Embed Size (px)
Citation preview

Volltextsuchen in RDBMS
Realisierung und Verwendung von Volltextsuchen in
den Relationalen DBMSM$ SQL Server 2000
PostgreSQLMySQL

Übersicht
• Vergleich der DBMS
• Was ist eine Volltextsuche?
• Realisierung in den DBMS
• Zusammenfassung

Vergleichsmöglichkeiten
• Werbung durch Hersteller
• Aufstellung von Feature Listen
• Benchmarks
• Erfahrungswerte sammeln
• Propaganda von Anwendern

Was vergleicht man?
• Einsatzgebiet
• Einsatzzweck
• Kosten
• Support
• Geschwindigkeit
• Funktionsumfang

Vergleichskriterien
• Unixoides Serverbetriebssystem
• Datenbanken für Community-Portal
• Möglichst geringe Kosten
• Schneller Support bei Fragen
• Gute Skalierung auch bei hoher Last
• Unterstützung für Volltextsuchen

MS SQL Server 2000
• Läuft nur auf MS Windows
• Verhältnismäßig preiswert (ab 1.500 US-$)
• Proprietäres System
• Keine Unterstützung für implizite FTI
• Skaliert gar schauerlich unter hoher Last
• Support... *hust*

MySQL AB's MySQL 4.x
• Läuft auf allen Unixoiden OS
• Verfügbar unter GPL
• Kommerzielle Lizenz ab 220 Euro
• Offenes System
• Hervorragender Support durch Community
• Kommerzieller Support durch Hersteller

MySQL AB's MySQL 4.x
• Skaliert hervorragend bei SELECT
• Schlechte Serialisierung bei hoher Last
• Leistungseinbruch ab Lesen:Schreiben ~ 7:3
• Unterstützung für impliziten FTI

PostgreSQL 7.4
• Läuft auf allen Unixoiden OS(inkl. Sony Playstation)
• Software kostenlos – BSD Lizenz
• Offenes System
• Support durch Community und Firmen
• Skaliert hervorragend durch genetischen Query Optimizer

PostgreSQL 7.4
• Keine Unterstützung für FTI
• Unterstützung für nutzerdefinierte Datentypen
• Unterstützung von eingebetteten Sprachen (Perl, C, Python, TCL)
• Unterstützung von GiST(Verallgemeinerter balancierter Suchbaum)
• Addon für implizite FTI

Benchmarks
• Traue keiner Statistik...
• Benchmarks sind einseitig
• Ergebnisse durch Know-How beeinflußbar
• eWeek Server Database Clash 2002
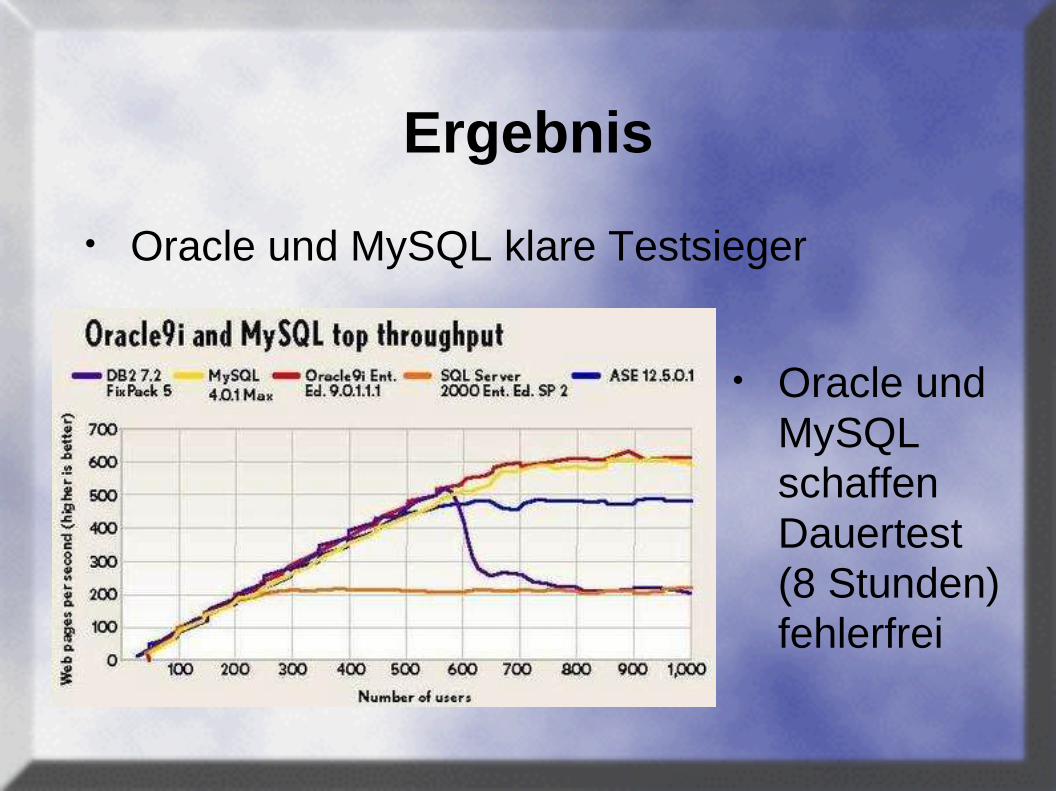
• AS3AP Benchmark 2000

eWeek-Benchmark 2002
• 5 RDBMS getestet
• Oracle 9i 9.0.1.1.1
• MS SQL Server 2000 Service Pack 2
• Sybase ASE 12.5.0.1
• IBM DB2 7.2 FixPack 5
• MySQL-Max 4.0.1-alpha
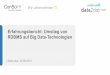
Ergebnis
• Oracle und MySQL schaffen Dauertest (8 Stunden) fehlerfrei
• Oracle und MySQL klare Testsieger
AS3AP Benchmark - 2000

