Embed Size (px)
Citation preview

Thema: Training eines humanoiden Roboters durchbestarkendes Lernen eines simulierten Agenten
NAO lernt Tore schießen
Reinforcement Learning of a Simulated Agent forTraining a Humanoid Robot
NAO learns to score a Goal
Bachelorarbeit
im Studiengang Angewandte Informatik der Fakultat Wirtschaftsinformatik undAngewandte Informatik der Otto-Friedrich Universitat Bamberg
Verfasser: Norman Steinmeier
Gutachter: Prof. Dr. Ute Schmid


Inhaltsverzeichnis
1 Einleitung 11.1 Maschinelles Lernen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.2 Hintergrund und Ziel der Arbeit . . . . . . . . . . . . . . . . . . . . . . 4
2 Stand der Forschung 62.1 Bezug zum Bachelor Projekt Nao Soccer der Universitat Bamberg . . . 62.2 Bezug auf Verwendung bestarkenden Lernens in der Praxis . . . . . . . 10
2.2.1 Generalized Model Learning for Reinforcement Learning on a Hu-manoid Robot . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.2.2 Reinforcement Learning for Parameter Control of Image-BasedApplications . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.2.3 Elevator Group Control Using Multiple Reinforcement LearningAgents . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3 Algorithmik und Simulationsumgebung 263.1 Markov Entscheidungsprozess . . . . . . . . . . . . . . . . . . . . . . . . 263.2 Der Aldebaran Nao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 273.3 Systeminformationen der Simulationsumgebung . . . . . . . . . . . . . . 293.4 Verwendete Software: Choregraphe, Webots for Nao und NaoQi . . . . . 303.5 Die freie machine learning Bibliothek PyBrain . . . . . . . . . . . . . . . 333.6 PGPE Learner: Policy Gradients with Parameter-Based Exploration for
Control . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
4 Ziele und Umsetzung des Versuchsaufbaus 374.1 Gesteckte Ziele . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 374.2 Konfiguration des neuronales Netzes . . . . . . . . . . . . . . . . . . . . 394.3 Klassendiagramm / Grundlegender Aufbau der Simulation . . . . . . . . 404.4 Aktivitatsdiagramm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 434.5 Zustandsraum und Aktionsraum . . . . . . . . . . . . . . . . . . . . . . 444.6 Abschatzung des zeitlichen Rahmens . . . . . . . . . . . . . . . . . . . . 45
5 Ergebnisse 475.1 Ubersicht der Ergebnisse . . . . . . . . . . . . . . . . . . . . . . . . . . . 475.2 Bewertung und Ubertragbarkeit . . . . . . . . . . . . . . . . . . . . . . . 50


1 Einleitung
1.1 Maschinelles Lernen
”As regards machines, we might say, very broadly, that a machine learns whenever it
changes its structure, program, or data [...] in such a manner that its expected future
performance improves.” [Nil98]
Maschinelles Lernen als Disziplin der Informatik befasst sich mit der Entwicklung und
Implementierung von Losungen zur Generierung von Wissen durch Uberwachung oder
Bewertung von Ablaufen. Dabei wird zwischen uberwachtem und unuberwachtem Ler-
nen unterschieden. Wahrend bei uberwachtem Lernen Eingabe- und Ausgabeparameter
fur ein spezifisches Problem bekannt sind und ein darunterliegendes, neuronales Netz in
seinen Gewichten so trainiert werden soll, versuchen Algorithmen des unuberwachten
Lernens Gesetzmaßigkeiten in den Eingabeparametern zu erkennen. Bestarkendes Ler-
nen oder Reinforcement Learning als Teilgebiete des maschinellen Lernens eignet sich
insbesondere zur Losung von Problemen, welche durch ihre Komplexitat an Parame-
tern und Zustanden durch regulare imperative Programmierung nur schwer oder gar
nicht gelost werden konnten. Darunter fallen viele Aufgaben der Robotik, wie zum Bei-
spiel der im weiteren Verlauf dieser Arbeit noch genannte Pole-Balancing Task (Kapitel
3.6) [Vin08].
”The basis of RL is an intelligent agent that seeks some reward or special signal, and
strives to receive this reward through exploring its environment. It also must exploit the
knowledge it has previously obtained through past actions and past rewards (or punish-
ments).” [Tay04]
”In order to maximize reward (or minimize the punishment) a learning algorithm
must choose actions which have been tried out in the past and found to be effective
in producing reward, i.e. it must exploit its current knowledge. On the other hand, to
discover those actions the learning algorithm has to choose actions not tried in the past
and thus explore the state space. There is no general solution to this dilemma, but that
neither of the two options can lead exclusively to an optimal strategy is clear.” [Vin08]
Abbildung 1 zeigt die grundsatzliche Interaktion zwischen Agenten und der Umge-
bung, innerhalb welcher dieser agiert. Dem Agenten bietet sich die Moglichkeit zur
Einsicht in den aktuellen Zustand seiner Umgebung. Er wahlt entsprechend seiner
vorgegebenen Grenzen eine mogliche Aktion des Aktionsraumes und erhalt von sei-
ner Umgebung Informationen uber die daraus resultierende Zustandsanderung, sowie
Belohnung oder Bestrafung. Ausgehend von mehreren Iterationen der Uberwachung
1

des aktuellen Zustandes, der Auswahl des nachsten Schrittes innerhalb des Ablaufes
und der daraus errechneten Belohnung, wahlt ein entsprechend implementiertes Sy-
stem nach einigen Durchlaufen in der Regel Routen, welche eine hohere Belohnung
versprechen als andere. Es existieren auch Ansatze, wie Q-Learning, denen auch eine
tabellarische Zustandstabelle (sgn. Lookup Tables) zu Grunde liegen kann. Der Agent
lernt nicht einfach bereits absolvierte Zustandsablaufe auswendig, sondern kann auf
Basis seines erworbenen Wissens auch Vorhersagen uber mogliche Resultate fur bis-
her unerforschte Eingabeparameter treffen. Durch verschiedene Optimierungen und die
Auswahl des Verhaltnisses von Erkundung des Zustandsraumes zur Ausnutzung bereits
erlernter Zusammenhange konnen verschiedene Algorithmen auf bestimmte Problem-
bereiche hin optimiert werden.
Abbildung 1: Interaktion von Agent und Umgebung
Dieser Sachverhalt ist der Grund dafur, dass Reinforcement Learning besonders in
den Disziplinen der Roboterprogrammierung und Mustererkennung Anwendung findet.
Darunter fallen motorische Steueraufgaben, sowie Objekterkennung in Standbildern
und Videos. Verschiedene Implementierungen von lernenden Agenten besitzen Starken
in unterschiedlichen Bereichen. Haufig jedoch ist fur einen Eignung der Implementie-
rung relevant, aus wie vielen Beispielen ein Algorithmus lernen muss, um Schlusse auf
den Ausgang anderer Eingabewerte ziehen zu konnen (Sample Effectiveness).
”RL is based on the idea that the tendency to produce an action should be strengthe-
ned reinforced if it produces favorable results, and weakened if it produces unfavorable
results. This framework is appealing from a biological point of view since an animal
has certain built in preferences (such as pleasure or pain), but does not always have a
teacher to tell it exactly what action it should take in every situation” [Bar97]
Es gilt zwischen nicht sequentiellen Aufgaben, bei welchen der Agent versucht nur
den direkt auf die nachste Aktion folgenden Gewinn zu maximieren und sequentielle
2

Aufgaben, bei denen der Agent versucht den durchschnittlichen Gewinn uber einen
Zeitraum hinweg zu maximieren. Grundsatzlich sind sequentielle Aufgaben schwieriger
zu losen, da zuruckliegende Aktionen den Gewinn oder Verlust in der Zukunft liegender
Aktionen beeinflussen konnen.
”An agent changes its current state by executing an action. Given that it knows of
Q-values relating each possible action to expected reward, we may think it should always
take the action associated with the highest Q-value, the greedy action. This is the naive
answer, as the agent must make a trade-off between immediate return and long-term
value. The agent that did not explore unseen states and only attempted to maximize its
return by choosing what it already knew would be a poor learner. There needs to be a
balance between exploration of unseen states and exploitation of familiar states.” [Tay04]
Das grundlegende Ziel des maschinellen Lernens liegt in der Verbesserung des eige-
nen Verhaltens im Bezug auf eine abgesteckte Problemstellung ohne außere Interventi-
on. Dabei soll das Festsitzen auf lokalen Maxima moglichst vermieden werden. Durch
Generalisierung eignet sich Reinforcement Learning auch fur Problemstellungen mit
hochdimensionalen Zustandsraumen und fortlaufenden Zustandsanderungen.
”The majority of successful examples in applying RL deal with decision making at a
highlevel, where actions are discrete and of low cardinality.” [Tay04]
3

1.2 Hintergrund und Ziel der Arbeit
Abbildung 2: Bachelor Project Nao Soccer [Win13]
Die nachfolgende Arbeit baut auf dem Projekt ”Bachelor Project Nao Soccer” (siehe
Abbildung 2) der Universitat Bamberg auf, bei dem ein humanoider Roboter der Firma
Aldebaran so programmiert wurde, dass er sich selbststandig im Raum bewegt, um
einen Ball in ein Fußballtor zu schießen. Zur Erkennung von Ball und Tor werden die
im Roboter vorhandenen Kameras genutzt. Der Roboter bewegt sich durch Laufen und
Rotation um die eigene Achse so innerhalb des Raumes, dass er sich vor dem erkannten
Ball positioniert. Dann beginnt der Roboter in einem Bogenkreis um den Ball herum
zu rotieren, wahrend er mit dem Kameras in seinem Kopf nach dem Tor Ausschau
halt. Sobald das Tor sich auf einer verlangerten Geraden zwischen dem Schussfuß des
Roboters und dem Ball befindet, begibt sich der Roboter in einem vordefinierten Ablauf
in Schussbereitschaft und schießt den Ball mit einer Animation in Richtung Tor. Dabei
stellte das Team des Projektes fest, dass auf Grund der Form und der Beschaffenheit des
Roboterfußes und die Komplexitat der moglichen Beinbewegung innerhalb von sechs
unterscheidbaren Achsen, eine Implementierung eines erfolgversprechenden Torschusses
durch manuelle Ubergabe der Parameter schwierig und durch automatische Berechnung
der notigen Parameter aus der aktuellen Situation unmoglich war.
Dieser Missstand soll in nachfolgender Arbeit genauer analysiert und durch die Imple-
4

mentierung eines Reinforcement Learning Agenten minimiert werden. Da die notigen,
mehreren tausend Iterationen bis zu einem umfangreichen Lernvorgang und die vor-
handene Sturzgefahr des Roboters diesen einer zu hohen Belastung aussetzen wurden,
soll der Lernvorgang vollstandig innerhalb einer Simulation stattfinden. Außerdem
ermoglicht eine Umsetzung innerhalb einer Simulation eine bessere Kontrolle uber alle
Trainingsdaten und das Rauschen dieser Daten wird minimiert. Des Weiteren kann der
Umfang der Eingabeparameter genauer kontrolliert werden [O05]. Ziel dieser Arbeit ist
es, einen Bewegungsablauf fur das Bein des Roboters zu finden, welcher eine maximale
Schussweite des Balles verspricht, ohne dass der Roboter dabei sein Gleichgewicht ver-
liert. Der Lernvorgang soll ohne außere Bewertung, rein durch Nutzung der Kameras
des Roboters erfolgen. Der Prozess soll autonom stattfinden, um moglichst Zeit effek-
tives Lernen zu ermoglichen.
5

2 Stand der Forschung
2.1 Bezug zum Bachelor Projekt Nao Soccer der Universitat Bamberg
Ein 2012 durchgefuhrtes Projekt von Jaime Delgado Granados, Fabian Selig, Norman
Steinmeier und Daniel Winterstein an der Universitat Bamberg legte wichtige Grund-
steine fur den Aufbau dieses Experiments. Die Studierenden nutzten den ihnen zur
Verfugung stehenden Nao Version H25 zur Implementierung einer Fußballsimulation.
Hierbei galt es, den Roboter entsprechend so zu programmieren, dass er in einer ihm
unbekannten Umgebung einen roten Spielball mit etwa sechs Zentimetern Durchmes-
ser findet. Hierzu wurden die vorhandenen Kameras innerhalb des Roboters eingesetzt.
Durch geschickte Rotation des Roboters um die eigene Achse und die wechselseitige
Verwendung der oberen sowie unteren Kamera, konnten Suchradien von 2-3 Metern er-
reicht werden. Nach Auffinden des Balles setzte sich der Roboter in Richtung des Balles
in Bewegung. Wahrend seiner Laufbewegung wurde jede zehnte Sekunde die Position
des Balles erneut mit den Kameras abgefragt und zur Verfeinerung der Zielkoordinaten
der Laufanimation verwendet. Dadurch konnte der Roboter selbst einen sich bewe-
genden Ball nachverfolgen, bis dieser schließlich zum Stehen kam. Um die Sicherheit
wahrend der Bewegung des Roboters zu gewahrleisten, wurden die integrierten Ul-
traschallsensoren eingesetzt, damit potentielle Hindernisse vor dem Roboter fruhzeitig
erkannt werden konnen. Der Roboter bewegte sich bis auf einen definierten Abstand
von etwa drei Zentimetern zum Ball hin. In einer sich wiederholenden Versuchsreiche
konnte dieser Abstand als außerst stabil bezeichnet werden. Der Ball lag stets mittig
vor beiden Fußen des Roboters, wie in Abbildung 3 zu sehen ist.
6

Abbildung 3: Ballposition in Relation zur Roboterposition [Win13]
Anschließend war es die Aufgabe des Roboters das gewunschte Ziel seines Ballschus-
ses zu finden. Hierzu wurde ein, mit speziellen geometrischen Erkennungsmarken, den
NaoMarks, markierter Kartonaufsteller vom Roboter gesucht. Da die Kopfrotation des
Roboters in ihrem Winkel eingeschrankt ist, war es notig, den Roboter durch Fuß-
bewegungen rotierend, nach dem Tor Ausschau halten zu lassen. Da dies jedoch eine
Veranderung der Position des Roboters zur Ballposition oder gar ein versehentliches
Verschießen des Balles mit sich gefuhrt hatte, wurde eine Methode gewahlt, bei der
durch geschickte Berechnung der Rotationsbewegung, unter Einsatz der Kameras, ein
konstanter Abstand zum Ball gehalten werden konnte. Dabei rotierte der Roboter auf
einer Kreisbahn um den Ball, wobei der Ball stets direkt mittig vor den Fußen im sel-
ben Abstand gehalten wurde. Dazu wurde die Ballposition stetig erneut uberpruft und
die Zielposition der Bewegung stetig angepasst. Abbildung 4 verdeutlicht den Vorgang.
7

