Embed Size (px)
Citation preview

WISTAWIRTSCHAFTSSTATISTIK
PROF. DR. ROLF HÜPEN
FAKULTÄT FÜR
WIRTSCHAFTSWISSENSCHAFT
Seminar für Theoretische Wirtschaftslehre
Vorlesungsprogramm 04.06.2013
Prof. Dr. Rolf Hüpen | Modul „Statistik I“ | Sommersemester 2013
Zweidimensionale Datensätze
1. Kontingenztabelle und Streudiagramm
2. Korrelationsanalyse: Korrelationskoeffizienten von Fechner, Bravais-Pearson und Spearman
3. Regressionsanalyse: lineare Regression, Methode der kleinsten Quadrate
Literatur: Degen, Horst / Lorscheid, Peter: Statistik-Lehrbuch, 2. Aufl., München-Wien 2002, S. 62–86.
Mosler, Karl und Schmid, Friedrich: Beschreibende Statistik und Wirtschaftsstatistik, 4. Aufl.,
Berlin-Heidelberg-New York 2009, S. 153–201.
von der Lippe, Peter: Deskriptive Statistik, Stuttgart 1993, Online-Ausgabe, S. 192 – 257, S.
259 – 301.
Wewel, Max C.: Statistik im Bachelor-Studium der BWL und VWL, 2. erw. Aufl., München
2011, S. 77 – 123.
Übungsaufgaben: WS 07/08 A3; WS 08/09 A1; SS 09 A4; WS 09/10 A3; SS 10 A2; SS 11 A1+ A3.

2Prof. Dr. Rolf Hüpen | Modul „Statistik I“ | Sommersemester 2013
Zweidimensionale Datensätze Einführung
Mehrdimensionale Datensätze:
Bei n Merkmalsträgern und 𝑚 nicht häufbaren Merkmalen liegt für jeden Merkmalsträger ein 𝑚−Tupel an Beobachtungswerten vor. Die Urliste besteht mithin aus 𝑛 solcher 𝑚− Tupel und somit
aus 𝑛𝑚 Einzeldaten.
Beispiel Absolventenumfrage 2002: 𝑛 = 39 Personen haben jeweils 𝑚 = 22 Fragen
beantwortet. Also liegen 39 22 = 858 Einzeldaten vor.
Hier: Beschränkung auf 𝑚 = 2 Merkmale
Zweidimensionaler Datensatz:
• n Merkmalsträger
• 2 Merkmale X und Y
• Für jeden Merkmalsträger i liegt ein Wertepaar 𝑥𝑖 , 𝑦𝑖 vor.
• 𝑥𝑖 = Beobachtungswert für Merkmal X beim Merkmalsträger i.
• 𝑦𝑖 = Beobachtungswert für Merkmal Y beim Merkmalsträger i.
• Die Urliste besteht dann aus n Wertepaaren 𝑥1, 𝑦1 , 𝑥2, 𝑦2 , … , 𝑥𝑛, 𝑦𝑛
Darstellungsmöglichkeiten der Urliste:
• Kontingenztabelle
• Streudiagramm

3Prof. Dr. Rolf Hüpen | Modul „Statistik I“ | Sommersemester 2013
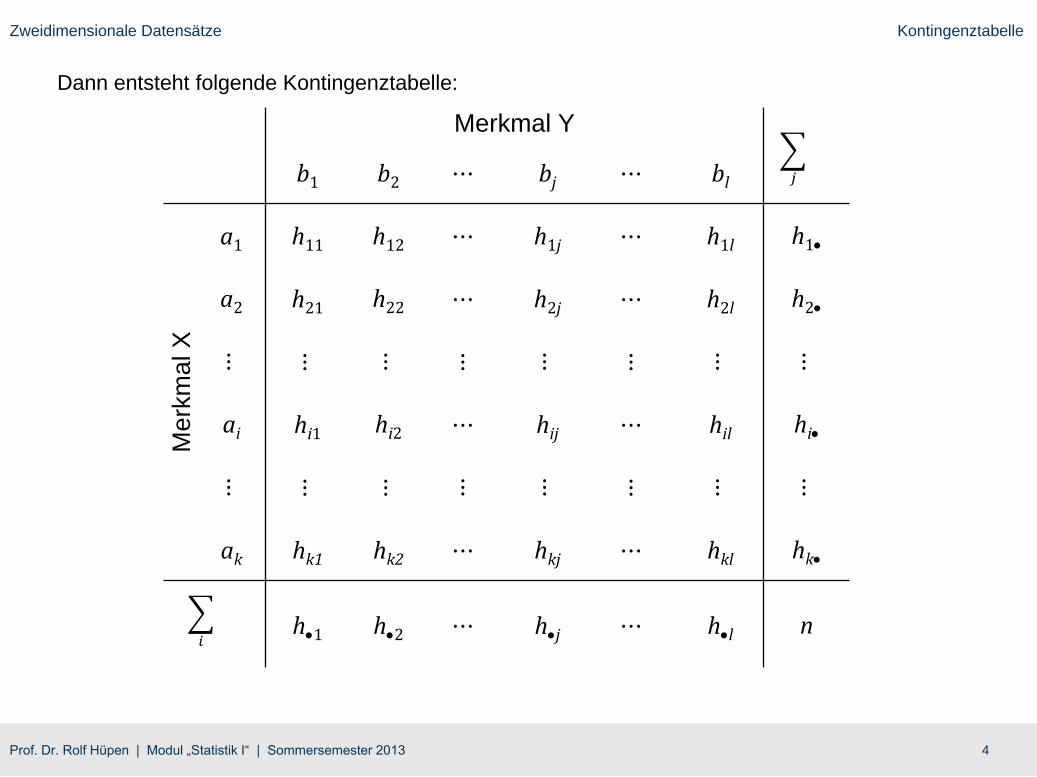
Zweidimensionale Datensätze Kontingenztabelle
Kontingenztabelle
Die Kontingenztabelle ist eine zweidimensionale Häufigkeitstabelle, in der für jede mögliche
Kombination von Ausprägungen der beiden Merkmale die absolute (oder relative) Häufigkeit
notiert wird. Bei 𝑘 möglichen Ausprägungen des Merkmals X und 𝑙 möglichen Ausprägungen des
Merkmals Y entsteht so eine 𝑘 × 𝑙-Matrix mit 𝑘 ∙ 𝑙 absoluten Häufigkeiten der möglichen
Wertepaare.
Notation:
● Merkmal X hat 𝑘 mögliche Ausprägungen 𝑎1, … , 𝑎𝑘
● Merkmal Y hat 𝑙 mögliche Ausprägungen 𝑏1, … , 𝑏𝑙
● ℎ𝑖𝑗 = absolute Häufigkeit, mit der die Ausprägung 𝑎𝑖 , 𝑏𝑗 als Wertepaar in der Urliste
auftritt.
● Randhäufigkeit Merkmal X: ℎ𝑖● =
𝑗=1
𝑙
ℎ𝑖𝑗 mit 𝑖 = 1,… , 𝑘
● Randhäufigkeit Merkmal Y: ℎ●𝑗 =
𝑖=1
𝑘
ℎ𝑖𝑗 mit 𝑗 = 1,… , 𝑙
● Zahl der Merkmalsträger: 𝑛 =
𝑖=1
𝑘
𝑗=1
𝑙
ℎ𝑖𝑗
4Prof. Dr. Rolf Hüpen | Modul „Statistik I“ | Sommersemester 2013
Zweidimensionale Datensätze Kontingenztabelle
Dann entsteht folgende Kontingenztabelle:
Merkmal Y
𝑗b1 b2 ⋯ bj ⋯ blM
erk
ma
l X
a1 h11 h12 ⋯ h1j ⋯ h1l h1
a2 h21 h22 ⋯ h2j ⋯ h2l h2
⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮
ai hi1 hi2 ⋯ hij ⋯ hil hi
⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮
ak hk1 hk2 ⋯ hkj ⋯ hkl hk
𝑖h1 h2 ⋯ hj ⋯ hl n
5Prof. Dr. Rolf Hüpen | Modul „Statistik I“ | Sommersemester 2013
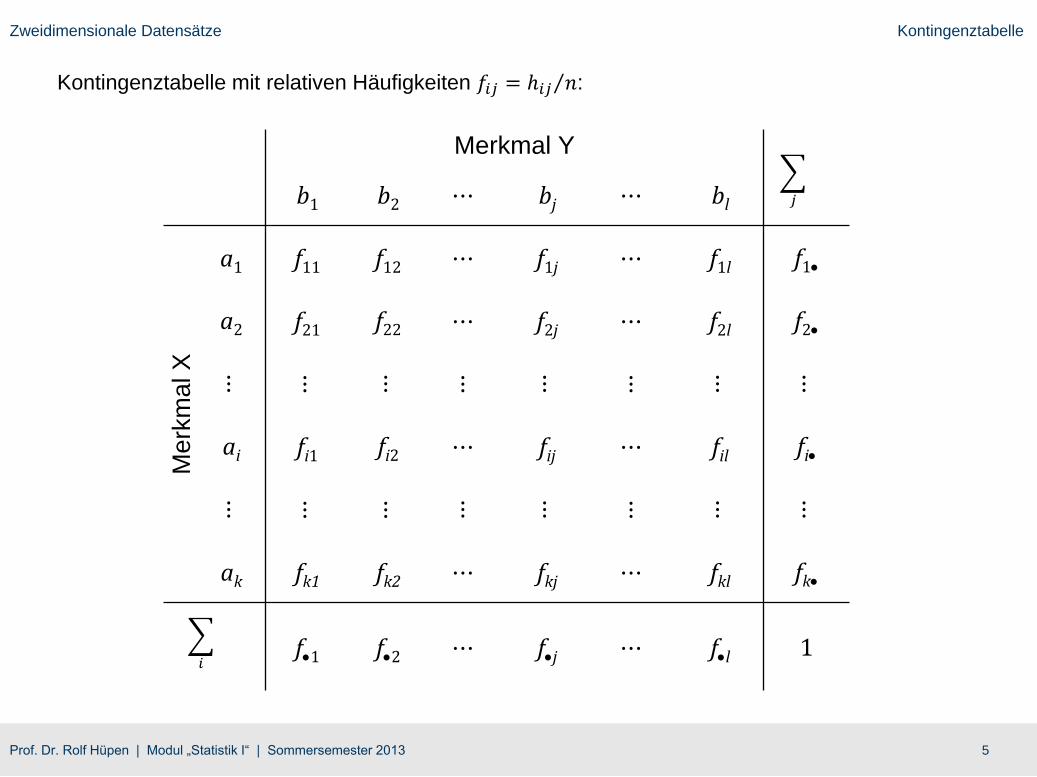
Zweidimensionale Datensätze Kontingenztabelle
Kontingenztabelle mit relativen Häufigkeiten 𝑓𝑖𝑗 = ℎ𝑖𝑗 𝑛:
