Embed Size (px)
Citation preview

FernUniversität in Hagen
Seminarband zum Kurs 1912 im SS 2006
Multimedia-Datenbanken
Prasenzphase: 30.06. - 01.07.2006
Betreuer:
Prof. Dr. Ralf Hartmut Guting
Dipl.-Inf. Thomas Behr
Fakultat fur Mathematik und Informatik
Datenbanksysteme fur neue Anwendungen
FernUniversitat in Hagen
58084 Hagen


Zeitplan und Inhaltsverzeichnis
Freitag, 30.06.2006
1100 - 1130 Uhr Begrußung
1130 - 1230 Uhr Thema 1 – Sebastian Irle
Compression Techniques
1230 - 1400 Uhr Mittagspause
1400 - 1500 Uhr Thema 2 – Peter Eggert
Indexing of Complex Data
1515 - 1615 Uhr Thema 3 – Maik Devrient
Text Retrieval 1
Sonnabend, 1.07.2006
900 - 1000 Uhr Thema 4 – Sylvia Zotz
Text Retrieval 2
1015 - 1115 Uhr Thema 5 – Karsten Mende
Content Based Image Retrieval
1130 - 1230 Uhr Thema 6 – Annette Schaffer
Music Retrieval 1
1245 - 1345 Uhr Thema 7 – Ernst Jansen
Music Retrieval 2
1345 - 1400 Uhr Auswertung und Abschluß


Seminar 1912: Multimedia-DatenbankenThema1: Compression Techniques
Sebastian Irle


Thema1: Compression Techniques 1 Sebastian Irle
Inhaltsverzeichnis1 Einleitung und Motivation 2
2 Standards 22.1 Notwendigkeit von Standards . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22.2 Standardisierungs-Komitees . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22.3 Entwicklungsschritte eines Standards am Beispiel MPEG . . . . . . . . . . . . . . . . . 3
3 Der JPEG-Standard 33.1 Anwendungen und Möglichkeiten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33.2 Grundlegende Schritte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
3.2.1 Schritte für die verlustbehaftete Kompression . . . . . . . . . . . . . . . . . . . 43.2.2 Kompression und Qualität der Bilder . . . . . . . . . . . . . . . . . . . . . . . 63.2.3 Verlustfreie Kompression . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
3.3 Dekomprimierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73.4 Mehrere Komponenten und Datenströme . . . . . . . . . . . . . . . . . . . . . . . . . . 83.5 Aufbau des Dateiformates . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
4 Der MPEG Standard 84.1 Anwendungsgebiete . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
4.1.1 Digitale Medien . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84.1.2 Asymmetrische Übertragung . . . . . . . . . . . . . . . . . . . . . . . . . . . . 94.1.3 Symmetrische Übertragung . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
4.2 Features . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 94.2.1 Wahlfreier Zugriff . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 94.2.2 Schneller Vorlauf/Rücklauf . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 94.2.3 Rückwärts abspielen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 94.2.4 Synchronisation zwischen Video und Audio . . . . . . . . . . . . . . . . . . . . 94.2.5 Fehlerunanfälligkeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 94.2.6 Flexibilität . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104.2.7 Echtzeitkomprimierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
4.3 Bestandteile . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104.3.1 Container . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104.3.2 Codec . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
4.4 Versionen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104.4.1 MPEG1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104.4.2 MPEG2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104.4.3 MPEG4 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
4.5 Bewegungskompensation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 114.5.1 Typen von Bildern . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 114.5.2 Vorhersage . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124.5.3 Interpolation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
4.6 Bewegungsestimation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124.7 DCT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
5 Zusammenfassende Beurteilung 12
6 Quellen 13

