Embed Size (px)
Citation preview

14.01.14
1
VL Methodenlehre I WS13/14 Schäfer
DAS THEMA: INFERENZSTATISTIK II – INFERENZSTATISTISCHE AUSSAGEN • Standardfehler • Konfidenzintervalle • Signifikanztests
VL Methodenlehre I WS13/14 Schäfer
Standardfehler • der Standardfehler • Interpretation • Verwendung

14.01.14
2
Ausgangspunkt: wir haben aufgrund von Daten aus einer Studie einen
Parameter für die Population geschätzt und eine Stichprobenverteilung für
diesen Parameter erstellt (zumindest theoretisch)
Ziel: eine Angabe darüber machen, wie gut die Parameterschätzung ist
3 Möglichkeiten: Standardfehler, Konfidenzintervalle, Signifikanztests
ZUR WIEDERHOLUNG...
VL Methodenlehre I WS13/14 Schäfer
wie gut ist die Parameterschätzung?
ist das S:chprobenergebnis durch Zufall entstanden oder
nicht?
• der Standardfehler ist die Standardabweichung der
Stichprobenverteilung
• er gibt daher die Güte/Verlässlichkeit der Schätzung an
• er zeigt an, welchen „durchschnittlichen“ Fehler man macht, wenn man
den gefundenen Kennwert als Parameterschätzung verwendet
Beispiel: wir haben für das Mögen von Klassik einen Mittelwert von 3 und
einen Standardfehler von 0,6 bestimmt:
DER STANDARDFEHLER
VL Methodenlehre I WS13/14 Schäfer
à ca. 68% aller möglichen S:chprobenergebnisse würden also hier zwischen den Werten 2,4 und 3,6 liegen

14.01.14
3
Wie kann man den Standardfehler interpretieren?
• lässt sich pauschal nicht beantworten, denn: je kleiner, desto besser
• günstig: schauen wie groß er im Verhältnis zur verwendeten Merkmals-
Skala ist
Beispiel: die Skala für das Mögen von Klassik ging von 1 bis 5 à der SE von
0,6 nimmt davon nur 12% ein, ist also recht klein
DER STANDARDFEHLER – INTERPRETATION
VL Methodenlehre I WS13/14 Schäfer
à der SE von 0,6 liefert uns eine Angabe darüber, wie weit wir mit unserer Schätzung prinzipiell daneben liegen könnten
à ob der SE zufriedenstellend klein ist, soll/muss der Forscher beurteilen
Wo wird der Standardfehler hauptsächlich verwendet?
• er wird als „Rechenergebnis“ im Text sehr selten angegeben
• dafür aber sehr häufig in Abbildungen, nämlich in Form von
Fehlerbalken (anstelle der Standardabweichung)
Beispiele:
DER STANDARDFEHLER – VERWENDUNG
VL Methodenlehre I WS13/14 Schäfer
SD SE SE

14.01.14
4
wenn man Abbildungen so gestaltet, dass die Y-Achse den gesamten
Wertebereich zeigt, kann man auch an solchen Abbildungen sehen, ob der
SE eher groß oder eher klein ist
DER STANDARDFEHLER – VERWENDUNG
VL Methodenlehre I WS13/14 Schäfer
VL Methodenlehre I WS13/14 Schäfer
Konfidenzintervalle • Konfidenzintervalle • Vertrauenswahrscheinlichkeit • Einfluss der Stichprobengröße • Verwendung

