Embed Size (px)
Citation preview

TECHNISCHEUNIVERSITÄT DRESDEN
FAKULTÄT INFORMATIK
INSTITUT FÜR SOFTWARE- UND MULTIMEDIATECHNIK
PROFESSUR FÜRCOMPUTERGRAPHIK UNDV ISUALISIERUNG
PROF. DR. STEFAN GUMHOLD
Großer Beleg
Matching und Registrierung von 3D-Scans
André Jähnig(Mat.-Nr.: 2850453)
Betreuer: Dipl.-Medien-Inf. Sören König
Dresden, 27. Februar 2007


Aufgabenstellung
Mit dem am Lehrstuhl für Computergrafik und Visualisierung entwickelten 3D-Scanner können schnelle
Folgen von Einzelrekonstruktionen durchgeführt werden, was die Erfassung von dynamischer Geometrie
ermöglicht. Bei einer Einzelrekonstruktion handelt es sich lediglich um den als Punktewolke vorliegen-
den und vom Scanner aus sichtbaren Teilausschnitt der Objektoberfläche. Zur Erfassung der Gesamto-
berflächengeometrie von starren Objekten ist es notwendig, verschiedene Teilscans aus der Folge anein-
ander auszurichten und somit zu einem Ganzen zusammenzusetzen (Registrierung). Dazu muss zuvor
eine Identifikation von sich überlappenden Ausschnitten (Matching) erfolgen. Ziel dieser Arbeit ist die
Entwicklung einer Software für das Matching und die Registrierung dynamischer 3D-Scans von starren,
während der Akquisition bewegten Objekten.


1
Inhaltsverzeichnis
1 Einleitung 3
1.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.2 Vorhandene Verfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . 6
2 Registrierung der Scandaten 11
2.1 Problembeschreibung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . 11
2.2 Iterative Closest Point . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . 13
2.3 Erweiterungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . 15
2.3.1 Initiale Ausrichtung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.3.2 Subsampling . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.3.3 Closest Point . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.3.4 Gewichtung von Punktpaaren . . . . . . . . . . . . . . . . . . . . . . . . . . .19
2.3.5 Verwerfen von Punktepaaren . . . . . . . . . . . . . . . . . . . . . . . . .. . . 20
3 Globale Registrierung 23
3.1 Multi-View-Registrierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . 24
3.1.1 Ansichten-Netzwerk . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.1.2 Erzeugung eines gut ausbalancierten Netzwerkes . . . . . . . . . . .. . . . . . 26
3.1.3 Anpassungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
4 Umsetzung 29
4.1 Datenhaltung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .29
4.2 Registrierungsalgorithmus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . 31
4.2.1 Selektion der Punkte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
4.2.2 Finden der korrespondierenden Punkte . . . . . . . . . . . . . . . . . .. . . . 32
4.2.3 Gewichten der Punktepaare . . . . . . . . . . . . . . . . . . . . . . . . . . . .33
4.2.4 Verwerfen von Punktepaaren . . . . . . . . . . . . . . . . . . . . . . . . .. . . 33
4.2.5 Fehlermetrik . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
4.3 Programmablauf . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .35

2
5 Tests 37
5.1 Testszenen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . 37
5.2 Überprüfung mit echten Daten . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . 42
6 Ergebnisse 45
7 Zusammenfassung und Ausblick 53
Literaturverzeichnis 55

3
1 Einleitung
1.1 Motivation
Visualisierungen verschiedener Sachverhalte durch Computer findet man heutzutage in fast allen Be-
reichen des täglichen Lebens, der Wirtschaft oder in der Forschung.Da das Leistungsvermögen der
verwendeten Rechner in den letzten Jahren sehr stark zugenommen hat, sind auch die Anforderungen an
die grafische Darstellung der benötigten Objekte gewachsen. Wo frühereinfache geometrische Formen
zur Darstellung genügten, werden nun immer mehr Details verlangt, um eine nahezu perfekte Abbildung
realer Gegenstände zu erreichen.
Neben der Visualisierung gibt es eine Vielzahl praktischer Anwendungen von 3D-Modellen, wie etwa
die Erkennung bzw. Wiedererkennung von Objekten. So kann eine dreidimensionale Abbildung eines
fremden Objektes mit anderen, in einer Datenbank gespeicherten Modellenverglichen werden, um es
zu identifizieren und dessen Orientierung im Raum zu finden. Oder aber es wird in der Fertigung ein-
gesetzt, um produzierte Artikel auf Fehler zu überprüfen. Eine weitereMöglichkeit der Nutzung wäre
die autonome Navigation von Robotern, welche selbstständig 3D-Landschaften ihrer unbekannten Um-
gebung erstellen und diese zu einer Karte zusammenfügen. So ist es danndem Roboter möglich etwaige
Gegenstände zu erkennen und Routen zu planen. Bei CAD-Programmenkönnen zusätzliche Informatio-
nen über Oberflächendetails geliefert werden, um den Designprozess zu erleichtern. Und, wie anfangs
erwähnt, werden diese 3D-Modelle natürlich in der Computergrafik genutzt. Hier werden reale Objekte
visualisiert, um sie dann möglicherweise in unbekannten Umgebungen und neuen Kontexten zu testen
oder um eine Virtuelle Realität zu erschaffen, in der man sich bewegen kann.
Dreidimensionale Modelle kommen also überall da zum Einsatz, wo eine präziseAbbildung verlangt
wird. Es gibt jedoch zahlreiche Situationen, in denen eine solche digitale Abbildung nicht immer vor-
handen oder die komplette Modellierung mittels CAD zu aufwendig und nicht praktikabel ist (z.B. bei
Skulpturen vor und nach einer Restauration). An dieser Stelle kommen 3D-Scanner-Systeme zum Ein-
satz, welche die Oberfläche der Objekte abtasten und digitale Daten für eine3D-Rekonstruktion liefern.
Die vorliegende Ausarbeitung nutzt dabei die Daten, die von dem Scanner aus [Kön06] stammen. Die-
ser besteht aus einer Hochgeschwindigkeitskamera und einem Hochgeschwindigkeitsprojektor und kann
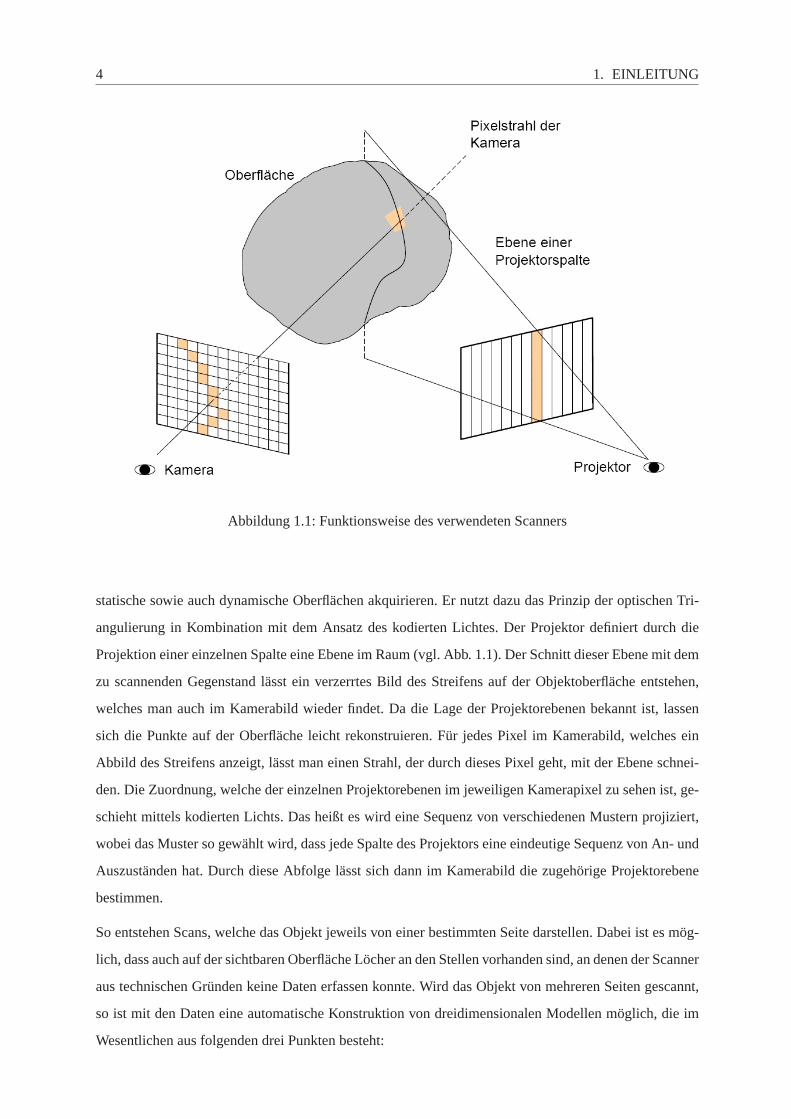
4 1. EINLEITUNG
Abbildung 1.1: Funktionsweise des verwendeten Scanners
statische sowie auch dynamische Oberflächen akquirieren. Er nutzt dazu das Prinzip der optischen Tri-
angulierung in Kombination mit dem Ansatz des kodierten Lichtes. Der Projektor definiert durch die
Projektion einer einzelnen Spalte eine Ebene im Raum (vgl. Abb. 1.1). Der Schnitt dieser Ebene mit dem
zu scannenden Gegenstand lässt ein verzerrtes Bild des Streifens aufder Objektoberfläche entstehen,
welches man auch im Kamerabild wieder findet. Da die Lage der Projektorebenen bekannt ist, lassen
sich die Punkte auf der Oberfläche leicht rekonstruieren. Für jedes Pixel im Kamerabild, welches ein
Abbild des Streifens anzeigt, lässt man einen Strahl, der durch dieses Pixel geht, mit der Ebene schnei-
den. Die Zuordnung, welche der einzelnen Projektorebenen im jeweiligenKamerapixel zu sehen ist, ge-
schieht mittels kodierten Lichts. Das heißt es wird eine Sequenz von verschiedenen Mustern projiziert,
wobei das Muster so gewählt wird, dass jede Spalte des Projektors eine eindeutige Sequenz von An- und
Auszuständen hat. Durch diese Abfolge lässt sich dann im Kamerabild die zugehörige Projektorebene
bestimmen.
So entstehen Scans, welche das Objekt jeweils von einer bestimmten Seite darstellen. Dabei ist es mög-
lich, dass auch auf der sichtbaren Oberfläche Löcher an den Stellen vorhanden sind, an denen der Scanner
aus technischen Gründen keine Daten erfassen konnte. Wird das Objekt von mehreren Seiten gescannt,
so ist mit den Daten eine automatische Konstruktion von dreidimensionalen Modellen möglich, die im
Wesentlichen aus folgenden drei Punkten besteht:

1.1. MOTIVATION 5
1. Akquisition der Daten aus verschiedenen Blickwinkeln (Ansichten)
2. Registrierung der einzelnen Ansichten
3. Integration der Ansichten zu einem Modell
Die Datenakquisition kann verschiedene Informationen liefern, z.B. eine Tiefenkarte, Farbwerte oder an-
dere Kameraparameter. Der 3D-Scanner von [Kön06] stellt die Daten alsdreidimensionale Punktewolken
bereit. Da es aus topologischen und geometrischen Gründen (Teile des Gegenstandes sind verdeckt oder
das Objekt ist größer als das Aufnahmefeld des Scanners) nicht möglichist, das Objekt komplett als
Ganzes zu scannen, werden mehrere Teilscans angefertigt.
Hier kommt oft eine der zwei folgenden Methoden zum Einsatz: Bei der ersten Möglichkeit befindet sich
der Gegenstand vor einem fest installierten Scanner und lässt sich beispielsweise mittels eines Drehtellers
bewegen. Dabei werden in diskreten Zeitschritten Bilder des Objektes aufgenommen. Bei der zweiten
Variante bewegt sich der Scanner selbst um das Objekt herum. Dazu kann er auf einem, sich bewegenden,
Roboterarm befestigt sein und so Bilder aus verschiedenen Blickwinkelnaufnehmen. Der hier verwen-
dete Scanner nutzt die erste Methode in Kombination mit einem Drehteller. Das Problem hierbei ist, dass
der Teller keinerlei Informationen über die jeweilige Objektbewegung zwischen zwei Scanvorgängen lie-
fert. Der einzige Anhaltspunkt ist, dass der Scanner die Informationen ineiner geordneten Reihenfolge
bereitstellt und die Zeitintervalle zwischen zwei aufeinander folgenden Scans sehr gering sind, da es sich
hierbei um einen Hochgeschwindigkeitsscanner handelt.
Deshalb ist es in einem zweiten Schritt nötig die einzelnen Scans, die jeweils Teilausschnitte des Ob-
jektes darstellen, zu registrieren. Das bedeutet, es ist ihre relative Lageund Orientierung zueinander
gesucht. Dazu muss zu jedem Punkt des einen Scans ein korrespondierender Punkt im anderen Scan ge-
funden werden, um in einem weiteren Schritt eine TransformationT (bestehend aus einer Rotation und
einer Translation) zu ermitteln, die alle Punkte des jeweiligen Scans (P,Q,R, ...) aus seinem lokalen
Koordinatensystem in ein gemeinsames globales Koordinatensystem transformiert.
P ′ = T (P ) (1.1)
In einem letzten Schritt werden dann dieN einzelnen registrierten Scans, unter zu Hilfenahme der er-
mittelten TransformationenT zu einem gemeinsamen ModellS zusammengefügt. Diese Vereinigung
aller transformierten PunktemengenP ′, Q′, R′, ... führt somit alle korrespondierenden Punkte räumlich
zusammen.
S = TP (P ) ∪ TQ(Q) ∪ TR(R) ∪ ... = P ′ ∪Q′ ∪R′ ∪ ... (1.2)
Da bei diesem Vorgehen schrittweise ein Scan an einem anderen ausgerichtet wird (z.B. ScanQ an
P , ScanR anQ, usw.), können sich selbst kleinere Fehler, die bei der Akquisition oderRegistrierung

6 1. EINLEITUNG
entstehen, zu einem größeren akkumulieren, je mehr Scans hinzugefügtwerden.
1.2 Vorhandene Verfahren
Viele aktuelle Forschungsansätze setzen eine Objektmodell-Konstruktion mittelsRegistrierung und In-
tegration von verschiedenen Scan-Ansichten um. Die Techniken zur Lösung des Registrierungsproblems
lassen sich in zwei Hauptkategorien teilen:
1. Umgehung des Problems der Registrierung, indem sich auf genau kalibrierte, mechanische Aus-
rüstung verlassen wird, um die Bewegungstransformation zwischen deneinzelnen Scans zu ermit-
teln. Dabei wird angenommen, dass die von der Datenakquisition geliefertenTransformationen
ausreichend genau sind, um die einzelnen Ansichten zu registrieren unddeshalb nicht weiter ver-
bessert werden müssen.
2. Berechnung der Transformation unter Nutzung verschiedener Informationen, die man von den
Daten direkt ableiten kann oder die vom Akquisitionssystem geliefert werden.
Der erste Ansatz ist oft unzureichend, um eine komplette Beschreibung von komplex geformten Objekten
zu erlangen, weil die Ansichten meist nur auf Drehungen oder auf einigewenige, bekannte Standpunkte
begrenzt sind. Eine Verwendung von Markern zur Bewegungsverfolgung ist auch nicht immer möglich.
Die zweite Kategorie ist allgemeiner und bezieht die Suche in einem höher-dimensionalen Parameter-
raum (sechs Dimensionen bei einer gesuchten Rotation und einer Translation) mit ein. Auch wenn gute
Heuristiken genutzt werden, ist dies rechnerisch oft sehr zeitaufwendig. In der vorliegenden Arbeit, wer-
den nur Methoden betrachtet, die der zweiten Kategorie angehören.
Der Iterative Closest Point (ICP) Algorithmus von Besl und McKay [BM92] ist die Standardlösung für
das Registrierungsproblem. Dieser iterative Algorithmus besteht aus dreiTeilen:
1. Finde zu jedem Punkt inP den nächstgelegenen Punkt inQ.
2. Berechne die Transformation, die den mittleren quadratischen euklidischen Abstand (MSE1) zwi-
schen den Punktepaaren minimiert.
3. Wende die Transformation aufP an und aktualisiere den MSE.
Diese drei Schritte werden iterativ wiederholt bis ein gewisses Abbruchkriterium erreicht ist. Dazu wird
meist der MSE direkt oder dessen relative Änderung betrachtet. Besl und McKay haben zudem bewiesen,
dass die Iterationen in Bezug auf den MSE konvergieren.
Unabhängig davon publizierten Chen und Medioni [CM92] ein ähnliches iteratives Schema, welches auf
einer etwas anderen Methode beruht, Korrespondenzen zwischen den Punkten zu bilden. Hierbei wird
1Mean Squared Error