Sebastian Irle 2 Thema1: Compression Techniques
1 Einleitung und Motivation
Gerade in Datenbanken werden sehr große Mengen von Daten abgespeichert. Mit der zunehmendenSpeicherung multimedialer Inhalte, insbesondere Bilder und Videos, werden Kompressionsverfahrenimmer wichtiger. In dieser Arbeit soll es darum gehen, Komprimierungsstandards am Beispiel von JPEGund MPEG grundlegend zu erklären.
2 Standards
2.1 Notwendigkeit von Standards
Um eine Kommunikation zwischen verschiedenen Programmen und Diensten zu ermöglichen, bedarf esStandards. Gerade im Bereich der digitalen Datenspeicherung ist es ohne einen Satz von Regeln nahezuunmöglich die einmal gespeicherten Daten weiterzuverarbeiten, da der grundlegende Bezug der binärenDaten zu den Nutzinformationen fehlt. Es bedarf der Kenntnis der Codierung, um die Daten überhauptverstehen zu können. An dieser Stelle unterscheidet sich die digitale Speicherung auch grundlegend vonanalogen Speicherformen (z.B. der Schrift), die grundlegende, nachvollziehbare Verknüpfungen besit-zen. So ist es uns heute möglich die Hyroglyphen der Ägypter zu verstehen, während ein Historiker inZukunft wohl nicht in der Lage sein wird, die Einsen und Nullen, die irgendwo abgelegt sind, in Nutz-informationen umwandeln zu können, ohne eine detailierte Anleitung zu besitzen wie die Codierung zuverstehen ist. Dieses Problem wird, für die Gegenwart, durch feste Absprachen und Regeln - in einemWort Standards - gelöst.
Standards können auf verschiedene Weisen entstehen. Zum einen gibt es die so genannten Industrie-standards, die etabliert werden indem eine Firma ihre Marktmacht ausnutzt, um durch starke Verbreitungder Technologie einen Defacto-Standard zu setzen. Beispiele hierfür sind das proprietäre doc Format vonMicrosoft Word oder, um einen anderen Bereich aufzugreifen, das VHS Format der Firma JVC. DieseStandards bergen allerdings die starke Gefahr, der technologischen Abhängigkeit von einer Firma. Diestandardsetzende Firma wird im Regelfall immer einen Technologievorsprung behalten, wenn die Spe-zifikationen überhaupt grundlegend offengelegt werden. Aus diesem Grund wird die Standardisierung invielen Fällen von unabhängigen Institutionen, die meist die Bestrebungen vieler Unternehmen bündeln,vorangetrieben. Es wird für jeden Interessenten die Spezifikation offen gelegt, so dass eine Kompatibi-lität immer sichergestellt wird. Damit ist zum einen der Endanwender nicht auf die Technologie einesHerstellers beschränkt, zum anderen wird die Verbreitung des Standards wahrscheinlicher. Mit den hierbehandelten Formaten JPEG und MPEG werden zwei sehr erfolgreiche, von unabhängigen Institutionengesetzte, Standards vorgestellt.
2.2 Standardisierungs-Komitees
Standardisierung wird auf nationaler, vor allem aber auf europäischer und internationaler Ebene vor-angetrieben. Als ältestes internationales Standardisierungsgremium ist die ITU (International Telecom-munication Union), für die technischen Aspekte der Telekommunikation zuständig. Die ITU geht aufdie CCITT zurück, die auch für die unten aufgeführten Standards JPEG und MPEG mit verantwortlichwar. Die ITU (bzw. vorher die CCITT) gibt nur Empfehlungen (recommendations) aus, die noch durchnormative Organisationen oder Regierungsstellen übernommen werden müssen, um z.B. in Deutschlandals Norm anerkannt zu sein. Ein Beispiel für solch eine Normierungsorganisation ist die ISO, die sichaus den Normierungsorganisationen von über 150 Ländern zusammensetzt. Vertreter für Deutschlandist die DIN. Als weitere Normierungsorganisationen kann die ETSI (European Institute for Telecommu-niactaion) genannt werden, die zusammen mit der ITU die europäischen Telekommunikationsstandardsentwickelt hat.