14.01.14
5
• neben dem Standardfehler lässt sich ein weiteres Maß für die Güte einer
Populationsschätzung für einen Parameter angeben: das
Konfidenzintervall (KI, englisch: CI für confidence interval)
• Konfidenzintervalle sind etwas informativer, da sie einen Wertebereich
(Vertrauens- oder Konfidenzbereich) beschreiben
Definition:
Ein Konfidenzintervall ist ein Wertebereich, der den wahren Parameter in
der Population mit der Wahrscheinlichkeit X beinhaltet.
(Achtung: die Wahrscheinlichkeitsaussage bezieht sich immer auf das
Intervall, nicht auf den Parameter! Man darf also nicht sagen: der
Parameter liegt mit der Wahrscheinlichkeit X im Intervall!)
KONFIDENZINTERVALLE
VL Methodenlehre I WS13/14 Schäfer
entscheidend sind zwei Dinge:
• die Höhe der Konfidenz (also der Wahrscheinlichkeit X) à die lege ich
selbst fest
• die beiden Grenzen des Intervalls (ausgedrückt in den Werten der
verwendeten Skala) à die will ich berechnen
die Logik dahinter: eine Parameterschätzung ist umso zuverlässiger, je
enger die Grenzen des Intervalls beieinander liegen
als Grundlage dient die Stichprobenverteilung
des berechneten Parameters
KONFIDENZINTERVALLE
VL Methodenlehre I WS13/14 Schäfer
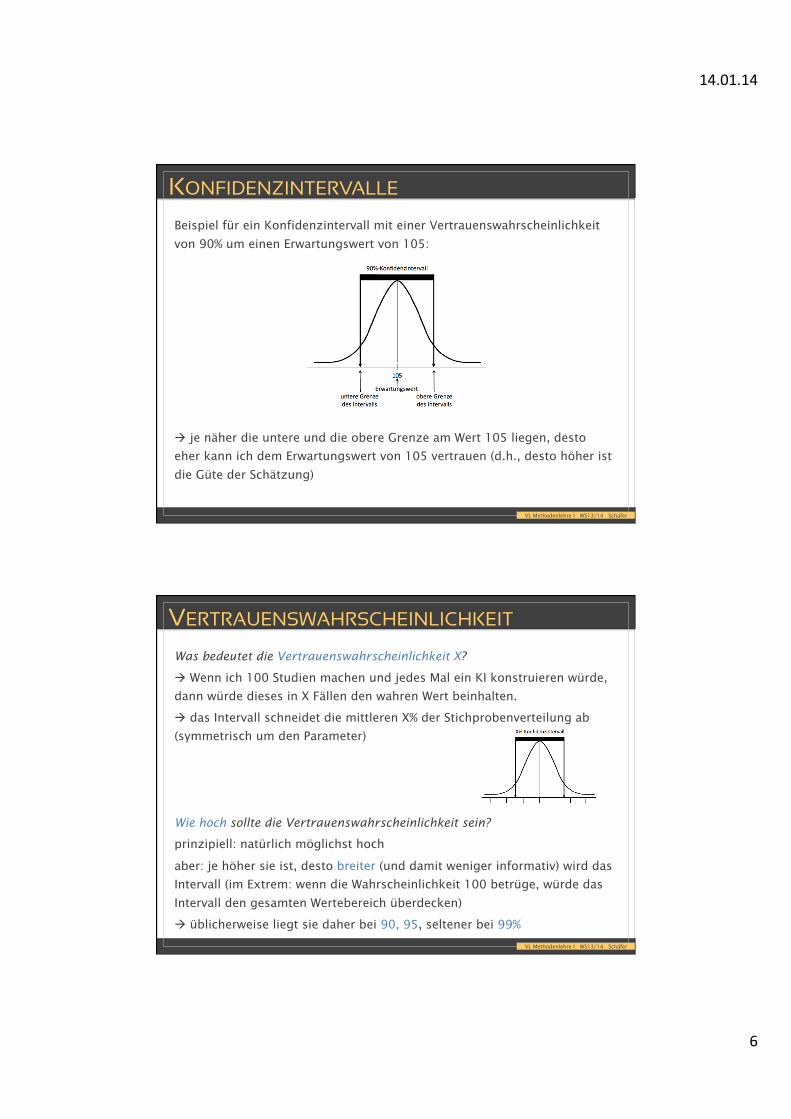
14.01.14
6
Beispiel für ein Konfidenzintervall mit einer Vertrauenswahrscheinlichkeit
von 90% um einen Erwartungswert von 105:
à je näher die untere und die obere Grenze am Wert 105 liegen, desto
eher kann ich dem Erwartungswert von 105 vertrauen (d.h., desto höher ist
die Güte der Schätzung)
KONFIDENZINTERVALLE
VL Methodenlehre I WS13/14 Schäfer
Was bedeutet die Vertrauenswahrscheinlichkeit X?
à Wenn ich 100 Studien machen und jedes Mal ein KI konstruieren würde,
dann würde dieses in X Fällen den wahren Wert beinhalten.
à das Intervall schneidet die mittleren X% der Stichprobenverteilung ab
(symmetrisch um den Parameter)
Wie hoch sollte die Vertrauenswahrscheinlichkeit sein?
prinzipiell: natürlich möglichst hoch
aber: je höher sie ist, desto breiter (und damit weniger informativ) wird das
Intervall (im Extrem: wenn die Wahrscheinlichkeit 100 betrüge, würde das
Intervall den gesamten Wertebereich überdecken)
à üblicherweise liegt sie daher bei 90, 95, seltener bei 99%
VERTRAUENSWAHRSCHEINLICHKEIT
VL Methodenlehre I WS13/14 Schäfer

