Embed Size (px)
Citation preview

FOCUS MUL 18, Heft 2 (2001) 1
Universität zu Lübeck
Bioinformatik – Informationsverarbeitung in der Biologie
Prof. Dr. Thomas Martinetz
Institut für Neuro- und Bioinformatik
#3624 Focus2/01 SoDr. 31.08.2001, 8:34 Uhr1
Schwarz

2 FOCUS MUL 18, Heft 2 (2001)
Sonderdruck aus FOCUS MUL 18, Heft 2 (2001)
#3624 Focus2/01 SoDr. 31.08.2001, 8:34 Uhr2
Schwarz

FOCUS MUL 18, Heft 2 (2001) 3
DAS KOLLEG
Die Bioinformatik ist derzeit in der Forschungspolitik,aber insbesondere auch in den Medien, ein sehr aktuel-les Thema. Es vergeht kaum eine Woche, in der nichtirgendwo eine Professur für Bioinformatik ausge-schrieben wird. Die entsprechenden Universitätenkämpfen um geeignete Kandidaten, und manche derProfessuren werden unbesetzt bleiben, weil die Nach-frage zu groß ist.
Was ist der Grund für das enorme Interesse an der Bio-informatik? Warum werden mehrere 100.000.000 DMin den nächsten Jahren in diese Forschungsrichtung in-vestiert? Hoffnungen auf einen hohen „Return of In-vestment“ wurden vor allem ausgelöst durch die er-folgreich klingenden Meldungen und den begleitendenMedienrummel zum „Human Genom Project“, die Se-quenzierung des menschlichen Genoms. Der Schlüsselzur Heilung vieler Krankheiten liegt im Verständnismolekulargenetischer Prozesse. Dies betrifft dashöchste Gut aller Menschen, und dafür ist man bereit,viel Geld auszugeben. Es ist jedoch auch eine erhöhteSkepsis gegenüber vielen dieser Heilsversprechungengeboten, und vieles, was als Vision verkauft wird, wirdUtopie bleiben. Die derzeit aktuelle Ethikdiskussionzur Biotechnologie wird hier hoffentlich zur Klärungüberzogener Erwartungen und Befürchtungen in derBevölkerung beitragen (siehe Beitrag Dr. Maio). DieIntegrität der Wissenschaftler wird angesichts derMöglichkeit, durch vielversprechende Zukunftsvisio-nen enorme Mengen an Fördergeldern in ihre Fachrich-tungen zu lenken, auf eine harte Probe gestellt.
Unbestritten ist, dass der Fortschritt in der Biotechno-logie wesentlich durch den Einsatz von Computern ge-tragen wird. Die Entschlüsselung des menschlichenGenoms konnte nur durch den Einsatz von Höchstleis-tungsrechnern gelingen. Clevere Algorithmen warenerforderlich, die enorme Flut von Daten zu sortierenund mosaikartig zum Gesamtbild zusammenzusetzen.Die Firma Celera, die als privates Unternehmen einge-stiegen war, um in Konkurrenz zum öffentlich geför-derten weltweiten „Human Genome Project“ im Al-leingang das menschliche Genom zu sequenzieren,konnte nur konkurrieren, weil es mit komplexeren Al-gorithmen an die Problemstellung heranging. Diese Al-gorithmen ermöglichten es auf clevere Art und Weise,mit bruchstückhafteren Daten auszukommen und indieser Hinsicht den Verfahren, die im öffentlich geför-derten „Human Genome Project“ angewandt wurden,
überlegen zu sein. Es war also die Informatik, die hierganz wesentlich den Ausgang des Rennens bestimmte.
Die Biologie, insbesondere die Molekularbiologie,braucht die Informatik, und dies noch mehr in der Zu-kunft. Unternehmen wie Celera produzieren moleku-larbiologische Daten in industriellem Maßstab. Hiersind ganze „Produktionsstraßen“ zur „Herstellung“dieser Daten im Einsatz, und Computer und Software,wie man sie aus Produktionsbetrieben kennt, werdenverwendet. Insbesondere werden aber Computer undentsprechende Software zur Speicherung und Nutzungdieser Daten benötigt. Die Menge dieser Daten hat sichin den vergangenen Jahren bereits alle drei Jahre ver-vierfacht. Dies wird sich noch steigern, insbesonderedurch den zunehmenden Einsatz der Genchiptechnolo-gie. Damit wird die Menge der Daten sogar schnelleransteigen als die Leistungsfähigkeit der Computer, wo-mit eine problematische Kluft entsteht. Auf der ande-ren Seite häufen sich Meldungen, dass viele der produ-zierten Daten noch sehr fehlerhaft sind. Die Auswerte-methoden müssen also noch erheblich verbessert wer-den, und Daten müssen im großen Maßstab auf Konsis-tenz geprüft werden. Auch dazu wird die Informatikdringend gebraucht.
