Embed Size (px)
Citation preview

1
A.Handl
Eine kleine Einführung in SAS
SAS ist ein System, mit dem man Daten speichern und manipulieren, statistische Analysen durchführen, Graphi-ken erstellen und Reports schreiben kann.
Anhand eines kleinen Beispiels soll nun dargestellt werden, wie man mit SAS arbeitet.
Stellen Sie sich vor, Sie haben einen Studienplatz in Bielefeld gefunden und suchen eine geeignete Wohnung. Sie schlagen am 28. August 1999 die NW auf und suchen alle Einzimmerwohnungen heraus, die explizit in Uninähe liegen. Es sind acht.
Die Kaltmieten betragen:
270 460 512 550 360 399 419 390
Wir wollen die Daten statistisch auswerten.
Uns interessieren zunächst einmal Maßzahlen wie der Mittelwert, der Median und die Varianz. Außerdem wollen wir uns ein Bild von den Daten machen. Bei so wenig Beobachtungen ist es nicht sinnvoll, ein Histogramm zu erste l-len. Ein Boxplot ist in einem solchen Fall viel geeigneter.
Weiterhin wollen wir ein Konfidenzintervall für die durchschnittliche Miete erstellen und einen Test durchführen, ob die durchschnittliche Miete 400 DM beträgt.
All dies und noch viel mehr ist mit SAS möglich.
Zunächst müssen wir SAS aufrufen. Wir klicken hierzu im Programm-Manager den SAS Schalter an.
Man landet im DMS (Display/Window-Manager)
Der DMS verwaltet 3 Fenster
PROGRAM hier werden die Befehle eingegeben
OUTPUT hier landen die Ergebnisse
LOG hier stellt das SAS-System Informationen über den Ablauf des Programms zur Verfügung

2
Das nachstehende Bild zeigt den standardmäßigen Aufbau des DMS in Version 6.12.
Das obere Fenster ist das LOG-Fenster und das untere das PROGRAM-Fenster.
Da wir ein Programm erstellen wollen, gehen wir ins PROGRAM-Fenster.
Programme in SAS bestehen aus SAS -Anweisungen, die zu Blöcken zusammengefaßt sind, die man als Steps bezeichnet.
Es gibt DATA Steps und PROC Steps.
Im DATA Step werden die Daten für die Analyse vorbereitet, während der PROC Step der Analyse dient.
Um im PROC Step die Daten analysieren zu können, müssen die Daten in Form einer SAS-Datei vorliegen. Der Zugriff auf einen Datensatz unter SAS ist nur über eine SAS -Datei möglich. SAS-Dateien besitzen ein spezielles Format, auf das wir später noch genauer eingehen werden.
Wir beginnen also mit einem DATA Step.

3
Dies bedeutet, eine SAS-Datei zu erstellen, die dann für die weitere Analyse benutzt wird.
1. Die SAS -Datei erhält einen Namen.
2. Es muß gesagt werden, wo die Daten stehen. Hierbei gibt es drei Möglichkeiten:
• die Daten stehen hinter dem DATA-Step
• die Daten stehen auf einer externen Datei
• die Daten stehen in einer SAS-Datei
3. Die Daten werden eingelesen.
Der DATA Step beginnt mit der Anweisung DATA.
Diese hat folgenden Aufbau:
DATA sasdatei;DATA sasdatei;
sasdatei ist der Name der SAS -Datei, die erzeugt werden soll.
Dabei kann sasdatei aus höchstens 8 Zeichen bestehen, wobei das erste Zeichen ein Buchstabe oder das
Unterstreichungszeichen _ sein muß. Als sonstige Zeichen kommen Buchstaben, Ziffern und das Unterstrei-chungszeichen _ in Frage .
Diese Konvention gilt für alle Namen in SAS.
Wir nennen die SAS-Datei wohnung.
Der erste Befehl lautet also:
DATA wohnung;DATA wohnung;
Wie wir sehen, endet diese Anweisung mit einem Semikolon.
Jede Anweisung in SAS endet mit einem Semikolon.
Wir betrachten zunächst den Fall, daß die Daten direkt eingegeben werden.
Der INPUT-Befehl liest die Daten ein.
Durch ihn wird folgendes bewirkt:
• Jeder Variablen wird ein Name gegeben.
• Der Typ jeder Variablen wird festgelegt.
• Die Position der Werte einer Variablen in der Rohdatei wird festgelegt.
Wir betrachten zunächst nur den ersten Fall. Auf die beiden anderen gehen wir bei einem komplexeren Datensatz ein.
Der Aufbau des INPUT Befehls ist:
INPUT variablenliste;INPUT variablenliste;
Dabei ist variablenliste eine Folge von Variablennamen, die durch Leerzeichen voneinander getrennt
sind.

4
Da wir nur die Variable Miete haben, ist unsere Variablenliste sehr kurz. Wir nennen die Variable miete.
Somit geben wir ein:
INPUT miete;INPUT miete; NICHT VERGESSEN:
Jede SAS-Anweisung endet mit einem Semikolon !!!
Nun müssen wir noch die Daten zur Verfügung stellen. Der CARDS Befehl markiert die Stelle, hinter der die Daten stehen.
Wie müssen die Daten hinter dem CARDS Befehl stehen?
In SAS müssen wir unterscheiden zwischen Beobachtungen und Variablen. Variablen kennen wir bereits. Unter einer Beobachtung versteht man die Werte der einzelnen Variablen bei einem Objekt. Die erste Beobachtung ist in unserem Fall der Wert 270 der Variablen Miete der ersten Wohnung.
Der DATA Step wird nun so abgearbeitet, daß die Befehlsfolge des Datasteps so lange wiederholt, bis die letzte Zeile der Rohdaten erreicht wurde. Dabei wird vor jeder erneuten Durchführung des DATA Steps in die nächste Zeile der Inputdatei beziehungsweise der Rohdaten gegangen. Wir müssen also die Zahlen untereinander schrei-ben.
Wir erhalten also folgende Befehlsfolge:
DATA wohnung;DATA wohnung; INPUT miete;INPUT miete; CARDS;CARDS; 270270 460460 512512 550550 360360 399399 419419 390390 ;; RUN;RUN;
Wir schließen die Befehlsfolge mit dem Befehl RUN ab.
Bisher haben wir diese Befehlsfolge nur im PROGRAM Fenster eingegeben. Um sie ausführen zu lassen, haben wir folgende Möglichkeiten:
• <Alt> <L> <S>
• <F3> oder <F8> drücken.
• Das laufende Männchen anklicken.

5
Nachdem wir die Befehlsfolge abgeschickt haben, werden im LOG Fenster Angaben gemacht.
In unserem Beispiel ist im LOG-Fenster folgendes zu finden:
1 DATA wohnung; 2 INPUT miete; 3 CARDS; NOTE: The data set WORK.WOHNUNG has 8 observations and 1 variables. NOTE: The DATA statement used 2.14 seconds. 12 ; 13 RUN;
Wenn das Programm Fehler enthält, so wird auf diese mit roter Farbe und mit unterstrichenem Text hingewiesen.
Hätten wir z.B. das Semikolon nach INPUT miete; vergessen, so hätte das OUTPUT Fenster folgende In-
formation erhalten:
14 DATA wohnung; 15 INPUT miete 16 CARDS; 17 270 --- 180 18 460 19 512 20 550 21 360 22 399 23 419 24 390 25 ; 26 RUN; ERROR 180-322: Statement is not valid or it is used out of proper order. ERROR: No CARDS or INFILE statement. NOTE: The SAS System stopped processing this step because of errors. WARNING: The data set WORK.WOHNUNG may be incomplete. When this step was stopped there were 0 observations and 2 variables. WARNING: Data set WORK.WOHNUNG was not replaced because this step was stopped. NOTE: The DATA statement used 1.04 seconds. Nach Ausführung des Programms ist das PROGRAM Fenster leer. Die abgeschickte Befehlsfolge erhält man
durch <Alt> <L> <R> zurück.
Wir gehen nun davon aus, daß wir das Programm richtig eingegeben haben. Somit existiert die SAS Datei woh-nung, die die Werte der Variablen miete enthält.

6
Wir wollen uns diese Datei nun anschauen.
Dies geschieht mit Hilfe von PROC PRINT.
Dies ist unser erster PROC Step.
Jeder PROC Step beginnt mit dem PROC Befehl.
Dieser ist folgendermaßen aufgebaut:
PROC <Name der Prozedur> DATA=<Name der SASPROC <Name der Prozedur> DATA=<Name der SAS--Datei(en)>;Datei(en)>;
In unserem Beispiel lautet die Prozedur PRINT und die SAS-Datei groesse.
Der PROC Step beginnt also mit
PROC PRINT DATA=wohnung;PROC PRINT DATA=wohnung;
Wenn wir mit der zuletzt erzeugten SAS-datei arbeiten wollen, können wir auf DATA=groesse; verzichten.
Wenn wir diesen Befehl gefolgt von RUN eingeben, werden die Werte aller Variablen ausgegeben. In unserem
Beispiel erhält die SAS -Datei nur eine Variable miete.
Der Aufruf
PROC PRINT DATA=wohnung;PROC PRINT DATA=wohnung; RUN;RUN;
liefert folgendes Ergebnis im OUTPUT-Fenster:
OBS MIETE 1 270 2 460 3 512 4 550 5 360 6 399 7 419 8 390
Wir sehen, daß SAS automatisch die Beobachtungen durchnumeriert und diese Nummern auch ausdruckt.
Wenn wir die SAS-Datei ohne Beobachtungsnummer drucken wollen, müssen wir folgende Befehlsfolge einge-ben:
PROC PRINT DATA=wohnung;PROC PRINT DATA=wohnung; ID miete;ID miete; RUN;RUN;

7
Die ID Anweisung bewirkt, daß die Variable, die nach dem ID zu finden ist, als erste gedruckt wird und die Beo-
bachtungsnummer nicht gedruckt wird. Wir erhalten also folgendes Ergebnis im OUTPUT Fenster:
MIETE 270 460 512 550 360 399 419 390
Zwei weitere Anweisungen sind in PROC PRINT noch möglich:
Mit der VAR Anweisung können die Namen der Variablen angegeben werden, deren Werte ausgegeben werden
sollen. Da die SAS-Datei wohnung nur eine Variable enthält, ist dies überflüssig. Wir werden noch ein Beispiel
betrachten, bei der wir die Anweisung VAR verwenden.
Die SUM Anweisung bildet die Summe der Variablen, deren Namen aufgeführt werden.
PROC PRINT DATA=wohnung;PROC PRINT DATA=wohnung; SUM miete;SUM miete; RUN;RUN;
OBS MIETE 1 270 2 460 3 512 4 550 5 360 6 399 7 419 8 390 ===== 3360

8
Schauen wir uns einmal an, was passiert wäre, wenn mehrere Werte einer Variablen in einer Zeile der Rohdaten-datei stehen. Wir nennen die SAS-Datei wohnungf, da sie falsch ist.
Wir geben ein:
DATA wohnuDATA wohnungf;ngf; INPUT miete;INPUT miete; CARDS;CARDS; 270 460 270 460 512 550 512 550 360 399 360 399 419 390419 390 ;; RUN;RUN;
Mit PROC PRINT können wir uns die Daten ansehen.
PROC PRINT DATA=wohnungf;PROC PRINT DATA=wohnungf; RUN;RUN;
Wir erhalten folgendes Ergebnis:
OBS MIETE 1 270 2 512 3 360 4 419
Es wurden nur 4 Beobachtungen erzeugt, da jeweils nur der erste Wert in der Zeile der Rohdatei genommen wur-de. Dies liegt daran, daß SAS nach jeder Abarbeitung des DATA Steps in eine neue Zeile springt. Und da nur eine
Variable vorliegt, geschieht dies nach dem ersten Wert.
Es ist möglich, zu verhindern, daß SAS nach jeder Abarbeitung des DATA Steps in eine neue Zeile springt. Man
muß nach dem Variablennamen im INPUT Befehl zweimal das Zeichen @, den Klammeraffen, eingeben. Dann
wird solange aus einer Zeile gelesen, bis kein Wert mehr vorhanden ist. Erst dann springt SAS in die nächste Ze i-le.

9
Wir müssen also das obige Programm modifizieren zu:
DATA wohnung1;DATA wohnung1; INPUT miete @@;INPUT miete @@; CARDS;CARDS; 270 460 270 460 512 550 512 550 360 399 360 399 419 390419 390 ;; RUN;RUN;
Nach Eingabe von
PROC PRINT DATA=wohnung1;PROC PRINT DATA=wohnung1; RUN;RUN;
erhalten wir folgendes richtiges Ergebnis
OBS MIETE 1 270 2 460 3 512 4 550 5 360 6 399 7 419 8 390
Nun wollen wir davon ausgehen, daß die Daten auf einer externen Datei stehen. Hierbei soll es sich um eine ASCII-Datei handeln, bei der in jeder Zeile eine Beobachtung steht.
Der Inhalt der ASCII-Datei sieht also folgendermaßen aus:
270270 460460 512512 550550 360360 399399 419419 390390
Diese Datei soll auf einer Diskette, also im Laufwerk a:, sein und den Namen wohnung.asc haben. Wir wollen
die SAS-Datei wiederum wohnung nennen.

