Embed Size (px)
Citation preview

Computerbasierte Modellierung und Analyse der Gestalt und Verteilung von Partikeln
zur Optimierung des Reinheitsgrades von Stahlwerkstoffen – Konzeption und
Implementierung eines Rahmenwerks
Von der Fakultät für Ingenieurwissenschaften
Abteilung Informatik und Angewandte Kognitionswissenschaft
der Universität Duisburg-Essen
zur Erlangung des akademischen Grades
Doktor der Ingenieurwissenschaften
genehmigte Dissertation
von
Christoph Buck
aus
Duisburg
1. Gutachter: Prof. Dr. Wolfram Luther
2. Gutachter: Prof. Dr. Josef Pauli
Tag der mündlichen Prüfung: 04.05.2016


C O M P U T E R B A S I E RT E M O D E L L I E R U N G U N D A N A LY S E D E RG E S TA LT U N D V E RT E I L U N G V O N PA RT I K E L N Z U R
O P T I M I E R U N G D E S R E I N H E I T S G R A D E S V O NS TA H LW E R K S T O F F E N
Konzeption und Implementierung eines Rahmenwerks
christoph buck

Christoph Buck: Computerbasierte Modellierung und Analyse der Ge-stalt und Verteilung von Partikeln zur Optimierung des Reinheitsgradesvon Stahlwerkstoffen, Konzeption und Implementierung eines Rahmen-werks

A B S T R A C T
Statistical analysis of particle systems is a crucial part of many applicationsin materials science. Within this context, the analysis of the individual partic-le morphology as well as the analysis of the spatial and size distribution ofwhole particle systems are relevant. In the past years, research focused incre-asingly on these topics, presenting various processes for analysing particlesystems. However, there is no holistic approach integrating these isolatedanalytical techniques. By providing a complete theoretical framework foranalysing particle systems and implementing it into a use case, this disser-tation faces the challenges arising with statistical particle analysis on threedimensional systems. The use case was defined within the project Silenos1,which is funded by the Ziel2 program of the European Union. During thecourse of Silenos, the partners conducted research on a method for fast quan-tification and characterisation of defects in steel samples, e.g. non-metallicinclusions or pores. The detection of these impurities is carried out by theuse of image capturing and processing methods on milled steel samples. Par-allel to the milling process, the defects are incrementally segmented in crosssections, reconstructed assuming a three dimensional spatial extent, classi-fied, and statistically evaluated. This process, called online-system, allowsto control the milling based on statistic results after each captured image. Inorder to implement these methods, the framework must allow for incremen-tal operation. The segmented images provide a basis for the development ofthese methods used within the framework. Therefore, this dissertation com-mences with a formal definition of the particle concept. This step allows toderive algorithms for an efficient reconstruction of a three dimensional par-ticle morphology during the image grabbing and processing. Based on thereconstruction, the particle morphology can be statistically quantified usingsuitable descriptors, and the distribution can be investigated. This dissertati-on aims at defining applicable models that adequately describe the size andspatial distribution, focusing on an extensive analysis of these aspects. Inaccordance to this aim, methods of exploratory data analysis are introducedthat support the modelling process. Subsequently, estimation proceduresfor model parametrisation are discussed based on observed data. To ensurethe consistency between model parameters and observed data, model vali-dation techniques are defined. In summary, these preliminarily introducedgeneric methods establish a framework, which is used to implement thethree main goals of the online-system, namely the reconstruction, classifi-cation and statistic evaluation of non-metallic inclusions and other defects.Furthermore, the framework is used to establish a model for the distributi-on of non-metallic inclusions in the inclusion band. Using this model onecan generate artificial steel samples, which are used to validate the runtimerequirements of framework algorithms.
1 http://www.scg.inf.uni-due.de/silenos.php
v

Z U S A M M E N FA S S U N G
Die statistische Analyse von Partikelsystemen spielt in vielen Anwendungs-kontexten der Materialwissenschaften eine wichtige Rolle. Dabei ist sowohldie statistische Analyse der Gestalt der individuellen Partikel als auch dieAnalyse der Verteilungseigenschaften des gesamten Partikelkollektivs vonBedeutung. Eine Vielzahl wissenschaftlicher Veröffentlichungen der letztenJahre fokussierte diese Themengebiete. Darin wurden diverse Verfahren zurAnalyse von Partikelsystemen vorgestellt. Eine Integration dieser Technikenzu einem einheitlichen Analysesystem für dreidimensionale Partikelsyste-me steht aber nach wie vor aus. Diese Lücke wird im Rahmen der vor-liegenden Arbeit durch das Bereitstellen eines theoretischen Rahmenwerkszur vollständigen statistischen Analyse von dreidimensionalen Partikelsys-temen nebst protoypischer Implementierung geschlossen. Die Entwicklungdieses Rahmenwerks wurde dabei maßgeblich durch das von der Europäi-schen Union geförderte Ziel2-Projekt Silenos2 beeinflusst. Im Zuge diesesProjekts wurde an einer Methode zur schnellen Quantifizierung und Cha-rakterisierung von Defekten, wie nichtmetallischen Einschlüssen und Po-ren, in Stahlproben geforscht. Die Detektion dieser Verunreinigungen er-folgt mittels Methoden der Bildverarbeitung in Bildern schichtweise abge-fräster Werkstoffproben. Parallel zum Fräs- und Bildaufnahmeprozess wer-den die Bilder inkrementell segmentiert, die detektierten Defekte unter derAnnahme einer dreidimensionalen Ausdehnung rekonstruiert, klassifiziertund schließlich statistisch ausgewertet. Dieser als Online-System bezeichne-te Betriebsmodus erlaubt das Steuern des Fräsprozesses auf Basis der Er-gebnisse der statistischen Auswertung nach jeder verarbeiteten Schicht undmuss demnach von Rahmenwerk unterstützt werden. Die vorsegmentiertenSchichtbilder des durch die Verunreinigungen geformten Partikelsystemsbilden dabei die Grundlage für die im Rahmenwerk entwickelten Metho-den. Ausgangspunkt ist die formale Definition des Partikelbegriffs, auf Ba-sis derer Algorithmen zur effizienten Rekonstruktion der dreidimensiona-len Morphologie der Partikel inkrementell aus den Schichtbildern abgleitetwerden. Anhand der Rekonstruktion lässt sich dann die Gestalt der Par-tikel statistisch, durch geeignete Deskriptoren, quantifizieren und die Ver-teilung dieser untersuchen. Im Zentrum der Arbeit steht die Analyse derGrößenverteilung und der räumlichen Verteilung mit dem Ziel, geeigneteModelle zu definieren, welche die Verteilungen adäquat beschreiben. Da-zu werden zunächst explorative Datenanalysewerkzeuge zur Unterstützungdes Modellbildungsprozesses eingeführt. Anschließend werden Schätzver-fahren zur Parametrisierung der Modelle aus den beobachteten Daten be-sprochen und in einem letzten Schritt Modellvalidierungstechniken defi-niert, mit welchen die Übereinstimmung von Modell und beobachteten Da-
2 http://www.scg.inf.uni-due.de/silenos.php
vi

ten überprüft werden kann. Zusammengenommen bilden diese, zunächstgenerisch eingeführten Methoden das Rahmenwerk. Dieses Rahmenwerkwird im weitern Verlauf der Arbeit verwendet, um die im Online-Systemdefinierten Operationen, nämlich Rekonstruktion, Klassifikation und statis-tische Auswertung umzusetzen. Des Weiteren werden die Methoden desRahmenwerks eingesetzt, um ein Modell für die Verteilung von nichtmetal-lischen Einschlüssen in Stahlproben zu konstruieren. Dieses Modell liefertdie Grundlage für eine Simulationssoftware, mit der künstliche Stahlprobengeneriert werden. Anhand dieser lassen sich schließlich die Laufzeitanforde-rungen der im Rahmenwerk definierten Methoden für das Online-Systemvalidieren.
vii

viii

P U B L I K AT I O N E N
[1] C. Buck, F. Bürger, J. Herwig und M. Thurau. „Rapid Inclusionand Defect Detection System for Large Steel Volumes“. In: ISIJInternational 53.11 (2013), S. 1927–1935.
[2] C. Buck, T. Pilz und W. Luther. „Personalized Fuzzy Searchin Historical Texts with Non Standard Spelling“. In: LinguisticStudies of Human Language. 2013, S. 325–337.
[3] F. Bürger, J. Herwig, C. Buck, W. Luther und J. Pauli. „AnAuto-adaptive Measurement System for Statistical Modelingof Non-metallic Inclusions through Image-based Analysis ofMilled Steel Surfaces“. In: 11th International Symposium on Mea-surement Technology and Intelligent Instruments. 2013.
[4] J. Herwig, C. Buck, M. Thurau, J. Pauli und W. Luther. „Real-time characterization of non-metallic inclusions by optical scan-ning and milling of steel samples“. In: Optical Micro- and Na-nometrology IV. 2012.
[5] M. Thurau, C. Buck und W. Luther. „IPFViewer – A VisualAnalysis System for Hierarchical Ensemble Data“. In: Procee-dings of the 5th International Conference on Information Visualiza-tion Theory and Applications. 2014, S. 259–266.
[6] M. Thurau, C. Buck und W. Luther. „IPFViewer: Incremental,Approximate Analysis of Steel Samples“. In: Proceedings of the13th SIGRAD. 2014.
ix

x

D A N K S A G U N G
Die Erstellung dieser Arbeit erfolgte in wesentlichen Teilen im Rah-men des durch die Europäische Union geförderten Ziel2-Projekts Si-lenos. An erster Stelle danke ich Herrn Prof. Dr. Wolfram Luther, derals Lehrstuhlinhaber die Durchführung des Forschungsvorhabens er-möglichte und unterstützte. Herzlichen Dank auch an Herrn Prof. Dr.Josef Pauli für die Übernahme des Korreferats. Des Weiteren möch-te ich der Firma Hüttenwerke Krupp Mannesmann GmbH und na-mentlich Herrn Dr. Thomas Schlüter für die gute Zusammenarbeitund das Bereitstellen der in der Dissertation verwendeten Daten dan-ken. Mein besonderer Dank geht an meinen Onkel Ludger Buck undan meine Freundin Anna Kötteritzsch für die Übernahme des Lek-torats. Zudem danke ich den Mitarbeitern des Lehrstuhls für Com-putergraphik und Wissenschaftliches Rechnen für die stets kollegialeAtmosphäre und das freundliche Arbeitsumfeld. Und nicht zuletztein großes Dankeschön an meine Familie, die mich in jeglicher Hin-sicht unterstützt.
xi

xii inhaltsverzeichnis

I N H A LT S V E R Z E I C H N I S
1 einleitung 1
1.1 Ziele . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.2 Silenos . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.3 Anforderungen an das Rahmenwerk . . . . . . . . . . . 5
1.4 Stand der Technik . . . . . . . . . . . . . . . . . . . . . . 7
1.5 Umsetzung und Struktur der Arbeit . . . . . . . . . . . 13
2 einzelpartikelanalyse 17
2.1 Partikelrekonstruktion . . . . . . . . . . . . . . . . . . . 18
2.1.1 Partikeldefinition . . . . . . . . . . . . . . . . . . 18
2.1.2 Connected Component Labeling . . . . . . . . . 20
2.1.3 Laufzeit . . . . . . . . . . . . . . . . . . . . . . . 28
2.2 Gestaltanalyse . . . . . . . . . . . . . . . . . . . . . . . . 33
2.2.1 Boundingbox . . . . . . . . . . . . . . . . . . . . 35
2.2.2 Konfigurationshistogramme . . . . . . . . . . . 36
2.2.3 Minkowskifunktionale . . . . . . . . . . . . . . . 38
2.2.4 Momente . . . . . . . . . . . . . . . . . . . . . . . 46
2.2.5 Konvexität . . . . . . . . . . . . . . . . . . . . . . 48
2.2.6 Fraktale Dimension . . . . . . . . . . . . . . . . . 51
2.3 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . 54
3 statistische methoden 57
3.1 Grundbegriffe . . . . . . . . . . . . . . . . . . . . . . . . 57
3.2 Größenverteilung . . . . . . . . . . . . . . . . . . . . . . 60
3.2.1 Schätzung der Verteilungs- und Dichtefunktion 61
3.2.2 Schätzen der Verteilungsparameter . . . . . . . 63
3.2.3 Überprüfung des Modells . . . . . . . . . . . . . 66
3.3 Räumliche Verteilung . . . . . . . . . . . . . . . . . . . . 67
3.3.1 Punktprozess . . . . . . . . . . . . . . . . . . . . 68
3.3.2 Homogener Poisson Punktprozess . . . . . . . . 69
3.3.3 Schätzen der Intensitätsfunktion . . . . . . . . . 71
3.3.4 Modellparametrisierung und Validierung . . . . 75
3.4 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . 81
4 anwendungsfall 83
4.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . 83
4.1.1 Nichtmetallische Einschlüsse . . . . . . . . . . . 84
4.1.2 Charakterisierungsmerkmale . . . . . . . . . . . 85
4.1.3 Statistische Eigenschaften . . . . . . . . . . . . . 87
4.1.4 Detektionsverfahren . . . . . . . . . . . . . . . . 88
4.2 Makroeinschluss-Detektion . . . . . . . . . . . . . . . . 91
4.2.1 Fräsprozess und Bildaufnahme . . . . . . . . . . 92
4.2.2 Bildverarbeitung . . . . . . . . . . . . . . . . . . 93
4.2.3 Morphologische und statistische Analyse . . . . 93
xiii

xiv inhaltsverzeichnis
4.3 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . 94
5 klassifikation von defekten in stahl 95
5.1 Einführungsbeispiel . . . . . . . . . . . . . . . . . . . . . 95
5.2 Maschinelles Lernen . . . . . . . . . . . . . . . . . . . . 98
5.2.1 Bewertung eines Klassifizierers . . . . . . . . . . 99
5.2.2 Lernalgorithmus . . . . . . . . . . . . . . . . . . 101
5.3 Auswertung . . . . . . . . . . . . . . . . . . . . . . . . . 104
5.3.1 Risse, Artefakte und globulare Defekte . . . . . 105
5.3.2 Poren und nichtmetallische Einschlüsse . . . . . 109
5.4 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . 112
6 statistische untersuchung von defekten in stahl 113
6.1 Größenverteilung . . . . . . . . . . . . . . . . . . . . . . 113
6.1.1 Modellauswahl . . . . . . . . . . . . . . . . . . . 114
6.1.2 Explorative Datenanalyse . . . . . . . . . . . . . 115
6.1.3 Modellparametrisierung und Validierung . . . . 121
6.1.4 Hierarchisches Modell . . . . . . . . . . . . . . . 125
6.2 Räumliche Verteilung . . . . . . . . . . . . . . . . . . . . 127
6.2.1 Modellauswahl . . . . . . . . . . . . . . . . . . . 128
6.2.2 Modellparametrisierung und Validierung . . . . 134
6.3 Simulation von Stahlproben . . . . . . . . . . . . . . . . 143
6.4 Evaluation verschiedener Frässzenarien . . . . . . . . . 146
6.4.1 Optimierung der Spanabnahme . . . . . . . . . 146
6.4.2 Abbruchkriterium . . . . . . . . . . . . . . . . . 147
6.5 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . 150
7 implementation 153
7.1 Particle Detection System . . . . . . . . . . . . . . . . . 153
7.1.1 Pipeline Stufen . . . . . . . . . . . . . . . . . . . 155
7.1.2 Vorverarbeitung . . . . . . . . . . . . . . . . . . . 157
7.1.3 Rekonstruktion . . . . . . . . . . . . . . . . . . . 158
7.1.4 Klassifikation . . . . . . . . . . . . . . . . . . . . 158
7.1.5 Statistische Auswertung . . . . . . . . . . . . . . 160
7.1.6 Archivierung . . . . . . . . . . . . . . . . . . . . 161
7.1.7 Zusammenfassung . . . . . . . . . . . . . . . . . 163
7.2 Particle Analysis System . . . . . . . . . . . . . . . . . . 164
7.2.1 Aufbau . . . . . . . . . . . . . . . . . . . . . . . . 165
7.2.2 Sichtprüfung der Partikel . . . . . . . . . . . . . 168
7.2.3 Statistische Analyse . . . . . . . . . . . . . . . . 173
7.3 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . 176
8 zusammenfassung 177
a anhang 181
a.1 Konfigurationstabellen . . . . . . . . . . . . . . . . . . . 181
literatur 185

A B B I L D U N G S V E R Z E I C H N I S
Abbildung 1 Laufzeit des OZP. . . . . . . . . . . . . . . . . . 31
Abbildung 2 Laufzeit und Speedup Messungen. . . . . . . . 32
Abbildung 3 Binärcodierung von 2× 2× 2 Voxelblöcken. . . 37
Abbildung 4 Diskrete konvexe Hülle eines Risses. . . . . . . 51
Abbildung 5 Auswirkung der Kantenkorrektur bei Kerndich-teschätzung der Intensität. . . . . . . . . . . . . 74
Abbildung 6 Kumulierter Anteil der Eigenwerte an der Ge-samtstreuung. . . . . . . . . . . . . . . . . . . . 96
Abbildung 7 Histogramm der Ladungen. . . . . . . . . . . . 97
Abbildung 8 Streudiagram der ersten beiden Hauptkompo-nenten. . . . . . . . . . . . . . . . . . . . . . . . 98
Abbildung 9 Auswirkung von der Anzahl der Deskriptorenauf die Korrektklassifikationsrate. . . . . . . . 106
Abbildung 10 Beispiele für Objekte der einzelnen Klassen. . 108
Abbildung 11 Auswirkung von der Anzahl der Deskriptorenauf die Korrektklassifikationsrate. . . . . . . . 109
Abbildung 12 Erstes Beispiel der explorativen Analyse. . . . 117
Abbildung 13 Zweites Beispiel der explorativen Analyse. . . 118
Abbildung 14 Explorative Analyse nach Bereinigung. . . . . 120
Abbildung 15 Drittes Beispiel der explorativen Datenanalyse. 121
Abbildung 16 Aufbau des Modells. . . . . . . . . . . . . . . . 122
Abbildung 17 A-posteriori Verteilung der Parameter. . . . . . 123
Abbildung 18 Posteriori-prädiktiver Test. . . . . . . . . . . . . 124
Abbildung 19 Aufbau des hierarchischen Modells. . . . . . . 126
Abbildung 20 Posteriori-Verteilung der Gruppenparameter. . 127
Abbildung 21 Schätzung der Intensitätsfunktion. . . . . . . . 129
Abbildung 22 Schätzung der Intensitätsfunktion im Einschluss-band. . . . . . . . . . . . . . . . . . . . . . . . . 130
Abbildung 23 Schätzung der Intensitätsfunktion in y-Richtung.132
Abbildung 24 Schätzung der Intensitätsfunktion nach Homo-genisierung. . . . . . . . . . . . . . . . . . . . . 134
Abbildung 25 Zerlegung des Einschlussbandes in Teilfenster. 134
Abbildung 26 Vergleich der A-posteriori Verteilung der In-tensität zwischen Teilfenstern. . . . . . . . . . . 135
Abbildung 27 Test der CSR-Eigenschaft für nichtmetallischeEinschlüsse. . . . . . . . . . . . . . . . . . . . . 136
Abbildung 28 Schätzung von L(r). . . . . . . . . . . . . . . . . 137
Abbildung 29 Schätzung von g(r). . . . . . . . . . . . . . . . . 138
Abbildung 30 Schätzung der Intensitätsfunktion entlang ver-schiedener Raumrichtungen. . . . . . . . . . . . 141
xv

Abbildung 31 Schätzung von D(r). . . . . . . . . . . . . . . . 142
Abbildung 32 Schätzung der Intensitätsfunktion in simulier-ter Probe. . . . . . . . . . . . . . . . . . . . . . . 145
Abbildung 33 Optimierung des Fräsprozesses. . . . . . . . . . 147
Abbildung 34 Abbruchkriterium auf Basis des HDI. . . . . . 149
Abbildung 35 Aufbau des PDS. . . . . . . . . . . . . . . . . . 155
Abbildung 36 Aufbau der Pipeline Stufen. . . . . . . . . . . . 156
Abbildung 37 Laufzeit der Deskriptorberechnung und der Klas-sifikation. . . . . . . . . . . . . . . . . . . . . . . 159
Abbildung 38 Referenzmodell der Informationsvisualisierung. 165
Abbildung 39 Screenshot des Hauptfensters vom PAS. . . . . 169
Abbildung 40 Raycasting-Ansicht eines Einschlusses. . . . . . 171
Abbildung 41 Raycasting-Ansicht eines Einschlusses mit ein-geblendeten Segmentierungsergebnisses. . . . 172
Abbildung 42 Auswahlwerkzeug zur Generierung von räum-lichen Filteranfragen. . . . . . . . . . . . . . . . 174
Abbildung 43 Report-Modul für statistische Auswertungen. . 175
TA B E L L E N V E R Z E I C H N I S
Tabelle 1 Laufzeiten der CCL-Algorithmen. . . . . . . . 30
Tabelle 2 Minkowskifunktionale bis zur dritten Dimen-sion. . . . . . . . . . . . . . . . . . . . . . . . . . 39
Tabelle 3 Beispiel einer Kontingenztabelle. . . . . . . . . 99
Tabelle 4 Zusammensetzung der Datensätze. . . . . . . . 104
Tabelle 5 Zur Klassifikation verwendete Deskriptoren. . 105
Tabelle 6 Die ersten 20 Deskriptorsätze beim Klassifizie-ren von Defekten. . . . . . . . . . . . . . . . . . 107
Tabelle 7 Gemittelte Sensitivität und Genauigkeit beimKlassifizieren von Defekten. . . . . . . . . . . . 107
Tabelle 8 Relative Häufigkeit der ersten 1000 Deskripto-ren beim Klassifizieren von Defekten. . . . . . 109
Tabelle 9 Die ersten 20 Deskriptorsätze beim Klassifizie-ren von Poren. . . . . . . . . . . . . . . . . . . . 110
Tabelle 10 Gemittelte Sensitivität und Genauigkeit beimKlassifizieren von Poren. . . . . . . . . . . . . . 110
Tabelle 11 Relative Häufigkeit der ersten 1000 Deskripto-ren beim Klassifizieren von Poren. . . . . . . . 111
Tabelle 12 A-posteriori Verteilung der Intensität. . . . . . 135
Tabelle 13 Die 22 Kongruenzklassen zur Reduktion derVoxelkonfigurationshistogramme. . . . . . . . 182
xvi

Tabelle 14 Die 22 Kongruenzklassen zur Reduktion derVoxelkonfigurationshistogramme dargestellt alsPiktogramm. . . . . . . . . . . . . . . . . . . . . 183
Tabelle 15 Tabelle mit den Minkowskifunktionalen für die2× 2× 2 Voxelblöcke. . . . . . . . . . . . . . . . 184
A L G O R I T H M E N V E R Z E I C H N I S
1 Multiphasen Algorithmus. . . . . . . . . . . . . . . . . . 22
2 Zwei-Phasen Algorithmus. . . . . . . . . . . . . . . . . . 24
3 Online Zwei-Phasen Algorithmus. . . . . . . . . . . . . 26
4 Paralleler Zwei-Phasen Algorithmus. . . . . . . . . . . 28
5 Generiert Tabelle mit allen 22 Kongruenzklassen undihren Elementen. . . . . . . . . . . . . . . . . . . . . . . 37
6 Berechnung der lokalen Minkowskifunktionale. . . . . 43
7 Simulator. . . . . . . . . . . . . . . . . . . . . . . . . . . 144
A B K Ü R Z U N G S V E R Z E I C H N I S
CCL Connected Component Labeling
CSR Complete Spatial Randomness
CT Computertomographie
EBNF Extended Backus-Naur Form
HDI Highest Density Interval
LIPS Laserinduzierte Plasmaspektroskopie
MCMC Markov-Ketten-Monte-Carlo
MCT Mikro-Computertomographie
MIDAS Mannesmann Inclusion Detection by Analysing Surfboards
MP Multi-Phasen Algorithmus
MRT Magnetresonanztomographie
xvii

OZP Online Zwei-Phasen Algorithmus
PAS Particle Analysis System
PCF Paar-Korrelationsfunktion
PDS Particle Detection System
PHOT Phase-Only Transformation
PP-Plot Probability-Probability-Plot
PPP homogener Poisson Punktprozess
PZP Paralleler Zwei-Phasen Algorithmus
QQ-Plot Quantile-Quantile-Plot
REM Rasterelektronenmikroskop
STL Standard Template Library
SVM Support Vector Machine
UML Unified Modeling Language
ZP Zwei-Phasen Algorithmus
S Y M B O LV E R Z E I C H N I S
R Menge der reellen ZahlenR
3 dreidimensionaler euklidischer RaumZ Menge der natürlichen ZahlenN Menge der positiven natürlichen ZahlenL
3 dreidimensionales GittersystemK Klasse der konvexen, beschränkten und abgeschlos-
senen MengenK Konvexer Ringδ1 Gitterabstand in x-Richtungδ2 Gitterabstand in y-Richtungδ3 Gitterabstand in z-Richtungδ Gitterabstand eines kubisch primitiven GittersystemC Elementarzelle des GittersX PartikelsystemΞ disperse Phase des PartikelsystemsΞc kontinuierliche Phase des PartikelsystemsΞ Gaußsche Diskretisierung der dispersen Phase Ξ
xviii

symbolverzeichnis xix
X Partikel, disjunkte zusammenhängende Teilmengevon Ξ
bX(i, j, k) Funktion die einem Voxel (i, j, k) ∈ L3 den Wert 1
zuordnet, wenn (i, j, k) ∈ X istSE(6) Strukturelement zur Beschreibung der 6er Nachbar-
schaftSE(18) Strukturelement zur Beschreibung der 18er Nach-
barschaftSE(26) Strukturelement zur Beschreibung der 26er Nach-
barschaftSE(26) Strukturelement zur Beschreibung der 26er Nach-
barschaft bei lexikographischer SortierungNSE(s)(x) Menge der Nachbarn von x ∈ Ξ bezüglich SE(s) mit
s ∈ 6, 18, 26TRec Laufzeit der BildaufnahmeTSeg Laufzeit der BildsegmentierungTPre Laufzeit der VorverarbeitungTCcl Laufzeit der dreidimensionalen RekonstruktionTClas Laufzeit der KlassifikationTSta Laufzeit der statistischen AuswertungTArch Laufzeit der ArchivierungTGes Laufzeit des gesamten AuswerteprozessBBXmin Minimaler Eckpunkt der BoundingboxBBXmax Maximaler Eckpunkt der BoundingboxBBX Voxel der Boundingbox
h(256)l Konfigurationshistogramm aller 256 Voxelblöcke ei-
nes Partikels
h(22)l Reduziertes Konfigurationshistogramm im Falle ei-
nes kubisch-primitiven GittersystemsM Menge der isometrischen AbbildungenV Volumen eines PartikelsS Oberfläche eines PartikelsB Mittlere Breite eines Partikelsχ Euler-Charakteristik eines PartikelsM Mittlere Krümmung eines PartikelsK Totale Krümmung eines PartikelsVV Verhältnis aus Volumen V zum Volumen der Boun-
dingbox BBX eines PartikelsSV Verhältnis aus Oberfläche S zum Volumen der Boun-
dingbox BBX eines PartikelsBV Verhältnis aus der mittleren Breite B zum Volumen
der Boundingbox BBX eines PartikelsMV Verhältnis aus der mittlere Krümmung M zum Vo-
lumen der Boundingbox BBX eines PartikelsKV Verhältnis aus der totalen Krümmung K zum Volu-
men der Boundingbox BBX eines Partikels

F1, F2, F3 Isoperimetrischen GestaltdeskriptorenJ1, J2, J3 Translation-, rotation-, und skaleninvariante Mo-
menteDIM Deskriptor über das Verhältnis der kürzesten zur
längsten und mittleren zur längsten Hauptachse ei-nes Partikels
ECC Deskriptor über das Verhältnis der längsten zur kür-zesten Hauptachse eines Partikels
CONV Verhältnis aus dem Volumen der konvexen Hüllezum Volumen eines Partikels
dimBF Boxdimension, empirische Approximation derHausdorffdimension
X Zufallsvariable(x1, . . . , xn) Stichprobe vom Stichprobenumfang nf (·) WahrscheinlichkeitsdichtefunktionF(·) VerteilungsfunktionFn(·) Empirische Verteilungsfunktion einer Stichprobef (·) Kerndichteschätzung von fθ Parametervektor einer Dichtefunktionp(x|θ) Likelihood-Funktionp(θ) A-priori Dichte von θ
p(θ|x) A-posteriori Dichtex1
(i), . . . , xn(i) Simulierte Stichprobe der posteriori-prädiktiven
Verteilung für Parameter θ(i)
∆(i) Posteriori-prädiktive Verteilung der DifferenzenN PunktprozessN(B) Anzahl der Punkte in einer Teilmenge B ⊂ R
d
Λ(B) Intensitätsmaßλ(·) Intensitätsfunktionλ(·) Schätzung der Intensitätsfunktionλ IntensitätD(r) Nächste-Nachbarschafts FunktionK(r) Ripleys K-FunktionL(r) L-Funktiong(r) Paar-Korrelationsfunktion
N O TAT I O N
Bei der Wahl von Symbolen wird wie folgt vorgegangen. Symbole, diekapitelübergreifend in der Arbeit verwendet werden, sind eindeutigdefiniert und werden in das Symbolverzeichnis aufgenommen. Dazu
xx

symbolverzeichnis xxi
gehören zum Beispiel alle Gestaltdeskriptoren aus Abschnitt 2.2. Sym-bole die hingegen nur verwendet werden, um weitere Definitionenabzuleiten, sind nur in dem Abschnitt eindeutig, in dem sie definiertsind. Sie können in Definitionen aus anderen Abschnitten in wech-selnder Bedeutung Verwendung finden. Dazu gehören zum BeispielSymbole für Zufallsvariablen, Mengen und Indizes.

xxii symbolverzeichnis

1E I N L E I T U N G
In vielen wissenschaftlichen Disziplinen und Industriezweigen, insbe-sondere den Materialwissenschaften und der Verfahrenstechnik, be-schäftigt man sich mit der Verarbeitung und Analyse von dispersenStoffsystemen. Disperse Stoffsysteme sind heterogene Gemische ausmindestens zwei Stoffen, die sich nicht ineinander lösen. Dabei ist Disperse
Stoffsystemeein Stoff, bezeichnet als die disperse Phase, in einem anderen Stoff infeinster Form verteilt. Der zweite Stoff umgibt den ersten vollständigund wird kontinuierliche Phase genannt. Abhängig von dem Aggre-gatzustand der beiden Stoffe lassen sich solche Systeme in verschie-dene Klassen einteilen. Liegen beide Stoffe in Form von Flüssigkeitenvor, spricht man von Emulsionen. Bei einer festen dispersen Phase ineinem flüssigen Medium spricht man hingegen von Suspensionen. Be-steht die disperse Phase hauptsächlich aus Körnern, Tröpfchen oderGasbläschen und ist die kontinuierliche Phase im festen Aggregatzu-stand, dann wird ein solches System als Partikelsystem bezeichnet[132, S. 17 ff.]. Luftblasen in Eis, poröse Gesteinsarten aber auch Mi- Partikelsysteme
neralien mit eingeschlossenen Fremdstoffen, wie Erdöl oder Tonerde,sind Beispiele für solche Partikelsysteme natürlichen Ursprungs. Inden Materialwissenschaften werden aber auch gezielt künstliche di-sperse Systeme erzeugt, um Produkte und Werkstoffe zu erstellen,die gewisse anwendungsrelevante Eigenschaften besitzen. Durch dasAnwenden von verfahrenstechnischen Prozessen versucht man dasdisperse System in einen definierten Zustand zu überführen, in demgewünschte Produkteigenschaften und Qualitätskriterien des zu er-zeugenden Materials erfüllt sind. Dabei beeinflusst der Prozess direktquantitative Eigenschaften sowohl der Einzelpartikel als auch des ge-samten Partikelkollektivs. Um also die Auswirkungen des Prozessesund damit die Qualität des erzeugten Produkts oder des Werkstoffsbeurteilen zu können, ist das Erfassen und Analysieren dieser quan-titativen Eigenschaften des Partikelsystems unabdingbar.
Als konkretes Anwendungsbeispiel sei hier die Stahlerzeugung ge-nannt. Stahl wird aus Roheisen hergestellt und bezeichnet Eisen mit Stahl
einem Kohlenstoffgehalt von unter 2.06 %. Um den Stahl auf den er-forderlichen Kohlenstoffgehalt zu bringen, wird im Laufe des verfah-renstechnischen Prozesses zunächst der überschüssige Kohlenstoffdurch Zugabe von Sauerstoff oxidiert und anschließend wird durchZugabe von Desoxidationsmittel der im flüssigen Stahl verbleibende
1

2 einleitung
Sauerstoff gebunden. Normalerweise wird der so gebundene Sauer-stoff in die Schlacke abgeschieden. Ein kleiner Teil dieser Desoxidati-onsprodukte verbleibt aber in der flüssigen Schmelze und wird vonder fortschreitenden Erstarrungsfront beim Erhärten des Stahls einge-schlossen. Diese, als nichtmetallische Einschlüsse bezeichneten Parti-Nichtmetallische
Einschlüsse kel, beeinflussen die Qualität und die mechanischen Eigenschaftendes fertigen Stahlwerkstoffs. Um den Herstellungsprozess also opti-mieren zu können, so dass weniger dieser Verunreinigungen im Pro-dukt verbleiben, ist es zunächst nötig die quantitativen Eigenschaf-ten sowohl der Einzelpartikel als auch des durch die Partikel ge-formten Partikelsystems zu bestimmen. Anhand dieser Auswertun-gen kann dann der Reinheitsgrad des Stahls festgelegt werden, derals Vergleichsmaß für die Qualität von Stahlwerkstoffen herangezo-gen wird.
Im Rahmen des durch die Europäische Union geförderten Ziel2-Pro-jekts Silenos1 wurde in Zusammenarbeit mit zwei Projektpartnernaus der Stahlindustrie an einer solchen Methode zur schnellen Cha-rakterisierung und Quantifizierung der nichtmetallischen Einschlüs-se geforscht. Dabei erfolgt die Detektion der nichtmetallischen Ein-Silenos
schlüsse in Bildern schichtweise abgefräster Stahlproben. In diesenSchichtbildern werden die nichtmetallischen Einschlüsse mittels Ver-fahren der Bildverarbeitung identifiziert und segmentiert. Die seg-mentierten Schichtbilder werden dann übereinandergelegt und dieeinzelnen Einschlüsse durch die Schichten verfolgt. Auf diese Wei-se lässt sich ihre dreidimensionale Morphologie rekonstruieren, undes entsteht ein computergestütztes Modell der gesamten Stahlprobe.Dies erlaubt die statistische Analyse sowohl ihrer Größenverteilungund räumlichen Verteilung als auch die Klassifikation nach ihrer drei-dimensionalen Form.
Die Erkenntnisse aus diesem Projekt bilden die Grundlage der vor-liegenden Arbeit, die zum Ziel hat, ein Rahmenwerk für die Analysevon Partikelsystemen zu entwickeln. Im Fokus stehen die TechnikenRahmenwerk
zur dreidimensionalen Rekonstruktion auf Basis von computerbasier-ten Modellen der Phasen, zur statistischen Quantifizierung und zurKlassifikation individueller Partikel. Dabei werden alle Techniken zu-nächst generisch für Partikelsysteme eingeführt und anschließend an-hand des gerade beschriebenen Szenarios konkrete Anwendungsfälleaufgezeigt.
1.1 ziele
Ziel dieser Arbeit ist es, ein Rahmenwerk zur vollständigen statisti-schen Analyse polydisperser Partikelsysteme zur Verfügung zu stel-
1 http://www.scg.inf.uni-due.de/silenos.php

1.1 ziele 3
len. Dabei wird im Rahmen dieser Arbeit unter der vollständigenAnalyse in Anlehnung an Saltykov [118, S. 245 ff.] die Untersuchungfolgender drei Aspekte eines Partikelsystems verstanden. Vollständige
statistische Analyse
1. Einzelpartikelanalyse: Bei der Einzelpartikelanalyse werdenden individuellen Partikeln des Partikelsystems quantitativeMerkmale zugeordnet, die es erlauben, eine ordnende Unter-scheidung zwischen ihnen zu treffen. Das wichtigste Unter-scheidungsmerkmal ist die Gestalt eines Partikels, welche so-wohl die Größe als auch die Form umfasst. Für diese Merk-male werden verschiedene Deskriptoren festgelegt, die späterdazu verwendet werden, verschiedene Gestaltklassen zu defi-nieren, systematische Gestaltveränderungen zu detektieren unddie Größenverteilung sowie die räumliche Verteilung des ge-samten Partikelkollektivs zu untersuchen. Eine Analyse vonTexturen findet allerdings nicht statt. Die Modellierung von kris-tallinen Verbänden oder Substrukturen ist nicht Ziel der Arbeit.
2. Partikelgrößenverteilung: Bei der Untersuchung der Partikel-größenverteilung wird ein stochastisches Modell ausgewähltund anhand der beobachteten Partikel parametrisiert. DiesesModell beschreibt die Größenverteilung der Partikel in Bezugauf das in der Einzelpartikelanalyse festgelegte Merkmal. Beikugelförmigen Partikeln kann hier beispielsweise der Durch-messer herangezogen werden, während bei unregelmäßig ge-formten Partikeln die Länge der längsten Achse am aussage-kräftigsten ist. Die Modellauswahl wird dabei entweder von ei-nem Experten vorgenommen oder unter Anwendung von ex-plorativen Methoden aus den Daten abgeleitet.
3. Räumliche Verteilung: Bei der Untersuchung der räumlichenVerteilung steht die Frage im Mittelpunkt, ob die Partikel zu-fällig und regellos im Raum verteilt sind oder ob sie sich gegen-seitig beeinflussen. Auch hier wird die Analyse wieder mittelseines stochastischen Modells vorgenommen, welches auf Basisder erhobenen Daten parametrisiert wird. Durch den Vergleichzwischen Modellvorhersagen und den realen Daten kann danneine Aussage über die Art der räumlichen Verteilung der Parti-kel getroffen werden. Bestimmte Annahmen, die zur Anwend-barkeit des Modells erfüllt sein müssen, können mittels explo-rativer Methoden überprüft werden.
Im Gegensatz zu Saltykov [118, S. 245 ff.], der unter vollständigerAnalyse eines Partikelsystems nur das Erheben der Anzahl der Par-tikel in der Volumeneinheit und das Schätzen der Parameter derNormalverteilung in Bezug auf die Partikelgröße versteht, wird dasVerständnis des Begriffs in der vorliegenden Arbeit also um die Ein-zelpartikelanalyse und die Untersuchung der räumlichen Verteilung

4 einleitung
erweitert. Außerdem wird keine Einschränkung bezüglich des ver-wendeten Modells zur Beschreibung der Größenverteilung vorgenom-men. Dem Autor dieser Arbeit ist kein vergleichbares Rahmenwerkbekannt, welches diese drei Aspekte bei der Analyse von Partikelsys-temen berücksichtigt.
Im Hinblick auf das im Silenos-Projekt entworfene Online-Auswer-tesystem soll dieses Rahmenwerk eingesetzt werden, um statistischgesicherte Informationen über den Gehalt von nichtmetallischen Ein-schlüssen in Stahl in ausgewählten Proben aus der laufenden Produk-tion abzuleiten. Dabei ergeben sich aus dieser konkreten Problem-stellung verschiedene Anforderungen an die drei Aspekte der sta-tistischen Analyse von Partikelsystemen, die im Folgenden genauerherausgearbeitet werden sollen. Dafür ist es aber zunächst nötig, diegrobe Funktionsweise des angesprochenen Auswertesystems näherzu erläutern. Dies soll im folgenden Abschnitt geschehen. Eine ge-nauere Betrachtung des Auswertesystems erfolgt dann in Abschnitt4.2. Anschließend werden die Anforderungen in einem separaten Ab-schnitt besprochen.
1.2 silenos
In Zusammenarbeit mit den Hüttenwerken Krupp Mannesmann undder Salzgitter Mannesmann Forschung GmbH wurde im Ziel2-Pro-jekt Silenos ein optisches Auswertesystem zur Detektion von nicht-metallischen Einschlüssen in Stahl entwickelt. Ausgangspunkt ist einOptisches
Auswertesystem direkt aus der Bramme geschnittener Stahlblock mit einer maxima-len Abmessung von 300× 120× 90 mm3. Dieser wird auf ein Verfahr-system gespannt, und durch kontinuierliches Abfräsen und Abfoto-graphieren werden Schichtbilder der Stahloberfläche generiert. Dieverwendete Optik ist dabei in der Lage, Grauwertbilder mit einerAuflösung von 20 µm bis zu 10 µm pro Pixel zu erzeugen. Die Span-abnahme der Fräse beträgt im Normalfall 10 µm. Damit ergeben sichpro Schicht Rohdaten im Umfang von ca. 350 MB. Wird der Stahl-block vollständig abgefräst, fallen bei angenommen 9000 Schichtbil-dern bis zu 3 TB an Daten an. In diesen Schichtbildern wird dannversucht, mittels Methoden der Bildverarbeitung die angesprochenennichtmetallischen Einschlüsse zu identifizieren und zu segmentieren.Neben den nichtmetallischen Einschlüssen sollen aber auch weitereDefekte wie Risse und Poren detektiert werden. Sind die möglichenDefekte in einem Schichtbild segmentiert, lassen sich die Teilsegmen-te inkrementell in den darauf folgenden Schichten verfolgen. So wirdes möglich, die dreidimensionale Morphologie der Defekte zu rekon-struieren. Für vollständig abgefräste Defekte erfolgt dann eine au-tomatische Klassifikation anhand ihrer Morphologie in die Defekt-klassen Riss, Pore und nichtmetallischer Einschluss. Über die Men-

1.3 anforderungen an das rahmenwerk 5
ge der nichtmetallischen Einschlüsse wird schließlich mittels statisti-scher Methoden der Reinheitsgrad bestimmt.
Wichtig bei dem hier beschriebenen Prozess ist, dass alle Auswer-tungen inkrementell, parallel zum Fräsprozess, durchgeführt werden.Das heißt, dass die Ergebnisse der statistischen Auswertungen überdie Menge der vollständig abgefrästen Einschlüsse nach jeder Schichtabgeschlossen sein müssen, bevor das Abfräsen der übernächstenSchicht beginnt. Man erlaubt also einen Versatz von einer Schicht. Online-Betrieb
Daraus ergibt sich ein Zeitfenster von ca. 30 Sekunden, um die Analy-se einer Schicht abzuschließen. Der Grund für diese Vorgehensweisebesteht darin, dass man beim Erkennen von auffälligen Strukturen inder Frässchicht den Prozess rechtzeitig stoppen kann, ohne die Struk-tur durch weiteres Abfräsen zu zerstören. So bleibt eine chemischeAnalyse mittels Spektralaufnahmen der angefrästen Defekte mög-lich. Des Weiteren erlaubt die statistische Online-Auswertung parallelzum Fräsprozess das Evaluieren eines Abbruchkriteriums, welchesauslösen soll, wenn der Reinheitsgrad der Probe mit einer vorgegebe-nen statistischen Sicherheit erfasst wurde. Dadurch wird die Anzahlder zu fräsenden Schichten reduziert, was zu weniger Verschleiß beidem eingesetzten Fräswerkzeug führt. Im weiteren Verlauf wird die-ser Betriebsmodus als Online-Betrieb bezeichnet. Er stellt den Nor-malbetrieb des Auswertesystems dar. Daneben gibt es einen Offline- Offline-Betrieb
Betrieb, bei dem alle Schichtbilder bereits vor der Auswertung vorlie-gen. Solche Datensätze dienen vor allem dazu, die Daten von bereitsgefrästen Proben neu auszuwerten. Dies kann hilfreich sein, um bei-spielsweise neue Parameter für die Klassifikation oder das Abbruch-kriterium zu kalibrieren. Erklärtes Ziel beim Offline-Betrieb ist also,die oben beschriebenen Auswertungen möglichst schnell durchzufüh-ren, damit die Ergebnisse zeitnah vorliegen.
1.3 anforderungen an das rahmenwerk
Aus dem im obigen Abschnitt vorgestellten Verfahren lassen sichkonkrete Anforderungen für das in dieser Arbeit entwickelte Rah-menwerk zur Analyse von Partikelsystemen ableiten. Ausgangspunktbei den folgenden Betrachtungen sind dabei vorsegmentierte Schicht-aufnahmen von Partikelsystemen, wie sie im Silenos-Projekt durchschichtweise abgefräste Werkstoffproben erzeugt werden. Theore-tisch lassen sich aber auch andere bildgebende Verfahren verwenden,wie beispielsweise die Magnetresonanztomographie (MRT). Die Seg-mentierung selbst wird in der vorliegenden Arbeit allerdings nichtbetrachtet, sondern das Problem als gelöst vorausgesetzt. Eine Un-terscheidung zwischen kontinuierlicher und disperser Phase in denSchichtbildern ist also bereits erfolgt. Für mehr Informationen, wie

6 einleitung
dieses Problem im Kontext des Silenos-Projekts gelöst wurde, wer-den auf die einschlägigen Veröffentlichungen des Lehrstuhls für In-telligente Systeme an der Universität Duisburg-Essen verwiesen [21,55, 56]. Da aber die Segmentierung Teil der Online-Auswertung ist,muss diese bei der Laufzeituntersuchung sehr wohl beachtet werden.Im weiteren Verlauf wird die Laufzeit der Segmentierung deshalb alsunbekannte Variable modelliert. Je früher die Rekonstruktion, Klassi-fikation und statistische Auswertung abgeschlossen sind, umso mehrZeit bleibt für diesen Prozess. Dabei wird ein Zeitfenster von 10 s fürdie Segmentierung als realistisch angesehen.
Um die Gestalt der einzelnen Partikel eines Partikelsystems quantifi-zieren zu können, ist es zunächst nötig, diese in den Schichtbildernzu rekonstruieren. Dies verlangt nach einer formalen Definition desRekonstruktion
Begriffs Partikel auf Basis derer dann Algorithmen zur Rekonstrukti-on angegeben werden können. Dabei sollen sowohl bei der Definitiondes Partikelbegriffs als auch bei der Entwicklung der Algorithmendie in Abschnitt 1.2 beschriebenen Anforderungen bezüglich Spei-cherverbrauch und Laufzeit beachtet werden. Die aus der Partikelde-finition abgeleiteten Algorithmen müssen trotz der immensen Daten-mengen den inkrementellen Echtzeitbetrieb gewährleisten. Des Weite-ren soll ein möglichst allgemeiner Partikelbegriff eingeführt werden,der zum einen die Rekonstruktion unterschiedlicher Partikeltypen er-laubt und zum anderen tolerant gegenüber Segmentierungsfehlernist.
Über die rekonstruierten Partikeln werden dann die Deskriptorenberechnet, welche die Quantifizierung der Gestalt erlauben. Bei derAuswahl dieser Deskriptoren steht wieder die Effizienz bezüglich derLaufzeit im Vordergrund, da auch der Quantifizierungs- und Klassi-fizierungprozess Teil des Online-Betriebs des Auswertesystems ausAbschnitt 1.2 ist. Zusätzlich soll bei der Auswahl darauf geachtetSelektive
Deskriptoren werden, möglichst selektive und unterscheidende Deskriptoren zuverwenden, damit verschiedene Charakteristiken der Partikel erfasstwerden können. Dies soll sicherstellen, dass das in Abschnitt 1.2 be-schriebene Klassifizierungsproblem mit ausreichend hoher Genauig-keit gelöst werden kann.
Die klassifizierten und quantifizierten Partikel bilden schließlich dieGrundlage für die statistische Auswertung. Wie bereits angesprochen,soll das Partikelsystem statistisch vollständig beschrieben werden.Im Rahmen dieser Arbeit ist damit die Analyse sowohl der räumli-chen Verteilung als auch der Größenverteilung gemeint. Für beideInkrementelle
statistischeAuswertung
Verteilungen sollen entsprechende Modelle entwickelt werden, diedann mittels der beobachteten Daten parametrisiert werden. Auchhier müssen wieder die speziellen Anforderungen beachtet werden,die sich aus dem in Abschnitt 1.2 beschriebenen inkrementellen Aus-werteprozess ergeben. So ist die Stichprobengröße beim Beginn des

1.4 stand der technik 7
Prozesses nicht bekannt. Dies erfordert die Definition eines Maßeszur Quantifizierung der statistischen Unsicherheit. Damit lässt sichdann feststellen, ab welchem Zeitpunkt genügend Material abgefrästwurde, um die Modelle mit den geschätzten Parametern bei vorgege-bener Genauigkeit zu akzeptieren oder zu verwerfen. Dieser Vorgangwird auch als optimales Stoppen und das Maß als Abbruchkriteriumbezeichnet.
1.4 stand der technik
Sowohl für den in Abschnitt 1.2 beschriebenen Anwendungsfall derDetektion von nichtmetallischen Einschlüssen, als auch für die Ana-lyse von Partikeln allgemein sind bereits zahlreiche Systeme undRahmenwerke auf dem Markt verfügbar. In diesem Abschnitt sollen Stand der Technik
die gängigsten Systeme mit dem in der vorliegenden Arbeit bereitge-stellten Rahmenwerk verglichen, Vor- und Nachteile herausgearbeitetund damit die Neuerungen des entwickelten Rahmenwerks hervor-gehoben werden. Begonnen wird mit der Beschreibung der Systemezur Analyse von nichtmetallischen Einschlüssen in Stahlproben. Beidiesen Systemen handelt es sich fast ausschließlich um kommerzielleProdukte, die keinen Einblick in die verwendeten Algorithmen erlau-ben. Deshalb wird sich bei der Untersuchung dieser Produkte auf dieFrage konzentriert, inwieweit die in Abschnitt 1.1 herausgearbeitetenZiele, also die Einzelpartikelanalyse und die Analyse der räumlichenVerteilung und Größenverteilung, unterstützt werden. Dabei werdenals Quelle häufig die Produktbroschüren der Hersteller herangezo-gen, da auch die Dokumentation nicht öffentlich zugänglich ist. DesWeiteren werden nur optische Verfahren zur Einschlussdetektion er-örtert, da diese am ehesten mit Silenos und dem in der vorliegen-den Arbeit entwickelten Rahmenwerk vergleichbar sind. In Abschnitt4.1.4 werden dann weitere Verfahren zur Detektion von nichtmetalli-schen Einschlüssen eingeführt und entsprechende Vor- und Nachtei-le gegenüber Silenos herausgearbeitet. Nach den Verfahren zur De-tektion von nichtmetallischen Einschlüssen werden anschließend all-gemeinere Systeme und Rahmenwerke zur Partikelanalyse betrach-tet.
Die bekanntesten kommerziellen Systeme zur Analyse des nichtme-tallischen Reinheitsgrades von Stahlwerkstoffen werden von den Fir-men Zeiss [150], Leica [78] und Olympus [100] hergestellt. Bei diesen Standardkonforme
Systeme zurAnalysenichtmetallischerEinschlüsse
Systemen werden nichtmetallische Einschlüsse in Mikroskopaufnah-men polierter Schnittflächen von Stahlproben detektiert, segmentiert,klassifiziert und anschließend der Reinheitsgrad ausgerechnet. LautHerstellerangaben erfüllen dabei alle genannten Systeme den euro-päischen Standard EN10247 [92] und die DIN-Norm 50602 [34] be-ziehungsweise die amerikanische Norm ASTM E45 [8]. Diese Stan-

8 einleitung
dards legen sowohl Probenentnahme und Probengröße, als auch dieKlassifikation der Einschlüsse nach ihrer Morphologie und die Be-rechnung des Reinheitsgrades fest. Die genaue Durchführung unter-scheidet sich zwar von Standard zu Standard, die grundlegende Ideeist aber dieselbe. In polierten Schnittflächen von mindestens 160 mm2
Größe [8] werden nichtmetallische Einschlüsse zunächst mittels ei-nes Mikroskops detektiert. Die detektierten Einschlüsse werden dannanhand ihrer Morphologie in vier Basistypen unterteilt. Laut DIN-Norm 50602 [34] unterscheidet man zwischen sulfidischen Einschlüs-sen in Strichform, oxidischen Einschlüssen in aufgelöster Form (auchals Einschlusszeile bezeichnet), oxidischen Einschlüssen in Strichformund oxidischen Einschlüssen in globularer Form. Für eine manuelleKlassifizierung in diese Basistypen werden entsprechende Bildreihen-tafeln bereitgestellt, mit welche die detektierten Einschlüsse vergli-chen werden. Für eine automatische Klassifizierung werden hinge-gen in EN10247 [92] formale Kriterien angegeben, welche eine Unter-scheidung zwischen einer Einschlusszeile und einem Einschluss alsEinzelereignis erlauben. Ist eine eindeutige Einteilung nicht möglich,kann die Farbe als zusätzliches Kriterium herangezogen werden. An-schließend werden den klassifizierten Einschlüssen Größenkennzif-fern zugeordnet. Der Reinheitsgrad ergibt sich schließlich entwederaus dem maximalen Größenwert der unterschiedlichen Einschlussty-pen (Verfahren M, siehe DIN-Norm 50602 [34]) oder aus dem Verhält-nis der gesamten Einschlussfläche je Einschlusstyp zur Probenfläche,wobei auf 1000 mm2 hochgerechnet wird (Verfahren K). Allerdingswird bei keiner der angegebenen Normen berücksichtigt, dass nicht-metallische Einschlüsse eine dreidimensionale Ausdehnung besitzen.Zumindest für globulare Partikel sind seit längerem stereologischeVerfahren bekannt, die das Hochrechnen der Durchmesserverteilungauf das Volumen anhand zweidimensionaler Profile erlauben [143].Sogar für die konkrete Problemstellung der Berechnung des nichtme-tallischen Reinheitsgrades wurden solche Verfahren bereits angewen-det [118, S. 245] und sind immer noch Gegenstand der aktuellen For-schung [140]. Sowohl in den angegebenen Normen als auch in denjeweiligen Broschüren der Hersteller wird diese Problematik nichtberücksichtigt. Insgesamt wird das Thema dreidimensionale (räumli-che) Verteilung, soweit ersichtlich, nicht behandelt. Die vorgestelltenSysteme scheinen nur die Mindestanforderungen der Standards zuerfüllen. Es stellt sich die Frage, ob mit dem in der vorliegenden Ar-beit entwickelten Rahmenwerk im Anwendungsfall (siehe Abschnitt1.2) standardkonforme Auswertungen durchgeführt werden können.Diese Frage lässt sich nicht ohne weiteres beantworten, da die in denStandards definierten Methoden trotz ähnlicher Ansätze sehr unter-schiedlich sind. Zunächst einmal ist es im Vorhaben Silenos das Ziel,den Meso- und Makroreinheitsgrad (siehe auch Abschnitt 4.1.2) zuuntersuchen, während die in den Normen beschriebenen Verfahren

1.4 stand der technik 9
die Analyse des Mikroreinheitsgrades zum Ziel haben. Für die Klas-sifikation der verschiedenen Einschlusstypen ist es nach EN10247
[92] nötig, Abstände von unter 40 µm und teilweise sogar bis un-ter 10 µm zwischen detektierten Einzelpartikeln zu messen. Anhanddieser Messwerte wird dann bestimmt, ob die detektierten Partikeleinzelne Einschlüsse darstellen oder Teil einer Einschlusszeile sind.Das Vermessen solcher kleinen Abstände ist mit der verwendetenOptik im Silenos-Projekt (siehe Abschnitt 4.2.1) auf Grund der ge-ringen Auflösung nicht möglich. Aber selbst bei Verwendung einerbesseren Optik, mit der die Kriterien in Standard EN10247 [92] um-gesetzt werden können, ist eine Übertragung der Vorgehensweise aufdas Silenos-System nicht ohne weiteres möglich. In den Standards istdie Entnahme und Vorverarbeitung der Proben genau definiert. Sowird beispielsweise festgelegt, wo die Probe zu entnehmen ist undwie die Oberfläche bearbeitet und poliert werden muss. Damit sollsichergestellt werden, dass nichtmetallische Einschlüsse während derProbenvorverarbeitung auf der Probenoberfläche nicht zerstört oderherausgebrochen werden. Beim Silenos-Verfahren wird aber nicht po-liert, sondern gefräst. Die Probenoberfläche ist also starker mechani-scher Beanspruchung ausgesetzt. Bei der Detektion von Meso- oderMakroeinschlüssen in kontinuierlich gefrästen Schichtbildern ist dieManipulation der Morphologie in einer Schicht vernachlässigbar. BeiMikroeinschlüssen, die aber, wenn überhaupt, nur in sehr wenigenaufeinander folgenden Schichten präsent sind, führt das Fräsen dazu,dass sie entweder in die falsche Einschlussklasse eingeordnet odererst gar nicht detektiert werden. Als letzter Punkt bleibt noch zu er-wähnen, dass die in den Standards beschriebenen Methoden nur fürgewalztes Material definiert sind, da sich erst durch das Walzen wei-che Einschlüsse zu einem Strich beziehungsweise spröde Einschlüssezu einer Einschlusszeile umformen. Im Normalbetrieb von Silenoswird die Probe hingegen ohne Walzen direkt aus der Bramme ge-schnitten. Zusammenfassend kann also festgehalten werden, dass diehier vorgestellten Systeme und Silenos verschiedene Problemstellun-gen lösen und nur bedingt vergleichbar sind. Während die standard-konformen Systeme der drei Hersteller Leica [78], Zeiss [150] undOlympus [100] den Mikroreinheitsgrad anhand zweidimensionalerpolierter Schnittflächen berechnen, wird bei Silenos der Einschluss-gehalt im Volumen mittels kontinuierlich gefräster Schichtbilder be-stimmt. Das in der vorliegenden Arbeit erarbeitete Rahmenwerk wirddabei eingesetzt, um die dreidimensionale Morphologie der Einzel-partikel zu rekonstruieren (siehe Abschnitt 2.1.2). Dazu ist keines dergenannten Systeme in der Lage. Des Weiteren können die im Rah-menwerk definierten statistischen Methoden dazu verwendet werdenstochastische Modelle sowohl für die räumliche Verteilung (siehe Ab-schnitt 3.3) als auch für die Größenverteilung (siehe Abschnitt 3.2)zu bestimmen und zu parametrisieren. Dies geht weit über die in

10 einleitung
den Standards definierten Verfahren M und K hinaus, bei denen essich um einfache Zählstatistiken handelt. Inwieweit solche Modelleauch mit den genannten Systemen erstellt werden können, lässt sichanhand der zugänglichen Dokumentation nicht erörtern.
Neben kommerziellen Systemen, die für den spezifischen Anwen-dungsfall aus Abschnitt 4.2 konzipiert wurden, gibt es auch zahlrei-che kommerzielle und quelloffene Systeme und Rahmenwerke, diezur Analyse von Partikelsystemen allgemein eingesetzt werden kön-nen. Zweidimensionale Analysewerkzeuge sind von den Firmen Me-Zweidimensionale
Systeme zurPartikelanalyse
diaCybernetics [91], Paxit [105], ImageMetrology [63] und Oxford La-sers [77] verfügbar. Der Funktionsumgfang ist bei diesen Werkzeugenin etwa derselbe. In zweidimensionalen Schichtbildern beliebigen Ur-sprungs werden Profile von Partikeln semi-automatisch segmentiert,klassifiziert und statistisch ausgewertet. Semi-automatisch heißt da-bei, dass der Nutzer durch das Festlegen des verwendeten Segmentie-rungsalgorithmus und entsprechender Schwellwerte in den Segmen-tierungsprozess eingreifen kann. Soweit es aus der bereitgestelltenDokumentation ersichtlich ist, werden die üblichen morphologischenParameter, nämlich der Flächeninhalt, der Umfang, die Rundheit, derFeret-Durchmesser und das Achsenverhältnis zur Klassifikation undAuswertung für den zweidimensionalen Fall verwendet. Diese Pa-rameter, neben zahlreichen weiteren, werden auch in dem Rahmen-werk der vorliegenden Arbeit (siehe Abschnitt 2.2) bereitgestellt, al-lerdings für den dreidimensionalen Fall. Konkrete Angaben zu denstatistischen Auswertungen lassen sich hingegen nur sehr wenige fin-den. Zwar stellen alle genannten Werkzeuge ein Report-Modul zurVerfügung, es fehlt aber die Angabe, welche konkreten statistischenAuswertungen angewendet werden können. Anhand von Bildschirm-fotos der Software lässt sich erkennen, dass Standardmethoden derdeskriptiven Statistik, wie die Berechnung vom Mittelwert, Medianund Modus der Größenverteilung und einfache explorative Daten-analysewerkzeuge, wie Histogramme, unterstützt werden. Ob dasParametrisieren von statistischen Modellen sowohl für die Größen-verteilung als auch für die räumliche Verteilung unterstützt wird,bleibt hingegen unerwähnt. Der Hersteller Oxford Lasers [77] ver-neint dies sogar explizit bei seinem Produkt. Als Begründung wirdangeführt, dass die Daten im Rohzustand ohne weitere Aufbereitungangezeigt werden sollen, damit besondere Charakteristiken der Da-ten erhalten bleiben. Nach Meinung des Autors dieser Arbeit schlie-ßen sich aber die Rohdatendarstellung und die Bereitstellung vonModellparametrisierungs- und Validierungsverfahren nicht gegensei-tig aus. So werden die in Abschnitt 7.2 beschriebenen explorativen Da-tenanalysewerkzeuge zur Visualisierung der Rohdaten mit Modellie-rungswerkzeugen kombiniert, um den Nutzer bei der Modellauswahlund Validierung zu unterstützen. Dabei werden zunächst alle gemes-senen Daten berücksichtigt, wobei sich diese entsprechend filtern las-

1.4 stand der technik 11
sen, um beispielsweise Ausreißer von der Berechnung auszuschlie-ßen (für einen konkreten Anwendungsfall siehe auch Abschnitt 6.1.2).Dies geschieht aber immer nur auf Anweisung des Nutzers. Automa-tisch werden keine Daten verworfen. Insgesamt kann, wie schon beiden Produkten zur Analyse von nichtmetallischen Einschlüssen, fest-gehalten werden, dass in den besprochenen Systemen nur eine reinzweidimensionale Analyse von Partikelsystemen vorgenommen wird.Eine Hochrechnung der Partikeldurchmesser von Profilen auf das Vo-lumen findet nicht statt. Die bereitgestellten statistischen Auswertun-gen sind soweit ersichtlich nur deskriptiver Natur und die räumlicheVerteilung wird nicht betrachtet.
Neben zweidimensionalen Verfahren sind auch dreidimensionaleSysteme zur Partikelanalyse verfügbar. Verschiedene Messmethodenwurden vorgeschlagen. Im Folgenden soll sich aber auf Verfahren Dreidimensionale
Systeme zurPartikelanalyse
beschränkt werden, welche die Analyse von eingebetteten Parti-keln in einer festen kontinuierlichen Phase erlauben. Messmethoden,wie die Laser-Diffraktions-Analyse oder Rasterelektronenmikroskop-Aufnahmen (REM), die im Nanometerbereich das Vermessen vondreidimensionalen Partikeln ermöglichen, bleiben außen vor. Die er-hobenen Daten sind nicht mit den im Rahmenwerk definierten Me-thoden, welche auf das Auswerten von Schichtbildern hin konzipiertwurden, kompatibel. Stattdessen wird auf den Artikel von Pirard[106] verwiesen, der eine ausführliche Literaturrecherche zu diesemThema durchgeführt hat. Eine Messmethode, welche zur Analyse vonMikrostrukturen in Festkörpern eingesetzt werden kann und starkeParallelen zu dem im Silenos-Projekt entworfenen System aufweist,ist das Robo-Met.3D [113] System. Dabei handelt es sich um ein voll-automatisches Messsystem für das Erstellen von Schnittbildern mit-tels kontinuierlichem Fräsen und Polieren des zu verarbeitenden Fest-körpers. Unter Einsatz der Robo-Met.3D Analytics Software [5] las-sen sich die Schichtbilder zu einem virtuellen dreidimensionalen Ab-bild der untersuchten Probe zusammensetzen und Mikrostrukturen,wie Korngrenzen und verschiedene Defekte, analysieren. Ein mögli-cher Anwendungsfall ist beispielsweise die Analyse von sogenanntenFreckle-Defekten, die beim Gießen von Superlegierungen entstehenkönnen [126]. Laut Herstellerangaben können Proben mit einer maxi-malen Abmessung von 2 mm× 1.5 mm× 15 mm verarbeitet werden.Die Spanabnahme der Fräse liegt zwischen 0.20 µm und 10 µm. ImVergleich zum Silenos-Projekt ist die maximal unterstützte Proben-größe zu klein, um das angestrebte Projektziel, also die Analyse desMeso- und Makroreinheitsgrades, umzusetzen. Leider hält sich derHersteller auch bezüglich der unterstützten Auswertungen der Soft-ware Robo-Met.3D Analytics [5] sehr bedeckt, so dass nicht weitererörtert werden kann, ob die drei definierten Ziele in Abschnitt 1.1damit umgesetzt werden können.

12 einleitung
Neben solchen voll integrierten Systemen zur dreidimensionalenAnalyse von Partikelsystemen gibt es zahlreiche Softwareproduk-te, die sich auf die Auswertung von Schichtbildern spezialisierthaben. Als Quelle für solche Schichtbilder dient dabei häufigdie Computertomographie (CT) oder Mikro-Computertomographie(MCT), aber auch andere bildgebende Verfahren, wie beispielswei-se das kontinuierliche Fräsen und Fotographieren von Schnittflächenkönnen als Quelle verwendet werden. Eine bekannte Open-SourceImplementierung, die einen ähnlichen Funktionsumfang wie das imRahmen dieser Arbeit entwickelte Rahmenwerk liefert, ist die Erwei-terung Particle Analyser [4] der Software BoneJ [16]. BoneJ ist wie-Open-Source
Systeme zurPartikelanalyse
derum eine Erweiterung der Bildverarbeitungssoftware ImageJ [62]und wird verwendet, um die Geometrie und Form von Knochen zuuntersuchen. Der Particle Analyser wurde entwickelt, um Osteozy-ten, einkernige Zellen die in der Knochenmatrix eingebettet sind, inMCT-Aufnahmen von Knochen zu analysieren. Ähnlich wie nicht-metallische Einschlüsse besitzen diese Zellen eine dreidimensiona-le Ausdehnung und lassen sich anhand ihrer Größe und Morpho-logie klassifizieren. Der Particle Analyser [4] kann aber auch verwen-det werden, um Partikelsysteme allgemein zu untersuchen. Der Ab-lauf sieht dabei wie folgt aus. Ausgangspunkt sind vorsegmentierteSchichtbilder. Die dreidimensionale Morphologie der segmentiertenPartikel wird mittels Connected Component Labeling (CCL) (sieheAbschnitt 2.1.2) rekonstruiert. Über die rekonstruierten Partikel wer-den dann verschiedene Deskriptoren, wie der Feret-Durchmesser, dasVolumen, die Oberfläche, die Eulerzahl und die invarianten Momenteberechnet. Zusätzlich können die rekonstruierten Partikel mittels desMarching-Cube-Algorithmus in Dreiecksnetze umgewandelt und vi-sualisiert werden. Damit ist der bereitgestellte Umfang durchaus ver-gleichbar mit der in Abschnitt 2 vorgestellten Einzelpartikelanalyseund dem Particle Analysis System (PAS) aus Abschnitt 7.2. Ein wich-tiger Unterschied besteht aber darin, dass die im Rahmenwerk be-reitgestellten Methoden die kontinuierliche Rekonstruktion von Parti-keln parallel zum Bildaufnahme- und Segmentierungsprozess erlau-ben. Damit wird der Einsatz in einem Online-Auswertesystem erstmöglich. Auch scheint der Particle Analyser nicht auf das Verarbeitenvon großen Schichtbildern optimiert zu sein. In der Dokumentationwerden Bilder mit einer Abmessung von 512× 512× 512 Pixeln alsReferenzwert angegeben. Beim Silenos-Projekt kommen Bilder mit ei-ner Auflösung von bis 15000× 7000× 3000 Pixeln vor. Zwar wurdekein Benchmark durchgeführt, es ist aber davon auszugehen, dass diein C++ implementierten Algorithmen des Rahmenwerks im Vergleichzu dem in Java implementierten BoneJ in Bezug auf Geschwindigkeitund Speicherverbrauch deutlich effizienter sind. Gerade Zeigerope-rationen auf kontinuierlichen Datenblöcken, wie sie bei Bildverarbei-tungsalgorithmen häufig vorkommen, werden durch moderne C++

1.5 umsetzung und struktur der arbeit 13
Compiler in sehr effizienten Maschinencode übersetzt. Dies wurdezum Beispiel von Hundt [60] in einem sehr ausführlichen Benchmarkbestätigt. Auch die Geschwindigkeitsmessungen aus Abschnitt 2.1.3lassen dies vermuten. Ein weiterer Nachteil im Vergleich zu dem ent-wickelten Rahmenwerk ist die fehlende Unterstützung von statisti-schen Methoden. Wie bereits bei den anderen hier vorgestellten Sys-temen werden nur sehr einfache deskriptive statistische Methodenangeboten, wie beispielsweise die Berechnung der Partikel mit mini-malem, mittlerem und maximalem Volumen. Methoden zur Unter-suchung der räumlichen Verteilung sind nicht implementiert. Genauandersherum ist der Fall bei Spatstat [125] gelagert, einem in der Pro-grammiersprache R [108] implementierten statistischen Rahmenwerkzur Analyse von Punktmustern. Hier sind zwar die gängigsten Me-thoden zur Analyse zwei- und dreidimensionaler Punktmuster im-plementiert (siehe Abschnitt 3.3), allerdings fehlt die komplette Un-terstützung der Einzelpartikelanalyse.
Insgesamt muss also konstatiert werden, dass keines der hier vorge-stellten Systeme alle geforderten Ziele aus Abschnitt 1.1 umsetzt. Aus Fazit
diesem Grund wird in der vorliegenden Arbeit eine eigene Imple-mentierung vorgenommen. Die Methoden der Einzelpartikelanalysewerden dabei von Grund auf entwickelt, da diese möglichst effizientin Bezug auf die Laufzeit und den Speicherverbrauch sein müssen,um einen echtzeitfähigen Betrieb gewährleisten zu können. BoneJ [16]und der Particle Analyser [4] werden im Zuge der Entwicklung da-zu verwendet die Ergebnisse der Algorithmen zur Berechnung derEulerzahl und der invarianten Momente zu validieren. Für die statis-tischen Methoden wird hingegen auf die Programmierumgebung R[108] zurückgegriffen und die einzelnen Auswertungen in Form vonR-Skripten zur Verfügung gestellt. Dabei wird R [108] in den C++-Kern des Rahmwerks eingebettet, so dass die Auswertungen übereine einheitliche Schnittstelle ausgeführt werden können. Die Metho-den zur Analyse der räumlichen Verteilung werden von Spatstat [125]bereitgestellt, da damit bereits ein etabliertes Rahmenwerk zur Aus-wertung von Punktmustern zur Verfügung steht. Die Kombinationund Integration dieser verschiedenen Techniken bilden das Rahmen-werk, mit welchem die in Abschnitt 1.1 definierten Ziele umgesetztwerden können. Weitere Details zur konkreten Implementierung sindin Kapitel 7 aufgeführt. Soweit dem Autor bekannt, ist derzeit keinSystem verfügbar, welches einen vergleichbaren Umfang zur Analysedreidimensionaler Partikelsysteme bereitstellt.
1.5 umsetzung und struktur der arbeit
Aus den definierten Anforderungen aus Abschnitt 1.3 ergibt sich fol-gender Aufbau für die vorliegende Arbeit. In Kapitel 2 wird zunächst Partikeldefinition

14 einleitung
die formale Definition des Partikelbegriffs erarbeitet. Dabei wird zu-nächst ein Nachbarschaftskriterium definiert, welches die Grundlagefür den Partikelbegriff bildet. Ein Partikel wird dann als zusammen-hängende Menge von volumetrischen Pixeln eingeführt. Zugelassenwerden verschiedene Nachbarschaftskritierien, um diese zusammen-hängenden Mengen zu bestimmen. Damit wird sichergestellt, dassbei der Rekonstruktion möglichst flexibel auf Segmentierungsfehlerreagiert werden kann. Auf Basis dieser Definition wird dann ein Al-gorithmus entwickelt, der die zusammenhängenden Mengen in denSchichtbildern detektiert. Im Gegensatz zu den üblicherweise in derLiteratur besprochenen Algorithmen wird das in der vorliegendenArbeit verwendete Verfahren aber nicht für Bilder, sondern für diediskretisierte disperse Phase eingeführt. Dieser Schritt erlaubt eineRekonstruktions-
Algorithmus drastische Reduktion der Daten, da die Pixel der kontinuierlichenPhase in jedem Schichtbild vor der Verarbeitung verworfen werdenkönnen. Erst damit ist es möglich, mit den in Abschnitt 1.2 ange-sprochenen Datenmengen umzugehen. Der Algorithmus wird dannschrittweise erweitert, um den inkrementellen Betrieb des Online-Auswertesystems zu unterstützen. Zusätzlich wird ein zweiter Algo-rithmus angegeben, der für den Offline-Betrieb optimiert ist. Beide Al-gorithmen werden dann anhand von simulierten Daten (siehe unten)extrem verunreinigter Stahlproben evaluiert. Damit soll sichergestelltwerden, dass die in Abschnitt 1.2 definierten Laufzeitanforderungenerfüllt sind. Im gleichen Kapitel werden schließlich die Gestaltde-Gestaltdeskriptoren
skriptoren eingeführt, die eine Quantifizierung der Form und Größeder individuellen Partikel erlauben. Hauptaugenmerk liegt auf denMinkowskifunktionalen. Sie bilden die Grundlage für eine Reihe wei-terer Deskriptoren. Außerdem lässt sich zeigen, dass sie eine Basis imVektorraum der bewegungsinvarianten, stetigen und additiven Funk-tionale bilden. Für die Berechnung wird ein effizienter Algorithmusmittels vorberechneter Tabellen angegeben, der eine direkte Erweite-rung des von Michielsen und De Raedt [94] propagierten Verfahrensdarstellt.
Nach der Beschreibung der Methoden der Einzelpartikelanalyse wer-den in Kapitel 3 dann geeignete statistische Verfahren eingeführt, diesowohl die Analyse der räumlichen Verteilung als auch der Parti-kelgrößenverteilung erlauben. Ziel ist es, für beide Verteilungen einModell zu konstruieren, welches mittels der beobachteten Daten pa-rametrisiert wird. Dabei wird rigoros auf die Methoden der bayes-schen Statistik gesetzt. Dies hat im Zusammenhang mit dem in Ab-Bayessche Statisik
schnitt 1.2 beschriebenen Online-Auswertesystem mehrere Vorteile.Zunächst lässt sich etwaiges Vorwissen über die Parameter adäquatin Form einer A-priori Verteilung modellieren. Des Weiteren kannder iterative Ablauf des Auswertesystems direkt abgebildet werden.So kann nach jeder Schicht aus der A-priori Verteilung, dem postu-lierten Modell und den beobachteten Daten die A-posteriori Vertei-

1.5 umsetzung und struktur der arbeit 15
lung bestimmt werden. Diese codiert das Wissen über die Modell-parameter nach Beobachtung der neuen Daten. Im nächsten Iterati-onsschritt wird dann die A-posteriori Verteilung zur neuen A-prioriVerteilung, da sich mit den neu beobachteten Daten auch das Wissenüber die Parameter aktualisiert hat. Schließlich lässt sich mittels derbayesschen Methoden die statistische Unsicherheit bei der Schätzungadäquat quantifizieren. Damit ist also auch die Grundlage für dasAbbruchkriterium geschaffen. Nach Einführen dieser grundlegendenstatistischen Methoden folgt dann die Definition von Modellvalidie-rungsverfahren und explorativen Datenanlysewerkzeugen, um einenExperten bei der Auswahl eines passenden Modells zu unterstützen.Dabei werden sowohl Methoden für die Analyse der räumlichen Ver-teilung als auch der Größenverteilung definiert.
Damit werden die theoretischen Grundlagen für das in dieser Ar-beit entwickelte Rahmenwerk gelegt. In den nächsten Kapiteln wirddann exemplarisch anhand von Daten aus dem Auswertesystem vonAbschnitt 1.2 gezeigt, wie die dort definierten Anforderungen mit-tels der Methoden aus dem Rahmenwerk umgesetzt werden können. Expertenwissen
Zunächst werden dafür in Kapitel 4 die wichtigsten optischen, chemi-schen, morphologischen und statistischen Eigenschaften von nicht-metallischen Einschlüssen zusammengefasst und verschiedene De-tektionsverfahren vorgestellt. Im Zuge dessen werden auch das imSilenos-Projekt entwickelte Detektionsverfahren genauer eingeführtund die Vorteile gegenüber den klassischen Verfahren herausgearbei-tet. Die in Kapitel 4 erarbeiteten Erkenntnisse werden in den darauffolgenden Kapiteln als Expertenwissen für die Modellbildung her-angezogen. Mittels der Methoden aus der Einzelpartikelanalyse undVerfahren des maschinellen Lernens wird dann in Kapitel 5 gezeigt,wie das in Abschnitt 1.2 angesprochene Klassifizierungsproblem ge-löst wird. Dazu wird aus allen definierten Deskriptoren ein optima- Defektklassifikation
ler Deskriptorsatz bestimmt und dieser verwendet, um die detektier-ten Defekte in globulare Defekte, Risse und Artefakte aufzuteilen.Die Klasse der Artefakte enthält dabei fälschlich als Defekt erkann-te zusammenhängende Mengen, die auf Grund von Segmentierungs-oder Bildaufnahmefehlern entstanden sind. Die Aufteilung der Klas-se der globularen Defekte wird anschließend nochmals verfeinert,und zwar in Poren und nichtmetallische Einschlüsse. Im Kapitel 6
werden dann anhand dieser Defektmenge die verschiedenen Mög-lichkeiten der statistischen Auswertung aufgezeigt. Als Modell fürdie Größenverteilung von nichtmetallischen Einschlüssen wird, wiein Kapitel 4 beschrieben, die logarithmische Normalverteilung ange-nommen. Mittels der in Kapitel 6 definierten explorativen Methodenwird diese Annahme zunächst auf Plausibilität geprüft. Anschließend Statistische
Modellbildungerfolgt die Parametrisierung und Validierung auf Basis der erhobenenDaten. Gleiches Prozedere wird für die räumliche Verteilung durch-geführt, wobei hier der homogene Poisson-Prozess das favorisierte

16 einleitung
Modell ist. Die Erkenntnisse aus diesem Prozess bilden die Grundla-ge für die Implementierung einer Simulationssoftware. Mittels dieserlassen sich synthetische Probendaten generieren, die wiederum dazugenutzt werden, einige der in Abschnitt 1.2 aufgestellten Anforderun-gen zu überprüfen.
In Kapitel 7 wird schließlich erfolgreich gezeigt, wie das in Kapitel 2
und 3 definierte Rahmenwerk dazu verwendet werden kann, das inAbschnitt 1.2 beschriebene Online-Auswertesystem mit den gegebe-nen Anforderungen zu implementieren. Die Implementierung setztImplementierung
und Anforderungs-evaluation
bei den vorsegmentierten Schichtbildern an und führt alle Operatio-nen, also Rekonstruktion, Klassifikation und die statistische Auswer-tung inkrementell durch. Die Implementierung ist dabei so generischwie möglich gehalten, so dass theoretisch auch andere bildgebendeVerfahren unterstützt werden, die schichtweise Bilder erzeugen. DasSystem wird in der vorliegenden Arbeit als Particle Detection Sys-tem (PDS) bezeichnet. Auf Basis simulierter Stahlproben mit extre-mem Verunreinigungsgrad wird überprüft, ob die Laufzeitanforde-rungen für Segmetierung, Rekonstruktion, Klassifikation und statis-tische Auswertung von 30 s pro Schicht eingehalten werden können.Zusätzlich wird ein zweites System Namens Particle Analysis Sys-tem (PAS) entwickelt. Dieses stellt die in Kapitel 3 entwickelten explo-rativen Datenanalysewerkzeuge bereit. Es wird unter anderem dazuverwendet, die vorklassifizierten Trainingsdaten für die Klassifikationaus Kapitel 5 zu erstellen. In Kapitel 8 wird dann eine Zusammenfas-sung der erreichten Ergebnisse präsentiert.