Zukünftig wird die Informatik jedoch auch als Grund-lagenwissenschaft informationsverarbeitender Prozes-se an zentraler Stelle zum Verständnis molekularbiolo-gischer Abläufe benötigt. Denn ein wirkliches Ver-ständnis der nun vorliegenden Genomsequenzen ver-langt das Verständnis der darauf basierenden kompli-zierten regulatorischen Netzwerke, der Wechselwir-kungsnetzwerke zwischen DNA und Proteinen sowieProteinen untereinander. Erst mit dem Verständnis die-ser hochkomplexen Regulationsmechanismen wird dasPotenzial, das die Sequenzierung des menschlichenGenoms verspricht, nutzbar gemacht werden können.Diese regulatorischen Netzwerke in ihrer Gesamtheit,mit dem Genom lediglich als ein Element dieser Netz-werke, bestimmen letztendlich die Expression phäno-typischer Aspekte. Zum Verständnis dieser hochkom-plexen Mechanismen braucht man die Informatik nichtnur als Lieferant von cleveren Algorithmen und schnel-len Supercomputern. Man wird die Informatik vor al-lem auch als Grundlagenwissenschaft der Informati-onsverarbeitung benötigen, denn es sind letztendlichInformationsverarbeitungsprozesse, die solch hoch-komplexe regulatorische Systeme determinieren.
Bioinformatik – Informationsverarbeitung in der BiologieTh. Martinetz
#3624 Focus2/01 SoDr. 31.08.2001, 8:34 Uhr3
Schwarz
4 FOCUS MUL 18, Heft 2 (2001)
Mit hochvernetzten Systemen beschäftigt sich ein an-derer, komplementärer Zweig der Bioinformatik schonseit langem. Unter Bioinformatik versteht man derzeitvor allem „Informatik für die Biologie“, den Einsatzund die Entwicklung von Algorithmen und Computernzur Unterstützung des Verständnisses und der Nutzungmolekulargenetischer Prozesse. Ich nenne dies Mole-kulare Bioinformatik. Die Bioinformatik in seiner ge-samten Breite beinhaltet jedoch noch ein zweites Teilge-biet, die „Biologie für die Informatik“. Was kann die In-formatik von der Informationsverarbeitung in der Biolo-gie, in biologischen Systemen, lernen? Welche Prinzipi-en der Informationsverarbeitung werden zum Beispielim Nervensystem genutzt? Oder auf welchen informati-onsverarbeitenden Prozessen basiert die biologischeEvolution? Die Evolution generiert Information, Infor-mation über die Umwelt, die wiederum im Genom ge-speichert wird. Informationsinhalte werden adaptiertdurch Mutation und optimiert durch Selektion, und diesoffensichtlich überaus erfolgreich. Biologische Systemesind von enormer Komplexität. Um solche Systeme her-
vorzubringen, aufzubauen, zu organisieren und in einerkomplexen Umwelt zu steuern, bedarf es besonderer In-formationsverarbeitungsprinzipien. Viele Aufgaben derInformationsverarbeitung können von biologischen Sys-temen immer noch um Größenordnungen besser bewäl-tigt werden als von den schnellsten heutigen Computern.Ein grundlegendes Verständnis dieser informationsver-arbeitenden Prinzipien wäre sowohl von hoher Erkennt-nis- als auch Praxisrelevanz. Immer wieder geht es dabeium hochvernetzte Systeme, am deutlichsten bei der In-formationsverarbeitung im Nervensystem, mit dem sichdie Neuroinformatik als Teilgebiet der Bioinformatikbeschäftigt. Ein Neuron ist im Mittel mit 10.000 anderenNeuronen verschaltet. Interessanterweise sind die ma-thematischen Gleichungen, die die Dynamik solch hoch-vernetzter Systeme beschreiben, ob neuronale Netzwer-ke oder regulatorische Netzwerke, immer von ähnlicherStruktur. Auf dieser grundlegenden Ebene treffen sichdie beiden Teilgebiete der Bioinformatik, die „Informa-tik für die Biologie“ und die „Biologie für die Informa-tik“, und können maßgeblich voneinander profitieren.
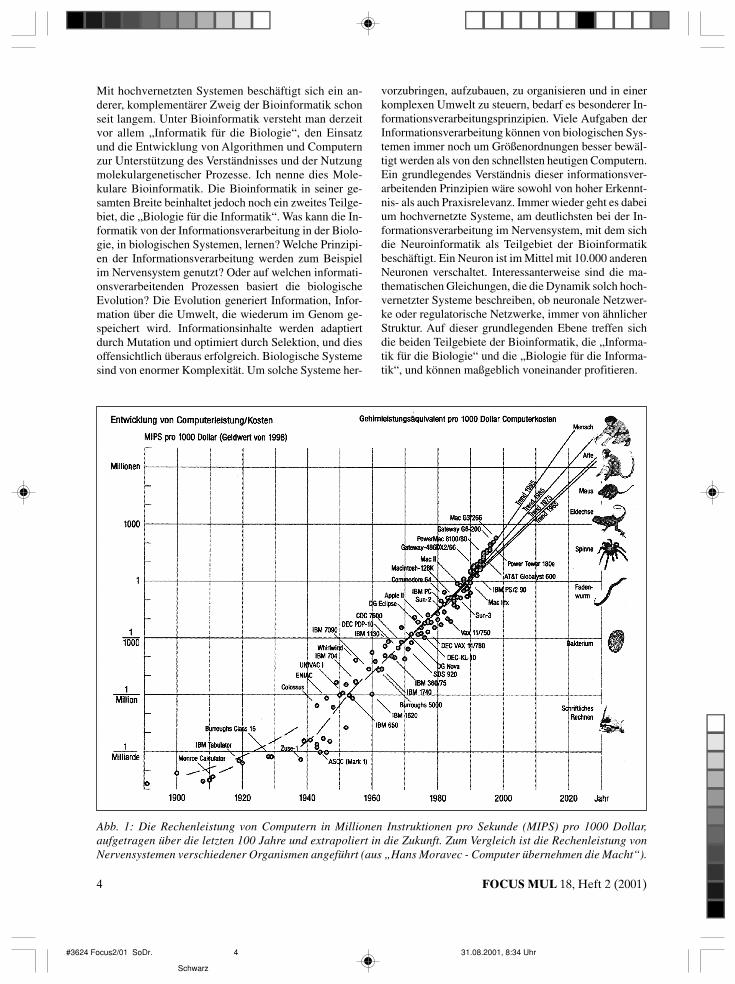
Abb. 1: Die Rechenleistung von Computern in Millionen Instruktionen pro Sekunde (MIPS) pro 1000 Dollar,aufgetragen über die letzten 100 Jahre und extrapoliert in die Zukunft. Zum Vergleich ist die Rechenleistung vonNervensystemen verschiedener Organismen angeführt (aus „Hans Moravec - Computer übernehmen die Macht“).