14.01.14
7
der Einfluss der Stichprobengröße auf das KI
• größere Stichproben sollten zu verlässlicheren Schätzungen führen
• das äußert sich darin, dass die Stichprobenverteilung schmaler wird und
damit die Grenzen enger zusammenrücken
EINFLUSS DER STICHPROBENGRÖßE
VL Methodenlehre I WS13/14 Schäfer
kleinere S:chprobe: größere S:chprobe:
Wo werden KI hauptsächlich verwendet?
• in der Regel als inferenzstatistische Angaben im Text: es werden die
Höhe der Konfidenz und die Lage der unteren und oberen Grenze
angegeben (z.B. in der Form „95% KI, untere Grenze: ..., obere
Grenze: ...“ oder „95% confidence interval, CI-: ..., CI+: ...)
• sehr häufig auch in Abbildungen: ebenfalls
in Form von Fehlerbalken
KONFIDENZINTERVALLE – VERWENDUNG
VL Methodenlehre I WS13/14 Schäfer

14.01.14
8
VL Methodenlehre I WS13/14 Schäfer
Signifikanztests • Signifikanztests • Ansatz nach Fisher • die Nullhypothese • der p-Wert • die Irrtumswahrscheinlichkeit • die Logik • einseitiges und zweiseitiges Testen • Einfluss der Stichprobengröße • Ansatz nach Neyman & Pearson • die Alternativhypothese • Fehler erster und zweiter Art • Einflussgrößen auf die Signifikanz
• Signifikanztests beurteilen nicht die Güte einer Parameterschätzung,
sondern, ob ein Ergebnis zufällig zustande kam oder ob es generalisiert
werden kann
• sie liefern damit eine ja/nein-Entscheidung
• der Begriff „Signifikanz“ ist irreführend, weil ein Signifikanztest-
Ergebnis zunächst nichts über die „Bedeutsamkeit“ aussagt!
• sie beruhen nicht mehr auf der Stichprobenverteilung, die aus den
Daten resultiert, sondern auf der abstrakten Idee der Nullhypothese
• ihr einziges Ergebnis ist der berühmte p-Wert, der dann zur
Entscheidung (signifikant oder nicht) führt
SIGNIFIKANZTESTS
VL Methodenlehre I WS13/14 Schäfer

14.01.14
9
nach dem Ansatz von Fisher (dem z.B. auch SPSS folgt):
• der Signifikanztest unterstellt immer, dass es in der
Population keinen Effekt gibt (der Mittelwert ist 0, es
gibt keinen Mittelwertsunterschied, es gibt keinen
Zusammenhang, usw.)
• diese Unterstellung wird durch die Nullhypothese ausgedrückt
• Ziel ist es nun zu zeigen, dass das Stichproben-Ergebnis unter der
Annahme der Nullhypothese so unwahrscheinlich ist, dass man die
Nullhypothese „verwerfen“ kann
ANSATZ NACH FISHER
VL Methodenlehre I WS13/14 Schäfer
• für die Nullhypothese H0 wird auch eine Stichprobenverteilung erstellt
• diese ist nicht um den gefundenen Kennwert konstruiert, sondern um die
0 herum:
à die Verteilung sagt, dass auch dann, wenn es in der Population keinen
Effekt gibt (0), Ergebnisse zustande kommen können, die zufällig von 0
abweichen (wobei größere Abweichungen immer unwahrscheinlicher werden)
DIE NULLHYPOTHESE
VL Methodenlehre I WS13/14 Schäfer

