WS09/10, © Prof. Dr. E. Rahm
9. Cloud-Datenspeicherung und
MapReduce-Parallelisierung
Einführung Cloud Data Management
Verteilte Datenhaltung– Dateisysteme (GFS)– Hbase (Google Big Table)– Amazon Dynamo
MapReduce– Idee– Open Source-Realisierung – Hadoop
MapReduce vs. Parallele DBS
MapReduce - Erweiterungen
– Hive
– HadoopDB
9-1
WS09/10, © Prof. Dr. E. Rahm
Cloud Computing“Cloud computing is using the internet to access someone else's software running on someone else's hardware in someone else's data center”
- Lewis Cunningham
Externe Bereitstellung von IT-Infrastrukturen sowie Applikations-Hosting über das Internet (bzw. Intranet)
– Public Cloud vs. Private Clouds
Charakteristika:
– Illusion unendlicher, „on demand“ verfügbarer Ressourcen
– Virtualisierung: gemeinsame Nutzung v. Ressourcen durch viele Nutzer
– „Elastizität“ - schnelle Belegung/Freigabe von Ressourcen nach Bedarf
(„Hinzuschalten“ weiterer Rechner)
– Abrechnung nach Verbrauch (CPU Zyklen, Speicherplatz,
Übertragungsvolumen)
9-2

WS09/10, © Prof. Dr. E. Rahm
Cloud Computing (2) Vorteile Cloud User
– Kein Einrichten/Betreiben eigener Rechenzentren
– Keine langfristige Ressourcenplanung
– Keine hohen Vorabinvestitionen - pay per use
– Verspricht wesentliche Kosteneinsparungen (u.a. für Startups)
Vorteile Cloud Provider
– Aufteilung verfügbarer Ressourcen auf mehrere Kunden
– Große Rechenzentren (50.000 Server) haben im Vrgl. zu mittelgroßen
(1000 Server) nur 1/5 - 1/7 der Kosten
– Standortvorteile - Elektrizitätspreise, Löhne, Steuern
– Green Computing- Bessere Auslastung der Clouds im gegenüber lokalen Rechenzentren
9-3
WS09/10, © Prof. Dr. E. Rahm
Cloud Computing - Einteilung
9-4
IaaS
Infrastructure as a Service
PaaS
Platform as a Service
SaaS
Software as a Service

WS09/10, © Prof. Dr. E. Rahm
Cloud-Einsatzbeispiele
Amazon EC2 (Electronic Compute Cloud)
– „Mieten“ einer Menge virtueller Maschinen
– Verwendung für Anwendungen beliebiger Art
„Online-Speicher“ Amazon S3
– Speichern und Lesen von Daten über Webservice von überall zu jeder
Zeit
– Schnell, billig, hochverfügbar, hochskalierbar
9-5
WS09/10, © Prof. Dr. E. Rahm
Cloud-Einsatzbeispiele 2
Google App Engine
– Plattform zum Entwickeln und Vorhalten von Webanwendungen
– Python, Java etc.
Cloud-basierte Office-Anwendungen (realisiert als Web-Dienste)
– Google Mail, Docs, Google Calendar, ...
– Keine lokale Software und Datenhaltung
– Universeller Zugang mittels Browser/
Thin Client
9-6

WS09/10, © Prof. Dr. E. Rahm
Cloud Data Management
Cloud-Anwendungen erfordern Datenhaltung / Austausch von Daten in der Cloud
Effiziente und persistente Verwaltung großer Datenmengen die Speicherkapazität eines Rechners übersteigen (mehrere TB-PB)
Möglichkeiten:
– Verteiltes Filesystem (Google File System, Hadoop DFS)
– Cloud-Datenbanken
- statt RDBMS oft Key-Value Stores (Bigtable/Hbase, Dynamo, Cassandra, CouchDB, …)
Map/Reduce-Paradigma zur Parallelisierung
Unterstützung für parallele Datenauswertungen / Data Mining
– OLAP - multidim. Aggregation großer Datenmengen
– ACID nicht erforderlich
9-7
WS09/10, © Prof. Dr. E. Rahm
Google File System1 (GFS)
Proprietäres, verteiltes Linux-basiertes Dateisystem
– Hochskalierend: tausende Festplatten, mehrere 100TB
– Open Source-Alternative - Hadoop Distributed File System
Netzknoten: „billige“ Standardhardware (kein RAID)
– Hardwarefehler- und ausfälle sind Regelfall
– Gewährleistung von Datensicherheit
optimiert für Streaming Access
– File-Änderungen durch Anhängen: write once - read many times
– Verteiltes, sequentielles Lesen (blockweise)
Hoher Durchsatz statt geringer Latenz1 S.Ghemawat, H. Gobioff, S. T. Leung. The Google File System. SOSP 2003
9-8
WS09/10, © Prof. Dr. E. Rahm
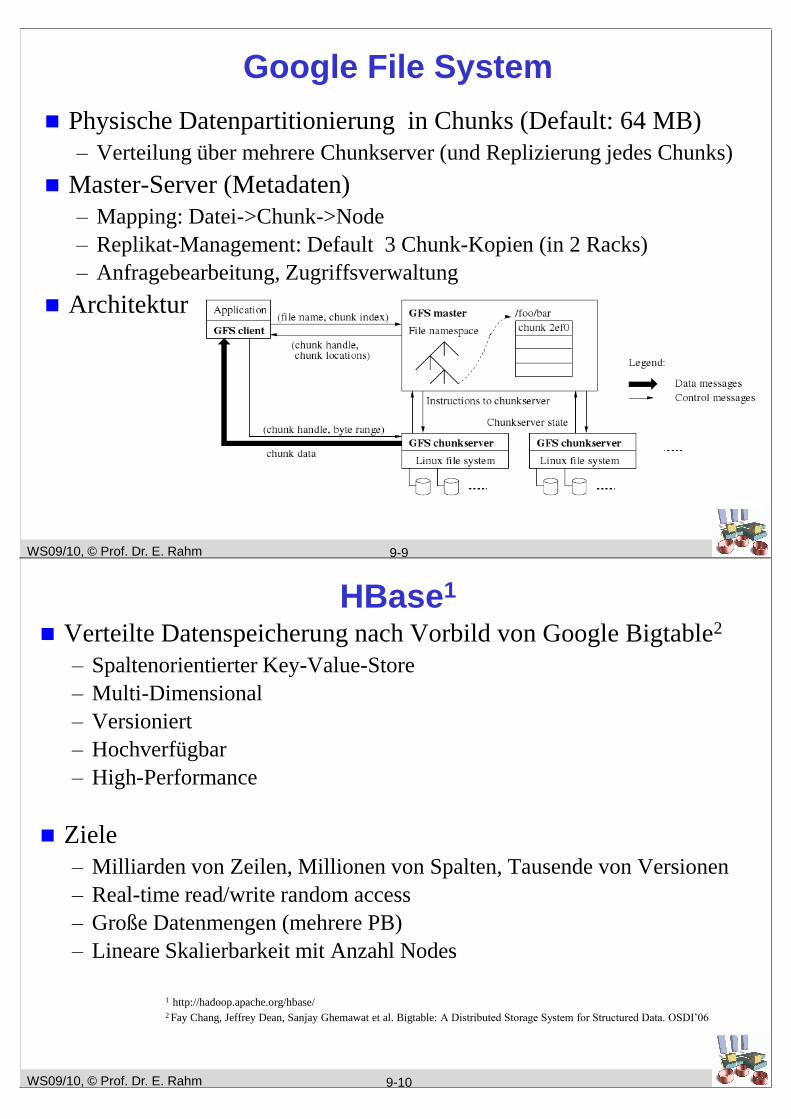
Google File System
Physische Datenpartitionierung in Chunks (Default: 64 MB)
– Verteilung über mehrere Chunkserver (und Replizierung jedes Chunks)
Master-Server (Metadaten)
– Mapping: Datei->Chunk->Node
– Replikat-Management: Default 3 Chunk-Kopien (in 2 Racks)
– Anfragebearbeitung, Zugriffsverwaltung
Architektur
9-9
WS09/10, © Prof. Dr. E. Rahm
HBase1
Verteilte Datenspeicherung nach Vorbild von Google Bigtable2
– Spaltenorientierter Key-Value-Store
– Multi-Dimensional
– Versioniert
– Hochverfügbar
– High-Performance
Ziele
– Milliarden von Zeilen, Millionen von Spalten, Tausende von Versionen
– Real-time read/write random access
– Große Datenmengen (mehrere PB)
– Lineare Skalierbarkeit mit Anzahl Nodes
1 http://hadoop.apache.org/hbase/2 Fay Chang, Jeffrey Dean, Sanjay Ghemawat et al. Bigtable: A Distributed Storage System for Structured Data. OSDI‟06
9-10