Abbildung 4: Rotation um den Ball
Sobald der Roboter sich zum Tor hin ausgerichtet hatte und nach Uberprufung den
Ball noch vor sich liegen hatte, wurde die Schussanimation eingeleitet. Diese konn-
te nicht im Quellcode definiert werden, da eine entsprechende Parameterfindung auf
Grund ihrer Komplexitat nicht durchfuhrbar gewesen ware. Deshalb wahlten die Stu-
dierenden die Software Choregraphe fur die Animation des Ballschusses. Dabei mach-
ten sie sich die Moglichkeit zu Nutze, den Roboter im sogenannten Animation-Mode
manuell, durch außere Einwirkung in entsprechende Positionen zu bewegen und diese
Positionen auf einer Zeitachse im Editor abzulegen. Abbildung 5 zeigt den Timeline
Editor.
8

Abbildung 5: Choregraphe Timeline Editor
”This mode allows you to register different key frames of the new animation into a
timeframe. Those keyframes are created by bringing Nao manually into this position
followed by saving them in the timeline. Nao then automatically calculates the missing
frames between those keyframes.” [Win13]
Durch manuelle Aufhebung der Starre innerhalb einer Achsengruppe kann diese Viel-
zahl von Gelenken des Roboters handisch in eine gewunschte Position gebracht werden.
Anschließend kann diese Position auf einem Zeitstrahl abgespeichert werden. Durch
Wiederholung der Prozedur und Variation der zeitlichen Abstande der neu gebildeten
Knoten kann ein Bewegungsablauf animiert werden. Die Software des Nao versucht aus
den vorgegebenen Punkten geeignete Zwischenstadien zu berechnen und wahrend der
Ausfuhrung des neu gelernten Ablaufes alle gesetzten Knotenpunkte zu erreichen. Da
wahrend der Erstellung der Animation eine Kollision oder Uberstreckung von Glied-
maßen nicht moglich ist, da der Roboter diese Position auch nicht manuell annehmen
kann, entstehen flussige Bewegungsablaufe. Durch mehrere Versuche konnte ein rudi-
mentarer Bewegungsablauf gefunden werden, welcher in der Regel zu einem Schuss des
Balles ohne Umfallen des Roboters fuhrte. Jedoch reichte dieser Schuss nur fur eini-
9

ge wenige Dezimeter. Nachfolgende Arbeit beschaftigt sich explizit mit dem Problem
der Implementierung des Ballschusses und versucht diesen ohne externe Einwirkung
vom Roboter selbst finden zu lassen. Hierzu sollen Techniken des maschinellen Lernens
Anwendung finden.
2.2 Bezug auf Verwendung bestarkenden Lernens in der Praxis
2.2.1 Generalized Model Learning for Reinforcement Learning on a HumanoidRobot
”As the tasks that we desire robots to perform become more complex, and as robots
become capable of operating autonomously for longer periods of time, we will need to
move from hand-coded solutions to having robots learn solutions to problems on their
own.” [Sto10]
Eine modellbasierte Implementierung von bestarkendem Lernen wurde an der Uni-
versitat von Texas in Huston dazu genutzt, erstmalig einem Nao Roboter die Wahl der
Schussrichtung bei einem Freistoß im RoboCup erlernen zu lassen. Ausschlaggebend
fur diese Zielsetzung war die Tatsache, dass in 43,75 % aller RoboCup Spiele in einem
Unentschieden enden und die Entscheidung uber Sieg oder Niederlage in einem Ren-
nen um die meisten getroffenen Freistoße endete. Allerdings wurden entsprechend der
Autoren nur 7,8 % aller Freistoße im RoboCup uberhaupt das Tor treffen.
Die Autoren wahlten eine modellbasierte Umsetzung, da diese aus einer deutlich
niedrigeren Stichprobenanzahl als modellfreie Algorithmen Ruckschlusse ziehen kann.
Dieser Vorteil wird dadurch unterstutzt, dass dem Lernalgorithmus RL-DT (Reinfor-
cement Learning with Decision Trees) Entscheidungsbaume zu Grunde liegen. Dabei
wird statt einem neuronalen Netz eine Baumstruktur aufgebaut und trainiert.
RL-DT ist so entworfen, dass bereits aus sehr wenigen Stichproben Ruckschlusse ge-
zogen werden konnen, da eine ausfuhrliche Erkundung aller Zustandsraume fur eine
derartige Anwendung nicht in kurzer Zeit ausfuhrbar ware. ”By generalizing the model
to unseen states, the agent can avoid exploring some states.” [Sto10] Der Algorithmus
wahlt, entsprechend des aktuellen Zustandes, eine mogliche Aktion aus und entscheidet
auf Grundlage der Belohnung, ob diese Aktion weiter erforscht oder als ausgeschopft ab-
gelegt werden soll. Dadurch wachst das zu Grunde liegende Modell des Algorithmus von
einer sehr groben Reprasentation zu einem konkreten Modell der Problemstellung. Die
Implementierung von RL-DT zielt auf schnelle Ergebnisse ab, statt den Problemraum
vollstandig auszuschopfen. Das Auffinden einer optimalen Strategie ist hierbei kein Ziel.
10
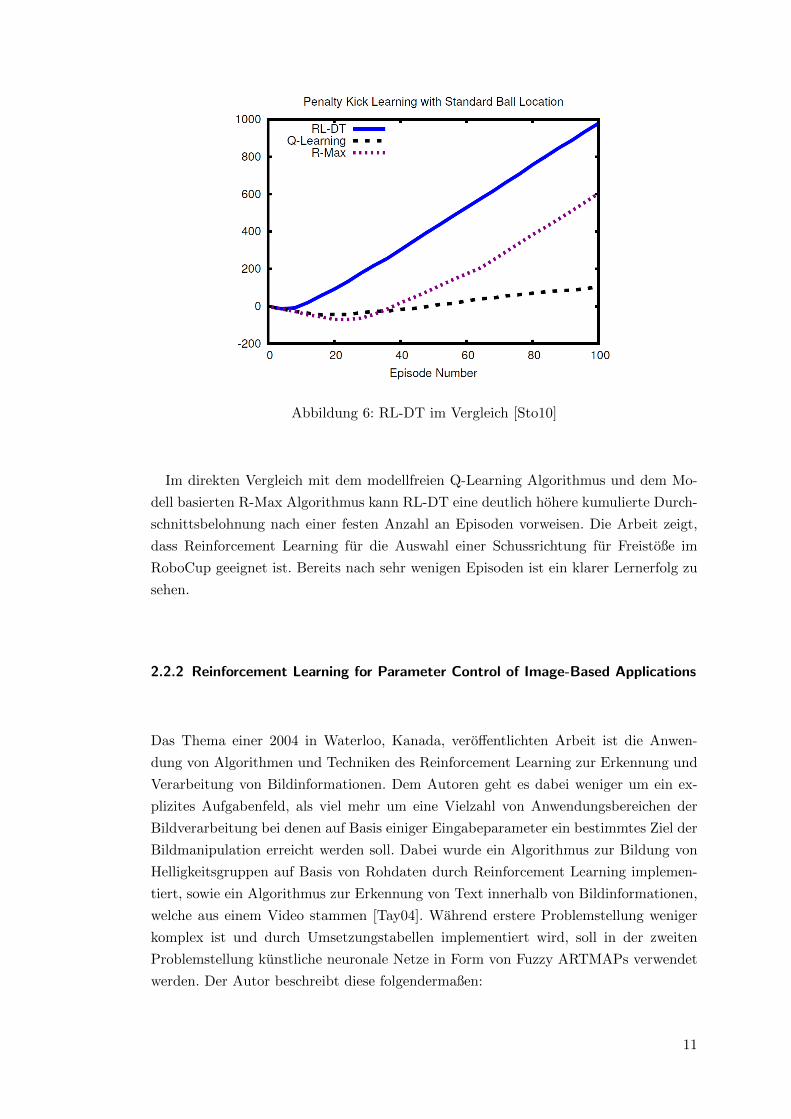
Abbildung 6: RL-DT im Vergleich [Sto10]
Im direkten Vergleich mit dem modellfreien Q-Learning Algorithmus und dem Mo-
dell basierten R-Max Algorithmus kann RL-DT eine deutlich hohere kumulierte Durch-
schnittsbelohnung nach einer festen Anzahl an Episoden vorweisen. Die Arbeit zeigt,
dass Reinforcement Learning fur die Auswahl einer Schussrichtung fur Freistoße im
RoboCup geeignet ist. Bereits nach sehr wenigen Episoden ist ein klarer Lernerfolg zu
sehen.
2.2.2 Reinforcement Learning for Parameter Control of Image-Based Applications
Das Thema einer 2004 in Waterloo, Kanada, veroffentlichten Arbeit ist die Anwen-
dung von Algorithmen und Techniken des Reinforcement Learning zur Erkennung und
Verarbeitung von Bildinformationen. Dem Autoren geht es dabei weniger um ein ex-
plizites Aufgabenfeld, als viel mehr um eine Vielzahl von Anwendungsbereichen der
Bildverarbeitung bei denen auf Basis einiger Eingabeparameter ein bestimmtes Ziel der
Bildmanipulation erreicht werden soll. Dabei wurde ein Algorithmus zur Bildung von
Helligkeitsgruppen auf Basis von Rohdaten durch Reinforcement Learning implemen-
tiert, sowie ein Algorithmus zur Erkennung von Text innerhalb von Bildinformationen,
welche aus einem Video stammen [Tay04]. Wahrend erstere Problemstellung weniger
komplex ist und durch Umsetzungstabellen implementiert wird, soll in der zweiten
Problemstellung kunstliche neuronale Netze in Form von Fuzzy ARTMAPs verwendet
werden. Der Autor beschreibt diese folgendermaßen:
11

”A new neural network architecture is introduced for incremental supervised learning
of recognition categories and multidimensional maps in response to arbitrary sequences
of analog or binary input vectors, which may represent fuzzy or crisp sets of features.
The architecture, called fuzzy ARTMAP, achieves a synthesis of fuzzy logic and ad-
aptive resonance theory (ART) neural networks by exploiting a close formal similarity
between the computations of fuzzy subsethood and ART category choice, resonance and
learning.” [Ros92]
Abbildung 7: Aufbau von ART1 Netzen [Ros92]
Abbildung 7 zeigt den grundlegenden Aufbau von Adaptive Resonance Theory Net-
zen. Dabei ist Fuzzy ARTMAP aus den klassischen ART 1 Netzen fur unuberwachtes
Lernen hervorgegangen. Sie bestehen aus zwei bidirektional vernetzten Feldern, den At-
tributen (F1) und den Kategorien (F2), sowie deren beiden Gewichtungsmatrizen. Die
Matrizen hinterlegen die Schwellenwerte fur alle Ubergange von F1 nach F2 (G1) und
alle Ubergange von F2 nach F1 (G2). Der sogenannte Wachsamkeitsparameter (P)
von ART 1 bestimmt die Anzahl der zu bildenden Kategorien. Ankommende Attribute
werden durch F1 an Hand von G1 bewertet und an die entsprechende Kategorie in
F2 weitergeleitet. Danach wird durch G2 die Attributkategorie fur den Ruckgabewert
ermittelt. Liegt der Wert uber P, wird das System in seinen Gewichten trainiert, da
das System sich in Resonanz befindet. Ansonsten wird der Vorgang wiederholt, wobei
12

ein Reset-Modul die erneute Uberprufung fur bereits getestete Neuronen verhindert.
Sollte keine passende Kategorie gefunden werden, so wird eine neue erstellt, bis der
zugewiesene Platz gefullt ist. Das System passt Kategorien fur ahnliche Eingangsattri-
bute an und erstellt neue Kategorien innerhalb seiner Grenzen fur ganzlich unbekannte
Eingabeparameter. Der Wachsamkeitsparameter legt fest, ob ein Attribut zu stark von
einer Kategorie abweicht oder nicht [Zac07].
Bildbearbeitung, Bildwiederherstellung, Objekterkennung und die Generierung von
entsprechenden Metadaten aus Bildinhalten sind zum Teil Einsatzgebiete von Re-
inforcement Learning. Die Schwierigkeit dieser Disziplinen liegt im Rauschen der Bild-
daten. Nur wenige Datensatze in einem Bild sind relevant fur die Erkennung der Inhal-
tes, ein Großteil der Informationen sind fur RL-Agenten lediglich Rauschen. Dadurch
ist es schwierig Zustandsraume zu generieren, welche dieses Rauschen minimieren. Des
weiteren ist der Entwurf von Bewertungsfunktionen fur solch einen Agenten ebenfalls
komplex, da entsprechende Ziele nur schwer auf einen einzigen Attributwert reduziert
werden konnen. Taylor sieht hierbei die Schwierigkeit in der Abwagung zwischen Erkun-
dung des Aktionsraumes und der Ausnutzung bereits erkannter Gegebenheiten. Seiner
Ansicht nach kann eine solche Abwagung nicht pauschalisiert werden, sondern hangt
immer von der jeweiligen Problemstellung ab.
Da ohne Reduktion der Komplexitat theoretisch jeder Bildpunkt als visuelles Si-
gnal verarbeitet werden musste und sich somit ein hochdimensionaler Zustandsraum
der Großenordnung Bildbreite multipliziert mit der Bildhohe und Farbraum ergeben
wurde, ist es in den meisten Fallen sinnvoll eine Umfangsreduktion anzustreben. Ei-
ne Moglichkeit zur Einschrankung der Komplexitat liegt in der Reduktion der Bild-
auflosung. Haufig ist es sinnvoll den Farbraum und Farbumfang des Bildes auf einen
Breich einzuschranken, der fur die jeweilige Anwendung sinnvoll ist. Oftmals wird das
YCbCr-Farbmodell fur die Vereinfachung der Erkennung einfarbiger Objekte genutzt,
da hierbei ohne komplexe Berechnung eine Konzentration auf bestimmte Farbwertbe-
reiche stattfinden kann. Außerdem konnen entsprechende Algorithmen zur Vorverar-
beitung der Bilder genutzt werden, um Große, Lage und Orientierung von Objekten
innerhalb des Bildes als Metadaten zu extrahieren.
In einem ersten Versuchsaufbau sollte ein Agent, fur ein zu verarbeitendes Bild, ei-
ne Kontrastkorrektur vornehmen. Der Agent sollte hierbei durch die Evaluierung des
Mean Opinion Score von externen Personen in seiner Auswahl beurteilt werden. Ein
Problem dieser Anordnung bestand jedoch darin, dass dieses episodisch konstruierte
Experiment lediglich einen einzelnen Schritt pro Episode zulasst. Nach jeder Kontrast-
korrektor war ein anderes Bild von dem Agenten zu verarbeiten und somit hatten bisher
gelernte Zusammenhange auf einer anderen Ausgangssituation basiert. Außerdem war
die externe Bewertung durch Betrachter ein ausschlaggebender Negativfaktor in der
maximalen Geschwindigkeit in der der Agent trainiert werden konnte.
13