Merkmal Y
𝑗b1 b2 ⋯ bj ⋯ blM
erk
ma
l X
a1 f11 f12 ⋯ f1j ⋯ f1l f1
a2 f21 f22 ⋯ f2j ⋯ f2l f2
⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮
ai fi1 fi2 ⋯ fij ⋯ fil fi
⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮
ak fk1 fk2 ⋯ fkj ⋯ fkl fk
𝑖f1 f2 ⋯ fj ⋯ fl 1
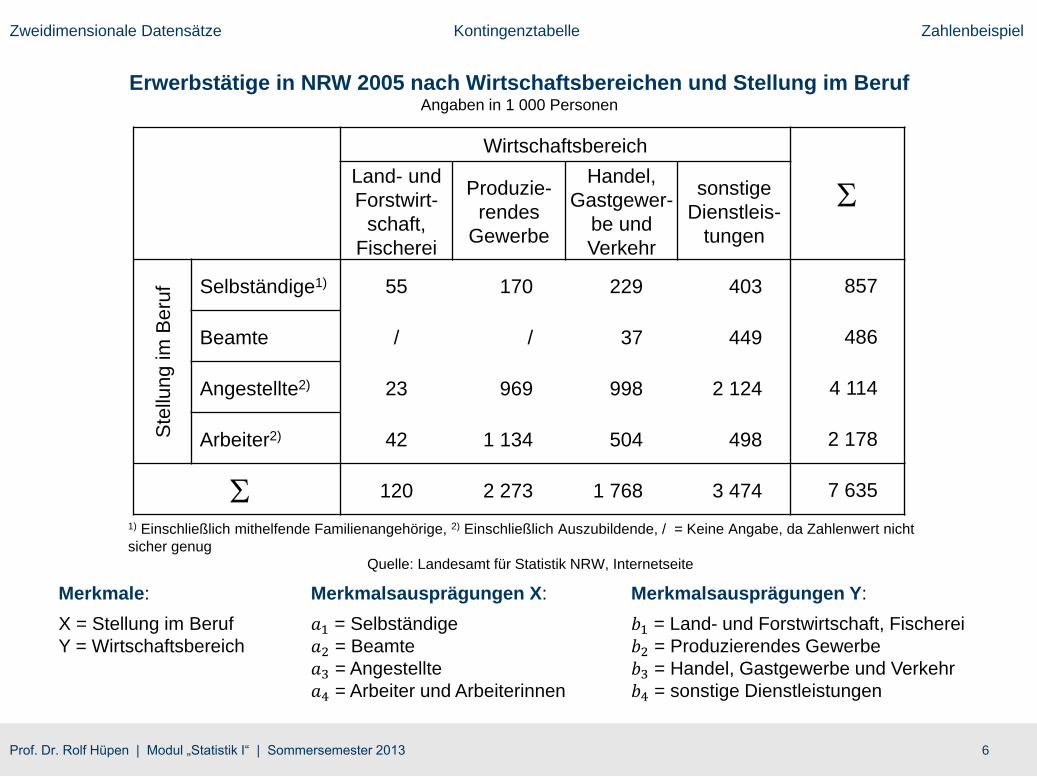
6Prof. Dr. Rolf Hüpen | Modul „Statistik I“ | Sommersemester 2013
Zweidimensionale Datensätze Kontingenztabelle Zahlenbeispiel
Wirtschaftsbereich
SLand- und
Forstwirt-
schaft,
Fischerei
Produzie-
rendes
Gewerbe
Handel,
Gastgewer-
be und
Verkehr
sonstige
Dienstleis-
tungen
Ste
llung im
Beru
f Selbständige1) 55 170 229 403 857
Beamte / / 37 449 486
Angestellte2) 23 969 998 2 124 4 114
Arbeiter2) 42 1 134 504 498 2 178
S 120 2 273 1 768 3 474 7 635
Erwerbstätige in NRW 2005 nach Wirtschaftsbereichen und Stellung im BerufAngaben in 1 000 Personen
1) Einschließlich mithelfende Familienangehörige, 2) Einschließlich Auszubildende, / = Keine Angabe, da Zahlenwert nicht
sicher genug
Quelle: Landesamt für Statistik NRW, Internetseite
Merkmale:
X = Stellung im Beruf
Y = Wirtschaftsbereich
Merkmalsausprägungen X:
𝑎1 = Selbständige
𝑎2 = Beamte
𝑎3 = Angestellte
𝑎4 = Arbeiter und Arbeiterinnen
Merkmalsausprägungen Y:
𝑏1 = Land- und Forstwirtschaft, Fischerei
𝑏2 = Produzierendes Gewerbe
𝑏3 = Handel, Gastgewerbe und Verkehr
𝑏4 = sonstige Dienstleistungen
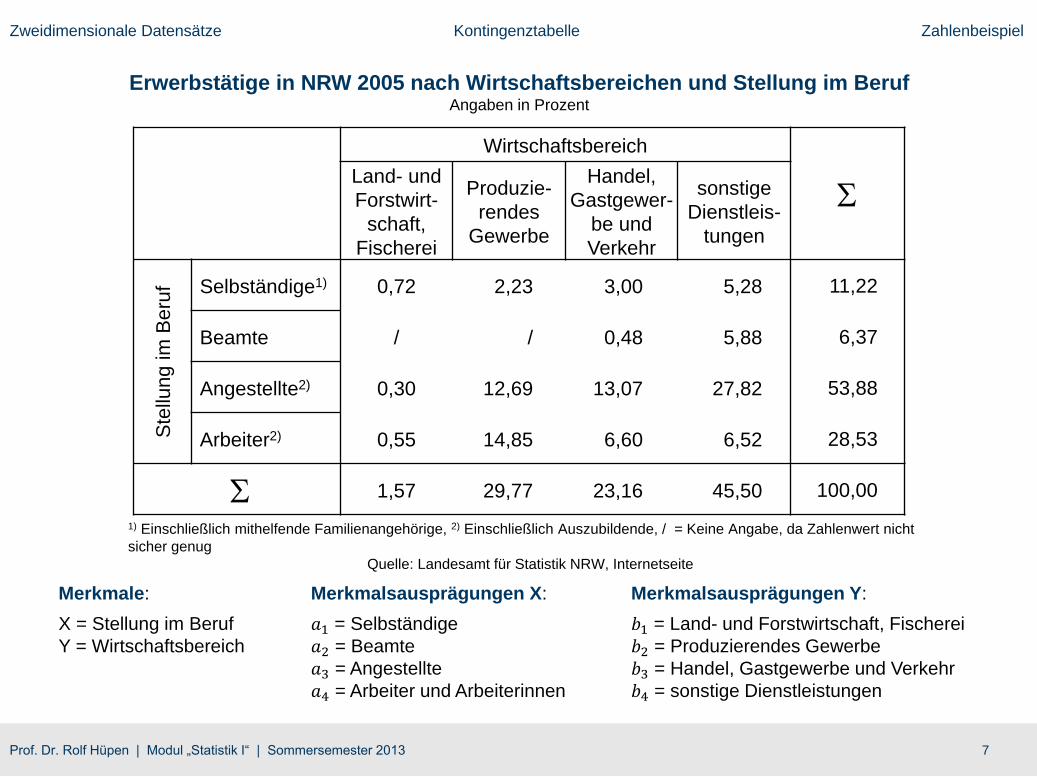
7Prof. Dr. Rolf Hüpen | Modul „Statistik I“ | Sommersemester 2013
Zweidimensionale Datensätze Kontingenztabelle Zahlenbeispiel
Wirtschaftsbereich
SLand- und
Forstwirt-
schaft,
Fischerei
Produzie-
rendes
Gewerbe
Handel,
Gastgewer-
be und
Verkehr
sonstige
Dienstleis-
tungen
Ste
llung im
Beru
f Selbständige1) 0,72 2,23 3,00 5,28 11,22
Beamte / / 0,48 5,88 6,37
Angestellte2) 0,30 12,69 13,07 27,82 53,88
Arbeiter2) 0,55 14,85 6,60 6,52 28,53
S 1,57 29,77 23,16 45,50 100,00
Erwerbstätige in NRW 2005 nach Wirtschaftsbereichen und Stellung im BerufAngaben in Prozent
1) Einschließlich mithelfende Familienangehörige, 2) Einschließlich Auszubildende, / = Keine Angabe, da Zahlenwert nicht
sicher genug
Quelle: Landesamt für Statistik NRW, Internetseite
Merkmale:
X = Stellung im Beruf
Y = Wirtschaftsbereich
Merkmalsausprägungen X:
𝑎1 = Selbständige
𝑎2 = Beamte
𝑎3 = Angestellte
𝑎4 = Arbeiter und Arbeiterinnen
Merkmalsausprägungen Y:
𝑏1 = Land- und Forstwirtschaft, Fischerei
𝑏2 = Produzierendes Gewerbe
𝑏3 = Handel, Gastgewerbe und Verkehr
𝑏4 = sonstige Dienstleistungen

8Prof. Dr. Rolf Hüpen | Modul „Statistik I“ | Sommersemester 2013
Zweidimensionale Datensätze Kontingenztabelle Bedingte relative Häufigkeit
Kontingenztabellen sind zur Darstellung zweidimensionaler Datensätze gut geeignet, wenn
• die Anzahl 𝑘 der Merkmalsausprägungen von X klein ist,
• die Anzahl 𝑙 der Merkmalsausprägungen von Y klein ist und
• viele der 𝑛 Wertepaare 𝑥𝑖 , 𝑦𝑖 identisch sind.
Diese Voraussetzungen sind in der Regel bei nominal skalierten Merkmalen erfüllt.
Bedingte relative Häufigkeit
𝑓 𝑎𝑖 𝑏𝑗 =ℎ𝑖𝑗
ℎ𝑗𝑖 = 1,… , 𝑘
Relative Häufigkeit, mit der die Ausprägung 𝑎𝑖 des Merkmals X bei
denjenigen Merkmalsträgern auftritt, die bezüglich des zweiten
Merkmals Y die Ausprägung 𝑏𝑗 besitzen.
𝑓 𝑏𝑗 𝑎𝑖 =ℎ𝑖𝑗
ℎ𝑖𝑗 = 1,… , 𝑙
Relative Häufigkeit, mit der die Ausprägung 𝑏𝑗 des Merkmals Y bei
denjenigen Merkmalsträgern auftritt, die bezüglich des ersten Merkmals
X die Ausprägung 𝑎𝑖 besitzen.
An den bedingten Häufigkeiten kann man erkennen, ob die beiden betrachteten Merkmale
voneinander unabhängig sind oder nicht.