#3624 Focus2/01 SoDr. 31.08.2001, 8:34 Uhr4
Schwarz

FOCUS MUL 18, Heft 2 (2001) 5
Auf Anwendungsebene profitiert die Molekulare Bio-informatik bereits jetzt von dem, was wir biologischenSystemen bislang abschauen konnten. Im Nervensys-tem müssen enorme Datenmengen intelligent verarbei-tet werden. Entsprechend bieten sich künstliche neuro-nale Netze für die Verarbeitung der enormen Datenflutin der Biotechnologie an. Als künstliche neuronaleNetze bezeichnet man im Computer simulierte Netz-werke schematisierter Neurone, mit denen sich an dieFunktionsprinzipien des Nervensystems angelehnteAlgorithmen realisieren lassen. Künstliche neuronaleNetze werden bereits zur Klassifikation von DNA- undProteinsequenzen eingesetzt, zur Vorhersage von Pro-teinstrukturen- und -funktionen, zur Auswertung vonGenchipdaten oder demnächst zur datengetriebenenModellierung von Genotyp-Phänotyp-Abbildungenbasierend auf SNPs (Single Nucleotide Polymor-phism), um nur einige Anwendungen zu nennen. Evo-lutionäre Algorithmen, Verfahren, die ähnlich wie dieEvolution durch Mutation und Selektion Strukturenoptimieren, werden z. B. zur Generierung alternativerProteinsequenzen mit ähnlichen Funktionseigenschaf-ten eingesetzt.
Was sind die großen Herausforderungen der Bioinfor-matik, was macht dieses Gebiet so spannend? Nebenden oben genannten Themen, die für sich gesehenbereits Herausforderungen von hoher Relevanz dar-stellen, gibt es eine zentrale Frage, die dieses Gebiettreibt und von deren Antwort viele Anwendungsgebietein hohem Maße profitieren würden: Warum sind biolo-gische Informationsverarbeitungssysteme, insbesondereunser Nervensystem, heutigen Computern in entschei-denden Aspekten immer noch so haushoch überlegen?Diese Frage stellt sich immer drängender, da die Leis-tungsfähigkeit der Computer, gerechnet in Instruktio-nen pro Zeiteinheit, Jahr für Jahr rasant ansteigt. Abbil-dung 1 zeigt über die letzten hundert Jahre die Rechen-geschwindigkeit, die man pro 1000 Dollar bekommenkonnte. Diese doppeltlogarithmische Darstellung ver-deutlicht das bekannte Moore’sche Gesetz, wonachsich die Rechengeschwindigkeit grob alle drei Jahrevervierfacht. Diese Darstellung extrapoliert diesenTrend, wofür es gute Gründe gibt, und zeigt zusätzlichnoch, wie sich die jeweiligen Computer in ihrer Leis-tungsfähigkeit mit entsprechenden biologischen Orga-nismen vergleichen. Dieser Vergleich kann natürlichnur eine Abschätzung sein, denn im Nervensystemkann man keine Rechengeschwindigkeit in Instruktio-nen/Zeiteinheit messen.
Es gibt verschiedene Ansätze, die Rechenleistung vonNervensystemen und Computern zu vergleichen. Derobige basiert darauf, dass man die visuellen Signalver-arbeitungsschritte auf der Retina bereits sehr gut kenntund man weiß, wie viel Rechenleistung benötigt wird,diese Verarbeitungsschritte im Computer nachzubil-
den. Da die Retina ein ausgelagerter Bestandteil desGehirns ist, kann dann über die Anzahl der involviertenNeurone auf Nervensysteme beliebiger Größe extrapo-liert werden.