WS09/10, © Prof. Dr. E. Rahm
Hbase: Einsatzfälle Web-Tabelle
– Tabelle mit gecrawlten Webseiten mit ihren Attributen/Inhalten
– Key: Webseiten-URL
– Millionen/Milliarden Seiten
Random-Zugriff durch Crawler zum Einfügen neuer/geänderter Webseiten
Batch-Auswertungen zum Aufbau eines Suchmaschinenindex
Random-Zugriff in Realzeit für Suchmaschinennutzer, um Cache-Version von Webseiten zu erhalten
9-11
WS09/10, © Prof. Dr. E. Rahm
Datenmodell Hbase / Bigtable Verteilte, mehrdimensionale, sortierte Abbildung
(row:string, column:string, time:int64) string
– Spalten- und Zeilenschlüssel
– Zeitstempel
– Daten bestehen aus beliebigen Zeichenketten / Bytestrings
Zeilen
– (nur) Lese- und Schreiboperationen auf eine Zeile sind atomar
– Speicherung der Daten in lexikographischer Reihenfolge der
Zeilenschlüssel
[CDG+08]
9-12
WS09/10, © Prof. Dr. E. Rahm
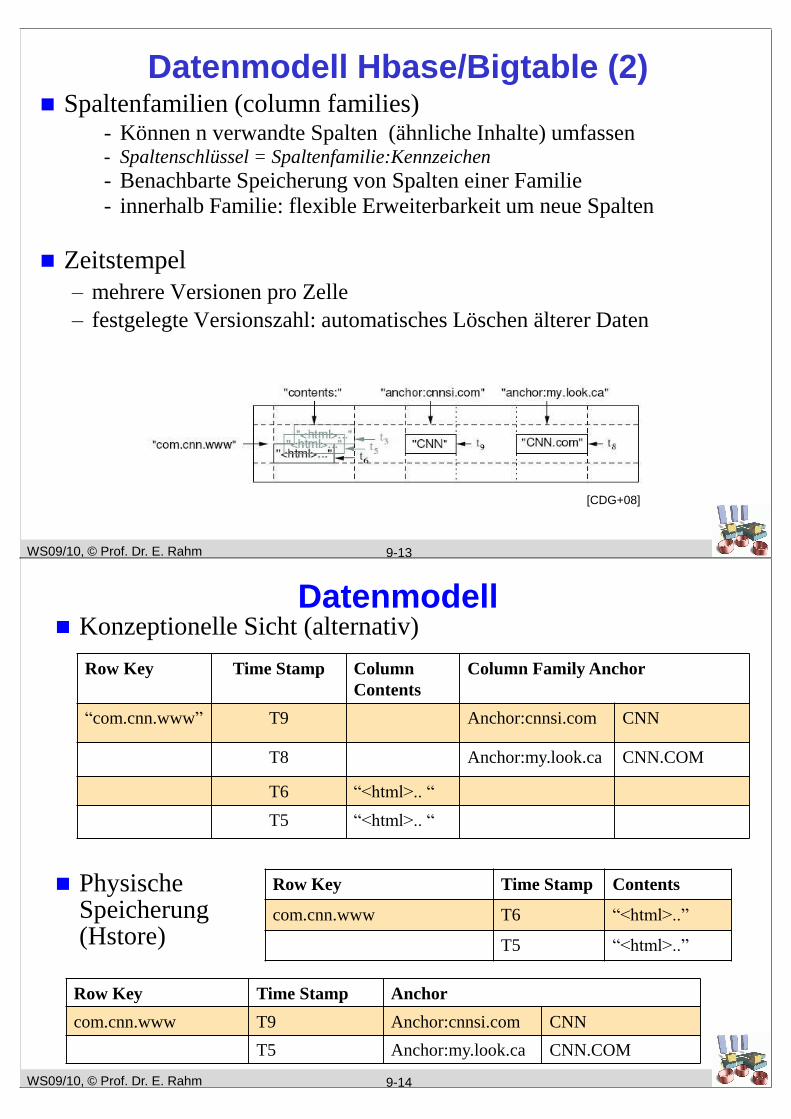
Datenmodell Hbase/Bigtable (2) Spaltenfamilien (column families)
- Können n verwandte Spalten (ähnliche Inhalte) umfassen- Spaltenschlüssel = Spaltenfamilie:Kennzeichen
- Benachbarte Speicherung von Spalten einer Familie
- innerhalb Familie: flexible Erweiterbarkeit um neue Spalten
Zeitstempel
– mehrere Versionen pro Zelle
– festgelegte Versionszahl: automatisches Löschen älterer Daten
[CDG+08]
9-13
WS09/10, © Prof. Dr. E. Rahm
Konzeptionelle Sicht (alternativ)
Physische Speicherung (Hstore)
Datenmodell
Row Key Time Stamp Column
Contents
Column Family Anchor
“com.cnn.www” T9 Anchor:cnnsi.com CNN
T8 Anchor:my.look.ca CNN.COM
T6 “<html>.. “
T5 “<html>.. “
Row Key Time Stamp Contents
com.cnn.www T6 “<html>..”
T5 “<html>..”
Row Key Time Stamp Anchor
com.cnn.www T9 Anchor:cnnsi.com CNN
T5 Anchor:my.look.ca CNN.COM
9-14