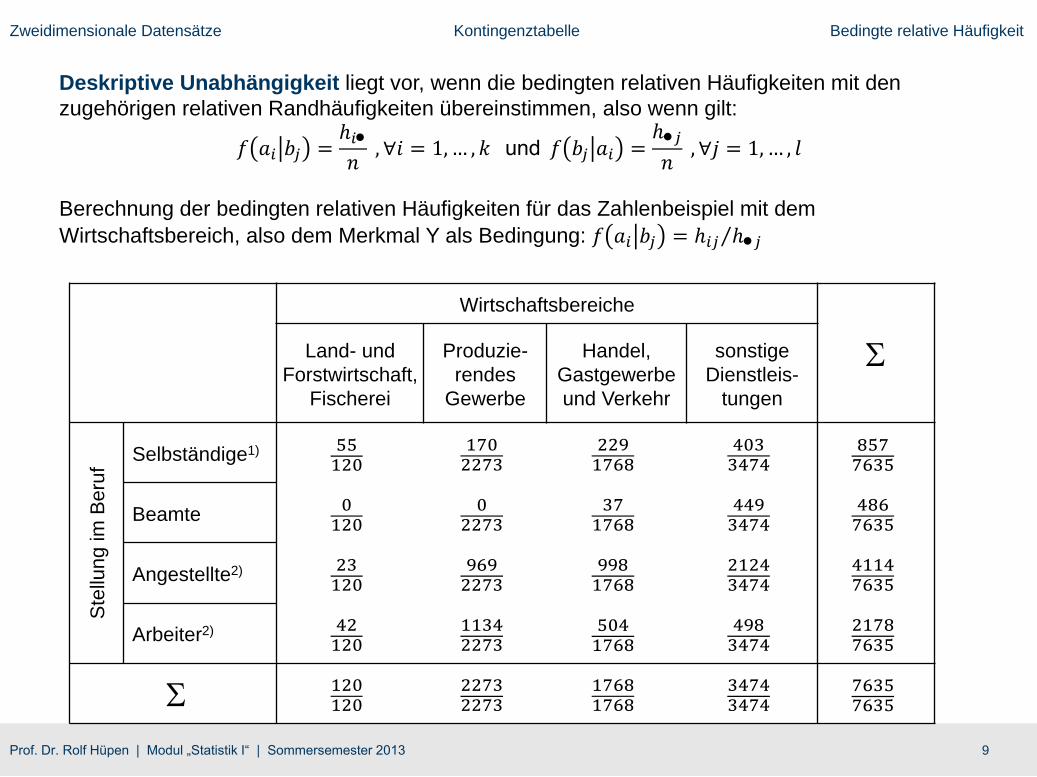
9Prof. Dr. Rolf Hüpen | Modul „Statistik I“ | Sommersemester 2013
Zweidimensionale Datensätze Kontingenztabelle Bedingte relative Häufigkeit
Deskriptive Unabhängigkeit liegt vor, wenn die bedingten relativen Häufigkeiten mit den
zugehörigen relativen Randhäufigkeiten übereinstimmen, also wenn gilt:
𝑓 𝑎𝑖 𝑏𝑗 =ℎ𝑖𝑛
, ∀𝑖 = 1,… , 𝑘 und 𝑓 𝑏𝑗 𝑎𝑖 =ℎ𝑗
𝑛, ∀𝑗 = 1,… , 𝑙
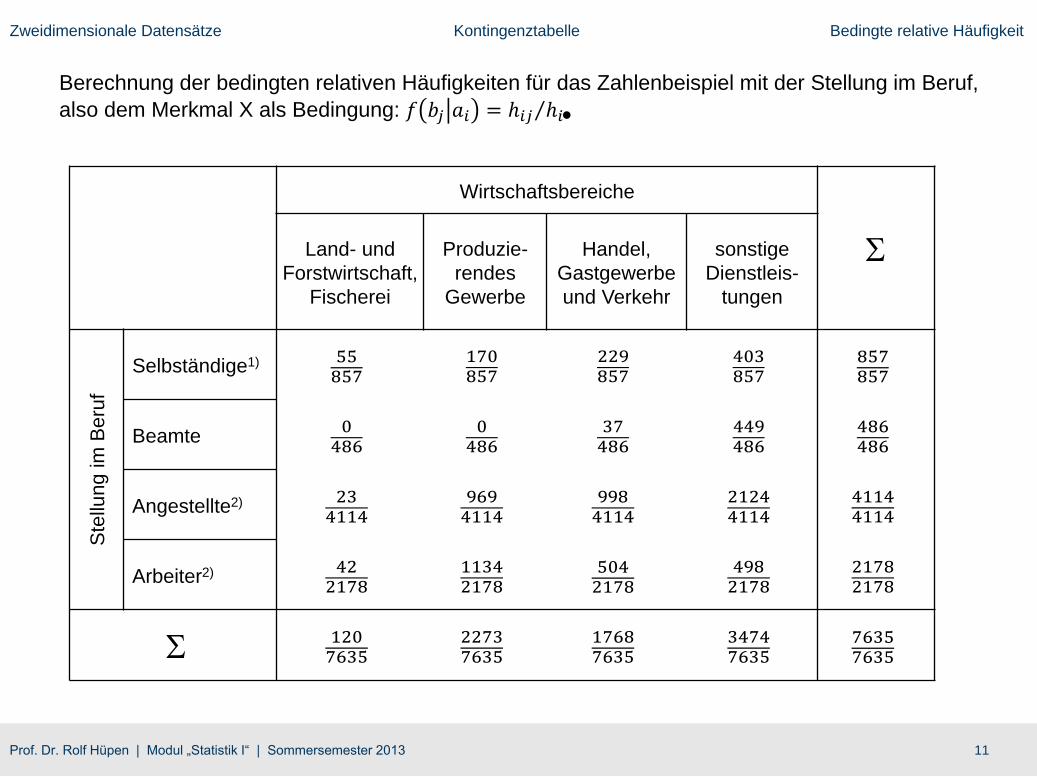
Berechnung der bedingten relativen Häufigkeiten für das Zahlenbeispiel mit dem
Wirtschaftsbereich, also dem Merkmal Y als Bedingung: 𝑓 𝑎𝑖 𝑏𝑗 = ℎ𝑖𝑗 ℎ𝑗
Wirtschaftsbereiche
SLand- und
Forstwirtschaft,
Fischerei
Produzie-
rendes
Gewerbe
Handel,
Gastgewerbe
und Verkehr
sonstige
Dienstleis-
tungen
Ste
llung im
Beru
f
Selbständige1) 55120
1702273
2291768
4033474
8577635
Beamte0
1200
227337
17684493474
4867635
Angestellte2) 23120
9692273
9981768
21243474
41147635
Arbeiter2) 42120
11342273
5041768
4983474
21787635
S 120120
22732273
17681768
34743474
76357635
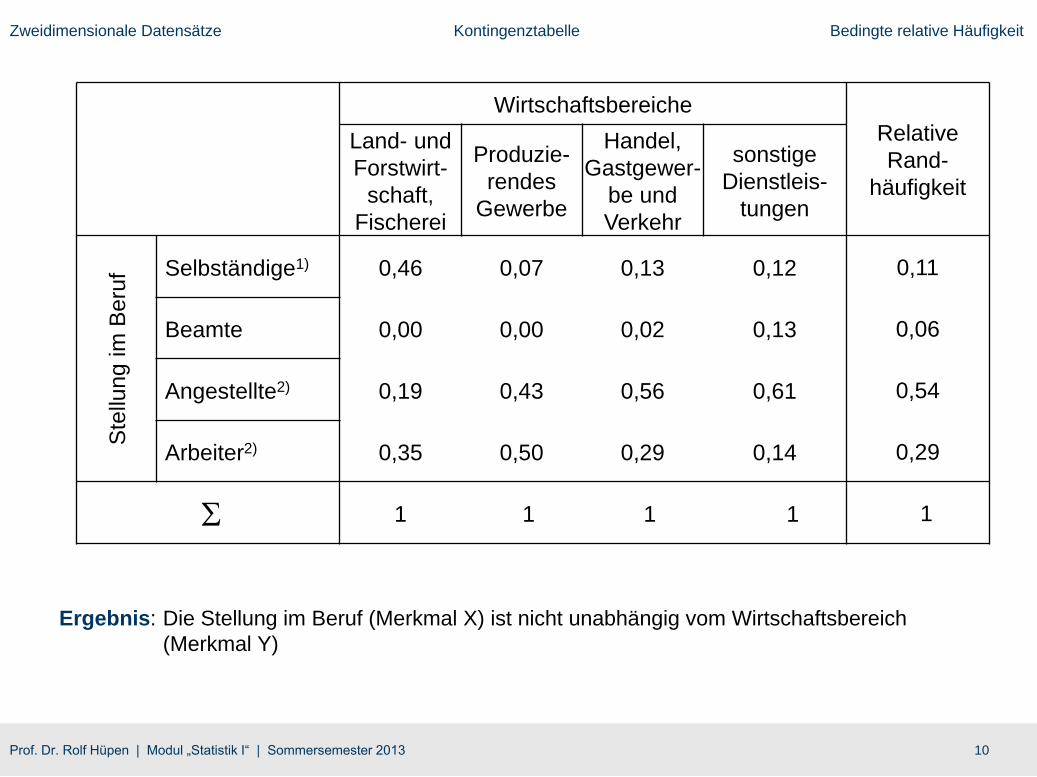
10Prof. Dr. Rolf Hüpen | Modul „Statistik I“ | Sommersemester 2013
Zweidimensionale Datensätze Kontingenztabelle Bedingte relative Häufigkeit
Ergebnis: Die Stellung im Beruf (Merkmal X) ist nicht unabhängig vom Wirtschaftsbereich
(Merkmal Y)
Wirtschaftsbereiche
Relative
Rand-
häufigkeit
Land- und
Forstwirt-
schaft,
Fischerei
Produzie-
rendes
Gewerbe
Handel,
Gastgewer-
be und
Verkehr
sonstige
Dienstleis-
tungen
Ste
llung im
Beru
f Selbständige1) 0,46 0,07 0,13 0,12 0,11
Beamte 0,00 0,00 0,02 0,13 0,06
Angestellte2) 0,19 0,43 0,56 0,61 0,54
Arbeiter2) 0,35 0,50 0,29 0,14 0,29
S 1 1 1 1 1
11Prof. Dr. Rolf Hüpen | Modul „Statistik I“ | Sommersemester 2013
Zweidimensionale Datensätze Kontingenztabelle Bedingte relative Häufigkeit
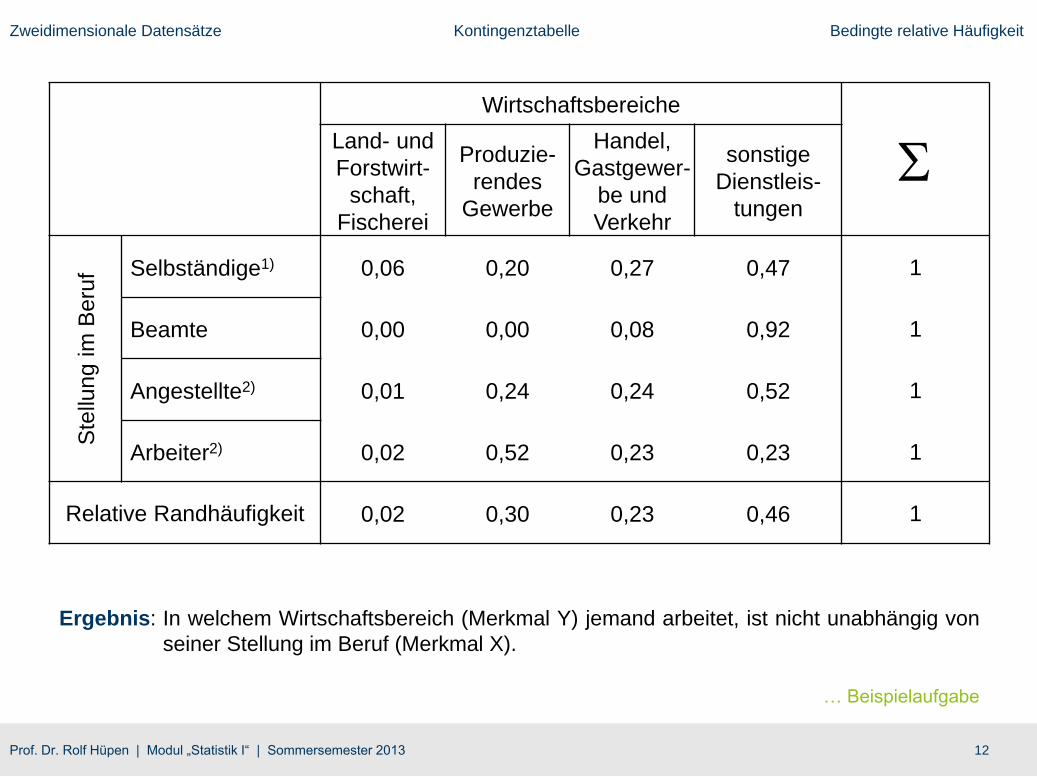
Berechnung der bedingten relativen Häufigkeiten für das Zahlenbeispiel mit der Stellung im Beruf,
also dem Merkmal X als Bedingung: 𝑓 𝑏𝑗 𝑎𝑖 = ℎ𝑖𝑗 ℎ𝑖
Wirtschaftsbereiche
SLand- und
Forstwirtschaft,
Fischerei
Produzie-
rendes
Gewerbe
Handel,
Gastgewerbe
und Verkehr
sonstige
Dienstleis-
tungen
Ste
llung im
Beru
f
Selbständige1) 55857
170857
229857
403857
857857
Beamte0
4860
48637486
449486
486486
Angestellte2) 234114
9694114
9984114
21244114
41144114
Arbeiter2) 422178
11342178
5042178
4982178
21782178
S 1207635
22737635
17687635
34747635
76357635
12Prof. Dr. Rolf Hüpen | Modul „Statistik I“ | Sommersemester 2013
Zweidimensionale Datensätze Kontingenztabelle Bedingte relative Häufigkeit
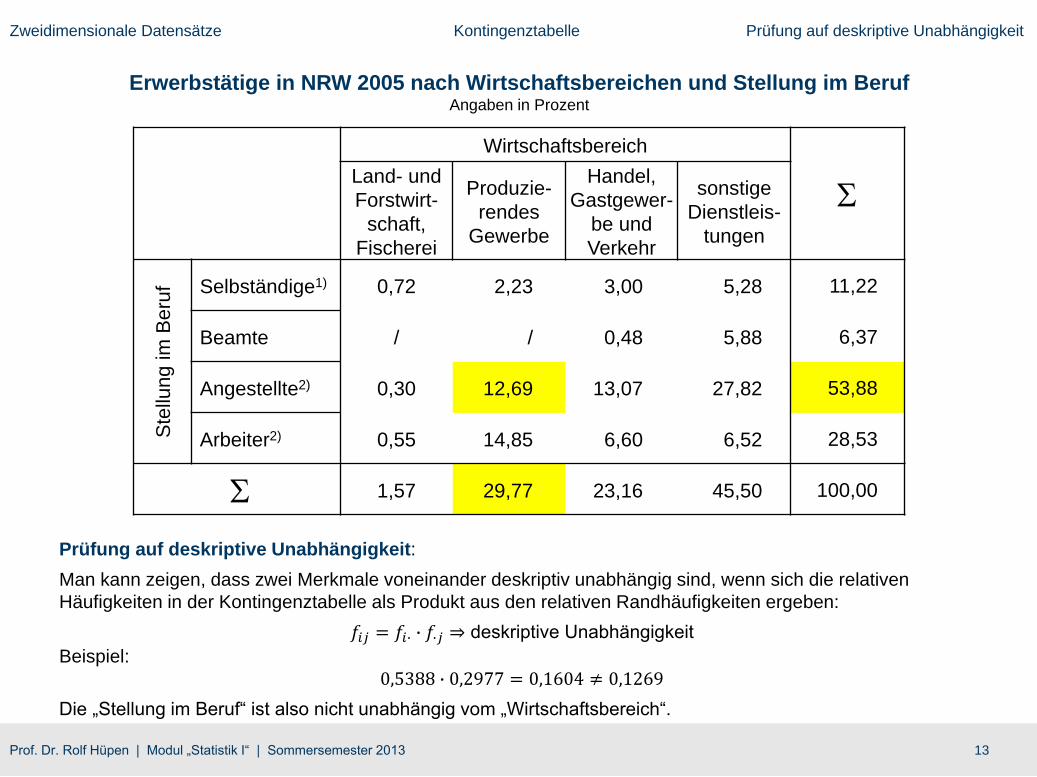
Ergebnis: In welchem Wirtschaftsbereich (Merkmal Y) jemand arbeitet, ist nicht unabhängig von
seiner Stellung im Beruf (Merkmal X).
Wirtschaftsbereiche
SLand- und
Forstwirt-
schaft,
Fischerei
Produzie-
rendes
Gewerbe
Handel,
Gastgewer-
be und
Verkehr
sonstige
Dienstleis-
tungen
Ste
llung im
Beru
f Selbständige1) 0,06 0,20 0,27 0,47 1
Beamte 0,00 0,00 0,08 0,92 1
