FO RU M
© 2011 Wiley-VCH Verlag GmbH & Co. KGaA, Weinheim www.pharmuz.de 4/2011 (40) Pharm. Unserer Zeit 355
M I K RO B I O LO G I E |Was bedeutet HUSEC041 MLST ST678?Über den enterohämorrhagischen Escherichia-coli-Stamm (EHEC), derdas gefürchtete hämolytisch-urämische Syndrom (HUS) auslösen kannund unter der Nummer 41 in der Referenzstammsammlung desKonsiliarlabors für HUS am Universitätsklinikum abgelegt ist, hat manmittlerweile schon mehr als genug gehört – es kommt einem schonschier zu den Ohren heraus. Aber ein Aspekt ist es unserer Meinungnach doch wert, noch einmal genauer betrachtet zu werden: das Geheimnis hinter dem Kürzel MLST ST678.
dere, breit angewendete Methode istdie Multilocus-Enzym-Elektrophorese(MLEE), bei der aus den BakterienEnzyme isoliert, über Gelelektro-phorese aufgetrennt und dann spezi-fisch angefärbt werden. Aber auchElektrophoresen sind störanfällig undnicht unbedingt immer eindeutigvergleichbar. Deshalb wurde irgend-wann die direkte DNA-Sequenzana-lyse als Identifikationsmöglichkeitvorgeschlagen.
Für eine derartige Analyse se-quenzierten die Autoren Maiden et al.1998 mehrere Loci (daher MLST) sogenannter housekeeping-Gene [1].Diese Gene codieren für Proteine, diefür das Bakterium lebenswichtig sindund aus diesem Grund meist rechtkonserviert vorliegen. Letztendlichwird bei dieser Methode ein nur ca.500 bp großes Fragment innerhalbeines jeden Gens zunächst perPolymerasenkettenreaktion vervielfäl-tigt und anschließend sequenziert.Maiden et al. hatten es seinerzeit an-hand von 6 housekeeping-Genen beiNeisseria menigitidis sehr anschau-lich demonstriert [1]. Der Vorteil die-ser Methode ist, dass die Sequenz na-türlich eindeutig zwischen unter-schiedlichen Labors vergleichbar ist,während Elektrophoresemuster einergewissen Varianz unterliegen. DieseMethode hat sich inzwischen so gutetabliert, dass etliche Datenbankenim Internet verfügbar sind, über dieman entsprechende MLST-Abgleichemachen kann.
Auch für pathogene E.-coli-Stämme hat sich das MLST bewährtund so hat das seit Mai kursierende
EHEC-Bakterium die Sequenztyp (ST)-Nummer ST678 erhalten.
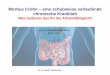
Für E. coli werden interne Frag-mente der Gene für Adenylatkinase(adk), Fumarat-Hydratase (fumC)DNA-Gyrase (gyrB), Isocitrat/Isopro-pylmalat-Dehydrogenase (icd), Malat-Dehydrogenase (mdh), Adenyl-succinat-Dehydrogenase (purA) so-wie für das ATP/GTP-Bindemotiv(recA) mit bestimmten Primern undunter bestimmten PCR-Bedingungenamplifiziert (Abb. 1A, Tab. 1) [2].Mittlerweile sind 600 Sequenztypenund 54 Sequenztyp-Komplexe in derDatenbank abgelegt.
In einer umfangreichen Analysevon 462 unterschiedlichen E.-coli-Isolaten, die von Menschen und 41
MLST steht für Multilocus SequenceTyping und wird seit 1998 als DIEMethode schlechthin propagiert, umpathogene Bakterien eindeutig zuidentifizieren [1]. Sei es, um frühzei-tig die richtige Therapie einleiten zukönnen, sei es um die Ausbreitung ei-ner Epidemie exakt verfolgen zu kön-nen oder auch um die Infektions-quelle sicher aufspüren zu können:Der „Feind“ sollte sicher und eindeu-tig charakterisierbar sein. Es heißt jaschließlich nicht umsonst: Gefahr er-kannt – Gefahr gebannt.
In der medizinischen Mikrobiolo-gie bedeutete die Stammcharakteri-sierung lange Zeit, dass Bakterien kul-tiviert werden müssen – möglichst ineiner „bunten Reihe“, d.h. gleichzei-tig auf unterschiedlichen Nährbödenmit verschiedenen Indikatorfarbstof-fen. Je nach Stoffwechselaktivität desBakteriums zeigten sich unterschied-liche Farbreaktionen, die anhand ei-nes Farbcodes interpretiert werdenkonnten. Das dauert und ist störan-fällig, so dass die Ergebnisse von Ver-such zu Versuch und von Labor zu La-bor nicht unbedingt immer vergleich-bar waren.
Seit die molekularbiologischenArbeitsmethoden Einzug in die ver-schiedenen Labors gehalten haben,werden unterschiedliche Genom-und Proteomanalysen angewendet,um Pathogene genauer diskriminie-ren zu können. Relativ gute Ergeb-nisse konnten mit der Pulsfeld-Gelelektrophorese (PFGE) von DNA-Fragmenten nach Hydrolyse mitbestimmten Restriktionsendo-nukleasen erhalten werden. Eine an-
gyrB
mdh
recA
fumC
purA adk
icd
A
BGen Fragment
adk 536 bp
fumC 469 bp
gyrB 460 bp
icd 518 bp
mdh 452 bp
recA 510 bp
purA 478 bp
Gesamt 3423 bp 0 2015105
Polymorphismus [%]
A B B . 1 | M L S T B E I E . COLI
A. Ungefähre Lokalisierung der für das Multilocus SequenceTyping verwendeten Gene im Genom von E. coli. B. Die geneti-sche Diversität der sieben housekeeping-Gene ist auf der Ebe-ne der Nukleotid-Sequenz (dunkelgelbe Balken) noch größerals auf der Ebene der Aminosäuresequenz des entsprechen-den Proteins (dunkelgrüne Balken). In der zweiten Spalte istdie Länge des sequenzierten Fragments angegeben.