Codequalität
• Microsoft zufolge haben Microsoft Produkte die höchste Codequalität
• Reasoning zufolge hat MySQL die höchste Codequalität aller verfügbaren DBMS
• Meiner Erfahrung nach sind 90% der Probleme an Servern durch Microsoft Produkte verursacht

Was ist eine Volltextsuche?
• Unscharfe Abfragen
• Keine eindeutigen Ergebnisse
• Suchergebnisse werden bewertet
• Suche nach Worten

LIKE sucks
SELECT ... COL LIKE „Begriff“SELECT ... COL LIKE „Begriff%“SELECT ... COL LIKE „%Begriff%“
• LIKE sucht nach Zeichenketten
• nicht optimierbar• „teurer“ Full Table Scan

FTI-Techniken
• Zeitpunkt der Erstellung• Automatisch (implizit)• auf Anforderung
• Art der Erstellung• Textuelle Indizierung• Konzeptionelle Indizierung
• Typ des FTI

Automatische Erstellung
• Indizierung wird beim Einfügen des Datensatzes vorgenommen
• Overhead durch permanentes traversieren und sortieren des Index
• Verlangsamt Schreiboperationen
• Änderungen On-the-Fly verfügbar

Erstellung auf Anforderung
• Index muß manuell erstellt werden
• Index liegt außerhalb der Datenbank
• Kein Overhead beim Schreiboperationen
• Änderungen erst nach Neuerstellung verfügbar
• Redundante Datenhaltung

Textuelle Indizierung
• Statistische Methoden
• häufige Worte sind „wertlos“• häufigste Worte werden gesucht und gefiltert• andere Worte werden indiziert
• Stoppwortlisten• Worte in der Stoppwortliste werden ausgefiltert• andere Worte werden indiziert

Konzeptuelle Indizierung
• beruht auf KI-Verfahren
• Linguistische Analyse
• Stemming• Präfix und Suffixe erkennen• Wortstamm finden
• Begriffshierarchien• Thesaurus• Wörterbücher

FTI-Typen
• Herkömmliche Bäume nicht geeignet
(B-Bäume, B+-Bäume, B*-Bäume)
• Andere Verfahren• Tries• Patricia-Bäume• Präfix-Bäume• GiST• Hash-Verfahren