10
Da wir eine SAS-Datei mit Namen wohnung erstellen wollen, lautet der erste Befehl lautet also:
DATA wohnung;DATA wohnung;
Nun müssen wir SAS mitteilen, wo die Rohdatendatei steht. Dies geschieht mit Hilfe des Befehls INFILE, der folgenden Aufbau hat:
INFILE "name der Rohdatendatei";INFILE "name der Rohdatendatei"; In unserem Beispiel also:
INFILE "a:wohnung.asc";INFILE "a:wohnung.asc";
Danach werden die Daten mit dem INPUT Befehl eingelesen.
Wir erhalten also folgende Anweisungsfolge:
DATA wohnungo;DATA wohnungo; INFILE "a:wohnung.asc";INFILE "a:wohnung.asc"; INPUT gr;INPUT gr; RUN;RUN;
Nachdem wir die Daten eingelesen und sie uns angesehen haben, wollen wir statistische Maßzahlen bestimmen. Wir operieren im folgenden auf der SAS-Date i wohnung.
Eine Möglichkeit bietet PROC MEANS.
Der Aufruf
PROC MEANS DATA=wohnung;PROC MEANS DATA=wohnung; RUN;RUN;
liefert folgendes Ergebnis:
Analysis Variable : MIETE N Mean Std Dev Minimum Maximum --------------------------------------------------------- 8 420.0000000 88.1605678 270.0000000 550.0000000 ---------------------------------------------------------
Ohne zusätzliche Angaben liefert PROC MEANS:
• den Stichprobenumfang N
• den Mittelwert Mean
• die Standardabweichung Std Dev
• das Minimum
• das Maximum.

11
Sind x x x n1 2, , . . . , die Werte einer Variablen in einer Stichprobe vom Umfang n, so sind
• der Mittelwert
xn
xii
n
==∑1
1
• die Standardabweichung s s= 2 mit der Stichprobenvarianz
( )sn
x xii
n2 2
1
11
=−
−=
∑
Ist x x x n( ) ( ) ( ), , .. . ,1 2 die geordnete Stichprobe mit x x x n( ) ( ) ( )...1 2≤ ≤ ≤ , so gilt:
• Minimum x ( )1
• Maximum x n( )
Wir sehen, daß die durchschnittliche Kaltmiete 420 DM beträgt. Die niedrigste Miete ist 270 DM und die höchste 550 DM. Außerdem beträgt die Standardabweichung 88.16 DM.
Wir können unter anderem noch folgende Werte erhalten:
• den RANGE (Spannnweite):
x n( ) - x( )1
• die Stichprobenvarianz VAR
• die SKEWNESS als Maß für die Schiefe
• die KURTOSIS als Maß für Wahrscheinlichkeitsmasse an den Rändern.
Wir wollen alle diese Statistiken ausdrucken:
PROC MEANS DATA=wohnung N MEAN STD MIN MAX RANGE VAR PROC MEANS DATA=wohnung N MEAN STD MIN MAX RANGE VAR SKEWNESS KURTOSIS;SKEWNESS KURTOSIS; RUN;RUN;
Analysis Variable : MIETE N Mean Std Dev Minimum Maximum Range Varian-ce ------------------------------------------------------------------------------------- 8 420.0000000 88.1605678 270.0000000 550.0000000 280.0000000 7772.29 ------------------------------------------------------------------------------------- Skewness Kurtosis ---------------------------- -0.1633353 0.0947079 ----------------------------

12
Mit PROC MEANS kann man auch ein Konfidenzintervall für den Erwartungswert unter Annahme einer Normalver-
teilung aufstellen.
Sind x x xn1 2, , . .. , die Werte der Variablen in einer Stichprobe vom Umfang n, x der Mittelwert und s die Standa-
rabweichung, so sind die Grenzen eines 100(1-α) Prozent Konfidenzintervalls für den Erwartungswert µ einer normalverteilten Zufallsvariablen gegeben durch:
x ts
nx t
s
nn n− ⋅ + ⋅
− − − −1 1 2 1 1 2; / ; /,α α .
Dabei ist t n− −1 1 2; /α das 1 2− α / Quantil einer t-Verteilung mit n-1 Freiheitsgraden.
In SAS erhalten wir das Konfidenzintervall durch folgende Befehlsfolge:
PROC MEANS DATA=wohnung CLM;PROC MEANS DATA=wohnung CLM; RUN;RUN;
Im OUTPUT Fenster sehen wir dann:
Analysis Variable : MIETE Lower 95.0% CLM Upper 95.0% CLM -------------------------------- 346.2959209 493.7040791 --------------------------------
Das Konfidenzintervall zum Konfidenzniveau 0.95 lautet somit [346.3,493.7].
Standardmäßig wird das Konfidenzintervall zum Konfidenzniveau 0.95 aufgestellt.
Um zum Beispiel das 99 Prozent Intervall aufzustellen, müssen wir eingeben:
PROC MEANS ALPHA=0.01 DATA=wohnung CLM;PROC MEANS ALPHA=0.01 DATA=wohnung CLM; RUN;RUN;
Wir erhalten dann folgendes Ergebnis:
Analysis Variable : MIETE Lower 99.0% CLM Upper 99.0% CLM -------------------------------- 310.9229685 529.0770315 --------------------------------
Wie zu erwarten war, ist das Konfidenzintervall größer.

13
PROC MEANS auch einen t-Test durchführen.
Dieser geht von folgenden Annahmen aus:
Die Beobachtungen x x xn1 2, , ..., sind Realisationen von unabhängigen Zufallsvariablen X X Xn1 2, ,..., , die identisch mit den Parametern µ und σ2 normalverteilt sind.
Es soll getestet werden:
H0 0:µ µ= gegen H0 0:µ µ≠
In unserem Beispiel ist µ 0 400= .
Die Teststatistik des t-Tests ist:
( )t
n X
S=
− µ0
mit
Xn
X ii
n
= ⋅=
∑1
1
und
( )Sn
X Xii
n
=−
−=
∑11
2
1
.
Wir lehnen H 0 ab ,wenn gilt
t t n≥ − −1 1 2; /α
Dabei ist t n− −1 1 2; /α das 1 2− α / Quantil einer t-Verteilung mit n-1 Freiheitsgraden.
Wir wollen also testen:
H 0 400:µ =
In SAS ist die Nullhypothese aber auf den Fall eingeengt, daß der hypothetische Erwartungswert gleich 0 ist. Wir müssen die Daten also vor Durchführung des Tests entsprechend modifizieren.
Ziehen wir von allen Daten den Wert 400 ab, so ist ein Test auf Erwartungswert 0 dieser modifizierten Daten äqui-valent zu einem Test auf Erwartungswert 400 der ursprünglichen Daten.
Hat nämlich die Zufallsvariable X den Erwartungswert µ, so gilt:
E(X- ) = E(X) - E( ) = - = 0.µ µ µ µ

14
Wir müssen vor Durchführung des Tests also einen DATA Step durchführen.
Hierzu erzeugen wir eine neue SAS-Datei wotest, die die Daten der SAS-Datei wohnung als Input erhält und die transformierte Variable erzeugt.
Eine SAS-Datei wird mit Hilfe des SET Befehls eingelesen.
DATA wotest;DATA wotest; SET wohnung;SET wohnung; miete=mietemiete=miete--400;400; RUN;RUN;
Der Befehl miete=miete-400; bildet die transformierte Variable.
Wir können uns die Variablen der SAS-Datei wotest anschauen:
PROC PRINT DATA=wotesPROC PRINT DATA=wotest;t; RUN; RUN;
OBS MIETE 1 -130 2 60 3 112 4 150 5 -40 6 -1 7 19 8 -10 Nun können wir den Test durchführen:
PROC MEANS T PRT DATA=wotest;PROC MEANS T PRT DATA=wotest; VAR miete;VAR miete; RUN;RUN;
und erhalten folgendes Resultat
Analysis Variable : MIETE T Prob>|T| ---------------------- 0.6416536 0.5415 ----------------------
SAS liefert den Wert der Teststatistik und die sogenannte Überschreitungswahrscheinlichkeit. Dies ist die Wahr-scheinlichkeit, den Wert der Teststatistik und noch extremere zu erhalten, wenn die Nullhypothese wahr ist. Sie beträgt im Beispiel 0.5415.

15
In unserem Beispiel beträgt die Überschreitungswahrscheinlichkeit 0.5415. Wir würden also zum Niveau 0.05 die Nullhypothese nicht ablehnen, da die Überschreitungswahrscheinlichkeit größer als das vorgegebene Signifikan z-niveau ist.
Der t-Test beruht auf der Annahme der Normalverteilung. Um diese zu überprüfen, sollte man die Daten graphisch darstellen.
Eine Möglichkeit bietet die PROC UNIVARIATE.
Diese ruft man mit dem Namen des SAS Datsets auf. Wählt man zusätzlich die Option PLOT, so erhält man einen Boxplot der Daten und einen Normal -Probability Plot.
Der Boxplot ist eine graphische Darstellung folgender 5 Maßzahlen:
• Minimum
• unteres Quartil x0 25.
• Median x0 5.
• oberes Quartil x0 75.
• Maximum
Bei einem Normal Probability Plot werden die geordneten Beobachtungen gegen spezielle Quantile der Normalverteilung gezeichnet. Im Idealfall liegen alle Beobachtungen auf einer Geraden.
PROC UNIVARIATE DATA=wohPROC UNIVARIATE DATA=wohnung;nung; RUN;RUN;
Univariate Procedure
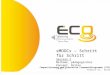
Variable=GR Moments Quantiles(Def=5) N 10 Sum Wgts 10 100% Max 196 99% 196 Mean 176.6 Sum 1766 75% Q3 183 95% 196 Std Dev 10.31935 Variance 106.4889 50% Med 177 90% 190 Skewness 0.483152 Kurtosis -0.55364 25% Q1 167 10% 165 USS 312834 CSS 958.4 0% Min 164 5% 164 CV 5.843344 Std Mean 3.263264 1% 164 T:Mean=0 54.1176 Pr>|T| 0.0001 Range 32 Num ^= 0 10 Num > 0 10 Q3-Q1 16 M(Sign) 5 Pr>=|M| 0.0020 Mode 182 Sgn Rank 27.5 Pr>=|S| 0.0020 Extremes Lowest Obs Highest Obs 164( 7) 182( 2)
16
166( 4) 182( 10) 167( 9) 183( 5) 170( 6) 184( 1) 172( 3) 196( 8) Stem Leaf # Boxplot 19 6 1 | 19 | 18 | 18 2234 4 +-----+ 17 *--+--* 17 02 2 | | 16 67 2 +-----+ 16 4 1 | ----+----+----+----+ Multiply Stem.Leaf by 10**+1 Normal Probability Plot 197.5+ * +++++ | +++++ | ++++ | * *++*+ * | +++++ | ++*++* | +*++* 162.5+ +*+++ +----+----+----+----+----+----+----+----+----+----+ -2 -1 0 +1 +2
Die Graphiken, die PROC UNIVARIATE erzeugt, sind nicht schön. Man kann eigenlich nichts erkennen. Da Graphi-ken ein sehr wesentlicher Bestandteil der statistischen Analyse sind, sollte man schöne Graphiken erzeugen. Ein wunderbares Buch über Graphik im Zusammenhang mit Statistik wurde von Howard Wainer geschrieben und heißt Visual Revelations. Wer nach der Lektüre dieses Buches immer noch einTortendiagramm erstellt oder den beschreibenden Text und die Graphik auf unterschiedlichen Seiten darstellt, ist selber schuld.
In SAS kann man wunderschöne Graphiken erstellen. Es ist aber sehr mühselig. Hier und auch bei der Einfachheit in der Programmierung ist S-PLUS SAS eindeutig überlegen. Trotzdem wollen wir einen schönen Boxplot erstellen.
Hierzu benötigt man PROC GPLOT. Mit dieser können Streudiagramm erstellt werden. Es werden also die Werte von zwei Variablen x und y gegeneinander abgetragen.
Die Kaltmieten der Einzimmerwohnungen sind sehr unterschiedlich. Dies zeigt sich in der großen Varianz.
Die unterschiedlichen Mieten kommen sicherlich dadurch zustande, daß die Wohnungen sich hinsichtlich einer Reihe von Merkmalen unterscheiden.
Es fallen einem sofort eine Vielzahl von Merkmalen ein:
• die Größe der Wohnung, also die Quadratmeterzahl
• die Lage der Wohnung
• die Ausstattung der Wohnung
• das Alter der Wohnung
Dies sind alles Variablen, die wir bei unserer Analyse nicht berücksichtigt haben.