Diese Abschätzungen liefern als Resultat, dass bereitsin rund 20 Jahren Computer prinzipiell an die Rechen-leistung unseres Gehirns heranreichen werden. Bereitsheute besitzen Computer die Rechenleistung des Ner-vensystems einer Eidechse. Jeder weiß, wie flink sichEidechsen in ihrer Umwelt zurechtfinden. Wir sindnicht ansatzweise in der Lage, Roboter ähnlich intelli-gent in der Umwelt agieren zu lassen. Die Computer-hardware wäre ausreichend leistungsfähig, jedoch sindwir nicht in der Lage, diese entsprechend zu program-mieren. In 20 Jahren werden wir (ob wir es wollen, isteine andere Frage) Computer bauen, die ähnlich leis-tungsfähig sein könnten, wie unser Gehirn. Uns fehlt esjedoch an den notwendigen Informationsverarbei-tungskonzepten. Hier können wir noch viel von biolo-gischen Systemen lernen. Die große Herausforderungist, dass wir wissen, dass es geht. Die Natur macht esuns vor.
Abbildung 2 zeigt einen weiteren interessanten Zusam-menhang. Es zeigt sich, dass Rechenleistung und Ar-beitsspeicherkapazität in informationsverarbeitendenSystemen dazu tendieren, stets im gleichen Verhältniszueinander zu stehen. Insbesondere ist interessant, dassdies nicht nur für technische, sondern auch für biologi-sche Informationsverarbeitungssysteme gilt.
Welches zentrale Problem muss gelöst werden, um dasPoteztial heutiger und zukünftiger Computer-Hard-ware in ähnlicher Weise zu nutzen, wie es uns biologi-sche Systeme mit ihrer „Hardware“ vormachen? Einwesentliches Merkmal, welches wir biologischen Sys-temen abschauen möchten, ist deren Fähigkeit, sich aufverschiedenen Ebenen permanent an Umweltgegeben-heiten anzupassen. Auf der einen oder anderen Ebenenennen wir es lernen. Diese Adaptivität ermöglicht esbiologischen Systemen, Strukturen zu realisieren, dieintelligent und robust in ihrer Umwelt agieren und aufhöchst komplexen Steuerungs- und Kontrollmechanis-men basieren. Adaptivität findet man auf verschiede-nen Ebenen, am bekanntesten sind die Ebenen der ge-netischen und neuronalen Adaption. Adaption findetdarüber auf verschiedenen Zeitskalen sowie auf Popu-lations- und Individualebene statt.
Die zentrale Struktur, sowohl in biologischen als auchin zu konzipierenden technischen Systemen, ist diedes sogenannten „autonomen Agenten“. Abbildung3 veranschaulicht diese zentrale Struktur. Ein sol-cher autonomer Agent soll basierend auf Informatio-nen über den Zustand der Welt bestimmte Aufgabenlösen. Die global zu lösende Aufgabe biologischerRealisierungen solch autonomer Agenten ist implizit
#3624 Focus2/01 SoDr. 31.08.2001, 8:34 Uhr5
Schwarz

6 FOCUS MUL 18, Heft 2 (2001)
gegeben, nämlich sich als Struktur zu erhalten. Bio-logische Agenten tun dies über einen cleveren Trick,über das Anlegen von Kopien (Fortpflanzung). Intechnischen Realisierungen wird die Aufgabe expli-ziter formuliert, etwa „sortiere Bauteile auf Fließ-band“, „steuere Stahlbandwalzstraße möglichst kos-tengünstig“, „finde gewünschte Information ausdem Internet“ oder „bestimme den Phänotyp zumvorliegenden Genotyp“. Wir wissen, dass manchedieser Aufgabenstellungen im Prinzip wesentlichbesser als heutzutage von technischen Systemen ge-löst werden könnten, denn ähnliche Aufgaben wer-den von biologischen autonomen Agenten als Teil-aufgabe mit dem Ziel der Strukturerhaltung sehr er-folgreich bewältigt.
Um die gestellte Aufgabe erfolgreich zu lösen, mussder Agent zunächst die für die Bewältigung der Aufga-be notwendigen Informationen über den Zustand derWelt erhalten. Dies erfolgt über die für diese Informati-onen passende Sensorik. Darüber entsteht „seine Welt-
Abb. 2: Die Rechenleistung verschiedener technischer als auch biologischer Informationsverarbeitungssystemein Millionen Instruktionen pro Sekunde (MIPS), aufgetragen gegen die in diesen Systemen jeweils verfügbareArbeitsspeicherkapazität in Megabyte. Beide Systemgrößen stehen in etwa stets in einem eins-zu-eins Verhältnis.Entlang der x-Achse sind reine Informationsspeicher- und entlang der y-Achse reine Informationsübertragungs-systeme aufgeführt (aus „Hans Moravec - Computer übernehmen die Macht“).
Abb. 3: Schematische Darstellung der prinzipiellenStruktur eines „autonomen Agenten“.