WS09/10, © Prof. Dr. E. Rahm
HBase Hohe Schemaflexibilität über Spaltenfamilien
– Optionale Verwendung von Spalten pro Satz
– Pro Spaltenfamilie können zur Laufzeit beliebig viele Spalten hinzugefügt
werden
Bsp:
9-15
create ‘test’, {NAME=>‘fam1’, VERSIONS=>2}put ‘test’, ‘row1’, ‘fam1:col7’, ‘value1’put ‘test’, ‘row2’, ‘fam1:col8’, ‘value2’put ‘test’, ‘row2’, ‘fam1:col8’, ‘value3’
scan‘test’ ROW COLUMN+CELLrow1 column=fam1:col7, timestamp=123, value=value1row2 column=fam1:col8, timestamp=125, value=value2row2 column=fam1:col8, timestamp=127, value=value3
WS09/10, © Prof. Dr. E. Rahm
HBase Regions (Tablets in Bigtable)
– Horizontale Partitionierung von Tabellen in Regions
– mehrere Region-Server zur Aufnahme der Regions Lastbalancierung
– Region-Split in 2 gleich große Regions, wenn max. Größe (z.B. 128 MB)
erreicht
Architektur
– Datenspeicherung in Region-Server
– Master
- weist Regions Region-Servern zu
- Recovery für Region-Server
RegionServer
RegionServer
RegionServer
Master Server
HStore HStore Region
9-16

WS09/10, © Prof. Dr. E. Rahm
HBase
9-17
region {
-ROOT-
.META.
user table 1
user table n
Zweistufige Katalogverwaltung: Tabellen ROOT, META
– META verwaltet Liste aller (user table) Regions
– ROOT: 1 Region mit Liste der META-Regions
Eintrag enthält 1st Row Key, Location, Status, …– Tabellen sind sortiert nach Start-Row-Key
Adressraum (Eintragsgröße 1 KB, Regiongröße 128 MB):
WS09/10, © Prof. Dr. E. Rahm
Hbase vs. RDBMS Hbase-Eigenschaften
– Verteilte Punkt- und Scan-Anfragen für Reads/Writes
– Built-In-Replikation
– Skalierbarkeit
– Batch-Verarbeitung (Source/Sink für MapReduce)
– Denormalisierte Daten / breite, spärlich besetzte Tabellen
– kostengünstig
– keine Query-Engine / kein SQL
– Transaktionen und Sekundär-Indexe (extern) möglich, jedoch schlechte
Performance
RDBMS
– deklarative Anfragen mit SQL (Joins, Group By, Order By …)
– automatische Parallelisierbarkeit auf verschiedenen PDBS-Architekturen
– Sekundär-Indexe
– Referenzielle Integrität
– ACID-Transaktionen, …9-18

WS09/10, © Prof. Dr. E. Rahm
Amazon Dynamo Verteilter, skalierbarer Key-Value-Speicher
– v.a. für kleine Datensätze (z.B. 1 MB/Key), z.B. Warenkörbe
– hochverfügbar
“Eventually consistent data store”
– Schreibzugriffe sollen immer möglich sein
– reduzierte Konsistenzzusicherungen zugunsten Verfügbarkeit
Performance SLA (Service Level Agreement)
– “response within 300ms for 99.9% of requests for peak client load of 500
requests per second”
P2P-artige Verteilung
– keine Master-Knoten
– alle Knoten haben selbe Funktionalität
9-19
WS09/10, © Prof. Dr. E. Rahm
Amazon Dynamo Knoten bilden logischen Ring
– Position entspricht zufälligem Punkt im Wertebereich einer Hashfunktion
Knoten speichert Daten, deren Key-Hashwert zwischen Vorgänger und ihm liegt
jedes Datum über N Knoten repliziert
– Präferenzliste: Liste der Knoten, die zur Datenspeicherung für einen Key
zuständig
9-20

WS09/10, © Prof. Dr. E. Rahm
Amazon Dynamo Key-Value-Store-Interface
– Put (key, context, object)
- Context enthält u. a. Versionsnummer des Objektes (aus vorheriger Leseoperation)
- Lokales Schreiben des Objektes, Erhöhen der Versionsnummer
- asynchrone Aktualisierung der Replikate -> Konsistenzprobleme
– Get (key)
- Kann mehrere Versionen eines Objektes zurückliefern: Liste von (object, context)-Paaren
Primary-Key-Zugriff; keine komplexen Queries – Anfrage kann an beliebigen Knoten des Ringes gesendet werden
– Weiterleitung der Anfrage an einen Knoten der Präferenzliste dieses Keys
Anwendungen sehen Versionierung
9-21
WS09/10, © Prof. Dr. E. Rahm
Amazon Dynamo Verwendung von Read/Write-Quoren
– R/W minimale Anzahl der N Replikat-Knoten, die für erfolgreiche Read/Write Operation übereinstimmen müssen
– Anwendung kann (N,R,W) an Bedürfnisse an bzgl. Performanz, Verfügbarkeit und Dauerhaftigkeit einstellen
– üblich ist (3,2,2)
Sloppy Quorum– strenge Konsistenz erfordert R + W > N, W > R/2 hohe Zugriffszeiten
– W=1 Schreiben möglich, solange mindestens ein Knoten arbeitet
– Nutzergesteuerte Konfliktbehandlung für abweichende Versionen
9-22
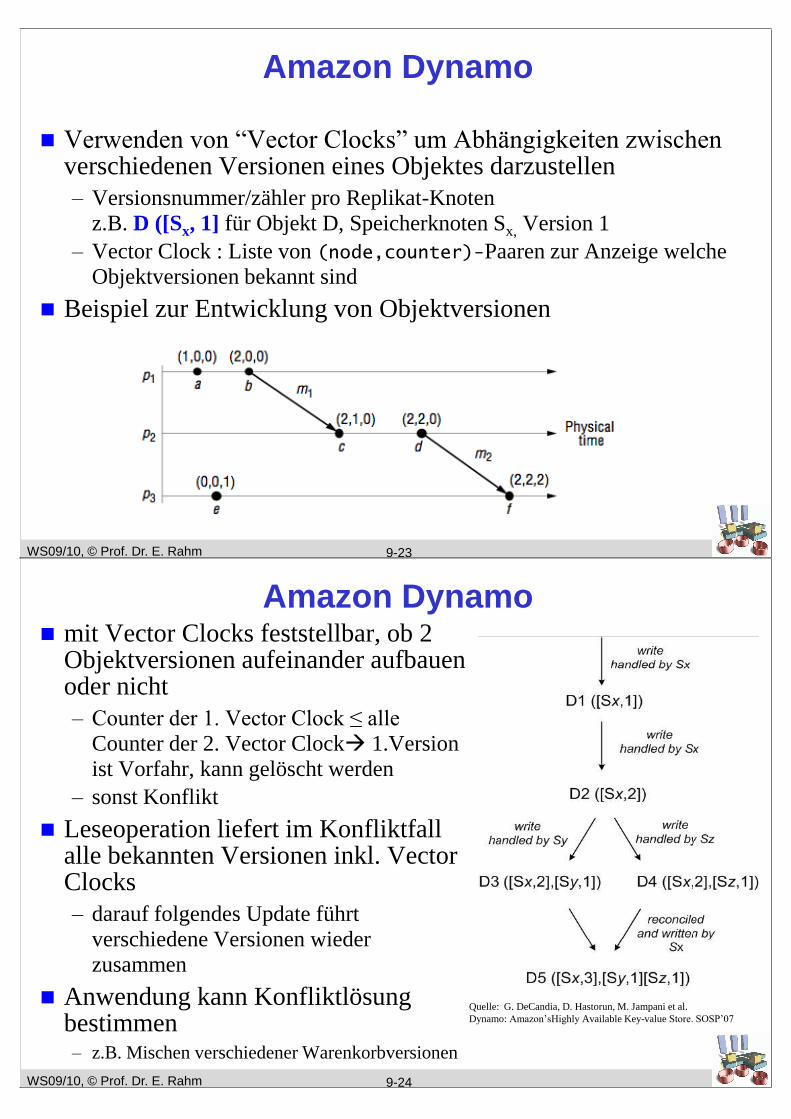
WS09/10, © Prof. Dr. E. Rahm
Amazon Dynamo
Verwenden von “Vector Clocks” um Abhängigkeiten zwischen verschiedenen Versionen eines Objektes darzustellen
– Versionsnummer/zähler pro Replikat-Knoten
z.B. D ([Sx, 1] für Objekt D, Speicherknoten Sx, Version 1
– Vector Clock : Liste von (node,counter)-Paaren zur Anzeige welche
Objektversionen bekannt sind
Beispiel zur Entwicklung von Objektversionen
9-23
WS09/10, © Prof. Dr. E. Rahm
Amazon Dynamo mit Vector Clocks feststellbar, ob 2
Objektversionen aufeinander aufbauen oder nicht
– Counter der 1. Vector Clock ≤ alle
Counter der 2. Vector Clock 1.Version
ist Vorfahr, kann gelöscht werden
– sonst Konflikt
Leseoperation liefert im Konfliktfall alle bekannten Versionen inkl. Vector Clocks
– darauf folgendes Update führt
verschiedene Versionen wieder
zusammen
Anwendung kann Konfliktlösung bestimmen– z.B. Mischen verschiedener Warenkorbversionen
9-24
Quelle: G. DeCandia, D. Hastorun, M. Jampani et al.
Dynamo: Amazon‟sHighly Available Key-value Store. SOSP‟07