17
Wir wollen die Fläche der Wohnungen bei der weiteren Analyse berücksichtigen.
Die folgende Tabelle gibt die neben der Fläche auch die Kaltmiete an.
Kaltmiete Fläche
270 20
460 26
512 32
550 48
360 26
399 30
419 30
390 40
Wir erstellen eine SAS-Datei mit Namen mietefl, die neben der Miete noch die Fläche enthält, di e wir mit
flaeche bezeichnen.
DATA MIETEFL;DATA MIETEFL; INPUT miete flaeche;INPUT miete flaeche; CARDS;CARDS; 270 20270 20 460 26 460 26 512 32 512 32 550 48 550 48 360 26 360 26 399 30 399 30 419 30 419 30 390 40 390 40 ;; RUN;RUN;
18
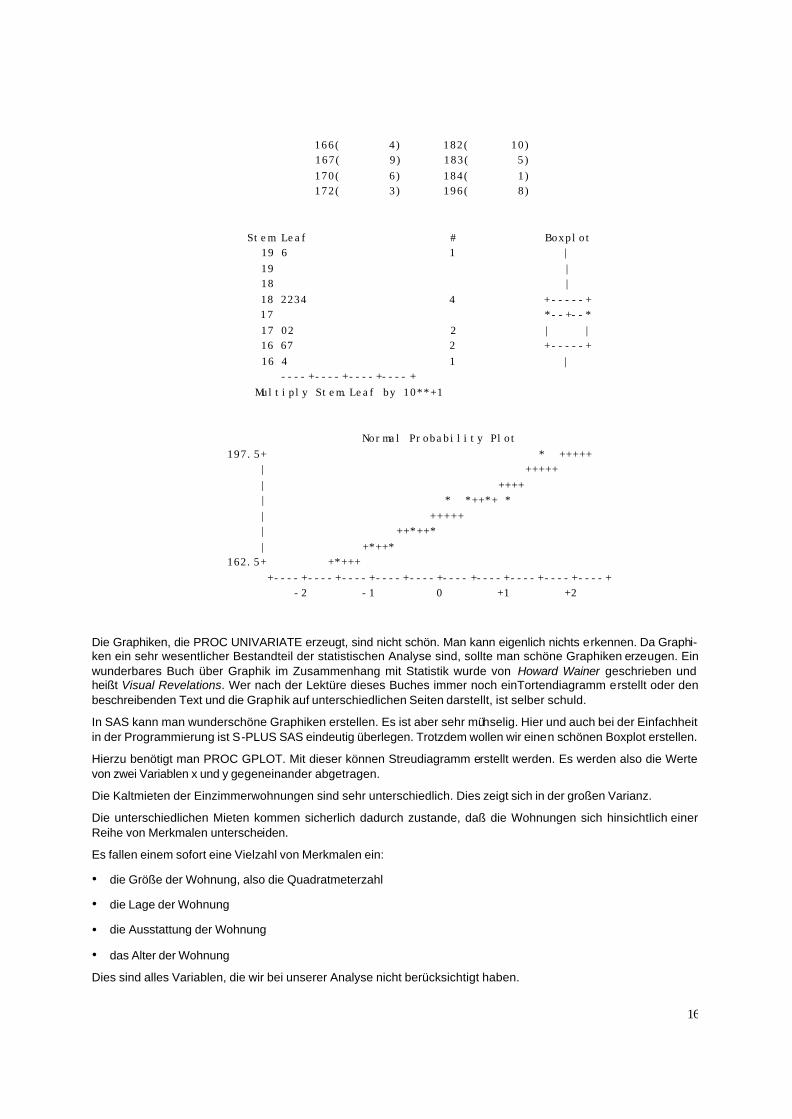
Wir schauen uns den Inhalt der Datei an.
PROC PRINT DATA=MIETEFL;PROC PRINT DATA=MIETEFL; RUN;RUN;
OBS MIETE FLAECHE 1 270 20 2 460 26 3 512 32 4 550 48 5 360 26 6 399 30 7 419 30 8 390 40
Nun wollen wir ein Streudiagramm der Daten erstellen. Auf der Abszisse soll die Fläche und auf der Ordinate die Miete abgetragen werden.
Dies geschieht durch
PROC GPLOT DATA=MIETEFL;PROC GPLOT DATA=MIETEFL; PLOT miete*flaeche;PLOT miete*flaeche; RUN;RUN;
Das Bild sieht folgendermaßen aus:
MIETE
200
300
400
500
600
FLAECHE
20 30 40 50
Wir sehen, daß mit wachsender Fläche die Kaltmiete höher wird. Der Zusammenhang scheint auch linear zu sein.

19
Jetzt legen wir eine Gerade nach der Methode der Kleinsten Quadrate durch die Punktewolke.
Gesucht sind also Schätzwerte für a und b in:
y a b x ui i i= + ⋅ +
wobei x i die Fläche und y i die Kaltmiete ist.
Die K-Q-Schätzer sind gegeben durch
( )( )
( )∃b
x x y y
x x
i ii
n
ii
n=− −
−
=
=
∑
∑1
2
1
und
∃ ∃a y b x= − ⋅
In SAS geben wir ein:
proc reg;proc reg; model model miete=flaeche;miete=flaeche; run;run;
und erhalten folgendes Ergebnis Model: MODEL1 Dependent Variable: MIETE Analysis of Variance Sum of Mean Source DF Squares Square F Value Prob>F Model 1 26698.18450 26698.18450 5.781 0.0530 Error 6 27707.81550 4617.96925 C Total 7 54406.00000 Root MSE 67.95564 R-square 0.4907 Dep Mean 420.00000 Adj R-sq 0.4058 C.V. 16.17991 Parameter Estimates Parameter Standard T for H0: Variable DF Estimate Error Parameter=0 Prob > |T| INTERCEP 1 198.918819 95.03395591 2.093 0.0812 FLAECHE 1 7.018450 2.91894475 2.404 0.0530

20
Schauen wir uns den Output an.
Zunächst erhalten wir eine ANOVA-Tabelle.
C Total ist die Streuung der Kaltmiete:
( )y yii
n
−=∑ 2
1
Im Beispiel beträgt diese 54406.
Durch die Regression wird ein Teil dieser Streuung erklärt.
Dieser ist
( )∑=
−n
ii yy
1
2ˆ
Dabei ist
ii xbay ⋅+= ˆˆˆ
Wir finden ihn im Output unter Model. Im Beispiel beträgt diese 26698.1845.
Die Differenz der beiden ist die Reststreuung, die mit Error bezeichnet wird.
Außerdem sind die Parameterschätzungen von Interesse. Diese finden wir unter Parameter Estimates. Der Schätzwert von a ist 198.92.
Der Schätzwert von b ist 7.02. Jeder zusätzliche Quadratmeter Wohnfl che kostet also rund 7 DM Kaltmiete.
Außerdem sind noch die geschätzten Standardfehler der Parameterschätzer, die Teststatistiken und Überschrei-tungswahrscheinlichkeiten der Tests auf
H a0 0: =
und
H b0 0: =
zu finden.
Wir sehen, daß b zum Signifikanzniveau 0.05 nicht signifikant von 0 verschieden ist. Das hei o-these nicht ablehnen können, daß die Fläche keinen Einfluß auf die Kaltmiete hat.

21
Kehren wir zum Boxplot zurück. Hierzu schauen wir uns die Hilfe zur Anweisung GPLOT an, wie wir sie unter SAS
mit Hilfe von HELP GPLOT erhalten:
PROC GPLOT options;PROC GPLOT options; PLOT yvariable*xvariable... / options; PLOT yvariable*xvariable... / options; PLOT2 yvariable*xvariable... / options; PLOT2 yvariable*xvariable... / options; BUBBLE yvariable*xvariable=zvariable; BUBBLE yvariable*xvariable=zvariable; BUBBLE2 yvariable*xvariable=zvariable; BUBBLE2 yvariable*xvariable=zvariable; SYMBOLn options;SYMBOLn options; PATTERNn options; PATTERNn options; TITLEn options 'text';TITLEn options 'text'; FOOTNOTEn options 'text'; FOOTNOTEn options 'text'; NOTE options 'text'; NOTE options 'text'; BY variables; BY variables; AXIS options; AXIS options; LEGENDn options; LEGENDn options;
Wir sehen eine Vielzahl von Optionen, deren Bedeutung wir mit der Hilfefunktion erfragen können.
Unter SYMBOL gibt es die Option INTERPOLATE, die wir mit I abkürzen können. Ein mögli I ist
BOX. Wählen wir diese Option, so erhalten wir einen Boxplot. Es stellt sich nur noch die Frage, was die zweite
Variable bei GPLOT ist. Auf der Ordinate wird die interessierende Variable abgetragen. Auf der Abszisse wird nun
an einer Stelle der Boxplot abgetragen. Dieser Stelle müssen wir noch einen Wert zuordnen. Wir wählen die 1.
Wir erzeugen zunächst eine SAS-Datei wohnungb, in der wir die SAS-Datei wohnung laden und noch die Vari-
able t hinzufügen, die den 1 annimmt.
DATA WOHNUNGB;DATA WOHNUNGB; SET WOHNUNG;SET WOHNUNG; t=1;t=1; RUN; RUN;
22
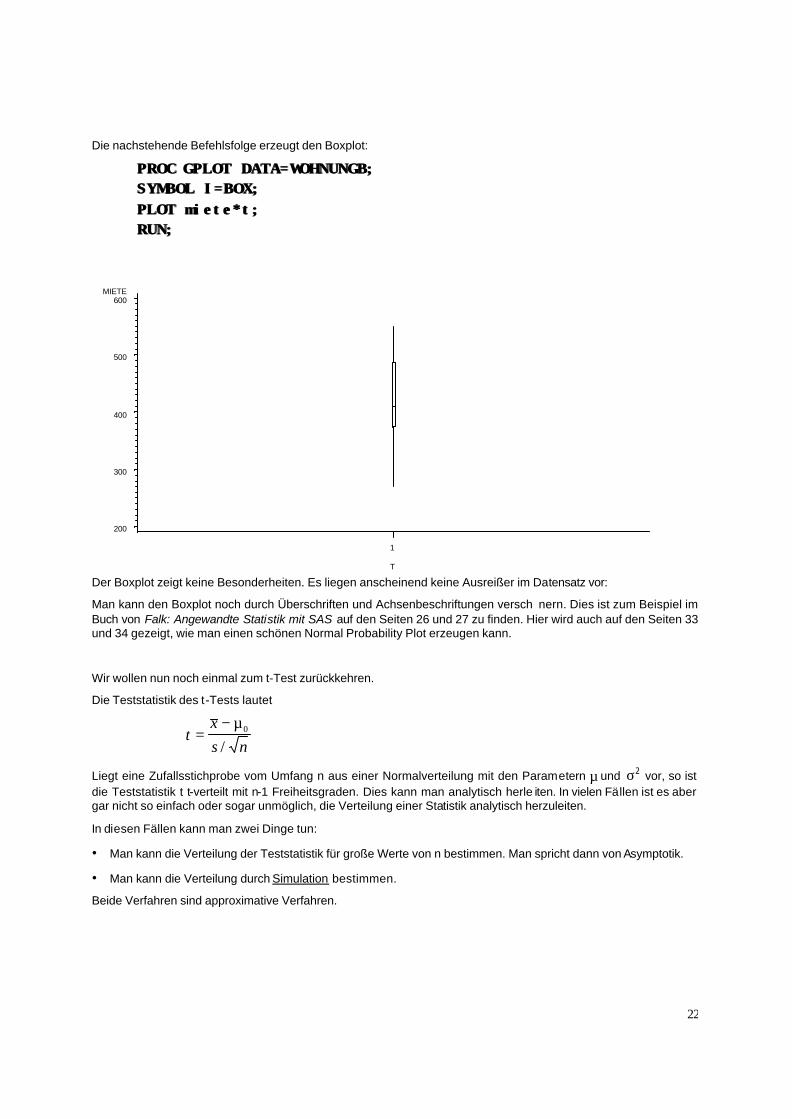
Die nachstehende Befehlsfolge erzeugt den Boxplot:
PROCPROC GPLOT DATA=WOHNUNGB;GPLOT DATA=WOHNUNGB; SYMBOL I=BOX;SYMBOL I=BOX; PLOT miete*t;PLOT miete*t; RUN;RUN;
MIETE
200
300
400
500
600
T
1
Der Boxplot zeigt keine Besonderheiten. Es liegen anscheinend keine Ausreißer im Datensatz vor:
Man kann den Boxplot noch durch Überschriften und Achsenbeschriftungen versch nern. Dies ist zum Beispiel im Buch von Falk: Angewandte Statistik mit SAS auf den Seiten 26 und 27 zu finden. Hier wird auch auf den Seiten 33 und 34 gezeigt, wie man einen schönen Normal Probability Plot erzeugen kann.
Wir wollen nun noch einmal zum t-Test zurückkehren.
Die Teststatistik des t-Tests lautet
tx
s n=
− µ0
/
Liegt eine Zufallsstichprobe vom Umfang n aus einer Normalverteilung mit den Parametern µ und σ2 vor, so ist die Teststatistik t t-verteilt mit n-1 Freiheitsgraden. Dies kann man analytisch herle iten. In vielen Fällen ist es aber gar nicht so einfach oder sogar unmöglich, die Verteilung einer Statistik analytisch herzuleiten.
In diesen Fällen kann man zwei Dinge tun:
• Man kann die Verteilung der Teststatistik für große Werte von n bestimmen. Man spricht dann von Asymptotik.
• Man kann die Verteilung durch Simulation bestimmen.
Beide Verfahren sind approximative Verfahren.