In einem anderen Versuch der Bildverarbeitung sollte ein Q-Learning Agent eine zwei-
stufige Graustufen Schwellwertbildung an einem Bild vornehmen. Dieses sogenannte
Thresholding stellt einen haufig angewendeten Verarbeitungsschritt der Segmentierung
eines Bildes dar, der in der Bildverarbeitung und Objekterkennung Anwendung findet.
Durch geschickte Manipulation des Histogrammes eines Graustufenbildes kann jenes
auf ein reines schwarzweiß Bild reduziert werden. An Hand entsprechender Merkmale
angewandt, kann eine vereinfachte Objekterkennung stattfinden, da fur die Erkennung
unnotige Bildinformationen entfernt und Kontrastverhaltnisse erhoht werden. Jedoch
liefern fur einige Bilder funktionale Thresholding Parameter gute Ergebnisse und fur
andere Bilder keine. Deshalb ist es notig die entsprechenden Schwellenwerte fur jede
Anwendung erneut richtig zu finden und zu definieren [Tiz10].
Durch Anwendung von Thresholding auf einen bestimmten Farbkanal innerhalb eines
YCbCr Farbraum kodierten Bildes kann jenes auf einen fur die Anwendung interessan-
ten Farbbereich reduziert werden. Dieses Vorgehen fand auch bei dem bereits genannten
Nao Roboter Projekt der Universitat Bamberg Nutzen, um einen orangeroten Spielball
innerhalb der Kamerabildinformationen zu extrahieren.
Alle Versuchsaufbauten haben gemein, dass jeweils ein nicht vorverarbeitetes oder
vorverarbeitetes Bild einen Teil oder den gesamten Input fur die Lernaufgabe darstellt.
Der erzielte Output jedoch kann aus einem oder mehreren Ergebnisbildern oder auch
einfachen Zahlenwerten, zum Beispiel Koordinaten, bestehen. Taylor wahlt fur seine Im-
plementierung eine Anordnung von Zustanden und Aktionen innerhalb der ARTMAP,
bei welcher bisherige Parameter genauso betrachtet werden wie der Iterationszahler des
Algorithmus. Abbildung 8 zeigt die Verknupfungen von Zustanden (s), Aktionen (a)
und dem Parametervektor (p).
Abbildung 8: Aufbau das Zustandsnetztes [Tay04]
14

Als grundsatzliche Probleme fur die Implementierung fuhrt Taylor folgende Aspekte
an:
1. Der Parametervektor kann in jedem moglichen Schritt hochdimensional und nicht
endlich sein.
2. Die Parameter unterliegen lokalen Maxima.
3. Die verwendeten Bilder enthalten große Mengen Daten, weshalb die Zustandser-
kennung erschwert wird.
4. Die Bewertung der Ergebnisse durch ein externes Publikum ist haufig subjektiv
gepragt.
Taylor sieht jedoch in der Anwendung von Reinforcement Learning fur die Losung
dieser Problemstellungen große Chancen. Durch Generalisierung kann die Problematik
der Hochdimensionalitat und Kontinuitat gelost werden, wahrend stochastische Model-
le lokale Maxima uberwinden konnen. Durch den nicht endlichen Aktionsraum bedarf
es laut Taylor einer speziellen Anpassung der Fuzzy ARTMAP. Normalerweise wird fur
jede Aktion ein eigenes Netzwerk angelegt, was im Falle eines nicht endlichen Aktions-
raumes nicht moglich ist. Taylor lost diese Problem folgendermaßen:
”We have chosen to implement one network per algorithm step (this meaning the
image-based algorithm and not the reinforcement learning algorithm!), and thus apply
the state and currently considered action to the network, which then returns the corre-
sponding Q-value.” [Tay04]
Im Hauptteil der Arbeit verwendet Taylor die entwickelte Vorgehensweise, um die
Helligkeit eines Bildes durch einen lernenden Agenten beschreiben zu lassen, der einer
Erkennung und Analyse der Graustufen eines Bildes vornimmt. Dabei soll der Agent
auf Basis des Bildhistogrammes, dieses in bestimmte Helligkeitskategorien (Membership
functions - MF) einteilen. Die MF sollte moglichst einfach konstruiert sein, um den
Zustandsraum geringst moglich zu halten. Abbildung 9 zeigt die von Taylor genutzte
MF. X ist die unabhangige Variable der Graustufe. A, B und C definieren die Form
der MF.
15

Abbildung 9: Membership Function [Tay04]
Des Weiteren soll ein lernender Agent versuchen, in Bildern, welche aus Videos extra-
hiert wurden, Texte zu erkennen. Taylors Motivation liegt in der Erkennung von Text
fur einen schnellere Durchsuchbarkeit von archivierten Videoinhalten. Haufig wird ihre
Eigenschaft, dass eingespielte Untertitel auch bei Kameraschwenks ubergreifend kon-
stant ihre Position behalten, zur Erkennung ausgenutzt. Der Autor will jedoch diese
Eigenschaft nicht nutzen.
”Detecting text is only one way of making this browsing possible. Other means include
speech recognition and face detection. Text, however, possesses “immediate” meaning,
thus providing information without a sophisticated interpretation process. Although its
interpretation is still subjective, it is less ambiguous than, say, low-level image features.
[...] For videos containing a well-defined structure, such as news broadcasts, individual
segments may be both opened and closed by on-screen text (the latter often being the na-
mes of the journalists or production team involved in that particular sequence).” [Tay04]
16

Abbildung 10: Artificial text and scene text [Jol03]
Hierbei muss zwischen Untertiteln (10 b), welche nachtraglich uber das Videoma-
terial gelegt wurden und haufig einen sehr guten Kontrast zum eigentlichen Videoin-
halt haben und abgefilmten Textinhalten (10 a), welche oft nur schwierig erkennbar
sind, unterschieden werden. Letztere lassen sich in unabsichtlich abgefilmten Inhalten
und absichtlich, zum Teil speziell herangezoomten Inhalten, unterscheiden. Zur Erken-
nung konnen folgende Eigenschaften von Textinhalten innerhalb von Videos ausgenutzt
werden: Textinhalte, wie Buchstaben und Worter, stehen in einem raumlich zusam-
menhangen Bereich. Textinhalte konnen je nach Sprache eine Haufung geometrischer
Regelmaßigkeiten aufweisen (z.B. senkrechte Linien in europaischen Sprachinhalten).
Außerdem werden Einblendungen haufig mit einem sehr starken Kontrast zum eigent-
lichen Videoinhalt dargestellt, teilweise sogar in einer gesonderten Farbgebung.
Eine bestehende Implementierungen zur Erkennung von Textinhalten in Videos nutzt
eine Farbraumreduzierung und versucht anschließend auf Basis der Gruppierung von
Farbgruppen eine Erkennung raumlicher Clusterbildung [Yu98]. Eine andere Implemen-
tierung sucht innerhalb der Bilder nach raumlich begrenzten Bereichen mit besonders
hohen Kontrastverhaltnissen und versucht anschließend an diesen Stellen einen Erken-
nung von Textinhalten durchzufuhren. Dabei macht sie sich die Eigenschaft zu nutze,
dass gesetzte Untertitel sich besonders haufig von ihrem Hintergrund abheben sollen
und somit kontrastierende Farbgestaltungen und Konturen Anwendung finden [Lie96].
17
Taylor hingegen baut seinen Algorithmus auf einer Arbeit von Christian Wolf und Jean-
Michel Jolion auf, welche folgendermaßen implementiert wurde:
”A first coarse detection calculates a text ”probability” image. After wards, for each
pixel we calculate geometrical properties of the eventual surrounding text rectangle.
These features are added to the features of the first step and fed into a support vector
machine classifier.” [Jol03]
Zwar geben Wolf und Jolion fur die Implementierung ihres Algorithmus eine Vor-
gabe fur grundsatzlich geeignete Parameter ihrer Implementierung vor, jedoch stellt
Taylor die Frage, ob durch Anwendung seiner Parameter-Control Algorithmen nicht
geeignetere Parameter durch Lernen gefunden werden konnen. Zur Endauswertung
der Versuchsanordnung vergleicht Taylor drei verschiedene RL Implementierungen, Q-
Learning, Sarsa und Sarsa(λ). Alle Algorithmen erreichen eine, fur sie optimale, Stra-
tegie bereits nach etwa 1000 Iterationen. Abbildung 11 zeigt die Implementierungen im
Vergleich:
Abbildung 11: Q-Learning, Sarsa und Sarsa(λ) im Vergleich [Tay04]
”We have also compared the running times for 5000 iterations of each algorithm
[...]. In all cases, we see that the algorithm converges far before the maximum number
of iterations is reached. It is of interest that Q-learning considerably outperforms Sarsa
for this task. There are documented cases [...] where the opposite is seen. As expected,
18
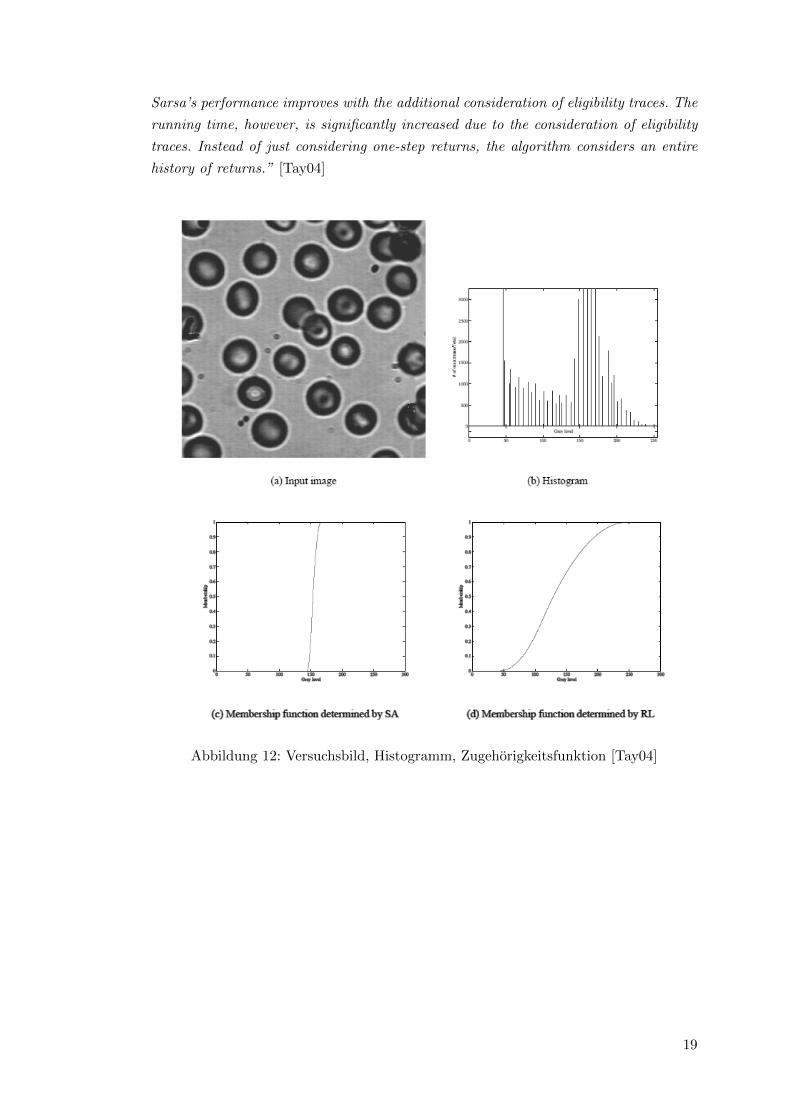
Sarsa’s performance improves with the additional consideration of eligibility traces. The
running time, however, is significantly increased due to the consideration of eligibility
traces. Instead of just considering one-step returns, the algorithm considers an entire
history of returns.” [Tay04]
Abbildung 12: Versuchsbild, Histogramm, Zugehorigkeitsfunktion [Tay04]
19

Abbildung 13: Anwendung der Zugehorigkeitsfunktion [Tay04]
Die Abbildung 12 zeigt den Vergleich zwischen der gefundenen Zugehorigkeitsfunktion
durch Reinforcement Learning (d) und Simulated Annealing (c). Die Abbildung 13 zeigt
die Anwendung der gefundenen Funktionen auf dasselbe Testbild. Dabei wird deutlich,
dass die durch Reinforcement Learning (d) definierte Zugehorigkeitsfunktion ein deut-
lich weniger rauschendes Ergebnis zuruckliefert und dennoch eine klare Abgrenzung
zwischen zugehorigem und nicht zugehorigem Inhalt ermoglicht.
20

2.2.3 Elevator Group Control Using Multiple Reinforcement Learning Agents
Bei diesem Projekt sollte die intelligente Steuerung einer Aufzuganlage mit vier Fahr-
stuhlen und zehn Stockwerken durch die Implementierung von Agenten des bestarkenden
Lernens erfolgen. Dadurch sollte eine hohere Flexibilitat, sowie eine erhohte Robustheit,
gegenuber Veranderungen und Unvorhersehbarkeiten erreicht werden [Bar97]. Durch
die Nutzung und Zusammenfuhrung unterschiedlicher Reinforcement Learning Algo-
rithmen soll eine optimale Leistungsfahigkeit und Anpassungsfahigkeit des Systems
garantiert werden. Die Nutzung und Zusammenfuhrung unterschiedlicher Reinforce-
ment Learning Algorithmen birgt neue Moglichkeiten zur Optimierung bei der Losung
von Lernaufgaben.
”Multi-agent RL combines the advantages of bottom-up and top-down approaches to
the design of multi-agent systems. It achieves the simplicity of a bottom-up approach
by allowing the use of relatively unsophisticated agents that learn on the basis of their
own experiences. At the same time, RL agents adapt to a top-down global reinforce-
ment signal, which guides their behavior toward the achievement of, complex specific
goals.” [Bar97]
Dabei sollen mehrere Agenten entsprechend auf dasselbe Problem hin trainiert wer-
den. Unterschiedliche Zielsetzungen waren zwar moglich, die Vereinfachung der Suche
durch den Strategie Raum hat jedoch Prioritat. Die Aufgabe der Aufzugsteuerung ist
in einen hochdimensionalen, nicht endlichen Zustandsraum einzuordnen und ist stark
von dynamischen außeren Einflussen (Anzahl an Fahrstuhlpassagieren pro Zeiteinheit
und Tageszeit) beeinflusst. Ein Team aus mehreren Agenten ist jeweils fur einen Fahr-
stuhlschacht zustandig. In einem Versuch sollen Agententeams mit einem unter ihnen
geteilten Neuronalen Netz und Agenten mit jeweils eigenstandigen Neuronalen Netzen
in ihrer Leistung und Eignung verglichen werden.
Statt ubergreifenden Systemen, welche eine vollstandige Einsicht in den Problem-
raum haben und dadurch in diesem Anwendungsfall besonders schwierig zu implemen-
tieren sind, soll ein Team von weniger komplexen lernenden Agenten in ihrer Gruppen-
dynamik und ihrer Fahigkeit zur Problemlosung in hochdimensionalen Problemstellun-
gen betrachtet werden.
21