WS09/10, © Prof. Dr. E. Rahm
MapReduce
Framework zur automatischen Parallelisierung von Auswertungen auf großen Datenmengen (Google-Ansatz1)
Nutzung v.a. zur Verarbeitung riesiger Mengen teilstrukturierter Daten in einem verteilten Dateisystem
– Konstruktion Suchmaschinenindex
– Clusterung von News-Artikeln
– Spam-Erkennung …
Ausnutzung vorhandener Datenpartitionierung (GFS, Bigtable)
Verwenden zweier Funktionen Map und Reduce
Map: Verarbeitung von Key-Value-Paaren, Generierung und
dynamische Partitionierung von Zwischenergebnissen (abgeleitete Key-
Value-Paare)
Reduce: Mischen aller Zwischenergebnisse mit demselben Key;
Datenreduktion; Generierung von Key-Value Paaren als Endergebnis
1 Jeffrey Dean,Sanjay Ghemawat. MapReduce: Simplified Data Processing on Large Clusters. OSDI'04
9-25
WS09/10, © Prof. Dr. E. Rahm
MapReducemap: (k1,v1) list(k2,v2)
reduce: (k2,list(v2)) list(k3,v3)
Bsp.
– Bestimmen der höchsten aufgezeichneten Temperatur pro Jahr in großer
Menge von ASCII-Files mit Wetterdaten
– 0043011990999991950051512004...9999999N9+00221+99999999999...
9-26
Adaptiert von: Hadoop The Definitive Guide, 2009, Tom White, O„Reilly
k1 vom Typ Long(File-Offset)
v1 vom Typ String(Zeile selbst)
pro (k1,v1)-Paar wirdEin (k2,v2)-Paar erzeugt(1-elementige Liste)
Sortieren der(k2,v2)-Paare undgruppieren nach k2
Zusammenfassung (Maximum)Aller v2 zu einem k2(1-elementige Liste)