Volltextsuche in MS SQL Server
• Unterstützung für FTI vorhanden
• ein FTI pro Tabelle
• Generierung des FTI auf Anforderung
• keine implizite Aktualisierung
• keine Stoppworte
• kein konzeptueller Index
• Index außerhalb der Datenbank
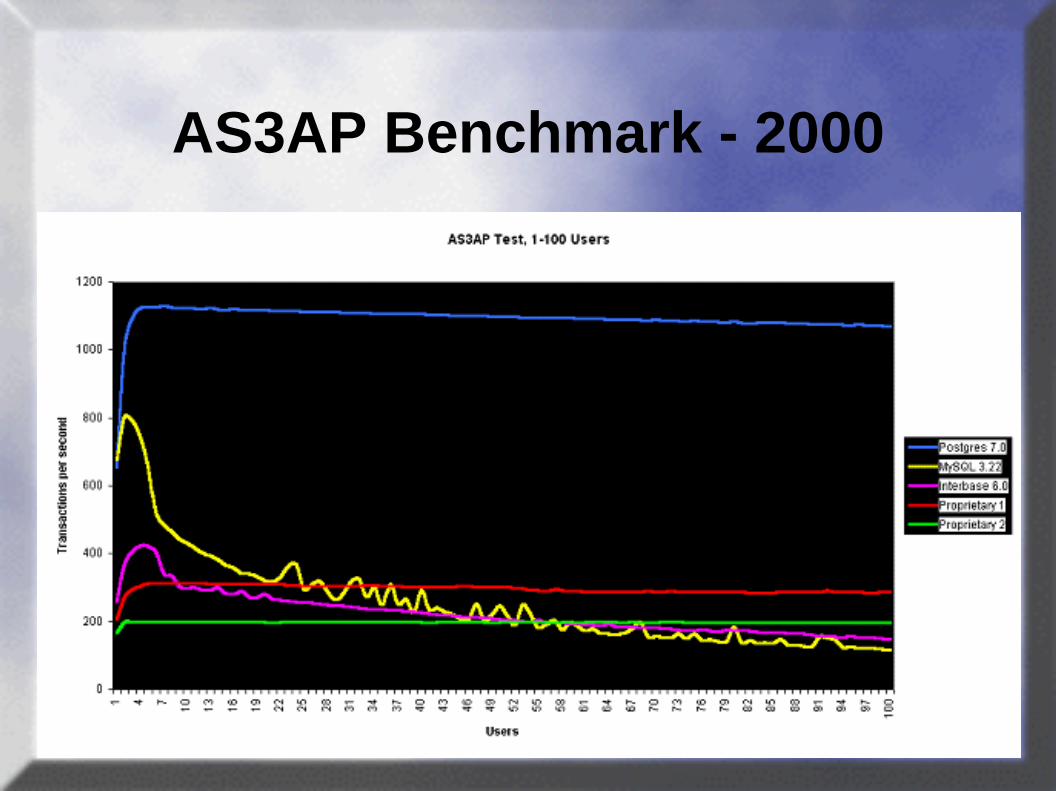
MS SQL Server - Anlegen
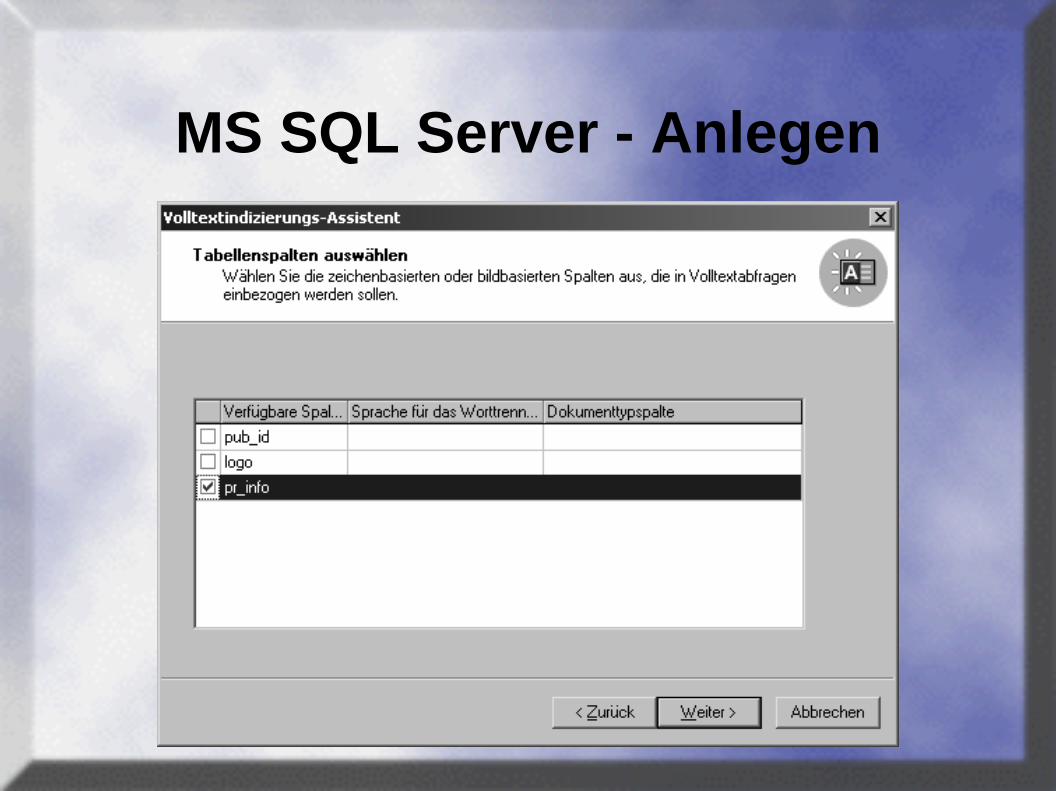
MS SQL Server - Anlegen