Abbildung 14: Schematisches Aufzugsschacht Diagramm [Bar97]
Die Abbildung 14 zeigt den Aufbau des Aufzugsystems, welches es mit den Agenten
zu steuern gilt. Die Plus- und Minussymbole im Diagramm reprasentieren Personen
die einen Fahrstuhl betreten oder verlassen mochten. Linksstehende Symbole werden
genutzt, um nach oben fahrende Gaste kenntlich zu machen, wahrend rechtsstehende
Symbole fur eine Fahrt in ein niedrigeres Stockwerk stehen. Da es sich bei dem Gebaude
um ein Buro handelt, ist ein massiver Anstieg aufwarts fahrender Fahrgaste (Up-peak)
in den Morgenstunden und abwarts Fahrender (Down-peak) in den Abendstunden zu
beobachten. Jedoch ist im Gegensatz zu erstem Fall im zweiten Fall das Zielstockwerk
haufiger das Erdgeschoss. Aufzugsysteme werden in ihren Kapazitaten in der Regel
so entworfen, dass sie den vorausberechneten Up-peak aufnehmen konnen, da dieser
durch die unterschiedlichen Zielstockwerke stets eine hohere Last bedeutet, als der
Down-peak.
Fruher ubliche Aufzugsteuerungen gingen nach dem Prinzip vor, die Aufzuge stets
an den nachstgelegenen Wunschhaltestellen in Fahrtrichtung anhalten zu lassen. Die-
se Methode fuhrt jedoch zwangslaufig zu einem haufigen Ankommen und Offnen von
Fahrstuhlen im selben Stockwerk (Bunching). Bunching sollte stets vermieden werden,
da das mehrfache Halten im selben Stockwerk keine optimale Lastverteilung darstellt
und in der Regel auch nicht notig ist, um alle Fahrgaste aufnehmen zu konnen. Andere,
nicht auf Lernen basierte Methoden die Anwendung finden sind:
22

Zoneneinteilung: Jedem Fahrstuhl wird eine spezifische Gruppe von Stockwerken zu-
geordnet, innerhalb welcher ausschließlich dieser Fahrstuhl Fahrgastanfragen an-
nimmt.
Such-Basiert: Anfragen werden entsprechend der Suche innerhalb vordefinierter Ak-
tionsablaufen ausgewahlt. Dabei wird zwischen Greedy Algorithmen basierten
Systemen, welche eine schnelle Wahl treffen und dann keine Anderung durch
weitere Fahrgastanfragen zulassen und nicht Greedy Algorithmen unterschieden.
Letztere wahlen fur jede Anfrage erneut einen Aktionsablauf, lassen somit aber
nicht zu, den wartenden Fahrgasten anzuzeigen, welcher Fahrstuhl ihre Anfrage
bearbeiten wird.
Regel-Basiert: Von Experten bewertete und optimierte Regelsatze werden von einem
Fuzzy Suchalgorithmus ausgewahlt und vom System angewendet.
Heuristische Ansatze: Ansatze, bei welchem die am langsten wartenden Fahrgaste
zuerst abgearbeitet werden, oder das hochste, bisher unbearbeitete Stockwerk.
Außerdem existiert eine Losung, bei der vordefinierte Abstande zwischen den
Fahrstuhlen moglichst eingehalten werden sollen [Bar97].
Das Agentensystem wurde in einer Simulation mit folgenden Parametern getestet:
Stockwerkwechsel 1,45 Sekunden
Haltezeit 7,19 Sekunden
Richtungswechsel 1 Sekunde
Beladezeit 0,6 - 6,0 Sekunden
Fahrstuhle 4
Kapazitat 20 Personen/Fahrstuhl
Durch diese Gegebenheiten ergibt sich folgender Zustandsraum:
Rufknopfe 18
Positionskombinationen 240
Richtungskombinationen 184
Zustande ˜ 1022
23

Grundsatzlich hat jeder Fahrstuhl einen relativ eingeschrankten Aktionsraum. Die
Moglichen Zustande beschranken sich auf die Bewegungsrichtungen und den Stillstand.
Außerdem kann er an einer Haltestation anhalten oder weiterfahren, wobei hier die
Einschrankung gilt, dass an einem Stockwerk, an welchem der Rufknopf oder Halte-
knopf betatigt wurde, auch angehalten werden muss. Außerdem soll in Stockwerken, in
denen bereits ein Fahrstuhlanfrage bearbeitet wird, nicht von einem anderen Fahrstuhl
zur Annahme gehalten werden.
Das System wurde fur das gemittelte Quadrat der Wartezeiten optimiert, um be-
sonders hohe Wartezeiten negativer zu bewerten, als in einem nicht quadrierten Mittel
der Wartezeiten. Eine angepasste Implementierung des Q-learning Algorithmus kam
zum Einsatz, um das Agentennetzwerk aufzubauen. Einerseits wurde der ubliche Se-
kundenwert, der zur Bewertung herangezogen wird, durch dem Faktor 106 dividiert,
um zu große Werte in der Funktion zu vermeiden. Andererseits wurde der Q-Learning
Algorithmus so angepasst, dass er kein Modell mehr benotigt, sondern nur tatsachlich
stattgefundene Ereignisse beachtet. Dieser Schritt war notig, um trotz des hohen Bran-
ching Faktors sinnvolle Annahmen treffen zu konnen.
Des Weiteren konnen dem System nur jene Wartezeiten bekannt sein, die mit dem
Drucken des Halteknopfes beginnen. Fahrgaste die erst verzogert zu bereits Wartenden
stoßen, konnen vom System nicht in ihrer tatsachlichen Wartezeit unterschieden wer-
den, obwohl sie ein ausschlaggebender Faktor fur die Last des Systems sein konnen.
Diese Tatsache kann entweder durch eine allwissende Simulationsumgebung umgangen
werden, oder durch Berechnung der mittleren Abweichung von der eigentlichen Warte-
zeit der Poisson-Verteilung.
Die Komplexitat der Aufgabe ubersteigt die Moglichkeiten einer tabellarischen Auf-
listung aller Ablaufe, weswegen ein vorwartsgerichtetes neuronales Netz mit 47 Ein-
gangswerten, 20 hidden sigmoid Einheiten und ein oder zwei linearen Ausgabewerten
aufgebaut wurde. Im Vergleich mit anderen Aufzugsteuerungen ergaben sich die in Ab-
bildung 15 dargestellten Resultate fur ein realitatsnahes Szenario:
Abbildung 15: RL im Vergleich mit anderen Aufzugsteuerungssystemen [Bar97]
24
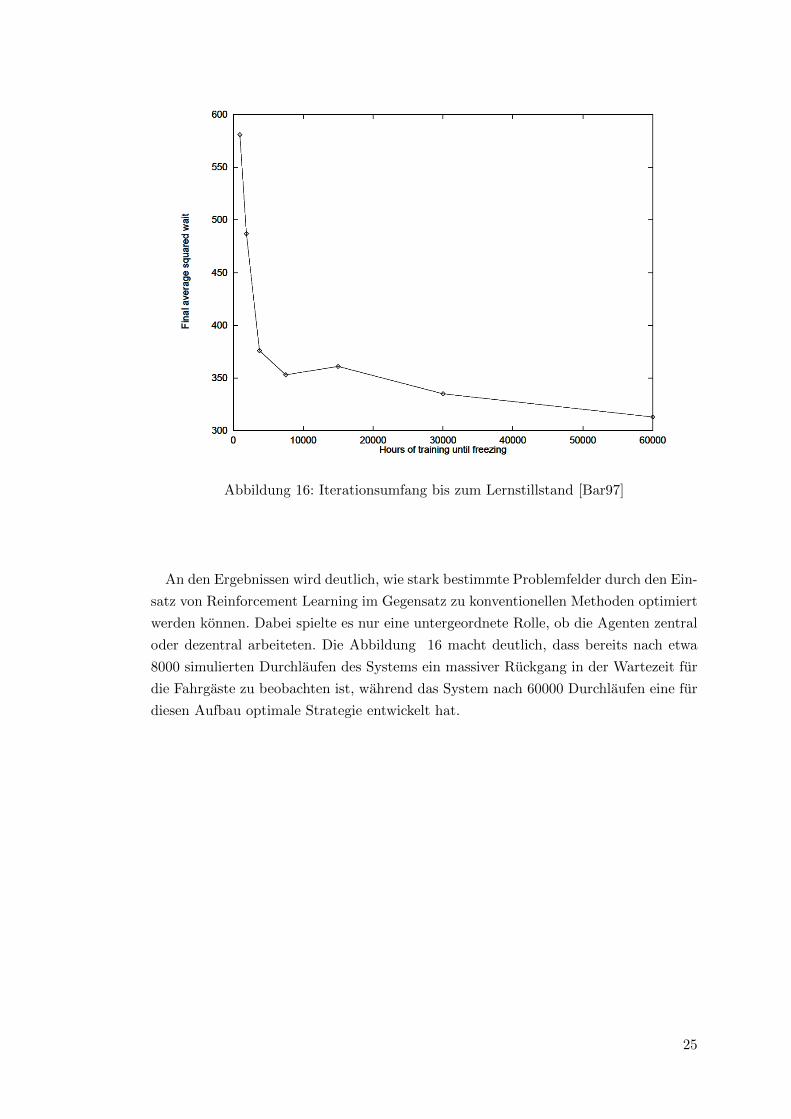
Abbildung 16: Iterationsumfang bis zum Lernstillstand [Bar97]
An den Ergebnissen wird deutlich, wie stark bestimmte Problemfelder durch den Ein-
satz von Reinforcement Learning im Gegensatz zu konventionellen Methoden optimiert
werden konnen. Dabei spielte es nur eine untergeordnete Rolle, ob die Agenten zentral
oder dezentral arbeiteten. Die Abbildung 16 macht deutlich, dass bereits nach etwa
8000 simulierten Durchlaufen des Systems ein massiver Ruckgang in der Wartezeit fur
die Fahrgaste zu beobachten ist, wahrend das System nach 60000 Durchlaufen eine fur
diesen Aufbau optimale Strategie entwickelt hat.
25

3 Algorithmik und Simulationsumgebung
3.1 Markov Entscheidungsprozess
Der Markov Entscheidungsprozess ist eine Darstellungsform von Optimierungsproble-
men durch ein mathematisches System zur sequentiellen Entscheidungsfindung. Der
MEP wird hierbei durch ein Tupel von Zustanden (S), Aktionen (A), Abbildungen
mit Wahrscheinlichkeiten (T : S x A x S’ → [0,1]), der Belohnungsfunktion (R)
und der Startverteilung (p0) definiert. Dabei besagt die Markov-Annahme, dass die
Wahrscheinlichkeit einen Folgezustand zu erreichen, lediglich vom aktuellen Zustand
abhangig ist und nicht von vorangegangenen Entscheidungen. In jedem Schritt findet,
ausgehend vom aktuellen Systemzustand, durch die Wahl einer Aktion ein Ubergang
mit einer bestimmten Wahrscheinlichkeit in einen Nachfolgezustand statt [Par11].
M = (S, A, T, R, p0)
Es wird angestrebt eine Losung des MEP zu finden und durch eine Strategie (π : S→A) zu formulieren. Die Strategie soll durch bestarkendes Lernen so definiert sein, dass
sie die Belohnungsfunktion, uber die verfugbare Zeitspanne hinweg kumuliert, maxi-
miert. Da jedoch in der hier vorliegenden Anwendung die Ubergangswahrscheinlichkeiten
unbekannt sind, wird versucht eine Strategie durch Mehrfachdurchlaufe innerhalb einer
Simulation zu finden. Die Markov Eigenschaft wird erfullt, da die Simulation jeweils
aus exakt demselben Ursprungszustand beginnt und keine Veranderungen an der Um-
gebungssimulation stattfinden sollen.
26
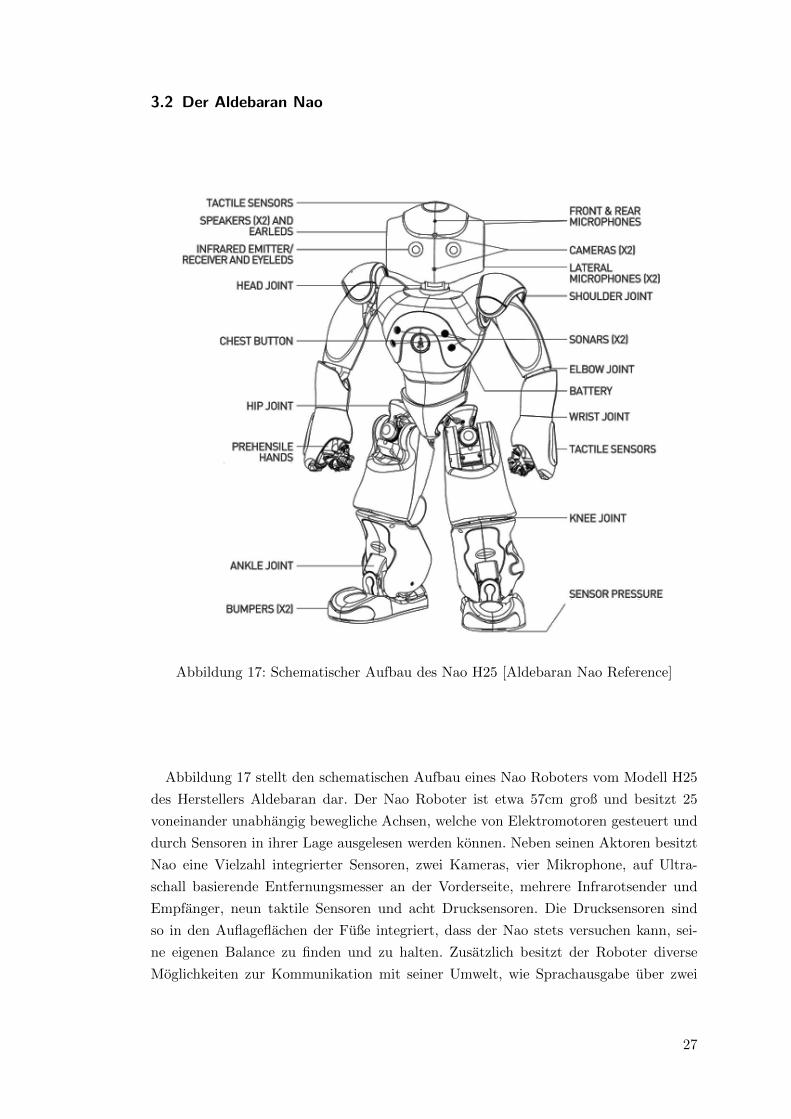
3.2 Der Aldebaran Nao
Abbildung 17: Schematischer Aufbau des Nao H25 [Aldebaran Nao Reference]
Abbildung 17 stellt den schematischen Aufbau eines Nao Roboters vom Modell H25
des Herstellers Aldebaran dar. Der Nao Roboter ist etwa 57cm groß und besitzt 25
voneinander unabhangig bewegliche Achsen, welche von Elektromotoren gesteuert und
durch Sensoren in ihrer Lage ausgelesen werden konnen. Neben seinen Aktoren besitzt
Nao eine Vielzahl integrierter Sensoren, zwei Kameras, vier Mikrophone, auf Ultra-
schall basierende Entfernungsmesser an der Vorderseite, mehrere Infrarotsender und
Empfanger, neun taktile Sensoren und acht Drucksensoren. Die Drucksensoren sind
so in den Auflageflachen der Fuße integriert, dass der Nao stets versuchen kann, sei-
ne eigenen Balance zu finden und zu halten. Zusatzlich besitzt der Roboter diverse
Moglichkeiten zur Kommunikation mit seiner Umwelt, wie Sprachausgabe uber zwei
27

