle (Source), Senke (Sink), Bedienprozeß (Server), Verweil-prozeß (Delay), Warteschlange (Queue) und zusätzlich Verteilerelemente (Merge, Split,Join, Distributor) zur Abbildung des Verhaltens an Knotenstellen des Bedienungsnetzes.Mit diesen Modellelementen lassen sich Bedienungsnetzwerke aufbauen. Sie sind auf-grund ihrer zu geringen Detaillierung aber noch nicht zur Simulation von Produktions-systemen geeignet.
147 Die dynamischen Elemente des Bedienungssystems sind implizit mit den verwendeten statischen Elemen-
ten verbunden: eine Quelle erzeugt Aufträge / Lose, eine Maschine bearbeitet Aufträge / Lose und eineSenke steuert Aufträge / Lose aus.
148 Bei RMI - Remote Method Invocation - handelt es sich um eine Java-Technik zur Verteilung von Anwen-dungen. Siehe dazu [RMI].

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 208
Source
Queue
Server
MergeOR
JoinAND
Distributor
random
Split
clone( )Delay
t: receice( ) t+x: send( )
Abbildung 97 - Übersicht über die Modellelemente in ParSimONY149
Die nachfolgend beschriebenen Modellelemente besitzen zum Teil Parameter, welche dieAngabe einer Verteilung (z.B. Ankunftszeiten, Bedienzeiten usw.) erfordern. Die Modell-elemente besitzen weiterhin Ergebnisgrößen, welche eine Statistik über das Modellelementpassierende Stück bzw. die durchschnittliche Dauer von Vorgängen im Modellelementführen. Die in ParSimONY vorhandenen Verteilungen und Ergebnisgrößenstatistiken sinddeshalb ausführlich im Anhang B beschrieben.
Das Modellelement Source stellt eine Quelle für Forderungen an das Bedienungssystemdar. Diese Quelle erwartet als einzigen Parameter ein Objekt, welches die Verteilung derAnkunftszeiten der Forderungen dieser Quelle darstellt. Alle Quellen erzeugen Forderun-gen des selben Typs, die sich nicht parameterisieren lassen. Dies ist üblich bei der Simula-tion von Bedienungsnetzen, für die Simulation von Produktionssystemen aber nicht aus-reichend (vergleiche Punkt 5.2.2.4 und Punkt 5.2.3.2). Eine Source besitzt nur einen aus-gehenden Kanal. Als Ergebnisgrößen wird eine Statistik über die Anzahl der generiertenForderungen und die Zwischenankunftszeit geführt.Das Modellelement Sink stellt die Senke des Bedienungssystems dar. Es erwartet keineParameter und besitzt nur einen eingehenden Kanal. Als Ergebnisgrößen wird eine Stati-stik über die Anzahl der „versenkten“ Forderungen und die Zwischenankunftszeit geführt.Das Modellelement Delay bildet einen Verweilprozeß ab. Als Parameter wird ein Objekterwartet, welches die Verteilung der Verweilzeit der Forderungen angibt. Ein Delay besitztjeweils einen eingehenden und ausgehenden Kanal. Als Ergebnisgrößen wird eine Statistiküber die Anzahl der Forderungen, die das Delay passiert haben, und die Verweilzeit ge-führt.Das Modellelement Server stellt einen Bedienprozeß dar. Als Parameter wird ein Objekterwartet, welches die Verteilung der Bedienzeit der Forderungen angibt. Ein Server besitzteinen eingehenden und zwei ausgehende Kanäle. Über den Eingangskanal werden Forde-rungen empfangen und über den ersten Ausgangskanal werden diese weitergegeben. Derzweite Ausgangskanal dient dazu, die nächste Forderung zur Bedienung anzufordern. Dazu
149 Die in der Abbildung aufgeführte Blocksymbolik ist nicht Bestandteil von ParSimONY. Diese Blocksym-
bole werden vom Autor an dieser Stelle eingeführt, um eine übersichtlichere Beschreibung von Modellenund Modellteilen erreichen zu können.

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 209
ist dieser Ausgang mit dem zweiten Eingang eines Queue-Elements zu verbinden. Als Er-gebnisgrößen wird eine Statistik über die Anzahl der Forderungen, die den Server passierthaben, und die Bedienzeit geführt.Das Modellelement Queue stellt einen Warteprozeß dar. Die Queue benötigt keine Para-meter. Eine Queue besitzt zwei eingehende und einen ausgehenden Kanal. Über den erstenEingangskanal werden Forderungen empfangen und über den Ausgangskanal werden dieseweitergegeben. Der zweite Eingangskanal dient dazu, auf Anforderung eines Server-Elements die nächste Forderung zur Bedienung freizugeben. Dazu ist dieser Eingang mitdem zweiten Ausgang eines Server-Elements zu verbinden. Als Ergebnisgrößen wird eineStatistik über die Anzahl der Forderungen, welche die Queue passiert haben, und dieWartezeit geführt. Das Queue-Element arbeitet alle vorliegenden Forderungen stets nachdem FIFO-Prinzip ab.Das Modellelement Merge gehört zu den Knotenelementen. Da die einfachen Elementejeweils nur einen Eingang besitzen und u.U. mehrere eingehende Verbindungen benötigen,ist es erforderlich, ein Merge-Element zwischenzufügen. Ein Merge-Element besitzt varia-bel viele Eingangskanäle aber nur einen Ausgangskanal. Das Merge-Element benötigt alsParameter die Anzahl der eingehenden Kanäle. Als Ergebnisgrößen wird eine Statistiküber die Anzahl der Forderungen, welche das Merge passiert haben, und die Zwischen-ankunftszeit geführt.Das Modellelement Join gehört zu den Knotenelementen. Es ähnelt dem Merge-Element.Hier jedoch müssen an allen Eingängen Forderungen anliegen, damit eine Forderung wei-tergeleitet wird (logisches Und). Ein Join-Element besitzt variabel viele Eingangskanäleaber nur einen Ausgangskanal. Das Join-Element benötigt als Parameter die Anzahl dereingehenden Kanäle. Als Ergebnisgrößen wird eine Statistik über die Anzahl der Forde-rungen, welche das Join erreicht und passiert haben, und die Zwischenankunftszeit geführt.Das Modellelement Split gehört zu den Knotenelementen. Da die einfachen Elemente je-weils nur einen Ausgang besitzen und u.U. mehrere ausgehende Verbindungen benötigen,ist es erforderlich ein Split- oder ein Distributor-Element zwischenzufügen. Ein Split-Element besitzt einen Eingangskanal aber variabel viele Ausgangskanäle. Das Split-Ele-ment benötigt als Parameter die Anzahl der ausgehenden Kanäle. Das Split-Element gibtjede der ankommenden Forderungen an jeden der Ausgänge weiter. Als Ergebnisgrößenwird eine Statistik über die Anzahl der Forderungen, welche das Split passiert haben, unddie Zwischenankunftszeit geführt.Das Modellelement Distributor arbeitet ähnlich wie das Split-Element. Es benötigt als Pa-rameter die Anzahl der ausgehenden Kanäle und ein Objekt, welches eine Verteilung an-gibt, welche die Wahrscheinlichkeit angibt, mit der die angekommene Forderung einen derAusgänge wählt150. Als Ergebnisgrößen wird eine Statistik über die Anzahl der Forde-rungen, welche den Distributor passiert haben, und die Zwischenankunftszeit geführt. DieAnnahme einer Übergangswahrscheinlichkeit ist üblich für Bedienungsnetzwerke, reichtzur Simulation von Produktionssystemen jedoch nicht aus (vergleiche Punkt 5.2.2.4 undPunkt 5.2.3.2).
Die beschriebenen Modellelemente sind zu einem Modell zu kombinieren und dabei unter-einander mittels der Channels zu einem Bedienungsnetz zu verbinden:
150 D.h., diese Verteilung muß eine ganze Zahl erzeugen, welche die Nummer des ausgehenden Kanals angibt.

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 210
Sink
Source
Source
QueueServer
QueueServer
MergeOR
Abbildung 98 Beispiel eines Bedienungsnetzwerks mit ParSimONY-Grund-elementen
Channels - Verbindungskanäle:
Channels verbinden die ParSimONY-Modellelemente miteinander. Zu einem Modellele-ment ist per Definition festgelegt, wieviel Eingangs- und Ausgangskanäle es besitzt. ImSimulationsmodell (von AbstractSimulation abgeleitete Klasse) müssen dann ebensovielChannel-Objekte erzeugt und mit den betreffenden Modellelementen verbunden werden.Die Channels stellen somit gerichtete, aber statische Verbindungen dar.
Modellelement A ChannelModellelement B
MessageHandler
ChannelTail ChannelHead
receive( )send( )
RMI
Abbildung 99 - Arbeitsweise der Channels in ParSimONY
Ein Channel besteht aus zwei Teilen: einem ChannelHead und einem ChannelTail151. DasChannelTail stellt den Eingang in den Verbindungskanal dar und das ChannelHead denAusgang. Das ChannelTail stellt eine Methode send() zur Verfügung, mit der Nachrichtenüber den Kanal gesendet werden können. Das ChannelHead besitzt dagegen die receive()-Methode zum Empfang der Nachrichten. receive() wird aufgerufen, sobald eine amChannelTail per send() abgesendete Nachricht am ChannelHead eintrifft (siehe Abbildung100).Jede gesendete Nachricht ist immer ein Objekt, welches von der Basisklasse Abstract-Message abgeleitet werden muß (siehe Punkt 5.2.2.3, Seite 212). Falls sich ein Channelzwischen zwei räumlich getrennten Rechnern erstreckt, so wird das Nachrichten-Objektper RMI152 zum Empfänger-Rechner übertragen. Im Falle der Verbindung zwischen zweiLogischen Prozessen auf einem Rechner führt RMI keine Aktionen aus, sondern das be-treffende Nachrichtenobjekt wird ggf. in einen anderen Thread verlagert.
151 Die ist eine Analogie zu anderen Methoden der verteilten Programmabarbeitung (wie z.B. bei CORBA
oder RPC). Oft existiert eine Unterteilung in einen sogenannten Skeleton und einen Stub. Ein Stub stellteinen lokalen Vertreter der Funktion dar, die an der entfernten Stelle realisiert ist. Der Skeleton stellt aufzentraler Seite eine Schnittstelle dar, in der alle entfernt aufrufbaren Funktionen zusammengefaßt sind. DasChannelTail würde somit dem Stub entsprechen, während das ChannelHead den Skeleton darstellt.
152 Bei RMI - Remote Method Invocation - handelt es sich um eine Java-Technik zur Verteilung von Anwen-dungen. Siehe dazu [RMI].

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 211
Modell-element
A
Channel-Tail
Message-Handler
Channel-Head
Channel(RMI)
send()
Serialisierung
Transport derNachricht
Deserialisierung
receive()
Initialisierungcreate()
run()
Aktion beiEintreffen
...
Modell-element
B
Abbildung 100 UML-Interaktionsdiagramm zur Arbeitsweise eines Channelsin ParSimONY
5.2.2.3 Funktionsprinzipien von ParSimONY
ParSimONY folgt dem ereignisorientierten Weltbild der Simulation. D.h., es müssen Erei-gnisse und die Aktivitäten bei Eintreten der Ereignisse definiert werden.
Ereignisse (engl. events) müssen dazu von der Klasse AbstractEvent abgeleitet werdenund alle im Interface Event aufgeführten Methoden implementieren.Ein Event besitzt zwei wesentliche Methoden: den Konstruktor und die Methode run(). DerKonstruktor weist als einzigen Parameter den späteren Aktivierungszeitpunkt des Ereignis-ses auf. Die Methode run() ist dagegen parameterlos. Sie wird von der lokalen Zeit-steuerung aufgerufen, wenn die lokale Zeit den Aktivierungszeitpunkt des Ereignisses er-reicht hat. Sämtliche bei Eintreten des Ereignisses notwendigen Funktionalitäten müsseninnerhalb der Methode run() ausgeführt werden. Unter diesen Aktivitäten können auchsolche sein, die neue (auch andere) Ereignisse erzeugen und einplanen und Aktivitäten wiedas Versenden von Nachrichten.Das Einplanen eines erzeugten Ereignisses in die lokale Zeitsteuerung geschieht mittelsder Methode schedule(), welche in jeder von AbstractModel abgeleiteten Klasse verfügbarist (in jedem Modellelement). schedule() verlangt als Parameter das Ereignis, welches lo-kal einzuplanen ist.
Nachfolgendes kurzes Beispiel soll die Wirkungsweise von Events und des Eventhandlingsaufzeigen:
Eine Bedienstation soll bei Eintreten eines Defektes (= Ereignis) den Zustand auf„defekt“ wechseln und nach Ablauf der Reparaturzeit (= auszulösendes Ereignis,Folgeereignis) den Zustand wieder auf „bereit“ wechseln.
Dies bedingt zwei Ereignisse: BedienstationDefektEreignis und BedienstationRepariert-Ereignis. Beide lösen sich wechselseitig aus (siehe Abbildung 101).

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 212
Zustand="defekt"
schedule( Takt + MTBF )
initialize()
create()
DefektEreignis
run()
RepariertEreignis
create()schedule( Takt + MTTR )
run()
Zustand="bereit"
create()schedule( Takt + MTBF )
Modellelement"Bedienstation"
lokaleZeitsteuerung
TSIM
0
MTBF
MTBF
MTBF+
MTTR
Abbildung 101 UML-Interaktionsdiagramm für ein Beispiel der Ereignis-mechanismen
Anfänglich wird bei der Initialisierung des Modellelements Bedienstation ein erstes Ereig-nis BedienstationDefektEreignis erzeugt und in der lokalen Zeitsteuerung mit schedule()eingeplant. Nachdem die Ausfallzeit erreicht ist (TSIM=MTBF) ruft die lokale Zeitsteue-rung die Methode run() des Ereignisses auf. In dieser Methode wird der Zustand derBedienstation geändert und es wird ein Ereignis BedienstationRepariertEreignis erzeugtund mittels schedule() an die lokale Zeitsteuerung übergeben. Nach der Ausführung vonrun() hört das Ereignis BedienstationDefektEreignis auf zu existieren153. Wenn die Repa-ratur ausgeführt wurde (TSIM=MTBF+MTTR) ruft die lokale Zeitsteuerung die Methoderun() des Ereignisses BedienstationRepariertEreignis auf. Hier wird der Zustand derBedienstation wieder geändert und es wird ein Ereignis BedienstationDefektEreignis er-zeugt und in der lokalen Zeitsteuerung eingeplant.
Auf Basis der vorgestellten Ereignismechanismen ist es möglich, innerhalb einer Partitionzeitgesteuert Aktivitäten auszulösen und zu verarbeiten. Es fehlt jedoch noch die Möglich-keit, Aktivitäten in anderen Partitionen auszulösen. Dazu dienen in ParSimONY die Nach-richten.Nachrichten (engl. messages) müssen von der Klasse AbstractMessage abgeleitet werdenund alle im Interface Message aufgeführten Methoden implementieren. In jeder neu zudeklarierenden Nachricht ist darauf zu achten, daß alle Attribute elementare Datentypenverwenden und nicht auf Objekte verweisen.154 Als einzige Methode muß eine Messageeinen Konstruktor definieren, der alle Attributfelder füllt. Eine Message wird beim Trans-
153 Es wird durch die Garbage Collection von Java als nicht mehr benutzt erkannt und deshalb freigegeben.154 Bei der Verwendung optimistischer Synchronisationsverfahren kommt es ansonsten zu Referenzierungs-
fehlern wegen mehrfachen Verweisen auf das selbe Objekt. Siehe auch Punkt 5.2.3.2, „Versenden vonAuftragsnachrichten“.

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 213
fer zwischen räumlich getrennten Partitionen serialisiert155. Das Senden einer Nachrichtgeschieht mittels der Methode send(), welche in jeder von AbstractModel abgeleitetenKlasse verfügbar ist (in jedem Modellelement). send() übergibt die als Parameter ange-gebene Nachricht an den angegebenen Kanal (Channel), dieser transferiert die Nachrichtzu einem anderen Logischen Prozeß.Um auf Nachrichten reagieren zu können, muß ein Modellelement einen Messagehandlerimplementieren. Aufgabe dieses Messagehandlers ist es, eingehende Nachrichten entge-genzunehmen und ggf. prozeßintern Ereignisse auszulösen (siehe Abbildung 102). EinMessagehandler ähnelt einer Ereignisklasse. Er wird von der Klasse MessageHandler ab-geleitet, besitzt einen parameterlosen Konstruktor und muß als einzige Methode run() de-finieren. Die Methode run() des Messagehandlers wird aufgerufen, wenn der lokale Prozeßeine Nachricht empfängt. Innerhalb von run() können dann neue prozeßinterne Ereignisseausgelöst werden (siehe Abbildung 101).
create()
Modellelement"Bedienstation"
lokaleZeitsteuerung
TSIM
0
Channel-Head 1 Message
Handler 1
Channel-Head 2 Message
Handler 2
interneEreignisse
Channel-Tail
initialize()
create()
setMessageHandler()
setMessageHandler()
receive()
schedule( )
run()create()
schedule( )
run()
send( )
Abbildung 102 UML-Interaktionsdiagramm eines Beispiels für Nachrichtenund Ereignismechanismen in ParSimONY
Da ein Modellelement mehrere Eingangskanäle unterschiedlicher Semantik besitzen kann,besteht in ParSimONY die Möglichkeit, innerhalb eines Modellelements mehrere verschie-dene Messagehandler zu besitzen, die dann mit einem konkreten Eingangskanal verbundenwerden. Dazu ist die Methode setMessageHandler() des Modellelements aufzurufen, die
155 Damit eine Information als Nachricht übertragen werden kann, muß die Information in ihre Grundbe-
standteile (Datenprimitive) zerlegt werden. Diese Grundbestandteile werden dann seriell - der Reihe nach -übertragen.

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 214
Nummer des Eingangskanal anzugeben und eine Instanz des gewünschten Message-handlers anzugeben.
5.2.2.4 Notwendige Anpassungen und Erweiterungen des Tools ParSimONY zuParSimONY-ProdSys
In der bisherigen Form ist ParSimONY auf die Simulation von Bedienungsnetzen ausge-richtet. D.h., von jeglichen Attributen der sich durch das Produktionssystem bewegendenAufträge - als dynamische Elemente des Bedienungssystems - wird abstrahiert. Außerdemreicht das Verhalten der vorhandenen Modellelemente zur Modellierung von Produktions-systemen noch nicht aus.
Folgende Erweiterungen von ParSimONY sind daher notwendig (vergleiche Punkt 2.4.2):
1. Modelle von Bedienungssystemen bilden naturgemäß nur einen Teilausschnitt der Da-ten von Modellen von Produktionssystemen ab. ParSimONY ist somit um diese zusätz-lichen Daten (siehe Punkt 2.3.2.2, Punkt 4.3.1) zu erweitern.
2. Bisher wurde in ParSimONY von attributierten dynamischen Elementen des Bedien-ungssystems - den Aufträgen - abstrahiert. Jetzt sind konkrete Auftragsobjekte zwischenden Logischen Prozessen zu transferieren.
3. Die in ParSimONY vorhandenen Modellelemente sind so zu gestalten, daß sie einfacherbenutzbar und passend für die Simulation von Produktionssystemen sind.
4. In realen Produktionssystemen auftretende komplexe Prozeßbedingungen (siehe Punkt2.3.2.3, Punkt 4.3.1) müssen in den zu entwickelnden Modellelementen Beachtung fin-den.
5. Zur simulationsbasierten Fertigungssteuerung von Produktionssystemen sind eine Reihevon Ergebnisgrößen im Simulationsmodell zu erfassen und statistisch aufzubereiten.Dies ist umfassend zu unterstützen (vergleiche Punkt 2.3.3, 5.1.2.20).
6. Im Hinblick auf die Anwendung in der Fertigungssteuerung ist die Möglichkeit derVerwendung verschiedenartigster Reihenfolgeplanungsansätze zu schaffen.
7. Die bereits in ParSimONY vorhandenen Synchronisationsverfahren sind ggf. an dieveränderten Gegebenheiten anzupassen.
8. Das dann neu erstellte Simulationstool ist in das Framework zur simulationsbasiertenFertigungssteuerung zu integrieren (siehe Punkt 5.3).
Die Umsetzung dieser Anforderungen führt zu einer stufenweisen Erweiterung des ur-sprünglichen Tools ParSimONY zur einem Parallelen Simulator für Produktionssysteme -ParSimONY-ProdSys:
Erweiterung ProdSys
ParSimONY
RMI als objektorientierter Verteilungsansatz
Java-Sprachumfang mit TCP/IP-Sockets und Threads Abbildung des Datenmodells von Produktionssystemen
Transfer von Auftrags- und Losobjekten alsdynamischen Elementen des Produktionssystems
Erweiterung des Modellelementesatzes
Beachtung komplexer Prozeßbedingungen
Unterstützung der Erfassung und statistischenAufbereitung von Ergebnisgrößen
Schaffung der Einsatzmöglichkeiten diverserReihenfolgeplanungsansätze
Anpassung der Synchronisationsverfahren an dieSimulation von Produktionssystemen
Abbildung 103 - Stufenweise Erweiterung von ParSimONY

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 215
5.2.3 Dokumentation der Erweiterungen von ParSimONY zum Parallelen Simu-lator für komplexe Produktionssysteme (ParSimONY-ProdSys)
Nachfolgend werden die einzelnen Erweiterungen des Tools ParSimONY besprochen, wo-bei die Anordnung der Gliederungspunkte dem stufenweisen Aufbau der Erweiterungenentspricht. Alle Erweiterungen wurden im Paket (engl. package) „ProdSys“ (productionsystems / Produktionssysteme) zusammengefaßt.
5.2.3.1 Einbringung zusätzlicher Daten für die Simulation von Produktionssystemen
Durch die Ausrichtung von ParSimONY auf die Simulation von Bedienungsnetzwerkenwurde von konkreten Produkten, Arbeitsplänen, Aufträgen und Einsteuerungen abstrahiert.Jetzt sind Möglichkeiten zu schaffen, die es erlauben, die Attribute von Produkten, Ar-beitsplänen, Aufträgen und die Einsteuerung von Aufträgen (siehe Punkt 2.3.2.2, AnhangC) im Simulationsmodell zu hinterlegen.Aus diesem Grund wurde für jede Art von Daten eine separate Java-Klasse erzeugt, mitderen Hilfe diese Daten strukturiert abgelegt werden können und die Methoden zumHandling dieser Daten bereitstellt. So entstanden Klassen um die Daten für Arbeitsgänge(Arbeitsgang.java), Arbeitspläne (Arbeitsplan.java), Lose (Los.java), Bearbeitungsmög-lichkeiten (Setup.java) und Bearbeitungsangebote (SetupListe.java) zu verwalten.Beeinflußt durch die Abbildung der komplexen Prozeßbedingungen in den Modell-elementen (siehe Punkt 5.2.3.4) und die Schaffung einfacher benutzbarer Modellelemente(siehe Punkt 5.2.3.3) ergaben sich nochmals Änderungen an der Art und Anzahl der benö-tigten Klassen zur Organisation der Daten. So sind weitere Klassen notwendig, um Anga-ben zu den Bedienstationen - wie z.B. die Arbeitsweise der Bedienstation (Prozess-typ.java), Daten zur Feststellung des aktuellen Loszustands (LosZusatzDaten.java), Anga-ben zur Position der Lose in den Warteschlangen (QueueItem.java), die Warteschlangeselbst (Warteschlange.java) und Angaben zu Art und Zustand der Bedienstation (Stations-Daten.java, StationsDatenContainer.java, MaschinenDaten.java) - zu verwalten.
Setup
wird verwendet in
Arbeitsgang
bilden
Arbeitsplan
SetupListewerden
zusammen-gefaßt in
ArbeitsplanListewerden
zusammen-gefaßt in
Abbildung 104 Darstellung der semantischen Beziehungen zwischen denJava-Klassen, Teil 1156
Angaben zu den Bearbeitungsmöglichkeiten (engl. setups) werden in der Klasse Setup auf-bewahrt. Die Klasse Arbeitsgang bezieht sich dann auf eine Bedienstation und ein Setup.Ein Arbeitsplan ist eine geordnete Liste von Arbeitsgang-Objekten.
156 Zur Interpretation: Die Kästchen symbolisieren die implementierten Java-Klassen. Die Pfeilspitzen geben
jeweils die Leserichtung an; die Beschriftung des Pfeils weist auf die Art von Beziehung hin. GestrichelteKästchen deuten auf abstrakte Klassen hin.

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 216
SetupListe
ArbeitsplanListe
Bedienstation
hat mehrerebesitzt die
besitzt die
hat einen Teil von
hat einen Teil von
Simulationsmodell
Abbildung 105 Darstellung der semantischen Beziehungen zwischen denJava-Klassen, Teil 2
Das Simulationsmodell besitzt mit der SetupListe und der ArbeitsplanListe die Gesamtheitaller Informationen zu Arbeitsplänen und Bearbeitungsmöglichkeiten. Das Simulations-modell hat weiterhin mehrere Bedienstationen. Jeder dieser Bedienstationen wird der Teilder SetupListe und ArbeitsplanListe zugeordnet, der für diese Bedienstation zutrifft.
Bedienstation
hat
Warteschlange
hat
ArbeitsplanListe
StationsDaten-Container
hat
QueueItem
besteht aus
StationsDatenMaschinenDaten
hat (mehrere) hat
SetupListeProzeßtyp
hat hat
Los
ist ein
LosZusatzDatenhat
Abbildung 106 Darstellung der semantischen Beziehungen zwischen denJava-Klassen, Teil 3
Eine Bedienstation verfügt u.a. über ein Attribut vom Typ StationsDatenContainer. DieserStationsDatenContainer faßt die Warteschlange, die MaschinenDaten und die Stations-Daten zusammen. Die Warteschlange umfaßt alle Lose, welche an dieser Bedienstation aufBearbeitung warten. Das QueueItem dient zur Ordnung der Los-Objekte in einer Warte-schlange. Die Klasse LosZusatzDaten faßt berechenbare Attribute des Loses zusammen,die sich durch den momentanen Status des Loses ergeben, um eine mehrfache Berechnungzu vermeiden. Die MaschinenDaten enthalten alle Angaben zum aktuellen Zustand einerMaschine und sind ggf. mehrfach vorhanden157. Die StationsDaten wiederum fassen die
157 Die Bedienstation ist die abstrakte Oberklasse für die Modellelemente Maschine und Maschinengruppe
(siehe Punkt 5.2.3.3).

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 217
Arbeitsweise der Bedienstation (Prozesstyp) und für die Bedienstation relevante Aus-schnitte aus der globalen Liste der Arbeitspläne (ArbeitsplanListe) bzw. der Liste der Be-arbeitungsmöglichkeiten (SetupListe) zusammen.
5.2.3.2 Transfer der dynamischen Elemente des Bedienungssystems zwischen denLogischen Prozessen
Bedingt durch den Einsatz von ParSimONY zur Simulation von Bedienungsnetzwerkenwurden zwischen den Stationen des Bedienungsnetzwerks bisher lediglich Nachrichtenüber Forderungen versandt. Diese Nachrichten trugen jedoch außer einem Zeitstempel kei-nerlei Informationen, da in Bedienungsnetzwerken von Attributen der Forderungen abstra-hiert wird. D.h., den Bedienstationen wurde lediglich der Fakt mitgeteilt, daß irgendeineForderung eingetroffen ist.Für die Simulation von Produktionssystemen mußte ParSimONY dahingehend angepaßtwerden, daß der Transfer von Auftrags- bzw. Los-Objekten durch das Produktionssystemerfolgt. Dazu sind Nachrichten zu versenden, welche die Aufträge bzw. Lose als Objektesamt ihren Attributen (Mengen, Termine, Arbeitsplan- und Arbeitsganginformationen)weitergeben. Damit ändert sich der „Lebensort“ des Objektes158.Es wurde entschieden, das Los als kleinste, unteilbare Einheit der dynamischen Elementeim Simulationsmodell sowohl in den Daten (Los.java) als auch in den Nachrichten abzu-bilden (siehe Punkt 4.3.1). Dazu wurde ein neuer Nachrichtentyp namens LotObject-Message von der Basisklasse AbstractMessage (siehe Punkt 5.2.2.3, Seite 212) abgeleitet.Dieses Nachrichtenobjekt enthält alle Daten eines Loses. Somit ist es möglich, ein kom-plettes Losobjekt über einen Channel zu senden und damit von Maschine zu Maschine zutransferieren. Hierzu wird das zu übertragende Objekt per RMI159 einem anderen Logi-schen Prozeß bereitgestellt (siehe Abbildung 100, Seite 211).ParSimONY stellt für die Übertragung von Objekten die Klasse ObjectMessage als Sub-klasse von AbstractMessage bereit. Leider konnte dieser Mechanismus zum Transfer vonObjekten nicht benutzt werden, da der Einsatz optimistischer Synchronisationsverfahrenaufgrund von Referenzierungsfehlern160 nicht möglich war. LotObjectMessage wurde des-halb so konzipiert, daß alle benötigten Attribute in Kopie als elementare Datentypen ent-halten sind, um Referenzierungsfehler zu vermeiden.Ein weiteres Problem ist, daß jedes Los einen Verweis auf seinen Arbeitsplan enthält. Diesbedeutet, daß strenggenommen zu den Attributen des Loses auch der Arbeitsplan als Folgevon Arbeitsgängen gehört. Bei jedem Transfer eines Loses müßten dann die komplettenDaten des Arbeitsplanes versendet werden, damit sie bei einer verteilten Abarbeitung ineinem Rechnernetz am notwendigen Ort überhaupt vorhanden sind. Dies würde eineenorme Erhöhung des Kommunikationsaufwandes bedeuten. Deswegen besitzt ein Los nurdie Arbeitsplannummer als Attribut und die Arbeitspläne werden einmalig bei Simula-tionsstart an alle Bedienstationen (und damit an alle Rechner) transferiert. Dadurch wirddie Kommunikationsmenge drastisch verringert.
158 Dies ist ein wesentlicher Fortschritt gegenüber der HLA, welche nur einen Zugriff auf Objekte erlaubt. Für
ein HLA-Modell würde dies bedeuten, es muß eine Partition geben, in der die Lose bzw. Aufträge „leben“,oder Kopien der Objekte sind ständig in allen Partitionen präsent.
159 Bei RMI - Remote Method Invocation - handelt es sich um eine Java-Technik zur Verteilung von Anwen-dungen. Siehe dazu [RMI].
160 ObjectMessage besitzt als Attribut eine Referenz zu dem zu versendenden Objekt. Da die Rollbackmecha-nismen der optimistischen Synchronisationsverfahren die eingegangenen und gesendeten Nachrichtenspeichern, bestehen jetzt mehrere Referenzen auf das selbe Objekt. Das Objekt in der eingehenden Nach-richt und das verarbeitete Objekt unterscheiden sich jedoch in den Attributen (Zustand), was aufgrund derReferenz auf das selbe Objekt nicht möglich ist. Die Lösung dieses Problems bedingt das Erstellen vonKopien des Objektes (Vermeidung der Referenzierung).

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 218
5.2.3.3 Kreierung einfacher benutzbarer Modellelemente
5.2.3.3.1 Atomare Elemente von Produktionssystemen
Bisher gab es in ParSimONY die Restriktion, daß i.d.R. ein Modellelement nur einen Ein-gang und einen Ausgang besitzen durfte, andernfalls war das Modellelement mit Knoten-elementen wie z.B. Merge (siehe Punkt 5.2.2.2, Seite 207) zu kombinieren. Außerdemmußte die Abbildung einer Bedienstation durch eine Kombination eines Queue- und einesServer-Elements geschehen. Aus diesen Gründen wurden die vorhandenen Modellele-mente zu leichter verwendbaren Einheiten zusammengefaßt (siehe Abbildung 107).Andererseits waren die ursprünglichen ParSimONY-Modellelemente noch nicht in derLage, die neuen dynamischen Elemente zu verarbeiten und mußten an den Empfang unddas Versenden von Losobjekten (LotObjectMessage) angepaßt werden.Eine der Änderungen bezog sich z.B. auf die Bedienzeit. In Bedienungsnetzwerken wirdzu jeder Maschine lediglich eine Bedienzeitverteilung angegeben. Jetzt jedoch ist die Be-dienzeit des Loses durch den Arbeitsplan und den aktuellen Arbeitsgang des Loses deter-miniert.
Folgende Modellelemente wurden geschaffen:
Quelle
MultiQuelleMaschine
MaschinenGruppe
Senke
Verteiler
Abbildung 107 - Zusätzliche Modellelemente
In den nachfolgend beschriebenen Modellelementen werden wieder Verteilungen und Sta-tistikobjekte benötigt. Diese sind detailliert im Anhang B beschrieben.
Das Modellelement Quelle stellt die Einsteuerung von Losen des selben Produkttyps in dasFertigungssystem dar. Als Parameter sind Objekte der Verteilungen zu Ankunftsrate undLosgröße anzugeben. Sind mehrere Produkttypen im Produktionssystem vorhanden, sokönnen mehrere Quellen-Elemente angelegt werden.Das Modellelement MultiQuelle stellt die Einsteuerung von Losen unterschiedlicher Pro-dukttypen dar. Als Parameter sind die Objekte der Verteilungen zur Ankunftsrate, der Los-größe und der Art des Produktes anzugeben. Bei einer MultiQuelle werden im Gegensatzzum Vorhandensein mehrerer Quellen alle Lose aus einem gemeinsamen Ankunftsstromgezogen.Das Modellelement Senke stellt die Aussteuerung von Losen dar. Eine Senke kann varia-bel viele Eingänge besitzen. Als Parameter ist daher die Anzahl der Eingangskanäle an-zugeben. Die Senke führt eine Statistik, in der zu jedem Produkttyp die Anzahl der ausge-steuerten Lose und Stück festgehalten wird.Das Modellelement Maschine stellt eine Bedieneinrichtung mit einem Bedienkanal undeiner vorgeschalteten Warteschlange dar. Als Parameter sind die Anzahl der Eingangs-

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 219
kanäle, als Objekt die Reihenfolgeregel161, die Liste mit den möglichen Bearbeitungs-angeboten und zugeordneten Bedienzeiten (SetupListe) anzugeben. Eine Maschine besitzteine variable Anzahl von Eingangskanälen, aber nur einen Ausgangskanal. Als Ergebnis-größen werden Statistiken über Zwischenankunfts-, Warte- und Bedienzeit sowie die An-zahl der angekommenen und bearbeiteten Lose und Stück geführt. Weiterhin werden dieKapazitätsauslastung und die Rüstzeit erfaßt.Das Modellelement Maschinengruppe stellt eine Erweiterung der Maschine dar. Hierwerden mehrere parallel arbeitende Bedienkanäle (Maschinen) aus einer gemeinsamenWarteschlange gespeist. Zusätzlich zu den Parametern der Maschine kommt noch die An-zahl der Maschinen der Maschinengruppe hinzu (vergleiche Punkt 2.3.2.3).Das Modellelement Verteiler ist ein Knotenelement. Es besitzt eine variable Anzahl vonEingängen und Ausgängen. Als Parameter sind die Anzahl der Ein- und Ausgänge anzu-geben, sowie eine Tabelle, die angibt, an welchem Ausgang welche Maschine / Maschi-nengruppe angeschlossen ist. Zu jeder an einem Eingang des Verteilers ankommende Lot-ObjectMessage wird das betreffende Los festgestellt und auf welcher Maschine / Maschi-nengruppe dieses Los im nächsten Arbeitsgang zu bearbeiten ist. Durch die als Parameterübergebene Tabelle kann der Verteiler feststellen, an welchen der Ausgänge dieLotObjectMessage weiterzuleiten ist. Ein Verteiler wird üblicherweise nach einer Multi-Quelle oder nach einer Maschine / Maschinengruppe eingesetzt, um Lose unterschied-lichen Typs an die in ihrem Arbeitsplan als nächste Anlaufstelle angegebene Bedienstationweiterzuleiten. Ein Verteiler kann auch dazu benutzt werden, eine Transporteinrichtungabzubilden.
Das in der Abbildung 98 auf Seite 210 angegebene Bedienungssystem kann durch dieseneuen Modellelemente wie folgt reduziert werden:
MaschineQuelle
MaschineQuelle Senke
Abbildung 108 Beispiel eines Bedienungssystems unter Verwendung derParSimONY-Zusatzelemente
5.2.3.3.2 Partitions-Modellelemente
Die bisher vorgestellten Modellelemente dienen zur Abbildung atomarer Bestandteile vonProduktionssystemen. Im Rahmen der Partitionierung entstehen jedoch Gruppierungen vonatomaren Elementen, die in einer Partition abgebildet werden sollen. Prinzipiell ist dies mitden bisher beschriebenen Elementen bereits möglich, jedoch nicht besonders effizient. ImKapitel 3 (siehe Seite 68) wurde bereits vorgestellt, daß das Verhältnis zwischen internenund externen Ereignissen einer Partition signifikanten Einfluß auf die Performance besitzt.Im Kapitel 3 wurde deswegen die Forderung geäußert (siehe Punkt 3.1.1.3, Punkt 3.1.4.3),Partitionen mit einem hohen Prozentsatz an internen Ereignissen zu bilden. Prinzipiell istein ParSimONY-Modellelement als Partition anzusehen (siehe Punkt 5.2.2.2). Aus diesem
161 Die Regel zur Entnahme eines Loses aus der Warteschlange ist als Java-Klasse implementiert. Durch die
Angabe einer konkreten Instanz einer Subklasse kann an der betreffenden Maschine die gewünschte Rei-henfolgeregel in Kraft gesetzt werden. Zu den Mechanismen zur Reihenfolgeplanung siehe Punkt 5.2.3.6.

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 220
Grund wurden zusätzliche Modellelemente geschaffen, die Gruppen von Bedienstationenabbilden (siehe Abbildung 110), um eine unnötige Benutzung von Channel-Mechanismenzu vermeiden und den Anteil von partitionsinternen Ereignissen deutlich zu erhöhen.
Bedienstation Bedienstation Bedienstation
StationsKette
...
Abbildung 109 Das Modellelement „StationsKette“ zur Abbildung von Parti-tionen von Bedienstationen
Werkstatt
...
Verteiler
Bedienstation Bedienstation Bedienstation
Abbildung 110 Das Modellelement „Werkstatt“ zur Abbildung von Partitionenvon Bedienstationen
Eine StationsKette ist dadurch gekennzeichnet, daß das Routing der Aufträge so gestaltetist, daß alle Bedienstationen der StationsKette in Reihe durchlaufen werden. Das Stations-Ketten-Element ist gut geeignet um Fertigungslinien abzubilden.In einer Werkstatt dagegen existiert keine solche Routingvorschrift. Prinzipiell kann einTransfer von Aufträgen bzw. Losen zwischen allen Bedienstationen der Werkstatt statt-finden. Werkstatt-Elemente sind gut geeignet, um vermaschte Netze von Bedienstationenoder eng interdependierende Stationen als Partition zusammenzufassen (siehe Punkt 4.3.3,Punkt 4.3.4.1).
5.2.3.4 Beachtung komplexer Prozeßbedingungen in den Modellelementen
Weiterhin sind die Modellelemente an das Vorliegen komplexer Bedingungen im zu mo-dellierenden Produktionssystem anzupassen, um die typischen Eigenschaften und das typi-sche Verhalten adäquat abzubilden (siehe Punkt 2.4.2).
Zur Modellierung der Prozeßbedingungen sind deshalb weitere Java-Klassen notwendig,welche die diesbezüglichen Parameter und Daten aufnehmen.Zum Einen sind Angaben zur Arbeitsweise einer Bedienstation (Prozesstyp) notwendig.Diese enthalten Informationen über das Vorhandensein der Prozeßbedingung der parallelarbeitenden Maschinen (Batchbearbeitung, siehe Punkt 2.3.2.3 und Punkt 4.3.1.2) sowiedie maximal mögliche Batchgröße (Beladegröße). Durch die Änderung des Prozesstyps istes dann möglich, die Modellelemente Maschine und Maschinengruppe zur Bildung vonBatchs (Batch, BatchListe) zu veranlassen. In einem solchen Batch werden Lose zur ge-meinsamen Bearbeitung zusammengefaßt. Die Anzahl der Lose ist dabei durch die maxi-male Stückzahl eines Batchs (Attribut von Prozesstyp) begrenzt.Um dem Auftreten von Rüstproblematiken (siehe Punkt 2.3.2.3, Punkt 4.3.1.2) zu begeg-nen, wurden bereits im Punkt 5.2.3.1 die Klassen Setup und SetupListe vorgestellt. Diese

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 221
enthalten die Bearbeitungsmöglichkeiten der Maschinen. Zusätzlich ist die Klasse Ueber-gangsTabelle notwendig, welche u.a. dazu benutzt wird, die Zeiten für den Wechsel zwi-schen den Rüstzuständen festzuhalten. Damit sind die neuen Modellelemente sogar in derLage, sequenzabhängige Rüstzeiten abzubilden (siehe Punkt 2.3.2.3 und Punkt 4.3.1.2).Die zwischen zwei Bearbeitungsvorgängen notwendige Rüstzeit wird jetzt nicht in jedemFall in gleicher Höhe angesetzt, sondern die Höhe der Rüstzeit ist abhängig von der Rich-tung des Wechsels zwischen den beiden Bearbeitungsvorgängen.
Außer der Anpassung der Modellelemente an diese Datenstrukturen ist allerdings noch dieAbbildung der für diese komplexen Strukturen notwendigen Steuerungsabläufe erforder-lich. So müssen Mechanismen zur Behandlung komplexerer Prozeßbedingungen wie Bela-de- und Rüstproblematiken (siehe Punkt 2.3.2.3) integriert werden. Allerdings treten dieseProzeßbedingungen nicht in jedem Fall auf und die benötigten Steuerungsabläufe könnenunterschiedlich sein, d.h. es ist notwendig, flexibel auf das Auftreten der komplexen Pro-zeßbedingungen zu reagieren. Deshalb können die Modellelemente durch Parameter überdas Auftreten von Prozeßbedingungen informiert werden und es existieren austauschbareObjekte, welche verschiedene Steuerungsabläufe beinhalten, über die das betreffende Mo-dellelement parameterisiert werden kann (siehe dazu Punkt 5.2.3.6).
5.2.3.5 Unterstützung der Erfassung und Aufbereitung von Ergebnisgrößen
In ParSimONY wurden bisher - bedingt durch die Natur von Bedienungsnetzwerken - nurwenige Ergebnisgrößen statistisch erfaßt162. Dies ging nicht über die Erfassung der Ausla-stung der Maschinen, die Verteilung von Bedien- und Wartezeit sowie die Anzahl der pas-sierenden Forderungen hinaus. Deshalb war es notwendig, diese nur rudimentär vorhan-denen statistischen Auswertungen auszuweiten. Bei der Simulation von Produktionssys-temen sind Auswertungen zu zahlreichen weiteren Ergebnisgrößen notwendig (siehe dazuPunkt 5.1.2.19). Für die Bedieneinrichtungen sind beispielsweise Größen wie die zeitlicheund quantitative Auslastung (Füllgrad der Batchs), der Durchsatz in Batchs, Losen undStück, die mittlere und maximale Warteschlangenlänge usw. interessant. Für die Lose sinddagegen Ergebnisgrößen wie z.B. die Durchlaufzeit und die Termineinhaltung interessant.Dafür mußten die in ParSimONY bestehenden Statistik-Objekte angepaßt und zusätzlicheStatistik-Objekte hinzugefügt werden (siehe dazu Anhang B). Anschließend wurde dieErfassung der genannten Größen in den betreffenden Modellelementen ergänzt. Anhang Centhält unter C-7 bis C-9 eine tabellarische Aufführung der Größen, die statistisch erfaßtwerden.Letztlich werden die für die Bewertung von Steuerungsentscheidungen im Produktions-system interessanten Größen in einem Report zusammengefaßt. Im Punkt 5.1.2.16 wurdebereits die Struktur dieser Reports für das Framework zur simulationsbasierten Fertigungs-steuerung beschrieben. Dieser durch die Erweiterung von ParSimONY erzeugte Report istBestandteil der Kopplung zum Framework in Punkt 5.3.2.
5.2.3.6 Schaffung der Einsatzmöglichkeiten für verschiedenartigste Reihenfolge-planungsansätze
Bei Auftreten einer Warteschlange von mehreren Aufträgen an einer Maschine sind diver-se Ansätze zur Planung der Reihenfolge der Abarbeitung dieser Aufträge denkbar. Bisherwird in ParSimONY ausschließlich FIFO (First In First Out) verwendet. Im Rahmen dersimulationsbasierten Fertigungssteuerung ist aber gerade ein Test verschiedener Reihen-folgeplanungsansätze notwendig. ParSimONY mußte demzufolge dahingehend erweitertwerden, daß unterschiedlichste Reihenfolgeplanungsansätze anwendbar sind. Hierbei wur-
162 Vergleiche Anforderungen und Probleme von Simulationstools, Punkt 2.3.3.

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 222
de insbesondere auf eine Unabhängigkeit der Modellelemente vom verwendeten Reihen-folgeplanungsansatz geachtet. D.h., es ist auf einfache Art und Weise möglich, ein Modell-element mit unterschiedlichen Ansätzen der Reihenfolgeplanung zu kombinieren. Weiter-hin ist zu beachten, daß diese Reihenfolgeplanungsansätze auch prinzipiell in der Lagesind, auf das Auftreten komplexer Prozeßbedingungen zu reagieren. Deshalb wurde in derErweiterung von ParSimONY zwischen Ansätzen zur Priorisierung von Losen und Ansät-zen, welche zusätzlich Batch- und Rüstbedingungen beachten, unterschieden (sieheAbbildung 111). Im Rahmen der objektorientierten Möglichkeiten von Java wurden ab-strakte Klassen geschaffen, welche eine Schnittstelle für diese Ansätze definieren. DieModellelemente verwenden dann nur die in dieser Schnittstelle definierten Attribute undMethoden. Somit war die Implementation verschiedener einfacher Prioritätsregeln zurPriorisierung von Losen unkompliziert lösbar (siehe Abbildung 112) und die Implementa-tion größerer, zusammengesetzter Prioritätsregeln konnte vorbereitet werden. Diese Regelnwurden als Java-Klassen angelegt und können in mehreren Simulationsmodellen Verwen-dung finden. Analog gilt dies für die Mechanismen zur Auswahl der Lose aus der Warte-schlange, welche als nächste auf der Maschine bzw. Maschinengruppe zu fertigen sind(siehe Abbildung 115). Hier spielen Faktoren der komplexen Prozeßbedingungen wie dieZusammenfassung von Losen zu Batchs oder die sequenzabhängigen Rüstzeiten eine ent-scheidende Rolle. Ein erster Lösungsansatz wurde als Java-Klasse hinterlegt und kann inbeliebigen Simulationsmodellen verwendet werden. Auf Basis dieses Ansatzes könnenjetzt differenzierte Ansätze zur Lösung des Reihenfolgeproblems unter komplexen Prozeß-bedingungen implementiert werden163.
AbstractSelektions-Mechanismus
benutzt
DynamicPriority-Computer
AbstractBatching-Mechanismus
benutzt benutzt
Warteschlange ArbeitsvorratListe Belegungsplan
sortiert benutzt erstellt benutzt erstellt
Bedienstation
Abbildung 111 Semantischen Beziehungen zwischen den Klassen zur Priori-sierung und Reihenfolgeplanung, Übersicht
Die Bedienstation benutzt zur Priorisierung der Lose eine abstrakte Klasse Dynamic-PriorityComputer (siehe Abbildung 112). Anschließend ist es Aufgabe des Abstract-BatchingMechanismus die Lose der Warteschlange zu Batchs zusammenzufassen (sieheAbbildung 114). Zum Schluß stellt der AbstractSelektionsMechanismus einen Belegungs-plan für die Maschinen der Bedienstation auf (siehe Abbildung 115).
Eine Warteschlange besteht aus QueueItems, welche sich wiederum auf ein Los beziehen.Die LosZusatzDaten enthalten - um eine mehrfache Berechnung zu vermeiden - Zustands-daten des Loses für den aktuellen Arbeitsgang (vergleiche dazu Abbildung 104 auf Seite215). Das Vorgehen bei der Sortierung der Warteschlange gemäß der Priorität der Lose ist
163 Es ist nicht Ziel der Arbeit, komplexe Reihenfolgeplanungsansätze zu entwerfen und zu testen. Ziel ist es
aber, die Abbildbarkeit eines solchen komplexen Reihenfolgeplanungsalgorithmus in einem Simulations-modell der Parallelen Simulation sicherzustellen.

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 223
in jedem Fall gleich, unterschiedlich ist lediglich die Berechnung der Priorität. Die ab-strakte Klasse DynamicPriorityComputer stellt die für diese Berechnung gemeinsameSchnittstelle dar.
DynamicPriority-Computer
Warteschlange
benutzt zurSortierung
QueueItem
besteht aus
berechnetPriorität
Los
ist ein
FIFOPriority LIFOPriority
SPTPriority
SlackPriority
MROPriority
sind
StaticPriority
LosZusatzDatenbesitzt
RandomPriority
LPTPriority
EDDPriority
LRWTPriority MRWTPriority
CRPriority
TardinessPriority
LROPriority
Abbildung 112 Semantische Beziehungen zwischen den Java-Klassen zurPriorisierung und Reihenfolgeplanung, Priorisierung der Lose
Konkrete Realisierungen der Prioritätsberechnung sind:
• Static: Sortierung der Lose nach gegebener fester (statischer) Priorität• Random: zufällige Sortierung• FIFO, LIFO: First / Last In First Out - Sortierung der Lose nach dem Eintritts-
zeitpunkt in die Warteschlange• SPT, LPT: Shortest / Longest Processing Time - Sortierung der Lose nach der
Operationszeit• EDD: Earliest Due Date - Sortierung der Lose nach dem frühsten
Planaussteuerungstermin• Tardiness: Sortierung der Lose nach Verzug zum Planaussteuerungstermin• LRWT, MRWT: Least / Most Remaining Working Time - Sortierung der Lose nach
der Restbearbeitungszeit• Slack: Sortierung der Lose gemäß der Schlupfzeitregel• CR: Critical Ratio - Sortierung der Lose gemäß Critical Ratio• MRO, LRO: Most / Least Remaining Operations - Sortierung der Lose nach der
Anzahl der verbleibenden Arbeitsgänge
Basierend auf diesen Beispielen lassen sich weitere Prioritätsregeln leicht implementieren.
Neu hinzugekommen ist in der Abbildung 113, daß die LosZusatzDaten die Beziehung desLoses zu dem im aktuellen Arbeitsgang verlangten Setup herstellen. Ein Batch besteht ausmehreren QueueItems und damit aus mehreren Losen. Ein Batch faßt dabei immer Lose mitder selben Bearbeitungsanforderung (Setup) zusammen. Die Begrenzung für das Zusam-menfassen ist dabei im Prozesstyp festgelegt. Können zur selben Bearbeitungsanforderungmehrere Batchs gebildet werden, so werden diese in einer BatchListe zusammengefaßt. DieArbeitsvorratListe stellt abschließend eine nach Setup geordnete Zusammenfassung derBatchListen dar. Die abstrakte Klasse Priorisierbar stellt die Schnittstelle für alle priori-sierbaren Elemente dar. Sie wird u.a. bei der Erstellung der ArbeitsvorratListe benutzt.

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 224
Priorisierbar
QueueItem
Los
ist ein
LosZusatzDaten
besitzt
Setup
bezieht sich auf
Batch
BatchListe
ArbeitsvorratListe
Prozesstyp
ist
hat mehrere
hat mehrere
beziehtsich auf
beziehtsich auf
benutzt
benutzt
hat mehrere
ist ist
benutzt
Abbildung 113 Semantische Beziehungen zwischen den Klassen zur Priori-sierung und Reihenfolgeplanung, Zusammenhang zwischenLos und Batch
Die abstrakte Klasse BatchingMechanismus stellt das zentrale Element in Abbildung 114dar. Sie benutzt die Warteschlange der Bedienstation, den Los-Priorisierungsmechanismus(DynamicPriorityComputer) und die Angaben zur Arbeitsweise der Bedienstation(Prozesstyp) um eine ArbeitsvorratListe zu erstellen. Der DynamicPriorityComputer dientdabei dazu, im Vorfeld die in der Warteschlange befindlichen Lose zu priorisieren. An-schließend werden in Abhängigkeit der Angaben im Prozesstyp die Batchs gebildet und inBatchListen bzw. in der ArbeitsvorratListe gesammelt. Die ArbeitsvorratListe stellt danneine nach den Möglichkeiten der parallelen Bearbeitung geordnete Warteschlange dar.Die abstrakte Klasse AbstractBatchingMechanismus erweitert die Schnittstelle vonBatchingMechanismus und stellt die Basisklasse für Realisierungen von Algorithmen zurZusammenfassung von Losen zu Batchs dar. Die Klasse SimpelBatchingMechanismus isteine erste Realisierung. Hier werden die Lose erst nach Priorität und dann nach der Los-größe geordnet. Dann werden solange Lose zum Batch hinzugefügt, bis dessen in Prozess-typ angegebene Batchgröße überschritten würde.

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 225
Batching-Mechanismus
SimpelBatching-Mechanismus
ist
AbstractBatching-Mechanismus
ist
DynamicPriority-Computer
benutzt
Prozesstypbenutzt
Warteschlange
benutzterstellt
ArbeitsvorratListe
hat mehrere
BatchListe
Batch
hat mehrere
QueueItem
hat mehrere
Los
ist ein
priorisiert
besteht aus
Abbildung 114 Semantische Beziehungen zwischen den Klassen zur Priori-sierung und Reihenfolgeplanung, Zusammenfassung der Lo-se zu Batchs
Bisher wurde eine Priorisierung der Lose durchgeführt (DynamicPriorityComputer) und eswurden die Lose zu Batchs zusammengefaßt (AbstractBatchingMechanismus). Offen istnoch die Zuordnung von Batchs zu Maschinen. Dazu benutzt der SelektionsMechanismusdie bereits erstellte WorkloadList und den StationsDatenContainer der betreffendenBedienstation (siehe Abbildung 116). Der StationsDatenContainer enthält u.a. (sieheAbbildung 106 auf Seite 216) Angaben über den Zustand der Bedienkanäle164. Diese Zu-standsdaten sind Basis für die Entscheidung der Zuordnung der Batchs zu den Maschinen.In den Zustandsdaten sind die Angaben zu speziellen Prozeßbedingungen enthalten, wiez.B. Rüstzustand, momentaner Bearbeitungsstand etc. Der SelektionsMechanismus erstelltals Ergebnis einen Belegungsplan. In diesem Belegungsplan ist zu den Maschinen derBedienstation vermerkt, mit welchem Batch sie beladen werden sollen. Der Belegungsplanbesteht aus mehreren Zuordnungs-Objekten, welche eine konkrete Zuordnung eines derBatchs auf eine der Maschinen vornehmen. Auch hier existiert mit AbstractSelektions-Mechanismus wieder eine Erweiterung der Basisklasse SelektionsMechanismus, welchedann Basis für konkrete Realisierungen zur Reihenfolgeplanung ist. Eine erste Realisie-rung ist SimpelSelektionsMechanismus - die Batchs werden gemäß ihrer Priorität auf diefreien Maschinen der Bedienstation verteilt, wobei für die Zuordnung zu Maschinen die
164 Die Bedienstation ist eine abstrakte Basisklasse für die Modellelemente Maschine und Maschinengruppe.
Eine Maschine besitzt nur eine Ausprägung der MaschinenDaten. Eine Maschinengruppe hat für jede ihrerMaschinen ein Objekt MaschinenDaten.

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 226
dort verbleibende Restbearbeitungszeit und die eventuell anfallende Rüstzeit berücksich-tigt wird, um zu gewährleisten, daß das höchstpriorisierteste Batch auch zuerst fertigge-stellt wird.
Selektions-Mechanismus
SimpelSelektions-Mechanismus
ist
AbstractSelektions-Mechanismus
ist
AbstractBatching-Mechanismus
benutzt
erstelltArbeitsvorratListe
hat mehrere
BatchListe
Batch
hat mehrere
benutzt
StationsDaten-Container
MaschinenDaten
hat mehrere
benutzt erstellt
Belegungsplan
Zuordnung
hat mehrere
bezieht sich auf
bezieht sich auf
Abbildung 115 Semantische Beziehungen zwischen den Klassen zur Priorisi-erung und Reihenfolgeplanung, Zuordnung von Batchs zuMaschinen
5.2.3.7 Lösung spezieller simulationstechnischer Probleme
Änderung des Ereignismanagements für gleichzeitige Ereignisse:
Wie viele andere Simulatoren hat auch ParSimONY Probleme mit der Ausführungsreihen-folge gleichzeitiger Ereignisse (vergleiche [Scriber, Brunner 1998], [Jha, Bagrodia 2000],[Fishman 2001, S. 52], siehe auch Punkt 2.3.3). Denn nicht in jedem Fall ist es belanglos,in welcher Reihenfolge Ereignisse, die den selben Ereigniszeitpunkt besitzen, ausgeführtwerden. Dies gilt insbesondere für die Simulation von Produktionssystemen. So muß z.B.ein Ankunftsereignis eines Auftrages an einer Maschine vor dem Auswahlereignis der Ma-schine ausgeführt werden. Würde man diese Reihenfolge nicht einhalten, so würde dieMaschine den zum Betrachtungszeitpunkt eigentlich bereits vorliegenden Auftrag nichtberücksichtigen können (siehe Punkt 2.3.3).Zu diesem Zweck wurden die Mechanismen von ParSimONY um Prioritätsklassen fürEreignisse erweitert, um eine korrekte Abarbeitungsreihenfolge dieser Ereignisse garantie-ren zu können. Dazu waren alle die Ereignisse betreffenden Mechanismen wie z.B. dieverschiedenen Typen von Ereignislisten zu verändern. Jetzt werden gleichzeitige Ereignis-se gemäß der vorgegebenen Priorität verarbeitet.