#3624 Focus2/01 SoDr. 31.08.2001, 8:34 Uhr6
Schwarz

FOCUS MUL 18, Heft 2 (2001) 7
sicht“, die über einen internen Zustand des Agenten re-präsentiert wird. Ist der Weltzustand bezüglich der fürdie Aufgabenstellung wichtigen Aspekte erfasst, somuss der Agent die passende Aktion generieren. Dazubraucht er eine der Aufgabenstellung entsprechendeAktuatorik. Zum Beispiel muss eine Fledermaus zumZwecke der Strukturerhaltung (überleben) Nahrungaufnehmen. Dazu sucht sie in vornehmlich dunklenRäumen umher. Informationen über die für diese Auf-gabe wichtigen Aspekte wie räumliche Gegebenhei-ten und Aufenthaltsort von Beuteobjekten holt siesich über ihre Ultraschallsensorik, um mit ihrem Fort-bewegungs- und Fangapparat diese Informationen zurLösung der Aufgabe umzusetzen. Entsprechend stat-tet man einen Roboter zum Beispiel mit einem Laser-scanner aus, damit er darüber die Lage von Bauteilenauf einem Fließband erfassen kann, um diese dannmit seinem Greifer vom Band zu nehmen und zu sor-tieren.
Der autonome Agent muss also mit der passenden Sen-sorik, der passenden Aktuatorik und vor allem dempassenden Aktionsverhalten ausgestattet werden. Beibiologischen Systemen hat die Evolution alle diese dreiAspekte optimiert. Bei heutigen technischen Realisie-rungen wird die Sensorik und Aktuatorik vorgegeben.Auf diesen beiden Ebenen meint man in der Regelrecht gut beurteilen zu können, was für die Lösung dergestellten Aufgabe notwendig ist. Wesentlich schwieri-ger ist es, den autonomen Agenten mit dem passendenAktionsverhalten auszustatten. Häufig wird dieses festvorgegeben. Basierend auf Modellen und Erfahrungs-werten wird dem Agenten „falls Weltzustand=x, dannAktion=y“ fest einprogrammiert. Selten ist jedoch einezu einem gegebenen Weltzustand passende, geschwei-ge denn optimale Aktion bekannt. Man hat es in derRegel mit hochdimensionalen Zustandräumen zu tun.Des Weiteren ist es häufig so, dass der nicht erfassteTeil der Welt sich ändert. Das kann dazu führen, dassdie Aktionen, die ja nur auf dem erfassten Teil der Weltbasieren, sich ebenfalls ändern, also adaptieren müs-sen. Die Gelenkmotoren eines Roboters können zumBeispiel über einen längeren Einsatz durch Verschleißihre Charakteristik verändern, weshalb das Steue-rungssystem entsprechend seine Ansteuerung ada-ptieren muss.
Biologische Systeme sind hervorragend in der Lage,ihr Aktionsverhalten selbständig an die Gegebenheitenanzupassen. Vor allem darin liegt ihre deutliche Über-legenheit gegenüber technischen Systemen. Insofernliegt es nahe, sich die dahinterliegenden Prinzipien nä-her anzuschauen. Dies ist eines der Kernthemen derBioinformatik und nicht nur von sehr hoher Praxis-,sondern auch Erkenntnisrelevanz. Denn wir kennendiese höchst erfolgreichen Informationsverarbeitungs-prinzipien bislang nur ansatzweise.
Abstrakt formuliert ist es der Natur gelungen, ein Ver-fahren zu konzipieren, welches eine Abbildung von ei-nem hochdimensionalen Eingaberaum auf einen Raumvon Ausgabewerten anhand von einzelnen Stichprobenlernen kann. Der Eingaberaum ist definiert durch alldie Zustände, die die Welt des autonomen Agenten be-züglich seiner zu lösenden Aufgabe annehmen kann.Diese Zustände sind in der Regel durch viele Aspektebestimmt, was diesen Raum sehr hochdimensionalmacht. Welche Aktion jetzt auf einen bestimmten„Weltzustand“ passt, soll das System lernen. Dazumuss es zunächst diejenigen Aspekte des Weltzustan-des, die für ihn wichtig sind, durch seinen internen Zu-stand repräsentieren. Zum Beispiel muss die Lage desObjektes auf dem Fließband intern kodiert werden, je-doch nicht etwa welcher Arbeiter es auf das Fließbandgelegt hat. Die interne Kodierung muss mächtig genugsein, um alle wichtigen Aspekte des Weltzustandes re-präsentieren zu können. Dieses Problem kann man alsgelöst ansehen, wenn man bedenkt, dass ein heutigerComputer in seinem Arbeitsspeicher im Prinzip10100.000.000 verschiedene Zustände repräsentieren kann.Das menschliche Gehirn liegt allerdings noch weit
Abb. 4: Der derzeit komplexeste autonome Roboter(Agent) weltweit, der humanoide Roboter P3 von Hon-da. Er ist 1,60 m groß, 130 kg schwer und kann aufzwei Beinen sogar Treppen steigen.
#3624 Focus2/01 SoDr. 31.08.2001, 8:34 Uhr7
Schwarz

8 FOCUS MUL 18, Heft 2 (2001)
darüber. Auf der anderen Seite hat das gesamte Univer-sum nicht mehr als 10100 Atome.
Das Problem liegt woanders. Wie kann dem Systembeigebracht werden, welche Aktion es jedem seiner in-ternen Kodierungszustände zuordnen muss. Diese Ak-tion muss ja zu dem Weltzustand, der durch die jeweili-ge interne Kodierung repräsentiert wird, passen. Ange-sichts der überwältigend großen Zahl verschiedenerZustände kann dies unmöglich explizit geschehen.Auch die Natur hat dies nicht explizit tun können, erstrecht nicht durch „trial and error“, denn selbst das Erd-alter wäre bei weitem nicht ausreichend gewesen.