1.2. VORHANDENE VERFAHREN 7
P
Q
1pr
1qr
1pnr
Abbildung 1.2: Abstand Punkt-Ebene (Chen & Medioni)
der Abstand zwischen einem Punkt inP und der Tangentialebene am korrespondierenden Punkt inQ
minimiert. Der korrespondierende Punkt inQ ist dabei der Schnittpunkt der Normale des Punktes inP
und der Oberfläche vonQ (siehe Abb. 1.2).
Die Idee des ICP wurde in mehreren späteren Arbeiten aufgegriffen und in Folge dessen entstand ei-
ne Vielzahl von Anwendungen, Verbesserungen und Modifikationen.Rusinkiewicz und Levoy [RL01]
verfassten eine Gegenüberstellung der verschiedenen Varianten, wobei der Algorithmus zuvor in folgen-
de sechs Teilschritte eingeteilt wurde: (1) Auswählen einer Untermenge von P undQ; (2) Finden von
Punktepaarungen; (3) Gewichten der einzelnen Punktepaare; (4) Verwerfen einiger Paare; (5) Zuweisen
einer Fehlermetrik; (6) Minimieren der Fehlermetrik.
Die meisten Modifikationen zielen darauf ab, den originalen ICP-Algorithmus inBezug auf seine Ro-
bustheit, Konvergenz (Schnelligkeit) und Präzision zu verbessern. Invielen Fällen ist das kritischste
Problem dabei das der Robustheit. Denn der ursprüngliche ICP-Algorithmus geht von einer Datenmenge
aus, die frei von Ausreißern ist. Außerdem mussP eine Untermenge vonQ sein, d.h. jeder Punkt inP
hat einen gültigen Korrespondenzpunkt inQ, der denselben Bereich auf dem gescannten Objekt darstellt.
Somit kann der ursprüngliche ICP-Algorithmus nicht dazu genutzt werden, zwei Scans zu registrieren,
die sich nur teilweise überlappen.
Fast alle Ansätze, die versuchen den ICP robuster zu gestalten und dasProblem des Überlappungsbe-
reiches der Scans zu lösen, nutzen dabei die einfache Heuristik des Verwerfens von Punktpaaren, die
zu weit auseinander liegen. Turk und Levoy [TL94] verbieten weiterhinPaare bei denen ein oder beide
Punkte auf dem Rand des Scans liegen. Das passiert meist dann, wenn es für einen Punkt keinen echten
Korrespondenzpunkt im anderen Scan gibt (siehe Abb. 2.6 auf Seite 21). Bei Godin et al. [GRB94] müs-
sen die Punkte eines Punktepaares zusätzlich noch kompatibel zueinander sein, indem die Werte eines
gewissen Merkmals (Farbe, Normalenvektor, etc.) innerhalb eines bestimmtenBereiches liegen. Dorai
et al. [DJWM96] verwerfen außerdem noch Punktpaare, die nicht kompatible mit ihren Nachbarpaaren
sind, d.h. die Distanz dieses Punktepaares unterscheidet sich stark vondenen der Nachbarn.
8 1. EINLEITUNG
Chen und Medioni schlugen vor, zuerst zwei Ansichten zu registrieren und sie zu einer Meta-Ansicht
zusammenzufassen. Danach sollen inkrementell alle anderen Ansichten registriert und in diese Meta-
Ansicht eingefügt werden [CM92]. Dieser Ansatz wurde ebenso vonMasuda et al. [MSY96] verfolgt.
Bergevin et al. [BSGL96] wiesen jedoch auf ein Problem bei der Methode der Meta-Ansicht hin: Wenn
weitere Scans hinzugefügt werden, so liefern diese auch neue Informationen und Daten, die die Regi-
strierung der bisherigen Scans verbessern könnte. Deshalb suchensie zu jedem Punkt eines Scans in
allen anderen Scans nach korrespondierenden Punkten. Unter Nutzung aller gefundenen Punktepaare
wird dann die Transformation zur Registrierung berechnet. Dieser Vorgang wird mit allen Scans wieder-
holt, bis die Registrierung langsam konvergiert und sich der Registrierungsfehler gleichmäßig zwischen
allen Scans verteilt.
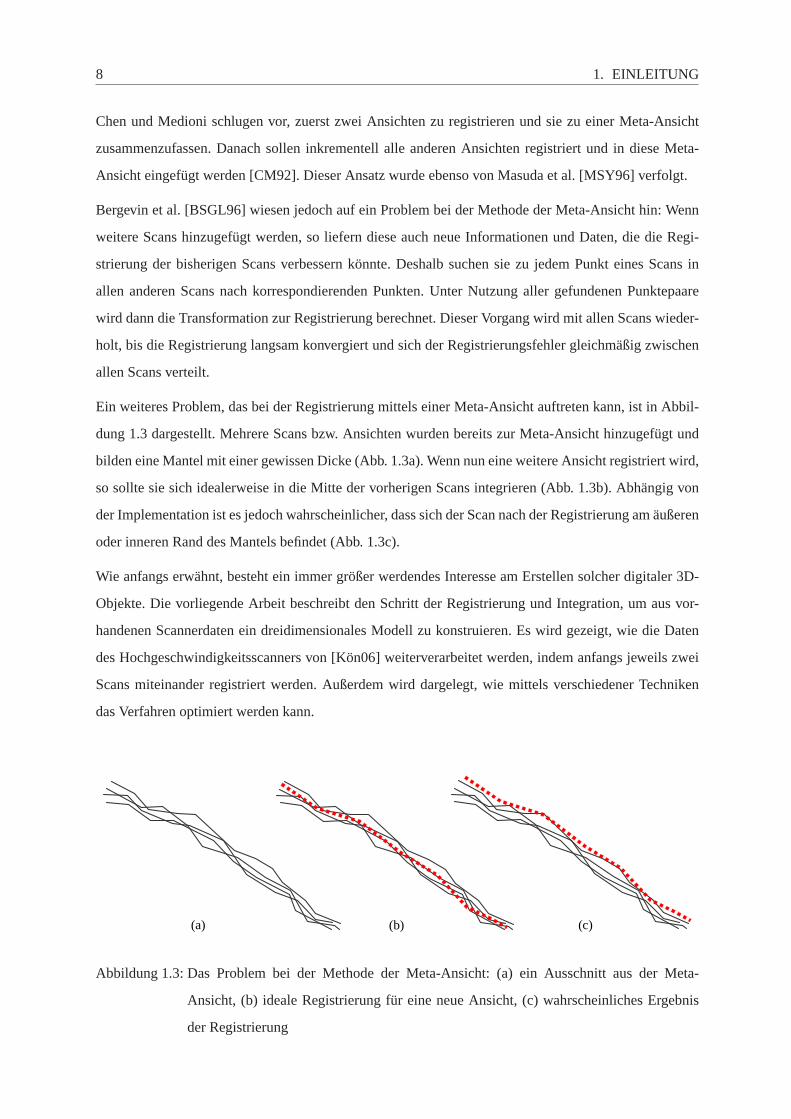
Ein weiteres Problem, das bei der Registrierung mittels einer Meta-Ansicht auftreten kann, ist in Abbil-
dung 1.3 dargestellt. Mehrere Scans bzw. Ansichten wurden bereits zurMeta-Ansicht hinzugefügt und
bilden eine Mantel mit einer gewissen Dicke (Abb. 1.3a). Wenn nun eine weitere Ansicht registriert wird,
so sollte sie sich idealerweise in die Mitte der vorherigen Scans integrieren (Abb. 1.3b). Abhängig von
der Implementation ist es jedoch wahrscheinlicher, dass sich der Scan nach der Registrierung am äußeren
oder inneren Rand des Mantels befindet (Abb. 1.3c).
Wie anfangs erwähnt, besteht ein immer größer werdendes Interesse amErstellen solcher digitaler 3D-
Objekte. Die vorliegende Arbeit beschreibt den Schritt der Registrierung und Integration, um aus vor-
handenen Scannerdaten ein dreidimensionales Modell zu konstruieren.Es wird gezeigt, wie die Daten
des Hochgeschwindigkeitsscanners von [Kön06] weiterverarbeitet werden, indem anfangs jeweils zwei
Scans miteinander registriert werden. Außerdem wird dargelegt, wie mittels verschiedener Techniken
das Verfahren optimiert werden kann.
(a) (b) (c)
Abbildung 1.3: Das Problem bei der Methode der Meta-Ansicht: (a) ein Ausschnitt aus der Meta-
Ansicht, (b) ideale Registrierung für eine neue Ansicht, (c) wahrscheinliches Ergebnis
der Registrierung

1.2. VORHANDENE VERFAHREN 9
Die Ausarbeitung ist so gegliedert, dass zu Beginn die paarweise Registrierung von Scans beschrieben
wird. Dabei wird zuerst noch einmal das Registrierungsproblem genauer erläutert und im Anschluss die
auf den ICP-Algorithmus basierende Lösung dargelegt. Neben der ausführlichen Erklärung desIterative
Closest Points Algorithmus, werden auch die angewendeten Erweiterungen und Modifikationen vorge-
stellt, die den Algorithmus robuster und schneller zu machen.
Daran anschließend wird ein Verfahren der globalen Registrierung vorgestellt. Diese haben den Vor-
teil, dass sie zur Registrierung alle verfügbaren Scans nutzen, wohingegen die paarweise Registrierung
nacheinander jeweils zwei Scans aneinander ausrichtet. So ist es möglicheventuell auftretende Fehler
gleichmäßiger zu verteilen bzw. eine zuvor durchgeführte paarweise Registrierung weiter zu verbessern.
Nach der Erläuterung der softwaretechnologischen Aspekte der Umsetzung des Verfahrens wird in den
weiteren Kapiteln dargelegt, wie die Registrierung anhand von künstlich erstellten Szenen und realen
Scannerdaten getestet wurde. Neben dem Ergebnis von verschiedenen, eingescannten Objekten, wird
auch geklärt, wie die vorliegende Arbeit noch verbessert bzw. erweitert werden kann.

10 1. EINLEITUNG

11
2 Registrierung der Scandaten
Um ein reales Objekt in ein virtuelles 3D-Modell umzuwandeln, wird es von verschiedenen Seiten mit-
tels des Scanners von [Kön06] eingescannt. Dieser stellt die ermittelten Daten als eine dreidimensionale
Punktewolke bereit. Zusätzlich zur Lage im Raum, liefert er außerdem die zweidimensionale Position im
Kamerabild, die Farbe und die Normale der eingescannten Punkte. Die dadurch entstehenden Ansichten
repräsentieren jeweils einen Teilausschnitt des Objektes. Dabei kann esvorkommen, dass selbst die vom
Scanner sichtbare Oberfläche Löcher an den Stellen aufweist, an denen es dem Scanner aus technischen
Gründen nicht möglich war Daten zu akquirieren. Es müssen also alle Teilscans, so zusammengebracht
werden, dass sie sich gegenseitig ergänzen und zusammen eine nahezu vollständige Abbildung des rea-
len Gegenstandes darstellen. Dieser Abschnitt beschreibt das Zusammenführen der Ansichten, welches
auch als Registrierung bekannt ist. Dazu wird in 2.1 zuerst das Problem erklärt und an einem Beispiel
dargestellt. Kapitel 2.2 beschreibt denIterative Closest Point (ICP) Algorithmus, der die Basis für die
in dieser Ausarbeitung beschriebene Anwendung ist. Abschnitt 2.3 befasst sich mit den Problemen, die
auftreten, wenn man den normalen ICP in der Praxis anwenden möchte.
2.1 Problembeschreibung
Unter einer Registrierung versteht man das Ermitteln der relativen Lage (Position und Orientierung)
zweier Repräsentationen des selben Objektes zueinander. Diese Repräsentationen können entweder geo-
metrisch oder fotometrisch sein und entweder zwei- oder dreidimensional vorliegen. Ziel der Registrie-
rung ist es eine räumliche Transformation zu finden, welche die zwei Objektrepräsentationen zusammen-
führt. Diese kann starr oder deformierend sein und eventuell einen Skalierungsterm beinhalten. Die Güte
der Transformation und somit auch die der Registrierung wird von einer Kostenfunktion beurteilt. Es gilt
somit diese Funktion zu minimieren, um die optimale Registrierung zu erhalten.
Die hier vorgestellte Anwendung konzentriert sich auf das Problem einerstarren Registrierung von drei-
dimensionalen geometrischen Objektrepräsentationen ohne Skalierung.
Eine geometrische Objektrepräsentation enthält Informationen über die Form eines Objektes. Eine vo-
lumetrische Formbeschreibung zum Beispiel repräsentiert den Raum oder die Fläche, die von einem
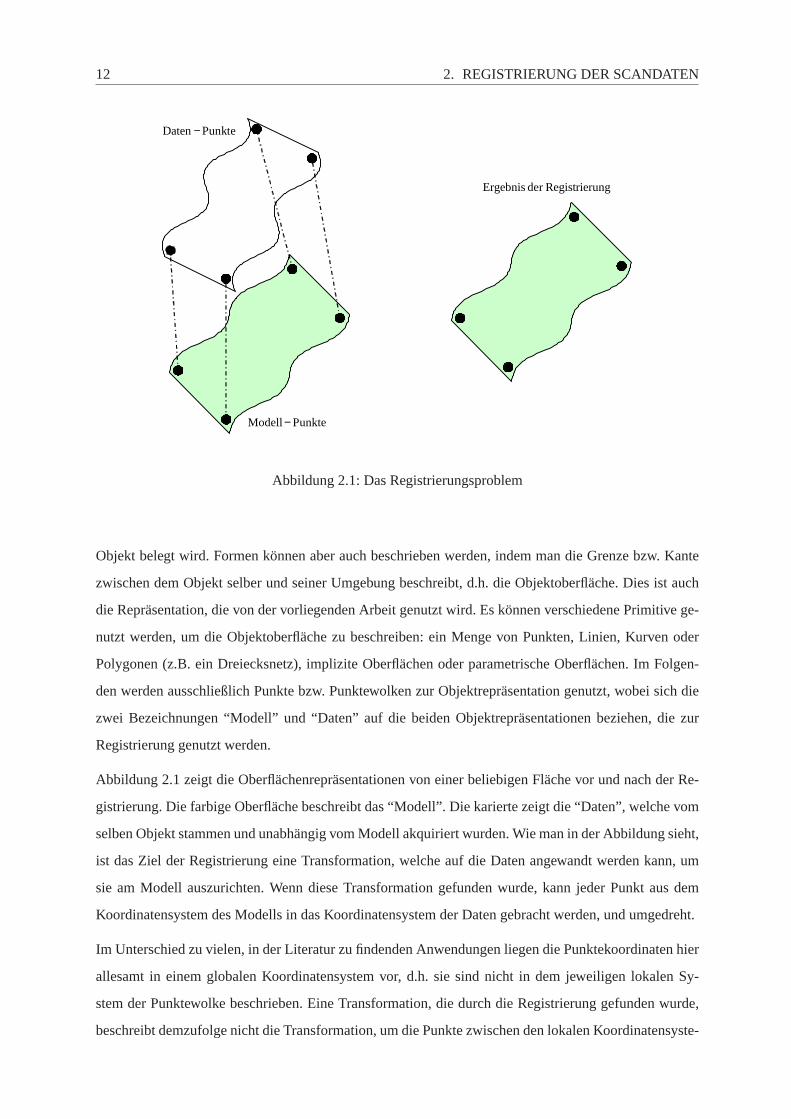
12 2. REGISTRIERUNG DER SCANDATEN
PunkteModell−
PunkteDaten−
ungRegistrierder Ergebnis
Abbildung 2.1: Das Registrierungsproblem
Objekt belegt wird. Formen können aber auch beschrieben werden, indem man die Grenze bzw. Kante
zwischen dem Objekt selber und seiner Umgebung beschreibt, d.h. die Objektoberfläche. Dies ist auch
die Repräsentation, die von der vorliegenden Arbeit genutzt wird. Es können verschiedene Primitive ge-
nutzt werden, um die Objektoberfläche zu beschreiben: ein Menge vonPunkten, Linien, Kurven oder
Polygonen (z.B. ein Dreiecksnetz), implizite Oberflächen oder parametrische Oberflächen. Im Folgen-
den werden ausschließlich Punkte bzw. Punktewolken zur Objektrepräsentation genutzt, wobei sich die
zwei Bezeichnungen “Modell” und “Daten” auf die beiden Objektrepräsentationen beziehen, die zur
Registrierung genutzt werden.
Abbildung 2.1 zeigt die Oberflächenrepräsentationen von einer beliebigen Fläche vor und nach der Re-
gistrierung. Die farbige Oberfläche beschreibt das “Modell”. Die karierte zeigt die “Daten”, welche vom
selben Objekt stammen und unabhängig vom Modell akquiriert wurden. Wieman in der Abbildung sieht,
ist das Ziel der Registrierung eine Transformation, welche auf die Daten angewandt werden kann, um
sie am Modell auszurichten. Wenn diese Transformation gefunden wurde, kann jeder Punkt aus dem
Koordinatensystem des Modells in das Koordinatensystem der Daten gebracht werden, und umgedreht.
Im Unterschied zu vielen, in der Literatur zu findenden Anwendungen liegen die Punktekoordinaten hier
allesamt in einem globalen Koordinatensystem vor, d.h. sie sind nicht in dem jeweiligen lokalen Sy-
stem der Punktewolke beschrieben. Eine Transformation, die durch die Registrierung gefunden wurde,
beschreibt demzufolge nicht die Transformation, um die Punkte zwischenden lokalen Koordinatensyste-