14.01.14
10
• die Verteilung der H0 beschreibt also die Wahrscheinlichkeit, mit der
man bestimmte Werte „ziehen“ kann, wenn die H0 stimmt
• diese Aussage steckt im p-Wert (p für probability)
Definition:
Der p-Wert ist die Wahrscheinlichkeit für das gefundene (oder ein noch
extremeres) Ergebnis unter der Annahme, dass in der Population die H0
gilt.
DER P-WERT
VL Methodenlehre I WS13/14 Schäfer
• für die Entscheidung (signifikant oder nicht) wird nun eine
Irrtumswahrscheinlichkeit Alpha (α) festgelegt
• Alpha wird auch Fehler erster Art, Signifikanzschwelle, Signifikanzniveau
oder Signifikanzkriterium genannt
• Logik: wenn p < α dann ist das Ergebnis so unwahrscheinlich, dass die
Nullhypothese wohl nicht stimmt und daher verworfen werden kann à
man spricht dann von einem signifikanten Ergebnis
• Alpha wird üblicherweise auf 10, 5 oder 1% festgelegt (5% sind die Regel)
• aber: diese Festlegung ist absolut willkürlich, tatsächlich sollte der
Forscher festlegen, wie groß Alpha sinnvollerweise sein soll/darf
DIE IRRTUMSWAHRSCHEINLICHKEIT
VL Methodenlehre I WS13/14 Schäfer

14.01.14
11
die Gretchen-Frage:
p < α ?
SIGNIFIKANZTESTS – DIE LOGIK
VL Methodenlehre I WS13/14 Schäfer
SIGNIFIKANZTESTS – DIE LOGIK
VL Methodenlehre I WS13/14 Schäfer

14.01.14
12
Warum „Fehler erster Art“?
• auch bei einem als signifikant eingestuften Ergebnis kann die H0
natürlich stimmen
• genauer: man wird – statistisch gesehen – in α Prozent der Fälle die H0
ablehnen, obwohl sie stimmt à man begeht also einen Fehler (nämlich
eine „falsch positive“ Entscheidung)
Achtung: Alpha sagt nichts über die Wahrscheinlichkeit der H0 aus, sondern
nur etwas über die Wahrscheinlichkeit, mit der man sich irrt, wenn man die
H0 anlehnt.
SIGNIFIKANZTESTS – DIE LOGIK
VL Methodenlehre I WS13/14 Schäfer
Woher kommt der p-Wert?
• genauer müsste man fragen: woher kommt die H0-Verteilung, aus der
der p-Wert abgelesen wird?
• sie wird genauso konstruiert wie die Stichprobenverteilung für den
Parameter, mit dem Unterschied, dass als Parameterschätzung der Wert
der Nullhypothese (meist 0) verwendet wird
• der p-Wert beschreibt die Lage des empirischen Wertes (also des
Ergebnisses) in dieser Verteilung
• um nicht für jede Studie bzw. jeden Test diese Verteilung konstruieren
zu müssen, gibt es bereits standardisierte Verteilungen für die
Nullhypothese à Prüfverteilungen (z.B., z, t, F...)
• Prüfverteilungen sind in allen Lehrbüchern abgedruckt bzw. in Statistik-
Software „hinterlegt“
SIGNIFIKANZTESTS – DIE LOGIK
VL Methodenlehre I WS13/14 Schäfer