Lautsprecher, Spracherkennung und Richtungserkennung von Gerauschen durch meh-
rere integrierte Mikrophone, sowie LEDs, welche in ihrer Farbe variiert werden konnen.
Die interne Verarbeitung der Sensorik und Ausfuhrung von Programmcode erfolge auf
zwei eingebauten Prozessoren der Marke Intel Atom, welche mit einer Taktfrequenz von
1,6Ghz arbeiten. Auf Softwareseite steht diesen ein Linux Kernel und ein proprietares
Betriebssystem sowie die Kommunikationsschnittstelle Naoqi gegenuber. Naoqi kann
uber die vorhandene Ethernet Schnittstelle oder durch Einbindung des Nao Roboters
in ein bestehendes WLAN-Netzwerk angesprochen werden [Win13].
Roboter des Typs Nao finden vorwiegend in der Forschung und Lehre an Schulen und
Universitaten Anwendung. Sie werden jedoch auch fur Roboter Fußball Wettkampfe
eingesetzt. Die großte entsprechende Liga heißt RoboCup Standard Platform League,
welche 1997 gegrundet und in welcher seit 2004 Weltmeisterschaften im Roboter Fuß-
ball von internationalen Teams ausgetragen werden.
”The Robot World Cup Initiative (RoboCup) is an international joint project to pro-
mote AI, robotics, and related field. It provides a standard platform for robotic soccer
game which includes a vision system, a strategic play algorithm and small mobile ro-
bots.” [O05]
Durch seine Vielzahl von Sensoren und seine motorischen Fahigkeiten eignet sich
Nao fur dieses Aufgabenfeld. Nichtsdestotrotz findet im RoboCup haufiger eine speziell
angepasste Version des Nao, die Robocup Version, ihren Einsatz. Diese Version des
Roboters hat eine andere Farbgestaltung, um die Unterscheidbarkeit zum Spielball zu
erhohen.
Nachfolgende Liste zeigt bekannte Probleme und Limitierungen des Roboters, die
wahrend der Durchfuhrung des Projektes der Universitat Bamberg aufgetreten sind.
• Cameraviewdistance Top: 1.1m - undefined
• Cameraviewdistance Bottom: 0.2m - 1.2m
• Maximum FOV horizontally: 60◦
• Maximum FOV vertically: 48◦
• Battery life: 1h
• Time to charge: 5h
• Active use time: 30min (limited by motor heat)
• Time to cool down: >1h
• RedBallTracker needs 2 seconds to initialize
28

• RedBallDetection is unprecise which leads to error cases: Detection of Objects
that are similar in colour and/or shape
• Head pitch to max 30◦ in each direction
• Maximum iterations of the ballposition is 10 times per second
• Reading empty values from memory will lead to a NullPointerException [Win13]
Ein Teil dieser Limitierungen wurde die Ausfuhrung der fur Algorithmen des bestarken-
den Lernens ublichen mehreren hundert Durchlaufen innerhalb eines normalen Zeitli-
chen Rahmens unmoglich machen. Ein weiterer Grund fur die Umsetzung des Experi-
ments innerhalb einer Simulation ist die Vermeidung eines Defektes, der eventuell durch
Uberbeanspruchung und Sturze des Roboters ausgelost werden konnte. Die Erkannten
Eigenschaften des Nao Roboters sollen in der Simulationsumgebung realitatsnah um-
gesetzt werden.
3.3 Systeminformationen der Simulationsumgebung
Um Ruckschlusse zwischen verwendeter Hardware, Komplexitat der Simulation und
aufzuwendender Zeit ziehen zu konnen, wird nachfolgend die Hardware des verwendeten
privaten Desktop PCs aufgefuhrt:
Prozessor Intel Core i7 3770K @ 4,4Ghz
Arbeitsspeicher 16GB DDR3
Datentrager Intel 180GB SSD
Grafikkarte Nvidia Geforce 670GTX
Folgende Softwareversionen wurden fur die Simulation verwendet:
29

Betriebssystem Microsoft Windows 8
Python 2.7.4
Numpy 1.7.1
Pynaoqi 1.14.0.218
Scipy 0.12.0
Python Setuptools 0.6c11
Webots for Nao 7.1.2
Aldebaran Choregraphe 1.14.2.5
3.4 Verwendete Software: Choregraphe, Webots for Nao und NaoQi
Die Implementierung des Versuchsaufbaus erfolgt auf Basis der Webots Software, einer
von Cyberbotics veroffentlichten Entwicklungsumgebung fur die Modellierung, Pro-
grammierung und Simulation diverser auf dem Markt erhaltlicher Roboter Modelle.
Die Software erlaubt es, eine Vielzahl von Objekten zu platzieren, die in ihren Eigen-
schaften wie Form, Große, Gewicht und physikalischen Eigenschaften variiert werden
konnen. Die fur die Simulation zur Verfugung stehenden Roboter Modelle konnen durch
simulierte Sensoren und Kameras ihre Umgebung innerhalb der Simulation wahrneh-
men. Die Objekte werden durch Knoten (Nodes) im Simulationsbaum reprasentiert und
sind hierarchisch voneinander anhangig. Die eigentlichen 3D-Modelle werden in einer
VRML-ahnlichen Sprache definiert und durch die freie Renderengine Ogre3D darge-
stellt.
30

Abbildung 18: Webots Userinterface [Aldebaran Webots for Nao]
Abbildung 18 zeigt den Aufbau der Software Webots for Nao. Im linken Teil der
Grafik wird der Scenetree dargestellt, welcher alle Objekte der Simulation mit deren
Eigenschaften und Abhangigkeiten umfasst. Im rechten Teil ist der Programmeditor
von Webots zu sehen, der ein Syntaxhighlight fur diverse Programmiersprachen bietet
und fur eine Editierbarkeit des auszufuhrenden Programmcodes genutzt werden kann.
Im mittleren Teil ist die eigentliche Simulation zu sehen, sowie drei abgegrenzte Render-
perspektiven, welche simulierte Kameras der Nao Roboter abbilden. Im unteren Teil ist
eine Debug-Konsole dargestellt, die Kommandozeilenausgaben der genutzten Agenten
ausgibt. Die obere Leiste beinhaltet Werkzeuge zum Eingreifen in die Simulation, die
bisher verstrichene Simulationszeit, sowie den aktuellen Faktor zwischen Genauigkeit
der Physikberechnung und Echtzeitdarstellung der Simulation.
Webots versucht stets ein passendes Maß zwischen Genauigkeit der Physikberech-
nung und Geschwindigkeit der Simulation zu finden, um im besten Fall in Echtzeit
simulieren zu konnen. Bei besonders aufwandigen Berechnungen und bei einer Vielzahl
von Objekten in der Simulation kann es vorkommen, dass Webots nicht mehr in der
Lage, ist in Echtzeit alle Berechnungen vorzunehmen. Tritt dieser Fall ein, wird die
Simulationsgeschwindigkeit unter den optimalen Wert von 1.0 (100 % Echtzeit) fallen
und die Genauigkeit der Berechnungen von Kollisionen und physikalischem Verhalten
kann in Mitleidenschaft gezogen werden. Auf einem aktuellen Computer tritt dieser
Fall jedoch nur bei mehreren Objekten und einer vom Nutzer zu kurz eingestellten
Berechnungswiederholung fur Kollisionen ein.
31
Abbildung 19: NaoQi [Aldebaran NaoQi]
Abbildung 20: Choregraphe [Aldebaran Choregraphe]
Die speziell fur den Einsatz des Nao Roboters konzipierte Version Webots for Nao,
ermoglicht es außerdem, denselben Programmcode auf dem echten, sowie dem in We-
bots for Nao simulierten Roboter auszufuhren. Hierbei wird das Betriebssystem des
Nao, NaoQi, auf dem lokalen PC simuliert und mit der Entwicklungsumgebung ver-
bunden (siehe Abbildung 19). Dann kann ein externer Zugriff uber das Netzwerk auf
32

NaoQi erfolgen, genauso wie auf ein echtes Robotermodell.
Die von Aldebaran publizierte Software Choregraphe (siehe Abbildung 20) erlaubt
eine einfache Uberwachung und Fernsteuerung von Nao Agenten, sowohl von simulier-
ten als auch von echten. Dabei kann eine Mischung aus visueller Programmierung und
Python-Programmierung erfolgen. Ein einzelner Nao Agent wird hierbei sowohl uber
seine Netzwerkadresse als auch uber seinen Port angesprochen, woraufhin dieser in sei-
nem aktuellen Zustand uberwacht werden kann. Eine dreidimensionale Darstellung des
Roboters zeigt dessen aktuelle Haltung in der Welt. Durch Abruf des Lagesensors kann
in der aktuellen Version von Choregraphe auch sichtbar gemacht werden, wenn der
Roboter hingefallen ist.
Die Kommunikation zwischen lernendem Agenten und der Simulation erfolgt mittels
der interpretierten Programmiersprache Python [Lee]. Python wurde deshalb gewahlt,
weil eine plattformunabhangige Implementierung erfolgen kann. NaoQi bietet eine Schnitt-
stelle zur Steuerung der Motorik und Sensorik des Nao Roboters aus Python heraus.
Einige quelloffene Implementierungen von Machine Learning Algorithmen als Biblio-
theken existieren ebenfalls fur Python.
3.5 Die freie machine learning Bibliothek PyBrain
Der Reinforcement Learning Algorithmus wurde fur diesen Versuchsaufbau nicht von
Grund auf neu implementiert, sondern basiert auf der freien Machine Learning Biblio-
thek PyBrain, welche durch eine Kooperation der Universitaten Dalle Molle Institute
for Artificial Intelligence in der Schweiz und der Technischen Universitat Munchen ent-
standen ist.
PyBrain unterstutzt eine Vielzahl von Algorithmen zur Realisierung von Aufgaben
des Maschinellen Lernens, welche teilweise untereinander austauschbar sind. Darunter
befinden sich Algorithmen des uberwachten und unuberwachten Lernens und diverse
Algorithmen des bestarkenden Lernens. Grundlage fur alle Algorithmen in PyBrain
sind neuronale Netze oder Datasets (Lookup Tables).
Implementierungen in PyBrain setzen sich aus Python Modulen zusammen. Der
Agent bestimmt das Vorgehen wahrend des Lernprozesses. Der Task regelt zusammen
mit dem Environment entsprechende Schnittstellen zwischen Simulation und Agenten.
Dazu zahlt die Moglichkeit zur Einsichtnahme in den aktuellen Zustand der Simulation,
die Ausfuhrung von entsprechenden Aktionen und die Ruckmeldung uber entsprechen-
de Belohnungen oder Bestrafungen. Alles umschließend steht das Experiment, welches
den Ablauf der Aufgabe regelt und die Anzahl der Durchlaufe uberwacht.
33