Angestellte2) 0,01 0,24 0,24 0,52 1
Arbeiter2) 0,02 0,52 0,23 0,23 1
Relative Randhäufigkeit 0,02 0,30 0,23 0,46 1
… Beispielaufgabe
13Prof. Dr. Rolf Hüpen | Modul „Statistik I“ | Sommersemester 2013
Zweidimensionale Datensätze Kontingenztabelle Prüfung auf deskriptive Unabhängigkeit
Wirtschaftsbereich
SLand- und
Forstwirt-
schaft,
Fischerei
Produzie-
rendes
Gewerbe
Handel,
Gastgewer-
be und
Verkehr
sonstige
Dienstleis-
tungen
Ste
llung im
Beru
f Selbständige1) 0,72 2,23 3,00 5,28 11,22
Beamte / / 0,48 5,88 6,37
Angestellte2) 0,30 12,69 13,07 27,82 53,88
Arbeiter2) 0,55 14,85 6,60 6,52 28,53
S 1,57 29,77 23,16 45,50 100,00
Erwerbstätige in NRW 2005 nach Wirtschaftsbereichen und Stellung im BerufAngaben in Prozent
Prüfung auf deskriptive Unabhängigkeit:
Man kann zeigen, dass zwei Merkmale voneinander deskriptiv unabhängig sind, wenn sich die relativen
Häufigkeiten in der Kontingenztabelle als Produkt aus den relativen Randhäufigkeiten ergeben:
𝑓𝑖𝑗 = 𝑓𝑖∙ ∙ 𝑓∙𝑗 ⇒ deskriptive Unabhängigkeit
Beispiel:
0,5388 ∙ 0,2977 = 0,1604 ≠ 0,1269
Die „Stellung im Beruf“ ist also nicht unabhängig vom „Wirtschaftsbereich“.

14Prof. Dr. Rolf Hüpen | Modul „Statistik I“ | Sommersemester 2013
Zweidimensionale Datensätze Streudiagramm
Streudiagramm
In einem Streudiagramm werden die Wertepaare 𝑥𝑖 , 𝑦𝑖 als Punkte in einem x-y-
Koordinatensystem dargestellt.
Voraussetzung: Beide Merkmale sind kardinalskaliert.
Streudiagramme sind zur Darstellung zweidimensionaler Häufigkeitsverteilungen
besonders gut geeignet,
• wenn die 𝑛 Wertepaare (fast) alle voneinander verschieden sind,
• wenn die Anzahl 𝑛 der Wertepaare sehr groß ist,
• um sich einen ersten Eindruck über den (möglichen) Zusammenhang zwischen
den Merkmalen zu verschaffen.
15Prof. Dr. Rolf Hüpen | Modul „Statistik I“ | Sommersemester 2013
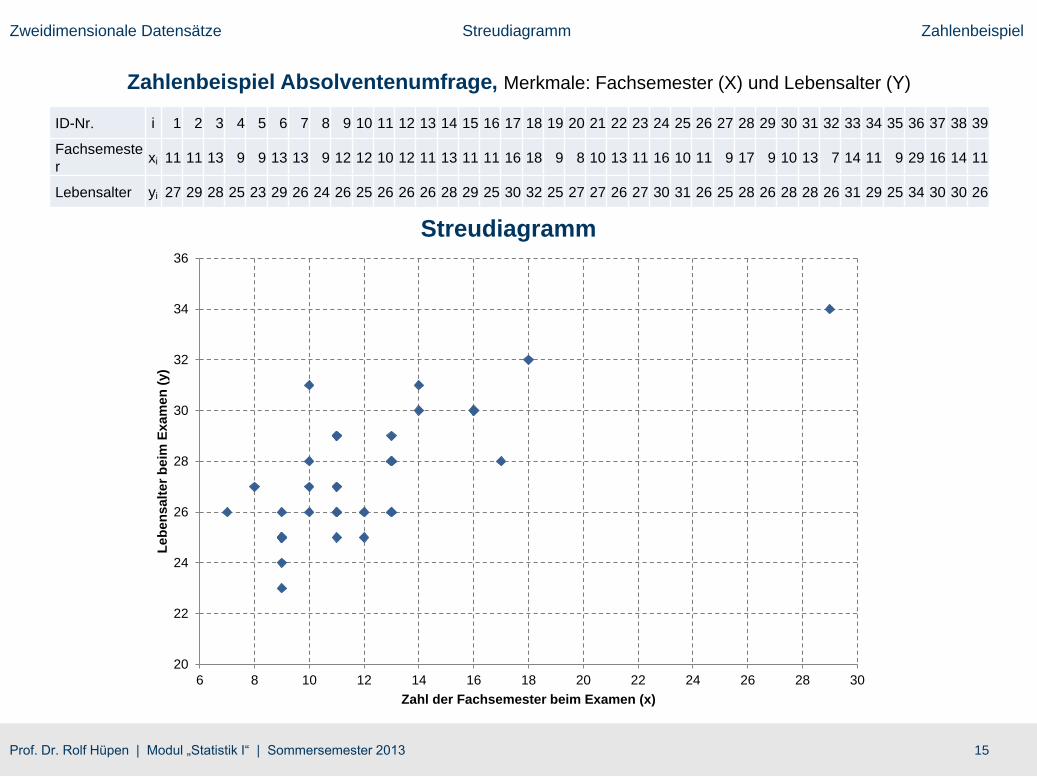
Zweidimensionale Datensätze Streudiagramm Zahlenbeispiel
Zahlenbeispiel Absolventenumfrage, Merkmale: Fachsemester (X) und Lebensalter (Y)
ID-Nr. i 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39
Fachsemeste
rxi 11 11 13 9 9 13 13 9 12 12 10 12 11 13 11 11 16 18 9 8 10 13 11 16 10 11 9 17 9 10 13 7 14 11 9 29 16 14 11
Lebensalter yi 27 29 28 25 23 29 26 24 26 25 26 26 26 28 29 25 30 32 25 27 27 26 27 30 31 26 25 28 26 28 28 26 31 29 25 34 30 30 26
20
22
24
26
28
30
32
34
36
6 8 10 12 14 16 18 20 22 24 26 28 30
Le
be
ns
alt
er
be
im E
xa
me
n (
y)
Zahl der Fachsemester beim Examen (x)
Streudiagramm
16Prof. Dr. Rolf Hüpen | Modul „Statistik I“ | Sommersemester 2013
Zweidimensionale Datensätze Korrelation allgemeine Aussagen
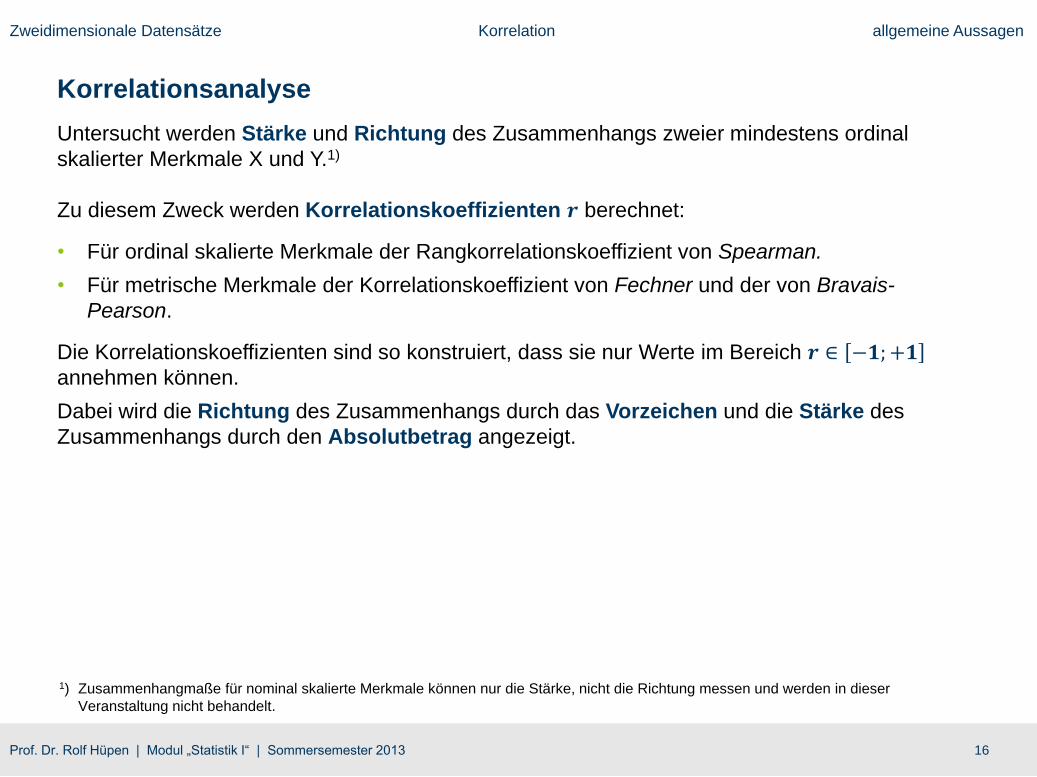
Korrelationsanalyse
Untersucht werden Stärke und Richtung des Zusammenhangs zweier mindestens ordinal
skalierter Merkmale X und Y.1)
Zu diesem Zweck werden Korrelationskoeffizienten 𝒓 berechnet:
• Für ordinal skalierte Merkmale der Rangkorrelationskoeffizient von Spearman.