Thema1: Compression Techniques 3 Sebastian Irle
2.3 Entwicklungsschritte eines Standards am Beispiel MPEGAls Beispiel für die Entwicklungsschritte eines erfolgreichen Standards betrachten wir die Standardisie-rung der MPEG. 1988 wurde entschieden, dass ein Standard für die Videokomprimierung nötig ist. Esbestand ein relativer Zeitdruck, da Verzögerungen zu Eigenentwicklungen der Industrie geführt hätten,wodurch viele inkompatible Defacto-Standards enstanden wären. Daher wurde ein sehr enger Termin-plan gesetzt, der die Entwicklung in drei Phasen einteilte:
1. Requirements: Um alle Bedürfnisse zu befriedigen, wurde in dieser Phase zuerst abgeklärt, wasdas Ergebnis der Bemühungen überhaupt sein soll. In diesem Fall war es vor allem ein offenerStandard, der viel Raum für individuelle Implementationen ließ.
2. Competition: Um den Standard auf dem aktuellen technischen Stand zu entwickeln, wurden ver-schiedene Vorschläge großer Firmen eingeholt, die dann ausgewertet wurden, um ein möglichstgroßes Spektrum des aktuellen Standes der Technik zu erhalten.
3. Convergence: In dieser dritten Phase wurden die vorher gesammelten Erkenntnisse dann abgegli-chen und zu einer Lösung zusammengeführt.
Da an der Entwicklung viele große Firmen beteiligt waren (u.a. AT&T, Intel, Mitsubishi, Sony) konnteder Terminplan eingehalten werden und im September 1990 stand der erste Entwurf auf dem Papier.
3 Der JPEG-Standard
3.1 Anwendungen und MöglichkeitenDer JPEG Standard wurde von 1986 bis 1992 von der JPEG (Joint Photografic Experts Group) entwi-ckelt, die eine Zusammenarbeit des ISO und des CCITT darstellt. Ziel war es, einen Kompressions-Standard für nicht-bewegte Bilder zu schaffen, um die Entwicklung im Multimedia Bereich zu beschleu-nigen. Zusammen mit der Entwicklung des WWW Anfang der neunziger Jahre fand der nach der Ent-wicklungsgruppe benannte Kompressionsstandard eine immense Verbreitung. Da die Bedarfe für denStandard im Vorhinein nicht klar absehbar waren, wurde versucht, die Spezifikation möglichst breitanzulegen und es wurden verschiedene Modi entwickelt. Folgende Vorrausetzungen wurden zugrunde-gelegt:
• der Standard soll eine gute Kompression, besonders aus hochqualitativen Quellen, ermöglichen.Dem Benutzer soll die Entscheidung, wie stark die Kompression auf Kosten der Qualität geht,selbst überlassen bleiben
• als Quelle soll praktisch jedes Bild unabhängig vom Farbraum, den Dimensionen oder ähnlichemmöglich sein
• die Implementierung in Soft- und Hardware soll mit angemessenen Aufwand möglich sein. Wieschon angesprochen, wurden verschiedene Kompressionsmodi entwickelt, um auf unterschiedli-che Anwendungsgebiete vorbereitet zu sein:
– sequentielle Komprimierung: jede Bildkomponente (also jeder Teil des Farbraumes) wird ineinem links-nach-rechts und oben-nach-unten Scan verarbeitet
– Progressive Komprimierung: Hier wird das Bild mehrfach gescannt um, gerade bei langsa-men Verbindungen, das Bild schnell erscheinen zu lassen und es dann nach und nach zuschärfen
– Hierarchische Komprimierung: das Bild wird in verschiedenen Auflösungen gespeichert, sodass es möglich ist, sich das Bild in einer niedrigen Auflösung anzeigen zu lassen, ohnevorher die volle Auflösung geladen zu haben.

Sebastian Irle 4 Thema1: Compression Techniques
– Verlustfreie Komprimierung: das Bild wird in der Original Qualität gespeichert. Hierbei istKompressionsrate entsprechend geringer
3.2 Grundlegende Schritte
3.2.1 Schritte für die verlustbehaftete Kompression
Der JPEG-Standard schreibt kein Farbmodell vor, allerdings wird aus Gründen der Qualität meist derYUV-Modus (Y: Helligkeit (Luminanz), U: Farbton, V: Farbsättigung (Chrominanz))oder der YCbCr-Modus gewählt. Das lässt sich darauf zurückführen, dass diese Farbräume die Helligkeitsunterschiedeabspeichern, was für das menschliche Auge besser wahrnehmbar ist, als die Farbunterschiede im RGB-Modell. Aus diesem Grund wird meist als erster Schritt der Farbraum umberechnet. Für die Umrechnungaus dem RGB-Farbraum in den YUV-Farbraum werden folgende Formeln verwendet:
Y = 0, 299R + 0, 587G + 0, 114B
U = R − Y
V = R − Y
Als zweiter Schritt wird eine FDCT (Forward Discrete Cosinus Transformation) durchgeführt. DieseFunktion hat eine inverse Operation (IDCT). Die Umorganisation verläuft also verlustfrei und bringt dieDaten nur in eine besser komprimierbare Form. Hierfür wird jede Komponente des Bildes (also, das Y,U, und V) in 8x8 Blöcke unterteilt, auf die dann die Formel
F (x, y) =1
4C(x)C(y)[
7∑
i=0
7∑
j=0
f(i, j) ∗ cos(2i + 1)xπ
16cos
(2j + 1)yπ
16]
wobei
C(x), C(y) = 1/√
2 für x, y = 0
C(x), C(y) = 1 sonst
f(i, j) =1
4[
7∑
x=0
7∑
y=0
C(x)C(y)F (x, y) ∗ cos(2i + 1)xπ
16cos
(2j + 1)yπ
16]
wobei
C(x), C(y) = 1/√
2 für x, y = 0
C(x), C(y) = 1 sonst
angewendet wird. Die erste Formel (F(i,j)) stellt hierbei die FDCT zur Komprimierung der Daten dar. Diezweite Formel (IDCT) wir entsprechend für die Dekomprimierung verwendet. Die DCT transformiertalso ein zeitdiskretes Signal vom Orts- in den Frequenzbereich. Da die Frequenzen (Helligkeiten) lokalnormalerweise keine großen Sprünge machen, sind die Veränderungen der Frequenzen, und damit dieKoeffizienten, relativ gering, was sie leicht komprimierbar macht.
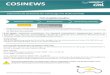
Die erste Komponente in der Matrix (mit der niedrigsten Frequenz) wird als DC bezeichnet und ist nurein Einheitsblock. Die weiteren Komponenten (AC) symbolisieren die Zunahme der Frequenz (Wechselzwischen Hell und Dunkel) und zwar von links nach rechts für die horizontale Anzahl von Zyklen undvon oben nach unten für die vertikale Anzahl von Zyklen. In diagonaler Richtung nehmen also sowohl diehorizontalen, als auch die vertikalen Zyklen zu. Die DCT kann mit der Diskreten Fourier Transformationverglichen werden, nur dass bei der DCT mit reellen anstatt mit komplexen Koeffizienten gerechnetwird. In Abbildungen 2 und 3 ist die bespielhafte Umrechnung einer 8x8 Matrix von den Bildpunktender Quelle in die DCT-Koeffizienten gezeigt.
Thema1: Compression Techniques 5 Sebastian Irle
Abbildung 1: Anwendung der FDCT und IDCT
Abbildung 2: Bildpunkte der Quelle Abbildung 3: DCT Koeffizienten