Haustieren, gefangenen und wildlebenden Säugetieren, aber auchVögeln und Reptilien aus Europa,Afrika, Nordamerika und dem Pazifik-Raum gesammelt worden waren,zeigte sich, dass sich die verschiede-nen Isolate in den sieben Proteinenrelativ wenig unterschieden (Abb.1B) [3]. Auf Nukleotidebene lag derPolymorphismus bei 8 bis 20 %. In-nerhalb der insgesamt 3423 sequen-zierten Basenpaare traten 630 singlenucleotide polymorphisms auf.Wirth et al. verwendeten diese Da-ten, um eine phylogenetische Bezie-hung zwischen ihren Isolaten herzu-stellen.
Was bedeutet das aber für ST678?HUSEC041 besitzt den Sequenztyp
adk 6, fumC 6, gyrB 5, icd 136,mdh 9, purA 7, recA 7. Durchsuchtman die MLST-E.coli-Datenbank nachentsprechenden Sequenztypen, fin-den sich gerade mal fünf verschie-dene Stämme, die aber in mindestenseiner Fragmentsequenz zu HUSEC041unterschiedlich sind, so dass dieserSequenztyp eigentlich eindeutig demderzeitigen Epidemiestamm zuzu-ordnen ist.
In einer deutsch/chinesischenKooperation wurde jetzt das gesamteGenom von HUSEC041 durchsequen-ziert. Ein entsprechender Eintrag inGenbank ist unter http://www.ncbi.nlm.nih.gov/nuccore/334717079 zufinden. Nach der eindeutigen Stamm-identifizierung will man über einen
Vergleich mit den Genomsequenzenanderer, bekannter HUSEC-Stämmeherausfinden, weshalb HUSEC041 sobesonders pathogen ist.
[1] Maiden, M.C.J., Bygraves, J.A., Feil, E.,et al.: Multilocus sequence typing: A por-table approach to the identification of clo-nes within populations of pathogenicmicroorganisms. Proc. Natl. Acad. Sci. USA95 (1998), 3140–3145.
[2] http://mlst.ucc.ie/mlst/dbs/Ecoli/documents/primersColi_html
[3] Wirth, T., Falush, D., Lan, R., et al.: Sex andvirulence in Escherichia coli: an evolutio-nary perspective. Mol. Microbiol. 60(2006), 1136–1151.
Thomas Winckler, Jena; Theo Dingermann, Ilse Zündorf,
Frankfurt
FO RU M
356 Pharm. Unserer Zeit 4/2011 (40) www.pharmuz.de © 2011 Wiley-VCH Verlag GmbH & Co. KGaA, Weinheim
TA B . 1 B E D I N G U N G E N F Ü R M L S T A N E . COLI [ 2 ]
Gen Primer Fragment- Annealing-länge [bp] Temperatur [°C]
adk adkF 5’-ATTCTGCTTGGCGCTCCGGG-3’ 583 54adkR 5’-CCGTCAACTTTCGCGTATTT-3’adkF1 5’-TCATCATCTGCACTTTCCGC-3’adkR1 5’-CCAGATCAGCGCGAACTTCA-3’
fumC fumCR1 5’-TCCCGGCAGATAAGCTGTGG-3’ 806 54fumCF 5’-TCACAGGTCGCCAGCGCTTC-3’fumCR 5’-GTACGCAGCGAAAAAGATTC-3’
gyrB gyrBF 5’-TCGGCGACACGGATGACGGC-3’ 911 60gyrBR1 5’-GTCCATGTAGGCGTTCAGGG-3’gyrBR 5’-ATCAGGCCTTCACGCGCATC-3’
icd icdF 5’-ATGGAAAGTAAAGTAGTTGTTCCGGCACA-3’ 878 54cdR 5’-GGACGCAGCAGGATCTGTT-3’
mdh mdhF 5’-ATGAAAGTCGCAGTCCTCGGCGCTGCTGGCGG-3’ 932 60mdhR 5’-TTAACGAACTCCTGCCCCAGAGCGATATCTTTCTT-3’mdhF1 5’-AGCGCGTTCTGTTCAAATGC-3’mdhR1 5’-CAGGTTCAGAACTCTCTCTGT-3’
purA purAF1 5’-TCGGTAACGGTGTTGTGCTG-3’ 816 54purAF 5’-CGCGCTGATGAAAGAGATGA-3’purAR 5’-CATACGGTAAGCCACGCAGA-3’
recA recAR1 5’-AGCGTGAAGGTAAAACCTGTG-3’ 780 58recAF 5’-CGCATTCGCTTTACCCTGACC-3’recAF1 5’-ACCTTTGTAGCTGTACCACG-3’recAR 5’-TCGTCGAAATCTACGGACCGGA-3’
PCR-Reaktionsansatz:50 ng chromosomale DNA, je 20 pmol der jeweiligen Primer, 200 μmol (10 μL einer 2-mM-Lösung) dNTPs, 10 μL 10x PCR-Puffer, 5 u Taq-Polymerase, ad 100 μL WasserPCR-Bedingungen:Initiale Denaturierung: 2 min bei 95°; anschließend 30 Zyklen: 1 min 95°, 1 min bei Annealing-Temperatur, 2 min 72°;abschließend 5 min 72°. Für die Sequenzanalyse werden die PCR-Primer verwendet.
Recommended