2.2. ITERATIVE CLOSEST POINT 13
men zu transferieren, sondern die tatsächliche räumliche Bewegung und Drehung, um die Punkte beider
Scans so gut wie möglich zusammen zu führen. Das bedeutet, da wo im Zuge des ICP-Algorithmus
oder verwandter Methoden die Rede von einer Transformation zwischenlokalen Koordinatensystemen
ist, so bezieht sich das in dieser Ausarbeitung auf die eigentlich räumliche Lageveränderung in einem
gemeinsamen, globalen Koordinatensystem.
Das Problem der Registrierung und der verbundenen Transformationssuche kann formell auch wie folgt
ausgedrückt werden:
min d [X,T (P )] (2.1)
wobeiX eine Repräsentation des Modells undP die Daten darstellt.T ist eine starre Transformation,
bestehend aus einer Translation und einer Rotation. Minimiert wird überd, ein Abstandsmaß zwischen
den Objektrepräsentationen. Bezogen auf die Anwendung in dieser Arbeit muss durch die Registrierung
eine Translation und eine Rotation gefunden werden, welche den mittleren quadratischen Abstand (MSE)
zwischen korrespondierenden Punkten aus beiden Repräsentationenminimiert.
2.2 Iterative Closest Point
Der Iterative Closest Point Algorithmus von Besl und McKay [BM92] ist eine Möglichkeit das Problem
der Registrierung zu lösen. Da diese Arbeit auf dem ICP aufbaut, wird er an dieser Stelle noch einmal
kurz erläutert.
Der ICP-Algorithmus ermittelt starre Transformationsparameter zwischen zwei 3D-Formen (Daten, Mo-
dell). Er besteht im Wesentlichen aus zwei Teilschritten: Der erste legt einetemporäre Korrespondenz
zwischen Punkten aus den Daten und dem Modell fest und der zweite berechnet mittels eines aus der
Korrespondenz ermittelten Quaternion eine Transformation.
Die Korrespondenz zwischen den Daten-Punkten und den Punkten im Modell wird gebildet, indem zu
einem Daten-Punktp der nächstgelegene Punkt im ModellX gesucht wird, so dassd(p, y) = d(p,X)
wobeiy ∈ X. Die Berechnung des nächstgelegenen Punktes ist beiN zu untersuchenden im schlech-
testen FallO(N). Wenn diese Closest-Point-Berechnung für jeden Punkt inP durchgeführt wird, so ist
dieser Vorgang im schlechtesten FallO(NpNx) (Np, Nx ist die Anzahl der Punkte inP undX). IstC
der Operator um den nächstgelegenen Punkt zu berechnen, so ergibt sich die Menge der nächstgelegenen
PunkteY wie folgt:
Y = C(P,X) (2.2)
Mittels dieser Korrespondenz kann nun ein Einheitsquaternion berechnet werden. Dies ist ein Gruppe von
vier Zahlen~qR = (q0, q1, q2, q3)t, wobeiq0 ≥ 0 undq20 +q21 +q22 +q23 = 1. Durch einen Quaternion kann

14 2. REGISTRIERUNG DER SCANDATEN
man den dreidimensionalen Raum beschreiben und so lässt sich aus dem erwähnten Einheitsquaternion
eine3x3 Rotationsmatrix wie folgt aufstellen:
R =
q20 + q21 − q22 − q23 2(q1q2 − q0q3) 2(q1q3 + q0q2)
2(q1q2 + q0q3) q20 + q22 − q21 − q23 2(q2q3 − q0q1)
2(q1q3 − q0q2) 2(q2q3 + q0q1) q20 + q23 − q21 − q22
(2.3)
Wenn ~qT = (q4q5q6)t der Translationsvektor ist, so kann der komplette Registrierungsvektor wiefolgt
geschrieben werden:
~q = ( ~qR| ~qT ) (2.4)
Für mehr Informationen zu Quaternions sei an dieser Stelle auf [Hor87] verwiesen. DessenClosed Form
Solution ist die Basis für den ICP-Alogrithmus und wird im Folgenden in den wesentlichen Grundzügen
noch einmal kurz dargelegt.
SeiP = {p} die akquirierte Daten-Punktewolke, welche an der Modell-PunktewolkeX = {x} ausge-
richtet werden soll. Die Anzahl der Punkte in den Daten und im Modell ist gleich (Np = Nx), wobei
zu jedem Punktpi der Korrespondenzpunkt der Punktxi mit demselben Index ist. Die zu minimierende
Funktion des mittleren quadratischen Abstandes ist:
f(~q) =1
Np
Np∑
i=1
‖~xi −R( ~qR)~pi − ~qT ‖2 (2.5)
Der Schwerpunkt~µp der Daten-Punktewolke und der Schwerpunkt~µx der Modell-Punktewolke sind
gegeben durch:
~µp =1
Np
Np∑
i=1
~pi und ~µx =1
Nx
Nx∑
i=1
~xi (2.6)
Die Kreuz-Kovarianz-MatrixΣpx der MengenP undX ergibt sich aus:
Σpx =1
Np
Np∑
i=1
[
(~pi − ~µp)(~xi − ~µx)t]
=1
Np
Np∑
i=1
[
(~pi ~xit)
]
− ~µp ~µxt (2.7)
Aus den zyklischen Komponenten der antisymmetrischen MatrixAij = (Σpx−ΣTpx)ij wird der Spalten-
vektor∆ = [A23A31A12]T gebildet. Dieser Vektor wird dann genutzt um die symmetrische4x4 Matrix
Q(Σpx) zu bilden:
Q(Σpx) =
tr(Σpx) ∆T
∆ Σpx + ΣTpx − tr(Σpx)I3
(2.8)
wobeiI3 eine3x3 Einheitsmatrix ist. Der zum maximalen Eigenwert der MatrixQ gehörende Eigenvek-
tor qR = (q0q1q2q3)t wird als optimale Rotation gewählt. Die optimale Translation ergibt sich dann wie
folgt:
~qT = ~µx −R( ~qR) ~µp (2.9)

2.3. ERWEITERUNGEN 15
• Gegeben sind die Daten-PunktemengeP mit Np Punkten und die Modell-PunktemengeX
mit Nx Punkten.
• Die Iteration wird initialisiert mitP0 = P , q0 = (1, 0, 0, 0, 0, 0, 0)t undk = 0. Der Regi-
strierungsvektor wird relativ zur PunktewolkeP0 definiert, so dass die finale Registrierung
die komplette Transformation darstellt. Schritt 1, 2, 3 und 4 werden wiederholt, bis die Kon-
vergenz innerhalb einer gewissen Toleranz ist.1. Berechne die nächstgelegenen Punkte:Yk = C(Pk, X)
2. Berechne die Registrierung:(qk, dk) = Q(P0, Yk)
3. Wende die Registrierung an:Pk+1 = qk(P0)
4. Beende die Iteration wenn die Änderung des mittleren quadratischen Fehlers unter einen
festgesetzten Schwellwertτ > 0 fällt, welcher die gewünschte Genauigkeit angibt:
dk − dk+1 < τ
Abbildung 2.2: ICP-Algorithmus
Diese Quaternion-Berechnung über den minimalen quadratischen Abstandhat eine Komplexität von
O(N) und kann als
(~q, dms) = Q(P,X) (2.10)
geschrieben werden. Hierbei istd der mittlere quadratische Fehler. Die Punktemenge nach der Registrie-
rung mit dem Vektor~q kann als~q(P ) geschrieben werden. Unter Nutzung der Gleichung 2.2 kann 2.10
auch in
(~q, d) = Q(P, Y ) (2.11)
umgeformt werden. Die Positionen der Punkte ausP werden nach der Berechnung durchPneu = ~q(Palt)
aktualisiert.
Nachdem alle Teilschritte beschrieben wurden, lässt sich der ICP-Algorithmus wie in Abbildung 2.2
zusammenfassen.
2.3 Erweiterungen
Der im letzten Kapitel vorgestellte ICP-Algorithmus ist in dieser Form praktischnicht nutzbar, um die
Daten des Scanners von [Kön06] zu registrieren. Die Gründe hierfürund die damit notwendigen Anpas-
sungen und Erweiterungen, um trotzdem ein gutes Ergebnis zu erreichen, werden im Folgenden aufge-
zeigt.

16 2. REGISTRIERUNG DER SCANDATEN
2.3.1 Initiale Ausrichtung
Der ICP, sowie auch viele andere Registrierungsmethoden, gehen davon aus, dass eine initiale Ausrich-
tung der beiden Punktemengen vorliegt, d.h. eine Transformation bekanntist, um die Punkte des einen
Scans in das lokale Koordinatensystem des anderen Scans zu transformieren. Durch die Registrierung
wird dann diese weiter verfeinert bzw. verbessert. Wird dagegen die Registrierungsmethode auf zwei
beliebig im Raum platzierte Scans angewendet, die nicht einmal annährend richtig zu einander orientiert
sind, so wird der Algorithmus in den meisten Fällen ein falsches Ergebnis liefern. Im Fall des ICP und
der Nutzung des mittleren quadratischen Abstands als zu minimierende Kostenfunktion heißt das, dass
der Algorithmus nicht im globalen, sondern in einem lokalen Minimum der Kostenfunktion terminiert
und somit nicht das optimale Ergebnis für die Transformation liefert.
Bei vielen Anwendungen werden zur Gewinnung der initialen AusrichtungInformationen genutzt, die
das kalibrierte Scannersystem liefert. Ist etwa der Scanner auf einem Ausleger montiert, so wäre eine
mögliche Information zur Gewinnung der ungefähren Lage der Scans zueinander die Bewegung des
Auslegers zwischen zwei Aufnahmen. Eine andere Möglichkeit wäre dieVerfolgung von Markern im
Scanbild, um so eine erste ungefähre Transformation zu errechnen. Es gibt auch verschiedene Ansätze
die unter Nutzung unterschiedlicher Eigenschaften (Farbe, Normalen, Geometrie, etc.) versuchen eine
initiale Ausrichtung der beiden Scans zu berechnen. Eine weitere einfache Möglichkeit wäre auch die
Eingabe durch einen Benutzer.
Der hier verwendete Scanner liefert zwar keine initiale Ausrichtung bzw.irgendeine Information über
die Lage der einzelnen Scans zueinander, dennoch muss keine aufwendige Berechnung durchgeführt
werden, um diese zu erlangen. Der Highspeedscanner führt eine Reihe von Scans durch und stellt diese
Daten in zeitlicher Ordnung bereit. Da das Zeitintervall zwischen zwei Scans sehr klein ist, ist auch die
räumliche Bewegung bzw. die Änderung der Lage und Orientierung des Objektes sehr klein. Die hier
beschriebene Anwendung ist so konzipiert, dass sie die Daten in der Reihenfolge weiterverarbeitet, wie
sie der Scanner liefert. Deshalb wird als initiale Transformationsmatrix die Einheitsmatrix genommen,
welche dann durch die Registrierung weiter verbessert wird.
2.3.2 Subsampling
Um die Komplexität der durchzuführenden Berechnungen, speziell dieder Closest-Point-Berechnung,
zu minimieren, werden diese Vorgänge nicht mit allen verfügbaren Punktendurchgeführt. In diesem Fall
wären dies nämlich ca.200.000−300.000 Punkte pro Scan. Um die Punktanzahl zu minimieren wird ein
Subsampling über alle Punkte eines Scans durchgeführt und dann nur mitdieser Auswahl weiter gearbei-

2.3. ERWEITERUNGEN 17
(a) (b)
Abbildung 2.3: Subsampling einer Punktemenge mit der Rate1/3: (a) uniform, (b) zufällig
tet. Folgende zwei Möglichkeiten wurden in dieser Arbeit umgesetzt: Ein gleichmäßiges Subsampling
[TL94] und ein zufälliges Subsampling, wie es von [MSY96] vorgeschlagen wird. Da die Punkte in
einer geordneten Reihenfolge vorliegen, wurde das gleichmäßige Subsampling für eine Rate von1/m
umgesetzt, in dem einfach jederm-te Punkte ausgewählt wurde. Beim zufälligen Subsampling wird die
Auswahl der Punkte aus dem Modell sowie aus den Daten nach jeder Iteration zufällig neu gewählt (vgl.
Abbildung 2.3).
Eine weitere Auswahlstrategie, die allerdings nicht umgesetzt wurde, wäre, eine Selektion der Punkte so
zu wählen, dass die Verteilung ihrer Normalen so groß wie möglich ist [RL01].Die Motivation für die-
ses Verfahren liegt darin, dass für einige Registrierungsszenarien kleine Regionen vom Modell bzw. den
Daten von hoher Wichtigkeit sind, um die genaue Ausrichtung der beiden Scans zu bestimmen. Eine Se-
lektion wie etwa das zufällige Subsampling wird oft nur einige Samples aus diesen Regionen auswählen,
was dann im weiteren Vollzug dazu führt, dass einige Komponenten der Transformation nicht richtig
berechnet werden können. Eine Möglichkeit, die Chance zu erhöhen,genügend Werte für die richtige
Berechnung aller Transformationskomponenten zu gewährleisten, ist das Gruppieren der Normalen in
Bezug auf ihre Position im Winkelraum, um dann gleichmäßig über diese Gruppen zu selektieren (siehe
Abb. 2.4). Dies ist eine einfache Methode, um Oberflächenmerkmale für die Registrierung zu nutzen.
Sie ist zwar rechnerischen nicht aufwendig, aber dafür auch weniger robust als traditionelle merkmals-
basierte Verfahren.
2.3.3 Closest Point
Die Suche des nächstgelegenen Punktes im Modell für einen Daten-Punkt lässt sich in Bezug auf Ge-
schwindigkeit und Korrektheit verbessern. Um die Suche zur Bildung der Punktepaare zu beschleunigen,
wird die Punktemenge vom Modell in einen Kd-Tree einsortiert [FBF77]. Ein Kd-Tree ist eine Verall-

18 2. REGISTRIERUNG DER SCANDATEN
(a) (b)
Abbildung 2.4: korrespondierende Punktepaare, die (a) bei einem zufälligen Subsampling und (b) bei
einem Sampling über die Normalenverteilung entstehen
gemeinerung eines einfachen binären Baumes, wobei jeder Knoten eine Untermenge des Scans darstellt
und die Wurzel alle Punkte vereinigt und somit den kompletten Scan verkörpert. Jeder Knoten hat zwei
Kinder, welche die Teilmengen repräsentieren, die entstehen wenn man denKnoten nach einem gewissen
Muster teilt. Die Blätter des Baumes beinhalten eine relativ kleine Teilmenge (Punkte), die nicht weiter
aufgeteilt wird. Um die Punktemenge eines Scans in einen Kd-Tree einzusortieren, wird der dreidimen-
sionale Raum entlang der drei Hauptachsen aufgeteilt. Dabei wird jeder Knoten entlang der Dimension
geteilt, welche die größte Streuung der Punkte aufweist. Angefangen mit der Wurzel, die den gesamten
Scan beinhaltet, werden dann im folgenden Verlauf die Kinder rekursivweiter aufgeteilt, bis die Kno-
ten nur noch eine geringe Anzahl von Punkten beinhalten. Die Teilung erfolgt dabei jeweils entlang des
Mittelwertes in dieser Dimension.
Dadurch muss bei gegebenem Datenpunkt nur noch ein Bruchteil der Punktemenge des Modells durch-
sucht werden, um den nächstgelegensten Punkt zu finden. Beginnend bei der Wurzel geht man den Baum
entsprechend der Teilungsdimension und des Teilungswertes abwärts und braucht so nur noch den Blatt-
knoten und die darin enthaltenen wenigen Punkte überprüfen.
Wird ein Punkt gefunden, so können verschiedene Merkmale herangezogen werden, um die Kompatibi-
1
2
2
3
3
33
Abbildung 2.5: beispielhafte Einsortierung einer zweidimensionalen Punktemenge in einen Kd-Tree

2.3. ERWEITERUNGEN 19
lität beider Punkte zueinander zu testen. [GRB94] prüfen zum Beispiel die Farbwerte beider Punkte. Da
beim hier verwendeten Scannersystem die Farbwerte derzeit noch stark von der Belichtungszeit abhän-
gen und auch generell nicht dem eigentlichen Farbwert entsprechen,kann diese Methode nicht genutzt
werden. Stattdessen wird eine andere Metrik genutzt, die auf den Winkeln zwischen den Normalen bei-
der Punkte basiert [Pul99]. Liegen diese nicht in einem gewissen Winkelzueinander (z.B.≤ 45◦), so
wird der gefundene Modell-Punkt verworfen und der nächst nähere gesucht.
2.3.4 Gewichtung von Punktpaaren
Die Daten, die der Scanner liefert, sind aufgrund von auftretenden Fehlern während der Rekonstruktion
nicht immer zu 100% korrekt. So kommt es oft vor, dass die Punktewolke neben den richtigen Punkten,
auch Ausreißer beinhaltet, die keine Regionen der eigentlichen realen Objektoberfläche repräsentieren.
Wenn diese Ausreißer bei der Bildung der Punktepaare als eine gültige Korrespondenz angenommen
werden, so bringen sie damit einen Fehler in die Berechnung der Transformation ein. Damit dieser Feh-
lerterm keinen großen Einfluss auf die Registrierung nimmt, gilt es diese nichtkorrekten Korrespon-
denzpaare zu finden und sie umgekehrt proportional ihres Fehlers zugewichten. Dazu wurden neben der
normalen konstanten Gewichtung aller Punktepaare noch zwei weitere Verfahren implementiert: Einmal
die Gewichtung entsprechend des euklidischen Abstandes der korrespondierenden Punkte zueinander.
Dabei bekommen Punktpaare(~pi, ~qi) mit einem größeren Abstandd ein kleineres Gewichtw zugewie-
sen, als nah beieinander liegende Punkte [GRB94]:
w = 1 −d(~pi, ~qi)
dmax
(2.12)
Dieser Ansatz ähnelt dem des Verwerfens von Punktepaare, deren euklidischer Abstand zueinander grö-
ßer als ein gewisser Grenzwert ist (siehe Kapitel 2.3.5). Allerdings wird hierbei die Unstetigkeit in den
Punktepaaren vermieden.
Die zweite Variante nutzt die Kompatibilität der Normalen( ~npi, ~nqi
) bzw. ihre Winkelabweichung, um
ein Gewicht zu berechnen:
w = ~npi· ~nqi
(2.13)
Auch hier werden die Punktepaare wieder umgekehrt proportional gewichtet. Aus dem Skalarprodukt
beider Normalen folgt, dass Paare, deren Normalen einen großen Winkeleinschließen, ein kleineres
Gewicht erhalten als jene, deren Normalen nahezu parallel zueinander sind.
Neben diesen Varianten kann man auch weitere Merkmale wie etwa die Farbennutzen [GRB94], um die
Punktepaare zu gewichten. Da aber, wie im vorherigen Abschnitt erläutert, dies aus technischen Gründen
praktisch nicht möglich ist, wird es an dieser Stelle nicht weiter verfolgt.