2E I N Z E L PA RT I K E L A N A LY S E
Die mathematische Beschreibung der Gestalt von Partikeln, also ih-rer Form und Größe, hat eine lange Historie. So werden in der Lite-ratur zahlreiche Beispiele für empirische und analytische Deskripto-ren angegeben, mit denen sich diese Merkmale quantifizieren lassen[14]. Dabei arbeiten viele dieser Deskriptoren auf zweidimensiona- Gestalt von
Partikelnlen Projektionen dreidimensionaler Partikel oder auf Partikelprofilen,die mittels Schnitten durch Festkörper mit eingebetteten Partikelngewonnen wurden [134, S. 72 ff., 132, S. 11 ff.]. Unter Anwendungstereologischer Techniken versucht man dann, die an Stichproben er-hobenen Werte dieser Deskriptoren auf das ganze Partikelkollektivhochzurechnen [118, S. 273 ff., 133, S. 412 ff.]. Im Allgemeinen istes aber nicht möglich, nur anhand des Profils eine Aussage überdie Form oder Größe eines individuellen Partikels des Systems zutreffen. Mit dem Aufkommen moderner bildgebender Verfahren, wieder MRT, stehen aber immer häufiger auch volumetrische Datensät-ze ganzer Partikelsyteme zur Verfügung, die eine dreidimensionaleRekonstruktion einzelner Partikel erlauben. Diese dreidimensionalenModelle sind der Ausgangspunkt, um mittels geeigneter dreidimen-sionaler Deskriptoren Merkmale, wie die spezifische Form, die Größeoder das Volumen, zu quantifizieren. Oft kann man im weiteren Ver-lauf der Untersuchungen anhand dieser Merkmale Rückschlüsse aufbestimmte Charakteristiken der einzelnen Partikel ziehen und dieseentsprechend der Charakteristiken klassifizieren. Darüber hinaus las-sen sich aber auch systematische Gestaltveränderungen erfassen undSchwankungen innerhalb verschiedener Gestaltklassen statistisch be-schreiben.
In diesem Kapitel sollen verschiedene dreidimensionale Deskriptorenvorgestellt werden, mit denen sich die Gestalt von Partikeln quanti-fizieren lässt. Ausgangspunkt sind dabei vorsegmentierte Schichtbil- Dreidimensionale
Deskriptorender von Partikelsystemen, wie sie von bildgebenden Verfahren, wieder CT oder dem Fräsen und Abfotografieren von Werkstoffproben,erzeugt werden. In diesen Schichtbildern sind die einzelnen Partikelbereits eindeutig detektiert und segmentiert, sie müssen aber nochzu einem vollständigen Modell zusammengesetzt werden. Dafür wer-den in diesem Kapitel effiziente Verfahren eingeführt. Ergebnis desEinsatzes dieser Verfahren ist eine Menge von volumetrischen Pixeln(im weiteren Verlauf als Voxel bezeichnet) pro Partikel. Über die Vo-xelmengen werden dann Deskriptoren definiert, welche die Gestalt,
17

18 einzelpartikelanalyse
also die Größe und die Form, quantifizieren. Nicht behandelt werdenzweidimensionale Deskriptoren oder Deskriptoren, die auf Texturenbasieren.
2.1 partikelrekonstruktion
Um die Rekonstruktion von Partikeln durchführen zu können, wirdzunächst eine formale Definition des Begriffs Partikel benötigt. In denfolgenden Abschnitten wird eine solche Definition erarbeitet und an-schließend ein Verfahren vorgestellt, welches die dreidimensionaleRekonstruktion von Partikeln aus den segmentierten Schichtbildernunter Verwendung dieser Definition erlaubt. Die verwendete Notati-on orientiert sich dabei an der von Ohser und Schladitz [99, S. 110 ff.]und Torquato [139, S. 26 ff.].
2.1.1 Partikeldefinition
Gegeben sei ein Partikelsysten X , welches eine wohldefinierte Teil-menge des dreidimensionalen euklidischen Raums R
3 ist. Für jedenIndikatorfunktion
Punkt x ∈ X des Systems lässt sich mittels der Indikatorfunktion
1X (x) =
1 für x ∈ Ξ
0 für x /∈ Ξ(1)
bestimmen, ob der Punkt x innerhalb der dispersen Phase Ξ oder derkontinuierlichen Phase Ξc = x ∈ X : x /∈ Ξ liegt. Weiter definiertman ein räumliches Gitter L
3 als
L3 = x ∈ R
3 : x =3
∑i=1
ziui, zi ∈ Z = UZ (2)
wobei u1, . . . , u3 ∈ R3 eine Basis des R
3 formen und U = (u1, . . . , u3)
die Matrix der Spaltenvektoren ist. Die Minkowski-Summe (siehe For-Gittersystem
mel 20) C = [0, u1]⊕ . . .⊕ [0, u3] der Segmente [0, ui] zwischen demUrsprung 0 und dem Gitterpunkt ui wird dabei als abgeschlosseneElementarzelle C des Gitters bezeichnet. Das Volumen von C ergibtsich aus der Determinanten von U. Die Menge C + x : x ∈ L
3überdeckt schließlich den gesamten R
3 [99, S. 44].
In den nachfolgenden Betrachtungen sind nur Gittersysteme von In-teresse, bei denen U eine Diagonalmatrix ist. Solche Gitter bezeichnetOrthorhombisch und
kubisch primitiveGittersysteme
man auch als orthorhombische primitive Gittersysteme. Die Gitter-zellen eines solchen Systems bestehen jeweils aus acht Vertices, zwölfKanten und sechs Flächen und haben die Form eines Quaders. Giltzusätzlich δ1 = δ2 = δ3, wobei δi = |ui| ist, spricht man von einem

2.1 partikelrekonstruktion 19
kubisch primitiven Gittersystem mit Gitterabstand δ. In diesem Fallsind die Gitterabstände entlang der Raumrichtungen gleich lang, unddie einzelnen Gitterzellen haben die Form eines Würfels.
Sei nun C0 die auf den Ursprung zentrierte Elementarzelle eines Git-ters L
3. Dann bezeichnet GaußscheDiskretisierung
Ξ =⋃
x∈Ξ∩L3
(C0 + x) (3)
die gaußsche Diskretisierung der dispersen Phase Ξ [99, S. 46, 70,S. 56], wobei die Elemente x der Menge Ξ volumetrische Pixel oderauch Voxel der dispersen Phase genannt werden. Die individuellen Voxel
Partikel eines Partikelsystems werden nun auf Basis von Nachbar-schaftsbeziehungen zwischen Voxeln definiert und ergeben sich ausder Menge aller disjunkten Teilmengen von Ξ.
Dazu definiert man
SE(6) = (0, 0, 0
) (−1, 0, 0
) (1, 0, 0
)
(0, −1, 0
) (0, 1, 0
),(0, 0, −1
)(4)
(0, 0, 1
)
als das Strukturelement zur Beschreibung der 6er Nachbarschaft,
SE(18) = (−1, 0, −1
) (0, 0, −1
) (1, 0, −1
)
(0, −1, −1
) (0, 1, −1
),(−1, −1, 0
)
(0, −1, 0
) (1, −1, 0
) (−1, 0, 0
)
(0, 0, 0
) (1, 0, 0
) (−1, 1, 0
)(5)
(0, 1, 0
) (1, 1, 0
) (−1, 0, 1
)
(0, 0, 1
) (1, 0, 1
) (0, −1, 1
)
(0, 1, 1
)
als das Strukturelement zur Beschreibung der 18er Nachbarschaftund
SE(26) = (−1, −1, −1
) (0, −1, −1
) (1, −1, −1
)
(−1, 0, −1
) (0, 0, −1
) (1, 0, −1
)
(−1, 1, −1
) (0, 1, −1
) (1, 1, −1
)
(−1, −1, 0
) (0, −1, 0
) (1, −1, 0
)(6)
(−1, 0, 0
) (0, 0, 0
) (1, 0, 0
)
(−1, 1, 0
) (0, 1, 0
) (1, 1, 0
)
(−1, −1, 1
) (0, −1, 1
) (1, −1, 1
)
(−1, 0, 1
) (0, 0, 1
) (1, 0, 1
)
(−1, 1, 1
) (0, 1, 1
) (1, 1, 1
)

20 einzelpartikelanalyse
als das Strukturelement zur Beschreibung der 26er Nachbarn für den
dreidimensionalen Fall. Weiter ist SE(s)h die Translation des Struktu-
relements der Nachbarschaft s ∈ 6, 18, 26 um den Punkt h ∈ L3,
also SE(s)h = t ∈ SE(s) : h + t. Die Nachbarn eines Voxels x ∈ ΞNachbarschaftskrite-
rium bezüglich der 6er, 18er, oder 26er Nachbarschaft sind dann gegebendurch
NSE(s)(x) = SE(s)x ∩ Ξ
.(7)
Zwei Voxel x, y ∈ Ξ werden als wechselseitig benachbart bezeichnet,wenn sowohl x ∈ NSE(s)(y) als auch y ∈ NSE(s)(x) ist. Es lässt sich zei-gen, dass wechselseitige Nachbarschaft eine Äquivalenzrelation ist,da die Eigenschaften Reflexivität, Symmetrie, sowie Transitivität er-füllt sind [70, S. 9 ff.].
Aufbauend auf diesen Definitionen lässt sich nun der Begriff des Par-tikels formal einführen. Ein Partikel wird definiert als endliche Voxel-Partikeldefinition
menge X ⊂ Ξ, für die gilt, dass zwei beliebige Voxel x, y ∈ X durcheinen Pfad verbunden sind, der selbst komplett in X liegt. Ein Pfadbesteht dabei aus n + 1 Voxeln pi mit p0 = x und pn = y, so dassjedes pi+1 wechselseitig benachbart mit pi im Sinne des oben einge-führten Nachbarschaftsbegriffs ist. Wird jedem Voxel der Menge X
mittels der Funktion f : X→ N der Bezeichner l ∈ N zugewiesen, sodass x ∈ X : f (x) = l gilt, nennt man diesen Vorgang ConnectedComponent Labeling (CCL).
Im nächsten Abschnitt wird nun ein Verfahren vorgestellt, mit dem al-le disjunkten Teilmengen von Ξ bestimmt werden können, indem fürjeden Voxel dieser als Partikel bezeichneten Mengen ein eindeutigerBezeichner zugewiesen wird.
2.1.2 Connected Component Labeling
Aufbauend auf dem Partikelbegriff und der Definition des CCL stelltsich die Frage nach der konkreten Umbesetzung dieses Verfahrens.Connected
Component Labeling Es wird von folgender Situation ausgegangen. Gegeben ist die Dis-kretisierung Ξ einer dispersen Phase eines Partikelsystems. Vorausge-gangen ist also die Diskretisierung durch ein geeignetes Gittersystemund die Trennung des Partikelsystems in die disperse und kontinuier-liche Phase mittels der Indikatorfunktion. Dieser Vorgang wird auchals Segmentierung bezeichnet. Es gilt nun die individuellen Partikelzu identifizieren, die disjunkte zusammenhängende Voxelmengen inΞ bilden. Zahlreiche Algorithmen sind bekannt, die dieses Problemlösen. Im Folgenden wird zunächst das grundlegende Prinzip am Bei-spiel des Multi-Phasen Algorithmus (MP) erläutert. Wie der Namebereits andeutet, muss hier die Eingabemenge mehrfach durchlaufen(gerastert) werden, bevor alle Partikel eindeutig bezeichnet sind. Die

2.1 partikelrekonstruktion 21
Anzahl der Durchläufe ist dabei vorher nicht bekannt und hängt vonder Form der Voxelkonfigurationen ab. Anschließend wird gezeigt,wie dieser Algorithmus durch das Speichern von Äquivalenzklassenoptimiert werden kann, so dass unabhängig von den Eingabedatennur noch zwei Durchläufe nötig sind. Durch die Wahl einer geeig-neten Datenstruktur zum Speichern der Äquivalenzklassen kann li-neares Laufzeitverhalten in Bezug auf die Größe der Eingabemengeerreicht werden. Schließlich wird dieser Algorithmus schrittweise er-weitert, so dass er speziellen Anforderungen des Anwendungsfallsaus Abschnitt 4 genügt.
2.1.2.1 Multi-Phasen Algorithmus
Es folgt die Beschreibung des MP, wie er zum Beispiel von Haralick[50] eingeführt wird. Allerdings wird hier eine modifizierte Versionvorgeschlagen. Statt, wie üblich, auf Binärbildern, wird der Algorith-mus an dieser Stelle für die diskrete Voxelmenge Ξ definiert. Dieseenthält, im Gegensatz zu Binärbildern, keine Voxel der kontinuierli-chen Phase. Unter der Annahme, dass Partikel im Vergleich zu demMaterial, in dem sie eingebettet sind, sehr klein sind, führt dieserSchritt zu einer drastischen Reduzierung des Speicherbedarfs. AlsNachbarschaftskriterium wird exemplarisch die 26er Nachbarschaftbenutzt. Für andere Nachbarschaften muss das Strukturelement ent-sprechend angepasst werden.
Gegeben sei also die diskrete disperse Phase Ξ eines Partikelsystems.Neben den bisherigen Eigenschaften wird von der Menge zusätzlich Lexikographische
Ordnunggefordert, dass sie lexikographisch geordnet ist. Dabei genügen zweiElemente x, y ∈ Ξ mit x = (xi, xj, xk) und y = (yi, yj, yk) der lexiko-graphischen Ordnung x ≤ y genau dann, wenn (xk ≤ yk) ∨ ((xk =
yk)∧ (xj ≤ yj))∨ ((xk = yk)∧ (xj ≤ yj)∧ (xi ≤ yi)) ist. Weiter sei mithΞ eine Datenstruktur gegeben, die jedem Voxel x ∈ Ξ einen Bezeich-ner l ∈ N, geschrieben hΞ(x) ← l , zuordnet. Üblicherweise wird fürhΞ eine Hashtabelle verwendet. Zu Beginn ist hΞ für alle Voxel mit 0initialisiert. Schließlich sei
SEˆ(26) =
(0, 0, 0
) (−1, 0, 0
) (1, −1, 0
)
(0, −1, 0
) (−1, −1, 0
) (0, 0, −1
)
(−1, −1, −1
) (0, −1, −1
) (1, −1, −1
)(8)
(−1, 0, −1
) (1, 0, −1
) (−1, 1, −1
)
(0, 1, −1
) (1, 1, −1
)
das Strukturelement der 26er Nachbarschaft, welches durch die fest-gelegte Verarbeitungsreihenfolge, basierend auf der lexikographi-schen Ordnung, optimiert wurde. Der Algorithmus lautet nun wie inListing 1 angegeben. Die sortierte Voxelmenge Ξ wird Voxel für Vo-

22 einzelpartikelanalyse
Algorithmus 1 Multiphasen Algorithmus.
1: l ← 12: repeat
3: for ∀x ∈ Ξ do
4: N ← NSE ˆ(26)(x)
5: if N = x and hΞ(x) = 0 then
6: hΞ(x)← l, l ← l + 17: else
8: for ∀n ∈ N do
9: hΞ(n)← min∀n∈N
(hΞ(n))
10: end for
11: end if
12: end for
13: until Keine Änderungen in hΞ
xel in lexikographischer Reihenfolge durchlaufen. Für jedes Elementx ∈ Ξ wird überprüft, ob es entsprechend dem Strukturelement Nach-barn in Ξ gibt. Ist dies nicht der Fall, wird ein neuer provisorischerBezeichner in hΞ eingetragen und ein neuer eindeutiger Bezeichnergeneriert. Falls es Nachbarn gibt, wird für jeden dieser Nachbarn derMulti-Phasen
Algorithmus aktuelle Bezeichner auf den minimalen Bezeichner aller Nachbarngesetzt. Der Algorithmus wird solange fortgesetzt, bis keine Ände-rungen in hΞ mehr vorgenommen werden. Dann ist jeder Partikel inΞ mit einem eindeutigen Bezeichner versehen. Die Anzahl der Durch-läufe hängt dabei von der Form der Partikel ab und ist vorher nichtbekannt.
2.1.2.2 Zwei-Phasen Algorithmus
Wie in Abschnitt 2.1.1 beschrieben, ist die Nachbarschaft zwischenVoxeln eine Äquivalenzrelation. Alle Voxel eines Partikels liegen inder gleichen Äquivalenzklasse. Ziel des in diesem Abschnitt beschrie-benen Zwei-Phasen Algorithmus (ZP) ist es, diese Äquivalenzklassenzu bestimmen und dann auf Basis dieser eindeutige Bezeichner zuvergeben. Im Gegensatz zu dem MP, werden bei diesem Algorith-mus lediglich zwei volle Durchläufe der diskreten Voxelmenge benö-tigt. Im ersten Durchgang werden provisorische Bezeichner vergebenund Äquivalenzbeziehungen festgehalten und im zweiten Durchgangdann die finalen Partikel bestimmt. Die Idee dieses Algorithmus gehtdabei auf Rosenfeld und Pfaltz [115] zurück, wobei im Laufe der Zeitzahlreiche Verbesserungen vorgeschlagen wurden. So wurden unteranderem verschiedene Datenstrukturen [127, 52] eingeführt, die dasSpeichern der Äquivalenzklassen in Bezug auf Laufzeitverhalten undSpeicherverbrauch optimieren. Im Folgenden wird eine für dreidi-mensionale Datensätze erweiterte Version des Algorithmus von Wu,

2.1 partikelrekonstruktion 23
Otoo und Suzuki [149] auf Basis von Voxelmengen vorgestellt. DieÄquivalenzklassen werden in einer Datenstruktur Namens Union-Find festgehalten.
Mit der Union-Find Datenstruktur werden disjunkte Partitionen vonMengen verwaltet. Üblicherweise werden drei Operationen, näm-lich make-set(x), union(x,y) und find(x) unterstützt. Die Operationmake-set(x) erstellt eine neue Menge mit einem Element x, wobeix auch gleichzeitig das repräsentative Element der Menge ist. Über Union-Find
Datenstrukturdas repräsentative Element wird später eine disjunkte Partition derMenge identifiziert. Die Operation find(x) liefert das repräsentativeElement derjenigen Menge, die das Element x enthält. Schließlichvereinigt die Operation union(x,y) diejenigen Mengen, die x bezie-hungsweise y als Element enthalten [28]. Das neue repräsentativeElement der Menge wird dabei das kleinste Element der Menge. Mit-tels dieser Datenstruktur werden nun im nachfolgenden Algorithmusdie Äquivalenzbeziehungen von Voxeln auf Basis der vergebenen Be-zeichner verwaltet. Zur Verdeutlichung der Funktionsweise folgt eineinfaches Beispiel. Gegeben sind zwei Mengen B1 = 7, 4, 9, 3 undB2 = 5, 10, 2 von Bezeichnern. Die zu den Bezeichnern zugehöri-gen Voxel liegen also in derselben Äquivalenzklasse. Das repräsen-tative Element von B1 ist gleich 3 und von B2 gleich 2. Es gilt also∀x ∈ B1 : find(x) = 3 beziehungsweise ∀x ∈ B2 : find(x) = 2. Stelltsich nun heraus, dass das Voxel mit dem Bezeichner 4 aus MengeB1 mit dem Voxel mit dem Bezeichner 10 aus der Menge B2 benach-bart ist, dann existiert nach der Definition aus Abschnitt 2.1.1 auchein Pfad zwischen allen anderen Voxeln der Mengen B1 und B2, derkomplett in B1 ∪ B2 liegt. Diese Beziehung wird durch union(4,10)abgebildet. Das neue repräsentative Element von B1 ∪ B2 ist dann 2.Es gilt also ∀x ∈ B1 ∪ B2 : find(x) = 2. Auf die Implementierungdieser drei Operationen soll an dieser Stelle nicht eingegangen wer-den, sondern stattdessen auf den Artikel von Wu, Otoo und Suzuki[149] verwiesen werden, in dem eine detaillierte Beschreibung mitPseudocode der Operationen zu finden ist.
Unter Verwendung der Union-Find Datenstruktur kann nun der ZP,wie in Listing 2 dargestellt, angegeben werden. Zunächst werden Zwei-Phasen
Algorithmusin Phase 1 (Zeile 2) die Voxel mit provisorischem Bezeichner verse-hen und die Äquivalenzen zwischen diesen Bezeichnern erfasst. Da-zu wird die sortierte Voxelmenge Ξ Voxel für Voxel in lexikographi-scher Reihenfolge durchlaufen. Für jedes Element x ∈ Ξ wird über-prüft, ob es entsprechend dem Strukturelement Nachbarn in Ξ gibt.Ist dies nicht der Fall, wird ein neuer provisorischer Bezeichner inhΞ eingetragen und eine neue Menge in der Union-Find Struktur mitdem provisorischen Bezeichner als repräsentatives Element angelegt.Falls aber Nachbarn vorhanden sind, wird für x der minimale Be-zeichner aller Nachbarn in hΞ eingetragen. Da alle Nachbarn von x

24 einzelpartikelanalyse
Algorithmus 2 Zwei-Phasen Algorithmus.
1: procedure TwoPhase(Ξ)2: for ∀x ∈ Ξ do ⊲ Phase 1
3: N ← NSE ˆ(26)(x)
4: if N = x then
5: hΞ(x)← l, l ← l + 16: make-set(hΞ(x))7: else
8: hΞ(x)← min∀n∈N
(hΞ(n))
9: for ∀n ∈ N do
10: union(hΞ(x), hΞ(n))11: end for
12: end if
13: end for
14: for ∀x ∈ Ξ do ⊲ Phase 2
15: hΞ(x)← find(hΞ(x))16: end for
17: return hΞ(x)18: end procedure
in der gleichen Äquivalenzklasse sind, wird diese Beziehung mittelsder Union-Operation in der Union-Find Datenstruktur festgehalten.Sind alle Voxel in Ξ durchlaufen, beginnt Phase 2 (Zeile 14). In dieserPhase werden alle provisorischen Bezeichner durch die zugehörigenrepräsentativen Elemente ersetzt. Bezeichner, die äquivalent zuein-ander sind, werden also auf den gleichen Bezeichner gesetzt. Dazuwird die find-Operation der Union-Find Datensturktur verwendet.Sind alle Voxel durchlaufen, sind die Partikel im Datensatz eindeu-tig bestimmt. Voxel mit dem gleichen Bezeichner gehören zu einemPartikel. Mittels der Hashtabelle hΞ lassen sich dann die Partikel ineinzelne Mengen partitionieren.
2.1.2.3 Modifikationen
Damit steht ein leistungsfähiger Algorithmus zur Verfügung, um Par-tikel nach der Definition aus Abschnitt 2.1.1 zu rekonstruieren. DurchKontinuierliche
Rekonstruktion die Definition des Algorithmus für die diskrete disperse Phase ei-nes Partikelsystems, in der nur während der Segmentierung als ein-deutige Teile eines Partikels identifizierte Voxel enthalten sind, fin-det eine starke Reduktion der Datenmenge statt. Allerdings könnendie rekonstruierten Partikel erst weiterverarbeitet werden, wenn diezweite Phase des Algorithmus komplett abgeschlossen ist. In gewis-sen Anwendungsszenarien kann es aber sinnvoll sein Partikel schonwährend der Datengewinnung kontinuierlich zu rekonstruieren und

2.1 partikelrekonstruktion 25
zu analysieren, insbesondere wenn auf Basis statistischer Auswertun-gen der rekonstruierten Partikel der Bildgewinnungsprozess gesteu-ert werden soll. Beispiele für solche Anwendungsszenarien sind Ver-fahren, bei denen die Bildgewinnung sequentiell erfolgt, wie bei derMRT oder dem sequentiellen, kontinuierlichen Abfräsen und Foto-grafieren von Werkstoffproben. Bei solchen Verfahren kann die Bild-segmentierung und Partikelrekonstruktion zeitlich parallel, um ei-ne Schicht versetzt, zur Bildaufnahme durchgeführt werden. Sobalddann ein Partikel vollständig rekonstruiert ist, werden seine Formund Größe statistisch quantifiziert und in die Menge der auswertba-ren Daten aufgenommen. Auf der anderen Seite ist der ZP nicht effizi-ent, wenn bereits der komplette segmentierte Bilddatensatz vorliegt,in dem die Partikel rekonstruiert werden sollen. So nutzt die präsen- Online Zwei-Phasen
Algorithmustierte Version des Algorithmus nur einen Prozessorkern und schöpftnicht die Möglichkeiten moderner Multiprozessor-Architekturen aus.Für diese beiden Szenarien werden in diesem Abschnitt entsprechen-de Erweiterungen vorgestellt, begonnen mit dem Verfahren zur konti-nuierlichen Rekonstruktion von Partikeln parallel zur Bildaufnahme.Das Verfahren wird als Online Zwei-Phasen Algorithmus (OZP) be-zeichnet.
Der OZP ist nach dem Erzeuger-Verbraucher Muster zu implemen-tieren. Der Erzeuger-Prozess ist die Bildaufnahme und Bildsegmen-tierung, welche die diskrete disperse Phase des Partikelsystems be-stimmt und diese Daten schichtweise an das Ende einer Warteschlan-ge schreibt. Der OZP selbst ist der Verbraucher, der die Daten Schicht Erzeuger-
Verbraucherfür Schicht aus der Warteschlange entgegennimmt und die Nachbar-schaftsbeziehungen zwischen den Voxeln berechnet. Sobald ein Parti-kel als vollständig rekonstruiert erkannt wurde, wird die entsprechen-de Voxelmenge an den nachfolgenden Prozess weitergegeben. Bleibtdie Frage, wie man überprüfen kann, wann ein Partikel vollständigrekonstruiert ist. Folgende Definition wird verwendet. Ein Partikelist vollständig rekonstruiert, wenn es auf der aktuellen Schicht keineVoxel gibt, die mit Voxeln des betrachteten Partikels der vorherigenSchicht benachbart sind. Angenommen der OZP ist bis Schicht t− 1 Vollständig erfasstes
Partikelgelaufen. Ein Partikel, welches bis zu Schicht t− 1 identifiziert wurde,ist eine Menge X ⊂ Ξ von Voxeln, so dass ∀x ∈ X : find(x) = r gilt,wobei r das konstante repräsentative Element des Partikels ist. Wirdnun der Zwei-Phasen Algorithmus für Schicht t fortgesetzt, dann än-dert sich die Anzahl der Voxel, deren Bezeichner auf das repräsen-tative Element r verweisen, nicht, wenn X vollständig erfasst wurde.Um also alle vollständig erfassten Partikel zwischen zwei Schichtenzu detektieren, müssen jeweils die Anzahl aller Voxel mit gleichemrepräsentativen Element der vorherigen Schicht t − 1 und der aktu-ellen Schicht t verglichen werden. Im folgenden Algorithmus wirddie Anzahl der Voxel mit gleichem repräsentativen Element in ei-ner weiteren Hashtabelle, genannt rt−1 für die vorherige und rt, für

26 einzelpartikelanalyse
die aktuelle Schicht, gespeichert. Die Operation comp(rt−1,rt) liefertdann die Menge der repräsentativen Elemente zurück, bei denen sichdie Anzahl der zugehörigen Voxel nicht geändert hat. Um den Al-gorithmus komplett angeben zu können, wird an dieser Stelle nochdie threadsichere Warteschlange mit ihren Operationen definiert. Aufdie konkrete Implementierung wird aber nicht eingegangen, sondernauf die einschlägige Literatur verwiesen [145, 54]. Die Warteschlan-Operationen der
Warteschlange ge, bezeichnet als Q, besitzt folgende Operationen. pop entfernt dasoberste Element der Schlange und gibt dieses zurück. Im Unterschieddazu gibt top das oberste Element nur zurück, ohne es zu entfernen.Schließlich liefert size die Anzahl der Elemente in der Schlange. DerAlgorithmus in Pseudocode ist in Listing 3 abgebildet.
Algorithmus 3 Online Zwei-Phasen Algorithmus.
1: while notdone do
2: if size(Q) < 2 then
3: wait
4: end if
5: Ξt−1 ← pop(Q), Ξt ← top(Q)6: Ξ← Ξ ∪ Ξt
7: for ∀x ∈ Ξt−1 ∪ Ξt do
8: N ← SE(26)x ∩ (Ξt−1 ∪ Ξt)
9: if N = x then
10: hΞ(x)← l, l ← l + 111: make-set(hΞ(x))12: else
13: hΞ(x)← min∀n∈N
(hΞ(n))
14: for ∀n ∈ N do
15: union(hΞ(x), hΞ(n))16: end for
17: end if
18: end for
19: for ∀x ∈ Ξt−1 ∪ Ξt do
20: rt(find(hΞ(x)))← rt(find(hΞ(x))) + 121: end for
22: for ∀r ∈ comp(rt−1,rt) do
23: for ∀x ∈ Ξ do
24: if find(hΞ(x)) = r then
25: hΞ(x)← r26: end if
27: end for
28: end for
29: rt−1 ← rt
30: end while

2.1 partikelrekonstruktion 27
Der Algorithmus läuft so lange, bis der Erzeuger-Prozess ein definier-tes Stop-Signal sendet, mit dem angezeigt wird, dass alle Daten ver-arbeitet sind. Sobald mehr als zwei Schichten in der WarteschlangeQ sind, beginnt das Bestimmen der provisorischen Bezeichner. Dafürwerden zunächst alle Voxel der diskreten dispersen Phase der vor-herigen Schicht, bezeichnet als Ξt−1, und der aktuellen Schicht, be-zeichnet als Ξt, aus der Schlange geladen. Die vorherige Schicht Ξt−1
wird dabei durch die pop Operation aus der Schlange entfernt, sodass im nächsten Durchlauf Ξt zu Ξt−1 wird. Die vollständige dis- Beschreibung des
OZPkrete disperse Phase bis zur aktuellen Schicht ergibt sich aus derVereinigung von Ξ und Ξt, wobei Ξ beim ersten Durchlauf mit derleeren Menge initialisiert ist. Auf Ξt ∪ Ξt−1 wird dann in Zeile 7 bis18 der bereits bekannte ZP aus Abschnitt 2.1.2.2 ausgeführt. Ist die-ser abgeschlossen, wird die Anzahl der Voxel für jedes der bis zumjetzigen Zeitpunkt bestimmten Partikel berechnet und in der Tabellert festgehalten (siehe Zeile 20). Durch den Vergleich mit der Tabelleder vorherigen Schicht rt−1, die beim ersten Durchlauf ebenfalls füralle Bezeichner mit 0 initialisiert ist, werden dann die repräsentati-ven Elemente der vollständig rekonstruierten Partikel bestimmt undschließlich jedem Voxel der fertigen Partikel der finale Bezeichner inhΞ zugewiesen. In der letzten Operation wird die Tabelle rt−1 mitrt überschrieben, und der nächste Durchlauf startet. Die zweite Pha-se des Algorithmus findet also nicht mehr am Ende des komplettenDurchlaufs statt, sondern wird nach jeder Schicht ausgeführt (sieheZeile 19 bis 28). Um den Algorithmus zu beschleunigen, können dieVoxel, die zu einem fertigen Partikel gehören, aus der Menge der zuverarbeiteten Voxel gelöscht werden, so dass in Ξ nur Voxel übrigblei-ben, die zu unfertigen Partikeln gehören.
In einem letzten Szenario, welches im Folgenden betrachtet werdensoll, liegt die diskrete disperse Phase Ξ in Form von n Schichtbildernvor dem Start des Algorithmus vollständig vor. Im Gegensatz zumoben beschriebenen OZP muss der Algorithmus also nicht auf neueDaten warten, sondern kann den kompletten Datensatz auf einmal inden Speicher laden. Dabei macht man sich wieder zunutze, dass nur Paralleler
Zwei-PhasenAlgorithmus
die Voxel der diskreten dispersen Phase Ξ verarbeitet werden müssen.Voxel der kontinuierlichen Phase werden erst gar nicht eingelesen, sodass der Algorithmus auch bei sehr großen Partikelsystemen anwend-bar bleibt. Wenn also im Folgenden von Schichtbildern die Rede ist,sind damit die Voxel der diskreten dispersen Phase gemeint, die ineinem Schichtbild identifiziert und segmentiert wurden. In einem sol-chen Fall lässt sich der ZP stark beschleunigen, indem der gesamteDatensatz Ξ in b + 1 Datenblöcke B0 bis Bb mit jeweils k = n/(b + 1)Schichten aufgeteilt und diese dann parallel verarbeitet werden. Dereigentliche Ablauf des parallelen Zwei-Phasen Algorithmus (PZP) istin Listing 4 grob skizziert. Für jeden Block Bi mit i = 0, . . . , b wirdder normale ZP parallel gestartet (siehe Zeile 2 bis 4) und an der

28 einzelpartikelanalyse
Algorithmus 4 Paralleler Zwei-Phasen Algorithmus.
1: procedure ParallelTwoPhase(B0, . . . , Bb)2: parallel for i← 0, b3: hBi ← TwoPhase(Bi)
4: end parallel for
5: barrier
6: for i← 0, b do
7: hB ← Merge(hB, hBi)
8: end for
9: for i← 1, b do
10: for ∀x ∈ B(i−1)k ∪ Bi0 do
11: N ← SE(26)x ∩ (B(i−1)k ∪ Bi0)
12: for ∀n ∈ N do
13: union(min∀n∈N
(hB(n)), hB(n))
14: end for
15: end for
16: end for
17: for ∀x ∈ ⋃
i=0,...,bBi do
18: hB(x)← find(hB(x))19: end for
20: return hB
21: end procedure
Speicherbarriere gewartet, bis alle Instanzen des Algorithmus been-det sind. Die vorläufigen Ergebnisse hBi mit den eindeutigen Bezeich-nern der Partikel im jeweiligen Block Bi werden dann in eine großeTabelle hB kopiert. Diese Operation wird durch die in Zeile 7 ange-gebene Merge-Operation zusammengefasst. Anschließend wird derZusammenhang zwischen der letzten Schicht B(i−1)k des Blocks Bi−1
und der ersten Schicht Bi0 des Blocks Bi mit i = 1, . . . , b detektiert.Die Äquivalenzen werden in der bereits vorgestellten Union-Find Da-tenstruktur gespeichert (Zeile 9 bis 16). Schließlich werden in einemletzten Schritt die endgültigen Bezeichner für alle Voxel
⋃
i=0,...,b Bi indie Tabelle hB eingetragen.
2.1.3 Laufzeit
Abschließend soll an dieser Stelle die Laufzeit der vorgestellten Ver-fahren empirisch evaluiert werden. Dabei steht besonders der OZPim Fokus, da dieser beim Einsatz zur Steuerung des Bildgewinnungs-prozesses echtzeitfähig sein muss. Stellt sich die Frage, wie Echtzeitin diesem Zusammenhang definiert wird. Wie noch genauer in Ab-schnitten 4.2 und 7.1 besprochen, ist das gesamte Analysesystem,

2.1 partikelrekonstruktion 29
welches im Rahmen dieser Arbeit entwickelt wird, nach dem Pipes-und Filter-Design Muster modelliert. Jede Komponente des Systemsverarbeitet die Ergebnisse der vorherigen Pipeline-Stufe und leitetdas Ergebnis an die nachfolgende Stufe weiter. Jede Stufe besitztdabei eine eigene Warteschlange, in der die Ergebnisse der vorhe-rigen Stufe zwischengespeichert werden, falls der jeweilige Verarbei-tungsschritt noch nicht abgeschlossen ist. Trotz des sequentiellen Auf-baus des Systems laufen die einzelnen Komponenten also parallelzueinander. Dabei führen die einzelnen Komponenten, also die Bild-gewinnung, die Bildsegmentierung, die Datenvorverarbeitung, diedreidimesionale Rekonstruktion, die Klassifizierung und die statis-tische Auswertung, ihre jeweiligen Operationen mit einer Laufzeitvon TRec für die Bildgewinnung, TSeg für die Bildsegmentierung, TPre
für die Vorverarbeitung TCcl für die dreidimensionale Rekonstruk-tion, TClas für die Klassifizierung und TSta für die statistische Aus-wertung durch. Echtzeit bedeutet in diesem Zusammenhang, dass Echtzeit
das Ergebnis für eine Schicht i − 1 spätestens dann vorliegt, wenndie Bildgewinnungsoperation für die nachfolgende Schicht i abge-schlossen ist. Konkret muss also für eine Probe mit n + 1 SchichtenTSegi−1 + TPrei−1 + TCcli−1
+ TClasi−1+ TStati−1 < TReci−1 + TReci für alle
i = 1, . . . , n gelten. Das heißt, dass die Ergebnisse der statistischenAuswertung, auf Basis derer die weitere Vorgehensweise entschiedenwird, spätestens nach Beendigung der Bildgewinnungsoperation derdarauf folgenden Schicht verfügbar sein müssen. Bei zerstörungsfrei-en Bildgewinnungsprozessen, wie beispielsweise der MRT, ist eineVerletzung dieses Kriteriums nicht kritisch, da eine bestimmte Schichterneut verarbeitet werden kann. Bei einem nicht-zerstörungsfreienBildgewinnungsprozess, wie dem Fräsen und Abfotografieren vonWerkstoffproben, wird durch das Einhalten des Echtzeitkriteriumsaber sichergestellt, dass zwischen einer Entscheidung über die wei-tere Vorgehensweise und der Umsetzung dieser Entscheidung nureine Schicht liegt. Im Folgenden wird die Laufzeit der dreidimensio-nalen Rekonstruktion TCcl für den ZP, OZP und PZP untersucht. Dieanderen Komponenten werden in Abschnitt 7.1 analysiert.
Um möglichst reale Bedingungen abzubilden, wurde wie folgt vor-gegangen. Die Messungen wurden anhand von Daten durchgeführt,die im Rahmen des in Abschnittes 4.2 beschriebenen Anwendungs-szenarios gewonnen wurden. Insgesamt 59 Stahlproben wurden auf Simulierte Proben
Verunreinigungen, wie nicht-metallische Einschlüsse oder Gasporen,untersucht und sowohl der durchschnittliche als auch der maxima-le Verunreinigungsgrad ausgerechnet. Der Verunreinigungsgrad istdabei das Verhältnis von Partikelvolumen zu kontinuierlicher Pha-se pro Liter. Diese Werte wurden dann dazu verwendet, den in Ab-schnitt 6.3 beschriebenen Simulator zu parametrisieren, um Probenmit einem leichten, einem mittlerem und einem schweren Verun-reiniungsgrad zu generieren. Die Analyse der Laufzeit erfolgt am

30 einzelpartikelanalyse
Beispiel dieser synthetischen Proben. Der durchschnittliche und ma-ximale Verunreinigungsgrad der 59 Proben beträgt 66.51 mm3 L−1
und 131.49 mm3 L−1. Diese Werte wurden jeweils zur Simulationder Proben mit leichtem und mittlerem Verunreinigungsgrad ver-wendet. Für die Probe mit einer extremen Verunreinigung wurdedas doppelte des maximal gemessenen Verunreinigungsgrades, also229.01 mm3 L−1, angenommen. Alle simulierten Proben haben eineDimension von 244 mm × 100 mm × 10 mm, wobei für das bei derDiskretisierung gewählte Gittersystem δ1 = 20 µm, δ2 = 20 µm undδ3 = 10 µm angenommen wurde. Gemessen wurde bei den Algo-rithmen die durchschnittliche Laufzeit pro Schicht in Millisekunden.Da beim ZP und beim PZP das Messen der Laufzeit pro Schichtnicht direkt möglich ist, wurde die Gesamtlaufzeit gemessen unddurch die Anzahl der Schichten geteilt. Beim OZP hingegen wurdedie Laufzeit pro Schicht gemessen und dann über alle Schichten ge-mittelt. Für den PZP wurde die Messung jeweils mit 2, 8 und 16
Threads wiederholt. Alle Messungen wurden auf einem TestsystemLaufzeitergebnis
mit Intel Xeon CPU E5-2680 mit jeweils acht 2.70 GHz Kernen und64 Gigabyte Arbeitsspeicher durchgeführt. Tabelle 1 fasst die Ergeb-
Tabelle 1.: Laufzeiten der CCL-Algorithmen.
Grad ZP PZP2 PZP8 PZP16 OZP
Schwach 64.10 ms 38.11 ms 16.47 ms 15.91 ms 1115.69 msMittel 134.20 ms 78.92 ms 34.69 ms 35.86 ms 1237.06 msStark 242.41 ms 142.36 ms 58.94 ms 60.72 ms 2734.59 ms
nisse zusammen. Dabei gibt „Grad“ den Grad der Verunreinigungan, wobei „Schwach“ der ersten, „Mittel“ der zweiten und „Stark“der dritten Probe entspricht. Man sieht, dass der OZP ca. 10 mallangsamer ist als der normale ZP. Wie bereits erwähnt, liegt es vorallem daran, dass die eigentliche zweite Phase des Algorithmus nachjeder Schicht durchlaufen werden muss, um die komplett rekonstru-ierten Defekte zu detektieren (siehe Algorithmus 3 Zeile 19 bis 28).Trotzdem liegt die Laufzeit pro Schicht bei der stark verschmutz-ten Probe für den OZP immer noch unter 3000 ms. Schaut man sichdie Laufzeit aller 1000 Schichten des OZPs an (siehe Abbildung 1),sieht man, dass die Laufzeiten pro Schicht für die stark verunrei-nigte Probe mit einer Standardabweichung von ca. 500 ms um einenWert von ca. 2700 ms schwanken. Dabei wird für keine Schicht eineLaufzeit von 3500 ms überschritten. Unter den gegebenen Umständenkann die Laufzeit des TOzp also, wenn man konservativ vorgeht undeinen Sicherheitspuffer berücksichtigt, auf das Doppelte der maxima-len Laufzeit für die Verarbeitung einer Schicht bei der Probe mit ex-tremem Verunreinigungsgrad gesetzt werden. Es ergibt sich ein Wertvon TOzp = 7000 ms.
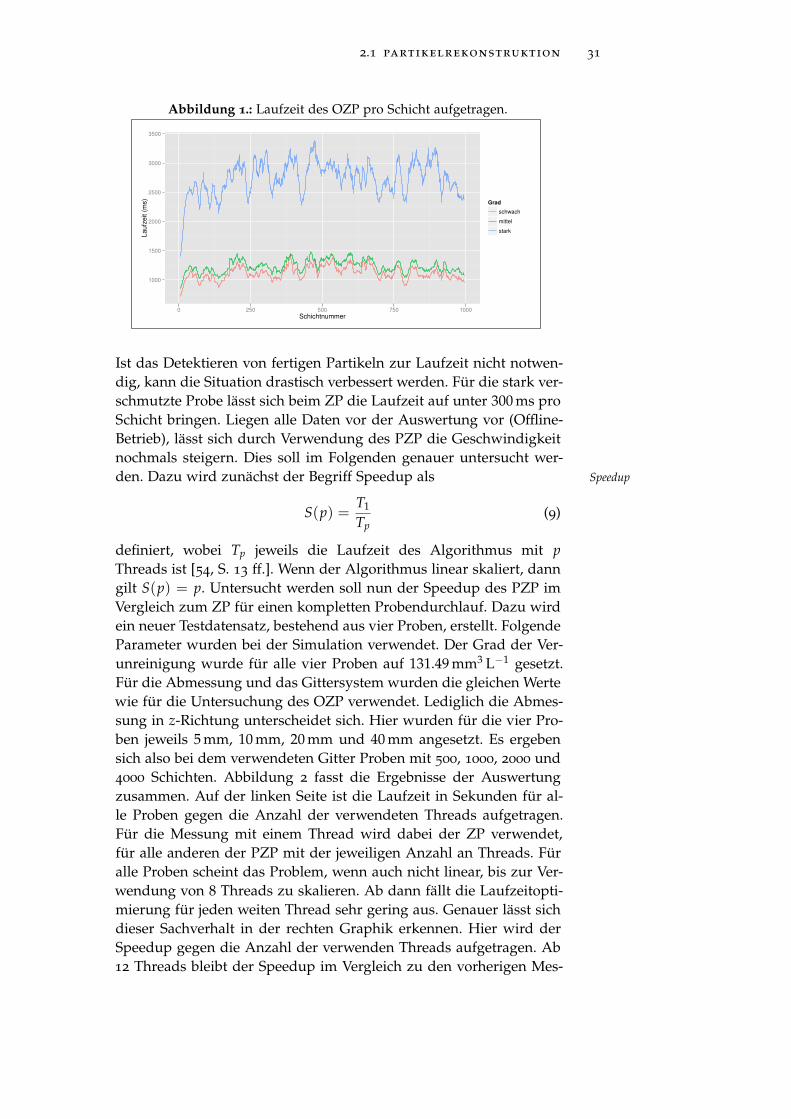
2.1 partikelrekonstruktion 31
Abbildung 1.: Laufzeit des OZP pro Schicht aufgetragen.
1000
1500
2000
2500
3000
3500
0 250 500 750 1000
Schichtnummer
Laufz
eit (
ms)
Grad
schwach
mittel
stark
Ist das Detektieren von fertigen Partikeln zur Laufzeit nicht notwen-dig, kann die Situation drastisch verbessert werden. Für die stark ver-schmutzte Probe lässt sich beim ZP die Laufzeit auf unter 300 ms proSchicht bringen. Liegen alle Daten vor der Auswertung vor (Offline-Betrieb), lässt sich durch Verwendung des PZP die Geschwindigkeitnochmals steigern. Dies soll im Folgenden genauer untersucht wer-den. Dazu wird zunächst der Begriff Speedup als Speedup
S(p) =T1
Tp(9)
definiert, wobei Tp jeweils die Laufzeit des Algorithmus mit pThreads ist [54, S. 13 ff.]. Wenn der Algorithmus linear skaliert, danngilt S(p) = p. Untersucht werden soll nun der Speedup des PZP imVergleich zum ZP für einen kompletten Probendurchlauf. Dazu wirdein neuer Testdatensatz, bestehend aus vier Proben, erstellt. FolgendeParameter wurden bei der Simulation verwendet. Der Grad der Ver-unreinigung wurde für alle vier Proben auf 131.49 mm3 L−1 gesetzt.Für die Abmessung und das Gittersystem wurden die gleichen Wertewie für die Untersuchung des OZP verwendet. Lediglich die Abmes-sung in z-Richtung unterscheidet sich. Hier wurden für die vier Pro-ben jeweils 5 mm, 10 mm, 20 mm und 40 mm angesetzt. Es ergebensich also bei dem verwendeten Gitter Proben mit 500, 1000, 2000 und4000 Schichten. Abbildung 2 fasst die Ergebnisse der Auswertungzusammen. Auf der linken Seite ist die Laufzeit in Sekunden für al-le Proben gegen die Anzahl der verwendeten Threads aufgetragen.Für die Messung mit einem Thread wird dabei der ZP verwendet,für alle anderen der PZP mit der jeweiligen Anzahl an Threads. Füralle Proben scheint das Problem, wenn auch nicht linear, bis zur Ver-wendung von 8 Threads zu skalieren. Ab dann fällt die Laufzeitopti-mierung für jeden weiten Thread sehr gering aus. Genauer lässt sichdieser Sachverhalt in der rechten Graphik erkennen. Hier wird derSpeedup gegen die Anzahl der verwenden Threads aufgetragen. Ab12 Threads bleibt der Speedup im Vergleich zu den vorherigen Mes-
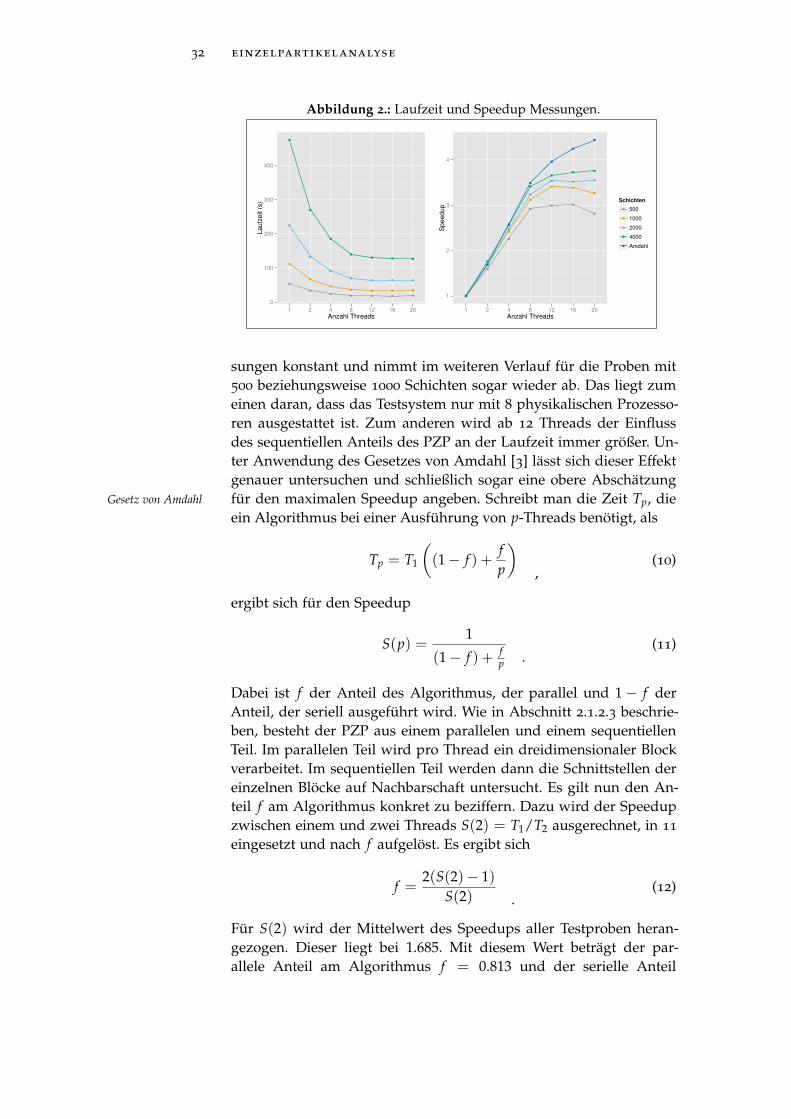
32 einzelpartikelanalyse
Abbildung 2.: Laufzeit und Speedup Messungen.
0
100
200
300
400
1 2 4 8 12 16 20
Anzahl Threads
Laufz
eit (
s)
1
2
3
4
1 2 4 8 12 16 20
Anzahl Threads
Speedup
Schichten
500
1000
2000
4000
Amdahl
sungen konstant und nimmt im weiteren Verlauf für die Proben mit500 beziehungsweise 1000 Schichten sogar wieder ab. Das liegt zumeinen daran, dass das Testsystem nur mit 8 physikalischen Prozesso-ren ausgestattet ist. Zum anderen wird ab 12 Threads der Einflussdes sequentiellen Anteils des PZP an der Laufzeit immer größer. Un-ter Anwendung des Gesetzes von Amdahl [3] lässt sich dieser Effektgenauer untersuchen und schließlich sogar eine obere Abschätzungfür den maximalen Speedup angeben. Schreibt man die Zeit Tp, dieGesetz von Amdahl
ein Algorithmus bei einer Ausführung von p-Threads benötigt, als
Tp = T1
(
(1− f ) +fp
)
,(10)
ergibt sich für den Speedup
S(p) =1
(1− f ) + fp .
(11)
Dabei ist f der Anteil des Algorithmus, der parallel und 1− f derAnteil, der seriell ausgeführt wird. Wie in Abschnitt 2.1.2.3 beschrie-ben, besteht der PZP aus einem parallelen und einem sequentiellenTeil. Im parallelen Teil wird pro Thread ein dreidimensionaler Blockverarbeitet. Im sequentiellen Teil werden dann die Schnittstellen dereinzelnen Blöcke auf Nachbarschaft untersucht. Es gilt nun den An-teil f am Algorithmus konkret zu beziffern. Dazu wird der Speedupzwischen einem und zwei Threads S(2) = T1/T2 ausgerechnet, in 11
eingesetzt und nach f aufgelöst. Es ergibt sich
f =2(S(2)− 1)
S(2) .(12)
Für S(2) wird der Mittelwert des Speedups aller Testproben heran-gezogen. Dieser liegt bei 1.685. Mit diesem Wert beträgt der par-allele Anteil am Algorithmus f = 0.813 und der serielle Anteil

2.2 gestaltanalyse 33
1− f = 0.187. Der maximale theoretische Speedup beträgt also, wenndie Anzahl der Threads p gegen unendlich läuft,
limp→∞
S(p) =1
(1− f ) + fp
=1
(1− f )
=1
0.187= 5.346 .
In Abbildung 2 ist in der rechten Graphik der theoretische Speedup Maximaler Speedup
für die ersten 20 Threads zusätzlich eingezeichnet (Amdahl). Mankann gut erkennen, dass ab ca. 12 Threads bei einem Speedup von4 eine Sättigung stattfindet. Dieses Verhalten deckt sich mit dem Ver-halten der Messdaten.
2.2 gestaltanalyse
Nachdem im vorherigen Abschnitt gezeigt wurde, wie einzelne Par-tikel innerhalb der diskreten Phase eines Partikelsystems detektiertund rekonstruiert werden können, sollen nun statistische Merkmaleeingeführt werden, mit denen sich die Form und Größe dieser Parti-kel quantifizieren lassen. Diese Merkmale werden im Folgenden alsGestaltdeskriptoren oder auch einfach nur als Deskriptoren bezeich-net.
Allgemein sind Gestaltdeskriptoren mathematische Funktionale, diespezifische Eigenschaften eines Partikels in numerische Werte über-führen. Je nachdem, welche Eigenschaften erfasst werden und für Klassen von
Deskriptorenwelche Dimension die Deskriptoren definiert sind, kann man sie inverschiedene Klassen unterteilen. Man unterscheidet grob zwischenDeskriptoren, die auf zweidimensionalen und solchen, die auf drei-dimensionalen Partikeln definiert sind. Die Untersuchung von zwei-dimensionalen Deskriptoren hat dabei eine lange wissenschaftlicheTradition, und zahlreiche Veröffentlichungen sind zu dem Thema er-schienen. Einen Überblick über die verschiedenen Verfahren liefernBeddow [14] und Zhang und Lu [151]. Die Gestaltanalyse von drei-dimensionalen Partikeln ist hingegen eine jüngere wissenschaftlicheDisziplin. Erst mit dem Aufkommen von leistungsfähigeren volume-trischen bildgebenden Verfahren, wie dem CT oder der MRT, istdas Interesse an diesen Techniken gestiegen. Eine ausführliche Zu-sammenfassung der gängigen Verfahren ist in der Dissertation vonMartinues-Ortiz [89, S. 22 ff.] und dem Artikel von Kazmi, You undZhang [69] zu finden. Abgesehen von der Dimensionalität kann man

34 einzelpartikelanalyse
Gestaltdeskriptoren auch dadurch unterscheiden, ob bei der Berech-nung die Kontur oder aber die gesamte Region des Partikels berück-sichtigt wird [151]. Dabei sind konturbasierte Methoden in der Regelsensibler für kleine Änderungen. Sie sind also besser dafür geeig-net, kleine Variationen der Form zu detektieren. Im Gegensatz dazusind regionbasierte Verfahren robuster und weniger anfällig für Rau-schen. Im zweidimensionalen Fall wird die Kontur als Rand und dieRegion als Innengebiet bezeichnet, während man im dreidimensio-nalen Fall von Oberfläche und Volumen spricht. Nach Zhang undLu [151] lässt sich diese Unterteilung noch weiter verfeinern, indemman einbezieht, ob die Form als Ganzes untersucht wird, oder mandie Partikel in Primitive aufteilt, über die dann jeweils distinktive De-skriptoren berechnet werden. Solche Deskriptoren werden als globalebeziehungsweise strukturelle Deskriptoren bezeichnet.
In der vorliegenden Arbeit werden ausschließlich dreidimensionaleDeskriptoren beschrieben, wobei diese sowohl in der globalen alsauch in der strukturellen Variante vorkommen. Es wird also impli-Invariant bezüglich
Translation zit davon ausgegangen, dass alle betrachteten Partikel eine dreidi-mensionale räumliche Ausdehnung haben. Alle Deskriptoren sollenzudem invariant bezüglich Translation sein. Das heißt, dass der Wertdes Deskriptors nicht von der Lage des Partikels im Raum abhängt.Erst dadurch wird es möglich, Deskriptoren verschiedener Partikelzu vergleichen. Teilweise sind die vorgestellten Deskriptoren sogarinvariant bezüglich der Rotation und der Skalierung. Die Ausrich-tung im Raum und die Größe des Partikels beeinflussen den Wertdes Deskriptors also nicht. In manchen Fällen können aber Ausrich-tung und Größe des Partikels selbst wichtige Charakteristika zumKlassifizieren darstellen. Deshalb werden diese Eigenschaften nichtstrikt gefordert. Alle Deskriptoren werden dabei auf Basis diskreterVoxelmengen berechnet. Eine Umwandlung in andere Primitiven, wieDreiecksnetze, findet nicht statt. Dadurch wird zum einen der Effizi-enzverlust durch die Transformation vermieden und zum anderenkein zusätzlicher Fehler durch einen weiteren Diskretisierungsschritteingeführt. Im Folgenden wird zunächst mit der Definition einigereinfacher Deskriptoren begonnen. Anschließend werden die Minkow-skifunktionale eingeführt. Dabei handelt es sich um ein Satz von be-wegungsinvarianten, additiven und stetigen Funktionalen, mit denensich alle Funktionale mit diesen Eigenschaften als Linearkombinati-on darstellen lassen. Die Minkowskifunktionale sind Berechnungs-grundlage weiterer Deskriptoren, wie beispielsweise der Spherizität.Abschließend werden die Konvexivität, die zentralen Momente undder Begriff der fraktalen Dimension definiert und passende Metho-den zur Berechnung vorgestellt. Diese Deskriptoren haben sich alsbesonders wirksam erwiesen, um Artefakte und Risse, die im eigent-lichen Sinne keine Partikel darstellen, zu klassifizieren. In den nach-

2.2 gestaltanalyse 35
folgenden Ausführungen ist X ⊂ Ξ eine Menge von Voxeln, welcheder Partikeldefinition aus Abschnitt 2.1.1 genügt.
2.2.1 Boundingbox
Die Boundingbox eines Partikels X bezeichnet das minimale, achsen-parallele Rechteck, das alle Punkte in X einschließt. Die Boundingboxeines Partikels X wird in der vorliegenden Arbeit durch die beidenEckpunkte BBXmin = (imin, jmin, kmin) und BBXmax = (imax, jmax, kmax)
angegeben, wobei BBXmin und BBXmax so gewählt sind, dass für∀(i, j, k) ∈ X die Ungleichungen imin ≤ i ≤ imax, jmin ≤ j ≤ jmax
und kmin ≤ k ≤ kmax erfüllt sind. Die inneren Punkte der Bounding- Boundingbox
box ergeben sich dann aus dem kartesischen Produkt der Intervalle
BBX = [imin, imax]× [jmin, jmax]× [kmin, kmax].
(13)
Die Boundingbox an sich eignet sich nicht als Deskriptor, da sievon der Position des Partikels im Raum abhängt. Allerdings kannman anhand der Achsenlängen der Boundingbox einfache Informa-tionen über die Form des Partikels ableiten. Dazu bestimmt man zu-nächst die minimale und maximale Koordinatenachse der Bounding-box durch
Wx = min((imax − imin)δ1, (jmax − jmin)δ2, (kmax − kmax)δ3)
Wz = max((imax − imin)δ1, (jmax − jmin)δ2, (kmax − kmin)δ3).
Ein einfacher globaler Deskriptor, der auch als Walz-Deskriptor be-kannt ist, kann dann durch
Wxz =Wx
Wz, Wyz =
Wy
Wz(14)
angegeben werden, wobei Wy die Länge der mittleren Achse ist. An-hand der beiden Achsenverhältnisse Wxz und Wyz kann nun die un-gefähre Form des Partikels abgeschätzt werden. Sind beispielsweise Walz-Deskriptor
Wxz = Wyz ≈ 1 ist dies ein Hinweis auf ein regelmäßiges oder ku-gelförmiges Partikel [132, S. 18][141]. Anzumerken ist, dass der De-skriptor nicht rotationsinvariant ist, da die Ausrichtung des Partikelsinnerhalb der Boundingbox maßgeblich die Länge der Achsen beein-flusst. Deshalb wird in der vorliegenden Arbeit eine abgewandelteForm dieses Deskriptors verwendet. Statt das Verhältnis der Achsender Boundingbox wird das Verhältnis der Hauptachsen verwendet(siehe Abschnitt 2.2.4).