14.01.14
13
zum Warmwerden: z-Test
• der z-Test ist ein Signifikanztest, der prüft, ob sich ein Wert signifikant
von einem vorgegebenen Mittelwert unterscheidet
• die Nullhypothese wäre hier durch diesen Mittelwert repräsentiert
• Prüfverteilung ist die z-Verteilung (Standardnormalverteilung)
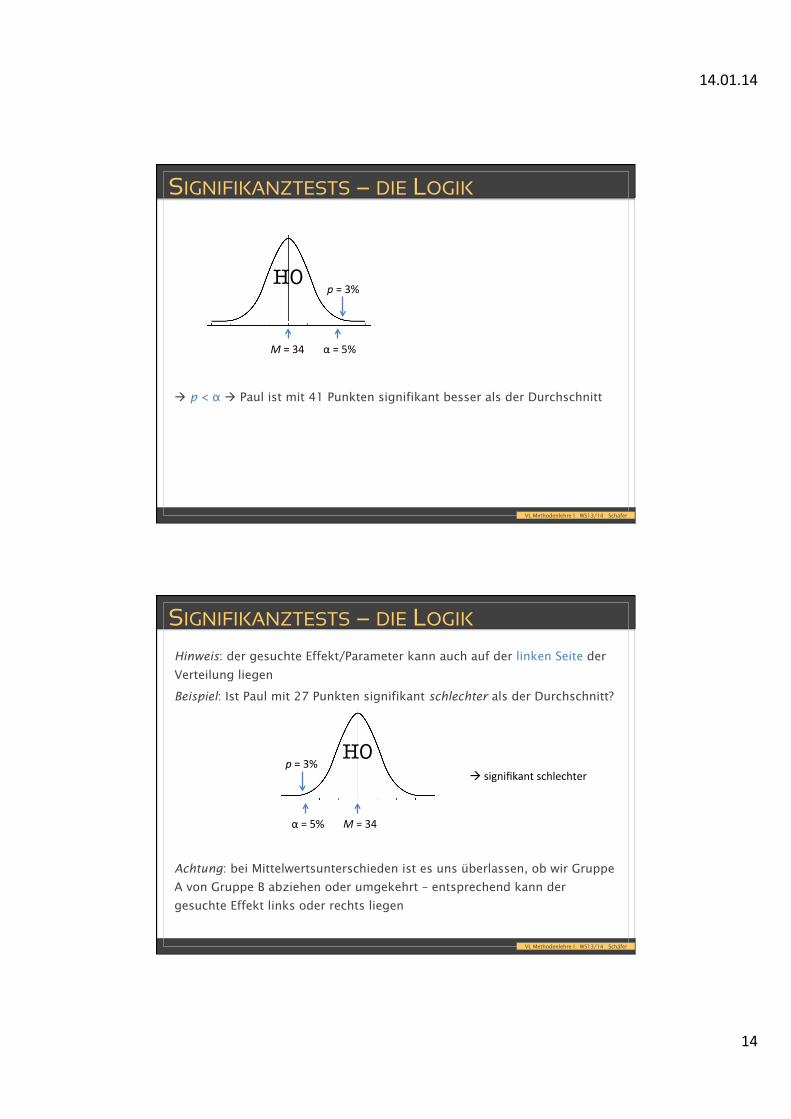
• Beispiel: in einer Klausur ist von 50 Studierenden ein Mittelwert von M =
34 Punkten erreicht worden (SD = 3,7) – ist Paul mit 41 Punkten
signifikant besser als der Durchschnitt (Alpha = 5%)?
SIGNIFIKANZTESTS – DIE LOGIK
VL Methodenlehre I WS13/14 Schäfer
H0
M = 34
Paul = 41 à wo liegt die 41 in dieser Verteilung? à z-‐Standardisierung:
SIGNIFIKANZTESTS – DIE LOGIK
VL Methodenlehre I WS13/14 Schäfer
z" 0" 0,01" 0,02" 0,03" 0,04" 0,05" 0,06" 0,07" 0,08" 0,09"0" 0,5$ 0,504$ 0,508$ 0,512$ 0,516$ 0,5199$ 0,5239$ 0,5279$ 0,5319$ 0,5359$0,1" 0,5398$ 0,5438$ 0,5478$ 0,5517$ 0,5557$ 0,5596$ 0,5636$ 0,5675$ 0,5714$ 0,5753$0,2" 0,5793$ 0,5832$ 0,5871$ 0,591$ 0,5948$ 0,5987$ 0,6026$ 0,6064$ 0,6103$ 0,6141$0,3" 0,6179$ 0,6217$ 0,6255$ 0,6293$ 0,6331$ 0,6368$ 0,6406$ 0,6443$ 0,648$ 0,6517$0,4" 0,6554$ 0,6591$ 0,6628$ 0,6664$ 0,67$ 0,6736$ 0,6772$ 0,6808$ 0,6844$ 0,6879$0,5" 0,6915$ 0,695$ 0,6985$ 0,7019$ 0,7054$ 0,7088$ 0,7123$ 0,7157$ 0,719$ 0,7224$0,6" 0,7257$ 0,7291$ 0,7324$ 0,7357$ 0,7389$ 0,7422$ 0,7454$ 0,7486$ 0,7517$ 0,7549$0,7" 0,758$ 0,7611$ 0,7642$ 0,7673$ 0,7704$ 0,7734$ 0,7764$ 0,7794$ 0,7823$ 0,7852$0,8" 0,7881$ 0,791$ 0,7939$ 0,7967$ 0,7995$ 0,8023$ 0,8051$ 0,8079$ 0,8106$ 0,8133$0,9" 0,8158$ 0,8186$ 0,8212$ 0,8238$ 0,8264$ 0,8289$ 0,8315$ 0,834$ 0,8365$ 0,8398$1" 0,8413$ 0,8438$ 0,8461$ 0,8485$ 0,8508$ 0,8531$ 0,8554$ 0,8577$ 0,8599$ 0,8621$1,1" 0,8643$ 0,8665$ 0,8686$ 0,8708$ 0,8729$ 0,8749$ 0,877$ 0,879$ 0,881$ 0,883$1,2" 0,8849$ 0,8869$ 0,8888$ 0,8907$ 0,8925$ 0,8944$ 0,8962$ 0,898$ 0,8997$ 0,9015$1,3" 0,9032$ 0,9049$ 0,9066$ 0,9082$ 0,9099$ 0,9115$ 0,9131$ 0,9147$ 0,9162$ 0,9177$1,4" 0,9192$ 0,9207$ 0,9222$ 0,9236$ 0,9251$ 0,9265$ 0,9279$ 