• Für metrische Merkmale der Korrelationskoeffizient von Fechner und der von Bravais-
Pearson.
Die Korrelationskoeffizienten sind so konstruiert, dass sie nur Werte im Bereich 𝒓 ∈ −𝟏;+𝟏annehmen können.
Dabei wird die Richtung des Zusammenhangs durch das Vorzeichen und die Stärke des
Zusammenhangs durch den Absolutbetrag angezeigt.
1) Zusammenhangmaße für nominal skalierte Merkmale können nur die Stärke, nicht die Richtung messen und werden in dieser
Veranstaltung nicht behandelt.

17Prof. Dr. Rolf Hüpen | Modul „Statistik I“ | Sommersemester 2013
Zweidimensionale Datensätze Korrelation allgemeine Aussagen
Richtung des Zusammenhangs:
𝒓 > 𝟎 „positive Korrelation“: „x und y überwiegend gleichläufig“.
Zu kleinen x-Werten gehören meist auch kleine y-Werte, zu großen x-Werten große
y-Werte. Je größer x umso größer tendenziell auch y.
𝒓 < 𝟎 „negative Korrelation“: „x und y überwiegend gegenläufig“.
Zu kleinen x-Werten gehören meist große y-Werte, zu großen x-Werten kleine y-
Werte. Je größer x umso kleiner tendenziell y.
Stärke des Zusammenhangs (Faustregel):
𝟎, 𝟖 < 𝒓 ≤ 𝟏 starke positive Korrelation
𝟎, 𝟓 < 𝒓 ≤ 𝟎, 𝟖 mittlere positive Korrelation
𝟎, 𝟑 < 𝒓 ≤ 𝟎, 𝟓 schwache positive Korrelation
𝟎 < 𝒓 ≤ 𝟎, 𝟑 fehlende positive Korrelation
−𝟎, 𝟑 ≤ 𝒓 < 𝟎 fehlende negative Korrelation
−𝟎, 𝟓 ≤ 𝒓 < −𝟎, 𝟑 schwache negative Korrelation
−𝟎, 𝟖 ≤ 𝒓 < −𝟎, 𝟓 mittlere negative Korrelation
−𝟏 ≤ 𝒓 < −𝟎, 𝟖 starke negative Korrelation
18Prof. Dr. Rolf Hüpen | Modul „Statistik I“ | Sommersemester 2013
Zweidimensionale Datensätze Korrelation allgemeine Aussagen
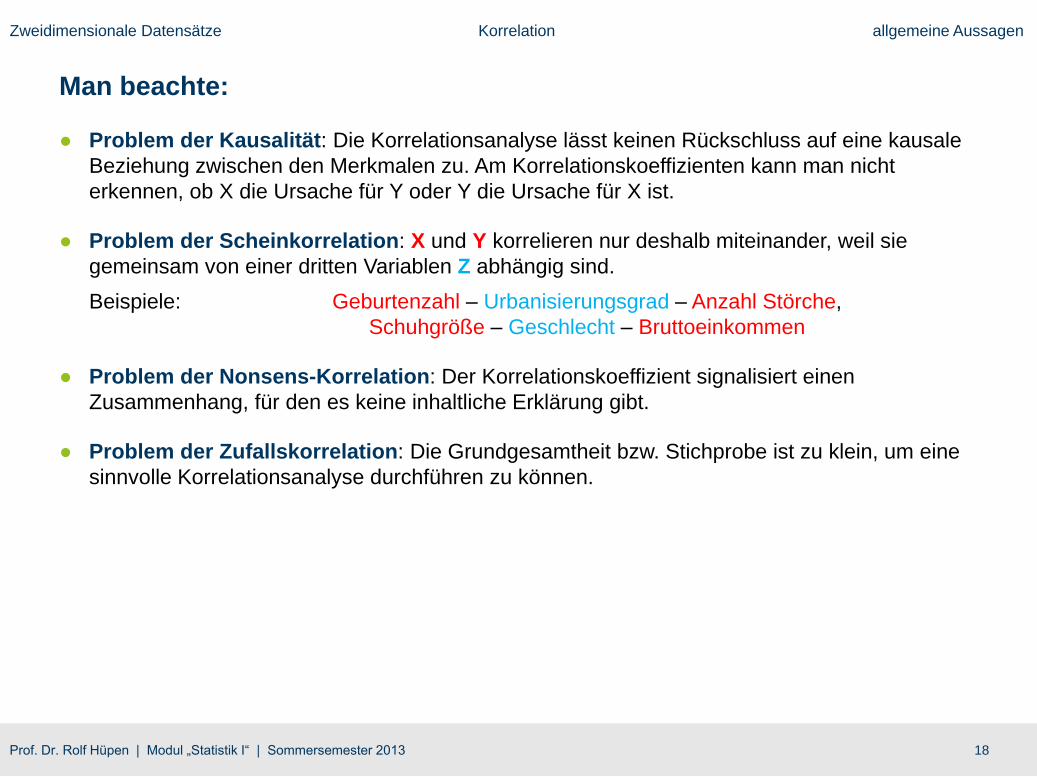
Man beachte:
● Problem der Kausalität: Die Korrelationsanalyse lässt keinen Rückschluss auf eine kausale
Beziehung zwischen den Merkmalen zu. Am Korrelationskoeffizienten kann man nicht
erkennen, ob X die Ursache für Y oder Y die Ursache für X ist.
● Problem der Scheinkorrelation: X und Y korrelieren nur deshalb miteinander, weil sie
gemeinsam von einer dritten Variablen Z abhängig sind.
Beispiele: Geburtenzahl – Urbanisierungsgrad – Anzahl Störche,
Schuhgröße – Geschlecht – Bruttoeinkommen
● Problem der Nonsens-Korrelation: Der Korrelationskoeffizient signalisiert einen
Zusammenhang, für den es keine inhaltliche Erklärung gibt.
● Problem der Zufallskorrelation: Die Grundgesamtheit bzw. Stichprobe ist zu klein, um eine
sinnvolle Korrelationsanalyse durchführen zu können.

19Prof. Dr. Rolf Hüpen | Modul „Statistik I“ | Sommersemester 2013
Zweidimensionale Datensätze Korrelation Korrelationskoeffizient von Fechner
Korrelationskoeffizient von Fechner
Gegeben: 𝑛 Wertepaare 𝑥𝑖 , 𝑦𝑖 , 𝑖 = 1,… , 𝑛 als Beobachtungswerte.
Dann ist der Korrelationskoeffizient von Fechner definiert als:
𝒓𝑭 =Ü−𝑵
Ü+𝑵
wobei Ü = Anzahl der in den Vorzeichen übereinstimmenden Paare 𝑥𝑖 − 𝑥, 𝑦𝑖 − 𝑦
und N = Anzahl der in den Vorzeichen nicht übereinstimmenden Paare 𝑥𝑖 − 𝑥, 𝑦𝑖 − 𝑦
Fälle, in denen eine der Differenzen den Wert Null besitzt, werden als Übereinstimmung gezählt.
● Der Korrelationskoeffizient von Fechner setzt für beide Merkmale metrisches Skalenniveau
voraus.
● Es gehen nur die Vorzeichen der Abweichungen und nicht die Abweichungen selbst in die
Berechnung ein.