36 einzelpartikelanalyse
2.2.2 Konfigurationshistogramme
Bis jetzt wurden Partikel als diskrete verbundene Voxelmengen be-trachtet. Im Folgenden ist es jedoch hilfreich, das Partikel X als dis-krete Funktion bX : Z
3 → 0, 1 zu beschreiben. Dabei istDiskreteBildfunktion
bX(i, j, k) =
1 für (i, j, k) ∈ X
0 für (i, j, k) /∈ X(15)
mit (i, j, k) ∈ L3.
Auf Basis dieser Definition lässt sich ein weiterer einfacher struktu-reller Deskriptor entwickeln, nämlich das sogenannte Voxelkonfigu-rationshistogramm. Bei diesem Deskriptor werden die Anzahl derKonfigurationshisto-
gramm 256 verschiedenen möglichen Konfigurationen von 2 × 2 × 2 Voxel-blöcken in einem Partikel gezählt. Die Verwendung dieser Konfigura-tionshistogramme als Gestaltdeskriptoren wurde unter anderen vonIvanko und Perevalov [65] vorgeschlagen. Bei der Berechnung wirdhier das von Ohser und Mücklich [98, S. 111 ff.] eingeführte Verfahrenzur Codierung der Konfigurationen als binäre Zeichenkette verwen-det. Dabei wird die 2× 2× 2 Nachbarschaft eines Voxels (i, j, k) ∈ X
durch
gi,j,k =20bX(i, j, k) + 21bX(i + 1, j, k) + 22bX(i, j + 1, k)+
23bX(i + 1, j + 1, k) + 24bX(i, j, k + 1)+
25bX(i + 1, j, k + 1) + 26bX(i, j + 1, k + 1)+ (16)
27bX(i + 1, j + 1, k + 1)
beschrieben. Das Histogramm h(256)l mit l = 0, . . . , 255 für die 256
verschiedenen Konfigurationsmöglichkeiten kann dann durch
h(256)l =
imax
∑i=imin−1
jmax
∑j=jmin−1
kmax
∑k=kmin−1
ξl(gi,j,k) (17)
berechnet werden, wobei
ξl(gi,j,k)
1 für gi,j,k = l
0 für gi,j,k 6= l(18)
ist. Abbildung 3 zeigt die Kodierung am Beispiel der Elementarzelle.
Im Falle eines kubisch primitiven Gittersystems können die 256 mög-lichen Konfigurationen auf 22 symmetrische Fälle reduziert werden.Reduziertes Konfigu-
rationshistogramm Sei dazu M die Menge der isometrischen Abbildungen (Translation,Rotation, Reflektion), welche das Gittersystem L
3 nicht verändern.Weiter definiert man mit D0, . . . , D21 die 22 Kongruenzklassen für die

2.2 gestaltanalyse 37
Abbildung 3.: a) Binärcodierung der 2 × 2 × 2 Konfiguration. b) Bei-spielkonfiguration für l = 92. Voxel, die zu einem Parti-kel gehören, sind als schwarze Kreise dargestellt.
24 25
20 21
26 27
22 23
a) b)
256 verschiedenen Konfigurationen l unter M. Eine Konfiguration list genau dann Element der Kongruenzklasse Dj, wenn es ein T ∈ Mgibt, so dass T l = nj ist. Dabei ist nj ein repräsentatives Element derKlasse Dj. Als repräsentatives Element wird im Folgenden die Kon-figuration mit der kleinsten Codierung gewählt. Listing 5 skizzierteinen Algorithmus, um eine Tabelle der 22 Klassen und ihrer Elemen-te zu generieren. Dabei werden für jede mögliche Konfiguration alleisometrischen Abbildungen durchgeführt und die Äquivalenzen mit-tels der in Abschnitt 2.1.2.2 definierten union-Operation gespeichert.Die Operation find(l) liefert dann das repräsentative Element der zu lzugehörigen Klasse zurück. Im Anhang sind zwei Tabellen zu finden,in denen alle 22 Klassen und ihre Elemente aufgeführt sind. In Tabel-le 13 sind die Konfigurationen mit ihren numerischen Codierungendargestellt, während in Tabelle 14 die Darstellung über Piktogrammenach dem Schema aus Abbildung 3 b) erfolgt. Die Ergebnisse stim-men mit denen von Ohser und Schladitz [99, S. 49 ff.] und Toriwakiund Yoshida [138, S. 86 ff.] überein, wobei dort nur die repräsentati-ven Elemente aufgelistet sind und nicht die Elemente der Menge Dj
selbst. Mittels der angeführten Tabellen kann nun das Histogramm
Algorithmus 5 Generiert Tabelle mit allen 22 Kongruenzklassen undihren Elementen.
1: procedure configurationLookupTable
2: for l ← 0, 255 do
3: for ∀T ∈ M do
4: Union(l, T l)5: end for
6: end for
7: end procedure

38 einzelpartikelanalyse
h(256)l eines Partikels X auf das Histogramm h(22)
l mit 22 Elementendurch simples Nachschlagen reduziert werden. Dieses eignet sich aufGrund der geringeren Dimension besser zum Klassifizieren.
Die eigentliche Idee bei diesem Deskriptor besteht nun darin, dasssich spezifische Eigenschaften der Oberfläche eines Partikels durchentsprechend starke Ausprägungen bestimmter Voxelkonfiguratio-nen im Histogramm niederschlagen. Bei sehr porösen Partikeln mitrauer Oberfläche sind beispielsweise mehr Konfigurationen mit dia-gonalen Voxelbelegungen zu erwarten als bei kompakten, kugelför-migen Partikeln. Darüber hinaus werden die Histogramme im nächs-ten Abschnitt dazu verwendet die Minkowskifunktionale zu berech-nen.
2.2.3 Minkowskifunktionale
In diesem Abschnitt werden die Minkowskifunktionale eingeführt.Zunächst werden sie für die Menge der konvexen Körper anhandder Steiner-Formel definiert. Anschließend erfolgt die Erweiterungauf den konvexen Ring.
Dazu betrachtet man zunächst folgendes Beispiel. Gegeben sei einWürfel C der Kantenlänge a im dreidimensionalen Raum. Setzt mannun den Mittelpunkt m des Balls
br = y ∈ R3 : ‖y−m‖ ≤ r (19)
mit Radius r auf jeden Punkt des Würfels C und bildet die Vereini-gung aller Punkte durch
Cr = C⊕ br = x + y : x ∈ C, y ∈ br,
(20)
dann ergibt sich die parallele Menge Cr. Dabei wird die OperationParallele Menge
⊕ Minkowski-Summe genannt. Das Volumen V(Cr) von Cr lässt sichdann durch
V(Cr) = a3 + 6a2r + 3aπr2 +4π
3r3
,(21)
also der Summe aus dem Volumen des ursprünglichen Würfels, dersechs Quader mit Dicke r über die Seitenflächen, der drei Zylinderüber jeweils vier gegenüberliegenden Kanten mit der Grundflächeπr2 und Höhe h und der acht Kugelausschnitte an den Ecken be-rechnen. Mit gewissen Einschränkungen lässt sich das Ergebnis aufbeliebige Mengen K ∈ R
3 verallgemeinern. Man kann zeigen, dassfür eine parallele Menge Kr ∈ R
3 einer Menge K das Volumen Vdurch
V(Kr) = V(K) + S(K)r + 2πB(K)r2 +4π
3r3 (22)

2.2 gestaltanalyse 39
berechnet werden kann, wobei V(K) das Volumen, S(K) die Oberflä-che und B(K) die mittlere Breite von K ist [94]. Stellt sich die Frage,wie die Restriktionen für die Menge K konkret aussehen. Gleichung22 gilt für alle konvexen, beschränkten und abgeschlossenen Mengenin R
3, deren Inneres nicht leer ist. Dabei ist eine Menge konvex, wenn Konvexe Menge
das Liniensegment zweier beliebiger Punkte dieser Menge selbst inder Menge liegt. Eine Menge mit solchen Eigenschaften bezeichnetman auch als konvexen Körper. Für die Menge aller konvexen Körperwird im Folgenden K geschrieben. Bis jetzt wurde nur der dreidimen-sionale Fall betrachtet. Formel 22 lässt sich aber für beliebige Dimen-sionen d ≥ 0 erweitern. Das d-dimensionale Volumen V(d) für einenparallelen Körper Kr mit Radius r eines konvexen Körpers K ∈ K istnämlich durch die sogenannte Steiner-Formel gegeben [47, S. 214]. Es Steiner-Formel
gilt
V(d)(Kr) =d
∑v=0
(dv
)
W(d)v (K)rv
,(23)
wobei W(d)v (K) die sogenannten Minkowskifunktionale oder auch
Quermaßintegrale sind. Für 0 < d ≤ 3 sind diese in Tabelle 2 aufge-führt. Wie man erkennen kann, entsprechen die Minkowskifunktio-nale bis auf einen konstanten Proportionalitätsfaktor bis zur drittenDimension bekannten Maßen, wie dem Volumen, der Oberfläche, derLänge, dem Flächeninhalt und der mittleren Breite. Minkowskifunktio-
nale
Tabelle 2.: Minkowskifunktionale bis zur dritten Dimension. Dabei istV das Volumen, S die Oberfläche, L die Länge, A die Flä-cheninhalt, U der Umfang, B die mittlere Breite und χ dieEuler-Charakteristik (siehe von Formel 26 ) von K
d = 3 d = 2 d = 1 d = 0
W(3)0 (K) = V(K) W(2)
0 (K) = A(K) W(1)0 (K) = L(K) W(0)
0 (K) = χ(K)
W(3)1 (K) = 1
3 S(K) W(2)1 (K) = 1
2 U(K) W(1)1 (K) = 2χ(k)
W(3)2 (K) = 2π
3 B(K) W(2)2 (K) = πχ(K)
W(3)3 (K) = 4π
3 χ(K)
Nach Hadwiger [47, S. 221 ff.] gelten für die Minkowskifunktiona-le folgende wichtige Eigenschaften, die im sogenannten Vollständig-keitssatz zusammengefasst sind. Sei ϕ eine über die Klasse K der Vollständigkeitssatz
konvexen Körper definierte Funktion, welche jedem Körper K ∈ K
eine reelle Zahl ϕ(K) zuordnet. Sind für ϕ folgende Eigenschaftenerfüllt:
• Bewegungsinvariant: ϕ(T K) = ϕ(K), wobei T K mit T ∈ Mdem beliebig bewegten Körper entspricht,
• Stetig: Für eine Sequenz von kompakten Mengen Ki ist ϕ
stetig, wenn der Abstand im Sinne der Hausdorff Distanz zwi-schen Ki und K gegen 0 läuft, falls i→ ∞,

40 einzelpartikelanalyse
• C-additiv: ϕ(K1 ∪ K2) = ϕ(K1) + ϕ(K2) − ϕ(K1 ∩ K2) mitK1, K2 ∈ K und K1 ∪ K2 ∈ K,
dann gilt
ϕ(K) =d
∑v=0
avW(d)v (K) (24)
mit passenden Koeffizienten für av ∈ R. Das heißt jedes bewegungs-invariante, C-additive und stetige Funktional ϕ lässt sich durch d + 1Linearkombinationen der Minkowskifunktionale darstellen. Für einkonvexes Partikel muss also nach dem Berechnen der d + 1 Funktio-nale auf nicht-additive beziehungsweise bewegungsabhänige Funk-tionale gewechselt werden, um weitere Charakteristiken des Partikelszu erfassen. Leider ist ein Partikel in der Praxis nicht zwangsläufigkonvex, so dass das Ergebnis in der jetzigen Form wenig brauchbarist. Es hat sich aber gezeigt, dass sich der Funktionalsatz auf den kon-vexen Ring erweitern lässt. Der konvexe Ring K ist dabei die KlasseKonvexer Ring
aller Teilmengen A ⊂ Rd, die sich als Vereinigung endlich vieler kon-
vexer Körper
A =n⋃
i=1
Ki (25)
mit Ki ∈ K darstellen lassen. Partikel sind im Sinne der Definitionaus Abschnitt 2.1.1 Elemente des konvexen Rings, da sie eine endli-che Vereinigung konvexer Körper, nämlich der Voxel, darstellen. DerFunktionalsatz kann also angewendet werden, wenn die Erweiterungauf den konvexen Ring gelingt. Diese soll im Folgenden vorgenom-men werden.
Dazu wird zunächst die Euler-Charakteristik χ(K) für einen konve-xen Körper K als
χ(K) =
1 für K 6= ∅
0 für K = ∅(26)
definiert. Es lässt sich nun zeigen, dass die Euler-Charakteristik einEuler-Charakteristik
additives, bewegungsinvariantes Funktional über den konvexen RingK ist (siehe Existenzbeweis Hadwiger [47, S. 237 ff.]). Unter Ausnut-zung der Additivitäts-Eigenschaft kann die Euler-Charakteristik mit-tels des Prinzips von Inklusion und Exklusion für ein Element A ∈ K
explizit durch
χ(A) =m
∑i=1
χ(Ki)−m−1
∑i=1
m
∑j=i+1
χ(Ki ∩ Kj) + . . .
+ (−1)m+1χ(m⋂
i=1
Ki)
(27)
berechnet werden. Die übrigen Minkowskifunktionale lassen sich aufErweiterung aufkonvexen Ring

2.2 gestaltanalyse 41
Basis der Euler-Charakteristik für A ∈ K als
W(d)v (A) =
∫
Gχ(A ∩ gEv)dg v = 0, . . . , d− 1 (28)
W(d)d (A) = wdχ(A) wd =
πd/2
Γ(1 + d2 )
einführen, wobei Ev die v-dimensionale Ebene im Rd, dg die kinema-
tische Dichte [119, S. 256 ff.] und Γ die Eulersche Gammafunktion ist,welche zur Berechnung des d-dimensionalen Volumens wd der Ein-heitskugel verwendet wird. Die Integration erfolgt über alle Elemen-te der Gruppe G der Rotationen und Translationen. Die Additivitätwird von χ an die übrigen Minkowskifunktionale vererbt. Es gilt also
W(d)v (A) =
m
∑i=1
W(d)v (Ki)−
m−1
∑i=1
m
∑j=i+1
W(d)v (Ki ∩ Kj) + . . .
+ (−1)m+1W(d)v (
m⋂
i=1
Ki).
(29)
Damit sind die Minkowskifunktionale für den konvexen Ring defi-niert und die Grundlagen für die Berechnung eben dieser Funktiona-le für Voxelmengen geschaffen. Wie bereits erwähnt, kann ein Partikelals endliche Vereinigung von k konvexen Körpern Ki mit i = 1, . . . , kaufgefasst werden, wobei jeder Körper Ki ein Voxel des Partikels ist.Für einen einzelnen Voxel in einem kubisch primitiven Gittersystemsind die Minkowskifunktionale bekannt und lassen sich somit unterAusnutzung der Additivitätseigenschaft und Formel 29 für das ge-samte Partikel ausrechnen. Diese Vorgehensweise ist allerdings sehrmühsam, da die Anzahl der Terme in Formel 29 selbst für kleine Par-tikel schnell sehr groß wird. Da im Folgenden die Minkowskifunk-tionale aber nur für Partikel auf Gittersystemen ausgerechnet wer-den sollen, ist es einfacher, zunächst die Voxel der dispersen Phaseselbst in disjunkte Teilmengen zu zerlegen. Jeder Voxel eines kubischprimitiven Gittersytems kann als die Vereinigung seiner disjunktenEcken S0, offenen Kanten S1, offenen Flächen S2 und Inneren S3 auf-gefasst werden [84]. Allgemein wird Sn mit n = 0, . . . , 3 auch als das Simplex
n-dimensionale Simplex bezeichnet. Nach Bieri und Nef [15] gilt nunfür die Euler-Charakteristik des n-dimensionalen Simplex
χ(Sn) = (−1)n
.(30)
Die übrigen Minkowskifunktionle lassen sich dann wegen Formel 28
und der Additivitätseigenschaft durch
W(d)v (Sn) = (−1)d+n+v (
v+nd )
(v+nn )
wv (31)

42 einzelpartikelanalyse
angeben, wobei wv das v-dimensionale Volumen der Einheitskugel ist[15]. Zerlegt man also ein Partikel in seine n-dimensionalen Simplexe,können seine Minkowskifunktionale durch
W(d)v (X) =
3
∑n=0
W(d)v (Sn)N(n)(X) (32)
berechnet werden, wobei N(n)(X) die Anzahl der n-dimensionalen
Simplexe im Partikel X angibt. Das Volumen V(X), die OberflächeS(X), die mittlere Breite B(X) und die Euler-Charakteristik χ(X) desPartikels X ergeben sich schließlich unter Berücksichtigung der Pro-portionalitätsfaktoren (siehe Tabelle 2) durch Verwendung von For-mel 32 aus:
V(X) = W(3)0 (X) = N
(3)(X)
S(X) = W(3)1 (X) = 2N(2)(X)− 6N(3)(X)
B(X) = W(3)2 (X) =
12N
(1)(X)−N(2)(X) +
32N
(3)(X)
χ(X) = W(3)3 (X) = N
(0)(X)−N(1)(X) +N
(2)(X)−N(3)(X)
(33)
Die vier Minkowskifunktionale eines dreidimensionalen Partikels las-sen sich also durch einfaches Zählen seiner Ecken, Kanten, Flächenund seinem Inneren berechnen. Dabei muss lediglich darauf geach-Zählen der Simplexe
tet werden, dass die Simplexe von benachbarten Voxeln nicht dop-pelt gezählt werden. Michielsen und De Raedt [94] schlagen zur Lö-sung dieses Problems folgenden Algorithmus vor. Alle Voxel einesPartikels werden nacheinander durchlaufen und in eine anfangs lee-re Menge eingefügt. Bevor das Voxel eingefügt wird, wird es in seineSimplexe zerlegt und überprüft, welche sich mit denen der bereits indie Menge eingefügten Voxel überlappen. Daraus kann dann die Än-derung der einzelnen Minkowskifunktionale berechnet werden, diebeim Einfügen des Voxels entsteht. Die Änderungsraten werden ge-speichert und der Vorgang solange wiederholt, bis alle Voxel einge-fügt sind. Die Minkowskifunktionale ergeben sich dann durch dasAufsummieren der Änderungsraten. Das Verfahren hat zwar ein gu-tes Laufzeitverhalten, da jeder Voxel nur einmal betrachtet werdenmuss, allerdings müssen zwei Kopien pro Partikel im Speicher ge-halten werden. Bei sehr großen Partikeln wird dementsprechend vielSpeicher verschwendet. Aus diesem Grund wird in der vorliegendenArbeit ein anderes Verfahren verwendet, welches auf den in Abschnitt2.2.2 eingeführten Konfigurationshistogrammen basiert. Mittels Algo-rithmus 6 werden für jedes der 22 möglichen Voxelkonfigurationenvon 2× 2× 2 Blöcken die Minkowskifunktionale vorberechnet. Dazuwird in Zeile 3 die an den Algorithmus übergebene Konfigurations-nummer durch konsekutives Shiften nach rechts in ein Bitfeld x0 . . . x7
mit acht Einträgen zerlegt. Anschließend kann die Anzahl der n-dimensionalen Simplexe Sn im Block durch geeignete Kombinationenvon bitweisen Orderverknüpfungen gezählt werden. Daraus werden

2.2 gestaltanalyse 43
Algorithmus 6 Berechnung der lokalen Minkowskifunktionale.
1: procedure getLocalMinkowski26(c)2: for i← 0, 7 do
3: xi ← (1&(c >> i))4: end for
5: S0 ← 16: S1 ← (x0|x2|x4|x6)
7: S1 ← S1 + (x2|x3|x6|x7)
8: S1 ← S1 + (x1|x3|x5|x7)
9: S1 ← S1 + (x0|x1|x4|x5)
10: S1 ← S1 + (x0|x1|x2|x3)
11: S1 ← S1 + (x4|x5|x6|x7)
12: S2 ← (x0|x4) + (x1|x5) + (x2|x6) + (x3|x7)
13: S2 ← S2 + (x0|x2) + (x1|x3) + (x4|x6) + (x5|x7)
14: S2 ← S2 + (x0|x1) + (x2|x3) + (x4|x5) + (x6|x7)
15: S3 ← x0 + x1 + x2 + x3 + x4 + x5 + x6 + x7
16: V ← S3
8
17: S← −6S3
8 + 2S2
4
18: B← 3S3
16 − 2S2
8 + S1
4
19: χ← −S3
8 + S2
4 − S1
2 + S0
20: return V, S, B, χ
21: end procedure
dann mittels Formel 33 die einzelnen Funktionale berechnet. Da beimBestimmen des Histogramms eines Partikels jede Kante zweimal, je-de Fläche viermal und jeder Voxel achtmal gezählt wird, müssen dieWerte aber entsprechend normalisiert werden. Des Weiteren ist in Al-gorithmus 6 nur der Fall für die 26er Nachbarschaft dargestellt. DieBerechnung für die 6er Nachbarschaft kann ebenfalls mittels Algo-rithmus 6 erfolgen. Dabei muss der Algorithmus lediglich mit derKomplementärkonfiguration, gebildet durch Negieren aller Bits desBitfeldes, aufgerufen werden [87]. Auch für die 18er Nachbarschaftbleibt Algorithmus 6 nahezu identisch. Lediglich für die Konfigurati-on (Konfigurationsnummer 24) gilt zu beachten, dass die beidenVoxel im Sinne der 18er Nachbarschaft nicht benachbart sind. Es giltalso in diesem Fall S0 = 2. Um nun die Minkowskifunktionale für einPartikel angeben zu können, wird zunächst das Voxelkonfigurations-histogramm dieses Partikels bestimmt. Die Anzahl jeder vorkommen-den 2× 2× 2 Konfiguration im Partikel wird zu den normalisiertenMinkowskifunktionalen des jeweiligen Blocks, berechnet mit Algo-rithmus 6, multipliziert und alle Werte aufaddiert. Dabei lassen sichdie Werte der einzelnen Blöcke vorberechnen und in einer Tabellespeichern. Im Anhang sind in Tabelle 15 für alle 22 Konfigurationendie Werte für die 6er, 18er und 26er Nachbarschaft aufgeführt. Ähn-liche Verfahren, allerdings nur für die Euler-Charakteristik wurden

44 einzelpartikelanalyse
auch von Lobregt, Verbeek und Groen [87], Ohser und Schladitz [99,S. 52 ff.] und Toriwaki und Yoshida [138, S. 94 ff.] beschrieben unddecken sich mit den Ergebnissen in Tabelle 15.
Das beschriebene Verfahren ist sehr schnell, da die Berechnung derFunktionale im Prinzip durch das Nachschlagen der 22 möglichen Vo-xelkonfigurationen in einer vorberechneten Tabelle geschieht. AuchErwartungstreuer
Schätzer der Speicherverbrauch kann vernachlässigt werden. Für jedes Parti-kel wird zusätzlich lediglich das aus 22 Integerwerten bestehende Vo-xelkonfigurationshistogramm abgespeichert. Allerdings hat das hiervorgestellte Verfahren zwei Nachteile. Zum einen können die mittle-re Breite und die Oberfläche nur für Partikel in einem kubisch pri-mitiven Gittersystem berechnet werden und zum anderen sind dieSchätzungen für die Oberfläche und die mittlere Breite nicht erwar-tungstreu, da die glatten Oberflächen der Partikel nur durch Voxelmit vertikalen und horizontalen Flächen approximiert werden. Zahl-reiche erwartungstreue Verfahren zur Schätzung der Oberfläche undder mittleren Breite werden in der Literatur diskutiert [85, 94, 146,153, 120]. In der vorliegenden Arbeit wird das oben beschriebeneVerfahren um die Methode von Schladitz, Ohser und Nagel [120]erweitert. Ausgangspunkt sind dabei wieder die im Abschnitt 2.2.2eingeführten Konfigurationshistogramme. Aber an Stelle der Formel33, werden im Falle eines kubisch primitiven Gittersystems die vonSchladitz, Ohser und Nagel [120] veröffentlichten 22 Gewichte ver-wendet. Diese liefern, wenn sie zu der Anzahl der vorkommendenKonfigurationen in einem Partikel multipliziert werden, eine erwar-tungstreue Schätzung für die Oberfläche beziehungsweise die mitt-lere Breite. Abgeleitet wurden sie mittels einer Diskretisierung derCroftonschen Formeln [121, S. 104]. Für 256 Fälle bei einem orthor-hombischen Gittersystem können die Gewichte dagegen mittels demvon Lang, Ohser und Hilfer [76] vorgeschlagenen Algorithmus vor-berechnet werden. In der vorliegenden Arbeit wird auf Grund derEffizienz eine von Matlab1 nach C++ portierte Version des Algorith-mus verwendet.
Auf Basis der Minkowskifunktionale lassen sich nun weitere Gestalt-deskriptoren ableiten. Zunächst kann gezeigt werden, dass die mitt-Krümmung
lere Breite B(A) und die Euler-Charakteristik χ(A) eines ElementsA ∈ K proportional zu dem aus der Differentialgeometrie bekann-ten Integral der mittleren Krümmung M(A) [47, S. 212 ff.] und demIntegral der Totalkrümmung K(A) [99, S. 29] ist. Und zwar gilt
M(A) = 2πB(A)
K(A) = 4πX(A).
(34)
1 https://www.mathworks.com/matlabcentral/fileexchange/33690-geometric-measures-in-2d-3d-images

2.2 gestaltanalyse 45
Man beachte dabei, dass die integralgeometrischen Größen immerwohl definiert sind und nicht nur für Elemente mit regulärer Flächegelten. Das Volumen, die Oberfläche und die mittlere Krümmungkönnen dann dazu verwendet werden, die isoperimetrischen Gestalt-deskriptoren zu definieren. Für A ∈ K mit Volumen V(A), Oberfläche Isoperimetrischen
GestaltdeskriptorenS(A) und mittlerer Krümmung M(A) ergeben sich diese durch
F1 = 6√
πV(A)√
S(A)3, F2 = 482 V(A)
M(A)3 , F3 = 4πS(A)
M(A)2 ,(35)
wobei F1, F2 und F3 für ein kugelförmiges A den Wert 1 annehmen.Bei Abweichungen von der Kugelform ergeben sich Werte zwischen0 ≤ F1, F2, F3 < 1. Schließlich soll an dieser Stelle noch die Dichte derMinkowskifunktionale für ein Partikel X eingeführt werden. Dabei Dichte der Minkow-
skifunktionalehandelt sich um das Verhältnis der Minkowskifunktionale eines Par-tikels X und dem Volumen der umgebenen minimalen BoundingboxBBX. Es gilt also
VV(X) =V(X)
V(BBX)
SV(X) =S(X)
V(BBX)
BV(X) =B(X)
V(BBX)(36)
MV(X) =M(X)
V(BBX)
KV(X) =K(X)
V(BBX)
χV(X) =χ(X)
V(BBX) .
Dadurch erreicht man eine Normalisierung der Funktionale undkann im direkten Vergleich interessante Informationen zur Strukturder Partikel ableiten. Die Dichte der Oberfläche eines Partikels X1
mit gleichem Boundingboxvolumen wie ein zweites Partikel X2 er-höht sich zum Beispiel, je „wilder“ seine Oberflächenstruktur ist. Ei-ne „wilde“ Oberfläche zeichnet sich dabei durch eine Vielzahl vonKonfigurationen mit diagonalen Nachbarn im Voxelkonfigurations-histogramm aus. Für fraktale Partikel würde sie, bei unbegrenztemAuflösungsvermögen der Kamera, schließlich gegen unendlich stre-ben (siehe auch Abschnitt 2.2.6).
Damit ist die Menge der additiven, bewegungsinvarianten und strei-tigen Funktionale vollständig beschrieben. In den nächsten Abschnit-ten werden Deskriptoren beschrieben, welche eine oder mehrere die-ser Eigenschaften nicht erfüllen.

46 einzelpartikelanalyse
2.2.4 Momente
In diesen Abschnitt werden Desktriptoren eingeführt, die auf Basisvon Momenten berechnet werden. Momente sind skalare Größen, umFunktionen zu charakterisieren. Verwendung finden sie vor allem inder Statistik und der Mechanik, um die Form von Dichtefunktionenoder die Massenverteilungen starrer Körper zu beschreiben. An die-ser Stelle werden die Momente für den dreidimensionalen Fall einge-führt.
Sei f : R3 → R eine stetige dreidimensionale Funktion. Nach Flusser,Zitova und Suk [40, S. 13] ist das Moment mpq vom (p + q + r)-tenGrades mit p, q, r ≥ 0 gegeben durch
mpqr =∫ ∞
−∞
∫ ∞
−∞
∫ ∞
−∞xpyqzr f (x, y, z)dxdydz
.(37)
Besonderes Interesse besteht an den Momenten, die invariant unterTranslation, Skalierung und Rotation sind, da sie sich als Formde-skriptoren eignen. Translationsvarianz wird über die sogenanntenZentrales Moment
zentralen Momente erreicht. Sie sind definiert als
µpqr =∫ ∞
−∞
∫ ∞
−∞
∫ ∞
−∞(x− x)p(y− y)q(z− z)r f (x, y, z)dxdydz (38)
mitx =
m100
m000, y =
m010
m000und z =
m001
m000 .
Wird f (x, y, z) als Massenverteilung eines Objektes aufgefasst, kannman x, y und z als Schwerpunkte des Objekts und die zentralen Mo-mente m200, m020, m002, m110, m011 und m101 als Trägheitsmomente derentsprechenden Richtungen interpretieren. Die Translationsinvarianzwird dann durch eine Verschiebung des Ursprungs des Koordinaten-systems auf den Objektschwerpunkt erreicht. Fasst man hingegenf (x, y, z) als Wahrscheinlichkeitsdichtefunktion auf, stellen x, y undz die Mittelwerte und m200, m020, m002 die Varianzen beziehungsweisem110, m011, m101 die Kovarianzen von x, y und z dar.
Skaleninvarianz bei gleichförmiger Skalierung wird durch geeigneteNormalisierung erreicht. In dieser Arbeit wird, wie in den meistenVeröffentlichungen, das Moment µ000 verwendet [40, S. 45]. Für denSkaleninvarianz
dreidimensionalen Fall ergibt sich die Skaleninvarianz durch Norma-lisierung der zentralen Momente 38 mit
ηpqr =µpqr
µp+q+r
3 +1000
.(39)
Schließlich bleibt noch die Invarianz unter Rotation. Für den zweidi-mensionalen Fall wurden rotationsinvariante Momente auf Basis von

2.2 gestaltanalyse 47
algebraischen Invarianten bereits 1962 von Hu [59] abgeleitet. Erst1980 folgte dann die Erweiterung für die dritte Dimension von Sad-jadi und Hall [117]. An dieser Stelle werden die Momente nur ange-geben. Die Herleitung ist in [59] und [86] beschrieben. Nach Flusser, Rotationsinvarianz
Zitova und Suk [40, S. 45] sind die rotationsinvarianten Momente biszum zweiten Grad gegeben durch
J1 = η200 + η020 + η002
J2 = η020η002 + η200η002 + η200η020 − (η2011 + η2
101 + η2110) (40)
J3 = η200η020η002 + 2η110η101η011 − η200η2011 − η020η2
101 − η002η2110
.
Neben den invarianten Momenten lassen sich auf Basis der zentralenMomente noch weitere Deskriptoren ableiten. Stellt man die Kovari-anzmatrix aus den zentralen Momenten bis zum zweiten Grad auf,nämlich Kovarianzmatrix
Cov =
µ′200 µ′110 µ′101µ′110 µ′020 µ′011µ′101 µ′011 µ′002
(41)
wobeiµ′pqr =
µpqr
µ000mit 0 ≤ p ≤ 2, 0 ≤ q ≤ 2, 0 ≤ r ≤ 2
ist, ergeben sich die Länge der drei Hauptachsen eines Partikels ausden Eigenwerten e1, e2 und e3 der Kovarianzmatrix Cov. Dabei wird Exzentrizität und
Dimensionalitätdie Belegung der e’s so gewählt, dass e1 dem betragsmäßig größtenEigenwert und e3 dem betragsmäßig kleinsten Eigenwert entspricht.Aus dem Verhältnis der so bestimmten Hauptachsen des Objektes las-sen sich zum Beispiel mit dem im Abschnitt 2.2.1 beschrieben Walz-Deskriptor Aussagen über die Form treffen. Weitere einfache Deskrip-toren sind die Exzentrizität, definiert durch
ECC =
√
1− e3
e1(42)
und die Dimensionalität, definiert durch
DIM =e3
e1+
e2
e1 .(43)
Das Verfahren zur Bestimmung der Hauptachsen findet auch in derStatistik bei der Untersuchung von multivariaten Datensätzen inForm der Hauptkomponentenanalyse Anwendung. Bei der Haupt- Hauptkomponenten-
analysekomponentananalyse wird nach einer neuen Basis gesucht, in derdie ursprünglichen Daten maximale Varianz besitzen. Dafür wirdder Datensatz durch eine Hauptachsentransformation, gebildet ausder orthogonalen Matrix der Eigenvektoren, in einen Raum niedrigerDimension transformiert. Die Wahl der zu verwendenden Eigenvek-toren wird dabei anhand der Beträge der zugehörigen Eigenwertegetroffen. Im Vergleich zu Eigenvektoren mit betragsmäßig großen

48 einzelpartikelanalyse
Eigenwerten können Eigenvektoren mit betragsmäßig kleinen Eigen-werten weggelassen werden, da sie sich zumeist auf Rauschen zurück-führen lassen. Die so neu gebildeten Variablen sind Linearkombina-tionen der Variablen des ursprünglichen Datensatzes. Die Hauptkom-ponentananalyse wird im Rahmen dieser Arbeit verwendet, um hochdimensionale Datensätze vor der Klassifizierung zu komprimierenund gegebenenfalls vorhandenes Rauschen zu entfernen. Das Verfah-ren selbst wird allerdings nicht noch einmal explizit eingeführt. Fürweitere Informationen wird auf das Buch von Handl und Niermann[48, S. 107 ff.] verwiesen.
Da im Rahmen dieser Arbeit nur mit diskreten Datensätzen (Voxel-mengen) gearbeitet wird, können Formel 37 und 38 für ein Partikel Xauch als
mpqr = ∑x
∑y
∑z
xpyqzrbX(x, y, z) (44)
undµpqr = ∑
x∑y
∑z(x− x)p(y− y)q(z− z)rbX(x, y, z) (45)
geschrieben werden, wobei über alle Voxel (x, y, z) der BoundingboxDiskrete Momente
BBX von X iteriert wird.
2.2.5 Konvexität
Die Konvexität eines Partikels X ist definiert als
CONV(X) =V(X)
CH(X) ,(46)
also dem Verhältnis des Volumens eines Partikels X zu dem Volumenseiner konvexen Hülle CH(X). Stellt sich die Frage, wie die konvexeHülle CH(X) für ein Partikel X definiert ist und berechnet werdenkann. Allgemein wird eine euklidische Menge als konvex bezeich-net, wenn die kürzeste Verbindungsstrecke von je zwei beliebigenPunkten der Menge selbst in der Menge liegt. Die konvexe Hülle istKonvexe Hülle
dann die kleinste konvexe Menge, welche die Ausgangsmenge ent-hält. Zahlreiche Algorithmen sind bekannt, um die konvexe Hüllevon euklidischen Mengen zu berechnen. Die bekanntesten Vertretersind der Q-Hull Algorithmus [13] und der Giftwrapping Algorithmus[68]. Allerdings lassen sich diese Algorithmen nicht ohne weiteres aufden in der vorliegenden Arbeit verwendeten Partikelbegriff übertra-gen, da die oben angegebene Definition von Konvexität bei diskretenMengen problematisch ist. So kann es bei diskreten Mengen vorkom-men, dass es mehrere kürzeste Pfade gibt, die zwei Punkte verbinden.Alternativ besteht die Möglichkeit, das durch Voxel beschriebene Par-tikel zunächst in ein Dreicksgitter zu überführen und die konvexe

2.2 gestaltanalyse 49
Hülle mit einem der oben vorgeschlagenen Algorithmen zu berech-nen. Die konvexe Hülle wird dann als Polygonzug zurückgeliefert.In dieser Arbeit wird allerdings ein anderer Ansatz gewählt. Die kon-vexe Hülle wird direkt aus der diskreten Voxelmenge berechnet undselbst als diskrete Voxelmenge angegeben, welche die Ausgangsmen-ge als Teilmenge enthält. Damit bleibt die Möglichkeit bestehen, diebisher besprochenen Formdeskriptoren auf die konvexe Hülle anzu-wenden. Dies ist insbesondere dann sinnvoll, wenn man Systeme un-tersucht, bei denen im Vorhinein bekannt ist, dass die Partikel einekonvexe Form haben. In solchen Fällen berechnet man für alle Parti-kel die konvexe Hülle und kann damit sichergehen, dass die Annah-me der Konvexität erfüllt ist und nicht durch Fehler bei Bildaufnah-me, der damit einhergehenden Diskretisierung oder der Segmentie-rung verletzt wird.
Es gibt mehrere Möglichkeiten, die oben angesprochenen Problemebei der Definition von konvexen diskreten Voxelmengen zu umge-hen [123]. Mit folgenden Definitionen lässt sich überprüfen, ob eineVoxelmenge diskret konvex ist: Diskret Konvex
1. Ein Partikel X ist diskret konvex, wenn für zwei beliebige Ele-mente x, y ∈ X alle kürzesten Pfade zwischen x mit y selbst inX liegen (starke Konvexität).
2. Ein Partikel X ist diskret konvex, wenn für zwei beliebige Ele-mente x, y ∈ X mindestens ein kürzester Pfad zwischen x undy existiert, der selbst in X liegt (schwache Konvexität).
Zwar lässt sich mit diesen Definitionen bereits ein Verfahren angeben,um die diskret konvexe Hülle einer Voxelmenge zu bestimmten, al-lerdings liefern beide Definitionen im Vergleich zur euklidischen kon-vexen Hülle nur eine sehr grobe Approximation. Alternativ schlägtSoille [123, S. 44] für diskrete Mengen folgende Definition vor, dieals Grundlage für die Berechnung der diskret konvexen Hülle die-nen soll. Ein Partikel X wird als diskret konvex bezeichnet, wennseine Voxel in den Schnitt aller geschlossenen Halbebenen fallen, dieX enthalten. Bevor der Algorithmus zur Berechnung der diskret kon-vexen Hülle mittels dieser Definition aufgestellt wird, ist es hilfreichzunächst die grundlegenden morphologischen Operationen, nämlichErosion, Dilatation, Closing und Opening einzuführen. Diese werdennicht nur für den nachfolgenden Algorithmus verwendet, sondern imweiteren Verlauf der Arbeit auch dazu benutzt, Segmentierungsfehler,wie beispielsweise Hohlstellen, zu bereinigen.
Die Erosion eines Partikels X mit dem Strukturelement SE ist durch MorphologischeOperatoren
ǫSE(X) =⋂
b∈SE
X−b (47)

50 einzelpartikelanalyse
und die Dilatation durch
ηSE(X) =⋃
b∈SE
X−b (48)
gegeben. Aufbauend auf diesen Definitionen gilt für das Opening
γSE(X) = ηSE(ǫSE(X)) (49)
und für das Closing
φSE(X) = ǫSE(ηSE(X)),
(50)
wobei SE =⋃
b∈SE−b das am Ursprung gespiegelte Strukturele-ment ist.
Sei nun Eω die Halbebene mit Orientierung ω und Eω die gespiegelteHalbebenene. Die konvexe Hülle eines Partikels X kann dann durch
CH(X) =⋂
ω
(⋂
xExω : X ⊆ Exω
)
︸ ︷︷ ︸
φEω
∩(⋂
x
Exω : X ⊆ Exω
)
︸ ︷︷ ︸
φEω
(51)
berechnet werden, wobei die beiden inneren Ausdrücke
⋂
x
Exω : X ⊆ Exω
und⋂
x
Exω : X ⊆ Exω
der Schnitt aller Translationen der Halbebenen in Richtung ω ist, wel-che das Partikel X enthalten. Dieses ist aber, wie Soille [123, S. 116]zeigt, gleich dem Closing der jeweils gespiegelten Halbebene. Diekonvexe Hülle kann also aus dem Schnitt der Closings aller Halbebe-nen über alle Richtungen ω berechnet werden.
Um das Closing der Halbebene Eω mit einem zweidimensionalenBild zu berechnen, schlägt Soille [123, S. 133] nun folgendes Verfah-ren vor. Es wird zunächst mittels Bresenham-Algorithmus eine Gera-Zweidimensionaler
Algorithmus de, die senkrecht zur Richtung ω einer bliebigen Halbene Eω steht,berechnet und so am Rand des Bildes positioniert, dass der Schnittzwischen dem Bild und der Geraden leer ist. Anschließend wird dieGerade Pixel für Pixel in Richtung ω verschoben und für jedes Pixelauf der Geraden getestet, ob der Pixel zum Partikel gehört, also denWert 1 hat. Für Pixel außerhalb des Bildes wird der Wert 0 angenom-men. Sobald ein Wert auf der Geraden im Partikel liegt, werden auchalle übrigen Pixel auf der Geraden und alle Pixel, welche die Gerade

2.2 gestaltanalyse 51
noch schneiden wird, auf 1 gesetzt. Daraus ergibt sich das Closingder Halbebene Eω. Durchgeführt für alle Richtungen ω und anschlie-ßender Schnittbildung liefert dieser Algorithmus die diskret konvexeHülle eines Partikels im zweidimensionalen Fall.
Soille [123] gibt allerdings keinen Algorithmus für den dreidimensio-nalen Fall an. In der vorliegenden Arbeit wird die von Hans u. a. [49]beschriebene Variante des oben beschriebenen Algorithmus verwen-det, um die diskret konvexe Hülle eines dreidimensionalen Partikelszu berechnen. Der Ablauf ist wie folgt. Zunächst werden eine Reihe Dreidimensionaler
Algortihmusvon normierten Richtungsvektoren ω vom Ursprung des Koordian-tensystems bestimmt, welche die Einheitskugel mit dem Mittelpunktim Koordinantenursprung gleichmäßig schneiden. Für jede Richtungω wird dann eine Gerade bestimmt, die senkrecht zum Richtungs-vektor ω steht. Die Gerade wird nun mit fester Schrittweise durch-laufen und alle Voxel in Richtung ω auf die Gerade projiziert. Liegenmehrere Voxel übereinander, werden diese für jeden Schritt in einerListe gespeichert. Diese Listen werden anschließend für jede GeradeVoxel für Voxel durchlaufen. Sobald einer der projizierten Voxel indem Partikel liegt, wird dieser und auch alle nachfolgenden Voxelauf 1 gesetzt. Der Schnitt zwischen allen auf diese Weise bestimmtenVoxelmengen aller Geraden ergibt dann die diskret konvexe Hülle.Abbildung 4 zeigt die Aufsicht auf einen Riss und seine mittels demhier vorgestellten Verfahren berechnete konvexe Hülle.
Abbildung 4.: a) Aufsicht auf Riss. b) Konvexe Hülle des Risses.
a) b)
2.2.6 Fraktale Dimension
Nach Meinung von Mandelbrot [88, S. 1 f.] sind viele Muster undObjekte der Natur so irregulär und komplex, dass sie sich nur un-zureichend durch die Idealisierungen der traditionellen euklidischenGeometrie beschreiben lassen. Naheliegende Beispiele für solche Ob-

52 einzelpartikelanalyse
jekte sind Küstenlinien, Gebirgszüge, Blitze oder Flussläufe. Bei nä-herer Betrachtung dieser Objekte fällt auf, dass sie oft ein hohes Maßan Selbstähnlichkeit aufweisen, also bei Vergrößerung immer wiederdieselben oder ähnliche Strukturen auftreten wie im Anfangszustand.Auch lässt sich für diese Objekte oft keine ganzzahlige Dimensionangeben. Mandelbrot bezeichnet diese Objekte als Fraktale und ihrenicht ganzzahlige Dimension als fraktale Dimension. Mit dem Kon-zept der fraktalen Geometrie führt er Techniken zum Beschreiben die-ser komplexen Systeme ein.
In der vorliegenden Arbeit werden vor allen Dingen die Technikenzur Messung der fraktalen Dimension von Objekten verwendet. Da-bei wird der Wert der fraktalen Dimension als Formdeskriptor in-terpretiert, der die Rauigkeit und Irregularität von Partikeln, dienicht zwangsläufig fraktales Verhalten aufweisen, beschreibt. In zahl-reichen Anwendungen kann man allerdings auch Partikel beobach-ten, die fraktale Strukturen besitzen. Oft entstehen diese Partikel aufGrund von Wachstumsprozessen, bei denen sich größere Teilchendurch Anlagerung von kleineren Teilchen bilden. Ist die Bewegungder Teilchen dabei zufällig, bezeichnet man diese Prozesse als dif-fusionsbegrenztes Wachstum [148]. Die fraktale Dimension kann beisolchen Prozessen als physikalische Größe interpretiert werden. ImKontext der Stahlerzeugung lässt sich beispielsweise das dendritischeWachstum von nichtmetallischen Mikroeinschlüssen mittels eines sol-chen Prozesses beschreiben [36, 82].
Um den Begriff Fraktal und fraktale Dimension formal zu definie-ren, wird im Folgenden zunächst die Hausdorff Dimension einge-führt. Auf Basis dieser erfolgt dann die Definition des Begriffs Fraktal.Anschließend werden empirische Messmethoden vorgestellt, die eineApproximation der fraktalen Dimension für Partikel erlauben.
Sei U eine nichtleere Teilmenge von Rn. Der Durchmesser von U wirdδ-Überdeckung
als |U| = sup |x− y| x, y ∈ U, also der größte Abstand zwischenzwei beliebigen Punkten der Menge, definiert. Weiter sei F ⊂ R
n ge-geben und Ui eine Folge abzählbarer Mengen mit F ⊂ ⋃∞
i=1 Ui, wo-bei |Ui| ≤ δ für alle i ∈ I ist. Man bezeichnet Ui als δ-Überdeckungvon F. Dann ist
Hsδ = inf
∞
∑i=1
|Ui|s : Ui ist eine δ-Überdeckung (52)
diejenige Überdeckung von F mit Mengen eines Durchmessers vonhöchstens δ deren Summe aus der s-ten Potenz der Durchmesser mi-nimal ist. Lässt man δ immer kleiner werden, nimmt die Anzahl dermöglichen Überdeckungen ab, während sich der Wert von Hs
δ erhöhtund für δ→ 0 gegen einen Grenzwert läuft. Man bezeichnet
Hs(F) = limδ→0Hs
δ(F) (53)

2.2 gestaltanalyse 53
als s-dimensionales Hausdorff-Maß [38, S. 75 f.]. Die Grenze aus For- Hausdorff-Maß
mel 53 existiert dabei für jede Teilmenge F ⊂ Rn, wobei der Grenz-
wert 0 oder ∞ annehmen kann. Für eine beliebige Menge F und δ < 1gilt nun nach Formel 52
∑i
|Ui|t = ∑i
|Ui|t−s|Ui|s ≤ δt−s ∑i
|Ui| (54)
mit t > s und nach Bilden des Infiniums
Htδ(F) ≤ δt−sHs
δ(F).
(55)
Im Grenzübergang δ→ 0 ergibt sich dann
Hs(F) < ∞⇒ Ht(F) = 0
Ht(F) > 0⇒ Hs(F) = ∞.
Dass heißt, es gibt einen kritischen Wert für s, bei dem Hs(F) von ∞
auf 0 springt. Diesen Wert bezeichnet man als Hausdorff Dimension. Hausdorff-DimensionFormal lässt sich die Hausdorf Dimension für eine Menge F als
dimFH = inf s : Hs(F) = 0 = sup s : Hs(F) = ∞ (56)
schreiben [38, S. 29 f.]. Ein Fraktal kann schließlich als Menge defi- Fraktal
niert werden, bei der die Hausdorff Dimension die topologische Di-mension überschreitet [88, S. 15 f.].
Aus dem oben eingeführten Dimensionsbegriff lässt sich nicht oh-ne weiteres ein Formalismus ableiten, der die Berechnung der frak-talen Dimension für beliebige Mengen erlaubt. Zwar rechnet Falco-ner [38, S. 31 f.] die Hausdorff Dimension für einige Beispiele explizitaus, nutzt dabei aber immer spezielle Eigenschaften der betrachtetenMenge, welche die Berechnung vereinfachen. Da für die automatischeKlassifizierung ein diskreter Algorithmus unabdingbar ist, wird fürdie Berechnung der fraktalen Dimension auf eine andere Definition,nämlich die sogenannten Boxdimension, zurückgegriffen. Im Folgen-den wird der Algorithmus zur Berechnung der fraktalen Dimensionunter Verwendung von Voxelmengen für den dreidimensionalen Fallbeschrieben.
Gegeben sei ein Partikel X, welches mit einem kubisch primitivenGittersystem mit Kantenlänge δ geschnitten wird. Sei nun Nδ(X) dieAnzahl der Würfel, die X schneidet. Die Dimension von X lässt sich Boxdimension
dann aus dem Potenzgesetz von Nδ(X) ableiten, wenn δ → 0 strebt.Hat X die Dimension s, so ist Nδ(X) proportional zu cδ−s, wobei c ei-ne Konstante ist. Durch Anwenden des Logarithmus auf beiden Sei-ten und Auflösen nach s ergibt sich im Grenzübergang für δ → 0
s = limδ→0
log Nδ(X)
− log δ .(57)

54 einzelpartikelanalyse
Da die Potenzgesetz-Eigenschaft von Nδ(X) aber nicht zwangsläufigerfüllt sein muss, wird die Boxdimension durch den Limes superiorund Limes inferior definiert. Die obere beziehungsweise untere Box-dimension sind gegeben durch
dimBF = limδ→0
log Nδ(X)
− log δ(58)
und
dimBF = limδ→0
log Nδ(X)
− log δ ,(59)
wobei lim der Limes superior und lim der Limes inferior ist. WenndimBF gleich dimBF ist, bezeichnet man
dimBF = limδ→0log Nδ(X)
− log δ(60)
als Boxdimension [38, S. 38 f.]. Man kann zeigen, dass
dimH F ≤ dimBF ≤ dimBF (61)
gilt [38, S. 43 f.], also die Boxdimension eine obere Schranke fürdie Hausdorff Dimension darstellt. Ein Verfahren zur Bestimmungder Boxdimension ergibt sich jetzt direkt aus Formel 60. Man über-deckt das Partikel X mit einem Gittersystem der Kantenlänge δ undzählt die Überschneidungen Nδ(X). Die Boxdimension ergibt sich ausder logarithmischen Rate, um die sich Nδ(X) erhöht, wenn δ → 0läuft. Konkret ergibt sie sich aus der Ausgleichsgeraden durch dieMesspunkte für die verschiedenen Auflösungen von δ im Graph vonlog Nδ(X) gegen − log δ. Die Auflösung von δ ist dabei in der Pra-xis natürlich durch den verwendeten Bildaufnahmesensor nach untenhin begrenzt. Interpretiert wird die Boxdimension dabei als Maßzahl,wie irregulär das Partikel X bei einer Auflösung von δ erscheint undwie sich diese Irregularität entwickelt, wenn die Auflösung geringerwird.
2.3 zusammenfassung
In diesem Kapitel wurde zunächst der im Kontext dieser Arbeit ver-wendete Begriff des Partikels definiert. Aufbauend auf dieser Defi-nition wurden Algorithmen für verschiedene Anwendungsszenarienvorgestellt, um Partikel aus vorsegmentierten Datensätzen zu rekon-struieren. Die Anwendungsszenarien unterteilen sich grob in zweiKlassen. Bei dem ersten Szenario läuft die Rekonstruktion und Wei-terverarbeitung parallel zur Bildaufnahme (Online-System), währendbeim zweiten Szenario alle Daten vor der Auswertung bereits zur Ver-fügung stehen. Für beide Klassen wurden passende Algorithmen vor-gestellt und das Laufzeitverhalten dieser untersucht. Anschließend

2.3 zusammenfassung 55
wurden Deskriptoren vorgestellt, mit denen sich die Gestalt von Par-tikeln quantifizieren lässt. Aufbauend auf diesen Deskriptoren kön-nen später Gestaltklassen festgelegt und eine automatische Klassifi-zierung der Partikel vorgenommen werden. Auch die im Folgendenbeschriebenen statistischen Untersuchungen basieren auf den in die-sem Kapitel beschriebenen Merkmalen. Konkret werden im nächstenKapitel anhand des Durchmessers und des Schwerpunkts statistischeVerfahren eingeführt, mit denen sich die Größenverteilung und dieräumliche Verteilung von Partikeln beschreiben lässt.

56 einzelpartikelanalyse

3S TAT I S T I S C H E M E T H O D E N
Während in Kapitel 2 Methoden beschrieben wurden, um die Formund Morphologie einzelner individueller Partikel zu erfassen, sollennun statistische Methoden erarbeitet werden, welche die Eigenschaf-ten von Partikelsystemen als Ganzes quantifizieren. Konkret sollendie Größenverteilung und die räumliche Verteilung von Partikelnuntersucht werden. Im Folgenden werden dafür zunächst einfachegraphische Werkzeuge vorgestellt, die im weiteren Verlauf dieser Ar-beit als Hilfsmittel für den Modellbildungsprozess verwendet wer-den. Anschließend werden Methoden eingeführt, um die Parameterdieser Modelle aus den Daten zu schätzen, welche mit Hilfe vonExpertenwissen und ebendieser Werkzeuge abgeleitet wurden. In ei-nem letzten Schritt wird dann gezeigt, wie die parametrisierten Mo-delle gegen die erhobenen Daten validiert werden können. Es wirdmit der Beschreibung der Verfahren zur Analyse der Größenvertei-lung begonnen. Anschließend folgen die Methoden zur Analyse derräumlichen Verteilung. Insgesamt wird sich bei der Beschreibung aufein System von polydispersen Kugeln beschränkt. Für den Anwen-dungsfall aus Abschnitt 4.2, in dem die hier erarbeiteten Technikeneingesetzt werden, stellt dies keine Einschränkung dar. Die dort un-tersuchten Poren und nichtmetallischen Einschlüsse sind annäherndkugelförmig (siehe Kapitel 5). Risse werden bei der statistischen Aus-wertung nicht betrachtet, da sie im eigentlichen Sinne keine Partikeldarstellen und viel zu selten auftreten, als dass gesicherte statistischeAussagen über sie erhoben werden können.
3.1 grundbegriffe
Im Folgenden werden zunächst die Grundbegriffe stochastischer Mo-dellierung eingeführt. Begonnen wird mit der Definition von soge-nannten Zufallsexperimenten, da sich die in Abschnitt 4.2 beschrie-bene Messmethode für Partikelsysteme als solches modellieren lässt.In den darauf folgenden Abschnitten werden dann statistische Ver-fahren vorgestellt, die es erlauben, anhand von beobachteten Da-ten solcher Zufallsexperimente Schlussfolgerungen zu ziehen. Bei al-len Ausführungen in diesem Abschnitt wird auf Beweise verzichtetund stattdessen auf die einschlägige Literatur zum Thema verwie-sen. Die nachfolgenden Ergebnisse orientieren sich an Arens u. a. [7,S. 1286 ff.] und Henze [53].
57

58 statistische methoden
Ein Zufallsexperiment ist ein beliebig oft wiederholbarer Vorgang,der nach einer bestimmten festgelegten Vorschrift ausgeführt wirdund dessen Ergebnis im Vorhinein nicht eindeutig bestimmt werdenkann, sondern vom Zufall abhängt. Der wiederholte Wurf einer Mün-Zufallsexperiment
ze oder eines Würfels kann beispielsweise als Zufallsexperiment auf-gefasst werden. Die Menge aller möglichen Ergebnisse, die bei einemsolchen Zufallsexperiment auftreten können, bezeichnet man als dieErgebnismenge Ω. Im Allgemeinen ist man aber nicht an dem ge-nauen Ergebnis des Zufallsexperiments interessiert, sondern an derFrage, ob der Ausgang zu einer gewissen Menge von Ergebnissen,den sogenannten Ereignissen, gehört. Ereignisse sind Teilmengen derGrundmenge Ω. Man sagt, ein Ereignis A ist eingetreten, wenn derEreignis
Ausgang eines Experiments zur Teilmenge A ⊂ Ω gehört. SpezielleEreignisse sind hierbei das sichere Ereignis A = Ω und das unmög-liche Ereignis A = Ω = ∅. Jede einelementige Teilmenge w vonΩ bezeichnet man als Elementarereignis. Zwei Ereignisse A, B ⊂ Ω
lassen sich durch die aus der Mengenlehre bekannten Operationenzu neuen Ereignissen zusammensetzen. So ist die Vereinigung A ∪ Bdas Ereignis, dass mindestens eines der beiden Ereignisse eingetre-ten ist, der Schnitt A ∩ B das Ereignis, dass A und B gemeinsamauftreten und AC das Komplement von A, also das Ereignis, dass Anicht aufgetreten ist. Um hinreichend komplexe Zufallsexperimentemodellieren zu können, fordert man zusätzlich von Ereignissen, dasssie unter Komplement und abzählbarer Vereinigung abgeschlossensind. Man sagt, die Gesamtheit der Ereignisse muss eine σ-Algebra Sσ-Algebra
bilden. Formal ist S definiert als System von Teilmengen von Ω, fürdie gilt:
1. Ω ∈ S
2. Wenn A ∈ S , dann ist auch AC ∈ S
3. Sind Ai ∈ S , i ∈ N, dann ist auch⋃∞
i=1 Ai ∈ S
Den Ereignissen in S sollen nun in konsistenter Weise Wahrschein-lichkeiten zugeordnet werden. Die Zuordnung erfolgt mittels der re-ellwertigen Abbildung P : S → [0, 1], die folgende Bedingungen er-füllt (Axiome nach Kolmogorov):Axiome nach
Kolmogorov
1. P(A) ≥ 0 für A ∈ S
2. P(Ω) = 1
3. P(∞⋃
j=1Aj) =
∞
∑j=1
P(Aj) für eine abzählbare Folge von disjunkten
Teilmengen Aj ∈ S
Das Tripel (Ω,S , P) bezeichnet man dann als Wahrscheinlichkeits-raum.

3.1 grundbegriffe 59
Um nun Wahrscheinlichkeiten für konkrete Probleme berechnen zukönnen, wird der abstrakte Raum Ω in R abgebildet, so dass auchdort Ereignisse und Wahrscheinlichkeiten definiert sind, die derStruktur des Wahrscheinlichkeitsraums (Ω,S , P) entsprechen. Dazulegt man zunächst die σ-Algebra für R fest. Man kann zeigen, dassdas System der Borelmengen B das kleinste System von Teilmen-gen von R darstellt, die den im Axiomensystem von Kolmogorovbeschriebenen Eigenschaften genügt und damit eine σ-Algebra überR ist. Die Menge B enthält dabei alle abgeschlossenen Intervalle derForm [a, b] = x ∈ R : a ≤ x ≤ b mit a, b ∈ R und jedes Intervall derForm (a, b), (a, b], [a, b), (−∞, a], (−∞, a), (a, ∞), [a, ∞) ist ebenfalls ei-ne Borelmenge. Für eine Abbildung X : Ω → R kann man nun ein Zufallsvariable
Wahrscheinlichkeitsmaß PX definieren, dass jedem Ereignis B ∈ B ei-ne Wahrscheinlichkeit zuordnet. Und zwar wird das Ereignis B füralle w ∈ Ω mit X(w) ∈ B ausgelöst, welches dem Urbild von X, be-zeichnet als X−1(B) entspricht. Dem Ereignis B wird nun also dieWahrscheinlichkeit seines Verursachers zugeordnet, nämlich
PX(B) = P(X ∈ B) = P(X−1(B)).
(62)
Damit X−1 aber eine Wahrscheinlichkeit besitzt, muss es ein Ereig-nis sein, das heißt Element der auf Ω erklärten σ-Algebra S . Ist die-se Eigenschaft erfüllt, bezeichnet man X als Zufallsvariable und denneuen Wahrscheinlichkeitsraum (R,B, PX) als den von X induziertenWahrscheinlichkeitsraum. Die Zufallsvariable X bildet Ω also in R
ab und überträgt die Wahrscheinlichkeiten der Ereignisse. Ist nun X Verteilungsfunktion
eine Zufallsvariable, so heißt die durch
F(u) = P(X ≤ u) (63)
definierte Funktion F : R :→ [0, 1] mit u ∈ R die Verteilungsfunktionvon X.
In der vorliegenden Arbeit wird zwischen zwei Klassen von Zufalls-variablen unterschieden, nämlich diskrete Zufallsvariablen und ste-tige Zufallsvariablen. Eine Zufallsvariable X heißt diskret verteilt, Diskrete
Zufallsvariablewenn sie endliche oder abzählbar unendliche Realisierungen xi be-sitzt, so dass
∞
∑i=1
P(X = xi) = 1 (64)
gilt. Die Angabe aller Wahrscheinlichkeiten pi = P(X = xi) > 0mit i = 1, . . . , ∞ heißt dabei Wahrscheinlichkeitsverteilung. Eine Zu- Stetige
Zufallsvariablefallsvariable wird hingegen als stetig bezeichnet, wenn es eine nichtnegative integrierbare Funktion f : R → R mit der Eigenschaft
∫ ∞
−∞f (t)dt = 1 (65)

60 statistische methoden
gibt, so dass die Verteilungsfunktion F von X die Darstellung
F(u) = P(X ≤ u) =∫ u
−∞f (t)dt ≤ 1 (66)
mit u ∈ R besitzt. Die Funktion f wird dabei auch als Wahrschein-Wahrscheinlichkeits-dichte lichkeitsdichte bezeichnet.
Zusammenfassend führt die Einführung von Zufallsvariablen zu fol-gendem Ergebnis. Um für einen Wahrscheinlichkeitsraum (Ω,S , P)das Wahrscheinlichkeitsmaß P auf S zu bestimmen, muss für jedesEreignis A ∈ S eine Wahrscheinlichkeit P(A) festgelegt werden. Be-steht Ω aus endlich vielen Elementarereignissen, wie beispielsweisebeim Wurf einer Münze oder eines Würfels, lässt sich die Wahrschein-lichkeit noch einfach explizit ausrechnen. Wenn Ω aber nicht nur ausendlich vielen Elementen besteht, enthält S überabzählbar viele Er-eignisse. Die Bestimmung von P(A) ist nicht ohne weiteres möglich.Bei dem durch X induzierten Wahrscheinlichkeitsraum (R,B, PX) ge-nügt dagegen die Angabe der Verteilungsfunktion F(u), da mittelsdieser die Wahrscheinlichkeit jedes Intervalls und damit auch jederBorelmenge bestimmt werden kann.
3.2 größenverteilung
Gegeben sei nun ein Partikelsystem X aus polydispersen Kugeln. Zu-fällig wird eine Kugel aus dem Partikelsystem ausgewählt und dieGröße dieser Kugel bestimmt. Für das Maß der Größe kann dabei ei-ner der in Abschnitt 2.2 beschriebenen Deskriptoren, wie die mittlereBreite, die im Falle von Kugeln gleich dem Durchmesser ist, oder dasVolumen verwendet werden. Diese Vorgehensweise beschreibt ein Zu-fallsexperiment. Die Grundmenge Ω besteht aus den Kugeln im Sys-tem, während mittels der Zufallsvariable X das Merkmal Größe einerKugel w ∈ Ω durch X(w) = x bestimmt wird, wobei x die Realisie-rung von X ist. Der Vorgang wird n-mal wiederholt und das Ergebnisin Form eines Vektors (x1, . . . , xn) ∈ R
n, der sogenannten Stichprobeder X1, . . . , Xn unabhängig und identisch verteilten Zufallsvariablenzusammengefasst. Dabei ist xi die Realisierung der Zufallsvariable XiStichprobe
mit i = 1, . . . , n. Die Verteilungsfunktion der Zufallsvariablen wird indiesem Zufallsexperiment auch als Größenverteilung bezeichnet.
Im Folgenden soll nun gezeigt werden, wie anhand der Stichproben-werte ein geeignetes Modell zur Beschreibung der Größenverteilungbestimmt und parametrisiert werden kann. Der Begriff Modell wirddabei als Synonym für die Wahrscheinlichkeitsdichte f verwendet.Implizit wird also davon ausgegangen, dass die Zufallsvariablen beidem gerade beschriebenen Zufallsexperiment stetig sind.

3.2 größenverteilung 61
3.2.1 Schätzung der Verteilungs- und Dichtefunktion
Gegeben ist eine Stichprobe (x1, . . . , xn), die bei der Durchführungdes in Abschnitt 3.2 beschriebenen Zufallsexperimentes gewonnenwurde. Stellt sich die Frage, wie anhand der Stichprobe die theore-tische Größenverteilung F geschätzt werden kann. Dazu führt man Empirische
Verteilungsfunktionzunächst die empirische Verteilungsfunktion Fn ein. Diese ergibt sichfür eine Stichprobe mit Umfang n aus
Fn(u) =1n
n
∑i=1
1xi≤u,
(67)
wobei 1xi≤u gleich 1 für xi ≤ u ist. Laut Satz von Glivenko-Cantelli[137] kann nun gezeigt werden, dass Fn in der Supremums-norm
dn = supu∈R
|Fn(u)− F(u)| (68)
mit Wahrscheinlichkeit 1 gegen F(u) konvergiert. Aus dieser Erkennt-nis lässt sich bereits ein einfaches graphisches Werkzeug definie-ren, mit dem überprüft werden kann, wie gut eine theoretische Ver-teilungsfunktion mit der empirischen Verteilungsfunktion überein-stimmt. Dazu trägt man die Werte der gewählten theoretischen Ver-teilungsfunktion F(u) gegen die Werte der empirischen Verteilungs-funktion Fn(u) mit u ∈ R auf. Stimmen beide Verteilungen überein, PP-Plot und
QQ-Plotergibt sich eine Diagonale. Dieses Verfahren wird als Probability-Probability-Plot (PP-Plot) bezeichnet. Ein ähnliches Verfahren, mitdem überprüft werden kann, wie gut eine gewählte Verteilungsfunk-tion zu den beobachteten Daten passt, ist der Quantile-Quantile-Plot(QQ-Plot). Dieser verwendet die sogenannten Quantile. Um die Quan-tile zu berechnen, wird die Stichprobe (x1, . . . xn) zunächst in aufstei-gender Reihenfolge, geschrieben als
x(1) ≤ x(2) ≤ . . . ≤ x(n),
(69)
angeordnet. Dabei wird x(i) als die i-te Ordnungsstatistik der Stich-probe bezeichnet. Das empirische α-Quantil ist nun definiert als
qα =
x[nα]+1 , falls nα /∈ N
12 (x[nα] + x[nα]+1) , falls nα ∈ N
(70)
wobei α ∈ (0, 1) ist und die eckigen Klammern in diesem Fall für dieGaußklammer stehen. Die theoretischen Quantile für eine Zufallsva-riable X mit Verteilungsfunktion F werden stattdessen mittels derQuantilfunktion
Q(α) = infu ∈ R : F(u) ≥ α (71)
berechnet. Trägt man nun die empirischen und theoretischen Quan-tile gegeneinander auf, liegen die Werte auf einer Geraden, wenn

62 statistische methoden
die Stichprobenwerte gut durch die gewählte Verteilungsfunktion be-schrieben werden. Beide Verfahren stellen explorative Werkzeuge dar,mit denen eine von einem Experten getroffene Annahme über die Ver-teilungsfunktion graphisch, durch visuelle Inspektion, anhand vonStichprobenwerten überprüft werden kann.
Geht man von einer stetig verteilten Zufallsvariable X aus, ist mannicht nur an der Verteilungsfunktion F, sondern auch an der Wahr-scheinlichkeitsdichte f interessiert. Zwar kann im Allgemeinen dieDichte f durch die Ableitung von F bestimmt werden, wenn aber nurdie empirische Verteilungsfunktion Fn einer Stichprobe (x1, . . . , xn)
vorliegt, ist dies nicht möglich, da Fn nicht differenzierbar ist. Im Fol-genden werden deshalb zwei Verfahren vorgestellt, mit denen mandie Dichte f anhand von einer Stichprobe eines Zufallsexperimentsschätzen kann. Im weiteren Verlauf werden diese Verfahren als gra-phisches Hilfsmittel verwendet, um anhand der Form der geschätztenDichte auf ein adäquates Modell zu schließen. Das bekannteste undHistogramm
älteste Verfahren, um eine solche Schätzung vorzunehmen, ist das Hi-stogramm. Für diese Methode werden die Stichprobenwerte zunächstin Intervalle konstanter Breite aufgeteilt. Dann wird die relative Häu-figkeit für jedes dieser Intervalle berechnet. Diese ergibt sich aus derAnzahl der Werte am Gesamtumfang der Stichprobe, die in das je-weilige Intervall fallen. Schließlich ergibt sich die Häufigkeitsdichteeines Intervalls aus dem Quotienten der relativen Häufigkeit und derIntervallbreite. Werden Intervallbreite und Häufigkeitsdichte der ein-zelnen Intervalle als Breite und Höhe von Rechtecken interpretiertund in einem Koordinatensystem eingezeichnet, kann das auf dieseWeise konstruierte Histogramm als stückweise konstante Schätzungder stetigen Dichtefunktion interpretiert werden [19, S. 252]. DieserAnsatz liefert eine erste Vermutung über die Form der gesuchtenDichtefunktion. Problematisch dabei ist, dass das Ergebnis stark vonder gewählten Intervallbreite abhängt und nur eine diskrete Approxi-mation der stetigen Dichte f liefert. Letzteres kann aber in der Praxisoft vernachlässigt werden, da durch Messungen gewonnene Stichpro-ben häufig diskret erfasst werden. Gerade bei dem in dieser Arbeitbeschriebenen Anwendungsfall, bei dem die Durchmesser der poly-dispersen Kugeln in digitalisierten Schnittbildern gemessen werden,kommt dies zum Tragen. Alternativ erlaubt die Anwendung einesKerndichteschätzer
Kerndichteschätzers die stetige Schätzung der Dichtefunktion. DerKerndichteschätzer hat dabei die Form
f (v) =1
nh
n
∑i=1
k
(v− xi
h
)
,(72)
wobei k der Kern des Schätzers und die Bandbreite h ein frei wähl-barer Parameter ist. In der vorliegenden Arbeit wird für k ein durch
k(t) =1√2π
exp
(
−12
t2)
(73)

3.2 größenverteilung 63
definierter Gaußkern verwendet [19, S. 260]. Histogramm und Kern-dichteschätzer werden bei der späteren Modellbildung zusammenmit Expertenwissen dafür verwendet, eine passende Dichtefunktionauszuwählen.
3.2.2 Schätzen der Verteilungsparameter
Angenommen, für die Verteilung der polydispersen Kugeldurchmes-ser wurde eine geeignete Dichtefunktion ausgewählt. Gemeinhinhängt diese von weiteren Parametern, beschrieben durch den Parame-tervektor θ, ab. Auf Grund der stochastischen Unabhängigkeit ergibtsich die gemeinsame Dichte der Stichprobe aus
p(x|θ) = f (X1 = x1 . . . , Xn = xn|θ) =n
∏i=1
f (xi|θ).
(74)
Formel 74 lässt sich als die Wahrscheinlichkeit für das Auftreten einer Likelihood-Funktion
Stichprobe mit den Stichprobenwerten x = (x1, . . . , xn) bei gegebe-nem Parameter θ interpretieren. Man bezeichnet p(x|θ) auch als dieLikelihood-Funktion. Der Parametervektor θ lässt sich nun ebenfallsals Zufallsvariable auffassen, dessen Dichte durch p(θ) angegebenwird. Dabei wird p(θ) als A-priori Dichte bezeichnet und modelliert A-priori Dichte
das Vorwissen über die Verteilung des Parameters θ. Nun ist manaber weniger an der Verteilung für das Auftreten einer beliebigenStichprobe bei festen θ interessiert, sondern an der Verteilung vonθ bei einer beobachteten Stichprobe mit Stichprobenwerten x. Diese,als A-posteriori Dichte bezeichnete Funktion, lässt sich unter Anwen-dung des Satzes von Bayes [102, S. 313 ff.] aus der A-priori Dichteund der Likelihood-Funktion berechnen. Es gilt Satz von Bayes
p(θ|x) = p(θ)p(x|θ)p(x) ,
(75)
wobei p(x) die totale Wahrscheinlichkeit für das Auftreten der Stich-probe x ist und durch das Integral
p(x) =∫
p(x|θ)p(θ)dθ (76)
über den Parameterraum θ berechnet werden kann. Formel 75 be-schreibt also die Verteilung des Parameters θ nach Beobachtung einerStichprobe und Beachtung des Vorwissens und gibt an, welche Wertefür θ relativ zu den anderen am glaubwürdigsten sind. Ist die durch A-posteriori Dichte
die A-posteriori Dichte beschriebene Verteilung sehr eng, liegen al-so die Werte mit der höchsten Wahrscheinlichkeit auf engem Raum,besteht eine hohe Sicherheit gegenüber den möglichen Werten von θ.Bei einer stark gestreckten Verteilung mit hoher Varianz ist die Schät-zung von θ dagegen mit hoher Unsicherheit behaftet. Diese Unsicher-heit soll im Folgenden genauer quantifiziert werden, um damit später

64 statistische methoden
das Abbruchkriterium für den Anwendungsfall konstruieren zu kön-nen. In dieser Arbeit werden dazu die Intervalle der höchsten DichteHighest Density
Interval (im Englischen Highest Density Interval (HDI)) verwendet. Das HDIfasst die Verteilung durch ein Intervall I = [ta, tb] zusammen, in dem1− α Prozent aller Punkte liegen, die mindestens eine so hohe Dichtehaben wie die Punkte außerhalb des Intervalls. Formal ist das HDIgegeben durch
∫ tb
ta
p(θ|x)dθ = 1− α,
(77)
wobei zusätzlich für alle θ ∈ I und alle θ /∈ I die Ungleichungp(θ|x) ≥ p(θ|x) gelten muss [44, S. 49 ff.]. Je enger das Intervall I ist,umso genauer ist die Schätzung des Parameters θ. Bei einer fortlau-fenden Messung kann das HDI kontinuierlich parallel zur Messungberechnet werden. Ist ein Intervall mit einer vorgegebenen Zielbrei-te unter der Angabe der Genauigkeit α erreicht, wird der Prozessgestoppt. Diese Art der Datensammelung wird auch in anderen wis-senschaftlichen Disziplinen angewandt [73, S. 590 ff.] und bildet denGrundbaustein des Abbruchkriteriums aus Abschnitt 6.4.2.
In der Praxis ist es auf Grund des Integrals im Nenner von Formel 75
häufig schwierig, die A-posteriori Dichte direkt anzugeben. Zwar ge-hören die A-posteriori und A-priori Dichten für bestimmte A-prioriDichten derselben Familie an (die sogenannten konjugierten A-prioriDichten), für die wiederum geschlossene Formen bekannt sind, imAllgemeinen existiert aber nicht für jede Likelihood-Funktion ein kon-jugiertes Prior. Auch numerische Integration mit Standardverfahrenstößt schnell an die Grenzen, wenn es sich bei θ um einen hochdi-mensionalen Parametervektor handelt. Alternativ versucht man des-Metropolis-
Algorithmus halb, die A-posteriori Dichte durch Stichproben diskret zu approxi-mieren. Eine Möglichkeit, dies zu tun, besteht in der Verwendungdes Metropolis-Algorithmus [93], der zur Klasse der Markov-Ketten-Monte-Carlo (MCMC)-Verfahren gehört. Unter der Voraussetzung,dass A-priori und die A-posteriori Dichte für jeden spezifizierten Pa-rameter θ und eine Stichprobe mit Stichprobenwerten x auswertbarsind, lässt sich der Algorithmus wie folgt angeben. Sei θ(1) ein festge-legter Startwert im Parameteraum und h(x|θ(t)) eine beliebige Dich-tefunktion, die vom aktuellen Zustand θ(t) abhängt und Vorschlags-dichte genannt wird. In der vorliegenden Arbeit wird eine symme-trische Dichtefunktion als Vorschlagsdichte verwendet und zwar dieNormalverteilung. In diesem speziellen Falll ist h(x|θ(t) = h(θ(t)|x).Gesucht wird nun die Stichprobe der Zufallsvariablen θ(1), . . . , θ(l),die eine Verteilung mit Dichte p(θ|x) haben. Um diese zu berechnenwird iterativ für t < l eine neue Zufallszahl θ aus der Vorschlagsdich-