WS09/10, © Prof. Dr. E. Rahm
MapReduce Parallele Ausführung der Map- und Reduce- Funktionen
– Lokale Speicherung des partitionierten Map-Outputs
– Reducer holen sich ihren Input ab
9-27
Quelle: http://www.jiahenglu.net/course/advancedDataManagement/
Output der Mapper mitselbem Key wird vom
selben Reducer bearbeitet
Reducer mischen sortierten Map-Output
und übergeben (k2,list(v2))an Reduce-Funktion R
Output d. Mappersortiert und par-
titioniert nach Key
WS09/10, © Prof. Dr. E. Rahm
Hadoop Googles MapReduce 2004 veröffentlicht
– Proprietär, nicht verfügbar
Hadoop ist Open Source Alternative
Inspiriert von Googles MR/GFS
Apache Top-Level-Projekt
Unterprojekte: HDFS, MapReduce, HBase, Pig, Hive et al.
Unix-ähnliche OS (Shell Skripte, passwortloses SSH)
Java 6
Große Community
Fertige Distributionen zur Ausführung in Amazon EC2
Sieger des Terabyte Sort Benchmark 2008 & 2009
100 TB Integer in 173 Minuten mit 3452 nodes (2 Quadcore Xeons, 8 GB
Memory, 4 SATA)
9-28
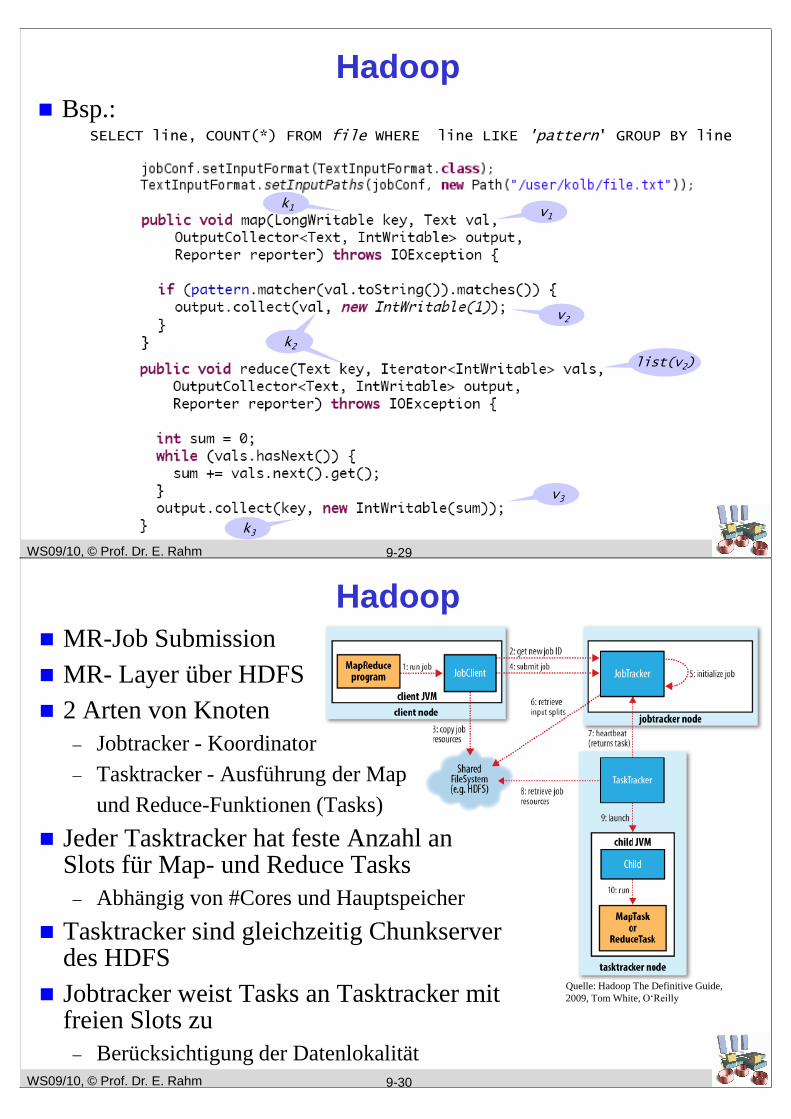
WS09/10, © Prof. Dr. E. Rahm
Hadoop
9-29
list(v2)
k1 v1
k2
v2
k3
v3
Bsp.:SELECT line, COUNT(*) FROM file WHERE line LIKE 'pattern' GROUP BY line
WS09/10, © Prof. Dr. E. Rahm
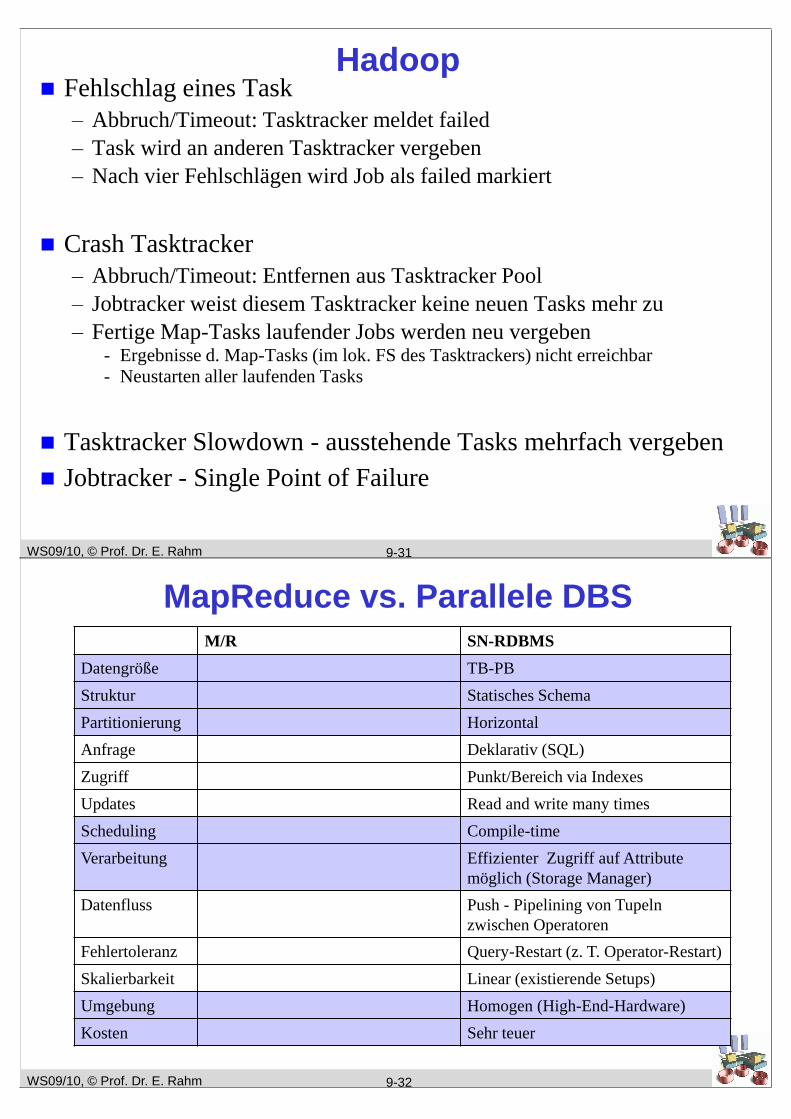
Hadoop
9-30
MR-Job Submission
MR- Layer über HDFS
2 Arten von Knoten
Jobtracker - Koordinator
Tasktracker - Ausführung der Map
und Reduce-Funktionen (Tasks)
Jeder Tasktracker hat feste Anzahl an Slots für Map- und Reduce Tasks
Abhängig von #Cores und Hauptspeicher
Tasktracker sind gleichzeitig Chunkserverdes HDFS
Jobtracker weist Tasks an Tasktracker mitfreien Slots zu
Berücksichtigung der Datenlokalität
Quelle: Hadoop The Definitive Guide,
2009, Tom White, O„Reilly
WS09/10, © Prof. Dr. E. Rahm
Hadoop Fehlschlag eines Task
– Abbruch/Timeout: Tasktracker meldet failed
– Task wird an anderen Tasktracker vergeben
– Nach vier Fehlschlägen wird Job als failed markiert
Crash Tasktracker
– Abbruch/Timeout: Entfernen aus Tasktracker Pool
– Jobtracker weist diesem Tasktracker keine neuen Tasks mehr zu
– Fertige Map-Tasks laufender Jobs werden neu vergeben- Ergebnisse d. Map-Tasks (im lok. FS des Tasktrackers) nicht erreichbar
- Neustarten aller laufenden Tasks
Tasktracker Slowdown - ausstehende Tasks mehrfach vergeben
Jobtracker - Single Point of Failure
9-31
WS09/10, © Prof. Dr. E. Rahm
MapReduce vs. Parallele DBS
9-32
M/R SN-RDBMS
Datengröße TB-PB
Struktur Statisches Schema
Partitionierung Horizontal
Anfrage Deklarativ (SQL)
Zugriff Punkt/Bereich via Indexes
Updates Read and write many times
Scheduling Compile-time
Verarbeitung Effizienter Zugriff auf Attribute
möglich (Storage Manager)
Datenfluss Push - Pipelining von Tupeln
zwischen Operatoren
Fehlertoleranz Query-Restart (z. T. Operator-Restart)
Skalierbarkeit Linear (existierende Setups)
Umgebung Homogen (High-End-Hardware)
Kosten Sehr teuer