Die Natur optimiert ihre Systeme zwar mit Hilfe von„trial and error“, dies alleine genügt jedoch nicht. Ent-scheidend ist, dass der Agent von einem eventuell zu-fällig erlangten Lernerfolg verallgemeinern kann. Hater durch eventuell zunächst zufällige Aktionen einezum Weltzustand passende gefunden, so muss er in derLage sein, daraus zu schließen, wie die Aktionen für ähn-liche Weltzustände aussehen müssen. Dazu muss er „wis-sen“, welche Zustände ähnlich sind in dem Sinne, dass sieähnliche Aktionen erfordern. Die interne Kodierung derWeltzustände muss also diese Ähnlichkeiten erfassen.Nur dann ist es möglich, die im wahrsten Sinne überastro-nomische Zahl möglicher Zustände mit passenden Aktio-nen des Agenten zu belegen. Um sich als autonomerAgent, ob biologisch oder technisch realisiert, an die Ge-gebenheiten oder Änderungen „seiner Welt“ adaptierenzu können, ist es also vor allem erforderlich, wie auchimmer gewonnene Adaptionserfolge generalisieren zukönnen. Offensichtlich hat die Natur eine interne Kodie-rung zur Repräsentation der Weltzustände gefunden, diedie Ähnlichkeitsstrukturen unserer Welt im Sinne der zulösenden Aufgaben hervorragend erfasst und damit Gene-ralisierungen ermöglicht. Dies gilt sowohl für den neuro-nalen als auch genetischen Kode.
Künstliche neuronale Netze ver-suchen, diese neuronale Kodie-rung zumindest ansatzweise zuimitieren, um damit Agenten zurLösung technischer Aufgabestel-lungen zu konzipieren. Aber auchwenn der Agent mit einer gutenGeneralisierungsfähigkeit ausge-stattet ist, so werden trotzdemimmer noch viele Versuche benö-tigt, um bei komplexen Aufga-benstellungen die Gegebenheitenzu lernen. Eine Anwendung, wokünstliche neuronale Netze zumersten Mal in größerem Maßstabkommerziell erfolgreich zumEinsatz kamen, ist bei der Steue-rung von Stahlbandwalzstraßen.
Abbildung 5 zeigt schematisiert solch eine Walzstraße.Ein auf rund 1000 Grad erhitzter Stahlblock von rund10 m Länge läuft in die Walzstraße ein, und heraus-kommen soll ein rund 1 mm dickes und 1 km langesStahlband, mit Dickentoleranzen im Mikrometerbe-reich. Verkauft werden diese Stahlbänder dann z. B. anAutohersteller. Die Steuerung solch einer Walzstraßeist eine hochkomplexe Angelegenheit, und die Fragewar, ob ein Agent, ausgestattet mit künstlichen neuro-nalen Netzen, zumindest die Steuerung von Teilaspek-ten dieser Walzstraße lernen kann. Bei der Walzkraft-steuerung zum Beispiel bekommt der Agent als Infor-mation über den „Weltzustand“ die Bandtemperatur,Walzgeschwindigkeit, Bandzüge, Walzenradien undStahlsorte, und muss daraus als „Aktion“ die für diegewünschte Enddicke notwendigen Walzkräfte an dieWalzwerksteuerung weitergeben. Es braucht mehreretausend Versuche, aber dann hat der Agent gelernt,welche Walzkräfte passen. Die erzielten Resultateübertreffen die mit konventionellen Techniken erreich-te Qualität. Mit mehreren tausend Versuchen hat manbei weitem nicht alle möglichen Gegebenheiten, dieauftreten können, abgedeckt. Aber offensichtlich istder Agent mit seinen künstlichen neuronalen Netzen inder Lage, bei dieser Aufgabe gut zu generalisieren undz. B. vorher noch nicht gewalzte Stahlsorten untervorher nicht angetroffenen Bedingungen gut zu wal-zen. Die von den künstlichen neuronalen Netzen ge-wählte Kodierung der „Weltzustände“ hat offensicht-lich deren Ähnlichkeiten im Sinne der Aufgabenstel-lung gut repräsentiert. Diese Agenten sind mittlerweileweltweit in Stahlproduktionsanlagen im Einsatz. DerenErfolg hat dazu geführt, dass nun alle möglichen senso-rischen Signale an solch einer Walzstraße aufgezeich-net werden. Den Agenten möchte man so viele „Welt-zustände“ wie möglich präsentieren, an denen sie sich
Abb. 5: Schematische Darstellung einer Walzstraße. Entscheidend ist die so-genannte Fertigstraße, wo das Stahlband auf Mikrometer genau auf wenigeMillimeter Dicke gewalzt werden muss.
#3624 Focus2/01 SoDr. 31.08.2001, 8:34 Uhr8
Schwarz

FOCUS MUL 18, Heft 2 (2001) 9
trainieren und „ihre Welt kennen lernen“ können. Dieenorme Entwicklung der Computertechnologie (obigesMoore’sche Gesetz) wird es in einigen Jahren ermögli-chen, die an solch einer Walzstraße anfallenden Datenüber dessen gesamte Lebensdauer aufzuzeichnen.