3.2 größenverteilung 65
te h(x|θ(t)) gezogen. Ob θ als neuer Zustand und damit als Zufallsva-riable θ(t+1) der Stichprobe akzeptiert wird, ergibt sich aus
θ(t+1) =
θ mit Wahrscheinlichkeit min(
1, p(θ|x)p(θ(t)|x)
)
θ(t) mit Wahrscheinlichkeit 1−min(
1, p(θ|x)p(θ(t)|x)
)
.
Die A-posteriori Dichte p(θ|x) geht in die Berechnung lediglich im
Verhältnis p(θ|x)p(θ(t)|x) ein. Der konstante Nenner von Formel 75 kürzt
sich also raus und muss nicht bekannt sein. Für die auf diese Weisegenerierte Stichprobe kann gezeigt werden, dass p(θ|x) die stationäreVerteilung von θ(1), . . . , θ(l) ist [112, S. 231 ff.]. Je mehr Zufallszahlenalso erzeugt werden, umso besser wird die Verteilung p(θ|x) appro-ximiert. In der Praxis müssen aber die ersten Stichprobenwerte ver-worfen werden, da der Algorithmus eine Zeit benötigt, bis er in denstationären Zustand übergeht. Außerdem müssen Startparameter θ(1)
und Vorschlagsdichte h(x|θ(t)) adäquat gewählt und parametrisiertwerden. In der vorliegenden Arbeit wird auf die Software JAGS1 zu-rückgegriffen, um eine Stichprobe der A-posteriori Dichte zu gene-rieren. Passende Vorschlagsdichten und Startwerte werden für denNutzer dann automatisch gewählt.
Auf Basis der Stichprobe θ(1), . . . , θ(l) lassen sich dann die zusammen-fassenden Statistiken wie Mittelwert, Varianz und das HDI berechnen,die später zum Vergleich verschiedener Messungen dienen und Basisdes Abbruchkriteriums sind. Der Mittelwert θ ergibt sich aus Mittelwert und
Varianz
E(θ|x) =∫
θp(θ|x)dθ
≈ 1n
l
∑i=1
θ(i) = θ(78)
und die Varianz s2 aus
Var(θ|x) =∫
(p(θ|x)− E(θ|x))2dθ
≈ 1n− 1
l
∑i=1
(θ(i) − θ)2 = s2
.
(79)
Das HDI wird mittels dem von Chen und Shao [25] vorgeschlagenenAlgorithmus berechnet. Dafür werden die Stichprobenwerte zunächstaufsteigend sortiert und anschließend alle Intervalle der Form
Ij =(
θ(j), θ(j+((1−α)n)))
(80)
mit j = 1, . . . , n− ((1− α)n) berechnet, wobei α die Wahrscheinlich-keitsmasse für das Intervall festlegt. Das Intervall Ij mit der gerings-ten Breite ist dann das HDI.
1 http://mcmc-jags.sourceforge.net/

66 statistische methoden
Nicht unerwähnt soll an dieser Stelle das Maximum-Likelihood Ver-fahren bleiben, mit dem ebenfalls Schätzungen der Verteilungspara-meter gewonnen werden können. Die Idee dabei ist, die Likelihood-Funktion aus Formel 74 für einen gegebenen Datensatz x in Bezugauf θ zu maximieren. Im Gegensatz zum oben vorgestellten bayess-Maximum-
Likelihood chen Ansatz wird θ aber nicht als Zufallsvariable betrachtet. DasMaximum-Likelihood Verfahren liefert also nur eine Punktschätzungfür den Parameter und nicht eine vollständige Verteilung. Das Ver-fahren wird in dieser Arbeit verwendet, um beim Modellbildungs-prozess schnell die Parameter für die ausgewählte Dichte zu berech-nen. Das so parametrisierte Modell kann dann direkt mit dem Histo-gramm und der Kerndichteschätzung verglichen werden.
3.2.3 Überprüfung des Modells
Gesetzt den Fall, eine passende Dichtefunktion wurde ausgewählt,die die Durchmesserverteilung der polydispersen Kugeln beschreibt,und die A-posteriori Dichte der Verteilungsparameter wurden mit-tels des im vorherigen Abschnitt beschriebenen Verfahrens geschätzt,dann soll im nächsten Schritt überprüft werden, inwieweit das so spe-zifizierte Modell wirklich zu den erhobenen Daten passt. Dieser Testsoll einerseits den Modellbildungsprozess unterstützen, andererseitsspäter im Anwendungsfall dafür sorgen, dass keine Daten, die grobdie getroffenen Annahmen verletzen, mit in die Auswertung einge-hen. Für die letztere Anforderung muss der Test nach Kalibrierungmöglichst autonom ablaufen.
Das Verfahren verwendet die Dichte der posteriori-prädiktiven Ver-teilung. Diese beschreibt die Verteilung von bis Dato unbeobachtetenDaten x in Abhängigkeit der schon beobachteten Daten x. Sie ist de-finiert durch
p(x|x) =∫
p(x|θ)p(θ|x)dθ,
(81)
ergibt sich also aus dem Produkt der Likelihood-Funktion für x undder A-posteriori Dichte für alle möglichen Werte von θ [43, S. 8 ff.].Posteriori-prädiktive
Verteilung In der Praxis wird die posteriori-prädiktive Verteilung durch Simu-lation berechnet. Dafür werden für jeden der durch das MCMC-Verfahren bestimmten Parameter θ(1), . . . , θ(l) jeweils n Stichprobenaus der Likelihood-Funktion gezogen. Für jede der i = 1, . . . , l aufdiese Weise generierten Stichproben x(i) = x1
(i), . . . , xn(i) mit Stich-
probenumfang n wird dann die posteriori-prädiktive Verteilung derDifferenzen
∆(i) = T(x, θ(i))− T(x(i), θ(i)),
(82)
über die gemessenen und simulierten Daten berechnet, wobei T eineTeststatistik ist. Üblicherweise verwendet man als Teststatistik Mini-Teststatistik

3.3 räumliche verteilung 67
mum, Maximum, Mittelwert oder Quantile, aber auch komplexereKriterien, wie beispielsweise der χ2 Test können angewendet werden[43, S. 163 ff.]. Ist nun die 0 ein Extremwert der posteriori-prädiktivenVerteilungen der Differenzen ∆(1), . . . , ∆(l), so ist dies ein Hinweis aufeine große Diskrepanz zwischen Modell und erhobenen Daten. Eineinfacher graphischer Test lässt sich wie folgt konstruieren. Man be-rechnet das Histogramm und das HDI über ∆(1), . . . , ∆(l) und über-prüft, ob 0 innerhalb des HDIs liegt. Ist dies nicht der Fall, kanndie Abweichung zwischen Daten und Modell nicht mehr als statisti-sches Rauschen interpretiert werden [43, S. 172]. Alternativ lässt sichauch ein zum p-Wert der Inferenzstatistik äquivalenter Wert, der so-genannte posteriori-prädiktive pB-Wert, berechnen [43, S. 163 ff.]. Die-ser gibt die Wahrscheinlichkeit dafür an, dass die generierten Datenbezogen auf die Teststatistik extremer ausfallen als die gemessenenDaten. Wenn die Daten die Modellannahme verletzen, ist T(x, θ(i))
signifikant verschieden von T(x, θ(i)), der pB-Wert wird also je nachgewählter Teststatistik einen extremen Wert nahe 0 oder 1 annehmen.Damit lässt sich der oben besprochene graphische Test nach entspre-chender Kalibrierung automatisieren. Vorzugsweise wird in der vor-liegenden Arbeit aber der graphische Test verwendet.
3.3 räumliche verteilung
Nachdem geeignete Methoden vorgestellt wurden, um die Größen-verteilung von Partikeln zu analysieren, soll nun ihre räumliche Ver-teilung genauer untersucht werden. Dabei stehen folgende Aspekteim Mittelpunkt. Zunächst stellt sich die Frage, ob die Partikel homo-gen, also gleichförmig, im Material verteilt sind. Der Begriff der Ho-mogenität wird im Folgenden exakt definiert und aufbauend auf die-ser Definition ein Verfahren abgeleitet, um diese Annahme zu über-prüfen. Die Annahme ist von großer Bedeutung für das in Abschnitt4.2 beschriebene Messverfahren. Ist nämlich die Homogenität der De-fektverteilung in der Bramme nicht gegeben, können keine gesicher-ten statistischen Erkenntnisse über den Reinheitsgrad aus zufälligder Bramme entnommen Materialproben abgeleitet werden. Weitersoll untersucht werden, ob und inwieweit zwischen den einzelnenPartikeln Interaktion stattfindet. Hängt also die Position eines einzel-nen Partikels von Partikeln in seiner Nachbarschaft ab oder sind siezufällig und unabhängig voneinander im Raum verteilt? Um dieseFrage zu beantworten, wird das durch die Partikelpositionen gebilde-te Punktmuster als Realisierung eines Modells, konkret eines Punkt-prozesses, interpretiert. Dieses Modell dient, zusammen mit den ausden Daten geschätzten Modellparametern, dann als Grundlage fürdie Simulation weiterer Punktmuster, die unter Verwendung geeigne-ter Statistiken gegen das beobachtete Punktmuster verglichen werden

68 statistische methoden
und Aufschluss über Verteilungseigenschaften liefern. Die Form desModells, die Methode zur Parameterschätzung und die Statistikenwerden in den folgenden Abschnitten erläutert. Begonnen wird mitder Definition der grundlegenden Begriffe.
3.3.1 Punktprozess
Gegeben ist, wie bereits im vorherigen Abschnitt eingeführt, ein Par-tikelsystem X ⊂ R
d aus polydispersen Kugeln, wobei deren Positionim Raum durch eine Sequenz von Zufallsvariablen X1, X2, . . . be-schrieben wird. Formal ist eine Zufallsvariable Xi der Sequenz alsoeine Abbildung Xi : Ω → R
d. Dabei wird in der vorliegenden ArbeitPunkte
die Position der Kugel durch ihren Schwerpunkt angegeben und inder Regel der Fall d = 3 untersucht. Die einzelnen Zufallsvariablenwerden auch als Punkte bezeichnet.
Sei nun N(B) = #i : Xi ∈ B mit i ∈ N die Anzahl der PunkteXi in einer Teilmenge B ⊂ R
d. Wenn N(B) < ∞ für alle beschränk-ten Mengen B gilt, dann wird X1, X2, . . . als zufälliger Punktpro-zess bezeichnet und man schreibt N = X1, X2, . . . [61, S. 24 ff.]. InPunktprozess
Übereinstimmung mit der gängigen Literatur zum Thema räumlicherStatistik wird N also als Symbol für zwei unterschiedliche Konzepteverwendet. Zum einen bezeichnet N ein Zählmaß auf zufälligen Men-gen, zum anderen wird damit die zufällige Menge der Punkte selbstbezeichnet.
Weiter definiert manP(N(B) = n) (83)
als die Wahrscheinlichkeit, dass in der Menge B exakt n Punkte desProzesses N liegen und
P(N(B1) = n1, . . . , N(Bk) = nk) (84)
als die Wahrscheinlichkeit, dass in den Mengen B1, . . . , Bk jeweils ex-akt n1, . . . , nk Punkte liegen. Die mittlere Anzahl der Punkte von Nin B wird schließlich als
Λ(B) = E(N(B)) (85)
geschrieben, wobei E der Erwartungswert ist und die Funktion Λ alsIntensitätsmaß bezeichnet wird. Wenn Λ absolut stetig ist, dann gibtIntensitätsmaß
es eine Lebesgue integrierbare Funktion λ(u), so dass
Λ(B) =∫
Bλ(u)du (86)
gilt. Die Dichtefunktion λ(u) wird auch als Intensität bezeichnet. For-Intensität
mel 86 lässt sich als Volumenintegral in Rd interpretieren, das heißt

3.3 räumliche verteilung 69
λ(u)du ist die Wahrscheinlichkeit, dass ein Punkt in der Kugel mitinfinitesimalem Volumen du mit Mittelpunkt u liegt [61, S. 28 ff.].
Ein Punktprozess N wird als homogen (oder auch stationär) bezeich-net, wenn N die gleiche Verteilung wie Nu für alle u ∈ R
d hat. Homogenität
Dabei ist Nu der um u verschobene Punktprozess N, also Nu =
X1 + u, . . . , Xn + u. Die gleiche Verteilung liegt dann vor, wenn
P(N(B1) = n1, . . . , N(BK) = nk)
= P(Nu(B1) = n1, . . . , Nu(Bk) = nk)
= P(N(B1 − u) = n1, . . . , N(Bk − u) = nk)
(87)
gilt. Dabei ergibt sich die letzte Zeile aus Nu(B) = N(B− u) für al-le B und u mit B − u = y − u : y ∈ B, also die um den Vektor−u verschobenen Menge B, auch als B−u bezeichnet. Anders ausge-drückt ist die Anzahl der Punkte für eine feste Menge B und einenum u verschobenen Punktprozess Nu gleich der Anzahl der Punkteder um −u verschobenen Menge B und einem festen Punktprozess N[61, S. 37 ff.]. Man bezeichnet deshalb auch den Punktprozess N alstranslations-invariant. Aus der Translations-Invarianz ergibt sich ei-ne weitere wichtige Eigenschaft. Für einen homogenen Punktprozessgilt für das Intensitätsmaß
Λ(B) = E(N(B)) = E(Nu(B)) = E(N(B−u)) = Λ(B−u).
(88)
Es ist also ebenfalls translations-invariant. Daraus folgt
Λ(B) = λv(B),
(89)
oder anders ausgedrückt, das Intensitätsmaß Λ(B) ist bis auf einemultiplikative Konstante λ gleich dem Lebesgue-Maß v(B) (für R
2
die Oberfläche und R3 das Volumen) [133, Satz 1.83, 31 ff.]. Wird
für das Volumen von B das Einheitsvolumen gewählt, kann λ als diedurchschnittliche Anzahl von Punkten in N interpretiert werden.
Neben der Homogenität wird in der Praxis häufig die Annahme ge-troffen, dass der Punktprozess isotrop, also invariant unter Rotation,ist. Ein homogener, isotroper Punktprozess wird auch als bewegungs-invariant bezeichnet.
3.3.2 Homogener Poisson Punktprozess
Nachdem im vorherigen Abschnitt die grundlegenden Begrifflichkei-ten definiert wurden, wird nun ein Modell vorgestellt, bei dem dieVerteilung der Punkte sehr starken Unabhängigkeitsbedingungen un-terliegt. Bei diesem Modell sollen sowohl die Anzahl der Punkteinnerhalb disjunkter Teilmengen, als auch die Position der Punkte

70 statistische methoden
im Raum stochastisch unabhängig voneinander sein. Zusätzlich sol-len die Punkte zufällig, das heißt im Sinn einer Gleichverteilungim Raum verteilt, sein. Diese Eigenschaft von Punktprozessen wirdComplete Spatial
Randomness in der englischsprachigen Literatur als Complete Spatial Random-ness (CSR) bezeichnet und lässt sich grob mit rein zufällige Anordnung(der Punkte) übersetzen. Begonnen wird, in Übereinstimmung mitStoyan, Kendall und Mecke [133, S. 37] sowie Illian u. a. [61, S. 59 ff.]mit der Definition des binomialen Punktprozesses. Bei diesem ist dieCSR-Eigenschaft noch nicht erfüllt. Er dient aber als Basis zur Kon-struktion des homogenen Poissonpunkprozess, der die gewünschtenEigenschaften besitzt.
Angenommen, in einer begrenzten Menge W ⊂ Rd liegen n Punkte,
die jeweils gleichverteilt und unabhängig voneinander auftreten. Eineinzelner Punkt X wird dabei als gleichverteilt in W angesehen, wenn
P(X ∈ B) =v(B)v(W)
(90)
für alle Teilmengen B von W gilt. Für n unabhängige PunkteX1, . . . , Xn gilt dann
P(X1 ∈ B1, . . . , Xn ∈ Bn)
= P(X1 ∈ B1) . . . P(XN ∈ Bn)
=v(B1) . . . v(Bn)
v(W)n .
(91)
Die Punkte X1, . . . , Xn bilden einen binomialen Punktprozess mit fes-BinomialerPunktprozess ter Anzahl n an Punkten. Der Name ergibt sich dabei aus der Eigen-
schaft, dass die Anzahl der Punkte k in einer Teilmenge B ⊂ W derBinomialverteilung folgt. Konkret gilt
P(N(B) = k) =
(nk
)
pk(1− p)n−k (92)
mit k = 0, . . . , n und p = v(B)v(W)
. Für die Binomialverteilung ist der Mit-telwert gleich np [72, S. 111]. Somit ist die durchschnittliche Anzahlvon Punkten in B gleich
np = nv(B)v(W)
= λv(B) (93)
wobei λ = nv(W)
ist. Die Intensität λ bezeichnet also die durchschnitt-liche Anzahl von Punkten im Einheitsvolumen. Man beachte, dassbeim binomialen Punktprozess die Anzahl der Punkte in disjunk-ten Teilmengen von W nicht unabhängig voneinander ist, da ausN(B) = m direkt N(W\B) = n−m folgt. Daher ist diese kein geeig-netes Modell für CSR. Eine Verteilung, bei der die zufällige Anzahlder Punkte in einer Teilmenge nicht die Anzahl in einer anderen Teil-menge beeinflusst, kann aber wie folgt konstruiert werden. Vergrö-ßert man das Beobachtungsfenster W, so dass es den gesamten R
d

3.3 räumliche verteilung 71
einnimmt, dann strebt p gegen 0, während n gegen unendlich läuft.Für ein fixes Verhältnis n
v(W)= λ gilt dann, wegen des Poissonschen
Grenzwertsatzes [72, S. 115], für alle Teilmengen B von W, dass dieAnzahl k der Punkte in N(B) einer Poisson-Verteilung mit Mittelwertλv(B) folgt. Die Wahrscheinlichkeit, dass in einer Teilmenge B also Homogener Poisson
Punktprozessexakt m Punkte liegen, ist durch
P(N(B) = m) =(λv(B))m
m!e−λv(B) (94)
gegeben. Für die disjunkten Teilmengen B1, . . . Bk sind bei einemsolchen Prozess N(B1), . . . N(Bk) unabhängige Zufallsvariablen, dieCSR-Eigenschaft ist also erfüllt [61, S. 60 ff.]. Ein solcher Prozess wirdals homogener Poisson Punktprozess (PPP) bezeichnet.
Zusammengefasst sind die wichtigsten Eigenschaften eines homoge-nen PPPs: Eigenschaften eines
homogenen PPPs1. Die Anzahl der Punkte in einem homogenen PPP folgt für jede
Teilmenge B der Poisson Verteilung mit dem Mittelwert λv(B).
2. Die Anzahl der Punkte in k disjunkten Teilmengen B1, . . . , Bk
eines homogenen PPP sind unabhängige Zufallsvariablen.
3. Ein homogener PPP ist bewegungs-invariant.
Damit der PPP aber als adäquates Modell für die Beschreibung derräumlichen Verteilung von Partikeln in Betracht gezogen werdenkann, müssen die Punkte homogen im Material verteilt, beziehungs-weise die Intensitätsfunktion λ(u) konstant sein. Wie man diese An-nahme überprüft, wird im nächsten Abschnitt gezeigt.
3.3.3 Schätzen der Intensitätsfunktion
Angenommen, mittels einer nicht näher spezifizierten Messmethodewurden in einem Beoachtungsfenster W ⊂ R
d die Schwerpunkte vonn Kugeln gemessen. Das Ergebnis lässt sich als Matrix
x11 . . . x1d...
. . ....
xn1 . . . xnd
(95)
schreiben, wobei der Vektor
xi =
xi1...
xid
(96)
mit i = 1, . . . , n dem Schwerpunkt der i-ten Kugel entspricht undaus den Zeilen der Matrix 95 gebildet wird. Weiter bezeichnet xij

72 statistische methoden
mit j = 1, . . . , d die j-te Koordinate des Schwerpunktes der i-tenKugel. Dann kann die Matrix (x1, . . . , xn)T als konkrete Realisierungdes Punktprozesses N interpretiert werden und wird als Punktmus-ter bezeichnet. Ausgangspunkt für die statistische Untersuchung vonPunktmustern ist nun die Frage, ob die räumliche Verteilung der be-obachteten Punkte gemäß der Definition in Abschnitt 3.3.1 homogenist. Lässt sich diese Annahme bestätigen, kann als nächstes überprüftPunktmuster
werden, ob zwischen den Punkten Interaktion stattfindet oder ob diePunkte, gemäß der CSR-Eigenschaft, rein zufällig im Raum verteiltsind. Dazu wird der im vorherigen Abschnitt beschriebene PPP ent-sprechend der beobachteten Daten parametrisiert und das theoreti-sche Muster mit dem beobachteten Muster verglichen. Liegt keinehomogene Verteilung vor, muss ein anderes Modell für weitere Un-tersuchungen herangezogen werden. Die Annahme von Homogenitäthat damit großen Einfluss auf den Modellierungsprozess.
In der Literatur zum Thema räumliche Statistik wird übereinstim-mend berichtet, dass der statistische Nachweis, ob ein Punktmustereinem homogenen Punktprozess entspringt, im Allgemeinen nichtmöglich ist [134, S. 220, 61, S. 38]. Üblicherweise stehen nur wenigeMuster, die in begrenzten Beobachtungsfenstern gemessen wurden,zur Verfügung, um den Nachweis zu führen. In einem begrenztenFenster ist es aber durchaus möglich, dass ein homogener Punkt-prozess eine inhomogene Verteilung besitzt. Auf der anderen Seitekann, wenn das Beobachtungsfenster beispielsweise zu klein gewähltwurde, ein eigentlich inhomogener Punktprozess in dem betrachtetenAusschnitt eine homogene Verteilung aufweisen. Aus diesem Grundmüssen immer fachliche Argumente und Expertenwissen herangezo-gen werden, um die Homogenität von Punkverteilungen zu begrün-den. Dennoch wurden Verfahren vorgestellt (siehe zum Beispiel Illianu. a. [61, S. 87]), um zumindest die Plausibilität der Annahme anhandvon beobachteten Daten zu überprüfen. In der vorliegenden Arbeitwird ein Verfahren auf Basis der bereits in Abschnitt 3.2.1 beschrie-benen Kerndichteschätzer verwendet. Konkret geht es darum, die In-tensitätsfunktion λ(u) aus Formel 86 in dem Beobachtungsfenster Wzu schätzen. Entspringt das Punktmuster einem homogenen Punkt-prozess und wurde W ausreichend groß gewählt, um die Charakte-ristiken der Daten zu erfassen, dann sollte λ(u), bis auf kleine Ab-weichungen, die mittels lokaler Fluktuationen der Intensität erklärtwerden können, um einen konstanten Wert schwanken. Dies ergibtsich direkt aus der Definition der Homogenität aus Abschnitt 3.3.1.Ist hingegen ein eindeutiger Trend auszumachen, muss die Ursachefür diesen durch genauere Untersuchung der Daten festgestellt wer-den.
Die Schätzung von λ(u) funktioniert analog, wie in Abschnitt 3.2.1beschrieben, außer dass der univariate Kern durch einen multivaria-

3.3 räumliche verteilung 73
ten ersetzt werden muss, da die Intensitätsfunktion von mehrerenParametern abhängt. Der Schätzer für ein Punktmuster hat die Form Kerndichteschätzer
λ(u)h =1hd
n
∑i=1
k
(u− xi
h
)
=1hd
n
∑i=1
k
(u1 − xi1
h, . . . ,
ud − xid
h
)
,(97)
wobei k der multivariate Kern mit d Parametern, h die Bandbreitefür alle Komponenten und u = (u1, . . . , ud) ∈ R
d ein Punkt im Wist. Wenn der Kern k separierbar ist, also als Produkt von univariatenKernen dargestellt werden kann, lässt sich Formel 97 auch als
λ(u) =1hd
n
∑i=1
(d
∏j=1
k
(uj − xij
h
))
(98)
schreiben. In der vorliegenden Arbeit wird ausschließlich der Gauß-Kern benutzt, der die gewünschten Eigenschaften besitzt. Die Schät-zung von λ(u) wird also mittels Formel 98 vorgenommen. Problema-tisch an Formel 98 ist allerdings, dass Randeffekte nicht beachtet wer-den. Das Beobachtungsfenster W ist üblicherweise nur ein Ausschnitteines Punktmusters, welches wiederum als Realisierung eines Punkt-prozesses mit möglicherweise unendlicher Ausdehnung interpretiertwird. Für Punkte, die nahe am Rand von W liegen, wird der Einflussvon Punkten, die außerhalb von W liegen, nicht beachtet. Um die-ses Problem zu beheben, wird die Kantenkorrektur von Diggle [33]verwendet. Für einen multivariaten und symmetrischen Kern ist das Kantenkorrektur
Verfahren durch
λ(u) =1
q(u)hd
n
∑i=1
(d
∏j=1
k
(uj − xij
h
))
(99)
gegeben, wobei
q(u) =∫
W
1hd
k
(u− a
h
)
da (100)
gilt. Die Idee dabei ist, dass Punkte, für die der Kern k aus dem Fens-ter W ragt, entsprechend dem überstehenden Anteil normalisiert wer-den. Dies führt dazu, dass Randpunkte stärker gewichtet werden alsPunkte, die in der Mitte des Fensters liegen und beugt dem Effektvor, dass die Intensität am Rand auf Grund fehlender Informationenauf 0 gezogen wird. In Abbildung 5 ist die Auswirkung der Kanten- Beispiel
korrektur zu sehen. In den beiden Bildern a) und b) ist die mittelsKerndichteschätzung berechnete Intensitätsfunktion λ(u) für einensimulierten PPP (siehe Abschnitt 6.3) mit Intensität λ = 0.00275 in ei-nem Beobachtungsfenster mit der Abmessung [100, 700] × [100, 700]eingezeichnet. Die Werte für λ(u) sind dabei durch eine Falschfar-bentransformation kodiert. Die schwarzen Kreise sind Positionen dereigentlichen Punkte des Prozesses. Die Bandbreite h des Gauß-Kerns

74 statistische methoden
k beträgt 75. In Abbildung 5 a) wurde λ(u) ohne Kantenkorrektur be-rechnet. In der Mitte des Bildes ist die Intensität nahezu konstant undschwankt um den erwarteten Wert von 0.00275. An den Rändern aller-dings bricht der Wert auf Grund der fehlenden Information ein undgeht gegen 0. Mit eingeschalteter Kantenkorretur entsteht hingegen,wie in Abbildung 5 b) zu sehen ist, ein homogener Farbverlauf, wel-cher auf eine konstante Intensität hindeutet. Das fehlerhafte Verhal-ten an den Rändern ist beseitigt. Entscheidend für die Schätzung von
Abbildung 5.: Kerndichteschätzung der Intensität eines simuliertenPPPs. a) ohne Kantenkorrektur b) mit Kantenkorrektur
a) b)
λ(u) ist die Wahl der Bandbreite h. Wird h zu klein gewählt, schlägtλ(u) schon bei lokalen Schwankungen von λ(u) stark aus. Wird h hin-gegen zu groß gewählt, gehen gegebenenfalls wichtige lokale Eigen-schaften von λ(u) verloren. Die Frage, wie h konkret gewählt werdenmuss, wird auch in der Fachliteratur intensiv diskutiert [29, S. 654].Wahl der Bandbreite
Eine einfache Daumenregel besteht darin, h auf 1/√
n zu setzen [61,S. 115]. Alternativ schlägt Diggle [33] vor, die mittlere quadratischeAbweichung des Schätzers zu minimieren. Konsens ist, dass eine all-gemeingültige Vorgehensweise nicht angegeben werden kann. In dervorliegenden Arbeit wird das Verfahren von Diggle [33] gewählt, umeinen ersten Wert für h zu erhalten. Ausgehend von diesem Wert wirddas Verhalten von λ(u) für kleine Änderungen von h untersucht.
Es sei an dieser Stelle noch darauf hingewiesen, dass in der vorliegen-den Arbeit am häufigsten dreidimensionale Punktmuster untersuchtwerden. Für dreidimensionale Punktmuster ist es zwar ohne weite-res möglich, λ(u) mit dem vorgestellten Verfahren zu schätzen, aller-dings ist das explorative Auswerten eines solchen hochdimensionalenDatensatzes schwierig. Aus diesem Grund wird in der vorliegendenArbeit bei dreidimensionalen Punktmustern λ(u) anhand von Schnit-ten und Projektionen entlang der Raumrichtungen geschätzt.

3.3 räumliche verteilung 75
3.3.4 Modellparametrisierung und Validierung
Unter der Voraussetzung, dass die Punktdichte homogen im Materi-al ist, kann der oben beschriebene PPP als sogenanntes Nullmodellherangezogen werden. Das heißt, man stellt die Hypothese auf, dassfür das beobachtete Punktmuster die CSR-Eigenschaft gilt. Der PPPwird also anhand der geschätzten Parameter aus den erhobenen Da-ten parametrisiert. Anschließend können verschiedene Teststatistikenberechnet und mit den jeweiligen Statistiken der beobachteten Datenverglichen werden. Stimmen die Statistiken für das theoretische Mo-dell und dem Punktmuster überein, deutet dies auf eine rein zufälli-ge Anordnung der Punkte hin, während Abweichungen vom theoreti-schen Modell ein Hinweis auf etwaige Interaktion der einzelnen Parti-kel ist. Die Hypothese wird verworfen und ein anderes, komplexeresModell muss betrachtet werden. Im Folgenden wird die Vorgehens-weise genauer beschrieben und die Teststatistiken werden eingeführt.Es wird mit der Schätzung der Modellparameter aus den beobachte-ten Daten begonnen.
Wie in Abschnitt 3.3.2 beschrieben, hängt der PPP nur von einemParameter ab, nämlich der Intensität λ. Die Anzahl der Punkte N(B)einer beliebigen Teilmenge B ⊂ R
d folgt der Poisson-Verteilung mitλv(B) als Parameter. Ein erwartungstreuer Schätzer des Parameters Punktschätzer
λ für ein Punktmuster x1, . . . , xn im Beobachtungsfenster W ist durch
λ =N(W)
v(W)(101)
gegeben [61, S. 189].
In der vorliegenden Arbeit soll aber λ nicht mittels Formel 101 ge-schätzt werden, sondern wieder mit dem aus Abschnitt 3.2.2 bekann-ten bayesschen Ansatz. Dieser erlaubt etwaiges Vorwissen über denPunktprozess zu berücksichtigen und die Sicherheit des geschätztenParameters adäquat zu quantifizieren. Die Likelihood-Funktion ei-nes PPPs wird dabei wie folgt konstruiert. Die zufällige Anzahl nder beobachteten Punkte x1, . . . xn eines Punktprozesses N im Fens-ter W ist gemäß Formel 94 Poisson-verteilt mit dem Erwartungswertλv(W). Die zufälligen Positionen der Punkte im Raum sind hingegen Likelihood-Funktion
gleichverteilt mit der Dichte f (x1, . . . , xn) = 1/v(W)n. Unter Berück-sichtigung dieser beiden Bedingungen lässt sich dann die Likelihood-Funktion eines Punktprozesses N als
p(N|λ) = p(x1, . . . , xn|λ)= [P(N(W) = n|λ]n! f (x1, . . . , xn)
=
((λv(W))n
n!e−λv(W)
)n!
v(W)n
= e−λv(W)λn
(102)

76 statistische methoden
aufstellen [79, S. 5]. Dabei ist die Fakultät von n in Zeile 2 von Formel102 dem Fakt geschuldet, dass die Reihenfolge der Punkte im Pro-zess N austauschbar ist. Die A-posteriori Verteilung kann nun wie-der nach Wahl einer geeigneten A-priori Verteilung, wie in Abschnitt3.2.2 beschrieben, mittels des MCMC-Verfahrens approximiert wer-den. Da der Punktprozess aber nur von einem Parameter abhängt,ist es in diesem Fall sinnvoller, die Schätzung der Intensität λ durchdie Wahl einer zur Poisson-Verteilung konjugierten A-priori Vertei-lung durchzuführen, so dass die A-posteriori Verteilung in geschlos-sener Form vorliegt. Die Gamma-Verteilung besitzt für eine Poisson-Gamma-Verteilung
Verteilung diese Eigenschaft. Die Dichte der Gamma-Verteilung mitParameter α und β ist gegeben durch
p(λ) = p(λ|α, β) =βα
Γ(α)λα−1e−βλ
,(103)
wobei Γ die Eulersche Gammafunktion (siehe auch Formel 28) ist.Für eine beobachtete Realisierung eines Punktprozesses N in FensterW mit n Punkten ergibt sich dann durch Anwenden der bayesschenRegeln 75 mit der Likelihood-Funktion aus Formel 102 und A-prioriVerteilung aus Formel 103
p(λ|N) =p(N|λ)p(λ)
p(N)
∝ p(N|λ)p(λ)
∝
(βα
Γ(α)λα−1e−βλ
)(
e−λv(W)λn)
∝(
λα−1e−βλ) (
e−λv(W)λn)
= λα−1+ne−(β+v(W))λ
.
(104)
Dabei ist p(N) die totale Wahrscheinlichkeit für das Auftreten desPunktprozesses N und ist durch das Integral
p(N) =∫
p(N|λ)p(λ)dλ (105)
gegeben, wobei die Integration über alle möglichen Werte von λ er-folgt. Für einen fixen Punktprozess N ist p(N) unabhängig von λ undKonjugierte A-priori
Verteilung kann als konstant angesehen werden. Daraus ergibt sich die Umfor-mung von der ersten in die zweite Zeile in Formel 104, wobei dasSymbol ∝ Proportionalität bedeutet. Die letzte Zeile in Formel 104
hat wieder die Form einer Gamma-Verteilung mit den Parameternαλ = α + n und βλ = β + v(W) und ist die A-posteriori Verteilungvon p(N|λ). Eine uninformierte A-priori Verteilung kann durch dieWahl von sehr kleinen Werten für α und β modelliert werden. Allge-mein soll sich in der folgenden Betrachtungsweise aber nicht auf denFall beschränkt werden, dass eine konjugierte A-priori Verteilung be-kannt ist. Es wird davon ausgegangen, dass die A-posteriori Vertei-lung nur in Form von Zufallstichproben approximiert wird, wie sie

3.3 räumliche verteilung 77
bei der Verwendung von MCMC-Verfahren entstehen. Im Falle derkonjugierten Gamma-Verteilung müssen diese also durch das Ziehenvon entsprechenden Stichproben aus der Verteilung generiert werden. Simulation von
PunktmusternDie Stichprobenwerte für λ werden im Folgenden als λ(1), . . . , λ(l)
bezeichnet, wobei l dem Stichprobenumfang entspricht. Diese Vorge-hensweise ermöglicht es nun, die erwartete Anzahl von Punkten ineiner beliebigen Teilmenge B ⊂ R
d mit Volumen v(B) zu bestimmen.Dafür werden i = 1, . . . , l Stichprobenwerte N(B)(1), . . . , N(B)(l) ausder Poisson-Verteilung von Formel 94, parametrisiert durch λ(i)v(B),gezogen. Diese approximieren die posteriori-prädiktive Verteilungder Anzahl der Punkte in B [79, S. 17]. Durch die Berechnung desHDIs lassen sich dann die glaubwürdigsten Werte konkret quanti-fizieren. In einem letzten Schritt können zusätzlich l PunktmusterN(1), . . . , N(l) in B, die sogenannten posteriori-prädiktiven Punktmus-ter, generiert werden. Dazu wird für jedes N(B)(1), . . . , N(B)(l) einPPP mit entsprechender Punktanzahl simuliert. Die Positionen derPunkte folgen dabei gemäß den Eigenschaften des PPPs der Gleich-verteilung im Intervall der Fenstergröße B. Das Punktmuster N(i) miti = 1, . . . , l besitzt also n = N(B)(i) Punkte mit den jeweiligen Ko-ordinaten x1, . . . , xn. Im Folgenden werden die posteriori-prädiktivenPunktmuster dazu verwendet, Abweichungen zwischen Modell undbeobachteten Daten zu detektieren. Für diese Anwendung werdendie im Folgenden eingeführten Teststatistiken benötigt.
Ein typischer Startpunkt bei der Analyse von Punktmustern ist dieBerechnung der Nächste-Nachbarn Funktion
D(r) = P(N(b(o, r) \ o) > 0) (106)
mit r ≥ 0. Diese gibt die Wahrscheinlichkeit an, dass mindestens Nächste-NachbarnFunktionein Punkt in der Kugel b mit Radius r und dem Mittelpunkt o liegt.
Der Punkt o wird dabei als typischer Punkt bezeichnet und wird zu-fällig aus dem Prozess ausgewählt. Eine empirische Schätzung vonD(r) kann wie folgt berechnet werden. Gegeben sei ein Beoachtungs-fenster W, in dem x1, . . . , xn Punkte eines Punktprozesses N beob-achtet wurden. Für jeden der N(W) = n Punkte wird die Anzahlder nächsten Punkte ti bestimmt, für die der Abstand zum aktuellbetrachteten Punkt xi kleiner als r ist. Die Summe ∑
ni=1 ti/n ist dann
eine Schätzung der Wahrscheinlichkeit, dass ein Punkt im Punktpro-zess seine nächsten Nachbarn in einem Abstand kleiner r hat [61,S. 177]. Natürlich ist das gerade beschriebene Verfahren nicht erwar-tungstreu, da Kanteneffekte nicht beachtet werden. Für eine ausführ-liche Behandlung dieses Themas wird auf Stoyan, Kendall und Me-cke [133, S. 145 ff.] verwiesen. In der vorliegenden Arbeit werdenzum Schätzen dieser und aller noch folgenden Teststatistiken das R-Rahmenwerk SpatStat2 verwendet. Dort werden die gängigsten Ver-fahren zur Kantenkorrektur implementiert.
2 http://www.spatstat.org

78 statistische methoden
Insgesamt eignet sich D(r) nur zur Analyse der lokalen Nachbar-schaft im Punktmuster, da auf Grund der kumulativen Eigenschaftfür mittlere und große Abstände r keine sinnvollen Informationen ab-geleitet werden können. Eine interessante Anwendung von D(r), diein der vorliegenden Arbeit Verwendung findet, ist das Bestimmendes minimalen Punktabstands r0 (in der englischen Literatur auch alshard-core Distanz bezeichnet). Wenn eine solche hard-core DistanzInterpretation
für einen Punktprozess existiert, dann gibt es ein positives r0, so dassgilt
D(r)
= 0 mit r < r0
> 0 mit r ≥ r0 .(107)
Eine weitere interessante Eigenschaft von D(r) ist, dass für den PPPeine geschlossene Form bekannt ist. Es gilt nämlich für einen PPP mitIntensität λ
DPois(r) = 1− e(−λbdrd)
,(108)
wobei bd das d-dimensionale Volumen der Einheitskugel ist [61, S. 75].Stimmt also die empirisch geschätzte Funktion D(r) mit der FunktionDPois(r) überein, ist dies ein Indiz, dass ein PPP ein passendes Mo-dell ist, um das durch x1, . . . , xn gegebene Punktmuster zu beschrei-ben. Nun wird D(r) aber auf Grund von statistischen Schwankungenund Kanteneffekten nie eins zu eins mit DPois(r) übereinstimmen. Umdie Entscheidung zu erleichtern, ob es sich um ein adäquates Mo-dell handelt, bietet sich folgende Vorgehensweise an. Dabei wird dasEnveloppen
Verfahren von der konkreten Funktion D(r) auf eine allgemeine Test-funktion S(r) erweitert, da es für die noch folgenden Teststatistikenebenfalls angewendet werden kann. Man berechnet zunächst für dieposteriori-prädiktiven Punktmuster N(1), . . . , N(l) jeweils die oberenund unteren Enveloppen
EL(r) =l
mini=1
S(i)(r)
EU(r) =l
maxi=1
S(i)(r) ,(109)
wobei S(i) der empirische Schätzer einer Funktion S(r) über demposteriori-prädiktiven Punktmuster N(i) ist. Liegt nun der empirischeSchätzer S(r) des beobachteten Punktmusters in der Enveloppe zwi-schen EL(r) und EU(r), kann der PPP als geeignetes Modell für dasPunktmuster angesehen werden. Das Verfahren ist jedoch kein forma-ler statistischer Test, sondern ein exploratives Werkzeug zur Daten-analyse [144, S. 77]. Ein solcher lässt sich aber im Sinne der in Kapitel3.2.3 eingeführten posteriori-prädiktiven Tests einfach konstruieren.Dazu wird die posteriori-prädiktive Verteilung der Differenzen
∆(i)(r) = S(r)− S(i)(r) (110)
mit i = 1, . . . , l und r > 0 berechnet. Ist nun für einen BereichBayesscher Test

3.3 räumliche verteilung 79
[r, r + ǫ] null ein Extremwert der posteriori-prädiktiven Verteilung∆(1)(r), . . . , ∆(l)(r), muss die CSR-Hypothese verworfen und ein an-deres Modell als der PPP in Betracht gezogen werden. Folgendesexploratives Hilfsmittel erleichtert die Auswertung. Es wird dasHDI für alle r > 0 über die posteriori-prädiktiven Verteilungen∆(1)(r), . . . , ∆(l)(r) berechnet und die Intervallgrenzen gegen r auf-getragen. Eine Modellverletzung liegt dann vor, wenn die 0 für einenBereich [r, r + ǫ] außerhalb des Intervalls liegt.
Neben der Nächste-Nachbarn Funktion D(r) gibt es eine Reihe weite-rer Funktionen, um Punktmuster zu analysieren. Als mächtiges Werk-zeug hat sich die K(r) Funktion von Ripley [111] erwiesen. Sie wird Ripleys K(r)
Funktiondefiniert als
K(r) =1λ
E(N(b(o, r) \ o)) (111)
und gibt die durchschnittliche Anzahl von Punkten in einer Kugelb mit Radius r um den typischen Punkt o im Punkprozess N an.Für einen PPP ist die durchschnittliche Anzahl in einer Kugel b(o, r)gleich λbdrd (siehe Abschnitt 3.3.1), deshalb gilt für einen PPP
KPois(r) = bdrd
.(112)
Eine allgemeine Version des Schätzers für λK(r) hat die Form
λK(r) =1n ∑
i∑j 6=i
1‖xi−xj‖ ≤r,
(113)
wobei die Indikatorfunktion 1‖xi−xj‖ ≤r gleich 1 ist, wenn der eukli-dische Abstand zwischen zwei Punkten des Prozesses xi und xj klei-ner gleich dem Radius r ist. Dieser Schätzer ist nicht erwartungstreu,da für Punkte dicht am Rand Punkte außerhalb des Randes nicht be-achtet werden. Zahlreiche erwartungstreue Schätzer für K(r) wurdenvorgeschlagen. Einen guten Überblick liefern Illian u. a. [61, S. 228].Die grundlegende Idee bei den meisten Ansätzen dabei ist, die Punk-te in Formel 113 in Abhängigkeit ihrer Position im Beobachtungs-fenster entsprechend zu gewichten. In der vorliegenden Arbeit wirdeine erwartungstreue Version für dreidimensionale Punktmuster vonBaddeley u. a. [12] verwendet. Eine entsprechende Implementierungbefindet sich in SpatStat. Wie schon bei der Funktion D(r) kann derSchätzer K gegen KPois verglichen werden, um Informationen überdie Struktur des betrachteten Musters abzuleiten. Allgemein gilt fürregelmäßige Punktmuster K(r) < KPois und K(r) > KPois für Muster,bei denen die Punkte in Form von Clustern auftreten [61, S. 215]. ZurBerechnung des posteriori-prädiktiven Tests ist K(r) hingegen unge-eignet, da sich gezeigt hat, dass mit wachsendem r die Fluktuationenstark zunehmen. Besser geeignet ist hier die L(r) Funktion, welcheals
L(r) = d
√
K(r)bd
(114)

80 statistische methoden
definiert ist. Die beiden Vorteile in der Verwendung von L(r) liegenL(r) Funktion
darin, dass zum einen durch das Ziehen der Wurzel die Varianz sta-bilisiert und zum anderen der Vergleich gegen den PPP leichter wird,da für diesen LPois(r) = r gilt [61, S. 217].
Abschließend soll als Methode zur Analyse von Punktmustern diePaar-Korrelationsfunktion (PCF) g(r) eingeführt werden. Diese be-sitzt den gleichen statistischen Informationsgehalt wie K(r) und L(r),weist aber nicht die kumulative Eigenschaft auf. Eine Interpretationfällt somit leichter, da die Daten in einer zugänglicheren Art und Wei-se dargestellt werden. Deshalb wird die PCF in der Literatur häufigPaar-
Korrelationsfunktion als eine der besten Methoden propagiert, um Punktmuster explorativzu untersuchen [61, S. 218]. Die PCF steht in enger Beziehung mitder Produktdichte zweiter Ordnung. Die Produktdichte zweiter Ord-nung ρ(x, y) = (x, y)dxdy ist die Wahrscheinlichkeit, dass jeweilsein Punkt des Prozesses N in den infinitesimalen Kugeln dx und dymit Mittelpunkt x und y liegt. Ist der betrachtete Punktprozess homo-gen und isotrop, hängt ρ(x, y) nur vom Abstand r, geschrieben ρ(r),zwischen x und y ab. Die PCF g(r) ergibt sich dann durch Normali-sierung mit λ2, also
g(r) =ρ(r)λ2 .
(115)
Für einen PPP ist auf Grund der zufälligen und unabhängigen Vertei-lung der Punkte (CSR-Eigenschaft) wegen des Multiplikationssatzesvon Wahrscheinlichkeiten die Punktdichte ρ(x, y) = λ2. Für die PCFergibt sich also im Falle eines PPP gPois(r) = 1. Bei einem Punktpro-zess, der zur Bildung von Clustern neigt, treten hingegen im Durch-schnitt Punkte in direkter Nachbarschaft häufiger auf als bei einemPPP. Die Wahrscheinlichkeit von ρ(x, y) für kleines r ist somit größerund damit nimmt g(r) für kleines r Werte größer als 1 an. Auf der an-deren Seite nimmt g(r) für regelmäßige Punktmuster Werte kleinerals 1 an, da in der direkten Nachbarschaft eines Punktes im Durch-schnitt weniger Nachbarn liegen als bei einem PPP. Geschätzt wirdg(r) mittels eines Kerndichteschätzers, welcher in SpatStat implemen-tiert ist [61, S. 232].
Zusammenfassend werden die definierten Funktionen in der vorlie-genden Arbeit wie folgt eingesetzt. Die Nächste-Nachbarn FunktionD(r) wird dazu verwendet, das Verhalten der lokalen Nachbarschaftim Muster zu analysieren. Insbesondere die Frage nach einem Min-destabstand zwischen den Punkten soll damit beantwortet werden.Aufbauend darauf wird das globale Verhalten des Musters mit derPCF untersucht. Als Interpretationshilfe werden die oberen und un-teren Enveloppen aus den simulierten posteriori-prädiktiven Punkt-mustern, parametrisiert mit A-posteriori Verteilung der geschätztenIntensität aus den beobachteten Daten, eingezeichnet. Erhärtet sichbei dieser explorativen Datenanalyse der Verdacht, dass das beobach-

3.4 zusammenfassung 81
tete Punktmuster durch einen PPP beschrieben werden kann, wirdschließlich der oben beschriebene Test auf Basis des HDIs und derL(r) Funktion durchgeführt. Die K(r) Funktion findet keine prakti-sche Verwendung und dient in der obigen Ausführung lediglich zurDefinition der L(r) Funktion.
3.4 zusammenfassung
In diesem Kapitel wurden Methoden vorgestellt, um Partikelsyste-me bezüglich ihrer statistischen Eigenschaften zu untersuchen. Zweigroße Themenfelder wurden behandelt und zwar die Analyse derGrößenverteilung und die der räumlichen Verteilung. Der Aufbaubeider Themenblöcke ist dabei weitestgehend kongruent. Zunächstwurden explorative Methoden vorgestellt, um die Dichtefunktion (imFalle der Größenverteilung) und die Intensität (im Falle der räumli-chen Verteilung) zu analysieren. Anschließend wurde der Prozess derModellbildung beschrieben, der auf den Erkenntnissen der explora-tiven Datenanalyse basiert. Dabei wurde gezeigt, wie die Parameteraus den beobachteten Daten geschätzt werden können und wie an-schließend getestet werden kann, wie gut das parametrisierte Modellzu den Daten passt. Konsequent wurde auf Methoden der bayesschenStatistik gesetzt, um zum einen Unsicherheit bei der Schätzung ad-äquat zu quantifizieren und zum anderen etwaiges Wissen über diestatistischen Parameter des Modells bei der Modellierung berücksich-tigen zu können. Die Methoden sind so flexibel, dass sich akquiriertesWissen über die Parameter jederzeit in das Modell aufnehmen lässt.In Kapitel 6 werden die hier präsentierten Methoden dazu verwen-det, die Verteilung von nichtmetallischen Einschlüssen und anderenDefekten in Stahl zu modellieren.

82 statistische methoden

4A N W E N D U N G S FA L L
In diesem Kapitel wird ein Anwendungsfall vorgestellt, bei dem dasin der vorliegenden Arbeit eingeführte Rahmenwerk verwendet wer-den kann, um statistische Aussagen über Partikelsysteme abzuleiten.Konkret wird ein Beispiel aus der Stahlerzeugung besprochen undzwar die Analyse von Defekten, wie nichtmetallischen Einschlüssen,Poren und Risse, die während der Stahlerzeugung entstehen und un-ter gewissen Umständen im fertigen Produkt verbleiben. Diese kön-nen dazu führen, dass zugesicherte Materialeigenschaften bestimm-ter Legierungen nicht mehr erfüllt sind und in drastischen Fällen dieRissbildung begünstigen und Materialbrüche hervorrufen. Eine ge-naue statistische Analyse der nichtmetallischen Einschlüsse und Po-ren in Hinblick auf die Optimierung des Produktionsprozesses, sodass weniger dieser Verunreinigungen im Produkt zurückbleiben, istdaher wünschenswert.
Der Aufbau des Kapitels gestaltet sich wie folgt. Zunächst wird be-schrieben, wie nichtmetallische Einschlüsse und Poren im Produktentstehen, wie sie anhand unterschiedlicher Kriterien unterschiedenwerden und welche statistischen Eigenschaften sie besitzen. Danachwerden bekannte Detektionsverfahren besprochen, die in der stahler-zeugenden Industrie eingesetzt werden, um den Einschlussgehalt inStahlproben zu bestimmen. Anschließend wird ein neues System vor-gestellt, welches in Zusammenarbeit mit zwei Projektpartnern aus derIndustrie im Zuge des Silenos-Projekts entwickelt wurde. Mit diesemSystem ist es erstmals möglich sowohl die dreidimensionale Morpho-logie einzelner Defekte als auch die räumliche Verteilung dieser zuuntersuchen. Unter Nutzung von Daten aus diesem System werdendann in den Kapiteln 5 und 6 exemplarische Auswertungen mittelsdes in dieser Arbeit entwickelten Rahmenwerks vorgenommen. DieErgebnisse dieser Auswertungen bilden schließlich die Basis des inKapitel 7 entwickelten automatischen Analysesystems.
4.1 motivation
Nichtmetallische Einschlüsse haben einen großen Einfluss auf die me-chanischen Eigenschaften und damit auf die Qualität von Stahl. Zwarkommen nichtmetallische Einschlüsse immer im fertigen Produkt vor,aber bei zu hoher Konzentration können sie die Rissfortsetzung und
83

84 anwendungsfall
damit einhergehende Ermüdungsbrüche begünstigen [97, S. 75]. Dieskann im schlimmsten Fall katastrophale Folgen haben, wie man amBeispiel des am 09.07.2008 entgleisten ICE 518 erkennen kann. Dieserwar auf Grund eines Achsenbruchs kurz hinter dem Kölner Haupt-bahnhof verunglückt. Laut eines Prüfungsberichtes des Bundesam-tes für Materialforschung [71] ist der Achsenbruch mit hoher Wahr-scheinlichkeit auf einen Materialfehler in Form von nichtmetallischenEinschlüssen zurückzuführen. Dieses Beispiel zeigt, wie wichtig esist, dass der zugesicherte Reinheitsgrad des verwendeten Werkstoffseingehalten wird. Um aber Produkte mit solchen Anforderungen er-stellen zu können, müssen sowohl die Entstehung als auch der Ur-sprung von nichtmetallischen Einschlüssen detektierbar sein. Mit die-sem Wissen lässt sich dann der Produktionsprozess dahingehend op-timieren, dass weniger dieser Verunreinigungen im fertigen Produktverbleiben. In diesem Abschnitt werden deshalb die gängigsten De-tektionverfahren für nichtmetallische Eigenschaften vorgestellt. Diesekönnen verwendet werden, um gesicherte statistische Informationenüber die Verteilung von Einschlüssen zu erheben und Qualitätskrite-rien festzulegen. Zunächst wird aber besprochen, wie genau nichtme-tallische Einschlüsse definiert sind, wie sie entstehen und wie sie sichunterscheiden lassen.
4.1.1 Nichtmetallische Einschlüsse
Allgemein definiert man nichtmetallische Einschlüsse als Teilchen,die bereits im flüssigen Stahl vorgelegen haben und bei der Erstar-rung eingeschlossen wurden oder die auf Grund des Löslichkeits-sprunges bei der Erstarrung entstanden sind [109]. Diese DefinitionDefinition
ist sehr weit gefasst und deutet bereits an, dass der Begriff „nichtme-tallischer Einschluss“ eine Vielzahl unterschiedlicher Partikel unter-schiedlichster Form und chemischer Zusammensetzung beschreibt.Verschiedene Unterscheidungskriterien wurden vorgeschlagen, umden Begriff weiter zu spezifizieren. Grob lassen sie sich zunächstin zwei Klassen nach ihrer Herkunft unterteilen. Man unterscheidetzwischen exogenen und endogenen Einschlüssen. Exogene Einschlüs-Endogene und
Exogene se sind Einschlüsse die von außen in die Schmelze gelangen. Sieentstehen beispielsweise durch abgetragenes Feuerfestmaterial ausabgebrochenen Ansätzen im Gießsystem oder durch das Einspülenvon Schlacken. Exogene Einschlüsse sind zwar vergleichsweise sel-ten, können aber mitunter sehr groß sein [101, S. 12 f.]. EndogeneEinschlüsse hingegen bilden sich aus chemischen Reaktionen, zumBeispiel während der Stahldesoxidation. Stahl wird aus Roheisen her-gestellt und bezeichnet Eisen mit einem Kohlenstoffgehalt von unter2.06 % [45, S. 107 f.]. Um den Stahl auf den erforderlichen Kohlen-stoffgehalt zu bringen, wird der Kohlenstoff durch die Zufuhr von

4.1 motivation 85
Sauerstoff oxidiert. Bei der Oxidation bleibt allerdings Sauerstoff imflüssigen Stahl zurück, der sich während der Erstarrung mit Koh-lenstoff zu Kohlenstoffmonoxid verbindet. Das Kohlenstoffmonoxid Entstehung
steigt auf und wird in die Luft abgeschieden. Ein Teil davon bleibtaber im erstarrten Block in Form von kleinen Gasbläschen zurück.Dies ist unerwünscht, da es die Schweißeigenschaften des Stahls be-einflusst. Deshalb wird während des Desoxidationsprozesses durchHinzugabe eines Desoxidationsmittels versucht den überschüssigenSauerstoff zu binden. Die dabei entstehenden Oxidverbindungen wer-den meist in die Schlacke abgeschieden [45, S. 110 f.]. Einige die-ser Oxidverbindungen werden aber auf Grund der Erstarrungsfrontam Aufsteigen gehindert und verbleiben als nichtmetallische Oxidein-schlüsse im festen Stahl zurück. Der größte Teil der Einschlüsse ent-steht auf diese Weise [101, S. 12 f.]. In Abhängigkeit des verwendeten Chemische
ZusammensetzungDesoxidationsmittels können Einschlüsse mit unterschiedlicher che-mischer Zusammensetzung entstehen. Häufig zu beobachten sind Si-likate, Korunde und Spinelle. Neben der Unterteilung nach ihrer che-mischen Zusammensetzung schlagen Plöckinger und Straube [107]eine Klassifizierung dieser Oxideinschlüsse nach ihrem Entstehungs-zeitpunkt vor. Direkt nach der Zugabe des Desoxidationsmittels ge-bildete Einschlüsse werden demnach als primäre Desoxidationspro-dukte bezeichnet. Sie sind am größten, da sie die meiste Zeit zumWachsen haben, werden aber auch fast vollständig in die Schlacke ab-geschieden. Sekundäre Desoxidationsprodukte bilden sich, währendder Stahl auf seine Liquidustemperatur abkühlt. Auf Grund der stei-genden Viskosität werden diese Einschlüsse nur noch schlecht in dieSchlacke abgeschieden. Im Allgemeinen sind sie kleiner als die pri-mären Desoxidationsprodukte. Schließlich gibt es Desoxidationspro- Entstehungszeit-
punktdukte, die während des Übergangs von der Liquidus- zur Solidu-stemperatur entstehen. Bei diesen Einschlusstypen ist ein Verbleibenim fertigen Produkt sehr wahrscheinlich, da sie an der fortschrei-tenden Erstarrungsfront an dem Aufstieg in die Schlacke gehindertwerden. Man nennt sie die tertiären Desoxidationsprodukte. Nebender Gruppe der Oxideinschlüsse gibt es in der Klasse der endogenenEinschlüsse noch weitere Einschlüsse, die sich ebenfalls durch ihrechemische Zusammensetzung unterscheiden. Dabei handelt sich zu-meist um chemische Verbindungen aus den Eisenbegleitern Schwefeloder Stickstoff, die sich in Form von Sulfid- und Nitrideinschlüssenmanifestieren [109].
4.1.2 Charakterisierungsmerkmale
Viele Veröffentlichungen beschäftigen sich mit der Frage, ob es mög-lich ist, Einschlüsse auf Basis von messbaren physikalischen Eigen-schaften in die oben aufgestellte Klassenhierarchie einzuordnen. Ein

86 anwendungsfall
einfaches und gängiges Verfahren besteht in der Unterteilung anhandihrer Größe. Bei Einschlüssen kleiner als 5 µm spricht man von Mikro-Mikroeinschlüsse
einschlüssen. In dieser Gruppe häufig anzutreffen sind Sulfid- undOxideinschlüsse [110], wobei letztere auf Grund ihrer kleinen Größeerst recht spät entstanden sind, also wahrscheinlich zu den sekun-dären oder tertiären Desoxidationsprodukten gehören. Als Makroein-schlüsse bezeichnet man hingegen Einschlüsse mit einer Größe vonmehr als 100 µm. Sie sind selten anzutreffen, da sie mehr Zeit hattenMakroeinschlüsse
in die Schlacke abgeschieden zu werden. Sie entstehen oft durch Ko-aleszenz von flüssigen Teilchen oder durch Agglomeration von festenTeilchen. Ersteres führt auf Grund der Minimierung der Oberflächezu kugelförmigen Partikeln [31, S. 110 f.], letzteres zu clusterartigenGebilden, wie sie bei diffusionbegrenzten Wachstumsprozessen ent-stehen [110, 31, S. 116 f.]. Es wird angenommen, dass Makrooxidein-schlüsse in diesem Bereich zu den primären Desoxidationsproduktengehören. Auch die endogenen Einschlüsse, wie Schlackeeinchlüsse,sind in diesem Größenbereich anzutreffen. Schließlich liegen in demMesoeinschlüsse
Bereich zwischen 5 µm und 100 µm die sogenannten Mesoeinschlüsse,bei denen eine genaue Einteilung schwer fällt.
Neben ihrer Größe werden weitere Eigenschaften zur Unterschei-dung betrachtet. Für Mikrooxid- und teilweise auch Sulfideinschlüs-Morphologie
se wurde die Morphologie sehr ausführlich untersucht [129, 130, 131,128]. Dabei wurde festgestellt, dass das Oxidwachstum stark von denörtlichen Aktivitätsverhältnissen des Sauerstoffs und des Desoxidati-onsmittels abhängt. Je nach Sauerstoffgehalt werden kugelige, koral-lenartige und dentritische Formen beobachtet.
Eine weitere Unterscheidungsmöglichkeit, die eine chemische Klas-sifizierung von Einschlüssen möglich macht, ist die Verformbarkeit[109]. Verformbare Einschlüsse werden bei der Warmumformung inVerformbarkeit
Umformrichtung gestreckt. Die Verformbarkeit ist dabei ein Hinweis,dass der betrachtete Einschluss der Klasse der Sulfide oder Silika-te angehört. Nicht verformbare Einschlüsse sind so hart, dass sie ihreursprüngliche Form beibehalten oder zertrümmert und zu einer Zeileaus unverformten Einzelpartikeln gestreckt werden. Dieses Verhaltenist ein Hinweis auf Tonerdeeinschlüsse (Aluminiumoxid).
Abschließend kann die Farbe von Einschlüssen als Kriterium heran-gezogen werden, um ihre chemische Zusammensetzung zu analysie-ren. In der Industrienorm [92, S. 37 f.] wird folgender Zusammen-Farbe
hang proklamiert. Sulfideinschlüsse erscheinen grau, Oxideinschlüs-se schwarz und Nitrideinschlüssen haben gelbliche bis rosa Farbtö-ne.
All diese Kriterien wurden entweder empirisch überprüft oder austheoretischen Überlegungen abgeleitet. Eine eindeutige Klassifizie-rung anhand dieser Merkmale ist im Allgemeinen nicht möglich. In

4.1 motivation 87
der Praxis verwendet man häufig spektrale Untersuchungsmethoden,um die genaue chemische Zusammensetzung bestimmen zu können.Damit kann dann auch die Frage beantwortet werden, ob die analy-sierten Einschlüsse eher endogenen oder exogenen Ursprungs sind.Den exakten Entstehungszeitpunkt zu bestimmen (primär, sekundäroder tertiär) ist aber nach wie vor ein offenes Problem. Insgesamtbieten die aufgestellten Kriterien aber bereits einige Hinweise, wienichtmetallische Einschlüsse anhand ihrer Morphologie oder Texturklassifiziert werden können.
4.1.3 Statistische Eigenschaften
Die bisher erwähnten Eigenschaften bezogen sich auf einzelne Ein-schlüsse. Häufig ist man aber an statistischen Werten interessiert, wel-che die Eigenschaften aller im Stahl vorkommenden Einschlüsse be-schreiben. Die gebräuchlichsten Angaben, um ein solches Einschluss-kollektiv statistisch zu erfassen, sind die Anzahl von Einschlüssen imVolumen, die Größenverteilung dieser Einschlüsse sowie deren mor-phologische Eigenschaften. Als qualitätsbeschreibende Größe dient Reinheitsgrad
darüber hinaus der Reinheitsgrad, der als das Verhältnis zwischender Gesamtgröße aller Einschlüsse und dem untersuchten Probenvo-lumen definiert ist. Sind Größenverteilung und Anzahl bekannt, kannder Reinheitsgrad direkt ausgerechnet werden. In der Praxis bestehtaber das Problem, dass viele Prüfverfahren nur die Oberfläche vonzweidimensionalen Schnitten durch die Stahlproben berücksichtigen.Die Anzahl von Einschlüssen pro Volumen und die Größenverteilungmuss also aus den in zweidimensionalen Schnitten beobachteten Pro-filen der Einschlüsse geschätzt werden. Um diese Schätzung durch-zuführen, müssen Annahmen über die räumliche Verteilung und dieForm der Einschlüsse getroffen werden. Die räumliche Verteilung inder Bramme muss homogen sein, während man die Form entwederauf kugelige Einschlüsse mit unterschiedlichen Durchmessern oderauf Einschlüsse mit konvexer Form und unterschiedlicher Größe be-schränkt. Unter der Bedingung, dass diese Annahmen erfüllt sind, Stereologische
Methodenwurden von Saltykov [118, S. 273 ff.] und Ohser und Mücklich [98,S. 199 ff.] Methoden zur Schätzung der Werte vorgestellt. Die Grund-lage lieferte dabei Wicksell [143] mit der Formulierung des KorpuskelProblems. In der einschlägigen Literatur über nichtmetallische Ein-schlüsse lassen sich nur wenig Informationen über Eigenschaften derräumlichen Verteilung finden. Bekannt ist, dass sich auf Grund derErstarrungseigenschaften von Stahl die Einschlüsse in einem schma-len Band unterhalb der Brammenoberseite sammeln [66, 41]. Das Er-starren der Bramme beginnt an den Außenseiten. Einschlüsse stei- Einschlussband
gen im flüssigen Stahl nach oben hin auf, bis sie an der Erstarrungs-front hängen bleiben. Es bildet sich das sogenannte Einschlussband.

88 anwendungsfall
Das heißt, dass die räumliche Verteilung innerhalb der Bramme kei-neswegs homogen ist. Weite Teile weisen nur eine geringe Konzen-tration an Einschlüssen auf, während die Konzentration innerhalbdes Einschlussbandes sprunghaft ansteigt. Bleibt die Frage, ob dieräumliche Verteilung innerhalb des Einschlussbandes homogen ist.Man geht davon aus, dass die Aufstiegsgeschwindigkeit von kugeli-gen Einschlüssen dem stockesschen Gesetz entspricht [67]. Das heißt,dass größere Einschlüsse schneller im flüßigen Stahl aufsteigen alskleine. Dementsprechend müsste die Konzentration von großen Ein-schlüssen im oberen Bereich des Einschlussbandes größer sein als imunteren. Jacobi und Wünnenberg [67] geben an, diesen Effekt in ih-ren Messdaten beobachtet zu haben, auch wenn die Abweichungenin den präsentierten Kurven minimal ist. In Abschnitt 6.2 wird dieräumliche Verteilung von Einschlüssen und Poren im Einschlussbandanhand dreidimensionaler Daten genauer untersucht.
Auch über die erwartete Größenverteilung von nichtmetallischen Ein-schlüssen lassen sich wenig Informationen finden. Übereinstimmendwird berichtet, dass sich die Größenverteilung von Einschlüssendurch die logarithmische Normalverteilung beschreiben lässt [118,S. 314 ff.][9, 41]. Allerdings werden keine verlässlichen WertebereicheLogarithmisch
Normalverteilt für die Verteilungsfunktion angegeben oder eine Erklärung geliefert,warum sich gerade dieses Modell zur Beschreibung der Daten eignet.In Abschnitt 6.1 wird eine mögliche Begründung geliefert und ge-zeigt, dass die logarithmische Normalverteilung ein geeignetes Mo-dell darstellt. Zunächst werden aber im nächsten Abschnitt mehre-re Detektionsverfahren vorgestellt, welche die Quanitifizierung derin diesem Abschnitt besprochenen statistischen Eigenschaften erlau-ben.
4.1.4 Detektionsverfahren
Eine Vielzahl verschiedener Detektionsmethoden für nichtmetallischeEinschlüsse wurde vorgeschlagen. Man unterteilt sie grob in zweiKlassen, die direkten und indirekten Methoden [152]. Bei den indirek-Direkte und
indirekte Methoden ten Methoden wird versucht, den Einschlussgehalt anhand indirekterParameter bei der Stahlerzeugung abzuschätzen. Eine Möglichkeit istzum Beispiel, den Einschlussgehalt durch Sauerstoffmessungen imflüssigen Stahl zu bestimmen. Bei den direkten Methoden hingegenversucht man die Einschlüsse als solche zu detektieren. Die Unter-suchungen werden oft auf kleinen Proben durchgeführt und die Er-gebnisse über den Einschlussgehalt dann auf die gesamte Brammehochgerechnet. Im nachfolgenden Abschnitt werden nur die bekann-testen direkten Methoden mit ihren Vor- und Nachteilen beschrieben.Auf die indirekten Methoden wird nicht weiter eingegangen, da diesein der vorliegenden Arbeit nicht relevant sind.

4.1 motivation 89
Eine der am häufigsten angewandten Methoden, die durch zahlreicheIndustrienormen standardisiert ist [92, 34, 8], ist die Einschlussdetek-tion in polierten Schnitten. Die genaue Durchführung unterscheidet Mikroskopuntersu-
chungen polierterOberflächen
sich von Standard zu Standard, die grundlegende Idee ist aber über-all dieselbe. Aus der Bramme wird nach einem fest vorgegebenenVerfahren eine Probe herausgetrennt und so zerschnitten, dass eineOberfläche von ca. 160 mm2 entsteht. Auf dieser Oberfläche werdenEinschlüsse mittels eines Mikroskops detektiert, vermessen und klas-sifiziert. Die Klassifizierung erfolgt dabei nach im Standard vorgege-benen Richtreihen und schließt die in Abschnitt 4.1.2 genannten Kri-terien, wie Form, Farbe und Verformbarkeit ein. Anschließend wirdmittels statistischer Verfahren versucht, den Reinheitsgrad auf die ge-samte Bramme hochzurechnen. Wenn manuell durchgeführt, ist dasVerfahren sehr aufwendig. Allerdings gibt es Systeme auf dem Mark,die unter Nutzung von Bildverarbeitungsverfahren vollautomatischarbeiten. Die Firma Leica vertreibt beispielsweise ein solches vollau-tomatisches System Namens Leica Steel Expert. Der Nachteil bei die-sem Verfahren ist, dass nur zweidimensionale Daten erhoben werden.Zwar gibt es Techniken, um den aus zweidimensionalen Schnittengeschätzten Reinheitsgrad auf das Volumen hochzurechnen, dafürmüssen aber Annahmen über die Partikelform getroffen werden [118,S. 273 f.]. In den Standards wird dieses Problem gar nicht thematisiertund die Durchmesserverteilung der zweidimensionalen Schnitte alsReinheitsgrad angenommen. Auch eignet sich das Verfahren nichtfür die Bestimmung des Makroreinheitsgrads, da die Proben viel zuklein sind, um gesicherte statistische Aussagen über die sehr seltenenMakroeinschlüsse zu treffen [109].
Ein weiteres, auf zweidimensionalen Schnitten arbeitendes Verfah-ren, ist die Einschlussdetektion mittels Rasterelektronenmikroskop(REM). Zunächst wird mittels Lichtmikroskop eine Vorauswahl von Rasterelektronenmi-
kroskopEinschlüssen erstellt. Diese Auswahl wird dann mit dem REM ange-fahren und genau vermessen. Dabei entstehen hochauflösende Bilderder Einschlüsse. Gleichzeitig kann, unter Nutzung der charakteris-tischen Röntgenstrahlung, die chemische Zusammensetzung analy-siert werden. Das Verfahren ist sehr genau und kann genutzt wer-den, um die Morphologie von Mikroeinschlüssen zu analysieren, wiezahlreiche Veröffentlichungen zeigen [74, 32, 129, 130, 131, 128]. Aller-dings lassen sich Einschlüsse nur als einzelne Ereignisse untersuchen.Für die statistische Untersuchung des gesamten Einschlusskollektivsist das Verfahren zu langsam.
Ein weiteres Verfahren zur Bestimmung der chemischen Zusammen-setzung ist die Funkenspektrometrie. Dabei wird Material mittels aufdie Schnittflächen gefeuerter Funken verdampft und die freigesetztenAtome und Ionen an ein optischen System geleitet, wo sie in ihre ein-zelnen spektralen Komponenten zerlegt werden. Auch hier können

90 anwendungsfall
Einschlüsse wieder nur als einzelne Ereignisse untersucht werden, dadas Verfahren insgesamt sehr langsam ist. Außerdem ist die FlugbahnSpektrometrie
der Funken zufällig, es kann also nicht das Spektrum für einen be-stimmten Punkt angegeben werden. Stattdessen wird das Spektrumüber eine vorher festgelegte Fläche gemittelt. Abhilfe schafft hier dienach einem ähnlichen Prinzip arbeitende laserinduzierte Plasmaspek-troskopie (LIPS). Dabei wird das Material nicht mit einem Funken,sonder einem Laser verdampft. Die lokale Auflösung pro Messpunktbeträgt dabei ca. 20 µm. Durch kontinuierliches Abfahren einer Flä-che oder Linie lässt sich dann die genaue chemische Zusammenset-zung eines Einschlusses bestimmen. In mehreren Veröffentlichungenwurde LIPS bereits für die Detektion von nichtmetallischen Einschlüs-sen evaluiert [90, 23, 75]. Um das System aber erfolgreich betreibenzu können, bedarf es immer noch einer Vorauswahl der zu unter-suchenden Einschlüsse. Auch sind beide hier genannten Systeme zulangsam, um statistische Eigenschaften für ganze Partikelkollektivezu bestimmen.
Neben zweidimensionalen Verfahren, die auf Schnittoberflächen ar-beiten, gibt es auch Verfahren, die Einschlüsse im soliden Stahlvolu-men detektieren können. Eine sehr verbreitete Technik ist die Mikro-Computertomographie (MCT) [103, 51, 83]. Die Funktionsweise istComputertomogra-
phie wie folgt. Eine Röntgenröhre emittiert mit einer bestimmten Intensi-tät Röntgenstrahlung in Form eines Kegelstrahls. Der Röntgenstrahldurchdringt die Probe und wird je nach Schwächungskoeffizientdes durchdrungenen Materials unterschiedlich stark absorbiert. DerStrahl fällt dann auf einen Detektor, und es ensteht ein zweidimensio-nales Projektionsbild. Nun wird die Probe rotiert und erneut aufge-nommen. Nach einer vollen Umdrehung kann ein Voxelmodell allerin der Probe vorhandenen nichtmetallischen Einschlüsse erstellt wer-den. Im Gegensatz zu den zweidimensionalen Verfahren kann mannun die Morphologie der Einschlüsse untersuchen und versuchen,diese mit statistischen Verfahren zu quantifizieren. Von Parra-Denisu. a. [103] wurden entsprechende Untersuchungen von nichtmetalli-schen Einschlüssen [104] mittels MCT vorgenommen. Ein weitererVorteil ist, dass das Verfahren, im Gegensatz zu allen bisher einge-führten, zerstörungsfrei arbeitet. Es lassen sich also auch fertige Bau-teile untersuchen. Allerdings funktioniert das Verfahren nur für sehrdünne Proben, da sonst keine Röntgenstrahlung mehr auf dem Detek-tor ankommt. Deshalb eignet sich das Verfahren nur für die Detektionvon Mikroeinschlüssen in sehr kleinen Proben.
Ein anderes dreidimensionales Detektionsverfahren erlaubt es eben-falls, Makroeinschlüsse im Stahlvolumen zu detektieren. Dabei nutztman Verformungseigenschaften von Einschlüssen aus. Es werdenzunächst Proben, die direkt aus der Bramme geschnitten werden,in einem speziellen Walzverfahren in sogenannte „Surfbrettproben“

4.2 makroeinschluss-detektion 91
umgewandelt. Mögliche Einschlüsse werden dabei ausgewalzt und MIDAS
für die Reflexion von Ultraschall sensibilisiert. Die Proben werdendann mit einem Ultraschallsensor verfahren und anhand des Echoslassen sich Einschlüsse detektieren und vermessen. Das Verfahrenwurde von Mannesmann entwickelt [41, 66] und trägt den NamenMannesmann Inclusion Detection by Analysing Surfboards (MIDAS).Mit diesem Verfahren können sehr große Proben mit mehreren Li-tern Probenvolumen untersucht werden. Einschlüsse können bis zueiner Größe von 50 µm detektiert werden. Allerdings kann man keineAussage mehr über ihre Morphologie treffen, da diese beim Walzenzerstört wird und der Sensor auch nicht in der Lage ist, diese zu de-tektieren. Die ursprüngliche Lage der Einschlüsse im Volumen kannebenfalls nur sehr grob, durch Rücktransformation der „Surfbrettpro-ben“ auf das Ausgangsvolumen, bestimmt werden [66]. Eine Untersu-chung der räumlichen Verteilung mit statistischen Techniken ist nichtohne weiteres möglich.
Zusammenfassend kann an dieser Stelle festgehalten werden, dass imMoment kein Verfahren verfügbar ist, welches sowohl die dreidimen-sionale Analyse der Morphologie als auch die dreidimensionale Ana-lyse der räumlichen Verteilung von nichtmetallischen Einschlüssen inStahlproben erlaubt. Die gängigen Verfahren liefern entweder nur In-formationen über die zweidimensionale Gestalt und Verteilung odersie sind zu langsam, um große Probenvolumina zu verarbeiten. Diesesind aber nötig, um auch gesicherte statistische Aussagen über Ma-kroeinschlüsse treffen zu können. Eine umfassendere Studie zu ver-schiedenen Verfahren zur Berechnung des Reinheitsgrades und zumDetektieren von Einschlüssen wurde von Zhang und Thomas [152]durchgeführt. Insbesondere die indirekten Methoden und Methoden,bei denen Einschlüsse noch im flüssigen Stahl detektiert werden, sinddort ausführlicher beschrieben. Aber auch hier ist kein Verfahren auf-geführt, welches die beiden Anforderungen der dreidimensionalenAnalyse von Form und Verteilung erfüllt.
4.2 makroeinschluss-detektion
Wie im vorherigen Abschnitt festgestellt, gibt es zur Zeit kein Analy-severfahren, mit dem sowohl dreidimensionale Gestalt als auch diedreidimensionale räumliche Verteilung nichtmetallischer Einschlüs-se in sehr großen Stahlproben detektiert werden können. In die-sem Abschnitt soll nun ein solches präsentiert werden. Es kombi-niert die Vorteile der MCT und MIDAS und erlaubt es, sowohl dieMorphologie von Einschlüssen als auch deren Größenverteilung undräumliche Verteilung zu untersuchen. Neben nichtmetallischen Ein-schlüssen können auch andere Defekte, wie Risse, Poren oder Lunker

92 anwendungsfall
analysiert werden. Entwickelt wurde das Verfahren im Rahmen desSilenos-Projekts mit zwei Partnern aus der Stahlindustrie.
Das Verfahren funktioniert ähnlich wie die Bestimmung des Rein-heitsgrades in zweidimensionalen polierten Schnittproben, erweitertdas Prinzip aber auf die dritte Dimension. Dabei werden aufeinander-folgende Schnittbilder einer Stahlprobe durch kontinuierliches Abfrä-sen und Abfotografieren erzeugt. Durch Stapeln dieser zweidimen-Silenos
sionalen Bilder lässt sich dann ein virtuelles dreidimensionales Bilddes Probenvolumens erstellen und die Morphologie der detektiertenDefekte rekonstruieren. Das System an sich besteht dabei aus einerReihe von lose gekoppelten Komponenten, welche die einzelnen Ver-arbeitungsschritte wie in einer Pipeline nacheinander abarbeiten. ImFolgenden werden die einzelnen Komponenten kurz beschrieben, wo-bei das Augenmerk auf der Bildaufnahme- beziehungsweise Bildver-arbeitungseinheit liegt. Die konkrete Implementierung der anderenKomponenten, welche die dreidimensionale Rekonstruktion, automa-tische Klassifikation und statistische Auswertung übernehmen undden thematischen Schwerpunkt dieser Arbeit darstellt, wird detail-liert in Kapitel 7 erläutert.
4.2.1 Fräsprozess und Bildaufnahme
Der Bildgewinnungprozess läuft bei dem hier beschriebenen Verfah-ren wie folgt ab. Ein direkt aus dem Strangguss geschnittener Stahl-block mit maximaler Abmessung von 300× 120× 90 mm3 wird aufein lineares Positioniersystem gespannt. Das Positioniersystem be-Positioniersystem
steht aus zwei separaten Achsen, der x-Achse, auf der die Probeeingespannt ist, und einer kombinierten y/z-Achse, die über der x-Achse montiert ist und auf welcher sich die Kamera und die Beleuch-tung befinden. Während der Bildaufnahme wird nur die x-Achse be-wegt und die Probe unter der Kamera verschoben. Ist eine Bahn auf-genommen, wird die Kamera mittels der y-Achse verschoben und dienächste Bahn abgescannt. Die z-Achse wird benutzt, um die Kame-Kamera
ra zu fokusieren. Für die Bildaufnahme wird entweder ein Flächen-sensor oder ein Zeilensensor verwendet. Die Einzelbilder werden an-schließend zu einem Bild der gesamten Oberfläche zusammengefügt.Die übliche lokale Auflösung pro Pixel beträgt 10 µm oder 20 µm proPixel in x, y-Richtung. Ist die Stahloberfläche vollständig abfotogra-fiert, wird mit einer Spanabnahme von bis zu 10 µm die Oberflächeabgefräst und der Bildaufnahmevorgang wiederholt. Das fertige Bildwird an die nächste Stufe der Pipeline weitergereicht. Eine umfang-reichere Darstellung des Bildaufnahmesystems ist in Herwig u. a. [55]beschrieben.