Abbildung 21: PyBrain Modulubersicht [PyBrain Reference]
PyBrain erlaubt mit seiner Vielzahl von Werkzeugen die Erzeugung diverser Ar-
ten von neuronalen Netzen. Dazu zahlen vorwartsgerichtete Netze, welche sich nicht
fur sequentielle Eingaben eigenen und jeden Eingabeparameter als unabhangig aller
vorangegangener Parameter betrachten. Unterstutzt werden ebenfalls wiederkehrende
Netze, die alle bisherigen Eingaben hinterlegen und somit einen Ruckblick in die vor-
angegangenen Parametereingaben erlauben. Den Netzen kann wahlweise der Tangens
Hyperbolicus fur die Schwellenwertdefinition oder die Softmax Activation Funktion zu
Grunde liegen.
3.6 PGPE Learner: Policy Gradients with Parameter-Based Exploration forControl
Policy Gradients with Parameter-Based Exploration for Control (PGPE), ist ein an der
Technischen Universitat in Munchen entwickelter modellfreier Reinforcement Learning
Algorithmus fur episodisches Lernen. Die Implementierung des Algorithmus ist Teil der
PyBrain Bibliothek und daraufhin optimiert, aus einer geringen Anzahl von Versuchs-
durchlaufen Lernerfolge nachzuweisen. Entwickelt wurde PGPE zur Losung von nur
teilweise uberwachbaren Markow Entscheidungsproblemen [Sch08].
Statt der Absuche des Strategieraumes verwendet PGPE die direkte Suche innerhalb
des Modellparameter Raumes. Dadurch wird eine deutlich geringere Streuung und eine
34
schnellere Konvergenz innerhalb der Teilstrategien, im Vergleich zu bekannten Policy
Gradient Methoden, wie zum Beispiel REINFORCE, erreicht. Wahrend REINFOR-
CE aus einer Reihe von gebildeten Versuchsaufbauten mit dazugehorigen Belohnungen
lernt, kann PGPE aus einer einzigen Stichprobe eine Action-State Entwicklung ermit-
teln.
Durch diese Eigenschaften eignet sich PGPE besonders fur Aufgabenfelder der Robo-
tik, bei denen durch Einschrankungen der Laufzeit und Langlebigkeit der eingesetzten
Komponenten besonders schnelle Lernerfolge Prioritat haben.
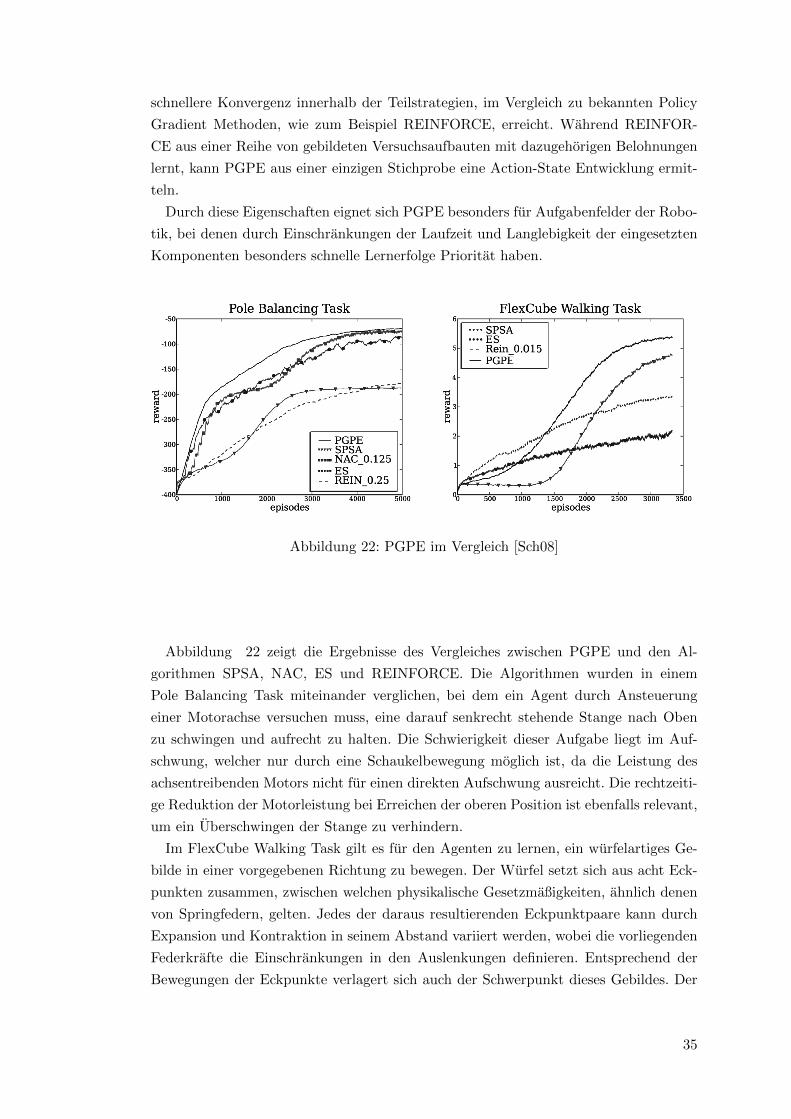
Abbildung 22: PGPE im Vergleich [Sch08]
Abbildung 22 zeigt die Ergebnisse des Vergleiches zwischen PGPE und den Al-
gorithmen SPSA, NAC, ES und REINFORCE. Die Algorithmen wurden in einem
Pole Balancing Task miteinander verglichen, bei dem ein Agent durch Ansteuerung
einer Motorachse versuchen muss, eine darauf senkrecht stehende Stange nach Oben
zu schwingen und aufrecht zu halten. Die Schwierigkeit dieser Aufgabe liegt im Auf-
schwung, welcher nur durch eine Schaukelbewegung moglich ist, da die Leistung des
achsentreibenden Motors nicht fur einen direkten Aufschwung ausreicht. Die rechtzeiti-
ge Reduktion der Motorleistung bei Erreichen der oberen Position ist ebenfalls relevant,
um ein Uberschwingen der Stange zu verhindern.
Im FlexCube Walking Task gilt es fur den Agenten zu lernen, ein wurfelartiges Ge-
bilde in einer vorgegebenen Richtung zu bewegen. Der Wurfel setzt sich aus acht Eck-
punkten zusammen, zwischen welchen physikalische Gesetzmaßigkeiten, ahnlich denen
von Springfedern, gelten. Jedes der daraus resultierenden Eckpunktpaare kann durch
Expansion und Kontraktion in seinem Abstand variiert werden, wobei die vorliegenden
Federkrafte die Einschrankungen in den Auslenkungen definieren. Entsprechend der
Bewegungen der Eckpunkte verlagert sich auch der Schwerpunkt dieses Gebildes. Der
35

Agent muss einen Weg lernen, durch geschickte Bewegung der Eckpunkte, den gesam-
ten Wurfel in einer Vorwartsbewegung zu versetzten.
36

4 Ziele und Umsetzung des Versuchsaufbaus
4.1 Gesteckte Ziele
Abbildung 23: Aufbau eines Roboterbeines [Aldebaran Nao Reference]
Durch Einsatz einer freien Implementierung eines Reinforcement Learners soll Nao
innerhalb einer Simulationsumgebung so trainiert werden, dass er selbststandig ei-
ne fur ihn optimale Ballschussanimation findet. Die Simulation orientiert sich hierbei
moglichst nahe an der Realitat. Durch Einsatz von Python und der Webots Simulati-
onssoftware konnen alle Versuche auch auf dem realen Roboter durchgefuhrt werden.
Der Nao Roboter und der Ball entsprechen in ihrer Konfiguration innerhalb der Simula-
tion dem realen Modell. Der Lernvorgang soll ohne außere Einwirkung oder Bewertung
stattfinden. Die Bewertung eines Schusses erfolgt auf Basis der Schussweite, der An-
zahl an Zwischenschritten in der Animation und der Frage, ob der Roboter bei diesem
Schuss umgefallen ware oder nicht. Zur Bewertung sollen die simulierbaren Kameras ge-
nutzt werden, welche in ihren Eigenschaften ebenfalls denen des tatsachlichen Roboters
entsprechen.
Der Lernprozess beginnt stets mit derselben Ausgangssituation, um dies sicherzustel-
len und eine Orientierung an der Realitat aufrecht zu erhalten, wird die Simulationssoft-
ware nach jedem Schuss mit denselben Parametern erneut initialisiert. Der Roboter be-
gibt sich vor jedem Schuss immer in eine vordefinierte Ausgangsposition. Die Ergebnisse
der Simulation sollen letztendlich auf das reale Robotermodell ubertragbar sein. Der
Versuchsaufbau ist lediglich auf das linke Bein des Roboters ausgelegt. Die Abbildung
37

24 zeigt die im Animation Mode am echten Robotermodell erstellte Ausgangsposition
fur einen Schuss. Dabei verlagert der Roboter seinen Schwerpunkt nach Rechts, indem
er beide Arme nach rechts fuhrt. Anschließende kippt er beide Huftachsen so ab, dass
sein Schwerpunkt rechts neben seinem Bein liegt. Danach hebt der Roboter sein linkes
Bein an, indem er das Knie- und Huftgelenk abknickt. Der Agent soll versuchen eine
maximale Schussweite mit einem minimalen Sturzrisiko des Roboters zu verknupfen.
Abbildung 24: Ausgangsposition fur den Schuss [Win13]
38

4.2 Konfiguration des neuronales Netzes
”An artificial neuron receives a number of floating point values either from the envi-
ronment or from other neurons. These floating point values compose a vector of inputs
which are modulated by being filtered by a set of weights. The weights model synaptic
efficiencies, the synapse being the connection between one neuron and the next.” [Fyf05]
Das neuronale Netz fur die Verwendung mit dem PGPE Learner nutzt die Tangens
Hyperbolicus Hyperbelfunktion (tanh) fur die Ausgabeschicht. Tanh wurde gewahlt,
weil seine Verwendung in Verbindung mit PGPE von den Entwicklern empfohlen wird.
Das neuronale Netz passt sich außerdem der Konfiguration der Simulation an. Bei
dem Start der Simulation wird uberpruft, wie viele Aktoren und Sensoren jeweils zur
Verfugung stehen. Die Anzahl der Aktoren bestimmt die Große der Eingabeschicht,
wahrend die Ausgabeschicht durch die Anzahl der Sensoren innerhalb der Simulation
bestimmt wird. Die Anzahl der verdeckten Schichten wird fest mit zwei definiert. Dieser
Wert entspricht der gebrauchlichen Praxis, die halbe Anzahl der Eingabeschicht Neuro-
nen fur die Anzahl der verdeckten Neuronen, zu verwenden. Komplexe Probleme konnen
durch hinreichend viele verdeckte Neuronen abgebildet werden, doch die Verwendung
zu vieler Neuronen fuhrt zu verschlechterter Performance und einem Neuronalen Netz,
welches anfalliger fur auftretendes Rauschen der Eingabeparameter ist [M12]. Das Netz
wird als vorwartsgerichtetes neuronales Netz konfiguriert, da ein Ruckblick auf voraus-
gegangene Entscheidungen fur den Lernprozess dieser Simulation nicht relevant ist.
39

4.3 Klassendiagramm / Grundlegender Aufbau der Simulation
Abbildung 25: Klassendiagramm
Abbildung 25 zeigt die in die Simulation involvierten Python Klassen. Der Einstiegs-
punkt in das Programm ist die Main-Klasse. Ausgehend von ihr werden die fur die
Simulation hauptverantwortlichen Klassen instantiiert:
NaoExperiment: (PyBrain Interface) Die umschließende Klasse des Experiments, wel-
che fur die Interaktion zwischen Agenten und Umgebung zustandig ist, sorgt
ebenfalls fur eine Einhaltung der gewunschten Anzahl an Durchlaufen und das
Lernverhalten des Agenten.
40