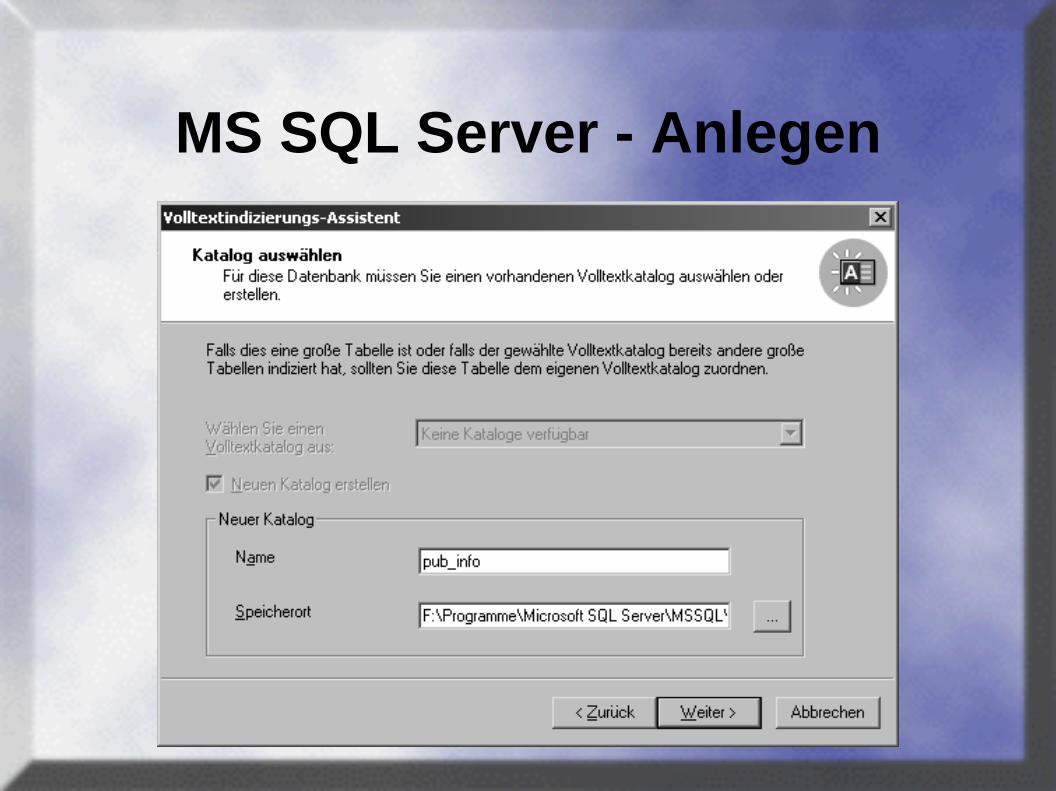
MS SQL Server - Anlegen
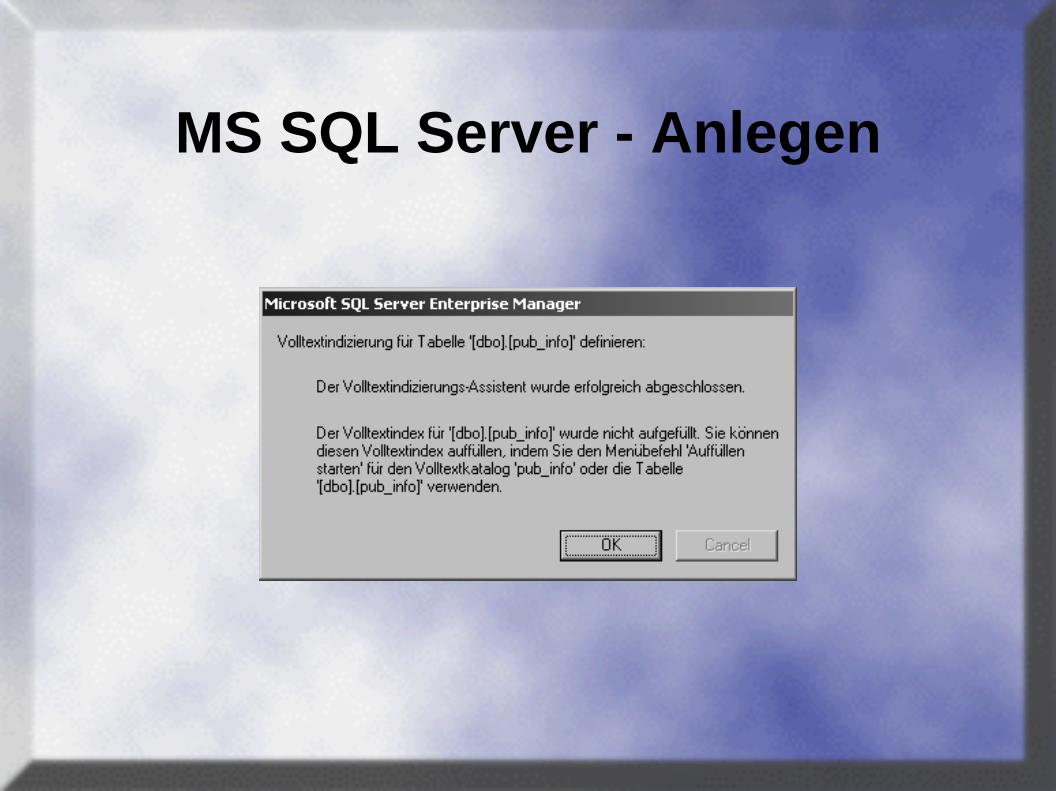
MS SQL Server - Anlegen
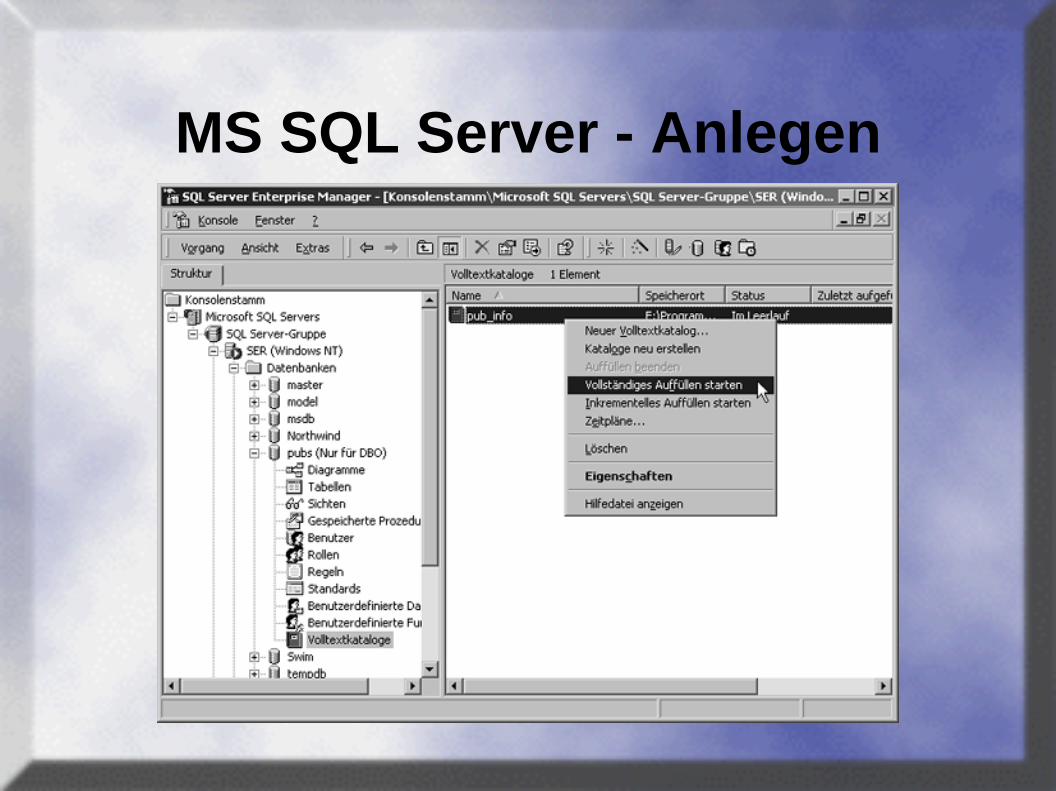
MS SQL Server - Anlegen
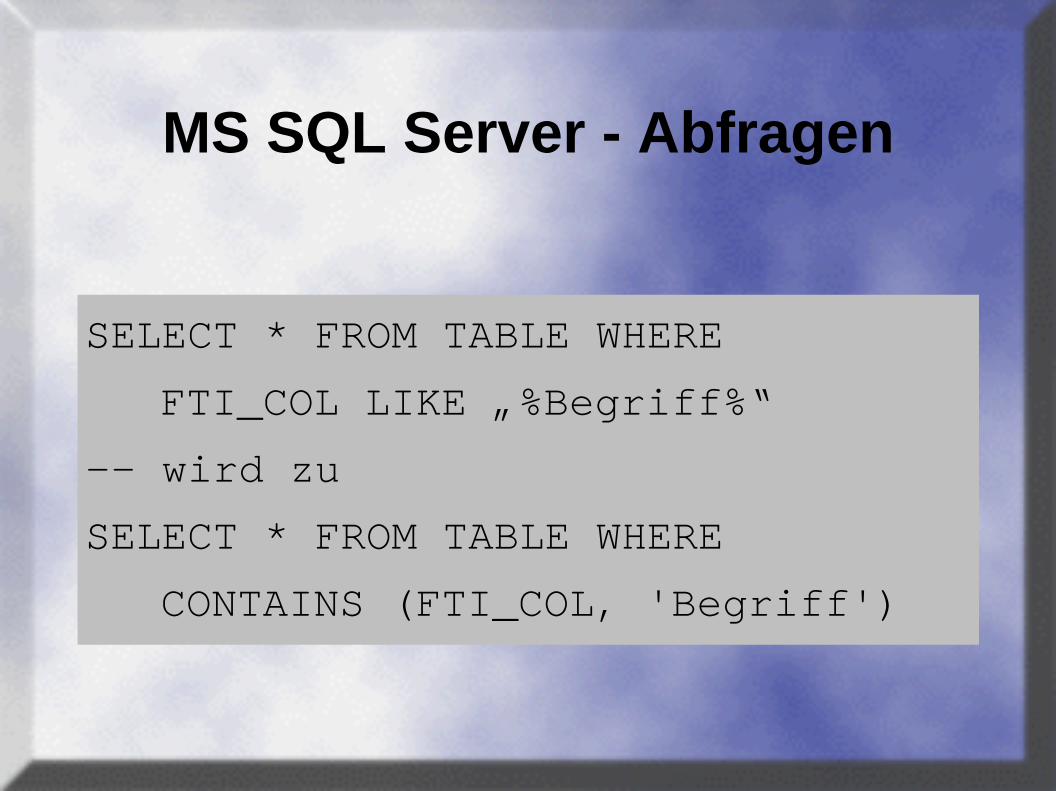
MS SQL Server - Abfragen
SELECT * FROM TABLE WHERE
FTI_COL LIKE „%Begriff%“
-- wird zu
SELECT * FROM TABLE WHERE
CONTAINS (FTI_COL, 'Begriff')