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 227
Tabelle 3 - Prioritätsklassen von Ereignissen
Ereignisklasse Priorität
Modellinitialisierung 16
Einsteuerung von Aufträgen/ Losen 14
Beginn des Defekts einer Maschine 12
Ende des Defekts einer Maschine 10
Ankunftsereignisse 8
Ende von Rüstvorgängen 6
Ende von Bearbeitungsvorgängen 4
Auswahlereignisse 2
Null-Messages 0
Die höchste Priorität - und damit Vorrang vor allen anderen Ereignissen - haben Ereignissezur Modellinitialisierung. Es folgen die Einsteuerung von Aufträgen bzw. Losen und An-kunftsereignisse. Geringere Priorität haben Ereignisse zur Benachrichtigung der Beendi-gung von Prozessen. Die geringste Priorität haben die Auswahlereignisse, um abzusichern,daß alle an einer Maschine zur selben Zeit stattfindenden Ereignisse bereits verarbeitetwurden. Die sogenannten Null-Messages (siehe Punkt 3.1.3.3) als Mechanismen der Syn-chronisationsverfahren haben bei Vorliegen gleichzeitiger Ereignisse keinen Wert undsollten nicht von der Berechnung weiterer, sicherer Ereignisse ablenken.
Probleme durch das Speichermanagement von Java:
Bedingt durch Mechanismen in Java ergibt sich bei der Reihenfolgeplanung ein weiteresProblem. Hier werden eine Menge von temporären Objekten benötigt, welche jedoch inihrer Summe einen nicht unerheblichen Speicherbedarf aufweisen. Java selbst bietet aberkeine Möglichkeit, nach Ablauf der Benutzung dynamisch zugewiesenen Speicher wiederfreizugeben. Man verläßt sich vielmehr auf die Garbage Collection [Sun-Java 1997, Seite„Simple.doc1.html#2333“], welche unreferenzierte Objekte erkennt und den zugewiesenenSpeicher freigibt. Dies führt durch die Reihenfolgeplanung dazu, daß die Garbage Collec-tion sehr oft aufgerufen werden muß, was jedoch die Simulation verzögert.
5.3 Entwicklung eines integrierten Unterstützungssystem für dieFertigungssteuerung komplexer Produktionssysteme mittelsParalleler und Verteilter Simulation
5.3.1 Ansatz zur Schaffung eines integrierten Unterstützungssystems für die si-mulationsbasierte Fertigungssteuerung komplexer Produktionssysteme
Durch die Erweiterungen von ParSimONY zu ParSimONY-ProdSys (siehe Punkt 5.2.3)steht ein Paralleler Simulator für die Simulation komplexer Produktionssysteme zur Verfü-gung. Dieser Simulator weist allerdings die selben Anwendungsdefizite auf, wie sie zurMotivation des Frameworks beitrugen (siehe Punkt 4.2.1). Es besteht das Problem, daß derAufwand zur Erstellung eines Simulationsmodells eines komplexen Produktionssystemssehr hoch ist. Es ist nicht sinnvoll, diese Aufgabe manuell ausführen zu lassen (siehe An-forderungen, Punkt 2.4.2, Punkt 4.7). Eine automatische Erstellung des Simulations-modells für ein solches komplexes Produktionssystem ist möglich und wird durch dasFramework zur simulationsbasierten Fertigungssteuerung unterstützt (siehe Punkt5.1.2.12). Weiterhin mangelt es an einer automatischen Aufbereitung und Auswertung derSimulationsergebnisse. Das Framework zur simulationsbasierten Fertigungssteuerung ist

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 228
prinzipiell in der Lage diese Probleme zu lösen (siehe Punkt 5.1.2.20). Dies ist Motivationzur Integration des Parallelen Simulators ParSimONY-ProdSys in das Framework zur si-mulationsbasierten Fertigungssteuerung (siehe Punkt 5.3.2).In den Punkten 3.1.1.3 und 4.5.1 wurde gezeigt, daß der Prozeß des Partitionierens desSimulationsmodells ebenfalls manuell ausgeführt wird und mit hohem Aufwand verbundenist. Es ist wünschenswert, diesen Prozeß zu automatisieren (vergleiche Anforderungen,Punkt 4.7). Im Punkt 4.5 wurde ein Partitionierungsverfahren für Modelle von Produk-tionssystemen vorgeschlagen. Dieser Partitionierungsansatz ist jetzt Basis für die auto-matische Simulationsprogrammgenerierung eines partitionierten Simulationsmodells.Auch für die Partitionierung des Modells ist eine automatisierte Lösung von Vorteil. ZumEinen ist bei Änderung von Parametern des Simulationsmodells eine Adaption der Partitio-nierung notwendig, um die Partitionierung den veränderten Gegebenheiten, d.h. verscho-benen Interdependenzen und einem anderen Kommunikationsprofil anzupassen (siehePunkt 4.5.1). Zum Anderen ist es bei der Suche nach einer günstigen Partitionierung mit-unter mehrfach notwendig, die Partitionierung zu verändern (siehe Punkt 3.1.1.4, 4.5.1).Durch die veränderte Zuordnung von Stationen zu Partitionen entsteht unter Umständenein völlig anders aufgebautes Simulationsmodell. Je nach Modellgröße würde der manuelleAufwand zur Anpassung des Modells an eine veränderte Partitionierung Tage oder garWochen betragen. D.h., es ist unumgänglich, das Partitionierungsverfahren auf Basis deraktuellen Ausprägungen von Modellparametern zu betreiben und mit der automatischenSimulationsprogrammgenerierung zu koppeln (vergleiche Anforderungen aus Punkt 4.7,siehe Punkte 5.3.3 und 5.3.4).
Abbildung 116 zeigt wie der Parallele Simulator ParSimONY-ProdSys, das Partitio-nierungsverfahren und die Simulationsprogrammgenerierung innerhalb des Frameworksverknüpft werden sollen.
Anordnungs-informationen
Partitionierungs-verfahren
Modelldaten
Partitionierungs-meßdaten
Simulations-programm-generator
Simulation mitParSimONY Ergebnisse des
Simulationslaufes
Framework
partitioniertesSimulationsmodell
Abbildung 116 Verknüpfung von Simulationsprogrammgenerator und Parti-tionierungsverfahren für den Parallelen Simulator ParSim-ONY-ProdSys im Framework zur simulationsbasierten Ferti-gungssteuerung
Um einen Simulator in das Framework zur simulationsbasierten Fertigungssteuerung inte-grieren zu können, ist es notwendig, für diesen eine spezielle Generator-Komponente be-reitzustellen (siehe Punkt 5.1.2.12). Mit Hilfe der Generator-Komponente ist das Frame-work in der Lage, automatisch ein Simulationsmodell auf Basis der aktuellen Modelldatenzu erzeugen. Der Punkt 5.3.2 befaßt sich deshalb mit der Umsetzung dieser Generator-Komponente für den Parallelen Simulator ParSimONY-ProdSys.Damit das in Punkt 4.5 beschriebene Partitionierungsverfahren anwendbar ist, bedarf esmindestens einer Ausführung des Simulationsmodells. Bei dieser Ausführung sind die im

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 229
Punkt 4.5.4 beschriebenen Meßgrößen zur Partitionierung zu erfassen. Der Punkt 5.3.3beschreibt deshalb, wie das ParSimONY-Simulationsmodell dazu erweitert werden muß.Auf Basis der nach der Simulationsausführung vorhandenen Meßgrößen kann das Partitio-nierungsverfahren ausgeführt werden. Dieses legt fest, wie die Stationen des Produktions-systems in Partitionen anzuordnen sind. Diese Anordnungsinformationen werden in einerDatenbank gespeichert. Später kann mit Hilfe dieser gespeicherten Informationen ohnenochmalige Anwendung des Partitionierungsverfahrens ein partitioniertes Modell generiertwerden. Die Speicherung der Informationen ist auch Basis für die iterative Verbesserungder Partitionierung durch den Partitionierungsansatz.Als letzter Schritt fehlt noch die Kopplung des Partitionierungsverfahrens und der auto-matischen Simulationsmodellgenerierung. Der Punkt 5.3.4 beschreibt, wie die Integrationzur Generator-Komponente für die automatische Erzeugung eines partitionierten Simula-tionsmodells vonstatten geht.
Nach Abschluß dieser Arbeiten ist es möglich, mit Hilfe des Frameworks die zur Simula-tion von komplexen Produktionssystemen notwendigen ParSimONY-Simulationsmodelleautomatisch zu partitionieren und zu erzeugen.
5.3.2 Integration des Simulators ParSimONY-ProdSys in das Framework zur si-mulationsbasierten Fertigungssteuerung
Das Framework zur simulationsbasierten Fertigungssteuerung definiert drei Integrations-punkte für Simulatoren:
• den Bau eines Simulationsprogrammgenerators (siehe Punkt 5.1.2.12),• die Parameterisierung der Simulationsausführungs-Komponente (siehe Punkt
5.1.2.14) und• die Notwendigkeit der Erzeugung von Ergebnisdateien eines speziellen Formats
(siehe Punkt 5.1.2.16).
Alle zur Erzeugung eines Simulationsmodells benötigten Daten des Produktionssystemssind bereits in der Modelldatenbank des Frameworks vorhanden (siehe Punkt 5.1.2.7). DerParSimONY-ProdSys-Generator kann auf dieser Basis das resultierende Simulations-modell erzeugen. Das Framework besitzt eine objektorientierte Schnittstelle165, welche esSimulationsmodellgeneratoren erlaubt, performant und strukturiert auf diese Modelldatenzuzugreifen. Aufgabe des Generators ist es, auf Basis der über die Schnittstelle ermitteltenDaten, alle zur Simulation benötigten Dateien des Simulationsmodells automatisch zu er-zeugen.
Ein ParSimONY-ProdSys-Simulationsmodell besteht aus mehreren Java-Dateien, die fürdie Simulationsausführung noch compiliert werden müssen. Das ParSimONY-ProdSys-Modell besteht aus zwei grundsätzlichen Teilen: einer Datenliste und dem eigentlichenModell. In der Datenliste werden alle zur Simulation benötigten Daten wie z.B. die Ar-beitspläne der Produkte, die Bearbeitungsmöglichkeiten der Maschinen, Rüstzeittabellenusw. abgelegt. Diese Datenliste macht einen nicht unerheblichen Teil des ParSimONY-ProdSys-Modells aus. Der Generator hat hier die Aufgabe, die notwendigen Daten in einerobjektorientierten Form als Java-Dateien166 zu erzeugen. Das ParSimONY-ProdSys-Modell im näheren Sinne besteht aus der Definition von Modellelementen, Logischen Pro-zessen und Verbindungskanälen zwischen den Modellelementen (vergleiche Punkt5.2.2.2). Die Schwierigkeit liegt hier in dem Problem, zu erkennen, welche Modell-
165 Vergleiche „Datenzugriffs-Komponente der Modelldatenbank“ im Punkt 5.1.2.7, 5.1.2.12.166 Die Codierung von z.B. Arbeitsplänen als Java-Klasse statt dem Einlesen einer Datendatei wurde gewählt
um Restriktionen der Abarbeitungsplattform zu umgehen.

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 230
elemente (siehe Punkt 5.2.3.3) verwendet werden müssen und wie diese zu para-meterisieren sind. Auch hier hat der Generator wieder objektorientierten Java-Quellcodezu erzeugen. Ein Problem dabei ist die Erkennung der Verbindungen der Modellelemente,wie sie sich aus den Strukturen des abzubildenden Modells des Produktionssystems erge-ben. Zur Bewältigung seiner Aufgaben besteht der Generator aus mehreren Modulen (sieheAbbildung 117).
Eine Kernkomponente übernimmt die Generierung des Rumpfes des Simulationsmodells.Dazu gehören u.a. Deklarationsanweisungen, Anweisungen zur Modellsteuerung und dieZuordnung von Modellelementen zu logischen Prozessen. Die im Simulationsmodell zuverwendenden Modellelemente und deren Parameterisierung sowie dazu benötigte Datenwerden über weitere Komponenten erzeugt. Die wichtigste davon ist die Verwaltung desProduktionssystemgraphen. Dieser Graph kann durch die Kenntnis über Arbeitspläne er-zeugt werden (vergleiche auch Punkt 4.5.8, Schritt 1). Bei der Erzeugung des Graphen istzu beachten, daß nur Arbeitspläne für Produkte verwendet werden, für die auch eine Ein-steuerung erfolgt (vergleiche auch Punkt 4.5.8, Schritt 1). In diesem Graphen werden dielaut der verwendeten Arbeitspläne betroffenen Maschinenelemente eingetragen. Zusätzlichenthält der Graph die Verbindungen dieser Stationen. Die Verwaltung der Maschinen-elemente und Verbindungen geschieht wieder in separaten Komponenten. Hier werden dieAngaben und Daten der Maschinenelemente und Verbindungskanäle gesammelt und ande-ren Generator-Komponenten bereitgestellt.
Der Arbeitsplangenerator muß für jeden im Modell verwendeten Arbeitsplan eine separateJava-Datei erzeugen, welche die Definition der Arbeitsgänge des Arbeitsplanes enthält167.Aufgabe des Modellelementgenerators ist es, für alle im Produktionssystemgraphen ver-wendeten Maschinenelemente die passenden Modellelemente zu erzeugen und korrekt zuparameterisieren. Zu diesen Parametern gehören u.a. die Verbindungskanäle zu benach-barten Elementen. Der Datengenerator wird benutzt, um umfangreiche Daten zur Para-meterisierung von Modellelementen in separaten Java-Dateien zu erzeugen. Dies wird z.B.für Rüstzeittabellen oder die Listen der Bearbeitungsmöglichkeiten benötigt168.
Die durch den Generator erzeugten Java-Dateien können anschließend compiliert und aus-geführt werden169 und erzeugen die Ergebnisdateien. Dazu ist bereits beim Generieren dar-auf zu achten, daß im Simulationsmodell die zur Erzeugung der Ergebnisdateien notwen-digen Java-Anweisungen plaziert werden (Aufgabe des Kerngenerators). Dies ist Voraus-setzung, um die bereits im Framework vorhandene Ergebnisaufbereitungs-Komponente(siehe Punkt 5.1.2.15) nutzen zu können, um die Ergebnisse der Simulation mit ParSimO-NY in die Ergebnisdatenbank das Frameworks zu importieren.
Der Vorteil der Integration des Simulators ParSimONY in das Framework zur simulations-basierten Fertigungssteuerung ist, daß kein manueller Eingriff mehr notwendig ist, um einParSimONY-ProdSys-Modell zu erzeugen und die Simulationsergebnisse des Modellsaufzubereiten.
167 Jeder konkrete Arbeitsplan stellt eine Java-Klasse dar. Prinzipiell könnten diese Klasse auch in der zentra-
len Modellklasse angelegt werden. Für Modelle von Produktionssystemen mit sehr großen Arbeitsplänenscheitert dies jedoch an Beschränkungen der Programmiersprache Java.
168 Bietet eine Maschine z.B. 60 Bearbeitungsmöglichkeiten, so sind 3.600 verschiedene Rüstwechsel mög-lich. Die Java-Klasse zur Aufnahme dieser Daten ist dementsprechend umfangreich. Auch hier greifenanalog zu den Arbeitsplänen Restriktionen der Programmiersprache Java.
169 Dies ist Aufgabe der Simulationsausführungs-Komponente (siehe Punkt 5.1.2.14). Es muß eine Batch-Datei angelegt werden, welche die notwendigen Befehle enthält. Der Simulationsausführungs-Komponenteist anschließend der Name dieser Batch-Datei mitzuteilen.
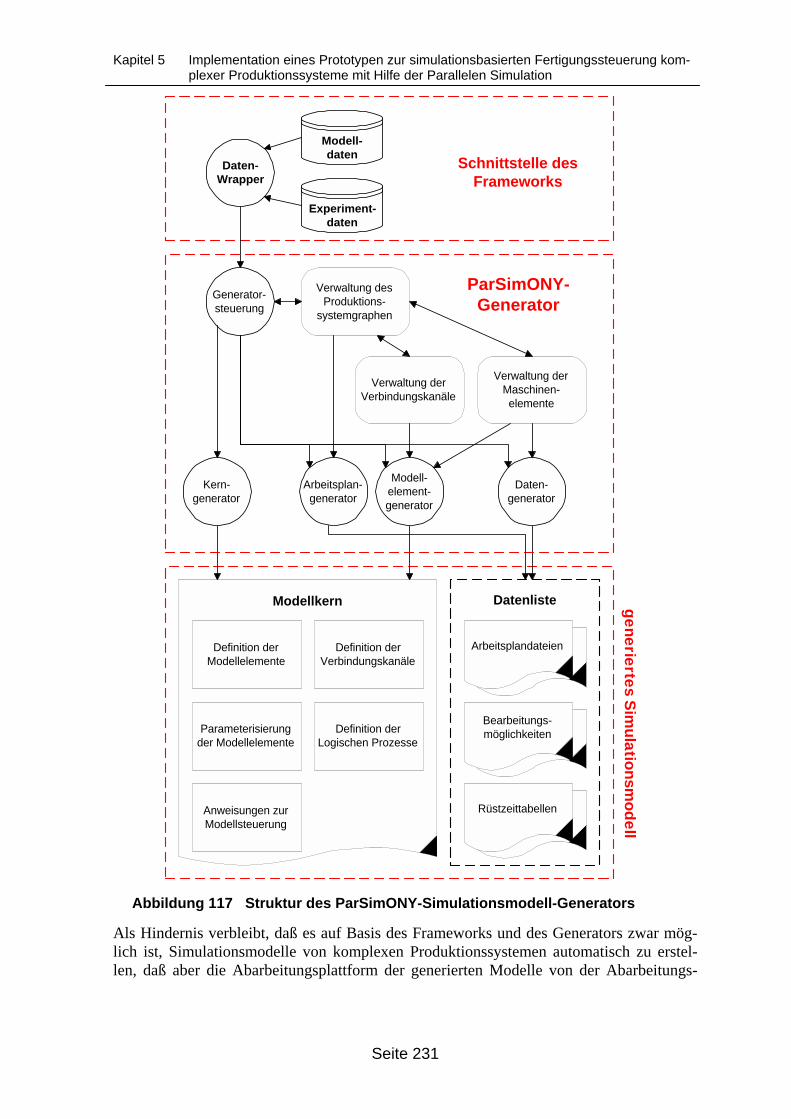
Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 231
Modellkern
Arbeitsplandateien
Bearbeitungs-möglichkeiten
Rüstzeittabellen
Datenliste
Definition derModellelemente
Definition derVerbindungskanäle
Parameterisierungder Modellelemente
Anweisungen zurModellsteuerung
Definition derLogischen Prozesse
ge
ne
rierte
s Sim
ula
tion
smo
de
llModell-daten
Experiment-daten
Daten-Wrapper
Schnittstelle desFrameworks
ParSimONY-Generator
Generator-steuerung
Verwaltung desProduktions-
systemgraphen
Arbeitsplan-generator
Verwaltung derMaschinen-elemente
Verwaltung derVerbindungskanäle
Modell-element-generator
Kern-generator
Daten-generator
Abbildung 117 Struktur des ParSimONY-Simulationsmodell-Generators
Als Hindernis verbleibt, daß es auf Basis des Frameworks und des Generators zwar mög-lich ist, Simulationsmodelle von komplexen Produktionssystemen automatisch zu erstel-len, daß aber die Abarbeitungsplattform der generierten Modelle von der Abarbeitungs-

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 232
plattform des Frameworks abweicht und momentan noch ein manueller Eingriff notwendigist.170
5.3.3 Integration des Partitionierungsverfahrens für Produktionssysteme in denSimulator ParSimONY-ProdSys
Im Punkt 4.5 wurde ein speziell für die Partitionierung von Produktionssystemen geeig-netes Partitionierungsverfahren vorgestellt. Die als Basis für dieses Verfahren dienendenMeßgrößen sind detailliert im Punkt 4.5.4 beschrieben. Um für ein gegebenes Simulations-modell die Ausprägungen dieser Meßgrößen feststellen zu können, ist es notwendig, An-weisungen zur Erfassung bzw. Berechnung dieser Meßgrößen im ParSimONY-ProdSys-Simulationsmodell zu plazieren. Weiterhin ist es notwendig, das Simulationsmodell umAnweisungen zu Ausgabe dieser Größen in eine Datei zu vervollständigen.
Folgende Meßgrößen sind zu erfassen und auszugeben (siehe Punkt 4.5.4):
• die Kommunikationsmenge zwischen zwei Stationen: AijKM
• die Kommunikationsdauer zwischen zwei Stationen: ijKD
• die Anzahl der Blockierungssituationen an der Station sj aufgrund nicht vorhan-dener Nachrichten von der Station si: ijABS
• die Anzahl der Blockierungssituationen an der Station sj: jABS
• die Anzahl der Garantiesituationen an der Station sj: jAGS
• die Anzahl der Entscheidungssituationen an der Station sj: jAES
Bereits im Punkt 4.5.5 wurde beschrieben, wie diese Größen während der Simulation zuberechnen sind. Dies würde bedeuten, daß die ParSimONY-Modellelemente Maschine,Maschinengruppe, StationsKette und Werkstatt (siehe Punkt 5.2.3.3) um eben diese Be-rechnungen zu ergänzen sind. Am Ende des Simulationslaufes sind die Ergebnisse dieserMeßgrößen dann in eine Datei zu schreiben. Dabei können bereits weitere Größen berech-net werden (siehe Punkt 4.5.6).
Die auszugebende Datei der Meßgrößen muß folgende Struktur besitzen171 (zur Erläute-rung und Berechnung der Größen siehe Punkt 4.5.5):
• In der ersten Zeile wird die Anzahl der Stationen (Modellelemente) im Report vermerkt.Dadurch ist die prinzipielle Länge der Datei im Voraus bekannt.
• Für jede Station wird ausgegeben:− In der ersten Zeile wird die Stationsnummer und die Stationsbezeichnung vermerkt.− Es folgt eine Zeile mit den Größen EMi, REMi, AGSi, ABSi, GHi und BHi.
170 Die Abarbeitung von ParSimONY-Simulationsmodellen kann prinzipiell auf drei verschiedenen Rechner-
plattformen geschehen: lokal auf einem PC, verteilt in einem Rechnernetz oder parallel auf einem Mehr-prozessorrechner. Das Problem hierbei ist, daß bei der verteilten bzw. parallelen Abarbeitung auf denRechnern unterschiedliche Betriebssysteme zum Einsatz kommen. Momentan wird das Framework lokal,auf einem einzelnen PC ausgeführt und ist damit an die Plattform der Microsoft Windows Betriebssystemegebunden. Mehrprozessorrechner laufen aber in der Regel unter UNIX. Ein automatisierter Dateiaustauschzwischen diesen Systemen ist nicht direkt möglich. Deshalb ist hier momentan noch der Eingriff des Nut-zers gefordert, der das Simulationsmodell zu dem Mehrprozessorrechner zu übertragen hat und der nachAbschluß des Simulationslaufes die Ergebnisse zum PC zurücktransferieren muß. Es wäre aber möglich,diesen Austausch für eine spezielle Lösung zu automatisieren oder z.B. mit Hilfe von Borland Kylix dasFramework auf Linux zu portieren.
171 Die lose Struktur dieser Datei hätte durch eine Aufteilung der Daten auf mehrere Dateien mit streng tabel-larischer Struktur umgangen werden können. Dies hätte den Prozeß des Schreibens und Lesens der Datenaber wesentlich kompliziert.

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 233
− Für jede potentielle Verbindung der aktuellen Station zu einer anderen Station wirdausgegeben:
> Die Stationsindizees i und j, EMij, REMij, AGSij, GHij, ABSij, BHij.− Für jede potentielle Verbindung der aktuellen Station zu einer anderen Station wird
ausgegeben:> Die Stationsindizees j und i, SMij und RSMij.
• Nach den Daten aller Stationen folgt eine Zeile mit den Größen EM, SM, AES, AGS, BHund GH.
Da die Erfassung dieser Meßgrößen nicht bei jedem Lauf mit dem Simulationsmodell not-wendig ist, muß die Erfassung, Berechnung und Ausgabe der Meßgrößen optional demSimulationsmodell hinzugefügt werden können. Dazu existiert in ParSimONY-ProdSys dieKlasse PartState, welche einen Schalter enthält, in dessen Abhängigkeit alle Modell-elemente die Partitionierungsmeßgrößen erfassen. Der Generator für das ParSimONY-Simulationsmodell muß nun die Klasse PartState verändern, um dieses Verhalten zu be-einflussen. Des Weiteren kann die Plazierung von Anweisungen zur Ausgabe der Meßgrö-ßen in die Datei über einen Parameter des Generators (de-)aktiviert werden.
5.3.4 Integration des Partitionierungsverfahrens für Produktionssysteme in dasFramework zur simulationsbasierten Fertigungssteuerung
Das Framework zur simulationsbasierten Fertigungssteuerung erlaubt die Integration ver-schiedener Simulatoren. Die Aufgabe der Partitionierung ist jedoch ein spezieller Aspektdes Parallelen Simulators ParSimONY. D.h., die Integration des Partitionierungsverfahrensobliegt vollständig der Generator-Komponente als dem Integrationspunkt für externe Si-mulatoren. So ist der durch ParSimONY-ProdSys erzeugte Report mit den Meßgrößen derPartitionierung (siehe Punkt 5.3.3) durch den Generator einzulesen, das Partitionierungs-verfahren auszuführen und erst dann ist das ParSimONY-ProdSys-Simulationsmodell aufBasis der Ergebnisse der Partitionierung zu generieren. Alle für das Partitionierungsver-fahren notwendigen Datenbestände wie Regeln und Parameter zur Partitionierung (ver-gleiche Punkt 4.5.7), sowie die Meßergebnisse der Partitionierung obliegen der vollstän-digen Verwaltung durch den Generator.
Abbildung 118 zeigt die Integration des Partitionierungsverfahrens in die Generator-Komponente des Frameworks.
Bereits im Framework vorhanden ist mit dem DatenWrapper (siehe Abbildung 78 in Punkt5.1.2.7) eine Schnittstelle zur Kopplung eines Simulationsmodellgenerators für einen ex-ternen Simulator (siehe auch Punkt 5.3.2). Die Simulationsexperimentsteuerung (siehePunkt 5.1.2.11) ruft den Generator auf, um das Simulationsmodell zu erzeugen. Jetzt sindzwei Fälle zu unterscheiden:
• es ist kein gültiger Partitionierungsreport für das Simulationsmodell vorhanden oder• der Partitionierungsreport existiert bereits.
Falls kein Partitionierungsreport vorhanden ist, so kann das in Punkt 4.5 beschriebene Par-titionierungsverfahren noch nicht angewendet werden, weil die konkreten Ausprägungender Meßgrößen fehlen. In diesem Fall wird über eine Grundpartitionierung172 eine Startlö-sung für die Einteilung der Stationen des Produktionssystems in Partitionen erstellt. Eswird vereinfachend angenommen, jede Station sei eine Partition173. Damit können für die
172 Zur Grundpartitionierung eines Modells siehe Punkt 3.1.1.2 , Punkt 4.3.3 und Punkt 4.5.1.173 Dadurch wird die vorhandene Parallelität maximal ausgenutzt. Allerdings bedingt diese Partitionierung
auch einen hohen Kommunikations- und Synchronisationsaufwand.

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 234
Stationen einfache Modellelemente wie Maschine oder Maschinengruppe (siehe Punkt5.2.3.3.1) benutzt werden.
DatenWrapper
Simulations-modell
Modelldaten
Datenzugriffs-komponente
Datenzugriffs-komponente
Daten derVersuchspläne
Generator-kopplung
im Framework
Generator-steuerung
Grund-partitionierung
Regeln zurPartitionierung
Partitionen
Modell-generierung
ParSimONY-ProdSys
Partitionierungs-meßdaten
Anpassung derPartitionierung
Partitionierungs-verfahren
Simulations-experiment-steuerung
ParSimONY-Generator
Ansteuerung desGenerators ausdem Framework
Abbildung 118 Integration des Partitionierungsverfahrens in die Generator-Komponente des Frameworks
Falls jedoch bereits ein Partitionierungsreport existiert, so kann das Partitionierungsver-fahren angewendet werden. Dieses erstellt die Informationen über die Zuordnung von Sta-tionen zu Partitionen. Jetzt jedoch sind eventuell komplexere Modellelemente wieStationsKette oder Werkstatt (siehe Punkt 5.2.3.3.2) notwendig.
Die durch das Partitionierungsverfahren erzeugten Plazierungsangaben zu den Stationenwerden anschließend vom eigentlichen Modellgenerator benutzt, um das Simulationsmo-dell zu erzeugen. Nach der Ausführung der Simulation steht dann eine Datei mit den Meß-daten zur Güte der Partitionierung zur Verfügung - der Partitionierungsreport. Bei noch-maliger Ausführung des ParSimONY-ProdSys-Generators kann jetzt eine Anpassung derPartitionierung erfolgen (wiederholte Anwendung des Partitionierungsverfahrens). Ergeb-nis ist eine eventuell veränderte Zuordnung der Stationen zu den Partitionen. Die Zuord-nungsangaben werden dann für die Modellgenerierung benutzt, um ein angepaßtes Modellzu erzeugen. Auf diese Weise kann das Partitionierungsverfahren iterativ angewendet wer-den, um schrittweise die Partitionierung zu verbessern (siehe Punkt 4.5.1).
5.3.5 Erweiterung des Simulations-Frameworks um den Aspekt einer verteiltenExperimentierumgebung
Bereits im Punkt 4.6 wurde die alternative Einrichtung eines verteilten Experimentier-systems zur Beschleunigung der Ausführung von Simulationsstudien besprochen. Prinzipi-ell besteht die Möglichkeit, die voneinander unabhängigen Simulationsexperimente auf dieRechner eines Rechnernetzwerks zu verteilen und dort parallel auszuführen. Dieses Ver-fahren führt für die simulationsbasierte Optimierung zu einer enormen Verringerung des

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 235
Zeitbedarfes (siehe u.a. [Bley, Wuttke 1997], [Arndt 2000], [Gehlsen, Page 2000],[Schneider, Reinhardt 2000]).D.h., ein verteiltes Experimentiersystem kann alternativ zu einer Parallelen oder VerteiltenSimulation eingesetzt werden, um den Zeitbedarf für die Ausführung einer Simulations-studie zu reduzieren.174
Das Framework zur simulationsbasierten Fertigungssteuerung kann mit verschiedenenSimulatoren betrieben werden. Bereits in das Framework integriert sind der SequentielleSimulator SLX und der Parallele Simulator ParSimONY (siehe Punkt 5.1.2.12, Punkt5.3.2). Das verteilte Experimentiersystem kann so unabhängige Experimente auf beispiels-weise zehn Rechnern durch eine Simulation mit SLX oder ParSimONY durchführen, wäh-rend ein elfter, zentraler Rechner eine koordinierende Funktion übernimmt (sieheAbbildung 67 in Punkt 4.6.3, Seite 174), um die abzuarbeitenden Experimente den anderenRechnern als Aufgabe zuzuweisen und der abschließend die Simulationsergebnisse kon-zentriert.
Im Punkt 4.6.3 wurde bereits festgelegt, welche Funktionalitäten prinzipiell zu verteilensind und welche zentral belassen werden sollen. Jetzt wäre zu konkretisieren, welcheKomponenten des Frameworks (vergleiche Abbildung 71, Seite 182) zentral bzw. verteiltausgeführt werden sollen (siehe Abbildung 119). Im Punkt 4.6.3 wurde bereits erläutert,daß alle zur Simulationsstudie gehörigen Experimente auf die zur Verfügung stehende Be-rechnungshardware verteilt werden sollen (siehe Abbildung 67, Seite 174). Jedem der Si-mulationsrechner wird dabei eine Menge von Experimenten zugeteilt. Ein Simulations-rechner benötigt zur Durchführung der Simulation eines Experimentes Zugriff auf die Mo-delldaten und die speziellen Gegebenheiten des Experimentes. Diese Daten liegen zentralauf dem Steuerrechner. Aufgabe des Steuerrechners ist es daher, diese Daten auszulesenund zu den Simulationsrechnern zu übertragen [Elsäßer 2001, S. 15f, 32-41]. Auf Basisdieser Daten erfolgt dann verteilt auf allen Simulationsrechner die automatische Simulati-onsmodellgenerierung. Jetzt kann jeder Simulationsrechner die zur Absicherung statistischgesicherter Aussagen notwendige Anzahl an Simulationsläufen mit dem für das Experi-ment generierten Simulationsmodell durchführen [Elsäßer 2001, S. 15f]. Nach jedem Si-mulationslauf werden die Simulationsergebnisse lokal auf den Simulationsrechnern in ei-ner Datenbank gespeichert. Nach Abschluß aller Läufe des Experiments hat der Simula-tionsrechner die Aufgabe, die Aggregation der Ergebnisdaten durchzuführen175. Diese ag-gregierten Ergebnisdaten werden dann als Fertigmeldung für das Experiment an den zen-tralen Steuerrechner übermittelt [Elsäßer 2001, S. 39-40].Zu den bereits als Komponenten im Framework enthaltenen Funktionalitäten kommen da-bei zusätzliche Aufgaben hinzu, die sich speziell mit der Verteilung und Zusammen-führung von Aufgaben und Daten befassen (siehe Abbildung 119). An zusätzlichen Funk-tionalitäten benötigt das Framework jetzt Komponenten zum Starten der Simulations-rechner (Komponente der Simulationsrechnerverwaltung), der Festlegung der Zuteilungder Experimente zu den Simulationsrechnern (Komponente der Experimentverteilung), derÜbergabe aller für die Modellgenerierung erforderlichen Daten an einen Simulationsrech-ner (Datenverteilungs-Komponente) und der Rücknahme der aggregierten Ergebnisse voneinem Simulationsrechner (Datenzusammenführungs-Komponente) . Das Framework zursimulationsbasierten Fertigungssteuerung ist deshalb um weitere Komponenten zu ergän-zen (vergleiche Punkt 4.6.3, [Elsäßer 2001, S. 35]).
174 Prinzipiell bestünde die Möglichkeit, parallel mehrere Simulationsexperimente auf mehreren Parallelrech-
nern (Parallele Simulation) oder in mehreren getrennten Rechnernetzen (Verteilte Simulation) durchzufüh-ren. Der dafür notwendige Mehrbedarf an Hardware ist aber i.d.R. nicht gegeben.
175 Vergleiche dazu Punkt 5.1.2.18.

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 236
Framework aufdem zentralenSteuerrechner
Modelldaten
Datenzugriffs-komponente
Generator(n verschiedene)
Simulations-modell
Ergebnis-konverter
Auswertungs-komponente
GUI
Datenzugriffs-komponente
Experiment-pläne
Experiment-planung
Ergebnisdaten
Datenzugriffs-komponente
Simulations-experiment-steuerung
externerSimulator
(n verschiedene)
Simulations-ausführung
(n verschiedene)
Datendateien(optional)
(definiertesFormat)
Simulations-ergebnisse
Laufergebnisse(temporär)
Simulations-laufsteuerung
Ergebnis-aggregation
Experimentplan-durchführung
Datenzugriffs-komponente
Datenverteilung
Experime-nt-Daten
Experiment-verteilung
Simulations-rechner-
verwaltung
Daten-zusammen-
führung
Datenent-gegennahme
Ergebnis-rückmeldung
Simulations-rechner-
steuerung
Datenzugriffs-komponente
aggregierteErgebnisse
(lokaler Ausschnitt)
Modell-Daten
Modell-Daten
Experime-nt-Daten
Framework aufden Simula-
tionsrechnern
Abbildung 119 Ergänzung des Frameworks um zusätzliche Komponenten zurErweiterung des Frameworks zu einem verteilten Experimen-tiersystem
Auf der Seite des zentralen Steuerrechners wird eine Komponente zur Simulations-rechnerverwaltung benötigt. Aufgabe dieser Komponente ist es, die für das Verteilte Expe-rimentieren zur Verfügung stehenden Rechner zu verwalten, den Dienst der Simulations-ausführung auf diesen Rechner vor dem Beginn des Experimentierens zu starten und nachdem Experimentieren zu beenden. Diese Komponente übernimmt auch die steuerndeKommunikation zu den einzelnen Simulationsrechnern [Elsäßer 2001, S. 40-41, S. 63-65].Aufgabe der Komponente der Experimentverteilung ist es, die Menge der im Rahmen desExperimentplans durchzuführenden Experimente zu sichten und anhand von Strategien zur

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 237
Verteilung (siehe Punkt 5.1.2.8, 5.1.2.10 [Elsäßer 2001, S. 63-65]) die Experimente desPlanes den einzelnen Simulationsrechnern zur Abarbeitung zuzuweisen. Dabei handelt essich um eine dynamische Aufgabe. D.h., während der Abarbeitung der Experimente durchdie Simulationsrechner kann sich die Zuordnung noch nicht abgearbeiteter Experimenteändern, wenn z.B. einzelne der Simulationsrechner zu lange für die Abarbeitung von Expe-rimenten benötigen [Elsäßer 2001, S. 86-87].Aufgabe der Datenverteilungs-Komponente ist es, die einzelnen Simulationsrechner mitden notwendigen Daten zu versorgen. Diese Daten bestehen aus zwei großen Paketen. DieModelldaten sind für alle durchzuführenden Experimente gleich. Die Experimente unter-scheiden sich lediglich in den Einstellungen des Experimentes (konkrete Einsteuerung,parameterisierte Steuerungsstrategien etc.). Für beide Fälle existiert eine objektorientierteStruktur - ein sogenannter DatenWrapper (siehe Punkt 5.1.2.7) - dieser enthält die jeweili-gen Daten. Die Datenverteilungs-Komponente muß bei Beginn des Experimentierens denModellDatenWrapper zu jedem Simulationsrechner transportieren und wiederholt - vorBeginn eines Experiments - den ExperimentDatenWrapper auf die Simulationsrechnertransferieren [Elsäßer 2001, S. 38, S. 41-42].Die Komponente der Datenzusammenführung hat die Aufgabe, die von den Simulations-rechnern erzeugten Ergebnisse zusammenzutragen und in der zentralen Ergebnisdatenbankabzulegen [Elsäßer 2001, S. 39-40].
Auf der Seite der Simulationsrechner existiert jeweils ein abgekoppelter Teil des Frame-works zur simulationsbasierten Fertigungssteuerung. Dieser besitzt wiederum zusätzlicheKomponenten.Die Komponente der Simulationsrechnersteuerung übernimmt die Kommunikation mitdem zentralen Steuerrechner und befolgt dessen Befehle. Sie dient auf der Seite der Simu-lationsrechner als Kommandozentrale [Elsäßer 2001, S. 41-42].Aufgabe der Datenentgegennahme-Komponente ist es, die vom zentralen Steuerrechnerempfangenen Daten zurück in die objektorientierte Form der DatenWrapper zu transfor-mieren [Elsäßer 2001, S. 51-53] und diese DatenWrapper der bereits im Framework vor-handenen Generator-Komponente als Schnittstelle anzubieten (siehe u.a. Punkt 5.3.2).Der Ablauf zur Ausführung eines Simulationsexperimentes erfolgt wie bereits im Punkt5.1.2.10 beschrieben. Es werden die in Kapitel 4.2 erläuterten Komponenten eingesetzt.Die Komponente der Ergebnisrückmeldung muß zum Schluß die Ergebnisse des Simula-tionsexperiments an den zentralen Steuerrechner zurückmelden. Da diese Datenübertra-gung aufgrund ihres Umfanges einen störenden Einfluß auf die Auslastung des zentralenSteuerrechners besitzt, werden die Simulationsergebnisse temporär in einer lokalen Ergeb-nisdatenbank gespeichert. Sobald der zentrale Steuerrechner in der Lage ist diese Datenentgegenzunehmen, ruft er diese ab [Elsäßer 2001, S. 54-55].
Die Beschreibung der Struktur und der Abläufe des Verteilten Experimentiersystems zeigteinen hohen Grad an Wiederverwendung der bereits vorhandenen Framework-Kompo-nenten (siehe Punkt 5.1.1, Abbildung 71, Seite 182). Damit konnte ein wesentliches Zieldes Frameworks erreicht werden (siehe Punkt 4.2.1, 4.2.2).Durch die aufgeführten Erweiterungen ist das Framework zur simulationsbasierten Ferti-gungssteuerung in der Lage, eine Vielzahl von im Rahmen einer Simulationsstudie defi-nierten Experimenten und Läufen auf mehrere Rechner zu verteilen und diese Experimenteparallel abzuarbeiten. Der Zeitbedarf zur Abarbeitung einer Simulationsstudie kann soentscheidend verringert werden.

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 238
5.4 Ausblick auf Erweiterungen der prototypischen Lösung
5.4.1 Diskussion von Erweiterungen des Frameworks
Das Framework wurde so konzipiert, daß es sehr einfach um zusätzliche Komponentenerweitert werden kann. Ebenso können zusätzliche externe Tools ohne größeren Aufwandin das Framework integriert werden. Eine wesentliche Voraussetzung dafür sind die Daten-zugriffs-Komponenten, welche eine definierte Schnittstelle auf die Daten und z.T. auch aufFunktionen zur Manipulation der Daten bereitstellen. Zum Anderen werden Funktionendes Frameworks wie z.B. die automatische Experimentplanabarbeitung über eine DLL-Schnittstelle angeboten und erleichtern so die Ausführung der notwendigen Methoden auseinem externen Tools heraus.Das Framework selbst kann aber auch um einige Komponenten ergänzt werden (sieheAbbildung 120).So ist es denkbar, den externen Simulator über eine Modell-Komponente auf die Daten desModells zugreifen zu lassen. Diese Modell-Komponente bedient sich der Datenzugriffs-Komponente der Modelldatenbank. So können Teile der Datenkonvertierung entfallen oderSchwierigkeiten des Simulators in Bezug auf Dateiarbeit oder Verwaltung von Datenüberbrückt werden. Die Modell-Komponente enthält also Teile des Simulationsmodellswie z.B. Auftrags- und Maschinenverwaltung, Organisation der Warteschlangen der Ma-schinengruppen, Führen von Statistiken und Erzeugung der Simulationsergebnisdateien.Im Simulationsmodell müssen dann nur noch die von der Modell-Komponente ange-botenen Funktionen aufgerufen werden. Für den Simulator SLX existiert z.B. eine solcheModell-Komponente.
externerSimulator
Generator
Modell-Komponente
Entscheidungs-Komponente
Simulations-modell
Datendateien(optional)
Modelldaten
Datenzugriffs-komponente
Datenzugriffs-komponente
Experiment-pläne
zusätzliche Komponenten
Abbildung 120 Erweiterung des Frameworks um zusätzliche Komponenten
Die Modell-Komponente kann noch durch eine Entscheidungs-Komponente ergänzt wer-den. Ziel der Entscheidungskomponente wäre es, verschiedene Reihenfolgeplanungsan-sätze anzubieten, damit diese in unterschiedlichen externen Simulatoren gemeinsam ge-nutzt werden können. Die Aufgabe der Entscheidungs-Komponente ist es, entweder direktmit dem Simulator oder über die Modell-Komponente, Steuerungsentscheidungen im mo-dellierten Produktionssystem zu treffen. So kann in der Entscheidungs-Komponente dasWissen zur Lösung des Reihenfolgeproblems abgelegt werden und das Simulationsmodellvon dieser Berechnungsaufgabe entkoppelt werden. Der Vorteil wäre hier, daß diese Rei-henfolgeplanungsverfahren nicht erst für den jeweils benutzten externen Simulator imple-mentiert werden müßten und daß alle externen Simulatoren die selbe Implementation derReihenfolgeplanungsverfahren benutzen.

Kapitel 5 Implementation eines Prototypen zur simulationsbasierten Fertigungssteuerung kom-plexer Produktionssysteme mit Hilfe der Parallelen Simulation
Seite 239
5.4.2 Ausblick auf Erweiterungen des Parallelen Simulators ParSimONY-ProdSys
Denkbar wäre eine Erweiterung der mit ParSimONY-ProdSys abbildbaren Komplexität.Im Kapitel 4.3.1 wurden für die prototypische Realisierung Einschränkungen vorge-nommen, die Berücksichtigung weiterer Prozeßbedingungen - wie z.B. Liegezeitbegren-zungen - ist jetzt möglich. Dazu wären:
• Klassen zur Aufnahme der notwendigen Daten zu schaffen (siehe Punkt 5.2.3.1),• die Parameterisierung der Modellelemente abzuändern (siehe Punkte 5.2.3.3, 5.2.3.4)• und in den Modellelementen müßten weitere, die Prozeßbedingung der Liegezeit-
begrenzung betreffende Ergebnisgrößen erfaßt werden (vergleiche Punkt 5.2.3.5).
Diese Flexibilität stellt einen Pluspunkt für die geschaffene Lösung dar.
Eine nächster Erweiterung von ParSimONY-ProdSys ist die Konstruktion weiterer, kom-plexer Modellelemente (vergleiche dazu auch Punkt 5.2.3.3.2). Denkbar wären hier so-wohl Modellelemente, welche typische Anordnungskombinationen von Maschinengruppenbeinhalten, als auch Modellelemente, die Spezialmaschinen abbilden. D.h., der Elemente-satz von ParSimONY kann noch beliebig erweitert werden.
Für den Einsatz von ParSimONY-ProdSys zur simulationsbasierten Fertigungssteuerungsind zur Zeit nur wenige Reihenfolgeplanungsansätze vorhanden. Die Integration beliebi-ger weiterer Prioritätsregeln ist problemlos möglich. Diese Prioritätsregeln sind von derabstrakten Basisklasse DynamicPriorityComputer (siehe Punkt 5.2.3.6, Seite 222) abzu-leiten. Ebenso können weitere Ansätze zum Zusammenfassen der Lose zu Batchs(Erweiterung der Basisklasse AbstractBatchingMechanismus, siehe Punkt 5.2.3.6, Seite226) und der Zuordnung der Batchs zur Bearbeitung auf den Maschinen (Erweiterung derBasisklasse AbstractSelektionsMechanismus, siehe Punkt 5.2.3.6, Seite 226) implementiertwerden. Somit ist die Implementation und der simulative Test komplizierter Reihenfolge-planungsansätze - welche differenziert auf das Auftreten von komplexen Prozeßbedin-gungen reagieren können - realisierbar. Der Abschluß studentischer Arbeiten, die eben dieszum Ziel haben, steht noch aus.Ebenso können weitere Verfahren der Reihenfolgeplanung wie z.B. Interaktionsansätze(Vorausschauende Arbeitsnachfrage (VANF) oder Vorausschauender Auftragsfortschritt(VAFS), siehe Punkt 2.1.4, [Holthaus, Ziegler 1993, S. 52 ff., S. 161f.], [Holthaus, Rosen-berg, Ziegler 1993, S. 6 ff., S. 11f.], [Weidner 1995, S. 21 ff., S. 71 ff.]) in ParSimONY-ProdSys-Modelle integriert werden. Interessant wäre hier, die Auswirkungen des Einsatzesder Interaktionsmechanismen auf die Performance der Parallelen und Verteilten Simulationzu untersuchen. Zu vermuten ist, daß die Interaktionsansätze - bedingt durch die Ver-mehrung der Kommunikation - zu einer Verschlechterung der Performance der ParallelenSimulation führen. Möglicherweise wird dieser Effekt jedoch durch die schnellere paral-lele Berechnung kompensiert.
Es zeigt sich, daß ParSimONY-ProdSys ein offenes System ist. Die Integration weitererAspekte ist stets möglich.

Kapitel 6 Empirische Untersuchung der Parallelen Simulation von Produktionssystemen
Seite 240
6 Empirische Untersuchung der Parallelen Simulationvon Produktionssystemen
6.1 Performanceungewißheit als Motivationsfaktor für die empi-rische Untersuchung
Im Gebiet der Parallelen und Verteilten Simulation besteht eine hohe Performance-ungewißheit. Bedingt durch den Mangel an allgemein anwendbaren Verfahren und eingroßes Spektrum an Verfahrensvarianten, sowie eine hohe Parameterisierbarkeit der Ver-fahren, kann ohne einen konkreten Test nicht vorhergesagt werden, welche Verfahrens-variante in welcher Situation performanter ist und somit ein höheres Speedup für den Ein-satz der Parallelen und Verteilten Simulation bietet. Zu den Unsicherheiten gehören:
• Es gibt kein allgemeines Verfahren zur Partitionierung (siehe Punkt 3.1.1.2).Durch die Partitionierung eines Gesamtmodells entstehen mehrere zeitparallelabarbeitbare Teilmodelle. Durch die parallele Abarbeitung kann es zu einer Ver-kürzung der benötigten Laufzeit kommen. Abhängig von der Partitionierung istzudem der Kommunikationsbedarf, der sich in vergangenen Arbeiten alsFallstrick herausstellte [Loucks, Preiss 1990], [Mehl 1994, S. 142f], [Bagrodia1996], [Holthaus, Rosenberg, Ziegler 1996].
• Es gibt kein allgemeines Verfahren zur Synchronisation (siehe Punkt 3.1.3.6). Esgibt viele Parameter für die Synchronisationsverfahren, die Änderung eines Para-meters reicht u.U. aus, um ein anderes Verfahren besser abschneiden zu lassen[Fujimoto 1988b], [Preiss 1990], [Fujimoto 1990], [Bagrodia 1996], [Fujimoto1999]. Das geeignetste Verfahren kann nur durch Testen herausgefunden werden[Smith 1999].
• Partitionierung und Synchronisation können nicht losgelöst voneinander betrach-tet werden. Je nach verwendeten Synchronisationsverfahren ist es günstiger einehohe oder niedrigere Anzahl von Partitionen aufzustellen. Ebenso hat die Art undGröße der gebildeten Partitionen starken Einfluß auf die Abarbeitungsgeschwin-digkeit mit dem gewählten Synchronisationsverfahren.
• Außerdem gibt es keine allgemeine Empfehlung für die Abarbeitungsplattform[Bagrodia 1996]. Parallelrechner mit mehreren Prozessoren haben den Vorteil,daß die Übertragungszeiten im Kommunikationsfall sehr gering sind. Dagegenläßt sich in Rechnernetzen der Bedarf an Hauptspeicher verteilen. Auch hier ist eswieder von den Parametern des Modells abhängig, welche Plattform die bessereEignung aufweist [Smith 1999] (siehe Punkt 3.3.2).
• Durch die Verwendung von Techniken der parallelen Programmierung wie z.B.Threads ist die effektive Verwaltung und Abarbeitung einer größeren Menge vonThreads sehr stark vom Betriebssystem abhängig [Mehl 1994, S. 11f], [Bagrodia1996], [Perumalla, Fujimoto 1998]. Hier lassen sich große Unterschiede fest-stellen (siehe Punkt 4.3.3, Punkt 3.1.4.3).
• Zu den Problemen der Verfahren kommt hinzu, daß die Gestaltung des Simula-tionsmodells selbst einen hohen Einfluß auf die Performance der Parallelen undVerteilten Simulation hat (z.B. Vernetzungsgrad, Lastzustand etc.) [Schlagenhaft1999a]. Hier müssen verschiedene Kategorien bzw. Klassen von Modellen unter-schieden werden.

Kapitel 6 Empirische Untersuchung der Parallelen Simulation von Produktionssystemen
Seite 241
Die tatsächliche Performance eines Simulationsmodells bei gegebener Partitionierung undSynchronisation läßt sich ex-ante nicht feststellen. Oft kann noch nicht einmal die Größen-ordnung der Performance prognostiziert werden. Angaben in der Literatur schwanken zwi-schen einem Slowdown um Faktor 5 bis zu einem Speedup von Faktor 40176. Hier ist esdringend notwendig, auf Basis einer Implementationsplattform Tests durchzuführen, umdie Wirkung der verschiedenen Faktoren auf die Performance festzustellen.Durch die entwickelte prototypische Lösung (siehe Kapitel 5) ist es möglich, Simulations-modelle für unterschiedlich strukturierte Produktionssysteme zu erstellen und diese mitverschiedenen Synchronisationsverfahren auf einem Parallelrechner oder in einem Rech-nernetz abzuarbeiten. Somit kann durch eine empirische Untersuchung die Performanceder unterschiedlichen Verfahren und Plattformen festgestellt und das Feld spekulativerAussagen verlassen werden. Es ist außerdem möglich, das Anwendungsfeld der Parallelenund Verteilten Simulation von Produktionssystemen in Modellklassen aufzuteilen (siehePunkt 6.2), um im Voraus Aussagen über den voraussichtlichen Nutzen des Einsatzes derParallelen und Verteilten Simulation im konkreten Anwendungsfall geben zu können(siehe Punkt 6.4).
6.2 Einteilung der Modelle in ModellklassenFür die nachfolgenden Untersuchungen ist zwischen verschiedenen Kategorien von Mo-dellen zu differenzieren. Dies ist notwendig, damit bei der Examinierung der Partitio-nierungs-, Kommunikations- und Synchronisationsverfahren modellspezifische Einfluß-faktoren ausgeschlossen werden können.Modelle von Produktionssystemen lassen sich anhand von fünf Parametergruppen typisie-ren (vergleiche Punkt 2.3.2.2):
1. Anzahl der statischen Modellelemente,
2. Anzahl der dynamischen Modellelemente,
3. auftretende Prozeßbedingungen,
4. Organisationsgrad der Produktion und
5. verwendete Reihenfolgeplanungsansätze.
Die Anzahl der statischen Modellelemente wie Maschinen, Werker, Transporteinrichtun-gen, Warteschlangen, Lagerplätze usw. gibt einen Ausblick auf die Größe des Modells. Jeumfangreicher ein Modell ist, desto größer ist der numerische Aufwand. Ein eher kleinesProduktionssystem kann einfacher und schneller durch eine Sequentielle Simulation abge-arbeitet werden. Ein sehr großes Produktionssystem kann - analog zu seiner realen Gliede-rung in Fertigungsbereiche - in Partitionen zerlegt und parallel simuliert werden.
Die Art und Anzahl der dynamischen Elemente (2.) gibt einen Eindruck vom Produkt-spektrum (Arten der dynamischen Elemente) und der Last des Produktionssystems (Ein-steuerung von Aufträgen). Die Belastungssituation des Produktionssystems ist maßgeblichfür die Synchronisation des Modells. Je mehr dynamische Elemente sich gleichzeitig imProduktionssystem bewegen, desto günstiger ist der Einsatz der Parallelen und VerteiltenSimulation, da der Grad der potentiellen Parallelität höher ist (das Verhältnis zwischeninternen und externen Ereignissen ist günstiger, siehe dazu Punkt 3.1.1.3, Seite 70). ImGegensatz dazu ist in einem kapazitiv überdimensionierten Produktionssystem oder einemProduktionssystem mit momentan niedriger Auslastung der Grad der potentiellen Paral-
176 Eine Übersicht über verschiedene Ansätze, Modelle und erreichten Speedups kann in [Meister 1993],
[Luksch 1995] bzw. [Vee, Hsu 1999] nachgelesen werden.