Environment: (PyBrain Interface) Diese Klasse dient der Verknupfung von Agenten
und Simulationsumgebung. Sie macht sich die beiden Klassen fur Sensorik und
Motorik zu Nutze, um dem Agenten ein Interaktionsinterface mit der Simulation
darzubieten. Außerdem nutzt sie die Webots connection-Klasse fur eine Fern-
steuerung der externen Webots Prozesse. Die Environment Klasse legt auch die
Anzahl der Aktoren und Sensoren fur den Agenten fest.
NaoTask: (PyBrain Interface) Diese Klasse definiert das gesetzte Ziel des Reinforce-
ment Learning Vorgangs. Sie ist direkt mit der Environment Klasse verknupft und
konfiguriert die physikalischen Grenzen der Parameterbereiche aller Aktoren. Au-
ßerdem ist sie fur die Belohnungsfunktion und die Moglichkeit zum Zurucksetzen
der Simulation zustandig.
Motion: Diese Klasse ist eine Erweiterung der bps motion-Klassen und stellt den zen-
tralen Zugriffspunkt fur alle motorischen Funktionen der Simulation dar. Ih-
re Hauptaufgabe bei diesem Experiment ist die Ausfuhrung der vom Agenten
gewahlten Beinbewegungsparameter und die Uberfuhrung des simulierten Robo-
ters in die Ausgangsposition.
Sensor: Zur Sensorik des Roboters zahlen die Positionen aller Achsen, die Erkennung
von Ballen und NaoMarks, die Initialisierung und Auswertung des Sonars, sowie
die Bestimmung und Berechnung der Ballposition. Diese Klasse ist des Weiteren
dafur zustandig festzustellen, ob der Roboter in der Simulation umgefallen ist.
Dies geschieht durch Auswertung der ebenfalls simulierten Drucksensoren, die in
den Fußen des Nao Roboters integriert sind.
CsvWriter: Mit Hilfe dieser Klasse werden sowohl Eingabeparameter, als auch die dar-
aus resultierende Belohnung in eine einfache Comma Seperated Value Datei ge-
schrieben. Da in diesem Fall eine Weiterverarbeitung und Auswertung der Daten
mit Excel erfolgen sollte und Excel CSV-Dateien entsprechend der Lokalisierung
des PCs unterschiedlich interpretiert, bietet sich hier die Moglichkeit das Trenn-
zeichen fur die Spalten als ASCII Dezimal Kode zu konfigurieren.
Logger: Die Logger-Klasse dient zur Hinterlegung aller Ablaufe in eigenstandigen Log-
buch Dateien. Dabei wird fur jedes Experiment ein eigenes Logbuch angelegt.
Das jeweils letzte Experiment wird im ”logfile latest.log” doppelt hinterlegt und
anschließend uberschrieben. Außerdem gibt die Logger-Klasse auch alle Ausgaben
auf der Systemkonsole aus.
41
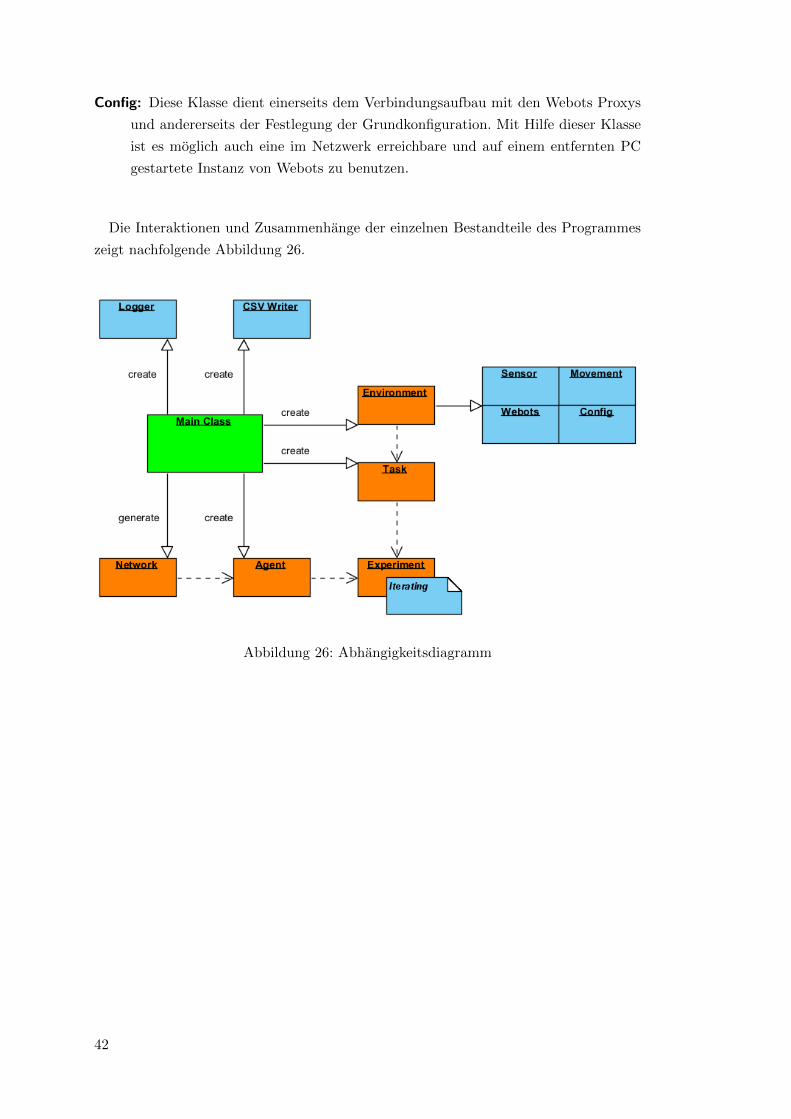
Config: Diese Klasse dient einerseits dem Verbindungsaufbau mit den Webots Proxys
und andererseits der Festlegung der Grundkonfiguration. Mit Hilfe dieser Klasse
ist es moglich auch eine im Netzwerk erreichbare und auf einem entfernten PC
gestartete Instanz von Webots zu benutzen.
Die Interaktionen und Zusammenhange der einzelnen Bestandteile des Programmes
zeigt nachfolgende Abbildung 26.
Abbildung 26: Abhangigkeitsdiagramm
42
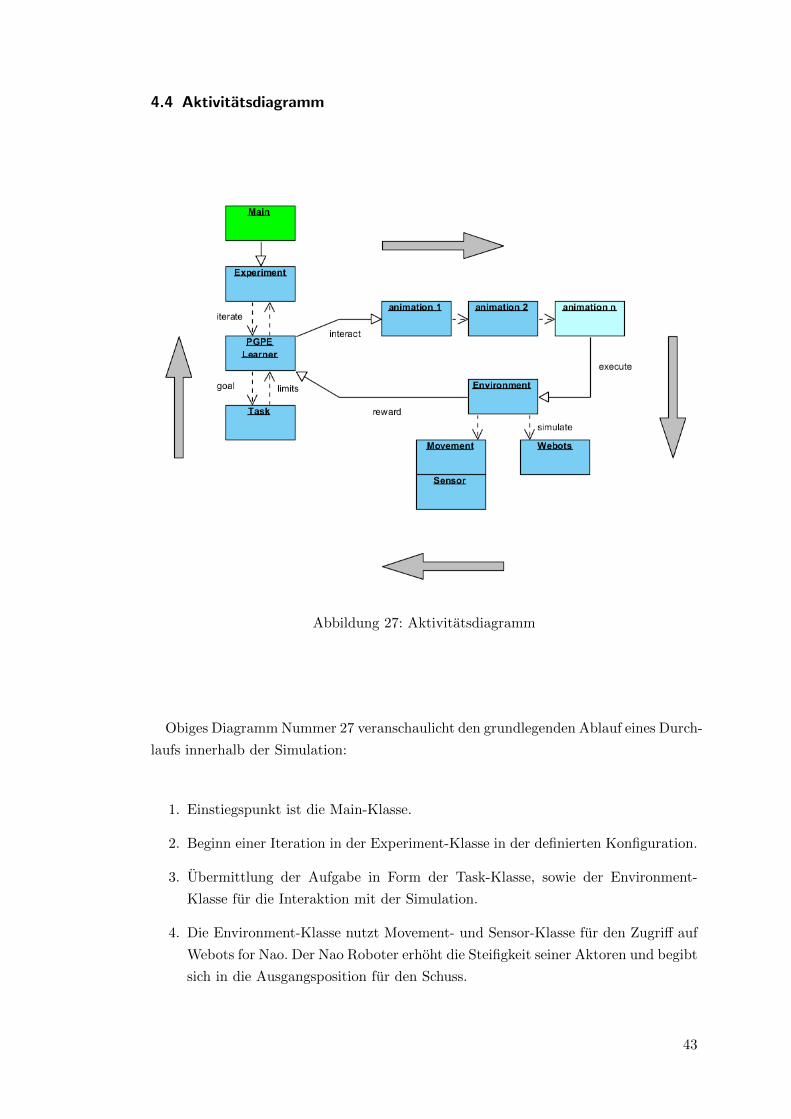
4.4 Aktivitatsdiagramm
Abbildung 27: Aktivitatsdiagramm
Obiges Diagramm Nummer 27 veranschaulicht den grundlegenden Ablauf eines Durch-
laufs innerhalb der Simulation:
1. Einstiegspunkt ist die Main-Klasse.
2. Beginn einer Iteration in der Experiment-Klasse in der definierten Konfiguration.
3. Ubermittlung der Aufgabe in Form der Task-Klasse, sowie der Environment-
Klasse fur die Interaktion mit der Simulation.
4. Die Environment-Klasse nutzt Movement- und Sensor-Klasse fur den Zugriff auf
Webots for Nao. Der Nao Roboter erhoht die Steifigkeit seiner Aktoren und begibt
sich in die Ausgangsposition fur den Schuss.
43

5. Der Agent erfragt den Zustand des Roboters und wahlt Parameter fur eine Teil-
animation. Die Anzahl der gewahlten Teilanimationen ist von der Konfiguration
des Experiments abhangig.
6. Das Environment fuhrt die Animationsschritte in der Simulation aus.
7. Die Bewertung der Parameter wird an den Agenten zuruckgeliefert.
8. Der Agent trainiert sein neuronales Netzwerk auf Basis der Parameterwahl und
der Belohnung.
9. Solange nicht alle Durchlaufe abgeschlossen sind, wird Webots for Nao reinitiali-
siert und bei Punkt 2 ein neuer Durchlauf gestartet.
4.5 Zustandsraum und Aktionsraum
Die Komplexitat des Zustandsraumes ergibt sich durch die Anzahl der Zustande in
denen sich der Nao Roboter im Experiment befinden kann. Nachfolgende Tabelle soll
eine Abschatzung der Komplexitat liefern. Da sich die momentane Konfiguration auf
die Ausfuhrung von ganzzahligen Parametern beschrankt, konnen die Integerwerte der
zulassigen Achsenpositionen fur eine Abschatzung herangezogen werden. Da jedoch
nicht jede Position des Beines erreicht werden kann, sei es durch Kollision mit ande-
ren Gliedmaßen oder dem Boden und auf Grund der Tatsache, dass etwa 25 % aller
Animationen zu einem Umfallen des Roboters fuhren, muss die Anzahl an realistisch
erreichbaren Zustanden um 75 % reduziert werden.
LHipPitch Zustande 71
LKneePitch Zustande 50
LAnklePitch Zustande 60
Geschwindigkeit 90
Durchlaufe 2
Zustande gesamt 38340000
Zustande realistisch 9585000
Der mogliche Aktionsraum des Nao Roboters ist von der Bewegungsfahigkeit inner-
halb seines Beines abhangig und kann folgendermaßen abgeschatzt werden:
44

LHipPitch Aktionsspanne 71
LKneePitch Aktionsspanne 50
LAnklePitch Aktionsspanne 60
Geschwindigkeit Aktions-
spanne
90
Aktionsraum gesamt 19170000
Aktionsraum realistisch 4792500
4.6 Abschatzung des zeitlichen Rahmens
Da Webots for Nao keine eigene API zur Integration in Python bereitstellt, muss die
Simulationssoftware per Batch Befehl gestartet und alle dazugehorigen Prozesse nach
Beendigung eines Durchlaufs gestoppt werden. Beim Start von Webots wird automa-
tisch die Simulation des NaoQi Systems im Hintergrund gestartet. Der Start von Webots
bis zur Verfugbarkeit von NaoQi dauert etwa funf bis sieben Sekunden. Eine manuel-
le Uberprufung zur Verfugbarkeit von NaoQi innerhalb des Python-Programmes jede
Sekunde ermoglicht ein gezieltes Starten des Experiments.
Das Experiment beginnt mit einer simplen Funktionsprufung aller Bestandteile des
Programmes. Dabei wird versucht eine Verbindung zu allen notigen Proxy Ankerpunk-
ten herzustellen. Ist dieser Test erfolgreich, wird der simulierte Roboter in die Aus-
gangsposition fur einen Schuss bewegt. Wenn dies alles erfolgreich stattgefunden hat
beginnen die eigentlichen Durchlaufe.
Die Ausfuhrung jedes Teils der Schussbewegung beansprucht, je nach der vom Agen-
ten gewahlten Geschwindigkeit, zwischen funf und funfundzwanzig Sekunden. Die an-
schließende Bewertung dauert im kurzesten Fall, wenn der Roboter umgefallen ist,
keine Sekunde, im Normalfall wird die Kamera und die Ballerkennung gestartet. Dann
mussen zwei Sekunden verstreichen, bis eine Ballerkennung als erfolgreich oder nicht
erfolgreich deklariert werden kann. Da die Kamera einen begrenzten vertikalen Bereich
abdeckt, erfolgt anschließend der Wechsel auf die obere Kamera, welche erneut zwei
Sekunden fur die Erkennung des Balles benotigt. Anschließend wird die Belohnung an
den Agenten ubergeben und die Daten in die CSV-Datei geschrieben. Nachfolgende
Tabelle soll Aufschluss uber den abgeschatzten Zeitlichen Rahmen bieten:
45

Startzeit Webots 5-7 Sekunden
Funktionsprufung 3 Sekunden
Teil Schussbewegung x · 5-25 Sekunden
Bewertung 0-6 Sekunden
Der Parameter x definiert die konfigurierte Anzahl an Teilschritten der Schussani-
mation und bestimmt somit ausschlaggebend den zeitlichen Rahmen. Andere Anwen-
dungen des PGPE Learners in ahnlichen Szenarien lassen auf einen Iterationsaufwand
von mindestens 1000 Durchlaufen bis zu ersten Ergebnissen schließen. Zur Festlegung
verlasslicher Ergebnisse sollen mindestens 2000 Durchlaufe stattfinden. Nachfolgende
Tabelle zeigt den voraussichtlichen zeitlichen Rahmen bis zum Erreichen dieses Ziels:
Durchlauf 35-60 Sekunden
Durchlaufe / Stunde 84 / x
2000 Durchlaufe 48 Stunden
46

5 Ergebnisse
5.1 Ubersicht der Ergebnisse
Der PGPE Learning Agent hat bei einem Experiment, welches aus uber 2000 Durch-
laufen bestand, das angestrebte Ergebnis erzielt. Der Agent hat die Exploration einge-
stellt und fur die gegebene Reward Funktion im Simulationsrahmens, fur sich optimale
Ballschuss-Parameter gefunden. Die vom Agenten gefundenen Parameter lauten, aus-
gehend von der dargestellten Ausgangsposition:
LHipPitch 1 -101◦
LKneePitch 1 80◦
LAnklePitch 1 80◦
Geschwindigkeit 1 23 %
LHipPitch 2 -101◦
LKneePitch 2 80◦
LAnklePitch 2 80◦
Geschwindigkeit 2 23 %
Reward 254,67
Schussweite 150cm
47
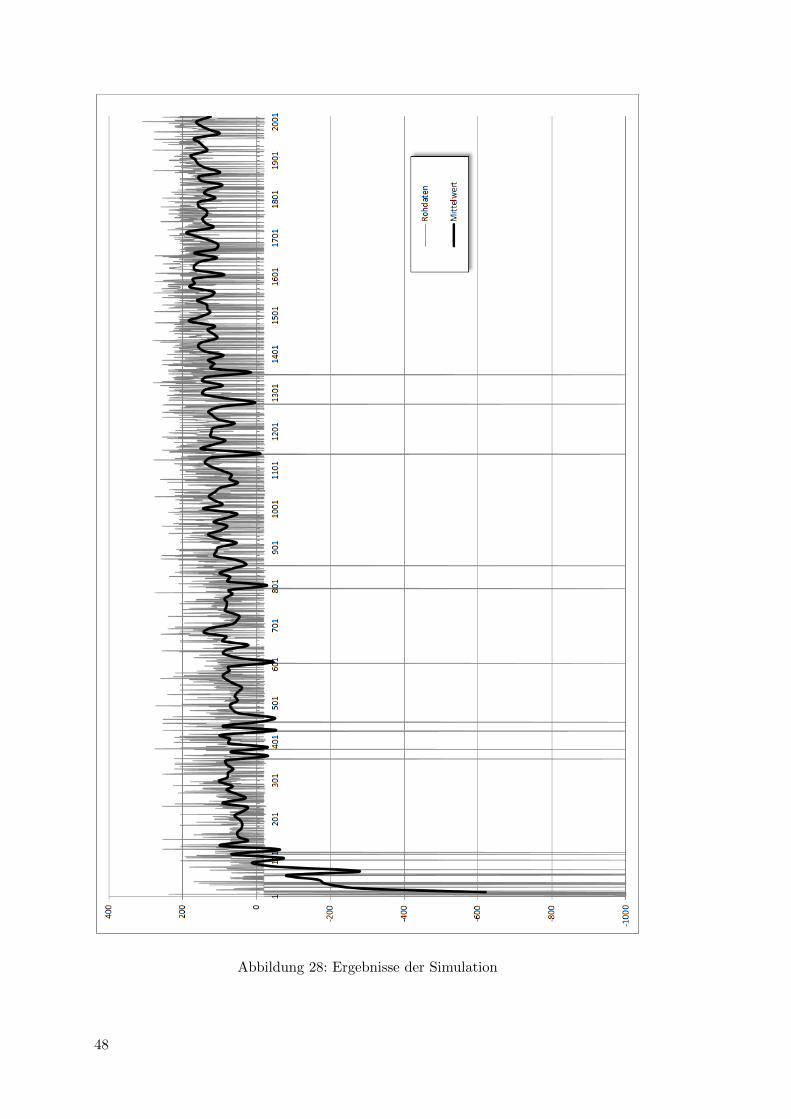
Abbildung 28: Ergebnisse der Simulation
48