Sebastian Irle 6 Thema1: Compression Techniques
Danach erst folgt der eigentlich Schritt zur Komprimierung: Die Quantisierung. Hierfür werden dieerrechneten DCT-Koeffizienten durch eine Quantisierungsmatrix geteilt und dann zur nächsten ganzenZahl gerundet. Die Quantisierungsmatrix wird von der Applikation oder dem Benutzer vorgegeben undbestimmt letztendlich die Kompressionsrate. Um die bestmögliche Kompressionsrate ohne sichtbare Ein-bußen zu erzeugen, sollten die Werte ungefähr die Empfindlichkeit der Augen für die entsprechendenOrtsfrequenzen repräsentieren. Für hohe Frequenzen sind die Werte also höher, da das Auge für grobeStrukturen empfindlicher ist.
Abbildung 4: Quantisierungsmatrix Abbildung 5: quantisierte Koeffizienten
Abbildung 6: Zig-Zag Sequenz
Nach der Quantisierung wird die so erzeugte Matrix um-sortiert. Zum einen wird hierfür der DC-Koeffizient in Be-ziehung zum benachbarten 8x8 Block gesetzt. Die AC-Koeffizientenwerden nach ihrer Frequenz, also nach der sogenannten Zig-Zag-Sequence sortiert.
Als letzter Schritt bleibt die Entropie-Komprimierung, al-so die Erstellung von Häufigkeitstabellen und die entspre-chende Komprimierung. Der JPEG-Standard bietet zwei Mög-lichkeiten. Die Huffmann-Kodierung und die arithmetischeKodierung.Obwohl die arithmetische Kodierung etwas klei-nere Dateien erzeugt, wird aus Lizenzgründen meist die Huffmann-Kodierung verwendet.
3.2.2 Kompression und Qualität der Bilder
Für den Zusammenhang zwischen Bildgröße und Qualitätwird folgendes angegeben:
• 0,25-0,5 bits /pixel: moderate bis gute Qualität
• 0,5-0,75 bits/pixel: gute bis sehr gute Qualität
• 0,75-1,5 bits/pixel: ekzellente Qualität
• 1,5-2,0 bits/pixel: normalerweise nicht vom Original zu unterscheiden.
Dazu ist noch anzumerken, dass die JPEG Komprimierungam Besten für natürliche Bilder funktioniert. Für Strichzeichnungen oder Zeitungsdruck liegt die Quali-tät wesentlich niedriger. Auch zu beachten ist, dass durch jeden Komprimierungs/Entkomprimierungs-vorgang ein Qualitätsverlust entsteht, der, ähnlich einer Analogkopie, die Qualität von Generation zuGeneration verschlechtert.