20Prof. Dr. Rolf Hüpen | Modul „Statistik I“ | Sommersemester 2013
Zweidimensionale Datensätze Korrelation Korrelationskoeffizient von Fechner
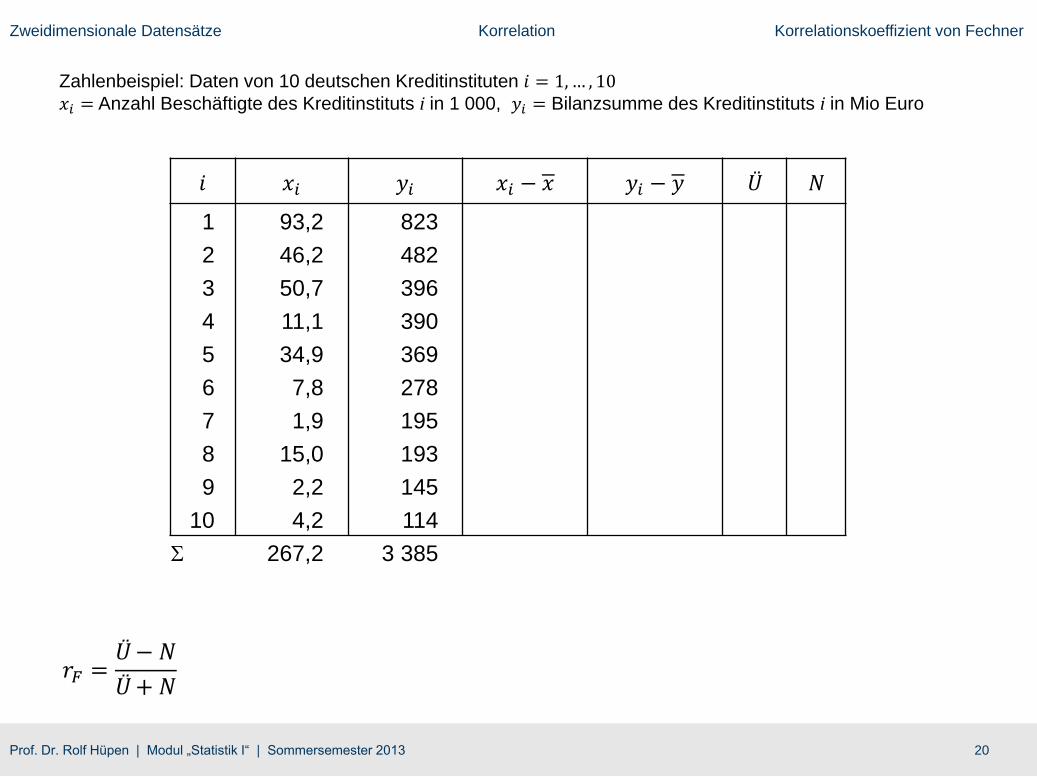
Zahlenbeispiel: Daten von 10 deutschen Kreditinstituten 𝑖 = 1,… , 10𝑥𝑖 = Anzahl Beschäftigte des Kreditinstituts i in 1 000, 𝑦𝑖 = Bilanzsumme des Kreditinstituts i in Mio Euro
𝑖 𝑥𝑖 𝑦𝑖 𝑥𝑖 − 𝑥 𝑦𝑖 − 𝑦 Ü N
1 93,2 823
2 46,2 482
3 50,7 396
4 11,1 390
5 34,9 369
6 7,8 278
7 1,9 195
8 15,0 193
9 2,2 145
10 4,2 114
S 267,2 3 385
𝑟𝐹 =Ü− 𝑁
Ü+ 𝑁
21Prof. Dr. Rolf Hüpen | Modul „Statistik I“ | Sommersemester 2013
Zweidimensionale Datensätze Korrelation Korrelationskoeffizient von Fechner
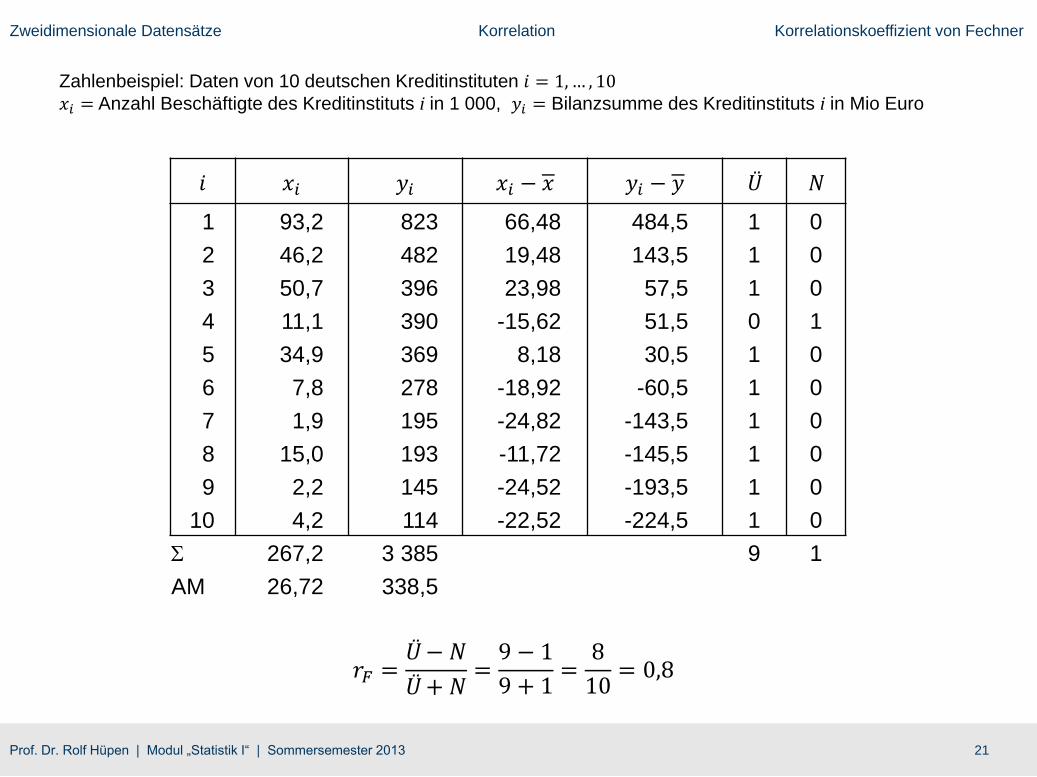
Zahlenbeispiel: Daten von 10 deutschen Kreditinstituten 𝑖 = 1,… , 10𝑥𝑖 = Anzahl Beschäftigte des Kreditinstituts i in 1 000, 𝑦𝑖 = Bilanzsumme des Kreditinstituts i in Mio Euro
𝑖 𝑥𝑖 𝑦𝑖 𝑥𝑖 − 𝑥 𝑦𝑖 − 𝑦 Ü N
1 93,2 823 66,48 484,5 1 0
2 46,2 482 19,48 143,5 1 0
3 50,7 396 23,98 57,5 1 0
4 11,1 390 -15,62 51,5 0 1
5 34,9 369 8,18 30,5 1 0
6 7,8 278 -18,92 -60,5 1 0
7 1,9 195 -24,82 -143,5 1 0
8 15,0 193 -11,72 -145,5 1 0
9 2,2 145 -24,52 -193,5 1 0
10 4,2 114 -22,52 -224,5 1 0
S 267,2 3 385 9 1
AM 26,72 338,5
𝑟𝐹 =Ü− 𝑁
Ü+ 𝑁=
9 − 1
9 + 1=
8
10= 0,8
22Prof. Dr. Rolf Hüpen | Modul „Statistik I“ | Sommersemester 2013
Zweidimensionale Datensätze Korrelation Korrelationskoeffizient von Fechner
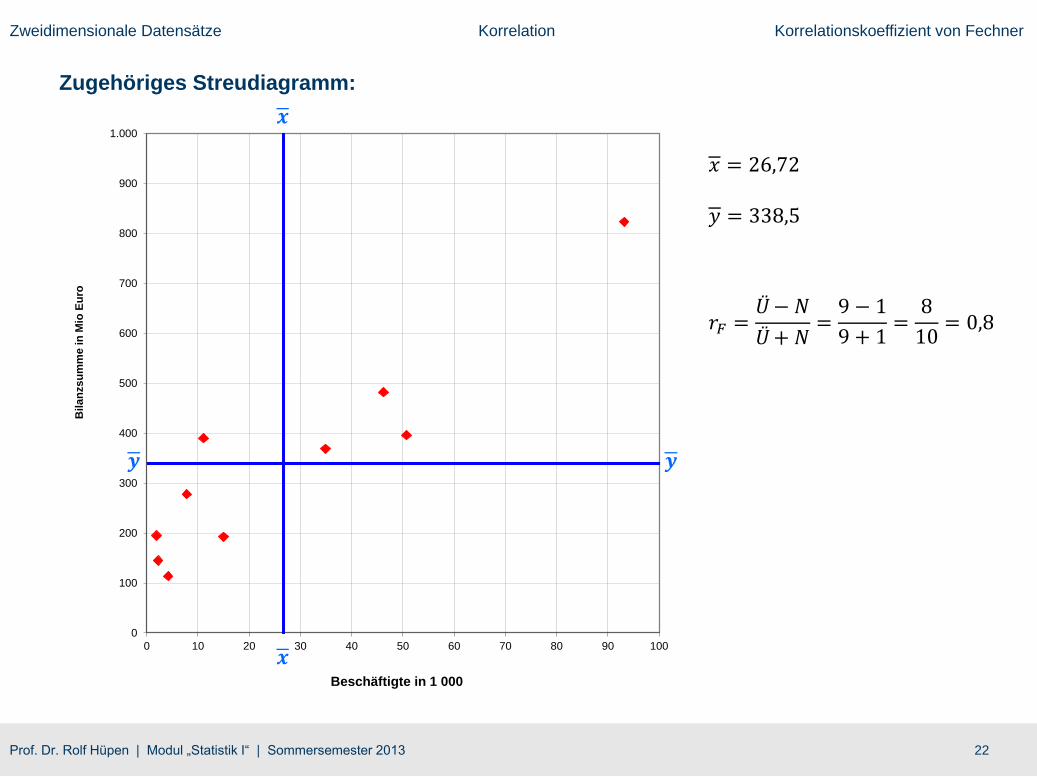
Zugehöriges Streudiagramm:
𝑥 = 26,72
𝑦 = 338,5
0
100
200
300
400
500
600
700
800
900
1.000
0 10 20 30 40 50 60 70 80 90 100
Bilan
zsu
mm
e in
Mio
Eu
ro
Beschäftigte in 1 000
𝑟𝐹 =Ü− 𝑁
Ü+𝑁=
9 − 1
9 + 1=
8
10= 0,8
𝒙
𝒚𝒚
𝒙

23Prof. Dr. Rolf Hüpen | Modul „Statistik I“ | Sommersemester 2013
Korrelationskoeffizient von Bravais-Pearson
Gegeben: n Wertepaare 𝑥𝑖 , 𝑦𝑖 , 𝑖 = 1,… , 𝑛 als Beobachtungswerte
Dann ist der Korrelationskoeffizient von Bravais-Person definiert als:
Zweidimensionale Datensätze Korrelation Korrelationskoeffizient von Bravais-Pearson
𝑟 =
1
𝑛∙
𝑖=1
𝑛
𝑥𝑖 − 𝑥 ∙ 𝑦𝑖 − 𝑦
2 1
𝑛∙
𝑖=1
𝑛
𝑥𝑖 − 𝑥 2 ∙1
𝑛∙
𝑖=1
𝑛
𝑦𝑖 − 𝑦 2
𝑟 =
𝑖=1
𝑛
𝑥𝑖 − 𝑥 ∙ 𝑦𝑖 − 𝑦
2
𝑖=1
𝑛
𝑥𝑖 − 𝑥 2 ∙
𝑖=1
𝑛
𝑦𝑖 − 𝑦 2
⇔
Definiert man den Ausdruck 𝑠𝑥𝑦 =1
𝑛⋅ 𝑖=1
𝑛 𝑥𝑖 − 𝑥 ⋅ 𝑦𝑖 − 𝑦 als empirische Kovarianz und berücksichtigt ferner
die Formeln für die Varianz (mittlere quadratische Abweichung) für X bzw. Y, nämlich 𝑠𝑥2 =
1
𝑛⋅ 𝑖=1
𝑛 𝑥𝑖 − 𝑥 2 und
𝑠𝑦2 =
1
𝑛⋅ 𝑖=1
𝑛 𝑦𝑖 − 𝑦 2, so gilt für r :
𝑟 =𝑠𝑥𝑦
𝑠𝑥2 ⋅ 𝑠𝑦
2
=𝑠𝑥𝑦
𝑠𝑥 ⋅ 𝑠𝑦
mit 𝑠𝑥 = 𝑠𝑥2 und 𝑠𝑦 = 𝑠𝑦
2 als jeweilige Standardabweichung. Somit ist r nur definiert, wenn 𝑠𝑥 ≠ 0 und 𝑠𝑦 ≠ 0.

24Prof. Dr. Rolf Hüpen | Modul „Statistik I“ | Sommersemester 2013
Zweidimensionale Datensätze Korrelation Korrelationskoeffizient von Bravais-Pearson
● Beide Merkmale müssen metrisches Skalenniveau haben.