4.2 makroeinschluss-detektion 93
4.2.2 Bildverarbeitung
In den Bildern müssen nun die zweidimensionalen Profile der Defek-te detektiert und segmentiert werden. Dieser Prozess wird dadurcherschwert, dass auf der Oberfläche der Stahlprobe durch den Fräspro-zess ein quasi periodisches Muster entsteht. Zwar kann man durchgeeignete Wahl der Beleuchtung die Ausprägung dieses Fräsmustersin den Fotos abschwächen [55], gänzlich unterdrücken lässt es sich Beleuchtung
aber nicht. Zwei verschiedene Verfahren haben sich beim Segmentie-ren als erfolgreich erwiesen. Beide Verfahren arbeiten im Frequenz-raum. Das Bild wird also zunächst mittels der Fouriertransformationin diesen überführt. Beim ersten Verfahren nutzt man aus, dass dasperiodische Fräsmuster im Frequenzraum die Form eines Keils be-sitzt. Schätzt man von diesem Öffnungswinkel und Richtung, dannkann ein Filter konstruiert werden, der alle Frequenzen des Keils un-terdrückt. Dadurch wird im rücktransformierten Bild das Fräsmuster Keilfilter
beseitigt und die Defekte können mittels eines einfachen Schwellwert-verfahrens segmentiert werden [55, 21]. Das andere Verfahren basiertauf der von Aiger und Talbot [2] eingeführten Phase-Only Transfor-mation (PHOT). Durch die PHOT werden alle regelmäßigen Struk-turen, in diesem Fall also das Fräsmuster, eines Bildes entfernt undDefekte mit einem hohen Evidenzwert identifiziert. Durch zusätzli- Phase-Only
Transformationches Betrachten der direkten Nachbarschichten lässt sich mit hoherGenauigkeit ein Defekt von einem durch die Fräse entstandenen Ar-tefakt unterscheiden. Dabei stützt man sich auf die Annahme, dassalle betrachteten Defekte eine dreidimensionale Ausdehnung haben[56, 21]. Alle Pixel, die zu den identifizierten Defekten gehören, wer-den dann mit ihren originalen Grauwerten an die nächste Stufe derPipeline übergeben. Dadurch wird eine drastische Reduktion der Da-ten erreicht.
4.2.3 Morphologische und statistische Analyse
Die letzten beiden Stufen werden in einem Abschnitt zusammenge-fasst. Zunächst werden die zweidimensionalen Profile der Defekte Rekonstruktion
mit den in Abschnitt 2.1.2 beschriebenen Algorithmen verarbeitetund die dreidimensionale Morphologie rekonstruiert. Die Defektewerden dabei so lange zwischengespeichert, bis sie gemäß der De-finition aus Abschnitt 2.1.2.3 vollständig abgefräst wurden. Auf denvollständig abgefrästen Defekten werden dann die in Abschnitt 2.2 be-schriebenen Verfahren der Einzelpartikelanalyse angewendet und ih-re Gestalt statistisch quantifiziert. Anschließend werden die Defekteanhand der berechneten Deskriptoren in Risse, Poren und nichtmetal-lische Einschlüsse klassifiziert. Auch Artefakte, bei denen es sich um Klassifikation

94 anwendungsfall
fälschlich segmentierte Objekte, wie Fräsrillen oder Verschmutzun-gen der Probenoberfläche durch Späne und Öltropfen handelt, kön-nen so erkannt werden. Mittels der klassifizierten Datensätze wirddann der Reinheitsgrad kontinuierlich parallel zum Fräsprozess be-rechnet. Beim Erreichen einer ausreichend hohen statistischen Sicher-Statistische
Auswertung heit wird ein Stopsignal an die anderen Stufen der Pipeline propa-giert und der gesamte Prozess beendet. Dies schont den Fräskopfund führt zu einem ökonomischeren Prozess mit weniger Material-verschleiß. Die gewonnenen Ergebnisse der statistischen Auswertungsowie die Ergebnisse der Klassifikation und die Werte der einzelnenDeskriptoren werden schließlich in einer Datenbank abgelegt.
4.3 zusammenfassung
In diesem Kapitel wurde ein möglicher Anwendungsfall für das indieser Arbeit entwickelte Rahmenwerk vorgestellt. Bei dem Anwen-dungsfall handelt es sich um die Analyse von Verunreinigungen inStahlproben, die während der Stahlerzeugung entstehen und untergewissen Umständen im fertigen Produkt verbleiben. Diese Verun-reinigungen werden als nichtmetallische Einschlüsse bezeichnet undformen ein Partikelsystem im erstarrten Stahl, welches mit den in Ka-pitel 2 und 3 beschriebenen Verfahren untersucht werden kann. Zielder Analyse ist dabei, gesicherte statistische Aussagen abzuleiten, sodass die Entstehung der Einschlüsse und der Einfluss auf die Qua-lität des Werkstoffs besser verstanden werden. Auf lange Sicht solldann mit diesen Erkenntnissen der Produktionsprozess dahingehendoptimiert werden, dass weniger dieser Verunreinigungen im Materialzurückbleiben. Bevor die Analyse der nichtmetallischen Einschlüsseaber durchgeführt werden kann, müssen diese zunächst detektiertwerden. In diesem Abschnitt wurden deshalb die gängigsten Detekti-onsverfahren vorgestellt, welche sich in der Industrie als Standard eta-bliert haben. Dabei wurde festgestellt, dass keines der bekannten Ver-fahren in der Lage ist sowohl die dreidimensionale Morphologie alsauch die dreidimensionale räumliche Verteilung der Einschlüsse zudetektieren. Abhilfe schafft hier das im Rahmen des Silenos-Projektsentwickelte Verfahren, auf dessen Ergebnissen die Auswertungen inKapitel 5 und 6 beruhen. Neben der Funktionsweise dieses Verfah-rens wurden im weiteren Verlauf die wichtigsten bekannten statisti-schen Eigenschaften von nichtmetallischen Einschlüssen zusammen-gefasst. Diese werden in den nachfolgenden Kapiteln als Experten-wissen für die statistische Modellierung herangezogen.

5K L A S S I F I K AT I O N V O N D E F E K T E N I N S TA H L
Bei der Analyse von Stahlproben mittels des in Abschnitt 4.2 beschrie-benen Verfahrens werden neben nichtmetallischen Einschlüssen auchandere Defekte, wie Risse und Poren detektiert. Aber auch Artefakte,bei denen es sich um fälschlich segmentierte Objekte wie Fräsrillenhandelt, können in der Ergebnismenge landen. Um den Reinheits-grad der untersuchten Probe bestimmen zu können, der als Gehaltan nichtmetallischen Einschlüssen definiert ist, müssen die erkann-ten Defekte also zunächst klassifiziert werden. Insbesondere eine Ab-grenzung der Risse und Artefakte ist dabei von großer Bedeutung, daes sich bei diesen um singuläre Ereignisse mit möglicherweise sehrgroßer Ausdehnung handelt. Fließen diese in die Berechnung desReinheitsgrades ein, kann es zu starken Verfälschungen des Ergeb-nisses kommen. Im vollautomatischen Verarbeitungsbetrieb kann esdann dazu kommen, dass das in Abschnitt 6.4.2 definierte Abbruch-kriterium zum falschen Zeitpunkt auslöst und die erhobenen Ergeb-nisse für die weitere Analyse unbrauchbar sind. In diesem Kapitelwird deshalb evaluiert, wie anhand der in Abschnitt 2.2 beschriebe-nen Gestaltdeskriptoren eine automatische Klassifizierung durchge-führt werden kann und welcher Satz von Deskriptoren zum bestenErgebnis führt. Zwei Szenarien werden dabei untersucht. Zunächstwerden die Defekte in globulare Defekte, Artefakte und Risse unter-teilt. Anschließend werden die globularen Defekte in einem zweitenDurchgang feiner aufgeteilt, und zwar in nichtmetallische Einschlüs-se und Poren. Die Klassifikation erfolgt auf Basis von Algorithmenaus dem Bereich des maschinellen Lernens. Im Folgenden wird einÜberblick über die wichtigsten Methoden aus diesem Bereich gege-ben und begründet, warum welche Methoden für die automatischeKlassifikation ausgesucht wurden. Begonnen wird mit einem Einfüh-rungsbeispiel, welches die Verwendung maschinellen Lernens moti-viert.
5.1 einführungsbeispiel
Man betrachtet dazu folgendes Beispiel. Eine Menge von Defekten,welche mit der in Abschnitt 4.2 beschriebenen Technik in einer Stahl-probe detektiert wurde, soll in drei Kategorien unterteilt werden. Beiden drei Kategorien handelt es sich um Risse, die auf Grund vonSpannungen während der Abkühlung im Material auftreten können,
95
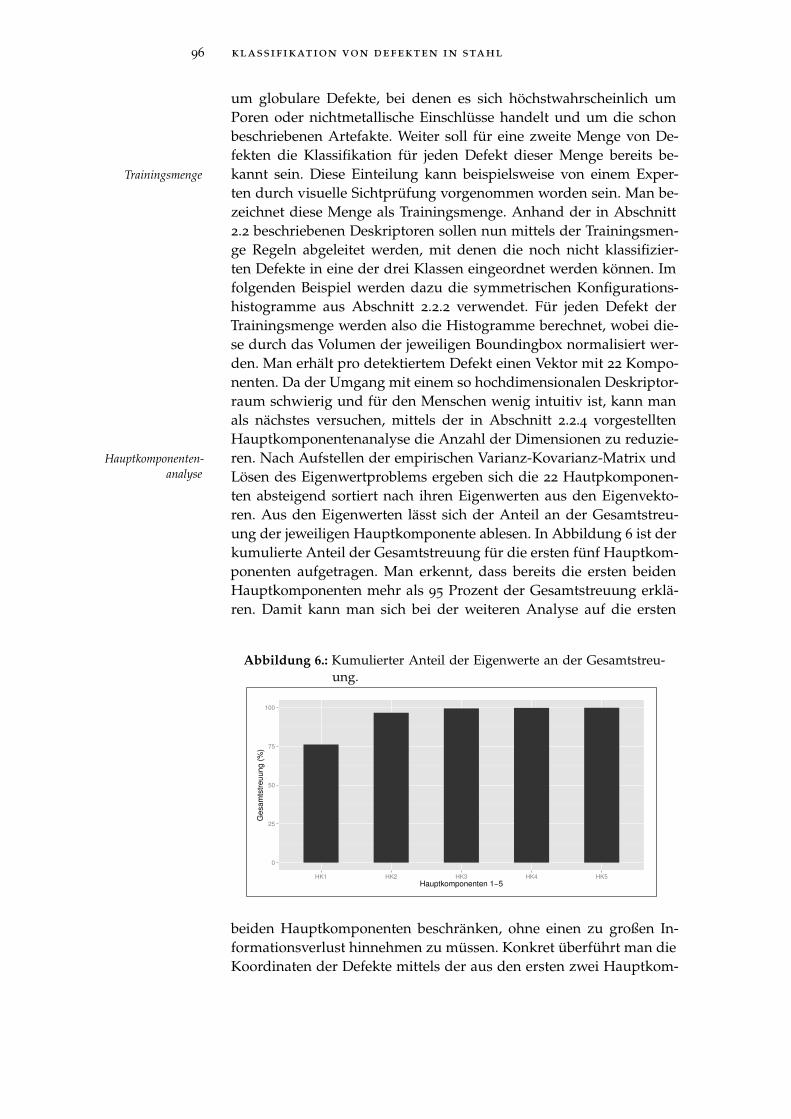
96 klassifikation von defekten in stahl
um globulare Defekte, bei denen es sich höchstwahrscheinlich umPoren oder nichtmetallische Einschlüsse handelt und um die schonbeschriebenen Artefakte. Weiter soll für eine zweite Menge von De-fekten die Klassifikation für jeden Defekt dieser Menge bereits be-kannt sein. Diese Einteilung kann beispielsweise von einem Exper-Trainingsmenge
ten durch visuelle Sichtprüfung vorgenommen worden sein. Man be-zeichnet diese Menge als Trainingsmenge. Anhand der in Abschnitt2.2 beschriebenen Deskriptoren sollen nun mittels der Trainingsmen-ge Regeln abgeleitet werden, mit denen die noch nicht klassifizier-ten Defekte in eine der drei Klassen eingeordnet werden können. Imfolgenden Beispiel werden dazu die symmetrischen Konfigurations-histogramme aus Abschnitt 2.2.2 verwendet. Für jeden Defekt derTrainingsmenge werden also die Histogramme berechnet, wobei die-se durch das Volumen der jeweiligen Boundingbox normalisiert wer-den. Man erhält pro detektiertem Defekt einen Vektor mit 22 Kompo-nenten. Da der Umgang mit einem so hochdimensionalen Deskriptor-raum schwierig und für den Menschen wenig intuitiv ist, kann manals nächstes versuchen, mittels der in Abschnitt 2.2.4 vorgestelltenHauptkomponentenanalyse die Anzahl der Dimensionen zu reduzie-ren. Nach Aufstellen der empirischen Varianz-Kovarianz-Matrix undHauptkomponenten-
analyse Lösen des Eigenwertproblems ergeben sich die 22 Hautpkomponen-ten absteigend sortiert nach ihren Eigenwerten aus den Eigenvekto-ren. Aus den Eigenwerten lässt sich der Anteil an der Gesamtstreu-ung der jeweiligen Hauptkomponente ablesen. In Abbildung 6 ist derkumulierte Anteil der Gesamtstreuung für die ersten fünf Hauptkom-ponenten aufgetragen. Man erkennt, dass bereits die ersten beidenHauptkomponenten mehr als 95 Prozent der Gesamtstreuung erklä-ren. Damit kann man sich bei der weiteren Analyse auf die ersten
Abbildung 6.: Kumulierter Anteil der Eigenwerte an der Gesamtstreu-ung.
0
25
50
75
100
HK1 HK2 HK3 HK4 HK5
Hauptkomponenten 1−5
Ge
sa
mts
tre
uu
ng
(%
)
beiden Hauptkomponenten beschränken, ohne einen zu großen In-formationsverlust hinnehmen zu müssen. Konkret überführt man dieKoordinaten der Defekte mittels der aus den ersten zwei Hauptkom-

5.1 einführungsbeispiel 97
ponenten mit den größten Eigenwerten gebildeten Transformations-matrix in ein neues Koordinatensystem. Um zu analysieren, welcheKonfigurationen des Histogramms besonders viele Informationen insich tragen, kann man sich die durch die Hauptkomponenten be-schriebenen Gewichtungen, auch Ladungen genannt, anschauen. In Ladungen
Abbildung 7 sind die Werte für die ersten beiden Hauptkomponentenaufgetragen. Die x-Achse gibt dabei den Index der jeweiligen Voxel-konfiguration an. Bei beiden Hauptkompontenten sind die Indizes 0
Abbildung 7.: Histogramm der Ladungen.
−0.8
−0.4
0.0
0.4
−0.8
−0.4
0.0
0.4
HK
1H
K2
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
Index
La
du
ng
en
und 21 stark abweichend von 0 gewichtet. Durch einen Blick auf Ta-belle 13 erfährt man, dass es sich dabei um die Konfigurationen fürdie leere und die komplett gefüllte 2× 2× 2 Voxelnachbarschaft han-delt. Vor dem Hintergrund, dass das Histogramm vorher durch dasVolumen der Boundingbox normalisiert wurde, lassen sich die Werteals eine Art Kompaktmaß der Defekte interpretieren. Bei dünn be-setzten Defekten mit großer räumlicher Ausdehnung ist das Verhält-nis zwischen der Anzahl der vollbesetzten Konfigurationen und demVolumen der Boundingbox sehr klein. Bei globularen Defekten hinge-gen wird das Verhältnis eher groß sein, da das Boundingboxvolumenim Vergleich zur Anzahl der vollen Belegungen klein ist. Die Auswir- Streudiagramm
kungen dieser Gewichtung kann man in Abbildung 8 sehen. In demStreudiagramm sind die transformierten Koordinaten der Defekte derTrainingsmenge gegeneinander aufgetragen und jeweils mit den ent-sprechenden bekannten Bezeichnern versehen. Die globularen Defek-te liegen relativ dicht beieinander und lassen sich gut von den Rissenund Artefakten trennen. Schwieriger sieht es bei den Artefakten undRissen aus. Hier ist im Streudiagramm keine klare Clusterbildung er-kennbar. Dies ist darauf zurückzuführen, dass das oben beschriebeneKompaktmaß auf Grund der ähnlichen Struktur von Rissen und Arte-fakten keine eindeutige Trennung erlaubt. Während man also globu-lare Defekte gut von den übrigen Strukturen trennen und eventuellsogar statische Regeln in Form von festen Schwellwerten aus Abbil-dung 8 ableiten kann, ist eine Unterscheidung zwischen Rissen und
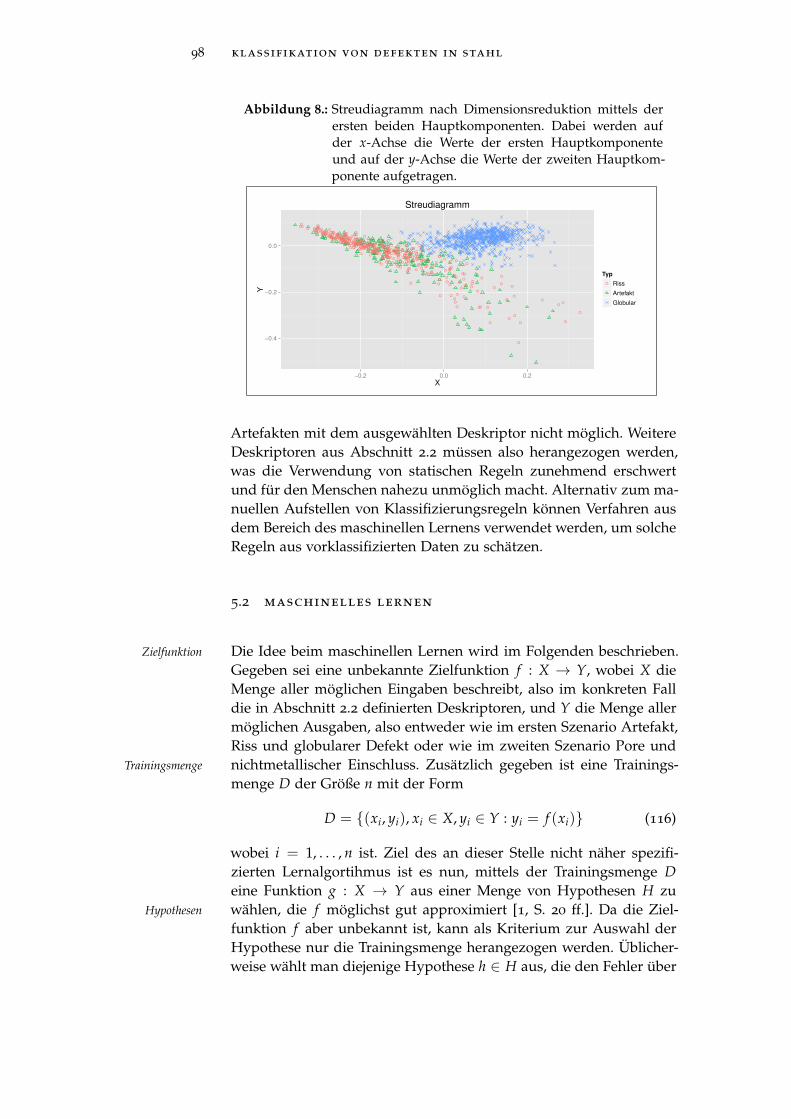
98 klassifikation von defekten in stahl
Abbildung 8.: Streudiagramm nach Dimensionsreduktion mittels derersten beiden Hauptkomponenten. Dabei werden aufder x-Achse die Werte der ersten Hauptkomponenteund auf der y-Achse die Werte der zweiten Hauptkom-ponente aufgetragen.
−0.4
−0.2
0.0
−0.2 0.0 0.2
X
Y
Typ
Riss
Artefakt
Globular
Streudiagramm
Artefakten mit dem ausgewählten Deskriptor nicht möglich. WeitereDeskriptoren aus Abschnitt 2.2 müssen also herangezogen werden,was die Verwendung von statischen Regeln zunehmend erschwertund für den Menschen nahezu unmöglich macht. Alternativ zum ma-nuellen Aufstellen von Klassifizierungsregeln können Verfahren ausdem Bereich des maschinellen Lernens verwendet werden, um solcheRegeln aus vorklassifizierten Daten zu schätzen.
5.2 maschinelles lernen
Die Idee beim maschinellen Lernen wird im Folgenden beschrieben.Zielfunktion
Gegeben sei eine unbekannte Zielfunktion f : X → Y, wobei X dieMenge aller möglichen Eingaben beschreibt, also im konkreten Falldie in Abschnitt 2.2 definierten Deskriptoren, und Y die Menge allermöglichen Ausgaben, also entweder wie im ersten Szenario Artefakt,Riss und globularer Defekt oder wie im zweiten Szenario Pore undnichtmetallischer Einschluss. Zusätzlich gegeben ist eine Trainings-Trainingsmenge
menge D der Größe n mit der Form
D = (xi, yi), xi ∈ X, yi ∈ Y : yi = f (xi) (116)
wobei i = 1, . . . , n ist. Ziel des an dieser Stelle nicht näher spezifi-zierten Lernalgortihmus ist es nun, mittels der Trainingsmenge Deine Funktion g : X → Y aus einer Menge von Hypothesen H zuwählen, die f möglichst gut approximiert [1, S. 20 ff.]. Da die Ziel-Hypothesen
funktion f aber unbekannt ist, kann als Kriterium zur Auswahl derHypothese nur die Trainingsmenge herangezogen werden. Üblicher-weise wählt man diejenige Hypothese h ∈ H aus, die den Fehler über

5.2 maschinelles lernen 99
die Trainingsmenge minimiert. Nun kann es aber vorkommen, dasses eine alternative Hypothese h′ ∈ H gibt, die zwar einen größerenFehler gegenüber von h auf den Trainingsdaten aufweist, aber einenkleineren bezogen auf alle möglichen Eingabedaten. Man spricht in Kreuzvalidierung
diesem Fall auch von Überanpassung. Die entscheidende Frage ist al-so, wie gut sich der gelernte Zusammenhang aus den Trainingsdatengeneralisieren lässt. Um dies zu testen, verwendet man das Kreuz-validierungsverfahren. Bei der Kreuzvalidierung wird die Trainings-menge D zufällig in k möglichst gleich große Teilmengen D1, . . . , Dk
aufgeteilt. Aus diesen k Teilmengen wird eine Teilmenge Di als Test-menge deklariert, während die k− 1 Teilmengen D1, . . . , Dk \ Didie neue Trainingsmenge darstellen. Der Lernalgorithmus wird alsomit k − 1 Mengen trainiert und mit der Testmenge Di anschließendvalidiert. Der Prozess wird k mal wiederholt, wobei jede Teilmengegenau einmal als Testmenge fungiert. Lässt sich der angelernte Algo-rithmus gut generalisieren, liefert der Algorithmus im Durchschnittfür jeden der k Durchläufe ein gutes Ergebnis.
5.2.1 Bewertung eines Klassifizierers
Stellt sich die Frage, wie genau man quantifizieren kann, ob ein Klas-sifizierer ein gutes Ergebnis liefert. Das Ergebnis eines Klassifiziererslässt sich als Datensatz mit zwei qualitativen Merkmalen mit jeweils nMerkmalsausprägungen auffassen, wobei n der Anzahl der Klassenentspricht. Das erste Merkmal, genannt A mit Aj Merkmalsausprä-gungen, wobei j = 1, . . . , n gilt, beschreibt, welcher Klasse das be-trachtete Objekt wirklich angehört, während das zweite Merkmal, ge-nannt B mit Bi Merkmalsausprägungen, wobei i = 1, . . . , n gilt, dievom Klassifizierer zugewiesene Klasse angibt. Daraus lässt sich eine Kontingenztabelle
Häufigkeitstabelle aller Merkmalskombinationen, auch Kontingenzta-belle oder Konfusionsmatrix genannt, aufstellen [48, S. 37 ff.]. Tabelle3 zeigt eine solche Matrix. Dabei ist hij die Häufigkeit eines Objektesmit Merkmalsausprägung Bi und Aj, oder anders ausgedrückt, dieHäufigkeit, wie oft ein Objekt vom Klassifizierer der Klasse Bi zuge-ordnet wurde, obwohl es der Klasse Aj angehört. Die Diagonale der
Tabelle 3.: Beispiel einer Kontingenztabelle.A
A1 A2 . . . An
B
B1 h11 h12 . . . h1n
B2 h21 h22 . . . h2n... . . . . . . . . . . . .Bn hn1 hn2 . . . hnn
Matrix gibt die Häufigkeit der richtig klassifizierten Objekte an. Die Korrektklassifikati-onsrate

100 klassifikation von defekten in stahl
Korrektklassifikationsrate oder Akkuratheit (im Englischen Accura-cy) ACC ergibt sich dann aus
ACC =
n∑
i=1hii
n∑
i=1
n∑
j=1hij
.(117)
Bei der Berechnung der Korrektklassifikationsrate wird aber nicht be-rücksichtigt, dass ein gewisses Maß an Übereinstimmung auch dannzu erwarten wäre, wenn der Klassifizierer per Zufall entscheidet. Mit-Kappa-Koeffizient
tels des Kappa-Koeffizienten lässt sich die Korrektklassifikationsrateum den Anteil der zufälligen Übereinstimmung bereinigen. Definiertist der Kappa-Koeffizient als
κ =ACC− e
1− e ,(118)
wobei e die Korrektklassifikationsrate bei zufälliger Klassifikation ist.Man kann e mittels
e =
n∑
k=1
(n∑
i=1hik
n∑
j=1hkj
)
(n∑
i=1
n∑
j=1hij)2
(119)
berechnen.
Des Weiteren lassen sich für jede Klasse die Kenngrößen Sensitivität(im Englischen Recall) und die Genauigkeit (im Englischen Precision)ausrechnen. Die Sensitivität ist die Anzahl der korrekt klassifiziertenSensitivität und
Genauigkeit Objekte einer Klasse geteilt durch die Gesamtheit aller Objekte dieserKlasse, während die Genauigkeit die Anzahl der korrekt klassifizier-ten Objekte einer Klasse geteilt durch die Anzahl aller als diese Klasseklassifizierten Objekte ist. Aus der Kontingenztabelle 3 ergibt sich dieSensitivität Rk und die Genauigkeit Pk einer Klasse k durch
Rk =hkk
n∑
i=1hik
(120)
und
Pk =hkk
n∑
j=1hkj
.(121)
Für die Berechnung der Gesamtsensitivität und der Gesamtgenauig-keit gibt es verschiedene Definitionen [124]. Eine Möglichkeit bestehtMakrosensitivität
undMakrogenauigkeit
darin, den Mittelwert der Sensitivität und Genauigkeit über alle Klas-sen zu berechnen. Diese Methode wird auch als Makrodurchschnittbezeichnet und entsprechend die Sensitivität als Makrosensitivität

5.2 maschinelles lernen 101
RM und die Genauigkeit als Makrogenauigkeit PM. Sie sind definiertals
RM =
n∑
k=1Rk
n(122)
und
PM =
n∑
k=1Pk
n .(123)
Bei dieser Methode werden Klassen mit wenig Objekten stärker ge-wichtet als Klassen mit vielen. Wenn die Anzahl von Objekten inner-halb der einzelnen Klassen sich also stark voneinander unterschei-det, wird das Ergebnis verfälscht. Abhilfe kann hier der Mikrodurch-schnitt schaffen, der alle Klassen gleich gewichtet. Die Mikrosensiti- Mikrosensitivität
undMikrogenauigkeit
vität Rµ und Mikrogenauigkeit Pµ sind definiert als
Rµ =
n∑
k=1hkk
n∑
i=1
n∑
j=1hij
(124)
und
Pµ =
n∑
k=1hkk
n∑
i=1
n∑
j=1hij
.(125)
Für den hier dargestellten Fall, in dem jedes Objekt immer einer Klas-se zugewiesen wird, sind Mikrosensitivität, Mikrogenauigkeit undKorrektklassifikationsrate gleich.
Schließlich wird häufig das F1-Maß verwendet, bei dem die Sensi-tivität und Genauigkeit zu einem Wert zusammengefasst werden. Es F1-Maß
kann sowohl klassenweise als auch für die Gesamtsensitivität und Ge-samtgenauigkeit berechnet werden. Allgemein ist das F1-Maß durch
F1 =2RP
R + P(126)
definiert, wobei R und P den oben angegebenen Definitionen für dieGenauigkeit beziehungsweise die Sensitivität entsprechen.
Für die in Abschnitt 5.3 beschriebene Auswertung werden alle hierdefinierten Maße berechnet.
5.2.2 Lernalgorithmus
Bleibt die Frage, welchen Lernalgorithmus man konkret verwendet.Zahlreiche Algorithmen wurden im Bereich des überwachten Ler-nens, also beim Lernen einer Funktion aus einem Paar von Ein-

102 klassifikation von defekten in stahl
und Ausgabedaten, vorgestellt. Die bekanntesten Vertreter sind dieprobabilistischen Klassifizierer, wie beispielsweise der naive Bayes-Klassifikator, die auf Entscheidungsbäumen oder auf künstlichenneuronalen Netzwerken basierenden Klassifikatoren und schließlichdie Support Vector Machine (SVM). Beim naiven Bayes-KlassifikatorNaiver
Bayes-Klassifikator lässt sich, unter der Voraussetzung, dass die einzelnen Deskripto-ren zum gleichen Teil zur Entscheidung beitragen und voneinan-der unabhängig sind, die Klassenzugehörigkeit eines Objektes durchAusrechnen der bedingten Wahrscheinlichkeiten bestimmen. Dazumuss die Wahrscheinlichkeitsdichtefunktion der einzelnen Deskrip-toren bekannt sein. Bei kontinuierlichen Daten geht man üblicherwei-se davon aus, dass die Deskriptoren normalverteilt sind. Die Vertei-lungsparameter lassen sich dann mittels der jeweiligen Schätzfunk-tion aus der Trainingsdatenmenge schätzen und ein neuer Daten-satz durch Aufstellen der bedingten Wahrscheinlichkeit klassifizie-ren [147, S. 88 ff.]. Entscheidungsbäume sind geordnete, gerichteteEntscheidungsbäu-
me Bäume, deren Knoten logische Regeln beschreiben und in deren Blät-tern die einzelnen Klassen hinterlegt sind. Um ein unbekanntes Ob-jekt zu klassifizieren, steigt man beginnend von Wurzelknoten denBaum entlang abwärts. Bei jedem Knoten wird die logische Regel aufdas Objekt beziehungsweise einen Deskriptor angewendet und ent-schieden, in welchen Teilbaum abgestiegen werden soll. Erreicht maneinen Blattknoten, ist das Objekt klassifiziert. Die Entscheidungsre-geln des Baums werden dabei entweder von Experten definiert oderaus Trainingsmengen induziert [114, S. 8 ff.]. Eine Erweiterung derEntscheidungsbäume sind Random Forests. Dabei werden mehrereEntscheidungsbäume aus zufällig gewählten Teilmengen aller De-skriptoren der Trainingsmenge gebildet und zum Klassifizieren ver-wendet. Dadurch wird eine verbesserte Generalisierung erreicht [57,17]. Künstliche neuronale Netzwerke sind Modelle zum Lernen vonNeuronale
Netzwerke Funktionen, die durch die Funktionsweise des zentralen Nervensys-tems von Menschen oder Tieren inspiriert sind. Ein sehr einfacherVertreter dieser Gattung ist das Perzeptron. Das einlagige Perzep-tron besteht aus einer Reihe von gewichteten Eingängen, welche beider Lösung eines Klassifizierungsproblems der Menge der Deskrip-toren entspricht. Die Eingänge sind über die Eingangsfunktion, wel-che die gewichtete Summe der Eingabewerte berechnet, mit einemAusgang verbunden. Am Ausgang wird nun im Falle eines Klassi-fizierungsproblems mittels einer Schwellwertfunktion überprüft, zuwelcher Klasse das zu identifizierende Objekt gehört. Um das Per-zeptron anzulernen, müssen die Gewichte so gewählt werden, dassder Klassifizierungsfehler über der Trainingsmenge minimiert wird[95, S. 86]. Das einlagige Perzeptron eignet sich nur für die Klassifi-zierung von linear separierbaren Datensätzen. Wie bereits festgestellt,ist die Unterscheidung von globularen und nicht globularen Defektenunter Verwendung der dimensionsreduzierten symmetrischen Konfi-

5.2 maschinelles lernen 103
gurationshistogramme, wie man in Abbildung 8 sieht, linear separier-bar, da sich die Daten durch eine Ebene voneinander trennen lassen.Möchte man auch nicht linear separierbare Daten voneinander tren-nen, wie beispielsweise in Abbildung 8 Risse und Artefakte, mussdas einlagige Perzeptron durch das Hinzufügen von weiteren ver-steckten Schichten zwischen Eingängen und Ausgängen zu einemmehrschichtigen Perzeptron erweitert werden. Angelernt wird dasmehrschichtige Perzeptron mittels des von Rumelhart, Hinton undWilliams [116] entwickelten Verfahrens der Fehlerrückführung (Back-propagation genannt). Bei den SVMs schließlich wird das Klassifi- Support Vector
Machineskationsproblem gelöst, indem für die Objekte der Trainingsmengeeine Hyperebene bestimmt wird, welche die Objekte entsprechendihrer Klassenzugehörigkeit voneinander trennt. Dabei wird der Ab-stand der Objekte, die der Ebene am nächsten liegen, maximiert. DieEbene hängt also nur von diesen Objekten ab und kann durch dieseexakt beschrieben werden. Man bezeichnet diese als Stützvektoren.Ein unbekanntes Objekt wird dann klassifiziert, indem seine Lage be-züglich der durch die Stützvektoren beschriebenen Ebene analysiertwird. Um bessere Generalisierungseigenschaften zu erreichen, kanndie sogenannte Schlupfvariable gesetzt werden. Die Schlupfvariableerlaubt es, dass eine bestimmte Anzahl von Objekten falsch klassifi-ziert werden darf. Dies kann beispielsweise sinnvoll sein, wenn dieDaten zwar linear separierbar sind, aber auf Grund von Rauschenkeine eindeutige Ebene gefunden werden kann. Prinzipiell arbeitetdie so beschriebene SVM aber nur optimal, wenn das Klassifikati-onsproblem linear ist. Um auch nicht linear separierbare Datensätzezu klassifizieren, kann man versuchen den Trainingsdatensatz durcheine nicht lineare Transformation Φ : R
n → H in einen möglicherwei-se unendlich dimensionalen Vektorraum abzubilden. In diesem wirdnach dem obenen beschriebenen Verfahren die Hyperebene bestimmt,welche den Datensatz in zwei Klassen separiert. Im ursprünglichenRaum stellt sich diese Hyperebene als gekrümmte Trennfläche dar.Wie beispielsweise von Burges [22] gezeigt wurde, lässt sich die op-timierende Zielfunktion zur Bestimmung der Hyperebene so formu-lieren, dass Φ nur als Skalarprodukt vorkommt. Damit muss Φ nichtexplizit angebenen werden, sondern lässt sich durch eine Funktion
K(xi, xj) = Φ(xi)Φ(xj) (127)
für zwei Elemente xi und xj der Trainingsmenge berechnen. Man be-zeichnet die Funktion K als Kernelfunktion. Häufig verwendete Ker-nel sind die Radiale Basisfunktion (auch als Gauß-Kernel bezeichnet)und der polynominale Kernel. Da in der vorliegenden Arbeit sowohllinear wie nicht linear separierbare Datensätze klassifiziert werdenmüssen, wird auf Grund dieser Eigenschaften im Nachfolgenden aus-schließlich eine SVM zur Klassifikation verwendet. Für die Klassifizie-rung von Poren und nichtmetallischen Einschlüssen wurde von Bür-

104 klassifikation von defekten in stahl
ger u. a. [20] bereits gezeigt, dass die SVM im direkten Vergleich zuden anderen Methoden sehr gute Ergebnisse liefert. Im Gegensatzzu den veröffentlichten Ergebnissen wird im Folgenden aber keinheuristisches Verfahren verwendet, um den optimalen Desktriptor-satz zu bestimmen, sondern, wie später noch beschrieben wird, eineerschöpfende Suche durchgeführt. Dieser Ansatz ist zwar rechenin-tensiver, da die Bestimmung des optimalen Parametersatzes aber nureinmal während der Trainingsphase durchgeführt werden muss, gibtes keine Einschränkungen für den Echtzeitbetrieb. Für die Implemen-tierung der SVM wird auf die von Chang und Lin [24] entwickeltelibSVM zurückgegriffen.
5.3 auswertung
Sowohl für das Klassifizieren von Artefakten, Rissen und globularenDefekten als auch für das Klassifizieren von nichtmetallischen Ein-schlüssen und Poren stehen per Hand vorklassifizierte Datensätzezur Verfügung, die als Grundwahrheit dienen. Beim ersten Szena-Datensätze
rio besteht der Datensatz aus insgesamt 1462 Defekten, die durchmanuelle Sichtung mehrerer Proben mittels des in Abschnitt 7.2 vor-gestellten Werkzeugs erstellt wurden. Durch direkten Vergleich dersegmentierten Daten mit den Originalbildern lässt sich ihre Klassen-zugehörigkeit schnell bestimmen. Schwieriger ist die Datenerfassungbeim zweiten Szenario. Hier wurde der Datensatz erstellt, indem par-allel zum Fräsprozess per visueller Inspektion nach markanten De-fekten auf der Stahloberfläche gesucht wurde. Hat man einen ver-meintlichen Defekt entdeckt, wird die Probe aus der Fräse genom-men und per Mikroskop überprüft, ob es sich bei dem entdecktenDefekt um eine Pore oder einen nichtmetallischen Einschluss handelt.Die Entscheidung stützt sich darauf, dass Poren von innen hohl sind.Nichtmetallische Einschlüsse hingegen weisen eine innere Strukturauf. Anschließend wird die Probe wieder in die Fräse gespannt undweiter gefräst. Insgesamt umfasst der Datensatz für das zweite Sze-Klassen
nario 464 Defekte. Die genaue Zusammensetzung der Datensätze istder Tabelle 4 zu entnehmen. Wie bereits erwähnt, wird zur Klassi-
Tabelle 4.: Zusammensetzung der Datensätze.
Szenario Riss Artefakt globularer Defekt Pore Einschluss
Szenario 1 404 204 854
Szenario 2 253 211
fizierung eine SVM mit Gauß-Kernel und gesetzter SchlupfvariableC verwendet. Dabei werden bei der Parametrisierung des Kernel-Parameters γ und der Schlupfvariable C die von Hsu, Chang undLin [58] aufgestellten Richtlinien umgesetzt. Konkret bedeutet dies,

5.3 auswertung 105
dass die Parameter mittels einer Gittersuche optimiert werden. Die Deskriptoren
verwendeten 18 Deskriptoren sind mit Verweis auf das jeweilige Un-terkapitel aus Tabelle 5 zu entnehmen. Die symmetrischen Konfigu-rationshistogramme sind, wie im Einführungsbeispiel in Abschnitt5.1 beschrieben, mittels Hauptkomponentenanalyse auf zwei Dimen-sionen reduziert. Bei 18 Deskriptoren ergeben sich 218 verschiedene
Tabelle 5.: Zur Klassifikation verwendete Deskriptoren.Deskriptor Beschreibung Verweis
h(22) .PC1 1. Hauptkomponente des Konfigurationshistogramms 2.2.2h(22) .PC2 2. Hauptkomponente des Konfigurationshistogramms 2.2.2dimB F Empirische Approximation der fraktalen Dimension 2.2.6J1 1. Translation-, rotation-, und skaleninvariantes Moment 2.2.4J2 2. Translation-, rotation-, und skaleninvariantes Moment 2.2.4J3 3. Translation-, rotation-, und skaleninvariantes Moment 2.2.4DIM Maß über das Verhältnis der Hauptachsen 2.2.4ECC Exzentrizität 2.2.4CONV Verhältnis aus Partikelvolumen zum Volumen der konvexen Hülle 2.2.5F1 1. Isoperimetrische Ungleichung 2.2.3F2 2. Isoperimetrische Ungleichung 2.2.3F3 3. Isoperimetrische Ungleichung 2.2.3χ8 Eulerzahl der 8er-Nachbarschaft 2.2.3χ26 Eulerzahl der 26er-Nachbarschaft 2.2.3VV Verhältnis aus Partikelvolumen zum Volumen der Boundingbox 2.2.3SV Verhältnis aus Partikeloberfläche zum Volumen der Boundingbox 2.2.3MV Verhältnis aus der mittleren Krümmung zum Volumen der Boundingbox 2.2.3KV Verhältnis aus der totalen Krümmung zum Volumen der Boundingbox 2.2.3
Kombinationen, für die jeweils jede Kombination aus Schlupfvaria-ble und Kernelparameter mittels k-facher Kreuzvalidierung getestetwird. Die Wertebereiche für den Kernel-Parameter γ und die Schlupf-variable C werden dabei für die Gittersuche auf 0.25, 0.50, 1.00, 2.00und 0.5, 1.0, 2.0, 4.0, 256.0, 512.0 gesetzt. Die Kreuzvalidierung wird Parametrisierung
mit 10facher Faltung durchgeführt. Für jeden Deskriptorsatz erge-ben sich also 240 Trainings- und Validierungsdurchläufe. Nach jedemKreuzvalidierungsschritt werden die in Abschnitt 5.2.1 beschriebenenMaße zur Beurteilung der Klassifizierung über alle Faltungen gemit-telt und zur späteren Auswertung gespeichert. Ziel ist es dann, denDeskriptor- und Parametersatz zu bestimmen, der bei dem gestell-ten Klassifizierungsproblem die höchste Korrektklassifikationsrate er-zielt. Durch die Kreuzvalidierung wird dabei sichergestellt, dass esnicht zur Überanpassung kommt. Implementiert wurde das Auswer-teskript mittels der Programmiersprache R.
5.3.1 Risse, Artefakte und globulare Defekte
Zunächst betrachtet man, wie sich die Anzahl der Deskriptorenauf die Korrektklassifikationsrate auswirkt. In Abbildung 9 sind der Anzahl der
DeskriptorenDurchschnitt (grüne Linie), die maximale (rote Linie) und die mini-male (blaue Linie) Korrektklassifikationsrate gegen die Anzahl derverwendeten Deskriptoren aufgetragen. Mit steigender Anzahl vonDeskriptoren verbessert sich auch das Klassifizierungsergebnis bisschließlich bei 6 Deskriptoren eine Sättigung erfolgt. Hinzuziehen
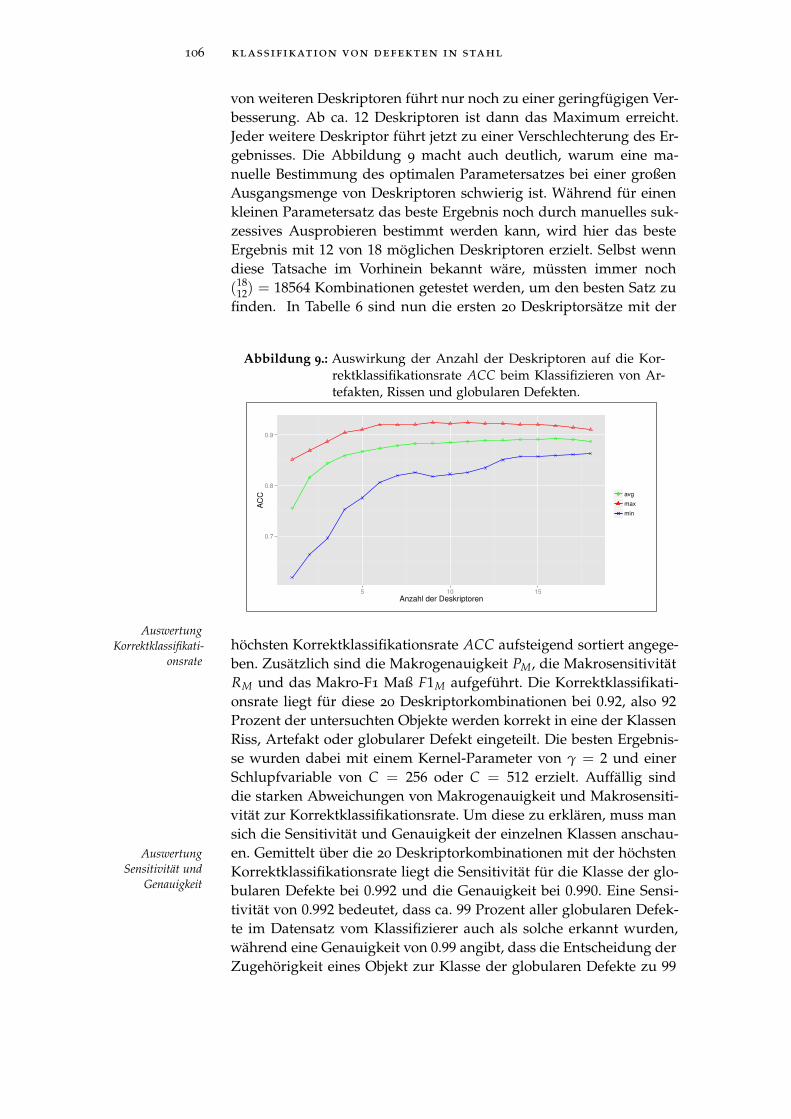
106 klassifikation von defekten in stahl
von weiteren Deskriptoren führt nur noch zu einer geringfügigen Ver-besserung. Ab ca. 12 Deskriptoren ist dann das Maximum erreicht.Jeder weitere Deskriptor führt jetzt zu einer Verschlechterung des Er-gebnisses. Die Abbildung 9 macht auch deutlich, warum eine ma-nuelle Bestimmung des optimalen Parametersatzes bei einer großenAusgangsmenge von Deskriptoren schwierig ist. Während für einenkleinen Parametersatz das beste Ergebnis noch durch manuelles suk-zessives Ausprobieren bestimmt werden kann, wird hier das besteErgebnis mit 12 von 18 möglichen Deskriptoren erzielt. Selbst wenndiese Tatsache im Vorhinein bekannt wäre, müssten immer noch(18
12) = 18564 Kombinationen getestet werden, um den besten Satz zufinden. In Tabelle 6 sind nun die ersten 20 Deskriptorsätze mit der
Abbildung 9.: Auswirkung der Anzahl der Deskriptoren auf die Kor-rektklassifikationsrate ACC beim Klassifizieren von Ar-tefakten, Rissen und globularen Defekten.
0.7
0.8
0.9
5 10 15
Anzahl der Deskriptoren
AC
C avg
max
min
AuswertungKorrektklassifikati-
onsratehöchsten Korrektklassifikationsrate ACC aufsteigend sortiert angege-ben. Zusätzlich sind die Makrogenauigkeit PM, die MakrosensitivitätRM und das Makro-F1 Maß F1M aufgeführt. Die Korrektklassifikati-onsrate liegt für diese 20 Deskriptorkombinationen bei 0.92, also 92Prozent der untersuchten Objekte werden korrekt in eine der KlassenRiss, Artefakt oder globularer Defekt eingeteilt. Die besten Ergebnis-se wurden dabei mit einem Kernel-Parameter von γ = 2 und einerSchlupfvariable von C = 256 oder C = 512 erzielt. Auffällig sinddie starken Abweichungen von Makrogenauigkeit und Makrosensiti-vität zur Korrektklassifikationsrate. Um diese zu erklären, muss mansich die Sensitivität und Genauigkeit der einzelnen Klassen anschau-en. Gemittelt über die 20 Deskriptorkombinationen mit der höchstenAuswertung
Sensitivität undGenauigkeit
Korrektklassifikationsrate liegt die Sensitivität für die Klasse der glo-bularen Defekte bei 0.992 und die Genauigkeit bei 0.990. Eine Sensi-tivität von 0.992 bedeutet, dass ca. 99 Prozent aller globularen Defek-te im Datensatz vom Klassifizierer auch als solche erkannt wurden,während eine Genauigkeit von 0.99 angibt, dass die Entscheidung derZugehörigkeit eines Objekt zur Klasse der globularen Defekte zu 99

5.3 auswertung 107
Tabelle 6.: Die ersten 20 Deskriptorsätze mit der höchsten Korrektklas-sifikationsrate ACC beim Klassifizieren von Rissen, Artefak-ten und globularen Defekten.
Deskriptoren γ C ACC RM PM F1M
h(22) .PC2,dimB F,CONV,J1 ,J2 ,J3 ,F1 ,F3 ,ECC,VV ,KV 2 256 0.924 0.852 0.88 0.865
h(22) .PC1,h(22) .PC2,dimB F,J1 ,J2 ,F1 ,F3 ,ECC,KV 2 512 0.924 0.856 0.875 0.865
h(22) .PC2,dimB F,J1 ,J2 ,J3 ,F1 ,F3 ,ECC,VV ,MV ,χ6 2 256 0.923 0.852 0.877 0.865
dimB F,CONV,J1 ,J2 ,J3 ,F1 ,F2 ,F3 ,ECC,SV ,VV ,KV 2 256 0.923 0.849 0.877 0.863
dimB F,J1 ,J2 ,J3 ,F1 ,F3 ,ECC,VV ,χ6 2 512 0.923 0.848 0.879 0.863
h(22) .PC1,dimB F,J1 ,J2 ,J3 ,F1 ,F3 ,ECC,SV 2 512 0.923 0.854 0.878 0.865
dimB F,J1 ,J2 ,J3 ,F1 ,F3 ,ECC,VV ,KV ,χ6 2 512 0.923 0.851 0.876 0.863
h(22) .PC2,dimB F,CONV,J1 ,J2 ,J3 ,F1 ,F2 ,F3 ,ECC,VV ,KV 2 256 0.923 0.851 0.876 0.863
h(22) .PC1,h(22) .PC2,dimB F,J1 ,J2 ,J3 ,F1 ,F3 ,ECC,KV ,χ6 2 256 0.923 0.851 0.872 0.861
h(22) .PC2,dimB F,CONV,J1 ,J2 ,J3 ,F1 ,F3 ,ECC,SV ,VV ,KV 2 256 0.923 0.849 0.877 0.862
h(22) .PC1,h(22) .PC2,dimB F,J1 ,J2 ,J3 ,F1 ,F3 ,ECC,SV ,MV 2 256 0.923 0.85 0.874 0.861
dimB F,CONV,J1 ,J2 ,J3 ,F1 ,F2 ,F3 ,ECC,VV ,KV ,χ6 2 256 0.923 0.85 0.876 0.863
h(22) .PC1,h(22) .PC2,dimB F,J1 ,J2 ,J3 ,F1 ,F2 ,F3 ,ECC 2 256 0.923 0.845 0.879 0.861
h(22) .PC2,dimB F,J1 ,J2 ,J3 ,F1 ,F3 ,ECC,VV 2 512 0.923 0.851 0.879 0.865
dimB F,CONV,J1 ,J2 ,J3 ,F1 ,F2 ,F3 ,ECC,SV ,VV ,KV ,χ6 2 256 0.923 0.849 0.875 0.862
h(22) .PC2,dimB F,J1 ,J2 ,J3 ,F1 ,F3 ,ECC,VV ,χ26 ,χ6 2 512 0.923 0.851 0.877 0.864
h(22) .PC1,h(22) .PC2,dimB F,J1 ,J2 ,J3 ,F1 ,F3 ,ECC 2 512 0.923 0.848 0.88 0.864
h(22) .PC2,dimB F,J1 ,J3 ,F1 ,F2 ,F3 ,ECC,VV ,MV 2 256 0.923 0.851 0.877 0.863
h(22) .PC2,dimB F,J1 ,F1 ,F2 ,F3 ,ECC,VV ,KV 2 512 0.923 0.855 0.872 0.863
h(22) .PC2,dimB F,J1 ,J3 ,F1 ,F3 ,ECC,MV ,χ6 2 512 0.923 0.854 0.869 0.862
Prozent richtig ist. Globulare Defekte werden also fast immer erkanntund es kommt selten vor, dass ein als globularer Defekt erkanntes Ob-jekt nicht dieser Klasse angehört. Dies bestätigt die im Einführungs-beispiel gewonnene Erkenntniss, dass sich die Klasse der globularenDefekte mit den vorhandenen Deskriptoren gut linear von den ande-ren beiden Klassen separieren lässt. Auffallend an den Ergebnissensind aber die Werte für die Sensitivität und Genauigkeit der anderenKlassen. Gemittelt über die besten 20 Kombinationen ergeben sich fürdie Klasse der Artefakte eine Sensitivität von 0.623 und eine Genauig-keit von 0.794, während sich für die Klasse der Risse die Werte 0.917für Sensitivität und 0.828 für Genauigkeit ergeben. Tabelle 7 fasstdie Ergebnisse zusammen. Während Risse noch recht zuverlässig im
Tabelle 7.: Sensitivität und Genauigkeit gemittelt über die 20 besten De-skriptorkombinationen von Rissen, Artefakten und globula-ren Defekten.
Sensitivität Genauigkeit
Globular 0.992 0.990Artefakt 0.623 0.794Riss 0.917 0.828
Datensatz gefunden werden (zu 91.7 Prozent) und die Zuordnungrecht genau ist, werden nur 62.3 Prozent aller Artefakte detektiert.Die Ursache dafür ist bei dem verwendeten Trainingsdatensatz zusuchen. Die üblichen Artefakte sind Objekte mit einer geringen Aus- Interpretation
dehnung entlang der z-Achse. Sie entstehen beispielsweise durch Ver-unreinigungen der Fräsoberfläche durch Öltropfen oder Metallspäne,die von der Kamera aufgenommen und im weiteren Prozess segmen-tiert wurden. Auch fälschlicherweise segmentierte Teile von Fräsrillen

108 klassifikation von defekten in stahl
gehören dieser Klasse an. Neben diesen Artefakten enthält der Trai-ningsdatensatz aber auch sogenannte Randartefakte. Dabei handeltes sich um Verunreinigungen, die während des Produktionsprozes-ses der Bramme entstehen und in die Metallmatrix gedrückt werden.Sie treten nur dicht an der Oberfläche auf. Schaut man sich einige die-ser Randartefakte an, wird deutlich, dass sie sich von ihrer Strukturkaum von Rissen unterscheiden. In Abbildung 10 sind, zusammenmit Beispielen für Objekte aus anderen Klassen, ein Riss (Objekt d)und ein Randartefakt (Objekt c) gegenübergestellt. Der Klassifizie-rer ordnet diese Randartefakte also sehr wahrscheinlich den Rissenzu, was dazu führt, dass die Sensitivität für Artefakte stark abnimmt.Gleichzeitig steigt aber die Anzahl der falsch klassifizierten Risse. DieGenauigkeit dieser sinkt also ebenfalls ab.
Abbildung 10.: Beispiele für Objekte der Trainingsmenge: a) globula-rer Defekt, b) Aufsicht auf Artefakt, c) Randartefakt, d)Riss.
a) b) c) d)
Abschließend soll untersucht werden, wie oft ein gewisser Deskrip-tor unter den ersten 1000 Kombinationen mit höchster Korrektklassi-fikationsrate verwendet wird. Daraus lässt sich ablesen, wie destink-tiv sich ein Deskriptor im gestellten Klassifizierungsproblem verhält.Tabelle 8 zeigt die relativen Häufigkeiten für alle 18 Deskriptoren.Häufigkeit der
Deskriptoren Sowohl die Boxdimension dimBF als auch die Maße für die Spheri-zität F1 und F2 werden für fast jede Kombination von Deskriptorenverwendet. Dies ist nicht sonderlich überraschend, da diese Deskrip-toren für die verschiedenen auftretenden Strukturen, insbesonderefür die sehr zerklüfteten, kompakten und fast zweidimensionale, di-stinktive Werte zurückliefern. Ebenfalls häufig verwendet wird dieerste Hauptkomponente der reduzierten, symmetrischen Konfigura-tionshistogramme h(22).PC und die Dimensionalität DIM. Das Konfi-gurationshistogramm kann, wie in Abschnitt 5.1 besprochen, als sehreffektives Kompaktmaß interpretiert werden, während die Dimensio-nalität sich insbesondere dafür eignet, die fast zweidimensionalenArtefakte von den restlichen Objekten zu unterscheiden. Die Euler-zahlen χ6 und χ26 und die Konvexivität hingegen scheinen für dasbesprochene Klassifizierungsproblem keine große Rolle zu spielen.

5.3 auswertung 109
Tabelle 8.: Relative Häufigkeit der Deskriptoren unter den ersten 1000
Kombinationen mit höchster Korrektklassifikationsrate beider Klassifizierung von globularen Defekten, Rissen und Ar-tefakten.
Deskriptor Häufigkeit
dimBF 1
F1 0.992
F3 0.874
DIM 0.759
h(22).PC1 0.683
J1 0.674
ECC 0.475
MV 0.421
KV 0.348
h(22).PC2 0.346
SV 0.306
VV 0.288
J3 0.231
J2 0.189
χ6 0.124
CONV 0.123
F2 0.123
χ26 0.008
5.3.2 Poren und nichtmetallische Einschlüsse
Die in Abschnitt 5.3.1 klassifizierten globularen Defekte sollen nunin einem weiteren Schritt in Poren und nichtmetallische Einschlüsseunterteilt werden. Zunächst betrachtet man dafür, wie im vorherigen Anzahl der
DeskriptorenAbschnitt, die Auswirkung der Anzahl der verwendeten Deskripto-ren auf die Korrektklassifikationsrate. Laut Abbildung 11 wird das
Abbildung 11.: Auswirkung der Anzahl der Deskriptoren auf die Kor-rektklassifikationsrate ACC beim Klassifizieren von Po-ren und nichtmetallischen Einschlüssen.
0.5
0.6
0.7
5 10 15
Anzahl der Deskriptoren
AC
C avg
max
min
beste Ergebnis mit einer Kombination von 9 Deskriptoren erzielt, wo-

110 klassifikation von defekten in stahl
Tabelle 9.: Die ersten 20 Deskriptorsätze mit der höchsten Korrektklas-sifikationsrate ACC beim Klassifizieren von Poren und nicht-metallischen Einschlüssen.
Deskriptoren γ C ACC RM PM F1M
h(22) .PC1,h(22) .PC2,J3 ,F1 ,F3 ,ECC,SV ,VV ,KV 2 512 0.698 0.7 0.699 0.7h(22) .PC1,h(22) .PC2,CONV,J1 ,J3 ,F1 ,F2 ,ECC,VV 2 512 0.696 0.696 0.695 0.696
h(22) .PC1,h(22) .PC2,J3 ,F1 ,F3 ,ECC,SV ,VV ,MV ,KV 2 512 0.696 0.695 0.695 0.695
h(22) .PC2,J3 ,F1 ,F3 ,ECC,VV ,MV ,KV 2 512 0.696 0.699 0.695 0.696
h(22) .PC1,h(22) .PC2,CONV,J1 ,J3 ,F2 ,F3 ,VV ,KV 2 256 0.696 0.696 0.694 0.695
h(22) .PC2,J2 ,J3 ,F3 ,SV ,VV ,MV 2 512 0.696 0.694 0.692 0.693
h(22) .PC1,h(22) .PC2,J3 ,F1 ,F3 ,ECC,SV ,VV 2 512 0.694 0.694 0.692 0.693
h(22) .PC1,h(22) .PC2,J3 ,F1 ,F3 ,ECC,VV ,MV ,χ26 2 512 0.694 0.698 0.698 0.698
h(22) .PC1,h(22) .PC2,J1 ,J3 ,F1 ,F3 ,VV ,MV ,KV ,χ26 2 512 0.694 0.692 0.694 0.693
h(22) .PC1,h(22) .PC2,J3 ,F1 ,F3 ,ECC,VV ,KV ,χ26 2 512 0.694 0.697 0.696 0.696
h(22) .PC1,h(22) .PC2,J2 ,J3 ,F2 ,F3 ,ECC,SV ,MV ,KV ,χ26 2 512 0.694 0.692 0.692 0.692
h(22) .PC1,h(22) .PC2,J3 ,F1 ,F3 ,ECC,VV 2 512 0.692 0.696 0.693 0.694
h(22) .PC1,h(22) .PC2,J3 ,F1 ,F3 ,ECC,VV ,χ26 2 512 0.692 0.695 0.693 0.694
h(22) .PC1,h(22) .PC2,J3 ,F1 ,F3 ,ECC,SV ,VV ,χ26 2 256 0.692 0.694 0.69 0.692
h(22) .PC1,h(22) .PC2,J3 ,F1 ,F3 ,ECC,SV ,VV ,MV ,χ26 2 512 0.692 0.691 0.691 0.691
h(22) .PC1,h(22) .PC2,CONV,J2 ,J3 ,F1 ,F2 ,F3 ,SV ,VV ,MV ,KV 1 512 0.692 0.692 0.688 0.69
h(22) .PC1,h(22) .PC2,J3 ,F1 ,F3 ,ECC,VV ,χ26 ,χ6 2 512 0.692 0.695 0.693 0.694
h(22) .PC1,CONV,J2 ,J3 ,SV ,MV 2 512 0.692 0.695 0.693 0.694
h(22) .PC2,dimB F,DIM,J3 ,F1 ,F3 ,ECC,SV ,VV ,MV 2 512 0.692 0.688 0.686 0.687
h(22) .PC1,h(22) .PC2,J2 ,J3 ,F3 ,SV ,χ26 ,χ6 2 512 0.692 0.691 0.694 0.692
bei schon nach 6 Deskriptoren eine Sättigung erreicht wird. Im wei-teren Verlauf ändert sich die Korrektklassifizerungsrate nur noch ge-ringfügig und nimmt dann ca. ab 12 Deskriptoren stark ab. Tabelle9 zeigt die 20 Kombinationen mit höchster KorrektklassifikationsrateACC. Das Ergebnis fällt nicht so eindeutig aus wie bei der Klassifizie-rung von Rissen, Artefakten und globularen Defekten. Die Korrekt-klassifikationsrate für die beste Kombination beträgt ca. 70 Prozent.Um das Ergebnis genauer aufzuschlüsseln, lassen sich wieder die Sen-sitivität und die Genauigkeit der einzelnen Klassen betrachten. In Ta-belle 10 sind beide Werte, gemittelt über die 20 besten Kombinationen,dargestellt. Es scheint, als würde der Klassifizierer Poren gegenübernichtmetallischen Einschlüssen bevorzugen. Stellt sich die Frage, wo-Interpretation
durch sich Poren und nichtmetallische Einschlüsse genau unterschei-den. Poren entstehen durch eingeschlossenes Gas. Sobald der Fräs-kopf die Pore anschneidet entweicht das Gas und eine Hohlstelle ver-bleibt in der Stahlmatrix. In den Schichtbildern erscheinen Poren alsrunde schwarze Kreise, da bei der Bildaufnahme kein Licht mehr ausihrem Inneren zurück ins Objektiv reflektiert wird. Einschlüsse sindzwar ebenfalls kugelige Objekte, sie erscheinen also auch als Kreiseauf den Schichtbildern, allerdings sind sie nicht hohl, sondern beste-
Tabelle 10.: Sensitivität und Genauigkeit von Poren und nichtmetalli-schen Einschlüssen gemittelt über die 20 besten Deskrip-torkombinationen.
Sensitivität Genauigkeit
Pore 0.725 0.721Einschluss 0.664 0.666

5.3 auswertung 111
hen im Gegensatz zu Poren aus nichtmetallischem Material. DiesesMaterial weist, je nach Einschlusstyp, unterschiedliche Eigenschaftenauf. Oxideinschlüsse sind zum Beispiel sehr spröde und hart (siehe4.1.2). Wird ein solcher Einschluss angefräst, entsteht eine sehr raueOberfläche, die bei der Bildaufnahme zu einem Grauwertprofil mithoher Dynamik führt. Bei der Segmentierung kann es dann vorkom-men, dass helle Bereiche des Einschlusses unterhalb des Schwellwer-tes liegen und nicht mitsegmentiert werden. Dadurch entsteht die pa-radoxe Situation, dass hohle Poren gegenüber den Deskriptoren alssehr kompakt erscheinen, während eigentlich mit Material gefüllteEinschlüsse porös wirken. Dies schlägt sich auch bei der Häufigkeitder verwendeten Deskriptoren der ersten 1000 Kombinationen mithöchster Korrektklassifikationsrate nieder. So liegen Deskriptoren zurBeschreibung der Kompaktheit, wie beispielsweise die Volumendich-te VV oder die ersten beiden Hauptkomponenten der symmetrischenKonfigurationshistogramme h(22).PC1 und h(22).PC2 auf den erstenPlätzen (siehe Tabelle 11). Insgesamt sind die Unterschiede zwischen
Tabelle 11.: Relative Häufigkeit der Deskriptoren unter den ersten 1000
Kombinationen mit höchster Korrektklassifikationsrate beider Klassifizierung von Poren und nichtmetallischen Ein-schlüssen.
Deskriptor Häufigkeit
J3 0.977
h(22).PC2 0.976
VV 0.918
h(22).PC1 0.745
F3 0.69
MV 0.608
SV 0.606
F2 0.57
F1 0.564
CONV 0.437
KV 0.427
ECC 0.417
J2 0.4J1 0.323
χ26 0.299
DIM 0.07
dimBF 0.067
χ6 0.023
Poren und nichtmetallischen Einschlüssen aber nicht so groß, dassmit den verwendeten Deskriptoren eine sichere Entscheidung getrof-fen werden kann. Das Ergebnis kann aber drastisch verbessert wer-den, wenn man zusätzlich zu morphologischen Deskriptoren nochauf Textur basierende Deskriptoren verwendet. Neben einfachen De-skriptoren, wie dem mittleren Grauwert oder der Varianz der Grau-erwerte, ist besonders der sogenannte Schweifdeskriptor hervorzuhe-

112 klassifikation von defekten in stahl
ben. Das harte Einschlussmaterial führt nämlich auch dazu, dass dieSchweifdeskriptor
Ränder der Einschlüsse keine harte Kante bilden, sondern sehr starkausfransen. Der Fräskopf bricht Teile des Einschlusses heraus undverschmiert diese über die Oberfläche. Tabelle 11 bestätigt dies, daauf den vorderen Plätzen viele Deskriptoren sind, die bei verrausch-ten Strukturen ausschlagen. Dazu zählen zum Beispiel die Oberflä-chendichte, die mittlere Krümmung und das dritte TSR-Moment. Dasparallel zur Fräsrichtung verteilte Einschlussmaterial führt in den Bil-dern dazu, dass Grauwerte in Richtung der Fräskopfbewegung dunk-ler sind als in entgegengesetzter Richtung. Ein Einschluss kann also,im Gegensatz zu einer Pore, einen „Schweif“ ausbilden. Der Schweif-deskriptor berechnet sich nun aus dem Helligkeitunterschied vor undhinter dem vermeintlichen Einschluss (bezogen auf die Fräsrichtung)und gibt bei Werten nahe 0 an, dass der Einschluss einen Schweif ausEinschlussmaterial nach sich zieht. Mit diesen zusätzlichen Deskripto-ren kann die Korrektklassifikationsrate auf über 90 Prozent gebrachtwerden [20].
5.4 zusammenfassung
In diesem Kapitel wurde gezeigt, wie auf Basis der in Kapitel 2 einge-führten morphologischen Deskriptoren Defekte in Stahlproben klas-sifiziert werden. Zunächst wurden die Defekte mittels einer angelern-ten SVM grob in drei Klassen unterteilt, nämlich Risse, Artefakteund globulare Defekte. Durch automatische Auswahl eines optima-len Deskriptorsatzes wurde eine maximale Korrektklassifikationsratevon ca. 92 Prozent erreicht. Anschließend wurde mittels von Exper-ten zusammengestellter Trainingsdaten die Klassifikation von globu-laren Defekten weiter verfeinert und zwar in die Klassen Poren undnichtmetallische Einschlüsse. Auch in diesem Anwendungsfall konn-te eine Klassifizierung mit morphologischen Deskriptoren erfolgreichdurchgeführt werden. Die beste Deskriptorkombination erzielte eineKorrektklassifikationsrate von ca. 70 Prozent.
In den folgenden Kapiteln wird gezeigt, wie anhand der klassifi-zierten Datensätze statistische Untersuchungen durchgeführt werdenkönnen. Dabei wird es insbesondere um die Größenverteilung undräumliche Verteilung von Defekten gehen. Die klassifizierten Datenwerden vor der Auswertung gefiltert, so dass singuläre Ereignissewie Risse und Artefakte nicht in die Auswertungen einfließen.