Thema1: Compression Techniques 7 Sebastian Irle
3.2.3 Verlustfreie Kompression
Die verlustfreie Kompression basiert nicht auf ein DCT, sondern auf eine Vorhersagetechnik. Aus biszu drei benachbarten „Samples“ wird eine Vorhersage berechnet. Diese wird vom eigentlichen Wertabgezogen und Entropie-Kodiert. Wie in Tabelle 1 und Abbildung 7 zu sehen gibt es verschiedene Vor-hersagetechniken. Das X in Abbildung 7 ist der zu berechnende Wert, der mittels verschiedener Formelnvorhergesagt (Tabelle 1) wird.Je nach ausgewählter Vorhersage Methode, ergibt sich eine typische Komprimierung von 2:1
Abbildung 7: Samples
Wert Vorhersage0 keine Vorhersage1 A2 B3 C4 A+B-C5 A+((B-C)/2)6 B+((A-C)/2)7 (A+B)/2
Tabelle 1: Prediktoren für die Verlustfreie Kompression
3.3 DekomprimierungDie Dekomprimierung läuft vollkommen analog zur Komprimierung. Als erstes wird die Entropie-Kodierung rückgängig gemacht und die Koeffizienten erden wieder in die ursprüngliche Reihenfolgegebracht. Anschließend multipliziert man die Koeffizienten mit der Quantisierungsmatrix. Da an dieserStelle vorher eine Integerdivision durchgeführt wurde, kommt man zwar auf ähnlich große aber nichtidentische Werte zum Originalbild. Hier entsteht also der Verlust. Die so enstandene Matrix muss dannnur noch durch die IDCT Funktion
f(i, j) =1
4[
7∑
x=0
7∑
y=0
C(x)C(y)F (x, y) ∗ cos(2i + 1)xπ
16cos
(2j + 1)yπ
16]
wobei
C(x), C(y) = 1/√
2 für x, y = 0
C(x), C(y) = 1 sonst
geschickt werden, um wieder ein Bild mit Informationen auf Pixelbasis zu erhalten.

Sebastian Irle 8 Thema1: Compression Techniques
3.4 Mehrere Komponenten und DatenströmeWie schon oben beschrieben, bestehen die Farbbilder aus mehreren Komponenten. Hierfür können meh-rere Quantisierungs- und Entropietabellen angelegt werden. Im Standard wurden jeweils 4 Tabellen alsMaximum festgelegt. Um eine Umsetzung der Dekomprimierung in einem Chip zu ermöglichen, müssendie verschiedenen Komponenten allerdings gleichzeitig (sequentiell) dekodiert werden, wodurch eineexzessive Zwischenspeicherung vermieden wird. Um diese Interleavingtechnik sowohl für die DCT-basierten als auch die Vorhersage-Codecs zu ermöglichen, werden sogenannte Data-Units eingeführt.Diese bestehen beim DCT aus einem 8x8 Block und bei der Vorhersage aus einem Sample. Diese Data-Units werden in einer Raster-Scan-Reihenfolge durchlaufen. Da die verschiedenen Komponenten ver-schiedene Dimensionen haben können, wird jede Komponente in Regionen eingeteilt die entsprechenddurchlaufen werden (siehe Abbildung 8).
Abbildung 8: Interleaving
3.5 Aufbau des DateiformatesDas umgangssprachlich als JPEG bezeichnete Dateiformat heißt eigentlich JFIF und weist einige Ein-schränkungen zum Original JPEG Dateiformat auf. Zum einen ist die Entropiekodierung auf Huffmannbeschränkt und als Farbraum ist ausschließlich YUV zugelassen. Eine JFIF Datei besteht aus einemHeader (FF E0 00 10 4A 46 49 46 00 01) und sich anschließenden Segmenten. So kann eine JFIF-Dateidurchaus mehrere Bilder (z.B. eine Thumbnail Version) enthalten. Um Informationen wie das Copy-right, die Huffmann- und Entropietabellen und die Begrenzungen zwischen den Segmenten abspeichernzu können gibt es spezielle Steuerbefehle. Steuerbefehle werden grundsätzlich mit FF eingeleitet. Einim Datenstrom vorkommendes FF wird mit einer folgenden 00 markiert.
4 Der MPEG StandardWie schon in Abschnitt 2 beschrieben, sollte der von der MPEG gesetzte Standard die Entwicklungim Bereich der digitalen Videoübertragung beschleunigen und Kosten senken. Allerdings gab es schonzu diesem Zeitpunkt sehr unterschiedliche Anwendungsgebiete und somit auch unterschiedliche An-forderungen. Der MPEG Standard wir daher als Generic Standard bezeichnet, da er nicht auf einzelneApplikationen zugeschnitten ist, sondern ganz universell bestimmte Dienste zur Verfügung stellt. Ob-wohl der Standard sowohl aus Audio- als auch aus Videokompressionsverfahren besteht, soll an dieserStelle nur auf die Videokomprimierung im Detail eingegangen werden.
4.1 Anwendungsgebiete4.1.1 Digitale Medien
Viele Medien besitzen (bzw. besaßen) nicht genügend Speicherplatz zur unkomprimierten Speicherungvon Videos. Die für den MPEG1 Standard festgelegte Datenrate von 1,5 MBits/s ist für viele Speicher-medien adäquat. CD-ROM (die Video-CD) ist ein sehr wichtiges Speichermedium geworden, aber auch