Volltextsuche in MySQL
• Unterstützung für FTI vorhanden
• beliebig viele FTI pro Tabelle
• Generierung zu jedem Zeitpunkt möglich
• implizite Aktualisierung
• Stoppwortlisten als Umgebungsvariable
• BOOLE'sche Suche möglich
• qualitativ gute Bewertungsfunktion

Volltextsuche in MySQL
• INSERT und UPDATE bis zu 10 mal langsamer
• SELECT kann zum TABLE LOCK führen
• Index ist 30% größer als Datenbestand
• Kein konzeptueller Index

MySQL - Anlegen
-- beim Anlegen einer Tabelle
CREATE TABLE fttest (
number int NOT NULL default '0',
text text NOT NULL,
FULLTEXT (text)
);

MySQL - Anlegen
-- bei einer existierenden Tabelle
CREATE TABLE fttest (
number int NOT NULL default '0',
text text NOT NULL
);
ALTER TABLE fttest ADD
FULLTEXT (text);

MySQL - Abfragen
-- einfache Suche
SELECT * FROM fttest WHERE
MATCH (text)
AGAINST ('datenbank');

MySQL - Abfragen
-- einfache Suche mit Bewertung
SELECT text, MATCH text
AGAINST ('datenbank') AS SCORE
FROM fttest WHERE
MATCH (text)
AGAINST ('datenbank');

MySQL - Abfragen
-- Suche im Boolean Mode
SELECT * FROM fttest WHERE
MATCH (text)
AGAINST ('+MySQL -YourSQL'
IN BOOLEAN MODE);

MySQL - Operatoren
'+' - Wort muß im Datensatz vorkommen
'-' - Wort darf nicht im Datensatz vorkommen
'>', '<' - Berücksichtigt das Wort stärker oder schwächer
'(', ')' - Gruppiert Worte, Nesting möglich
'~' - Negiert ein Matching
'“' - Phrasierung mehrerer Worte
'*' - Wortanfang kennzeichnen

MySQL - Operatoren
-- Suche mit Operatoren
'datenbank microsoft'
'+datenbank +microsoft'
'+datenbank -microsoft'
'+datenbank microsoft'
'“datenbank microsoft“'
'daten*'
'+datenbank +(„microsoft sql“)'

Volltextsuche in PostgreSQL
• Keine Unterstützung für FTI
• aber dafür tsearch2• neuer Datentyp tsvector• Unterstützung für Stemming• Verwendet GiST-Index• implizite Aktualisierung des FTI• Generierung zu jedem Zeitpunkt möglich