23
Wir wollen uns auf die Simulation beschränken. Hierzu benötigt man Zufallszahlengeneratoren, die von SAS zur Verfügung gestellt werden. Einer mit Namen NORMAL erzeugt standardnormalverteilte Zufallszahlen.
Die Idee einer Simulation ist ganz einfach:
Es werden wiederholt mit Hilfe eines Zufallszahlengenerators Stichproben vom Umfang n aus der Grundgesamt-heit gezogen und für jede dieser Stichproben der Wert der Teststatistik bestimmt. Bei B Wiederholungen erhält man dann B Werte der Teststatistik, deren Verteilung man sich dann anschaut, also Maßzahlen bestimmt oder Graphiken erstellt.
Schauen wir uns dazu ein Beispiel an.
Wir wollen die Verteilung des arithmetischen Mittels bei einer Stichprobe vom Umfang n=4 aus einer Standard-normalverteilung mit Hilfe einer Simulation bestimmen. Diese Simulation ist eigentlich nicht nötig.
Wir wissen ja aus der Grundausbildung in Statistik:
Sind die Zufallsvariablen X X X X1 2 3 4, , , unabhängig und identisch standardnormalverteilt, so ist
( )X X X X X= ⋅ + + +1
4 1 2 3 4 normalverteilt mit dem Erwartungswert 0 und der Varianz 0.25. Also beträgt die
Standardabweichung des arithmetischen Mittels 0.5.
Anhand dieses Ergebnis können wir dann sehen, wie gut die Simulation ist.
Wir fangen behutsam an.
Wir ziehen zunächst einmal eine Zufallsstichprobe vom Umfang n=4 aus einer Standardnormalverteilung und bestimmen den Wert des arithmetischen Mittels. Dies leistet der folgende DATA Step.
DATA norstich;DATA norstich; DO i=1 TO 4;DO i=1 TO 4; x=NORMAL(0);x=NORMAL(0); OUTPUT;OUTPUT; END;END;
Diesen wollen wir natürlich nicht unkommentiert stehen lassen.
Die erste Zeile enthält nichts Neues. Wir erzeugen eine SAS-Datei mit Namen norstich. Die Daten werden nun aber nicht wie bei allen vorherigen Beispielen aus einer Datei eingelesen, sondern sie werden mit Hilfe eines Zufallszahlengenerators erzeugt. Dies geschieht mit einer Funktion. Diese hat den Namen NORMAL und hat das
Argument SEED. Dies ist der Startwert des Zufallszahlengenerators. Wir wählen hier für SEED den Wert 0. Wir
wollen eine Zufallsstichprobe vom Umfang 4 aus einer Standardnormalverteilung erzeugen. Also müssen wir fünfmal die Funktion NORMAL aufrufen. Dies machen wir mit Hilfe einer Schleife oder Iteration.
Diese wird über eine Indexvariable gesteuert.

24
Der Aufbau ist folgendermaßen:
DO Zaehlvariable=Startwert TO Endwert BY Inkrement;DO Zaehlvariable=Startwert TO Endwert BY Inkrement; Folge von Anweisungen;Folge von Anweisungen;
END;END;
Der Standardwert von inkrement ist 1.
In unserem Beispiel lautet die Zählvariable i, der Startwert 1 und der Endwert 4. Da das Inkrement gleich 1 ist, kann es weggelassen werden. Die Wirkung der DO-Schleife ist, daß die Anweisungsfolge viermal ausgeführt wird.
Die Anweisungsfolge besteht aus zwei Befehlen.
• Zunächst wird eine standardnormalvert eilte Zufallszahl erzeugt und der Variablen x zugewiesen.
• Dann wird mit Hilfe des Befehls OUTPUT der Wert von x in die SAS-Datei norstich geschrieben.
Das Ergebnis der Anweisungsfolge können wir uns anschauen mit
PROC PRINT DATA=norstich; RUN;
OBS I X 1 1 -1.24755 2 2 -1.54785 3 3 0.40943 4 4 0.30407
Der OUTPUT-Befehl ist notwendig. Schauen wir uns das Ergebnis der Befehlsfolge an, wenn der OUTPUT Be-fehl fehlt.
DATA norstich;DATA norstich; DO i=1 TO 4;DO i=1 TO 4; x=NORMAL(0);x=NORMAL(0); END;END;
PROC PRINT DATA=norstich;PROC PRINT DATA=norstich; RUN;RUN;
OBS I X 1 5 0.46852 In der Datei norstich steht nur eine einzige Beobachtung. Dies liegt daran, wie SAS den DATA Step abarbeitet.
SAS schreibt erst in die Datei, wenn der DATA-Step abgearbeitet ist. Der DATA-Step besteht in diesem Fall aus der Iteration. Die Iteration ist erst nach der vierten Wiederholung beendet. Es wird die letzte Zufallszahl in die Variable X geschrieben. Eine sehr schöne Beschreibung ist in Kapitel 17 des Buches How SAS works von Paul A. Herzberg zu finden.

25
Den Mittelwert in der Stichprobe erhalten wir dann mit PROC MEANS:
PROC MEANS DATA=norstich MEAN;PROC MEANS DATA=norstich MEAN; VAR x;VAR x; RUN;RUN;
Analysis Variable : X Mean ------------ 0.4685195 ------------
Nun wissen wir, wie wir eine Stichprobe aus normalverteilten Zufallszahlen bestimmt. Im Rahmen einer Simulati-on erzeugt man nun sehr viele Stichproben und bestimmt für jede den Wert der interessierenden Statistik. Dann kann man sich die Verteilung dieser Statistik anschauen. Wir müssen die obige Befehlsfolge also B-mal wiederholen. Wir fangen ganz klein an und wählen B=2. Dies geht wiederum mit einer Schleife.
Wir erhalten folgendes Programm:
DATA simnor;DATA simnor; DO sample=1 TO 2; DO sample=1 TO 2; DO i=1 TO 4; DO i=1 TO 4; x=NORMAL(0); x=NORMAL(0); OUTPUT; OUTPUT; END; END; END; END; RUN;RUN;
Der nachfolgende Output zeigt die 8 Beobachtungen der Datei simnor:
PROC PRINT DATA=simnor;PROC PRINT DATA=simnor; RUN;RUN;
OBS SAMPLE I X 1 1 1 -0.56661 2 1 2 -0.15976 3 1 3 -0.01153 4 1 4 -1.60171 5 2 1 -0.29079 6 2 2 1.43374 7 2 3 -0.71443 8 2 4 0.81165
Wir sehen hier die Variable SAMPLE, die für die ersten 4 Beobachtungen den Wert 1 und für die nächsten 4 Beo-bachtungen den Wert 2 annimmt.

26
Nun bestimmen wir das arithmetische Mittel der ersten und das der zweiten Stichprobe. Hierzu rufen wir PROC MEANS auf mit der SAS-Datei simnor. Wir wollen das arithmetische Mittel jeder Stichprobe bestimmen. Dies
geht durch die BY-Anweisung, durch die festgelegt wird, daß die interessierende Variable für die Beobachtungen
ausgewertet wird, die bei der Variablen den gleichen Wert annehmen, die hinter BY steht. Wir wollen den Mittel-
wert der Werte von x bestimmen, bei denen sample den gleichen Wert annimmt.
Wir erhalten also folgende Befehlsfolge:
PROC MEANS DATA=simnor NOPRINT;PROC MEANS DATA=simnor NOPRINT; VAR x;VAR x; BY sample;BY sample; OUTPUT OUT=simxq MEAN=mue;OUTPUT OUT=simxq MEAN=mue;
Der OUTPUT-Befehl bewirkt, daß die Ergebnisse in die hinter OUT bezeichnete Datei geschrieben werden. Au-
ßerdem soll nur der Mittelwert MEAN unter dem Namen mue ausgegeben werden.
Die beiden Mittelwerte stehen nun in der Datei simxq unter dem Namen mue.
Wir schauen uns simxq an:
PROC PRINT DATA=simxq;PROC PRINT DATA=simxq; RUN;RUN;
OBS SAMPLE _TYPE_ _FREQ_ MUE 1 1 0 4 -0.58490 2 2 0 4 0.31004
Wir können jetzt die Daten in simxq weiter analysieren:
PROC MEANS DATA=simxq;PROC MEANS DATA=simxq; VAR mue;VAR mue; RUN;RUN;
Analysis Variable : MUE N Mean Std Dev Minimum Maximum --------------------------------------------------------- 2 -0.1374302 0.6328223 -0.5849031 0.3100427 ---------------------------------------------------------

27
Zwei Wiederholungen sind bei einer Simulation natürlich ein bißchen wenig. Wir simulieren die Verteilung des Mittelwerts nun für B=10000 Stichproben.
DATA simnor;DATA simnor; DO sample=1 TO 10000; DO sample=1 TO 10000; DO i=1 TO 4; DO i=1 TO 4; x=NORMAL(0); x=NORMAL(0); OUTPUT; OUTPUT; END; END; END; END;
PROC MEANS DATA=simnor NOPRINT;PROC MEANS DATA=simnor NOPRINT; VAR x;VAR x; BY sample;BY sample; OUTPUT OUT=simxq MEAN=mue;OUTPUT OUT=simxq MEAN=mue;
PROC MEANS DATA=simxq;PROC MEANS DATA=simxq; VAR mue;VAR mue; RUN;RUN;
Analysis Variable : MUE N Mean Std Dev Minimum Maximum ------------------------------------------------------------- 10000 0.000695225 0.5020516 -1.8364225 2.0930371 -------------------------------------------------------------
Wir sehen, daß die Schätzungs der Simulation ziemlich gut sind. Der Mittelwert der 10000 Mitte lwerte ist mit 0.000695 sehr nahe an 0 und auch die Standardabweichung ist in der Nähe des theoretischen Wertes 0.5.
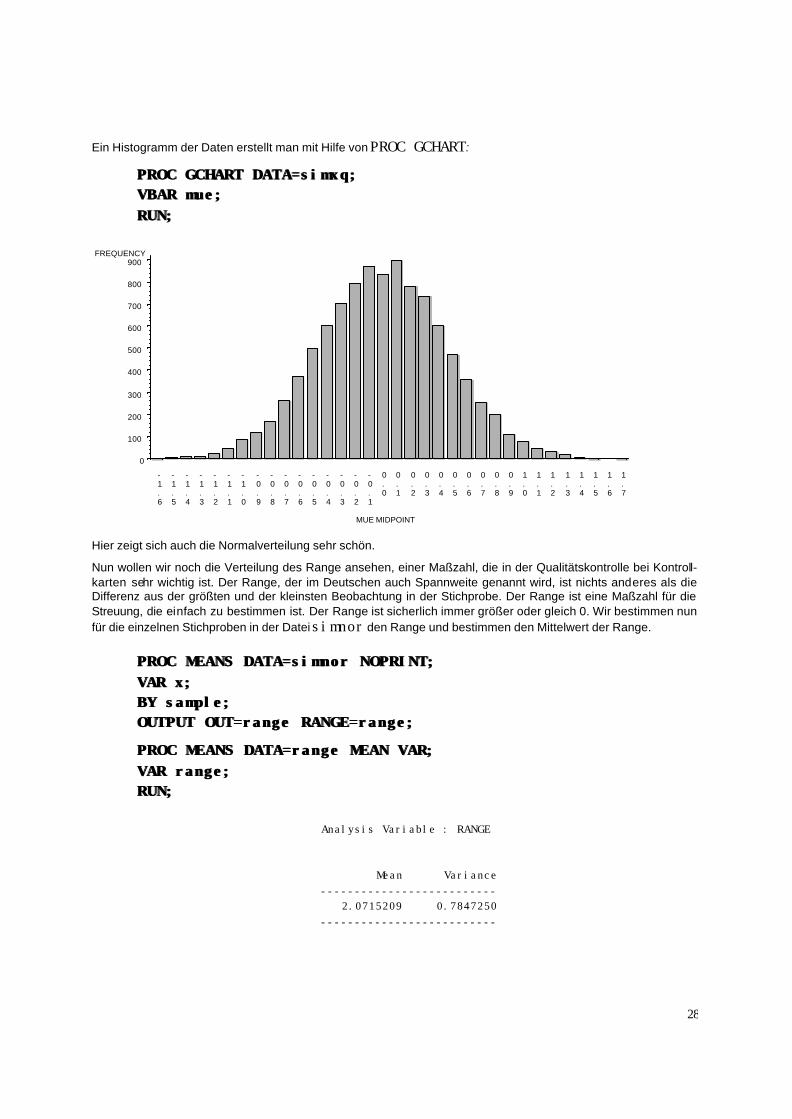
28
Ein Histogramm der Daten erstellt man mit Hilfe von PROC GCHART:
PROC GCHART DATA=simxq;PROC GCHART DATA=simxq; VBAR mue;VBAR mue; RUN;RUN;
FREQUENCY
0
100
200
300
400
500
600
700
800
900
MUE MIDPOINT
-1.6
-1.5
-1.4
-1.3
-1.2
-1.1
-1.0
-0.9
-0.8
-0.7
-0.6
-0.5
-0.4
-0.3
-0.2
-0.1
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
1.1
1.2
1.3
1.4
1.5
1.6
1.7
Hier zeigt sich auch die Normalverteilung sehr schön.
Nun wollen wir noch die Verteilung des Range ansehen, einer Maßzahl, die in der Qualitätskontrolle bei Kontroll-karten sehr wichtig ist. Der Range, der im Deutschen auch Spannweite genannt wird, ist nichts anderes als die Differenz aus der größten und der kleinsten Beobachtung in der Stichprobe. Der Range ist eine Maßzahl für die Streuung, die einfach zu bestimmen ist. Der Range ist sicherlich immer größer oder gleich 0. Wir bestimmen nun für die einzelnen Stichproben in der Datei simnor den Range und bestimmen den Mittelwert der Range.
PROC MEANS DATA=simnor NOPRINT;PROC MEANS DATA=simnor NOPRINT; VAR x;VAR x; BY sample;BY sample; OUTPUT OUT=range RANGE=range;OUTPUT OUT=range RANGE=range;
PROC MEANPROC MEANS DATA=range MEAN VAR;S DATA=range MEAN VAR; VAR range;VAR range; RUN;RUN;
Analysis Variable : RANGE Mean Variance -------------------------- 2.0715209 0.7847250 --------------------------
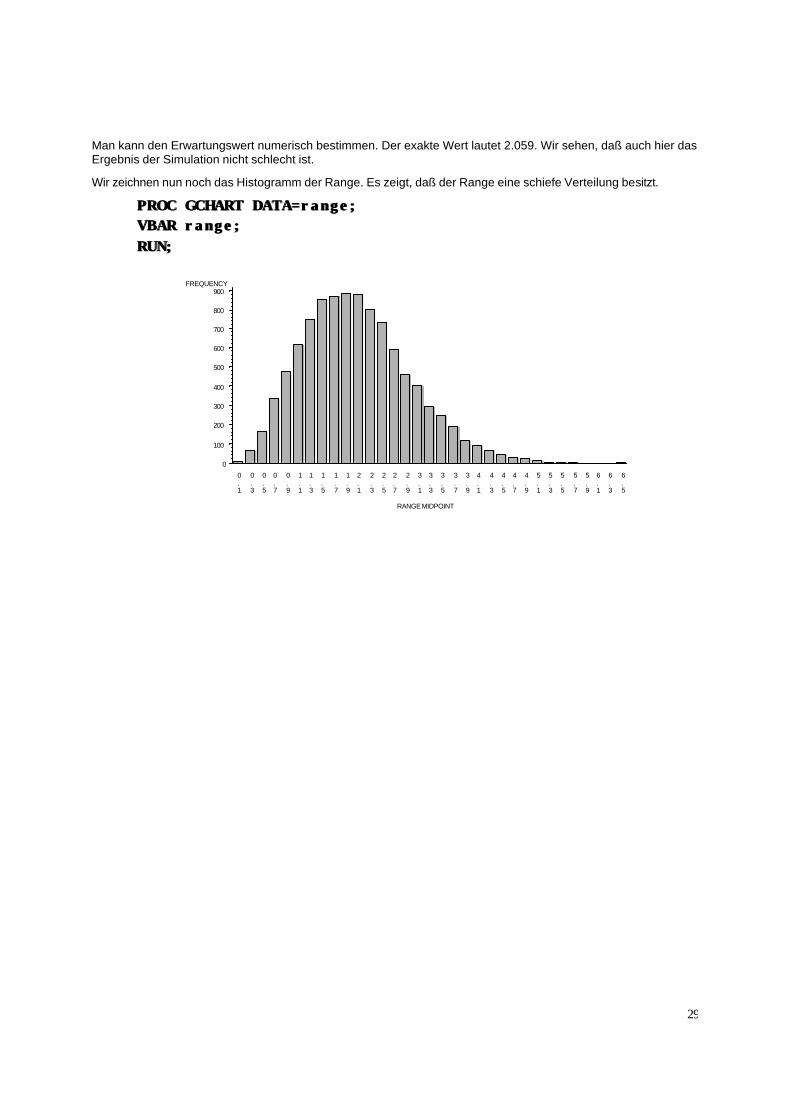
29
Man kann den Erwartungswert numerisch bestimmen. Der exakte Wert lautet 2.059. Wir sehen, daß auch hier das Ergebnis der Simulation nicht schlecht ist.
Wir zeichnen nun noch das Histogramm der Range. Es zeigt, daß der Range eine schiefe Verteilung besitzt.
PROC GCHART DATA=range;PROC GCHART DATA=range; VBAR range;VBAR range; RUN;RUN;
FREQUENCY
0
100
200
300
400
500
600
700
800
900
RANGE MIDPOINT
0.1
0.3
0.5
0.7
0.9
1.1
1.3
1.5
1.7
1.9
2.1
2.3
2.5
2.7
2.9
3.1
3.3
3.5
3.7
3.9
4.1
4.3
4.5
4.7
4.9
5.1
5.3
5.5
5.7
5.9
6.1
6.3
6.5