Thema1: Compression Techniques 9 Sebastian Irle
das Digital Audio Tape (DAT), als Konkurrenz zu Sonys MD-Player nutzte den MPEG Standard. Einwichtiges Feature für die Speichermedien ist der wahlfreie Zugriff.
4.1.2 Asymmetrische Übertragung
Asymmetrische Übertragung ist dadurch gekennzeichnet, dass die Dekomprimierung an jedem Endgeräterfolgt (also relativ günstig sein muss), die Komprimierung aber zentral an der aussendenden Stelle er-folgt. Beispiele hierfür sind elektronische Veröffentlichungen oder das Bereitstellen von Fernsehsignalen(DVB Technologie).
4.1.3 Symmetrische Übertragung
Bei der symmetrischen Übertragung wird im Gegensatz hierzu auf beiden Seiten sowohl eine Kompri-mierung als auch eine Dekomprimierung erforderlich. Ein Beispiel hierfür ist die Videotelefonie.
4.2 Features
Aufgrund der sehr verschiedenen Ansprüche wurden eine ganze Reihe von Anforderungen definiert, dieje nach Anwendung implementiert werden, oder auch nicht.
4.2.1 Wahlfreier Zugriff
Der Zugriff auf beliebige Stellen des Videos ist vor allem für gespeicherte Filme essentiell. Für dieÜbertragungstechnologien ist es eher unwesentlich. Um den wahlfreien Zugriff (Random Access) zuermöglichen, müssen Access Points im Stream bereitgestellt werden, auf die direkt zugegriffen werdenkann.
4.2.2 Schneller Vorlauf/Rücklauf
Auch gerade für abgespeicherte Streams ist es interressant einen schnellen Vorlauf oder schnellen Rück-lauf zu ermöglichen. Dieser muss nicht die volle Qualität erreichen sondern wird meist einfach durchAnzeigen der AccessPoints(I-Bilder) realisiert.
4.2.3 Rückwärts abspielen
Auch wenn das rückwärts Abspielen kein grundlegendes Feature für viele Applikationen ist, wurdeim Standard die Möglichkeit festgelegt, um eine Implementation ohne immensen Speicheraufwand zuermöglichen.
4.2.4 Synchronisation zwischen Video und Audio
Eine allgemeingültige Forderung ist die Synchronisation zwischen dem Video und dem Audio Stream.Es muss also einen Mechanismus geben, der ständig die beiden Streams abgleicht und im Bedarfsfallnachsteuert.
4.2.5 Fehlerunanfälligkeit
Gerade für die Übertragungstechniken ist die Fehlerunanfälligkeit sehr wichtig, so dass auch bei fehler-behafteter Übertragung genügend Redundanz verfügbar ist um eine gleich bleibende Qualität zu erlau-ben.

Sebastian Irle 10 Thema1: Compression Techniques
4.2.6 Flexibilität
Der MPEG Standard sollte zum einen flexibel sein einerseits in Bezug auf die Bildgröße und die ge-nutzte Bandbreite sein, um die verschiedenen Applikationen zu ermöglichen (eine Videotelefonie mit1,5 MBits/s war im Jahr 1990 eher unrealistisch) andererseits aber auch in Bezug auf die eingesetzteTechnologie. So wird im Standard nur das Format nicht aber die eigentliche Komprimierung festgelegt.
4.2.7 Echtzeitkomprimierung
Für die synchronen Übertragungen ist eine Echtzeitkomprimierung erforderlich, um eine vernünftigeInteraktion zwischen den Systemen zu ermöglichen. Dafür ist es widerrum wichtig, dass die Daten se-quentiell verschlüsselt werden können, um nicht auf riesige Pufferspeicher zurückgreifen zu müssen.
4.3 Bestandteile
Um, wie bereits angesprochen, die technologische Entwicklung nicht durch einen starren Standard zubremsen, gibt es zwei wesentliche Komponenten.
4.3.1 Container
Der Container (bzw. das Containerformat) legt fest, auf welche Art und Weise der Stream übermitteltwird (Bitstream). Das ist auch die grundlegende Funktion des MPEG Standards. Es wird festgelegt, dassder Stream mit einem Zwischenspeicher von annehmbarer Größe dekodiert werden kann. Darüberhinauswerden Testverfahren zur Sicherung der Verbindung beschrieben. Andere Beispiele für Videocontainer-formate sind avi, DVD-Video, Quicktime oder RealMedia.
4.3.2 Codec
Der andere Bestandteil des Videostreams ist der Codec (Codierer-Decodierer). Während für viele For-mate der Codec und das Containerformat den gleichen Namen tragen, sind diese Komponenten dennochzu unterscheiden. Für den MPEG Standard wurde kein Codec festgelegt; nur der Dekodierungsprozesswurde beschrieben. Daher existieren inzwischen eine ganze Reihe unterschiedlicher Codecs, die, für denLaien, die Verwendung des MPEG Standards erschweren.
4.4 Versionen
4.4.1 MPEG1
Der MPEG1 Standard ist von 1990 und legt eine Übertragungsrate von 1,5 Mbits/s fest. Die maximaleGröße des Bildes ist auf 720x576 pixel festgelegt und die Bildrate wurde auf 30 Frames/s beschränkt.Die Video-CD ist im MPEG1 Format encodiert. Als Audio Formate sind verschiedene Layer definiertworden, wobei gerade der Layer 3 (besser bekannt als MP3), der vom Fraunhofer Institut entwickeltwurde, besondere Bekanntheit erreicht hat.
4.4.2 MPEG2
1994 wurde mit MPEG2 der MPEG Standard deutlich verbessert und verfeinert. Er ist vor allem aufhöhere Videoqualitäten und somit auch höhere Bandbreiten (bis 15 MBits/s) ausgerichtet. Es wurde fürdie Fernsehübertragung entwickelt und besitzt daher auch die Fähigkeit für Interlace (Darstellung vonHalbbildern). Bekannt geworden ist das MPEG2 Format vor allem durch DVDs die das MPEG2 VideoFormat einsetzen. Auch die DVB-Standards setzen MPEG2 ein.