Installation von tsearch2
$ tar -zxvf tsearch-v2.tar.gz
$ mv tsearch2 $PGSQL_SRC/contrib/
$ cd $PGSQL_SRC/contrib/tsearch2
$ gmake
$ gmake install
$ createdb fttest
$ psql fttest < tsearch2.sql

Anlegen der Tabelle
CREATE TABLE fttest (
number int NOT NULL default '0',
text text NOT NULL,
fti tsvector
);
CREATE INDEX idxFTI ON
fttest USING gist(fti);

Erstellen des Trigger
CREATE TRIGGER tsvectorupdate
BEFORE UPDATE OR INSERT ON
fttest
FOR EACH ROW EXECUTE PROCEDURE
tsearch2(fti, text);
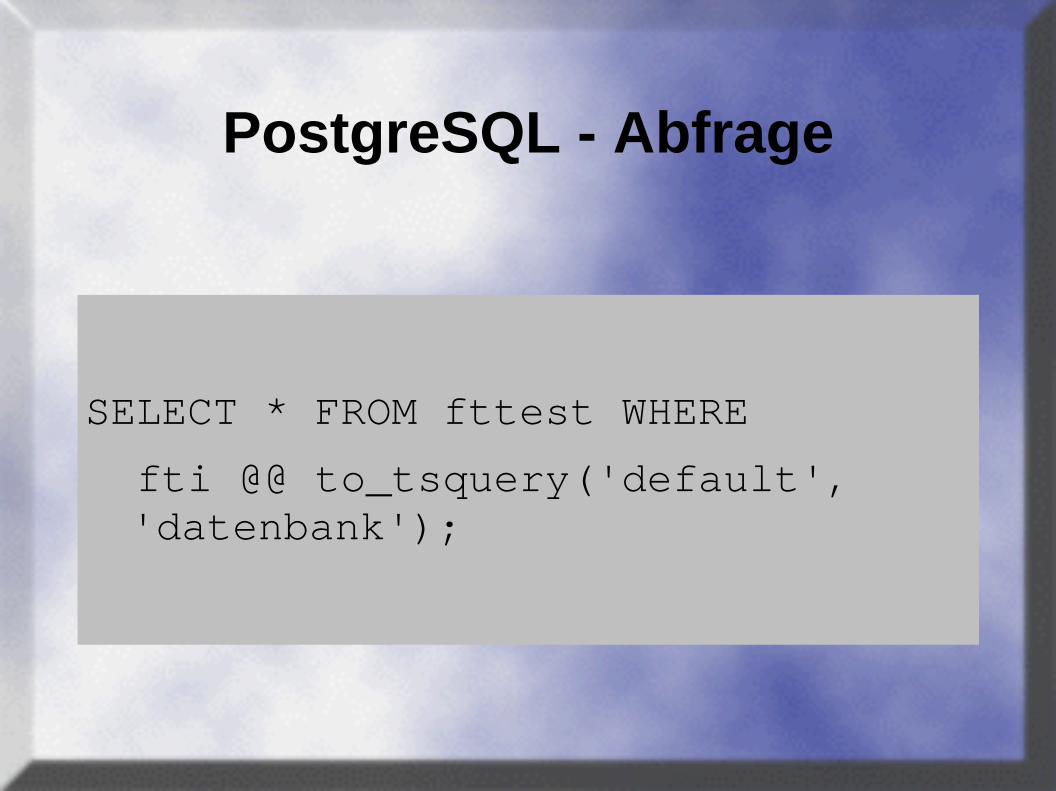
PostgreSQL - Abfrage
SELECT * FROM fttest WHERE
fti @@ to_tsquery('default', 'datenbank');

PostgreSQL - Stopwords
-- Konfiguration erstellen
INSERT INTO pg_ts_cfg (ts_name, prs_name, locale)
VALUES ('default_german', 'default', 'de_DE');