● Zerlegungsformeln: 𝑠𝑥𝑦 =1
𝑛⋅
𝑖=1
𝑛
𝑥𝑖𝑦𝑖 − 𝑥 ∙ 𝑦 𝑠𝑥2 =
1
𝑛⋅
𝑖=1
𝑛
𝑥𝑖2 − 𝑥
2𝑠𝑦2 =
1
𝑛⋅
𝑖=1
𝑛
𝑦𝑖2 − 𝑦
2
● Weitere Formel für den
Korrelationskoeffizienten von
Bravais-Pearson:
𝑟 =𝑛 ⋅ 𝑖=1
𝑛 𝑥𝑖 ⋅ 𝑦𝑖 − 𝑖=1𝑛 𝑥𝑖 ⋅ 𝑖=1
𝑛 𝑦𝑖
𝑛 ⋅ 𝑖=1𝑛 𝑥𝑖
2 − 𝑖=1𝑛 𝑥𝑖
2⋅ 𝑛 ⋅ 𝑖=1
𝑛 𝑦𝑖2 − 𝑖=1
𝑛 𝑦𝑖2
● Empirische Kovarianz
linearer Transformationen:
𝑥𝑖 = 𝑎 + 𝑏 ⋅ 𝑥𝑖 , 𝑦𝑖 = 𝑐 + 𝑑 ⋅ 𝑦𝑖⇒ 𝑠 𝑥 𝑦 = 𝑏 ⋅ 𝑑 ⋅ 𝑠𝑥𝑦
● Korrelation linearer
Transformationen:𝑟 𝑥, 𝑦 =
𝑟 𝑥, 𝑦 falls 𝑏 ⋅ 𝑑 > 0
−𝑟 𝑥, 𝑦 falls 𝑏 ⋅ 𝑑 < 0
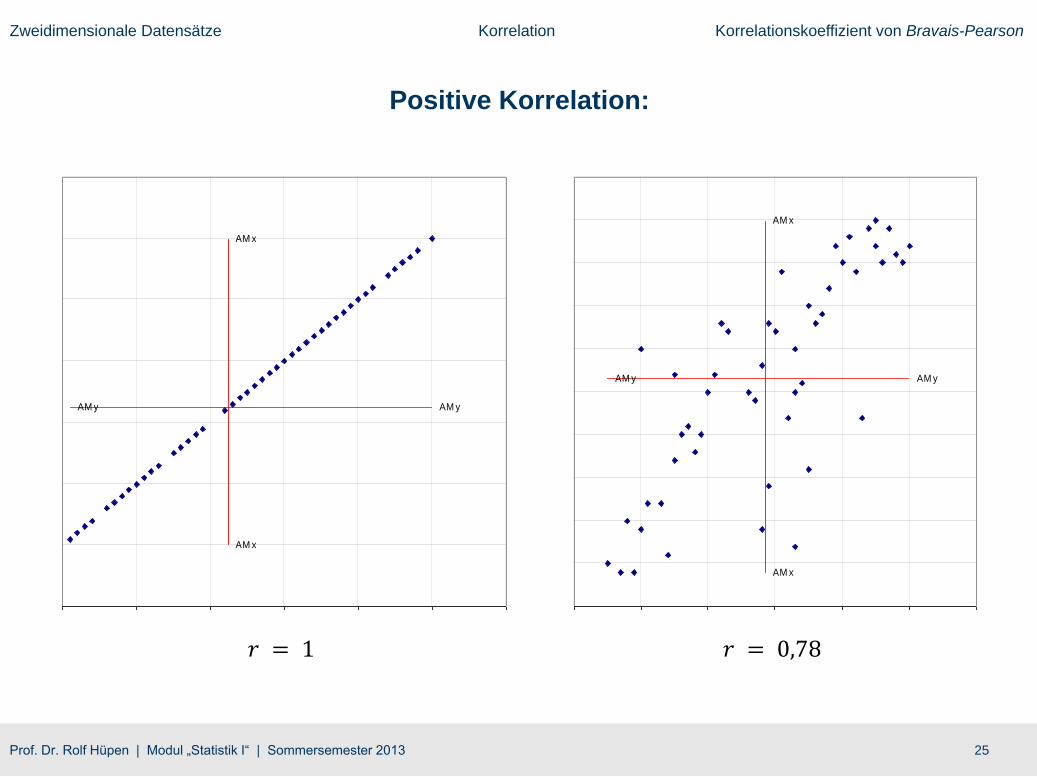
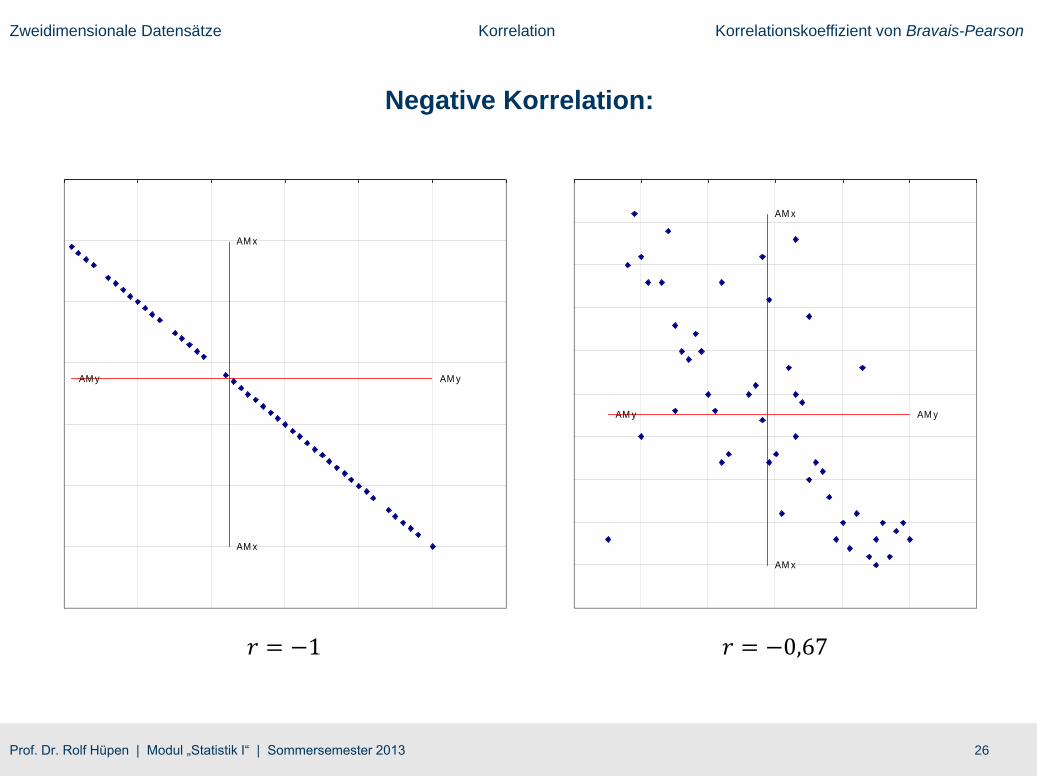
● 𝒓 = 𝟏 erhält man, wenn alle Wertepaare einer Geradengleichung 𝑦𝑖 = 𝑎 + 𝑏 ∙ 𝑥𝑖 mit positiver Steigung
(𝑏 > 0) genügen.
● 𝒓 = −𝟏 erhält man, wenn alle Wertepaare einer Geradengleichung 𝑦𝑖 = 𝑎 + 𝑏 ∙ 𝑥𝑖 mit negativer
Steigung (𝑏 < 0) genügen.
Eigenschaften des Korrelationskoeffizienten von Bravais-Pearson
25Prof. Dr. Rolf Hüpen | Modul „Statistik I“ | Sommersemester 2013
Zweidimensionale Datensätze Korrelation Korrelationskoeffizient von Bravais-Pearson
AM x
AM x
AM y AM y
AM x
AM x
AM y AM y
𝑟 = 1 𝑟 = 0,78
Positive Korrelation:
26Prof. Dr. Rolf Hüpen | Modul „Statistik I“ | Sommersemester 2013
Zweidimensionale Datensätze Korrelation Korrelationskoeffizient von Bravais-Pearson
AM x
AM x
AM y AM y
AM x
AM x
AM y AM y
𝑟 = −1 𝑟 = −0,67
Negative Korrelation:
27Prof. Dr. Rolf Hüpen | Modul „Statistik I“ | Sommersemester 2013
Zweidimensionale Datensätze Korrelation Korrelationskoeffizient von Bravais-Pearson
AM x
AM x
AM y AM y
AM x
AM x
AM y AM y
𝑟 = 0 𝑟 = −0,07
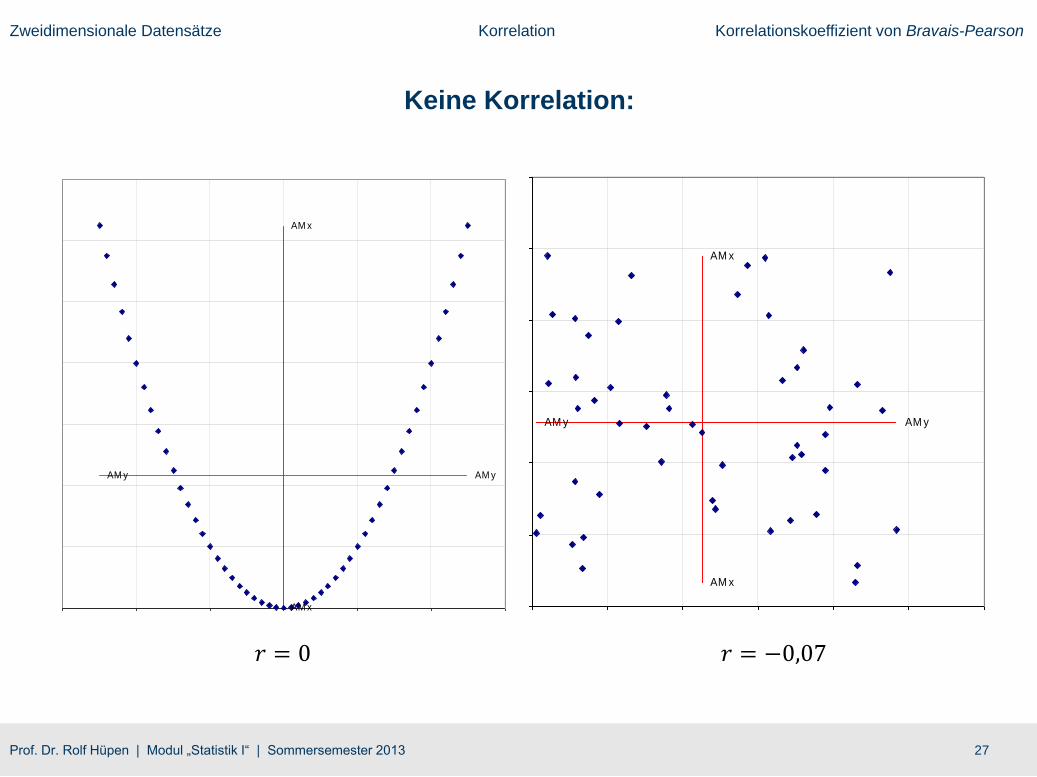
Keine Korrelation:
28Prof. Dr. Rolf Hüpen | Modul „Statistik I“ | Sommersemester 2013
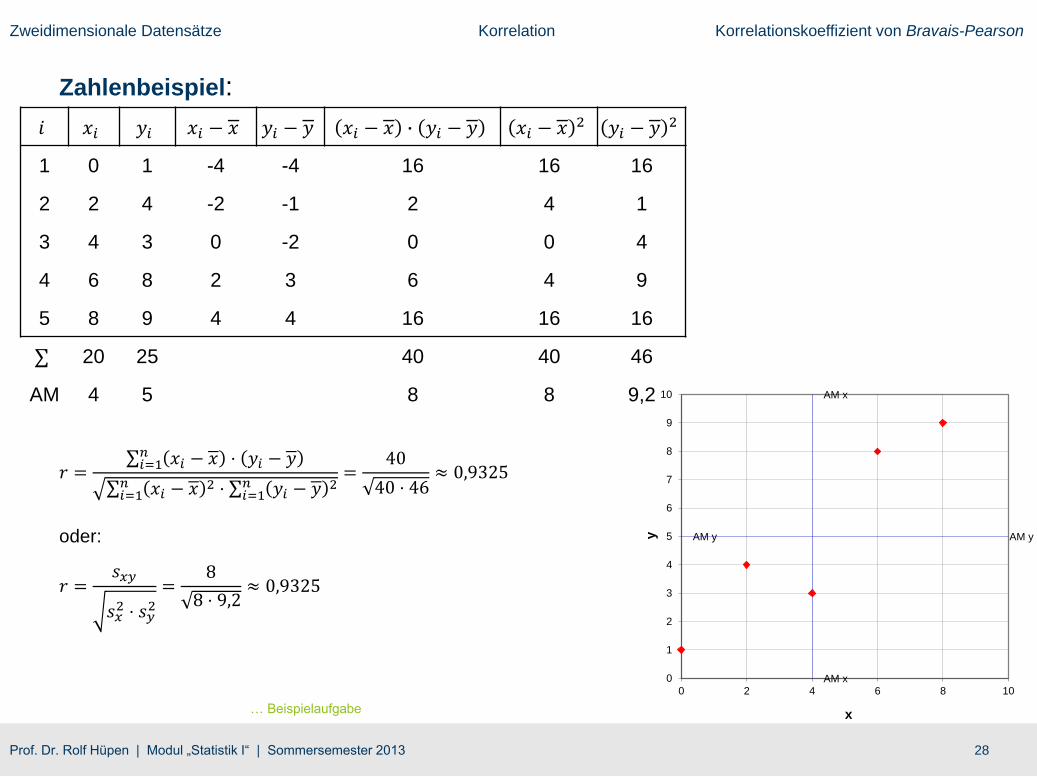
𝑖 𝑥𝑖 𝑦𝑖 𝑥𝑖 − 𝑥 𝑦𝑖 − 𝑦 𝑥𝑖 − 𝑥 ∙ 𝑦𝑖 − 𝑦 𝑥𝑖 − 𝑥 2 𝑦𝑖 − 𝑦 2
1 0 1 -4 -4 16 16 16
2 2 4 -2 -1 2 4 1
3 4 3 0 -2 0 0 4
4 6 8 2 3 6 4 9
5 8 9 4 4 16 16 16
20 25 40 40 46
AM 4 5 8 8 9,2
Zweidimensionale Datensätze Korrelation Korrelationskoeffizient von Bravais-Pearson
𝑟 = 𝑖=1𝑛 𝑥𝑖 − 𝑥 ⋅ 𝑦𝑖 − 𝑦
𝑖=1𝑛 𝑥𝑖 − 𝑥 2 ⋅ 𝑖=1
𝑛 𝑦𝑖 − 𝑦 2=
40
40 ⋅ 46≈ 0,9325
oder:
𝑟 =𝑠𝑥𝑦
𝑠𝑥2 ⋅ 𝑠𝑦
2
=8
8 ⋅ 9,2≈ 0,9325
Zahlenbeispiel:
AM x
AM x
AM y AM y
0
1
2
3
4
5
6
7
8
9
10
0 2 4 6 8 10
y
x… Beispielaufgabe

29Prof. Dr. Rolf Hüpen | Modul „Statistik I“ | Sommersemester 2013
Zweidimensionale Datensätze Korrelationskoeffizient von Spearman
Korrelationskoeffizient von Spearman(Rangkorrelationskoeffizient)
● Gegeben sind n Wertepaar (𝑥𝑖 , 𝑦𝑖), i = 1,…n, als Beobachtungswerte
● Voraussetzung: Die Merkmale X und Y sind mindestens ordinal skaliert. Hauptanwendungsgebiet sind