WS09/10, © Prof. Dr. E. Rahm
MapReduce vs. Parallele DBS Vorteile MapReduce
– Skalierbarkeit/Fehlertoleranz
– Konfigurationsaufwand
– Kosten
– Kein initialer Ladevorgang
Vorteile SN-DBS
– Deklarative Anfragesprache
– Anfragen werden um Größenordnungen schneller beantwortet
– (Zzt.) Arbeit auf komprimierten Daten
– Random Access
Typische Anwendungsfälle MapReduce
– ETL
– Data-Mining, Data-Clustering
– Analyse semistrukturierter Daten (Web-Logs, …)
– Einmal-Analysen eines Datenbestandes
9-33
WS09/10, © Prof. Dr. E. Rahm
Hive1
Data Warehouse-Infrastruktur, setzt auf Hadoop auf
Entwickelt für Facebook
– 4TB komprimierte Daten pro Tag
– 135TB komprimierte Daten werden pro Tag analysiert
– 7500 MapReduce/HiveJobs jeden Tag
MapReduce Programmierung Low-Level
– Programme schwer zu warten, kaum Reuse
– Barriere für Nicht-Experten
– Fehlende Ausdrucksmächtigkeit- Hoher Zeitaufwand, um simple Count/Avg-Anfragen in MapReduce zu realisieren
Ziel - Erweiterung der Anfragemöglichkeiten an Hadoop
1 http://hadoop.apache.org/hive/
9-34

WS09/10, © Prof. Dr. E. Rahm
Hive What is Hive
– Verwaltung und Analayse strukturierter Daten mit Hilfe Hadoop
– Anfragen mit HiveQL, Ausführung mit MapReduce
– Datenhaltung im HDFS, Metadaten für Abbildung auf Tabellen
– Skalierbarkeit und Fehlertoleranz
– Erweiterbarkeit (UDTF, UDAF)
What Hive is NOT1
– Hive does not and cannot promise low latencies on queries
– The paradigm here is strictly of submitting jobs and being notified when
the jobs are completed as opposed to real-time queries
– Hive queries response times for even the smallest jobs can be of the order
of several minutes
1 http://wiki.apache.org/hadoop/Hive
9-35
WS09/10, © Prof. Dr. E. Rahm
Hive HiveQL - SQL-ähnliche Anfragesprache
– σ, π, Equi-⋈, Union, Sub-Queries, Group By, Aggregatfunktionen
– Übersetzung d. Anfragen in MapReduce Jobs
– Ausführung in Hadoop Cluster
– MapReduce Skripte können Bestandteil von Queries sein
Architektur
9-36
– Thrift - Cross-language Service
– Metastore - Tabellen, Spalten/Typ,
Location, Partitionen,
(De)Serialisierungs-informationen, …
– Compiler - Anfrageoptimierung und
Übersetzung des HiveQL-Statements in
DAG von MapReduce Jobs
– Executor - Ausführung der MR-Jobs
entsprechend DAGQuelle: Ashish Thusoo, Joydeep Sen Sarma, Namit Jain et. Al.
Hive - A Warehousing Solution Over a Map-Reduce Framework. VLDB‟09