30
Nun kehren wir wieder zur Datenanalye zurück. Wir schauen uns einen größeren Datensatz an. Bei einem Lehr-gang nahmen 25 Teilnehmer teil. Diesen wurden am Anfang des Lehrgangs ein Fragebogen verteilt. Es wurden folgende Fragen gestellt:
Die Antworten auf folgende Fragen wurden notiert:
1. Geschlecht (SEX) mit den Ausprägungen w(eiblich) und m(ännlich)
2. ALTER
3. KoeperGROESSE
4. Haben Sie den Film TITANIC gesehen mit den Ausprägungsmöglichkeiten j(a) und n(ein)
5. Wie hat der Film Titanic Ihnen GEFALLEN mit den Ausprägungsmöglichkeiten 1,2,3,4 und 5, wobei 1 für sehr gut und 5 für sehr schlecht steht.
6. Sie haben in einem Restaurant eine Rechnung über 43,20 DM zu zahlen.
7. Wieviel (Trink)GELD geben Sie?
• 0,80 DM • 1,80 DM • 2,80 DM • 3,80 DM • 4,80 DM • 5,80 DM • 6,80 DM
8. Bitte ergänzen Sie den folgenden SATZ:
Zu Risiken und Nebenwirkungen ....
mit den Ausprägungsmöglichkeiten r(ichtig), falls der Satz richtig ergänzt wurde, und f(alsch), falls der Satz
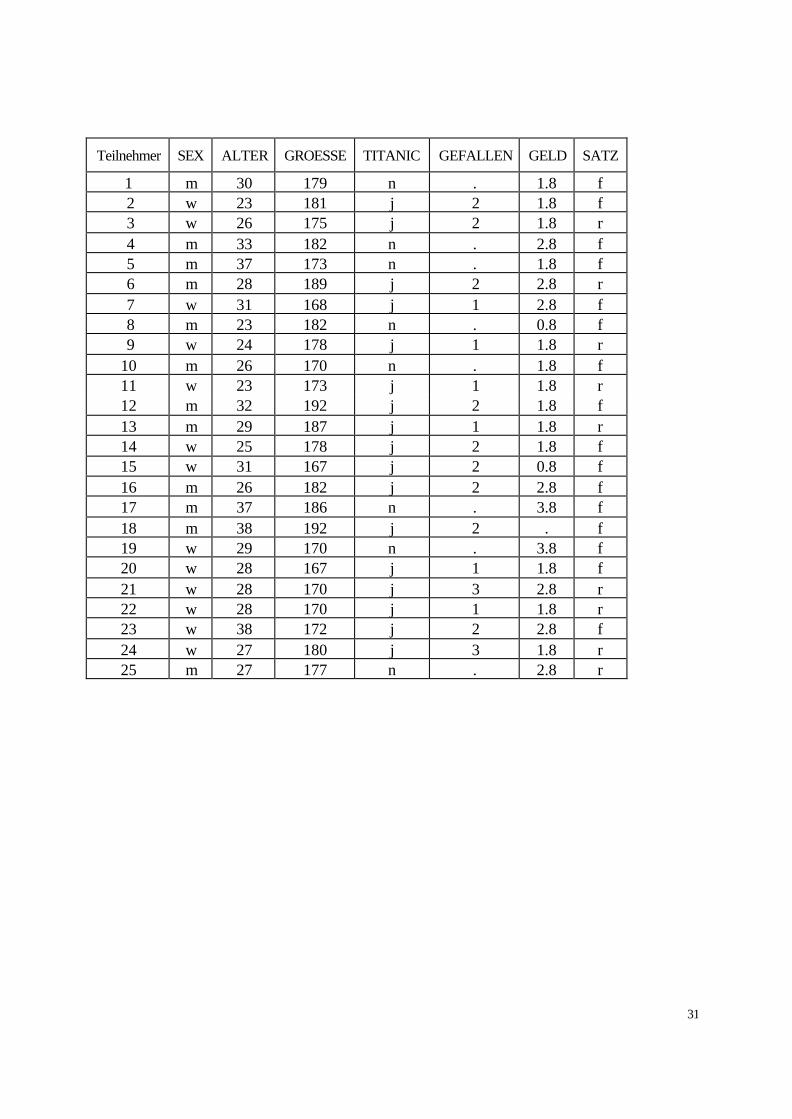
Die Tabelle auf der folgenden Seite zeigt die Ergebnisse der Umfrage.
31
Teilnehmer SEX ALTER GROESSE TITANIC GEFALLEN GELD SATZ
1 m 30 179 n . 1.8 f 2 w 23 181 j 2 1.8 f 3 w 26 175 j 2 1.8 r 4 m 33 182 n . 2.8 f 5 m 37 173 n . 1.8 f 6 m 28 189 j 2 2.8 r 7 w 31 168 j 1 2.8 f 8 m 23 182 n . 0.8 f 9 w 24 178 j 1 1.8 r 10 m 26 170 n . 1.8 f 11 w 23 173 j 1 1.8 r 12 m 32 192 j 2 1.8 f 13 m 29 187 j 1 1.8 r 14 w 25 178 j 2 1.8 f 15 w 31 167 j 2 0.8 f 16 m 26 182 j 2 2.8 f 17 m 37 186 n . 3.8 f 18 m 38 192 j 2 . f 19 w 29 170 n . 3.8 f 20 w 28 167 j 1 1.8 f 21 w 28 170 j 3 2.8 r 22 w 28 170 j 1 1.8 r 23 w 38 172 j 2 2.8 f 24 w 27 180 j 3 1.8 r 25 m 27 177 n . 2.8 r

32
Die Daten stehen folgendermaßen in der Rohdatei:
m 30 179 n . 1.8 f w 23 181 j 2 1.8 f w 26 175 j 2 1.8 r m 33 182 n . 2.8 f m 37 173 n . 1.8 f m 28 189 j 2 2.8 r w 31 168 j 1 2.8 f m 23 182 n . 0.8 f w 24 178 j 1 1.8 r m 26 170 n . 1.8 f w 23 173 j 1 1.8 r m 32 192 j 2 1.8 f m 29 187 j 1 1.8 r w 25 178 j 2 1.8 r w 31 167 j 2 0.8 f m 26 182 j 2 2.8 f m 37 186 n . 3.8 f m 38 192 j 2 . f w 29 170 n . 3.8 f w 28 167 j 1 1.8 f w 28 170 j 3 2.8 r w 28 170 j 1 1.8 r w 38 172 j 2 2.8 f w 27 180 j 3 1.8 r m 27 177 n . 2.8 r
Beim ersten Teilnehmer ist ein Punkt beim Merkmal GEFALLEN zu finden. Ein Punkt steht in SAS für eine fehlende Beobachtung. Dieser Teilnehmer hat also bei dieser Frage keine Antwort gegeben.
Einige der Variablen sind numerisch, andere alphanumerisch. Die numerischen Variablen sind Za hlen, die alpha-numerischen Zeichenketten.
Wir müssen nun im INPUT Befehl folgendes leisten:
• Jede einzelne Variable erhält einen Namen.
• Der Typ jeder Variablen wird festgelegt.
Wir wählen die Namen GESCHLECHT, ALTER, GROESSE, TITANIC, GEFALLEN, GELD und SATZ.
Die alphanumerischen Variablen sind: GESCHLECHT, TITANIC und SATZ.
Der Typ der alphanumerischen Variablen wird durch ein auf den Namen folgendes Dollarzeichen $ im INPUT-
Befehl gekennzeichnet.
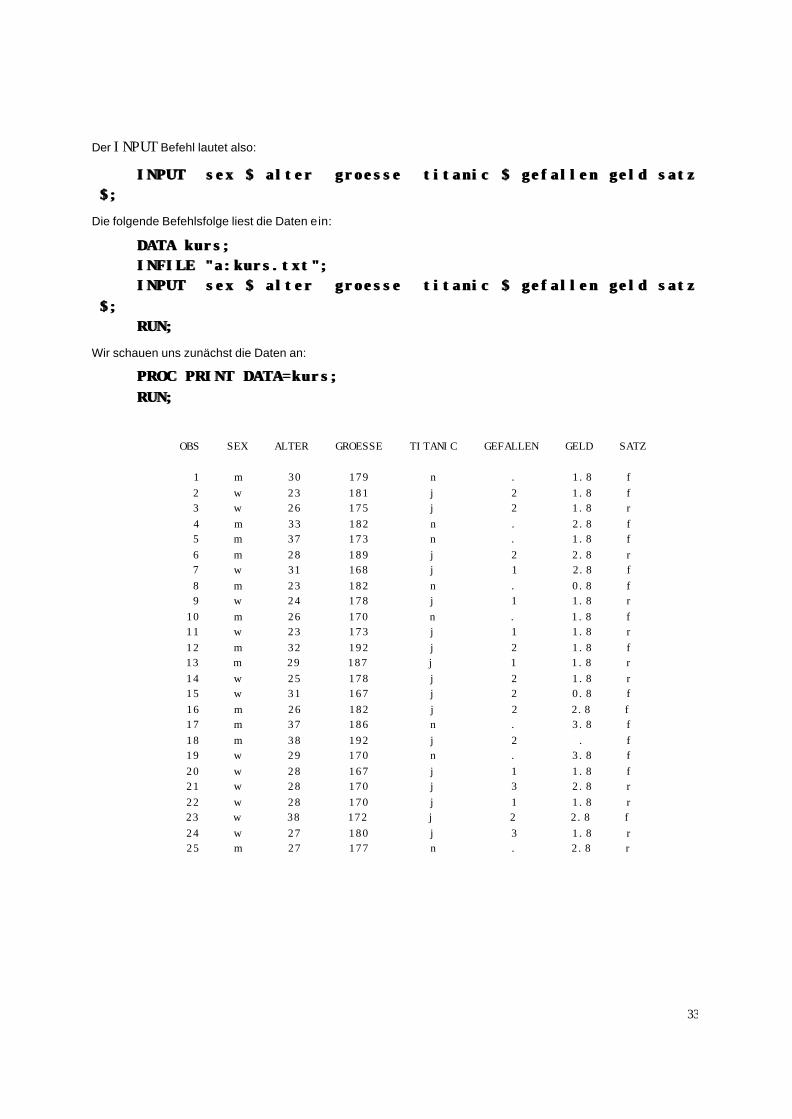
33
Der INPUT Befehl lautet also:
INPUT sex $ alter groesse titanic $ gefallen geld satz INPUT sex $ alter groesse titanic $ gefallen geld satz $;$;
Die folgende Befehlsfolge liest die Daten ein:
DATA kurs;DATA kurs; INFILE "a:kurs.txt";INFILE "a:kurs.txt"; INPUT sex $ alter groesse titanic $ gefallen geld satz INPUT sex $ alter groesse titanic $ gefallen geld satz
$;$; RUN;RUN;
Wir schauen uns zunächst die Daten an:
PROC PRINT DATA=kurs;PROC PRINT DATA=kurs; RUN;RUN;
OBS SEX ALTER GROESSE TITANIC GEFALLEN GELD SATZ 1 m 30 179 n . 1.8 f 2 w 23 181 j 2 1.8 f 3 w 26 175 j 2 1.8 r 4 m 33 182 n . 2.8 f 5 m 37 173 n . 1.8 f 6 m 28 189 j 2 2.8 r 7 w 31 168 j 1 2.8 f 8 m 23 182 n . 0.8 f 9 w 24 178 j 1 1.8 r 10 m 26 170 n . 1.8 f 11 w 23 173 j 1 1.8 r 12 m 32 192 j 2 1.8 f 13 m 29 187 j 1 1.8 r 14 w 25 178 j 2 1.8 r 15 w 31 167 j 2 0.8 f 16 m 26 182 j 2 2.8 f 17 m 37 186 n . 3.8 f 18 m 38 192 j 2 . f 19 w 29 170 n . 3.8 f 20 w 28 167 j 1 1.8 f 21 w 28 170 j 3 2.8 r 22 w 28 170 j 1 1.8 r 23 w 38 172 j 2 2.8 f 24 w 27 180 j 3 1.8 r 25 m 27 177 n . 2.8 r