20 2. REGISTRIERUNG DER SCANDATEN
2.3.5 Verwerfen von Punktepaaren
Der Standard-ICP-Algorithmus verlangt, dass der Daten-Scan entweder denselben Ausschnitt wie das
Modell darstellt oder aber eine Untermenge des Modells ist. Möchte man allerdings aus den einges-
cannten Ansichten ein dreidimensionale Abbildung des realen Objektes erststellen, so überlappen sich
die einzelnen Scans lediglich und es wird kaum auftreten, dass ein Scan dieUntermenge eines anderen
darstellt, da sich das Objekt vor dem Scanner permanent bewegt und somit jeder einzelne Scan einen
anderen Ausschnitt zeigt.
Um trotzdem den ICP-Algorithmus anwenden zu können, dürfen nur Punktepaare betrachtet werden, die
sich in dem überlappenden Bereich beider Scans befinden. Um das zu erreichen, werden auf verschiedene
Arten aus der Menge aller gefundenen Punktepaare, diejenigen verworfen, bei denen es am wahrschein-
lichsten ist, dass ein oder beide Punkte in den Bereichen des Scans liegen,die sich nicht überlappen.
Dieses Thema entspricht in etwa dem der Gewichtung von Korrespondenzpaaren, wobei hier bestimmte
Punktepaare komplett verworfen werden und somit gar nicht mehr in die weitere Berechnung eingehen.
Mit dem Verwerfen von Punkten löst man neben dem Problem der Überlappung einzelner Scans noch
ein weiteres, nämlich das der Ausreißer in einer Punktemenge.
In dieser Arbeit wurden vier Heuristiken für das Verwerfen umgesetzt.Die ersten drei nutzen dabei
wiederum den euklidischen Abstand zwischen zwei korrespondierenden Punkten. So können Punkte
verworfen werden, deren Abstand größer als ein gewisser (vom Benutzer definierter) Maximalwert ist.
[Pul99] hingegen definiert nicht einen festen Distanzwert als Entscheidungskriterium, sondern verwirft
die schlechtestenn% der Punkt-zu-Punkt-Entfernungen. In seiner Arbeit empfiehlt er10% der Punkte
nicht in die weitere Berechnung einfließen zu lassen.
Im Idealfall spiegelt diese Prozentzahl den Teil des Daten-Scans wieder, der das Modell nicht überlappt
und somit verworfen werden kann. [CSSK02] haben eine ziemlich einfache Methode entwickelt einen
Näherungswert für diese Prozentzahl bzw. die Überlappungξ beider Scans zu errechnen. Sie ermitteln
diesen Wert, indem sie folgende Funktion minimieren:
ψ(ξ) = e(ξ)ξ−(1+λ) (2.14)
wobeiλ ≥ 0 ein voreingestellter Parameter ist, den [CSSK02] in ihren Tests mitλ = 2 festgelegt haben.
ψ(ξ) minimiert den MSEe(ξ) (vgl. Gleichung 2.5 auf Seite 14), unter Nutzung so vieler Korrespondenz-
paare wie möglich. Dabei wurden vorher die Punktepaare nach ihrem euklidischen Abstand aufsteigend
sortiert und die Minimierung der Funktion mit den Paaren begonnen, die denkleinsten Abstand zu ein-
ander haben. Durch Erhöhung vonλ kann man versuchen ungewollte Ausrichtungen von symmetrischen
oder merkmalslosen Regionen der beiden Scans zu vermeiden.

2.3. ERWEITERUNGEN 21
Das Minimum vonψ(ξ) wird in einem Bereich von40 − 100% der zur Verfügung stehenden Punkte-
paare gesucht, welches dem typischen Bereich einer Überlappung zweier Punktemengen entspricht. Die
Zielfunktion hat einen ziemlich glatten Verlauf, so dass gewöhnlich5 − 8 ICP-Iterationen reichen, um
das Minimum mit hinreichender Genauigkeit zu bestimmen.
Die letzte Möglichkeit auf Basis des euklidischen Abstandes Punktpaare zuverwerfen, verwendet die
Standardabweichung. Hier werden Punkte verworfen, deren Abstand größer als ein gewisses Vielfaches
der Standardabweichung ist. Bei [MSY96] werden Korrespondenzpaare verworfen, deren Distanz mehr
als das2.5-fache der Standardabweichung beträgt.
Neben diesen drei Varianten wurde noch eine weitere Strategie implementiert,die immer und eventuell
in Kombination mit den anderen angewandt werden sollte, da sie wenig rechenintensiv, dafür aber sehr
wirkungsvoll ist. Bei diesem Ansatz geht es um das Verwerfen von Punktepaaren, bei denen einer oder
beide Punkte auf dem Rand der Punktewolke liegen [TL94]. Abbildung 2.6verdeutlicht das Problem
an einem Beispiel. Dadurch, dass sich die beiden Scans nur teilweise überlappen, entstehen viele Kor-
respondenzpaare unter Beteiligung solcher Randpunkte. Da dies in denmeisten der Fälle keiner echten
Korrespondenz entspricht, führen sie nur zu Fehlern in der Registrierung und werden verworfen.
(a) (b)
Abbildung 2.6: (a) Wenn bei der Registrierung von zwei Scans, die sichnicht komplett überlappen (wie
es meistens der Fall ist), Punktepaare erlaubt werden, von denen einerauf der Meshgren-
ze liegt, so führt dies zu einem Fehler in der weiteren Berechnung. (b) Das Verbieten
solcher Punktepaare eliminiert viele dieser falschen Korrespondenzen.

22 2. REGISTRIERUNG DER SCANDATEN

23
3 Globale Registrierung
Die bisherige Registrierungsmethode aus dem vorherigen Kapitel zielte darauf ab, immer zwei Scans
miteinander zu registrieren. Dazu wurde einer der beiden Scans als Modell betrachtet, an dem der an-
dere Scan (die Daten-Punktemenge) ausgerichtet wird. Durch die Registrierung wurde versucht eine
Transformation zu finden, um beide Scans räumlich optimal zusammen zubringen. Die nun ausgerichte-
te Daten-Punktewolke dient in einem nächsten Schritt als Modell für den nachfolgenden (in diesem Fall
dritten) Scan, der neuen Daten-Punktewolke.
Das neue Modell wurde durch die Registrierung bereits in seiner Lage und Orientierung verändert, so
dass die Position gegenüber dem neuen Daten-Scan nicht mehr der Ausgangslage entspricht, wie sie das
Scanner-System geliefert hat. Die dadurch nicht mehr vorhandene initiale Ausrichtung (vgl. Abschnitt
2.3.1) muss also wieder hergestellt werden. Dazu wird vor der erneuten Registrierung die zuvor errech-
nete Transformation auch auf die neue Daten-Punktewolke angewendet.Dadurch werden beide Scans,
das Modell und die Daten, in ihre ursprüngliche Lage zueinander gebracht und als initiale Transformati-
onsmatrix kann wieder die Einheitsmatrix angenommen werden. Nun wird die Registrierung mit diesen
beiden Punktewolken und im Anschluss daran mit weiteren Scans (4, 5, 6,...) durchgeführt.
Diese mehrfachen, aufeinander folgenden Registrierungen von jeweilszwei Scans haben allerdings einen
großen Nachteil. Der ICP-Algorithmus [BM92] neigt öfters dazu nicht in einem globalen, sondern in ei-
nem lokalen Minimum zu terminieren. Selbst wenn die korrespondierenden Punktepaare richtig sind,
kann der Algorithmus eine Transformation liefern, die zwar das lokale Minimumdarstellt, jedoch nicht
dem gewünschten Ergebnis entspricht. Dient der Scan, der fehlerhaft registriert wurde, im nächsten
Schritt als Modell, um einen weiteren Scan zu registrieren, wirkt sich dieser Fehler auf den kompletten
Registrierungsprozess aller nachfolgenden Scans aus. Da solch ein Registrierungsfehler nicht nur ein-
mal auftreten wird, sondern jede einzelne Registrierung einen, wenn auch geringen, Fehlerterm enthält,
addieren sich diese zu einem immer größer werdenden Fehler auf.
Wird zum Beispiel ein Objekt nacheinander von allen Seiten gescannt undwerden dann diese Scans in
dieser Reihenfolge teilweise fehlerhaft registriert, so kann dies bei der Betrachtung eines Ausschnittes
der registrierten Scans (z.B. Scan 1, 2 und 3 von insgesamt 12 Scans) nicht weiter auffallen. Betrachtet
man allerdings den ersten und den letzten Scan, welche sich theoretisch auch überlappen und eigentlich

24 3. GLOBALE REGISTRIERUNG
indirekt nun auch optimal zueinander registriert sein sollten, so wird an dieser Stelle eine größere Lücke
vorhanden sein bzw. die beiden Scans einen größeren Abstand zueinander haben.
Um dieses Problem zu beheben, wurde in dieser Ausarbeitung eine globale Registrierung implementiert,
welche die abgeschlossene Registrierung aus dem vorhergehenden Kapitel als Ausgangslage nimmt und
dann versucht den vorhandenen Fehler zwischen allen beteiligten Scans gleich zu verteilen und weiter zu
minimieren. Die globale Registrierung arbeitet, im Gegensatz zur bisher erklärten paarweisen Registrie-
rungsmethode, mit allen verfügbaren Scans, um die bestmögliche Orientierung der Scans zueinander zu
finden. Dabei wurde eine Methode basierend auf [BSGL96] umgesetzt,die im Folgenden näher beschrie-
ben wird. Nachdem die grundsätzliche Vorgehensweise des Ansatzes dargelegt wurde, werden im darauf
folgenden Abschnitt die Anpassungen erläutert, die für diesen speziellen Anwendungsfall notwendig
waren.
3.1 Multi-View-Registrierung
Wie der Name “Multi-View-Registrierung” bereits vermuten lässt, nutzt diese Registrierung mehrere
Views (Ansichten, Scans) auf einmal, um eine Registrierung zu berechnen. Diese Methode gehört damit
zur Gruppe derglobalen Registrierungs-Algorithmen ([SH96], [Pul97], [Pul99]).
Der Vorteil gegenüber der paarweisen Registrierung besteht darin, dass durch die Nutzung mehrerer
Scans auch mehr Information und Daten zur Verfügung stehen, um eine genauere Transformation zu be-
rechnen. Die hier beschriebene Methode versucht dabei, den dennoch auftretenden Fehler so gleichmäßig
wie möglich zwischen allen Scans zu verteilen und zu minimieren.
3.1.1 Ansichten-Netzwerk
Da mehrere Scans verwendet werden, müssen sie in eine gewisse Beziehung zueinander gebracht wer-
den. Dazu ordnen [BSGL96] diese in einem Netzwerk an. Jede Teilansicht wird als Knoten des Netzwer-
kes betrachtet. Zwischen ihnen befindet sich ein Pfad, welcher die Translation und Rotation speichert,
die die Punkte des einen Scans in das Koordinatensystem des anderen Scans transformiert. Alle ver-
fügbaren Ansichten sind so untereinander zu einem Netzwerk verbunden, d.h. für jedes Ansichten-Paar
existiert mindestens ein Pfad im Netzwerk, welcher beide miteinander verbindet. Dieser Pfad drückt
somit eine Aneinanderreihung von Transformationen, also eine Folge vonMatrixmultiplikationen, aus.
Wenn einige dieser, durch die Registrierung gefundenen Transformationen fehlerhaft sind, so führt die
Matrixmultiplikation zu einer Akkumulation des Registrierungsfehlers. Deshalbist es notwendig eine
Netzwerktopologie zu finden, welche die Pfadlänge zwischen den Knotenminimiert. Damit die Infor-

3.1. MULTI-VIEW-REGISTRIERUNG 25
2
3
4
5
1 23
4 5
1
2 3
4 5
(a) (b)
(c)
1
Abbildung 3.1: drei verschiedene Netzwerk-Topologien für fünf Scans
mationen aller Scans durch die Registrierungen in eine gemeinsame Ansicht integriert werden können,
ist es außerdem notwendig einen von ihnen als Referenz-Scan zu betrachten, dessen lokales Koordina-
tensystem das globale der späteren gemeinsamen Ansicht darstellt.
Abbildung 3.1 zeigt drei mögliche Topologien eines Netzwerkes bestehendaus fünf Scans. Die num-
merierten Knoten stellen dabei die einzelnen Scans dar und in den grauen Boxen ist die Transformation
für jeden Pfad gespeichert, welche die Punkte eines Scans in das Koordinatensystem des anderen Scans
überträgt. In 3.1a ist ein typisches lineares Netzwerk von Ansichten abgebildet, wie es auch im vorheri-
gen Kapitel 2 auf Seite 11 zur paarweisen Registrierung genutzt wird. In3.1b sieht man ein sternförmiges
Netzwerk mit einem Scan als Referenz-Scan in der Mitte, an den die vier anderen Scans über einen Pfad
der Länge1 angebunden sind. Die letzte Abbildung zeigt einen gewöhnlichen Fall, wennbeliebige Scans
von einem Objekt genommen werden und keine feste Reihenfolge besteht.
[BSGL96] wählten für ihre Anwendung das sternförmige Netzwerk da jedes Knotenpaar durch ma-
ximal zwei Matrixmultiplikationen miteinander verbunden ist und somit die Pfadlänge so gering wie
möglich gehalten wird. Ziel der globalen Registrierung ist es, die schon gefundenen bzw. vorhandenen
Transformationsmatrizen weiter zu verbessern. Deshalb hat die sternförmige Topologie auch noch einen
weiteren Vorteil: Es müssen lediglichN − 1 Transformationsmatrizen zwischen den Knoten betrachtet
und verfeinert werden. Zudem lässt sich jede andere Topologie in einesternförmige umwandeln. Dabei
wird derjenige Scan als Referenz-Scan und somit als Zentrum gewählt, bei dem die wenigsten Matrix-
multiplikationen notwendig sind, um die Punkte aller anderen Scan in dessen Koordinatensystem zu
transformieren. Im Fall von Abbildung 3.1 wäre dies jeweils der Knoten3.
Solch ein Netzwerk von mehreren Scans bzw. Ansichten ist dann gut ausbalanciert wenn:
1. Der Registrierungsfehler für alle Transformationsmatrizen gleich großist.