daher ordinal skalierte Merkmale.1
● Vorgehensweise: Man ordnet jedem 𝑥𝑖-Wert bzw. 𝑦𝑖-Wert eine Rangnummer 𝑅(𝑥𝑖) bzw. 𝑅(𝑦𝑖) zu, welche
seinen Platz in der geordneten Urliste 𝑥(1) ≤ 𝑥 2 ≤ ⋯ ≤ 𝑥(𝑛) bzw. 𝑦(1) ≤ 𝑦 2 ≤ ⋯ ≤ 𝑦(𝑛) widerspiegelt. Im
ersten Schritt erhält man dadurch die natürlichen Zahlen 1 bis n als vorläufige Rangnummern für jedes
Merkmal. Gibt es nur voneinander verschiedene Beobachtungswerte, ist man fertig. Sind die Ausprägungen
jeweils nicht alle voneinander verschieden (sog. „Bindungen“), werden in einem zweiten Schritt den jeweils
gleichen Werten das arithmetische Mittel der auf sie entfallenden vorläufigen Rangnummern als endgültige
Rangnummern zugeordnet. Schließlich wird aus den 𝑛 resultierenden Rangnummern 𝑅 𝑥𝑖 , 𝑅(𝑦𝑖) nach
dem Verfahren von Bravais-Pearson der Korrelationskoeffizient berechnet.2
● Formel: Für den Spearmanschen Korrelationskoeffizienten kann folgende Formel verwendet werden:3
𝑟𝑆𝑝 = 1 −6∙
𝑖=1
𝑛𝑑𝑖
2
𝑛∙ 𝑛2−1, mit 𝑑𝑖 = 𝑅 𝑥𝑖 − 𝑅 𝑦𝑖
● Extremwerte: 𝑟𝑆𝑝 = 1, wenn die Rangordnung der Merkmalsträger bei beiden Merkmalen dieselbe ist. 𝑟𝑆𝑝 =
− 1, wenn die Reihenfolge der Merkmalsträger beim zweiten Merkmal genau umgekehrt ist.4
1 Man kann den Spearmanschen Korrelationskoeffizienten zwar auch für metrische Merkmale berechnen, würde dabei aber vorhandene Informationen – etwa
über Differenzen zwischen den Beobachtungswerten – ignorieren.2 Mit den Rangnummern wird gerechnet wie mit einem metrischen Merkmal, was eigentlich gleiche Abstände zwischen den Rängen voraussetzt.3 Die Formel ist nur exakt, wenn keine Bindungen vorkommen.4 Im ersten Fall ist 𝑅 𝑥𝑖 = 𝑅(𝑦𝑖), im zweiten 𝑅 𝑥𝑖 = 𝑛 + 1 − 𝑅(𝑦𝑖) für alle 𝑖 = 1,… , 𝑛
30Prof. Dr. Rolf Hüpen | Modul „Statistik I“ | Sommersemester 2013
Zweidimensionale Datensätze Korrelationskoeffizient von Spearman
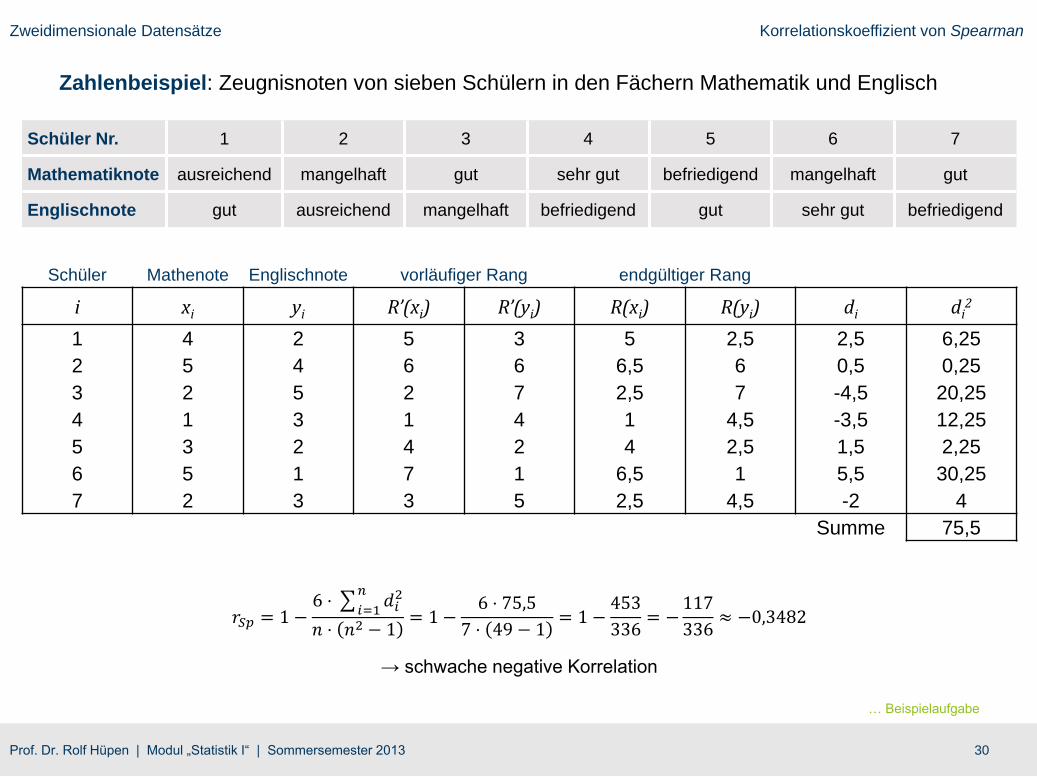
Zahlenbeispiel: Zeugnisnoten von sieben Schülern in den Fächern Mathematik und Englisch
Schüler Nr. 1 2 3 4 5 6 7
Mathematiknote ausreichend mangelhaft gut sehr gut befriedigend mangelhaft gut
Englischnote gut ausreichend mangelhaft befriedigend gut sehr gut befriedigend
Schüler Mathenote Englischnote vorläufiger Rang endgültiger Rang
i xi yi R’(xi) R’(yi) R(xi) R(yi) di di2
1 4 2 5 3 5 2,5 2,5 6,25
2 5 4 6 6 6,5 6 0,5 0,25
3 2 5 2 7 2,5 7 -4,5 20,25
4 1 3 1 4 1 4,5 -3,5 12,25
5 3 2 4 2 4 2,5 1,5 2,25
6 5 1 7 1 6,5 1 5,5 30,25
7 2 3 3 5 2,5 4,5 -2 4
Summe 75,5
𝑟𝑆𝑝 = 1 −6 ⋅
𝑖=1
𝑛𝑑𝑖2
𝑛 ⋅ 𝑛2 − 1= 1 −
6 ⋅ 75,5
7 ⋅ 49 − 1= 1 −
453
336= −
117
336≈ −0,3482
→ schwache negative Korrelation
… Beispielaufgabe