6S TAT I S T I S C H E U N T E R S U C H U N G V O N D E F E K T E NI N S TA H L
Nachdem im vorherigen Kapitel gezeigt werden konnte, dass mittelsder in Abschnitt 2.2 definierten Gestaltdeskriptoren eine präzise Klas-sifikation von Defekten in Stahl möglich ist, sollen in diesem Kapiteldie klassifizierten Datensätze statistisch untersucht werden. Im Vor-dergrund steht dabei die Frage, ob sich für die Größenverteilung unddie räumliche Verteilung ein stochastisches Modell entwickeln lässt,mit dem verschiedene Stahlsorten verglichen und Vorhersagen überden Einschlussgehalt getroffen werden können. Die Untersuchungenwerden dabei exemplarisch anhand von realen Daten durchgeführt,die mittels des in Abschnitt 4.2 beschriebenen Systems gewonnenwurden. Die Vorgehensweise sieht wie folgt aus. Zunächst wird dasin der Literatur propagierte Modell zur Beschreibung der Größen-verteilung einer rigorosen statistischen Untersuchung unterzogen. Ingleicher Weise wird dann nach einem Punktprozess gesucht, der dieräumliche Verteilung von Defekten in Stahl beschreibt. In der Fachli-teratur lassen sich zu diesem Thema nur wenig Informationen fin-den. Deshalb dient das einfachste stochastische Modell zur Beschrei-bung von Punktmustern, der PPP, als Ausgangspunkt. Beide Model-le werden dann, nach erfolgreicher Validierung, in einem Algorith-mus zusammengefasst, mit dem synthetische Defektverteilungen ge-neriert werden. Dies erlaubt schließlich die Evaluation unterschiedli-cher Frässzenarien des in Abschnitt 4.2 vorgestellten Detektionsver-fahrens für Makroeinschlüsse.
6.1 größenverteilung
Wie bereits in Abschnitt 4.1.3 beschrieben, wird übereinstimmend inder Literatur berichtet, dass die Durchmesser von Einschlüssen lo-garithmisch normalverteilt [118, S. 314 ff.] [9, 41] sind. Allerdingswerden weder konkrete Verteilungsparameter angegeben, noch eineErklärung geliefert, warum sich gerade dieses Modell zur Beschrei-bung der Größenverteilung eignet. Dies soll im Folgenden nachge-holt werden. Anschließend wird für real gemessene Daten die Plau-sibilität der Annahme mittels der in Abschnitt 3.2.1 eingeführten ex-plorativen Methoden überprüft und aufbauend auf diesen Erkennt-nissen die Modellfunktion parametrisiert. Dazu werden die in Ab-schnitt 3.2.2 beschriebenen bayesschen Methoden verwendet. Mittels
113

114 statistische untersuchung von defekten in stahl
des posteriori-prädiktiven Tests erfolgt dann die Validierung des Mo-dells. Abgeschlossen wird der Abschnitt mit einem Anwendungsfall,der zeigt, wie das gewonnene Modell verwendet werden kann, umkonkrete Aussagen aus den Messdaten abzuleiten.
6.1.1 Modellauswahl
Eine stetige Zufallsvariable X unterliegt der logarithmischen Normal-verteilung, wenn sie die DichtefunktionLogarithmische
Normalverteilung
f (x) =1
xσ√
2πe−
(lnx−µ)2
2σ2 (128)
mit x > 0 besitzt, wobei µ und σ die beiden Parameter der Verteilungsind. Anders ausgedrückt ist eine Zufallsvariable X logarithmischnormalverteilt, wenn Y = ln(X) normalverteilt ist [30, S. 2], wobeidie Dichtefunktion der Normalverteilung durch
f (x) =1
σ√
2πe−
(x−µ)2
2σ2 (129)
gegeben ist.
Stellt sich die Frage, warum die Größe von nichtmetallischen Ein-schlüssen ausgerechnet durch diese Verteilung beschrieben werdenkann. Eine mögliche Erklärung ergibt sich, wenn man Koaleszenzals Mechanismus für das Wachstum der Einschlüsse zu Grunde legt.Koaleszenz beschreibt das Verschmelzen flüssiger Teilchen bei Zu-sammenstoß. Das auf diese Art neu gebildete Teilchen ist bestrebtseine Oberfläche zu minimieren, und nimmt die Form einer Kugelan, da diese von allen geometrischen Körpern die mit der gerings-ten Oberfläche ist. Gegeben sei nun ein Teilchen x, dessen VolumenWachstumsprozess
nach i = 0, . . . n Zusammenstößen gemessen wird. Der Anstieg imVolumen lässt sich dabei als
xi = xi−1(1 + ǫi) (130)
schreiben, wobei ǫi unabhängige Zufallsvariablen sind, die der glei-chen unbekannten Verteilung genügen. Mit anderen Worten nimmtdas Volumen des neuen Teilchens um einen zufälligen Bruchteil desVolumens des alten Teilchens zu. Nach n Zusammenstößen beträgtdas Volumen von Teilchen x dann
xn =
(n
∏i=1
(1 + ǫi)
)
x0.
(131)
Wendet man nun auf beiden Seiten den Logarithmus an, ergibt sichfür kleine zufällige Zuwachsraten ǫi
ln(xn) =n
∑i=1
ln(1 + ǫi) + ln(x0) ≈n
∑i=1
ǫi + ln(x0).
(132)

6.1 größenverteilung 115
Man kann nach Anwendung des zentralen Grenzwertsatzes derWahrscheinlichkeitsrechnung [102, S. 436] dann folgern, dass ln(xn)
asymptotisch normalverteilt ist. Wenn aber ln(xn) normalverteilt ist,dann genügt xn der logarithmischen Normalverteilung. Die obige Ar- Grenzwertsatz
gumentation geht auf Crow und Shimizu [30, S. 4 ff.] zurück undwurde beispielsweise dazu verwendet, das logarithmische Wachstumvon Organismen [96] oder feinen Metallpartikeln in Gasen [46] zubegründen. Ob sich der beschriebene Prozess auf die Entstehungvon nichtmetallischen Einschlüssen übertragen lässt, kann im Rah-men dieser Arbeit nicht ergründet werden. Die Detektion von vor-nehmlich kugeligen Einschlüssen und Defekten (siehe Kapitel 2) istzumindest ein Hinweis, dass Koaleszenz bei der Bildung bestimm-ter Einschlusstypen eine Rolle spielt. Auch in der Literatur werdenähnliche Erfahrungen beschrieben [31, S. 110]. Wichtigste Erkenntnisaus der obigen Ausführung ist, dass bei der Bildung logarithmischerVerteilungen ein multiplikativer Mechanismus wirkt. Die Entstehungvon Normalverteilungen geht hingegen auf die Summierung vielerkleiner zufälliger Schwankungen zurück.
Wegen dieser Ausführungen aber insbesondere auch wegen des inAbschnitt 4.1.3 herausgearbeiteten Expertenwissens fällt die Entschei-dung für ein Modell zur Beschreibung der Größenverteilung vonnichtmetallischen Eigenschaften auf die logarithmische Normalver-teilung mit der Dichte aus Formel 128. Im nächsten Abschnitt wirduntersucht, inwieweit das theoretische Modell zu den empirisch er-hobenen Daten passt.
6.1.2 Explorative Datenanalyse
In diesem Abschnitt wird untersucht, inwieweit das im vorherigenAbschnitt festgelegte Modell zu real gemessenen Daten passt. AlsMessverfahren wird die in Abschnitt 4.1.4 beschriebene Methode ver-wendet. Die Datensätze werden dabei entsprechend dem in Kapitel5 eingeführten Verfahrens klassifiziert. Dabei wird allerdings nur die Globulare Defekte
Vorklassifikation angewandt, also eine Entscheidung zwischen globu-laren Defekten, Artefakten und Rissen vorgenommen. Die Klassifi-kation zwischen Poren und nichtmetallischen Einschlüssen nur aufBasis morphologischer Deskriptoren ist bei der verwendeten Optiknoch zu ungenau. Die Statistiken werden über alle globularen Defek-te, im Folgenden nur noch als Defekte bezeichnet, berechnet. Die An-nahme dabei ist, dass die Bildung von Einschlüssen und Poren unab-hängig voneinander passiert und dass ähnliche Wachstumsprozessezu Grunde liegen. Ein Indiz dafür ist, dass beide Defekttypen eine ku- Durchmesser
gelige Form ausbilden. Das erhobene Merkmal ist der Durchmesserder Defekte. Diese Vorgehensweise ist Standard bei der Analyse von

116 statistische untersuchung von defekten in stahl
nichtmetallischen Einschlüssen [34, 35], auch wenn die Erhebung nor-malerweise nur in zweidimensionalen Schnitten erfolgt. Die dreidi-mensionale Durchmesserverteilung wird dann auf das Volumen mit-tels geeigneter Verfahren hochgerechnet. Da eine dreidimensionaleMesstechnik eingesetzt wird, ist dieser Schritt nicht von Nöten. DerDurchmesser ergibt sich für kugelförmige Teilchen aus der mittlerenBreite und wird mittels des in Abschnitt 2.2.3 beschrieben Verfahrensberechnet. Die Verwendung der mittleren Breite hat den Vorteil, dassAbweichungen von der Kugelform beispielsweise durch Versatz zwei-er aufeinanderfolgender Schichten in der x, y-Ebene durch die Mitt-lung keinen Einfluss auf den Durchmesser haben. In Anlehnung anKapitel 3 beschreibt im Folgenden die Zufallsvariable X den Durch-messer. Für eine Stichprobe X1, . . . , Xn werden mittels des beschrie-benen Messystems die Stichprobenwerte x1, . . . , xn erhoben, wobei ndie Anzahl der detektierten Defekte ist.
Die erste untersuchte Probe hat eine Abmessung von 286 mm ×140 mm× 37 mm und wurde mit einer Auflösung von 20 µm× 20 µmpro Pixel in x, y-Richtung fotografiert. Die Schichtabnahme der FräseErste Probe
betrug 10 µm. Nach der Klassifikation sind 28839 Objekte eindeutigals globulare Defekte erkannt. Der Durchmesser der Defekte wurdewie oben beschrieben aus der mittleren Breite berechnet, allerdingszusätzlich noch logarithmisch transformiert. Demnach wird erwartet,dass die Stichprobenwerte x1, . . . , xn annähernd normalverteilt sind.In Abbildung 12 wurden die Schätzer der Dichtefunktion und die ver-schiedenen Methoden zur explorativen Analyse des Modells mit denempirisch erhobenen Daten berechnet. In der Abbildung 12 a) ist dasHistogramm mit einer Intervallbreite von 0.10 über alle Defekte einge-zeichnet. Zusätzlich wurde mit einem Gauß-Kernel eine Kerndichte-schätzung mit Bandbreite h = 0.054 vorgenommen. Das Ergebnis istKerndichteschät-
zung als halb-transparente grüne Fläche über das Histogramm gelegt. Ab-schließend wurden die Modellparameter der Normalverteilung mit-tels der Maximum-Likelihood Methode aus den empirisch erhobenenDaten geschätzt und das parametrisierte Modell zusätzlich zum Hi-stogramm und zum Kerndichteschätzer als rote Kurve eingezeichnet.Die empirischen Modellparameter sind µ = 5.047 und σ = 0.473.Das Histogramm beziehungsweise der Kerndichteschätzer nehmendie Gestalt der erwarteten Glockenfunktion der Normalverteilung an.Im direkten Vergleich zum Modell kann man erkennen, dass für Wer-te größer 5, das entspricht in etwa einem Durchmesser von 150 µm,das Modell und die Dichteschätzer dicht beieinander liegen. Aller-dings scheint die geschätzte Dichte nicht ganz symmetrisch zu sein,sondern weist eine leichte Rechtsschiefe auf. Dieser ZusammenhangQQ-Plot
wird noch deutlicher, wenn man sich den QQ-Plot anschaut. Wie inAbschnitt 3.2.1 beschrieben, trägt man bei diesem die theoretischenQuantile des Modells gegen die empirischen Quantile auf. StimmenModell und Daten überein, ergibt sich eine Gerade. Als visuelle Hilfe

6.1 größenverteilung 117
wurde durch das 5 %- und 95 %-Quantil eine rote Vergleichsgeradein den QQ-Plot eingezeichnet (siehe Abbildung 12 b)). Man erkennt
Abbildung 12.: a) Schätzen der Dichtefunktion, b) QQ-Plot, c) Vertei-lungsfunktion, d) PP-Plot.
0.0
0.2
0.4
0.6
0.8
4 5 6
Durchmesser(in Log µm)
Dic
hte
Dichteschätzung
4
5
6
3 4 5 6 7
Theo. Quantile
Em
p.
Qu
an
tile
Q−Q−Plot
0.00
0.25
0.50
0.75
1.00
4 5 6
Log(µm³)
rela
tive
Hä
uifg
keit
Verteilungsfunktion
0.00
0.25
0.50
0.75
1.00
0.00 0.25 0.50 0.75 1.00
Theo. Wahrscheinlichkeit
Em
p.
Wa
hrs
ch
ein
lich
keit
P−P−Plot
a)
c)
b)
c)
deutlich, dass die Gerade für kleine Werte überschritten wird. Dasheißt die kleinsten Werte in den Daten sind größer als man bei derangenommenen Normalverteilung erwarten würde. Auf der anderenSeite wird die Gerade für große Werte unterschritten. Die größtenDurchmesser sind also nicht so groß (nicht so extrem), wie man beiNormalverteilung erwarten würde. Das Verhalten auf der linken Sei-te lässt sich einfach erklären. Die maximale Größe der Defekte istauf Grund der physikalischen Eigenschaften des Bildaufnahmesen-sors nach unten hin begrenzt. Defekte mit weniger als 100 µm Durch-messer sind auf Grund von Sensorrauschen bei einer Auflösung von20 µm× 20 µm pro Pixel nicht mehr sicher zu erkennen. Deshalb istdie Verteilung zur linken Seite hin beschnitten, was zur beobachtetenRechtsschiefe führt. Über den Grund für die Abweichungen auf derrechten Seite kann hingegen nur spekuliert werden. Eventuell wardas abgefräste Probenvolumen zu gering, um die Verteilung korrektzu approximieren. Die Abweichungen liegen aber noch in einem Rah-men, dass sie als statistisches Rauschen interpretiert werden können.Insgesamt zeigt der QQ-Plot für den mittleren Bereich der Verteilung

118 statistische untersuchung von defekten in stahl
eine gute Übereinstimmung zwischen Modell und Daten. Neben derDichte und dem QQ-Plot sind in Abbildung 12 c) noch die empirischeund die theoretische Verteilungsfunktion in einem Graph eingezeich-net, wobei die theoretische Verteilungsfunktion wieder rot dargestelltist. Sie wurde mit den Werten der Punktschätzung, also µ = 5.047Verteilungsfunktion
und σ = 0.473, parametrisiert. Abschließend sind in Abbildung 12
d) die empirischen und theoretischen Wahrscheinlichkeiten in Formeines PP-Plots gegeneinander aufgetragen. Da es sich bei den zuletztgenannten Funktionen aber um Summenfunktionen handelt, ist dieInterpretation eher schwierig. In den nachfolgenden Analysen wer-den deshalb nur die Dichteschätzer und der QQ-Plot verwendet.
Die zweite untersuchte Probe wurde aus einem Rundstab geschnitten.Zweite Probe
Der Durchmesser der Stahlprobe beträgt ca. 30 mm, wobei die einzel-nen Schnittbilder mit einer Auflösung von 20 µm× 20 µm aufgenom-men wurden. Insgesamt wurden 5 mm bei einer Spanabnahme von10 µm abgefräst. Nach erfolgreicher Segmentierung und Klassifikati-on bleiben 212 Objekte übrig, die als globulare Defekte identifiziertwurden. In Abbildung 13 a) sind wieder das Histogramm, der Kern-
Abbildung 13.: a) Schätzen der Dichtefunktion, b) QQ-Plot
0.0
0.5
1.0
1.5
2.0
4.0 4.5 5.0
Durchmesser(in Log µm)
Dic
hte
Dichteschätzung
3.9
4.2
4.5
4.8
5.1
3.6 4.0 4.4 4.8
Theo. Quantile
Em
p. Q
uantile
Q−Q−Plot
a) b)
dichteschätzer und das parametrisierte Modell zu sehen. Die Inter-vallbreite des Histogramms beträgt dabei 0.08. Die Kerndichteschät-zung wurde mittels Gauß-Kernel mit einer Bandbreite von h = 0.07vorgenommen. Die Schätzung der Modellparameter ergab schließlichKerndichteschät-
zung µ = 4.35 und σ = 0.24. An dieser Probe erkennt man ebenfalls, dassdie Verteilung nach links hin auf Grund der begrenzten Auflösungdes Kamerasystems beschnitten ist. Defekte mit einem Wert unter 4,was einem Durchmesser von 54.60 µm entspricht, werden im direk-ten Vergleich mit der Normalverteilung viel zu selten detektiert. DieAbweichung im QQ-Plot von der Geraden in Abbildung 13 b) bestäti-gen diese Beobachtung. Ein Unterschied ist aber an den rechten Aus-läufern der Verteilung auszumachen. Im Gegensatz zur ersten Pro-QQ-Plot
be scheinen große Defekte viel häufiger beobachtet zu werden. Dies

6.1 größenverteilung 119
erkennt man sowohl an dem Ausschlag des letzten rechten Balkensim Histogramm als auch an dem Überschreiten der Normallinie fürgroße Durchmesser im QQ-Plot. Die Häufigkeit von großen Defektenliegt also höher als man bei der angenommenen Normalverteilungerwarten würde. In der Literatur sind ähnliche Effekte bei der Ver-teilung von nichtmetallischen Einschlüssen beschrieben [9]. Es wird Modellierung der
Ausläuferangenommen, dass für die Ausläufer der Verteilung die logarithmi-sche Normalverteilung (oder die Normalverteilung bei logtransfor-mierten Werten) nicht das geeignete Modell ist, da große Einschlüssenicht so selten sind, wie durch die Verteilung vorhergesagt wird. Al-ternativ versucht man die Ausläufer mit einer anderen Verteilung zumodellieren. Ein sehr häufig eingesetztes Modell dafür ist die Pareto-Verteilung [6]. Diese gehört zu den endlastigen Verteilungen, besitztalso im Vergleich zur Normalverteilung mehr Masse in den Ausläu-fern und eignet sich besser zur Modellierung von seltenen Ereignis-sen, wie beispielsweise dem Auftreten von sehr großen nichtmetalli-schen Einschlüssen. Für Einschlüsse kleiner und mittlerer Größe istaber nach wie vor die logarithmische Normalverteilung das geeigne-tere Modell. Man kann deshalb beide Verteilungen kombinieren. Da-zu wird aus den Daten ein Schwellwert geschätzt, bei dem von derlogarithmischen Normalverteilung auf die Pareto-Verteilung gewech-selt wird [27]. Schaut man sich aber im konkreten Beispiel die dreidi-mensionalen Visualisierungen der Defekte der Rundprobe mittels derin Abschnitt 7.2 vorgeschlagenen Software genauer an, wird man fest-stellen, dass der gerade beschriebene Effekt nicht für die Abweichungverantwortlich ist. Stattdessen hat sich im Mittelpunkt ein für Rund- Lunker
proben charakteristischer Lunker gebildet. Lunker sind Hohlräume,die auf Grund der Volumenabnahme beim Erstarren der Stahlschmel-ze entstehen. Sie können um ein Vielfaches größer sein als nichtme-tallische Einschlüsse und Poren. Wie es scheint, besteht der Lunker inder Probe aus mehreren, nicht zusammenhängenden Kammern, diefälscherlicherweise als globulare Defekte klassifiert wurden, da sieebenfalls eine kugelige Form aufweisen. Dies führt zu der beobach-teten Abweichung zwischen Daten und dem Modell. Filtert man die Gefilterter QQ-Plot
als Defekt erkannten Teile des Lunkers heraus, die oberhalb des 95 %-Quantils liegen, ergibt sich für die Dichteschätzung und den QQ-Plotdas in Abbildung 14 präsentierte Ergebnis. Anhand des QQ-Plots inAbbildung 14 b) sieht man, dass für den gefilterten Datensatz dasModell auch für die Ausläufer der Verteilung eine gute Übereinstim-mung liefert. Insgesamt muss man aber sowohl für den ungefiltertenals auch für den gefilterten Datensatz der zweiten Probe konstatie-ren, dass die Anzahl der detektierten Defekte zu klein ist, um dasModell adäquat mittels der Maximum-Likelihood Methode zu para-metrisieren. Die Auswertung ist auf Grund der wenigen Daten nichtrobust gegen Rauschen. Dies erkennt man an den starken Ausschlä-gen einzelner Balken im Histogramm. Im nächsten Abschnitt wird

120 statistische untersuchung von defekten in stahl
Abbildung 14.: Explorative Analyse nach Bereinigung der Ausreißer. a)Schätzen der Dichtefunktion, b) QQ-Plot.
0.0
0.5
1.0
1.5
2.0
4.0 4.4 4.8
Durchmesser(in Log µm)
Dic
hte
Dichteschätzung
4.00
4.25
4.50
4.75
4.0 4.5 5.0
Theo. Quantile
Em
p. Q
uantile
Q−Q−Plot
a) b)
dieser Punkt behandelt und ein Schätzverfahren auf Basis der bayess-chen Statistik verwendet, um das Modell zu parametrisieren. Dies er-laubt das Quantifizieren der statistischen Unsicherheit bei der Schät-zung.
Zusammenfassend kann anhand dieser exemplarischen Untersuchun-gen geschlussfolgert werden, dass die logarithmische Normalvertei-lung ein probates Mittel ist, um die beobachteten Defektverteilungenzu beschreiben. Mit Vorsicht müssen allerdings die Ergebnisse an denRändern der Verteilung betrachtet werden. Für die linken Ausläufersind die Ergebnisse auf Grund der physikalischen Beschränkungendes Bildaufnahmesensors verfälscht. In den rechten Ausläufern kannes hingegen auf Grund statistischen Rauschens oder fälschlich alsglobular klassifizierter Artefakte zu Abweichungen kommen. Han-delt es sich bei den Defekten um nichtmetallische Einschlüsse, mussberücksichtigt werden, dass nach Expertenmeinung die logarithmi-sche Normalverteilung das Auftreten von sehr großen Einschlüssennicht adäquat modelliert, da sie zu schnell auf 0 fällt. Abhilfe kannhier die Modellierung durch eine zusammengesetzte Dichtefunkti-on schaffen. Alternativ bietet sich die Verwendung von Methodenaus der Extremwert-Statistik an. In Bezug auf die Untersuchung vonnichtmetallischen Einschlüssen bietet die Veröffentlichung von Atkin-son und Shi [9] einen guten Überblick über den Einsatz dieser Tech-niken.
In den nachfolgenden Abschnitten werden diese Beobachtungen beider Modellierung berücksichtigt, insbesondere wenn es darum geht,das mittels der bayesschen Methoden parametrisierte Modell anhandbeobachteter Daten zu validieren. Die dazu verwendete Teststatistiksoll so definiert werden, dass nur die mittleren Bereiche der Vertei-lung in die Berechnung einfließen. Die möglicherweise verfälschtenRänder bleiben außen vor. Falls zu einem späteren Zeitpunkt eine Ka-

6.1 größenverteilung 121
mera mit höherer Auflösung eingesetzt wird oder die Wahl auf einanderes Modell fällt, welches die rechten Ausläufer besser beschreibt,reicht es aus, die Teststatistik entsprechend anzupassen. Die beschrie-bene Vorgehensweise bleibt identisch.
6.1.3 Modellparametrisierung und Validierung
In diesem Abschnitt soll statt der Punktschätzung mittels Maximum-Likelihood das in Abschnitt 3.2.2 vorgestellte bayessche Verfahrenzur Schätzung der Verteilungsparameter eingesetzt werden. Anschlie-ßend wird mit Hilfe der posteriori-prädiktiven Verteilung das Modellanhand der empirisch erhobenen Daten validiert. Alle Berechnungen Dritte Probe
werden am Beispiel einer dritten Probe durchgeführt. Diese hat eineAbmessung von 286 mm× 140 mm× 31 mm und wurde wieder miteiner Auflösung von 20 µm× 20 µm aufgenommen. Die Spanabnah-me der Fräse betrug ebenfalls 10 µm. Nach der Klassifikation sind10612 Objekte eindeutig als globulare Defekte erkannt. Abbildung 15
Abbildung 15.: a) Schätzen der Dichtefunktion, b) QQ-Plot.
0.00
0.25
0.50
0.75
1.00
3.5 4.0 4.5 5.0 5.5 6.0
Durchmesser(in Log µm)
Dic
hte
Dichteschätzung
4.0
4.5
5.0
5.5
6.0
4 5 6
Theo. Quantile
Em
p. Q
uantile
Q−Q−Plot
a) b)
zeigt das schon bekannte Histogramm und den QQ-Plot. Die Schät-zung wurde dabei wieder anhand der logtransformierten Durchmes-ser der x1, . . . , xn detektierten Defekte vorgenommen. Es wird alsodavon ausgegangen, dass die logtransformierten Durchmesser nor-malverteilt sind, wobei die Parameter µ und σ unbekannt sind undgeschätzt werden müssen. Die Punktschätzung für die beiden Para- Punktschätzung
meter, mit denen auch das in Abbildung 15 a) und b) dargestellte Mo-dell parametrisiert wurde, ergab µ = 4.931 und σ = 0.382. Deutlichlässt sich am Histogramm wieder die Rechtsschiefe der Verteilungerkennen, die aus der begrenzten physikalischen Auflösung des Bild-sensors resultiert. Ansonsten zeigt der QQ-Plot in Abbildung 15 b) fürdie Werte zwischen 4.5 und 6 eine gute Übereinstimmung zwischen

122 statistische untersuchung von defekten in stahl
Modell und Daten. Lediglich an den rechten Ausläufern kommt eszu einer leichten Abweichung.
Die Likelihood-Funktion für eine Stichprobe X1, . . . , Xn mit Stichpro-benwerten x1, . . . , xn ergibt sich bei gegebener Normalverteilung ge-mäß Formel 74 und Formel 129 ausLikelihood-Funktion
p(x|µ, σ) = f (X1 = xi, . . . , Xn = xn|µ, σ)
=n
∏i=1
f (xi|µ, σ)
=n
∏i=1
1
σ√
2πe−
(xi−µ)2
2σ2
.(133)
Unter Anwendung des bayesschen Theorems gilt dann für die A-posteriori VerteilungA-posteriori
p(µ, σ|x) = p(x|µ, σ)p(µ, σ)∫ ∫
p(x|µ, σ)p(µ, σ)dµdσ ,(134)
wobei p(µ, σ) die A-priori Verteilung über den Parameterraum ist.Im Folgenden wird von der Unabhängigkeit der Parameter ausge-gangen, es gilt also p(µ, σ) = p(µ)p(σ). Die A-posteriori Dichte sollnun mittels des in Kapitel 3 beschriebenen MCMC-Verfahrens appro-ximiert werden. Dafür müssen konkrete A-priori Dichten für µ undσ festgelegt werden. Abbildung 16 zeigt die Vorgehensweise für die-Graphische
Modellierung sen Schritt in der von Kruschke [73] eingeführten graphischen Kon-vention. Anhand der Graphik lässt sich folgender Zusammenhang
Abbildung 16.: Aufbau des Modells.
~
HL
μσ
xi
~
MS
~
erkennen. Der Pfeil von der Normalverteilung zu xi gibt an, dassder Durchmesser eines Partikels xi der Normalverteilung mit denunbekannten Parametern µ und σ unterliegt. Symbolisch wird diesnach gängiger statistischer Konvention auch als xi ∼ Normal(µ, σ)

6.1 größenverteilung 123
geschrieben. Daher wird dem Pfeil eine Tilde (˜) beigestellt. Für die A-priori Verteilung von µ wird wieder die Normalverteilung mit den Pa-rametern M und S für den Mittelwert und die Standardabweichunggewählt, da die Normalverteilung die konjugierte A-priori Verteilungzur Normalverteilung ist [73, S. 392 ff.]. Als A-priori Verteilung fürσ wird die Gleichverteilung (in der Graphik Uniform genannt) an-genommen. Diese hängt von den Parametern L und H ab. Konkretwerden die Parameter der A-priori Verteilung so gewählt, als ob überdie beiden Parameter µ und σ keine Informationen vorliegen. Dafür Parametrisierung
wird für die A-priori Verteilung von µ der Mittelwert M = 0 undS = 1× 106 gesetzt. Durch die hohe Standardabweichung wird dieUnsicherheit über den Parameter µ modelliert. Für die A-priori Ver-teilung wird nach dem gleichen Prinzip L = 0 und H = 1× 106
gesetzt. Der MCMC-Algorithmus wird schließlich so parametrisiert,dass 30000 Werte nach der Konvergenzphase von 1000 Schritten ausder A-posteriori Verteilung gezogen werden. Abbildung 17 zeigt dieapproximierte A-posteriori Verteilung von den Parametern µ (Bild a)und σ (Bild b). Neben der eigentlichen Verteilung sind jeweils das
Abbildung 17.: a) A-posteriori Verteilung von µ, b) A-posteriori Vertei-lung von σ.
95% HDI
µ = 4.932
0
1000
2000
3000
4.92 4.93 4.94 4.95µ
Häufigke
it
95% HDI
σ = 0.383
0
1000
2000
3000
0.370 0.375 0.380 0.385 0.390 0.395σ
Häufigke
it
a) b)
95 % HDI als roter Balken auf der x-Achse und das Ergebnis derPunktschätzung aus dem vorherigen Abschnitt als senkrechter Bal-ken zur x-Achse eingezeichnet. Das HDI für µ erstreckt sich in einem Ergebnis
Intervall von [4.925, 4.940]. Mit 95 % Wahrscheinlichkeit liegt also derwahre Wert von µ nach den bisher beobachteten Daten für die ak-tuell betrachtete Probe innerhalb dieses Intervalls. Das Ergebnis derPunktschätzung liegt, wie erwartet, ebenfalls in diesem Intervall. Dasgleiche gilt für den Parameter σ. Hier erstreckt sich das HDI in einemIntervall von [0.377, 0.388]. Beide Intervalle sind relativ eng, was einHinweis darauf ist, dass die Schätzung nicht mit Unsicherheit behaf-tet ist. Diese Aussagen gelten immer nur unter der Voraussetzung,dass die propagierte Normalverteilung auch wirklich das geeigneteModell zur Beschreibung der Durchmesser ist. Im nächsten Schritt

124 statistische untersuchung von defekten in stahl
soll untersucht werden, inwieweit die beobachteten Daten wirklichzu dem Modell passen.
Um das Modell anhand der beobachteten Daten zu validieren, wirddie in Abschnitt 3.2.3 beschriebene Methode durchgeführt. ZunächstPosteriori-
prädiktiverTest
werden zufällig jeweils l Parameterkombinationen θ(1), . . . θ(l) mitθ = (µ, σ) aus den beiden per MCMC Verfahren generierten A-posteriori Verteilungen gezogen. Für jede dieser i = 1, . . . l Parameter-
kombinationen werden dann n Stichprobenwerte x(i) = x1(i), . . . , x(i)n
aus der Modellverteilung, in diesem Fall also der Normalverteilung,gezogen und die Teststatistik T(x, θ) für jedes θ(i) sowohl über diebeobachteten Daten x = x1, . . . xn also auch die simulierten Daten x(i)
berechnet. Konkret wird als TeststatistikTeststatistik
T(x, µ) = |qh − µ| − |qk − µ| (135)
gewählt, wobei qh beziehungsweise qk das h%- und k%-Quantil derStichprobe x nach Definition aus Formel 70 ist. Für eine symmetri-sche Verteilung streut T(x, µ) um den 0 Wert, wenn für die Wahl vonh beziehungsweise k die Beziehung h = 1− k gilt. Die Teststatistikist demnach sensitiv gegenüber Asymmetrien in der Mitte der Vertei-lung, wobei die rechten und linken Ausläufer entsprechend der Wahlvon h und k ignoriert werden. Abbildung 18 zeigt die nach Formel 82
berechnete posteriori-prädiktive Verteilung der Differenzen zwischender Teststatistik der simulierten Daten und den beobachteten Daten.Dabei wurde in Abbildung 18 a) jeweils das 0.01 % Quantil und das
Abbildung 18.: a) A-posteriori Verteilung von ∆(i) im 0 % bis 100 %Quantil, b) A-posteriori Verteilung von ∆(i) im 10 % bis90 % Quantil.
95% HDI0
1000
2000
3000
−0.075 −0.050 −0.025 0.000 0.025
∆(i)
Häufigke
it
95% HDI0
1000
2000
3000
−0.050 −0.025 0.000 0.025 0.050
∆(i)
Häufigke
it
a) b)
0.99 % Quantil gewählt. Man erkennt, dass die durch den grünen Bal-ken parallel zur y-Achse markierte 0 knapp außerhalb des HDIs liegt.Ergebnis
Der Unterschied zwischen erhobenen und simulierten Daten ist alsozu groß, um noch als statistische Schwankung auf Grund der Unsi-cherheit bei der Parameterschätzung interpretiert werden zu können.

6.1 größenverteilung 125
Allerdings werden durch die Wahl dieser spezifischen Quantile so-wohl die linken, als auch die rechten Ausläufer der Verteilung bei derBerechnung der Teststatistik berücksichtigt, obwohl bereits bekanntist, dass diese schlecht durch das gewählte Modell beschrieben wer-den. In Abbildung 18 b) ist die Untersuchung mit dem 10 %- und90 %-Quantil wiederholt worden, die extremen Ausläufer der Vertei-lung werden also ignoriert. Man erkennt, dass die 0 nahe der Mittedes HDIs liegt. Dies ist ein Zeichen dafür, dass der mittlere Bereichzwischen Modell und Daten sehr ähnlich ist und durch eine symme-trische Verteilung beschrieben werden kann. Die Normalverteilungwird also für die logtransformierten Durchmesser der Defekte als Mo-dell akzeptiert.
6.1.4 Hierarchisches Modell
Bis zum jetzigen Zeitpunkt wurden alle Proben als individuelle Ob-jekte ohne Bezug zueinander behandelt. In der Praxis liegt aber die Vorgehensweise
Vermutung nahe, dass Proben, die aus der gleichen Stahlgüte erho-ben und unter gleichen Produktionsbedingungen hergestellt wurden,auch ähnliche Defektverteilungen aufweisen. Lediglich im Rahmenvon statistischen Schwankungen weichen die Verteilungsparametersolcher, in Gruppen zusammengefasster Proben, voneinander ab. DieGruppenbildung muss dabei natürlich von einem Experten vorge-nommen werden und ist abhängig von dem jeweiligen Anwendungs-fall. Möchte man beispielsweise die Auswirkung eines bestimmtenProduktionsparameters auf den durchschnittlichen Defektdurchmes-ser untersuchen, bietet sich folgende Vorgehensweise an. Stahlprobenmit gleicher Güte werden in Abhängigkeit eines Produktionsparame-ters in zwei Gruppen unterteilt. Anschließend werden für beide Grup-pen der Mittelwert aller Proben und aufbauend darauf der jeweiligeGruppenmittelwert mittels des bayesschen Ansatzes geschätzt. Dafürmüssen sowohl für die Verteilung der Durchmesser der einzelnen Pro-ben als auch für die Verteilung der mittleren Probendurchmesser derjeweiligen Gruppe ein passendes Modell gewählt und die A-prioriDichten definiert werden. Unter Anwendung des bayesschen Theo-rems und des MCMC Verfahrens können dann die A-posteriori Ver-teilungen approximiert werden. Schließlich lässt sich durch den Ver-gleich der A-posteriori Verteilung der Gruppenmittelwerte beurteilen,ob der Einfluss des Produktionsparameters auf den mittleren Durch-messer signifikant ist oder nur im Rahmen von statistischen Schwan-kungen liegt. Dazu bildet man die A-posteriori Verteilung der Diffe-renzen der Gruppenmittelwerte und berechnet das HDI. Liegt die 0außerhalb des HDIs an den Rändern der Verteilung, ist dies ein star-ker Hinweis darauf, dass der Produktionsparameter Einfluss auf denDefektdurchmesser hat. Liegt die 0 hingegen im HDI, sind die Unter-

126 statistische untersuchung von defekten in stahl
schiede in den mittleren Defektdurchmessern nicht signifikant genugund könnten auch durch statistische Schwankungen auf Grund vonUnsicherheit bei der Parameterschätzung erklärt werden. Ein direk-ter Einfluss des Produktionsparameters auf den Defektdurchmesserkann nicht postuliert werden.
Wie man die A-posteriori Parameter der Gruppen konkret berech-net, soll nun exemplarisch gezeigt werden. Da bei der Erstellung derArbeit aber keine Metainformationen zu den erhobenen Daten vorla-gen, sind Auswertungen, wie der oben beschriebene Anwendungsfall,nicht möglich. Ohne weitere Informationen zu den Proben lassen sichModellaufbau
keine sinvollen Gruppen bilden. Stattdessen werden im Folgendenalle 59 vorliegenden Proben in einer Gruppe zusammengefasst, umzumindest einen Gesamtüberlick über die Verteilung der individu-ellen Defektdurchmesser zu erhalten. Nach wie vor wird angenom-
men, dass die logtransformierten Durchmesser x(j)1 , . . . x(j)
n der j-tenProbe mit j = 1, . . . , 59 normalverteilt mit den Parametern µj undσj sind. Darüber hinaus wird zusätzlich angenommen, dass die ein-zelnen Probenmittelwerte µj einer Gruppe ebenfalls normalverteiltsind und um einen Gruppenmittelwert µG mit StandardabweichungσG streuen. Abbildung 19 zeigt den Aufbau des gesamten Modellsund stellt dabei eine direkte Erweiterung von dem Modell aus Ab-bildung 16 dar. Um die Grupppenparameter µG und σG berechnen
Abbildung 19.: Aufbau des hierarchischen Modells.
~
H2
L2
H1
L1
μ j
σ
xi
( j)
~
μG
σG
~
MS
~ ~
zu können, müssen für diese ebenfalls die A-priori Dichten festgelegtwerden. Wie man an Abbildung 19 sieht, wird für µG die Normal-verteilung als A-priori Verteilung gewählt. Parametrisiert wird dieseParametrisierung
Verteilung mit M = 0 und S = 1× 106, um auszudrücken, dass nochkeine Informationen über den Gruppenmittelwert bekannt sind. Fürdie Streuung σG wird, wie bereits für die Streuung σj der einzelnen

6.2 räumliche verteilung 127
Proben, die Gleichverteilung als A-priori Verteilung mit L1 = 0 undH1 = 1× 106 verwendet. Auf diese Weise wird auch hier modelliert,dass noch kein Wissen über die Verteilung von σG vorliegt. Die A-priori Dichte für den Parameter σj bleibt unverändert und wird wiein Abbilung 16 modelliert.
Abbildung 20 zeigt die A-posteriori Verteilungen von µG und σG überalle 59 Proben. Das HDI für µG in Abbildung 20 a) beträgt dabei Interpretation
Abbildung 20.: a) A-posteriori Verteilung von µG, b) A-posteriori Ver-teilung von σG.
95% HDI0
1000
2000
3000
4.4 4.5 4.6 4.7µG
Häufigke
it
95% HDI0
1000
2000
3000
0.20 0.25 0.30 0.35 0.40σG
Häufigke
it
a) b)
[4.486, 4.617] bei einem A-posteriori Mittelwert von 4.551. Für σG hin-gegen ist das HDI laut Abbildung 20 b) gleich [0.210, 0.302] bei einemA-posteriori Mittelwert von 0.256. Die durchschnittliche Größe allerglobularen Defekte aller 59 Proben beträgt also ca. 94.747 µm.
6.2 räumliche verteilung
Nachdem für die Größenverteilung von Defekten ein adäquates Mo-dell definiert, parametrisiert und anhand erhobener Daten validiertwurde, soll in diesem Abschnitt der Prozess für die räumliche Vertei-lung von globularen Defekten wiederholt werden. Die Vorgehenswei-se ist dabei nahezu äquivalent zur Vorgehensweise aus Abschnitt 6.1.Zunächst wird auf Basis explorativer Datenanalyse und der Fachli-teratur ein geeignetes Modell ausgesucht, welches sich zur Beschrei-bung der räumlichen Verteilung eignet. Anschließend wird gezeigt,wie das Modell parametrisiert und anhand erhobener Daten validiertwerden kann.

128 statistische untersuchung von defekten in stahl
6.2.1 Modellauswahl
Üblicherweise werden nichtmetallische Einschlüsse in zweidimensio-nalen polierten Schnitten von Stahlproben detektiert. Man ist nunaber nicht an der Größenverteilung der in den Schnitten beobachte-ten Profile interessiert, sondern vielmehr an der dreidimensionalenGrößenverteilung im gesamten Stahlvolumen. Dieses Problem, alsodas Hochrechnen der Durchmesser der Profile auf eine dreidimen-sionale Größenverteilung, wird als Wicksells Korpuskelproblem be-zeichnet [143]. Zahlreiche Lösungen sind für dieses Problem bekannt[133, S. 426 ff.]. Drei Annahmen werden in der Regel getroffen, umAnnahmen
die Berechnung zu vereinfachen. Erstens sind die nichtmetallischenEinschlüsse kugelförmig. Zweitens unterliegen die Durchmesser dernichtmetallischen Einschlüsse der lognormalen Verteilung, wobei teil-weise die Ausläufer durch andere Verteilungen beschrieben werden.Drittens sind die Schwerpunkte der nichtmetallischen Einschlüssezufällig und unabhängig voneinander im Volumen verteilt und las-sen sich mittels eines homogenen Poisson Punkprozesses (PPP) be-schreiben [6]. Die erste Annahme stellt eine starke Vereinfachungder Wirklichkeit dar und ist in der Praxis nicht gegeben (siehe Ka-pitel 4). Sie erleichtert aber die Berechnung des Korpuskelproblems.Die zweite Annahme wurde bereits im Abschnitt 6.1 ausführlich un-tersucht und konnte anhand erhobener Daten exemplarisch validiertwerden. Die dritte Annahme macht das Hochrechnen des Reinheits-grades von Schnitten auf das Volumen erst möglich, da man postu-liert, dass die Bedingungen im Schnitt repräsentativ für den ganzenBlock sind. Während eine physikalische Begründung für dieses Ver-halten von nichtmetallischen Einschlüssen im Rahmen dieser Arbeitnicht gegeben werden kann, ist es aber zumindest möglich, mittelsder in Abschnitt 3.3 eingeführten statistischen Methoden diese An-nahme anhand von erhobenen Daten zu validieren. Im Gegensatzzu den üblichen Messtechniken für die Detektion von nichtmetalli-schen Einschlüssen kann nämlich mittels des in Abschnitt 4.2 vor-gestellten Verfahrens die dreidimensionale räumliche Verteilung derSchwerpunkte von Defekten rekonstruiert werden. Anhand dieser Re-konstruktion soll nun überprüft werden, ob der PPP ein geeignetesModell für die räumliche Verteilung von globularen Defekten ist.
In Anlehnung an Abschnitt 3.3.3 wird eine Stichprobe mit Stichpro-benumfang n von Schwerpunkten in einer aus der Bramme geschnit-tenen Stahlprobe W ⊂ R
3 (W wird auch als Beobachtungsfenster be-zeichnet) durch die MatrixStichprobe
x11 x12 x13...
......
xn1 xn2 xn3
(136)

6.2 räumliche verteilung 129
dargestellt, wobei der Vektor
xi =
xi1...
xi3
(137)
mit i = 1, . . . , n dem Schwerpunkt des i-ten Defektes mit den Ko-ordinaten (xi1, xi2, xi3) ∈ R
3 entspricht und aus den Zeilen der Ma-trix 136 gebildet wird. Im Folgenden wird (x, y, z) als Synonym für(xi1, xi2, xi3) verwendet.
Zunächst soll die Intensitätsfunktion λ(u) mit u = (u1, u2, u3) ∈ Waus Abschnitt 3.3.3 geschätzt werden, um zu überprüfen, ob es einegrobe Verletzung gegen die Annahme einer homogenen Verteilungder Defekte im Volumen gibt. Bei angenommener Homogenität sollte,bis auf kleine lokale Fluktuationen, die geschätzte Funktion λ(u) imProbenvolumen konstant sein. Da die explorative Auswertung von Schätzung der
Intensitätλ(u) im R3 allerdings unhandlich ist, werden im Folgenden Schnitte
zwischen einer Ebene und dem Volumen betrachtet. Dabei werdendie Schwerpunkte aller durch die Ebene geschnittener Defekte aufdiese projiziert und λ(u) dann nur in dieser Ebene geschätzt. Für λ(u)wird dann λ(x, y) beziehungsweise λ(x, z) und λ(y, z) geschrieben,um anzugeben, auf welche Achse projiziert wird.
Abbildung 21 zeigt λ(u) für eine Schnittebene senkrecht zur Fräsrich-tung bei einer Tiefe von ca. z = 18 mm in der ersten Probe aus Ab-schnitt 6.1.2. Die schwarzen Punkte stellen dabei die Schwerpunkte Interpretation
der detektierten Defekte dar. Diese Probe wird auch für alle nach-folgenden Berechnungen verwendet. Man kann erkennen, dass ab-
Abbildung 21.: Schätzung der Intensität λ(u) in der Schnittebene z =18 mm mit Bandbreite h = 4.375.
gesehen von einem schmalen Band mit einer Breite von ca. 35 mm,weite Teile der Probenoberfläche leer sind. Dies ist das in Abschnitt4.1.3 beschriebene Band, das auf Grund der Erstarrungseigenschaf-ten von flüssigem Stahl entsteht. Das Band liegt ca. 35 mm unterhalb

130 statistische untersuchung von defekten in stahl
der Oberfläche, die sich in der Abbildung bei y = 0 befindet. Dieungefähren Grenzen des Bandes sind durch die beiden schwarzenLinien bei 35 mm und 70 mm eingezeichnet. Es wurde senkrecht zudiesem Band gefräst, so dass es in jeder Schicht getroffen wird. Da-mit zeigt die Abbildung 21 deutlich, dass die Annahme einer homo-genen Defektverteilung im gesamten Probenvolumen verletzt ist. Derhomogene PPP scheint kein geeignetes Modell zur Beschreibung derDefektverteilung in der gesamten Stahlprobe zu sein. Eventuell lässtsich aber die Verteilung der Defekte im Band durch einen homogenenPPP modellieren, wenn dabei der restliche Teil der höchst wahrschein-lich leeren Probe ignoriert wird. Dazu betrachtet man die SchätzungIntensität λ(u) begrenzt auf 35 mm bis 70 mm in y-Richtung. Wie-der wird die Probe bei 18 mm in z-Richtung geschnitten, diesmal al-lerdings mit einer „dicken“ Ebene mit einer Breite von 4 mm. DieSchwerpunkte der getroffenen Defekte werden in eine Ebene proji-ziert und dort die Intensität geschätzt. Durch die Verwendung einerSchätzung der
Intensität imEinschlussband
„dicken“ Ebene werden Defekte in direkter Nachbarschaft ebenfallsprojiziert, so dass sich die totale Anzahl im Schnitt erhöht. Dies er-leichtert es, einen Trend in der räumlichen Verteilung in x- oder y-Richtung auszumachen. Auf gleiche Weise wird eine Schnittebenedurch y = 45 mm gelegt, um die Intensität in z-Richtung zu un-tersuchen. Abbildung 22 zeigt beide Graphiken. Man betrachte zu-
Abbildung 22.: a) Intensität λ(u) in der Schnittebene z = 18 mm mitBandbreite h = 4.375 mm, b) Intensität λ(u) in derSchnittebene y = 45 mm mit Bandbreite h = 4.375 mm.
a)
b)
nächst die Intensität in x-Richtung in der x, y-Ebene in Abbildung 22
a). Dabei fällt auf, dass in einem ca. 10 mm großen Streifen am lin-Interpretation
ken Rand überhaupt keine Defekte liegen. Dieser Umstand ist einemKalibrierungsfehler der Rohbilder geschuldet. Die Bilder enthaltenauf der linken Seite noch ca. 10 mm vom Hintergrund der Aufnah-mefläche. Weiter fällt auf, dass die Intensität in x-Richtung in regel-

6.2 räumliche verteilung 131
mäßigen Abständen von ca. 20 mm stark einbricht. Auch hierfür liegtder Grund an der verwendeten Messtechnik. Die Rohbilder werdenin x-Richtung aus 14 Einzelbildern zusammengesetzt. Der Intensi-tätsabfall findet dabei genau an den Verbindungskanten der einzel-nen Aufnahmen statt. Durch Inhomogenitäten in der Ausleuchtungkommt es anscheinend zu Problemen bei der Segmentierung, so dassan den Kanten weniger Defekte detektiert werden. Darüber hinaussind in x-Richtung keine interessanten Eigenschaften zu entdecken.Mehr Aufschluss über die räumliche Verteilung lässt sich aber ge-winnen, wenn man die y-Richtung betrachtet. Es ist deutlich zu er-kennen, dass die Defektverteilung hier keinesfalls homogen ist. Statt-dessen liegen am unteren Rand des Ausschnittes bei ca. 80 mm nursehr wenige Defekte. Je näher man aber der Probenoberfläche kommt,umso größer wird die Intensität und erreicht bei ca. 45 mm das Maxi-mum. Bei geringeren Abständen zur Probenoberfläche treten Defektewieder seltener auf, bis schließlich ab ca. 40 mm nur noch vereinzel-te Defekte beobachtet werden können. In x, z-Projektion der Schnitt-ebene y = 45 mm in Abbildung 22 b) sieht es hingegen so aus, alsob die Intensität bis auf lokale Schwankungen nahezu homogen ist.Zusammenfassend muss also festgestellt werden, dass die Annahmeder homogenen Verteilung der Defekte in x- und z-Richtung zwarplausibel ist, für die y-Richtung aber eine grobe Verletzung vorliegt.Dabei deckt sich das Ergebnis mit denen aus der Literatur (siehe Ab-schnitt 4.1.3) und hängt mit den Erstarrungseigenschaften von flüs-sigem Stahl zusammen. Die Erstarrung beginnt an den Außenseitender Bramme und wandert nach innen. Sowohl Poren als auch nicht-metallische Einschlüsse sind aber bestrebt, im flüssigem Stahl nachoben aufzusteigen. Bei dem Übergang von der flüssigen zur festenPhase werden sie durch die nach innen wandernde Erstarrungsfrontam Aufsteigen behindert und werden im aushärtenden Stahl einge-schlossen. Da anscheinend die nachrückenden Defekte schneller auf-steigen als die Erstarrungsfront vorrückt, kommt es in einem schma-len Bereich zu einer sehr hohen Konzentration, während mit größerwerdendem Abstand zur Probenoberfläche diese stark abnimmt. Dascharakteristische Bild in Abbildung 22 a) entsteht. Damit ist aber derhomogene PPP kein adäquates Mittel, um die räumliche Defektvertei-lung zu beschreiben, da die Defekte nicht zufällig im Raum verteiltsind. Stattdessen nimmt die Wahrscheinlichkeit zu, dass ein Defektdetektiert wird, je näher man der Oberfläche kommt. Als Alternativekann auf die allgemeinere Variante des PPP, den sogenannten inho-mogenen Poisson Punktprozess, zurückgegriffen werden. Bei diesemwird die konstante Intensität λ in Formel 94 durch die ortsabhängigeIntensitätsfunktion λ(u) ersetzt. Entsprechend wurden abgewandelteTeststatistiken für einen solchen Prozess vorgestellt [11]. Da die Inten-sitätsfunktion λ(u) in dem hier präsentierten Fall anscheinend abernur von einer Koordinate abhängt, wird eine andere Vorgehensweise

132 statistische untersuchung von defekten in stahl
verwendet. Dazu wird zunächst versucht, das Verhalten der Intensi-tät entlang der y-Richtung durch eine Funktion zu beschreiben. DieParameter der Funktion werden dabei aus den Daten geschätzt. An-schließend werden die Daten dann mittels dieser Funktion homogeni-siert, so dass die auf diese Weise transformierten Daten wieder durcheinen homogenen PPP beschrieben werden können. Dies erlaubt es,die in Abschnitt 3.3.4 beschriebenen Verfahren zu verwenden, um dieCSR-Eigenschaft zu testen. Zwar ist bereits bekannt, dass die Vertei-lung der Defekte im Stahl nicht zufällig, sondern ortsabhängig ist. Esbleibt aber immer noch die Frage bestehen, ob die Defekte unabhän-gig voneinander verteilt sind oder ob sie sich gegenseitig durch ihreLage beeinflussen.
Um besser bewerten zu können, welche Funktion das Verhalten derIntensität in y-Richtung adäquat beschreibt, ist in Abbildung 23 dieIntensität nur für diese Richtung geschätzt. Dazu wurde die Ebene inSchätzung der
Intensität iny-Richtung
Abbildung 22 in 1 mm große, zur x-Achse parallele Streifen zerlegtund die Intensität in eben diesen Streifen berechnet. Das Ergebnis ist
Abbildung 23.: Intensitätsfunktion in y-Richtung berechnet für 1 mmbreite Streifen, dargestellt als Histogramm. Das Er-gebnis des Kerndichteschätzers mit einer Bandbreitevon h = 1 ohne Kantenkorretur ist als grüne Flächeüber das Histogramm gelegt. Die Exponentialfunktionλ(y) = ae−by mit a = 28840.3 und b = 0.147, geschätztaus den Daten, ist als rote Kurve eingezeichnet.
als Histogramm dargestellt. Zusätzlich wurde die Intensität noch mit-tels Kerndichteschätzer mit einer Bandbreite von h = 1 berechnet undals grüne Fläche über das Histogramm gelegt. Noch deutlicher als inAbbildung 22 ist der sprunghafte Anstieg der Intensität zu erkennen,je näher man der Oberfläche kommt. Der Anstieg bis zur maximalenExponentialfunktion
Intensität bei ca. y = 45 mm lässt sich, wie man an der roten Kurve

6.2 räumliche verteilung 133
in Abbildung 23 sehen kann, sehr gut durch die Exponentialfunktionder Form
λ(u) = λ(x, y, z) = λ(y) = ae−by (138)
approximieren. Die Parameter wurden dabei aus den Daten geschätztund sind a = 28840.3 und b = 0.147. Eine physikalische Begründungfür die Wahl genau dieser Funktion kann nicht angegeben werden.Allerdings ist die Exponentialfunktion ein häufig verwendetes Mo-dell zur Beschreibung der Intensitätsfunktion und wurde unter ande-rem auch schon dafür benutzt, das inhomogene Verhalten von Porenin gegossenem Stahl zu beschreiben [122]. Natürlich wird auch nurdas Verhalten von rechts kommend bis zum Punkt mit maximalerIntensität modellliert. Die linken Ausläufer wurden bei der Parame-terschätzung ignoriert und lassen sich auch nicht durch die Exponen-tialfunktion beschreiben. Im Folgenden werden deshalb Defekte nurim Intervall [45, 85]mm betrachtet.
Da ein mögliches Modell zur Beschreibung des Verhaltens der In-tensität in y-Richtung bekannt ist und parametrisiert wurde, kannnun die Homogenisierung vorgenommen werden. Die Idee dabei ist, Homogenisierung
den Abstand der Punkte des Musters in Abhänigigkeit der Intensi-tätsfunktion in y-Richtung so zu verändern, dass die Intensität imgesamten Fenster konstant wird. Dabei werden für Bereiche mit ho-hen Intensitätswerten die Abstände vergrößert und für kleine Intensi-tätswerte die Abstände entsprechend komprimiert [39]. Konkret wirddie Transformation für ein Beobachtungsfenster W mit den Maßen[xmin, xmax]× [ymin, ymax] mit
t(y) = b∫ y
ymin
λ(u)du + ymin (139)
durchgeführt, wobei
b =(ymax − ymin)∫ ymax
yminλ(t)dt
(140)
ist. Die Schätzung der Intensität nach Transformation für die Schnit-tebene aus Abbildung 22 a) im Fenster [0, 286] × [45, 85]mm ist inAbbildung 24 dargestellt. Man kann deutlich die viel gleichmäßigereVerteilung der Punkte im Fenster erkennen. Allerdings ist gleichzeitigdie Untererkennung der Defekte an den Sensorkanten viel deutlicherauszumachen, da die Punkte nun über die gesamte Fläche verteiltsind. Die Sensorkanten sind in Abbildung 24 als schwarze Hilfslinieneingezeichnet. Dieser Effekt wird im Folgenden ignoriert und die An-nahme einer homogenen Verteilung der transformierten Defekte imEinschlussband akzeptiert. Im nächsten Abschnitt wird nun versucht,die CSR-Eigenschaft mit den auf diese Weise transformierten Datenzu validieren.

134 statistische untersuchung von defekten in stahl
Abbildung 24.: Intensität λ(x, y) nach Transformation für die Schnitt-ebene aus Abbildung 22 a) im Fenster [0, 286] ×[45, 85]mm. Die ca. 20 mm auseinander liegenden Sen-sorkanten sind als schwarze Linien eingezeichnet.
6.2.2 Modellparametrisierung und Validierung
Nachdem im vorherigen Abschnitt die Annahme der homogenen Ver-teilung der Defekte untersucht und nach entsprechender Transforma-tion der Schwerpunkte auch akzeptiert werden konnte, soll nun über-prüft werden, ob die Defekte unabhängig voneinander in der Probeverteilt sind (CSR-Eigenschaft). Dafür wird, wie in Abschnitt 3.3.4 be-Vorgehensweise
schrieben, der homogene PPP als Modell eingesetzt. Der Parameterdes Modells, also die konstante Intensität λ, wird aus Teilfenstern derhomogenisierten Probe im Bereich [0, 286] × [45, 85] × [0, 37]mm ge-schätzt. Die Teilfenster haben dabei die Form eines Würfels, um denEinfluss von Kanteneffekten zu verringern. Anschließend werden diein Abschnitt 3.3.4 beschriebenen Teststatistiken für die Punktmusterin den Teilfenstern berechnet und mit dem theoretischen Modell ver-glichen.
Abbildung 25 zeigt die Projektion aller Defekte in die x, y-Ebene imBereich [0, 286] × [45, 85] × [0, 37]mm und die entsprechenden Teil-fenster nach der Homogenisierung. Insgesamt wurden 16 Teilfens-Schätzung der
Intensität
Abbildung 25.: Projektion aller Defekte in die x, y-Ebene im Bereich[0, 286] × [45, 85] × [0, 37]mm nach der Homogenisie-rung. Teilfenster mit einer Abmessung von 15 × 15 ×15mm3 sind als rote beziehungsweise blaue Rechteckeeingezeichnet.

6.2 räumliche verteilung 135
Tabelle 12.: Mittelwert und HDI der A-posteriori Verteilung von λi inden Teilfenstern i = 1, . . . , 16.i Position Mittelwert 95 %HDI
1 [64.18, 79.18]× [50, 65]× [15, 30]mm 0.0404 [0.0331, 0.0464]2 [64.18, 79.18]× [65, 80]× [15, 30]mm 0.0448 [0.0381, 0.0515]3 [84.66, 99.66]× [50, 65]× [15, 30]mm 0.0489 [0.0413, 0.0558]4 [84.66, 99.66]× [65, 80]× [15, 30]mm 0.0528 [0.0451, 0.0602]5 [105.14, 120.14]× [50, 65]× [15, 30]mm 0.0549 [0.0477, 0.0638]6 [105.14, 120.14]× [65, 80]× [15, 30]mm 0.0441 [0.0372, 0.051]7 [125.62, 140.62]× [50, 65]× [15, 30]mm 0.0483 [0.0412, 0.0556]8 [125.62, 140.62]× [65, 80]× [15, 30]mm 0.0409 [0.034, 0.0471]9 [146.1, 161.1]× [50, 65]× [15, 30]mm 0.0513 [0.0435, 0.059]
10 [146.1, 161.1]× [65, 80]× [15, 30]mm 0.0412 [0.0341, 0.0483]11 [166.58, 181.58]× [50, 65]× [15, 30]mm 0.0494 [0.0426, 0.0574]12 [166.58, 181.58]× [65, 80]× [15, 30]mm 0.0413 [0.0337, 0.0479]13 [187.06, 202.06]× [50, 65]× [15, 30]mm 0.0486 [0.0408, 0.0557]14 [187.06, 202.06]× [65, 80]× [15, 30]mm 0.0359 [0.0292, 0.0419]15 [207.54, 222.54]× [50, 65]× [15, 30]mm 0.0444 [0.0378, 0.0515]16 [207.54, 222.54]× [65, 80]× [15, 30]mm 0.0432 [0.0365, 0.0504]
ter mit einer Abmessung von 15× 15× 15mm festgelegt und so po-sitioniert, dass sie zwischen den Sensorkanten, markiert durch dieschwarzen Linien, liegen. Damit soll der Einfluss der Untersegmentie-rung an eben diesen Kanten verringert werden. Die Teilfenster selbstsind als rote beziehungsweise blaue Rechtecke in Abbildung 25 ein-gezeichnet. Tabelle 12 zeigt den Mittelwert und das 95 % HDI derA-posteriori Verteilung für die Intensität λi des PPPs in den Teilfens-tern i = 1, . . . , 16. Die Schätzung wurde mittels des in Abschnitt 3.3.4beschriebenen Verfahrens durchgeführt. Man kann erkennen, dassdie Intensitäten der einzelnen Teilfenster sehr dicht beieinander lie-gen. Um festzustellen, ob die Unterschiede signifikant oder nur aufGrund von statistischen Schwankungen entstanden sind, wurde inAbbildung 26 exemplarisch für jeweils 2 Teilfenster überprüft, ob die0 in den Extremwerten der A-posteriori Verteilung der Differenzenliegt. Die Teilfenster wurden dabei so ausgewählt, dass eine Korrela- Vergleich der
A-posterioriVerteilungen
Abbildung 26.: a) A-posteriori Verteilung von λ16 − λ1, b) A-posterioriVerteilung von λ15 − λ2.
95% HDI0
20
40
60
80
−0.01 0.00 0.01
λ^
16 − λ^
1
Häufigke
it
95% HDI0
25
50
75
−0.01 0.00 0.01
λ^
15 − λ^
2
Häufigke
it
a) b)
tion auf Grund der räumlichen Position ausgeschlossen werden kann.Abbildung 26 a) zeigt die A-posteriori Verteilung von λ16 − λ1 und

136 statistische untersuchung von defekten in stahl
Abbildung 26 b) die von λ15 − λ2 mit dem jeweils als grünen Bal-ken eingezeichneten Mittelwert. Bei beiden liegt die 0 im 95 % HDI,die Variabilität der beiden Parameter ist also nicht groß genug, umals unterschiedlich angesehen werden zu können. Dies ist ein weite-rer Hinweis darauf, dass nach der in Abschnitt 6.2.1 durchgeführtenTransformation die Defektverteilung homogen ist.
Mittels der A-posteriori Verteilung von λ der 16 Teilfenster werdennun jeweils l posteriori-prädiktive Punktmuster N(1), . . . , N(l) nachdem Verfahren aus Abschnitt 3.3.4 generiert und die Teststatistik nachFormel 110 berechnet. Für die resultierende posteriori-prädiktive Ver-teilung ∆(1)(r), . . . , ∆(l)(r) wird dann für alle r > 0 das HDI berech-net und die oberen und unteren Intervallgrenzen gegen r aufgetra-gen. Abbildung 27 zeigt das Ergebnis für alle 16 Teilfenster, wobeiPosteriori-
prädiktiverTest
für die Berechnungen l = 1000 Punktmuster simuliert wurden. Das
Abbildung 27.: Die Ober- und Untergrenze des 95 % HDI berechnetüber ∆(1)(r), . . . , ∆(l)(r) für alle r > 0 in allen Teilfens-tern i = 1, . . . 16 aufgetragen gegen r (rot umrandetergrauer Bereich). Für die Berechnung wurden jeweilsl = 1000 Punktmuster pro Teilfenster simuliert.
1 2 3 4
5 6 7 8
9 10 11 12
13 14 15 16
−0.5
0.0
0.5
−0.5
0.0
0.5
−0.5
0.0
0.5
−0.5
0.0
0.5
0 5 10 0 5 10 0 5 10 0 5 10
r (in mm)
HD
I(∆
(1) (r
),..
,∆(l) (r
))
Resultat ist nicht ganz eindeutig. Für einige Teilfenster, beispielsweiseNummer 1, 5, 7, 14 oder 15, wird die 0 relativ mittig vom HDI einge-schlossen. Dies ist ein starker Hinweis darauf, dass die Hypothese derInterpretation
zufälligen und unabhängigen Verteilung der transformierten Defekteim Raum (CSR-Eigenschaft) zutrifft. Für andere Teilfenster hingegenliegt die 0 für einen signifikant großen Bereich von r außerhalb desHDIs. Als Beispiel sind hier die Teilfenster 3, 11 und 13 zu nennen.