Die Abbildung 28 zeigt die Ergebnisse der Simulation. Aufgetragen sind die Roh-
daten der Belohnungswerte uber die Durchlaufsachse hinweg verteilt. Werte von -1000
Punkten zeigen ein Umfallen des Agenten innerhalb der Simulation. Starker aufgetragen
ist eine geglattete Mittelwertslinie der jeweils zehn vorausgegangenen Belohnungswer-
te. Sie verdeutlicht den Lernerfolg des eingesetzten Learners. Außerdem sind folgende
Punkte zu beachten:
1. Das Experiment erfolgte in Echtzeit, weswegen die Simulation der 2000 Durchlaufe
uber 48 Stunden dauerte.
2. Der PGPE Algorithmus benotigt etwa einhundert Durchlaufe bis der Roboter
in seiner Parameterwahl derart vorsichtig vorgeht, dass er nicht mehr umfallt
(Reward: -1000). Spatere Falle von Stolpern sind der Exploration des Agenten
geschuldet.
3. Der Agent erreicht gegen Ende der Simulation einen maximalen Reward von etwa
250 Bewertungspunkten, was einer Schussweite von etwa 1,5 Metern entspricht.
Der Nao Roboter ware zwar in der Lage hohere Schussweiten zu erreichen, jedoch
sind die simulierten Kameras hier der limitierende Faktor. Der Agent erreicht in
einigen Durchlaufen eine deutlich hohere Schussweite, jedoch konnen die Kameras
auf diese Entfernung den Ball nicht mehr wahrnehmen. Somit fallt die Bewertung
fur den Agenten negativ aus. Er trainiert also die maximale Schussweite innerhalb
der Grenzen der Kameras. Es ware moglich gewesen, die Auflosung der Kameras
kunstlich innerhalb der Simulation zu erhohen, jedoch wurden diese Werte nicht
mit den Moglichkeiten des tatsachlichen Roboters ubereinstimmen. Eine manuel-
le Bewertung der 2000 Durchlaufe ware im zeitlichen Rahmen dieser Arbeit nicht
moglich gewesen. Trotzdem wird davon ausgegangen, dass die letztendlich vom
Agenten gelernten Parameter, ausgefuhrt mit einer hoheren Animationsgeschwin-
digkeit, eine hohere Schussweite bedeuten wurde.
4. Der Aufbau der Simulation sieht eine zweistufige Schussanimation vor. Wahrend
der Agent zu Beginn der Simulation noch unterschiedliche Parameter fur beide
Animationsbestandteile wahlt, werden gegen Ende des Experiments jeweils glei-
che Parameter ausgewahlt. Der Agent hat sich also dazu entschieden, die Schussa-
nimation auf eine Stufe zu reduzieren. Dies ist deshalb naheliegend, da der Agent
die maximal mogliche Beingeschwindigkeit, ausgehend von der Anfangsposition,
erreichen kann, ohne mit seinem Bein nach hinten ausholen zu mussen.
49

5. Das Ausmaß der Exploration des PGPE Learners nimmt wahrend der Simula-
tion rasch ab. Dadurch und durch die Eigenschaft der zufalligen Wahl der Aus-
gangsparameter ist es nicht auszuschließen, dass in weiteren Experimenten eine
zweistufige Schussanimation vom Agenten gewahlt werden konnte.
6. In der aktuellen Konfiguration werden zur Eingrenzung des Zustands- und Akti-
onsraums alle Eingabeparameter als Integerwerte gerundet. Diese Funktionalitat
kann entsprechend angepasst werden, um eine hohere Komplexitat der Simula-
tion zu erreichen. Durch den steigenden Simulationsaufwand kann eine genauere
Parameterfindung stattfinden.
7. Die Schatzung der benotigten Simulationszeit entsprach abschließend den Pro-
gnosen. Jedoch konnte das Ziel erst nach mehreren Versuchen erreicht werden, da
die Webots Software in Zusammenhang mit externer Ausfuhrung und Beendigung
der Anwendung fehleranfallig ist.
5.2 Bewertung und Ubertragbarkeit
Der Agent lernte innerhalb einer simulierten Umgebung einen komplexen Bewegungs-
ablauf nur auf Basis seiner Bewegungsfreiheiten und einer nachfolgenden Bewertung
seiner Interaktionen. Eine manuelle Implementierung des Bewegungsauflauf ware nur
schwer umsetzbar gewesen. Der PGPE Learner stellte sich wahrend der Planungsphase
als geeigneter Kandidat fur das vorgesehene Experiment heraus. Dies lag vor allem an
der vielversprechenden Geschwindigkeit mit der der Learner bereits aus wenigen Stich-
proben brauchbare Ruckschlusse ziehen kann. Die Vielzahl an Simulationsdurchlaufen
ware mit einem echten Roboter nicht moglich gewesen, da sowohl der zeitliche Aufwand
immens, als auch die Gefahr einer Beschadigung der Roboters durch die vielen Sturze
zu Beginn des Experimentes zu hoch gewesen ware.
Zielsetzung und Umsetzung der Arbeit sind als voller Erfolg zu bezeichnen. Die Er-
gebnisse des Experiments zeigen die Moglichkeiten von Reinforcement Learning in der
Robotik auf und machen deutlich, dass in der Realitat nicht umsetzbare Lernvorgange
innerhalb einer Simulation erfolgreich durchgefuhrt werden konnen. Letztendlich konn-
te PGPE uberzeugende Ergebnisse liefern und zeigte schnelle Resultate. Der aktuelle
Simulationsaufbau mit der Sprache Python und PyBrain als Bibliothek eignet sich auch
fur Versuchsaufbauten zum Vergleich der Leistungsfahigkeit unterschiedlicher Reinfor-
cement Learning Algorithmen, da PyBrain direkt eine Vielzahl jener unterstutzt und
diese teilweise untereinander austauschbar sind.
50

Die hier vorliegende Arbeit beruht auf dem Grundgedanken Simulation und Wirklich-
keit in einem moglichst großen Einklang zu bringen. Deshalb sind die Ergebnisse auch
insofern eingeschrankt, als dass sie sich auch in der Realitat, unter hoheren Aufwand,
durchfuhren ließen. Es ware durchaus denkbar die Simulation uber die Moglichkeiten
des Roboters in der Realitat hinweg zu erweitern. Eine Simulation sehr hoher Kame-
raauflosungen hatte zu genaueren und weiteren Schussen des Agenten fuhren konnen.
Das Experiment beschrankte sich auf drei Beinachsen und der Geschwindigkeit der
Ausfuhrung. Durch die Erweiterung auf weitere Aktoren innerhalb eines Beines ware
das Erlernen komplexerer Schussanimationen moglich. Durch die Erweiterung der Ge-
nauigkeit der Schussparameter auf weitere Nachkommastellen wurde ebenfalls eine
Moglichkeit zum Erlernen komplexerer Bewegungsablaufe bieten. In beiden Fallen je-
doch wurde der Zustandsraum immens anwachsen und der zeitliche Aufwand des Lern-
vorgangs deutlich steigen.
Außerdem ware es denkbar eine andere Ausgangsposition fur den Schuss zu ver-
wenden, oder diese ebenfalls vom Roboter erlernen zu lassen. Daraus konnten noch
erfolgreichere Schussanimationen erlernt werden, welche auch in ihrer Stabilitat und
Standhaftigkeit des Roboters uberlegen waren. Der zeitliche Aufwand wurde aber auch
hier immens anwachsen.
Der Arbeit liegt eine CD-ROM bei, welche zur Nachvollziehbarkeit und Weiterfuhr-
bakeit der Arbeit dienen soll. Sie enthalt den vollstandigen Quellcode der Implemen-
tierung, sowie eine ausfuhrliche Anleitung zur Umsetzung. Außerdem sind auf ihr alle
Abbildungen in hoherer Auflosung enthalten. Ebenfalls enthalten ist die in Webots for
Nao genutzte Simulationsumgebung, sowie die Choregraphe Animation um den Ro-
boter in die Ausgangsposition fur den Schuss versetzen zu konnen. Die ausfuhrlichen
Logbuchdaten, welche das Ergebnis dieser Arbeit sind, liegen ebenfalls bei. Die Arbeit
selbst ist mit farbigen Abbildungen im PDF Format auf der CD-ROM zu finden.
51

Literatur
[Bar97] Robert H. Crites; Andrew G. Barto. Elevator group control using multiplereinforcement learning agents. Department of Computer Science, University ofMassachusetts, Amherst, MA 01003, Feb 1997.
[Fyf05] Colin Fyfe. Hebbian Learning and Negative Feedback Networks. Springer-VerlagLondon Limited, ISBN 1-85233-883-0, 2005.
[Jol03] Christian Wolf; Jean-Michel Jolion. Model based text detection in images andvideos: a learning approach. PhD thesis, INSA de Lyon, 2003.
[Lee] Kent D. Lee. Python Programming Fundamentals. ISBN: 978-1-84996-536-1.
[Lie96] R. Lienhart. Automatic text recognition for video indexing. In Proceedings ofthe ACM Mltimedia 96, 96:11–20, 1996.
[M12] Gregoire Montavon; Genevieve B. Orr; Klaus-Robert Muller. Neural Networks:Tricks of the Trade. Springer-Verlag Berlin Heidelberg 1998, ISBN: 978-3-642-35288-1, 2012.
[Nil98] Nils J. Nilsson. Introduction to machine learning. Robotics Laboratory Depart-ment of Computer Science, Stanford University, Stanford, CA 94305, November1998.
[O05] Cagdas Yetisenler; Ahmet Ozkurt. Artificial Intelligence and Neural Networks- Multiple Robot Path Planning for Robot Soccer, volume 14th Turkish Sympo-sium, TAINN. Springer Berlin Heidelberg NewYork, ISBN 3-540-36713-6, June2005.
[Par11] Gerardo I. Simari; Simon D. Parsons. Markov Decision Processes and theBelief-Desire-Intention Model - Bridging the Gap for Autonomous Agents. Sprin-ger New York Dordrecht Heidelberg London, ISBN: 978-1-4614-1471-1, 2011.
[Ros92] Gail A. Carpenter; Stephen Grossberg; Natalya Markuzon; John H. Reynolds;David B. Rosen. Fuzzy artmap: A neutral network architecture for incrementalsupervised learning of analog multidimensional maps. IEEE Transactions onNeural Networks, 3(5), September 1992.
[Sch08] Frank Sehnke; Christian Osendorfer; Thomas Ruckstieß; Alex Graves; Jan Pe-ters; Jurgen Schmidhuber. Policy gradients with parameter-based exploration forcontrol. Faculty of Computer Science, Technische Universitat Munchen, Ger-many IDSIA, Manno-Lugano, Switzerland Max-Planck Institute for BiologicalCybernetics Tubingen, Germany, 2008.
[Sto10] Todd Hester; Michael Quinlan; Peter Stone. Generalized model learning forreinforcement learning on a humanoid robot. IEEE International Conference onRobotics and Automation (ICRA 2010), Anchorage, Alaska, May 2010.
[Tay04] Graham William Taylor. Reinforcement learning for parameter control ofimage-based applications. Master’s thesis, University of Waterloo, 2004.
[Tiz10] Ahmed A. Othman; Hamid R. Tizhoosh. Artificial Neural Networks - ICANN2010 - A Neural Approach to Image Thresholding, volume 20th International
52

Conference Thessaloniki; Greece. Springer Berlin Heidelberg NewYork, ISBN3-642-15818-8, September 2010.
[Vin08] Francesco Camastra; Alessandro Vinciarelli. Machine Learning for Audio,Image and Video Analysis - Theory and Applications. Springer-Verlag LondonLimited, ISBN: 978-1-84800-006-3, 2008.
[Win13] Jaime A. Delgado Granados; Fabian Selig; Norman Steinmeier; Daniel Win-terstein. Cogsys-project-b: Project nao soccer. Bachlor Project in KognitiveSysteme, February 2013.
[Yu98] A.K. Jain; B. Yu. Automatic text location in images and video frames. PatternRecognition 31, 2055-2076, 1998.
[Zac07] Mbaitiga Zacharie. Adaptive resonance theory 1 (art1) neural network basedhorizontal and vertical classification of 0-9 digits recognition. Journal of Compu-ter Science, Department of Media Information Engineering, Okinawa NationalCollege of Technology, 905 Henoko, Nago, 905-2192, Okinawa Prefecture, Japan,ISSN 1549-3636, 3(11), 2007.
53

Abbildungsverzeichnis
1 Interaktion von Agent und Umgebung . . . . . . . . . . . . . . . . . . . 22 Bachelor Project Nao Soccer [Win13] . . . . . . . . . . . . . . . . . . . . 43 Ballposition in Relation zur Roboterposition [Win13] . . . . . . . . . . . 74 Rotation um den Ball . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85 Choregraphe Timeline Editor . . . . . . . . . . . . . . . . . . . . . . . . 96 RL-DT im Vergleich [Sto10] . . . . . . . . . . . . . . . . . . . . . . . . . 117 Aufbau von ART1 Netzen [Ros92] . . . . . . . . . . . . . . . . . . . . . 128 Aufbau das Zustandsnetztes [Tay04] . . . . . . . . . . . . . . . . . . . . 149 Membership Function [Tay04] . . . . . . . . . . . . . . . . . . . . . . . . 1610 Artificial text and scene text [Jol03] . . . . . . . . . . . . . . . . . . . . 1711 Q-Learning, Sarsa und Sarsa(λ) im Vergleich [Tay04] . . . . . . . . . . . 1812 Versuchsbild, Histogramm, Zugehorigkeitsfunktion [Tay04] . . . . . . . . 1913 Anwendung der Zugehorigkeitsfunktion [Tay04] . . . . . . . . . . . . . . 2014 Schematisches Aufzugsschacht Diagramm [Bar97] . . . . . . . . . . . . . 2215 RL im Vergleich mit anderen Aufzugsteuerungssystemen [Bar97] . . . . 2416 Iterationsumfang bis zum Lernstillstand [Bar97] . . . . . . . . . . . . . . 2517 Schematischer Aufbau des Nao H25 [Aldebaran Nao Reference] . . . . . 2718 Webots Userinterface [Aldebaran Webots for Nao] . . . . . . . . . . . . 3119 NaoQi [Aldebaran NaoQi] . . . . . . . . . . . . . . . . . . . . . . . . . . 3220 Choregraphe [Aldebaran Choregraphe] . . . . . . . . . . . . . . . . . . . 3221 PyBrain Modulubersicht [PyBrain Reference] . . . . . . . . . . . . . . . 3422 PGPE im Vergleich [Sch08] . . . . . . . . . . . . . . . . . . . . . . . . . 3523 Aufbau eines Roboterbeines [Aldebaran Nao Reference] . . . . . . . . . 3724 Ausgangsposition fur den Schuss [Win13] . . . . . . . . . . . . . . . . . 3825 Klassendiagramm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4026 Abhangigkeitsdiagramm . . . . . . . . . . . . . . . . . . . . . . . . . . . 4227 Aktivitatsdiagramm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4328 Ergebnisse der Simulation . . . . . . . . . . . . . . . . . . . . . . . . . . 48
54

Eigenstandigkeitserklarung
”Ich erklare hiermit gemaß § 17 Abs. 2 APO, dass ich die vorstehende Bachelorarbeitselbststandig verfasst und keine anderen als die angegebenen Quellen und Hilfsmittelbenutzt habe.”
...............................................................Datum / Unterschrift