0,9292$ 0,9306$ 0,9319$1,5" 0,9332$ 0,9345$ 0,9357$ 0,937$ 0,9382$ 0,9304$ 0,9406$ 0,9418$ 0,9429$ 0,9441$1,6" 0,9452$ 0,9463$ 0,9474$ 0,9484$ 0,9495$ 0,9505$ 0,9515$ 0,9525$ 0,9535$ 0,9545$1,7" 0,9554$ 0,9564$ 0,9573$ 0,9582$ 0,9591$ 0,9599$ 0,9608$ 0,9616$ 0,9625$ 0,9633$1,8" 0,9641$ 0,9649$ 0,9656$ 0,9664$ 0,9671$ 0,9678$ 0,9686$ 0,9693$ 0,9699$ 0,9706$1,9" 0,9713$ 0,9719$ 0,9726$ 0,9723$ 0,9738$ 0,9744$ 0,975$ 0,9756$ 0,9761$ 0,9767$2" 0,9772$ 0,9778$ 0,9783$ 0,9788$ 0,9793$ 0,9798$ 0,9803$ 0,9808$ 0,9812$ 0,9817$2,1" 0,9821$ 0,9826$ 0,983$ 0,9834$ 0,9838$ 0,9842$ 0,9846$ 0,985$ 0,9854$ 0,9857$2,2" 0,9861$ 0,9864$ 0,9868$ 0,9871$ 0,9875$ 0,9878$ 0,9881$ 0,9884$ 0,9887$ 0,989$2,3" 0,9893$ 0,9896$ 0,9898$ 0,9901$ 0,9904$ 0,9906$ 0,9909$ 0,9911$ 0,9913$ 0,9916$2,4" 0,9918$ 0,992$ 0,9922$ 0,9925$ 0,9927$ 0,9929$ 0,9931$ 0,9932$ 0,9934$ 0,9936$2,5" 0,9938$ 0,994$ 0,9941$ 0,9943$ 0,9945$ 0,9946$ 0,9948$ 0,9949$ 0,9951$ 0,9952$2,6" 0,9953$ 0,9955$ 0,9956$ 0,9957$ 0,9959$ 0,996$ 0,9961$ 0,9962$ 0,9963$ 0,9964$2,7" 0,9965$ 0,9966$ 0,9967$ 0,9968$ 0,9969$ 0,997$ 0,9971$ 0,9972$ 0,9973$ 0,9974$2,8" 0,9974$ 0,9975$ 0,9976$ 0,9977$ 0,9977$ 0,9978$ 0,9979$ 0,9979$ 0,998$ 0,9981$2,9" 0,9981$ 0,9982$ 0,9982$ 0,9983$ 0,9984$ 0,9984$ 0,9985$ 0,9985$ 0,9986$ 0,9986$3" 0,9987$ 0,9987$ 0,9987$ 0,9988$ 0,9988$ 0,9989$ 0,9989$ 0,9989$ 0,999$ 0,999$
!
p-‐Wert: 1 – 0,97 = 3%
14.01.14
14
à p < α à Paul ist mit 41 Punkten signifikant besser als der Durchschnitt
SIGNIFIKANZTESTS – DIE LOGIK
VL Methodenlehre I WS13/14 Schäfer
H0
M = 34 α = 5%
p = 3%
Hinweis: der gesuchte Effekt/Parameter kann auch auf der linken Seite der
Verteilung liegen
Beispiel: Ist Paul mit 27 Punkten signifikant schlechter als der Durchschnitt?
Achtung: bei Mittelwertsunterschieden ist es uns überlassen, ob wir Gruppe
A von Gruppe B abziehen oder umgekehrt – entsprechend kann der
gesuchte Effekt links oder rechts liegen
SIGNIFIKANZTESTS – DIE LOGIK
VL Methodenlehre I WS13/14 Schäfer
H0
α = 5% M = 34
p = 3% à signifikant schlechter