6.2 räumliche verteilung 137
In allen Teilfenstern zusammengenommen liegt die 0 in 76.26 % derFälle im HDI. Für die Mehrzahl der Fälle scheint der homogene PPPnach Transformation der y-Achse mittels der Exponentialfunktion al-so ein adäquates Modell zu sein.
Allerdings gibt es auch einige Fälle, in denen das Modell nicht zuden erhobenen Daten passt. Im Folgenden wird deshalb jeweils einPunktmuster mit einer guten Übereinstimmung zwischen Modellund Daten und ein Punktmuster, bei dem es eine hohe Diskrepanzzwischen Modell und Daten gibt, genauer untersucht und mitein-ander verglichen. Konkret wird das Punktmuster aus Teilfenster 11als Vertreter für eine schlechte Übereinstimmung und das Teilfens-ter 15 als Vertreter für eine gute Übereinstimmung zwischen Datenund Modell gewählt. Für beide Punktmuster werden zunächst L(r)- L(r) Funktion
Funktionen aus Abschnitt 3.3.4 aus den Daten geschätzt. Abbildung28 zeigt das Ergebnis. Dabei ist jeweils die L(r)-Funktion dunkelgrün
Abbildung 28.: Funktionsgraph der Teststatistiken L(r) als grüne Linieund LPois(r) als schwarz-gestrichelte Linie für Teilfens-ter 15 in Abbildung a) und Teilfenster 11 in Abbildungb). Zusätzlich wurden die Enveloppen nach Formel 109
als grau-rot begrenzte Bereiche eingezeichnet.
0
2
4
6
0 2 4 6
r (in mm)
L^(r
)
0
2
4
6
0 2 4 6
r (in mm)
L^(r
)
L^(r)
LPois(r)
a) b)
und LPois(r), also der Verlauf der L(r)-Funktion für einen homoge-nen PPP mit gleicher Intensität wie das jeweilige Punktmuster, alsschwarz-gestrichelte Linie eingezeichnet. Zusätzlich wurden die En-veloppen nach Formel 109 als grau-rot begrenzte Bereiche in die Ab-bildung aufgenommen. Bei beiden Abbildungen fällt auf, dass L(r) Interpretation
für ca. r < 0.51 mm in Teilfenster 15 und 0.613 mm in Teifenster 11gleich 0 ist. Es scheint also ein minimaler Punktabstand (hard-coreDistanz, siehe Abschnitt 3.3.4) im Bereich r0 = 0.51 mm beziehungs-weise 0.613 mm zu existieren. Eine Begründung dafür liegt in denvereinfachten Annahmen, die bei der Modellbildung getroffen wur-den. So werden bei allen Defekten nur die Schwerpunkte betrachtet.In Wirklichkeit haben Defekte aber einen individuellen Durchmes-ser und können sich nicht überschneiden. Im Nahbereich weisen die

138 statistische untersuchung von defekten in stahl
Schwerpunkte deshalb eine reguläre räumliche Verteilung auf, wassich in Abbildung 28 dadurch niederschlägt, dass L(r) < LPois(r) fürr ≤ r0 ist. Für Werte r > r0 springt L(r) dann sehr schnell auf das Ni-veau von LPois(r) und oszilliert in beiden Fällen bis ca. r < 2 mm umdiese. In dem Bereich von r0 < r < 2 mm scheinen beide Punktmus-ter die CSR-Eigenschaften aufzuweisen. Während aber L(r) für dasPunktmuster aus Teilfenster 15 in Abbildung 28 a) auch für r ≥ 2 mmsehr eng an LPois(r) und noch in der Enveloppe liegt, entfernt sichL(r) von LPois(r) für Teilfenster 11 in Abbildung 28 b) nach oben. Fürr > 2 mm haben die Defekte im Punktmuster aus Teilfenster 11 imVergleich zu einem homogenen PPP mit gleicher Intensität also mehrNachbarn. Dies ein Hinweis darauf ist, dass die Defekte im Punkt-muster in diesem Größenbereich ein clusterartiges Verhalten aufwei-sen.
Für eine genauere Analyse bietet sich die PCF g(r) an, da diese nichtdie kumulative Eigenschaft von L(r) besitzt und somit besser dafürgeeignet ist, das lokale Verhalten des Punktmusters zu beschreiben.Paar-
Korrelationsfunktion In Abbildung 29 ist das Ergebnis der Schätzung für die Teilfenster 15und Teilfenster 11 dargestellt. Für beide Teilfenster wurde g(r) jeweils
Abbildung 29.: PCF geschätzt für Teilfenster 15 in Abbildung a) undfür Teilfenster 11 in Abbildung b) für die zwei Band-breiten h1 = 0.1 mm, bezeichnet als gh1
(r) und h2 =0.4 mm, bezeichnet als gh2
(r). Die Schätzung gh1(r)
wurde als grün-gestrichelte, gh2(r) als grüne Linie ein-
gezeichnet. Zusätzlich wurde wieder durch gPois(r) derVerlauf der PCF für einen homogenen PPP mit gleicherIntensität wie das jeweilige Punktmuster als schwarz-gestrichelte Linie eingezeichnet.
0.0
0.5
1.0
1.5
2.0
2.5
0 2 4 6
r (in mm)
g(r
)
0.0
0.5
1.0
1.5
2.0
2.5
0 2 4 6
r (in mm)
g(r
)
gh2(r)
gh1(r)
gPois(r)
a) b)
für zwei Bandbreiten, nämlich h1 = 0.1 mm, bezeichnet als gh1(r) und
h2 = 0.4 mm, bezeichnet als gh2(r), geschätzt. Die Schätzung gh1(r) ist
dabei als grün-gestrichelte Linie, die von gh2(r) als grüne Linie ein-gezeichnet. Zusätzlich wurde wieder durch gPois(r) der Verlauf derPCF für einen homogenen PPP mit gleicher Intensität wie das jeweili-

6.2 räumliche verteilung 139
ge Punktmuster als schwarz-gestrichelte Linie eingezeichnet. Bei derInterpretation wird sich an der Vorgehensweise von Illian u. a. [61,S. 240 ff.] orientiert. Dafür werden für jedes Punktmuster eine Rei-he von Distanzen definiert, an denen man das Verhalten des Musterscharakterisieren kann. Diese sind: Interpretation
• r0: Der minimale Punktabstand (hard-core Distanz, siehe For-mel 107).
• r1: Distanz, an der g(r) das erste Maximum hat. Kann als durch-schnittlicher Abstand der Punkte zu den nächsten Nachbarn in-terpretiert werden.
• r2: Distanz, an der g(r) mit g(r) ≤ 1 das erste Minimum nach r1
hat. Kann als durchschnittlicher Abstand zu Regionen mit weni-gen Punkten von den nächsten Nachbarn interpretiert werden.
Für Abbildung 29 a) ergeben sich r0 = 0.512 mm, r1 = 0.920 mm undr2 = 3.784 mm. Der minimale Punktabstand wurde dabei aus gh1
(r)berechnet, da bei zu großen Bandbreiten der Kerndichteschätzer po-sitive Werte für g(r) < r0 schätzt. Die Funktion würde in diesemFall also an der Stelle r0 nicht direkt auf 0 fallen. Insgesamt wurder0 bereits aus der L(r)-Funktion abgelesen, wird hier aber nochmalsexplizit für beide Muster angegeben. Interessanter an dieser Stelle istder Wert von r1, welcher, wie auch r2, aus gh2(r) abgelesen wurde,da gh1
(r) auf Grund der gewählten Bandbreite sehr verrauscht ist.Dieser Wert gibt den Abstand zu den nächsten Nachbarn im Punkt-muster an und beträgt, wie oben aufgeführt, r1 = 0.920 mm. Im Nah-bereich zwischen r0 und r1 hat ein typischer Punkt im Punktmus-ter aus Teilfenster 15 also verhältnismäßig viele Nachbarn, was einHinweis darauf ist, dass im Nahbereich die Defekte zur Clusterbil-dung neigen. Schaut man sich aber den weiteren Verlauf von gh2(r)an, wird man feststellen, dass die Funktion relativ schnell auf 1, alsoden Wert der PCF für einen homogenen PPP fällt. Ab ca. 2 mm os-zilliert gh2(r) nur noch in kleinen Abständen um gPois(r). Zwar wirdbei r2 = 3.784 mm das Minimum von ˆgh2(r) erreicht, allerdings fälltdieses nicht signifikant genug aus, um als Hinweis für das Verhaltender Defekte in diesem Größenbereich interpretiert werden zu können.Insgesamt scheint, wie schon bei der Analyse der L(r)-Funktion ver-mutet, der homogene PPP für diese Punktmuster ein gutes Modell zusein. Die Abweichungen im Nahbereich zwischen r0 = 0.512 mm undr1 = 0.920 mm vom Modell lassen sich mit der bereits angesproche-nen Vereinfachung erklären. Da nur die Schwerpunkte der Defektebetrachtet werden, können im Bereich des durchschnittlichen Durch-messers keine Nachbarn liegen. Für Werte r > r0 steigt dann g(r)sprunghaft an und pendelt sich erst für Werte mit r > r1 wiederein. Allgemein beobachtet man ein solches Verhalten bei sogenann-ten Softcore-Prozessen [61, S. 241]. Für einen bestimmten Grenzwert,

140 statistische untersuchung von defekten in stahl
in diesem Fall der durchschnittliche Durchmesser, werden nur sehrwenig Punktpaare mit eben diesem oder einem kleineren Abstanddetektiert. Für größere Abstände gibt es dann die Tendenz entspre-chende Nachbarpunkte zu finden. Im Gegensatz zu einem Hardcore-Prozess, wie bei einem Parikelsystem mit konstantem Durchmesser,ist bei einem Softcore-Prozess r0 nicht fix, sondern hängt von derGrößenverteilung der Partikel ab. Ein anderes Bild ergibt sich für dasPunktmuster in Abbildung 29 b) aus Teilfenster 11. Für den Nah-bereich ist wieder das Verhalten eines Softcore-Prozesses zu sehen,wobei der minimale Punktabstand r0 = 0.613 mm beträgt. Das Maxi-mum erreicht die Funktion gh2(r) bei r1 = 1.738 mm. Im Gegensatzzum ersten Punktmuster liegt die Funktion aber für alle r > r1 si-gnifikant über 1. Konkret bedeutet dies, dass für ein bestimmtes rmit r > r1 mehr Paare von Punkten mit dem Abstand r existieren,als man bei einem Punktmuster mit CSR-Eigenschaft erwarten wür-de. Dies ist ein Hinweis darauf, dass die Defekte im Punktmusterzur Clusterbildung neigen und damit ein klarer Verstoß gegen dieCSR-Hypothese.
Der Grund für dieses unterschiedliche Verhalten der Punktmusterist in Abbildung 30 zu erkennen. Hier wurde die Intensitätsfunkti-Intensität entlang
verschiedenerRaumrichtungen
on λ(x, y) beziehungsweise λ(x, z) für die Teilfenster 15 und 11 nachProjektionen der Defekte auf die x, y-Ebene (Abbildung 30 a) und c) )und auf x, z-Ebene (Abbildung 30 b) und d) ) geschätzt. Während fürTeilfenster 15 in Abbildung 30 a) und b) ein bis auf lokale Schwankun-gen homogener Verlauf der Intensität vorliegt, gibt es zumindest inder x, y-Projektion für Teilfenster 11 in Abbildung 30 c) trotz Homo-genisierung einen starken Intensitätsgradienten in y-Richtung. Sehrwahrscheinlich ist der Einfluss der Sensorkanten auf die Defektvertei-lung doch größer als zunächst angenommen, so dass die Annahmeeiner homogenen Verteilung nach Transformationen nicht für jedesTeilfenster aufrecht erhalten werden kann. Wird für solche Teilfenstermit nicht konstanter Intensität trotzdem eine der in Abschnitt 3.3.4eingeführten Teststatiken berechnet, kommt es zu dem in Abbildung29 b) beobachteten Effekt. Das gleiche gilt auch, wie individuell über-prüft werden kann, für die restlichen Teilfenster aus Abbildung 27,bei denen der Test fehlschlägt.
Zusammenfassend können also folgende Erkenntnisse festgehaltenwerden. Die Intensität von Defekten ist nicht homogen im Stahl. Statt-Zusammenfassung
der Ergebnisse dessen sammeln sie sich in einem schmalen Band unterhalb der Pro-benoberseite. Auch in diesem Band ist die Verteilung nicht homogen,lässt sich aber annähernd mit einer Exponentialfunktion nach Formel138 beschreiben. Aufbauend auf dieser Erkenntnis kann mit gewis-sen Einschränkungen gezeigt werden, dass die räumliche Verteilungder Defekte unabhängig voneinander (CSR-Eigenschaft) ist. Konkretwurde dafür das Band in 16 Teilfenster zerlegt, jedes der in den 16

6.2 räumliche verteilung 141
Abbildung 30.: Die Intensität λ(x, y) beziehungsweise λ(x, z) für Teil-fenster 15 und Teilfenster 11 nach Projektion in die x, y-Ebene in Abbildung a) und c) und nach Projektion indie x, z-Ebene in Abbildung b) und d).
b)
a) c)
d)
Teilfenster liegenden Punktmuster mit der in Formel 139 beschriebe-nen Transformation homogenisiert und die A-posteriori Verteilungder Intensität für jedes Punktmuster geschätzt. Anschließend wur-de für jedes Punktmuster l = 1000 Werte aus der A-posteriori Ver-teilung der Intensität gezogen und damit jeweils l homogene PPPssimuliert. Für das beobachtete Punktmuster und den entsprechen-den simulierten l Punktmustern wurden eine Teststatistik in Formder L(r)-Funktion berechnet und der in Abschnitt 3.3.4 beschriebe-ne posteriori-prädiktive Test durchgeführt. Dabei konnte in 76.26 %aller Fälle eine gute Übereinstimmung zwischen Daten und Modellfestgestellt werden. Im weiteren Verlauf wurde mittels der ebenfallsin Abschnitt 3.3.4 beschriebenen explorativen Methoden die Ursachefür die Diskrepanz zwischen Daten und Modell für die restlichen23.74 % der Fälle untersucht. Zwei mögliche Gründe für die Abwei-chung wurden identifiziert. Zum einen ist der homogene PPP keingeeignetes Modell, um die Verteilung für sehr kleine Punktabständezu beschreiben, da bei der Modellierung nicht berücksichtigt wur-de, dass jeder Defekt einen Durchmesser besitzt, in dem kein ande-

142 statistische untersuchung von defekten in stahl
rer Defekt liegen kann. Für sehr kleine Punktabstände ist die CSR-Eigenschaft also nicht erfüllt. Im Vergleich zur Größe des gesamtenBandes sind die Abstände aber so klein (unter 1 mm), dass dieserEffekt im Folgenden ignoriert wird. Als zweiter Grund für die Ab-weichung wurde festgestellt, dass der posteriori-prädiktive Test sehrfehleranfällig ist, wenn die Annahme der homogenen Verteilung ver-letzt wird. Im Anwendungsbeispiel kommt es insbesondere durchSensorrauschen und Untersegmentierung an den Sensorkanten zu ei-nem nicht homogenen Intensitätsverlauf im Teilfenster. Dies führt zuden detektierten Abweichungen zwischen der Teststatistik der simu-lierten und beobachteten Punktmuster. Unter Berücksichtigung die-ser Erkenntnisse wird das Ergebnis in Abbildung 27 als ausreichendbetrachtet, um das Modell anzunehmen. Die räumliche Verteilungder Defekte ist also unabhängig voneinander, wobei die Position dereinzelnen Defekte von der als Intensitätsfunktion λ(u) angenommenExponentialfunktion aus Formel 138 abhängt.
Abgeschlossen wird dieser Abschnitt mit der Betrachtung derNächste-Nachbar Funktion D(r) (siehe Abschnitt 3.3.4), da in dieserder minimale Punktabstand abgelesen werden kann, ab dem jederPunkt im Punktmuster mindestens einen Nachbarn hat. AbbildungNächste-Nachbar
Funktion 31 zeigt die Schätzung von D(r) für die schon bekannten Punktmus-ter aus Teilfenster 15 und 11. Beim Punktmuster aus dem Teilfenster
Abbildung 31.: Schätzung der Nächste-Nachbar Funktion D(r) für dasPunktmuster von Teilfenster 15 in Abbildung a) unddas Punktmuster von Teilfenster 11 in Abbildung b).
0.00
0.25
0.50
0.75
1.00
0 2 4 6
r (in mm)
D^(r
)
0.00
0.25
0.50
0.75
1.00
0 2 4 6
r (in mm)
D^(r
)
D^ (r)
DPois(r)
a) b)
15 in Abbildung 31 und dem Punktmuster aus Teilfenster 11 in Ab-bildung 31 nimmt die Funktion D(r) jeweils ab r = 2.864 mm bezie-hungsweise r = 3.580 mm einen Wert von 1 an. Interpretiert man dieInterpretation
Nächste-Nachbar Funktion als kumulative Verteilungsfunktion, dannbeträgt an diesen Stellen die Wahrscheinlichkeit, dass ein Punkt imPunktmuster mindestens einen Nachbar mit der Entfernung r hat,100 %.

6.3 simulation von stahlproben 143
Auf Basis der Erkenntnisse, die in diesem und im vorherigen Ab-schnitt 6.2.2 gewonnen wurden, wird nun im nächsten Teilabschnittein Algorithmus entworfen, mit dem künstliche Stahlproben mit De-fekten generiert werden können. Anhand dieser künstlichen Stahlpro-ben werden dann später verschiedene Frässzenarien evaluiert.
6.3 simulation von stahlproben
Mit den Erkenntnissen aus den vorherigen Abschnitten lässt sich nunein Algorithmus angeben, mit dem synthetische Stahlproben gene-riert werden können. Der Algorithmus hängt dabei von 5 Parame- Parameter
tern ab, nämlich dem Mittelwert µ und der Standardabweichung σ
der logarithmischen Normalverteilung, der Intensität λ des homoge-nisierten Punktmusters, den Parametern a und b der Intensitätsfunk-tion aus Formel 138, welche den Intensitätsgradienten in y-Richtungbeschreiben und den Abmessungen des Fensters in der Stahlprobeder Form W = [xmin, xmax] × [ymin, ymax] × [zmin, zmax], in dem simu-liert werden soll. Als Rückgabewert liefert der Algorithmus das si-mulierte Punktmuster mit zugehörigem Durchmesser für jeden De-fekt zurück. Listing 7 zeigt den Algorithmus in Pseudocode. Groblässt sich der Algorithmus in drei Teile aufteilen. Zunächst wird inZeile 2 die Anzahl n der Punkte im Muster aus der Poissonvertei-lung, parametrisiert mit λv(W), gezogen. Anschließend werden dieListen, welche die x, y, z Koordinaten der Schwerpunkte der n De-fekte enthalten und die Liste mit den jeweiligen Durchmessern mit0 initialisiert. Dann beginnt die eigentliche Simulationsphase des Al-gorithmus. Dafür werden zunächst entsprechend der Eigenschaften Funktionsweise
eines homogenen PPPs die Koordinaten (xt, yt, zt) eines potenziellenDefektes im Intervall der Fenstergröße aus der Gleichverteilung ge-zogen. Zusätzlich wird der Durchmesser des Defektes entsprechendder logarithmischen Normalverteilung bestimmt. Nun wurde aber imvorherigen Abschnitt festgestellt, dass die Schwerpunkte zwar unab-hängig voneinander, aber nicht zufällig im Raum verteilt sind. DieIntensität steigt exponentiell an, je weiter man sich der Oberflächenähert. Dies wird im Algorithmus ab Zeile 11 durch eine Ausdün-nungsoperation nach Lewis und Shedler [81] umgesetzt. Für jedenmöglichen Defekt wird nämlich die ortsabhängige Wahrscheinlich-keit
p(y) =ae−byt
ae−byymin(141)
berechnet und auf Basis dieser entschieden, ob der temporär gene-rierte Defekt Teil des Punktmusters ist oder verworfen wird (sieheZeile 12). Gemäß Formel 141 hat dabei ein potenzieller Defekt mitKoordinate yt eine höhere Wahrscheinlichkeit als Punkt des Mustersangenommen zu werden, je näher er an ymin liegt. Dieser Vorgang

144 statistische untersuchung von defekten in stahl
Algorithmus 7 Simulator.
1: procedure SimulateSteelSample(µ, σ, λ, a, b, W)2: n ∼ Poisson(1, λv(W)) ⊲ Initialisierung3: x[n]← 0, y[n]← 0, z[n]← 04: d[n]← 05: c← 16: while c ≤ n do
7: xt ∼ Uni f orm(1, xmin, xmax) ⊲ Simulationsphase8: yt ∼ Uni f orm(1, ymin, ymax)
9: zt ∼ Uni f orm(1, zmin, zmax)
10: dt ∼ Lognormal(1, µ, σ)
11: p← ae−byt
ae−bymin
12: if p < Uni f orm(1, 0, 1) then ⊲ Ausdünnungsphase13: continue
14: else
15: for i← 1, c do
16: m←√
(x[i]− xt)2 + (y[i]− yt)2 + (z[i]− zt)2
17: if(
b←(
m ≤(
d[i]2 + dt
2
)))
then
18: break
19: end if
20: end for
21: if b = false then
22: x[c]← xt, y[c]← yt, z[c]← zt
23: d[c]← dt
24: c← c + 125: end if
26: end if
27: end while
28: return x, y, z, d29: end procedure
wird nun solange wiederholt, bis n Punkte im Muster sind. Aller-dings wird so nicht berücksichtigt, dass ein Defekt für sehr kleineAbstände keine Nachbarn haben kann, da jeder Defekt einen indi-viduellen Durchmesser hat und diese sich nicht überlappen können.Dieser Fall wird im Algorithmus in Zeile 15 bis 19 behandelt, indemfür jeden Defekt mit Durchmesser dt überprüft wird, ob in der Umge-bung seiner finalen Position bereits ein anderer Defekt liegt, so dasses zu einer Überlappung kommt. Ist dies der Fall, wird der Defektebenfalls verworfen und der Algorithmus fortgesetzt. Man beachtet,dass die resultierenden Positionen der Defekte bei Verwendung die-ses Kriteriums nicht mehr unabhängig voneinander sind. Allerdingstritt der Fall einer Überlappung zweier Defekte bei den in der vorlie-genden Arbeit verwendeten Dimensionen so selten auf, dass in derPraxis kein messbarer Einfluss festgestellt werden kann.

6.3 simulation von stahlproben 145
Algorithmus 7 wurde speziell für den in Abschnitt 6.2.1 beschriebe-nen Fall angegeben, bei der der Intensitätsverlauf exponentiell in y-Richtung zur Oberfläche der Stahlprobe zunimmt. In der praktischen Generische Variante
Implementierung können für die Intensitätsfunktion aber beliebigeWahrscheinlichkeitsdichten eingesetzt werden. Wird keine Intensitäts-funktion angegeben, erfolgt die Simulation eines klassischen homoge-nen PPP.
In Abbildung 32 wird das beobachtete Punktmuster aus dem vor-herigen Abschnitt in der Schnittebene z = 10 in einem FensterW = [20, 266]× [44, 84]× [5, 25]mm mit einem simulierten Punktmus-ter gleicher Abmessung gegenübergestellt. Die logarithmische Nor-
Abbildung 32.: Schätzung der Intensitätsfunktion λ(x, y) in der Schnitt-ebene z = 10 mm des beobachteten Punktmustersin Abbildung a) und des simulierten Punktmustersin Abbildung b) in einem Fenster mit Abmessung[20, 266] × [44, 84] × [5, 25]mm. Die Parameter des si-mulierten Punktmusters betrugen dabei λ = 0.0453,a = 28840.3, b = 0.146, µ = 4.931 und σ = 0.455.
a)
b)
malverteilung wurde mittels der in Abbildung 17 durchgeführtenPunktschätzung mit µ = 4.932 und σ = 0.383 parametrisiert. Für Anwendungsbeispiel
die Intensität und die Parameter der Exponentialverteilung wurdenhingegen jeweils der Mittelwert der A-posteriori Mittelwerte der Teil-fenster aus Tabelle 12, also λ = 0.0453 und die in Abbildung 23 be-schriebenen Parameter a = 28840.3 und b = 0.146 verwendet. DerAnteil der Defekte, die auf Grund von Kollisionen bei der Simulationverworfen werden mussten, betrug 0.26 % der Gesamtanzahl. Insge-samt besitzt das finale Punktmuster n = 8060 Defekte. Wie man inAbbildung 32 sehen kann, ist kein großer Unterschied, von der Un-tersegmentierung an den Sensorkanten einmal abgesehen, zwischendem beobachteten und simulierten Punktmuster auszumachen. So-wohl das beobachtete als auch das simulierte Punktmuster werdenin dem nachfolgenden Abschnitt dazu verwendet, unterschiedlicheFrässzenarien zu evaluieren.

146 statistische untersuchung von defekten in stahl
6.4 evaluation verschiedener frässzenarien
In diesem Abschnitt sollen nun anhand von simulierten Daten, diemittels des Algorithmus 7 generiert wurden, verschiedene Frässze-narien untersucht werden. Insbesondere der Einfluss verschiedenerSpanabnahmen auf die Schätzung der Parameter der Durchmesser-verteilung ist dabei von Interesse. Aber auch die Frage soll beleuchtetwerden, ab wann genügend Material abgefräst wurde, um eine statis-tisch sichere Aussage über die Qualität der Bramme zu treffen.
6.4.1 Optimierung der Spanabnahme
Um den Einfluss der Spanabnahme auf die Parameterschätzung be-stimmen zu können, wird wie folgt vorgegangen. Zunächst wird eineProbe mit den in Abbildung 32 verwendeten Parametern generiert.Vorgehensweise
Diese Probe wird dann verwendet, um verschiedene Fräsdurchläufemit verschiedenen Spanabnahmen durchzuführen. Konkret wird dieSpanabnahme pro Durchlauf in einem Intervall von [5, 200]µm um5 µm erhöht. Die Ober- und Untergrenzen des Intervalls entsprechendabei in etwa den minimalen beziehungsweise maximalen Betriebs-parametern der realen Fräse. Für jeden Durchlauf wird dann eineSchnittebene im Abstand der aktuell gewählten Spanabnahme in z-Richtung durch den simulierten Stahlblock geschoben und die Durch-messer der Schnittkreise zwischen der Ebene und den geschnittenenDefekten bestimmt. Das Volumen der einzelnen Defekte ergibt sichdurch Aufsummieren der Flächeninhalte der einzelnen Schnittkrei-se multipliziert mit der aktuell verwendeten Spanabnahme. Diesesals Cavalieri-Schätzer bezeichnete Verfahren ist ein erwartungstreu-er Schätzer für das Volumen [10, S. 63 ff.]. Aus dem Volumen wirddann der Durchmesser der als kugelförmig angenommenen Defekteberechnet. Auf diese Weise wird also das in Abschnitt 4.2 beschrie-bene Verfahren simuliert, wobei Artefakte durch Diskretisierung beider Bildaufnahme oder Segmentierung außen vorgelassen werden. Ineinem letzten Schritt erfolgt dann für jeden der 40 Simulationsdurch-läufe die Berechnung der A-posteriori Verteilung der Durchmesser.Diese werden dann gegen Verteilungsparameter, die zur Simulationder Ausgangsprobe verwendet wurden, verglichen.
Abbildung 33 zeigt das Ergebnis für den Mittelwert µ der logarithmi-schen Normalverteilung der Durchmesser. Dabei wurde der Mittel-wert der A-posteriori Verteilung µ als schwarze Linie und das HDIals grau-rot begrenzter Bereich gegen die Spanabnahme aufgetragen.Zusätzlich wurde der Parameter µ = 4.931, der zur Simulation desPunktmusters verwendet wurde, als schwarz-gestrichelte Linie ein-gezeichnet. Man kann deutlich erkennen, dass bei einer Spanabnah-Auswertung

6.4 evaluation verschiedener frässzenarien 147
Abbildung 33.: Mittelwert µ als schwarze Linie und das HDI der A-posteriori Verteilung als grau-rot begrenzter Bereichaufgetragen gegen die Spanabnahme. Zusätzlich wur-de der Parameter µ = 4.931 der Simulation als schwarz-gestrichelte Linie eingezeichnet.
5.00
5.05
5.10
5.15
0 50 100 150 200
Spanabnahme (in µm)
µ
µ
µ
me im Bereich zwischen 5 und ca. 65 µm der wahre Parameter vomHDI der A-posteriori Verteilung eingeschlossen wird. Erst für größereSpanabnahmen kommt es zu einer stetigen Überschätzung des Para-meters, so dass sich dieser immer weiter vom wahren Wert entfernt.Dies liegt daran, dass Defekte mit kleinerem Durchmesser als die ein-gestellte Spanabnahme mit zunehmender Spanabnahme immer häu-figer übersprungen werden, ohne dass sie von der Schnittebene ge-troffen werden. Die fehlenden Informationen auf der linken Seite derVerteilung führen dann dazu, dass der Mittelwert µ immer größerwird. Für die simulierte Probe sind aber weniger als 1 % der Defektekleiner als 50 µm und somit haben Spanabnahmen kleiner als 50 µmnur einen sehr kleinen Einfluss auf die Schätzung der Verteilungs-parameter. Die Konsequenz daraus ist, dass Proben mit ähnlichenVerteilungseigenschaften wie die Simulierte mit einer Spanabnahmebis zu 50 µm gefräst werden können, ohne die Schätzung der Vertei-lungsparameter stark zu verfälschen.
6.4.2 Abbruchkriterium
Eine weitere Möglichkeit, den Fräsvorgang zu optimieren, besteht inder Einführung eines Abbruchkriteriums. Dieses wird parallel zum

148 statistische untersuchung von defekten in stahl
Fräsvorgang überwacht und löst, sobald es erfüllt ist, ein Stopsignalaus. Wie bereits in Abschnitt 3.2.2 erwähnt, wird die Breite des HDIsVorgehensweise
als konkretes Kriterium verwendet. Diese gibt an, wie unsicher dieParameterschätzung der Durchmesserverteilung bei der bis zum ak-tuell betrachteten Zeitpunkt erhobenen Datenmenge ist. Parallel zumFräsprozess werden also für alle vollständig abgefrästen Defekte mit-tels MCMC-Verfahren die A-posteriori Verteilung der Parameter derlogarithmischen Normalverteilung erhoben und das HDI berechnet.Sobald eine vorgegebene Zielbreite des HDIs erreicht ist, wird derFräsvorgang angehalten. Abschließend kann dann mittels des posteri-ori-prädiktiven Tests überprüft werden, ob die erhobenen Daten wirk-lich zu dem parametrisierten Modell passen. Ist dies der Fall, wer-den die Daten archiviert. Andernfalls muss ein Experte entscheiden,warum es zu den Abweichungen gekommen ist. In jedem Fall mussdie vorgegebene Zielbreite des HDIs im Vorhinein für die verschie-denen Stahlsorten kalibriert werden. Dazu müssen natürlich schonentsprechende Erfahrungswerte vorliegen. Da dies zum Zeitpunktdes Erstellens dieser Arbeit nicht der Fall war, wird im Folgendendas Abbruchkriterium anhand von simulierten Daten evaluiert. Dabeiwird wie folgt vorgegangen. Wie schon in Abschnitt 6.4.1 beschrieben,wird eine Schnittebene mit vorgegebener Spanabnahme durch diesimulierte Bramme getrieben und für jeden Schnitt die Menge dervollständigen Defekte (siehe Abschnitt 2.1.2.3) bestimmt. Für diesewachsende Liste von Defekten wird dann nach jedem Schnitt das Ab-bruchkriterium evaluiert. Zusätzlich zu der simulierten Probe wirddas Abbruchkriterium auch für die Ausgangsprobe aus Abbildung32 a) evaluiert, auf deren Basis die simulierte Probe parametrisiertwurde. Als Spanabnahme wurde eine Breite von 10 µm gewählt, dadie Ausgangsprobe mit dieser Einstellung gefräst wurde.
Abbildung 34 zeigt die Auswertung des Abbruchkriteriums beiderProben für den Parameter µ der logarithmischen Normalverteilung.Auswertung
In Abbildung 34 a) sind jeweils die Breiten der HDIs, berechnet ausden A-posteriori Verteilungen für alle vollständig abgefrästen Defek-te bei einer Spanabnahme von 10 µm gegen die Frästiefen in mm fürdie simulierte Probe und die gemessene Probe aufgetragen. Wie zuerwarten, nimmt die Breite mit zunehmender Frästiefe ab, da immermehr Defekte in die Schätzung der A-posteriori Verteilung einfließen.Wird als Zielbreite des HDIs h = 0.05 gewählt, wird das Abbruchkri-terium für die simulierte Probe bei 2.95 mm und für die gemesseneProbe bei 3.75 mm ausgelöst. In der Abbildung ist das Auslösen desAbbruchkriteriums durch senkrechte Striche parallel zur y-Achse inder entsprechender Farbe der jeweiligen Probe eingezeichnet. Um zubewerten, wie sich das vorzeitige Abbrechen auf den geschätzten Pa-rameter µ der logarithmischen Normalverteilung auswirkt, wurde inAbbildung 34 zusätzlich das HDI und der Mittelwert der A-posterioriVerteilung für die simulierte Probe, bezeichnet als µSim, und für die

6.4 evaluation verschiedener frässzenarien 149
Abbildung 34.: a) Breite des HDIs für die gemessene Probe als rote Li-nie und für die simulierte Probe als grüne Linie auf-getragen gegen die Frästiefe, b) A-posteriori Mittelwertvon µ und das HDI für die gemessene (rote Linie) undsimulierte Probe (grüne Linie) gegen die Frästiefe auf-getragen.
0.0
0.1
0.2
0.3
0.4
0.5
0 1 2 3 4 5
Bre
ite H
DI
Probe
gemessen
simuliert
4.8
4.9
5.0
0 1 2 3 4 5
Frästiefe (in mm)
µ
A−post. Mittelwert
µMes
µSim
µ
HDI
HDI(µMes)
HDI(µSim)
a)
b)
gemessene Probe, bezeichnet als µMes, gegen die Frästiefe aufgetra-gen. Als wahrer Wert für µ wurde schließlich der Mittelwert der A-posteriori Verteilung der gemessenen Probe nach vollständigem Ab-fräsen mit µ = 4.931 angenommen und als gestrichelte Linie einge-zeichnet. Dieser Wert wurde ebenfalls zur Parametrisierung der si-mulierten Probe verwendet, stellt also für diese den wahren Wert vonµ dar. Wird das Abbruchkriterium ausgelöst, ergibt sich für die si-mulierte Probe an der Stelle 2.95 mm ein Wert für die Schätzung desParameters µ von µSim = 4.984 und für die gemessene Probe an derStelle 3.75 mm ein Wert von µMes = 4.966. In beiden Fällen liegt dieAbweichung vom wahren Wert also unter 5 % bei gleichzeitiger Re-duktion von 2000 auf unter 400 zu fräsenden Schichten für die ausAbbildung 32 verwendeten Maße.
Diese Auswertungen haben natürlich nur exemplarischen Charakter,da nicht genügen Probenmaterial vorhanden war, um das Abbruch-kriterium ausreichend zu kalibrieren. Um das Abbruchkriterium inden realen Prozess integrieren zu können, sind folgende Schritte not-wendig. Zunächst muss eine Datenbank aufgesetzt werden, in der so-wohl die Schwerpunkte als auch die mittleren Breiten aller rekonstru-ierter Defekte der jeweils bearbeiteten Proben nach entsprechenderKlassifizierung gespeichert werden. Dann müssen die Proben bezüg-lich der Stahlgüte gruppiert werden, da die Vermutung nahe liegt,dass unterschiedliche Stahlsorten auch unterschiedliche Verteilungs-parameter besitzen. In diesen Gruppen werden dann mittels der inAbschnitt 6.1.4 eingeführten hierarchischen Modelle die Parameter-intervalle in Form des HDIs, sowohl für die Größenverteilung alsauch für die räumliche Verteilung, bestimmt. Aus den HDIs lassen

150 statistische untersuchung von defekten in stahl
sich Zielbreiten für jede Stahlsorte ableiten, die als Abbruchkriteriumfür zukünftige Fräsvorgänge verwendet werden. Wird ein zukünfti-ger Fräsvorgang abgebrochen, wird überprüft, ob die ermittelten Pa-rameter in dem Gruppen-HDI der jeweiligen Stahlsorte liegen undob die neu erhobenen Daten zu den Modellannahmen passen. Fürletzteres werden wieder die in Abschnitt 3.2.3 und 3.3.4 eingeführtenTeststatistiken verwendet. Falls es schließlich zur Modellverletzungkommt, muss ein Experte zu Rate gezogen werden.
6.5 zusammenfassung
In diesem Kapitel wurde gezeigt, wie anhand der in Kapitel 3 ein-geführten Methoden stochastische Modelle sowohl für die räumlicheVerteilung als auch für die Durchmesserverteilung von Defekten inStahl entwickelt, parametrisiert und validiert werden können. Kon-kret hat sich dabei herausgestellt, dass die Defektdurchmesser der lo-garithmischen Normalverteilung folgen, während die räumliche Ver-teilung adäquat durch einen PPP mit exponentieller Intensitätsfunkti-on in y-Richtung beschrieben werden kann. Die rigorose Verwendungvon bayesschen Methoden zur Parameterschätzung erlaubt dabei, zu-künftig erworbenes Wissen in Form einer geeigneten A-priori Vertei-lung zu modellieren. Da zum Zeitpunkt der Erstellung dieser Arbeitkeine Erfahrungswerte über die Parameter vorlagen, wurden ledig-lich uninformierte A-priori Verteilungen verwendet. Beide Modellewurden dann in einem Algorithmus zusammengefasst, der die Gene-rierung von synthetischen Stahlproben erlaubt. Anhand von solchensimulierten Proben konnten dann verschiedene Frässzenarien undein automatisches Abbruchkriterium evaluiert werden. Exemplarischließ sich zeigen, dass unter den drei Annahmen, nämlich die Durch-messer der Defekte sind logarithmisch normalverteilt, die räumlicheVerteilung folgt einem PPP und die Form der Defekte sind annäherndkugelförmig, die Anzahl der zu fräsenden Schichten um ca. das 5fa-che reduziert werden kann, ohne dass der Fehler zum wahren Wertdes Parameters 5 % überschreitet. Dieses Ergebnis konnte auch an-hand von real gefrästen Proben nachvollzogen werden.
Alle Auswertungen in diesem Kapitel wurden nur exemplarisch fürwenige Proben durchgeführt und erheben nicht den Anspruch, statis-tisch gesicherte Aussagen über die Qualität der untersuchten Stahl-sorten zu treffen. Vielmehr sollte verdeutlicht werden, wie das in dervorliegenden Arbeit entwickelte theoretische Rahmenwerk eingesetztwerden kann, um den gesamten Prozess von der Modellbildung bishin zur Modellvalidierung zu unterstützen. Um wirklich gesichertestatistische Aussagen zu treffen, müssen die vorgestellten Auswer-tungen für eine Vielzahl von Proben unterschiedlichster Güte durch-geführt werden. Erst dann kann das in Abschnitt 6.4.2 vorgestellte

6.5 zusammenfassung 151
Abbruchkriterium kalibriert werden. Dies war zum Zeitpunkt der Er-stellung dieser Arbeit nicht möglich, da nicht genügend Probendatenvorlagen. Im nächsten Kapitel wird gezeigt, wie die Methoden desRahmenwerks zu einem kompletten Auswertesystem integriert wer-den können. Mit diesem ist es dann möglich, autonom Proben zuverarbeiten und das Abbruchkriterium sowie die Klassifikation derDefekte zu kalibrieren.

152 statistische untersuchung von defekten in stahl

7I M P L E M E N TAT I O N
In diesem Kapitel sollen die in Kapitel 2 und 3 eingeführt Methodenzu einem vollständigen Analysesytem für Partikelsysteme integriertwerden. Dabei lässt sich dieses System grob in zwei Teilsysteme zer-legen. Der erste Teil umfasst die bereits in Abschnitt 4.2 für den An-wendungsfall zur Detektion von Defekten in Stahl grob beschriebe-ne Verarbeitungspipeline. Die einzelnen Komponenten sowie derenImplementierung sollen nun genauer erläutert werden. Hauptaugen-merk liegt dabei auf den morphologischen und statistischen Analy-sekomponenten, welche die dreidimensionale Rekonstruktion, Klas-sifikation und Parameterschätzung der stochastischen Modelle sowiedie Evaluierung des Abbruchkriteriums durchführen. Auf die Bild-aufnahme und Bildsegmentierung wird an dieser Stelle nicht einge-gangen, sondern auf die entsprechende Literatur verwiesen [18, 21].Das System wird als Particle Detection System (PDS) bezeichnet.
Das zweite große Teilsystem ist eine interaktive Auswertesoftware,welche es erlaubt, explorative Analysen auf den erhobenen Datenanzuwenden. Dieses wurde parallel zum PDS entwickelt und da-zu verwendet, den Modellbildungsprozess des Anwendungsfalles zuunterstützen. So wurden beispielsweise alle statistischen Auswertun-gen aus Kapitel 6 mittels dieser Software durchgeführt. Auch für dieSichtprüfung der Klassifikationsergebnisse wurde diese Software ver-wendet. Zwar erfolgte die Entwicklung mit Blick auf den konkretenAnwendungsfall, die Umsetzung wurde aber so allgemein gehalten,dass auch Datensätze aus anderen Anwendungsfällen analysiert wer-den können. Das System wird als Particle Analysis System (PAS) be-zeichnet.
7.1 particle detection system
Das PDS hat die Aufgabe, in segmentierten Schichtbildern Partikelzu detektieren, zu rekonstruieren und statistisch auszuwerten. Dafür Funktionalität PDS
werden die Schichtbilder sukzessiv übereinander gelegt und die Par-tikel mit dreidimensionaler Ausdehnung in den Schichten verfolgt.Sobald ein Partikel vollständig abgefräst wurde, also in der aktuel-len Schicht kein Profil mehr erkennbar ist, wird es zu einem drei-dimensionalen Modell zusammengesetzt und die Formdeskriptoren
153

154 implementation
über dieses Modell werden berechnet. Anhand dieser Formdeskripto-ren erfolgt dann die Klassifikation. Der klassifizierte Datensatz kannentsprechend gefiltert werden, um beispielsweise Artefakte oder stö-rende Einzelereignisse zu beseitigen. Mit dem gefilterten Datensatzwerden schließlich die stochastischen Modelle parametrisiert und dasAbbruchkriterium evaluiert. Grundsätzlich wird davon ausgegangen,dass der gesamte Prozess von Rekonstruktion, Klassifikation und sta-tistischer Analyse parallel zur Bildaufnahme abläuft. Es liegt alsokein vollständiger Datensatz vor, sondern neue Schichtbilder werdenkontinuierlich parallel zur Auswertung erzeugt.
Wie bereits in Abschnitt 2.1.3 beschrieben, muss der gesamte Pro-zess echtzeitfähig sein. Echtzeitfähig wurde in diesem Zusammen-Echtzeit
hang so definiert, dass alle Auswertungen der aktuellen Schicht fer-tig sein müssen, sobald ein neues Schichtbild aufgenommen wurde.Abhängig vom eingesetzten bildgebenden Verfahren kann sich dieZeit für die Aufnahme zweier aufeinanderfolgender Schichten starkunterscheiden. Für den Anwendungsfall aus Abschnitt 4.2 ergebensich ca. 30 s. Dieser Wert soll auch in der nachfolgenden Betrachtungals Refenzwert angesehen werden, der nach Möglichkeit nicht über-schritten werden soll.
Um einen echtzeitfähigen Prozess mit einem Durchsatz von mehrerenhundert Megabyte pro Schichtbild gewährleisten zu können, wurdedie gesamte Verarbeitungspipeline nach dem Pipes und Filter Archi-tekturmuster entworfen. Jede Komponente des Systems verarbeitetArchitektur PDS
die Ergebnisse der vorherigen Pipeline-Stufe und leitet das Ergebnisan die nachfolgende Stufe weiter. Dabei besitzt jede Stufe eine eige-ne Warteschlange, in der die Ergebnisse der vorherigen Stufe zwi-schengespeichert werden, falls der jeweilige Verarbeitungschritt nochnicht abgeschlossen ist. Dadurch ist es möglich, die einzelnen Kom-ponenten unabhängig voneinander parallel auszuführen. Abbildung35 zeigt den schematischen Aufbau der Pipeline. Der Vollständigkeithalber wurden in der Graphik auch die Bildaufnahme und die Seg-mentierung aufgenommen, obwohl auf diese Komponenten im weite-ren Verlauf nicht eingegangen wird. Es ist lediglich darauf zu achten,dass gemäß der Definition von Echtzeit in Abschnitt 2.1.3 die Gesamt-laufzeit von Segmentierung, Rekonstruktion, Vorverarbeitung, Klas-sifizierung, statistischer Auswertung und Archivierung nicht größerist als die Bildaufnahme eines Schichtbildes. Dabei wird ein eventu-ell vorhandener Prozess, der die Probe mechanisch verarbeitet, wiebeispielsweise das Fräsen aus dem Anwendungsfall mit zur Bildauf-nahme gezählt.
In den folgenden Abschnitten werden nun die Implementierung derVorgehensweisePDS einzelnen Komponenten und deren Laufzeitverhalten besprochen.
Als Referenzprobe wird die schon in Abschnitt 2.1.3 angesprochenesimulierte Probe mit höchstem Verunreinigunggrad verwendet. Die

7.1 particle detection system 155
Abbildung 35.: Aufbau des PDS.
Bildaufnahme Segmentierung
VorverarbeitungRekonstruktion
Klassifizierung Stat. Auswertung
Archivierung
Frässchichten Rohbilder
BinärbilderPixeldaten
Partikel Partikel
Partikel
PDS
verwendete Probe wurde dabei mit Algorithmus 7 simuliert. Um al-lerdings die Verarbeitungspipeline ab der Vorverarbeitungstufe tes-ten zu können, werden segmentierte Schichtbilder benötigt. Diesewurden wie folgt aus der simulierten Probe gewonnen. Mit der einge-stellten Frästiefe von 10 µm wurde eine Schnittebene durch die Pro-be getrieben und alle Schnittkreise der getroffenen Partikel durchdie größte Menge an Pixeln approximiert, die komplett im jewei-ligen Schnittkreis liegen. Für die Größe eines Pixels wurde dabei10 µm× 10 µm angenommen. Schicht für Schicht wurden dann allePixel aller getroffenen Partikel in Form von Rohbildern auf der Fest-platte gespeichert. Bei einer Probe mit Standardabmessung beträgtdie Größe eines auf diese Weise generierten Bildes ca. 350 MB. Dieauf diese Weise diskretisierte Version der simulierten Probe wird imFolgenden zur empirischen Analyse der Laufzeit der einzelnen Pi-pelinestufen verwendet. Das Ziel dabei ist es herauszufinden, ob zu-mindest für den Anwendungsfall die Verarbeitungspipeline schnellgenug ist, um einen Echtzeitbetrieb gewährleisten zu können.
7.1.1 Pipeline Stufen
Basisdatentyp der Verarbeitungspipeline ist eine generische KlasseNames Stage. Jede spezifische Komponente der Pipeline ist als Spe- Stage
zialisierung dieser Klasse implementiert. Die Stage-Klasse besitztzwei Attribute, nämlich einen Zeiger auf eine Warteschlange für ein-gehende Daten, bezeichnet als inQueue und eine Instanzvariable Na-mens outQueue, in der die Ergebnisse der jeweiligen Pipeline-Stufe ge-speichert werden. Dabei sind beide Attribute vom generischen Daten-typ Queue, welcher eine thread-sichere Implementierung einer War-teschlange auf Basis der Standard Template Library (STL) von C++

156 implementation
ist. Zwei Standardoperationen werden von Queue angeboten. MittelsWarteschlange
push wird ein Datenobjekt vom Typ T in die Warteschlange einge-reiht. Mittels waitAndPop wird das vorderste Element der Schlan-ge hingegen entfernt und an den Aufrufer zurückgegeben. Ist dieWarteschlange beim Aufruf von waitAndPop leer, legt der aufrufen-de Thread sich solange schlafen, bis ein neues Element mittels push
eingefügt wird und gibt dieses dann zurück. Abbildung 36 zeigt bei-de Klassen in Unified Modeling Language (UML)-Notation. Wie man
Abbildung 36.: Aufbau der Pipeline Stufen.
erkennen kann, besitzt Stage zusätzlich noch einen öffentlichen Kon-struktor, mit dem der Zeiger inQueue initialisiert wird. Schließlichexistiert noch eine öffentliche Methode namens getOutQueue, wel-che einen Zeiger auf outQueue zurückliefert. Damit ist der minima-Datenfluss PDS
le Funktionsumfang vorhanden, um verschiedene Pipelinestufen zueiner kompletten Verarbeitungspipeline zu verbinden. Dabei wird im-mer die Warteschlange mit den Ergebnissen outQueue einer Instanzvon Stage per getOutQueue an den Konstruktor von Stage der neuenInstanz übergeben. Die neu angelegte Instanz ist nun mit der alten In-stanz verbunden, wobei die Verarbeitungsergebnisse der ersten Stufedie Eingaben für die zweite Stufe sind. Wie man in Abbildung 35
sieht, können sich die Typen der Elemente, die in den Warteschlan-gen gespeichert sind, zwischen Eingabe und Ausgabe unterscheiden.So nimmt beispielsweise die Rekonstruktions-Stufe Pixeldaten entge-gen und leitet fertig rekonstruierte Partikel an die nächste Stufe wei-ter. Aus diesem Grund ist die Stage-Klasse eine Template-Klasse mitzwei Template-Parametern, mit denen die Typen von inQueue undoutQueue festgelegt werden. Für jede der Stufen der Pipeline wirdeine eigene Klasse implementiert, welche von Stage erbt und entspre-chend Template-Parameter Substitution vornimmt. In Abbildung 36
ist dies beispielhaft für die 5 Stufen des PDS aus Abbildung 35 gezeigt(englische Namen verwendet). Die Template-Parameter Substitutionist dabei durch die in UML gängige Bind-Notation symbolisiert. Zwarist damit der Datenfluss zwischen den einzelnen Stufen der Pipelinemodelliert, allerdings fehlt der eigentliche Verarbeitungschritt. Dieserwird mittels des klassischen Entwurfsmusters der Template-Methode

7.1 particle detection system 157
von Gamma u. a. [42, S. 360 ff.] umgesetzt. Die Basis-Klasse besitzt Template-Methode
eine als privat markierte abstrakte Methode process, die von der öf-fentlichen run Methode aufgerufen wird. Die abgeleiteten Klassenvon Stage implementieren nun die abstrakte Methode process, sodass die entsprechende Transformation von den Eingabedaten hinzu den Ausgabedaten durchgeführt wird. Aufgerufen wird die run-Methode jeder Stufe in einem eigenen Thread, so dass langsame Stu-fen im hinteren Teil der Pipeline nicht schnellere Stufen im vorderenTeil blockieren.
Insgesamt besitzt diese Architektur mehrere Vorteile. Zum einen lässtsich die Pipeline sehr einfach fast beliebig verändern, solange die Da-tentypen der Ein- und Ausgabewarteschlange übereinstimmen. Soll Vorteile PDS
beispielsweise ein Zwischenergebnis festgehalten werden, muss le-diglich eine entsprechende Spezialisierung von Stage implementiertwerden, welche den Eingabedatenstrom unverändert an die Ausgabekopiert. In der process-Methode wird dann die entsprechende Pro-tokollierung, zum Beispiel in eine Datenbank, vorgenommen. Zumanderen können einzelne Stufen genauso einfach aus der Pipelineentfernt werden, wenn man an deren Ergebnis nicht interessiert ist.Da die einzelnen Pipeline-Stufen nur sehr lose über die Warteschlan-ge Queue gekoppelt sind, können die Stufen schließlich ohne größereAnpassung auf mehrere Rechner im Netzwerk verteilt werden. EineAnpassung der Stage-Klasse ist dafür nicht notwendig, lediglich dieMethoden von Queue müssen netzwerkfähig gemacht werden. Im Fol-genden werden nun die einzelnen Stufen der Pipeline aus Abbildung35 besprochen, die als Spezialisierung der Stage-Klasse implemen-tiert sind.
7.1.2 Vorverarbeitung
Die Vorverarbeitung bildet die Schnittstelle zwischen den bilderver-arbeitenden Systemen und dem PDS. Üblicherweise werden hier diesegmentierten Daten in ein für das PDS lesbares Format konvertiert.Dabei werden nur noch Pixel, die während der Segmentierung alszugehörig zu einem Partikel identifiziert wurden, gespeichert. Alle Reduktion
anderen Pixel werden verworfen, was zu einer drastischen Redukti-on der Datenmenge führt. Wie in Abschnitt 2.1.2.3 beschrieben, istdas Übergabeformat als eine lexikographisch sortierte Menge der Pi-xelkoordinaten definiert, wobei zusätzlich die Schichtnummern als z-Koordinate gespeichert werden. Werden die Pixel aus Schichtbildern Sortierung
gelesen, ist die Sortierung implizit gegeben. Aus diesen Voxelmengenwerden dann mittels des OZP-Algorithmus (siehe Abschnitt 2.1.2.3)disjunkte Teilmengen bestimmt, die als dreidimensionale Rekonstruk-tion der Partikel interpretiert werden. Abhängig davon, wie die Bilder

158 implementation
an das PDS übergeben werden, kann das Konvertieren der Daten un-terschiedlich aufwändig sein. Für den Anwendungsfall aus Abschnitt4.2 wurden drei unterschiedliche Szenarien vorgesehen und jeweilsals austauschbare Pipeline-Stufe implementiert. Unterstützt wird dieÜbergabe über das Netzwerk, über das Dateisystem oder direkt imArbeitsspeicher. Für die simulierte Probe werden zum Laden einesLaufzeit
Vorverarbeitung Schichtbildes von der Festplatte, Identifizieren der zu einem Partikelzugehörigen Pixel und der lexikographischen Sortierung im Mittelüber alle Schichtbilder ca. 1524 ms pro Bild benötigt. Die Geschwin-digkeit lässt sich weiter steigern, wenn das Bild von der Segmentie-rungstufe direkt über den Arbeitspeicher an die Vorverarbeitung wei-tergeleitet wird. Bei Übergabe über das Netzwerk ist die Bandbreiteder limitierende Faktor. Die Laufzeit der Vorverarbeitungsstufe wirdsomit inklusive eines Sicherheitspuffers auf TPrep = 2000 ms spezifi-ziert.
7.1.3 Rekonstruktion
Die Rekonstruktionsstufe wurde bereits ausführlich im Rahmen desAbschnittes 2.1.2 besprochen. Der OZP (Algorithmus 3) wird in die-ser Stufe verwendet, um die Partikel aus den Schichtbildern zu rekon-struieren. Sobald ein Partikel vollständig rekonstruiert wurde, wirdes an die nächste Stufe der Pipeline weitergereicht. Die Laufzeit die-Laufzeit
Rekonstruktion ser Stufe wurde bei gegebener Hardware mit TCcl = 7000 ms (sieheAbschnitt 2.1.3) spezifiziert. Wenn die statistische Analyse parallelzum Bildgewinnungsverfahren nicht benötigt wird und die Schicht-bilder vor Beginn der Analyse bereits vollständig vorliegen, kann derAlgorithmus durch einen anderen in Abschnitt 2.1.2 beschriebenenausgetauscht werden. Für den ZP und PZP wurde jeweils eine eigenePipeline-Stufe implementiert.
7.1.4 Klassifikation
Um die vollständig rekonstruierten Partikel klassifizieren zu können,müssen zunächst die in Abschnitt 2.2 beschriebenen Formdeskrip-toren berechnet werden. Die Berechnung der einzelnen Deskripto-ren wird in dieser Pipelinestufe durchgeführt. Dabei wird sequen-tiell jeder Algorithmus zur Berechnung des spezifischen Deskriptorsauf die vollständig abgefrästen Partikel aus der Warteschlange ange-wendet. Bei harten Echtzeitanforderungen lässt sich dieser Vorgangparallelisieren, da die einzelnen Algorithmen unabhängig voneinan-der laufen. So können für ein Partikel gleichzeitig mehrere Algorith-Deskriptoren
men, am besten abgestimmt auf die physikalische Anzahl der Pro-zessoren, berechnet werden. Abhängig von dem konkreten Klassi-

7.1 particle detection system 159
fizierungsproblem sind bestimmte Deskriptoren besser geeignet alsandere. Für den Anwendungsfall wurden in Abschnitt 5.3 ausführli-che Untersuchungen durchgeführt und der optimale Deskriptorsatzbestimmt, mit dem eine Klassifizierung zwischen globularen Defek-ten, Rissen und Artefakten sowie nichtmetallischen Einschlüssen undPoren möglich ist. Berechnet man also nur diesen optimalen Deskrip-torsatz, lässt sich die Laufzeit der Pipelinestufe weiter verbessern. Inder folgenden Betrachtung sollen allerdings alle Deskriptoren aus Ab-schnitt 2.2 berücksichtigt werden, um die Laufzeit TClas dieser Stufeabzuschätzen. Verwendet man wieder die simulierte Probe mit ei- Laufzeit
Klassifikationnem hohen Verunreinigungsgrad, die im Vergleich zu allen bisherreal beobachteten Daten extreme Werte für Intensität und die Para-meter der logarithmischen Normalverteilung aufweist, werden imMittel pro Schicht 9.23 Partikel bei einer Standardabweichung von3 als vollständig abgefräst identifiziert. Da das Worst-Case Szenariountersucht werden soll, wird die Anzahl der vollständig abgefrästenPartikel pro Schicht auf 19 festgelegt. Dies entspricht aufgerundet beigegebener Konfiguration einer Abweichung von mehr als drei Stan-dardabweichungen vom Mittelwert und kommt nur in weit unter 1 %der Fälle vor. Um die Laufzeit TClas zu schätzen, werden nun 19 Parti-kel zufällig aus der Probe gezogen und die Laufzeit der Berechnungder Deskriptoren und die Klassifizierung mittels einer bereits antrai-nierten SVM gemessen. Diese Messung wird über 1000 Durchgängegemittelt, was der Anzahl der zu fräsenden Schichten entspricht. Ab-bildung 37 zeigt das Histogramm mit Intervallbreite h = 300 ms derLaufzeiten für die Berechnung der Formdeskriptoren und Klassifi-kation. Es ist nicht überraschend, dass das Histogramm die Form
Abbildung 37.: Laufzeiten der Deskriptorberechnung und der Klassifi-kation als Histogramm mit Intervallbreite h = 300 msfür 1000 Schichten.
0
40
80
120
3000 6000 9000
Laufzeit (in ms)
Hä
ufig
keit
der logarithmischen Normalverteilung hat, da der Durchmesser dereinzelnen Partikel direkt mit der Laufzeit der Formdeskriptoren kor-

160 implementation
reliert. Die maximale Laufzeit, die für eine Schicht benötigt wurde,beträgt 10 410 ms und wird als maximale Laufzeit TClas dieser Pipeli-nestufe festgelegt. Dabei ist zu beachten, dass dieser Wert die extre-me Laufzeit bei einer simulierten Probe mit extremen Verteilungspa-rametern widerspiegelt. Für real erhobene Daten wird der Wert imDurchschnitt weit niedriger sein.
7.1.5 Statistische Auswertung
In dieser Stufe werden die klassifizierten Partikel statistisch ausgewer-tet und das Abbruchkriterium evaluiert. Dafür wird in den Prozessder Pipeline eine Instanz der Statistiksoftware R1 eingebettet. Die Be-Bibliothek Rcpp
rechnung der statistischen Auswertungen erfolgt dann in Form vonR-Skripten, die für jede neue Schicht auf den bis zum aktuellen Zeit-punkt erhobenen Daten ausgeführt werden. Die Kommunikation zwi-schen der in C++ implementierten Pipelinestufe und der Instanz vonR wird über die Rcpp-Bibliothek von Eddelbuettel und Francois [37]abgewickelt. Sowohl für die Analyse der Größenverteilung als auchfür die Analyse der räumlichen Verteilung sind alle Methoden ausAbschnitt 3 in Form solcher Skripte implementiert. Da aber einige Me-thoden, wie beispielsweise das MCMC-Verfahren zur Approximationder A-posteriori Verteilung oder die Testfunktionen für Punktprozes-se, sehr rechenintensiv sind, wird in der Praxis vorerst nur das aufdem HDI basierende Abbruchkriterium evaluiert. Für den Anwen-dungsfall müssen dafür die Parameter des gewählten Modells, alsowie in Abschnitt 6.1 beschrieben, der logarithmischen Normalvertei-lung, geschätzt werden. Wählt man die zur Likelihood-Funktion kon-Laufzeit
jungierte A-priori Verteilung, liegt für die A-posteriori Verteilung eingeschlossener Ausdruck vor, der sich selbst für sehr große Datenmen-gen schnell auswerten lässt. Für die logarithmische Normalverteilungist die Herleitung dieses Ausdruckes in Gelman u. a. [43, S. 78 ff.]beschrieben. Das HDI wird dann anhand von Stichprobenwerten be-rechnet, die aus der A-posteriori Verteilung gezogen wurden. Die-ser Vorgang dauert selbst für mehrere Millionen Partikel nur wenigeMillisekunden. Der Einfluss auf die Echtzeitfähigkeit der gesamtenPipeline kann also vernachlässigt werden. Die Laufzeit dieser Stufewird also mit TStat = 0 ms spezifiziert. Ist das Abbruchkriterium aus-gewertet und das Ergebnis an die Bildaufnahmestufe propagiert, istder echtzeitkritische Abschnitt der Pipeline für die aktuelle Schichterfolgreich abgeschlossen. Die Ergebnisse aller nachfolgenden Ope-rationen müssen nicht bis zum Ende der Bildaufnahme der nächs-ten Schicht vorliegen. Stattdessen können sich die Laufzeiten dieserOperationen über mehrere Schichten erstrecken. Alle komplexeren
1 http://www.r-project.org/

7.1 particle detection system 161
statistischen Auswertungen werden also erst nach Evaluation des Ab-bruchkriteriums durchgeführt.
7.1.6 Archivierung
Die Archivierungsstufe stellt den letzten Abschnitt der Pipeline dar.Hier werden alle Ergebnisse, die in den anderen Stufen erhoben wur-den, kanalisiert und in einem geeigneten Format auf die Festplatte ge-schrieben. Prinzipiell muss grob zwischen zwei verschiedenen Typenvon Datensätzen mit verschiedenen Speicherstrategien unterschiedenwerden. Zum einen fallen die als Voxelmengen repräsentierten rekon- Rohdaten
struierten Partikel an, die abhängig von der Größe des jeweiligen Par-tikels mehrere tausend Voxel pro Partikel beinhalten können. DieseDaten werden im Folgenden als Rohdaten bezeichnet. Zum anderenwerden bei einem kompletten Durchlauf der Pipeline eine Vielzahlverschiedener statistischer Parameter, die sogenannten Metadaten, er-hoben. Dazu gehören zum Beispiel die Formdeskriptoren, die fürjedes Partikel der Probe berechnet werden, aber auch die Parame-terschätzungen für die verwendeten Modelle. An beide Klassen von Metadaten
Daten sind unterschiedliche Anforderungen gestellt. Die Rohdatenwerden hauptsächlich dafür verwendet, die Ergebnisse der statisti-schen Auswertung und der Klassifikation nachzuvollziehen. So kannbeispielsweise mit dem in Abschnitt 7.2 vorgestellten Werkzeug eindreidimensionales Modell der Voxelmengen erstellt und eine visuelleInspektion des Klassifikationsergebnisses durchgeführt werden. Al-ler Voraussicht nach wird eine solche manuelle Inspektion aber eherselten und nur bei offensichtlichen Funktionsstörungen des Prozes-ses durchgeführt. Gleichzeitig müssen die Rohdaten gegebenenfallsmehrere Jahre abrufbar sein, um bei zweifelhaften Ergebnissen derstatistischen Auswertung diese wiederholen zu können. Das Daten-format sollte also in Hinblick auf den Speicherverbrauch und nichtauf die Zugriffszeit optimiert werden. Anders sieht es bei den Meta-daten aus. Diese werden bei einem regelmäßig angewendeten Prüf-system immer wieder herangezogen, um das Ergebnis einer aktuel-len Auswertung ins Verhältnis zu den bisher erhobenen Daten zusetzen. Als Beispiel ist hier der probenübergreifende Vergleich derGrößenverteilung der Partikeldurchmesser mittels des in Abschnitt6.1.4 beschriebenen hierarchischen Modells zu nennen. Im Gegensatzzu den Rohdaten müssen die Metadaten also möglichst schnell undgezielt zur Verfügung gestellt werden. Es ist naheliegend, für beideDatentypen unterschiedliche Speicherstrategien zu implementieren.Im Folgenden werden beide Strategien genauer erläutert.

162 implementation
Die Wahl für das Speichern der Rohdaten fiel auf das HDF5-Format2.Das HDF5-Format ist ein universelles Datenformat, welches für dasSpeichern und Archivieren von großen Binärdatensätzen entwor-fen wurde. Der Aufbau einer HDF5-Datei ist vergleichbar mit demHDF5-Format
Aufbau eines Dateisystems. Basiselement ist eine Gruppe (englischGroup), welche bei der Dateisystemanalogie einem Verzeichnis ent-spricht. Ausgehend von einer Vatergruppe lassen sich diese innerhalbder HDF5-Datei schachteln, so dass beliebige hierarchische Bäume de-finiert werden können. Der durch die Namen der einzelnenen Grup-pen gebildete Pfad, kann dazu benutzt werden, jede Gruppe im Baumgezielt zu adressieren. Die eigentlichen Daten werden dann in Formvon sogenannten Datasets an beliebigen Punkten des Baumes einge-hängt. Die für das PDS entworfene Struktur ist wie folgt aufgebaut.Jede Voxelmenge eines Partikels wird in einer eigenen Gruppe miteindeutigem Bezeichner gespeichert und in einer gemeinsamen Vater-gruppe eingehängt. Damit ist sichergestellt, dass die Voxeldaten jedeseinzelnen Partikels individuell adressiert und geladen werden kön-nen. Die Speicherung der Voxel der einzelnen Partikel erfolgt in Formeiner Tabelle, bei der die x, y, z-Koordinaten und Grauwerte spalten-weise eingetragen sind. Jede Zeile dieser Tabelle beschreibt also einenVoxel des betrachteten Partikels. Zusätzlich werden in einer gesonder-ten Tabelle in einer eigenen Gruppe die wichtigsten Formdeskripto-ren wieder zeilenweise pro Partikel abgespeichert. In der ersten Spal-te ist dabei der eindeutige Bezeichner des Partikels aufgeführt, sodass die zugehörigen Voxeldaten zu dem jeweiligen Deskriptoren in-nerhalb der HDF5-Datei identifiziert werden können. Alle Datensät-ze sind mittels LZW-Verfahren komprimiert, um den Speicherbedarfzu verringern. Die so definierte HDF5-Datei kann also als vollstän-diger Datensatz des Messsystems interpretiert werden, aus dem alleweiteren Ergebnisse durch Anwenden der entsprechenden Methodenrekonstruiert werden können. Der Speicherverbrauch der Testprobemit höchstem Verunreinungsgrad nach Kompression beträgt dabei ca.300 MB. Eine Langzeitarchivierung mehrerer tausend Proben ist dem-nach ohne Einsatz spezieller Hardware möglich. Zusätzlich könnenexterne Softwarelösungen, wie Matlab, Mathematica oder R verwen-det werden, um die Ergebnisse weiterzuverarbeiten, da das HDF5-Format ein standardisiertes Format ist und für die angesprochenenProgramme entsprechende Import-Funktionen existieren.
Die Metadaten der verarbeiteten Proben werden hingegen in einerrelationalen Datenbank abgelegt. Vereinfacht sieht der Aufbau derTabellen dabei wie folgt aus. Für jede verarbeitete Probe wird einEintrag in der Proben-Tabelle erzeugt. Dieser enthält neben einer ein-Datenbank
deutigen Probenidentifikationsnummer (Proben-ID) und den Datei-namen der zugehörigen HDF5-Datei die probenübergreifenden sta-tistischen Auswertungen, beispielsweise die geschätzten Parameter
2 http://www.hdfgroup.org/HDF5/

7.1 particle detection system 163
der Modelle. Für jedes detektierte Partikel in der betrachteten Probewird zusätzlich in der Partikel-Tabelle ein Eintrag mit den individu-ellen Formdeskriptoren angelegt. Dabei wird wieder jedem Partikelein eindeutiger Bezeichner (Partikel-ID) zugewiesen, der mit dem Be-zeichner aus der HDF5 Datei übereinstimmt. Die Relation, die schließ-lich einer bestimmten Probe die zugehörigen Partikel zuordnet, wirddurch eine dritte Tabelle abgebildet. Hier wird für jedes Partikel einEintrag mit seiner Partikel-ID und der zugehörigen Proben-ID ange-legt. Dieser Aufbau erlaubt es, sowohl Proben als auch individuellePartikel nach den erhobenen statistischen Parametern zu durchsu-chen und zu filtern. Der Einsatz eines standardisierten Datenbank-systems, im konkreten Fall wurde PostgreSQL3 eingesetzt, erleichtertdabei die Anbindung von zusätzlichen Analysewerkzeugen. Für denAnwendungsfall wurde beispielsweise eine speziell auf die Bedürf-nisse der Stahlindustrie zugeschnittene Software entwickelt, mit derEndanwender komplexe Suchanfragen in Form einfacher interaktiverEingaben formulieren können. Diese werden dann in SQL-Anfragentransformiert und an die Datenbank gesendet. Die Ergebnisse wer-den in Form standardisierter graphischer Berichte nahezu in Echtzeitbereitgestellt [136, 135]. Mit ähnlicher Motivation wurde von Wehr-bein [142] im Rahmen seiner Diplomarbeit ein Werkzeug erstellt, mitdem die in der Datenbank gespeicherten Auswertungen im Unterneh-mensnetzwerk bereitgestellt werden.
Implementiert werden beide Speicherstrategien in Form einer Pipe-linestufe. Die Voxelmengen der Partikel und die Formdeskriptorenwerden kontinuierlich, parallel zur Bildaufnahme, in das jeweilige Da-tenformat geschrieben. Sobald der Prozess beendet ist, werden dann Laufzeit
Archivierungdie Probenmetadaten berechnet und ebenfalls abgespeichert. DieseVorgehensweise erlaubt es, den Prozess zu pausieren und zu einemspäteren Zeitpunkt fortzusetzen. Da diese Stufe, wie schon erwähnt,keinen Einfluss mehr auf die Echtzeitfähigkeit des gesamten Systemsbesitzt, wird sie mit einer Laufzeit von TArch = 0 ms spezifiziert.
7.1.7 Zusammenfassung
In den vorherigen Abschnitten wurden alle Komponenten des PDSbeschrieben und die Vorzüge der einzelnen Designentscheidungenerläutert. Anhand simulierter Daten von Stahlproben mit extremerVerunreinigung konnte außerdem gezeigt werden, dass das PDS imAnwendungsfall aus Abschnitt 4.2 die Anforderung bezüglich derEchtzeitfähigkeit erfüllt. Konkret liegt die Laufzeit beim kontinuierli- Gesamtlaufzeit
chen Fräsen und Abfotografieren pro Schicht ohne Segmentierung bei
3 http://www.postgresql.org

164 implementation
TGes = 19 410 ms. Bei der maximal angesetzten Laufzeit von 30 s blei-ben also ca. 10 s für die Bildsegmentierung, bis der Schichtwechselerfolgt und das Abbruchkriterium evaluiert sein muss. Dieser Wertkann als realistisch angesehen werden, um die Segmentierung durch-zuführen.
7.2 particle analysis system
Bei dem im vorherigen Abschnitt beschriebenen PDS gibt es eine Viel-zahl möglicher Fehlerquellen und Parameter, die das Gesamtergeb-nis beeinflussen können. Schon im ersten Schritt der Bildaufnahmekann ein falsch eingestellter Parameter enorme Auswirkungen aufdie nachfolgenden Auswertungen besitzen. Da die Ergebnisse dereinzelnen Pipelinestufen aufeinander aufbauen, pflanzt sich ein sol-cher Fehler im gesamten System immer weiter fort. Als einfaches Bei-Kalibrierung
spiel sei hier eine zu kurz eingestellte Belichtungszeit der Kameraangeführt. Die unterbelichteten Bilder führen zu einer starken Über-segmentierung, welche sich nach der Rekonstruktion als Artefaktemanifestieren. Werden diese nicht herausgefiltert, beeinflussen sie di-rekt die Parameterschätzung der Modelle und damit die Evaluationdes Abbruchkriteriums. Die korrekte Wahl der entsprechenden Para-meter ist also entscheidend für die Qualität der Auswertung. Für dieeinzelnen Pipelinestufen gibt es mehrere Parameter, die das Verhal-ten beeinflussen. Allein die Klassifizierung mittels einer SVM hängtvon den gewählten Deskriptoren, dem verwendeten Trainingsdaten-satz und den eigentlichen Parametern der SVM ab. Der optimale Pa-rametersatz wird, wie in Abschnitt 5 beschrieben, automatisch perKreuzvalidierung bestimmt. Eine solche trainierte SVM kann zwarim Durchschnitt eine sehr hohe Korrektklassifikationsrate besitzen,im Einzelfall ist es aber unmöglich, nur auf Basis der Werte der einzel-nen Deskriptoren die Entscheidung der SVM nachzuvollziehen undzu bewerten. Aber gerade diese Einzelfallprüfung kann wichtig sein,um Fehler zu detektieren und die Klassifikationsrate weiter zu opti-mieren. Auch kann von der aktuellen Korrektklassifikationsrate nichtauf das zukünftige Verhalten des Klassifizierers geschlossen werden.So kann eine Änderung von bestimmten Betriebsbedingungen völligandere Formen hervorbringen, die im Trainingsdatensatz gar nichterfasst sind. Gleiches gilt für die statistischen Auswertungen. SindExpertenprüfung
die in Abschnitt 6.2.1 getroffenen Annahmen verletzt, können keinestatistischen Aussagen getroffen werden. Zwar lässt sich mittels derin Abschnitt 6.2.2 beschriebenen Verfahren automatisch detektieren,ob die erhobenen Daten zu den Modellen passen, im Einzelfall mussaber trotzdem ein Experte die Daten manuell untersuchen, um dieAbweichung erklären zu können. Für diese und ähnliche Aufgabenwurde ein spezielles Werkzeug namens PAS parallel zum PDS im-

7.2 particle analysis system 165
plementiert. Drei Ziele wurden bei der Entwicklung verfolgt, näm-lich die Unterstützung des Modellbildungsprozesses, die Kalibrie-rung der Verarbeitungspipeline und die Ergebnisvalidierung der Pi-peline im laufenden Betrieb. Im Folgenden wird gezeigt, wie diesedrei Ziele mit dem PAS umgesetzt werden können. Dabei werden dieTechniken zunächst unspezifisch für Partikelsysteme allgemein einge-führt. Exemplarisch werden dann mögliche Untersuchungen bezogenauf den Anwendungsfall aus Abschnitt 4.2 aufgezeigt. Zwar wurdedas PAS speziell in Hinblick auf die Detektion, Klassifizierung undstatistische Untersuchung von nichtmetallischen Einschlüssen undähnlichen Defekten entworfen, die verwendeten Methoden sind abergenerisch implementiert, so dass auch andere Anwendungsfälle mitähnlichen Kontexten untersucht werden können. Im Folgenden wirdzunächst der grobe Aufbau des Systems besprochen. Anschließendwird gezeigt, wie die drei definierten Ziele in Bezug auf die Klas-sifikation und in Bezug auf die statistische Auswertung umgesetztwerden können.
7.2.1 Aufbau
Der grobe Aufbau des PAS wird im Folgenden an dem Referenzmo-dell der Informationsvisualisierung von Chi [26] erläutert. Abbildung Referenzmodell der
Informationsvisuali-sierung
38 zeigt den Aufbau des Referenzmodells mit den jeweiligen Entspre-chungen im PAS. Prinzipiell beschreibt das Modell in abstrakter Wei-
Abbildung 38.: Referenzmodell der Informationsvisualisierung nachChi [26].
PAS
Datenraum Darstellungsraum
RohdatenAnalytische
Abstraktion
Visuelle
AbstraktionBild
Voxelmengen
Metadaten
Internes
Speicherformat
Dreiecksgitter
3D-Textur
Gerendertes
Bild
Operationen Operationen Operationen
se den Datenfluss wie man ihn in allgemeiner Form in Visualisie-rungsanwendungen vorfindet. Ausgangspunkt sind die Rohdaten, inwelchen der Anwender visuell Hypothesen überprüfen und neue Zu-sammenhänge aufdecken soll. Dazu werden auf den Rohdaten eineReihe von Transformationsschritten angewendet, an deren Ende ei-ne graphische Repräsentation der Daten in Form eines gerenderten

166 implementation
Bildes steht. Zunächst werden die Rohdaten im ersten Transformati-onsschritt in die sogenannte analytische Abstraktion überführt. Dabeihandelt es sich um das interne Datenformat der Anwendung. ÜblicheTransformationsschritte sind das Laden und Entpacken von kompri-mierten Datensätzen. Im nächsten Transformationsschritt werden dieDaten von der analytischen Abstraktion in ein speziell für den ver-wendeten Renderalgorithmus optimiertes Format gebracht. Im Mo-dell wird dieses als die visuelle Abstraktion der Daten bezeichnet. Imletzten Schritt wird schließlich aus der visuellen Abstraktion mittelsdes Renderalgorithmus die eigentliche graphische Repräsentation derDaten erzeugt. Das Verhalten der einzelnen Transformationsschritteund damit die resultierende graphische Repräsentation kann der Nut-zer durch Anwendung verschiedener Operationen beeinflussen. DasZiel dabei ist, die Daten in eine Repräsentation zu überführen, wel-che die Bestätigung oder das Verwerfen der Arbeitshypothese erlaubt.Man unterscheidet grob zwischen den Operationen im Datenraum,die vor allem auf der analystischen Abstraktion angewendet werdenund den Operationen im Darstellungsraum, die auf der visuellen Ab-straktion und dem gerenderten Bild arbeiten. Typische Operationenim Datenraum sind Such- und Filteranfragen, um die Datenmenge ge-zielt zu verkleinern beziehungsweise auf Daten mit bestimmten Cha-rakteristiken einzuschränken. Der Darstellungsraum beinhaltet bei-spielsweise Operationen zur Anpassung von Farbtransferfunktionenoder geometrische Transformationen, wie Rotation, Translation undSkalierung.
Auf das PAS übertragen sieht das Modell wie folgt aus. Ausgangs-punkt sind hier die erzeugten HDF5-Dateien mit den Partikeln alsVoxeldaten und den Gestaltdeskriptoren sowie das Klassifizierungs-ergebnis als Metadaten. Diese werden von der Anwendung geladen,entpackt und in ein für die Anwendung optimales internes Formatkonvertiert. Das interne Datenformat ist sehr einfach aufgebaut. DieInternes
Datenformat desPAS
Voxelmengen der einzelnen Partikel werden jeweils als Listen gespei-chert, wobei sukzessiv die x, y, z-Koordinaten und die Grauwerte imSpeicher hintereinander liegen. Diese Speicherweise ist bei linearemZugriff auf die Liste äußert effizient, da der L2-Cache der CPU opti-mal genutzt wird. Die Metadaten werden hingegen in einer N × MMetadatenformat
des PAS Matrix gespeichert, wobei N der Anzahl der Partikel und M der An-zahl der Deskriptoren zuzüglich der Klassifizierungsergebnisse undeiner eindeutigen Identifikationsnummer entspricht. Über die eindeu-tige Identifikationsnummer werden Metadaten und Voxeldaten derPartikel miteinander verknüpft. Dazu werden in einer zweiten ListeZeiger auf die Voxellisten gespeichert, wobei die Indexposition derIdentifikationsnummer aus den Metadaten entspricht. Dieser Schrittentspricht im Modell in Abbildung 38 der Transformation in die ana-lytische Abstraktion. Auf den Metadaten lassen sich mit einer speziellAnfragesprache
entwickelten Anfragesprache Such- und Filteroperationen ausführen.