Mit der Bioinformatik sind wir nun beim Stahlwerkgelandet. Das verdeutlicht die Breite dieses Gebietes.Ein kleiner Schritt bringt uns aber sofort wieder zurückzu den Anwendungsproblemen der molekularen Bioin-formatik. Dieselben Konzepte, die dem Agenten erlau-ben, erfolgreich zur Steuerung eines Walzwerkes bei-zutragen, können ja vielleicht auch eingesetzt werden,um zum Beispiel Proteinfunktionen oder Genotyp-Phänotyp-Abbildungen zu lernen. Es liegen großeMengen von Daten vor, wobei die für eine bestimmteProblemstellung relevanten Daten allerdings schnellauf wenige zusammenschmelzen, zumindest im Ver-gleich zur Komplexität des Problems. Daher entschei-det auch hier wieder die Generalisierungsfähigkeit desAgenten.
Hochaktuell ist zum Beispiel der aller Ortens gestarteteVersuch, über die Bestimmung sogenannter SNPs
liegt immer das gleiche Nukleotid vor. An drei Millio-nen Positionen können also Unterschiede auftreten.Geht man davon aus, dass nur rund drei Prozent desGenoms kodierend genutzt werden und rund 50.000Gene vorliegen, so gibt es im Mittel auf jedem Gen nurrund 2 Positionen, auf denen dieses zwischen zweiMenschen variieren kann (es gibt Ausnahmen, Gene,die in einer wesentlich höheren Anzahl von Variantenvorkommen können). Da es praktisch ausgeschlossenist, dass an derselben Position zweimal eine Mutationaufgetreten ist, werden dort höchstens zwei verschie-dene Nukleotide auftreten können. Der Informations-gehalt eines menschlichen Gens beträgt also im Mittellediglich 2 Bit und der relevante Teil des gesamtenmenschlichen Genoms damit nur 100.000 Bit (basie-rend auf dem Vorwissen, um welches Gen bzw. Genomes sich handelt. Natürlich sind dies Abschätzungen vonGrößenordnungen). Mit rund 13 Kilobyte kann das Ge-nom eines menschlichen Individuums spezifiziert wer-den.
So wie beim Walzwerk ein Agent in der Lage ist, denZusammenhang zwischen den aktuellen Gegebenhei-ten in der Walzstraße und den erforderlichen Walzkräf-ten zu lernen, so wäre im Prinzip ein Agent vorstellbar,der basierend auf den 13 Kilobyte Informationen überden vorliegenden Genotyp den dazugehörigen Phäno-typ vorhersagt. Davon sind wir natürlich weit entfernt,die Komplexität ist viel zu groß. Auf eingeschränkterEbene möchte man dies aber versuchen. Lässt sich dieAnzahl der für ein bestimmtes Krankheitsbild odereine bestimmte Medikamentenverträglichkeit verant-wortlichen Gene stark einschränken, so hat manvielleicht eine Chance. Die Information, auf der derAgent dann seine Entscheidung treffen muss, reduziertsich auf wenige Bit. Die „Welt“, in der der Agent sichzurechtfinden muss, könnte dann einfach genug wer-den. Entscheidend für den Erfolg wird es auch hiersein, dass dem Agenten ein Kodierungsschema für den„Weltzustand“ (Genotyp) mitgegeben wird, das dieÄhnlichkeiten in dieser „Welt“ gut repräsentiert unddamit dem Agenten Generalisierungen ermöglicht.Eine der großen Fragen der Bioinformatik wird es sein,dieses Kodierungsschema zu finden.
Von einzelnen Agenten ist es dann ein naheliegenderSchritt zu Populationen von Agenten. Was gewinnt dasGesamtsystem, wenn jeder Agent nicht mehr nur fürsich agiert, sondern die Agenten die Möglichkeit ha-ben, miteinander zu kommunizieren, um eine Aufgabegemeinsam zu lösen. Abhängig von der speziellenWechselwirkung zwischen den Agenten ergibt sich einspezielles globales Verhalten der gesamten Population.Ein in diesem Zusammenhang häufig zitiertes Beispielist der Ameisenhaufen. Viele für sich „dumme“ Indivi-duen bringen durch entsprechende Interaktion ein ho-härentes Verhalten der Gesamtpopulation hervor, so
Abb. 6: Anstoß beim Spiel zweier RoboCup-Mann-schaften der Softwareliga bei der Europameisterschaft2000 in Amsterdam. Unter http://www.inb.mu-luebeck.de/robocup/robocup-d.html kann man sich dieentscheidenden Szenen dieses Spiels anschauen (LuckyLübeck gegen PSI aus Russland).