Kapitel 6 Empirische Untersuchung der Parallelen Simulation von Produktionssystemen
Seite 242
lelität gering und somit eventuell eine Sequentielle Simulation - aufgrund des nicht not-wendigen Overheads zur Synchronisation - besser geeignet.
Die Einbeziehung auftretender Prozeßbedingungen (3.) wie z.B. das Vorhandenseinvon Maschinengruppen, die Einbeziehung eines Werkermodells, auftretende Batch- undRüstproblematiken usw. führt zu einer höheren Abbildungsgenauigkeit des Modells, aberauch zu einem höheren numerischen Aufwand. Dies hat Einfluß auf die Frage, was zu ei-ner gemeinsamen Partition zusammengefaßt werden sollte.
Der Organisationsgrad der Produktion (4.) beschreibt Anordnung und Wege innerhalbdes Produktionssystems. Ein Produktionssystem kann z.B. eine Linienstruktur aufweisenoder aus einem Netz von Werkstätten bestehen. Dies hat starken Einfluß auf die Partitio-nierung, die Kommunikation und die Synchronisation. Existieren mehrere separate Ferti-gungslinien, so ist ersichtlich, daß eine Gruppierung dieser Fertigungslinien als Partitionensinnvoll wäre. In einem stark vernetzten Produktionssystem dagegen ist es notwendig,Kommunikationsbeziehungen und -profil zu analysieren und daraus einen Vorschlag zurPartitionierung abzuleiten (vergleiche Punkt 4.5).
Letzten Endes bestimmt der verwendete Reihenfolgeplanungsansatz (5.) die Häufigkeitund Höhe des Parameters Lookahead (siehe Punkt 4.3.4.2). Der Lookahead ist aber einmaßgeblicher Parameter zur Beeinflussung der Performance der Parallelen und VerteiltenSimulation (siehe Punkt 3.1.3.3). Ein Ansatz wie FIFO führt zu einem sehr hohen Look-ahead und wirkt damit günstig auf die Performance der Parallelen und Verteilten Simula-tion (siehe Punkt 4.3.4.2, Seite 78, vergleiche [Nicol 1988], [Preiss, Loucks 1990],[Loucks, Preiss 1990], [Jha, Bagrodia 1993], [Greenberg, Lubachevsky 1996], [Paprotny,Fowler 2001]). Aus Sicht der Fertigungssteuerung ist der alleinige Einsatz von FIFO aller-dings nicht akzeptabel. Es ist explizit erforderlich, verschiedenartige Ansätze zur Reihen-folgeplanung in der Simulation einsetzen zu können (siehe „Anforderungen“, Punkt 3.3).Der Berechnungsaufwand der Reihenfolgeplanungsansätze steigt beim Einsatz einfacherPrioritätsregeln bis zum Einsatz komplexer Reihenfolgeplanungsansätze an. Ziel ist es,umfangreiche Berechnungen zur Planung der Reihenfolge parallel auszuführen, um durchAusnutzung der Parallelität eine höhere Abarbeitungsgeschwindigkeit der Simulation zuerreichen.
Betrachtet man die grundlegenden Ausprägungen dieser fünf Parametergruppen (sieheAbbildung 121), so wird deutlich, daß durch die Kombination der Ausprägungen dieserParameter eine hohe Anzahl von Modellklassen (im Beispiel 4.608 Varianten) entsteht.
Eine empirische Untersuchung aller Modellklassen würde vom Aufwand her den Rahmender Arbeit sprengen, deswegen soll an dieser Stelle eine Auswahl repräsentativer Regionenvon Modellklassen erfolgen, wie sie typisch für existierende Produktionssysteme sind:
• Region A (vergleiche Abbildung 121):
• Es sind nur wenige statische Elemente vorhanden. Es existieren nur wenige Produk-te. Die Einsteuerung ist mäßig, das Einsteuerungsprofil wechselt. Es werden keinekomplexen Prozeßbedingungen betrachtet. Das Produktionssystem besitzt eine ein-fache Fertigungslinien- oder Netzstruktur. Als Reihenfolgeplanungsansätze kommenFIFO oder einfache Prioritätsregeln zum Einsatz.
• Diese Untersuchungsregion ist vergleichbar mit bisher aufgestellten Modellen vonProduktionssystemen in der Parallelen und Verteilten Simulation.
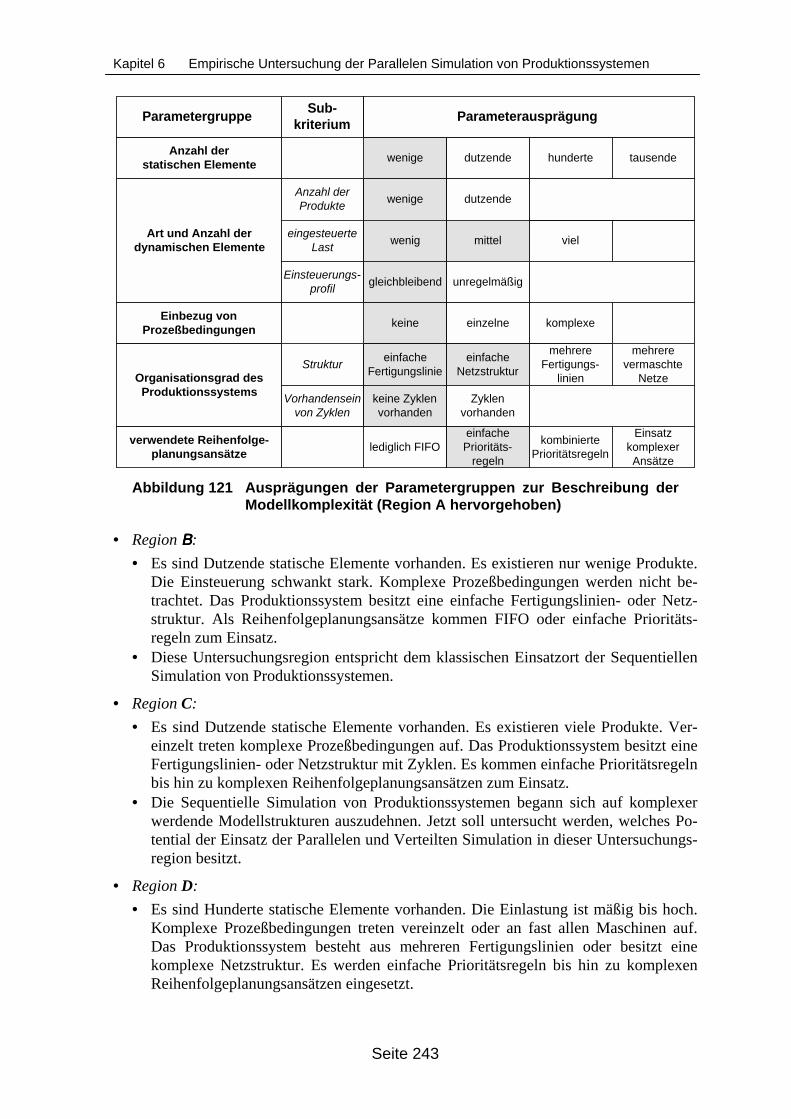
Kapitel 6 Empirische Untersuchung der Parallelen Simulation von Produktionssystemen
Seite 243
Anzahl derstatischen Elemente
Art und Anzahl derdynamischen Elemente
Einbezug vonProzeßbedingungen
Organisationsgrad desProduktionssystems
verwendete Reihenfolge-planungsansätze
wenige dutzende hunderte tausende
Anzahl derProdukte
eingesteuerteLast
Einsteuerungs-profil
wenige dutzende
wenig mittel viel
gleichbleibend unregelmäßig
keine einzelne komplexe
Struktureinfache
Fertigungslinieeinfache
Netzstruktur
mehrereFertigungs-
linien
mehrerevermaschte
Netze
Vorhandenseinvon Zyklen
keine Zyklenvorhanden
Zyklenvorhanden
lediglich FIFOeinfachePrioritäts-
regeln
kombiniertePrioritätsregeln
EinsatzkomplexerAnsätze
ParametergruppeSub-
kriteriumParameterausprägung
Abbildung 121 Ausprägungen der Parametergruppen zur Beschreibung derModellkomplexität (Region A hervorgehoben)
• Region ΒΒΒΒ:
• Es sind Dutzende statische Elemente vorhanden. Es existieren nur wenige Produkte.Die Einsteuerung schwankt stark. Komplexe Prozeßbedingungen werden nicht be-trachtet. Das Produktionssystem besitzt eine einfache Fertigungslinien- oder Netz-struktur. Als Reihenfolgeplanungsansätze kommen FIFO oder einfache Prioritäts-regeln zum Einsatz.
• Diese Untersuchungsregion entspricht dem klassischen Einsatzort der SequentiellenSimulation von Produktionssystemen.
• Region C:
• Es sind Dutzende statische Elemente vorhanden. Es existieren viele Produkte. Ver-einzelt treten komplexe Prozeßbedingungen auf. Das Produktionssystem besitzt eineFertigungslinien- oder Netzstruktur mit Zyklen. Es kommen einfache Prioritätsregelnbis hin zu komplexen Reihenfolgeplanungsansätzen zum Einsatz.
• Die Sequentielle Simulation von Produktionssystemen begann sich auf komplexerwerdende Modellstrukturen auszudehnen. Jetzt soll untersucht werden, welches Po-tential der Einsatz der Parallelen und Verteilten Simulation in dieser Untersuchungs-region besitzt.
• Region D:
• Es sind Hunderte statische Elemente vorhanden. Die Einlastung ist mäßig bis hoch.Komplexe Prozeßbedingungen treten vereinzelt oder an fast allen Maschinen auf.Das Produktionssystem besteht aus mehreren Fertigungslinien oder besitzt einekomplexe Netzstruktur. Es werden einfache Prioritätsregeln bis hin zu komplexenReihenfolgeplanungsansätzen eingesetzt.
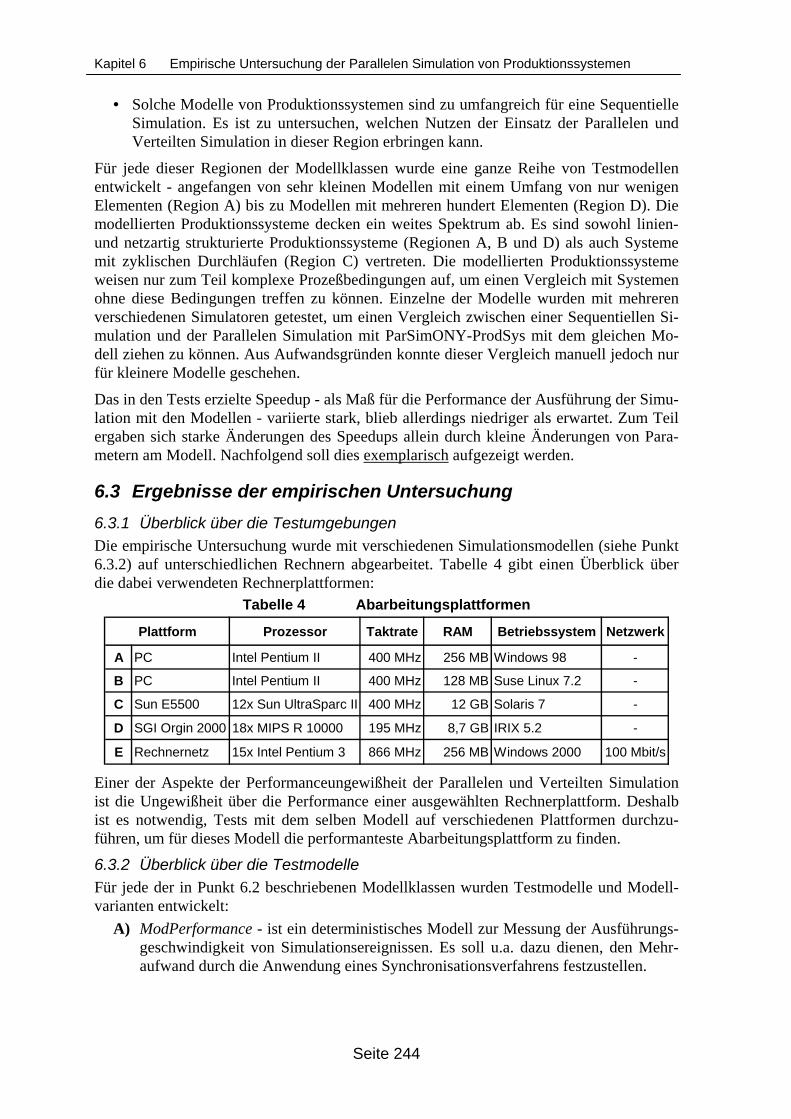
Kapitel 6 Empirische Untersuchung der Parallelen Simulation von Produktionssystemen
Seite 244
• Solche Modelle von Produktionssystemen sind zu umfangreich für eine SequentielleSimulation. Es ist zu untersuchen, welchen Nutzen der Einsatz der Parallelen undVerteilten Simulation in dieser Region erbringen kann.
Für jede dieser Regionen der Modellklassen wurde eine ganze Reihe von Testmodellenentwickelt - angefangen von sehr kleinen Modellen mit einem Umfang von nur wenigenElementen (Region A) bis zu Modellen mit mehreren hundert Elementen (Region D). Diemodellierten Produktionssysteme decken ein weites Spektrum ab. Es sind sowohl linien-und netzartig strukturierte Produktionssysteme (Regionen A, B und D) als auch Systememit zyklischen Durchläufen (Region C) vertreten. Die modellierten Produktionssystemeweisen nur zum Teil komplexe Prozeßbedingungen auf, um einen Vergleich mit Systemenohne diese Bedingungen treffen zu können. Einzelne der Modelle wurden mit mehrerenverschiedenen Simulatoren getestet, um einen Vergleich zwischen einer Sequentiellen Si-mulation und der Parallelen Simulation mit ParSimONY-ProdSys mit dem gleichen Mo-dell ziehen zu können. Aus Aufwandsgründen konnte dieser Vergleich manuell jedoch nurfür kleinere Modelle geschehen.
Das in den Tests erzielte Speedup - als Maß für die Performance der Ausführung der Simu-lation mit den Modellen - variierte stark, blieb allerdings niedriger als erwartet. Zum Teilergaben sich starke Änderungen des Speedups allein durch kleine Änderungen von Para-metern am Modell. Nachfolgend soll dies exemplarisch aufgezeigt werden.
6.3 Ergebnisse der empirischen Untersuchung
6.3.1 Überblick über die Testumgebungen
Die empirische Untersuchung wurde mit verschiedenen Simulationsmodellen (siehe Punkt6.3.2) auf unterschiedlichen Rechnern abgearbeitet. Tabelle 4 gibt einen Überblick überdie dabei verwendeten Rechnerplattformen:
Tabelle 4 Abarbeitungsplattformen
Plattform Prozessor Taktrate RAM Betriebssystem Netzwerk
A PC Intel Pentium II 400 MHz 256 MB Windows 98 -
B PC Intel Pentium II 400 MHz 128 MB Suse Linux 7.2 -
C Sun E5500 12x Sun UltraSparc II 400 MHz 12 GB Solaris 7 -
D SGI Orgin 2000 18x MIPS R 10000 195 MHz 8,7 GB IRIX 5.2 -
E Rechnernetz 15x Intel Pentium 3 866 MHz 256 MB Windows 2000 100 Mbit/s
Einer der Aspekte der Performanceungewißheit der Parallelen und Verteilten Simulationist die Ungewißheit über die Performance einer ausgewählten Rechnerplattform. Deshalbist es notwendig, Tests mit dem selben Modell auf verschiedenen Plattformen durchzu-führen, um für dieses Modell die performanteste Abarbeitungsplattform zu finden.
6.3.2 Überblick über die Testmodelle
Für jede der in Punkt 6.2 beschriebenen Modellklassen wurden Testmodelle und Modell-varianten entwickelt:
A) ModPerformance - ist ein deterministisches Modell zur Messung der Ausführungs-geschwindigkeit von Simulationsereignissen. Es soll u.a. dazu dienen, den Mehr-aufwand durch die Anwendung eines Synchronisationsverfahrens festzustellen.

Kapitel 6 Empirische Untersuchung der Parallelen Simulation von Produktionssystemen
Seite 245
B) Mod11M - stellt die Realisierung eines 11-Maschinen-Test-Problems einer typi-schen Werkstattfertigung dar, welches auch für verschiedene Sequentielle Simula-toren - darunter GPSS/H - vorhanden ist.
C) ModKlein - ist ein Beispielmodell mit fünf Maschinengruppen. Es dient dazu, denEinfluß von Modellparametern auf die Performance der Parallelen Simulation mitParSimONY-ProdSys zu untersuchen.
D) ModKleineKetten - ist ein Beispielmodell mit 25 Maschinengruppen, die in mehre-ren Linien angeordnet sind. In diesem Modell wird u.a. die Partitionierung verän-dert, um den Performanceeinfluß der Partitionierung aufzudecken.
E) KomplexMod - ist ein vereinfachtes Modell eines Produktionssystems mit hoch-komplexen Prozeßbedingungen. Es handelt sich dabei um den typischen Ausschnitteines realen Fertigungssystems, in dem alle Kombinationen der komplexen Prozeß-bedingungen auftreten.
F) LinienMod - ist ein großes Modell eines fiktiven Produktionssystems als Beispielfür Produktionssysteme in Linienstruktur mit komplexen Prozeßbedingungen.
Nachfolgend sollen die Ergebnisse der Ausführung dieser Testmodelle mit dem ParallelenSimulator ParSimONY-ProdSys vorgestellt werden und es soll der Einfluß von Parameternwie z.B. dem verwendeten Synchronisationsverfahren oder der Partitionierung des Modellsaufgezeigt werden.
6.3.3 Überblick über verwendeten Simulatoren und Synchronisationsverfahren
Für die lokale Abarbeitung (PC, Mehrprozessorrechner) wurden die ParSimONY-Simula-toren (Synchronisationsverfahren) SequentialSimulator, ThreadedCMBSimulator undThreadedTWSimulator verwendet (siehe Punkt 5.2.2.2, Seite 211f).
Für die verteilte Abarbeitung in einem Rechnernetz wurden die ParSimONY-SimulatorenSequentialSimulator, DistributedCMBSimulator und DistributedTWSimulator verwendet(siehe Punkt 5.2.2.2, Seite 211f).
Sequential-Simulator
ThreadedCMB-Simulator
ThreadedTW-Simulator
Distributed-CMBSimulator
Distributed-TWSimulator
konservativeSynchronisation
konservativeSynchronisation
optimistischeSynchronisation
optimistischeSynchronisation
Parallele SimulationParallele SimulationSequentielleSimulation
Lokale Abarbeitung(PC, Mehrprozessorrechner)
Verteilte Abarbeitung(im Rechnernetzwerk)
Abbildung 122 Übersicht über die verwendeten Synchronisationsverfahren
6.3.4 Ergebnisse der Experimente mit dem Modell ModPerformance
Ziel der Experimente mit dem Modell:
Mit dem Modell ModPerformance ist es möglich, die Ausführungsgeschwindigkeit desmomentan verwendeten Simulators auf der aktuellen Abarbeitungsplattform zu bestimmen.So kann ein Wert in Ereignissen je Millisekunde177 berechnet werden, der dann Basis fürdie Bemessung des Overheads durch das momentan verwendete Synchronisationsver-
177 Dieser Wert wird oft auch als „moves per second“ bezeichnet.
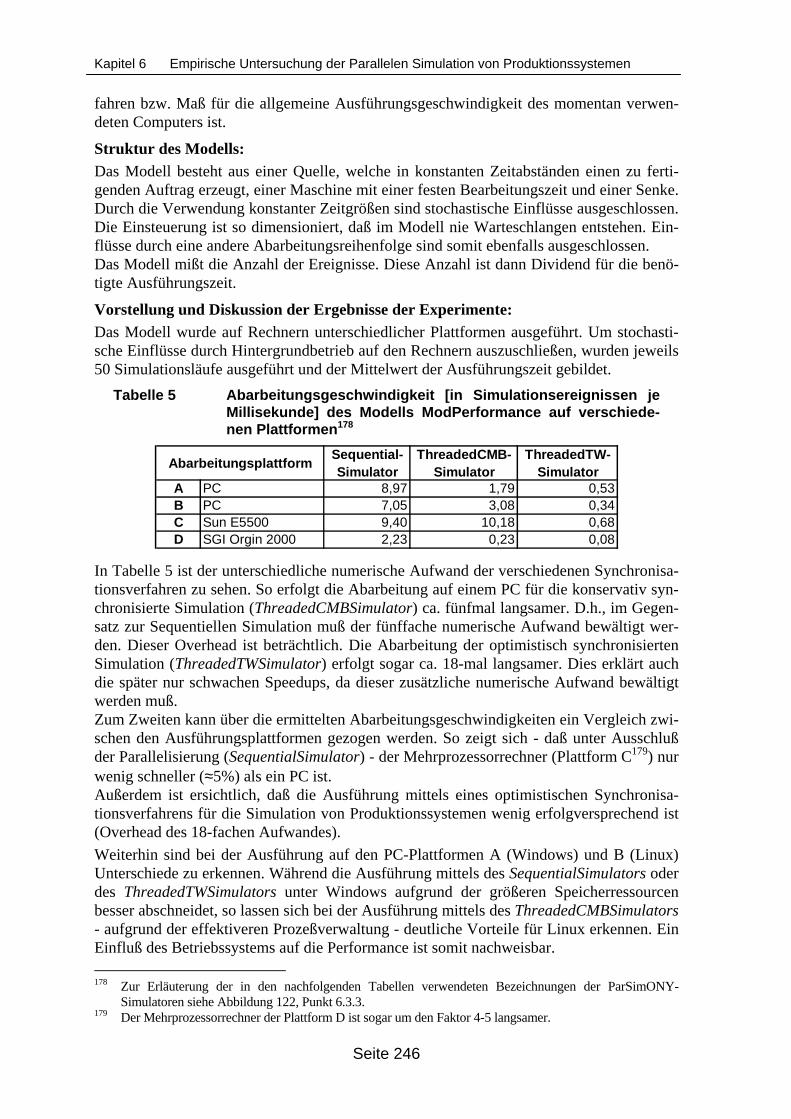
Kapitel 6 Empirische Untersuchung der Parallelen Simulation von Produktionssystemen
Seite 246
fahren bzw. Maß für die allgemeine Ausführungsgeschwindigkeit des momentan verwen-deten Computers ist.
Struktur des Modells:
Das Modell besteht aus einer Quelle, welche in konstanten Zeitabständen einen zu ferti-genden Auftrag erzeugt, einer Maschine mit einer festen Bearbeitungszeit und einer Senke.Durch die Verwendung konstanter Zeitgrößen sind stochastische Einflüsse ausgeschlossen.Die Einsteuerung ist so dimensioniert, daß im Modell nie Warteschlangen entstehen. Ein-flüsse durch eine andere Abarbeitungsreihenfolge sind somit ebenfalls ausgeschlossen.Das Modell mißt die Anzahl der Ereignisse. Diese Anzahl ist dann Dividend für die benö-tigte Ausführungszeit.
Vorstellung und Diskussion der Ergebnisse der Experimente:
Das Modell wurde auf Rechnern unterschiedlicher Plattformen ausgeführt. Um stochasti-sche Einflüsse durch Hintergrundbetrieb auf den Rechnern auszuschließen, wurden jeweils50 Simulationsläufe ausgeführt und der Mittelwert der Ausführungszeit gebildet.
Tabelle 5 Abarbeitungsgeschwindigkeit [in Simulationsereignissen jeMillisekunde] des Modells ModPerformance auf verschiede-nen Plattformen178
AbarbeitungsplattformSequential-Simulator
ThreadedCMB-Simulator
ThreadedTW-Simulator
A PC 8,97 1,79 0,53B PC 7,05 3,08 0,34C Sun E5500 9,40 10,18 0,68D SGI Orgin 2000 2,23 0,23 0,08
In Tabelle 5 ist der unterschiedliche numerische Aufwand der verschiedenen Synchronisa-tionsverfahren zu sehen. So erfolgt die Abarbeitung auf einem PC für die konservativ syn-chronisierte Simulation (ThreadedCMBSimulator) ca. fünfmal langsamer. D.h., im Gegen-satz zur Sequentiellen Simulation muß der fünffache numerische Aufwand bewältigt wer-den. Dieser Overhead ist beträchtlich. Die Abarbeitung der optimistisch synchronisiertenSimulation (ThreadedTWSimulator) erfolgt sogar ca. 18-mal langsamer. Dies erklärt auchdie später nur schwachen Speedups, da dieser zusätzliche numerische Aufwand bewältigtwerden muß.Zum Zweiten kann über die ermittelten Abarbeitungsgeschwindigkeiten ein Vergleich zwi-schen den Ausführungsplattformen gezogen werden. So zeigt sich - daß unter Ausschlußder Parallelisierung (SequentialSimulator) - der Mehrprozessorrechner (Plattform C179) nurwenig schneller (≈5%) als ein PC ist.Außerdem ist ersichtlich, daß die Ausführung mittels eines optimistischen Synchronisa-tionsverfahrens für die Simulation von Produktionssystemen wenig erfolgversprechend ist(Overhead des 18-fachen Aufwandes).
Weiterhin sind bei der Ausführung auf den PC-Plattformen A (Windows) und B (Linux)Unterschiede zu erkennen. Während die Ausführung mittels des SequentialSimulators oderdes ThreadedTWSimulators unter Windows aufgrund der größeren Speicherressourcenbesser abschneidet, so lassen sich bei der Ausführung mittels des ThreadedCMBSimulators- aufgrund der effektiveren Prozeßverwaltung - deutliche Vorteile für Linux erkennen. EinEinfluß des Betriebssystems auf die Performance ist somit nachweisbar. 178 Zur Erläuterung der in den nachfolgenden Tabellen verwendeten Bezeichnungen der ParSimONY-
Simulatoren siehe Abbildung 122, Punkt 6.3.3.179 Der Mehrprozessorrechner der Plattform D ist sogar um den Faktor 4-5 langsamer.

Kapitel 6 Empirische Untersuchung der Parallelen Simulation von Produktionssystemen
Seite 247
Tabelle 6 Abarbeitungsgeschwindigkeit [in Simulationsereignissen jeMillisekunde] des Modells ModPerformance in einem Rech-nernetz
AbarbeitungsplattformSequential-Simulator
Distributed-CMBSimulator
Distributed-TWSimulator
E 1 Rechner im Netz 14,270 2,848 0,843E 2 Rechner im Netz - 0,163 0,048E 3 Rechner im Netz - 0,177 0,052
Tabelle 6 zeigt die Abarbeitungsgeschwindigkeit bei einer verteilten Abarbeitung. DieErgebnisse zeigen eine deutliche Verringerung der Abarbeitungsgeschwindigkeit im Falleeiner verteilten Abarbeitung auf mehreren Rechnern. Ursache dafür ist die im Test fest-gestellte mittlere Übertragungszeit zwischen den Rechnern von ca. 20 ms. In der Zeit-spanne der Übertragung einer Nachricht werden auf dem selben Rechner aber ca. 285weitere Ereignisse abgearbeitet. Das bedeutet, daß eigentlich nur auf das Eintreffen vonNachrichten gewartet werden muß, oder daß ein Logischer Prozeß ein Verhältnis von mehrals 285 internen Ereignissen zu einem externen Ereignis aufweisen muß. Ein solches Ver-hältnis ist jedoch aufgrund der Vernetzung der Fertigungssysteme und der dort herrschen-den hohen Dependenzen faktisch ausgeschlossen. Die verteilte Abarbeitung in Rechner-netzen ist daher nicht sinnvoll.
6.3.5 Ergebnisse der Experimente mit dem Modell Mod11M
Ziel der Experimente mit dem Modell:
Das Modell realisiert ein Beispiel eines typischen Produktionssystems eines Auftrags-fertigers. Von den Dimensionen (11 Maschinen, 5 Produkttypen, hohe Einlastung) ähneltes den bisher in der Parallelen und Verteilten Simulation behandelten Bedienungsnetzen(siehe u.a. [Nicol 1988], [Preiss, Loucks 1990], [Jha, Bagrodia 1993], [Holthaus, Ziegler,Rosenberg 1996], [Greenberg, Lubachevsky 1996], [Preiss, Wan 1999]). Ziel der Experi-mente mit diesem Modell ist, die Anwendbarkeit des Parallelen Simulators ParSimONY-ProdSys für Modelle von Produktionssystemen aufzuzeigen und Vergleiche mit anderenSimulatoren - insbesondere GPSS/H180 - zu ziehen.
Struktur des Modells:
Abbildung 123 zeigt den Aufbau des Produktionssystems.
Es werden fünf unterschiedliche Produkte hergestellt. Für den Fertigungsprozeß werden elfMaschinen benötigt. Tabelle 7 zeigt die Arbeitspläne und Bearbeitungszeiten für die ein-zelnen Produkte. Die Einsteuerung von Fertigungsaufträgen für die Produkte geschiehtexponentialverteilt mit dem Mittelwert von 25 Zeiteinheiten. Die Losgröße der Fertigungs-aufträge ist gleichverteilt im Intervall [1;5].
180 GPSS/H ist die Implementierung der General Purpose Simulation Languague von Hendriksen, Wolverine
Simulation Software Corporation.
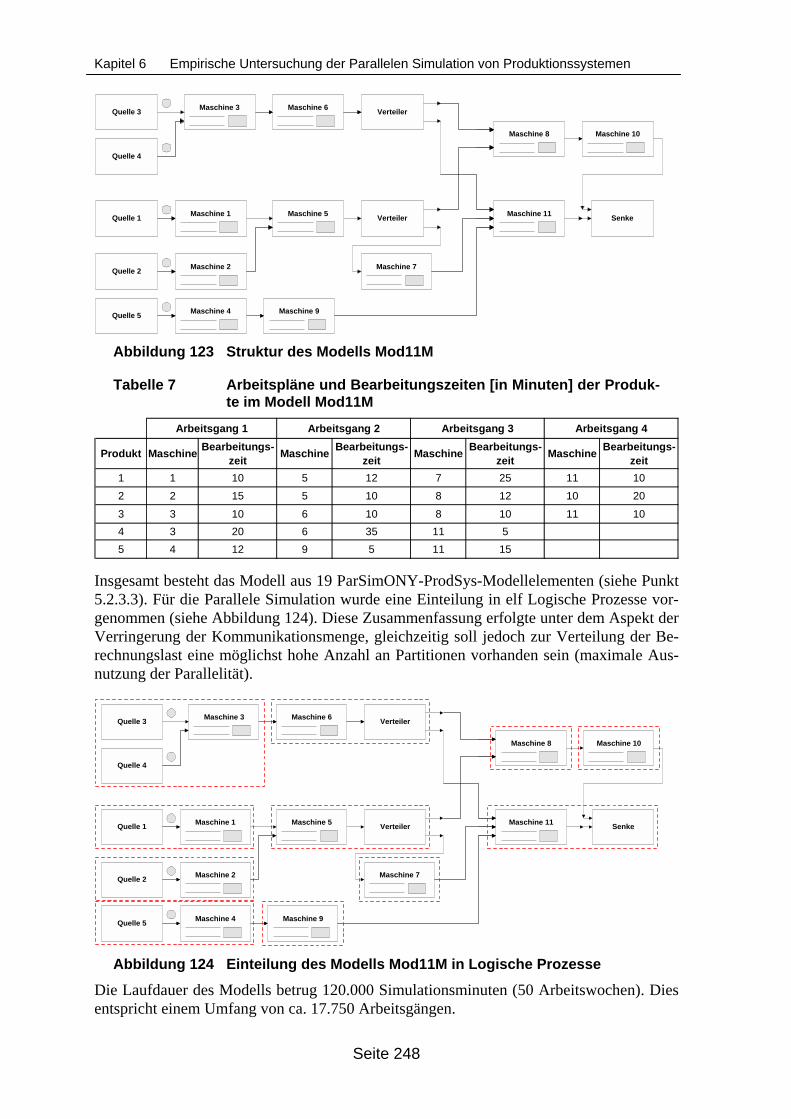
Kapitel 6 Empirische Untersuchung der Parallelen Simulation von Produktionssystemen
Seite 248
Quelle 1
Quelle 2
Quelle 5
Maschine 11
Maschine 6Verteiler
Maschine 4 Maschine 9
Verteiler
Maschine 7
Maschine 8 Maschine 10
Senke
Maschine 2
Maschine 5Maschine 1
Quelle 4
Maschine 3Quelle 3
Abbildung 123 Struktur des Modells Mod11M
Tabelle 7 Arbeitspläne und Bearbeitungszeiten [in Minuten] der Produk-te im Modell Mod11M
Arbeitsgang 1 Arbeitsgang 2 Arbeitsgang 3 Arbeitsgang 4
Produkt MaschineBearbeitungs-
zeitMaschine
Bearbeitungs-zeit
MaschineBearbeitungs-
zeitMaschine
Bearbeitungs-zeit
1 1 10 5 12 7 25 11 10
2 2 15 5 10 8 12 10 20
3 3 10 6 10 8 10 11 10
4 3 20 6 35 11 5
5 4 12 9 5 11 15
Insgesamt besteht das Modell aus 19 ParSimONY-ProdSys-Modellelementen (siehe Punkt5.2.3.3). Für die Parallele Simulation wurde eine Einteilung in elf Logische Prozesse vor-genommen (siehe Abbildung 124). Diese Zusammenfassung erfolgte unter dem Aspekt derVerringerung der Kommunikationsmenge, gleichzeitig soll jedoch zur Verteilung der Be-rechnungslast eine möglichst hohe Anzahl an Partitionen vorhanden sein (maximale Aus-nutzung der Parallelität).
Quelle 1
Quelle 2
Quelle 5
Maschine 11
Maschine 6Verteiler
Maschine 4 Maschine 9
Verteiler
Maschine 7
Maschine 8 Maschine 10
Senke
Maschine 2
Maschine 5Maschine 1
Quelle 4
Maschine 3Quelle 3
Abbildung 124 Einteilung des Modells Mod11M in Logische Prozesse
Die Laufdauer des Modells betrug 120.000 Simulationsminuten (50 Arbeitswochen). Diesentspricht einem Umfang von ca. 17.750 Arbeitsgängen.
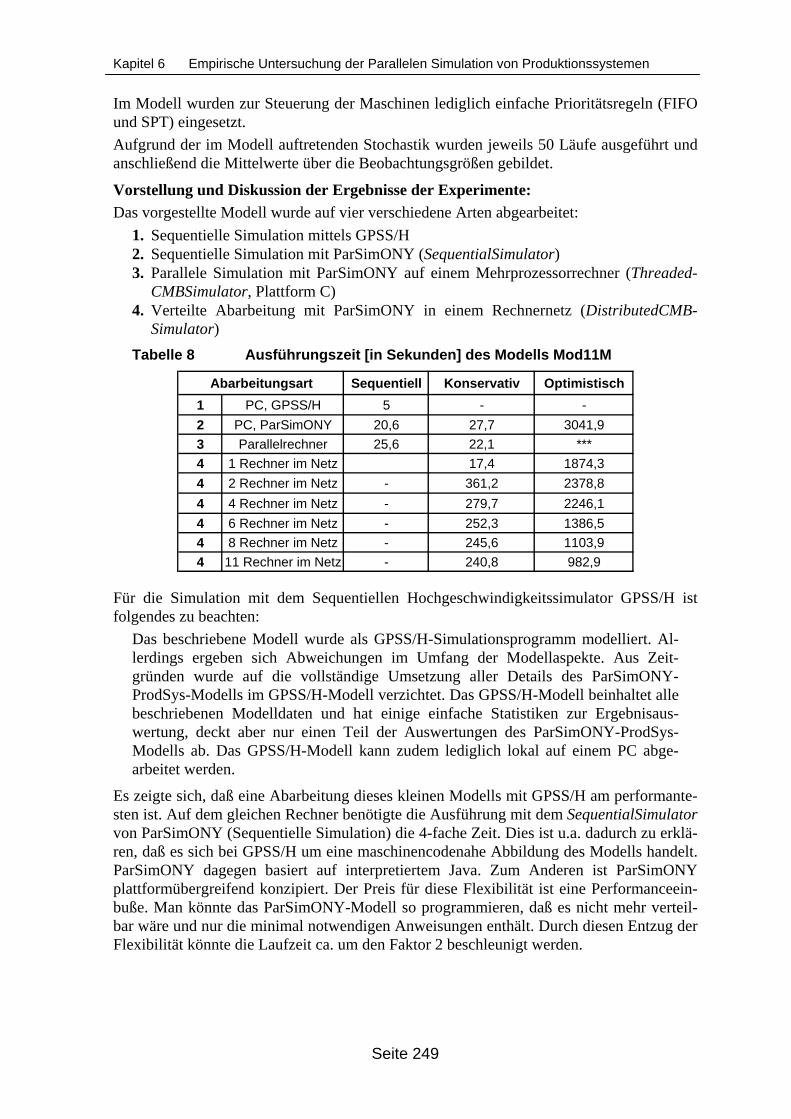
Kapitel 6 Empirische Untersuchung der Parallelen Simulation von Produktionssystemen
Seite 249
Im Modell wurden zur Steuerung der Maschinen lediglich einfache Prioritätsregeln (FIFOund SPT) eingesetzt.
Aufgrund der im Modell auftretenden Stochastik wurden jeweils 50 Läufe ausgeführt undanschließend die Mittelwerte über die Beobachtungsgrößen gebildet.
Vorstellung und Diskussion der Ergebnisse der Experimente:
Das vorgestellte Modell wurde auf vier verschiedene Arten abgearbeitet:
1. Sequentielle Simulation mittels GPSS/H2. Sequentielle Simulation mit ParSimONY (SequentialSimulator)3. Parallele Simulation mit ParSimONY auf einem Mehrprozessorrechner (Threaded-
CMBSimulator, Plattform C)4. Verteilte Abarbeitung mit ParSimONY in einem Rechnernetz (DistributedCMB-
Simulator)
Tabelle 8 Ausführungszeit [in Sekunden] des Modells Mod11M
Abarbeitungsart Sequentiell Konservativ Optimistisch
1 PC, GPSS/H 5 - -
2 PC, ParSimONY 20,6 27,7 3041,9
3 Parallelrechner 25,6 22,1 ***
4 1 Rechner im Netz 17,4 1874,3
4 2 Rechner im Netz - 361,2 2378,8
4 4 Rechner im Netz - 279,7 2246,1
4 6 Rechner im Netz - 252,3 1386,5
4 8 Rechner im Netz - 245,6 1103,9
4 11 Rechner im Netz - 240,8 982,9
Für die Simulation mit dem Sequentiellen Hochgeschwindigkeitssimulator GPSS/H istfolgendes zu beachten:
Das beschriebene Modell wurde als GPSS/H-Simulationsprogramm modelliert. Al-lerdings ergeben sich Abweichungen im Umfang der Modellaspekte. Aus Zeit-gründen wurde auf die vollständige Umsetzung aller Details des ParSimONY-ProdSys-Modells im GPSS/H-Modell verzichtet. Das GPSS/H-Modell beinhaltet allebeschriebenen Modelldaten und hat einige einfache Statistiken zur Ergebnisaus-wertung, deckt aber nur einen Teil der Auswertungen des ParSimONY-ProdSys-Modells ab. Das GPSS/H-Modell kann zudem lediglich lokal auf einem PC abge-arbeitet werden.
Es zeigte sich, daß eine Abarbeitung dieses kleinen Modells mit GPSS/H am performante-sten ist. Auf dem gleichen Rechner benötigte die Ausführung mit dem SequentialSimulatorvon ParSimONY (Sequentielle Simulation) die 4-fache Zeit. Dies ist u.a. dadurch zu erklä-ren, daß es sich bei GPSS/H um eine maschinencodenahe Abbildung des Modells handelt.ParSimONY dagegen basiert auf interpretiertem Java. Zum Anderen ist ParSimONYplattformübergreifend konzipiert. Der Preis für diese Flexibilität ist eine Performanceein-buße. Man könnte das ParSimONY-Modell so programmieren, daß es nicht mehr verteil-bar wäre und nur die minimal notwendigen Anweisungen enthält. Durch diesen Entzug derFlexibilität könnte die Laufzeit ca. um den Faktor 2 beschleunigt werden.

Kapitel 6 Empirische Untersuchung der Parallelen Simulation von Produktionssystemen
Seite 250
Die Parallele Simulation des Modells auf einem Rechner mit 12 Prozessoren181 ergab fürdie konservativ synchronisierte Variante (ThreadedCMBSimulator) ein Speedup von ca.30%. Die Abarbeitung mit dem optimistischen Synchronisationsverfahren (ThreadedTW-Simulator) dauerte mehr als 20 Minuten und war durch vielfache Abstürze aufgrundHauptspeichermangels gekennzeichnet182.
Die verteilte Abarbeitung in einem Rechnernetz wurde in unterschiedlichen Konstellatio-nen getestet. Das Simulationsmodell enthält elf logische Prozesse, deswegen wurde eineverteilte Abarbeitung mit 2, 4, 6, 8 und 11 Rechnern getestet. Die verteilte Abarbeitungzeigte einen erheblichen Slowdown. Bei der konservativ synchronisierten Variante(DistributedCMBSimulator) waren die zur Ausführung benutzen Rechner nur gering aus-gelastet. Der überwiegende Teil der Laufzeit wurde von der Nachrichtenübermittlung ver-braucht. Die Abarbeitung mit dem optimistischen Synchronisationsverfahren (Distributed-TWSimulator) dauerte zwischen 15 und 40 Minuten und war damit indiskutabel hoch.
D.h., die Simulation dieses Modells erfolgt durch den Einsatz der Parallelen und VerteiltenSimulation nicht performanter.
Der Report mit den Meßgrößen des Partitionierungsverfahrens (siehe dazu Punkt 5.3.3)zeigt die Gründe auf: Die Garantiehäufigkeit GHj (siehe Punkt 4.5.6, Seite 149) beträgtzwischen 31% und 42%. Dies bedeutet, daß im Mittel lediglich 34% der Ereignisse sichersind, in allen anderen Fällen tritt eine Blockierungssituation auf. Ein konservativ synchro-nisiertes Teilmodell blockiert hier, bei Einsatz optimistischer Synchronisationsverfahrenwerden dagegen auch unsichere Ereignisse ausgeführt, die später oft zurückgenommenwerden müssen und somit Rollbacks und im Beispiel Rollbackkaskaden verursachen. Miteiner Garantiesituationshäufigkeit von 34% ist die im Modell Mod11M verfügbare Paral-lelität nur gering.
6.3.6 Ergebnisse der Experimente mit dem Modell ModKlein
Ziel der Experimente mit dem Modell:
Das nachfolgende Beispielmodell soll exemplarisch aufzeigen, daß durch die Änderungnur eines Parameters plötzliche und sprunghafte Änderungen des resultierenden Speedupsauftreten können. Es wurde bewußt ein kleines Modell konstruiert, damit sich die Ursa-chen der Effekte besser ermitteln lassen. Die beschriebenen Effekte treten auch in größerenModellen auf, sie sind hier lediglich exemplarisch aufgeführt.
Struktur des Modells:
Abbildung 125 zeigt den Aufbau des Beispielmodells.
Es handelt sich hierbei um ein simples Fertigungssystem von fünf Maschinen. Es gibt zweiProdukte. Jedes der Produkte wird in drei Arbeitsgängen fertiggestellt.
181 Leider ist durch das Betriebssystem des Rechners die Anzahl der zu verwendenden Prozessoren nicht
wählbar. Es wird immer die momentan maximal verfügbare Prozessorenanzahl eingesetzt.182 In den Tests wurden sowohl eine Zustandssicherung durch Kopieren, eine inkrementelle Zustands-
sicherung, als auch eine Sicherung nach jedem 10. Ereignis verwendet (siehe Punkt 3.1.3.4). In jeder Vari-ante ergaben sich Probleme aufgrund Hauptspeichermangels. Die Zahlen in der Tabelle geben den günstig-sten Fall an - die Zustandssicherung durch Kopieren.

Kapitel 6 Empirische Untersuchung der Parallelen Simulation von Produktionssystemen
Seite 251
Senke
Maschine 1 Maschine 2
Maschine 3
Quelle(Produkt A)
Quelle(Produkt B)
Maschine 4
Maschine 5
Abbildung 125 Struktur des Beispielmodells ModKlein
Die Arbeitspläne sind wie folgt gestaltet:
Tabelle 9 Arbeitspläne im Beispielmodell ModKlein
Produkt A Produkt BArbeitsgang Maschine Zeit Arbeitsgang Maschine Zeit
1 Maschine 1 10 ZE 1 Maschine 3 20 ZE2 Maschine 2 20 ZE 2 Maschine 4 10 ZE3 Maschine 5 10 ZE 3 Maschine 5 10 ZE
Die Einsteuerung von Aufträgen erfolgt konstant alle 50 ZE sowohl für Produkt A als auchfür Produkt B.Es handelt sich somit um ein ausbalanciertes System. Alle eingesteuerten Aufträge werdenfertiggestellt, bevor der nächste Auftrag eingesteuert wird (Verkehrsgleichung des Bedie-nungssystems: λ / µ = 1).Die Maschinen 1 bis 4 sind völlig unkritisch, lediglich an Maschine 5 kann sich eine War-teschlange ergeben, die jedoch maximal die Länge 1 erreichen kann.
Weiterhin sei der Simulationszeitraum auf 96.000 ZE (40 Arbeitswochen) festgelegt. Diesentspricht ca. 11.520 Arbeitsgängen.
Das Modell hat damit einen ähnlichen Umfang wie in der Literatur vorgestellte Unter-suchungen zu Bedienungssystemen mittels Paralleler und Verteilter Simulation [Nicol1988], [Preiss, Loucks 1990], [Jha, Bagrodia 1993], [Holthaus, Ziegler, Rosenberg 1996],[Greenberg, Lubachevsky 1996], [Preiss, Wan 1999].
Für die Parallele Simulation mit ParSimONY-ProdSys wurde nachfolgende Einteilung inPartitionen verwendet:
Senke
Maschine 1 Maschine 2
Maschine 3
Quelle(Produkt A)
Quelle(Produkt B)
Maschine 4
Maschine 5
Partition 2
Partition 1
Partition 3
Abbildung 126 Einteilung des Modells ModKlein in Partitionen
Ergebnisse der Experimente:
Das vorgestellte Beispielmodell wurde mit den aufgeführten Simulatoren sowohl auf ei-nem PC als auch auf einem Mehrprozessorrechner ausgeführt. Dabei ergaben sich folgendeErgebnisse:

Kapitel 6 Empirische Untersuchung der Parallelen Simulation von Produktionssystemen
Seite 252
Tabelle 10 Abarbeitungsdauer [in Sekunden] des Modells ModKlein
AbarbeitungsplattformSequential-Simulator
ThreadedCMB-Simulator
ThreadedTW-Simulator
A PC 7,4 - -C Sun E5500 6,3 5,0 596
Tabelle 10 zeigt, daß sich ein Speedup von ungefähr 17% für die Abarbeitung auf demMehrprozessorrechner gegenüber der Abarbeitung auf dem PC ergibt.Die Abarbeitung mittels des konservativen Synchronisationsverfahrens ergab gegenüberdem Sequentiellen Simulator einen Speedup von ca. 26%.Die Abarbeitung mittels des TimeWarp-Verfahren war indiskutabel hoch.
Ergebnisse bei Veränderung von Modellparametern:
Nachfolgend soll gezeigt werden, daß durch Änderung einzelner Modellparameter ein Ein-fluß auf die Performance erzielt werden kann. Alle nachfolgend vorgestellten Ergebnissebeziehen sich auf eine Ausführung auf der 12-Prozessor-Maschine (Plattform C).
Änderung der Simulationsdauer:
Für den nachfolgenden Versuch wurden alle Modellparameter beibehalten, lediglich dieSimulationsdauer wurde verändert. Tabelle 11 zeigt einen unerwarteten Effekt:
Tabelle 11 Abhängigkeit des Speedups von der Simulationsdauer
Simulations-dauer
Sequential-Simulator
ThreadedCMB-Simulator
Speedup
2.400 ZE 0,998 s 0,843 s 1,18496.000 ZE 6,281 s 5,668 s 1,108
288.000 ZE 17,655 s 20,377 s 0,8663.679.200 ZE 31,893 s 48,415 s 0,659
Da es sich um ein ausgewogenes Produktionssystem handelt, ist dieser Effekt nicht durchden Aufbau von Warteschlangen etc. erklärbar.183
Änderung des Einsteuerungsverhaltens:
Im Grundmodell erzeugen die Quellen konstant nach 50 ZE den nächsten Auftrag, jetztsoll mit anderen, aber weiterhin konstanten Werten experimentiert werden. Ebenso soll dasAktivitätsverhältnis der Partitionen belassen werden, d.h. für beide Quellen muß die selbeAnkunftszeit verwendet werden.
Tabelle 12 Abhängigkeit des Speedups von der Einsteuerung
Ankunftszeiten Sequential-Simulator
ThreadedCMB-Simulator
Speedup
25 ZE 12,174 s 11,665 s 1,04445 ZE 7,035 s 5,819 s 1,20950 ZE 6,281 s 5,668 s 1,108
100 ZE 3,393 s 2,918 s 1,163
183 Eine mögliche Ursache ist in der Speicherverwaltung des javabasierten Tools ParSimONY zu suchen. Je
mehr Objekte zu verwalten sind, desto länger dauert ein Zugriff auf ein Objekt und desto höher ist die Fre-quenz der Garbage Collection zur Beseitigung unreferenzierter Objekte. Dies sind jedoch nicht beeinfluß-bare Mechanismen der Laufzeitumgebung von Java.
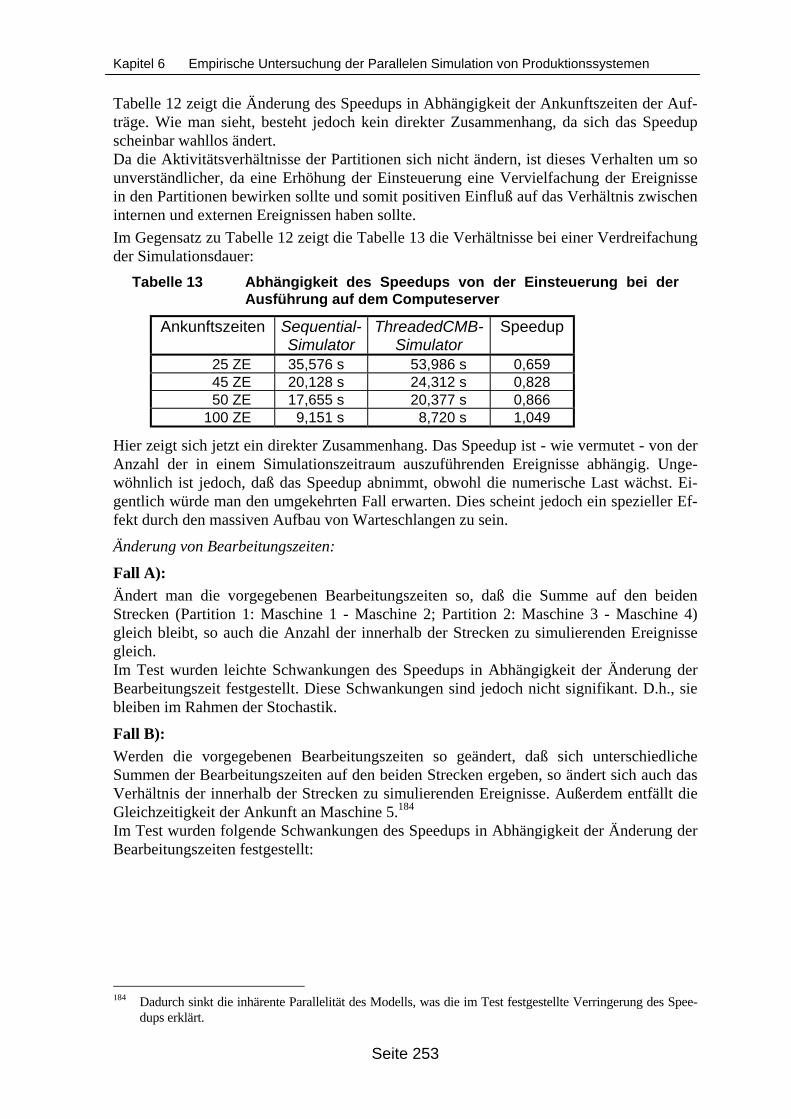
Kapitel 6 Empirische Untersuchung der Parallelen Simulation von Produktionssystemen
Seite 253
Tabelle 12 zeigt die Änderung des Speedups in Abhängigkeit der Ankunftszeiten der Auf-träge. Wie man sieht, besteht jedoch kein direkter Zusammenhang, da sich das Speedupscheinbar wahllos ändert.Da die Aktivitätsverhältnisse der Partitionen sich nicht ändern, ist dieses Verhalten um sounverständlicher, da eine Erhöhung der Einsteuerung eine Vervielfachung der Ereignissein den Partitionen bewirken sollte und somit positiven Einfluß auf das Verhältnis zwischeninternen und externen Ereignissen haben sollte.
Im Gegensatz zu Tabelle 12 zeigt die Tabelle 13 die Verhältnisse bei einer Verdreifachungder Simulationsdauer:
Tabelle 13 Abhängigkeit des Speedups von der Einsteuerung bei derAusführung auf dem Computeserver
Ankunftszeiten Sequential-Simulator
ThreadedCMB-Simulator
Speedup
25 ZE 35,576 s 53,986 s 0,65945 ZE 20,128 s 24,312 s 0,82850 ZE 17,655 s 20,377 s 0,866
100 ZE 9,151 s 8,720 s 1,049
Hier zeigt sich jetzt ein direkter Zusammenhang. Das Speedup ist - wie vermutet - von derAnzahl der in einem Simulationszeitraum auszuführenden Ereignisse abhängig. Unge-wöhnlich ist jedoch, daß das Speedup abnimmt, obwohl die numerische Last wächst. Ei-gentlich würde man den umgekehrten Fall erwarten. Dies scheint jedoch ein spezieller Ef-fekt durch den massiven Aufbau von Warteschlangen zu sein.
Änderung von Bearbeitungszeiten:
Fall A):
Ändert man die vorgegebenen Bearbeitungszeiten so, daß die Summe auf den beidenStrecken (Partition 1: Maschine 1 - Maschine 2; Partition 2: Maschine 3 - Maschine 4)gleich bleibt, so auch die Anzahl der innerhalb der Strecken zu simulierenden Ereignissegleich.Im Test wurden leichte Schwankungen des Speedups in Abhängigkeit der Änderung derBearbeitungszeit festgestellt. Diese Schwankungen sind jedoch nicht signifikant. D.h., siebleiben im Rahmen der Stochastik.
Fall B):
Werden die vorgegebenen Bearbeitungszeiten so geändert, daß sich unterschiedlicheSummen der Bearbeitungszeiten auf den beiden Strecken ergeben, so ändert sich auch dasVerhältnis der innerhalb der Strecken zu simulierenden Ereignisse. Außerdem entfällt dieGleichzeitigkeit der Ankunft an Maschine 5.184
Im Test wurden folgende Schwankungen des Speedups in Abhängigkeit der Änderung derBearbeitungszeiten festgestellt:
184 Dadurch sinkt die inhärente Parallelität des Modells, was die im Test festgestellte Verringerung des Spee-
dups erklärt.
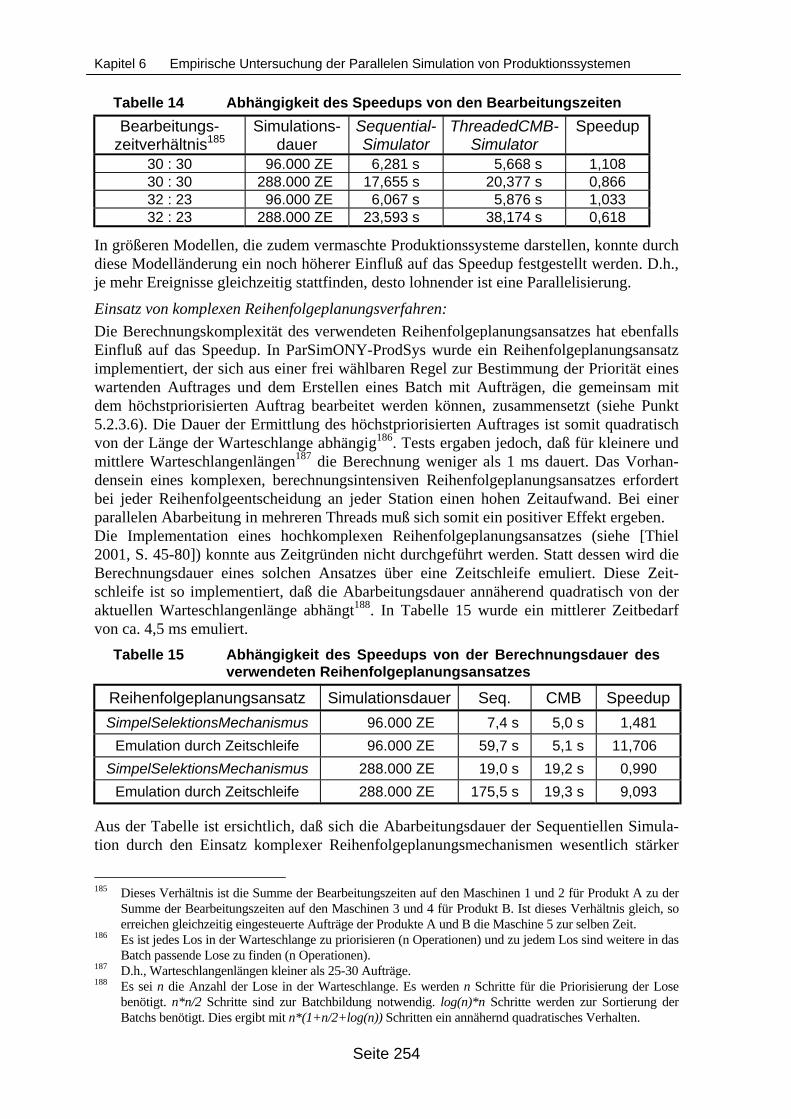
Kapitel 6 Empirische Untersuchung der Parallelen Simulation von Produktionssystemen
Seite 254
Tabelle 14 Abhängigkeit des Speedups von den Bearbeitungszeiten
Bearbeitungs-zeitverhältnis185
Simulations-dauer
Sequential-Simulator
ThreadedCMB-Simulator
Speedup
30 : 30 96.000 ZE 6,281 s 5,668 s 1,10830 : 30 288.000 ZE 17,655 s 20,377 s 0,86632 : 23 96.000 ZE 6,067 s 5,876 s 1,03332 : 23 288.000 ZE 23,593 s 38,174 s 0,618
In größeren Modellen, die zudem vermaschte Produktionssysteme darstellen, konnte durchdiese Modelländerung ein noch höherer Einfluß auf das Speedup festgestellt werden. D.h.,je mehr Ereignisse gleichzeitig stattfinden, desto lohnender ist eine Parallelisierung.
Einsatz von komplexen Reihenfolgeplanungsverfahren:
Die Berechnungskomplexität des verwendeten Reihenfolgeplanungsansatzes hat ebenfallsEinfluß auf das Speedup. In ParSimONY-ProdSys wurde ein Reihenfolgeplanungsansatzimplementiert, der sich aus einer frei wählbaren Regel zur Bestimmung der Priorität eineswartenden Auftrages und dem Erstellen eines Batch mit Aufträgen, die gemeinsam mitdem höchstpriorisierten Auftrag bearbeitet werden können, zusammensetzt (siehe Punkt5.2.3.6). Die Dauer der Ermittlung des höchstpriorisierten Auftrages ist somit quadratischvon der Länge der Warteschlange abhängig186. Tests ergaben jedoch, daß für kleinere undmittlere Warteschlangenlängen187 die Berechnung weniger als 1 ms dauert. Das Vorhan-densein eines komplexen, berechnungsintensiven Reihenfolgeplanungsansatzes erfordertbei jeder Reihenfolgeentscheidung an jeder Station einen hohen Zeitaufwand. Bei einerparallelen Abarbeitung in mehreren Threads muß sich somit ein positiver Effekt ergeben.Die Implementation eines hochkomplexen Reihenfolgeplanungsansatzes (siehe [Thiel2001, S. 45-80]) konnte aus Zeitgründen nicht durchgeführt werden. Statt dessen wird dieBerechnungsdauer eines solchen Ansatzes über eine Zeitschleife emuliert. Diese Zeit-schleife ist so implementiert, daß die Abarbeitungsdauer annäherend quadratisch von deraktuellen Warteschlangenlänge abhängt188. In Tabelle 15 wurde ein mittlerer Zeitbedarfvon ca. 4,5 ms emuliert.
Tabelle 15 Abhängigkeit des Speedups von der Berechnungsdauer desverwendeten Reihenfolgeplanungsansatzes
Reihenfolgeplanungsansatz Simulationsdauer Seq. CMB Speedup
SimpelSelektionsMechanismus 96.000 ZE 7,4 s 5,0 s 1,481
Emulation durch Zeitschleife 96.000 ZE 59,7 s 5,1 s 11,706
SimpelSelektionsMechanismus 288.000 ZE 19,0 s 19,2 s 0,990
Emulation durch Zeitschleife 288.000 ZE 175,5 s 19,3 s 9,093
Aus der Tabelle ist ersichtlich, daß sich die Abarbeitungsdauer der Sequentiellen Simula-tion durch den Einsatz komplexer Reihenfolgeplanungsmechanismen wesentlich stärker
185 Dieses Verhältnis ist die Summe der Bearbeitungszeiten auf den Maschinen 1 und 2 für Produkt A zu der
Summe der Bearbeitungszeiten auf den Maschinen 3 und 4 für Produkt B. Ist dieses Verhältnis gleich, soerreichen gleichzeitig eingesteuerte Aufträge der Produkte A und B die Maschine 5 zur selben Zeit.
186 Es ist jedes Los in der Warteschlange zu priorisieren (n Operationen) und zu jedem Los sind weitere in dasBatch passende Lose zu finden (n Operationen).
187 D.h., Warteschlangenlängen kleiner als 25-30 Aufträge.188 Es sei n die Anzahl der Lose in der Warteschlange. Es werden n Schritte für die Priorisierung der Lose
benötigt. n*n/2 Schritte sind zur Batchbildung notwendig. log(n)*n Schritte werden zur Sortierung derBatchs benötigt. Dies ergibt mit n*(1+n/2+log(n)) Schritten ein annähernd quadratisches Verhalten.
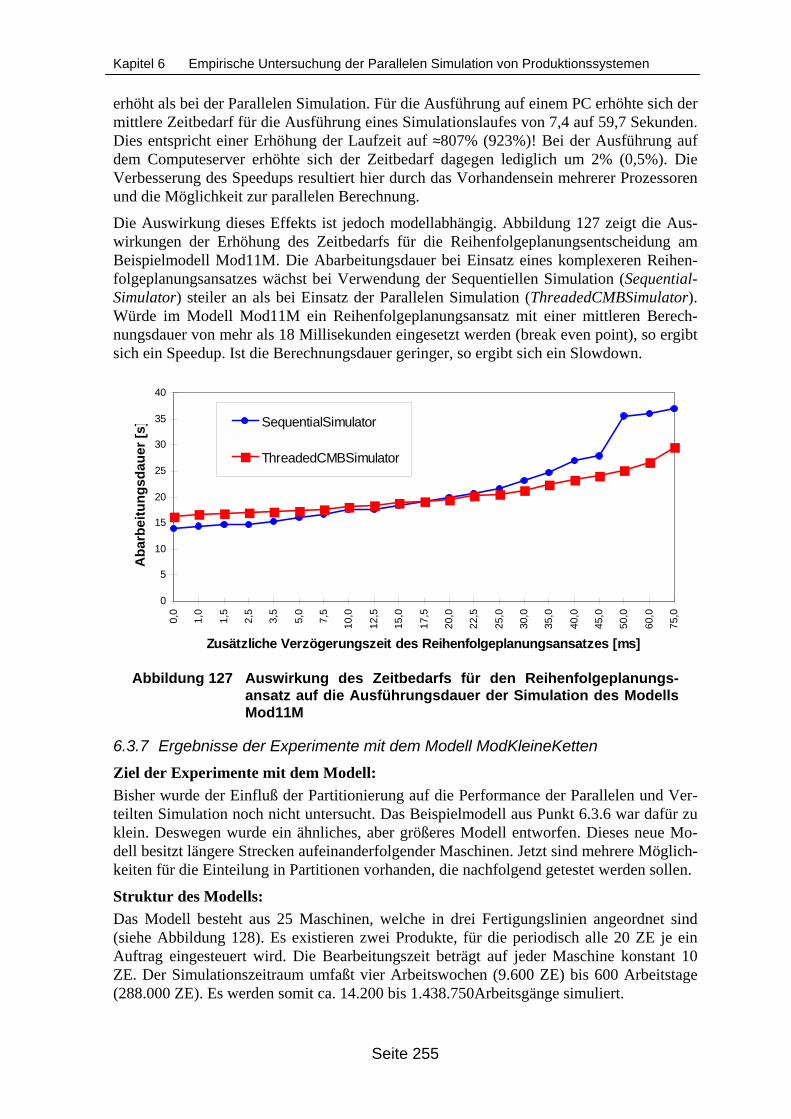
Kapitel 6 Empirische Untersuchung der Parallelen Simulation von Produktionssystemen
Seite 255
erhöht als bei der Parallelen Simulation. Für die Ausführung auf einem PC erhöhte sich dermittlere Zeitbedarf für die Ausführung eines Simulationslaufes von 7,4 auf 59,7 Sekunden.Dies entspricht einer Erhöhung der Laufzeit auf ≈807% (923%)! Bei der Ausführung aufdem Computeserver erhöhte sich der Zeitbedarf dagegen lediglich um 2% (0,5%). DieVerbesserung des Speedups resultiert hier durch das Vorhandensein mehrerer Prozessorenund die Möglichkeit zur parallelen Berechnung.
Die Auswirkung dieses Effekts ist jedoch modellabhängig. Abbildung 127 zeigt die Aus-wirkungen der Erhöhung des Zeitbedarfs für die Reihenfolgeplanungsentscheidung amBeispielmodell Mod11M. Die Abarbeitungsdauer bei Einsatz eines komplexeren Reihen-folgeplanungsansatzes wächst bei Verwendung der Sequentiellen Simulation (Sequential-Simulator) steiler an als bei Einsatz der Parallelen Simulation (ThreadedCMBSimulator).Würde im Modell Mod11M ein Reihenfolgeplanungsansatz mit einer mittleren Berech-nungsdauer von mehr als 18 Millisekunden eingesetzt werden (break even point), so ergibtsich ein Speedup. Ist die Berechnungsdauer geringer, so ergibt sich ein Slowdown.
0
5
10
15
20
25
30
35
40
0,0
1,0
1,5
2,5
3,5
5,0
7,5
10,0
12,5
15,0
17,5
20,0
22,5
25,0
30,0
35,0
40,0
45,0
50,0
60,0
75,0
Zusätzliche Verzögerungszeit des Reihenfolgeplanungsansatzes [ms]
Ab
arb
eit
un
gs
da
ue
r [s
] SequentialSimulator
ThreadedCMBSimulator
Abbildung 127 Auswirkung des Zeitbedarfs für den Reihenfolgeplanungs-ansatz auf die Ausführungsdauer der Simulation des ModellsMod11M
6.3.7 Ergebnisse der Experimente mit dem Modell ModKleineKetten
Ziel der Experimente mit dem Modell:
Bisher wurde der Einfluß der Partitionierung auf die Performance der Parallelen und Ver-teilten Simulation noch nicht untersucht. Das Beispielmodell aus Punkt 6.3.6 war dafür zuklein. Deswegen wurde ein ähnliches, aber größeres Modell entworfen. Dieses neue Mo-dell besitzt längere Strecken aufeinanderfolgender Maschinen. Jetzt sind mehrere Möglich-keiten für die Einteilung in Partitionen vorhanden, die nachfolgend getestet werden sollen.
Struktur des Modells:
Das Modell besteht aus 25 Maschinen, welche in drei Fertigungslinien angeordnet sind(siehe Abbildung 128). Es existieren zwei Produkte, für die periodisch alle 20 ZE je einAuftrag eingesteuert wird. Die Bearbeitungszeit beträgt auf jeder Maschine konstant 10ZE. Der Simulationszeitraum umfaßt vier Arbeitswochen (9.600 ZE) bis 600 Arbeitstage(288.000 ZE). Es werden somit ca. 14.200 bis 1.438.750Arbeitsgänge simuliert.
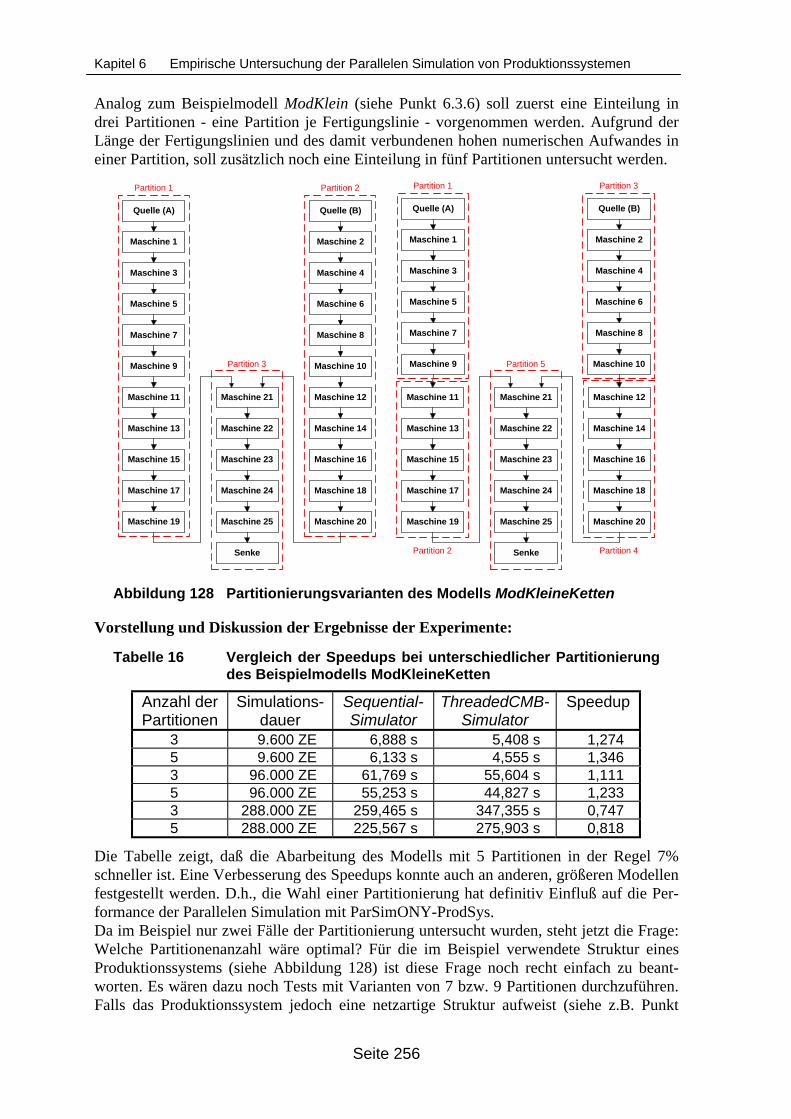
Kapitel 6 Empirische Untersuchung der Parallelen Simulation von Produktionssystemen
Seite 256
Analog zum Beispielmodell ModKlein (siehe Punkt 6.3.6) soll zuerst eine Einteilung indrei Partitionen - eine Partition je Fertigungslinie - vorgenommen werden. Aufgrund derLänge der Fertigungslinien und des damit verbundenen hohen numerischen Aufwandes ineiner Partition, soll zusätzlich noch eine Einteilung in fünf Partitionen untersucht werden.
Senke
Quelle (A)
Maschine 1
Partition 1
Maschine 3
Maschine 5
Maschine 7
Maschine 9
Maschine 11
Maschine 13
Maschine 15
Maschine 17
Maschine 19
Quelle (B)
Maschine 2
Maschine 4
Maschine 6
Maschine 8
Maschine 10
Maschine 12
Maschine 14
Maschine 16
Maschine 18
Maschine 20Maschine 25
Maschine 24
Maschine 23
Maschine 22
Maschine 21
Partition 2
Partition 3
Senke
Quelle (A)
Maschine 1
Partition 1
Maschine 3
Maschine 5
Maschine 7
Maschine 9
Maschine 11
Maschine 13
Maschine 15
Maschine 17
Maschine 19
Quelle (B)
Maschine 2
Maschine 4
Maschine 6
Maschine 8
Maschine 10
Maschine 12
Maschine 14
Maschine 16
Maschine 18
Maschine 20Maschine 25
Maschine 24
Maschine 23
Maschine 22
Maschine 21
Partition 3
Partition 5
Partition 2 Partition 4
Abbildung 128 Partitionierungsvarianten des Modells ModKleineKetten
Vorstellung und Diskussion der Ergebnisse der Experimente:
Tabelle 16 Vergleich der Speedups bei unterschiedlicher Partitionierungdes Beispielmodells ModKleineKetten
Anzahl derPartitionen
Simulations-dauer
Sequential-Simulator
ThreadedCMB-Simulator
Speedup
3 9.600 ZE 6,888 s 5,408 s 1,2745 9.600 ZE 6,133 s 4,555 s 1,3463 96.000 ZE 61,769 s 55,604 s 1,1115 96.000 ZE 55,253 s 44,827 s 1,2333 288.000 ZE 259,465 s 347,355 s 0,7475 288.000 ZE 225,567 s 275,903 s 0,818
Die Tabelle zeigt, daß die Abarbeitung des Modells mit 5 Partitionen in der Regel 7%schneller ist. Eine Verbesserung des Speedups konnte auch an anderen, größeren Modellenfestgestellt werden. D.h., die Wahl einer Partitionierung hat definitiv Einfluß auf die Per-formance der Parallelen Simulation mit ParSimONY-ProdSys.Da im Beispiel nur zwei Fälle der Partitionierung untersucht wurden, steht jetzt die Frage:Welche Partitionenanzahl wäre optimal? Für die im Beispiel verwendete Struktur einesProduktionssystems (siehe Abbildung 128) ist diese Frage noch recht einfach zu beant-worten. Es wären dazu noch Tests mit Varianten von 7 bzw. 9 Partitionen durchzuführen.Falls das Produktionssystem jedoch eine netzartige Struktur aufweist (siehe z.B. Punkt