WS09/10, © Prof. Dr. E. Rahm
Hive Tabellen1
– Kann auf exist. Daten im HDFS verweisen
– Tabelle hat korrespond. HDFS-Verzeichnis- /wh/pvs
– Definition von Spalten, anhand denen Daten partitioniert werden- /wh/pvs/ds=20090801/ctry=US- /wh/pvs/ds=20090801/ctry=CA
– Bucketing- Aufteilen der Dateien eines Verzeichnisses anhand Hash-Wert einer Spalte
(Datenparallelität)- /wh/pvs/ds=20090801/ctry=US/part-00000 … - /wh/pvs/ds=20090801/ctry=US/part-00020
Laden von Daten in Tabellen1
– status_updates(user_id int, status string, ds string)
– LOAD DATA LOCAL INPATH ‘/logs/status_updates’ INTO TABLE status_updates PARTITION (ds=’2009-03-20’)
1 http://www.slideshare.net/ragho/hive-user-meeting-august-2009-facebook
9-37
CREATE EXTERNAL TABLE pvs(userid int, pageid int, ds string, stry string)
PARTITIONED ON(ds string, ctry string)STORED AS textfileLOCATION ‘/path/to/existing/file’
WS09/10, © Prof. Dr. E. Rahm
Hive Anfrageübersetzung
SELECT * FROM status_updates WHERE status LIKE ‘michael jackson’
Anfrageoptimierung
– Verwerfen nicht benötigter Spalten- Berücksichtigung von. (Outer-)Join- und Selektionsattributen
– Frühes Anwenden von Selektionsprädikaten
– Verwerfen nicht benötigter Partitionen
9-38
Quelle: http://www.slideshare.net/ragho/hive-user-meeting-august-2009-facebook
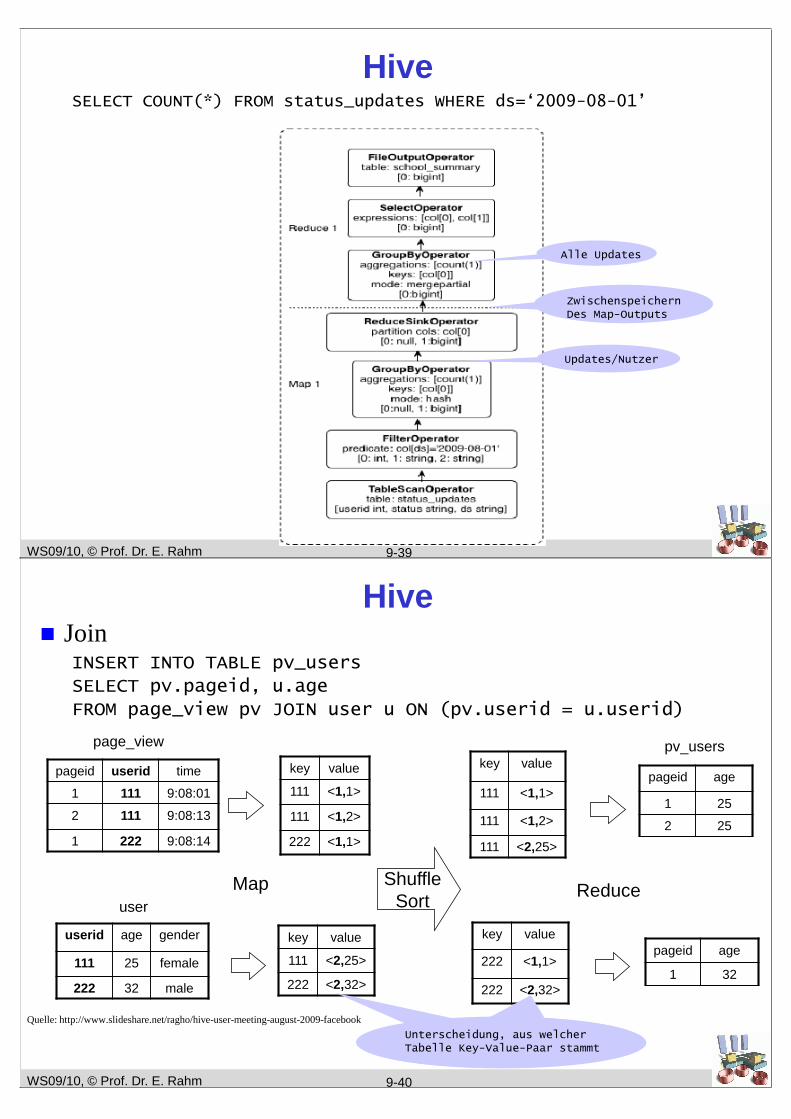
WS09/10, © Prof. Dr. E. Rahm
HiveSELECT COUNT(*) FROM status_updates WHERE ds=‘2009-08-01’
9-39
Updates/Nutzer
Alle Updates
ZwischenspeichernDes Map-Outputs
WS09/10, © Prof. Dr. E. Rahm
Hive Join
INSERT INTO TABLE pv_users
SELECT pv.pageid, u.age
FROM page_view pv JOIN user u ON (pv.userid = u.userid)
9-40
key value
111 <1,1>
111 <1,2>
222 <1,1>
pageid userid time
1 111 9:08:01
2 111 9:08:13
1 222 9:08:14
userid age gender
111 25 female
222 32 male
page_view
user
key value
111 <2,25>
222 <2,32>
Map
key value
111 <1,1>
111 <1,2>
111 <2,25>
key value
222 <1,1>
222 <2,32>
Shuffle
SortReduce
pageid age
1 25
2 25
pageid age
1 32
pv_users
Unterscheidung, aus welcherTabelle Key-Value-Paar stammt
Quelle: http://www.slideshare.net/ragho/hive-user-meeting-august-2009-facebook
WS09/10, © Prof. Dr. E. Rahm
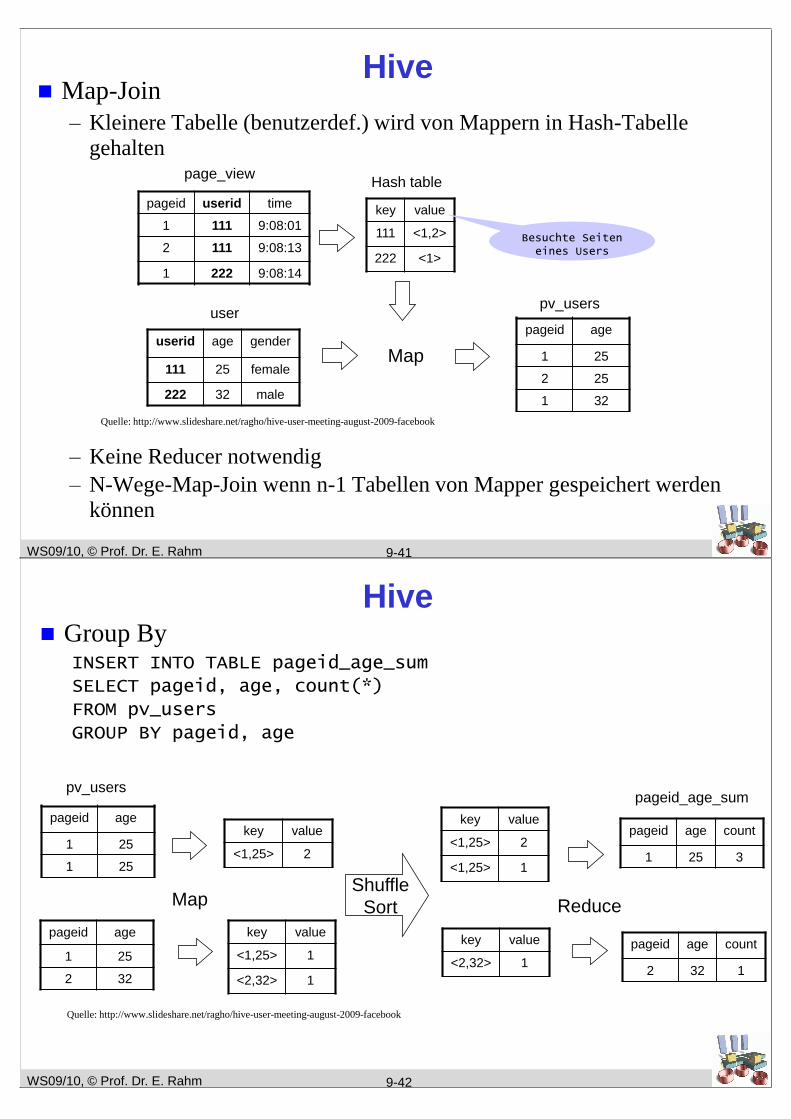
Hive Map-Join
– Kleinere Tabelle (benutzerdef.) wird von Mappern in Hash-Tabelle
gehalten
– Keine Reducer notwendig
– N-Wege-Map-Join wenn n-1 Tabellen von Mapper gespeichert werden
können
9-41
pageid userid time
1 111 9:08:01
2 111 9:08:13
1 222 9:08:14
userid age gender
111 25 female
222 32 male
page_view
user
key value
111 <1,2>
222 <1>
Hash table
Map
pageid age
1 25
2 25
1 32
pv_users
Besuchte Seiteneines Users
Quelle: http://www.slideshare.net/ragho/hive-user-meeting-august-2009-facebook
WS09/10, © Prof. Dr. E. Rahm
Hive Group By
INSERT INTO TABLE pageid_age_sum
SELECT pageid, age, count(*)
FROM pv_users
GROUP BY pageid, age
9-42
pageid age
1 25
1 25
pageid age
1 25
2 32
pv_users
Map
key value
<1,25> 2
key value
<1,25> 1
<2,32> 1
Shuffle
Sort
key value
<1,25> 2
<1,25> 1
key value
<2,32> 1
Reduce
pageid age count
1 25 3
pageid age count
2 32 1
pageid_age_sum
Quelle: http://www.slideshare.net/ragho/hive-user-meeting-august-2009-facebook