PostgreSQL - Stopwords
INSERT INTO pg_ts_dict
(SELECT 'de_stem',
dict_init,
'postgresql/contrib/german.stop',
dict_lexize
FROM pg_ts_dict
WHERE dict_name = 'en_stem');
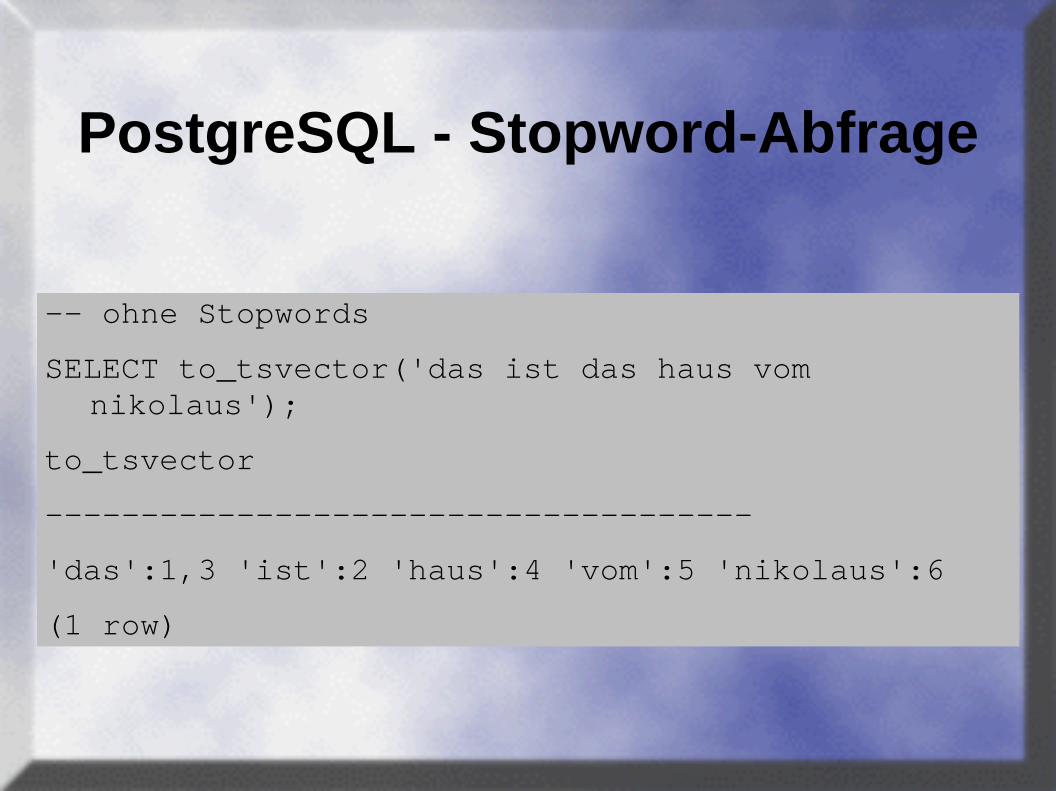
PostgreSQL - Stopword-Abfrage
-- ohne Stopwords
SELECT to_tsvector('das ist das haus vom nikolaus');
to_tsvector
-------------------------------------
'das':1,3 'ist':2 'haus':4 'vom':5 'nikolaus':6
(1 row)
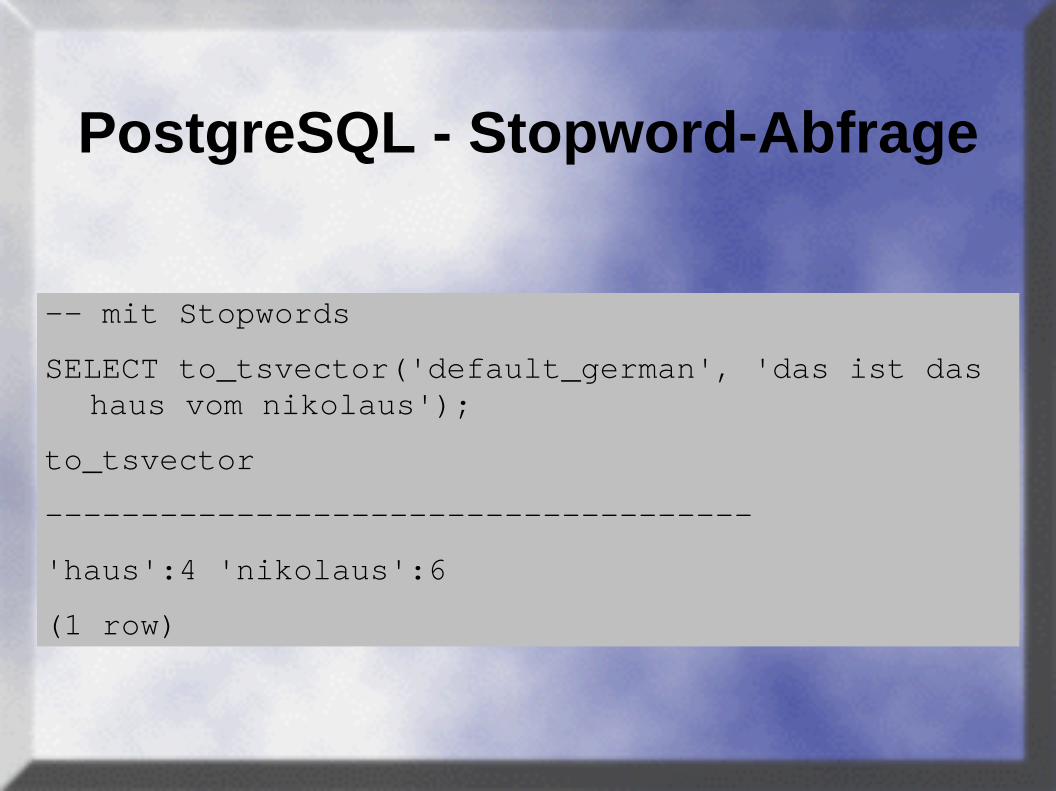
PostgreSQL - Stopword-Abfrage
-- mit Stopwords
SELECT to_tsvector('default_german', 'das ist das haus vom nikolaus');
to_tsvector
-------------------------------------
'haus':4 'nikolaus':6
(1 row)