Kapitel 6 Empirische Untersuchung der Parallelen Simulation von Produktionssystemen
Seite 257
6.3.8), so sind die möglichen Partitionierungsvarianten nicht so einfach absehbar. Zur Bil-dung sinnvoller Partitionierungsvarianten sind eine Reihe von Kriterien auszuwerten.Durch das Partitionierungsverfahren (siehe dazu Punkt 4.5) wird festgelegt, welche Ma-schinen gemeinsam in eine Partition eingeordnet werden sollen. Prinzipiell kann man je-doch festhalten, daß eine steigende Unterteilung des Modells in Partitionen nicht immer ineiner verbesserten Performance münden muß. Die in Tabelle 16 gezeigte Verbesserung desSpeedups kann z.B. durch eine Veränderung der Gleichzeitigkeit der Ereignisse189 sehrleicht kompensiert werden. Grundsätzlich existiert stets eine Obergrenze für eine sinnvolleAnzahl an Partitionen, da der Berechnungsaufwand in der Partition den Kommunikations-aufwand zwischen den Partitionen übersteigen muß (vergleiche Formel 2, Seite 69).
6.3.8 Ergebnisse der Experimente mit dem Modell KomplexMod
Ziel der Experimente mit dem Modell:
Das nachfolgende Modell ist als ein Beispiel eines Produktionssystems mit hochkomple-xen Prozeßbedingungen anzusehen. Es sind sowohl zyklische Durchläufe, Parallelbearb-eitung in Maschinengruppen, temporäre Zusammenfassung von Losen zu Batchs zur ge-meinsamen Bearbeitung, als auch Rüstproblematiken wie z.B. sequenzabhängige Rüst-zeiten anzutreffen. Es handelt sich bei dem Modell um einen Ausschnitt aus einem typi-schen Fertigungssystem in der Halbleiterfertigung.
Struktur des Modells:
Das Modell umfaßt 22 Maschinengruppen mit bis zu 12 Maschinen. Es werden drei Pro-dukte gefertigt. Die Arbeitspläne bestehen aus 62, 82 und 43 Arbeitsgängen. Das Modellwird über einen Zeitraum von 43.200 Simulationsminuten (30 Arbeitstage) bis zu 504.000Simulationsminuten (50 Arbeitswochen) simuliert. Die Einsteuerung ist gleichverteilt undfür jedes der drei Produkte gleich. Die Einsteuerung wurde zwischen einem Auftrag alle300-900 ZE bis zu einem Auftrag alle 50-250 ZE variiert. Dies entspricht einem Umfangvon ca. 10.000 bis ca. 500.000 Arbeitsgängen. An jeder Maschinengruppe kommt als Rei-henfolgeplanungsansatz SimpelSelektionsMechanismus (siehe Punkt 5.2.3.6) zum Einsatz.Die nachfolgende Abbildung zeigt die vereinfachte Darstellung der Struktur des Beispiel-modells. In der Abbildung wurden Maschinengruppen mit ähnlichen Aufgaben zu Funkti-onskomplexen zusammengefaßt. Dadurch war es möglich, die Anzahl der real vorhan-denen Verbindungswege für die Darstellung in der Abbildung zu reduzieren.Aus der vereinfachten Abbildung wird bereits die komplexe Struktur des Produktions-systems deutlich. Fast jeder Funktionskomplex besitzt mehrere technologische Vorgängerund Nachfolger. Zum Teil sind die technologischen Vorgänger und Nachfolger die selbenMaschinengruppen. D.h., das Produktionssystem ist stark vernetzt. Weiterhin ist aus derAbbildung ersichtlich, daß zyklische Durchläufe vorhanden sind. Ein Auftrag kann dieselben Maschinengruppen wiederholt - z.T. sogar in anderer Folge - durchlaufen.
189 Im Beispiel erfolgt alle 20 ZE eine Einsteuerung und jeder Bearbeitungsvorgang dauert exakt 10 ZE. Da-
durch finden alle Ereignisse in der Simulation zu durch 10 teilbaren Zeiten statt (alle Bearbeitungen derMaschinen einer Partition finden gleichzeitig statt). Finden die Simulationsereignisse einer Partition jedochzu unterschiedlichen Zeiten statt so sinkt das erzielbare Speedup, da die inhärente Parallelität des Modellsgeringer ist.
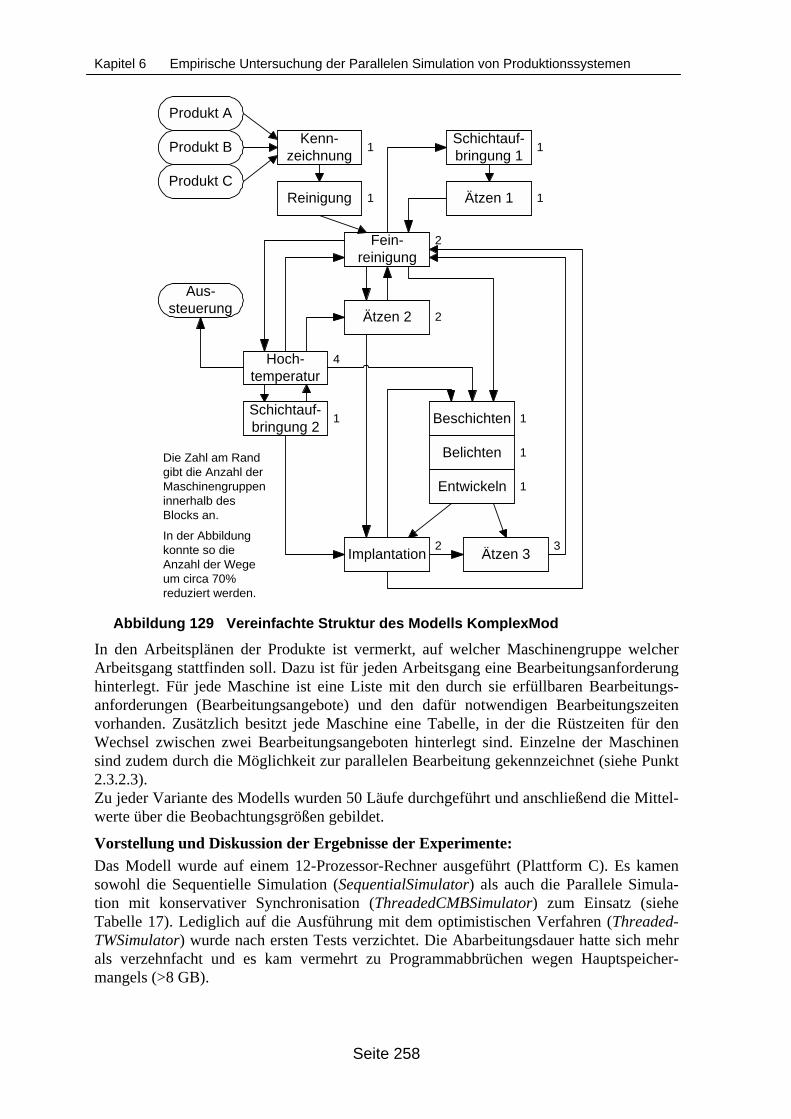
Kapitel 6 Empirische Untersuchung der Parallelen Simulation von Produktionssystemen
Seite 258
Kenn-zeichnung
Reinigung
Hoch-temperatur
Fein-reinigung
Schichtauf-bringung 1
Ätzen 1
Schichtauf-bringung 2
Ätzen 2
Implantation Ätzen 3
Beschichten
Belichten
Entwickeln
Produkt A
Produkt B
Produkt C
Aus-steuerung
1
1 1
1
2
2
4
1 1
1
1
32
Die Zahl am Randgibt die Anzahl derMaschinengruppeninnerhalb desBlocks an.
In der Abbildungkonnte so dieAnzahl der Wegeum circa 70%reduziert werden.
Abbildung 129 Vereinfachte Struktur des Modells KomplexMod
In den Arbeitsplänen der Produkte ist vermerkt, auf welcher Maschinengruppe welcherArbeitsgang stattfinden soll. Dazu ist für jeden Arbeitsgang eine Bearbeitungsanforderunghinterlegt. Für jede Maschine ist eine Liste mit den durch sie erfüllbaren Bearbeitungs-anforderungen (Bearbeitungsangebote) und den dafür notwendigen Bearbeitungszeitenvorhanden. Zusätzlich besitzt jede Maschine eine Tabelle, in der die Rüstzeiten für denWechsel zwischen zwei Bearbeitungsangeboten hinterlegt sind. Einzelne der Maschinensind zudem durch die Möglichkeit zur parallelen Bearbeitung gekennzeichnet (siehe Punkt2.3.2.3).Zu jeder Variante des Modells wurden 50 Läufe durchgeführt und anschließend die Mittel-werte über die Beobachtungsgrößen gebildet.
Vorstellung und Diskussion der Ergebnisse der Experimente:
Das Modell wurde auf einem 12-Prozessor-Rechner ausgeführt (Plattform C). Es kamensowohl die Sequentielle Simulation (SequentialSimulator) als auch die Parallele Simula-tion mit konservativer Synchronisation (ThreadedCMBSimulator) zum Einsatz (sieheTabelle 17). Lediglich auf die Ausführung mit dem optimistischen Verfahren (Threaded-TWSimulator) wurde nach ersten Tests verzichtet. Die Abarbeitungsdauer hatte sich mehrals verzehnfacht und es kam vermehrt zu Programmabbrüchen wegen Hauptspeicher-mangels (>8 GB).
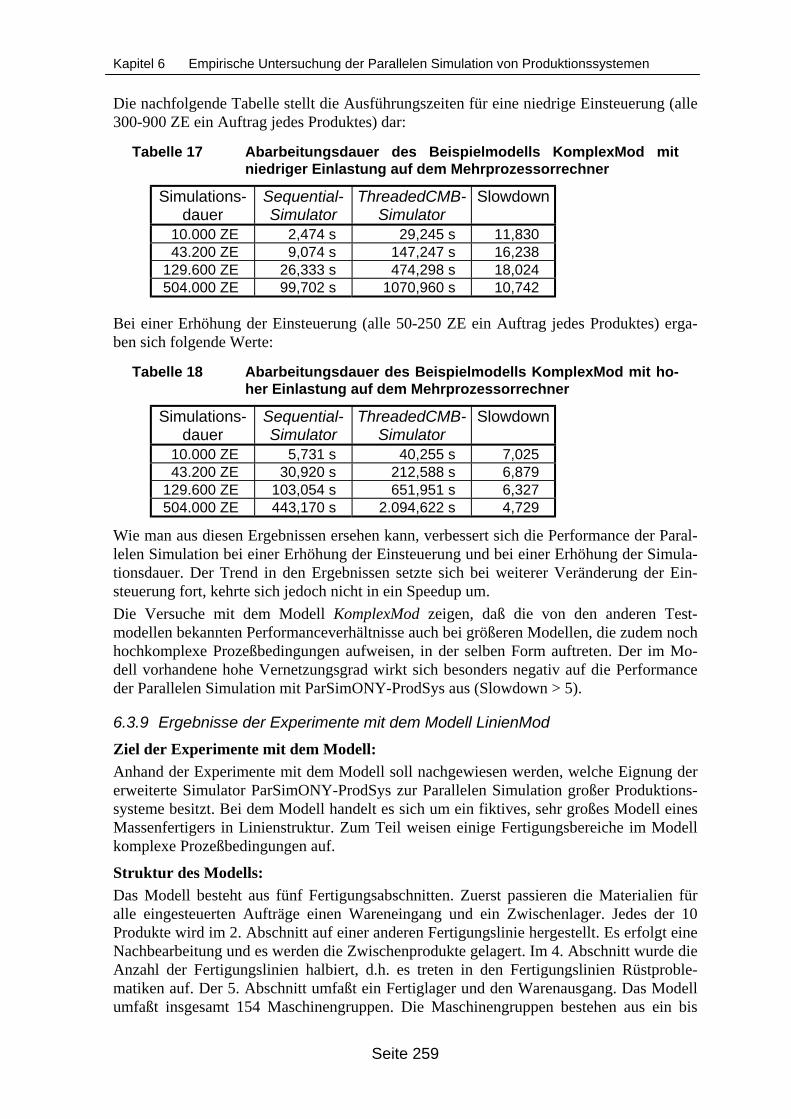
Kapitel 6 Empirische Untersuchung der Parallelen Simulation von Produktionssystemen
Seite 259
Die nachfolgende Tabelle stellt die Ausführungszeiten für eine niedrige Einsteuerung (alle300-900 ZE ein Auftrag jedes Produktes) dar:
Tabelle 17 Abarbeitungsdauer des Beispielmodells KomplexMod mitniedriger Einlastung auf dem Mehrprozessorrechner
Simulations-dauer
Sequential-Simulator
ThreadedCMB-Simulator
Slowdown
10.000 ZE 2,474 s 29,245 s 11,83043.200 ZE 9,074 s 147,247 s 16,238
129.600 ZE 26,333 s 474,298 s 18,024504.000 ZE 99,702 s 1070,960 s 10,742
Bei einer Erhöhung der Einsteuerung (alle 50-250 ZE ein Auftrag jedes Produktes) erga-ben sich folgende Werte:
Tabelle 18 Abarbeitungsdauer des Beispielmodells KomplexMod mit ho-her Einlastung auf dem Mehrprozessorrechner
Simulations-dauer
Sequential-Simulator
ThreadedCMB-Simulator
Slowdown
10.000 ZE 5,731 s 40,255 s 7,02543.200 ZE 30,920 s 212,588 s 6,879
129.600 ZE 103,054 s 651,951 s 6,327504.000 ZE 443,170 s 2.094,622 s 4,729
Wie man aus diesen Ergebnissen ersehen kann, verbessert sich die Performance der Paral-lelen Simulation bei einer Erhöhung der Einsteuerung und bei einer Erhöhung der Simula-tionsdauer. Der Trend in den Ergebnissen setzte sich bei weiterer Veränderung der Ein-steuerung fort, kehrte sich jedoch nicht in ein Speedup um.
Die Versuche mit dem Modell KomplexMod zeigen, daß die von den anderen Test-modellen bekannten Performanceverhältnisse auch bei größeren Modellen, die zudem nochhochkomplexe Prozeßbedingungen aufweisen, in der selben Form auftreten. Der im Mo-dell vorhandene hohe Vernetzungsgrad wirkt sich besonders negativ auf die Performanceder Parallelen Simulation mit ParSimONY-ProdSys aus (Slowdown > 5).
6.3.9 Ergebnisse der Experimente mit dem Modell LinienMod
Ziel der Experimente mit dem Modell:
Anhand der Experimente mit dem Modell soll nachgewiesen werden, welche Eignung dererweiterte Simulator ParSimONY-ProdSys zur Parallelen Simulation großer Produktions-systeme besitzt. Bei dem Modell handelt es sich um ein fiktives, sehr großes Modell einesMassenfertigers in Linienstruktur. Zum Teil weisen einige Fertigungsbereiche im Modellkomplexe Prozeßbedingungen auf.
Struktur des Modells:
Das Modell besteht aus fünf Fertigungsabschnitten. Zuerst passieren die Materialien füralle eingesteuerten Aufträge einen Wareneingang und ein Zwischenlager. Jedes der 10Produkte wird im 2. Abschnitt auf einer anderen Fertigungslinie hergestellt. Es erfolgt eineNachbearbeitung und es werden die Zwischenprodukte gelagert. Im 4. Abschnitt wurde dieAnzahl der Fertigungslinien halbiert, d.h. es treten in den Fertigungslinien Rüstproble-matiken auf. Der 5. Abschnitt umfaßt ein Fertiglager und den Warenausgang. Das Modellumfaßt insgesamt 154 Maschinengruppen. Die Maschinengruppen bestehen aus ein bis
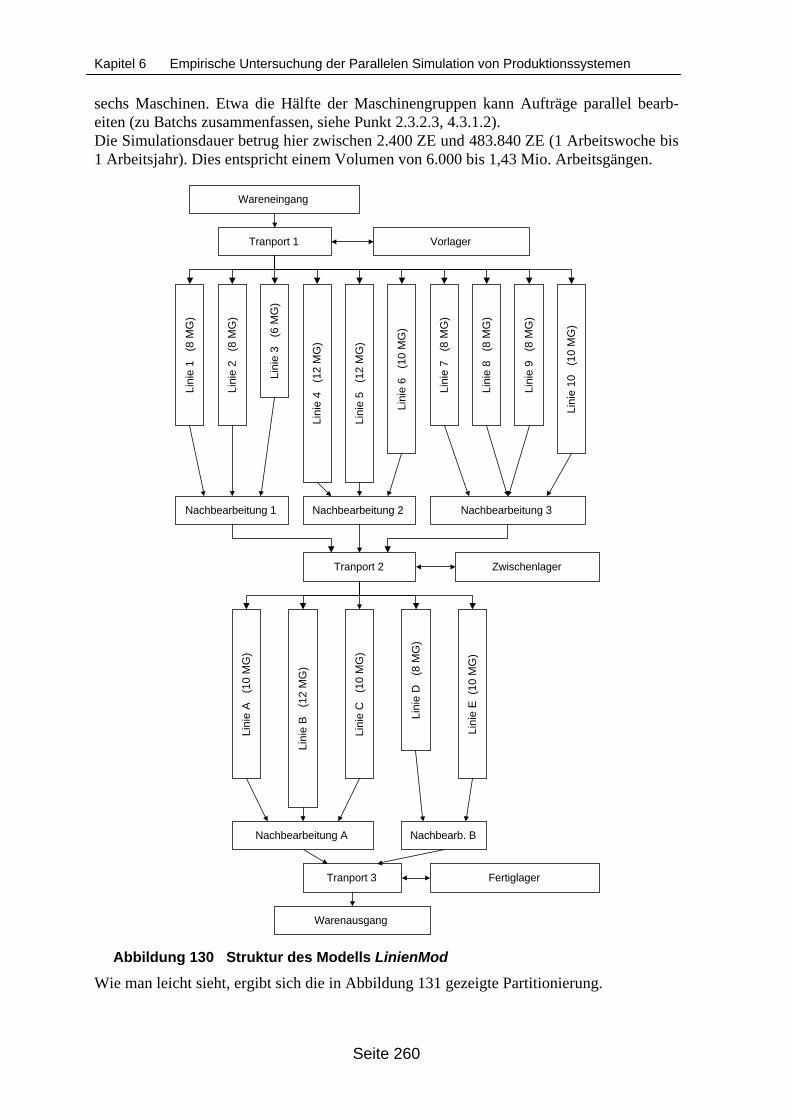
Kapitel 6 Empirische Untersuchung der Parallelen Simulation von Produktionssystemen
Seite 260
sechs Maschinen. Etwa die Hälfte der Maschinengruppen kann Aufträge parallel bearb-eiten (zu Batchs zusammenfassen, siehe Punkt 2.3.2.3, 4.3.1.2).Die Simulationsdauer betrug hier zwischen 2.400 ZE und 483.840 ZE (1 Arbeitswoche bis1 Arbeitsjahr). Dies entspricht einem Volumen von 6.000 bis 1,43 Mio. Arbeitsgängen.
Wareneingang
VorlagerTranport 1
Lin
ie 1
(
8 M
G)
Lin
ie 2
(
8 M
G)
Lin
ie 3
(
6 M
G)
Lin
ie 4
(
12 M
G)
Lin
ie 5
(
12 M
G)
Lin
ie 6
(
10 M
G)
Lin
ie 7
(
8 M
G)
Lin
ie 8
(
8 M
G)
Lin
ie 9
(
8 M
G)
Lin
ie 1
0 (
10 M
G)
Nachbearbeitung 1 Nachbearbeitung 2 Nachbearbeitung 3
ZwischenlagerTranport 2
Lin
ie A
(
10 M
G)
Lin
ie B
(
12 M
G)
Lin
ie C
(
10 M
G)
Lin
ie D
(
8 M
G)
Lin
ie E
(1
0 M
G)
Nachbearbeitung A Nachbearb. B
Tranport 3
Warenausgang
Fertiglager
Abbildung 130 Struktur des Modells LinienMod
Wie man leicht sieht, ergibt sich die in Abbildung 131 gezeigte Partitionierung.
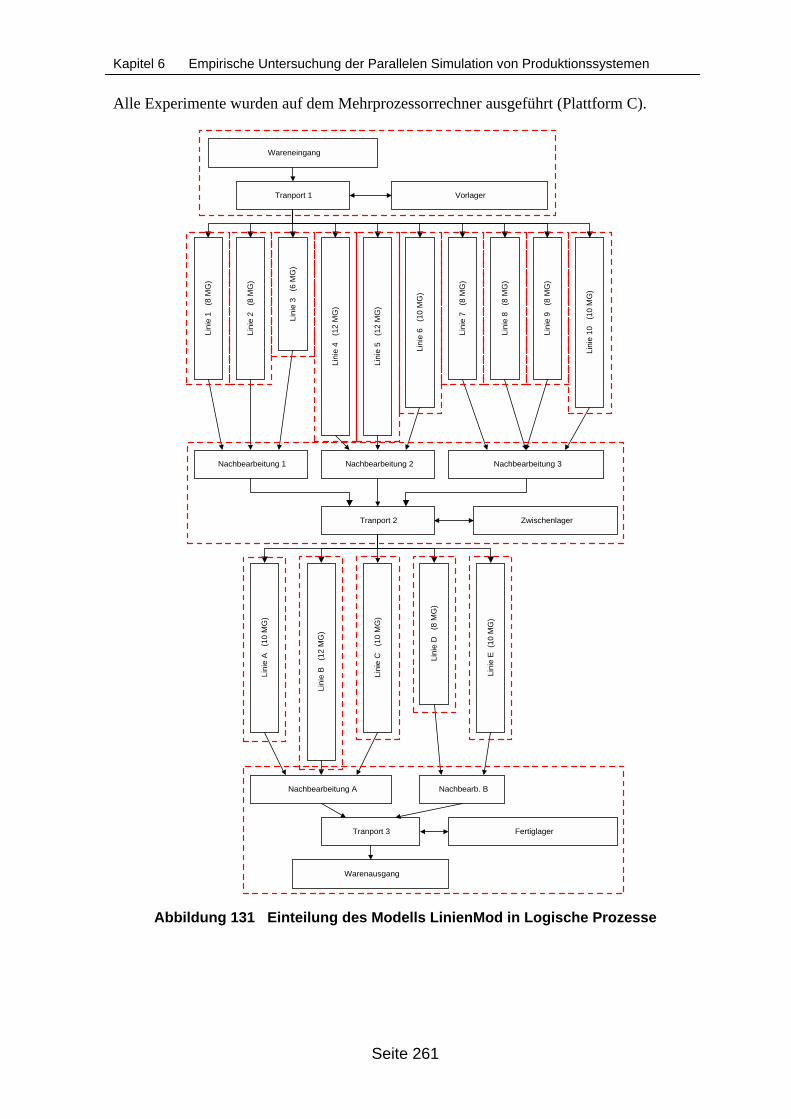
Kapitel 6 Empirische Untersuchung der Parallelen Simulation von Produktionssystemen
Seite 261
Alle Experimente wurden auf dem Mehrprozessorrechner ausgeführt (Plattform C).
Wareneingang
VorlagerTranport 1
Lin
ie 1
(
8 M
G)
Lin
ie 2
(
8 M
G)
Lin
ie 3
(
6 M
G)
Lin
ie 4
(
12 M
G)
Lin
ie 5
(
12 M
G)
Lin
ie 6
(
10 M
G)
Lin
ie 7
(
8 M
G)
Lin
ie 8
(
8 M
G)
Lin
ie 9
(
8 M
G)
Lin
ie 1
0 (
10 M
G)
Nachbearbeitung 1 Nachbearbeitung 2 Nachbearbeitung 3
ZwischenlagerTranport 2
Lin
ie A
(
10 M
G)
Lin
ie B
(
12 M
G)
Lin
ie C
(
10 M
G)
Lin
ie D
(
8 M
G)
Lin
ie E
(1
0 M
G)
Nachbearbeitung A Nachbearb. B
Tranport 3
Warenausgang
Fertiglager
Abbildung 131 Einteilung des Modells LinienMod in Logische Prozesse
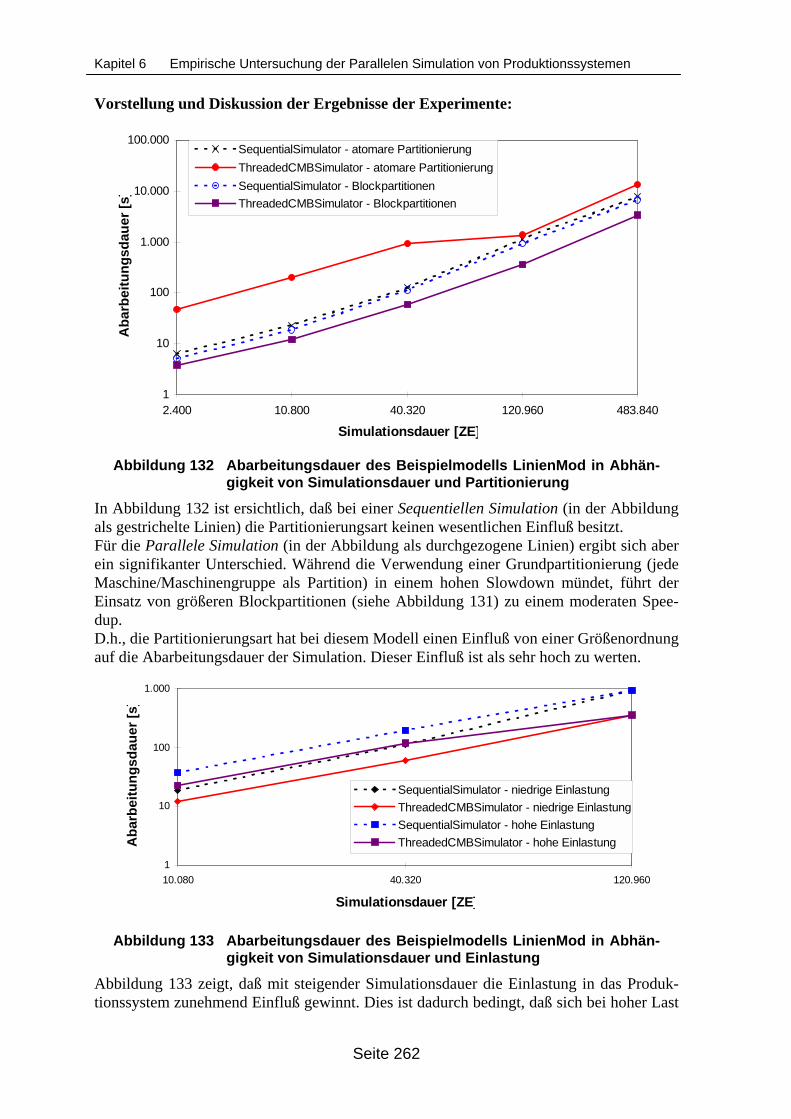
Kapitel 6 Empirische Untersuchung der Parallelen Simulation von Produktionssystemen
Seite 262
Vorstellung und Diskussion der Ergebnisse der Experimente:
1
10
100
1.000
10.000
100.000
2.400 10.800 40.320 120.960 483.840
Simulationsdauer [ZE]
Ab
arb
eit
un
gs
da
ue
r [s
]
SequentialSimulator - atomare Partitionierung
ThreadedCMBSimulator - atomare Partitionierung
SequentialSimulator - Blockpartitionen
ThreadedCMBSimulator - Blockpartitionen
Abbildung 132 Abarbeitungsdauer des Beispielmodells LinienMod in Abhän-gigkeit von Simulationsdauer und Partitionierung
In Abbildung 132 ist ersichtlich, daß bei einer Sequentiellen Simulation (in der Abbildungals gestrichelte Linien) die Partitionierungsart keinen wesentlichen Einfluß besitzt.Für die Parallele Simulation (in der Abbildung als durchgezogene Linien) ergibt sich aberein signifikanter Unterschied. Während die Verwendung einer Grundpartitionierung (jedeMaschine/Maschinengruppe als Partition) in einem hohen Slowdown mündet, führt derEinsatz von größeren Blockpartitionen (siehe Abbildung 131) zu einem moderaten Spee-dup.D.h., die Partitionierungsart hat bei diesem Modell einen Einfluß von einer Größenordnungauf die Abarbeitungsdauer der Simulation. Dieser Einfluß ist als sehr hoch zu werten.
1
10
100
1.000
10.080 40.320 120.960
Simulationsdauer [ZE]
Ab
arb
eit
un
gs
da
ue
r [s
]
SequentialSimulator - niedrige Einlastung
ThreadedCMBSimulator - niedrige Einlastung
SequentialSimulator - hohe Einlastung
ThreadedCMBSimulator - hohe Einlastung
Abbildung 133 Abarbeitungsdauer des Beispielmodells LinienMod in Abhän-gigkeit von Simulationsdauer und Einlastung
Abbildung 133 zeigt, daß mit steigender Simulationsdauer die Einlastung in das Produk-tionssystem zunehmend Einfluß gewinnt. Dies ist dadurch bedingt, daß sich bei hoher Last
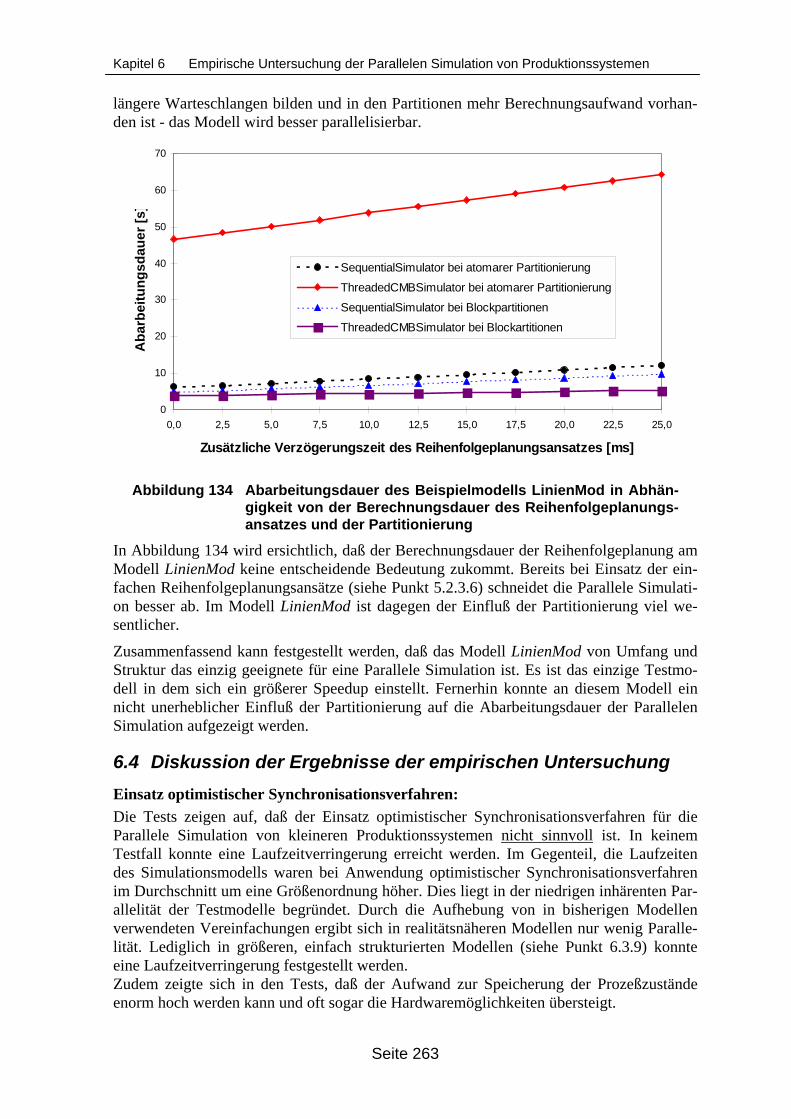
Kapitel 6 Empirische Untersuchung der Parallelen Simulation von Produktionssystemen
Seite 263
längere Warteschlangen bilden und in den Partitionen mehr Berechnungsaufwand vorhan-den ist - das Modell wird besser parallelisierbar.
0
10
20
30
40
50
60
70
0,0 2,5 5,0 7,5 10,0 12,5 15,0 17,5 20,0 22,5 25,0
Zusätzliche Verzögerungszeit des Reihenfolgeplanungsansatzes [ms]
Ab
arb
eit
un
gs
da
ue
r [s
]
SequentialSimulator bei atomarer Partitionierung
ThreadedCMBSimulator bei atomarer Partitionierung
SequentialSimulator bei Blockpartitionen
ThreadedCMBSimulator bei Blockartitionen
Abbildung 134 Abarbeitungsdauer des Beispielmodells LinienMod in Abhän-gigkeit von der Berechnungsdauer des Reihenfolgeplanungs-ansatzes und der Partitionierung
In Abbildung 134 wird ersichtlich, daß der Berechnungsdauer der Reihenfolgeplanung amModell LinienMod keine entscheidende Bedeutung zukommt. Bereits bei Einsatz der ein-fachen Reihenfolgeplanungsansätze (siehe Punkt 5.2.3.6) schneidet die Parallele Simulati-on besser ab. Im Modell LinienMod ist dagegen der Einfluß der Partitionierung viel we-sentlicher.
Zusammenfassend kann festgestellt werden, daß das Modell LinienMod von Umfang undStruktur das einzig geeignete für eine Parallele Simulation ist. Es ist das einzige Testmo-dell in dem sich ein größerer Speedup einstellt. Fernerhin konnte an diesem Modell einnicht unerheblicher Einfluß der Partitionierung auf die Abarbeitungsdauer der ParallelenSimulation aufgezeigt werden.
6.4 Diskussion der Ergebnisse der empirischen Untersuchung
Einsatz optimistischer Synchronisationsverfahren:
Die Tests zeigen auf, daß der Einsatz optimistischer Synchronisationsverfahren für dieParallele Simulation von kleineren Produktionssystemen nicht sinnvoll ist. In keinemTestfall konnte eine Laufzeitverringerung erreicht werden. Im Gegenteil, die Laufzeitendes Simulationsmodells waren bei Anwendung optimistischer Synchronisationsverfahrenim Durchschnitt um eine Größenordnung höher. Dies liegt in der niedrigen inhärenten Par-allelität der Testmodelle begründet. Durch die Aufhebung von in bisherigen Modellenverwendeten Vereinfachungen ergibt sich in realitätsnäheren Modellen nur wenig Paralle-lität. Lediglich in größeren, einfach strukturierten Modellen (siehe Punkt 6.3.9) konnteeine Laufzeitverringerung festgestellt werden.Zudem zeigte sich in den Tests, daß der Aufwand zur Speicherung der Prozeßzuständeenorm hoch werden kann und oft sogar die Hardwaremöglichkeiten übersteigt.

Kapitel 6 Empirische Untersuchung der Parallelen Simulation von Produktionssystemen
Seite 264
Verteilte Abarbeitung in einem Rechnernetz:
Für die verteilte Abarbeitung in einem Rechnernetzwerk ergab sich das Problem, daß dieÜbertragung von Nachrichten zwischen den Rechnern eine hohe Zeitspanne in Anspruchnimmt (ca. 20 ms). In dieser Übertragungszeit können lokal auf den Rechnern bereits vieleweitere Berechnungen ausgeführt werden. Dadurch besitzt die verteilte Abarbeitung ge-genüber der Ausführung auf einem Parallelrechner stets eine schlechtere Performance. DieUmkehrung dieses Performanceverhaltens ist sehr unwahrscheinlich, da dafür ein Verhält-nis von deutlich mehr als 285 internen zu einem externen Simulationsereignis (siehe Punkt6.3.4) bestehen müßte. In den durchgeführten Tests betrug dieses Verhältnis im Maximal-fall jedoch nur 59:1190.
Abarbeitung auf einem Mehrprozessorrechner:
Die Parallele Simulation mit ParSimONY-ProdSys auf einem Mehrprozessorrechner er-zielt gegenüber der verteilten Abarbeitung eine wesentlich höhere Berechnungsgeschwin-digkeit, da hier die extrem hohen Transferzeiten im Rechnernetzwerk entfallen und jetztnur noch Transferzeiten im Mikrosekundenbereich durch die Kommunikation der Prozes-soren über den gemeinsamen Speicher entstehen [Mehl 1994, S. 143], [Bagrodia 1996],[Smith 1999]. Jedoch konnte nicht in jedem Testfall ein Speedup ermittelt werden und dasim Mittel erreichte Speedup ist nur gering.
Diskussion der Gründe für den erzielten geringen Speedup:
Das mit den Beispielmodellen maximal erreichte Speedup ist sehr gering. D.h., verglichenmit dem Aufwand für die Erstellung eines auf dem Parallelrechner abarbeitbaren Modellsist der Performancegewinn gering. Durch die Parallelisierung von Hilfsfunktionen des Si-mulators konnten bereits ähnliche Performanceverbesserungen erreicht werden [Mehl1994, S. 7-8], [Fishman 2001, S. 199-211]. Lediglich bei dem größten Testmodell (siehePunkt 6.3.9) konnte eine mäßige Beschleunigung erzielt werden.Die Ursachen für das geringe resultierende Speedup sind darin zu suchen, daß die simu-lierten Modelle nur eine geringe inhärente Parallelität aufweisen und das andererseits derAufwand zur Synchronisation der Logischen Prozesse einen beträchtlichen Umfang an-nimmt (Overhead von Faktor 5; siehe Punkt 6.3.4).Die geringe inhärente Parallelität von Modellen von Produktionssystemen resultiert u.a.daraus, daß die bisher in der Literatur angesetzten begünstigenden Modellbedingungen inder Praxis nicht haltbar sind. Die Annahme von konstanten Bearbeitungszeiten oder füralle Maschinen gleich angesetzte Verteilungen der Bearbeitungszeit führt zwangsläufig zueinem hohen Anteil gleichzeitiger Ereignisse und damit zu einer höheren Parallelität desModells. Zudem sind Annahmen wie eine Abarbeitungsreihenfolge gemäß FIFO förderlichzur Erhöhung des Performanceeinflußfaktors Lookahead [Nicol 1988], [Preiss, Loucks1990], [Loucks, Preiss 1990], [Jha, Bagrodia 1993], [Greenberg, Lubachevsky 1996],[Paprotny, Fowler 2001]. Weiterhin werden bisher fast ausschließlich geschlossene Bedie-nungssysteme modelliert, welche durch einen geringen Grad an externen Ereignissen ge-kennzeichnet sind. Außerdem sind die betrachteten Strukturen (kleine Produktionssysteme,lineare oder gitterförmige Anordnung) in realen Produktionssystemen nicht anzutreffen.Reale Produktionssysteme weisen oft vernetzte, nicht uniform gerichtete Produktions-systemgraphen auf. D.h., der bisher postulierte Kommunikationsaufwand ist durch denhöheren Vernetzungsgrad deutlich nach oben zu korrigieren. Die begünstigenden Modell-
190 Siehe dazu Punkt 4.3.4.1 („Abschätzung der Berechnungslast einer Partition“; Tabelle 2, Seite 135). Für
jeden eintreffenden Auftrag werden 5 Ereignisse ausgelöst. In den Beispielmodellen waren im Maximalfall10 in Reihe angeordnete Maschinen in einer Partition. D.h., es stehen im Maximalfall 10*5+(10-1) = 59interne Ereignisse dem Ereignis des in der Partition eintreffenden Auftrags gegenüber.

Kapitel 6 Empirische Untersuchung der Parallelen Simulation von Produktionssystemen
Seite 265
bedingungen sind in der Praxis nicht haltbar, wodurch sich das schlechtere Abschneidender praxisnäheren Testmodelle erklärt.Das Verhältnis zwischen Berechnungs- und Kommunikationsaufwand ist für die Simula-tion von Modellen von Produktionssystemen sehr gespannt. Häufiger Kommunikationsteht ein nur geringer Berechnungsaufwand bei eintreffenden Ereignissen gegenüber (sieheFormel 2). Die Forderung lautet hier, in einer Partition eine möglichst große Anzahl vonMaschinen zusammenzufassen, damit der Anteil der partitionsinternen Ereignisse erhöhtwird und die Kommunikation zwischen den Partitionen sinkt (vergleiche Partitions-Modellelemente, Punkt 5.2.3.3). Oft ist es jedoch aufgrund der in der Praxis auftretenden,eng vernetzten Produktionssysteme nicht möglich, die Partitionen zu entkoppeln. Die ge-bildeten Partitionen sind noch durch eine Vielzahl häufig benutzter Kommunikationswegeverbunden. Weiterhin verbleiben bei der Partitionierung abseits einer großen Block-partition, welche den stark vernetzten Teil des Produktionssystems enthält, oft nur kleineTeilsysteme, die nur einen geringen Berechnungsaufwand enthalten und somit die Gesamt-simulation durch ihre parallele Abarbeitung nur unwesentlich beschleunigen.Ein letzter Einflußfaktor ist die Anzahl Modellelemente. In der Logiksimulation (siehePunkt 3.2.3) wird die Parallele und Verteilte Simulation mit Erfolg eingesetzt. Die Simula-tionsmodelle bestehen hier jedoch nicht nur aus Dutzenden bis hin zu wenigen hundertElementen (LinienMod - 154 Maschinengruppen), sondern aus Hunderttausenden von ele-mentaren Logikbausteinen. Die Partitionen enthalten so um Größenordnungen mehr Ele-mente und damit wesentlich mehr Berechnungsaufwand.
Schlußfolgerungen:
Der Einsatz der Parallelen Simulation von Produktionssystemen lohnt nur, wenn:
• Modelle von Produktionssystemen mit sehr vielen Elementen simuliert werdensollen191,
• die Elemente untereinander nur wenige Verbindungen aufweisen und der Vernet-zungsgrad des Produktionssystems niedrig ist192,
• Produktionssysteme unter hoher Last (Einsteuerung) simuliert werden sollen193
und• ein komplexer Reihenfolgeplanungsansatz mit einem hohen Berechnungsaufwand
eingesetzt wird194.
D.h., von den im Punkt 6.2 aufgestellten Regionen lohnt sich der Einsatz der Parallelenund Verteilten Simulation nur in der Region D.
191 Damit bestehen die Partitionen aus einer größeren Menge von Elementen - die Wahrscheinlichkeit, daß in
mehreren Partitionen zur selben Simulationszeit gleichzeitig Ereignisse auftreten, ist wesentlich höher - dieinhärente Parallelität des Modells ist größer.
192 Der Anteil partitionsexterner Ereignisse sollte möglichst niedrig sein, damit der Kommunikationsaufwandgeringer ist. Durch die niedrigere Vernetzung ist die Wahrscheinlichkeit, daß zwei Partitionen gegeneinan-der zu synchronisieren sind, wesentlich geringer.
193 Durch die höhere Last im Produktionssystem werden häufiger Ereignisse ausgelöst. Die Wahrschein-lichkeit, daß eines der vielen internen Ereignisse zeitlich vor einem möglichen externen Ereignis liegt, isthöher - Blockierungssituationen sind seltener.
194 Durch den höheren Berechnungsaufwand muß seltener auf das Eintreffen eines externen Ereignisses ge-wartet werden. Andere Logische Prozesse können während dieser Berechnungen Nachrichten empfangenoder senden. Das Verhältnis zwischen Berechnungsaufwand und Kommunikationsdauer wird verbessert.Die inhärente Parallelität des Modells steigt.

Kapitel 7 Zusammenfassung
Seite 266
7 Zusammenfassung
7.1 Überblick über die erreichten ErgebnisseMit den geschaffenen Erweiterungen des Tools ParSimONY (siehe Punkt 5.2.3) steht erst-mals mit ParSimONY-ProdSys ein Paralleler Simulator für Produktionssysteme zur Verfü-gung. Mit dessen Hilfe ist es möglich, ein Simulationsmodell ohne Änderung verteilt ineinem Rechnernetz oder lokal auf einem Mehrprozessorrechner einzusetzen. Die geschaf-fenen Erweiterungen von ParSimONY erlauben es, komplexe Produktionssysteme mit spe-zifischen Prozeßbedingungen zu simulieren. Durch die Verwendung des Frameworks zursimulationsbasierten Fertigungssteuerung ist es dabei außerdem möglich, das zur Simulati-on benötigte Simulationsmodell automatisch durch einen Simulationsprogrammgeneratorzu erzeugen. Weiterhin hat sich das Framework bei der Verwaltung, Ausführung undAuswertung von Simulationsexperimenten hervorragend bewährt (siehe Punkt 5.1.3). Mitdem Einsatz der durch das Framework zur Verfügung gestellten Dienste entfallen eineReihe bisher ausschließlich manuell durchführbarer Tätigkeiten während des Experimen-tier- und Auswerteprozesses. Ohne diese Unterstützung wäre es nicht möglich, Experi-mente mit Modellen von größeren Produktionssystemen durchzuführen, da allein der Auf-wand zur Erstellung der Simulationsmodelle mehrere Mannmonate beansprucht. Durch dieIntegration von ParSimONY-ProdSys in das Framework zur simulationsbasierten Ferti-gungssteuerung (siehe Punkt 5.3) konnten erstmals Experimente mit umfangreichen Mo-dellen komplexer Produktionssysteme durchgeführt werden, um Einflußfaktoren auf diePerformance der Parallelen Simulation zu identifizieren (siehe Kapitel 6). Dabei ist festzu-stellen, daß die verteilte Abarbeitung in einem Rechnernetz durch die dort anfallendenhohen Übertragungszeiten nicht lohnend ist. Im Gegensatz dazu wurde bei der Ausführungauf Mehrprozessorsystemen z.T. eine beschleunigte Ausführung der Simulationsabarbei-tung festgestellt. Allerdings ist das im Mittel erzielbare Speedup im Vergleich zu vielen inder Literatur vorgestellten Lösungen [Nicol 1988], [Preiss, Loucks 1990], [Jha, Bagrodia1993], [Holthaus, Ziegler, Rosenberg 1996], [Greenberg, Lubachevsky 1996], [Preiss, Wan1999] gering. Dies ist zum Einen dadurch bedingt, daß die Simulation von Produktions-systemen durch weniger begünstigende Vereinfachungen gekennzeichnet ist als z.B. dieLogiksimulation oder die Simulation von Bedienungsnetzen (vergleiche Punkt 3.2.3). An-dererseits erfordert ein Verfahren, welches es ermöglicht, verschiedene Teile eines Mo-dells parallel auszuführen und zu synchronisieren, einen ungleich höheren numerischenAufwand als ein einfacher Sequentieller Simulator. Dieser zusätzliche Aufwand muß derMöglichkeit zur schnelleren parallelen Abarbeitung gegengerechnet werden (siehe Punkt6.3.4). Außerdem wurde durch die durchgeführten Experimente festgestellt, daß die oft inder Literatur propagierten optimistischen Synchronisationsverfahren für die Simulationvon Produktionssystemen nicht geeignet sind. Diese Erkenntnisse sind wesentlich, um diebisher herrschende Ungewißheit über die Performance der Parallelen und Verteilten Si-mulation erheblich auszuräumen. Künftige Arbeiten können sich jetzt auf die erfolgs-trächtigen Verfahren und Modellklassen konzentrieren: die Parallele Simulation großerund komplexer Produktionssysteme auf Mehrprozessormaschinen mit gemeinsamen Spei-cher unter Verwendung konservativer Synchronisationsverfahren.Des Weiteren wurde ein spezielles Partitionierungsverfahren entworfen und implementiert,daß an die Belange der Simulation von Produktionssystemen angepaßt ist. Durch den Ein-satz dieses Verfahrens an verschiedenen Modellen konnte ein nicht unerheblicher Einflußder Partitionierung auf die Performance der Parallelen und Verteilten Simulation nachge-wiesen werden (siehe Punkt 6.3.7). Die Integration dieses Partitionierungsverfahrens in dasFramework zur simulationsbasierten Fertigungssteuerung (siehe Punkt 5.3) erlaubt es

Kapitel 7 Zusammenfassung
Seite 267
zudem, den aufwendigen, bisher manuell durchgeführten Partitionierungsprozeß zu auto-matisieren.Mit den geschaffenen Erweiterungen von ParSimONY steht mit ParSimONY-ProdSys einSimulationstool für die Simulation komplexer Produktionssysteme zur Verfügung. Vieleherkömmliche Simulatoren erlauben keine Abbildung von spezifischen Prozeßbedingun-gen im Simulationsmodell und sind auch nicht für einen solchen Einsatzzweck anpaßbar.D.h., für die Simulation komplexer Produktionssysteme sind nur wenige Simulations-systeme überhaupt geeignet. Dies sind zudem meist Spezialsysteme mit Fokus auf einkonkretes Anwendungsgebiet. Mit ParSimONY-ProdSys steht jetzt ein anwendungs-neutrales, offenes, leicht anpaßbares Paralleles Simulationssystem zur Verfügung, welchesdurch die Integration in das Framework zur simulationsbasierten Fertigungssteuerung nochan Wert gewinnt.
7.2 AusblickObwohl der erreichte Stand einen wesentlichen Fortschritt darstellt, sind noch Erweiterun-gen denkbar. Diese lassen sich in drei Gruppen einteilen:
• Verbesserungen des Frameworks zur simulationsbasierten Fertigungssteuerung,• Verbesserungen des Parallelen Simulators ParSimONY-ProdSys und• Einsatz der geschaffenen Lösung auf anderen Anwendungsgebieten.
Verbesserungen des Frameworks zur simulationsbasierten Fertigungssteuerung:
Mit dem Framework zur simulationsbasierten Fertigungssteuerung steht dem Anwendereine Lösung zur Verfügung, welche es erlaubt, Simulationsmodelle komplexer Produk-tionssysteme automatisch zu erstellen und mit diesen Modellen zu experimentieren (sieheKapitel 3). Dabei sind die folgenden Verbesserungen denkbar: Zum Einen ist die geschaf-fene Lösung lediglich ein Prototyp. Nicht alle vorgesehenen Komponenten (siehe Punkt4.2.3.2) konnten im wünschenswerten Umfang realisiert werden. Zum Anderen können fürdie geschaffene Lösung neue Anwendungsgebiete erschlossen werden.
Bedingt durch den prototypischen Charakter ist nur eine rudimentäre Auswertungs-Komponente vorhanden. Die Kopplungskomponenten zum Umfeld des Frameworks wur-den nicht realisiert und die Experimentplanung wäre noch mit Optimierungstools zu kop-peln.Die Auswertungs-Komponente des Frameworks kann durch den Einsatz von Visualisie-rungstools wie z.B. MatLab, Animate!, VRML u.v.a.m. erheblich aufgewertet werden.Dazu notwendige Schnittstellen sind bereits im Framework vorhanden.Der Prototyp des Frameworks wird noch ohne die Kopplungskomponenten zu externenInformations- und Kommunikationssystemen betrieben. Möglich wäre hier, Im- und Ex-port-Komponenten zu ergänzen, welche z.B. den Datentransfer vom bzw. zum externenERP-System SAP R/3 betreiben.In der Experimentplanungs-Komponente des Frameworks (siehe Punkt 5.1.2.8) wurde be-reits angesprochen, daß Simulation lediglich eine Prognosemethode ist und eine zielge-richtete Optimierung des modellierten Produktionssystems allein mit Simulation nichtdurchführbar ist (vergleiche Punkt 2.1.1). Hier ist es notwendig, die Methode Simulationmit einem Optimierungsverfahren zu koppeln. Bisher erlaubt das Framework eine lediglicheinfache Definition von Experimenten gemäß einer Rastersuche. Eine Kopplung zu Opti-mierungssoftware wie z.B. ISSOP ist angedacht und die notwendigen Schnittstellen sindvorhanden.