WS09/10, © Prof. Dr. E. Rahm
HadoopDB1
9-43
M/R (SN-)RDBMS
Struktur Un-/semistrukturierte Daten Strukturierte relationale Daten
Anfrage Map/Reduce Programme
(„etwas SQL“ mit Hive)
SQL
Abfrage-
ausführung
Materialisierung der Ergebnisse
zwischen Map- und Reduce-Phase
Pipelining von Ergebnissen
zwischen Operatoren
Quelle: http://db.cs.yale.edu/hadoopdb/HadoopDB_CLUE.pdf
1 Azza Abouzeid, Kamil Bajda-Pawlikowski, Daniel J. Abadi at al. An Architectural
Hybrid of MapReduce and DBMS Technologies for Analytical Workloads. VLDB„09.
WS09/10, © Prof. Dr. E. Rahm
HadoopDB Idee
– Viele unabhängige Single-Node DBS (PostgreSQL/MySQL)
– Hadoop als Koordinator und Kommunikations-Layer
– Anfragen mit MapReduce parallelisiert
– Großteil der Arbeit wird in DBS-Nodes verrichtet
Kombination Fehlertolleranz Hadoop und Performance paralleler DBS
9-44
WS09/10, © Prof. Dr. E. Rahm 9-45
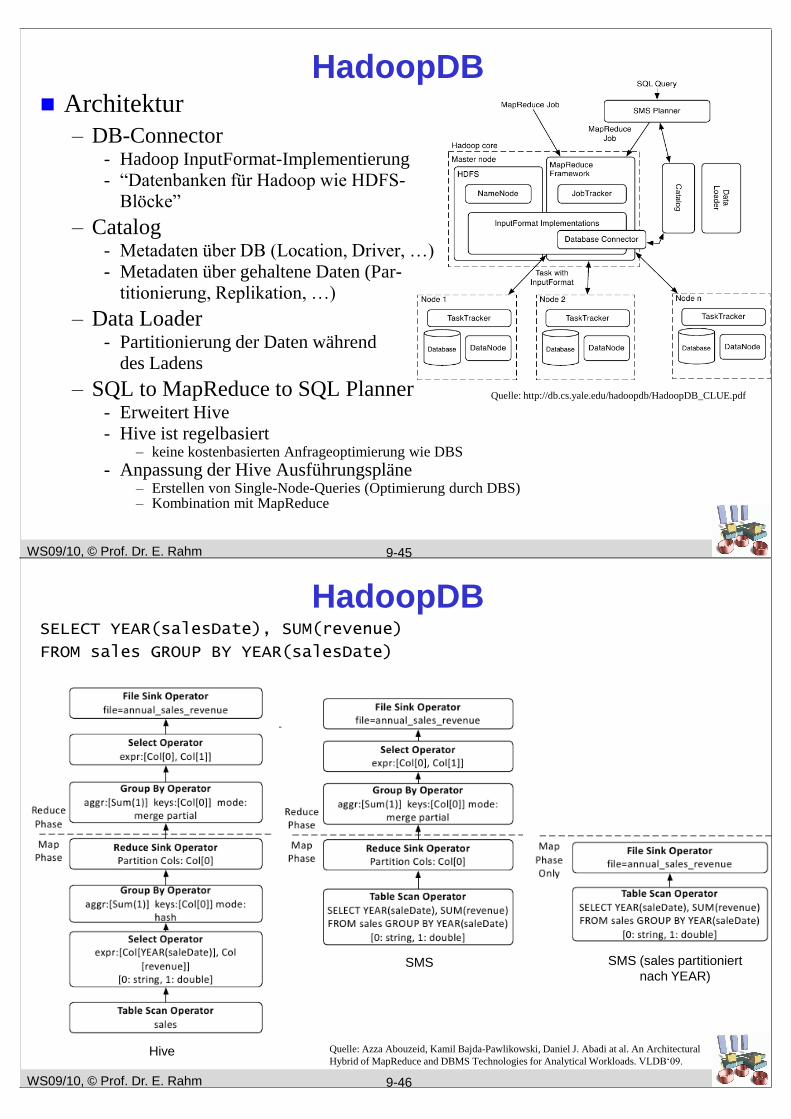
Architektur
– DB-Connector- Hadoop InputFormat-Implementierung
- “Datenbanken für Hadoop wie HDFS-
Blöcke”
– Catalog- Metadaten über DB (Location, Driver, …)
- Metadaten über gehaltene Daten (Par-
titionierung, Replikation, …)
– Data Loader- Partitionierung der Daten während
des Ladens
– SQL to MapReduce to SQL Planner- Erweitert Hive
- Hive ist regelbasiert– keine kostenbasierten Anfrageoptimierung wie DBS
- Anpassung der Hive Ausführungspläne– Erstellen von Single-Node-Queries (Optimierung durch DBS)– Kombination mit MapReduce
HadoopDB
Quelle: http://db.cs.yale.edu/hadoopdb/HadoopDB_CLUE.pdf
WS09/10, © Prof. Dr. E. Rahm
HadoopDBSELECT YEAR(salesDate), SUM(revenue)
FROM sales GROUP BY YEAR(salesDate)
9-46
Quelle: Azza Abouzeid, Kamil Bajda-Pawlikowski, Daniel J. Abadi at al. An Architectural
Hybrid of MapReduce and DBMS Technologies for Analytical Workloads. VLDB„09.Hive
SMS SMS (sales partitioniert
nach YEAR)

WS09/10, © Prof. Dr. E. Rahm
Zusammenfassung Cloud Computing - Illusion unendlicher, „on demand“
verfügbarer Ressourcen
Verteilte Dateisysteme, z.B. Google FileSystem
– replizierte Speicherung großer Datenmengen
verteilte Speicherung semistrukturierter Daten: Key-Value-Stores
– Beispiele: Google Bigtable/Hbase, Dynamo
– Replikation, Lastbalancierung, sehr einfache Operationen
MapReduce - automatische Parallelisierung von Auswertungen auf großen Datenmengen
Hive - Erweiterung von MapReduce um SQL-ähnliche Anfragemöglichkeiten
HadoopDB – versucht Vorteile von MapReduce und parallelen DBS zu kombinieren
9-47
WS09/10, © Prof. Dr. E. Rahm
Literatur The Google File System, Sanjay Ghemawat, Howard Gobioff, Shun T.
Leung, SOSP‟03
MapReduce: Simplified Data Processing on Large Clusters, Jeffrey Dean and Sanjay Ghemawat, OSDI‟04
Bigtable: A Distributed Storage System for Structured Data, Fay Chang, Jeffrey Dean, Sanjay Ghemawat et al., OSDI‟06
Dynamo: Amazon‟s Highly Available Key-value Store, G. DeCandia, D. Hastorun, M. Jampani et al., SOSP‟07
http://hadoop.apache.org
Hadoop The Definitive Guide, 2009, Tom White, O„Reilly
Hive - A Warehousing Solution Over a Map-Reduce Framework, Ashish Thusoo, Joydeep Sen Sarma, Namit Jain et. al., VLDB‟09
http://www.slideshare.net/ragho/hive-user-meeting-august-2009-facebook
HadoopDB: An Architectural Hybrid of MapReduce and DBMS Technologies for Analytical Workloads, Azza Abouzeid, Kamil Bajda-Pawlikowski, Daniel J. Abadi et al., VLDB‟09
9-48

WS09/10, © Prof. Dr. E. Rahm
Vorschau SS2010 Datenbanksysteme 2
Relationales Datenbankpraktikum (IBM DB2)
Data Warehouse-Praktikum
Bio-Datenbanken
Lehrveranstaltungen können auch in Module im WS10/11 eingebracht werden
9-49
WS09/10, © Prof. Dr. E. Rahm
MRDBS-Klausur Donnerstag, 11.2.2008, 15:00 Uhr, HS 3
Klausurdauer: 60 Minuten
Anmeldung: OLAT (Anmeldeschluss 31.01.2010)
Stoff: Kap. 1 - 8
Vorbereitung
– Buch Mehrrechner-DBS
– VL-Skript und -mitschriften
– LOTS
9-50
Recommended