14.01.14
15
• bei ungerichteten Hypothesen (exploratives Forschen) verteilt sich die
Irrtumswahrscheinlichkeit auf beide Seiten der H0-Verteilung
à es wird entsprechend schwieriger ein signifikantes Ergebnis zu
bekommen
à daher sind gerichtete Hypothesen besser
EINSEITIGES UND ZWEISEITIGES TESTEN
VL Methodenlehre I WS13/14 Schäfer
H0 H0
Beispiel: Mittelwertsunterschied Gruppe A – Gruppe B:
EINSEITIGES UND ZWEISEITIGES TESTEN
VL Methodenlehre I WS13/14 Schäfer
H0
hier verteilen sich alle möglichen Ergebnisse, bei denen der
Mi\elwertsunterschied nega:v ist (also Gruppe B besser ist)
hier verteilen sich alle möglichen Ergebnisse, bei denen der Mi\elwertsunterschied posi:v ist (also Gruppe A besser ist)

14.01.14
16
der Vorteil gerichteter Hypothesen
am selben Beispiel: Unterscheidet sich Paul signifikant vom Durchschnitt
(Alpha = 5%)? ß ungerichtete Hypothese
EINSEITIGES UND ZWEISEITIGES TESTEN
VL Methodenlehre I WS13/14 Schäfer
H0
α = 2,5% M = 34 α = 2,5%
p = 3% à p > α à kein signifikanter Unterschied
altbekanntes Prinzip: bei steigender Stichprobengröße wird die
Stichprobenverteilung schmaler
à es ist dann leichter, ein signifikantes
Ergebnis zu bekommen
DER EINFLUSS DER STICHPROBENGRÖßE
VL Methodenlehre I WS13/14 Schäfer
H0
α = 2,5% M = 34 α = 2,5%
p = 3%
H0
α = 2,5% M = 34 α = 2,5%
p = 0,00...%
Ausgangs-‐Beispiel:
Beispiel mit größerer S:chprobe: à das gleiche Testergebnis führt
zu einem kleineren p-‐Wert

14.01.14
17
Prinzipieller Ablauf:
1. formuliere eine Nullhypothese und konstruiere die entsprechende
Stichprobenverteilung (macht i.d.R. eine Software für uns, z.B. SPSS)
2. prüfe, ob der p-Wert kleiner oder größer als Alpha ist
3. ist p < α, „verwerfe“ die Nullhypothese und argumentiere, dass es einen
Effekt gibt; ist p > α, ...? (Fisher macht dazu keine Aussage)
à die H0 sollte „annehmbar“ gemacht werden
à neuer Ansatz nach Neyman und Pearson
ANSATZ NACH FISHER – ZUSAMMENFASSUNG
VL Methodenlehre I WS13/14 Schäfer
• oft ist die Nullhypothese allein eine wenig sinnvolle Annahme
• in der Regel geht man ja von einem Effekt aus
• der erhoffte Effekt wird durch die Alternativhypothese H1 ausgedrückt
• die H1 ist auch eine Stichprobenverteilung, deren Mittelwert um den
erhofften Effekt von der H0 verschoben ist
• der erhoffte Effekt ist nicht das Studienergebnis, sondern tatsächlich
eine Schätzung des erwarteten Effektes, den man vor der Studie festlegt!
ANSATZ NACH NEYMAN & PEARSON
VL Methodenlehre I WS13/14 Schäfer