Kapitel 7 Zusammenfassung
Seite 268
Es zeigte sich, daß das Framework ein offenes System ist. Es ist stets möglich, die ge-wünschten Erweiterungen zu integrieren. Die geschaffene Lösung kann sogar auf neueAnwendungsgebiete ausgedehnt werden.
Die momentane Schwachstelle für die Anpaßbarkeit des Frameworks an unterschiedlicheArten von Simulationsmodellen ist die Generator-Komponente. Möglich wäre es hier, diesyntaktischen Gegebenheiten zum Aufbau eines Simulationsmodells in XML-Notation ineiner Datenbank abzulegen. Dann ist einmalig eine Generator-Komponente zu implemen-tieren, welche diese XML-Notation verarbeiten kann und das Simulationsmodell aus denin einer Datenbank gespeicherten parameterisierbaren Modellbausteinen zusammensetzt.Diese Realisierungsform wurde - aus Gründen des wesentlich höheren Implementations-aufwandes - im Prototyp nicht umgesetzt. Dies ist jedoch ein lohnender Aspekt, der inweiterführenden Arbeiten vertieft werden sollte.
Es ist empfehlenswert, im Framework ein allgemeiner gefaßtes Datenmodell zu ver-wenden. So ist - um vielfältige und anders strukturierte Daten zu verwenden - XML alsMetasprache zur Beschreibung des Datenmodells des Frameworks benutzbar. Damit kön-nen dann Modelle aus anderen Anwendungsgebieten mit dem Framework verarbeitet wer-den. Über ein spezielles Pflegetool könnte der Anwender ein für sein Produktionssystempassendes Datenmodell definieren (analog einem Data Dictionary). Das Framework würdediese in XML verfaßte Definition des Datenmodells benutzen, um für das aktuell betrach-tete Produktionssystem angepaßte Datenbanken zu erzeugen und zu verwenden. Ebensokann für den Import bzw. Export von Daten ein Datenmodell definiert werden, welchesBasis für einen Transformationsprozeß zu den Daten im Framework ist. Auf diese Weiseist nur ein einziger Konverter notwendig, um Daten zwischen den verschiedensten Forma-ten anhand der beiden Datenmodellbeschreibungen zu transformieren.
Das Framework ist vom Ansatz her als ein offenes, leicht erweiterbares System konzipiertund kann - wie diese Beispiele zeigen - erheblich erweitert werden.
Verbesserungen des Parallelen Simulators ParSimONY-ProdSys:
Obwohl es mit ParSimONY-ProdSys möglich ist, eine Parallele Simulation eines komple-xen Produktionssystems durchzuführen, sind noch Erweiterungen denkbar. Zum Einenerfolgte im Punkt 4.3.1 eine Konzentration auf ausgewählte spezifische Prozeßbedingun-gen. ParSimONY-ProdSys kann dahingehend erweitert werden, daß weitere Prozeß-bedingungen einbezogen werden (siehe Punkt 5.4). Bisher sind nur einfache Modell-elemente und Zusammenfassungen dieser einfachen Elemente (Partitionselemente) vorhan-den (siehe Punkt 5.2.3.3). Hier sind weitere Modellbausteine (z.B. Transportsysteme, Clu-stertools usw.) vorstellbar (siehe Punkt 5.4). Außerdem sind in ParSimONY-ProdSys bis-her nur ausgewählte Reihenfolgeplanungsansätze integriert. Die Implementation und Inte-gration weiterer Reihenfolgeplanungsansätze ist problemlos möglich (siehe Punkt 5.4,5.2.3.6). Der Anwender könnte hier durch eine reichhaltigere Bibliothek an Steue-rungsansätzen von eigener Implementationsarbeit entlastet werden.Die Tests in Kapitel 6 zeigten ein sehr schlechtes Abschneiden optimistischer Synchro-nisationsverfahren. Interessant wäre hier ein hybrides Synchronisationsverfahren wie z.B.die Spekulative verteilte Simulation nach Mehl [Mehl 1994, S. 108-144] einzusetzen. Dieswürde bedeuten, daß ein weiterer ParSimONY-Simulator (siehe Seite 205) implementiertwerden müßte. Hierzu läßt sich aber noch nicht abschätzen, ob die Spekulative verteilteSimulation ohne größere Probleme in die bestehenden Mechanismen von ParSimONYintegrierbar ist. Der Aufwand für diese Integration ist jedoch mit Sicherheit beträchtlich.

Kapitel 7 Zusammenfassung
Seite 269
Für die Ausführung von Experimenten standen lediglich relativ kleine Computeserver zurVerfügung (siehe Punkt 6.3.1). Es wäre wünschenswert, eine Rechenhardware mit 128oder 256 Prozessoren für die Modellabarbeitung zu testen.
Durch die Experimente mit Beispielmodellen auf unterschiedlichen Ausführungsplatt-formen wurden Performanceeinflußfaktoren identifiziert (siehe Punkt 6.3, 6.4) und Spee-dup-Messungen vorgenommen. Ausgehend davon ist jetzt eine Verbesserung der Perfor-mance des Tools ParSimONY-ProdSys erzielbar, indem man nicht mehr benötigte Flexi-bilität aus dem Tool entfernt. Dies betrifft z.B. die Ausführung in einem Rechnernetzwerkoder den Einsatz optimistischer Synchronisationsverfahren. Durch die alleinige Ausrich-tung des Tools auf die Parallele Simulation auf einem Mehrprozessorrechner mittels eineskonservativen Synchronisationsverfahrens und die diesbezügliche Überarbeitung des Pro-gramms läßt sich eine höhere Performance erzielen. Ebenso wäre es denkbar, eine Portie-rung der bestehenden Mechanismen aus Java in eine nicht-interpretierte Programmier-sprache vorzunehmen, um einen weiteren Performancegewinn zu erzielen. Möglich wäreeine Portierung auf C++. Leider steht jedoch momentan für Parallelrechner keine einheitli-che Variante von C++ zur Verfügung.
Einsatz der geschaffenen Lösung auf anderen Anwendungsgebieten:
Eine Anwendung des Parallelen Simulators ParSimONY-ProdSys in eine ganz andereRichtung wäre, ParSimONY-ProdSys als Infrastruktur für Multiagentensysteme einzu-setzen. Die Analogien zwischen Agentensystemen und einer verteilt abgearbeiteten Simu-lation sind offenkundig. Beide bestehen aus relativ autonomen Teilen, die miteinanderkommunizieren. Im Agentensystem ist eine Synchronisation nicht explizit notwendig, da-gegen verfügen Agentensysteme über Koordinationsmechanismen zur Abstimmung derAgenten bei der Lösungssuche. ParSimONY-ProdSys ist hier in der Lage, die Infrastrukturfür ein Agentensystem bereitzustellen. Die Agenten sind als Logische Prozesse in ParSi-mONY als Modellelemente zu implementieren. Über die in ParSimONY integrierten Me-chanismen zur parallelen bzw. verteilten Abarbeitung der Modellelemente kann dann eineparallele Ausführung der „Agenten“ erfolgen. Zur Kommunikation stellt ParSimONY be-reits Nachrichtenstrukturen bereit (siehe Punkt 5.2.2.3), die Reaktionen eines Agenten aufNachrichten lassen sich mittels der Ereignismechanismen (siehe Punkt 5.2.2.3) komfor-tabel abbilden. Die Erweiterung ParSimONY-ProdSys enthält bereits das Datenmodell,wie es für ein anwendungsneutrales Agentensystemtool ebenfalls noch implementiert wer-den müßte.Zur Zeit finden am Fachgebiet Arbeiten statt, die ParSimONY-ProdSys mit einem exter-nen, ebenfalls in Java geschriebenen Agentenframework koppeln.
Eine weitere Erweiterung von ParSimONY-ProdSys ist der Einsatz als Webbasierte Si-mulation. Es ist prinzipiell möglich, Modelle und Teile des Modells sowie die Laufzeit-bibliothek von ParSimONY-ProdSys an geographisch getrennten Orten abzulegen und eineverteilte Abarbeitung eines so erstellten Simulationsmodells auszuführen. Dabei ist ParSi-mONY-ProdSys dank der Mechanismen von RMI in der Lage, die auf verschiedenenWebservern plazierten Teile des Simulationsmodells anzusprechen und über das HTTP-Protokoll sogar Firewalls zwischen den Servern und dem Internet zu überbrücken, um einegemeinsame Simulation zu ermöglichen. Es ist also mit ParSimONY-ProdSys möglich,einen Benutzer ein Simulations(teil)modell entwickeln zu lassen und die auf einem zen-tralen Webserver bereitgestellte Laufzeitbibliothek und Funktionalität zu benutzen. In dermomentanen Version würde die Simulation zwar noch auf dem Rechner des auslösendenAnwenders ausgeführt, aber durch nur wenige Änderungen könnte die Ausführung derSimulation auf der zentralen Seite durch einen leistungsstarken Computeserver erfolgen.

Kapitel 7 Zusammenfassung
Seite 270
Dadurch besteht die Möglichkeit, Application Service Providing (ASP) für eine ParalleleSimulation mit ParSimONY-ProdSys anzubieten.
Unter Aufgriff des Gedankens der verteilten Abarbeitung und den Erkenntnissen aus Un-tersuchungsregionen mit lohnender Modellgestaltung (siehe Punkt 6.4) wäre ein sinnvollerEinsatz der Parallelen Simulation die Unterstützung des Supply Chain Managements.Bei der Supply Chain Simulation sind mehrere große Modellblöcke untereinander zu ver-binden. Jeder solche Modellblock stellt im Prinzip ein Werk dar. Ein Simulationsmodelleines solchen Werks ist bereits sehr umfangreich. Unterstützend zu den Zielen des SupplyChain Managements kann jetzt eine Parallele Simulation eingesetzt werden, welche mehre-re solcher großen Modellblöcke verbindet. Jeder solche Modellblock wäre als eine Partiti-on eines Parallelen Simulationsmodells aufzufassen. Verglichen mit den festgestelltenPerformanceeinflußfaktoren besteht in diesen Partitionen ein hoher Berechnungsaufwand,aber zwischen den Partitionen existieren nur wenige Verbindungen und nur wenig Kom-munikation (vergleiche Formel 2, Seite 69). Ein solches Simulationsmodell ist demzufolgeperformant abarbeitbar. Unterstützend kommt hinzu, daß ParSimONY in der Lage ist, einegeographische Verteilung der Teilmodelle zu überwinden (Möglichkeit zur WebbasiertenSimulation). So kann jetzt in jedem Werk eigenständig ein Teilmodell gepflegt werden undjedes Werk kann - auf Basis der von den anderen Werken zur Verfügung gestellten Teil-modelle - die Simulation der gesamten Supply Chain auslösen195. Dies wäre eine sinnvolleAnwendung der Parallelen Simulation, die in weiterführenden Arbeiten untersucht werdensollte.
195 Es besteht sogar die Möglichkeit die Teilmodelle zu verschlüsseln (Obfuscation des Java-Bytecodes). So-
mit müßten die Details eines Teilmodells gegenüber den anderen an der Supply Chain beteiligten Unter-nehmen nicht offengelegt werden.

Seite 271
Anhang
Inhalte:
Anhang A - Vergleich der Implementationsansätze zurParallelen und Verteilten Simulation ____________________272
Anhang B - Erläuterung von Mechanismen in ParSimONY ____276B.1 Verteilungen in ParSimONY ________________________________________ 276B.2 Statistiken in ParSimONY __________________________________________ 278B.3 Ereignislisten in ParSimONY _______________________________________ 278B.4 Beispiel eines ParSimONY-Simulationsmodells _________________________ 279
Anhang C - Datenstrukturen der Datenbanken im Frameworkzur simulationsbasierten Fertigungssteuerung ___________282C.1 Benutzerdefinierte Datentypen_______________________________________ 282C.2 Überblick über die Zusammenhänge zwischen den Datenbanken im
Framework ______________________________________________________ 283C.3 Datenstrukturen der Verwaltungsdatenbank ___________________________ 284C.4 Datenstrukturen der Metadatenbank__________________________________ 284C.5 Datenstrukturen der Modelldatenbank ________________________________ 285C.6 Datenstrukturen der Experimentplandatenbank ________________________ 289C.7 Datenstrukturen der Ergebnisdateien der Simulatoren ___________________ 292C.8 Datenstrukturen der Laufergebnisdatenbank ___________________________ 294C.9 Datenstrukturen der Ergebnisdatenbank ______________________________ 295
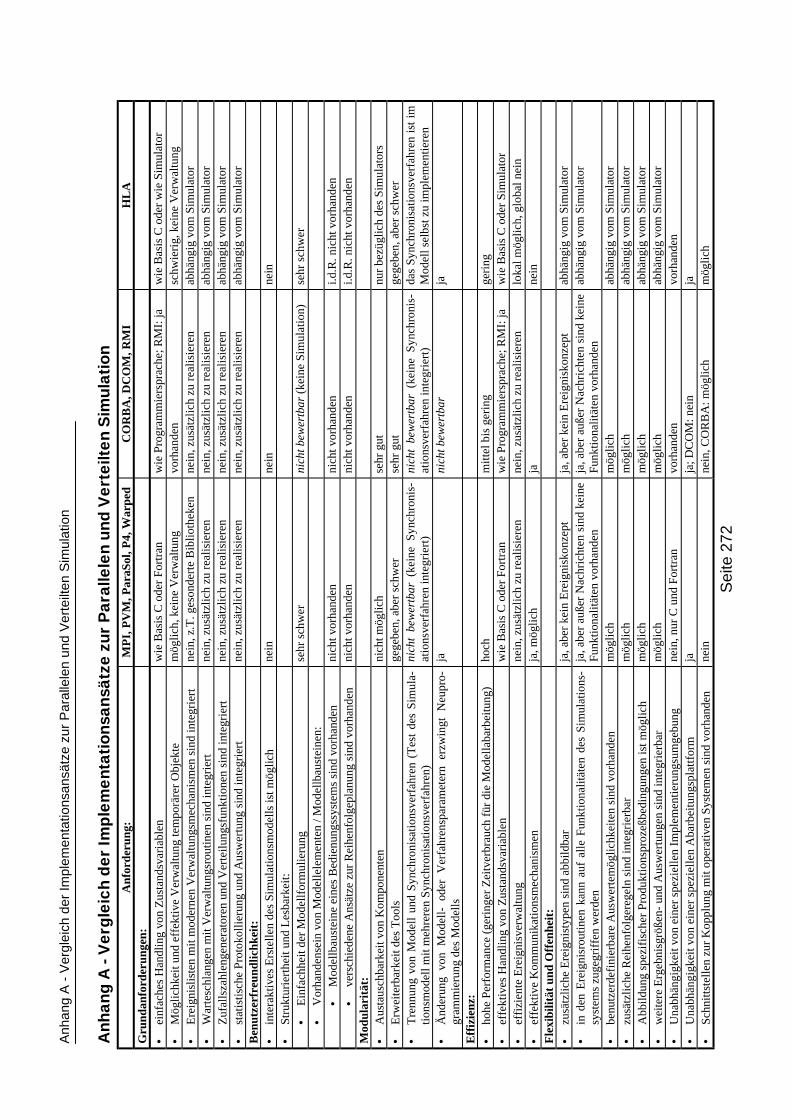
An
ha
ng
A -
Ve
rgle
ich
de
r Im
ple
me
nta
tion
san
sätz
e z
ur
Pa
ralle
len
un
d V
ert
eilt
en
Sim
ula
tion
Seite
272
An
ha
ng
A -
Ve
rgle
ich
de
r Im
ple
me
nta
tio
nsa
nsä
tze
zu
r P
ara
llele
n u
nd
Ve
rte
ilte
n S
imu
lati
on
An
ford
eru
ng:
MP
I, P
VM
, Par
aSol
, P4,
War
ped
CO
RB
A, D
CO
M, R
MI
HL
AG
run
dan
ford
eru
nge
n:
• ei
nfac
hes
Han
dlin
g vo
n Z
usta
ndsv
aria
blen
wie
Bas
is C
ode
r F
ortr
anw
ie P
rogr
amm
iers
prac
he; R
MI:
jaw
ie B
asis
C o
der
wie
Sim
ulat
or
• M
ögli
chke
it u
nd e
ffek
tive
Ver
wal
tung
tem
porä
rer
Obj
ekte
mög
lich
, kei
ne V
erw
altu
ngvo
rhan
den
schw
ieri
g, k
eine
Ver
wal
tung
• E
reig
nisl
iste
n m
it m
oder
nen
Ver
wal
tung
smec
hani
smen
sin
d in
tegr
iert
nein
, z.T
. ges
onde
rte
Bib
liot
heke
nne
in, z
usät
zlic
h zu
rea
lisi
eren
abhä
ngig
vom
Sim
ulat
or
• W
arte
schl
ange
n m
it V
erw
altu
ngsr
outi
nen
sind
inte
grie
rtne
in, z
usät
zlic
h zu
rea
lisi
eren
nein
, zus
ätzl
ich
zu r
eali
sier
enab
häng
ig v
om S
imul
ator
• Z
ufal
lsza
hlen
gene
rato
ren
und
Ver
teil
ungs
funk
tion
en s
ind
inte
grie
rtne
in, z
usät
zlic
h zu
rea
lisi
eren
nein
, zus
ätzl
ich
zu r
eali
sier
enab
häng
ig v
om S
imul
ator
• st
atis
tisc
he P
roto
koll
ieru
ng u
nd A
usw
ertu
ng s
ind
inte
grie
rtne
in, z
usät
zlic
h zu
rea
lisi
eren
nein
, zus
ätzl
ich
zu r
eali
sier
enab
häng
ig v
om S
imul
ator
Ben
utz
erfr
eun
dli
chk
eit:
• in
tera
ktiv
es E
rste
llen
des
Sim
ulat
ions
mod
ells
ist m
ögli
chne
inne
inne
in
• S
truk
turi
erth
eit u
nd L
esba
rkei
t:•
Ein
fach
heit
der
Mod
ellf
orm
ulie
rung
sehr
sch
wer
nich
t bew
ertb
ar (
kein
e S
imul
atio
n)se
hr s
chw
er
• V
orha
nden
sein
von
Mod
elle
lem
ente
n / M
odel
lbau
stei
nen:
• M
odel
lbau
stei
ne e
ines
Bed
ienu
ngss
yste
ms
sind
vor
hand
enni
cht v
orha
nden
nich
t vor
hand
eni.d
.R. n
icht
vor
hand
en
• ve
rsch
iede
ne A
nsät
ze z
ur R
eihe
nfol
gepl
anun
g si
nd v
orha
nden
nich
t vor
hand
enni
cht v
orha
nden
i.d.R
. nic
ht v
orha
nden
Mod
ula
ritä
t:•
Aus
taus
chba
rkei
t von
Kom
pone
nten
nich
t mög
lich
sehr
gut
nur
bezü
glic
h de
s S
imul
ator
s
• E
rwei
terb
arke
it d
es T
ools
gege
ben,
abe
r sc
hwer
sehr
gut
gege
ben,
abe
r sc
hwer
• T
renn
ung
von
Mod
ell
und
Syn
chro
nisa
tion
sver
fahr
en (
Tes
t de
s S
imul
a-ti
onsm
odel
l mit
meh
rere
n S
ynch
roni
sati
onsv
erfa
hren
)ni
cht
bew
ertb
ar (
kein
e S
ynch
roni
s-at
ions
verf
ahre
n in
tegr
iert
)ni
cht
bew
ertb
ar (
kein
e S
ynch
roni
s-at
ions
verf
ahre
n in
tegr
iert
)da
s S
ynch
roni
sati
onsv
erfa
hren
ist
im
Mod
ell s
elbs
t zu
impl
emen
tier
en
• Ä
nder
ung
von
Mod
ell-
ode
r V
erfa
hren
spar
amet
ern
erzw
ingt
Neu
pro-
gram
mie
rung
des
Mod
ells
jani
cht b
ewer
tbar
ja
Eff
izie
nz:
• ho
he P
erfo
rman
ce (
geri
nger
Zei
tver
brau
ch f
ür d
ie M
odel
laba
rbei
tung
)ho
chm
itte
l bis
ger
ing
geri
ng
• ef
fekt
ives
Han
dlin
g vo
n Z
usta
ndsv
aria
blen
wie
Bas
is C
ode
r F
ortr
anw
ie P
rogr
amm
iers
prac
he; R
MI:
jaw
ie B
asis
C o
der
Sim
ulat
or
• ef
fizi
ente
Ere
igni
sver
wal
tung
nein
, zus
ätzl
ich
zu r
eali
sier
enne
in, z
usät
zlic
h zu
rea
lisi
eren
loka
l mög
lich
, glo
bal n
ein
• ef
fekt
ive
Kom
mun
ikat
ions
mec
hani
smen
ja, m
ögli
chja
nein
Fle
xib
ilit
ät u
nd
Off
enh
eit:
• zu
sätz
lich
e E
reig
nist
ypen
sin
d ab
bild
bar
ja, a
ber
kein
Ere
igni
skon
zept
ja, a
ber
kein
Ere
igni
skon
zept
abhä
ngig
vom
Sim
ulat
or
• in
den
Ere
igni
srou
tine
n ka
nn a
uf a
lle
Fun
ktio
nali
täte
n de
s S
imul
atio
ns-
syst
ems
zuge
grif
fen
wer
den
ja, a
ber
auße
r N
achr
icht
en s
ind
kein
eF
unkt
iona
litä
ten
vorh
ande
nja
, abe
r au
ßer
Nac
hric
hten
sin
d ke
ine
Fun
ktio
nali
täte
n vo
rhan
den
abhä
ngig
vom
Sim
ulat
or
• be
nutz
erde
fini
erba
re A
usw
erte
mög
lich
keit
en s
ind
vorh
ande
nm
ögli
chm
ögli
chab
häng
ig v
om S
imul
ator
• zu
sätz
lich
e R
eihe
nfol
gere
geln
sin
d in
tegr
ierb
arm
ögli
chm
ögli
chab
häng
ig v
om S
imul
ator
• A
bbil
dung
spe
zifi
sche
r P
rodu
ktio
nspr
ozeß
bedi
ngun
gen
ist m
ögli
chm
ögli
chm
ögli
chab
häng
ig v
om S
imul
ator
• w
eite
re E
rgeb
nisg
röße
n- u
nd A
usw
ertu
ngen
sin
d in
tegr
ierb
arm
ögli
chm
ögli
chab
häng
ig v
om S
imul
ator
• U
nabh
ängi
gkei
t von
ein
er s
pezi
elle
n Im
plem
enti
erun
gsum
gebu
ngne
in, n
ur C
und
For
tran
vorh
ande
nvo
rhan
den
• U
nabh
ängi
gkei
t von
ein
er s
pezi
elle
n A
barb
eitu
ngsp
latt
form
jaja
; DC
OM
: nei
nja
• S
chni
ttst
elle
n zu
r K
oppl
ung
mit
ope
rati
ven
Sys
tem
en s
ind
vorh
ande
nne
inne
in, C
OR
BA
: mög
lich
mög
lich
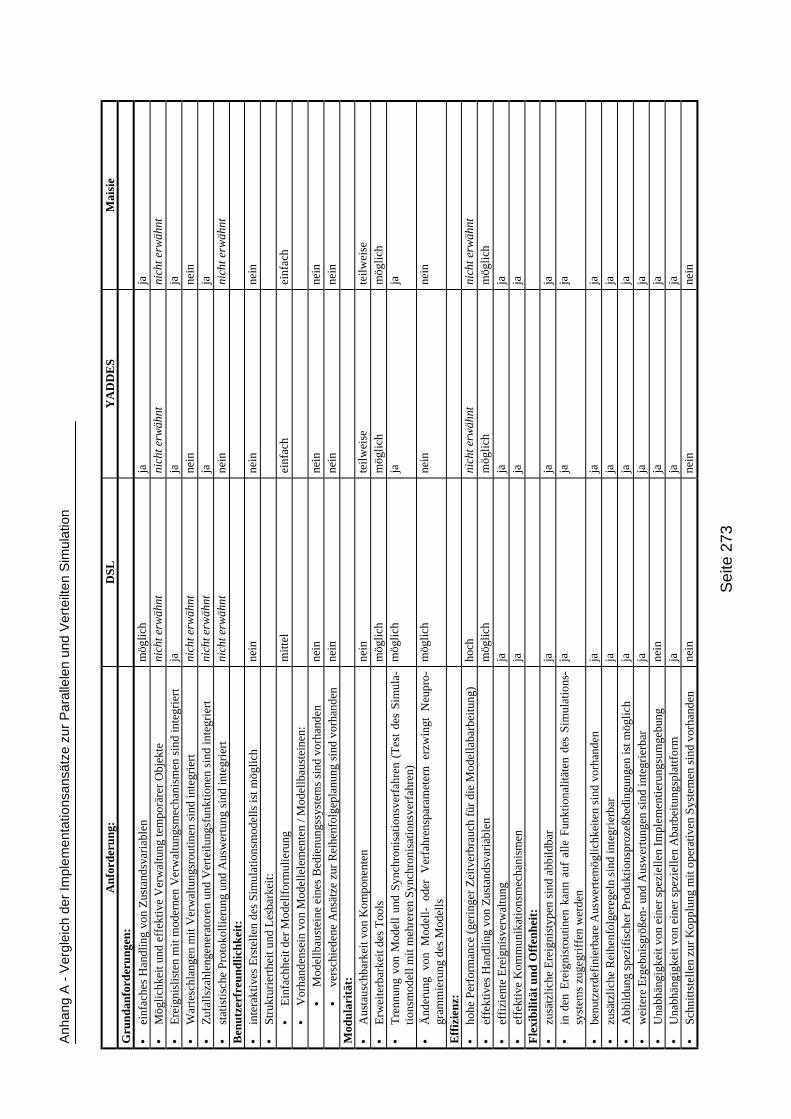
An
ha
ng
A -
Ve
rgle
ich
de
r Im
ple
me
nta
tion
san
sätz
e z
ur
Pa
ralle
len
un
d V
ert
eilt
en
Sim
ula
tion
Seite
273
An
ford
eru
ng:
DS
LY
AD
DE
SM
aisi
eG
run
dan
ford
eru
nge
n:
• ei
nfac
hes
Han
dlin
g vo
n Z
usta
ndsv
aria
blen
mög
lich
jaja
• M
ögli
chke
it u
nd e
ffek
tive
Ver
wal
tung
tem
porä
rer
Obj
ekte
nich
t erw
ähnt
nich
t erw
ähnt
nich
t erw
ähnt
• E
reig
nisl
iste
n m
it m
oder
nen
Ver
wal
tung
smec
hani
smen
sin
d in
tegr
iert
jaja
ja
• W
arte
schl
ange
n m
it V
erw
altu
ngsr
outi
nen
sind
inte
grie
rtni
cht e
rwäh
ntne
inne
in
• Z
ufal
lsza
hlen
gene
rato
ren
und
Ver
teil
ungs
funk
tion
en s
ind
inte
grie
rtni
cht e
rwäh
ntja
ja
• st
atis
tisc
he P
roto
koll
ieru
ng u
nd A
usw
ertu
ng s
ind
inte
grie
rtni
cht e
rwäh
ntne
inni
cht e
rwäh
ntB
enu
tzer
freu
nd
lich
kei
t:•
inte
rakt
ives
Ers
tell
en d
es S
imul
atio
nsm
odel
ls is
t mög
lich
nein
nein
nein
• S
truk
turi
erth
eit u
nd L
esba
rkei
t:•
Ein
fach
heit
der
Mod
ellf
orm
ulie
rung
mit
tel
einf
ach
einf
ach
• V
orha
nden
sein
von
Mod
elle
lem
ente
n / M
odel
lbau
stei
nen:
• M
odel
lbau
stei
ne e
ines
Bed
ienu
ngss
yste
ms
sind
vor
hand
enne
inne
inne
in
• ve
rsch
iede
ne A
nsät
ze z
ur R
eihe
nfol
gepl
anun
g si
nd v
orha
nden
nein
nein
nein
Mod
ula
ritä
t:•
Aus
taus
chba
rkei
t von
Kom
pone
nten
nein
teil
wei
sete
ilw
eise
• E
rwei
terb
arke
it d
es T
ools
mög
lich
mög
lich
mög
lich
• T
renn
ung
von
Mod
ell
und
Syn
chro
nisa
tion
sver
fahr
en (
Tes
t de
s S
imul
a-ti
onsm
odel
l mit
meh
rere
n S
ynch
roni
sati
onsv
erfa
hren
)m
ögli
chja
ja
• Ä
nder
ung
von
Mod
ell-
ode
r V
erfa
hren
spar
amet
ern
erzw
ingt
Neu
pro-
gram
mie
rung
des
Mod
ells
mög
lich
nein
nein
Eff
izie
nz:
• ho
he P
erfo
rman
ce (
geri
nger
Zei
tver
brau
ch f
ür d
ie M
odel
laba
rbei
tung
)ho
chni
cht e
rwäh
ntni
cht e
rwäh
nt
• ef
fekt
ives
Han
dlin
g vo
n Z
usta
ndsv
aria
blen
mög
lich
mög
lich
mög
lich
• ef
fizi
ente
Ere
igni
sver
wal
tung
jaja
ja
• ef
fekt
ive
Kom
mun
ikat
ions
mec
hani
smen
jaja
jaF
lexi
bil
ität
un
d O
ffen
hei
t:•
zusä
tzli
che
Ere
igni
styp
en s
ind
abbi
ldba
rja
jaja
• in
den
Ere
igni
srou
tine
n ka
nn a
uf a
lle
Fun
ktio
nali
täte
n de
s S
imul
atio
ns-
syst
ems
zuge
grif
fen
wer
den
jaja
ja
• be
nutz
erde
fini
erba
re A
usw
erte
mög
lich
keit
en s
ind
vorh
ande
nja
jaja
• zu
sätz
lich
e R
eihe
nfol
gere
geln
sin
d in
tegr
ierb
arja
jaja
• A
bbil
dung
spe
zifi
sche
r P
rodu
ktio
nspr
ozeß
bedi
ngun
gen
ist m
ögli
chja
jaja
• w
eite
re E
rgeb
nisg
röße
n- u
nd A
usw
ertu
ngen
sin
d in
tegr
ierb
arja
jaja
• U
nabh
ängi
gkei
t von
ein
er s
pezi
elle
n Im
plem
enti
erun
gsum
gebu
ngne
inja
ja
• U
nabh
ängi
gkei
t von
ein
er s
pezi
elle
n A
barb
eitu
ngsp
latt
form
jaja
ja
• S
chni
ttst
elle
n zu
r K
oppl
ung
mit
ope
rati
ven
Sys
tem
en s
ind
vorh
ande
nne
inne
inne
in
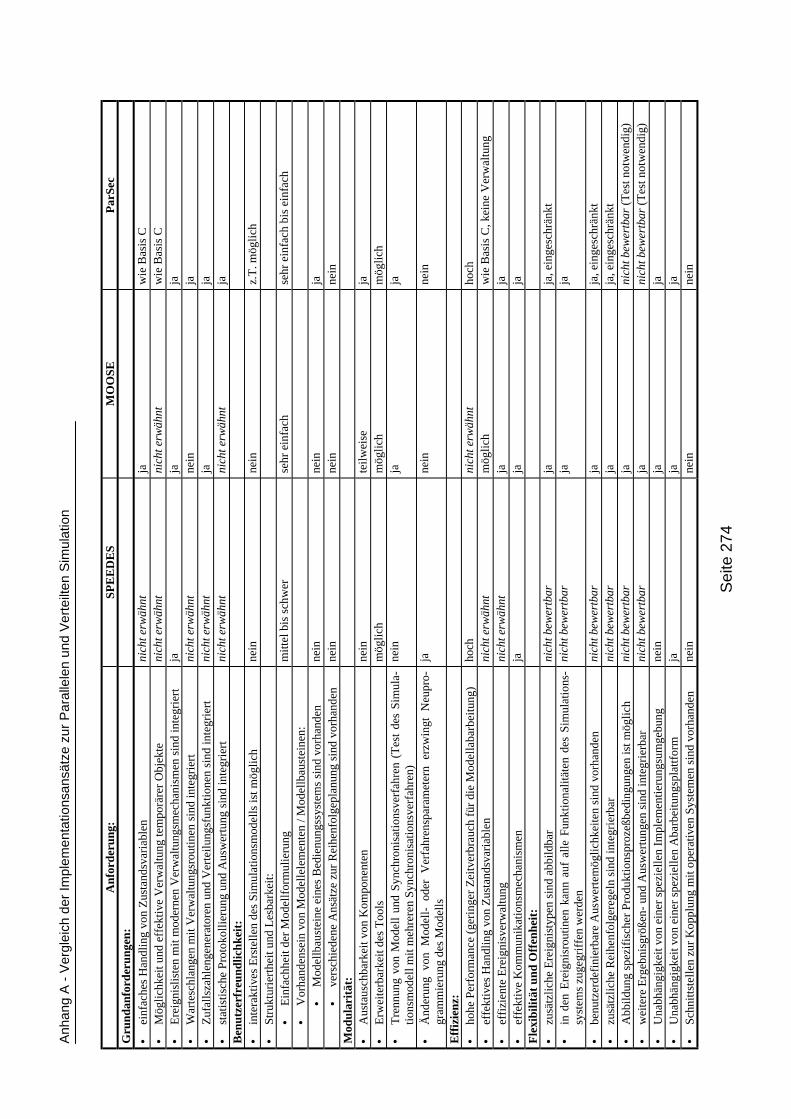
An
ha
ng
A -
Ve
rgle
ich
de
r Im
ple
me
nta
tion
san
sätz
e z
ur
Pa
ralle
len
un
d V
ert
eilt
en
Sim
ula
tion
Seite
274
An
ford
eru
ng:
SP
EE
DE
SM
OO
SE
Par
Sec
Gru
nd
anfo
rder
un
gen
:
• ei
nfac
hes
Han
dlin
g vo
n Z
usta
ndsv
aria
blen
nich
t erw
ähnt
jaw
ie B
asis
C
• M
ögli
chke
it u
nd e
ffek
tive
Ver
wal
tung
tem
porä
rer
Obj
ekte
nich
t erw
ähnt
nich
t erw
ähnt
wie
Bas
is C
• E
reig
nisl
iste
n m
it m
oder
nen
Ver
wal
tung
smec
hani
smen
sin
d in
tegr
iert
jaja
ja
• W
arte
schl
ange
n m
it V
erw
altu
ngsr
outi
nen
sind
inte
grie
rtni
cht e
rwäh
ntne
inja
• Z
ufal
lsza
hlen
gene
rato
ren
und
Ver
teil
ungs
funk
tion
en s
ind
inte
grie
rtni
cht e
rwäh
ntja
ja
• st
atis
tisc
he P
roto
koll
ieru
ng u
nd A
usw
ertu
ng s
ind
inte
grie
rtni
cht e
rwäh
ntni
cht e
rwäh
ntja
Ben
utz
erfr
eun
dli
chk
eit:
• in
tera
ktiv
es E
rste
llen
des
Sim
ulat
ions
mod
ells
ist m
ögli
chne
inne
inz.
T. m
ögli
ch
• S
truk
turi
erth
eit u
nd L
esba
rkei
t:•
Ein
fach
heit
der
Mod
ellf
orm
ulie
rung
mit
tel b
is s
chw
erse
hr e
infa
chse
hr e
infa
ch b
is e
infa
ch
• V
orha
nden
sein
von
Mod
elle
lem
ente
n / M
odel
lbau
stei
nen:
• M
odel
lbau
stei
ne e
ines
Bed
ienu
ngss
yste
ms
sind
vor
hand
enne
inne
inja
• ve
rsch
iede
ne A
nsät
ze z
ur R
eihe
nfol
gepl
anun
g si
nd v
orha
nden
nein
nein
nein
Mod
ula
ritä
t:•
Aus
taus
chba
rkei
t von
Kom
pone
nten
nein
teil
wei
seja
• E
rwei
terb
arke
it d
es T
ools
mög
lich
mög
lich
mög
lich
• T
renn
ung
von
Mod
ell
und
Syn
chro
nisa
tion
sver
fahr
en (
Tes
t de
s S
imul
a-ti
onsm
odel
l mit
meh
rere
n S
ynch
roni
sati
onsv
erfa
hren
)ne
inja
ja
• Ä
nder
ung
von
Mod
ell-
ode
r V
erfa
hren
spar
amet
ern
erzw
ingt
Neu
pro-
gram
mie
rung
des
Mod
ells
jane
inne
in
Eff
izie
nz:
• ho
he P
erfo
rman
ce (
geri
nger
Zei
tver
brau
ch f
ür d
ie M
odel
laba
rbei
tung
)ho
chni
cht e
rwäh
ntho
ch
• ef
fekt
ives
Han
dlin
g vo
n Z
usta
ndsv
aria
blen
nich
t erw
ähnt
mög
lich
wie
Bas
is C
, kei
ne V
erw
altu
ng
• ef
fizi
ente
Ere
igni
sver
wal
tung
nich
t erw
ähnt
jaja
• ef
fekt
ive
Kom
mun
ikat
ions
mec
hani
smen
jaja
jaF
lexi
bil
ität
un
d O
ffen
hei
t:•
zusä
tzli
che
Ere
igni
styp
en s
ind
abbi
ldba
rni
cht b
ewer
tbar
jaja
, ein
gesc
hrän
kt
• in
den
Ere
igni
srou
tine
n ka
nn a
uf a
lle
Fun
ktio
nali
täte
n de
s S
imul
atio
ns-
syst
ems
zuge
grif
fen
wer
den
nich
t bew
ertb
arja
ja
• be
nutz
erde
fini
erba
re A
usw
erte
mög
lich
keit
en s
ind
vorh
ande
nni
cht b
ewer
tbar
jaja
, ein
gesc
hrän
kt
• zu
sätz
lich
e R
eihe
nfol
gere
geln
sin
d in
tegr
ierb
arni
cht b
ewer
tbar
jaja
, ein
gesc
hrän
kt
• A
bbil
dung
spe
zifi
sche
r P
rodu
ktio
nspr
ozeß
bedi
ngun
gen
ist m
ögli
chni
cht b
ewer
tbar
jani
cht b
ewer
tbar
(T
est n
otw
endi
g)
• w
eite
re E
rgeb
nisg
röße
n- u
nd A
usw
ertu
ngen
sin
d in
tegr
ierb
arni
cht b
ewer
tbar
jani
cht b
ewer
tbar
(T
est n
otw
endi
g)
• U
nabh
ängi
gkei
t von
ein
er s
pezi
elle
n Im
plem
enti
erun
gsum
gebu
ngne
inja
ja
• U
nabh
ängi
gkei
t von
ein
er s
pezi
elle
n A
barb
eitu
ngsp
latt
form
jaja
ja
• S
chni
ttst
elle
n zu
r K
oppl
ung
mit
ope
rati
ven
Sys
tem
en s
ind
vorh
ande
nne
inne
inne
in
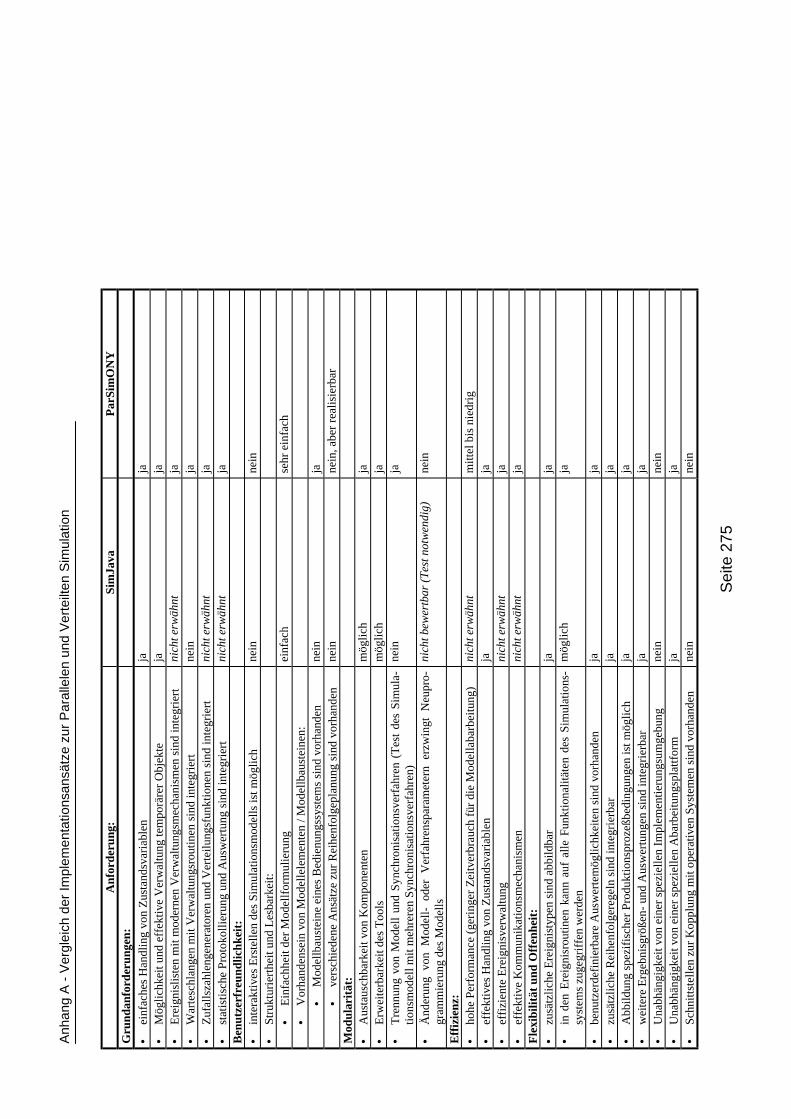
An
ha
ng
A -
Ve
rgle
ich
de
r Im
ple
me
nta
tion
san
sätz
e z
ur
Pa
ralle
len
un
d V
ert
eilt
en
Sim
ula
tion
Seite
275
An
ford
eru
ng:
Sim
Java
Par
Sim
ON
YG
run
dan
ford
eru
nge
n:
• ei
nfac
hes
Han
dlin
g vo
n Z
usta
ndsv
aria
blen
jaja
• M
ögli
chke
it u
nd e
ffek
tive
Ver
wal
tung
tem
porä
rer
Obj
ekte
jaja
• E
reig
nisl
iste
n m
it m
oder
nen
Ver
wal
tung
smec
hani
smen
sin
d in
tegr
iert
nich
t erw
ähnt
ja
• W
arte
schl
ange
n m
it V
erw
altu
ngsr
outi
nen
sind
inte
grie
rtne
inja
• Z
ufal
lsza
hlen
gene
rato
ren
und
Ver
teil
ungs
funk
tion
en s
ind
inte
grie
rtni
cht e
rwäh
ntja
• st
atis
tisc
he P
roto
koll
ieru
ng u
nd A
usw
ertu
ng s
ind
inte
grie
rtni
cht e
rwäh
ntja
Ben
utz
erfr
eun
dli
chk
eit:
• in
tera
ktiv
es E
rste
llen
des
Sim
ulat
ions
mod
ells
ist m
ögli
chne
inne
in
• S
truk
turi
erth
eit u
nd L
esba
rkei
t:•
Ein
fach
heit
der
Mod
ellf
orm
ulie
rung
einf
ach
sehr
ein
fach
• V
orha
nden
sein
von
Mod
elle
lem
ente
n / M
odel
lbau
stei
nen:
• M
odel
lbau
stei
ne e
ines
Bed
ienu
ngss
yste
ms
sind
vor
hand
enne
inja
• ve
rsch
iede
ne A
nsät
ze z
ur R
eihe
nfol
gepl
anun
g si
nd v
orha
nden
nein
nein
, abe
r re
alis
ierb
arM
odu
lari
tät:
• A
usta
usch
bark
eit v
on K
ompo
nent
enm
ögli
chja
• E
rwei
terb
arke
it d
es T
ools
mög
lich
ja
• T
renn
ung
von
Mod
ell
und
Syn
chro
nisa
tion
sver
fahr
en (
Tes
t de
s S
imul
a-ti
onsm
odel
l mit
meh
rere
n S
ynch
roni
sati
onsv
erfa
hren
)ne
inja
• Ä
nder
ung
von
Mod
ell-
ode
r V
erfa
hren
spar
amet
ern
erzw
ingt
Neu
pro-
gram
mie
rung
des
Mod
ells
nich
t bew
ertb
ar (
Tes
t not
wen
dig)
nein
Eff
izie
nz:
• ho
he P
erfo
rman
ce (
geri
nger
Zei
tver
brau
ch f
ür d
ie M
odel
laba
rbei
tung
)ni
cht e
rwäh
ntm
itte
l bis
nie
drig
• ef
fekt
ives
Han
dlin
g vo
n Z
usta
ndsv
aria
blen
jaja
• ef
fizi
ente
Ere
igni
sver
wal
tung
nich
t erw
ähnt
ja
• ef
fekt
ive
Kom
mun
ikat
ions
mec
hani
smen
nich
t erw
ähnt
jaF
lexi
bil
ität
un
d O
ffen
hei
t:•
zusä
tzli
che
Ere
igni
styp
en s
ind
abbi
ldba
rja
ja
• in
den
Ere
igni
srou
tine
n ka
nn a
uf a
lle
Fun
ktio
nali
täte
n de
s S
imul
atio
ns-
syst
ems
zuge
grif
fen
wer
den
mög
lich
ja
• be
nutz
erde
fini
erba
re A
usw
erte
mög
lich
keit
en s
ind
vorh
ande
nja
ja
• zu
sätz
lich
e R
eihe
nfol
gere
geln
sin
d in
tegr
ierb
arja
ja
• A
bbil
dung
spe
zifi
sche
r P
rodu
ktio
nspr
ozeß
bedi
ngun
gen
ist m
ögli
chja
ja
• w
eite
re E
rgeb
nisg
röße
n- u
nd A
usw
ertu
ngen
sin
d in
tegr
ierb
arja
ja
• U
nabh
ängi
gkei
t von
ein
er s
pezi
elle
n Im
plem
enti
erun
gsum
gebu
ngne
inne
in
• U
nabh
ängi
gkei
t von
ein
er s
pezi
elle
n A
barb
eitu
ngsp
latt
form
jaja
• S
chni
ttst
elle
n zu
r K
oppl
ung
mit
ope
rati
ven
Sys
tem
en s
ind
vorh
ande
nne
inne
in
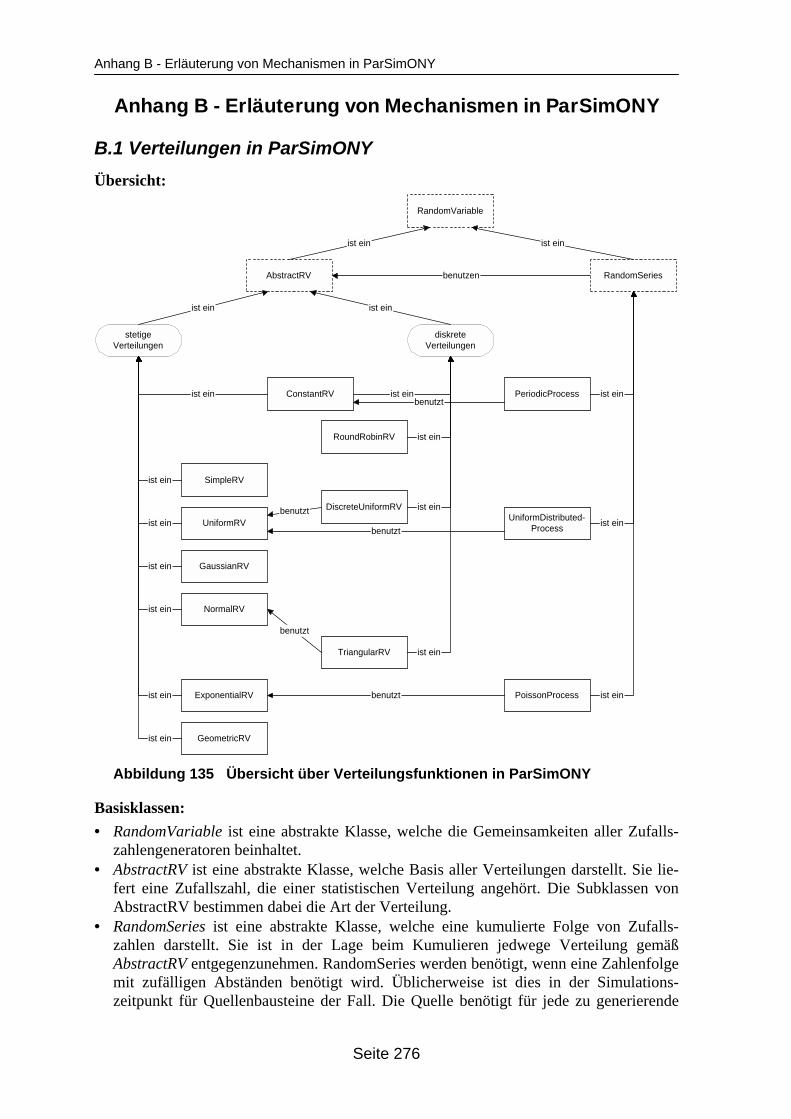
Anhang B - Erläuterung von Mechanismen in ParSimONY
Seite 276
Anhang B - Erläuterung von Mechanismen in ParSimONY
B.1 Verteilungen in ParSimONY
Übersicht:
RandomVariable
AbstractRV
SimpleRV
RandomSeries
PeriodicProcess
PoissonProcess
ist einist ein
ConstantRV
RoundRobinRV
UniformRV
stetigeVerteilungen
diskreteVerteilungen
DiscreteUniformRVbenutzt
ExponentialRV
benutzen
benutzt
benutzt
GaussianRV
NormalRV
GeometricRV
TriangularRV
UniformDistributed-Processbenutzt
benutzt
ist ein
ist ein
ist ein
ist ein
ist ein
ist ein
ist ein
ist ein
ist ein
ist ein
ist ein
ist ein
ist ein
ist ein
ist ein ist ein
Abbildung 135 Übersicht über Verteilungsfunktionen in ParSimONY
Basisklassen:
• RandomVariable ist eine abstrakte Klasse, welche die Gemeinsamkeiten aller Zufalls-zahlengeneratoren beinhaltet.
• AbstractRV ist eine abstrakte Klasse, welche Basis aller Verteilungen darstellt. Sie lie-fert eine Zufallszahl, die einer statistischen Verteilung angehört. Die Subklassen vonAbstractRV bestimmen dabei die Art der Verteilung.
• RandomSeries ist eine abstrakte Klasse, welche eine kumulierte Folge von Zufalls-zahlen darstellt. Sie ist in der Lage beim Kumulieren jedwege Verteilung gemäßAbstractRV entgegenzunehmen. RandomSeries werden benötigt, wenn eine Zahlenfolgemit zufälligen Abständen benötigt wird. Üblicherweise ist dies in der Simulations-zeitpunkt für Quellenbausteine der Fall. Die Quelle benötigt für jede zu generierende

Anhang B - Erläuterung von Mechanismen in ParSimONY
Seite 277
Forderung eine monoton steigende Ankunftszeit. Die Ankunftszeit kann dabei einereinfachen statistischen Verteilung unterliegen. Über den Parameter SEED kann ein in-itialer Wert vorgegeben werden.
Statistische Verteilungen:
• SimpleRV ist eine stetige Verteilung, welche gleichverteilt eine Zufallszahl aus demIntervall [0;1] liefert (R*).
• ConstantRV ist Verteilung, welche den als Parameter angegebenen Wert (Objekt) liefert(Singleton).
• RoundRobinRV ist eine diskrete Verteilung, welche eine geordnete Folge der Werte desals Parameter übergebenen Intervalls [US;OS] zurückliefert (round robin - engl. Kinder-Abzählreim).
• UniformRV ist eine stetige Verteilung, welche gleichverteilt eine Zufallszahl aus demIntervall [US;OS] liefert.
• DiscreteUniformRV ist eine diskrete Verteilung, welche gleichverteilt eine ganze Zahlaus dem Intervall [US;OS] liefert. Diese Verteilung war nicht im Standardumfang vonParSimONY vorhanden.
• ExponentialRV ist eine stetige Verteilung, welche exponentialverteilt mit dem Parame-ter λ eine Zufallszahl liefert.
• GaussianRV ist eine stetige Verteilung, welche normalverteilt eine Zufallszahl mit denParametern µ und ω liefert.
• NormalRV ist eine stetige Verteilung, welche normalverteilt eine Zufallszahl mit denParametern µ=0 und ω=1 liefert.
• GeometricRV ist eine stetige Verteilung, welche geometrisch-verteilt eine Zufallszahlmit dem Parameter µ liefert.
• TriangularRV ist eine diskrete Verteilung, welche eine Zufallszahl gemäß einer Drei-ecksverteilung mit den Parametern US, EX, OS liefert. Zur Näherung des Wertes wirdeine gestreckte Normalverteilung genutzt. Diese Verteilung war nicht im Standard-umfang von ParSimONY vorhanden.
Kumulierte Verteilungen:
• PeriodicProcess benutzt RandomSeries und ConstantRV um in exakt gleich großen Ab-ständen eine Zufallszahl zu liefern.
• PoissonProcess benutzt RandomSeries und ExpotentialRV um in expotentialverteiltenAbständen eine Zufallszahl zu liefern (Poissonverteilung).
• UniformDistributedProcess benutzt RandomSeries und UniformlRV um in gleichver-teilten Abständen eine Zufallszahl zu liefern. Diese Verteilung war nicht im Standard-umfang von ParSimONY vorhanden.
Gewährleitung von nichtkorrelierten Zufallszahlenströmen in ParSimONY:
Werden mehrere Verteilungsfunktionen der gleichen Art innerhalb des selben Simulations-modells benutzt, so muß sichergestellt werden, daß diese unterschiedliche Startwerte zurInitialisierung der Verteilung (Seed) benutzen. Andernfalls korrelieren die Zufallszahlen-ströme. Die Vergabe unterschiedlicher Startwerte oblag bisher dem Anwender.Deswegen wurde die Klasse Randomizer angelegt. In jedem Simulationsmodell wird eineInstanz von Randomizer verwendet. Über den Konstruktor wird mitgeteilt, wieviel unter-schiedliche Zufallszahlenströme im Modell benötigt werden. Über die Methode Get-RandomNumberForStream kann dann später ein Startwert für eine Verteilung ermittelt

Anhang B - Erläuterung von Mechanismen in ParSimONY
Seite 278
werden. Randomizer liefert für jede Zufallszahlenstromnummer einen völlig anderenStartwert196.
B.2 Statistiken in ParSimONY
Tabelle 19 In ParSimONY vorhandene Statistik-Objektklassen
Klassenname BeschreibungStatistic Interface, welches die Gemeinsamkeiten aller Statistiken (get-
Name, getMinimum, getMaximum, getMean, getStandardDevia-tion) als Deklaration beinhaltet.
AbstractStatistic Abstrakte Klasse basierend auf Statistic. Durch die Methodeaccumulate werden gewichtete Werte (value, weight) aufsum-miert. AbstractStatistic implementiert die in Statistic genanntenMethoden. Zusätzlich ist noch die Methode toString enthalten,welche eine Zusammenfassung der Ergebnisse in textueller Formproduziert.
PopulationStatistic Basiert auf AbstractStatistic. Alle Gewichte sind Eins. Wird be-nutzt um Ankunftsstatistiken zu führen. Erfaßt werden Größen wieAnzahl angekommener Einheiten, durchschnittliche, minimale undmaximale Ankunftszeit oder Einheitengröße.
TimeAveragedStatistic Basiert auf AbstractStatistic. Alle Werte sind zeitintervall-ge-wichtet. Dies wird benutzt um Auslastungs- oder Warteschlangen-längenstatistiken zu führen. Erfaßt werden Größen wie die Anzahlangekommener Einheiten, die durchschnittliche, minimale undmaximale Warteschlangenlänge.
LotTypeStatistic Basiert auf AbstractStatistic. Die Zählstatistik erfaßt je Produkttypdie Anzahl der Lose und Stück. Der Methode zaehlen wird dazuein Los-Objekt übergeben. Diese Statistikklasse war nicht imStandardumfang von ParSimONY enthalten.
B.3 Ereignislisten in ParSimONYAlle Ereignislisten basieren auf dem Interface EventList. Dieses definiert die MethodenisEmpty, nextTime, nextEvent und addEvent.Alle Simulatoren in ParSimONY verwenden die Klasse EventlistFactory. In dieser Klasseexistiert eine Klassenvariable, welche den Namen der zu verwendenden Ereignisliste an-gibt. Über die Methode createEventList kann ein beliebiger Simulator (siehe Seite 205) zurLaufzeit eine Ereignisliste anlegen.
196 Liegen die Startwerte zu dicht beieinander und erfolgt das Ziehen von Zufallszahlen für zwei Ströme unter-
schiedlich oft, so korrelieren diese Ströme zeitweise.