34
Wenn wir uns einzelne Variablen anschauen wollen, so müssen wir durch einen VAR Befehl die Namen der inte-
ressierenden Variablen festlegen. Schauen wir uns das Geschlecht und das Alter der Teilnehmer an.
PROC PRINT DATA=kurs;PROC PRINT DATA=kurs; VAR sex alter;VAR sex alter; RUN;RUN;
OBS SEX ALTER 1 m 30 2 w 23 3 w 26 4 m 33 5 m 37 6 m 28 7 w 31 8 m 23 9 w 24 10 m 26 11 w 23 12 m 32 13 m 29 14 w 25 15 w 31 16 m 26 17 m 37 18 m 38 19 w 29 20 w 28 21 w 28 22 w 28 23 w 38 24 w 27 25 m 27
35
Die Variablen wie SEX, TITANIC und SATZ sind nominalskaliert. Für stabellen erstel-len.
Dies geschieht mit PROC FREQ.
Der Aufruf
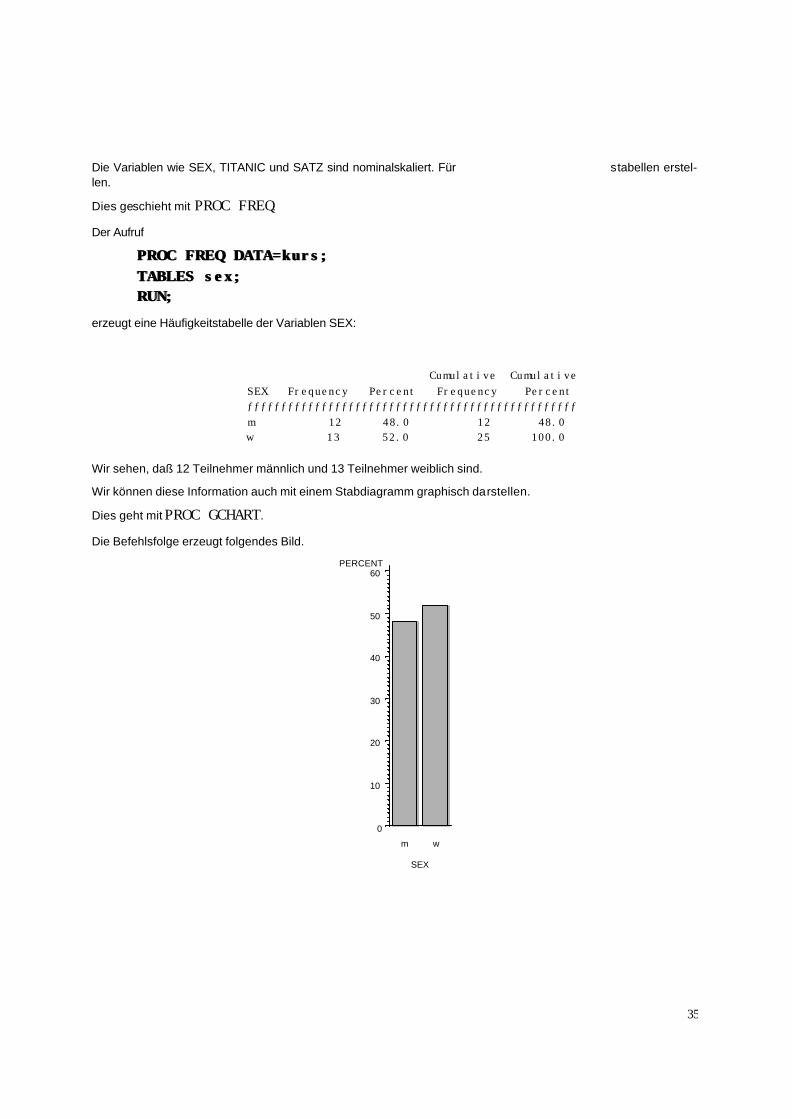
PROC FREQ DATA=kurs;PROC FREQ DATA=kurs; TABLES sex;TABLES sex; RUN;RUN;
erzeugt eine Häufigkeitstabelle der Variablen SEX:
Cumulative Cumulative SEX Frequency Percent Frequency Percent ƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒ m 12 48.0 12 48.0 w 13 52.0 25 100.0 Wir sehen, daß 12 Teilnehmer männlich und 13 Teilnehmer weiblich sind.
Wir können diese Information auch mit einem Stabdiagramm graphisch darstellen.
Dies geht mit PROC GCHART.
Die Befehlsfolge erzeugt folgendes Bild.
PERCENT
0
10
20
30
40
50
60
SEX
m w

36
Mit PROC FREQ kann man auch zweidimensionale Häufigkeitstabellen erzeugen. Das heißt, daß wir zwei Variab-len gleichzeitig betrachten können.
Eine zweidimensionale Tabelle mit den Variablen SEX und TITANIC erhält man durch:
PROCPROC FREQ DATA=kurs; FREQ DATA=kurs; TABLES sex*titanic; TABLES sex*titanic; RUN;RUN;
TABLE OF SEX BY TITANIC SEX TITANIC Frequency‚ Percent ‚ Row Pct ‚ Col Pct ‚j ‚n ‚ Total ƒƒƒƒƒƒƒƒƒˆƒƒƒƒƒƒƒƒˆƒƒƒƒƒƒƒƒˆ m ‚ 5 ‚ 7 ‚ 12 ‚ 20.00 ‚ 28.00 ‚ 48.00 ‚ 41.67 ‚ 58.33 ‚ ‚ 29.41 ‚ 87.50 ‚ ƒƒƒƒƒƒƒƒƒˆƒƒƒƒƒƒƒƒˆƒƒƒƒƒƒƒƒˆ w ‚ 12 ‚ 1 ‚ 48.00 ‚ 4.00 ‚ 52.00 ‚ 92.31 ‚ 7.69 ‚ ‚ 70.59 ‚ 12.50 ‚ ƒƒƒƒƒƒƒƒƒˆƒƒƒƒƒƒƒƒˆƒƒƒƒƒƒƒƒˆ Total 17 8 25 68.00 32.00 100.00 Die Tabelle enthält in jeder Zelle:
• die absolute Häufigkeit
• die relative Häufigkeit
• die bedingten relativen Häufigkeiten jeder Zeile
• die bedingten relativen Häufigkeiten jeder Spalte
Jede Zelle enthält sehr viel Information.
In der Regel benötigt man zwei Informationen:
Die absolute Häufigkeit einer Zelle, um zu wissen, wieviele diese Merkmalskombination aufweisen und eine be-dingte relative Häufigkeit. In unserem Beispiel könnte der Anteil derjenigen, die den Film gesehen haben, anden Frauen und an den Männern interessieren.

37
Wir geben also ein:
PROC FREQ DATA=kurs;PROC FREQ DATA=kurs; TABLES sex*titanic / NOPERCENT NOCOL;TABLES sex*titanic / NOPERCENT NOCOL; RUN;RUN;
und erhalten
TABLE OF SEX BY TITANIC SEX TITANIC Frequency‚ Row Pct ‚j ‚n ‚ Total ƒƒƒƒƒƒƒƒƒˆƒƒƒƒƒƒƒƒˆƒƒƒƒƒƒƒƒˆ m ‚ 5 ‚ 7 ‚ 12 ‚ 41.67 ‚ 58.33 ‚ ƒƒƒƒƒƒƒƒƒˆƒƒƒƒƒƒƒƒˆƒƒƒƒƒƒƒƒˆ w ‚ 12 ‚ 1 ‚ 13 ‚ 92.31 ‚ 7.69 ‚ ƒƒƒƒƒƒƒƒƒˆƒƒƒƒ Total 17 8 25 Wir sehen, daß von den Männern nur 41,67 Prozent, von den Frauen hingegen 92,31 Prozent den Film gesehen haben. Dies spricht dafür, daß zwischen den Merkmalen ein Zusammenhang besteht.
Wir können diese Aussage natürlich auch mit einem Chiquadrattest best tigen. Diesen führt man auch mit PROC FREQ durch. Die Option CHISQ bei der TABLES Anweisung führt den Test durch. Soll keine Kontingenztabelle
ausgegeben werden, muß man die Option NOPRINT beim TABLES Befehl verwenden.
PROC FREQ DATA=kurs;PROC FREQ DATA=kurs; TABLES sex*titanic / NOPRINT CHISQ;TABLES sex*titanic / NOPRINT CHISQ; RUN;RUN;
STATISTICS FOR TABLE OF SEX BY TITANIC Statistic DF Value Prob ƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒ Chi-Square 1 7.354 0.007 Likelihood Ratio Chi-Square 1 7.992 0.005 Continuity Adj. Chi-Square 1 5.211 0.022 Mantel-Haenszel Chi-Square 1 7.060 0.008 Fisher's Exact Test (Left) 9.98E-03 (Right) 1.000 (2-Tail) 0.011 Phi Coefficient -0.542 Contingency Coefficient 0.477 Cramer's V -0.542 Sample Size = 25 WARNING: 50% of the cells have expected counts less than 5. Chi-Square may not be a valid test.