7.2 particle analysis system 167
Die Syntax dieser Anfragesprache ist in der nachfolgenden Box mit-tels der Extended Backus-Naur Form (EBNF) [64] definiert.
Anfrage = ["!"], Ausdruck BoolscherOperator Ausdruck ;
Ausdruck = Test | Anfrage | "("Anfrage")";
Test = Platzhalter, VergleichsOperator, Konstanten;
Platzhalter = "%v"| "%cx"| "%cy"| "%cz"| . . . ;
BoolscherOperator = "&"| "|";
VergleichsOperator = ">"| "<"| "=="| "!="| ">="| "<=";
Das Hauptelement der Sprache ist ein Test. Ein Test evaluiert immerzu einem Wahrheitswert und wird zeilenweise auf die Metadaten-Matrix angewendet. Für jede Zeile, bei welcher der Test wahr ist, wirddie Identifikationsnummer zur Ergebnismenge hinzugefügt. Sind al-le Zeilen der Matrix durchlaufen, enthält die Ergebnismenge diejeni-gen Partikel, welche die durch den Test beschriebene Charakteristikerfüllen. Ein Test besteht dabei immer aus einem Platzhalter, einemVergleichsoperator und einer Konstanten. Der Platzhalter ist ein Syn-onym für eine bestimmte Spalte in der Matrix, in welcher die Wer-te eines bestimmten Formdeskriptors der Partikel gespeichert sind.Für jede Zeile wird der Platzhalter durch den konkreten Wert er-setzt und mit dem Vergleichsoperator durch die vom Nutzer defi-nierte Konstante verglichen. Das Verhalten der Vergleichsoperatorenentspricht dabei dem Verhalten der entsprechenden Operatoren inder Programmiersprache C++. Ein möglicher Test sieht zum Beispielso aus: %v >= 2000. Der Platzhalter %v bezieht sich auf die Spaltemit dem Volumen der Partikel. Der Test wird also wahr, wenn das Vo-lumen größer gleich 2000 µm3 ist. Mehrere Tests lassen sich nun lautder oben definierten Syntax durch die boolschen Operatoren Und(&),Oder(|) und Nicht(!) zu komplexeren Anfragen kombinieren. Eine typi-sche Anfrage sieht zum Beispiel so aus: (%cy >= 44)&(%cy <= 84).Der Platzhalter %cy entspricht dabei der y-Koordinate des Schwer-punktes. Die Anfrage liefert also alle Partikel zurück, die im vermeint-lichen Band zwischen 44 mm und 84 mm liegen. Man beachte, dassin der oben definierten Grammatik aus Platzgründen nur ein Auszugaus den möglichen Platzhaltern angegeben ist. Tatsächlich existiertfür jeden in Abschnitt 2 beschriebenen Deskriptor ein entsprechen-der Platzhalter. Außerdem fehlt eine formale Definition des Nicht-terminalsymbols Konstante. Die Anfragesprache entspricht im Refe-renzmodell den Operationen auf der analytischen Form der Daten.Im nächsten Transformationsschritt werden diese nun in die visuel-le Abstraktion überführt. Bei den Metadaten unterscheidet sich die

168 implementation
analytische Form kaum von der visuellen, da die Darstellung im Pro-gramm als Tabelle erfolgt. Lediglich in einigen Spalten findet eine Er-setzung der als Bitwerte kodierten Informationen in aussagekräftigeBezeichner statt. Bei den Voxeldaten hingegen werden je nach An-Rendering
wendungsfall unterschiedliche Transformationen durchgeführt. Stan-dardmäßig wird mittels des Marching Cubes Algorithmus ein Drei-ecksnetz aus den Voxelmengen der Partikel berechnet. Diese Drei-ecksnetze lassen sich sehr effizient auf modernen Graphikkarten ren-dern und erlauben es, mehrere hundert Partikel parallel darzustellenund deren Form zu analysieren. Für die Analyse der inneren Struk-tur einzelner Partikel ist diese Darstellungsweise aber ungeeignet, dadie Dreiecksnetze nur eine hohle Hülle der Partikel beschreiben. Al-ternativ bietet sich für ausgewählte Partikel das Rendern mittels desRaycasting-Algorithmus [80] an. Dafür werden die Voxeldaten in einedreidimensionale Textur umgewandelt und als Intensitätswerte inter-pretiert. Für jeden Punkt der Bildebene wird dann ein Strahl vom Au-ge des Betrachters durch diese Textur geschickt. In regelmäßigen Ab-ständen werden die Intensitätswerte der Textur entlang dieses Strahlsabgetastet und der Einfluss etwaiger Lichtquellen für jeden Wert be-rechnet. Anschließend werden mittels einer Transferfunktion die In-tensitätswerte auf Farb- und Transparentwerte abgebildet und unterBerücksichtigung der Lichtquelle der finale Farbwert des Punktes aufder Bildebene abgemischt. Durchgeführt für alle Punkte der Bildebe-ne ergibt sich so ein dreidimensionales Bild des Partikels. Dieses er-laubt aber, im Gegensatz zum Marching Cube Algorithmus, die Ana-lyse der inneren Struktur. Dazu kann entweder die Transferfunktionangepasst werden, um innere Strukturen freizulegen, oder eine belie-big parametrisierte Schnittebene durch die dreidimensionale Texturgelegt werden, mit welcher ein Querschnitt des Partikels untersuchtwerden kann. In beiden Fällen entspricht das Rendern dem letztenTransformationsschritt im Referenzmodell aus Abbildung 38. Das Ma-nipulieren der Transferfunktion und Parametrisieren des MarchingCube Algorithmus können hingegen als die Operationen auf der visu-ellen Abstraktion aufgefasst werden. Auf das gerenderte Bild könnenschließlich die oben bereits beschriebenen geometrischen Transforma-tionen angewendet werden.
7.2.2 Sichtprüfung der Partikel
In Abbildung 39 ist ein Screenshot des Hauptfensters vom PAS nachdem Laden einer HDF5-Datei abgebildet. Das Fenster ist grob in zweiTeile aufgeteilt. Auf der linken Seite befindet sich die Tabelle mit denHauptfenster des
PAS Metadaten, während auf der rechten Seite das als Partikelgalerie be-zeichnete Übersichtsfenster angesiedelt ist. In der Partikelgalerie wer-den die mittels Marching Cube Algorithmus generierten Vorschau-

7.2 particle analysis system 169
Abbildung 39.: Screenshot des Hauptfensters vom PAS.
bilder der in der Probe enthaltenen Partikel angezeigt. Die gewählteMonitorauflösung begrenzt dabei die Anzahl der gleichzeitig darge-stellten Partikel. Es ist aber möglich, nahezu in Echtzeit durch dieProbe zu blättern. Dazu werden die Vorschaubilder der an das Über-sichtsfenster angrenzenden Partikel bereits in eine Textur gerendertund müssen nur noch geladen werden, sobald die Position des Fens-ters weit genug verschoben wurde. Wie bereits erwähnt, sind Meta-daten und die gerenderten Partikel über eine Identifikationsnummermiteinander verknüpft. Wird ein Partikel in der Partikelgalerie selek-tiert, wird auch die korrespondierende Zeile in der Metadatentabelleselektiert. Gleiches gilt für den umgekehrten Fall. Die Interaktion zwi-schen der Tabelle und dem Übersichtsfenster ist aber nicht nur auf dieSelektion beschränkt, sondern umfasst sämtliche Sortier- und Filter-operationen. Die Sortierung der Tabelle kann spaltenweise für jedenDeskriptor sowohl aufsteigend als auch absteigend festgelegt werden.Filter hingegen lassen sich durch die Eingabe einer Filteranfrage inder im letzten Abschnitt definierten Sprache festlegen. Diese Opera-tionen wirken sich direkt auf das Übersichtsfenster aus. Partikel, dienicht die mittels der Filteranfrage beschriebenen Charakteristiken er-füllen, werden sowohl in der Tabelle als auch in der Partikelgalerieausgeblendet. Auch die Sortierung der Tabelle wirkt sich direkt aufdie Sortierung der Partikelgalerie aus. Im Bild 39 wurde beispielswei-se absteigend nach der Größe der Partikel sortiert. Damit stehen auchin der Partikelgalerie die größten Partikel vorne.
Mittels dieser drei einfachen Operationen, also Selektion, Sortierungund Filterung, sowie deren Verknüpfung lassen sich bereits die dreidefinierten Ziele in Abschnitt 7.2 bezogen auf die Partikelklassifika-tion umsetzen. In der Modellbildungsphase kann ein Experte das Modellbildungphase
Werkzeug zunächst dazu nutzen, die Annahmen über die morpho-

170 implementation
logischen Eigenschaften der Partikel im jeweiligen Anwendungsfallzu bestätigen. Im konkreten Anwendungsfall aus Abschnitt 4.2 wur-de zum Beispiel zunächst davon ausgegangen, dass alle detektierba-ren Defekte annähernd kugelförmig sind. Bei genauerer Inspektionder Formen in der Partikelgalerie hat man aber festgestellt, dass auchrissartige Strukturen sehr häufig vorkommen und deshalb als eige-ne Klasse berücksichtigt werden müssen. Haben sich die Annahmenüber die Partikeltypen bestätigt und ist man in der Lage, diese durchvisuelle Inspektion ihrer Morphologie zu unterscheiden, kann dasPAS im nächsten Schritt zur Bestimmung von Trainingsmengen fürden Klassifizierer verwendet werden. Dazu ist es hilfreich, wenn be-Kalibrierung
reits ein Deskriptor identifiziert wurde, mit dem dem eine distinktivemorphologische Eigenschaft einer Partikelklasse erfasst wird. Im An-wendungsfall eignet sich beispielsweise der Deskriptor F1 für einegrobe Unterteilung zwischen Rissen und globularen Defekten. Durchdas Setzen von Filtern und einer geeigneten Sortierung kann danndie Größe der möglichen Trainingsmenge stark reduziert werden. DerExperte entscheidet schließlich manuell von Fall zu Fall, um welchenPartikeltyp es sich konkret handelt. Dazu können im PAS alle Par-tikel einer Klasse selektiert und jeweils eine eindeutige Klassenbe-zeichnung zugewiesen werden. Im letzten Schritt wird die so erstellteTrainingsmenge als neue HDF5-Datei exportiert. Die Trainingsmengezur Klassifikation von globularen Defekten, Rissen und Artefaktenaus Abschnitt 5 wurde auf diese Weise bestimmt. Damit lässt sichauch das zweite große Ziel, nämlich die Kalibrierung der Verarbei-tungspipeline in Bezug auf die Partikelklassifikation mit dem PASumsetzen. Schließlich kann das PAS auch zur ErgebnisvalidierungErgebnisvalidierung
verwendet werden. Dazu werden die klassifizierten Ergebnisse derVerarbeitungspipeline mittels des PAS geladen und durch visuelleInspektion überprüft, ob die Zuordnung der Klassen plausibel ist.Eine mögliche Vorgehensweise sieht dabei wie folgt aus. Zunächstwerden die Partikel in der Partikelgalerie mittels einer geeigneten Fil-teranfrage auf eine Klasse beschränkt. Ein Experte überprüft dann fürjedes dargestellte Partikel, ob die Form in etwa der erwarteten Mor-phologie entspricht. Ist dies nicht der Fall, kann gegebenenfalls an-hand der zugehörigen Deskriptoren herausgefunden werden, warumdie Klassifikation fehlschlägt. Konkret auf den Anwendungsfall bezo-gen wurde so beispielsweise festgestellt, dass einige nichtmetallischeEinschlüsse als Risse klassifiziert werden. Beim Fräsen kann es näm-lich vorkommen, dass Material aus dem Einschluss herausgebrochenund entlang der Fräsrillen verschmiert wird. Die Einschlüsse prägeneinen sogenannten Schweif aus, der dafür sorgt, dass Deskriptoren,welche die Sphärizität von Partikeln bewerten, falsche Werte liefern.Begrenzt man die Partikelgalerie nur auf Risstypen, sind solche Aus-reißer schnell zu identifizieren. Da nur Einschlüsse einen Schweif aus-bilden, konnte dieser im konkreten Fall selbst als Deskriptor heran-

7.2 particle analysis system 171
gezogen werden, um die Unterscheidung zwischen Poren und nicht-metallischen Einschlüssen zu verbessern [20].
In Hinblick auf die Partikelklassifikation lassen sich also die drei defi-nierten Ziele in Abschnitt 7.2 mit dem PAS umsetzen. Darüber hinauskann das PAS dazu verwendet werden, individuelle Partikel näher zuanalysieren. Damit lässt sich einerseits die innere Struktur von Par-tikeln untersuchen, anderseits der Einfluss der Segmentierung aufdie Form des Partikels beurteilen. Durchgeführt werden diese Un- Strukturanalyse
tersuchungen mit dem in Abschnitt 7.2.1 beschriebenen Raycasting-Algorithmus. Dazu wird zunächst für ein ausgewähltes Partikel ei-ne dreidimensionale Textur mit den Koordinaten der Boundingboxaus den Rohbildern der Kamera erzeugt. Diese wird dann auf dieGraphikkarte übertragen und mittels des Raycasting-Algorithmus ge-rendert. Mit den bereits erwähnten Operationen, wie Querschnittsbil-dung und Anpassung der Transferfunktionen, kann dann der Auf-bau des Partikels näher untersucht werden. Abbildung 40 zeigt diesam Beispiel eines Querschnittes durch einen nichtmetallischen Ein-schluss. Die Intensitätswerte wurden dabei mittels einer Transferfunk-
Abbildung 40.: Mit Raycasting gerenderter Querschnitt durch einennichtmetallischen Einschluss. Die Intensitätswerte wur-den mittels einer Transferfunktion auf Farbwerte (hell= blau, dunkle = rot) abgebildet.
tion auf Farbwerte abgebildet, die üblicherweise zur Kodierung vonTemperaturen verwendet werden. Deutlich kann man das kreisrundeProfil des nichtmetallischen Einschlusses in der x, y-Ebene erkennen.Des Weiteren fällt auf, dass das Innere des Einschlusses keineswegshomogen ist, sondern die Intensitätswerte stark schwanken. Wahr-

172 implementation
scheinlich führt das Abfräsen des im Vergleich zur Stahloberflächesehr harten Einschlussmaterials zu einer zerklüfteten Schnittfläche, sodass Licht nur unregelmäßig ins Objektiv der Kamera reflektiert wird.Im Gegensatz dazu haben Poren eine homogene Intensitätswertvertei-lung in der Querschnittsoberfläche, da kaum Licht durch den von derPore gebildeten Hohlraum reflektiert wird. Neben der Form sind alsoauch auf der Textur basierende Deskriptoren hilfreich, um zwischenPoren und nichtmetallischen Einschlüssen zu unterscheiden. DiesesWissen wurde unter anderem in Bürger u. a. [20] dazu verwendet,die Korrektklassifikationsrate zwischen Poren und nichtmetallischenEinschlüssen weiter zu steigern.
Ein letzter Anwendungsfall des Raycasting-Algorithmus, der hier vor-gestellt wird, ist die Bewertung des Segmentierungsergebnisses. Da-Bewertung der
Segmentierung zu können die Voxel der Rohbilder mit denen der durch die Seg-mentierung eindeutig als zum Partikel zugehörig identifizierten Vo-xeln überlagert werden. Im Idealfall wird die Form des Partikels sehrgenau durch die Voxel der Segmentierung approximiert. In Abbil-dung 41 ist eine solche Untersuchung am Beispiel eines Querschnittesdurch einen Riss dargestellt. Dabei überlagern die durch die Segmen-
Abbildung 41.: Mit Raycasting gerenderter Querschnitt durch einenRiss. Die durch die Segmentierung identifizierten Vo-xel überlagern die Farbwerte der Rohbilder dunkel rot.
tierung identifizierten Voxel die Farbwerte der Rohbilder dunkel rot.Zwar wurde ein Teil des Risses identifiziert, der genaue Rissverlaufwurde aber nicht erfasst. Deutlich kann man erkennen, wie sich derRiss in ca. 45 senkrecht zu den Fräsrillen fortsetzt. Diese Unterseg-mentierung führt häufig dazu, dass Risse im Anwendungsfall zu Teil-

7.2 particle analysis system 173
rissen zerfallen. Zwar können mit dem PAS solche Teilrisse manuellwieder zusammengefügt werden, aber trotzdem findet ein Informati-onsverlust in Form von nicht detektierten Voxeln statt. Untersuchun-gen wie in Abbildung 41 können hilfreich sein, um den Grund fürdie Untersegmentierung zu erkennen und den Segmentierungsalgo-rithmus zu optimieren.
7.2.3 Statistische Analyse
Neben der Modellbildung, Kalibrierung und Ergebnisvalidierung fürdie Partikelklassifikation können mit dem PAS diese drei Aufgabenauch in Bezug auf die statistische Auswertung gelöst werden. Dazuwurde wie schon bei der Verarbeitungspipeline die offene Statistik-software R4 in das PAS eingebettet. Der Datenaustausch zwischen R und
Rcpp-Bibliothekdem R-Prozess und dem PAS wird dabei über die Rcpp-Bibliothek[37] realisiert. Es findet eine Zwei-Wege-Kommunikation zwischenbeiden Anwendungen statt, die vom Nutzer des PAS angestoßenwird. Zunächst wird, wie schon im vorherigen Abschnitt besprochen,mittels der Filter- und Sortieroperationen ein entsprechender Daten-satz im Hauptbildschirm des PAS (siehe Abbildung 39) selektiert. Die- Datenfluss
se Daten werden dann in Form der in Abschnitt 7.2.1 beschriebenenN × M Matrix an den R-Prozess übertragen. Zusätzlich werden dervollständige Pfad zur aktuell geöffneten HDF5-Datei und der voll-ständige Pfad zu einem R-Skript, welches auf die Daten angewendetwerden soll, übermittelt. Damit besitzt der R-Prozess eine vollständi-ge Kopie des selektierten Datensatzes und ist bei Bedarf dazu in derLage, mittels der eindeutigen Indentifikationsnummer die Voxelda-ten zu individuellen Partikeln aus der HDF5-Datei nachzuladen. Das R-Skript
R-Skript wird dann selbständig von dem R-Prozess aus dem Pfadgeladen und auf die übermittelten Daten angewendet. Das Ergebnisdieser Auswertung wird wiederum mittels der Rcpp-Bibliothek andas PAS zurückgeliefert. Zwei Formate werden dabei vom PAS un-terstützt. Abhängig von der Komplexität der Auswertung wird dasErgebnis entweder als Bild im PNG-Format oder als HTML-Dateientgegengenommen. In beiden Fällen wird aber nicht die Datei selbstübertragen, sondern wieder nur der Pfad zur Datei, in der das Ergeb-nis im jeweiligen Format gespeichert ist. Die typische Anatomie eines Anatomie des
R-SkirptsR-Skriptes, welches im PAS eingebunden werden soll, sieht also wiefolgt aus. Zunächst werden die Daten aus der übergebenen Matrixextrahiert und die jeweilige Auswertung durchgeführt. Kann das Er-gebnis durch einen einfachen Graphen dargestellt werden, wird derZeichenvorgang von R angestoßen und das resultierende Bild in ei-ne Datei gespeichert. Üblicherweise wird als Zielpfad das temporäre
4 http://www.r-project.org/

174 implementation
Verzeichnis des Betriebssystems gewählt. Bei komplexen Auswertun-gen mit mehreren Graphiken, viel Text und Tabellen wird stattdesseneine entsprechend formatierte HTML-Datei erzeugt und im temporä-ren Verzeichnis gespeichert. Das PAS lädt dann die Datei und rendertdas Ergebnis im sogenannten Report-Modul.
Um die Funtionsweise zu verdeutlichen wird im Folgenden ein mögli-ches Anwendungsszenario durchgespielt. Angenommen, man möch-te anhand einer durch das PDS verarbeiteten Probe aus dem Anwen-dungsfall aus Abschnitt 4.2 überprüfen, ob eine grobe Verletzungder Modellannahme bezüglich der Durchmesserverteilung der glo-bularen Defekte vorliegt. Wie in Abschnitt 6.1 ausgeführt geht mandavon aus, dass globulare Defekte der logarithmischen Normalver-teilung folgen. Zunächst wird also die entsprechende HDF5-DateiFilterung
der Proben in das PAS geladen. Da man nur an globularen Defek-ten interessiert ist, blendet man alle Defekte aus, die nicht dem TypPore oder Einschluss entsprechen. Zusätzlich macht es Sinn, die Aus-wahl der Defekte auf das schmale Band nahe der Stahloberfläche zubegrenzen (siehe dazu Abschnitt 6.2.1). Ein solcher Filter lässt sichmanuell mittels der in Abschnitt 7.2.1 definierten Anfragesprache er-stellen. Dieser Prozess ist aber sehr mühselig und fehleranfällig. Des-halb wurde im PAS ein passendes Werkzeug bereitgestellt, welchesden Nutzer bei der Erstellung des Filterausdruckes unterstützt. Ab-bildung 42 zeigt einen Screenshot dieses Werkzeugs. In jeweils dreiRäumliche Auswahl
Abbildung 42.: Auswahlwerkzeug zur Generierung von räumlichenFilteranfragen.
Teilfenstern ist die Projektion aller Voxel der in der Probe enthaltenenDefekte in der x, y-, x, z- und y, z-Ebene farblich codiert nach dem je-weiligen Typ dargestellt. Der Nutzer kann nun die Auswahl auf be-stimmte Regionen in der Probe beschränken. Dafür zeichnet er in dieentsprechenden Projektionsansichten ein Auswahlrechteck. Die Koor-dinaten dieses Rechtecks werden dann in einen Filterausdruck umge-

7.2 particle analysis system 175
wandelt, so dass nur Defekte berücksichtigt werden, deren Schwer-punkte in dem durch die Rechtecke definierten Quarder liegen. InAbbildung 42 kann man in der x, y-Ebene deutlich das schmale Bandmit der höchsten Defektkonzentration erkennen. Als visuelles Hilfs-mittel wurde anhand des Intensitätsabfalls in y-Richtung die Breitedes Bandes geschätzt und das Ergebnis als Hilfslinie eingezeichnet.An diesen Hilfslinien kann sich der Nutzer bei der Konstruktion desFilters orientieren. Die Auswahl in Abbildung 42, dargestellt durchdie blauen Rechtecke, erstreckt sich nur auf das Defektband. DerRest der Probe wird ignoriert. Auf diesen gefilterten Datensatz kön- Report-Modul
nen nun die verschiedenen statistischen Tests in Form von R-Skriptenangewendet werden. Dazu wird vom Nutzer das Report-Modul auf-gerufen, in dem die verschiedenen R-Skripte ausgewählt und ausge-führt werden können. Abbildung 43 zeigt ein Screenshot des Report-Moduls. Auf der linken Seite können in einer Liste die verschiedenen
Abbildung 43.: Report-Modul für statistische Auswertungen.
Skripte ausgewählt werden. Diese liegen in einem fest definierten Ver-zeichnis auf der Festplatte und werden zur Laufzeit eingelesen. Sollein neues Skript hinzugefügt werden, wird eine Datei mit dem ent-sprechenden Skript in dem Verzeichnis erstellt. Der Aufbau des R-Skriptes muss dabei natürlich der oben beschriebenen Anatomie ent-sprechen. In Abbildung 43 wurde das Skript fitlnorm.R vom Nutzerausgewählt. Dieses implementiert die in Abschnitt 3.2.3 beschriebe-nen Methoden zur explorativen Analyse der Modellannahmen, wiesie während des Modellbildungsprozesses häufig verwendet werden.Konkret wird der QQ-Plot und PP-Plot für die übergebenen Datenberechnet. Dafür werden mittels der Maximum-Likelihood Methodedie Verteilungsparameter über die log-transformierten Durchmesserder Defekte berechnet. Anschließend werden anhand dieser Parame-terschätzung die theoretischen Quantile ermittelt und gegen die em-

176 implementation
pirischen Quantile, erhoben aus den beobachteten Daten, aufgetragen(siehe auch Abschnitt 3.2.3). Das Ergebnis wird als Bild zurückgelie-fert und im rechten Teilfenster des Report-Moduls angezeigt. Für dieverwendete Probe aus Abbildung 43 ergibt sich das aus Abschnitt6.1.2 bekannte Verhalten. An den linken Ausläufern kommt es aufGrund der begrenzten Kameraauflösung zu Abweichungen, welchezu einer rechtsschiefen Verteilung führen.
Dieses Anwendungsbeispiel beschreibt nur eines von vielen ver-schiedenen Auswertungen, die mittels des PAS durchgeführt wer-den können. Faktisch lassen sich alle in Abschnitt 3 beschriebenenMethoden anwenden. Dies umfasst sowohl explorative Methodenzur Unterstützung des Modellbildungsprozesses, wie die schon er-wähnten QQ-Plots für die Durchmesserverteilung oder die Methodenzur Schätzung der Intensitätsfunktion (siehe Abschnitt 3.3.3) für dieräumliche Verteilung, als auch die Methoden zur Modellvalidierung(Abschnitt 3.2.3 und 3.3.4). Auch das Abbruchkriterium aus Abschnitt6.4.2 kann nachträglich für bereits verarbeitete Proben evaluiert unddie Ergebnisse zur Parametrisierung der Verarbeitungspipeline ver-wendet werden. Somit können die drei definierten Ziele, welche dieMotivation zur Entwicklung des PAS waren, auch in Bezug auf diestatistische Auswertung umgesetzt werden.
7.3 zusammenfassung
In diesem Kapitel wurden die beiden Systeme PDS und PAS vorge-stellt, in denen die einzelnen Methoden aus den Kapiteln 2 und 3
zu einem vollständigen Analysesystem für Partikelsysteme integriertwurden. Zunächst wurde der Aufbau des PDS beschrieben und dieFunktionsweise der einzelnen Pipelinestufen erläutert. Anhand vonsimulierten Daten, die mittels des Algorithmus 7 erzeugt wurden,konnte dann gezeigt werden, dass das PDS schnell genug ist, umdie Echtzeitanforderungen des Anwendungsfalls aus Abschnitt 4.2zu erfüllen. Anschließend wurden unter Verwendung des Referenz-modells der Informationsvisualisierung das PAS eingeführt und dieMotivation für die Entwicklung dargelegt. Am Beispiel zweier An-wendungsfälle wurde schließlich gezeigt, dass die drei definiertenZiele, die Unterstützung des Modellbildungsprozesses, die Kalibrie-rung des PDS und die Modellvalidierung, sowohl für die Partikel-klassifikation als auch für die statistische Auswertung der räumlichenVerteilung und der Durchmesserverteilung mittels dem System um-gesetzt werden können.

8Z U S A M M E N FA S S U N G
In dieser Arbeit wurde ein Rahmenwerk zur vollständigen statisti-schen Analyse von Partikelsystemen entwickelt. Die vollständige sta-tistische Analyse umfasst dabei die Analyse der Gestalt von indivi-duellen Partikeln, die Analyse der Größenverteilung des Partikelkol-lektivs und die Analyse der räumlichen Verteilung des Partikelkol-lektivs. Zu jedem dieser drei Aspekte sind in den letzten Jahren zahl-reiche Veröffentlichungen erschienen. Allerdings sind dem Autor dervorliegenden Arbeit keine Systeme oder Implementierungen bekannt,die diese drei Ansätze in einem einheitlichen Rahmenwerk für dendreidimensionalen Fall vereinen. Diese Lücke wurde mit der vorlie-genden Arbeit geschlossen. Dabei war die Entwicklung des Rahmen- Anforderungen
werks stark an die Anforderungen des Silenos-Projektes gekoppelt,welches die Zielsetzung hat, ein optisches Online-Auswertesystemzur Detektion von Defekten, wie nichtmetallischen Einschlüssen, Ris-sen und Poren, in Stahlproben zu entwickeln. Die Defekte sollen inBildern schichtweise abgefräster Werkstoffproben mittels Verfahrender Bildverarbeitung identifiziert, segmentiert und unter der Annah-me einer dreidimensionalen räumlichen Ausdehnung rekonstruiertwerden. Anhand der rekonstruierten dreidimensionalen Morpholo-gie soll schließlich eine automatische Klassifizierung in die jewei-ligen Defekttypen und die statistische Auswertung vorgenommenwerden. Dreidimensionale Rekonstruktion, Klassifikation und statis-tische Auswertungen wurden mittels der Methoden des in der vorlie-genden Arbeit entwickelten Rahmenwerks umgesetzt. Folgende An-forderungen ergaben sich dabei für das Rahmenwerk. Hauptvorgabewar, dass alle Auswertungen parallel zum Fräsprozess inkrementellfür jede Schicht mit einer maximalen Laufzeit von 30 s durchgeführtwerden können. Des Weiteren verlangte die große Menge der zu er-warteten Rohdaten die Entwicklung effizienter Algorithmen in Bezugauf den Speicherverbrauch. Da das Fräsen von Stahl mit sehr hohenKosten verbunden ist, sollte schließlich ein Abbruchkritierum festge-legt werden, welches nach Erreichen einer vorgegebenen statistischenSicherheit den Prozess unterbricht.
Um diesen Anforderungen gerecht zu werden, wurde bei der De-finition und Implementierung des Rahmenwerks wie folgt vorgegan-gen. Zunächst wurde der Begriff Partikel formal nach der Einführungvon Nachbarschaftskriterien auf Basis von zusammenhängenden Vo-xelmengen definiert. Dabei wurden unterschiedliche Nachbarschafts- Umsetzung
177

178 zusammenfassung
kritierien zugelassen, um möglichst flexibel auf Segmentierungsfeh-ler reagieren zu können. Anhand dieser Definition erfolgte dann dieImplementierung eines Algorithmus zur dreidimensionalen Rekon-struktion. Dazu wurde der von Wu, Otoo und Suzuki [149] propa-gierte Labeling-Algorithmus schrittweise erweitert, bis ein inkremen-teller Betrieb möglich war. Anschließend erfolgte ebenfalls auf Basisdes eingeführten Partikelbegriffs die Definition distinktiver Gestalts-deskriptoren, welche die Quantifizierung unterschiedlicher Charakte-ristiken der individuellen Partikel erlauben soll. Deskriptoren für dieGröße und die Position der Partikel im Raum bildeten wiederum dieGrundlage für die statistische Analyse der Größenverteilung und derräumlichen Verteilung. Für beide Verteilungstypen wurden explora-tive Datenanalysewerkzeuge zur Plausibiliätsprüfung einer Modell-annahme, Parameterschätzer und Modellvalidierungsverfahren ein-geführt. Dabei wurde rigoros auf die Methoden der bayesschen Sta-tistik gesetzt, da sie zum einen den intuitiven Umgang mit inkremen-tell erhobenen Daten erlauben und zum anderen einfach auswertbareMaße zum Bestimmen der statistischen Unsicherheit bei der Parame-terschätzung anbieten. Außerdem kann Vorwissen über die Modell-parameter adäquat in Form einer A-priori Verteilung modelliert wer-den.
Zusammengefasst bilden diese Methoden das Rahmenwerk, welchesdie vollständige Analyse von Partikelsystemen erlaubt. Dieses Rah-menwerk wurde zunächst dazu verwendet, jeweils ein Modell fürdie Größenverteilung und die räumliche Verteilung von nichtmetalli-schen Einschlüssen festzulegen. So hat sich gezeigt, dass die Größen-Rahmenwerk
verteilung von nichtmetallischen Einschlüssen der logarithmischenNormalverteilung folgt, während sich die räumliche Verteilung nachHomogenisierung mit der Exponentialfunktion senkrecht zur Ober-fläche mittels eines homogenen Poisson-Punktprozesses beschreibenlässt. Auf Basis dieser Erkenntnis wurde dann eine Software entwi-ckelt, welche die Simulation von synthetischen Stahlproben erlaubt.Anschließend wurden die Methoden des Rahmenwerks dazu verwen-det, ein Online-Auswertesystem Namens PDS zu entwickeln, welchesdie Anforderungen des Silenos-Projekts erfüllt. Ausgehend von seg-mentierten Schichtbildern führt dieses System die dreidimensiona-le Rekonstruktion, Klassifikation und statistische Auswertung inkre-mentell, also Schicht für Schicht, durch. Mittels der implementiertenErgebnisse
Deskriptoren konnte für den konkreten Anwendungsfall gezeigt wer-den, dass eine Klassifikation von Rissen, globularen Defekten und Ar-tefakten mit ca. 92 % und die Klassifikation von Poren und nichtme-tallischen Einschlüssen mit ca. 70 % Korrektklassifikationsrate gelingt.Auf Basis der getroffenen Modellannahmen und des HDIs konntedes Weiteren ein Abbruchkriterium implementiert und erfolgreichanhand real gemessener und simulierter Proben evaluiert werden. Sowar es im konkreten Testfall möglich, die Anzahl der zu fräsenden

zusammenfassung 179
Schichten um ca. 80 % zu reduzieren. Auch für das Laufzeitverhaltendes gesamten Prozesses konnten unter Verwendung simulierter Stahl-proben mit extremem Verunreinigungsgrad gezeigt werden, dass dieVorgaben des Projektes eingehalten werden können. Rekonstrukti-on, Klassifikation und statistische Auswertung benötigen für extremeProben ca. 20 s. Als letzter Schritt wurden alle Methoden des Rah-menwerks in einer einheitlichen Software bereitgestellt, die es auchdem unerfahrenen Nutzer möglich macht, testweise Auswertungenauf bereits gefrästen Proben durchzuführen. Diese als PAS bezeich-nete Software implementiert alle explorativen Datenanalysewerkzeu-ge und statistischen Auswertungen und stellt komplexe Such- undFiltermechanismen in Form einer eigenen Anfragesprache zur Verfü-gung. Gepaart mit der Möglichkeit der Visualisierung rekonstruierterDefekte, kann das PAS unter anderem zur Erstellung von Trainings-mengen für die automatische Klassifikation verwendet werden.
Trotz der bereits vielverspechenden Ergebnisse lassen sich noch eini-ge Optimierungen und Verbesserungen an den vorgestellten Metho-den vornehmen. Dies betrifft insbesondere Kapitel 6, in dem anhandreal gemessener Daten Modelle für die Größenverteilung und dieräumlichen Verteilung parametrisiert wurden. Zunächst einmal stellt Ausblick
sich die Frage, ob die verwendeten Modelle adäquat gewählt wurden.Während in der Fachliteratur allgemeiner Konsens darüber herrscht,dass die logarithmische Normalverteilung ein geeignetes Modell zurBeschreibung der Größenverteilung von nichtmetallischen Einschlüs-sen ist [118, S. 314 ff.][9, 41], lassen sich Angaben über Modelle für dieräumliche Verteilung kaum finden. Dies liegt vor allem daran, dassdie meisten Detektionsverfahren nicht in der Lage sind die räumli-che Position von Defekten in Stahlbrammen zu detektieren. Ledig-lich einige Untersuchungen der räumlichen Verteilung anhand zwei-dimensionaler Schnitte wurden durchgeführt [122]. Deshalb wurdein der vorliegenden Arbeit zunächst das einfachste Modell ausge-wählt, nämlich der homogene PPP. Dieser wurde dann im weiterenVerlauf verwendet, um die CSR-Eigenschaft zu überprüfen. Schnellhat sich aber herausgestellt, dass die Verteilung der nichtmetallischenEinschlüsse im Einschlussband nicht homogen ist, sondern in Rich-tung der Oberfläche exponentiell zunimmt. Da die Inhomogenitätnur in einer Raumrichtung auftritt, war es möglich, die Punktmus-ter zu homogenisieren und zu überprüfen, ob die Positionen der De-fekte unabhängig voneinander sind. Diese Annahme konnte exem-plarisch, abgesehen vom Nahbereich, bestätigt werden. In Zukunftmacht es also Sinn, die räumliche Verteilung von nichtmetallischenEinschlüssen mit einem inhomogenen PPP mit geeigneter Intensi-tätsfunktion zu modellieren. Um die in Abschnitt 3.3.4 eingeführtenTeststatistiken verwenden zu können, müssen diese aber auf eineninhomogenen PPP generalisiert werden. Baddeley und Møller [11]haben eine solche Generalisierung am Beispiel der K(r) Funktion

180 zusammenfassung
für den zweidimensionalen Fall durchgeführt. Die Erweiterung aufden dreidimensionalen Fall ist aber Gegenstand der aktuellen For-schung. Des Weiteren wurde die Parameterschätzung bisher nur ex-emplarisch an einigen wenigen Proben durchgeführt. Um wirklichstatistisch verlässliche Aussagen über Parameterintervalle für beideVerteilungstypen treffen zu können, müssen diese Untersuchungenfür eine Vielzahl von Proben unterschiedlicher Stahlsorten wieder-holt werden. Erst dann kann auch das Abbruchkriterium adäquatkalibriert werden, da die Vermutung nahe liegt, dass unterschiedli-che Stahlsorten auch unterschiedliche Verteilungsparameter besitzen.Gegebenenfalls muss also eine Datenbank erstellt werden, in der fürjede vorkommende Stahlsorte eine eigene Zielbreite des HDIs hinter-legt ist. Dies war zum Zeitpunkt der Erstellung dieser Arbeit nichtmöglich, da zu wenig Proben vorlagen. Auch bei der Unterscheidungzwischen nichtmetallischen Einschlüssen und Poren besteht noch Op-timierungspotenzial. Im Rahmen des Projektes wurde bereits vonBürger u. a. [20] gezeigt, dass durch Hinzuziehen von texturbasier-ten Deskriptoren die Korrektklassifikationsrate stark verbessert wer-den kann. Aber auch bei der Verwendung von Morphologie-basiertenDeskriptoren sind noch Verbesserungen möglich. Insgesamt war dieverwendete Trainingsmenge auf 464 Defekte beschränkt. Dies ist demFakt geschuldet, dass die Auswahl der Daten in der Trainingsmengemanuell per Sichtprüfung unter Verwendung eines Mikroskops er-folgt ist. In Zukunft plant der Projektpartner aber automatisch spek-trale Aufnahmen angefräster Defekte zu erstellen. Damit ist es mög-lich, im großen Maßstab die Klasse einzelner Defekte zu bestimmenund somit große Trainingsmengen automatisiert zu erzeugen. UnterVerwendung dieser Trainingsmengen ist es sehr wahrscheinlich, dassauch die Ergebnisse der Klassifikation weiter verbessert werden kön-nen. Bei ausreichend hoher Korrektklassifikationsrate kann dann dasregelmäßige Erstellen von Spektralaufnahmen entfallen, da dieses imdirekten Vergleich zur automatischen Klassifikation mittels maschi-nellen Lernens sehr zeitaufwändig ist.

AA N H A N G
a.1 konfigurationstabellen
181

182 anhang
Ta
be
lle
13
.:D
ie2
2K
ongr
uen
zkla
ssen
mit
ihre
nE
lem
ente
n.
nj
beze
ich
net
das
rep
räse
nta
tive
Ele
men
td
erM
enge
Dj.
Dab
eiw
ird
nj
soge
wäh
lt,
das
ses
dem
klei
nst
enE
lem
ent
der
Men
geen
tsp
rich
t.#(
Dj)
ist
die
An
zah
ld
erE
lem
ente
ind
erK
lass
eD
j.
jn
j#(
Dj)
Dj
00
10
11
81
,2,4
,8,1
6,3
2,6
4,1
28
23
12
3,5
,10
,12,1
7,3
4,4
8,6
8,8
0,1
36
,16
0,1
92
36
12
6,9
,18
,20
,33
,40,6
5,7
2,9
6,1
30
,13
2,1
44
47
24
7,1
1,1
3,1
4,1
9,2
1,3
5,4
2,4
9,5
0,6
9,7
6,8
1,8
4,1
12
,13
8,1
40
,16
2,1
68
,17
6,1
96
,20
0,2
08
,22
4
51
56
15
,51,8
5,1
70
,20
4,2
40
62
28
22
,41,7
3,9
7,1
04
,13
4,1
46
,14
8
72
38
23
,43,7
7,1
13
,14
2,1
78
,21
2,2
32
82
44
24
,36,6
6,1
29
92
52
42
5,2
6,2
8,3
7,3
8,4
4,5
2,5
6,6
7,7
0,7
4,8
2,8
8,9
8,1
00
,13
1,1
33
,13
7,1
45
,15
2,1
61
,16
4,1
93
,19
4
10
27
24
27
,29,3
9,4
6,5
3,5
8,7
1,7
8,8
3,9
2,1
14
,11
6,1
39
,14
1,1
63
,17
2,1
77
,18
4,1
97
,20
2,2
09
,21
6,2
26
,22
8
11
30
24
30
,45
,54
,57,7
5,8
6,8
9,9
9,1
01
,10
6,1
08
,12
0,1
35
,14
7,1
49,1
54
,15
6,1
66
,16
9,1
80
,19
8,2
01
,21
0,2
25
12
31
24
31
,47
,55
,59,7
9,8
7,9
3,1
15
,11
7,1
43
,17
1,1
74
,17
9,1
86
,20
5,2
06
,21
3,2
20
,23
4,2
36
,24
1,2
42
,24
4,2
48
13
60
66
0,9
0,1
02
,15
3,1
65
,19
5
14
61
24
61,6
2,9
1,9
4,1
03
,11
0,1
18
,12
2,1
24
,15
5,1
57
,16
7,1
73
,18
1,1
85
,18
8,1
99
,20
3,2
11
,21
7,2
18
,22
7,2
29
,23
0
15
63
12
63,9
5,1
19
,17
5,1
87
,20
7,2
21
,23
8,2
43
,24
5,2
50
,25
2
16
10
52
10
5,1
50
17
10
78
10
7,1
09
,12
1,1
51
,15
8,1
82
,21
4,2
33
18
11
11
21
11
,12
3,1
25
,15
9,1
83
,19
0,2
15
,22
2,2
35
,23
7,2
46
,24
9
19
12
64
12
6,1
89
,21
9,2
31
20
12
78
12
7,1
91
,22
3,2
39
,24
7,2
51
,25
3,2
54
21
25
51
25
5

A.1 konfigurationstabellen 183
Ta
be
lle
14.:
Die
22
Kon
gru
enzk
lass
enm
itih
ren
Ele
men
ten
,d
arge
stel
ltal
sP
ikto
gram
mm
itd
eren
tsp
rech
end
enB
eleg
egu
ng.
nj
beze
ich
net
das
rep
räse
nta
tive
Ele
men
td
erM
enge
Dj.
Dab
eiw
ird
nj
soge
wäh
lt,d
ass
esd
emkl
ein
sten
Ele
men
td
erM
enge
ents
pri
cht.
#(D
j)is
td
ieA
nza
hl
der
Ele
men
tein
der
Kla
sse
Dj.
jn
j#(
Dj)
Dj
00
1
11
8
23
12
36
12
47
24
51
56
62
28
72
38
82
44
92
52
4
10
27
24
11
30
24
12
31
24
13
60
6
14
61
24
15
63
12
16
10
52
17
10
78
18
11
11
2
19
12
64
20
12
78
21
25
51

184 anhang
Tabelle 15.: Tabelle mit den Minkowskifunktionalen der 2× 2× 2 Vo-xelblöcke für die 6er-, 18er- und 26er-Nachbarschaft.
6er 18er 26er
nj 8V 8S 16B 8χ 8V 8S 16B 8χ 8V 8S 16B 8χ
0 0 0 0 0 0 0 0 0 0 0 0 0
1 1 6 3 1 1 6 3 1 1 6 3 1
3 2 8 2 0 2 8 2 0 2 8 2 0
6 2 12 6 2 2 12 2 -2 2 12 2 -2
7 3 10 1 -1 3 10 1 -1 3 10 1 -1
15 4 8 0 0 4 8 0 0 4 8 0 0
22 3 18 9 3 3 18 -3 -1 3 18 -3 -1
23 4 12 0 -2 4 12 0 -2 4 12 0 -2
24 2 12 6 2 2 12 6 2 2 12 6 -6
25 3 14 5 1 3 14 1 -3 3 14 1 -3
27 4 12 0 -2 4 12 0 -2 4 12 0 -2
30 4 16 4 0 4 16 -4 0 4 16 -4 0
31 5 10 -1 -1 5 10 -1 -1 5 10 -1 -1
60 4 16 4 0 4 16 -4 0 4 16 -4 0
61 5 14 -1 -3 5 14 -5 1 5 14 -5 1
63 6 8 -2 0 6 8 -2 0 6 8 -2 0
105 4 24 12 4 4 24 -12 4 4 24 -12 4
107 5 18 3 -1 5 18 -9 3 5 18 -9 3
111 6 12 -2 -2 6 12 -6 2 6 12 -6 2
126 6 12 -6 -6 6 12 -6 2 6 12 -6 2
127 7 6 -3 1 7 6 -3 1 7 6 -3 1
255 8 0 0 0 8 0 0 0 8 0 0 0

L I T E R AT U R
[1] Y. S. Abu-Mostafa, M. Magdon-Ismail und H.-T. Lin. LearningFrom Data. AMLBook, 2012.
[2] D. Aiger und H. Talbot. „The phase only transform for unsu-pervised surface defect detection“. In: 2010 IEEE Conference onComputer Vision and Pattern Recognition (CVPR). 2010, S. 295–302.
[3] G. M. Amdahl. „Validity of the Single Processor Approachto Achieving Large Scale Computing Capabilities“. In: Procee-dings of the Spring Joint Computer Conference. 1967, S. 483–485.
[4] Particle Analyser. Particle Analyser. 2015. url: http://bonej.org/particles (besucht am 28. 08. 2015).
[5] Robo-Met.3D Analytics. A Multipurpose Optical Image AnalysisSoftware. 2015. url: http://www.ues.com/content/robomet3d(besucht am 28. 08. 2015).
[6] C. W. Anderson und S. G. Coles. „The Largest Inclusions in aPiece of Steel“. In: Extremes 5.3 (2003), S. 237–252.
[7] T. Arens, F. Hettlich, C. Karpfinger, U. Kockelkorn, K. Lichte-negger und H. Stachel. Mathematik. Spektrum, 2010.
[8] Standard Test Methods for Determing the Inclusion Content of Steel.Norm. 1985.
[9] H. V. Atkinson und G. Shi. „Characterization of inclusionsin clean stells: a review including the statistics of extremesmethods“. In: Progress in Materials Science 48.5 (2002), S. 458–516.
[10] A. Baddeley. Stereology for Statisticians. CRC Press, 2005.
[11] A. Baddeley und J. Møller. „Non- and semi-parametric esti-mation of interaction in inhomogeneous point patterns“. In:Statistica Neerlandica 54.3 (2000), S. 329–350.
[12] A. Baddeley, R. A. Moyeed, C. V. Howard und A. Boyde. „Ana-lysis of a Three-Dimensional Point Pattern with Replication“.In: Journal of the Royal Statistical Society 42.4 (1993), S. 641–668.
[13] C. B. Barber, D. P. Dobkin und H. Huhdanpaa. „The Quick-hull Algorithm for Convex Hulls“. In: ACM Transactions onMathematical Software 22.4 (1996), S. 469–483.
[14] J. K. Beddow. Particle Characterization in Technology: Morpholo-gical Analysis. CRC Press, 1984.
185

186 Literatur
[15] H. Bieri und W. Nef. „Algorithms for the euler characteristicand related additive functionals of digital objects“. In: Com-puter Vision, Graphics, and Image Processing 28.2 (1984), S. 166–175.
[16] BoneJ. A plugin for bone image analysis in ImageJ. 2015. url:http://bonej.org (besucht am 28. 08. 2015).
[17] L. Breiman. „Random Forests“. In: Machine Learning 45.1(2001), S. 5–32.
[18] C. Buck, F. Bürger, J. Herwig und M. Thurau. „Rapid Inclusionand Defect Detection System for Large Steel Volumes“. In: ISIJInternational 53.11 (2013), S. 1927–1935.
[19] H. Büning und G. Trenkler. Nichtparametrische statistische Me-thoden. Walter de Gruyter, 1994.
[20] F. Bürger, C. Buck, J. Pauli und W. Luther. „Image-based Ob-ject Classification of Defects in Steel using Data-driven Machi-ne Learning Optimization“. In: Proceedings of VISAPP 2014 -International Conference on Computer Vision Theory and Applicati-ons. 2014.
[21] F. Bürger, J. Herwig, C. Buck, W. Luther und J. Pauli. „AnAuto-adaptive Measurement System for Statistical Modelingof Non-metallic Inclusions through Image-based Analysis ofMilled Steel Surfaces“. In: 11th International Symposium on Mea-surement Technology and Intelligent Instruments. 2013.
[22] C. J. Burges. „A Tutorial on Support Vector Machines for Pat-tern Recognition“. In: Data Mining and Knowledge Discovery 2.2(1998), S. 121–167.
[23] L. M. Cabalin, M. P. Mateo und J. J. Laserna. „Large areamapping of non-metallic inclusions in stainless steel by an au-tomated system based on laser ablation“. In: SpectrochimicaActa Part B 59 (2004), S. 567–575.
[24] C.-C. Chang und C.-J. Lin. „LIBSVM: A Library for SupportVector Machines“. In: ACM Transactions on Intelligent Systemsand Technology 2.3 (2011), S. 1–27.
[25] M.-H. Chen und Q.-M. Shao. „Monte Carlo Estimation of Baye-sian Credible and HPD Intervals“. In: Journal of Computationaland Graphical Statistics 8.1 (1999), S. 69–92.
[26] E. H. Chi. „A taxonomy of visualization techniques using thedata state reference model“. In: IEEE Symposium on InformationVisualization. 2000, S. 69–75.
[27] K. Cooray und M. A. Ananda. „Modeling actuarial data witha composite lognormal-Pareto model“. In: Scandinavian Actua-rial Journal 2005.5 (2005), S. 321–334.

Literatur 187
[28] T. H. Cormen, C. E. Leiserson, R. L. Rivest und C. Stein. Intro-duction to algorithms. MIT Press, 2009.
[29] N. Cressie. Statistics for Spatial Data. Wiley, 1993.
[30] E. Crow und K. Shimizu. Lognormal Distributions: Theory andApplications. CRC Press, 1987.
[31] R. Dekkers. „Non-Metallic Inclusions in Liquid Steel“. Diss.Katholieke Universiteit Leuven, 2002.
[32] R. Dekkers, B. Blanpain, F. Wollants, F. Haers, C. Vercruyssenund B. Gommers. „Non-metallic inclusions in aluminium kil-led steels“. In: Ironmaking and Steelmaking 29.6 (2002), S. 437–444.
[33] P. Diggle. „A Kernel Method for Smoothing Point Process Da-ta“. In: Journal of the Royal Statistical Society 34.2 (1985), S. 138–147.
[34] Mikroskopische Prüfung von Edelstählen auf nichtmetallische Ein-schlüsse mit Bildreihen. Norm. 1985.
[35] Begriffsbestimmung für die Einteilung der Stähle. Norm. DIN EN10020. 2000.
[36] W.-C. Doo, D.-Y. Kim, S.-C. Kang und K.-W. Yi. „Measurementof the 2-Dimensional Fractal Dimensions of Alumina ClustersFormed in an Ultra Low Carbon Steel Melt during RH Pro-cess“. In: ISIJ International 47.7 (2007), S. 1070–1072.
[37] D. Eddelbuettel und R. Francois. „Rcpp: Seamless R and C++Integration“. In: Journal of Statistical Software 40.8 (2011), S. 1–18.
[38] K. Falconer. Fractal Geometry: Mathematical Foundations and Ap-plications. Wiley, 1990.
[39] F. Fleischer, S. Eckel, I. Schmid, V. Schmidt und M. Kazda.„Point process modelling of root distribution in pure stands ofFagus sylvatica and Picea abies“. In: Canadian Journal of ForestResearch 36.1 (2006), S. 227–237.
[40] J. Flusser, B. Zitova und T. Suk. Moments and Moment Invariantsin Pattern Recognition. Wiley, 2009.
[41] A. Fuchs, H. Jacobi, K. Wagner und K. Wünnenberg. „Be-stimmung des makroskopischen Reinheitsgrades an Strang-gußbrammen durch eine Offline-Ultraschallprüfung“. In: Stahlund Eisen 113.11 (1993).
[42] E. Gamma, R. Helm, R. E. Johnson und J. Vlissides. DesignPatterns. Elements of Reusable Object-Oriented Software. PrenticeHall, 1994.
[43] A. Gelman, J. B. Carlin, H. S. Stern, D. B. Dunson, A. Vehtariund D. B. Rubin. Bayesian Data Analysis, Third Edition. CRCPress, 2003.

188 Literatur
[44] J. K. Ghosh, M. Delampady und T. Samanta. An Introductionto Bayesian Analysis: Theory and Methods. Springer, 2007.
[45] J. Gobrecht. Werkstofftechnik - Metalle. Oldenbourg, 2006.
[46] C. Granqvist und R. A. Buhrman. „Ultrafine metal particles“.In: Journal of Applied Physics 47 (1976), S. 2200–2219.
[47] H. Hadwiger. Vorlesungen über Inhalt, Oberfläche und Isoperime-trie. Springer, 1957.
[48] A. Handl und S. Niermann. Multivariate Analysemethoden.Springer, 2010.
[49] A. Hans, K. Krissian, J. Schoepf, R. Kikinis und C.-F. Westin.Using 3D Convex Hulls to Detect Coronary Artery Stenoses andAtherosclerotic Vessel Wall Lesions in Contrast Enhanced MDCTImages. Techn. Ber. Department of Radiology, Brigham undWomen’s Hospital, Harvard Medical School, 2004.
[50] R. M. Haralick. „Some Neighborhood Operators“. In: Real-Time Parallel Computing. Springer, 1981, S. 11–35.
[51] B. Harrer und J. Kastner. „Charakterisierung von Inhomoge-nitäten in metallischen Gusswerkstoffen mittels 3D-Röntgen-Computertomographie“. In: DGZfP Jahrestagung. 2007.
[52] L. He, Y. Chao und K. Suzuki. „Two Efficient Label-Equivalence-Based Connected-Component Labeling Algo-rithms for 3-D Binary Images“. In: IEEE Transition on ImageProcessing 20.8 (2011), S. 2122–2134.
[53] N. Henze. Stochastik für Einsteiger: Eine Einführung in die faszi-nierende Welt des Zufalls. Deutsch. Springer Spektrum, 2013.
[54] M. Herlihy. The art of multiprocessor programming. MorganKaufmann, 2008.
[55] J. Herwig, C. Buck, M. Thurau, J. Pauli und W. Luther. „Real-time characterization of non-metallic inclusions by opticalscanning and milling of steel samples“. In: Optical Micro- andNanometrology IV. 2012.
[56] J. Herwig, S. Lessmann, Bürger F. und J. Pauli. „Adaptiveanomaly detection within near-regular milling textures“. In:International Symposium on Image and Signal Processing and Ana-lysis. 2013, S. 113–118.
[57] T. K. Ho. „Random decision forests“. In: Proceedings of the ThirdInternational Conference on Document Analysis and Recognition.Bd. 1. 1995, S. 278–282.
[58] C.-W. Hsu, C.-C. Chang und C.-J. Lin. A practical guide to sup-port vector classification. 2010.
[59] M.-K. Hu. „Visual pattern recognition by moment invariants“.In: IRE Transactions on Information Theory 8.2 (1962), S. 179–187.

Literatur 189
[60] R. Hundt. „Loop Recognition in C++/Java/Go/Scala“. In:Proceedings of Scala Days 2011. 2011.
[61] J. Illian, A. Penttinen, H. Stoyan und D. Stoyan. Statistical ana-lysis and modelling of spatial point patterns. Wiley, 2008.
[62] ImageJ. Image Processing and Analysis in Java. 2015. url: http://rsbweb.nih.gov/ij/ (besucht am 28. 08. 2015).
[63] ImageMetrology. Particle and Pore Analysis. 2015. url: http://www.imagemet.com/index.php?main=products&sub=modules&
id=10 (besucht am 28. 08. 2015).
[64] ISO/IEC 14977 Information technology – Syntactic metalanguage –Extended BNF. Norm. ISO/IEC 14977. 1996.
[65] E. Ivanko und D. Perevalov. „Q-Gram Statistics Descriptorin 3D Shape Classification“. In: Pattern Recognition and ImageAnalysis. Bd. 3687. Springer, 2005, S. 360–367.
[66] H. Jacobi, H.-J. Bäthmann und J. Gronsfeld. „Neuartige Be-stimmung des Makro-Reinheitsgrades am unkonventionell ge-waltzten Strangguß“. In: Stahl und Eisen 108 (1988), S. 946–958.
[67] H. Jacobi und K. Wünnenberg. „Reinheitsgrad tiefentschwefel-ter calciumbehandelter Stähle“. In: Stahl und Eisen 107 (1987),S. 773–779.
[68] R. A. Jarvis. „On the identification of the convex hull of a finiteset of points in the plane“. In: Information Processing Letters 2.1(1973), S. 18–21.
[69] I. K. Kazmi, L. You und J. Zhang. „A Survey of 2D and 3DShape Descriptors“. In: Computer Graphics, Imaging and Visuali-zation(CGIV). 2013, S. 1–10.
[70] R. Klette und A. Rosenfeld. Digital Geometry: Geometric Me-thods for Digital Picture Analysis. Morgan Kaufmann, 2004.
[71] C. Klinger, D. Bettge, R. Häcker, T. Heckel, D. Gohlke und D.Klingbeil. „Failure analysis on a broken ICE3 railway axle“.In: Proceedings ESIS TC 24. 2010.
[72] E. Kreyszig. Statistische Methoden und ihre Anwendungen. Van-denhoeck & Ruprecht, 1979.
[73] J. K. Kruschke. „Bayesian estimation supersedes the t test.“ In:Journal of Experimental Psychology: General 142.2 (2013), S. 573–603.
[74] A. L. Kundu, K. M. Gupt und P. K. Rao. „Morphology ofnonmetallic inclusions using silicon, aluminum, and calcium-silicon alloy in steel melt“. In: Metallurgical Transactions B 20.5(1989).

190 Literatur
[75] H.-M. Kuss, H. Mittelstaedt und G. Mueller. „Inclusion map-ping and estimation on inclusion contents in ferrous materi-als by fast scannning laser-induced optical emission spectro-metry“. In: Journal of Analytical Atomic Spectrometry 20 (2005),S. 730–735.
[76] C. Lang, J. Ohser und R. Hilfer. „On the analysis of spatialbinary images“. In: Journal of Microscopy 203.3 (2001), S. 303–313.
[77] Oxford Lasers. Visisize Particle Sizing Software. 2015. url: http://www.oxfordlasers.com/imaging/particle-size-measur
ement/visisize- particle- sizing- software/ (besucht am28. 08. 2015).
[78] Leica. Leica Steel Expert 2.0. 2015. url: http://www.leica-microsystems.com/de/produkte/mikroskop-software/mikro
skopsoftware-fuer-industrie-und-materialanalyse/detai
ls/product/leica-steel-expert-20/downloads (besucht am28. 08. 2015).
[79] T. Leininger. „Bayesian Analysis of Spatial Point Pattern“.Diss. Duke University, 2014.
[80] M. Levoy. „Display of Surfaces from Volume Data“. In: IEEEComput. Graph. Appl. 8.3 (1988), S. 29–37.
[81] P. Lewis und G. S. Shedler. „Simulation of nonhomogeneouspoisson processes by thinning“. In: Naval Research LogisticsQuarterly 26.3 (1979), S. 403–413.
[82] H. Li, L. Ning, J. Zhang und Y. Sasaki. „Simulation researchon monomer agglomeration of nonmetallic inclusions in steelwith a diffusion limited aggregation model“. In: Journal ofUniversity of Science and Technology Beijing, Mineral, Metallurgy,Material 13.2 (2006), S. 117.
[83] T. Li, S.-I. Shimasaki, S. Taniguchi, K. Uesugi und S. Narita.„Morphology of Nonmetallic-inclusion Clusters Observed inMolten Metal by X-ray Micro-Computed Tomography (CT)“.In: ISIJ International 53.11 (2013), S. 1943–1952.
[84] C. N. Likos und K. R. Mecke. „Statistical morphology of ran-dom interfaces in microemulsions“. In: Chemical Physics 102.23
(1995), S. 9350–9361.
[85] J. Lindblad und I. Nyström. „Surface Area Estimation of Di-gitized 3D Objects Using Weighted Local Configurations“. In:Image and Vision Computing 23.2 (2005), S. 111–122.
[86] C. H. Lo und H. S. Don. „3-D Moment Forms: Their Construc-tion and Application to Object Identification and Positioning“.In: IEEE Transactions on Pattern Analysis and Machine Intelligence11.10 (1989), S. 1053–1064.

Literatur 191
[87] S. Lobregt, P. W. Verbeek und Frans C. A. Groen. „Three-Dimensional Skeletonization: Principle and Algorithm“. In:IEEE Transactions on Pattern Analysis and Machine Intelligence2.1 (1980), S. 75–77.
[88] B. B. Mandelbrot. The Fractal Geometry of Nature. Spektrum,1977.
[89] C. Martinues-Ortiz. „2D and 3D Shape Descriptors“. Diss.University of Exeter, 2010.
[90] M. P. Mateo, L. M. Cabalin und J. J. Laserna. „Automated Line-Focused Laser Ablation for Mapping of Inclusions in StainlessSteel“. In: Applied Spectroscopy (2006), S. 1461–1467.
[91] MediaCybernetics. Particle Detection and Analysis. 2015. url:http://www.mediacy.com/index.aspx?page=ParticleAnalys
is (besucht am 28. 08. 2015).
[92] Metallographische Prüfung des Gehaltes nichtmetallischer Ein-schlüsse in Stählen mit Bildreichen. Norm. DIN EN 10247. 2007.
[93] N. Metropolis, A. W. Rosenbluth, M. N. Rosenbluth, A. H. Tel-ler und E. Teller. „Equation of State Calculations by Fast Com-puting Machines“. In: The Journal of Chemical Physics 21 (1953),S. 1087–1092.
[94] K. Michielsen und H. De Raedt. „Integral-geometry morpho-logical image analysis“. In: Physics Reports 347.6 (2001), S. 461–538.
[95] T. M. Mitchell. Machine Learning. McGraw-Hill, 1997.
[96] M. Mitzenmacher. „A Brief History of Generative Models forPower Law and Lognormal Distributions“. In: Internet Mathe-matics 1.2 (2004), S. 226–251.
[97] Y. Murakami. Metal fatigue. Elsevier, 2002.
[98] J. Ohser und F. Mücklich. Statistical Analysis of Microstructuresin Materials Science. Wiley, 2000.
[99] J. Ohser und K. Schladitz. 3D Images of Materials Structures.Wiley, 2006.
[100] Olympus. Non-Metallic Inclusion Analysis in Steel. 2015. url:http://www.olympus-ims.com/de/applications/nmi-analys
is/ (besucht am 28. 08. 2015).
[101] S. Ovtchinnikov. „Kontrollierte Erstarrung und Einschlußbil-dung bei der Desoxidation von hochreinen Stahlschmelzen“.Diss. University of Freiberg, 2002.
[102] L. Papula. Mathematik für Ingenieure und NaturwissenschaftlerBand 3. German. Vieweg + Teubner, 2011.

192 Literatur
[103] E. Parra-Denis, C. Barat, D. Jeulin und C. Ducottet. „3D com-plex shape characterization by statistical analysis: Applicationto aluminium alloys“. In: Materials Characterization 59.3 (2008),S. 338–343.
[104] E. Parra-Denis, C. Ducottet und D. Jeulin. „3D morphologicalanalysis of non metallic inclusions“. In: 9th European congresson stereology and image analysis. 2005, S. 111–122.
[105] Paxit. Particle Size Analysis. 2015. url: http://www.paxit.com/particle-size-analysis/ (besucht am 28. 08. 2015).
[106] E. Pirard. „3D IMAGING OF INDIVIDUAL PARTICLES: AREVIEW“. In: Image Analysis & Stereology 31.2 (2012), S. 65–77.
[107] E. Plöckinger und H. Straube. „Die Desoxydation“. In: Diephysikalische Chemie der Eisen- und Stahlerzeugung. Verein Deut-scher Eisenhüttenleute, 1964.
[108] The R Project. The R Project for Statistical Computing. 2015. url:https://www.r-project.org/ (besucht am 28. 08. 2015).
[109] F. Rakoski. „Nichtmetallische Einschlüsse in Stählen“. In: Stahlund Eisen 114.7 (1994), S. 71–77.
[110] F. Rakoski und H. Jacobi. „Hohe Reinheit der Stähle als Krite-rium der Werkstoffentwicklung“. In: Stahl und Eisen 116 (1996),S. 59–68.
[111] B. D. Ripley. „The Second-Order Analysis of Stationary PointProcesses“. In: Journal of Applied Probability 13.2 (1976).
[112] C. Robert und G. Casella. Monte Carlo Statistical Methods. Sprin-ger, 2005.
[113] Robo-Met.3D. A Fully Automated, Serial Sectioning System ForThree-Dimensional Microstructural Investigations. 2015. url:http : / / www . ues . com / content / robomet3d (besucht am28. 08. 2015).
[114] L. Rokach und O. Maimon. Data Mining with Decision Trees:Theory and Applications. World Scientific Pub Co, 2007.
[115] A. Rosenfeld und J. L. Pfaltz. „Sequential Operations in DigitalPicture Processing“. In: Journal of the ACM 13.4 (1966), S. 471–494.
[116] D. E. Rumelhart, G. E. Hinton und R. J. Williams. „Learningrepresentations by back-propagating errors“. In: Nature 323.9(1986), S. 533–536.
[117] F. A. Sadjadi und E. L. Hall. „Three-Dimensional Moment In-variants“. In: IEEE Transactions on Pattern Analysis and MachineIntelligence 2.2 (1980), S. 127–136.
[118] S. A. Saltykov. Stereometrische Metallographie. VEB DeutscherVerlag für Grundstoffindustrie, 1974.

Literatur 193
[119] L. A. Santaló. Integral Geometry and Geometric Probability. Cam-bridge University Press, 2004.
[120] K. Schladitz, J. Ohser und W. Nagel. „Measuring Intrinsic Vo-lumes in Digital 3d Images“. In: Discrete Geometry for ComputerImagery. Bd. 4245. Springer, 2006, S. 247–258.
[121] J. Serra. Image Analysis and Mathematical Morphology. AcademicPress, 1982.
[122] U. Siegel, J. Lambrecht und D. Stoyan. „Die Titaninhomoge-nität in Gußblöcken titanstabilisierter korrosionsbeständigerStähle“. In: Neue Huette 35.1 (1990), S. 81–89.
[123] P. Soille. Morphological Image Analysis - Principles and Applicati-ons. Springer, 2003.
[124] M. Sokolova und G. Lapalme. „A systematic analysis of per-formance measures for classification tasks“. In: InformationProcessing and Management 45.4 (2009), S. 427–437.
[125] SpatStat. Analysing Spatial Point Patterns. 2015. url: https://spatstat.github.io/ (besucht am 28. 08. 2015).
[126] J. E. Spowart, H. Mullens und B. T. Puchala. „Collecting andanalyzing microstructures in three dimensions: A fully auto-mated approach“. English. In: JOM 55.10 (2003), S. 35–37. issn:1047-4838.
[127] D. I. Stefano und A. Bulgarelli. „A simple and efficient connec-ted components labeling algorithm“. In: International Confe-rence on Image Analysis and Processing. 1999, S. 322–327.
[128] E. Steinmetz und H.-U. Lindberg. „Ausbildungsformen undEntstehung von Aluminiumoxiden in Rohblöcken und Strang-gußbrammen“. In: Stahl und Eisen 97 (1977), S. 1154–1159.
[129] E. Steinmetz und H.-U. Lindberg. „Oxidmorphologie beiMangan- und Mangan-Silicium-Desoxidation“. In: Archiv fu-er deutsches Eisenhuettenwesen 47 (1976), S. 71–76.
[130] E. Steinmetz und H.-U. Lindberg. „Wachstumsformen vonAluminiumoxiden in Stählen“. In: Archiv fuer deutsches Eisen-huettenwesen 48 (1977), S. 569–574.
[131] E. Steinmetz, H.-U. Lindenberg und F.-J. Wahlers. „Morpho-logie der Oxide und Sulfide bei der Desoxidation von Eisen-schmelzen mit Mangan und Silicium“. In: Stahl und Eisen 106
(1986), S. 611–618.
[132] M. Stieb. Mechanische Verfahrenstechnik - Partikeltechnologie 1.Springer, 2007.
[133] D. Stoyan, W. S. Kendall und J. Mecke. Stochastic Geometry andIts Applications. Wiley, 2013.

194 Literatur
[134] D. Stoyan und H. Stoyan. Frakale Formen Punktfelder: Methodender Geometrie - Statistik. Akademie Verlag, 1992.
[135] M. Thurau, C. Buck und W. Luther. „IPFViewer – A VisualAnalysis System for Hierarchical Ensemble Data“. In: Procee-dings of the 5th International Conference on Information Visualiza-tion Theory and Applications. 2014, S. 259–266.
[136] M. Thurau, C. Buck und W. Luther. „IPFViewer: Incremental,Approximate Analysis of Steel Samples“. In: Proceedings of the13th SIGRAD. 2014.
[137] Flemming Topsøe. „On the Glivenko–Cantelli theorem“. In:Zeitschrift für Wahrscheinlichkeitstheorie und verwandte Gebiete14.3 (1970), S. 239–250.
[138] J. Toriwaki und H. Yoshida. Fundamentals of Three-DimensionalDigital Image Processing. Springer, 2009.
[139] S. Torquato. Random Heterogeneous Materials: Microstructure andMacroscopic Properties. Springer, 2002.
[140] M.-A. Van Ende, M. Guo, E Zinngrebe, B. Blanpain und I.-H. Jung. „Evolution of Non-Metallic Inclusions in SecondarySteelmaking: Learning from Inclusion Size Distributions“. In:ISIJ International 53.11 (2013), S. 1974–1982.
[141] K. Walz. „Die Bestimmung der Kornform der Zuschlagstoffe“.In: Die Betonstraße 11.2 (1936), S. 27–32.
[142] T. Wehrbein. „Interaktive webbasierte Auswertung vonnichtmetallischen Einschlüssen in Brammen“. University ofDuisburg-Essen, 2012.
[143] S. D. Wicksell. „The Corpuscle Problem: A Mathematical Stu-dy of a Biometric Problem“. In: Biometrika 17.12 (1925), S. 84–99.
[144] T. Wiegand und K. A. Moloney. Handbook of Spatial Point-Pattern Analysis in Ecology. CRC Press, 2013.
[145] A. Williams. C++ concurrency: Pratical Multithreading. Man-ning, 2011.
[146] G. Windreich, N. Kiryati und G. Lohmann. „Surface Area Esti-mation in Practice“. In: Discrete Geometry for Computer Imagery.Bd. 2886. Springer, 2003, S. 358–367.
[147] I. H. Witten, E. Frank und M. A. Hall. Data mining : practicalmachine learning tools and techniques. Morgan Kaufmann, 2011.
[148] T. A Witten und L. M. Sander. „Diffusion-limited aggregation“.In: Physical Review B 27.9 (1983).
[149] K. Wu, E. Otoo und K. Suzuki. „Optimizing two-passconnected-component labeling algorithms“. In: Pattern Ana-lysis and Applications 12.2 (2009), S. 117–135.

Literatur 195
[150] Zeiss. The NMI System. 2015. url: https : / / www . zeiss .
com/microscopy/en_de/products/imaging- systems/non-
metallic-inclusions.html (besucht am 28. 08. 2015).
[151] D. Zhang und G. Lu. „Review of shape representation and de-scription techniques“. In: Pattern Recognition 37.1 (2004), S. 1–19.
[152] L. Zhang und B. G. Thomas. „State of the Art in Evaluationand Control of Steel Cleanliness“. In: ISIJ International 43.3(2003), S. 271–291.
[153] J. Ziegel und M. Kiderlen. „Stereological estimation of surfacearea from digital images“. In: Image Analysis & Stereology 29.2(2011), S. 99–110.





