Anhang B - Erläuterung von Mechanismen in ParSimONY
Seite 279
Tabelle 20 In ParSimONY vorhandene Ereignislistentypen
Klassenname BeschreibungSinglyLinkedEventList Eine einfach verkettete Liste.ArrayOfListsEventList Ein Feld von einfach verketteten Listen. Durch eine Hash-
funktion erfolgt eine Zuordnung auf eine der Listen desFeldes.
CalendarQueueEventList Eine Ereignisliste als Calendar Queue (Feld von zeitinter-vall-sortierten Listen).
LeftistHeapEventList Die Ereignisliste wird unter Nutzung der KlassenLeftistHeap und PriorityQueue aus der Bibliothek Opus5angelegt (Hashing).
SplayTreeEventList Jedes der Ereignisse wird in eine Baumstruktur einsortiert.In jedem Knoten werden die Ereignisse nach kleinerer,größerer oder gleicher Ereigniszeit sortiert. Die Baum-struktur wird durch regelmäßige Reorganisation in einemausbalancierten Zustand gehalten.
B.4 Beispiel eines ParSimONY-SimulationsmodellsDas nachfolgende Beispielmodell gehört zum Standardumfang von ParSimONY. Es ist imVerzeichnis DEMOS als QueueingNetwork.java zu finden.
public class QueueingNetwork extends AbstractSimulation{
public void run(){
final int channels = 8;Channel chan[] = new Channel[channels];for (int i = 0; i < channels; ++i) chan[i] = createChannel();
Process source = createProcess( new Parsimony.Models.Source(new PoissonProcess(1000,1)), new ChannelHead[] {}, new ChannelTail[] { chan[0] });
Process merge = createProcess( new Parsimony.Models.Merge(2), new ChannelHead[] { chan[0], chan[6] }, new ChannelTail[] { chan[1] });
Process queue = createProcess( new Parsimony.Models.FIFOQueue(), new ChannelHead[] { chan[1], chan[2] }, new ChannelTail[] { chan[3] });
1
2
3
4
5
6
7
Abbildung 136 Beispiel eines ParSimONY-Simulationsmodells, Teil 1

Anhang B - Erläuterung von Mechanismen in ParSimONY
Seite 280
Das Simulationsmodell trägt den Namen QueueingNetwork (1) und muß von der Basis-klasse AbstractSimulation (2) abgeleitet werden.Ein ParSimONY-Simulationsmodell muß eine run-Methode definieren (3), welche dasauszuführende Simulationsmodell spezifiziert.Als Erstes sind die zwischen den logischer Prozessen benötigten Kommunikationskanäle(Channels) anzulegen (4).Es folgt das Anlegen der logischen Prozesse. Die Syntax zum Anlegen eines logischerProzesses lautet wie folgt:
Process <LP_Name> = createProcess(new <Modellelement>,new ChannelHead[] { <eingehende Kanäle> },new ChannelTail[] { <ausgehende Kanäle> },[<Placement>]
);
<LP_Name> ist ein beliebiger Variablenname. <Modellelement> ist der Aufruf eines pa-rameterisierten Konstruktors eines Modellelements (siehe Seite 207). ChannelHead defi-niert eine Liste mit eingehenden Verbindungskanälen und ChannelTail definiert eine Listemit ausgehenden Verbindungskanälen. Zusätzlich existiert das optionale Argument<Placement>. Über dieses Argument wird das Mapping der logischen Prozesse geregelt.
In Abbildung 136 zu sehen ist das Anlegen je eines Logischen Prozesses für:
• eine poissonverteilte Quelle (Source) (5),• ein Merge-Element mit zwei Eingängen (6) und• eine Warteschlange (FIFOQueue) (7).
Process server = createProcess(new Parsimony.Models.NonPreemptiveServer( new ExponentialRV(500,2) ),new ChannelHead[] { chan[3] },new ChannelTail[] { chan[2], chan[4] }
);
Process distributor = createProcess(new Parsimony.Models.Distributor( new UniformRV(0, 2, 3), 2 ),new ChannelHead[] { chan[4] },new ChannelTail[] { chan[5], chan[7] }
);
Process delay = createProcess(new Parsimony.Models.Delay( new ConstantRV(new Long(500)) ),new ChannelHead[] { chan[5] },new ChannelTail[] { chan[6] }
);
Process sink = createProcess(new Parsimony.Models.Sink(),new ChannelHead[] { chan[7] },new ChannelTail [] {}
);
1
2
3
4
Abbildung 137 Beispiel eines ParSimONY-Simulationsmodells, Teil 2
Abbildung 137 zeigt das Anlegen weiterer logischer Prozesse für:
• einen Bedienprozeß (NonPreemptiveServer) mit exponentialverteilter Bedienzeit (1),• ein Distributor-Element mit zwei Ausgängen (2),• ein Verzögerungselement (Delay) mit einer konstanten Verzögerung von 500 ZE (3)

Anhang B - Erläuterung von Mechanismen in ParSimONY
Seite 281
• und eine Senke (Sink) (4).
Zu beachten ist, daß Modellelemente, die Verbindungskanäle gleicher Nummer referenzie-ren, über diese Verbindungskanäle unidirektional Nachrichten austauschen können. Fürjede potentielle Kommunikationsverbindung ist statisch ein Verbindungskanal anzulegen(siehe Abbildung 136, Punkt 4).
setFinishTime(100000);super.run();
Log logger = getLogger();logger.println( source.getString() );logger.println( merge.getString() );logger.println( queue.getString() );logger.println( server.getString() );logger.println( distributor.getString() );logger.println( delay.getString() );logger.println( sink.getString() );
1
2
3
Abbildung 138 Beispiel eines ParSimONY-Simulationsmodells, Teil 3
Nach der Definition der Modellbestandteile erfolgt die Festlegung der Modelllaufzeit inSimulationszeiteinheiten (1).Dann wird die geerbte run-Methode aufgerufen (2), welche das Simulationsmodell aus-führt.Nach der Ausführung des Modells erfolgt am Simulationsende das Sammeln der erfaßtenErgebnisse (3). Hierzu wird für jeden logischen Prozeß die Methode getString aufgerufen,welche eine textuelle Repräsentation der Ergebnisse erzeugt, die anschließend am Bild-schirm ausgegeben wird.
Auf eine Darstellung eines Beispiels eines Simulationsmodells in ParSimONY-ProdSyswird aus Umfangsgründen verzichtet. Es wird jedoch ausdrücklich auf die kommentiertenBeispielmodelle im Verzeichnis ProdSys\Models hingewiesen (z.B. Mod11M.java).

Anhang C - Struktur der Datenbanken im Framework
Seite 282
Anhang C - Datenstrukturen der Datenbanken im Frameworkzur simulationsbasierten Fertigungssteuerung
C.1 Benutzerdefinierte DatentypenDie verwendete Datenbank Borland Interbase Server erlaubt mit der Definition von Domä-nen das Anlegen benutzerdefinierter Datentypen.Zum Teil wurden eigene Domänen für in Interbase 6.0.1 vorhandene Typen angelegt, danicht jede Datenbank Datentypen wie z.B. TIMESTAMP besitzt, prinzipiell jedoch dieMöglichkeit bestehen sollte, eine beliebige Datenbank zu verwenden. Durch diese zusätz-lichen Typen können vorhandene SQL-Skripte zum Anlegen der Tabellen weiter verwen-det werden.Zu jedem der aufgeführten Datentypen existiert im Framework ein Gegenstück. Diese Da-tentypen sind in der Unit „Typen“ definiert. Diese Unit enthält zudem Konvertierungs-routinen.
Tabelle 21 Übersicht über die benutzerdefinierten Datentypen, Teil 1
Domäne Datentyp BeschreibungD_KUERZEL VARCHAR(25) eine KurzbezeichnungD_BEZEICHNUNG VARCHAR(40) Datentyp für alle Bezeichnungen, Namen
oder sonstigen BenennungenD_DATETIME TIMESTAMP ein Datums- und ZeitwertD_MINUTEN FLOAT ein Zeitwert in MinutenD_LOGICAL SMALLINT CHECK
(VALUE IN (0,1))Ersatz für den logischen Datentyp Boolean
D_PROZESSTYP SMALLINT CHECK(VALUE IN(0,1,2,3))
Der Prozeßtyp gibt die Arbeitsweise derMaschine an.197
D_SETUP VARCHAR(16) Das Setup ist die Bezeichnung für eine Be-arbeitungsanforderung bzw. für ein Bear-beitungsangebot.
D_VERTEILUNGS-ART
SMALLINT CHECK(VALUE IN (0-8))
zur Angabe einer Verteilung198
D_VERTEILUNGS-PARAMETER
VARCHAR(60) Dieser Datentyp dient zur Aufbewahrungder Parameter von Verteilungen. Verteilun-gen besitzen eine unterschiedliche Anzahlan Parametern. Die einzelnen Parameter sindjeweils durch Semikoli zu separieren.
197 Im Punkt 2.3.2.3 wurde die spezifische Prozeßbedingung der parallelen Bearbeitung beschrieben. Der
Prozeßtyp spezifiziert die Arbeitsweise einer Maschine in Bezug auf Parallelbearbeitung. Null steht fürEinzelverarbeitung (Standard), d.h. es kann immer nur ein Werkstück nach dem anderen prozessiert wer-den (Normalfall). Eins steht für Gleitprozeß - mit der Bearbeitung des nächsten Werkstücks kann schonbegonnen werden, bevor die Bearbeitung abgeschlossen ist. Die Zeit des ersten Taktes ist etwas länger. DerProzeßtyp zwei steht für Batchprozeß - eine begrenzte Anzahl von Werkstücken kann gemeinsam bearbei-tet werden. Die Zeit für den Bearbeitungsprozeß ist nicht von der Stückzahl abhängig. Der Prozeßtyp dreisteht für Batch-Seriell-Prozeß. Dies ist eine Mischung aus Gleit- und Batchprozeß.
198 Der Anhang B.1 enthält einen Überblick über mögliche Verteilungen und ihre Äquivalente in ParSimO-NY.

Anhang C - Struktur der Datenbanken im Framework
Seite 283
Tabelle 22 Übersicht über die benutzerdefinierten Datentypen, Teil 2
Domäne Datentyp BeschreibungD_STRATEGIE-CODE
SMALLINT CHECK(VALUE IN (0-35))
Dieser Datentyp dient zur Angabe einer Steue-rungsregel für eine Maschine. Es sind einfacheund zusammengesetzte Prioritätsregeln, aberauch umfangreiche regelbasierte Ansätze an-gebbar. Die möglichen Werte und deren Be-deutung können dem Inhalt der Tabelle„STRATEGIE“ entnommen werden.
D_STRATEGIE-PARAMETER
VARCHAR(80) Dieser Datentyp dient zur Aufbewahrung derParameter von Steuerungsregeln. Steuerungs-regeln besitzen eine unterschiedliche Anzahl anParametern. Die einzelnen Parameter sind indiesem Datentyp durch Semikoli zu separieren.
D_ER_KENN-ZEICHEN
CHAR(1) CHECK(VALUE IN ('G', 'P'))
Dieser Datentyp stellt ein Einsteuerungsreihen-kennzeichen dar. Dieses gibt an, ob es sich beieiner Einsteuerungsreihe um eine Gesamtein-steuerung (G) oder eine Produktvektoreinsteue-rung (P) handelt.199
C.2 Überblick über die Zusammenhänge zwischen den Daten-banken im Framework
Die Daten des Frameworks verteilen sich auf mehrere Datenbanken. Abbildung 139 zeigtdie verschiedenen Arten der Datenbanken im Framework. Die Struktur der Tabellen dieserDatenbanken wird in den nachfolgenden Punkten erläutert.
Verwaltungs-datenbank
Meta-datenbank
ModelldatenbankVersuchs- und
Ergebnis-datenbank
je Modell vorhanden
Laufergebnis-datenbank
verwaltetn Modelle
modellunabhängigeDaten
temporär
1
n
Abbildung 139 Zusammenhänge der Datenbanken im Framework
199 Siehe dazu auch Anhang C.6.
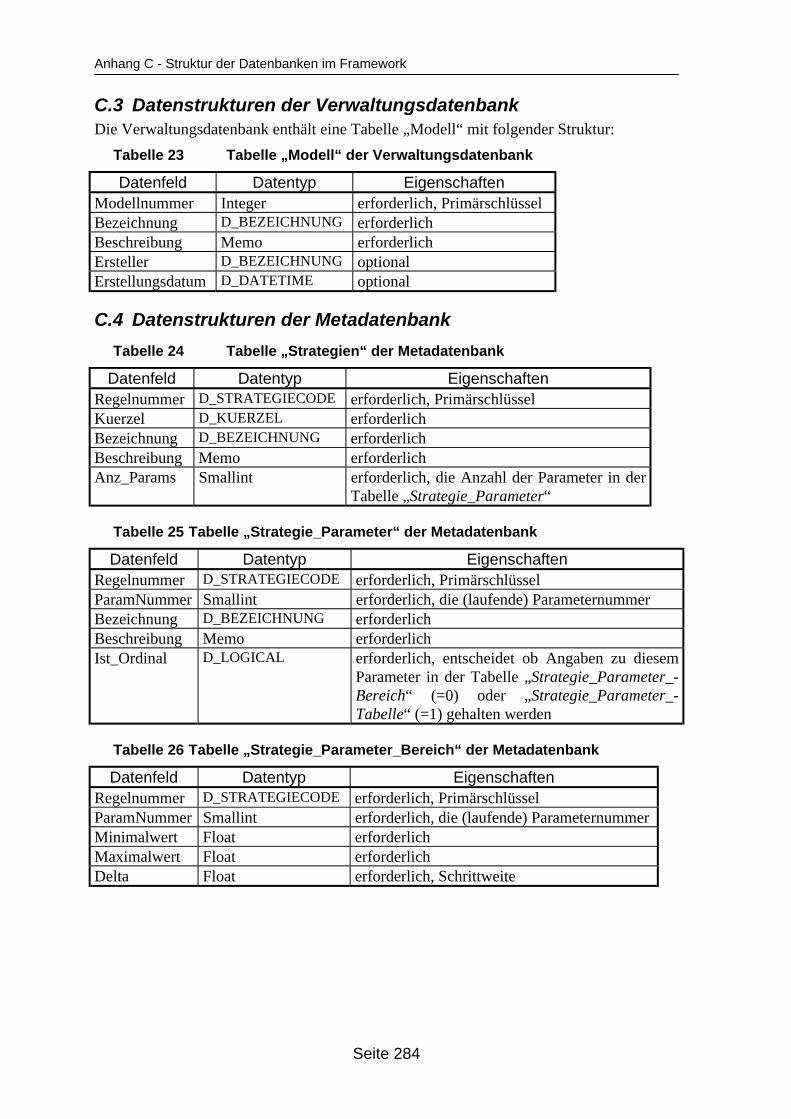
Anhang C - Struktur der Datenbanken im Framework
Seite 284
C.3 Datenstrukturen der VerwaltungsdatenbankDie Verwaltungsdatenbank enthält eine Tabelle „Modell“ mit folgender Struktur:
Tabelle 23 Tabelle „Modell“ der Verwaltungsdatenbank
Datenfeld Datentyp EigenschaftenModellnummer Integer erforderlich, PrimärschlüsselBezeichnung D_BEZEICHNUNG erforderlichBeschreibung Memo erforderlichErsteller D_BEZEICHNUNG optionalErstellungsdatum D_DATETIME optional
C.4 Datenstrukturen der Metadatenbank
Tabelle 24 Tabelle „Strategien“ der Metadatenbank
Datenfeld Datentyp EigenschaftenRegelnummer D_STRATEGIECODE erforderlich, PrimärschlüsselKuerzel D_KUERZEL erforderlichBezeichnung D_BEZEICHNUNG erforderlichBeschreibung Memo erforderlichAnz_Params Smallint erforderlich, die Anzahl der Parameter in der
Tabelle „Strategie_Parameter“
Tabelle 25 Tabelle „Strategie_Parameter“ der Metadatenbank
Datenfeld Datentyp EigenschaftenRegelnummer D_STRATEGIECODE erforderlich, PrimärschlüsselParamNummer Smallint erforderlich, die (laufende) ParameternummerBezeichnung D_BEZEICHNUNG erforderlichBeschreibung Memo erforderlichIst_Ordinal D_LOGICAL erforderlich, entscheidet ob Angaben zu diesem
Parameter in der Tabelle „Strategie_Parameter_-Bereich“ (=0) oder „Strategie_Parameter_-Tabelle“ (=1) gehalten werden
Tabelle 26 Tabelle „Strategie_Parameter_Bereich“ der Metadatenbank
Datenfeld Datentyp EigenschaftenRegelnummer D_STRATEGIECODE erforderlich, PrimärschlüsselParamNummer Smallint erforderlich, die (laufende) ParameternummerMinimalwert Float erforderlichMaximalwert Float erforderlichDelta Float erforderlich, Schrittweite
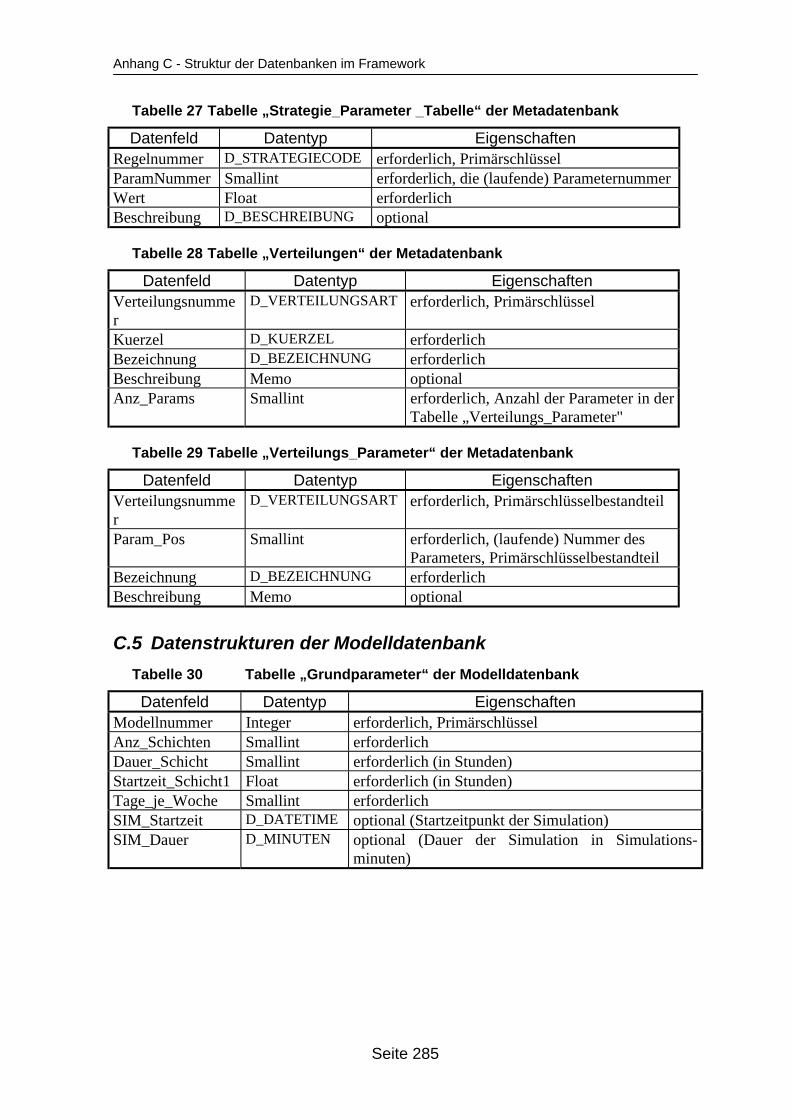
Anhang C - Struktur der Datenbanken im Framework
Seite 285
Tabelle 27 Tabelle „Strategie_Parameter _Tabelle“ der Metadatenbank
Datenfeld Datentyp EigenschaftenRegelnummer D_STRATEGIECODE erforderlich, PrimärschlüsselParamNummer Smallint erforderlich, die (laufende) ParameternummerWert Float erforderlichBeschreibung D_BESCHREIBUNG optional
Tabelle 28 Tabelle „Verteilungen“ der Metadatenbank
Datenfeld Datentyp EigenschaftenVerteilungsnummer
D_VERTEILUNGSART erforderlich, Primärschlüssel
Kuerzel D_KUERZEL erforderlichBezeichnung D_BEZEICHNUNG erforderlichBeschreibung Memo optionalAnz_Params Smallint erforderlich, Anzahl der Parameter in der
Tabelle „Verteilungs_Parameter"
Tabelle 29 Tabelle „Verteilungs_Parameter“ der Metadatenbank
Datenfeld Datentyp EigenschaftenVerteilungsnummer
D_VERTEILUNGSART erforderlich, Primärschlüsselbestandteil
Param_Pos Smallint erforderlich, (laufende) Nummer desParameters, Primärschlüsselbestandteil
Bezeichnung D_BEZEICHNUNG erforderlichBeschreibung Memo optional
C.5 Datenstrukturen der Modelldatenbank
Tabelle 30 Tabelle „Grundparameter“ der Modelldatenbank
Datenfeld Datentyp EigenschaftenModellnummer Integer erforderlich, PrimärschlüsselAnz_Schichten Smallint erforderlichDauer_Schicht Smallint erforderlich (in Stunden)Startzeit_Schicht1 Float erforderlich (in Stunden)Tage_je_Woche Smallint erforderlichSIM_Startzeit D_DATETIME optional (Startzeitpunkt der Simulation)SIM_Dauer D_MINUTEN optional (Dauer der Simulation in Simulations-
minuten)
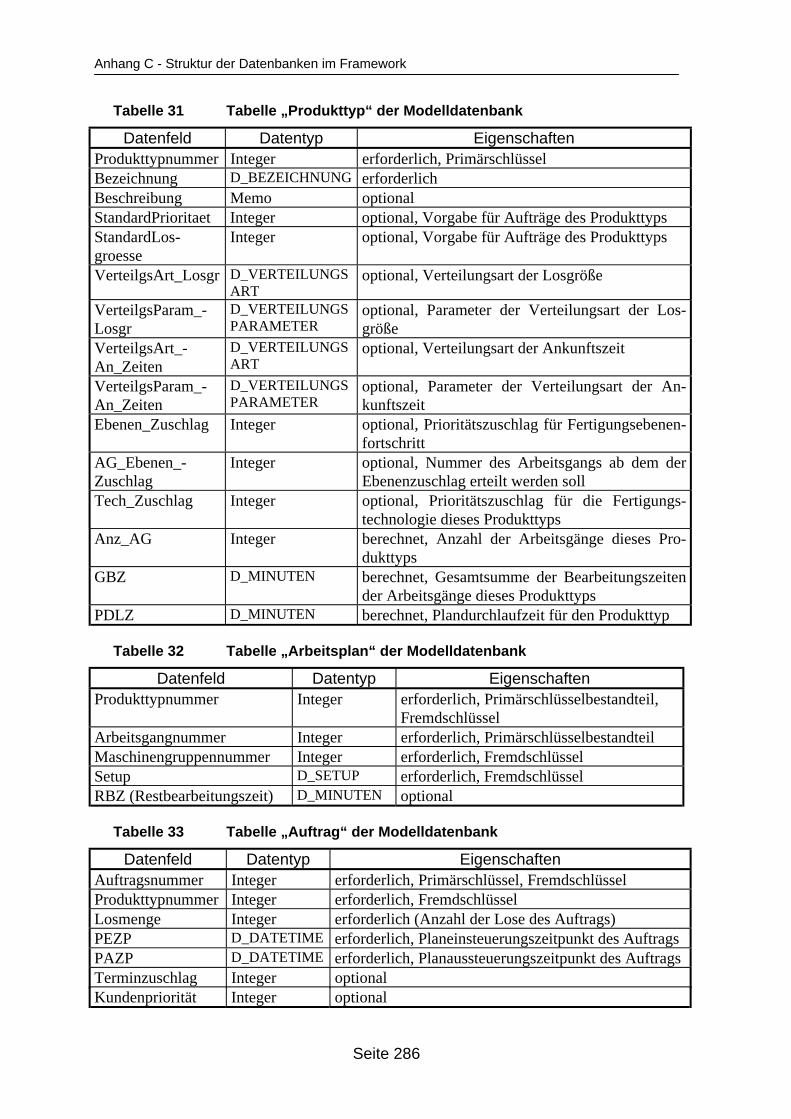
Anhang C - Struktur der Datenbanken im Framework
Seite 286
Tabelle 31 Tabelle „Produkttyp“ der Modelldatenbank
Datenfeld Datentyp EigenschaftenProdukttypnummer Integer erforderlich, PrimärschlüsselBezeichnung D_BEZEICHNUNG erforderlichBeschreibung Memo optionalStandardPrioritaet Integer optional, Vorgabe für Aufträge des ProdukttypsStandardLos-groesse
Integer optional, Vorgabe für Aufträge des Produkttyps
VerteilgsArt_Losgr D_VERTEILUNGSART
optional, Verteilungsart der Losgröße
VerteilgsParam_-Losgr
D_VERTEILUNGSPARAMETER
optional, Parameter der Verteilungsart der Los-größe
VerteilgsArt_-An_Zeiten
D_VERTEILUNGSART
optional, Verteilungsart der Ankunftszeit
VerteilgsParam_-An_Zeiten
D_VERTEILUNGSPARAMETER
optional, Parameter der Verteilungsart der An-kunftszeit
Ebenen_Zuschlag Integer optional, Prioritätszuschlag für Fertigungsebenen-fortschritt
AG_Ebenen_-Zuschlag
Integer optional, Nummer des Arbeitsgangs ab dem derEbenenzuschlag erteilt werden soll
Tech_Zuschlag Integer optional, Prioritätszuschlag für die Fertigungs-technologie dieses Produkttyps
Anz_AG Integer berechnet, Anzahl der Arbeitsgänge dieses Pro-dukttyps
GBZ D_MINUTEN berechnet, Gesamtsumme der Bearbeitungszeitender Arbeitsgänge dieses Produkttyps
PDLZ D_MINUTEN berechnet, Plandurchlaufzeit für den Produkttyp
Tabelle 32 Tabelle „Arbeitsplan“ der Modelldatenbank
Datenfeld Datentyp EigenschaftenProdukttypnummer Integer erforderlich, Primärschlüsselbestandteil,
FremdschlüsselArbeitsgangnummer Integer erforderlich, PrimärschlüsselbestandteilMaschinengruppennummer Integer erforderlich, FremdschlüsselSetup D_SETUP erforderlich, FremdschlüsselRBZ (Restbearbeitungszeit) D_MINUTEN optional
Tabelle 33 Tabelle „Auftrag“ der Modelldatenbank
Datenfeld Datentyp EigenschaftenAuftragsnummer Integer erforderlich, Primärschlüssel, FremdschlüsselProdukttypnummer Integer erforderlich, FremdschlüsselLosmenge Integer erforderlich (Anzahl der Lose des Auftrags)PEZP D_DATETIME erforderlich, Planeinsteuerungszeitpunkt des AuftragsPAZP D_DATETIME erforderlich, Planaussteuerungszeitpunkt des AuftragsTerminzuschlag Integer optionalKundenpriorität Integer optional
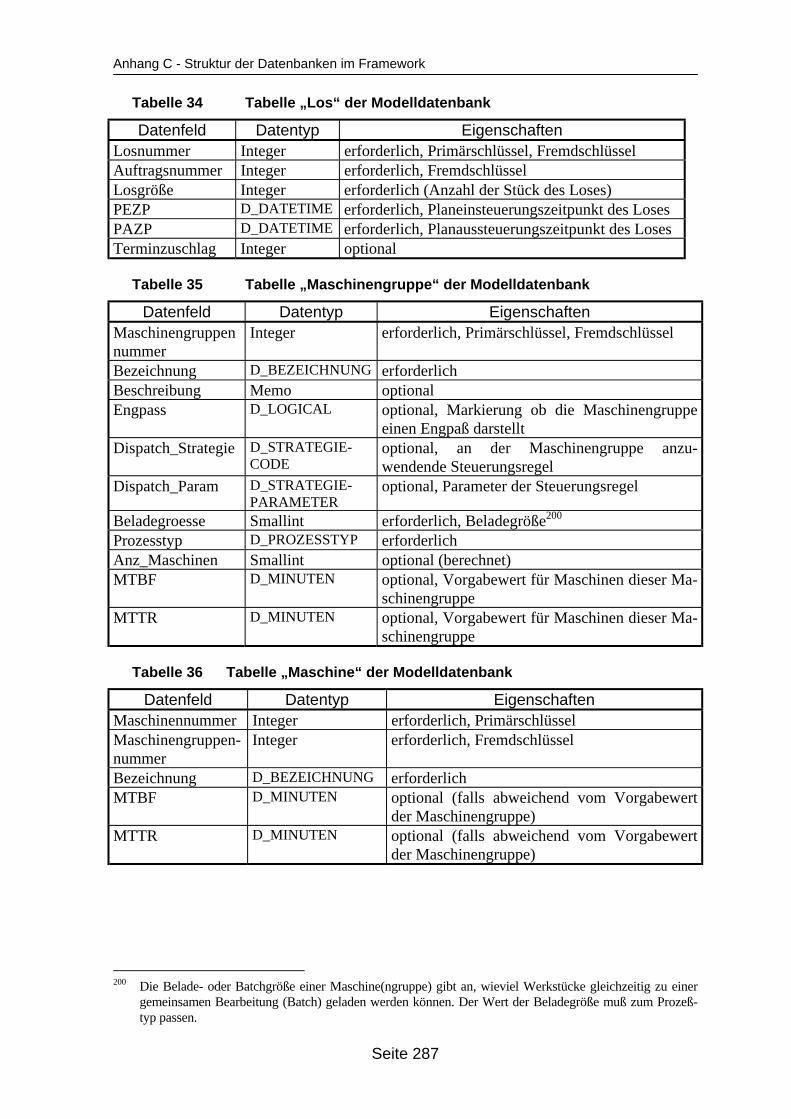
Anhang C - Struktur der Datenbanken im Framework
Seite 287
Tabelle 34 Tabelle „Los“ der Modelldatenbank
Datenfeld Datentyp EigenschaftenLosnummer Integer erforderlich, Primärschlüssel, FremdschlüsselAuftragsnummer Integer erforderlich, FremdschlüsselLosgröße Integer erforderlich (Anzahl der Stück des Loses)PEZP D_DATETIME erforderlich, Planeinsteuerungszeitpunkt des LosesPAZP D_DATETIME erforderlich, Planaussteuerungszeitpunkt des LosesTerminzuschlag Integer optional
Tabelle 35 Tabelle „Maschinengruppe“ der Modelldatenbank
Datenfeld Datentyp EigenschaftenMaschinengruppennummer
Integer erforderlich, Primärschlüssel, Fremdschlüssel
Bezeichnung D_BEZEICHNUNG erforderlichBeschreibung Memo optionalEngpass D_LOGICAL optional, Markierung ob die Maschinengruppe
einen Engpaß darstelltDispatch_Strategie D_STRATEGIE-
CODEoptional, an der Maschinengruppe anzu-wendende Steuerungsregel
Dispatch_Param D_STRATEGIE-PARAMETER
optional, Parameter der Steuerungsregel
Beladegroesse Smallint erforderlich, Beladegröße200
Prozesstyp D_PROZESSTYP erforderlichAnz_Maschinen Smallint optional (berechnet)MTBF D_MINUTEN optional, Vorgabewert für Maschinen dieser Ma-
schinengruppeMTTR D_MINUTEN optional, Vorgabewert für Maschinen dieser Ma-
schinengruppe
Tabelle 36 Tabelle „Maschine“ der Modelldatenbank
Datenfeld Datentyp EigenschaftenMaschinennummer Integer erforderlich, PrimärschlüsselMaschinengruppen-nummer
Integer erforderlich, Fremdschlüssel
Bezeichnung D_BEZEICHNUNG erforderlichMTBF D_MINUTEN optional (falls abweichend vom Vorgabewert
der Maschinengruppe)MTTR D_MINUTEN optional (falls abweichend vom Vorgabewert
der Maschinengruppe)
200 Die Belade- oder Batchgröße einer Maschine(ngruppe) gibt an, wieviel Werkstücke gleichzeitig zu einer
gemeinsamen Bearbeitung (Batch) geladen werden können. Der Wert der Beladegröße muß zum Prozeß-typ passen.