38
Wir erhalten eine Menge an Information. Der Wert des Teststatistik des Chiquadrattests beträgt 7.354. Die Über-schreitungswahrscheinlichkeit des Chiquadrattests beträgt 0.007. Somit wird die Hypothese der Unabzum Signifikanzniveau 0.05 abgelehnt. Der Anteil derjenigen, die den Film Titanic gesehen haben, ist also bei den Frauen höher als bei den Männern.
Wir wollen die Informationen in der Kontingenztabelle graphisch darstellen. Hierzu erstellen wir ein vergleichendes Paretodiagramm. Bei einem Paretodiagramm werden die Merkmalsausprägungen in der Reih u-figkeit aufgezählt. Bei einem vergleichenden Paretodiagramm wird ein Merkmal in mehreren Gruppen betrachtet. Für eine Gruppe wird das Paretodiagramm erstellt, für die anderen Gruppen wird jeweils ein Stabdiagramm er-stellt, wobei die Merkmalsausprägungen genauso angeordnet sind wie beim ersten Paretodiagramm.
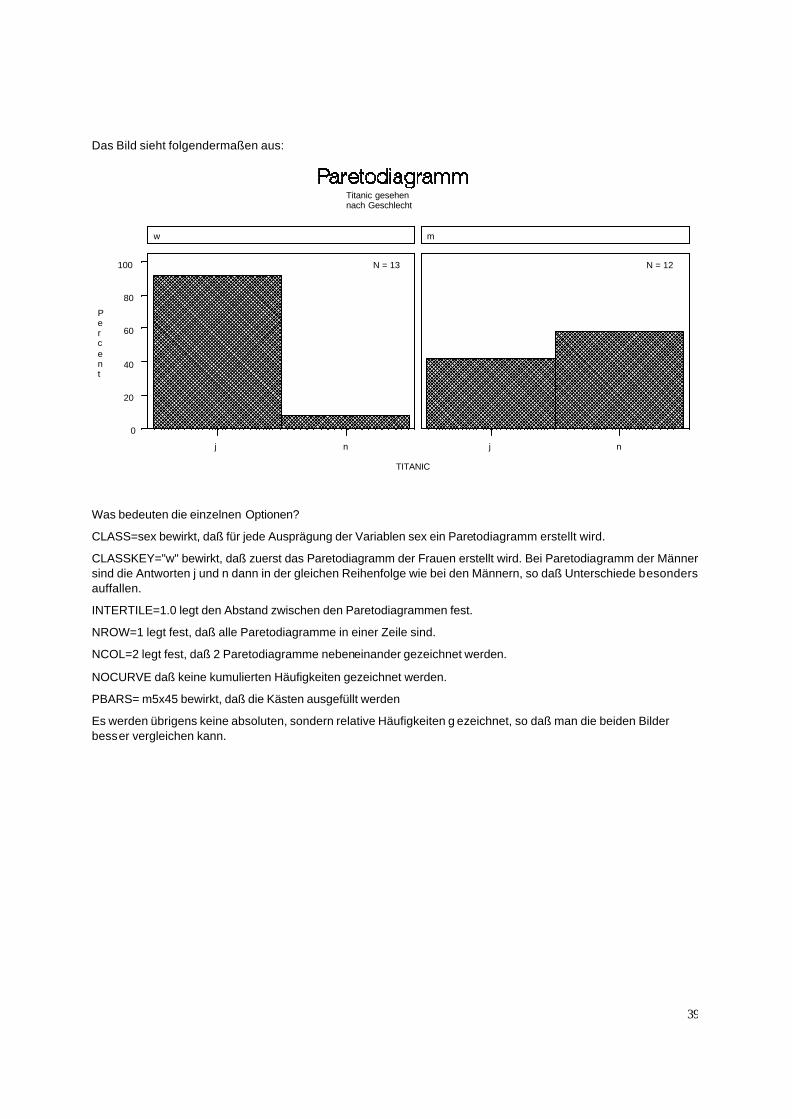
Die folgende Befehlsfolge erstellt das gewünschte Paretodiagramm.
GOPTIONS RESET=all;GOPTIONS RESET=all; TITLE1 "Paretodiagramm";TITLE1 "Paretodiagramm"; TITLE2 "Titanic gesehen";TITLE2 "Titanic gesehen"; TITLE3 "nach Geschlecht";TITLE3 "nach Geschlecht"; PROC PARETO DATA=kurPROC PARETO DATA=kurs GRAPHICS;s GRAPHICS; VBAR titanic/VBAR titanic/ CLASS=sex CLASS=sex CLASSKEY="w" CLASSKEY="w" INTERTILE=1.0INTERTILE=1.0 NROW=1 NROW=1 NCOL=2 NCOL=2 NOCURVENOCURVE PBARS=m5x45 PBARS=m5x45 NLEGEND; NLEGEND; RUN;RUN;
39
Das Bild sieht folgendermaßen aus:
Titanic gesehennach Geschlecht
N = 13
j n
0
20
40
60
80
100
Percent
w
N = 12
j n
m
TITANIC
Was bedeuten die einzelnen Optionen?
CLASS=sex bewirkt, daß für jede Ausprägung der Variablen sex ein Paretodiagramm erstellt wird.
CLASSKEY="w" bewirkt, daß zuerst das Paretodiagramm der Frauen erstellt wird. Bei Paretodiagramm der Männer sind die Antworten j und n dann in der gleichen Reihenfolge wie bei den Männern, so daß Unterschiede besonders auffallen.
INTERTILE=1.0 legt den Abstand zwischen den Paretodiagrammen fest.
NROW=1 legt fest, daß alle Paretodiagramme in einer Zeile sind.
NCOL=2 legt fest, daß 2 Paretodiagramme nebeneinander gezeichnet werden.
NOCURVE daß keine kumulierten Häufigkeiten gezeichnet werden.
PBARS= m5x45 bewirkt, daß die Kästen ausgefüllt werden
Es werden übrigens keine absoluten, sondern relative Häufigkeiten g ezeichnet, so daß man die beiden Bilder besser vergleichen kann.

40
Schauen wir uns die Variable GEFALLEN an. Wir erstellen eine Häufigkeitstabelle dieser Variablen.
PROC FREQ DATA=kurs;PROC FREQ DATA=kurs; TABLES gefallen;TABLES gefallen; RUN;RUN;
Cumulative Cumulative GEFALLEN Frequency Percent Frequency Percent ƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒ 1 6 35.3 6 35.3 2 9 52.9 15 88.2 3 2 11.8 17 100.0 Frequency Missing = 8 Diese Tabelle hat einen Nachteil. Eigentlich bedeutet die 1, daß den Personen der Film Ti tanic sehr gut gefallen hat, die 2, daß er ihnen gut gefallen hat, und die 3, daß sie ihn mittelmäßig fanden. Es wäre sinnvoll, daß in der Tabelle anstatt der 1 sehr gut, anstatt der 3 gut und anstatt der 3 mittelmäßig stände stände. Dies ist möglich mit Hilfe der FORMAT Anweisung.
Zunächst verknüpfen wir mit den Werten der Variablen GEFALLEN die Bezeichnungen der einzel
Dies geht folgendermaßen:
PROC FORMAT;PROC FORMAT; VALUE wieVALUE wie
1="sehr gut" 1="sehr gut" 2="gut" 2="gut" 3="mittel" 3="mittel" ;;
Das Format wird durch die VALUE Anweisung in PROC FORMAT definiert. Der Name, der auf VALUE folgt, gibt
dem Format einen Namen. Da wir für die Variable fach ein Format definieren wollen, nennen wir dieses wie. Jeder andere Name, der die Namenskonventionen von SAS einhält, ist n rlich möglich. Es ist aber besser, die Dinge so zu benennen, daß man aus dem Namen ihre Bedeutung erkennen kann.
Dahinter folgt eine Reihe von Gleichungen, in der den einzelnen Werten von GEFALLEN Zeichenketten zugewiesen werden.
Vorsicht:
die VALUE Anweisung geht bis zur letzten Gleichung. Erst dann kommt das Semikolon.

41
Beim Aufruf von PROC FREQ müssen wir SAS mitteilen, daß wir diese FORMAT Anweisung verwenden wollen.
Dies geht folgendermaßen:
PROC FREQ DATA=kurs;PROC FREQ DATA=kurs; TABLES gefallen;TABLES gefallen; FORMAT gefaFORMAT gefallen wie.;llen wie.; RUN;RUN;
Die FORMAT Anweisung nennt die Variable und den Namen ihres Formats, wobei der Name des Formats mit
einem Punkt endet. Hierdurch "weiß" SAS, daß es sich um den Namen eines Formats und nicht den einer Variab-len handelt.
Wir erhalten dann die gewünschte Tabelle.
Cumulative Cumulative GEFALLEN Frequency Percent Frequency Percent ƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒ sehr gut 6 35.3 6 35.3 gut 9 52.9 15 88.2 mittel 2 11.8 17 100.0 Frequency Missing = 8 Sehr oft will man Teilgruppen analysieren. So könnte zum Beispiel die Verteilung des Alters bei Männern und Frauen von Interesse sein.
Um für Teilgruppen eines Datensatzes statistische Analysen durchführen zu können, müssen wir den Datensatz nach der die Gruppen definierenden Variablen sortieren. Dies geschieht mit Hilfe von PROC SORT.
Wir schauen uns dies für die SAS-Datei kurs.
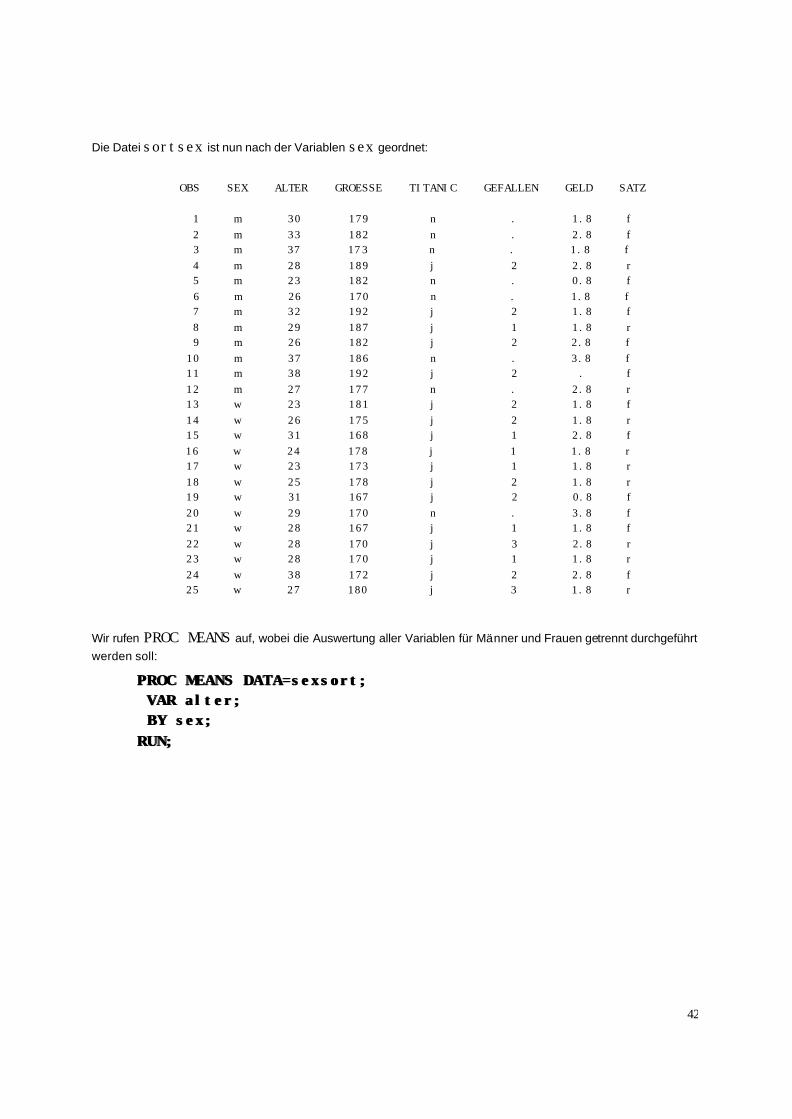
Wir wollen die SAS Datei kurs nach der Variablen sex sortieren und dieses Ergebnis in die SAS Datei sexsort schreiben. Dies geschieht mit folgender Befehlsfolge:
PROC SORT DATA=kurs OUT=sexsort;PROC SORT DATA=kurs OUT=sexsort; BY sex; BY sex; RUN;RUN;
Wir schauen uns das Ergebnis an:
PROC PRINT DATA=sexsort;PROC PRINT DATA=sexsort; RUN;RUN;
42
Die Datei sortsex ist nun nach der Variablen sex geordnet:
OBS SEX ALTER GROESSE TITANIC GEFALLEN GELD SATZ 1 m 30 179 n . 1.8 f 2 m 33 182 n . 2.8 f 3 m 37 173 n . 1.8 f 4 m 28 189 j 2 2.8 r 5 m 23 182 n . 0.8 f 6 m 26 170 n . 1.8 f 7 m 32 192 j 2 1.8 f 8 m 29 187 j 1 1.8 r 9 m 26 182 j 2 2.8 f 10 m 37 186 n . 3.8 f 11 m 38 192 j 2 . f 12 m 27 177 n . 2.8 r 13 w 23 181 j 2 1.8 f 14 w 26 175 j 2 1.8 r 15 w 31 168 j 1 2.8 f 16 w 24 178 j 1 1.8 r 17 w 23 173 j 1 1.8 r 18 w 25 178 j 2 1.8 r 19 w 31 167 j 2 0.8 f 20 w 29 170 n . 3.8 f 21 w 28 167 j 1 1.8 f 22 w 28 170 j 3 2.8 r 23 w 28 170 j 1 1.8 r 24 w 38 172 j 2 2.8 f 25 w 27 180 j 3 1.8 r
Wir rufen PROC MEANS auf, wobei die Auswertung aller Variablen für Männer und Frauen getrennt durchgeführt werden soll:
PROC MEANS DATA=sexsort;PROC MEANS DATA=sexsort; VAR alter; VAR alter; BY sex; BY sex; RUN;RUN;

43
Dies führt zu folgenden Tabellen:
The SAS System 14:17 Tuesday, September 26, 2000 12 Analysis Variable : ALTER --------------------------------------------- SEX=m ------------------------------------- N Mean Std Dev Minimum Maximum ---------------------------------------------------------- 12 30.5000000 4.9267360 23.0000000 38.0000000 ---------------------------------------------------------- --------------------------------------------- SEX=w ------------------------------------- N Mean Std Dev Minimum Maximum ---------------------------------------------------------- 13 27.7692308 4.0651742 23.0000000 38.0000000 ----------------------------------------------------------
Das Durchschnittsalter der Männern beträgt 20.5 Jahre und das der Frauen 27.8 Jahre.
Um zu überprüfen, ob diese Differenz signifikant ist führen wir einen t-Test durch. Dieser beruht auf der Annahme der Normalverteilung.
Dies geht mit der PROC TTEST. Für unser Beispiel wird diese folgendermaßen aufgerufen:
PROC TTEST DATA=sexsort;PROC TTEST DATA=sexsort; CLASS sex; CLASS sex; VAR alter;VAR alter; RUN;RUN;
Wir erhalten folgende Informationen:
TTEST PROCEDURE Variable: ALTER SEX N Mean Std Dev Std Error Variances T DF Prob>|T| -------------------------------------------------- --------------------------------------- m 12 30.50000000 4.92673597 1.42222617 Unequal 1.5046 21.4 0.1470 w 13 27.76923077 4.06517417 1.12747645 Equal 1.5166 23.0 0.1430 For H0: Variances are equal, F' = 1.47 DF = (11,12) Prob>F' = 0.5185
Zunächst werden wichtige Maßzahlen für beide Variablen in der linken Tabelle ausgegeben. Wir sehen noch ein-mal die beiden unterscheidlichen Mittelwerte.