14.01.14
18
• der erhoffte Effekt kann aus vorhergehenden Studien resultieren (was
wurde bisher gefunden?) oder die Hoffnung des Forschers repräsentieren
(welchen Effekt ist von Interesse?)
• H0 und H1 stehen im Widerstreit
• der Signifikanztest soll helfen, sich für eine der beiden Hypothesen zu
entscheiden
• entscheidend dabei ist der Überschneidungsbereich beider Hypothesen
• dort liegen Daten drin, die zu beiden Hypothesen gehören können – das
kann zu verschiedenen Fehlern führen
DIE ALTERNATIVHYPOTHESE
VL Methodenlehre I WS13/14 Schäfer
Alpha bekommt nun eine
weitere wichtige Bedeutung:
wenn p < α, lehne ich die H0 ab – das kann
• richtig sein à alles perfekt
• falsch sein à Fehler erster Art (Alpha-Fehler)
wenn p > α, „nehme ich die H0 an“ – das kann ebenfalls • richtig sein à alles perfekt
• falsch sein à Fehler zweiter Art (Beta-Fehler)
FEHLER ERSTER UND ZWEITER ART
VL Methodenlehre I WS13/14 Schäfer

14.01.14
19
• im Ansatz von Neyman und Pearson geht es darum, eine sinnvolle
Abwägung der beiden Fehlerarten zu machen
• daran sollte sich dann die Festlegung des Signifikanzniveaus orientieren
FEHLER ERSTER UND ZWEITER ART
VL Methodenlehre I WS13/14 Schäfer
Prinzipieller Ablauf:
1. formuliere eine Nullhypothese und konstruiere die entsprechende
Stichprobenverteilung (mit Hilfe einer Software)
2. formuliere eine Alternativhypothese und konstruiere die entsprechende
Stichprobenverteilung (mit Hilfe einer Software)
3. mache eine Abwägung der Wichtigkeit der Fehler erster und zweiter Art
4. prüfe, ob der p-Wert kleiner oder größer als Alpha ist
5. ist p < α, „verhalte dich so“, als ob die Alternativhypothese stimmt; ist p
> α, „verhalte dich so“, als ob die Nullhypothese stimmt
à dieser Ansatz zwingt uns über die Bedeutsamkeit von Effekten
nachzudenken und diese in den Signifikanztest einzubeziehen
NEYMAN & PEARSON – ZUSAMMENFASSUNG
VL Methodenlehre I WS13/14 Schäfer

14.01.14
20
Drei Größen beeinflussen die Wahrscheinlichkeit, ein signifikantes Ergebnis
zu finden: Populationseffekt, Stichprobengröße, Alpha
EINFLUSSGRÖßEN AUF DIE SIGNIFIKANZ
VL Methodenlehre I WS13/14 Schäfer
größereStichproben
größerer/Populationseffekt
!
• die Ergebnisse führen oft zu Missverständnissen
• Signifikanz hat nichts mit Bedeutsamkeit
• es gibt keine Aussagen über die Wahrscheinlichkeit von Hypothesen,
sondern stets nur von Daten!
• häufiger Vorwurf: mit genügend großen Stichproben wird jeder Effekt
signifikant
• Abhilfe: auf besser interpretierbare Angaben zurückgreifen – vor allem
Effektgrößen und Konfidenzintervalle
KRITIK ZUM SIGNIFIKANZTEST
VL Methodenlehre I WS13/14 Schäfer

14.01.14
21
• drei inferenzstatistische Maße: Standardfehler, Konfidenzintervalle,
Signifikanztests
• Standardfehler: gibt die Verlässlichkeit der Parameterschätzung als einen Wert an
• Konfidenzintervalle: geben die Verlässlichkeit der Parameterschätzung als
Intervall an
• beide Maße basieren auf der Stichprobenverteilung um den gefundenen Wert
• Signifikanztests prüfen, ob ein Ergebnis zufällig zustande kam oder nicht
• sie basieren auf Stichprobenverteilungen, die um Null- oder Alternativhypothese
konstruiert sind
• sie sollen eine Entscheidungshilfe sein, wenn es um das Abwägen von Hypothesen
geht
• sie sagen aber nichts über die Größe von Effekten oder die Wahrscheinlichkeit von
Hypothesen aus!
INFERENZSTATISTIK STECKBRIEF
VL Methodenlehre I WS13/14 Schäfer





