(Single Nucleotide Polymorphism) im Genom phäno-typische Aspekte eines Organismus vorherzusagen.Die Daten der Sequenzierung des menschlichen Ge-noms führen zu der Schätzung, dass im menschlichenGenom im Mittel nur an jeder tausendsten Positioneine Mutation aufgetreten ist. Könnte man die Genomealler Menschen übereinander legen, so würde man fest-stellen, das im Mittel nur an jeder tausendsten Stelleunterschiedliche Nukleotide auftreten und damit einsogenannter Polymorphismus vorliegt. An 99.9 % derrund 3 Milliarden Positionen im menschlichen Genom
#3624 Focus2/01 SoDr. 31.08.2001, 8:34 Uhr9
Schwarz

10 FOCUS MUL 18, Heft 2 (2001)
dass solch beeindruckende Leistungen wie das Bauenvon Ameisenhügeln erbracht werden. Welche Wechsel-wirkungen verursachen welches globale Verhalten,und, weit schwieriger, welche Wechselwirkungen be-nötigt man für ein gewünschtes globales Verhalten. Mitsolchen Populationen von Agenten lassen sich zumBeispiel auch gesellschaftliche Phänomene simulierenund besser verstehen, bis hin zu solch abstrakten As-pekten wie die Auswirkungen gesellschaftlicher Ver-haltensnormen. In den Wirtschaftwissenschaften ver-sucht man mit solchen Agentenpopulationen, Wirt-schaftsysteme zu modellieren. Die Auswirkungen vonmakroökonomischen Eingriffen können darüber simu-liert und besser abgeschätzt werden.
Durch die Kommunikation zwischen Agenten kommenneue Dimensionen der Komplexität ins Spiel. Nichtohne Grund vermutet man, dass der größte Teil desmenschlichen Gehirns für die soziale Interaktion benö-tigt wird, darin also die größte Intelligenzleistung desMenschen liegt. Auf jeden Fall sind Computer hierganz besonders schlecht. Erfolgreiche soziale Interak-tion erfordert das Einfühlen in die Situation des ande-ren, was wiederum ein „Bewusstsein“ des eigenen Ichsund das des Gegenübers voraussetzt. Es lässt sich spe-kulieren, ob sich mit Sozialverhalten auch Bewusstseinentwickeln muss und umgekehrt. Je höher entwickeltdas Sozialverhalten einer Spezies, desto ausgeprägterderen Bewußsein? Dann sollte sich auch die SpeziesMensch in noch weit höhere Bewusstseinszustände be-geben können.
Zurück zu dem, was heutzutage bereits möglich ist. Vorgut einem Jahr ist das Institut für Neuro-und Bioinfor-matik der MUL mit einem Team von Studenten beimsogenannten RoboCup eingestiegen. RoboCup ist einweltweites wissenschaftliches Projekt, dessen Ziel dieErforschung von Konzepten und Techniken für dieEntwicklung von Systemen interagierender autonomer
Agenten ist. Als Szenario wird bei RoboCup ein Fuß-ballspiel verwendet, bei dem die Spieler durch künstli-che Agenten (Software- oder Hardwareroboter) reprä-sentiert werden. Dieses Szenario stellt für alle Aspekteder Multiagentenentwicklung eine Herausforderungdar, von den limitierten Informationen, die den Agen-ten zur Verfügung stehen, der motorisch-sensorischenKoordination, der Kooperation zwischen Agenten ei-nes Teams zur Lösung der gemeinsamen Aufgabe bishin zur Bewältigung widriger Umstände (in Form derAgenten des gegnerischen Teams). Von besondererBedeutung ist dabei die Tatsache, daß sich unter-schiedliche wissenschaftliche Konzepte einander imdirekten Vergleich gegenüberstellen lassen. So findenim Rahmen des RoboCup-Projektes alljährlich Welt-meisterschaften und weitere Turniere statt. Abbildung6 zeigt die Szene beim Anstoß zu einem Spiel zweierTeams aus der Softwareliga bei der Europameister-schaft 2000 in Amsterdam. Beide Teams bestehen aus11 Agenten. Jeder Agent bekommt abhängig von sei-ner Position auf dem Feld und seiner Blickrichtung be-stimmte Informationen über die aktuelle Spielsituati-on, die er dann in passende Aktionen umsetzen muß.Jeder Agent muß dabei seine Rolle innerhalb derMannschaft einnehmen. Der Torwart braucht ein an-deres Aktionsverhalten als die Stürmer. Die erstenSpiele erinnerten an die der F-Jugend, an einenSchwarm von Spielern, der sich mit dem Ball bewegt.Unter http://www.inb.mu-luebeck.de/robocup/robo-cup-d.html kann man sich anschauen, dass sich seit-dem viel getan hat. Trotzdem glauben wir natürlichnicht, dass sich bereits Bewusstsein bei den Agenteneingestellt hat.
Prof. Dr. rer. nat. Thomas Martinetz ist Direktor des Instituts fürNeuro- und Bioinformatik der Medizinischen Universität zu Lübeck.Dem vorliegenden Beitrag liegt seine Antrittsvorlesung vor der Tech-nisch-Naturwissenschaftlichen Fakultät vom 6. Juli 2000 zugrunde.
#3624 Focus2/01 SoDr. 31.08.2001, 8:34 Uhr10
Schwarz

FOCUS MUL 18, Heft 2 (2001) 11
#3624 Focus2/01 SoDr. 31.08.2001, 8:34 Uhr11
Schwarz

12 FOCUS MUL 18, Heft 2 (2001)
#3624 Focus2/01 SoDr. 31.08.2001, 8:34 Uhr12
Schwarz





