44
Die rechte Tabelle enthält die Ergebnisse des t-Tests für das unverbundene Zweistischprobenproblem.
Schauen wir uns kurz noch einmal die Annahmen und die Teststatistik des t-Tests an.
Ausgangspunkt sind die Zufallsvariablen X X X m1 2, ,. .. , ,Y Y Yn1 2, ,. .. , , wobei gilt X Ni x X~ ( , )µ σ 2 und
Y Nj Y Y~ ( , )µ σ2. Die X i beziehen sich auf die erste Stichprobe und die Yj auf die zweite Stichprobe.
Zu testen ist im zweiseitigen Problem:
H X Y0 :µ µ= gegen H X Y1:µ µ≠
Die Teststatistik des t-Tests lautet:
nm
YXt
11ˆ +⋅
−=
σ.
mit
−+−⋅
−+= ∑∑
==
n
jj
m
ii YYXX
nm 1
2
1
22 )()(2
1σ̂ ,
Wenn H X Y0:µ µ= zutrifft, ist die Teststatistik t-verteilt mit m+n-2 Freiheitsgraden.
Die Entscheidungsregel lautet somit Entscheidung für H 0, wenn gilt − ≤ ≤+ − − + − −t t tm n m n2 1 2 2 1 2; / ; /α α
Entscheidung für H1, wenn gilt t t m n< − + − −2 1 2; /α oder t tm n> + − −2 1 2; /α .
Dabei ist t m n p+ −2; das p-Quantil einer t- Verteilung mit m+n-2 Freiheitsgraden.
Der klassische t-Test beruht auf der Annahme gleicher Varianzen. Also müssen wir unter EQUAL nachschauen. Die Überschreitungswahrscheinlichkeit beträgt 0.1605. Also ist die beobachtete Differenz zwischen den Mittelwer-ten zum Signifikanzniveau 0.05 nicht signifikant.

45
Die rechte Tabelle erhält noch weitere Angaben.
Sind die Varianzen ungleich, liegt es nahe folgende Teststatistik zu verwenden:
tX Y
sm
sn
X Y
' = −
+2 2
mit
( )sm
x xX ii
m2 2
1
11
=−
⋅ −=∑
und
( )sn
y yY ii
n2 2
1
11
=−
⋅ −=
∑
Diese ist unter H0 nicht t-verteilt. Von Welch wurde 1947 vorgeschlagen, die Freiheitsgrade der t-Verteilung so zu korrigieren, daß die Teststatistik approximativ t-verteilt ist. Eine Herleitung dieses Vorschlags ist bei Miller: Beyond Anova, S.60-63 zu finden.
Die korrigierten Freiheitsgrade sind:
df
sm
sn
msm n
sn
X Y
X Y
=+
−⋅
+
−⋅
2 2 2
2 2 2 21
11
1
.
In SAS wird der Welch-Test durchgeführt. In unserem Beispiel kommt er zum gleichen Ergebnis wie der t-Test.
In SAS wird auch die Annahme identischer Varianzen mit dem F-Test überprüft.
Es ist zu testen:
H X Y02 2:σ σ= gegen H X Y1
2 2:σ σ≠
Der geeignete Test ist der F-Test, der auf der Teststatistik
FSS
X
Y
=2
2
mit
( )Sm
X XX ii
m2 2
1
11
=−
⋅ −=
∑ und ( )Sn
Y YY ii
n2 2
1
11
=−
⋅ −=∑ beruht.
Unter H X Y02 2:σ σ= ist F F-verteilt mit m-1 und n-1 Freiheitsgraden.
Eine Herleitung ist bei Mood,Graybill,Boes(1974): Introduction to the theory of statistics, S.246 ff. zu finden.
In unserem Beispiel beträgt die Überschreitungswahrscheinlichkeit 0.1587, so daß die Hypothese identischer Varianzen nicht abgelehnt werden kann.
Ist die Annahme der Normalverteilung nicht gerechtfertigt, sollte man einen verteilungsfreien Test durchführen. Der bekannteste unter diesen ist der Wilcoxon Rangsummentest.

46
Es wird angenommen, daß X X Xm1 2, ,..., unabhängige, identisch mit stetiger Verteilungsfunktion F xX ( ) verteilte Zufallsvariablen und Y Yn1,..., unabhängige, identisch mit stetiger Verteilungsfunktion F yY( ) verteil-te Zufallsvariablen sind, wobei sich F xX ( ) und F yY ( ) nur bezüglich der Lage unterscheiden können.
Das zweiseitige Testproblem lautet
H F z F zY Y0: ( ) ( )= für alle z.
H F z F zY Y1: ( ) ( )= − ∆ für alle z, ∆ ≠ 0
Ein geeigneter Test für diese Hypothesen ist der Wilcoxon Rangsummentest.
Dieser beruht auf den Rängen R X i( ) der X i in der gemeinsamen Stichprobe
X X X Y Ym n1 2 1, ,..., , ,..., .
Dabei gibt R X i( ) an, wieviele der Beobachtungen kleiner oder gleich X i sind.
Schauen wir uns dies für den Datenssatz an.
x1 12= , x2 10 5= . , x3 115= . , x4 13 25= . , x5 12 75= . ,
y1 9 5= . , y2 9 75= . , y3 10 25= . , y4 10 75= . , y5 9 25= .
Es gilt R x R x R x R x R x( ) , ( ) , ( ) , ( ) , ( )1 2 3 4 58 5 7 10 9= = = = = .
Unter der Nullhypothese kommen alle Beobachtungen aus einer Grundgesamtheit. Dies sollte sich in der Stichprobe dadurch zeigen, daß die Beobachtungen der einen Stichprobe nicht alle an dem einen Ende und die der anderen Stichprobe nicht alle an dem anderen Ende der gemeinsamen geordneten Stichprobe liegen.
Schauen wir uns dazu den Fall m=n=3 an.
Die Konfiguration x y y x x y deutet darauf hin, daß die Beobachtungen aus einer Grundgesamtheit, während die Konfigurationen x x x y y y und y y y x x x auf unterschiedliche Verteilungen der Grundgesamtheiten hindeuten. Im ersten Fall sind die Ränge der x-Werte 1 4 5, während sie im zweiten Fall die Werte 1 2 3 und im dritten Fall die Werte 4 5 6 annehmen. Bildet man nun die Summe der Ränge der x-Werte, so ist diese im zweiten und dritten Fall sehr klein bzw. sehr groß. Sehr kleine oder sehr große Werte der Summe der
so darauf hin, daß die Beobachtungen aus unterschiedlichen Verteilungen kommen.

47
Auf dieser Idee basiert der Wilcoxon Rangsummentest.
Seine Teststatistik lautet:
W R Xi
i
m
==
∑ ( )1
Im Beispiel gilt W=8+5+7+10+9=39.
Folgender Aufruf führt einen Wilcoxon Test durch:
PROC NPAR1WAY DATA=sexsort WILCOXON;PROC NPAR1WAY DATA=sexsort WILCOXON; CLASS sex; CLASS sex; VAR alter;VAR alter; RUN;RUN;
Er liefert folgendes Ergebnis:
N P A R 1 W A Y P R O C E D U R E Wilcoxon Scores (Rank Sums) for Variable ALTER Classified by Variable SEX Sum of Expected Std Dev Mean SEX N Scores Under H0 Under H0 Score m 12 181.0 156.0 18.3032784 15.0833333 w 13 144.0 169.0 18.3032784 11.0769231 Average Scores Were Used for Ties Wilcoxon 2-Sample Test (Normal Approximation) (with Continuity Correction of .5) S = 181.000 Z = 1.33856 Prob > |Z| = 0.1807 T-Test Approx. Significance = 0.1933 Kruskal-Wallis Test (Chi-Square Approximation) CHISQ = 1.8656 DF = 1 Prob > CHISQ = 0.1720 N P A R 1 W A Y P R O C E D U R E Wilcoxon Scores (Rank Sums) for Variable ABINOTE Classified by Variable SEX Sum of Expected Std Dev Mean SEX N Scores Under H0 Under H0 Score

48
0 173 21226.5000 20587.0 459.883655 122.696532 1 64 6976.5000 7616.0 459.883655 109.007813 Average Scores Were Used for Ties Wilcoxon 2-Sample Test (Normal Approximation) (with Continuity Correction of .5) S = 6976.50 Z = -1.38948 Prob > |Z| = 0.1647 T-Test Approx. Significance = 0.1660 Kruskal-Wallis Test (Chi-Square Approximation) CHISQ = 1.9337 DF = 1 Prob > CHISQ = 0.1644
Der t-Test und der Wilcoxon Test unterscheiden sich für diesen Datensatz hinsichtlich der Entscheidung nicht.
49
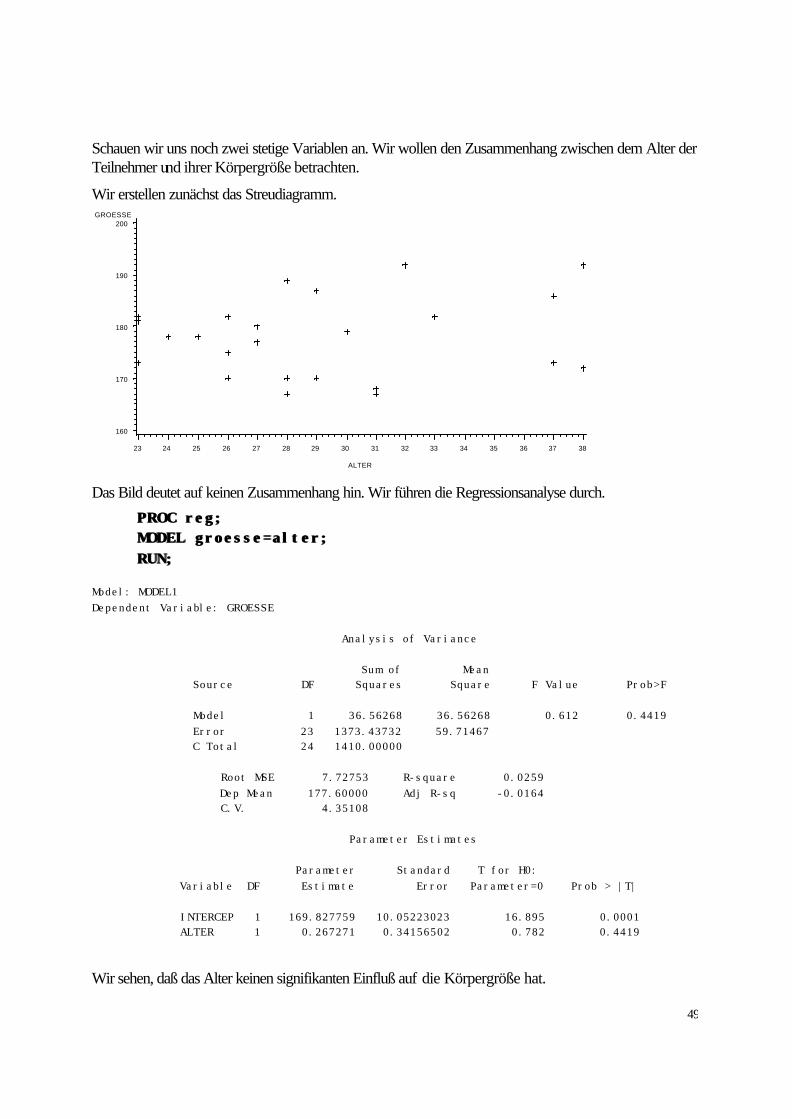
Schauen wir uns noch zwei stetige Variablen an. Wir wollen den Zusammenhang zwischen dem Alter der Teilnehmer und ihrer Körpergröße betrachten.
Wir erstellen zunächst das Streudiagramm. GROESSE
160
170
180
190
200
ALTER
23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38
Das Bild deutet auf keinen Zusammenhang hin. Wir führen die Regressionsanalyse durch.
PROC reg;PROC reg; MODEL groesse=alter;MODEL groesse=alter; RUN;RUN;
Model: MODEL1 Dependent Variable: GROESSE Analysis of Variance Sum of Mean Source DF Squares Square F Value Prob>F Model 1 36.56268 36.56268 0.612 0.4419 Error 23 1373.43732 59.71467 C Total 24 1410.00000 Root MSE 7.72753 R-square 0.0259 Dep Mean 177.60000 Adj R-sq -0.0164 C.V. 4.35108 Parameter Estimates Parameter Standard T for H0: Variable DF Estimate Error Parameter=0 Prob > |T| INTERCEP 1 169.827759 10.05223023 16.895 0.0001 ALTER 1 0.267271 0.34156502 0.782 0.4419
Wir sehen, daß das Alter keinen signifikanten Einfluß auf die Körpergröße hat.