PostgreSQL - Dictionaries
INSERT INTO pg_ts_dict
(SELECT 'de_ispell',
dict_init,
'DictFile="ispell/deutsch.med",'
'AffFile="ispell/deutsch.aff",'
'StopFile="postgresql/contrib/german.stop"',
dict_lexize
FROM pg_ts_dict
WHERE dict_name = 'ispell_template');
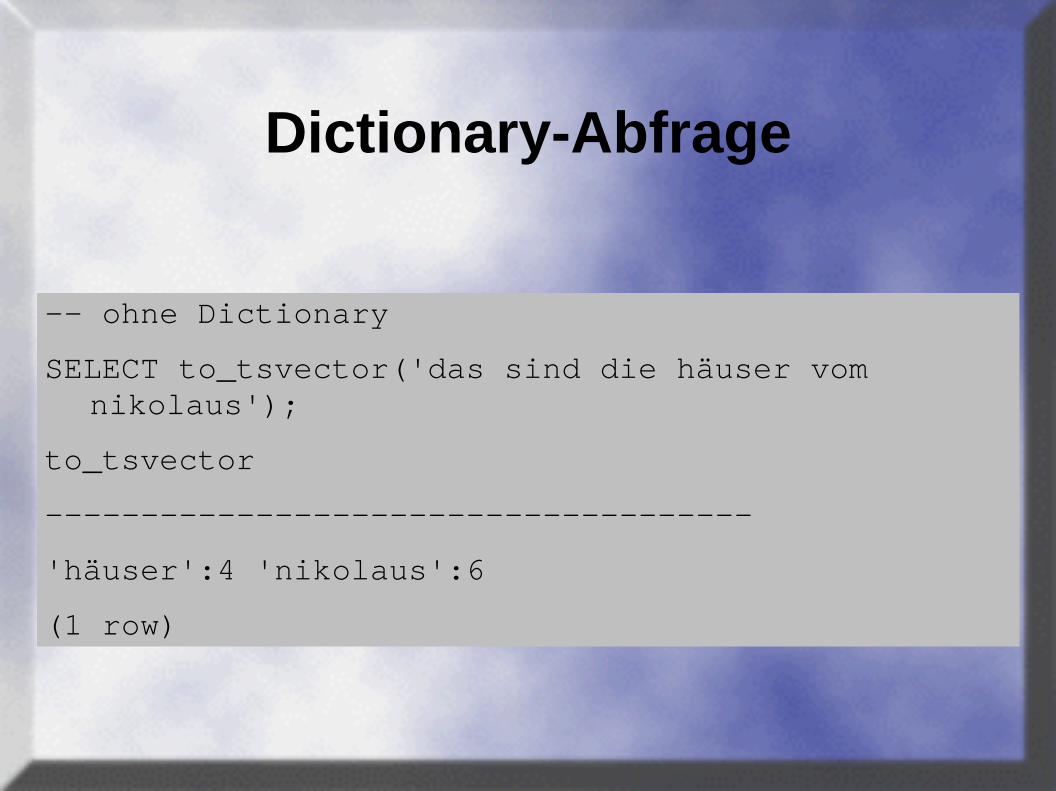
Dictionary-Abfrage
-- ohne Dictionary
SELECT to_tsvector('das sind die häuser vom nikolaus');
to_tsvector
-------------------------------------
'häuser':4 'nikolaus':6
(1 row)
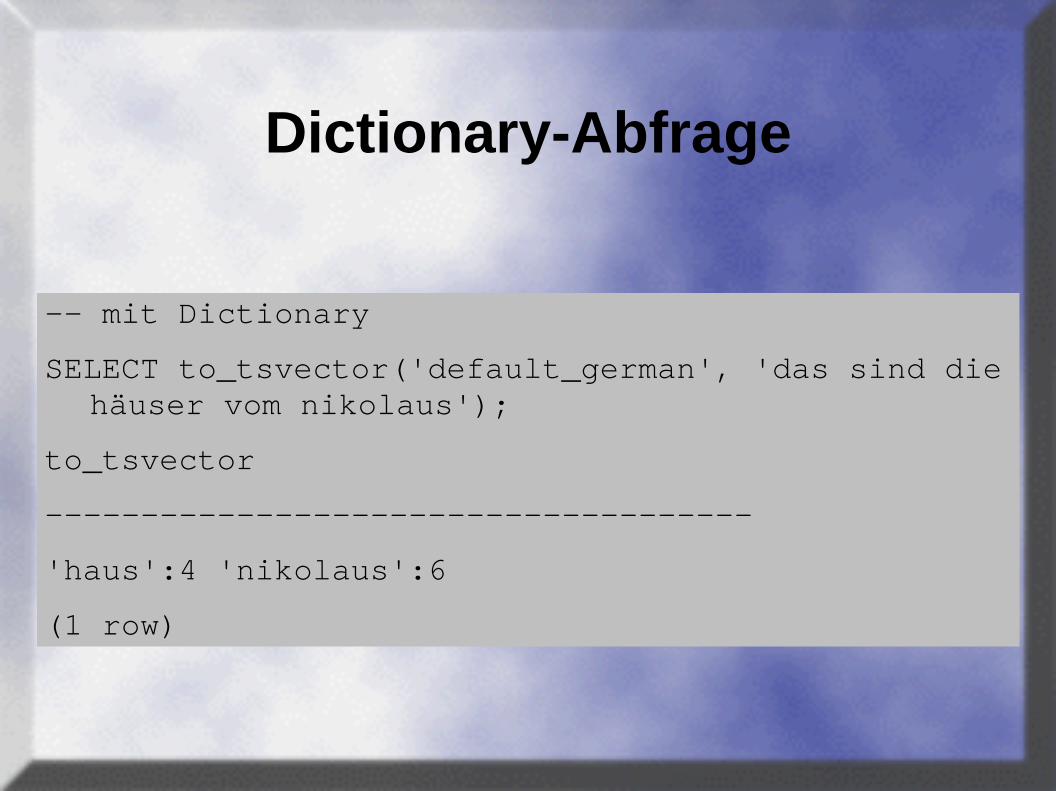
Dictionary-Abfrage
-- mit Dictionary
SELECT to_tsvector('default_german', 'das sind die häuser vom nikolaus');
to_tsvector
-------------------------------------
'haus':4 'nikolaus':6
(1 row)

Zusammenfassung
• Volltextsuchen sind rechenintensive Operationen
• Aktualität vs. Geschwindigkeit
• Integration von tsearch in PostgreSQL ermöglicht große Flexibilität
May the Source be with you!
Noch Fragen?