26 3. GLOBALE REGISTRIERUNG
2. Die Transformationsmatrix zwischen zwei Ansichten eindeutig ist, egal welcher Pfad genutzt wird.
Eine Verbesserung der bestehenden Registrierung sollte also zu einem gut ausbalancierten Netzwerk
führen. Für das sternenförmige Netzwerk ist die zweite Bedingung bereits erfüllt, da immer nur ein
Pfad zwischen jeweils zwei Knoten existiert. Die erste Bedingung wird laut [BSGL96] erfüllt, indem
der Fehler derN − 1 Transformationsmatrizen minimiert wird. Dabei ist es notwendig, dass alle Scans
mit demselben Scanner erstellt wurden und somit bei allen gleiche Voraussetzungen (z.B. ein gleicher
Akquisitionsfehler) herrschen.
3.1.2 Erzeugung eines gut ausbalancierten Netzwerkes
Zum Erreichen eines gut ausbalancierten Netzwerkes müssen zwei Bedingungen erfüllt sein. Die Eindeu-
tigkeit der Transformationsmatrizen ist durch die sternförmige Topologie automatisch gegeben. Um die
Gleichverteiltheit des Registrierungsfehlers zu erreichen, werden alle imNetzwerk befindlichen Ansich-
ten zusammen betrachtet und alle Registrierungsfehler simultan minimiert. [BSGL96] nutzen dafür eine
Vereinfachung ihres Algorithmus zur paarweisen Registrierung von zwei Scans. Dieser baut wiederum
auf den Ansätzen von [CM92] auf.
Das Netzwerk mit den schon vorhandenen Transformationsmatrizen (entweder durch eine paarweise
Registrierung berechnet oder durch initial vorgegebene Parameter erstellt) ist typischerweise in einer
linearen Topologie wie in Abbildung 3.1a, z.B. ein sich drehendes Objekt vor einem fest installierten
Scanner. Deshalb wird das vorherrschende Netzwerk zuerst in ein sternförmiges umgewandelt. Das Zen-
trum bildet der Referenz-ScanC, dessen Transformationsmatrix unverändert bleibt. Bei einer linearen
Topologie ist das der Scan, der am mittigsten entlang des Pfades vom erstenzum letzten Scan liegt.
Der Algorithmus geht nun so vor, dass er in jeder IterationN − 1 inkrementelle Transformationsmatri-
zen berechnet, und zwar für jeden Scan (V1, V2, V3, ..., VN ), der mit dem Zentrum verbunden ist. Dabei
werden zuerst alle Punkte eines jeden nicht-zentralen Scans in das jeweilslokale Koordinatensystem al-
ler anderen nicht-zentralen Scans transformiert. Dafür sind zwei Matrixmultiplikationen notwendig. Die
erste transformiert alle Punkte in das Koordinatensystem des zentralen Referenz-Scans und die zweite
danach in das des jeweils anderen nicht-zentralen Scan. Für die beiden Punktemengen der zwei Scans,
die sich jetzt im selben Koordinatensystem befinden, kann nun der erste Teil des normalen Registrie-
rungsalgorithmus durchgeführt werden: Die Bildung der korrespondierenden Punktepaare. Dies wird
pro nicht-zentralem Scan mit allen anderen nicht-zentralen Scans wiederholt, so dass jeder Scan (außer
der Referenz-Scan) einmal in jeden anderen nicht-zentralen Scan transformiert wurde, um dann jeweils
eine Suche nach korrespondierenden Punkten durchzuführen.

3.1. MULTI-VIEW-REGISTRIERUNG 27
• Falls das Netzwerk keine sternförmige Topologie hat, wandle es entsprechend um.
• Lege das Zentrum der sternförmigen Topologie als Referenz-ScanC fest.
• Transformiere alle anderen ScansV1, V2, V3, ..., VN in das Koordinatensystem des Referenz-
Scans.
• Solange der Algorithmus nicht konvergiert, wiederhole folgende Schritte:1. Transformiere jeden nicht-zentralen Scan nacheinander in alle anderen nicht-zentralen
Scans und berechne jeweils die korrespondierenden Punktepaare.
2. Berechne unter Nutzung aller je Scan gesammelten Punktepaare die inkrementelle
Transformationsmatrix für jeden nicht-zentralen Scan.
3. Wende die gefundene Transformation auf den nicht-zentralen Scan an.
Abbildung 3.2: globaler Registrierungsalgorithmus nach [BSGL96]
Im Anschluss daran wird unter Nutzung aller gefundenen Punktepaaredie inkrementelle Transformati-
onsmatrix eines jeden Scans wie bei der paarweisen Registrierungsmethode errechnet und die Lage der
Scans aktualisiert.
Diese Schritte werden iterativ wiederholt und der Vorgang konvergiert,wenn die inkrementellen Trans-
formationsmatrizen aller nicht-zentralen Scans annähernd der Einheitsmatrixentsprechen. Dazu wird
nach jeder Iteration die SummeA der quadrierten Elemente der Differenzmatrix zwischen der inkremen-
tellen Transformationsmatrix∆T und der EinheitsmatrixI errechnet:
A =∑
(∆Ti,j , Ii,j)2 (3.1)
Das MaßA ist allerdings nur dazu da, die Konvergenz des Algorithmus zu überwachen. Es kann daraus
nicht auf die Größe des Registrierungsfehlers geschlossen werden.
Abbildung 3.2 zeigt noch einmal eine Zusammenfassung über die einzelnen Schritte des globalen Regi-
strierungsalgorithmus.
3.1.3 Anpassungen
Für die Anwendung in dieser Ausarbeitung wurde die globale Registrierungsmethode von [BSGL96]
nicht in allen Schritten übernommen, da teilweise andere Voraussetzungengegeben sind. So wird gene-
rell der Schritt der globalen Registrierung nur als eventueller Zusatzschritt gesehen und ist nicht zwangs-
läufig Teilschritt des Registrierungsprozesses. Er ist lediglich dazu gedacht, das Ergebnis der paarweisen
Registrierung noch weiter zu verbessern. Das heißt, dass die globale Registrierung als eigenständige Ein-

28 3. GLOBALE REGISTRIERUNG
heit angesehen werden kann, die als Eingabe nicht mehr die Daten des Scanners bekommt, sondern schon
registrierte Punktewolken. Der Teil der Anwendung kann also unabhängig von paarweisen Registrierung
durchgeführt werden. Somit wird nicht versucht schon vorhandenen Transformationsmatrizen weiter zu
verbessern, sondern es wird die gegebene Lage und Orientierung der Scans als Ausgangspunkt genom-
men und mit der Einheitsmatrix als Startwert für die iterative Verbesserung der Transformationsmatrix
begonnen, da dies ja die Abbildung auf sich selbst beschreibt.
Ein weiterer Punkt, der wegfällt, ist die Transformation der Punktemengen indie jeweiligen lokalen Ko-
ordinatensysteme der anderen Scans, da bereits alle Punktekoordinatenin einem gemeinsamen globalen
Koordinatensystem eingetragen sind und auch so vom Scanner geliefert werden. Trotzdem wird ein Zen-
trum bzw. ein Referenz-Scan bestimmt, damit der Registrierungsprozess einen festen Bezugspunkt hat,
der seine Lage nicht verändert und somit auch konvergieren kann.
Natürlich kommt es auch hier wieder zu korrespondieren Punktepaaren,die fehlerhaft sind und die Be-
rechnung der Registrierung negativ beeinflussen. Zum Beispiel solltenPunktepaare von zwei Scans, die
gegenüberliegende Seiten eines Objektes repräsentieren, komplett vermieden werden.
Um dies zu erreichen wurden wieder die Verwerfungsstrategien aus Kapitel 2 angewandt. So wurden bei
der unmittelbaren Korrespondenzfindung jene Punkte verworfen, die auf den Randgebieten der Punkte-
mengen liegen. Auf die Gesamtheit der gefundenen Punktepaare wurdendann noch die Heuristiken an-
gewandt, die Punktepaare auf Basis des Abstandes der Punkte zueinander aussortieren. Mit den verblei-
benden Punktepaaren wurde dann die Berechnung der Transformation durchgeführt. Zusätzlich könnte
man noch vor der Bildung der Punktepaare anhand der Normalen eine Sichtbarkeitsprüfung durchführen,
so dass erst gar nicht nach Punktepaaren gesucht wird, wenn die Scans von gegenüberliegenden Seiten
des Objektes stammen.
Desweiteren wurden zur Geschwindigkeitsoptimierung wie bei der paarweisen Registrierung ein Sub-
sampling bei allen Scans durchgeführt, um die Punkteanzahl zu verringern und die Korrespondenzbil-
dung mittels eines Kd-Tree [FBF77] beschleunigt.

29
4 Umsetzung
In den vorherigen Kapiteln wurde der Registrierungsalgorithmus in seineneinzelnen Schritten erklärt
und dargelegt, welche Modifikationen vorgenommen wurden, damit dieser unter den gegebenen Voraus-
setzungen gute Ergebnisse liefert. Dieses Kapitel befasst sich mit den Aspekten der softwaretechnologi-
schen Umsetzung.
Programmiert wurde die Anwendung komplett in C++ unter Nutzung des CGV-Frameworks des Lehr-
stuhls für Computergrafik und Visualisierung an der TU Dresden. Das Framework ist ein C++-Toolkit,
welches auf OpenSceneGraph und Boost basiert und verschiedenecomputergrafische Algorithmen zur
Verfügung stellt. So vereinfacht es die Nutzung von immer wiederkehrenden Aufgaben, wie etwa einem
3D-Viewer mit Kamerasteuerung oder einem Szenengrafen. Neben fltk,das für diese Ausarbeitung ver-
wendet wurde, können auch anderen grafischen Toolkits, wie etwa Gtk+, mit diesem Framework genutzt
werden. Generell ist die Benutzeroberfläche von der eigentlichen Registrierungslogik getrennt und kann
beliebig ausgewechselt werden.
Da sich das CGV-Framework noch im Aufbau befindet, wird für die Eigenwertberechnung bei der Re-
gistrierung zurzeit noch die freie Bibliothek Newmat verwendet. Die mathematischen Strukturen, wie
etwa Matrizen oder Vektoren, wurden von [Kön06] übernommen.
4.1 Datenhaltung
Abbildung 4.1: PointCloud- und Point-Klasse
Zur Speicherung der Punktewolke während der Laufzeit dient die KlassePointCloud. Diese enthält
neben dem Dateinamen und der Punkteanzahl ein dynamisches Array, welches zur Laufzeit angelegt

30 4. UMSETZUNG
Abbildung 4.2: RegistrationInfo- und CorrespondInfo-Struktur
und mit Punkten gefüllt wird. Dazu dienen die FunktionenLoad(), welche die Punktewolke direkt aus
einer Datei einliest oderSetPoint(), mit der einzelne Punkte der Punktewolke hinzugefügt werden
können. Die Transformation der Punktewolke erfolgt überTransform() unter Angabe einer Trans-
formationsmatrix.
Ein Punkt wird durch die KlassePoint repräsentiert. Diese enthält lediglich die Attribute, die vom
Scanner geliefert werden. Neben der gescannten Farbe (acquiredColor) kann noch eine zusätzliche
Farbe (assignedColor) zur besseren Unterscheidung der einzelnen Punktewolken im Viewer gesetzt
werden. Die Entscheidung, ob ein Punkt auf dem Rand liegt oder nicht (boundary), geschieht während
des Ladens der Punktewolke. Dabei wird vereinfacht angenommen, dass ein Punkt dann auf dem Rand
eines Scans liegt, wenn er im Kamerabild (position2d) keine acht Nachbarn hat. Dadurch wird aller-
dings nicht beachtet, dass im Kamerabild keine Tiefeninformationen vorliegen und ein Punkt auch auf
einem Rand liegen kann, obwohl er acht Nachbarn hat.
Neben diesen zwei Klassen gibt es noch zwei weitere Strukturen. DieRegistrationInfo gibt die
Einstellungen für den paarweisen Registrierungsalgorithmus weiter, welche über die Benutzeroberfläche
getätigt wurden. Außerdem beinhaltet die Struktur die zwei Punktewolken, die registriert werden sol-
len.CorrespondInfo dient zur Erfassung der korrespondierenden Punktepaare. Dabei wird jeweils
der Index der Punkte in den Daten und im Modell (dataIdx und modelIdx) und deren euklidi-
scher Abstand und Gewichtung gespeichert. Da sich bei der globalen Registrierung die Punktepaare über
mehr als zwei Punktewolken erstrecken, wird hier noch zusätzlich der Index der Punktewolke angegeben
(dataPcIdx undmodelPcIdx).

4.2. REGISTRIERUNGSALGORITHMUS 31
4.2 Registrierungsalgorithmus
Abbildung 4.3: PointSetRegistration-Klasse
Der Algorithmus für die paarweise Registrierung ist in der KlassePointSetRegistration gekap-
selt. Als Input benötigt er lediglich dieRegistrationInfo, in der die beiden Punktewolken und alle
wichtigen Parameter gespeichert sind. Die Idee von [RL01] die Registrierung in die sechs Teilschrit-
te (1) Punkte auswählen, (2) korrespondierende Punkte finden, (3)Punktepaare gewichten, (4) einige
Punktepaare verwerfen, (5) Zuweisen und (6) Minimieren einer Fehlermetrik zu zerlegen, wurde bei der
Erstellung der Software weitestgehend übernommen, um den Prozess modularer zu machen. Dadurch ist
es möglich gewisse Teilschritte auszutauschen und den Algorithmus an die jeweiligen Anforderungen
anzupassen. Die Einzelschritte werden im Folgenden noch einmal kurz näher erläutert. Dabei gibt es für
jeden Teilschritt eine abstrakte Klasse, damit dem Registrierungsalgorithmuseine einheitlich Schnitt-
stelle für die Ausführung dieses Schrittes zur Verfügung steht. Davon abgeleitet wird dann die spezielle
Umsetzung.
4.2.1 Selektion der Punkte
Abbildung 4.4: Klassendiagramm für das Subsampling der Punktewolken
Der TeilschrittSelektion befasst sich mit dem Subsampling der Punkte, das genutzt wird, um den Algo-
rithmus schneller zu machen. Von der abstrakten KlasseSelection wurden die beiden konkreten Um-
setzung für das uniforme (UniformSelection) und zufällige Subsampling (RandomSelection)

32 4. UMSETZUNG
abgeleitet. Die Klasse gibt für jede zugewiesenePointCloud ein Array mit Indizes der ausgewählten
Punkte zurück. Außerdem kann für die beiden konkreten Implementierungen eine Prozentzahl angegeben
werden, wie viele der Punkte ausgewählt werden sollen und zusätzlich eine Mindestanzahl der Punkte,
die nicht unterschritten werden darf.
4.2.2 Finden der korrespondierenden Punkte
Abbildung 4.5: Klasse zum Finden von korrespondierenden Punkten
Für das Finden der korrespondierenden Punkte gibt es momentan nur dieImplementierung, die auf dem
euklidischen Abstand zwischen zwei Punkten basiert (PointToPointMatching). Allerdings könnte
man leicht auch eine zweite Klasse ableiten und mit ihr die Punktepaarbildung nach [CM92] umsetzen,
bei der der Abstand zwischen einem Punkt und der Tangentialebene amanderen Punkt betrachtet wird.
Die KlasseMatching bekommt als Eingabe die beiden Punktewolken der Daten und des Modells. Wur-
de zuvor ein Subsampling ausgeführt, so enthalten zu diesem Zeitpunkt diePunktewolken nur noch die
selektierten Punkte, da während der Registrierung in jeder Iteration die inkrementell errechnete Trans-
formationsmatrix auf die Daten angewandt wird und bei Nutzung der kompletten Punktewolke unnötig
Punkte transformiert werden müssten, die für die Berechnung gar nichtrelevant wären. Alternativ zur
Modell-Punktewolke kann auch der KdTree der Punkte übergeben werden, um die Suche zu beschleu-
nigen. Über den ParameternormalCompatibility kann festgelegt werden, ob bei der Suche nach
einem korrespondierenden Punkt die Winkel der Normalen zueinanderbzw. deren Kompatibilität mit
beachtet werden soll. Als Ergebnis liefert diese Klasse ein Array vonCorrespondInfo über alle ge-
fundenen Punktepaare. Außerdem wird noch der Wert des maximalen euklidischen Abstandes zwischen

4.2. REGISTRIERUNGSALGORITHMUS 33
zwei Punkten ausgegeben, der für spätere Schritte, wie zum Beispiel das Verwerfen von Punktepaaren
aufgrund des Abstandes, nutzbar ist.
4.2.3 Gewichten der Punktepaare
Abbildung 4.6: Klassen zur Gewichtung von Punktepaaren
Die abstrake KlasseWeighting ist für die Gewichtung der Punktepaare zuständig und schließt di-
rekt an die Suche nach den korrespondierenden Punkten an. Umgesetzt wurden drei verschiedene Ar-
ten des Gewichtens.ConstantWeighting gewichtet alle Punktepaare mit demselben Wert, z.B.1.
DistanceWeighting und NormalWeighting hingehen gewichten die Punktepaare umgekehrt
proportional zur Wahrscheinlichkeit, dass diese Korrespondenz zwischen den Punkten falsch ist. Einmal
wird dazu der euklidische Abstand in Relation zum maximal auftretenden Abstand genutzt und einmal
der Winkel zwischen den Normalen.
Die Klasse benötigt zur Berechnung die beiden Punktewolken und das Array mit den korrespondierenden
Punkten. Die Gewichtung für jedes Punktepaar wird in dieCorrespondInfo geschrieben.
4.2.4 Verwerfen von Punktepaaren
Für das Verwerfen von Punktepaaren dient die KlasseRejecting bzw. deren abgeleitete Klassen.
Zur Ausführung werden die beiden Punktewolken und das Array mit denkorrespondierenden Punkten
benötigt. Aus dem Array werden dann jene Punktepaare gelöscht, deren Korrespondenz höchstwahr-
scheinlich falsch ist. Die KlasseThresholdRejecting legt dazu einen maximalen Wert für den
euklidischen Abstand zwischen dem Punktepaar fest und verwirft alle Paare, deren Abstand größer ist.
WorstRejecting definiert keinen festen Wert, sondern verwirft die schlechtesten Punktepaare, deren
Menge in Prozent angegeben werden kann. Die dritte Möglichkeit Punkteaufgrund des Abstandes zu
verwerfen, realisiertDeviationRejecting. Hierbei wird die Standardabweichung des Abstandes