Anhang C - Struktur der Datenbanken im Framework
Seite 288
Tabelle 37 Tabelle „Uebergangszeit“ der Modelldatenbank
Datenfeld Datentyp Eigenschaftenvon_Maschinengruppe Integer erforderlich, Primärschlüsselbestandteilauf_Maschinengruppe Integer erforderlich, PrimärschlüsselbestandteilUebergangszeit D_MINUTEN erforderlich
Tabelle 38 Tabelle „BearbMoeglichkeit“ der Modelldatenbank201
Datenfeld Datentyp EigenschaftenMaschinennummer Integer erforderlich, PrimärschlüsselbestandteilSetup D_SETUP erforderlich, PrimärschlüsselbestandteilTaktzeit D_MINUTEN erforderlichDelay_Taktzeit1 D_MINUTEN erforderlich
Tabelle 39 Tabelle „Setupgruppen“ der Modelldatenbank
Datenfeld Datentyp EigenschaftenMaschinengruppennummer Integer erforderlich, PrimärschlüsselbestandteilSetup D_SETUP erforderlich, PrimärschlüsselbestandteilSetupgruppe D_SETUP erforderlich
Tabelle 40 Tabelle „Ruestzeiten_zwischen_Gruppen“ der Modelldatenbank
Datenfeld Datentyp EigenschaftenMaschinengruppennummer Integer erforderlich, Primärschlüsselbestandteilvon_Setupgruppe D_SETUP erforderlich, Primärschlüsselbestandteilauf_Setupgruppe D_SETUP erforderlich, PrimärschlüsselbestandteilRuestzeit D_MINUTEN erforderlich
Tabelle 41 Tabelle „Ruestzeit_in_Gruppe“ der Modelldatenbank
Datenfeld Datentyp EigenschaftenMaschinengruppennummer Integer erforderlich, PrimärschlüsselbestandteilSetupgruppe D_SETUP erforderlich, PrimärschlüsselbestandteilRuestzeit D_MINUTEN erforderlich
Tabelle 42 Tabelle „Anfangsbelegung_Auftrag“ der Modelldatenbank202
Datenfeld Datentyp EigenschaftenAuftragsnummer Integer erforderlich, PrimärschlüsselProdukttypnummer Integer erforderlich, FremdschlüsselKundenprioritaet Integer erforderlich
201 Mittels dieser Tabelle wird angegeben, welche Maschine welche Bearbeitung (Setup) in welcher Zeit aus-
führen kann. Die Interpretation der Zeiten ist von Prozeßtyp der Maschine abhängig. Bei einem Batch oderBatch-Seriell-Prozeß enthält die Taktzeit die Zeit für das Batch. Bei einem Einzel- oder Gleitprozeß enthältdie Taktzeit die Zeit für ein Werkstück. Bei einem Batch-Seriell- oder einem Gleitprozeß enthält De-lay_Taktzeit1 eine zusätzliche Zeit für den 1. Takt.
202 Vergleiche Tabelle 33.
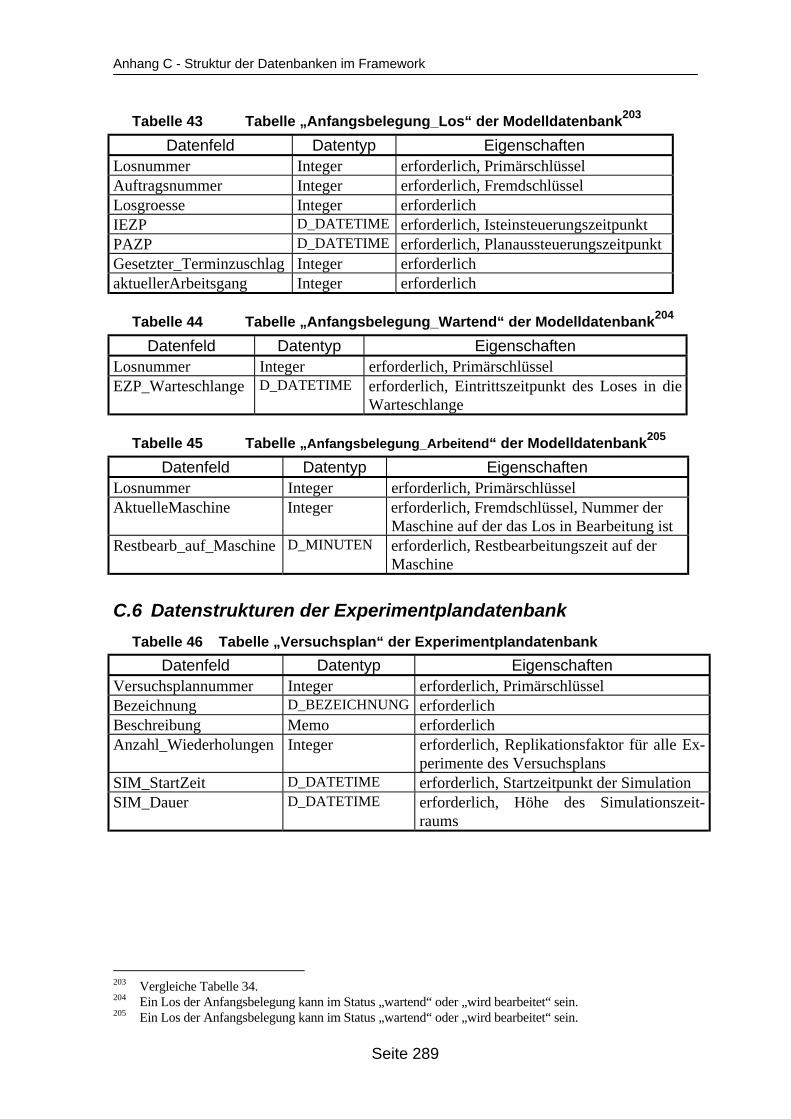
Anhang C - Struktur der Datenbanken im Framework
Seite 289
Tabelle 43 Tabelle „Anfangsbelegung_Los“ der Modelldatenbank203
Datenfeld Datentyp EigenschaftenLosnummer Integer erforderlich, PrimärschlüsselAuftragsnummer Integer erforderlich, FremdschlüsselLosgroesse Integer erforderlichIEZP D_DATETIME erforderlich, IsteinsteuerungszeitpunktPAZP D_DATETIME erforderlich, PlanaussteuerungszeitpunktGesetzter_Terminzuschlag Integer erforderlichaktuellerArbeitsgang Integer erforderlich
Tabelle 44 Tabelle „Anfangsbelegung_Wartend“ der Modelldatenbank204
Datenfeld Datentyp EigenschaftenLosnummer Integer erforderlich, PrimärschlüsselEZP_Warteschlange D_DATETIME erforderlich, Eintrittszeitpunkt des Loses in die
Warteschlange
Tabelle 45 Tabelle „Anfangsbelegung_Arbeitend“ der Modelldatenbank205
Datenfeld Datentyp EigenschaftenLosnummer Integer erforderlich, PrimärschlüsselAktuelleMaschine Integer erforderlich, Fremdschlüssel, Nummer der
Maschine auf der das Los in Bearbeitung istRestbearb_auf_Maschine D_MINUTEN erforderlich, Restbearbeitungszeit auf der
Maschine
C.6 Datenstrukturen der Experimentplandatenbank
Tabelle 46 Tabelle „Versuchsplan“ der Experimentplandatenbank
Datenfeld Datentyp EigenschaftenVersuchsplannummer Integer erforderlich, PrimärschlüsselBezeichnung D_BEZEICHNUNG erforderlichBeschreibung Memo erforderlichAnzahl_Wiederholungen Integer erforderlich, Replikationsfaktor für alle Ex-
perimente des VersuchsplansSIM_StartZeit D_DATETIME erforderlich, Startzeitpunkt der SimulationSIM_Dauer D_DATETIME erforderlich, Höhe des Simulationszeit-
raums
203 Vergleiche Tabelle 34.204 Ein Los der Anfangsbelegung kann im Status „wartend“ oder „wird bearbeitet“ sein.205 Ein Los der Anfangsbelegung kann im Status „wartend“ oder „wird bearbeitet“ sein.
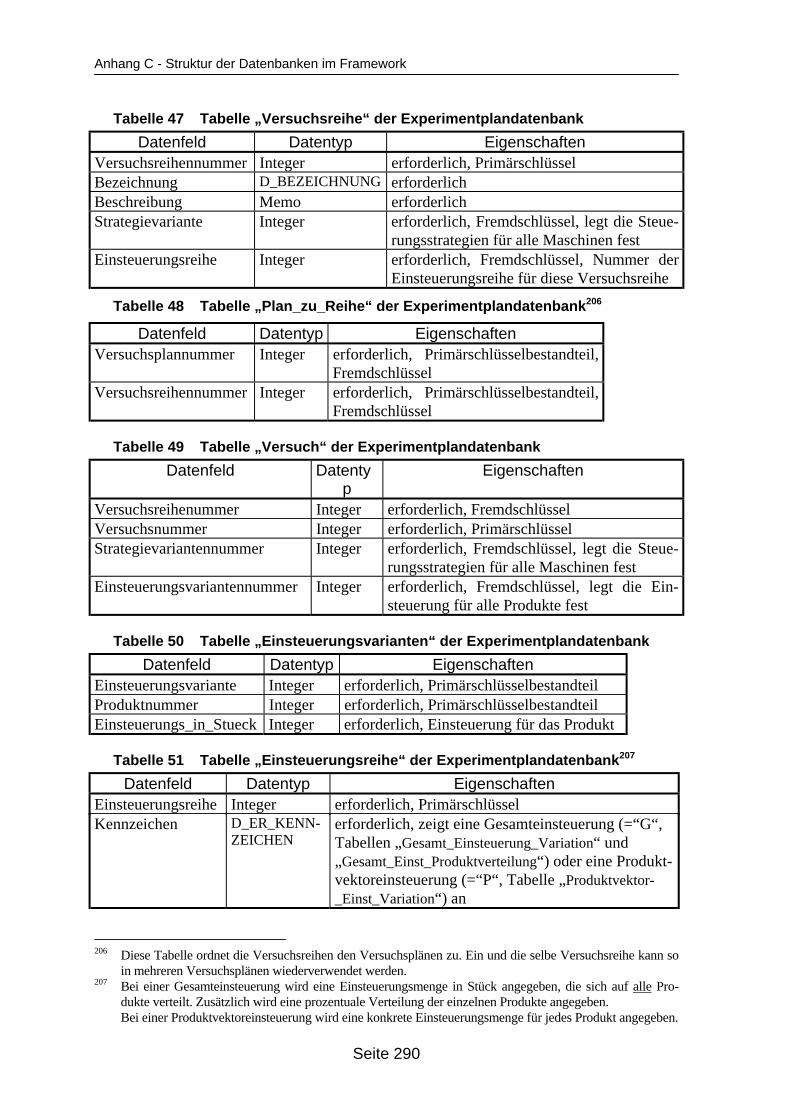
Anhang C - Struktur der Datenbanken im Framework
Seite 290
Tabelle 47 Tabelle „Versuchsreihe“ der Experimentplandatenbank
Datenfeld Datentyp EigenschaftenVersuchsreihennummer Integer erforderlich, PrimärschlüsselBezeichnung D_BEZEICHNUNG erforderlichBeschreibung Memo erforderlichStrategievariante Integer erforderlich, Fremdschlüssel, legt die Steue-
rungsstrategien für alle Maschinen festEinsteuerungsreihe Integer erforderlich, Fremdschlüssel, Nummer der
Einsteuerungsreihe für diese Versuchsreihe
Tabelle 48 Tabelle „Plan_zu_Reihe“ der Experimentplandatenbank206
Datenfeld Datentyp EigenschaftenVersuchsplannummer Integer erforderlich, Primärschlüsselbestandteil,
FremdschlüsselVersuchsreihennummer Integer erforderlich, Primärschlüsselbestandteil,
Fremdschlüssel
Tabelle 49 Tabelle „Versuch“ der Experimentplandatenbank
Datenfeld Datentyp
Eigenschaften
Versuchsreihenummer Integer erforderlich, FremdschlüsselVersuchsnummer Integer erforderlich, PrimärschlüsselStrategievariantennummer Integer erforderlich, Fremdschlüssel, legt die Steue-
rungsstrategien für alle Maschinen festEinsteuerungsvariantennummer Integer erforderlich, Fremdschlüssel, legt die Ein-
steuerung für alle Produkte fest
Tabelle 50 Tabelle „Einsteuerungsvarianten“ der Experimentplandatenbank
Datenfeld Datentyp EigenschaftenEinsteuerungsvariante Integer erforderlich, PrimärschlüsselbestandteilProduktnummer Integer erforderlich, PrimärschlüsselbestandteilEinsteuerungs_in_Stueck Integer erforderlich, Einsteuerung für das Produkt
Tabelle 51 Tabelle „Einsteuerungsreihe“ der Experimentplandatenbank207
Datenfeld Datentyp EigenschaftenEinsteuerungsreihe Integer erforderlich, PrimärschlüsselKennzeichen D_ER_KENN-
ZEICHENerforderlich, zeigt eine Gesamteinsteuerung (=“G“,Tabellen „Gesamt_Einsteuerung_Variation“ und„Gesamt_Einst_Produktverteilung“) oder eine Produkt-vektoreinsteuerung (=“P“, Tabelle „Produktvektor-_Einst_Variation“) an
206 Diese Tabelle ordnet die Versuchsreihen den Versuchsplänen zu. Ein und die selbe Versuchsreihe kann so
in mehreren Versuchsplänen wiederverwendet werden.207 Bei einer Gesamteinsteuerung wird eine Einsteuerungsmenge in Stück angegeben, die sich auf alle Pro-
dukte verteilt. Zusätzlich wird eine prozentuale Verteilung der einzelnen Produkte angegeben.Bei einer Produktvektoreinsteuerung wird eine konkrete Einsteuerungsmenge für jedes Produkt angegeben.
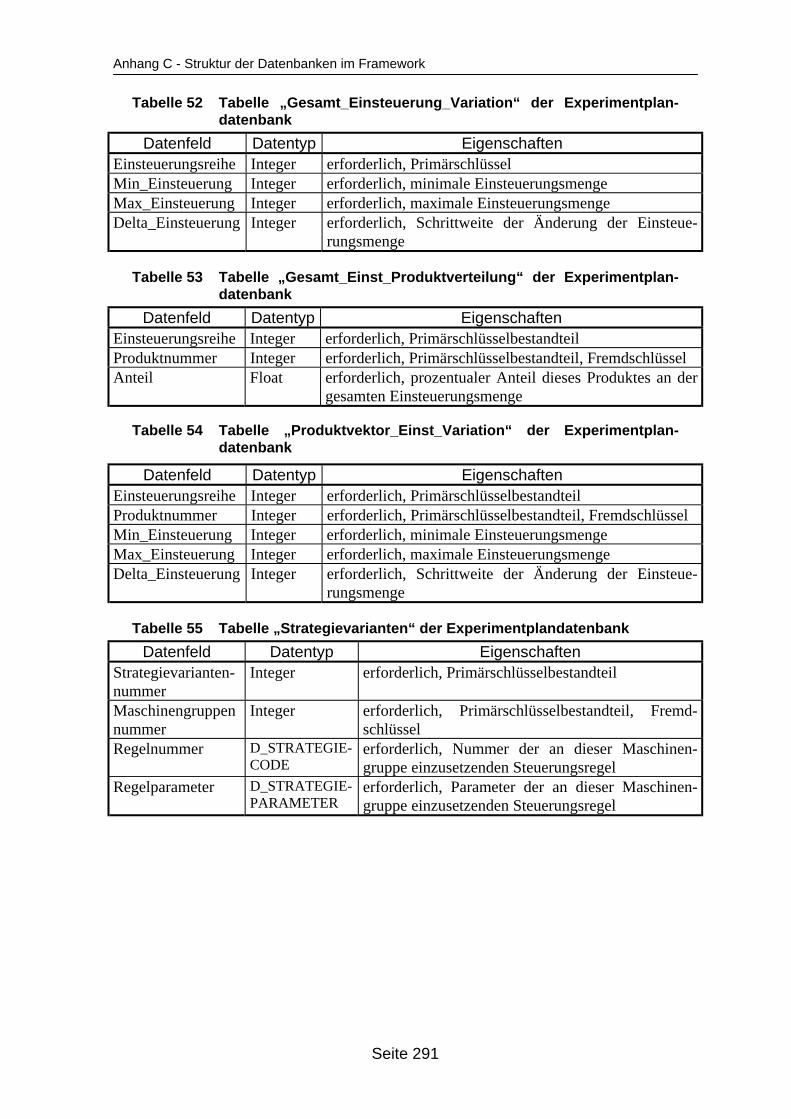
Anhang C - Struktur der Datenbanken im Framework
Seite 291
Tabelle 52 Tabelle „Gesamt_Einsteuerung_Variation“ der Experimentplan-datenbank
Datenfeld Datentyp EigenschaftenEinsteuerungsreihe Integer erforderlich, PrimärschlüsselMin_Einsteuerung Integer erforderlich, minimale EinsteuerungsmengeMax_Einsteuerung Integer erforderlich, maximale EinsteuerungsmengeDelta_Einsteuerung Integer erforderlich, Schrittweite der Änderung der Einsteue-
rungsmenge
Tabelle 53 Tabelle „Gesamt_Einst_Produktverteilung“ der Experimentplan-datenbank
Datenfeld Datentyp EigenschaftenEinsteuerungsreihe Integer erforderlich, PrimärschlüsselbestandteilProduktnummer Integer erforderlich, Primärschlüsselbestandteil, FremdschlüsselAnteil Float erforderlich, prozentualer Anteil dieses Produktes an der
gesamten Einsteuerungsmenge
Tabelle 54 Tabelle „Produktvektor_Einst_Variation“ der Experimentplan-datenbank
Datenfeld Datentyp EigenschaftenEinsteuerungsreihe Integer erforderlich, PrimärschlüsselbestandteilProduktnummer Integer erforderlich, Primärschlüsselbestandteil, FremdschlüsselMin_Einsteuerung Integer erforderlich, minimale EinsteuerungsmengeMax_Einsteuerung Integer erforderlich, maximale EinsteuerungsmengeDelta_Einsteuerung Integer erforderlich, Schrittweite der Änderung der Einsteue-
rungsmenge
Tabelle 55 Tabelle „Strategievarianten“ der Experimentplandatenbank
Datenfeld Datentyp EigenschaftenStrategievarianten-nummer
Integer erforderlich, Primärschlüsselbestandteil
Maschinengruppennummer
Integer erforderlich, Primärschlüsselbestandteil, Fremd-schlüssel
Regelnummer D_STRATEGIE-CODE
erforderlich, Nummer der an dieser Maschinen-gruppe einzusetzenden Steuerungsregel
Regelparameter D_STRATEGIE-PARAMETER
erforderlich, Parameter der an dieser Maschinen-gruppe einzusetzenden Steuerungsregel
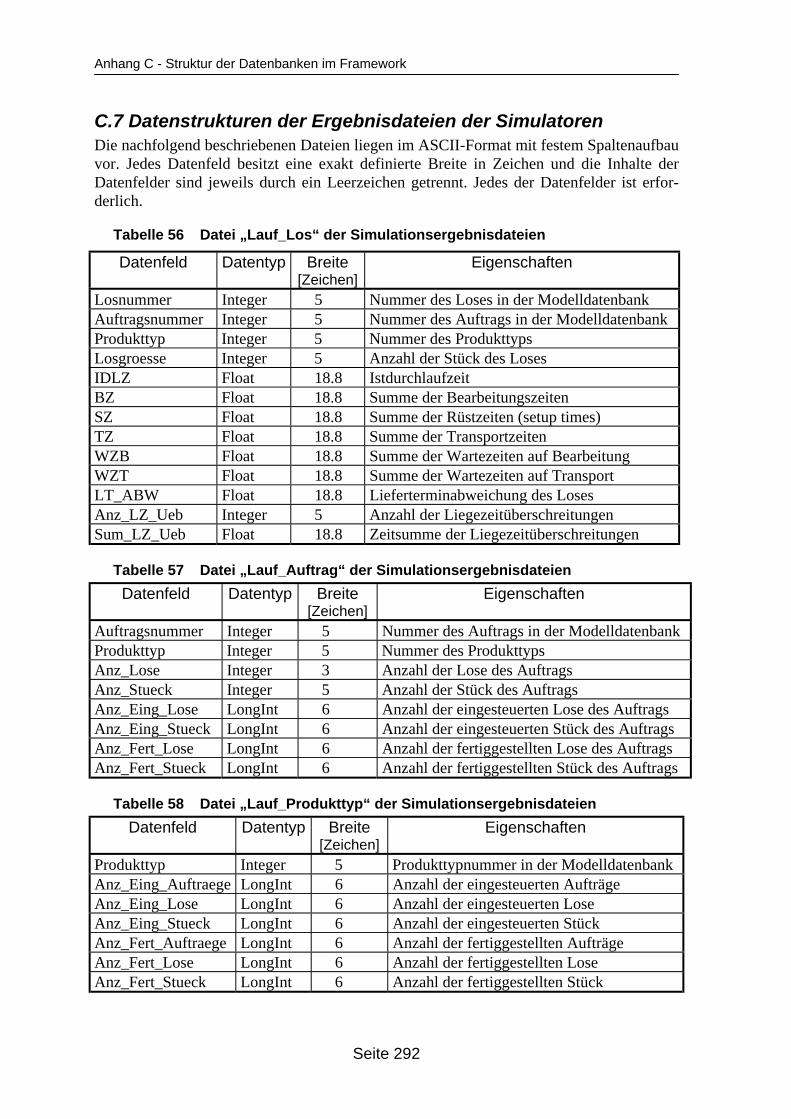
Anhang C - Struktur der Datenbanken im Framework
Seite 292
C.7 Datenstrukturen der Ergebnisdateien der SimulatorenDie nachfolgend beschriebenen Dateien liegen im ASCII-Format mit festem Spaltenaufbauvor. Jedes Datenfeld besitzt eine exakt definierte Breite in Zeichen und die Inhalte derDatenfelder sind jeweils durch ein Leerzeichen getrennt. Jedes der Datenfelder ist erfor-derlich.
Tabelle 56 Datei „Lauf_Los“ der Simulationsergebnisdateien
Datenfeld Datentyp Breite[Zeichen]
Eigenschaften
Losnummer Integer 5 Nummer des Loses in der ModelldatenbankAuftragsnummer Integer 5 Nummer des Auftrags in der ModelldatenbankProdukttyp Integer 5 Nummer des ProdukttypsLosgroesse Integer 5 Anzahl der Stück des LosesIDLZ Float 18.8 IstdurchlaufzeitBZ Float 18.8 Summe der BearbeitungszeitenSZ Float 18.8 Summe der Rüstzeiten (setup times)TZ Float 18.8 Summe der TransportzeitenWZB Float 18.8 Summe der Wartezeiten auf BearbeitungWZT Float 18.8 Summe der Wartezeiten auf TransportLT_ABW Float 18.8 Lieferterminabweichung des LosesAnz_LZ_Ueb Integer 5 Anzahl der LiegezeitüberschreitungenSum_LZ_Ueb Float 18.8 Zeitsumme der Liegezeitüberschreitungen
Tabelle 57 Datei „Lauf_Auftrag“ der Simulationsergebnisdateien
Datenfeld Datentyp Breite[Zeichen]
Eigenschaften
Auftragsnummer Integer 5 Nummer des Auftrags in der ModelldatenbankProdukttyp Integer 5 Nummer des ProdukttypsAnz_Lose Integer 3 Anzahl der Lose des AuftragsAnz_Stueck Integer 5 Anzahl der Stück des AuftragsAnz_Eing_Lose LongInt 6 Anzahl der eingesteuerten Lose des AuftragsAnz_Eing_Stueck LongInt 6 Anzahl der eingesteuerten Stück des AuftragsAnz_Fert_Lose LongInt 6 Anzahl der fertiggestellten Lose des AuftragsAnz_Fert_Stueck LongInt 6 Anzahl der fertiggestellten Stück des Auftrags
Tabelle 58 Datei „Lauf_Produkttyp“ der Simulationsergebnisdateien
Datenfeld Datentyp Breite[Zeichen]
Eigenschaften
Produkttyp Integer 5 Produkttypnummer in der ModelldatenbankAnz_Eing_Auftraege LongInt 6 Anzahl der eingesteuerten AufträgeAnz_Eing_Lose LongInt 6 Anzahl der eingesteuerten LoseAnz_Eing_Stueck LongInt 6 Anzahl der eingesteuerten StückAnz_Fert_Auftraege LongInt 6 Anzahl der fertiggestellten AufträgeAnz_Fert_Lose LongInt 6 Anzahl der fertiggestellten LoseAnz_Fert_Stueck LongInt 6 Anzahl der fertiggestellten Stück
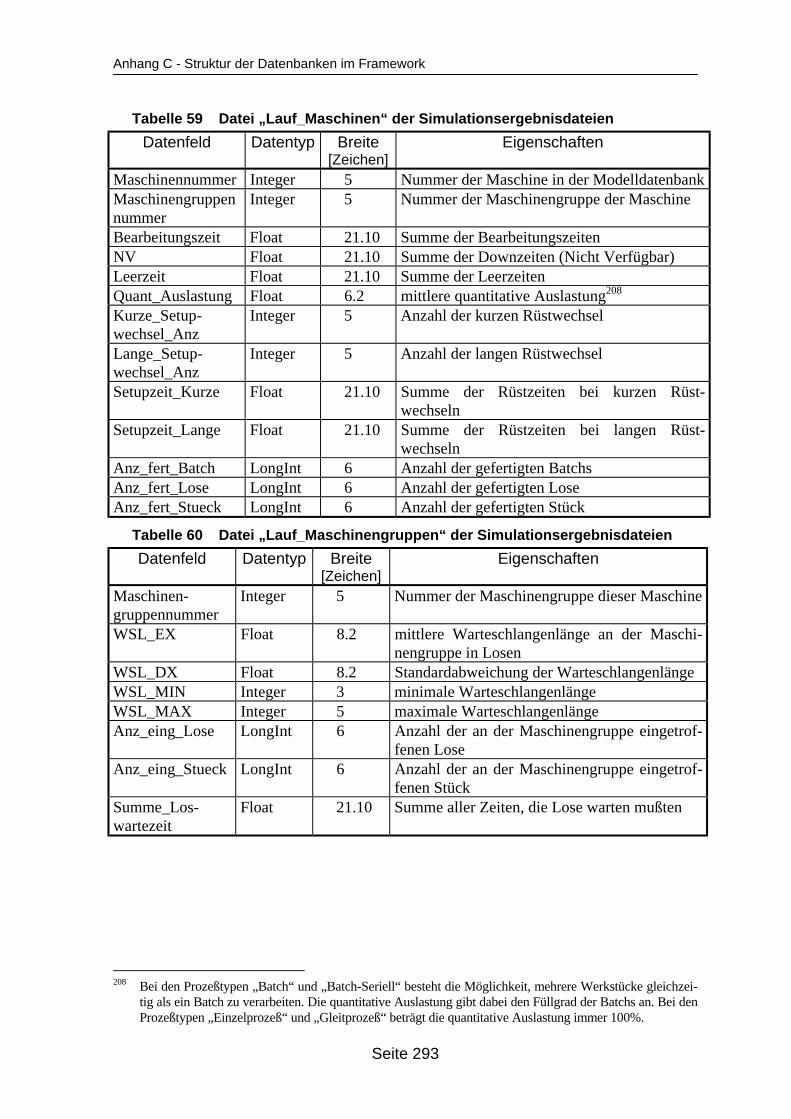
Anhang C - Struktur der Datenbanken im Framework
Seite 293
Tabelle 59 Datei „Lauf_Maschinen“ der Simulationsergebnisdateien
Datenfeld Datentyp Breite[Zeichen]
Eigenschaften
Maschinennummer Integer 5 Nummer der Maschine in der ModelldatenbankMaschinengruppennummer
Integer 5 Nummer der Maschinengruppe der Maschine
Bearbeitungszeit Float 21.10 Summe der BearbeitungszeitenNV Float 21.10 Summe der Downzeiten (Nicht Verfügbar)Leerzeit Float 21.10 Summe der LeerzeitenQuant_Auslastung Float 6.2 mittlere quantitative Auslastung208
Kurze_Setup-wechsel_Anz
Integer 5 Anzahl der kurzen Rüstwechsel
Lange_Setup-wechsel_Anz
Integer 5 Anzahl der langen Rüstwechsel
Setupzeit_Kurze Float 21.10 Summe der Rüstzeiten bei kurzen Rüst-wechseln
Setupzeit_Lange Float 21.10 Summe der Rüstzeiten bei langen Rüst-wechseln
Anz_fert_Batch LongInt 6 Anzahl der gefertigten BatchsAnz_fert_Lose LongInt 6 Anzahl der gefertigten LoseAnz_fert_Stueck LongInt 6 Anzahl der gefertigten Stück
Tabelle 60 Datei „Lauf_Maschinengruppen“ der Simulationsergebnisdateien
Datenfeld Datentyp Breite[Zeichen]
Eigenschaften
Maschinen-gruppennummer
Integer 5 Nummer der Maschinengruppe dieser Maschine
WSL_EX Float 8.2 mittlere Warteschlangenlänge an der Maschi-nengruppe in Losen
WSL_DX Float 8.2 Standardabweichung der WarteschlangenlängeWSL_MIN Integer 3 minimale WarteschlangenlängeWSL_MAX Integer 5 maximale WarteschlangenlängeAnz_eing_Lose LongInt 6 Anzahl der an der Maschinengruppe eingetrof-
fenen LoseAnz_eing_Stueck LongInt 6 Anzahl der an der Maschinengruppe eingetrof-
fenen StückSumme_Los-wartezeit
Float 21.10 Summe aller Zeiten, die Lose warten mußten
208 Bei den Prozeßtypen „Batch“ und „Batch-Seriell“ besteht die Möglichkeit, mehrere Werkstücke gleichzei-
tig als ein Batch zu verarbeiten. Die quantitative Auslastung gibt dabei den Füllgrad der Batchs an. Bei denProzeßtypen „Einzelprozeß“ und „Gleitprozeß“ beträgt die quantitative Auslastung immer 100%.
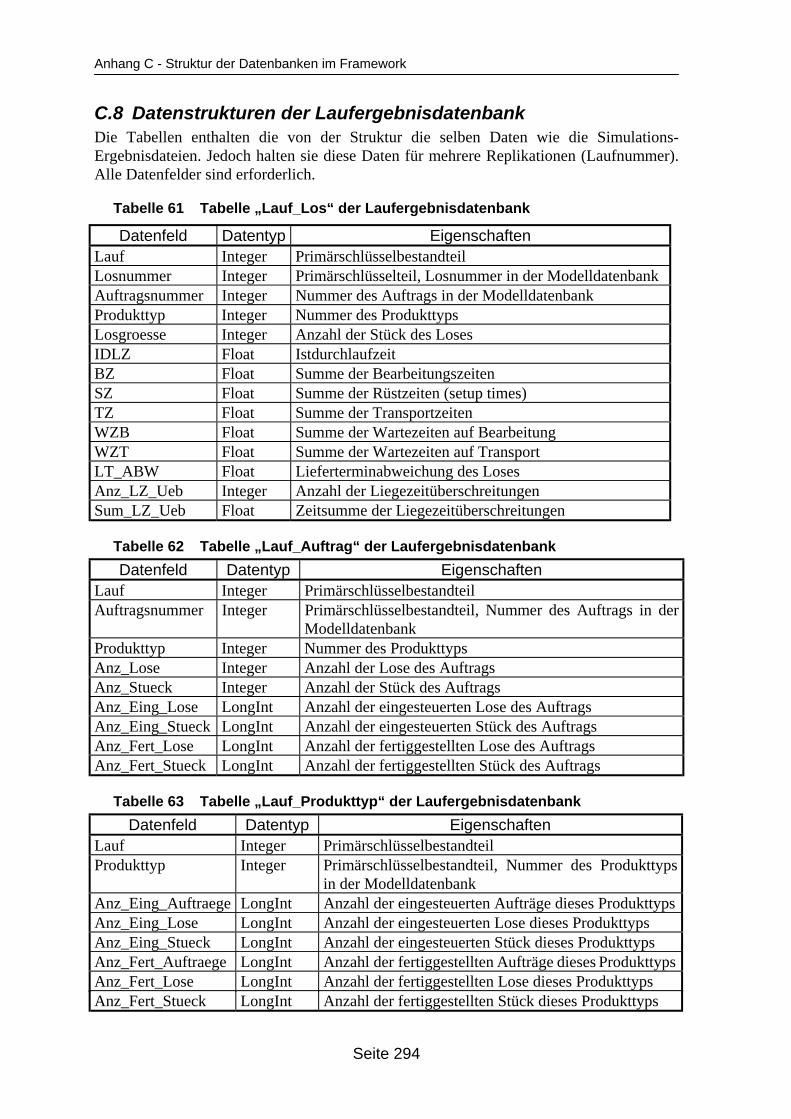
Anhang C - Struktur der Datenbanken im Framework
Seite 294
C.8 Datenstrukturen der LaufergebnisdatenbankDie Tabellen enthalten die von der Struktur die selben Daten wie die Simulations-Ergebnisdateien. Jedoch halten sie diese Daten für mehrere Replikationen (Laufnummer).Alle Datenfelder sind erforderlich.
Tabelle 61 Tabelle „Lauf_Los“ der Laufergebnisdatenbank
Datenfeld Datentyp EigenschaftenLauf Integer PrimärschlüsselbestandteilLosnummer Integer Primärschlüsselteil, Losnummer in der ModelldatenbankAuftragsnummer Integer Nummer des Auftrags in der ModelldatenbankProdukttyp Integer Nummer des ProdukttypsLosgroesse Integer Anzahl der Stück des LosesIDLZ Float IstdurchlaufzeitBZ Float Summe der BearbeitungszeitenSZ Float Summe der Rüstzeiten (setup times)TZ Float Summe der TransportzeitenWZB Float Summe der Wartezeiten auf BearbeitungWZT Float Summe der Wartezeiten auf TransportLT_ABW Float Lieferterminabweichung des LosesAnz_LZ_Ueb Integer Anzahl der LiegezeitüberschreitungenSum_LZ_Ueb Float Zeitsumme der Liegezeitüberschreitungen
Tabelle 62 Tabelle „Lauf_Auftrag“ der Laufergebnisdatenbank
Datenfeld Datentyp EigenschaftenLauf Integer PrimärschlüsselbestandteilAuftragsnummer Integer Primärschlüsselbestandteil, Nummer des Auftrags in der
ModelldatenbankProdukttyp Integer Nummer des ProdukttypsAnz_Lose Integer Anzahl der Lose des AuftragsAnz_Stueck Integer Anzahl der Stück des AuftragsAnz_Eing_Lose LongInt Anzahl der eingesteuerten Lose des AuftragsAnz_Eing_Stueck LongInt Anzahl der eingesteuerten Stück des AuftragsAnz_Fert_Lose LongInt Anzahl der fertiggestellten Lose des AuftragsAnz_Fert_Stueck LongInt Anzahl der fertiggestellten Stück des Auftrags
Tabelle 63 Tabelle „Lauf_Produkttyp“ der Laufergebnisdatenbank
Datenfeld Datentyp EigenschaftenLauf Integer PrimärschlüsselbestandteilProdukttyp Integer Primärschlüsselbestandteil, Nummer des Produkttyps
in der ModelldatenbankAnz_Eing_Auftraege LongInt Anzahl der eingesteuerten Aufträge dieses ProdukttypsAnz_Eing_Lose LongInt Anzahl der eingesteuerten Lose dieses ProdukttypsAnz_Eing_Stueck LongInt Anzahl der eingesteuerten Stück dieses ProdukttypsAnz_Fert_Auftraege LongInt Anzahl der fertiggestellten Aufträge dieses ProdukttypsAnz_Fert_Lose LongInt Anzahl der fertiggestellten Lose dieses ProdukttypsAnz_Fert_Stueck LongInt Anzahl der fertiggestellten Stück dieses Produkttyps
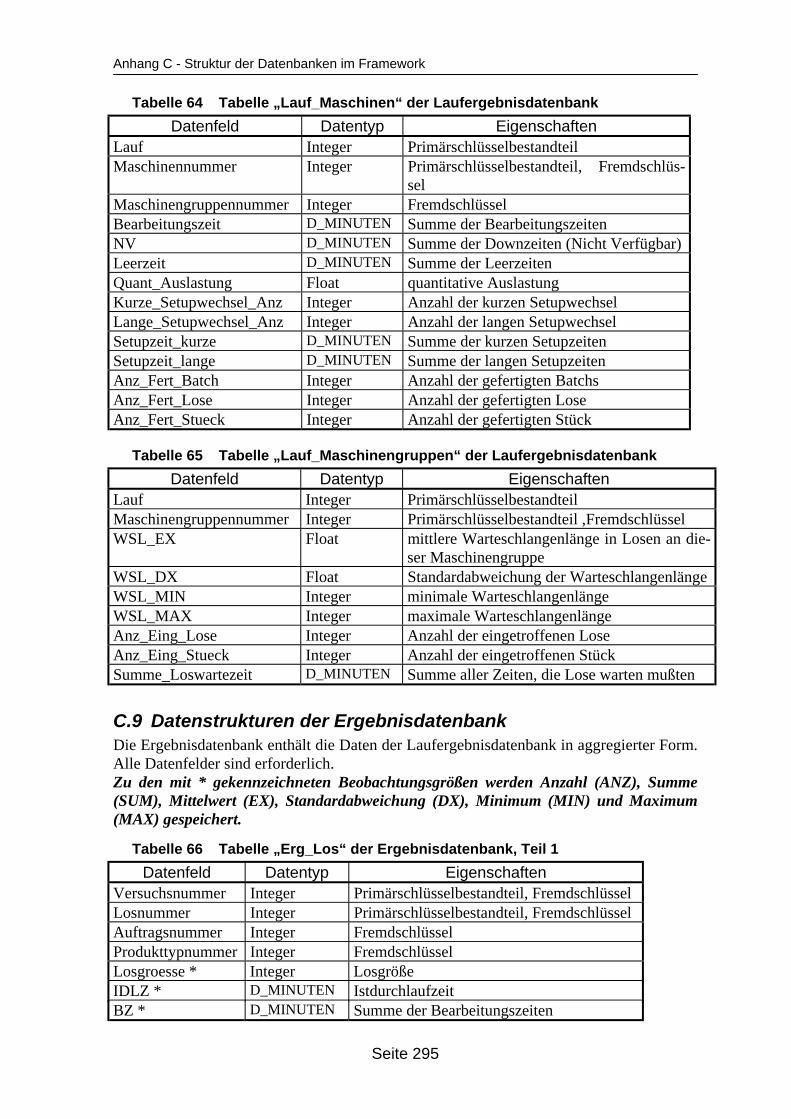
Anhang C - Struktur der Datenbanken im Framework
Seite 295
Tabelle 64 Tabelle „Lauf_Maschinen“ der Laufergebnisdatenbank
Datenfeld Datentyp EigenschaftenLauf Integer PrimärschlüsselbestandteilMaschinennummer Integer Primärschlüsselbestandteil, Fremdschlüs-
selMaschinengruppennummer Integer FremdschlüsselBearbeitungszeit D_MINUTEN Summe der BearbeitungszeitenNV D_MINUTEN Summe der Downzeiten (Nicht Verfügbar)Leerzeit D_MINUTEN Summe der LeerzeitenQuant_Auslastung Float quantitative AuslastungKurze_Setupwechsel_Anz Integer Anzahl der kurzen SetupwechselLange_Setupwechsel_Anz Integer Anzahl der langen SetupwechselSetupzeit_kurze D_MINUTEN Summe der kurzen SetupzeitenSetupzeit_lange D_MINUTEN Summe der langen SetupzeitenAnz_Fert_Batch Integer Anzahl der gefertigten BatchsAnz_Fert_Lose Integer Anzahl der gefertigten LoseAnz_Fert_Stueck Integer Anzahl der gefertigten Stück
Tabelle 65 Tabelle „Lauf_Maschinengruppen“ der Laufergebnisdatenbank
Datenfeld Datentyp EigenschaftenLauf Integer PrimärschlüsselbestandteilMaschinengruppennummer Integer Primärschlüsselbestandteil ,FremdschlüsselWSL_EX Float mittlere Warteschlangenlänge in Losen an die-
ser MaschinengruppeWSL_DX Float Standardabweichung der WarteschlangenlängeWSL_MIN Integer minimale WarteschlangenlängeWSL_MAX Integer maximale WarteschlangenlängeAnz_Eing_Lose Integer Anzahl der eingetroffenen LoseAnz_Eing_Stueck Integer Anzahl der eingetroffenen StückSumme_Loswartezeit D_MINUTEN Summe aller Zeiten, die Lose warten mußten
C.9 Datenstrukturen der ErgebnisdatenbankDie Ergebnisdatenbank enthält die Daten der Laufergebnisdatenbank in aggregierter Form.Alle Datenfelder sind erforderlich.Zu den mit * gekennzeichneten Beobachtungsgrößen werden Anzahl (ANZ), Summe(SUM), Mittelwert (EX), Standardabweichung (DX), Minimum (MIN) und Maximum(MAX) gespeichert.
Tabelle 66 Tabelle „Erg_Los“ der Ergebnisdatenbank, Teil 1
Datenfeld Datentyp EigenschaftenVersuchsnummer Integer Primärschlüsselbestandteil, FremdschlüsselLosnummer Integer Primärschlüsselbestandteil, FremdschlüsselAuftragsnummer Integer FremdschlüsselProdukttypnummer Integer FremdschlüsselLosgroesse * Integer LosgrößeIDLZ * D_MINUTEN IstdurchlaufzeitBZ * D_MINUTEN Summe der Bearbeitungszeiten
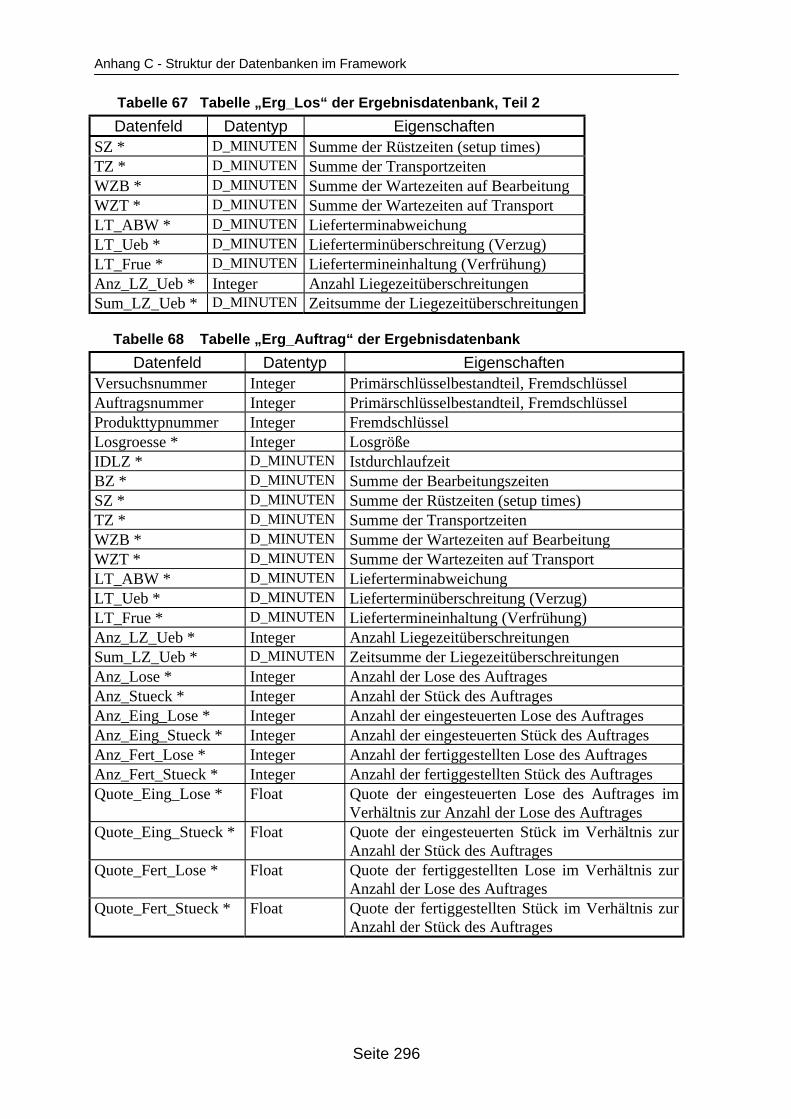
Anhang C - Struktur der Datenbanken im Framework
Seite 296
Tabelle 67 Tabelle „Erg_Los“ der Ergebnisdatenbank, Teil 2
Datenfeld Datentyp EigenschaftenSZ * D_MINUTEN Summe der Rüstzeiten (setup times)TZ * D_MINUTEN Summe der TransportzeitenWZB * D_MINUTEN Summe der Wartezeiten auf BearbeitungWZT * D_MINUTEN Summe der Wartezeiten auf TransportLT_ABW * D_MINUTEN LieferterminabweichungLT_Ueb * D_MINUTEN Lieferterminüberschreitung (Verzug)LT_Frue * D_MINUTEN Liefertermineinhaltung (Verfrühung)Anz_LZ_Ueb * Integer Anzahl LiegezeitüberschreitungenSum_LZ_Ueb * D_MINUTEN Zeitsumme der Liegezeitüberschreitungen
Tabelle 68 Tabelle „Erg_Auftrag“ der Ergebnisdatenbank
Datenfeld Datentyp EigenschaftenVersuchsnummer Integer Primärschlüsselbestandteil, FremdschlüsselAuftragsnummer Integer Primärschlüsselbestandteil, FremdschlüsselProdukttypnummer Integer FremdschlüsselLosgroesse * Integer LosgrößeIDLZ * D_MINUTEN IstdurchlaufzeitBZ * D_MINUTEN Summe der BearbeitungszeitenSZ * D_MINUTEN Summe der Rüstzeiten (setup times)TZ * D_MINUTEN Summe der TransportzeitenWZB * D_MINUTEN Summe der Wartezeiten auf BearbeitungWZT * D_MINUTEN Summe der Wartezeiten auf TransportLT_ABW * D_MINUTEN LieferterminabweichungLT_Ueb * D_MINUTEN Lieferterminüberschreitung (Verzug)LT_Frue * D_MINUTEN Liefertermineinhaltung (Verfrühung)Anz_LZ_Ueb * Integer Anzahl LiegezeitüberschreitungenSum_LZ_Ueb * D_MINUTEN Zeitsumme der LiegezeitüberschreitungenAnz_Lose * Integer Anzahl der Lose des AuftragesAnz_Stueck * Integer Anzahl der Stück des AuftragesAnz_Eing_Lose * Integer Anzahl der eingesteuerten Lose des AuftragesAnz_Eing_Stueck * Integer Anzahl der eingesteuerten Stück des AuftragesAnz_Fert_Lose * Integer Anzahl der fertiggestellten Lose des AuftragesAnz_Fert_Stueck * Integer Anzahl der fertiggestellten Stück des AuftragesQuote_Eing_Lose * Float Quote der eingesteuerten Lose des Auftrages im
Verhältnis zur Anzahl der Lose des AuftragesQuote_Eing_Stueck * Float Quote der eingesteuerten Stück im Verhältnis zur
Anzahl der Stück des AuftragesQuote_Fert_Lose * Float Quote der fertiggestellten Lose im Verhältnis zur
Anzahl der Lose des AuftragesQuote_Fert_Stueck * Float Quote der fertiggestellten Stück im Verhältnis zur
Anzahl der Stück des Auftrages
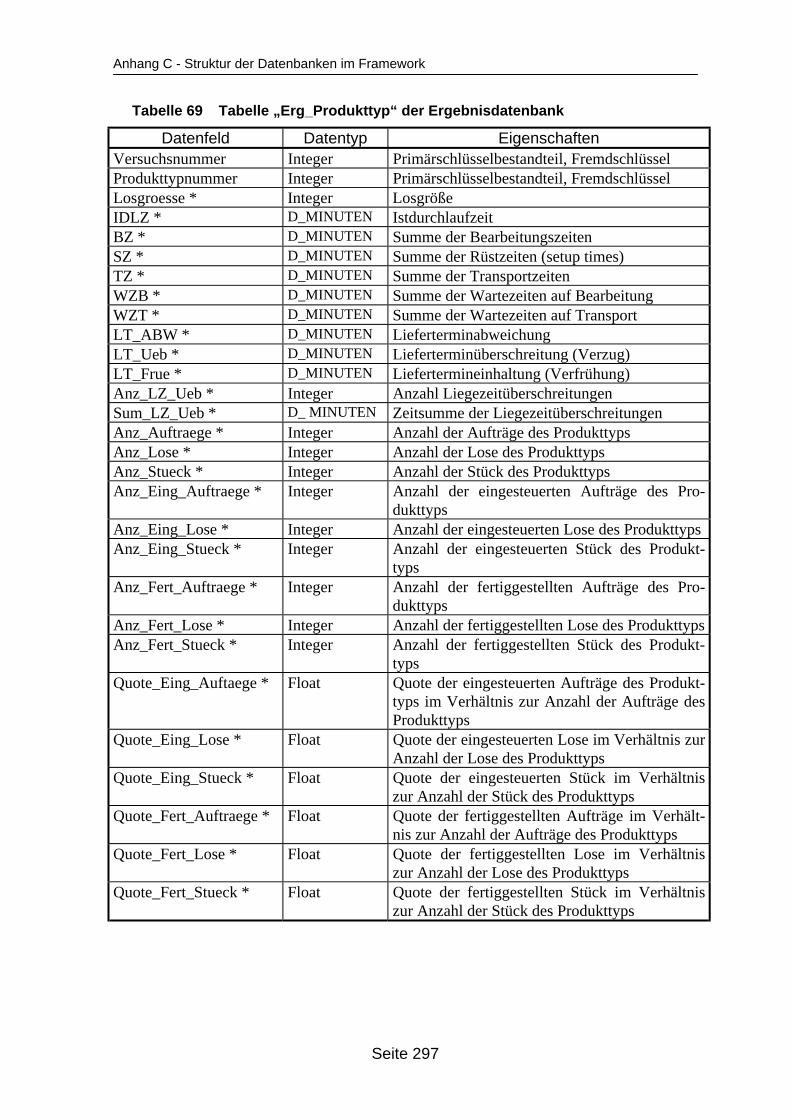
Anhang C - Struktur der Datenbanken im Framework
Seite 297
Tabelle 69 Tabelle „Erg_Produkttyp“ der Ergebnisdatenbank
Datenfeld Datentyp EigenschaftenVersuchsnummer Integer Primärschlüsselbestandteil, FremdschlüsselProdukttypnummer Integer Primärschlüsselbestandteil, FremdschlüsselLosgroesse * Integer LosgrößeIDLZ * D_MINUTEN IstdurchlaufzeitBZ * D_MINUTEN Summe der BearbeitungszeitenSZ * D_MINUTEN Summe der Rüstzeiten (setup times)TZ * D_MINUTEN Summe der TransportzeitenWZB * D_MINUTEN Summe der Wartezeiten auf BearbeitungWZT * D_MINUTEN Summe der Wartezeiten auf TransportLT_ABW * D_MINUTEN LieferterminabweichungLT_Ueb * D_MINUTEN Lieferterminüberschreitung (Verzug)LT_Frue * D_MINUTEN Liefertermineinhaltung (Verfrühung)Anz_LZ_Ueb * Integer Anzahl LiegezeitüberschreitungenSum_LZ_Ueb * D_ MINUTEN Zeitsumme der LiegezeitüberschreitungenAnz_Auftraege * Integer Anzahl der Aufträge des ProdukttypsAnz_Lose * Integer Anzahl der Lose des ProdukttypsAnz_Stueck * Integer Anzahl der Stück des ProdukttypsAnz_Eing_Auftraege * Integer Anzahl der eingesteuerten Aufträge des Pro-
dukttypsAnz_Eing_Lose * Integer Anzahl der eingesteuerten Lose des ProdukttypsAnz_Eing_Stueck * Integer Anzahl der eingesteuerten Stück des Produkt-
typsAnz_Fert_Auftraege * Integer Anzahl der fertiggestellten Aufträge des Pro-
dukttypsAnz_Fert_Lose * Integer Anzahl der fertiggestellten Lose des ProdukttypsAnz_Fert_Stueck * Integer Anzahl der fertiggestellten Stück des Produkt-
typsQuote_Eing_Auftaege * Float Quote der eingesteuerten Aufträge des Produkt-
typs im Verhältnis zur Anzahl der Aufträge desProdukttyps
Quote_Eing_Lose * Float Quote der eingesteuerten Lose im Verhältnis zurAnzahl der Lose des Produkttyps
Quote_Eing_Stueck * Float Quote der eingesteuerten Stück im Verhältniszur Anzahl der Stück des Produkttyps
Quote_Fert_Auftraege * Float Quote der fertiggestellten Aufträge im Verhält-nis zur Anzahl der Aufträge des Produkttyps
Quote_Fert_Lose * Float Quote der fertiggestellten Lose im Verhältniszur Anzahl der Lose des Produkttyps
Quote_Fert_Stueck * Float Quote der fertiggestellten Stück im Verhältniszur Anzahl der Stück des Produkttyps
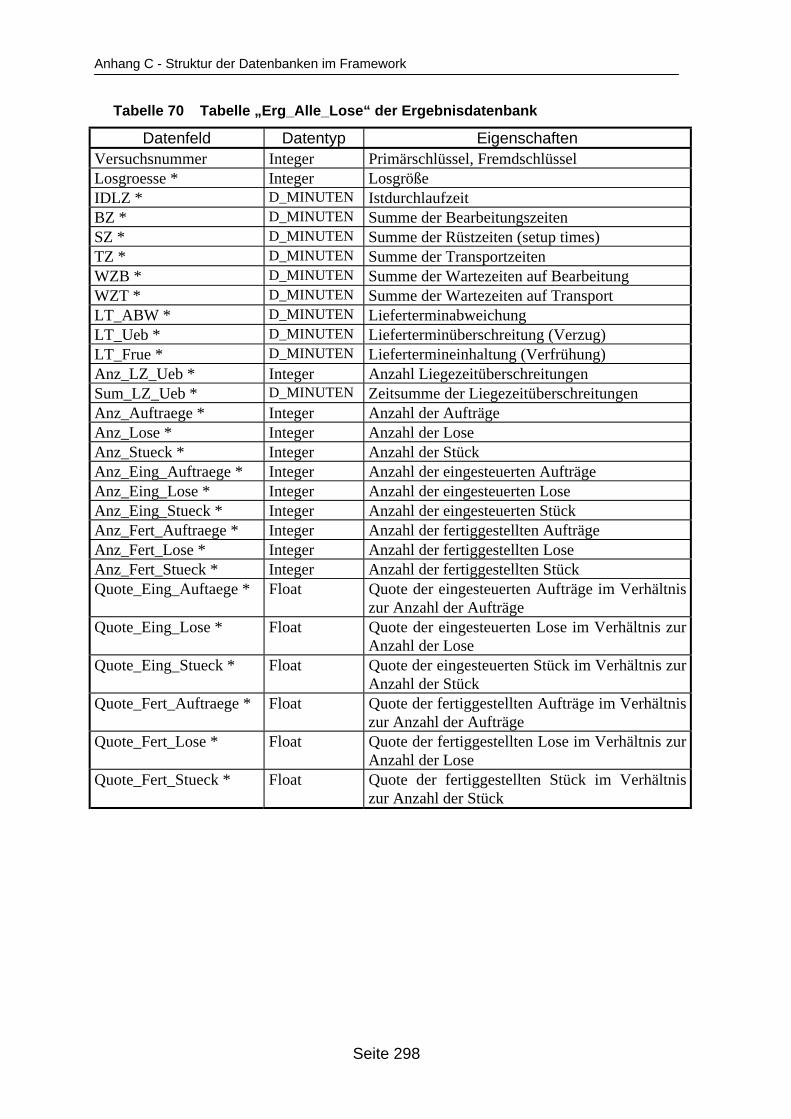
Anhang C - Struktur der Datenbanken im Framework
Seite 298
Tabelle 70 Tabelle „Erg_Alle_Lose“ der Ergebnisdatenbank
Datenfeld Datentyp EigenschaftenVersuchsnummer Integer Primärschlüssel, FremdschlüsselLosgroesse * Integer LosgrößeIDLZ * D_MINUTEN IstdurchlaufzeitBZ * D_MINUTEN Summe der BearbeitungszeitenSZ * D_MINUTEN Summe der Rüstzeiten (setup times)TZ * D_MINUTEN Summe der TransportzeitenWZB * D_MINUTEN Summe der Wartezeiten auf BearbeitungWZT * D_MINUTEN Summe der Wartezeiten auf TransportLT_ABW * D_MINUTEN LieferterminabweichungLT_Ueb * D_MINUTEN Lieferterminüberschreitung (Verzug)LT_Frue * D_MINUTEN Liefertermineinhaltung (Verfrühung)Anz_LZ_Ueb * Integer Anzahl LiegezeitüberschreitungenSum_LZ_Ueb * D_MINUTEN Zeitsumme der LiegezeitüberschreitungenAnz_Auftraege * Integer Anzahl der AufträgeAnz_Lose * Integer Anzahl der LoseAnz_Stueck * Integer Anzahl der StückAnz_Eing_Auftraege * Integer Anzahl der eingesteuerten AufträgeAnz_Eing_Lose * Integer Anzahl der eingesteuerten LoseAnz_Eing_Stueck * Integer Anzahl der eingesteuerten StückAnz_Fert_Auftraege * Integer Anzahl der fertiggestellten AufträgeAnz_Fert_Lose * Integer Anzahl der fertiggestellten LoseAnz_Fert_Stueck * Integer Anzahl der fertiggestellten StückQuote_Eing_Auftaege * Float Quote der eingesteuerten Aufträge im Verhältnis
zur Anzahl der AufträgeQuote_Eing_Lose * Float Quote der eingesteuerten Lose im Verhältnis zur
Anzahl der LoseQuote_Eing_Stueck * Float Quote der eingesteuerten Stück im Verhältnis zur
Anzahl der StückQuote_Fert_Auftraege * Float Quote der fertiggestellten Aufträge im Verhältnis
zur Anzahl der AufträgeQuote_Fert_Lose * Float Quote der fertiggestellten Lose im Verhältnis zur
Anzahl der LoseQuote_Fert_Stueck * Float Quote der fertiggestellten Stück im Verhältnis
zur Anzahl der Stück
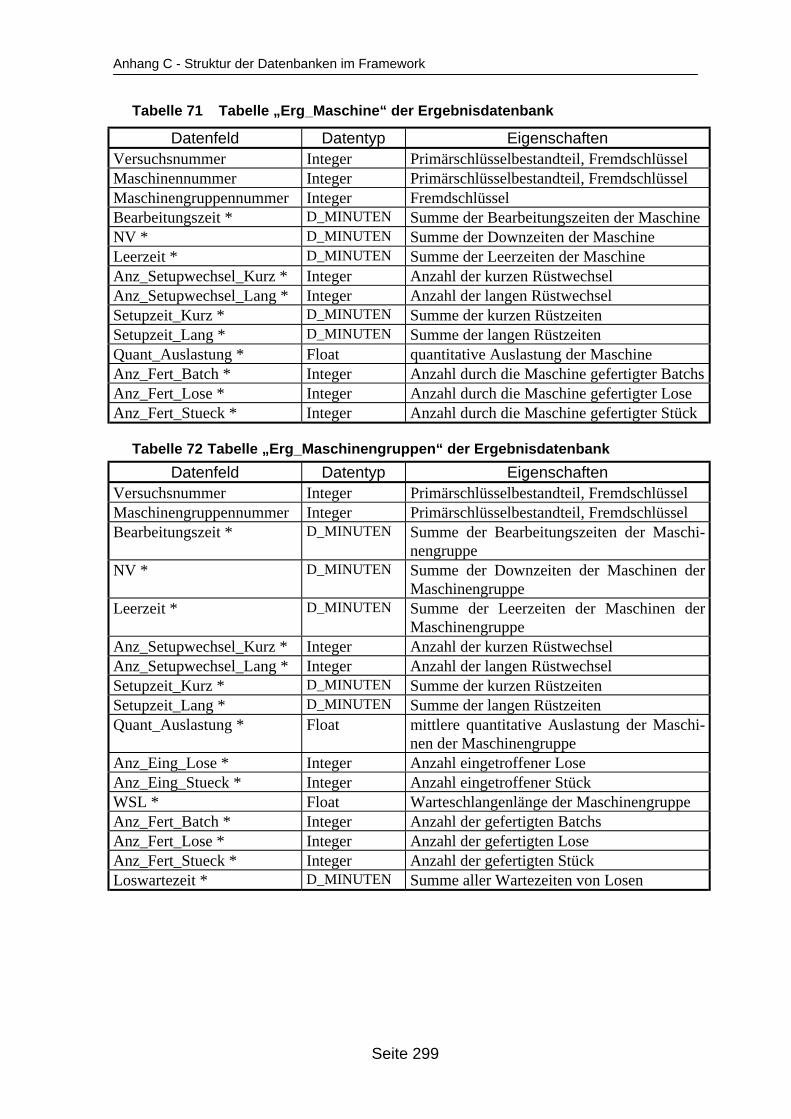
Anhang C - Struktur der Datenbanken im Framework
Seite 299
Tabelle 71 Tabelle „Erg_Maschine“ der Ergebnisdatenbank
Datenfeld Datentyp EigenschaftenVersuchsnummer Integer Primärschlüsselbestandteil, FremdschlüsselMaschinennummer Integer Primärschlüsselbestandteil, FremdschlüsselMaschinengruppennummer Integer FremdschlüsselBearbeitungszeit * D_MINUTEN Summe der Bearbeitungszeiten der MaschineNV * D_MINUTEN Summe der Downzeiten der MaschineLeerzeit * D_MINUTEN Summe der Leerzeiten der MaschineAnz_Setupwechsel_Kurz * Integer Anzahl der kurzen RüstwechselAnz_Setupwechsel_Lang * Integer Anzahl der langen RüstwechselSetupzeit_Kurz * D_MINUTEN Summe der kurzen RüstzeitenSetupzeit_Lang * D_MINUTEN Summe der langen RüstzeitenQuant_Auslastung * Float quantitative Auslastung der MaschineAnz_Fert_Batch * Integer Anzahl durch die Maschine gefertigter BatchsAnz_Fert_Lose * Integer Anzahl durch die Maschine gefertigter LoseAnz_Fert_Stueck * Integer Anzahl durch die Maschine gefertigter Stück
Tabelle 72 Tabelle „Erg_Maschinengruppen“ der Ergebnisdatenbank
Datenfeld Datentyp EigenschaftenVersuchsnummer Integer Primärschlüsselbestandteil, FremdschlüsselMaschinengruppennummer Integer Primärschlüsselbestandteil, FremdschlüsselBearbeitungszeit * D_MINUTEN Summe der Bearbeitungszeiten der Maschi-
nengruppeNV * D_MINUTEN Summe der Downzeiten der Maschinen der
MaschinengruppeLeerzeit * D_MINUTEN Summe der Leerzeiten der Maschinen der
MaschinengruppeAnz_Setupwechsel_Kurz * Integer Anzahl der kurzen RüstwechselAnz_Setupwechsel_Lang * Integer Anzahl der langen RüstwechselSetupzeit_Kurz * D_MINUTEN Summe der kurzen RüstzeitenSetupzeit_Lang * D_MINUTEN Summe der langen RüstzeitenQuant_Auslastung * Float mittlere quantitative Auslastung der Maschi-
nen der MaschinengruppeAnz_Eing_Lose * Integer Anzahl eingetroffener LoseAnz_Eing_Stueck * Integer Anzahl eingetroffener StückWSL * Float Warteschlangenlänge der MaschinengruppeAnz_Fert_Batch * Integer Anzahl der gefertigten BatchsAnz_Fert_Lose * Integer Anzahl der gefertigten LoseAnz_Fert_Stueck * Integer Anzahl der gefertigten StückLoswartezeit * D_MINUTEN Summe aller Wartezeiten von Losen
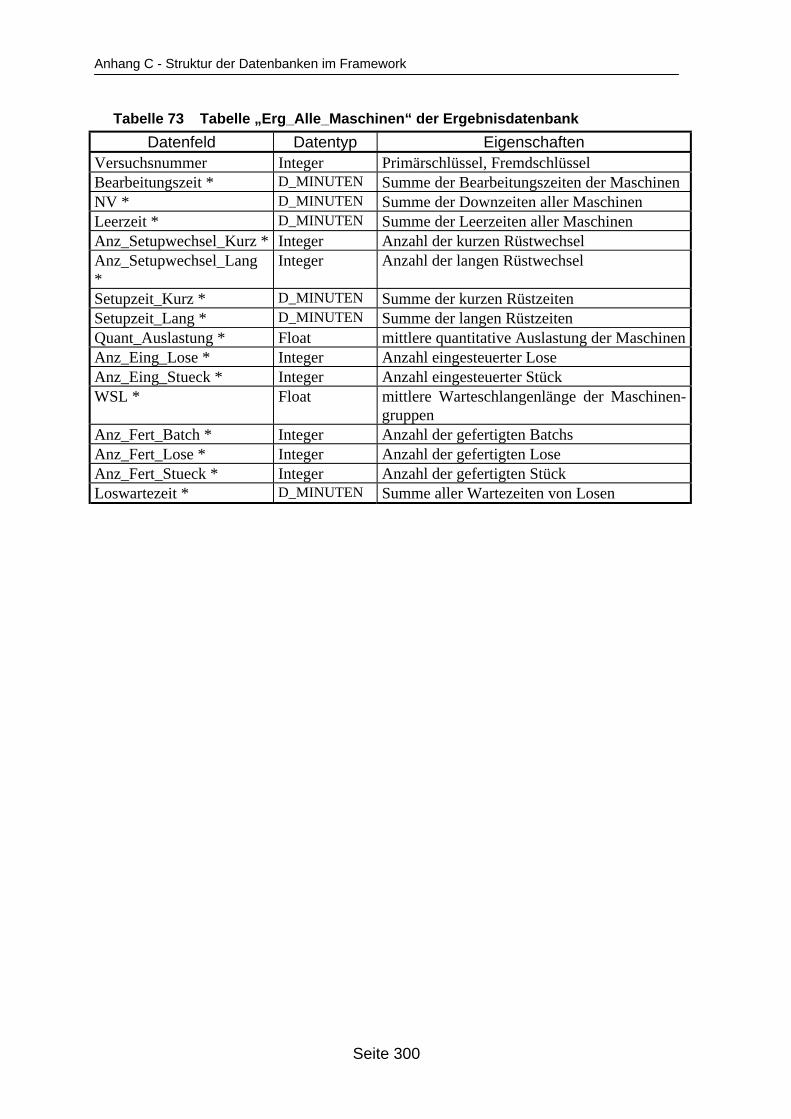
Anhang C - Struktur der Datenbanken im Framework
Seite 300
Tabelle 73 Tabelle „Erg_Alle_Maschinen“ der Ergebnisdatenbank
Datenfeld Datentyp EigenschaftenVersuchsnummer Integer Primärschlüssel, FremdschlüsselBearbeitungszeit * D_MINUTEN Summe der Bearbeitungszeiten der MaschinenNV * D_MINUTEN Summe der Downzeiten aller MaschinenLeerzeit * D_MINUTEN Summe der Leerzeiten aller MaschinenAnz_Setupwechsel_Kurz * Integer Anzahl der kurzen RüstwechselAnz_Setupwechsel_Lang*
Integer Anzahl der langen Rüstwechsel
Setupzeit_Kurz * D_MINUTEN Summe der kurzen RüstzeitenSetupzeit_Lang * D_MINUTEN Summe der langen RüstzeitenQuant_Auslastung * Float mittlere quantitative Auslastung der MaschinenAnz_Eing_Lose * Integer Anzahl eingesteuerter LoseAnz_Eing_Stueck * Integer Anzahl eingesteuerter StückWSL * Float mittlere Warteschlangenlänge der Maschinen-
gruppenAnz_Fert_Batch * Integer Anzahl der gefertigten BatchsAnz_Fert_Lose * Integer Anzahl der gefertigten LoseAnz_Fert_Stueck * Integer Anzahl der gefertigten StückLoswartezeit * D_MINUTEN Summe aller Wartezeiten von Losen

Quellenverzeichnis
Seite 301
Quellenverzeichnis
[Adam 1990] Adam, D.; „Produktionsdurchführungsplanung“; in Jacob, H. „Industrie-betriebslehre, Handbuch für Studium und Praxis“; 4. Auflage; GablerVerlag, Wiesbaden, 1990.
[Adam 1992] Adam, Dietrich; „Fertigungsteuerung - Grundlagen und Systeme“;Schriften zur Unternehmensführung Bd. 38/39; Wiesbaden, 1992.
[Adam 1993] Adam, D.; „Produktions-Management“; 7. Auflage; Gabler Verlag;Wiesbaden, 1993.
[Adamo 1998] Adamo, Jean-Marc; „Multi-threaded MPI-based Message Passing Inter-face: The ARCH Library“; Kluwer Academic Publishers, 1998.
[Agrawal 1986] Agrawal, Prathima; „Concurrency and Communication in Hardware Si-mulators“; IEEE Transactions on Computer-Aided Design, 1986,5(4):617-623.
[Appelrath 1998] Appelrath, H.-J.; „Implementierung von Informationssystemen“; Univer-sität Oldenburg, 1998.
[ArgonneMPI 2000] The Argonne MPI page, http://www-unix.mcs.anl.gov/mpi/,Abruf Mai 2000.
[Arndt 2000] Arndt, S.; „Optimierung mit verteilten Simulationsmodellen im Linux-Cluster“; in „Frontiers in Simulation - 14. Symposium Simulationstechnik(ASIM 2000)“; Hamburg, September 2000, S. 105-110.
[Bagrodia, Liao 1990] Bagrodia, R. L.; Liao, Wentoh; „Maisie: A language and optimizationenvironment for distributed simulation“; Proceedings of 1990 SCS Multi-conference of Distributed Simulation, San Diego, Januar 1990, Seiten205-210.
[Bagrodia 1994] Bagrodia, R. L.; „Language Support for Parallel Discrete-Event Simulati-ons“; Proceedings of the 1994 Winter Simulation Conference - WSC '94;J. D. Tew, S. Manivannan, D. A. Sadowski, and A. F. Seila (Eds.), 1994,Seiten 1324-1331.ftp://pcl.cs.ucla.edu/pub/papers/wsc94-lang.ps.gz
[Bagrodia, Liao 1994] Bagrodia, R. L.; Liao, Wentoh; „Maisie: A language for Design of Effi-cient Discrete Event Simulation“; IEEE Transactions on Software Engi-neering, April 1994.
[Bagrodia 1996] Bagrodia, Rajive L.; „Perils and Pitfalls of Parallel Discrete-Event Simu-lation“; Proceedings of the 1996 Winter Simulation Conference; ed. J. M.Charnes and D. J. Morrice, 1996http://pcl.cs.ucla.edu/slides/wsc96/
[Bagrodia u.a. 1998] Bagrodia, R.; Meyer, R.; Takai, M.; Chen, Y.; Zeng, X.; Martin, J.; Park,B.; Song, H.; „Parsec: A Parallel Simulation Environment for ComplexSystems“; IEEE Computer, Vol. 31(10), Oktober 1998, Seiten 77-85.
[Bauer 1994] Bauer, Herbert; „Verteilte diskrete Simulation komplexer Systeme“; Dis-sertation, Lehrstuhl für Rechnergestütztes Entwerfen der TechnischenUniversität München, 1994.
[Beguelin u.a. 1991] Beguelin; Dongarra; Geist; Manchek; Sunderam; „A user’s guide toPVM: Parallel virtual machine“; Technical Report TM-11826, Oak RidgeNational Laboratory, 1991.
[Berten 1997] http://pi.informatik.uni-siegen.de/berten/studienarbeit/[Biendl 1984] Biendl, P.; „Ablaufsteuerung von Montagefertigungen“; Paul Haupt
Verlag; Bern, Stuttgart, 1984.[Bishop, Hembruch, Trudeau 1999] Bishop, William D.; Hembruch, Mattias G. und Trudeau, Christopher;
„Simulating Colliding Particles in Java Using ParSimONY“; Proceedingsof the 1999 Canadian Conference on Electrical and Computer Enginee-ring, Edmonton, Mai 1999.
[Blackstone, Phillips, Hogg 1982] Blackstone, J. H.; Phillips, D. T.; Hogg, G. L.; „A state-of-the-art surveyof dispatching rules for manufacturing job shop operations“; InternationalJournal of Production Research, 20/1982-1, S. 27-45.

Quellenverzeichnis
Seite 302
[Blazejewski 2000] Blazejewski, Gert; „Produktionssteuerung mittels modularer Simulation“;Dissertation, TU Chemnitz, 2000.
[Bley, Wuttke 1997] Bley, H.; Wuttke, C.C.; „Distributed Simulation Applied to ProductionSystems“; Annals of the CIRP, Vol. 46/1/97, Seiten 361-364.
[Bley, Oltermann, Wuttke 1999] Bley, H.; Oltermann, R.; Wuttke, C.C.; „Distributed Model ManagementSystem for Material Flow Simulation“; Proceedings of the 15th Interna-tional Conference on Computer-Aided Production Engineering; Durham(UK), 1999, Seiten 657-662.
[Bley, Franke, Wuttke 2000] Bley, H.; Franke, C.; Wuttke, C.C.; „New strategies and tools for increa-sing simulation efficiency“; Annals of the CIRP, Vol. 49/1/00, Sydney,2000, Seiten 339-342.
[Bley u.a. 2000a] Bley, H.; Franke, C.; Ostermann, A.; Wuttke, C.C.; „Methods and Toolsfor the Building of Huge Simulation Models“; Proceedings of the 2ndCIRP International Seminar on Intelligent Computation in Manufactu-ring; Capri, 2000, Seiten 33-41.
[Bley u.a. 2000b] Bley, H.; Franke, C.; Wuttke, C.C.; Gross, A.; „Automation of Simulati-on Studies“; Proceedings of the 2nd CIRP International Seminar on In-telligent Computation in Manufacturing; Capri, 2000, Seiten 89-94.
[Bobrowski, Kim 1994] Bobrowski, Paul Michael; Kim, Seung Chul; „The Impact of SequenceDependent Setup Time on Job Shop Scheduling Performance“; Inter-national Journal of Production Research, Vol. 32, No. 7, 1994, Seiten1503-1520.
[Briner 1990] Briner, Jack Vedder; „Parallel Mixed-Level Simulation of Digital CircuitsUsing Virtual Time“; Ph.D. Thesis, Duke University, 1990.
[Brucker 1998] Brucker, Peter; „Scheduling Algorithms“; Second, Revised and EnlargedEdition; Springer Publishing; 1995-1998.
[Brunkhorst 2001] http://www.kbs.uni-hannover.de/Lehre/SWT2/WS00/Uebung/ooframeworks/frameworks.html
[Bryant 1979] Bryant, R.; „Simulation on a Distributed System“; Proceedings of the 1stInternational Conference on Distributed Computer Systems, 1979, Seiten544-552.
[Calvert 1997] Calvert, Charlie; „A Technical View of Borland MIDAS“; Borland Inter-national, 1997.http://www.borland.com
[Carothers, Perumalla, Carothers, Christopher D.; Perumalla, Kaylan S. and Fujimoto, RichardFujimoto 1999] M.; „Efficient optimistic parallel simulations using reverse compu-
tation“; Proceedings of the 13th workshop on Parallel and Distributedsimulation; Atlanta, 1.-4. Mai 1999, Seiten 126-135.
[Cassandras 1993] Cassandras, Christos G.; „Discrete Event Systems - Modeling and Per-formance Analysis“; University of Massachusetts at Amherst, Richard D.Irwin Inc. and Aksen Associates Incorporated Publishers, Homewood Il-linois and Boston Massachusetts, 1993.
[Chandy, Misra 1978] Chandy, K.; Misra, J.; „A non-trivial example of concurrent processing:Distributed simulation“; Proceedings of COMPSAC, 1978, Seiten 822-826.
[Chandy, Misra 1979] Chandy, K.; Misra, J.; „Distributed Simulation: A Case Study in Designand Verification of Distributed Programs.“; IEEE Transactions on Soft-ware Engineering, Vol. SE-5, No. 5, Seiten 440–452, 1979.
[Chandy, Sherman 1989a] Chandy, K. M.; Sherman, R.; „The Conditional Event Approach to Dis-tributed Simulation“; in Proceedings of the SCS Multiconference on Dis-tributed Simulation; Tampa (Florida), März 1989, Seiten 95-99.
[Chandy, Sherman 1989b] Chandy, K. M.; Sherman, R.; „Space-Time and simulation“; in Distribu-ted Simulation 1989; The Society for Computer Simulation, Seiten 53-57.
[Chandy, Misra 1981] Chandy, K. M. and Misra, Jayadev; „Asynchronous distributed simulati-on via a sequence of parallel communications“; CACM, V24, N4, April1981, Seiten 198-206.
[Chen, Chen 1994] Chen, T. K.; Chen, D. J.; „An experimental study of using reusable soft-ware design frameworks to achieve software reuse“; Journal of Object-oriented Programming; Mai 1994, Seiten 56-67.

Quellenverzeichnis
Seite 303
[Chen, Jha, Bagrodia 1995] Chen, Yu-an; Jha, Vikas; Bagrodia, Rajive; „Parallel Switch-level Simu-lation of VLSI Circuits“; in Computer Science Tech Report: 950020, Juni1995, University of California, Los Angeles, 1995.
[Cleverly 2000] Cleverley, James; „Com+ Watch. Wrox“;http://www.comdeveloper.com, Abruf Mai 2000
[Coffman, Garey, Johnson 1978] Coffman, E. G. Jr.; Garey, M. R.; Johnson, D. S.; „An Application of BinPacking to Multiprocessor Scheduling“; in SIAM Journal on Computing,7(1); Seiten 1-17, Februar 1978.
[Coffman, Garey, Johnson 1996] Coffman, E. G. Jr.; Garey, M. R.; Johnson, D. S.; „Approximation Algo-rithms For Bin Packing: A Survey“; in „Approximation Algorithms forNP-Hard Problems“; Hochbaum, D. (ed.); PWS Publishing, Boston,1996; Seiten 46-93.
[Cong, Smith 1993] Cong, Jason; Smith, M'Lissa; „A Parallel Bottom-up Clustering Algo-rithm with Applications to Circuit Partitioning in VLSI Design“; in Pro-ceedings ACM/IEEE Design Automation Conference, 1993, Seiten 755-760.
[Corsten, May 1994] Corsten, H.; May, C.; „Unterstützungspotential Künstlicher NeuronalerNetze für die Produktionsplanung und -steuerung“; (Artikel), 1994.
[COVISE] http://www-ks.rus.uni-stuttgart.de/PROJ/suntrec/covise.html,Abruf Mai 2000.
[Dahlin 1998] Dahlin, Michael; „Interpreting Stale Load Information“; InternationalConference on Distributed Computing Systems, 1998.Ebenfalls erschienen in: IEEE Transactions on Parallel and DistributedSystems; Vol. 11, No. 10, Oktober 2001, Seiten 1033-1047.
[Dahmann, Fujimoto, Dahmann, Judith ; Fujimoto, Richard; Weatherly, Richard M.; „The DoDWeatherly 1998] High Level Architecture: An Update“; Proceedings of the 1998 Winter
Simulation Conference, eds. Medeiros, D.J., Watson, E.F., Carson, J.S.,Manivannan, M.S., Washington, DC, 1998, Seiten 797-804.
[Das, Fujimoto 1997] Das, Samir R.; Fujimoto, Richard M.; „An Empirical Evaluation of Per-formance-Memory Trade-Offs in Time Warp“; IEEE Transactions onParallel and Distributed Systems; Vol. 8, No. 2, Februar 1997.
[Daub 1994] Daub, A.; „Ablaufplanung - Modellbildung, Kapazitätsbestimmung undUnsicherheit“; Verlag Josef Eul Bergisch Gladbach, Köln 1994.
[Davis, Moeller 1999] Davis, Wayne J.; Moeller, Gerald L.; „The High Level Architecture: Isthere a better way ?“; Proceedings of the 1999 Winter Simulation Confe-rence, P. A. Farrington, H. B. Nembhard, D. T. Sturrock, and G. W.Evans, eds.; Phoenix, 1999.
[DCOM] Microsoft DCOM Homepage.www.microsoft.com/com.
[Domschke, Scholl, Voß 1997] Domschke, Wolfgang; Scholl, Armin; Voß, Stefan; „Produktionsplanung- Ablauforganisatorische Aspekte“; Zweite, überarbeitete und erweiterteAuflage, Springer Verlag, 1993-1997.
[DOORS] http://imat.mb.uni-magdeburg.de/Forschung/Schwerpunkte/Doors/[Dulger 1993] Dulger, A.; „Prioritätsregeln für die industrielle Werkstattfertigung“;
Dissertation, Universität Regensburg, 1993.[DVSIM] http://www.informatik.th-darmstadt.de/VS/Mitarbeiter/Meister/ pro-
ject/dvsim/[Eggenschwiler u.a. 1995] Eggenschwiler, Th.; Birrer, A.; Bischofberger, W. R.; „Wiederver-
wendung durch Framework-Technik - vom Mythos zur Realität“; in Ob-jektSpektrum, Nr. 5, 1995, S. 18-26.
[Elsäßer 2001] Elsäßer, Sven; „Konzeption und Implementation einer verteilten Experi-mentierumgebung zur Simulation von Produktionssystemen“; Diplomar-beit; TU Ilmenau, 2001.
[EPPC 2000] Edinburgh Parallel Computing Center; „Writing Message-Passing Paral-lel Programs with MPI;http://www.epcc.ed.ac.uk/epcc-tec/documents/mpi-course/mpi-course.pdf, Abruf Mai 2000.
[Eversheim, Intra, Abels 2000] Eversheim, W.; Intra, C.; Abels, I.; „Vereinfachte Simulation durch An-wendung einer Bausteinbibliothek“; in „Frontiers in Simulation - 14.