Thema1: Compression Techniques 11 Sebastian Irle
4.4.3 MPEG4
Die ursprüngliche Intention von MPEG4 war die Übertragung von Videosignalen über Schmalband-verbindungen (Handy, UMTS). Da dies vom Standard H.263 der ITU bereits abgedeckt wurde, konntedieser fast vollständig übernommen werden und wurde lediglich um verschiedene Funktionalitäten aufBildkomponenten erweitert. Die bekannteste Codec Implementation im MPEG4 Format ist DIVX.
4.5 BewegungskompensationMPEG basiert technisch zum einen auf die block-based motion-compensation (Bewegungskompensati-on) und zum anderen auf die DCT, die schon beim JPEG Standard beschrieben wurde. Es besteht alsonicht nur eine Abhängigkeit zwischen den Frequenzen benachbarter Bildpunkte, wie beim unbeweg-ten Bild, sondern auch ganz bedeutende Abhängigkeiten zwischen den Einzelbildern, da sich oft nurAusschnitte bewegen.
4.5.1 Typen von Bildern
Für die Bewegungskompensation unterscheiden wir 4 Typen von Bildern:
• I-Bilder: Das I Steht für Intrapicture. Es wird das komplette Bild abgespeichert ohne Abhängigkei-ten zu den vorhergehenden oder nachfolgenden Bildern zu berechnen. Damit werden die I-Bilderals Access Points für den Sprung mitten in einen Stream benutzt. Werden nur I-Bilder kodiert,entspricht das dem MJPEG Verfahren.
• P-Bilder: Das P steht für Predictive Pictures. Diese vorhergesagten Bilder werden auf Grundlagevorheriger Bilder erstellt. Sie dienen dennoch als Referenz für zukünftige Bilder.
• B-Bilder: Die Bidirektionalen Bilder liefern die höchste Kompressionsrate, da sie aus den sowohlvorhergehenden als auch aus den nachfolgenden Bildern berechnet werden. Sie dienen daher nichtals Referenzpunkt für andere Bilder.
Durch die Anordnung der verschieden Bildtypen ergeben sich unterschiedliche Qualitäten und Kompres-sionsraten. Eine relativ typische Anordnung ist die Platzierung von jeweils 3 B-Bildern zwischen einemI-Bild und einem P-Bild
Abbildung 9: Anordnung der Bildtypen