34 4. UMSETZUNG
Abbildung 4.7: Klassen zum Verwerfen von Punktepaaren
als Kriterium genommen und alle Punkte verworfen, deren Abstand größerals ein Vielfaches der Stan-
dardabweichung ist. Auch hier kann der Faktor angegeben werden. Die KlasseBoundaryRejecting
verwirft jene Punktepaare, von denen mindestens ein Punkt auf dem Rand des Scans liegt.
4.2.5 Fehlermetrik
Abbildung 4.8: Klassen zum Erstellen und Minimieren der Fehlermetrik
Die letzten beiden Schritte des Registrierungsalgorithmus, das Aufstellen undMinimieren einer Feh-
lermetrik, werden von der KlasseErrorMetric umgesetzt. Diese errechnet aus den Punktepaaren
eine Transformation, um den auftretenden Fehler zu minimieren. Im Fall derhier umgesetzten kon-
kreten ImplementierungSqrDistanceSumErrorMetric wird als Fehler der mittlere euklidische
Abstand zwischen den Punktepaaren bzw. dessen Quadrat genommen.Den Fehler sowie die errechnete
Transformation liefern die beidenGet-Funktionen. Die Iterationen über die einzelnen Teilschritte des
4.3. PROGRAMMABLAUF 35
Algorithmus werden beendet, wenn eines der folgenden Abbruchkriterien erfüllt ist:
1. Die maximale Iterationsanzahl wurde erreicht.
2. Der auftretende Fehler ist ausreichend gering.
3. Die relative Änderung des Fehlers|e− e′| /e ist ausreichend gering.
4.3 Programmablauf
Als Voraussetzung für eine erfolgreiche Registrierung müssen alle Punktewolken des gescannten Objek-
tes in einer geordneten Reihenfolge vorliegen. Und zwar so, wie sie vom Scanner erstellt wurden. Der
Benutzer wählt nach dem Start der Registrierungssoftware diese Scans aus und stellt die gewünschten
Parameter für die Registrierung ein.
Abbildung 4.9: Einstellungen für die Registrierung
Da das Scannersystem von [Kön06] ein Highspeed-System ist und mit biszu 17fps scannen kann, ist
es nicht sinnvoll jeden Scan zu Registrierung zu nutzen, da sich zwei aufeinander folgende Scans kaum
unterscheiden. Deshalb wird aus der Folge der Scans, nur dann ein Scan zur Registrierung ausgewählt,
wenn dieser zum Referenz-Scan, d.h. zum davor ausgewählten Scan, einen gewissen Fehler überschreitet.
Dazu wird bei beiden Scans ein Subsampling durchgeführt und versucht, korrespondierende Punkte zu
finden. Anhand dieser Punkte wird dann mit derSqrDistanceSumErrorMetric-Klasse der Fehler,
in diesem Fall der mittlere quadratische Abstand der Punktepaare, berechnet.

36 4. UMSETZUNG
Danach wird mittels derPointSetRegistration-Klasse eine paarweise Registrierung durchge-
führt und die gefundene Transformation auf die Daten-Punktewolke angewandt. Bevor eine Registrie-
rung von einer weiteren Daten- und der Modell-Punktewolke erfolgt, transformiert das Programm die
Daten noch mit der zuvor errechneten Transformationsmatrix des Modells,um beide Scans wieder in die
selbe Position zu bringen, wie sie der Scanner geliefert hat.

37
5 Tests
Um zu überprüfen, wie gut der Registrierungsalgorithmus arbeitet und wie sich verschiedene Parame-
tereinstellungen auf das Ergebnis auswirken, wurde der Algorithmus zuerst an drei künstlich erstellten
Szenen getestet. Die dabei gewonnenen Erkenntnisse wurden danachbei einer Registrierung mit richti-
gen Scannerdaten überprüft.
5.1 Testszenen
Für den ersten Teil wurden folgende drei Szenen erstellt: Eine Welle, diefür den ICP-Algorithmus eine
einfache Aufgabe darstellen sollte, da es eine einfache, primitive und glatteOberfläche ist. Desweite-
ren eine Art Fraktal oder auch Terrain-Szene, welche alle Arten von Details beinhaltet und eine flache
Ebene, in die ein Kreuz eingelassen ist. Dies sollte die schwierigste Szene sein und die Registrierung
dürfte oft ein falsches Ergebnis liefern, da sehr wenige geometrische Merkmale vorhanden sind, die der
ICP-Algorithmus nutzen kann. Für den Test wird eine Szene jeweils in ihrerLage und Orientierung ge-
ändert, um sie dann mit der Originalszene zu registrieren. Da künstlich erstellte Szenen genutzt werden,
sind die genauen Transformationen bekannt und man kann so die Arbeitsweise der Registrierung besser
beurteilen.
Diese drei Szenen (Abb. 5.1) decken natürlich nicht alle möglichen Formenvon gescannten Objekten
ab, jedoch repräsentieren sie Oberflächen, die in vielen verschiedenen Anwendungen vorkommen. Zum
Beispiel beim digitalen Michelangelo-Projekt [LPC+00], bei dem zehn Statuen von Michelangelo, zwei
Inneneinrichtungen und alle Fragmente der Forma Urbis Romae, eine riesigeKarte des antike Roms aus
Marmor, eingescannt wurden. Hier treten Oberflächen mit wenigen Details(z.B. glatte Statuen), fraktal-
ähnliche Geometrien (z.B. unfertige Statue mit noch sichtbaren Bearbeitungsspuren) oder Einkerbung
(z.B. die Marmorkarte) auf.
Zuerst wurde die reine horizontale sowie vertikale Verschiebung der beiden Punktewolken zueinander
betrachtet (siehe Abb. 5.2). Dabei zeigte sich, dass eine reine vertikaleVerschiebung kein Problem für
die Registrierung darstellt. Für die Welle und das Fraktal gilt dasselbe auchbei der horizontalen Ver-
schiebung. Allerdings terminiert die Szene mit dem eingelassenen Kreuz bei einer reinen Verschiebung

38 5. TESTS
Abbildung 5.1: die drei verwendeten Testszenen
Abbildung 5.2: horizontale (grün) und vertikale (rot) Verschiebung derFraktal-Szene

5.1. TESTSZENEN 39
in der Ebene oft nur in einem lokalen Minimum und liefert damit nicht die richtigeTransformation für die
Registrierung. Dies ist besonders der Fall, wenn ein uniformes Subsampling gewählt wird, bei dem der
Algorithmus, unabhängig von den gewählten Parameter-Einstellungen, fast jedes Mal zu einem falschen
Ergebnis kam. Bei einem zufälligen Subsampling, das nach jeder Iteration die Teil-Punktemenge neu
auswählt, lieferte die Registrierung öfter ein richtiges Ergebnis. Jedoch ist es auch hier abhängig davon,
wie oft dabei Punkte aus den eingelassenen Stellen gewählt werden. Diein Kapitel 2.3.2 auf Seite 16 be-
schriebene Methode des Normalensampling dürfte hier ein besseres Ergebnis liefern, da dabei viel mehr
Punkte aus dem Bereich des Kreuzes gewählt werden, als beim uniformen oder zufälligen Subsampling.
Generell gilt, dass die Entfernung beider Punktemengen keinen Einfluss auf die Geschwindigkeit und
Genauigkeit der Registrierung hat, sofern beide Punktemengen soweit voneinander entfernt sind, dass
sie sich nicht mehr überlappen. Denn in der ersten Iteration wird eine Transformation errechnet, die bei-
de Punktewolken räumlich soweit zusammenbringt, dass diese sich wieder überlappen, unabhängig von
deren vorheriger Distanz zueinander. Dies liegt in der Berechnungsreihenfolge des ICP-Algorithmus,
der zuerst, ungeachtet der Punktentfernungen, eine Rotation berechnet, um beide Punktemengen optimal
zueinander auszurichten und danach erst die Translation berechnet,die beide Schwerpunkte der Punkte-
wolken räumlich zusammenführt.
Neben der Verschiebung wurde auch die Rotation getestet (Abb. 5.3). Als erstes die Drehung um die
y-Achse. Hier arbeitet die Registrierung bei der Fraktal-Geometrie am besten und liefert bis zu einer ma-
ximalen Verdrehung von45◦ zueinander richtige Ergebnisse. Da die Testszenen auf quadratischenEbe-
nen basieren, schlägt die Berechnung der Transformationsmatrix bei größeren Winkeln fehl. Die Szene
mit der Welle besitzt im Gegensatz zum Fraktal weniger Geometrie-Informationen und daher arbeitet
der Algorithmus in diesem Fall nicht ganz so gut. So liefert er bei einem uniformen Subsampling nur
bis ca.30◦ Abweichung das richtige Ergebnis. Die Kreuz-Szene bereitet jedoch wiederholt die meisten
Abbildung 5.3: Drehung der Fraktal-Szene um30◦ um die x- bzw. y-Achse

40 5. TESTS
Abbildung 5.4: typisches Ergebnis einer falschen Registrierung bei derKreuz-Szene
Schwierigkeiten. Hier schlägt dir Registrierung schon bei kleinen Verdrehungen unter10◦ fehl. Auch
ein zufälliges Subsampling hilft nicht immer und es hängt wiederum sehr starkdavon ab, wie oft dabei
Punkte aus dem Bereich des Kreuzes ausgewählt werden.
Bei einer Drehung um die x- bzw. z-Achse (da die Testszenen eine quadratische Grundfläche haben, sind
beide Fälle gleichbedeutend) fällt der Unterschied zwischen den einzelnen Oberflächenarten nicht so
stark aus. Hier schafft es die Registrierung bei allen Szenen eine richtige Transformationsmatrix bis zu
einem Winkel von maximal90◦ zu berechnen. Wird ein Winkel gewählt, der größer als90◦ ist, so kann
dies aufgrund der Closest-Point-Suche des ICP-Algorithmus nur in einemfalschen Ergebnis enden.
Abgesehen von der Erkenntnis über den Einfluss der Lage und Orientierung beider Punktewolken auf
die Registrierung, wurde auch geprüft, wie sich die Parametereinstellungen des Subsamplings, der Ge-
wichtung und der Normalenkompatibilität auf die Geschwindigkeit und Genauigkeit der Registrierung
auswirken. So lässt sich allgemein sagen, dass ein zufälliges Subsampling dem uniformen Subsampling
immer vorzuziehen ist, da es durch die Neuauswahl der Punkte nach jederIteration mehr Details der Ob-
jektoberfläche in die Berechnung einfließen lässt. Nur bei glatten Oberflächen, wie der Welle, bietet die
zufällige Auswahl keinen wirklichen Vorteil. Hier ist die uniforme Selektierung von der reinen Berech-
nungszeit sogar etwas schneller, da die Neuauswahl der Punkte nachjeder Iteration nicht vorgenommen
werden muss.
Bei der Gewichtung ist in allen untersuchten Fällen die Variante, welche die Normalen und ihre Winkel
zueinander nutzt, jene, die am wenigsten Iteration benötigt. Nur bei der glatten Oberfläche der Wellen-
Szene liegt die konstante Gewichtung der Punktepaare gleichauf mit der Normalengewichtung. Wurden
die Punkte nach ihrer euklidischen Distanz gewichtet, so benötigte der ICP-Algorithmus im Schnitt50−
80% mehr Iterationen als bei den anderen Gewichtungsmethoden.
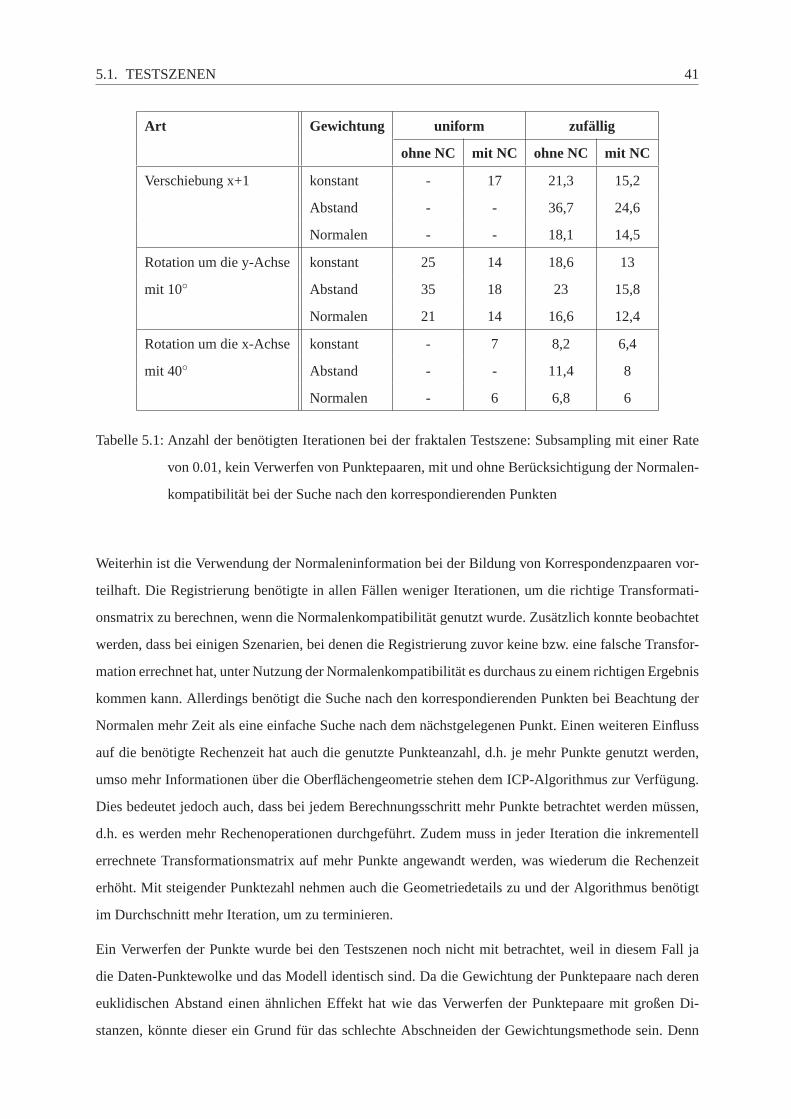
5.1. TESTSZENEN 41
Art Gewichtung uniform zufällig
ohne NC mit NC ohne NC mit NC
Verschiebung x+1 konstant - 17 21,3 15,2
Abstand - - 36,7 24,6
Normalen - - 18,1 14,5
Rotation um die y-Achse konstant 25 14 18,6 13
mit 10◦ Abstand 35 18 23 15,8
Normalen 21 14 16,6 12,4
Rotation um die x-Achse konstant - 7 8,2 6,4
mit 40◦ Abstand - - 11,4 8
Normalen - 6 6,8 6
Tabelle 5.1: Anzahl der benötigten Iterationen bei der fraktalen Testszene: Subsampling mit einer Rate
von 0.01, kein Verwerfen von Punktepaaren, mit und ohne Berücksichtigung der Normalen-
kompatibilität bei der Suche nach den korrespondierenden Punkten
Weiterhin ist die Verwendung der Normaleninformation bei der Bildung von Korrespondenzpaaren vor-
teilhaft. Die Registrierung benötigte in allen Fällen weniger Iterationen, um die richtige Transformati-
onsmatrix zu berechnen, wenn die Normalenkompatibilität genutzt wurde. Zusätzlich konnte beobachtet
werden, dass bei einigen Szenarien, bei denen die Registrierung zuvor keine bzw. eine falsche Transfor-
mation errechnet hat, unter Nutzung der Normalenkompatibilität es durchauszu einem richtigen Ergebnis
kommen kann. Allerdings benötigt die Suche nach den korrespondierenden Punkten bei Beachtung der
Normalen mehr Zeit als eine einfache Suche nach dem nächstgelegenen Punkt. Einen weiteren Einfluss
auf die benötigte Rechenzeit hat auch die genutzte Punkteanzahl, d.h. je mehr Punkte genutzt werden,
umso mehr Informationen über die Oberflächengeometrie stehen dem ICP-Algorithmus zur Verfügung.
Dies bedeutet jedoch auch, dass bei jedem Berechnungsschritt mehr Punkte betrachtet werden müssen,
d.h. es werden mehr Rechenoperationen durchgeführt. Zudem muss in jeder Iteration die inkrementell
errechnete Transformationsmatrix auf mehr Punkte angewandt werden,was wiederum die Rechenzeit
erhöht. Mit steigender Punktezahl nehmen auch die Geometriedetails zu undder Algorithmus benötigt
im Durchschnitt mehr Iteration, um zu terminieren.
Ein Verwerfen der Punkte wurde bei den Testszenen noch nicht mit betrachtet, weil in diesem Fall ja
die Daten-Punktewolke und das Modell identisch sind. Da die Gewichtung der Punktepaare nach deren
euklidischen Abstand einen ähnlichen Effekt hat wie das Verwerfen der Punktepaare mit großen Di-
stanzen, könnte dieser ein Grund für das schlechte Abschneiden der Gewichtungsmethode sein. Denn