Quellenverzeichnis
Seite 304
Symposium Simulationstechnik (ASIM 2000)“, Hamburg, September2000, S. 437-442.
[Exner 2000] Exner, Alexander; „Importance Sampling: Theorie und Anwendungen inder Optionsbewertung“; Diplomarbeit, Universität Wien, Oktober 2000.
[Feldmann u.a. 1992] Feldmann, U., Wever, U., Zheng, Q., Schultz, R., Wriedt, H.,„Algorithms for Modern Circuit Simulation“, AEÜ, Vol. 46, No 4, Seiten274-285, 1992.
[Fiduccia, Mattheyses 1982] Fiduccia, C. M.; Mattheyses, R. M.; „A Linear-Time Heuristic for Impro-ving Network Partitions“, Proceedings ACM/IEEE Design AutomationConference (DAC), New York, 1982, Seiten 175-181.
[Fishman 2001] Fishman, George S.; „Discrete-Event Simulation - Modeling, Program-ming and Analysis“; Springer Series in Operations Research, Springer-Verlag, New York, Berlin, Heidelberg, 2001.
[Fowler, Phillips, Hogg 1992] Fowler, J. W.; Phillips, D. T.; Hogg, G. L.; „Real-time scheduling ofmultiproduct bulk-service semiconductor manufacturing processes“; inIEEE Transactions on Semiconductor manufacturing; Band 5, Vol. 2, S.158-163, 1992.
[Friedl 1994] Friedl, B.; „Anforderungen an Kostenrechnung bei neuen Fertigungs-technisken“; in: Corsten, H., Handbuch Produktionsmanagement, Gabler,Wiesbaden, 1994.
[Fröhlich, Schlagenhaft, Fröhlich, N.; Schlagenhaft, R.; Fleischmann, J.; „A New Approach forFleischmann 1997] Partitioning VLSI Circuits on Transistor Level“; Proceedings of the 11th
Workshop on Parallel and Distributed Simulation; Burg Lockenhaus,1997, Seiten 64-67.
[Fujimoto 1988a] Fujimoto, R.; „Performance Measurements of Distributed SimulationStrategies“; Proceedings of the Distributed Simulation Conference; SanDiego, 3.-5.02.1988, Seiten 14-20.
[Fujimoto 1988b] Fujimoto, R.; „Lookahead in Parallel Discrete Event Simulation“; Inter-national Conference on Parallel Processing; Vol. 3, Seiten 34–41, 1988.
[Fujimoto, Tsai, Gopalakrishan 1988] Fujimoto, R., Tsai, J., Gopalakrishnan, G.; „Design and Evaluation of theRollback Chip: Special Purpose Hardware for Time Warp.“; TechnicalReport UUCS-88-011, Department of Computer Science, University ofUtah, 1988.
[Fujimoto 1989] Fujimoto, R. M.; „Time Warp on a Shared Memory Multiprocessor“;Transactions of the Society for Computer Simulation; Vol. 6, No. 3, Sei-ten 211-239, Juli 1989.
[Fujimoto 1990] Fujimoto, R.; „Parallel Discrete Event Simulation“; Communications ofthe ACM, Vol. 33, No. 10, Seiten 30–53, 1990.
[Fujimoto 1998] Fujimoto, R. M.; „Time Management in The High Level Architecture“; in1998 Annual Index for SIMULATION; Volume 71, Number 6, Seiten388-400.
[Fujimoto 1999] Fujimoto, R.; „Parallel and Distributed Simulation“; Proceedings of the1999 Winter Simulation Conference, P. A. Farrington, H. B. Nembhard,D. T. Sturrock, and G. W. Evans, eds.; Phoenix, 1999.
[Gafni 1988] Gafni, A.; „Rollback mechanisms for optimistic distributed simulationsystems“; Proceedings of the SCS Multiconference on Distributed Simu-lation; San Diego, Juli 1988, Seiten 61-67.
[Gamma u.a. 1995] Gamma, E.; Helm, R.; Johnson, R.; Vlissides, J.; „Design Patterns: Ele-ments of Reusable Object-Oriented Software“; Reading Mass., AddisonWesley, 1995.
[Garbers u.a. 1990] Garbers, Jörn; Prömel, Hans Jürgen; Steger, Angelika; „Finding Clustersin VLSI Circuits“; Proceedings IEEE International Conference on Com-puter-Aided Design (ICCAD); Santa Clara 1990, Seiten 520-523.
[Gäse, Günther, Wirth 2000] Gäse, Th.; Günther, S.; Wirth, S.; „Datenbankbasierte Generierung vonSimulationsmodellen zur Planung von Produktionssystemen“; „Frontiersin Simulation - 14. Symposium Simulationstechnik (ASIM 2000)“, Ham-burg, September 2000, S. 431-436.
[Gehlsen, Page 2000] Gehlsen, Björn; Page, Bernd; „Verteilte Ausführung von Simula-tionsstudien zur Optimierung komplexer Szenarien“; „Frontiers in Simu-

Quellenverzeichnis
Seite 305
lation - 14. Symposium Simulationstechnik (ASIM 2000)“, Hamburg,September 2000, S. 117-122.
[GM-VHDL] http://www.gmvhdl.com/VHDL.html, Abruf Mai 2000.[Gomes 1996] Gomes, Fabian A. F. B.; „Optimizing Incremental State Saving and Res-
tauration“; Dissertation; University of Calgary, 1996.[Gomes 2001] Gomes, Fabian; Simulation Links;
http://pages.cpsc.ucalgary.ca/~gomes/HTML/sim.html[Greenberg, Lubachevsky 1996] Greenberg, Albert G.; Lubachevsky, Boris D.; „Superfast Parallel Dis-
crete Event Simulations“; ACM Transactions on Modeling and ComputerSimulation; Vol. 6, No. 2, April 1996.
[Gropp, Lusk 1994] Gropp, William; Lusk, Ewing; „Using MPI - An Introduction to MPI –Parallel Programming with the Message Passing Interface“; The MITPress, 1994,http://www.mcs.anl.gov/mpi, Abruf Mai 2000.
[Gumbel, Vetter, Cárdenas 2000] Gumbel, Markus; Vetter, Marcus; Cárdenas, Carlos; „Java Standard Li-braries - Java 2 Collections Framework und Generic Collection Libraryfor Java“; Addison-Wesley Verlag, München, 2000.
[Gurnani, Anupindi, Akella 1992] Gurnani, H.; Anupindi, R.; Akella, R.; „Control of Batch ProcessingSystems in Semiconductor Wafer Fabrication“; IEEE Transactions onSemiconductor manufacturing, Band 5, Vol. 4, S. 319-328, 1992.
[Harju, Salmi 1993] Harju, J.; Salmi, M.; „Parallel Simulation of the GSM Mobile Commu-nication Network on Minisupercomputer“:, Proceedings of the 1993 Si-mulation Multiconference on the High Performance Computing Sympo-sium (Ed. Tentner A. M.); The Society for Computer Simulation, 1993,S. 182-187.
[Haupt 1989] Haupt, R.; „A Survey of Priority Rule-Based Scheduling, OR Spektrum1989/11, S. 3-16.
[Heinen 1990] Heinen, E.; „Grundtatbestände betrieblicher Entscheidungen“; in: Jacob,H; „Industriebetriebslehre - Handbuch für Studium und Praxis“; 4. Auf-lage, Wiesbaden: Gabler, 1990.
[Helm, Gamma 1994] Helm, Richard; Gamma, Erich; „Design Patterns: Elements of ReusableObject-Oriented Software“; Addison Wesley, 1995, Additional Authors:Ralph Johnson, John Vlissides.
[Hendriksen 1995] Henriksen, James O.; „An Introduction to SLX“; The 1995 Winter Simu-lation Conference, William R. Lilegdon, David Goldsman, Christos Ale-xopoulos, Keebom Kang (eds.); 3.-6.12. 1995, Arlington, Seiten 502-509.
[Herzog 1999] Herzog, Holger; „Moderne Zeiten - Objektorientiertes Programmieren inGFA-Basic“; in ATOS - Around the Operation System, 01/99,http://www.atos-magazin.de/download.html#1999
[Hilberg 1981] Hilberg, W.; „Partitionierung mit Hilfe der Verbindungsmatrix“; ntzArchiv, 1981, 3(3):57-62.
[Hirsch u.a. 2000] Hirsch, Bernd E.; Klußmann, Jens; Thoben, Klaus-Dieter; Weber, Frith-jof; „Ein Simulationssystem für die Produktionsfeinplanung von kunden-spezifischen Printprodukten in der Druckindustrie“; in 12. European Si-mulation Symposium (ESS) / 14. Symposium Simulationstechnik der Ar-beitsgruppe Simulation (ASIM) an der Universität Hamburg,25.-28.09.2000, S. 203-209.
[HLA] http://hla.dmso.mil/[HLA-MD] http://isgsim.cs.uni-magdeburg.de/hla/, Abruf Mai 2000.[Hollenbach, Alexander 1997] Hollenbach, James; Alexander, William; „Executing the DoD Modeling
and Simulation Strategy - Making Simulation Systems of Systems a Rea-lity“; Proceedings of the 1997 Winter Simulation Conference, eds. ed. S.Andradóttir, K. J. Healy, D. H. Withers, and B. L. Nelson; Atlanta, 1997.
[Holthaus, Ziegler 1993] Holthaus, Oliver; Ziegler, Hans; „Zur Koordination dezentraler Werk-stattsteuerungsregeln“; Dyckhoff, H. u.a. (Hrsg.), Operations ResearchProceedings 1993, S. 157-163, Berlin 1993.
[Holthaus, Ziegler, Rosenberg 1993] Holthaus, Oliver; Ziegler, Hans; Rosenberg Otto; „Verteilte Simulationdezentraler Werkstattsteuerungssysteme“; in Information Management1993/ 2, S. 6-12.

Quellenverzeichnis
Seite 306
[Holthaus, Rosenberg, Ziegler 1996] Holthaus, Oliver; Rosenberg, Otto; Ziegler, Hans; „Development andSimulation of Methods for Scheduling and Coordinating DecentralizedJob Shops Using Multi-Computer Systems“; in „Distributed InformationSystems in Business“, König, W., Kurbel, K., Mertens, P. und D. Press-mar (Eds.); Berlin, 1996, Seiten 123-137.
[Hotovy, Shen, Zollweg 1995] Hotovy, Steven; Shen, Xianneng; Zollweg, John; „MPI-Applications atthe Cornell Theory Center“; Proceedings of the Second MPI DevelopersConference; 22.-23. Juni 1995http://www.mpi.nd.edu/downloads/mpidc95/papers/html/hotovy/
[Iotov u.a. 1995] Iotov, Mihail; Lim, Kian-Tat; Goddard, William A.; Brunett, Sharon;Taylor, Stephen; „Million Particle Molecular Dynamics Using MPI“;Proceedings of the Second MPI Developers Conference, 22.-23. Juni1995http://www.mpi.nd.edu/downloads/mpidc95/abstracts/html/iotov/
[IPCA 2000] Internet Parallel Computing Archive,http://nscp01.physics.upenn.edu/parallel/internet/usenet/comp.parallel.mpi/articles/, Abruf Mai 2000.
[Jefferson 1985] Jefferson, David R.; „Virtual Time“; ACM Transactions on ProgrammingLanguages and Systems; Vol. 7, No. 3, Seiten 404–425, 1985.
[Jefferson, Sowizral 1985] Jefferson, D.; Sowizral, H.; „Fast Concurrent Simulation Using the TimeWarp Mechanism“; Proceedings of the Conference on Distributed Simu-lation, Juli 1985, Seiten 63-69.
[Jefferson u.a. 1987] Jefferson, D.; Beckman, B.; Wieland, F.; Blume, L.; DiLoreto, M.; Hon-talas, P.; Laroche, P.; Sturdevant, K.; Tupman, J.; Warren, V.; Wedel, J.;Younger, H. and Bellenot, S.; „Distributed simulation and the TimeWarp Operating System“; Proceedings of the SIGOPS-Symposium onOperating Systems Principles; ACM, November 1987, Seiten 77–93.
[Jha, Bagrodia 1993] Jha, Vikas; Bagrodia, Rajive L.; „Transparent Implementation of Conser-vative Algorithms in Parallel Simulation Languages“; Proceedings of the1993 Winter Simulation Conference, Evans, G. W.; Mollaghsemi, M.;Russell, E. C.; Biles, W., E. (Eds.); Dezember 1993, Seiten 677-686.
[Jha, Bagrodia 1994] Jha, Vikas; Bagrodia, Rajive L.; „A unified framework for conservativeand optimistic distributed simulation“; Proceedings of the 8th Workshopon Parallel and Distributed Simulation, eds. D. K. Arvind, R. Bagrodia.,J. Y. Lin; IEEE Computer Society Press, 1994, Seiten 12-19.
[Jha, Bagrodia 1996] Jha, Vikas; Bagrodia, Rajive L.; „A Performance Evaluation Meth-odology for Parallel Simulation Protocols“; Proceedings of the 10thWorkshop on Parallel and Distributed Simulation (PADS '96); Philadel-phia, 22.-24.5.1996, Seiten 180-183.
[Jha, Bagrodia 2000] Jha, Vikas; Bagrodia, Rajive L.; „Simultaneous Events and Lookahead inSimulation Protocols“; ACM Transactions on Modeling and ComputerSimulation (TOMACS); Vol. 10(3), Seiten 241-267, 2000.
[Jordan, Drexl 1995] Jordan, C.; Drexl, A.; „A Comparison of Constraint and Mixed-IntegerProgramming Solvers for Batch Sequencing with Sequence-DependentSetups“; ORSA Journal on Computing 7, S. 160-165, 1995.
[Jung 1998] Jung, Hans; „Allgemeine Betriebswirtschaftslehre“; 4. Auflage, R. Ol-denbourg Verlag München Wien, 1998.
[Kahlert, Frank 1993] Kahlert, J.; Frank, H.; „Fuzzy-Logik und Fuzzy-Control“, Vieweg Wies-baden, 1993.
[Kaudel 1987] Kaudel, F.; „A Literature Survey on Distributed Discrete Event Simulati-on“; Simuletter, Vol. 18, No. 2, Seiten 11–21, 1987.
[Kelton, Sadowski, Sadowski 1998] Kelton, W. David; Sadowski, Randall P.; Sadowski, Deborah A.;„Simulation with Arena“; WCB/McGraw-Hill, 1998.
[Kernighan, Lin 1970] Kernighan, B. W.; Lin, S.; „An Efficent Heuristic Procedure for Partitio-ning Graphs“; Bell System Technical Journal, 1970, 49:291-307.
[Kim, Jean 1996] Kim, Hong. K.; Jean, Jack; „Concurrency Preserving Partitioning (CPP)for Parallel Logic Simulation“; Proceedings of the 10th Workshop on Par-allel and Distributed Simulation (PADS); Philadelphia, 22.-24.05.1996,Seiten 98-105.

Quellenverzeichnis
Seite 307
[Kleeberg 1993] Kleeberg, K.; „Kapazitätsorientierte Produktionssteuerung“; Gabler Ver-lag, 1993.
[Klein u.a. 1998] U. Klein, T. Schulze, S. Strassburger und H.-P. Menzler, „Traffic Simu-lation based on the High Level Architecture“; Proceedings of the 1998Winter Simulation Conference, eds. Medeiros, D.J., Watson, E.F., Car-son, J.S., Manivannan, M.S., Washington, DC, 1998, Bd. 2, Seiten 1095-1103.
[Kleis u.a. 1994] Kleis, U.; Wallat, O.; Wever, U.; Zheng, Q.; „Domain DecompositionMethods for Circuit Simulation“; Proceedings of the 8th Workshop onParallel and Distributed Simulation; Edinburgh, 1994.
[Kobylka, Gäse, Wirth 2000] Kobylka, Andrea; Gäse, Thomas; Wirth, Siegfried; „DatenbankbasierteGenerierung von Simulationsmodellen zur Planung von Produktionssy-stemen“; Simulation und Visualisierung 2000, Magdeburg 23.-24.03.2000, Seite 157ff.
[Kosonen 1996] Kosonen, Iisakki; „HUTSIM - Simulation Tool for Traffic Signal ControlPlanning“; PhD thesis, Helsinki University of Technology, 1996.
[Kosturiak, Gregor 1995] Kosturiak, Jan; Gregor, Milan; „Simulation von Produktionssystemen“;Springer-Verlag Wien New York, Wien, 1995.
[Kramer 1994] Kramer, D.; „Kostenorientierte Reihenfolgeplanung“; Verlag Josef EulBergisch Gladbach, Köln, 1994.
[Kreutzer, Hopkins, van Mierlo 1997] Kreutzer, Wolfgang; Hopkins, Jane; van Mierlo, Macel; „SimJAVA - AFramework for Modelling Queueing Networks in Java“; Proceedings ofthe 1997 Winter Simulation Conference, ed. S. Andradóttir, K. J. Healy,D. H. Withers, and B. L. Nelson, 1997.
[Krishnamurthy 1984] Krishnamurthy, Balakrishnan; „An Improved Min-Cut Algorithm forParallel VLSI Networks“; IEEE Transactions on Computers, 1984,33(5):438-446.
[Krug, Wiedemann 2000] Krug, W. ; Wiedemann, T.; „High-Performance-Optimierung mit ISSOPund SLX“; 12. European Simulation Symposium (ESS) / 14. SymposiumSimulationstechnik der Arbeitsgruppe Simulation (ASIM) an der Univer-sität Hamburg, 25.-28.09.2000, Seiten 491-496.
[Kvasnicka 1995] Kvasnicka, Bronislav; „Verteilte Simulation als eine Validierungs-methode für komplexe Steuerungen“; Dissertation; TU Ilmenau, 1995.
[Langendörfer 1992] Langendörfer, H.; „Leistungsanalyse von Rechensystemen: Messen,Modellieren, Simulation“; Carl Hanser, 1992.
[Lantsch, Straßburger, Urban] Lantsch, G.; Straßburger, Steffen; Urban, C.; „HLA-basierte Kopplungder Simulatoren SIMPLEX III und SLX“; Proceedings Simulation undVisualisierung 1999; Magdeburg, März 1999, Seiten 153-166; SCS-Society for Computer Simulation Int., Erlangen, 1999.
[Lengauer 1990] Lengauer, T.; „Combinatorial Algorithms for Integrated Circuit Layout“;John Wiley & Sons, Chichester, New York, Brisbane, Toronto, Signapo-re, 1990.
[Leung u.a. 1989] Leung, E.; Cleary, J.G.; Lomow, G.; Baezner, D.; Unger, B.; „The effectsof feedback on the performance of conservative algorithms“; Eastern Si-mulation Conference; Tampa (Florida), Vol. 21, Seiten 44-49, März1989.
[Lin, Lazowska 1990a] Lin, Y.; Lazowska, E.; „Exploiting Lookahead in Parallel Simulation“;IEEE Transactions on Parallel and Distributed Systems; Vol. 1, No. 4,Seiten 457–469, 1990.
[Lin, Lazowska, 1990b] Lin, Y.; Lazowska, E.; „Optimality Considerations of Time Warp ParallelSimulation“; Proceedings of the Distributed Simulation Conference, SanDiego, 17.-19.01.1990, Seiten 29-34.
[Lin, Lazowska, 1990c] Lin, Y.; Lazowska, E.; „Reducing the State Saving Overhead for TimeWarp Parallel Simulation“; Technical Report 90-02-03, University ofWashington, Department of Computer Science, Seattle, 1990.
[Lin, Lazowska, 1990d] Lin, Y.; Lazowska, E.; „Processor Scheduling for Time Warp ParallelSimulation“; Technical Report 90-03-03, University of Washington, De-partment of Computer Science, Seattle, 1990.

Quellenverzeichnis
Seite 308
[Lin, Lazowska, 1990e] Lin, Y.; Lazowska, E.; „Determining the Global Virtual Time in a Distri-buted Simulation“; Technical Report 90-01-02, University of Washing-ton, Department of Computer Science Seattle, 1990.
[Lin, Lazowska, Baer 1990] Lin, Y.; Lazowska, E.; Baer, J.-L.; „Conservative Parallel Simulation forSystems with No Lookahead Prediction“; Proceedings of the DistributedSimulation Conference; San Diego, 17.-19.01.1990, Seiten 144-151.
[Lin, Lazowska 1991] Lin, Y.; Lazowska, E.; „A Study of Time Warp Rollback Mechanisms“;ACM Transactions on Modeling and Computer Simulation, 1:1, Seiten51-72, 1991.
[Lin, Preiss 1991] Lin, Y.; Preiss, B. R.; „Optimal Memory Management for Time WarpParallel Simulation“; ACM Transactions on Modeling and Computer Si-mulation;1:4, Seiten 283-307, 1991.
[Lin 1992a] Lin, Y.; „Memory Management Algorithms for Optimistic Parallel Si-mulation“; Proceedings of the 6th Workshop on Parallel and DistributedSimulation (PADS92); Newport Beach (California), 20.-22.01.1992,Seiten 43-52.
[Lin 1992b] Lin, Y.; „Parallelism Analyzers for Parallel Discrete Event Simulation“;ACM Transactions on Modeling and Computer Simulation; 2:3, Seiten239-264, 1992.
[Lin u.a. 1993] Lin, Y.; Preiss, B. R.; Loucks, W.; Lazowska, E.; „Selecting the Check-point Interval in Time Warp Simulation“; Proceedings of the 7th Work-shop on Parallel and Distributed Simulation; San Diego, 16.-19.05.1993,Seiten 3-10.
[Loucks, Preiss 1990] Loucks, Wayne M.; Preiss, Bruno R.; „The Role of Knowledge in Distri-buted Simulation“; Proceedings of the Western Multiconference: Distri-buted Simulation; Vol. 22, Seiten 9-16, San Diego, Januar 1990.
[Low u.a. 1999] Low, Yoke-Hean; Lim, Chu-Cheow; Cai, Wentong; Huang, Shell-Ying;Hsu, Wen-Jing; Jain, Sanjay; Turner, Stephen J.; „Survey of Languagesand Runtime Libraries for Parallel Discrete-Event Simulation“; TechnicalArticle; SIMULATION 72:3, Seiten 170-186, März 1999.
[Lu, Ramaswamy, Kumar 1994] Lu, C. H.; Ramaswamy, D.; Kumar, P. R.; „Scheduling ManufacturingSystems Of Re-Entrant Lines“; IEEE Transactions on SemiconductorManufacturing, 1994/7-4, S. 374-388.
[Luksch 1993] Luksch, Peter; „Parallelisierung ereignisgetriebener Simulationsverfahrenauf Mehrprozessorsystemen mit verteiltem Speicher“; Dissertation; In-stitut für Informatik, Technische Universität München, 1993.
[Luksch 1995] Luksch, Peter; „Parallel Logic Simulation on Distributed Memory Multi-processors - Classification and Evaluation of different Approaches“; inSystems Analysis Modeling Simulation, 21:123-145, 1995.
[Manjikian 1992] Manjikian, Naraig; „High Performance Parallel Logic Simulation on aNetwork of Workstations“; Technischer Bericht CCNG T-220, Univer-sity of Waterloo, 1992.
[Manjikian, Loucks 1993] Manjikian, N.; Loucks, W. M.; „High Performance Parallel Logic Simu-lation On A Network of Workstations“; Proceedings of the 7th Workshopon Parallel and Distributed Simulation, 1993, Seiten 76-84.
[ManSim 1997] „ManSim OnTime - User Manual“; TYECIN Systems Inc., Los Altos,1997.
[Maisie] http://may.cs.ucla.edu/projects/maisie/, Abruf Mai 2000.[Meister 1993] Meister, Gerd; „A Survey on Parallel Logic Simulation“; Technischer
Bericht Nr. TR 14-1993, SFB 124; Universität des Saarlandes, Fachbe-reich Informatik, 1993.
[Meister 1996] Meister, Gerd; „Evaluation of Parallel Logic Simulation Using DVSIM“;Proceedings of the 29th Hawaii International Conference on SystemSciences, Vol. 1,Seiten 397 - 406, Wailea, Hawaii, Januar 1996.
[Mehl 1994] Mehl, Horst; „Methoden verteilter Simulation“; Dissertation; ViewegVerlag, Wiesbaden 1994.
[Meyer, Bagrodia 1998] Meyer, Richard A. ; Bagrodia, Rajive L.; „Improving Lookahead in Par-allel Wireless Network Simulation“; Proceedings of the 6th International

Quellenverzeichnis
Seite 309
Symposium on Modeling, Analysis and Simulation of Computer and Te-lecommunication Systems; Montreal, 1998.
[Miser 1998] Miser, Dan; „Creating Multi-tier Applications with MIDAS“; BorlandInternational, 1998.
[Misra 1986] Misra, Jayadev; „Distributed Discrete-Event Simulation“; COMPSUR,März 1986, Vol. 18, Nr. 1, Seiten 39-65.
[MPI FAQ 2000] „Message Passing Interface (MPI) FAQ“;http://www.erc.msstate.edu/labs/hpcl/projects/mpi/mpi-faq.html,Abruf Mai 2000.
[MPI Implementations 2000] „Freely Available MPI Implementations“;http://www.erc.msstate.edu/labs/hpcl/projects/mpi/implementations.htmlAbruf Mai 2000.
[MSU MPI 2000] „The MSU MPI page“;http://www.erc.msstate.edu/labs/hpcl/projects/mpi/,Abruf Mai 2000.
[Myjak, Clark, Lake 1988] Myjak, M.D.; Clark, D.; Lake, T.; „RTI Interoperability Study GroupFinal Report“; 1988.http://www.sisostds.org/stdsdev, Abruf Mai 2000.
[Nandy, Loucks 1993] Nandy, B.; Loucks, W.M.; „On the Parallel Partitioning Technique forUse with Conservative Parallel Simulation“; Proceedings of the 7thWorkshop on Parallel and Distributed Simulation; Seiten 43-51, San Die-go, 17.-19. Mai 1993.
[Nicol 1988] Nicol, David M.; „High performance parallelized discrete event Simulati-on of stochastic queueing networks“; Proceedings of the 1988 WinterSimulation Conference, M. Abrams, P. Haigh, and J. Comfort (eds.).
[OMG] OMG - Object managment group.http://www.omg.org.
[P4] http://www.it.kth.se/labs/cs/sim-group/misc/p4.html,Abruf Mai 2000.
[Page 1991] Page, Bernd; „Diskrete Simulation - Eine Einführung mit Modula-2“;Springer-Verlag, 1991.
[Page, Moose, Griffin 1997] Page, Ernest H.; Moose, Robert L.; Griffin, Sean P.; „Web-Based Simu-lation in SimJAVA using Remote Method Invocation“; Proceedings ofthe 1997 Winter Simulation Conference, ed. S. Andradóttir, K. J. Healy,D. H. Withers, and B. L. Nelson, 1997.
[Palaniswamy, Wilsey 1993] Palaniswamy, A.; Wilsey, P.; „An Analytical Comparisation of PeriodicCheckpointing and Incremental State Saving“; Proceedings of the 7thWorkshop on Parallel and Distributed Simulation; San Diego, 16.-19.05.1993, Seiten 127-134.
[Paprotny, Fowler 2001] Paprotny, Igor; Fowler, John W.; „Investigating Run-Time Behavior ofDistributed Semiconductor Manufacturing Simulation through Emulationof Distributed Environment“; in Advanced Simulation Technology Con-ference 2001 (ASTC’2001); 22.-26.04.2001, Seattle.
[ParaSol] http://www.cs.purdue.edu/research/PaCS/parasol.html,Abruf Mai 2000.
[ParSec] http://pcl.cs.ucla.edu/projects/parsec/,Abruf Mai 2000.
[ParSim] http://www.ece.nwu.edu/~sgoh/project.html,Abruf Mai 2000.
[ParSimONY] http://dictator.uwaterloo.ca/Bruno.Preiss/parsimony/,Abruf Mai 2000.
[Paulik 1984] Paulik, R.; „Kostenorientierte Reihenfolgeplanung in der Werkstatt-fertigung“; Bern, 1984.
[Perumalla, Fujimoto 1998] Perumalla, Kalyan S.; Fujimoto, Richard M.; „Efficient Large-Scale Pro-cess-Oriented Parallel Simulations“; Proceedings of the 1998 Winter Si-mulation Conference, eds. Medeiros, D.J., Watson, E.F., Carson, J.S.,Manivannan, M.S., Washington, DC, 1998, Seiten 459-466.
[Pixius u.a. 2000] Pixius, K.; Menzler, H.-P.; Krosta, U.; Ufer, H.; Tietje, H.; „Die Entwick-lung einer universellen Schnittstelle ψ-SA für verteilte Simulations-

Quellenverzeichnis
Seite 310
systeme der Bundeswehr unter der High Level Architecture“; Simulationund Visualisierung 2000, Magdeburg 23.-24.03.2000; Seite 53ff.
[Porras, Harju, Ikonen 1995] Porras, J.; Harju, J.; Ikonen, J.; „Parallel Simulation of Mobile Commu-nication Networks using a Distributed Workstation Environment“; Pro-ceedings of the Eurosim '95.
[Pree 1995] Pree, W.; „Design Patterns for Object-Oriented Software Development“;Addison-Wesley, 1995.
[Preiss 1989] Preiss, Bruno Richard; „The Yaddes distributed discrete event simulationspecification language and execution environments“; Proceedings of theSCS Multiconference on Distributed Simulation; Seiten 139-144, Tampa(Florida), März 1989http://www.pads.uwaterloo.ca/Bruno.Preiss/yaddes.html
[Preiss 1990] Preiss, Bruno Richard; „Performance of Discrete Event Simulation on aMultiprocessor Using Optimistic and Conservative Synchronization“;International Conference on Parallel Processing, 13.-17.08.1990, Seiten218-222.
[Preiss, Loucks 1990] Preiss, Bruno Richard; Loucks, Wayne Mervin; „The impact of looka-head on the performance of conservative distributed simulation“; Procee-dings of the 1990 European Multiconference - Simulation Methodologies,Languages and Architectures; Seiten 204-209, Nürnberg, Juni 1990.
[Preiss, Loucks, MacIntyre 1991] Preiss, Bruno Richard; Loucks, Wayne Mervin; MacIntyre, Ian Donald;„Null Message Cancellation in Conservative Distributed Simulation“;Proceedings of the SCS Multiconference on Advances in Parallel andDistributed Simulation; Anaheim (California), 23.-25.01.1991, Seiten 33-38.
[Preiss, MacIntyre 1991] Preiss, Bruno Richard; MacIntyre, Ian Donald; „Multi-threaded pipeli-ning in a RISC processor“; Proceedings of the 1991 Canadian Conferenceon Electric and Computer Enginering, Québec, September 1991, Seiten7.3.1-7.3.6.
[Preiss, MacIntyre, Loucks 1992] Preiss, Bruno Richard; MacIntyre, Ian Donald; Loucks, Wayne Mervin;„On the trade-off between time and space in optimistic parallel discreteevent simulation“; Proceedings of the 6th Workshop on Parallel and Dis-tributed Simulation (PADS '92), Seiten 33-42, Newport Beach(California), Januar 1992.
[Preiss, Loucks 1995] Preiss, Bruno Richard; Loucks, Wayne Mervin; „Memory ManagementTechniques for Time Warp on a Distributed Memory Machine“; Procee-dings of the 9th Workshop on Parallel and Distributed Simulation(PADS'95); Lake Placid (NY); Juni 1995, Seiten 30-39.
[Preiss 1998a] Preiss, Bruno Richard; „On the Design of the Parsimony Package Version1“; Technical Report, PADS Research Group, Department of Electricaland Computer Engineering, University of Waterloo, Mai 1998.
[Preiss 1998b] Preiss, Bruno Richard; „Getting Started Using The Parsimony Check-pointing Package“; Technical Report, PADS Research Group, Depart-ment of Electrical and Computer Engineering, University of Waterloo,Mai 1998.
[Preiss, Wan 1999] Preiss, Bruno Richard; Wan, K. W. Carey; „The Parsimony Project: ADistributed Simulation Testbed in Java“; Proceedings of the 1999 Inter-national Conference On Web-Based Modelling & Simulation, Januar1999, Seiten 89-94http://dictator.uwaterloo.ca/Bruno.Preiss/parsimony/
[Pursula 1999] Pursula, Matti; „Simulation of Traffic Systems - An Overview“; Journalof Geographic Information and Decision Analysis, vol.3, no.1, Seiten 1-8,1999.
[Rajan, Wilsey 1995] Rajan, R.; Wilsey, P.A.; „Dynamically switching between lazy and ag-gressive cancellation in a Time Warp parallel simulator“; in Proceedingsof the 28th Annual Simulation Symposium, 1995.http://dlib.computer.org/conferen/ss/7091/pdf/70910022.pdf

Quellenverzeichnis
Seite 311
[Reiche 1990] Reiche, H. J.; „Zehn Jahre rechnerunterstützte Fabrikplanung in einemAutomobilunternehmen“; VDI-Berichte 824, VDI Verlag, Düsseldorf,1990, Seiten 151-173.
[Reiher, Wieland, Jefferson 1989] Reiher, L.; Wieland, F.; Jefferson, D.; „Limiting the Optimism in theTime Warp Operation System“; Proceedings of the 1989 Winter Simula-tion Conference, Seiten 765-770, 1989.
[Reißing 1998] Reißing, Ralf; „OOSE: Objektorientierte Software-Entwicklung“, Uni-versität Stuttgart, 1998.
[Reynolds 1991] Reynolds, P.; „An Efficient Framework for Parallel Simulations“; Pro-ceedings of the SCS Multiconference on Advances in Parallel and Distri-buted Simulation; Vol. 23, No. 1, Seiten 167–174, 1991.
[Richter u.a. 1998] Richter, K.; Thiel, M.; Prause, M.; Schmalfuß, V.; Kämpf, B.; Mönch,G.; „Produktionssteuerung“; in Smart Fabrication Verbund CIM, 3. Offe-ner Workshop, München, 29.-30. Oktober 1998, Seiten 66–74.
[Riess, Doll, Johannes 1994] Riess, B. M.; Doll, K.; Johannes, F. M.; „Partitioning Very Large CircuitsUsing Analytical Placement Techniques“; Proceedings of the 31stACM/IEEE Design Automation Conference, Seiten 646-651, 1994.
[RMI] „Remote Method Invocation“; Sun Microsystems 1997,http://java.sun.com/products/jdk/1.1/docs/guide/rmi/spec/rmi-intro.doc.html, rmi-objmodel.doc.html, rmi-arch.doc.html,Abruf Mai 2000.
[Rotithor 1994] Rotithor, H. G.; „Taxonomy of dynamic task scheduling schemes in dis-tributed computing systems“; IEE Proceedings on Computer and DigitalTechniques; 141, No. 1 (Jan. 1994), Seiten 1-10.
[Salmi 1992] Salmi, M.; „Parallel Simulation and Its Usage in the Simulation of GSMMobile Network“; Master's thesis; University of Joensuu, Joensuu, 1992.
[Sanders, Wosch 1997] Sanders, Peter; Worsch, Thomas; „Parallele Programmierung mit MPI –ein Praktikum“; Logos Verlag Berlin, 1997.
[Saucier u.a. 1993] Saucier, G.; Brasen, D.; Hiol, J. P.; „Partitioning With Cone Structures“;Proceedings IEEE Conference on Computer-Aided Design (ICCAD),Santa Clara, 1993, Seiten 236-239.
[Schärpers 1998] Schäpers, Arne; „Kurze Leine - Lokale COM-Server und -Clients“; c'tMagazin, 3:174, 1998.
[Schierenbeck 1995] Schierenbeck, Henner; „Grundzüge der Betriebswirtschaftslehre“; 12.Auflage, Oldenbourg Verlag, München, 1995.
[Schlagenhaft u.a. 1995] Schlagenhaft, Rolf; Ruhwandl, Martin; Sporrer, Christian; Bauer, Her-bert; „Dynamic Load Balancing of a Multi-Cluster Simulator on a Net-work of Workstations“; Proceedings of the 9th Workshop on Parallel andDistributed Simulation (PADS95); 14-16 Juni 1995, Lake Placid, NewYork; Seiten 175-180.http://www.rolf-schlagenhaft.de/biblio.htm
[Schlagenhaft 1999a] Schlagenhaft, Rolf; „Dynamischer Lastausgleich optimistisch synchro-nisierter verteilter Simulation“; Workshop der Arbeitsgemeinschaft Simu-lation in der Gesellschaft für Informatik: „Verteilte Simulation und par-allele Prozesse“, Otto-von-Guericke-Universität Magdeburg, Magdeburg,1999.http://www.rolf-schlagenhaft.de/biblio.htm
[Schlagenhaft 1999b] Schlagenhaft, Rolf; „Dynamischer Lastausgleich verteilter diskreterSimulation“; Dissertation, Technische Universität München, 1999.http://www.rolf-schlagenhaft.de/biblio.htm
[Schmidt 1999] Schmidt, Bernd; „Simulation, Kognition und Emotion - kooperierendeAgenten mit Verstand und Gefühl“, Plenarvortrag im Rahmen der ASIM1999 - 13. Symposium Simulationstechnik, Weimar, 21.-24. September1999.
[Schneider, Reinhardt 2000] Schneider, Stefan; Reinhardt, Adolf; „Eine anwendungsunabhängigeOptimierungsumgebung mit kooperativ arbeitenden Verfahren am Bei-spiel der Fabriksimulation“; in „Frontiers in Simulation - 14. SymposiumSimulationstechnik (ASIM 2000)“, Hamburg, September 2000, S. 333-338.

Quellenverzeichnis
Seite 312
[Schulz 1996] Schulz, Roland; „Entwicklung und Implementierung einer Software-lösung zur Präsentation der Einsatzmöglichkeiten der Simulation zur Pla-nung und Steuerung von Produktionssystemen“; Diplomarbeit, TU Ilme-nau, Oktober 1996.
[Schulze u.a. 1998] Schulze, T.; Klein, U.; Strassburger, S.; Ritter, K.-C.; Blümel, E.; Schu-mann, M.; „HLA-basierte verteilte Simulationsmodelle für die Ferti-gung“; in P. Lorenz und B. Preim, editors; Proceedings Simulation undVisualisierung 1998, Seiten 19-31.
[Schweikert, Kernighan 1972] Schweikert, D. G.; Kernighan, B. W.; „A Proper Model for the Partitio-ning of Electrical Circuits“; Proceedings ACM/IEEE Design AutomationWorkshop (DAC), 1972, Seiten 57-62.
[Scriber, Brunner 1998] Scriber, Thomas J.; Brunner, Daniel T.; „Inside Discrete-Event Simulati-on Software: How it works and Why it matters“; Proceedings of the 1998Winter Simulation Conference, eds. Medeiros, D.J., Watson, E.F., Car-son, J.S., Manivannan, M.S., Washington, DC, 1998, Seiten 77-86.
[Seelbach 1975] Seelbach, H.; „Ablaufplanung“; physica-Verlag, Würzburg, 1975.[Seila, Miller 1999] Seila, Andrew F.; Miller, John A.; „Scenario Management in Web-Based
Simulation“; Proceedings of the 1999 Winter Simulation Conference,P.A. Farrington, H. B. Nembhard, D. T. Sturrock, and G. W. Evens, eds.,Phoenix, 1999.
[SimBa] http://www.fzi.de/esm/projects/simba/simba_uk.html,Abruf Mai 2000.
[Simul8 1999] „SIMUL8 User’s Manual“; SIMUL8 Corporation, Herndon (Virginia) /Glasgow, 1999.
[Skjellum, Lusk, Gropp 1994] Skjellum, Anthony; Lusk, Ewing; Gropp, William; „Early Applications inthe Message-Passing Interface (MPI)“; Department of Computer Science& NSF Engineering Research Center for Computational Field Simulation,Mississippi State University, Argonne National Laboratory, Mathematicsand Computer Science Division, Argonne, 1994http://www.cs.msstate.edu/~tony/documents/Applications/early_apps_mpi.ps.Z
[Smith u.a. 1987] Smith, Stevens P.; Underwood, Bill; Mercer, M. Ray; „An Analysis ofSeveral Approaches to Circuit Partitioning for Parallel Logic Simulati-on“; Proceedings IEEE International Conference on Computer Design(ICCD): New York, 1987. Seiten 664-667.
[Smith 1999] Smith, Roger D.; „Strategic Directions in Distributed Simulation“; Pro-ceedings of the 1999 Winter Simulation Conference P. A. Farrington, H.B. Nembhard, D. T. Sturrock, and G. W. Evans, eds., Phoenix, 1999.
[Snir 1996] Snir, Marc; „MPI – The Complete Reference“; The MIT Press, 1996.[Sokol, Stucky, Hwang 1989] Sokol, L.; Stucky, B.; Hwang, V.; „MTW: A Control Mechanism for
Parallel Discrete Simulation“; International Conference on Parallel Pro-cessing; Vol. 3, Seiten 250–254, August 1989.
[SPEEDES] http://www.speedes.com, Abruf Mai 2000.[Sporrer, Bauer 1993] Sporrer, Christian; Bauer, Herbert; „Corolla Partitioning for Distributed
Logic Simulation of VLSI-Circuits“; Proceedings of the 7th Workshop onParallel and Distributed Simulation (PADS), 1993, Seiten 85-92.
[Sporrer 1995] Sporrer, Christian; „Verfahren zur Schaltungspartitionierung für die par-allele Logiksimulation“; Dissertation; Lehrstuhl für RechnergestütztesEntwerfen der Technischen Universität München, 1995.
[Steinman 1991] Steinman, Jeff; „SPEEDES: Synchronous Parallel Environment forEmulation and Discrete Event Simulation“; Proceedings of Advances inParallel and Distributed Simulation; Seiten 95-103, 1991.
[Steinman 1992] Steinman, Jeff; „SPEEDES: A Multiple-Synchronization Environmentfor Parallel Discrete-Event Simulation“; International Journal in Compu-ter Simulation; Volume 2, Seiten 251-286, 1992.
[Steinman 1993] Steinman, Jeff; „Breathing Time Warp“; Proceedings of the 7th Workshopon Parallel and Distributed Simulation (PADS93); Vol. 23, No. 1, Seiten109-118, 1993.

Quellenverzeichnis
Seite 313
[Steinman, Wieland 1994] Steinman, Jeff; Wieland, Frederick; „Parallel proximity detection and thedistribution list algorithm“; Proceedings of the 1994 workshop on Paralleland distributed simulation, 6.-8. Juli 1994, Edinburgh, Seiten 3-11.
[Straßburger, Klein 1998] Straßburger, Steffen; Klein, Ulrich; „Integration des Simulators SLX indie High Level Architecture“; Proceedings Simulation und Visualisierung1998, Peter Lorenz and Bernhard Preim, editors; SCS-Society for Com-puter Simulation Int., Delft, Erlangen, Ghent, 1998, Seiten 32-40.
[Straßburger 2001] Straßburger, Steffen; „Distributed Simulation Based on the High LevelArchitecture in Civilian Application Domains“; Dissertation; Otto-von-Guericke-Universität Magdeburg; Magdeburg, April 2001.
[Su, Seitz 1989] Su, Wen-king; Seitz, C.L.; „Variants of the Chandy-Misra-Bryant distri-buted simulation algorithm“; in 1989 Simulation Multiconference: Distri-buted Simulation; Miami, März 1989.
[Sun-Java 1997] http://java.sun.com/docs/white/langenv/, Abruf Mai 2000.[Thiel, Schulz, Gmilkowsky 1998a] Thiel, M.; Schulz, R.; Gmilkowsky, P.; „Simulation-based Production
Control in the Semiconductor Industry by the Use of a Multilevel Con-cept“; in Bargiela, A., Kerckhoffs, E. (eds.), Simulation Technology: Sci-ence and Art – 10th European Simulation Symposium and Exhibition,26.–28. Oktober 1998, S. 445–447.
[Thiel, Schulz, Gmilkowsky 1998b] Thiel, M.; Schulz, R.; Gmilkowsky, P.; „Simulation-based ProductionControl in the Semiconductor Industry“, in Medeiros, D. J., Watson, E.F., Carson, J. S., Manivannan, M. S. (eds.), Simulation in the 21st Cen-tury, Proceedings of the 1998 Winter Simulation Conference, Washing-ton, DC, 13.-16. Dezember 1998, S. 1029-1035.
[Thiel, Schulz 2000a] Thiel, M.; Schulz, R.; „Simulationsbasierte Fertigungssteuerung in derHalbleiterindustrie unter Einbeziehung von Interaktionsverfahren“; in:Simulation und Visualisierung 2000, Magdeburg, 23.–24. März 2000, S.277-290.
[Thiel, Schulz 2000b] Thiel, M.; Schulz, R.; „Reihenfolgeplanung in der Halbleiterindustrieunter der Beachtung von Liegezeitbegrenzungen zwischen Arbeitsgän-gen“; Symposium über Operations Research 2000; Dresden, 10.-12.09.2000.
[Thiel 2001] Thiel, Matthias; „Simulationsbasierte Reihenfolgeplanung in der Halb-leiterindustrie“; Dissertation; TU Ilmenau, 2001.
[Tree 1999] Tree, Philip J.; „Network Simulation of IP and ATM over IP using aDiscrete Event Simulator“; July 1999http://atm.cs.waikato.ac.nz/atm/publications/ptree_thesis/ptree_thesis.html
[Unger 1988] Unger, Brian W.; „Distributed Simulation“; Proceedings of the 1988Winter Simulation Conference, M. Abrams, P. Haigh, and J. Comfort(eds.), 1988.
[Ungerer 1997] Ungerer, Theo; „Parallelrechner und parallele Programmierung“; Spek-trum Akademischer Verlag, Heidelberg, Berlin, 1997
[VDI 3633] VDI-Richtlinie 3633, „Simulation von Logistik-, Materialfluß- und Pro-duktionssystemen“
[Vee, Hsu 1999] Vee, Voon-Yee; Hsu, Wen-Jing; „Parallel Discrete Event Simulation: ASurvey“; Technical Report 1999-23, Center for Advanced InformationSystems, Nanyang Technological University, Singapore, 1999.
[VHDL] http://www.vhdl.org/, Abruf Mai 2000.[Vijayan 1989] Vijayan, Gopalakrishnan; „Min-Cost Partitioning an a Tree Structures
and Applications“; Proceedings ACM/IEEE Design Automation Confe-rence (DAC), 1989, Seiten 771-774.
[Vijayan 1991] Vijayan, Gopalakrishnan; „Generalization of Min-Cut Partitioning toTree Structures and its Applications“; Proceedings ACM/IEEE DesignAutomation Conference (DAC), 1991.
[Völker, Munkelt, Gmilkowsky 2000] Völker, Sven; Munkelt, Torsten; Gmilkowsky, Peter; „Reduced Simulati-on Models for Medium-Term Production Scheduling“; in: Giambiasi,Norbert; Frydman, Claudia (eds.): Simulation in Industry - 13th EuropeanSimulation Symposium, Proceedings. Marseille, October 2001, Seiten187-191.

Quellenverzeichnis
Seite 314
[VRML] http://www.vrml.org/, Abruf Mai 2000.[Waheed, Yan 1998] Waheed, Abdul; Yan, Jerry; „Performance Modeling and Measurement of
Parallelized Code for Distributed Shared Memory Multiprocessors“; Pro-ceedings of the 6th International Symposium on Modeling, Analysis andSimulation of Computer and Telecommunication Systems; Montreal,1998.
[Waldorf 1992] Waldorf, Jerry; „Moose: A concurrent object-oriented language for si-mulation“; Master's thesis; Univeristy of California, Los Angeles, Com-puter Science Department, UCLA, Los Angeles, 1992.
[Waldorf, Bagrodia 1994] Waldorf, Jerry; Bagrodia, Rajive; „MOOSE: A Concurrent Object Ori-ented Language for Simulation“; International Journal of Computer Si-mulation; Vol. 4(2), 1994, Seiten 235-257.
[Warped] http://www.ececs.uc.edu/~paw/warped/, Abruf Mai 2000.[Wei, Cheng 1989] Wei, Yen-Chuen; Cheng Chung-Kuan; „Towards Efficent Hierarchical
Design by Ratio Cut Partitioning“; Proceedings IEEE International Con-ference on Computer-Aided Design (ICCAD), Santa Clara, 1989, Seiten298-301.
[Wei, Cheng 1990] Wei, Yen-Chuen; Cheng Chung-Kuan; „A Two-Level Two-Way Parti-tioning Algorithm“; Proceedings IEEE International Conference onComputer Aided Design (ICCAD), 1990, Seiten 516-519.
[Wei, Cheng 1991] Wei, Yen-Chuen; Cheng Chung-Kuan; „Ratio Cut Partitioning for Hier-archical Designs“; IEEE Transactions on Computer-Aided Design, 1991,10(7):911-921.
[Weidner 1995] Weidner, J.; „Koordinierter und erweiterter Prioritätsregeleinsatz in derFertigungssteuerung“; Diplomarbeit, TU Ilmenau, 1995.
[Weigelt 1994] Weigelt, Mark; „Dezentrale Produktionssteuerung mit Agenten-Systemen“; Deutscher Universitäts-Verlag; Gabler, Wiesbaden, 1994.
[Welch 1983] Welch, P. D.; „The Statistical Analysis of Simulation Results“; in: S.S.Lavenberg (Herausgeber): Computer Performance Modeling Handbook,S. 267-329, Academic Press, 1983.
[Wiedemann 2000] Wiedemann, Thomas; „VisualSLX - ein modalares, datenbankbasiertesSimulationssystem“; in „Frontiers in Simulation - 14. Symposium Simu-lationstechnik (ASIM 2000)“, Hamburg, September 2000, Seiten 413-418.
[Wiendahl 1992] Wiendahl, H.-P.; „Die belastungsorientierte Fertigungssteuerung“; in:SzU Bd. 38/39, Gabler Verlag, 1992.
[Wiendahl, Pritschow, Milberg 1993] Wiendahl, H.-P.; Pritschow, G.; Milberg, J.; „Produktionsregelung -interdisziplinäre Zusammenarbeit führt zu neuen Ansätzen“; in Zeitungfür wirtschaftliche Fertigung und Automation; 88/6, Seiten 265-268,1993.
[Wilsey 1997] Wilsey, Philip A.; „Feedback Control in Time Warp Synchronized Par-allel Simulators“; First International Workshop on Distributed InteractiveSimulation and Real Time Applications, 1997.
[Wilsey u.a. 1998] Wilsey, Philip A.; Radhakrishnan, Radharamanan; Abu-Ghazaleh, Nael;Chetlur, Mololan; „On-Line Configuration of a Time Warp Parallel Dis-crete Event Simulator“; Proceedings of the 1998 International Conferenceon Parallel Processing, Cincinnati University, 10.-14. August 1998.
[wombat] http://wombat.doc.ic.ac.uk/foldoc/foldoc.cgi[Xiao u.a. 1999] Xiao, Z.; Unger, B.W.; Simmonds, R; Cleary, J.; „Scheduling Critical
Channels in Conservative Parallel Discrete Event Simulation“; Procee-dings of the 1999 Workshop on Parallel and Distributed Simulation(PADS99), Atlanta, Mai 1999.
[YADDES] http://www.pads.uwaterloo.ca/Bruno.Preiss/yaddes.html,Abruf Mai 2000.
[Zäpfel 1982] Zäpfel, G.; „Produktionswirtschaft - Operatives Produktions-Manage-ment“; Verlag de Gruyter, 1982.
[Zäpfel 1994] Zäpfel, G.; „Entwicklungsstand und -tendenzen von PPS-Systemen“; inCorsten, H., Handbuch Produktionsmanagement, Gabler, Wiesbaden1994.

Index
Seite 315
Stichwortverzeichnis
Abarbeitungsplattform .............. 240; 244; 246Abarbeitungsreihenfolge .......................... 140Abarbeitungsstrategie ................................ 53AbstractBatchingMechanismus........ 222; 224AbstractEvent ........................................... 211AbstractMessage.............................. 212; 217AbstractModel .......................................... 206AbstractProcess ....................................... 206AbstractSelektionsMechanismus ..... 222; 225Anti-Messages...................................... 80; 86Anti-Nachricht........................................... 140Auftragsfreigabe ................................... 28; 29Ausführungsplattform ............... 240; 244; 246Batch ........................................................ 224Batchbildung............................................. 224Batching.................................................... 127Beladeregeln ............................................ 128Berechnungslast
Abschätzung ............................................... 134Betriebssystem................................... 93; 240Broadcast ........................................... 72; 131Chandy, Misra and Bryant.......................... 78Channel .................................................... 207ChannelHead ........................................... 210Channels .................................................. 210ChannelTail .............................................. 210Commit ....................................................... 79Common Request Broker Architecture ...... 98CORBA....................................................... 98Datenobjekt ................................ 48; 188; 215Datenwrapper................... 188; 195; 233; 237DCOM......................................................... 98Deadlock......................................... 73; 77; 83Deadlock-Recovery .................................... 83Discrete Event Simulation .......................... 39Distributed Component Object Model ........ 98Distributed Simulation Language ............. 101DistributedCMBSimulator ......................... 206DistributedMLSimulator ............................ 205DistributedRTSimulator ............................ 206DistributedTWSimulator ........................... 206DSL........................................................... 101DynamicPriorityComputer ................ 222; 223Einsteuerungsstrategie............................... 52Ereignislisten ............................................ 278Ereignisse................................................. 211
Einplanen.................................................... 211im Prozeß einer Maschinengruppe ............. 135Prioritätsklassen.......................................... 226
Ergebnisgrößen........................................ 221Experiment ............................................... 176Fertigungssteuerung .................................. 27
globale Ansätze ...................................... 29; 32lokale Ansätze ........................................ 30; 31
Ziele...............................................................28Framework
Architekturübersicht....................................120Auswertungs-Komponente..................123; 201Begriff .........................................................117Datenimport-Komponente...................120; 185Datenpflege-Komponente ...........................186Einsatz .........................................................227Ergebnisaggregations-Komponente ............199Ergebnisaufbereitungs-Komponente ...122; 197Ergebnisdatenbank ..............................123; 200Ergebnisübernahme-Komponente .......123; 201Erweiterungen .............................................238Experimentdurchführungs-Komponente122; 191Experimentplandatenbank...................122; 190Experimentplanungs-Komponente......121; 188Generator-Komponente.............. 122; 195; 237GUI..............................................................182Implementation............................................182Konzeption ..................................................119Kopplung.....................................................227Laufergebnisdatenbank ...............................199Metadaten....................................................184Modelldatenbank.................................120; 186Modellverwaltung ...............................183; 185Motivation ...................................................114Simulationsausführungs-Komponente ........196Simulationsergebnisse.................................198Simulationsexperimentsteuerung ................193Simulationslaufsteuerung ............................195Simulatorausführungs-Komponente............122verteiltes Experimentiersystem ...................234Verwaltungsdatenbank................................183
Garantie.......................................................78Garantie-Nachrichten ..................................78Garbage Collection .................................. 227Generator ......................................... 228; 233
für den Parallelen Simulator ParSimONY-ProdSys...................................................229
geschirmtes Netzwerk.......................... 72; 73global virtual time ........................................81
Berechnung ...................................................86Grundpartitionierung .............. 68; 70; 89; 105GVT .............................................................81
Berechnung ...................................................86High Level Architecture ........................ 42; 98Hintergrundlast ............................................73HLA ...................................................... 42; 98hybride Synchronisationsverfahren.............81Interactive Simulation........................... 42; 99Interaktionsregeln............................... 32; 128kausale Ordnung............................ 62; 75; 79Kausalitätsverletzung ........................... 62; 75

Index
Seite 316
Kombination von Steuerungsansätzen .... 128Kommunikation
über einen gemeinsamen Speicher ................72Kommunikationsbedarf
Abschätzung................................................132Kommunikationsoverhead............ 70; 73; 240Kommunikationstopologie .......................... 71komplexe Prozeßbedingungen................. 220Komplexität
von Produktionssystemen..............................45Lazy Cancellation ..................................... 144Load-Balancing............................... 62; 88; 89Logischer Prozeß ............................... 41; 207lokale Abarbeitung...................................... 40lokale Sequentielle Simulation ................... 40Lookahead.................... 78; 82; 138; 139; 143Maisie ....................................................... 100Mapping........................................ 89; 90; 280Message ................................................... 212Message Passing ....................................... 97Messagehandler ....................................... 213Methode
createProcess() ............................................207receive() ......................................................210run().............................................................211schedule() ....................................................211send()...................................................210; 213
Modell ......................................................... 34Modellelement .......................................... 207
Bedienstation.......................................216; 222Distributor ...................................................209Join ..............................................................209Maschine .............................................218; 232Maschinengruppe ................................219; 232Merge ..........................................................209MultiQuelle .................................................218Quelle ..........................................................218Queue ..........................................................209Senke...........................................................218Server ..........................................................208Sink .............................................................208Source..........................................................208Split .............................................................209StationsKette .......................................220; 232Verteiler ......................................................219Werkstatt .............................................220; 232
Modellelementevon Produktionssystemen..............................46
Modellgenerierung...................... 44; 122; 195Modellierung ............................................... 33Modellklassen........................................... 241MOOSE .................................................... 101MultiListSimulator ..................................... 205Nachrichten ...................................... 212; 217Null-Message...................................... 78; 139Operationsobjekt ........................................ 48Parallel Discrete Event Simulation ............. 39parallele Anlagen...................................... 127parallele Bearbeitung ............................... 127Parallele Simulation.................................... 42
Parallele und Verteilte Simulation .............. 39Anwendungsgebiete.................................... 102Performanceungewissheit ........................... 240
ParSec.............................................. 101; 202ParSimONY.............................. 101; 195; 202
Ereignislisten .............................................. 278Grundlagen ................................................. 203Probleme ..................................................... 204Statistiken.................................................... 278Verteilungsfunktionen ................................ 276
Partition ...................................................... 41Partitionierung ...................................... 61; 67
Ziele ............................................................ 146Partitionierungsansatz
Basisgrößen................................................. 147Berechnungsgrößen .................................... 149Erfassung der Meßgrößen........................... 149Lösungsidee ................................................ 144Meßgrößen.................................................. 148Regelwerk ................................................... 152
Partitionierungsreport ............... 160; 232; 234Partitionierungsverfahren ......................... 232
Ablauf ......................................................... 228Integration in den Parallelen Simulator
ParSimONY- ProdSys............................ 232Meßgrößen.................................................. 232
Polylemma der Parallelen und VerteiltenSimulation .............................................. 62
Prioritätsregeln ................... 31; 128; 223; 225Produktionsplanung und -steuerung .......... 27Prototyp
Basis für empirische Untersuchungen ........ 241Überblick .................................................... 180
Prozeßbedingung ....................................... 53Backupproblematik ....................................... 56gemeinsame Bearbeitung .............................. 55Klassifikation ................................................ 54Maschinenausfälle ........................................ 56parallele Bearbeitung .................................... 55Rüstproblematik............................................ 55sequenzabhängige Rüstzeiten ....................... 56technologisch bedingte Liegezeiten.............. 55Transportsystem............................................ 53Werker .......................................................... 53
Prozeßführungsstrategie.......... 26; 29; 30; 33Prozeßtyp ................................................. 220Randomizer .............................................. 277RealTimeSimulator................................... 206Reihenfolgeplanung ............................. 28; 29Reihenfolgeplanungsansätze........... 221; 225Reihenfolgeplanungsproblem .................... 29Remote Method Invocation 98; 101; 207; 217reverse computing...................................... 80RMI ..................................... 98; 101; 207; 217Rollback.............................................. 79; 140Rollbackkaskade ................................ 87; 140Rüstgruppen............................................. 127Rüstproblematik ....................................... 127Rüstregeln ................................................ 128Scheduling............................................ 79; 89

Index
Seite 317
SemantikdiagrammErläuterung der Darstellungsform ................ 49
semantische DarstellungErläuterung der Darstellungsform ................ 49
SequentialSimulator ................................. 205Sequentielle Simulation.............................. 39sequenzabhängige Rüstzeiten................. 127Simulation
Ablaufsteuerung ........................................... 36Begriff .......................................................... 33Nachteile....................................................... 35Probleme..................................................... 116Vorteile ......................................................... 34
Simulationsbasierte Fertigungssteuerung.. 26Simulationsmodell ................................ 35; 36
automatische Erstellung.............................. 227Simulationsrechner................................... 235Simulationsstudie ..................................... 175
Ablauf ........................................................... 33Zeitbedarf für die Durchführung ............ 37; 64
Simulator .............. 35; 36; 122; 196; 204; 205SLX........................................... 195; 197; 235SPEEDES................................................. 100Speedup ..................................................... 42Spekulative Verteilte Simulation................. 81Statistikobjekte ......................................... 278Steuerobjekt ............................................... 48Steuerrechner........................................... 235Synchronisation.................................... 62; 75Synchronisationsverfahren
Einflußfaktoren........................................... 137Lösungsansatz............................................. 141
Testmodelle.............................................. 244Thread .............................................. 131; 240ThreadedCMBSimulator........................... 206ThreadedMLSimulator.............................. 205ThreadedTWSimulator ............................. 206Topologiewissen ................................ 77; 131Transportstrategie .......................................53Unicast ........................................................72Untersuchungsregionen........................... 242Verbindungskanäle .................................. 210Verklemmung ................................. 73; 77; 91verteilte Abarbeitung ...................................40verteilte Sequentielle Simulation 40; 173; 234Verteilte Simulation .....................................42verteiltes Experimentiersystem 173; 175; 234
Datenentgegennahme-Komponente ............237Datenverteilungs-Komponente............235; 237Datenzusammenführungs-Komponente ......235Ergebnisrückmeldungs-Komponente ..........237Experimentverteilungs-Komponente...235; 236Simulationsrechnersteuerung ......................237Simulationsrechnerverwaltung............235; 236Struktur........................................................236
Verteilungsfunktionen............................... 276Vorausschauhorizont ..................................78YADDES................................................... 100Zustandssicherung
durch Kopieren............................................144inkrementell...........................................80; 144reverse computing .........................................80vollständig .....................................................80





