42 5. TESTS
dadurch stehen dem ICP-Algorithmus nicht alle Geometrie-Informationen zur Verfügung bzw. werden
einige vernachlässigt, was besonders in den ersten Iterationen zu einerlangsameren Annäherung an die
richtige Transformationsmatrix führt.
5.2 Überprüfung mit echten Daten
Auf Basis der bisher gewonnenen Erkenntnisse wurden nun entsprechende Tests mit den eigentlichen
Scandaten durchgeführt. Dazu wurden zwei Ansichten des gescannten Objektes mit verschiedenen Pa-
rametern registriert und dies bezüglich der benötigten Iterationsanzahl, des Registrierungsfehlers (MSE)
und des optischen Ergebnisses ausgewertet.
In den vorangegangenen Tests mit den künstlich erstellten Szenen wurdeherausgefunden, dass eine Re-
gistrierung mit einem zufälligen Subsampling und einer Berücksichtigung derNormalenkompatibilität
bei der Suche nach den korrespondierenden Punkten sowie bei deren Gewichtung wohl das beste Ergeb-
nis für eine Vielzahl von verschiedenen Scans liefert. Bei der Registrierung mit den vom Scannersystem
gelieferten Daten stellte sich allerdings heraus, dass dies nur bedingt zutrifft.
Es ist zu beobachten, dass die Gewichtung nach dem euklidischen Abstand der korrespondierenden Punk-
te immer noch die langsamste der drei verschiedenen Methoden ist und somit die meisten Iterationen
benötigt. Die Verteilung der Gewichte entsprechend ihrer Normalenkompatibilität ist in den meisten Fäl-
len die beste Wahl, wobei die konstante und einheitliche Berücksichtigung der Punktepaare einige Male
gleich aufliegt. Einen weiteren Vorteil bringt auch die Beachtung der Normalen bei der Suche nach den
Korrespondenzpaaren, wie es auch schon bei den künstlichen Testszenen der Fall war.
Überraschend ist jedoch, dass eine Registrierung unter Verwendungeines zufälligen Subsamplings, im
Gegensatz zu den künstlich erstellten Testszenen, nicht mehr schneller istals bei einer uniformen Selekti-
on der Punkte. Stattdessen benötigt sie bis zu 40% mehr Iterationen. Ein möglicher Grund hierfür könnte
das Vorhandensein von Ausreißern im Scan sein. Beim uniformen Selektieren werden in jedem Durch-
gang die gleichen Ausreißer betrachtet, wohingegen bei einem zufälligenSubsampling immer wieder
eine andere Teilmenge von Ausreißern ausgewählt wird. Da alle Verwerfungsstrategien mit dem eukli-
dischen Abstand arbeiten, werden speziell in den ersten Iterationen, wenn die Scans und somit auch die
korrekt akquirierten Punkte noch relativ weit auseinander liegen, vielefalsche Korrespondenzen nicht
erkannt. Somit sind immer wieder neue, falsche Punktepaare bei der Berechnung der inkrementellen
Transformationsmatrix vorhanden und führen dadurch zu einer fehlerbehafteten Lösung, die erst im wei-
teren Verlauf der Registrierung langsamer korrigiert wird als bei einer uniformen Selektion. Die zufällige
Auswahl der Punkte hat nur dann einen Vorteil, wenn der ICP-Algorithmus mit den uniform gewählten
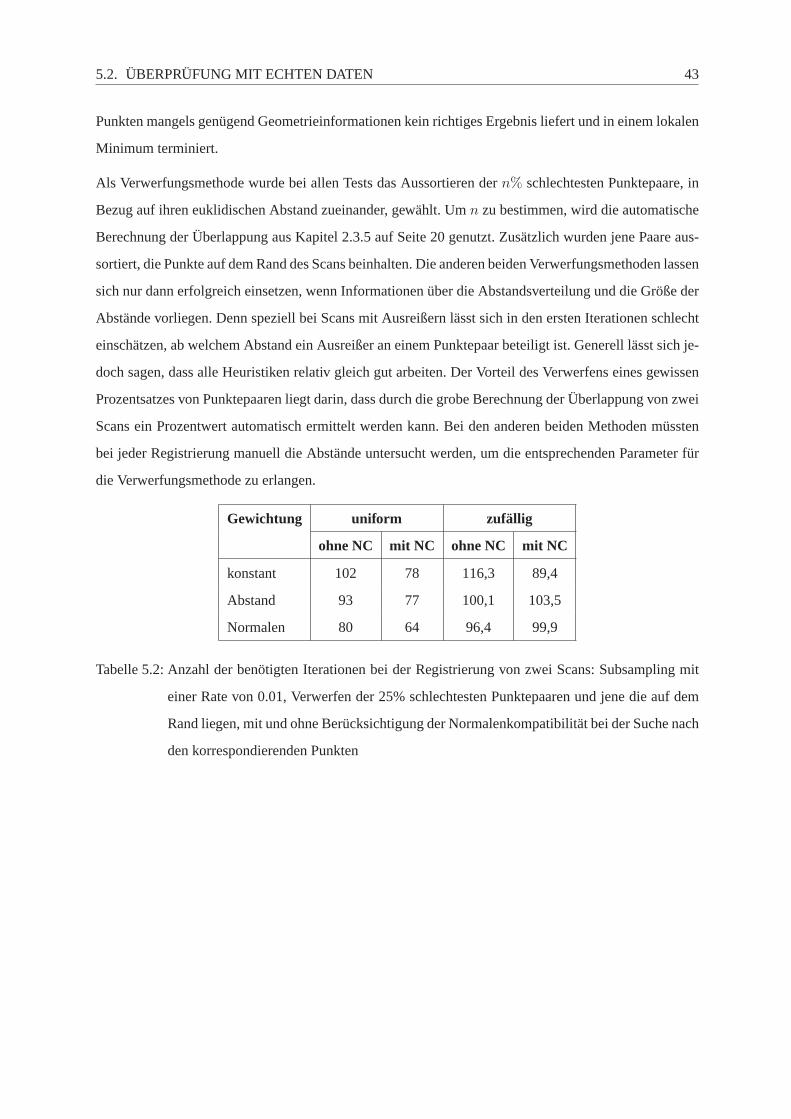
5.2. ÜBERPRÜFUNG MIT ECHTEN DATEN 43
Punkten mangels genügend Geometrieinformationen kein richtiges Ergebnis liefert und in einem lokalen
Minimum terminiert.
Als Verwerfungsmethode wurde bei allen Tests das Aussortieren dern% schlechtesten Punktepaare, in
Bezug auf ihren euklidischen Abstand zueinander, gewählt. Umn zu bestimmen, wird die automatische
Berechnung der Überlappung aus Kapitel 2.3.5 auf Seite 20 genutzt. Zusätzlich wurden jene Paare aus-
sortiert, die Punkte auf dem Rand des Scans beinhalten. Die anderen beiden Verwerfungsmethoden lassen
sich nur dann erfolgreich einsetzen, wenn Informationen über die Abstandsverteilung und die Größe der
Abstände vorliegen. Denn speziell bei Scans mit Ausreißern lässt sich inden ersten Iterationen schlecht
einschätzen, ab welchem Abstand ein Ausreißer an einem Punktepaar beteiligt ist. Generell lässt sich je-
doch sagen, dass alle Heuristiken relativ gleich gut arbeiten. Der Vorteildes Verwerfens eines gewissen
Prozentsatzes von Punktepaaren liegt darin, dass durch die grobe Berechnung der Überlappung von zwei
Scans ein Prozentwert automatisch ermittelt werden kann. Bei den anderen beiden Methoden müssten
bei jeder Registrierung manuell die Abstände untersucht werden, um dieentsprechenden Parameter für
die Verwerfungsmethode zu erlangen.
Gewichtung uniform zufällig
ohne NC mit NC ohne NC mit NC
konstant 102 78 116,3 89,4
Abstand 93 77 100,1 103,5
Normalen 80 64 96,4 99,9
Tabelle 5.2: Anzahl der benötigten Iterationen bei der Registrierung vonzwei Scans: Subsampling mit
einer Rate von 0.01, Verwerfen der 25% schlechtesten Punktepaaren und jene die auf dem
Rand liegen, mit und ohne Berücksichtigung der Normalenkompatibilität bei der Suche nach
den korrespondierenden Punkten

44 5. TESTS
Abbildung 5.5: Vor der Registrierung: der Daten-Scan (grün) ist gegenüber dem Modell deutlich gedreht
Abbildung 5.6: Nach der Registrierung: der Daten-Scan (grün) ist am Modell ausgerichtet, was an den
sich durchdringenden Farben gut zu erkennen ist

45
6 Ergebnisse
Zur Registrierung wurden die verschiedenen Tonfiguren bzw. derenAufnahmen aus [Kön06] genutzt.
Jeder Scan besteht aus ca.200.000 − 300.000 Punkten. Zuvor wurden die Normalen noch einmal neu
berechnet, da sie den meisten Nutzen bei der Registrierung bringen und die ursprünglichen Normalen,
die der Scanner liefert, speziell an den Rändern fehlerhaft sind.
Zuerst wurden14 Teilansichten einer Büste registriert (siehe Abb. 6.2). Dazu wurde ein uniformes Sub-
sampling (Rate:0.01), Gewichtung nach den Normalen und ein Verwerfen eines gewissen Prozentsatzes
der schlechtesten Punktepaare genutzt. Der Prozentwert wurde dabei automatisch berechnet und außer-
dem wurden die Normalen bei der Korrespondenzfindung berücksichtigt. Die Berechnung benötigte auf
einem Intel Pentium 4 mit 3 GHz und 1 GB Ram ungefähr180 Sekunden.
In einem zweiten Versuch wurden nur neun Scans genutzt. Hierbei wurde mit den vorherigen Einstel-
lungen kein zufrieden stellendes Ergebnis mehr erreicht. Speziell um denHinterkopf herum arbeitete der
Algorithmus nicht sauber, so dass das Gesicht zweigeteilt war. Denn diesist der Bereich, in dem sich der
erste und letzte Scan überlappt. Ein zufälliges Subsampling schafft hier jedoch Abhilfe. Dadurch erhöht
sich allerdings auch die Berechnungszeit auf ca.330 Sekunden.
Zum Vergleich: Auf einem Intel Pentium 4 mit 2,4 GHz und 1 GB Ram wurden20 Scans der Büste ohne
Subsampling, d.h. mit allen verfügbaren Punkten, registriert. Dies dauerteungefähr 18 Stunden.
Bei dem zweiten eingescannten Objekt handelt es sich um eine Tonfigur,die einen Frosch darstellt.
Dieser hat sehr viele glatte Oberflächen, welche nahezu symmetrischen Charakter haben, wenn man
einzelne Teilbereiche betrachtet. Aus diesem Grund wurde hier das Subsampling auf 0.02 erhöht, um
mehr Details in die Berechnung einfließen zu lassen.
Um die Registrierung neben der reinen optischen Betrachtung zu beurteilen, wurde das Ergebnis aber-
mals analysiert. Mittels des zufälligen Subsamplings wurde eine Menge von Punkte aus jedem registrier-
ten Scan gewählt. Zu jedem Punkt sucht man nun seine unmittelbaren Nachbarn in allen anderen Scans,
die diesen überlappen. In diesem Fall wurden die 20 nächstgelegenen Nachbarn gesucht. Bei einer gu-
ten Registrierung sollten jeder betrachtete Punkt und seine unmittelbaren Nachbarn annähernd in einer
Ebene liegen. Deshalb wurde die Streuung in Normalenrichtung des selektierten Punktes als Kriterium

46 6. ERGEBNISSE
für die Güte der Registrierung gewählt. Dazu wurde für diesen Punkt und seine Nachbarn eine Kovari-
anzmatrix aufgestellt und deren Eigenwerte berechnet. Um eine Visualisierung der Güte zu erreichen,
wurde der HSV-Farbraum genutzt und der kleinste Eigenwert auf die Skala in Abbildung 6.1 abgebildet.
Dadurch erhält man ein eingefärbtes Modell der Registrierung und sieht,in welchen Bereichen die ein-
zelnen Scans gut bzw. nicht so gut aneinander ausgerichtet wurden. So erkennt man in Abbildung 6.4,
gut0
schlecht1
Abbildung 6.1: Skala zur Visualisierung der Güte der Registrierung
dass bei der Büste die ersten Scans (angefangen bei der linken Seite des Gesichtes und dann gegen den
Uhrzeiger um das Objekt herum) relativ gut registriert wurden. Auf der Rückseite ist es jedoch schon
etwas schlechter. Dabei sind jene Scans beteiligt, die den Haardutt enthalten, dessen Geometrie für den
Algorithmus etwas schwierig zu sein scheint. Die andere Stelle, an der die Punkte eine große Streuung
aufweisen, ist im Bereich des ersten und letzten Scans. Dies betrifft die rechte Schulter, sowie die Mitte
des Gesichtes. Durch die Aufsummierung des Fehlers bei der paarweisen Registrierung kommt es hier
zu einem größeren Abstand zwischen den Scans.
Danach wurde eine globale Registrierung auf die bereits paarweise registrierten Scans der Büste ange-
wandt. Diese dauerte bei den 14 zu registrierenden Scans ca. 12 Minuten wobei in jeder der 22 Iterationen
13 inkrementelle Transformationsmatrizen errechnet wurden. Als Ergebnis erhält man eine Ausrichtung
der Scans, bei denen der zuvor aufgetretene Fehler minimiert bzw. gleichmäßiger zwischen den Punkte-
wolken verteilt wurde. Vergleicht man die Gütevisualisierungen vor und nach der globalen Registrierung
(Abb. 6.4 und 6.6), so ist dies gut zu erkennen.

47
Abbildung 6.2: Ergebnis der paarweisen Registrierung von 14 Scans einer Büste
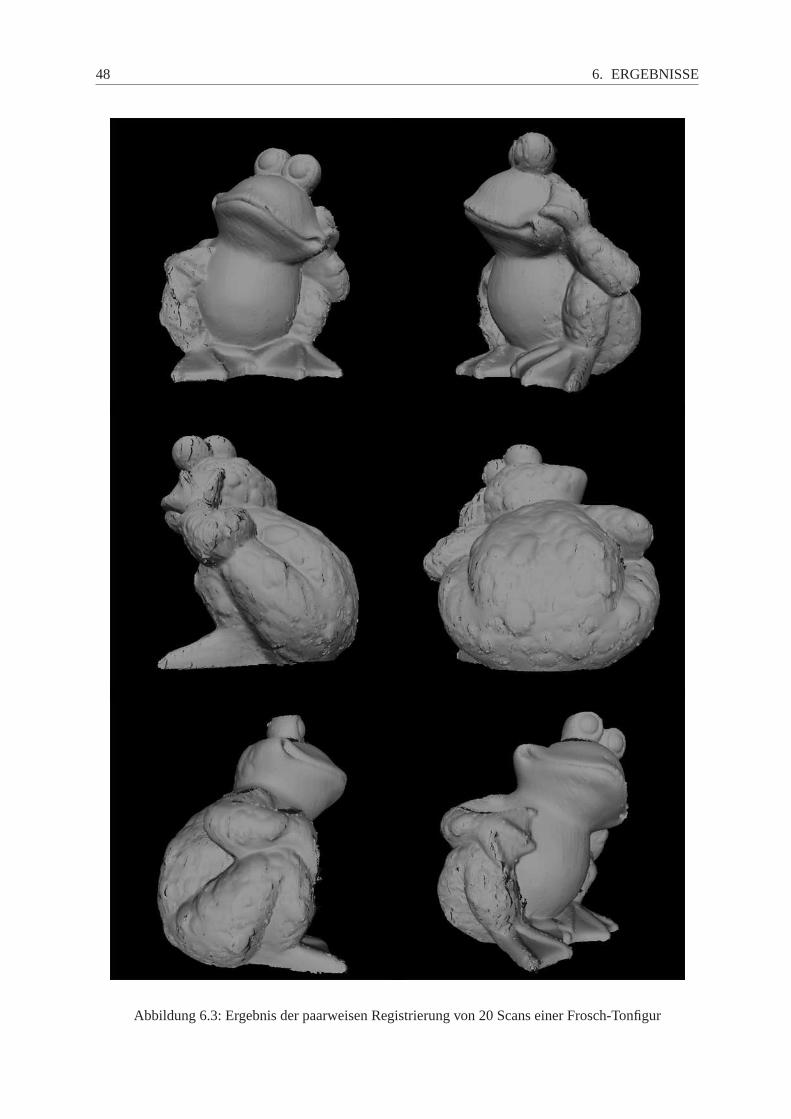
48 6. ERGEBNISSE
Abbildung 6.3: Ergebnis der paarweisen Registrierung von 20 Scans einer Frosch-Tonfigur
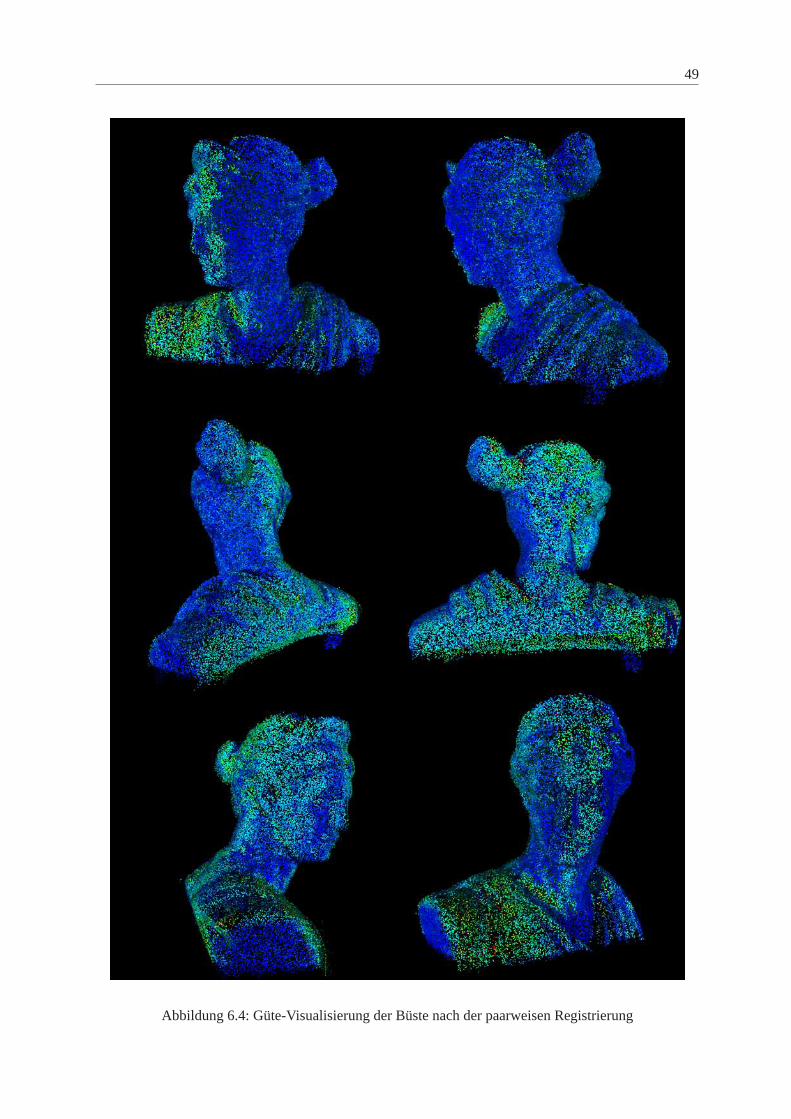
49
Abbildung 6.4: Güte-Visualisierung der Büste nach der paarweisen Registrierung
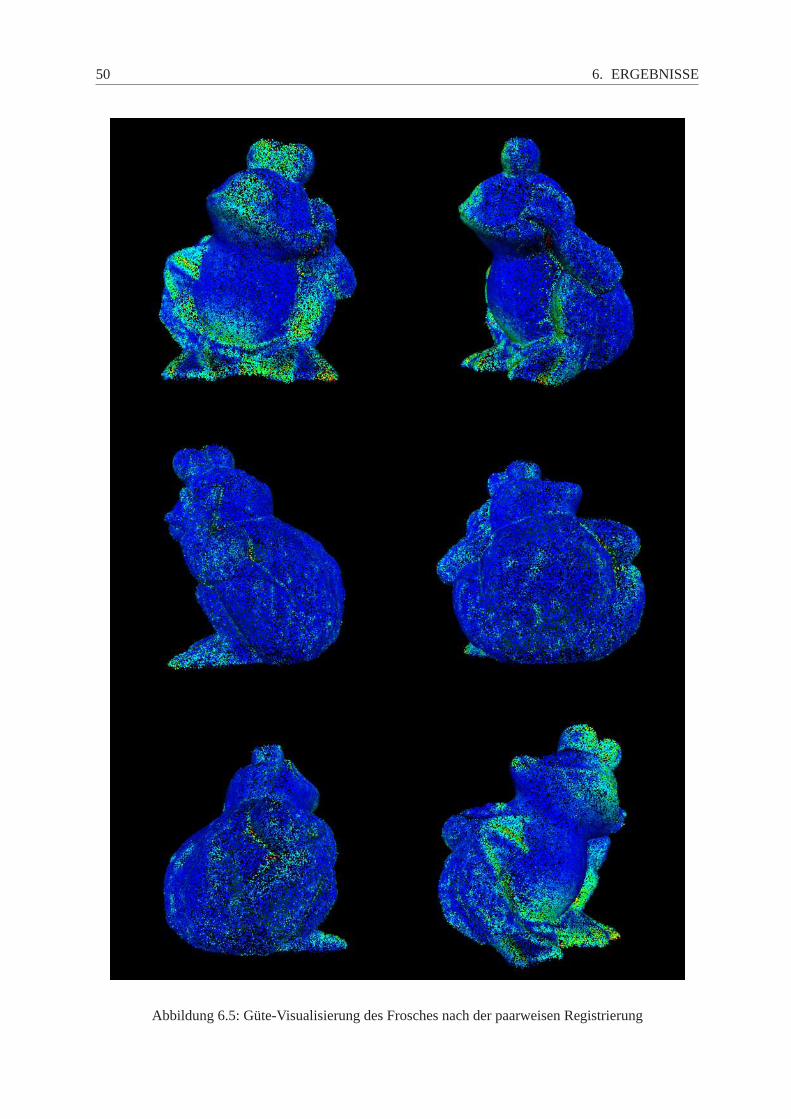
50 6. ERGEBNISSE
Abbildung 6.5: Güte-Visualisierung des Frosches nach der paarweisenRegistrierung
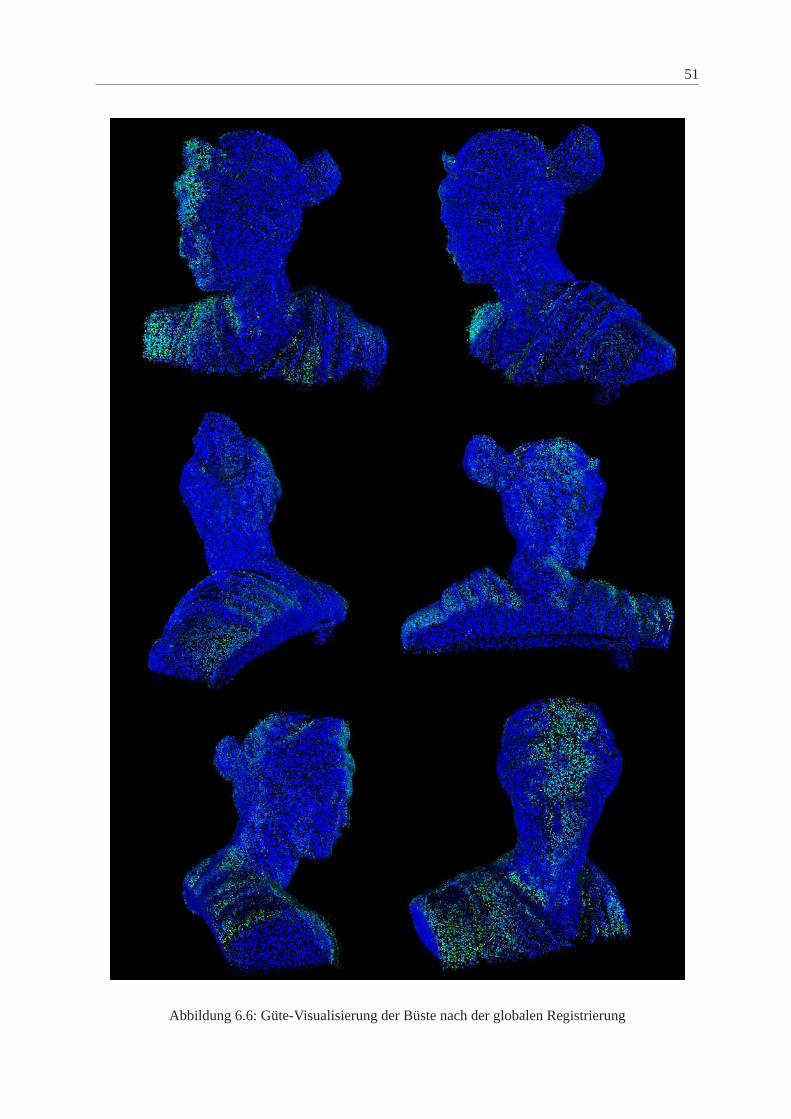
51
Abbildung 6.6: Güte-Visualisierung der Büste nach der globalen Registrierung

52 6. ERGEBNISSE

53
7 Zusammenfassung und Ausblick
Im Rahmen dieser Arbeit sollte eine Methode entwickelt werden, um einzelneScans eines Hochge-
schwindigkeitsscanners aneinander auszurichten und somit zu einer Punktewolke zusammenzuführen,
die das komplette, gescannte Modell darstellt. Dazu müssen die sich überlappenden Bereiche der einzel-
nen Scans identifiziert und in einem weiteren Schritt räumlich zusammengeführt werden.
Verschiedene, in der Literatur zu findende Verfahren wurden daraufhin auf ihre Möglichkeiten und Nutz-
barkeit unter den gegebenen Voraussetzungen untersucht. Als Basisalgorithmus wurde der Standard-ICP
von Besl und McKay genutzt. Da dieser jedoch nur für Szenen geeignet ist, bei denen beide Scans iden-
tisch sind oder einer ein Teilausschnitt des anderen repräsentiert, ließ ersich in seiner Ursprungsform
nicht nutzen. Mittels Erweiterungen wie das Gewichten und Verwerfen vonPunktepaaren wurde der
ICP-Algorithmus so modifiziert, dass er für eine Registrierung von sich nurteilweise überlappenden
Scans geeignet ist. Durch die Aufteilung des Registrierungsalgorithmus in sechs Schritte, ließ sich das
Programm modular aufbauen, so das einzelne Teilabschnitte ausgetauscht oder verändert werden kön-
nen, um die Funktionsweise an die entsprechenden Gegebenheiten anzupassen. Die vorhandenen Module
lassen sich über eine einfache Oberfläche mit wenigen Optionen einstellen.
Die so realisierte paarweise Registrierung hat jedoch den Nachteil, dass die einzelnen Scans nacheinan-
der registriert werden und Information, die später hinzugefügte Scansliefern, nicht mehr genutzt werden
können, um bereits registrierte Scans zu korrigieren. Ein weiterer Nachteil ist, dass sich einmal vorhande-
ne Fehler aufsummieren und es somit passieren kann, dass bei einem Rundum-Scan der erste und letzte
Scan nicht korrekt zusammenpasst. Aus diesem Grund wurde noch ein globales Registrierungsverfahren
implementiert, welches alle zur Verfügung stehenden Scans nutzt und dieseaneinander ausrichtet.
Neben dem ICP-Algorithmus gibt es noch weitere Methoden der Registrierung, wie z.B. [CM92] und
die darauf aufbauenden Verfahren. Diese arbeiten oftmals mit Tiefenbildern, d.h. zu jedem Bild im Ka-
merapixel liegt die Information vor, wie tief der abgetastete Punkt im Raum liegt. So könnte man aus den
vorhandenen Punktewolken und weiteren Scannerparametern solche Tiefenbilder berechnen, um dann
die Performance von [CM92] oder auch [LB94] zu testen.
Das Problem der Ausreißer wurde zwar in dieser Ausarbeitung durch das Verwerfen und Gewichten der
Punktepaare minimiert, jedoch haben diese speziell in den ersten Iterationennoch einen großen Einfluss

54 7. ZUSAMMENFASSUNG UND AUSBLICK
auf den Verlauf der Registrierung. So könnte man diese über weitere Nachbarschaftsbeziehungen und
speziell die Streuung der Nachbarn identifizieren und herausfiltern. Dadurch dürfte die eigentliche Re-
gistrierung noch schneller und vor allem korrekter verlaufen. Neben der Detektion der Ausreißer könnte
auch der Einsatz weiterer globaler Verfahren die Registrierung verbessern. Eine schnellere Variante zur
hier genutzten Methode könnte [Pul99] sein. Dabei werden nicht alle Scans bei der Registrierung eines
einzelnen genutzt, sondern zuvor dessen Beziehungen zu den anderen Punktewolken geprüft, um dann
nur seine Nachbarn für die Ausrichtung zu nutzen.
Mit der Weiterentwicklung des Scannersystems könnte dieses in der Lage sein, mehr Informationen über
das gescannte Objekt zu liefern. Ist es zum Beispiel möglich, dass der Scanner Texturdaten bereitstellt,
so wäre dies ein weiteres Kriterium für die Kompatibilität korrespondierender Punkte. Ebenso könnten
markante Punkte im Kamerabild verfolgt werden, um so eine bessere initiale Ausrichtung der Scans für
die Registrierung zu erlangen.

55
Literaturverzeichnis
[BM92] BESL, P. J. ; MCKAY , N. D.: A Method for Registration of 3-D Shapes. In:IEEE Transac-
tions on Pattern Analysis and machine Intelligence 14 (1992), Februar, Nr. 2, S. 239–258
[BSGL96] BERGEVIN, Robert ; SOUCY, Marc ; GAGNON, Hervé ; LAURENDEAU, Denis: Towards a
General Multi-View Registration Technique. In:IEEE Trans. Pattern Anal. Mach. Intell 18
(1996), Nr. 5, S. 540–547
[CM92] CHEN, Y. ; MEDIONI, G. G.: Object Modeling by Registration of Multiple Range Images.
In: USC Computer Vision (1992)
[CSSK02] CHETVERIKOV, Dmitry ; SVIRKO, Dmitry ; STEPANOV, Dmitry ; KRSEK, Pavel: The
Trimmed Iterative Closest Point Algorithm. In: KASTURI, R. (Hrsg.) ; LAURENDEAU, D.
(Hrsg.) ; C., Suen (Hrsg.):ICPR 02: Proceedings 16th International Conference on Pattern
Recognition Bd. 3. CA 90720-1314, Los Alamitos, USA : IEEE Computer Society, August
2002. – ISBN 0–7695–1695–X, S. 545–548
[DJWM96] DORAI, C. ; JAIN , A. K. ; WANG, G. ; MERCER, C.: From Images to Models: Automatic 3D
Object Model Construction from Multiple Views. In:International Conference on Pattern
Recognition (1996), S. I: 770–774
[FBF77] FRIEDMAN, J. H. ; BENTLEY, J. L. ; FINKEL , R. A.: An Algorithm for Finding Best
Matches in Logarithmic Expected Time. In:ACM Trans. on Mathematical Software 3
(1977), September, Nr. 3, S. 209–226
[GRB94] GODIN, G. ; RIOUX, M. ; BARIBEAU, R.: Three-Dimensional Registration Using Range
and Intensity Information. In:Proc. SPIE Videometrics III 2350 (1994), S. 279–290
[Hor87] HORN, B.: Closed-form solution of absolute orientation using unit quaternions. In: J of the
Optical Society of America 4 (1987), S. 629–642
[Kön06] KÖNIG, Sören.Akquisition dynamischer Geometrie mit strukturiertem Licht.
http://www.inf.tu-dresden.de/index.php?node_id=1158. 2006
[LB94] L EVINE, M. D. ; BLAIS, G.: Registering Multiview Range Data to Create 3D Computer
Objects. In:McGill University, 1994

56 Literaturverzeichnis
[LPC+00] LEVOY, Marc ; PULLI , Kari ; CURLESS, Brian ; RUSINKIEWICZ, Szymon ; KOLLER, David
; PEREIRA, Lucas ; GINZTON, Matt ; ANDERSON, Sean E. ; DAVIS, James ; GINSBERG,
Jeremy ; SHADE, Jonathan ; FULK , Duane: The digital Michelangelo project: 3D scanning
of large statues. In:SIGGRAPH, 2000, S. 131–144
[MSY96] MASUDA, T. ; SAKAUE , K. ; YOKOYA, N.: Registration and Integration of Multiple Range
Images for 3-D Model Construction. In:International Conference on Pattern Recognition
(1996), S. I: 879–883
[Pul97] PULLI , Kari: Surface reconstruction and display from range and color data, University of
Washington, Diss., 1997
[Pul99] PULLI , K.: Multiview registration for large data sets. In:3DIM99, 1999, S. 160–168
[RL01] RUSINKIEWICZ, Szymon ; LEVOY, Marc: Efficient Variants of the ICP Algorithm. In:
Proceedings of the Third Intl. Conf. on 3D Digital Imaging and Modeling (2001), S. 145–
152
[SH96] STODDART, A. J. ; HILTON, A.: Registration of Multiple Point Sets. In:International
Conference on Pattern Recognition, 1996, S. II: 40–44
[TL94] TURK, G. ; LEVOY, M.: Zippered Polygon Meshes from Range Images. In:SIGGraph-94
(1994), S. 311–318

57
Erklärungen zum Urheberrecht
Hiermit erkläre ich, André Jähnig, die vorliegende Belegarbeit selbstständig und ausschließlich unter
Verwendung der angegebenen Literatur- und Informationsquellen verfasst zu haben.

58 Erklärungen zum Urheberrecht





