Sebastian Irle 12 Thema1: Compression Techniques
4.5.2 Vorhersage
Für die Bewegungsvorhersage (Prediction) wird das Bild in 16x16 Blöcke eingeteilt. Es werden nur dieBlöcke abgespeichert, die sich verändert haben. Es wird also davon ausgegangen, dass lokal das Bildaus den vorhergehenden Bildern heraus aufgebaut werden kann. Die Bewegungsinformation ist alsogrundlegend und wird zusätzlich zu den vorher gespeicherten Bildern benötigt.
4.5.3 Interpolation
Die Interpolation ist ein weiteres sehr wichtiges Feature des MPEG Standards. Sie ermöglicht zum einendie Verbesserung des wahlfreien Zugriffs, zum anderen die Auswirkungen von Fehlern zu verringern.Das Videosignal wird aus einem vorhergehenden und einem nachfolgenden Bild durch Interpolation undanschließender Addition eines Korrekturterms wiederhergestellt. Die Auflösung liegt meist relativ nied-rig (1/2 oder 1/3 der Frame Rate). Dieses Verfahren verursacht zwar zusätzlichen Aufwand, verbessertaber die Bildqualität erheblich.
4.6 BewegungsestimationDie Bewegungsestimation geht einen etwas anderen Weg. Sie geht davon aus, dass die Bewegung vonObjekten nicht nur eine Verschiebung, sondern auch eine Drehung beinhalten kann. Wenn die Kameraalso langsam nach links schwingt, kann das gesamte Bild wieder verwendet werden, nur der Streifen amlinken Rand muss neu abgespeichert werden. Dieses Verfahren wird allerdings schnell sehr aufwendig,da unter Umständen Hintergründe und Blickwinkel neu berechnet werden müssen. Es ist aber durchausmöglich, dass auch die Bewegungsestimation, gerade im Bereich der hohen Kompression für langsameVerbindungen noch eine große Rolle spielen wird.
4.7 DCTDie verschiedenen Bilder werden ähnlich dem JPEG Verfahren abgespeichert. Sie werden in 8x8 Pi-xel große Blöcke unterteilt, durchlaufen dann eine DCT Funktion, und werden anschließend durch ei-ne Quantisierungsmatrix geteilt. Nach der Umorganisation (Zig-Zag-Sequence) werden sie mittels desHuffmanns Algorithmus Entropie-Codiert. Allerdings sind hier bei der Quantisierung unterschiedlicheMatrizen für die I-Bilder und die P-Bilder bzw. B-Bilder anzuwenden. Auch die Art der Bilder kannsich im Laufe des Streams grundlegend ändern, so dass die Anwendung einer jeweils anderen Quanti-sierungstabellen pro Block ermöglicht werden muss.
5 Zusammenfassende BeurteilungDie beiden vorgestellten Standards JPEG und MPEG haben ihr Ziel in allen Punkten erreicht. Ihre Ver-breitung hat in den entsprechenden Bereichen die Entwicklung, zum einen gefördert, zum anderen aberauch in Bahnen gelenkt, die die Kompatibilität verschiedener Anwendungen und Geräte ermöglichen.Insbesondere am MPEG Format wird deutlich, wie wichtig es ist, auch im Detail feste Standards zuvereinbaren. So ist es heute z.B. nicht möglich auf einen Blick zu sagen, ob ein MPEG File auf demRechner abgespielt werden kann, da mehrere verschiedene Codecs zu Grunde liegen können.Auf der anderen Seite sind Standards, die schon zum Zeitpunkt Ihrer Fertigstellung auf veraltete Tech-nologie aufbauen, auch zum Scheitern verurteilt.Es bleibt also ein schmaler Grat zwischen engen Vorgaben, die die Kompatibilität sichern, und Freihei-ten, die die Anpassung an den technische status quo ermöglichen.

Thema1: Compression Techniques 13 Sebastian Irle
6 Quellen• http://de.wikipedia.org/wiki/JPEG
• http://de.wikipedia.org/wiki/Diskrete_Kosinustransformation
• http://de.wikipedia.org/wiki/MPEG
• http://de.wikipedia.org/wiki/Containerformat
• http://de.wikipedia.org/wiki/MPEG-1
• http://de.wikipedia.org/wiki/MPEG-2
• http://de.wikipedia.org/wiki/MPEG-4
• http://de.wikipedia.org/wiki/Motion_Compensation
• Björn Eisert: „Was ist MPEG?“http://www.cybersite.de/german/service/Tutorial/mpeg/, 1995
• Sandra Bartl: „jpg“, http://goethe.ira.uka.de/seminare/redundanz/vortrag11/ , 1999
• Gregory K. Wallace: „The JPEG Still Image Compression Standard“, in: Communications of theACM, April 1991
• Didler Le Gall: „MPEG: A Video Compression Standard for Multimedia Applications“, in: Inni-cations of the ACM, April 1991


Seminar 1912 Multimedia-Datenbanken
Indexing of Complex Data
Peter EggertProject Management
Erstellt am: 15.03.2006 Druckdatum: 22.05.2006_19:06:36 Stand: 08.05.2006 Ausarbeitung_Indexing of Complex Data_V 3.0_Revised_Final
Autor: Peter Eggert Seite 1 von 18
Fernuniversität in Hagen Fachbereich Informatik
Datenbanksysteme für neue Anwendungen Prof. Dr. R. H. Güting
Sommersemester 2006
Seminar 1912 – Multimedia Datenbanken
Thema: Indexing of Complex Data
Name: Peter Eggert Matrikelnummer: 5871409
Adresse: Im Höllengrund 3, 69118 Heidelberg Telefon: 069/6601-3225 (beruflich); 06221/802066 (privat)
eMail-Adresse: [email protected]


Seminar 1912 Multimedia-Datenbanken Thema: Indexing of Complex Data 1
1 Inhaltsverzeichnis
1 Inhaltsverzeichnis .......................................................................................................................1 2 Aufgabenstellung........................................................................................................................2 3 Einleitung...................................................................................................................................2
3.1 Gegenstand der Ausarbeitung..............................................................................................2 3.2 Ansätze zur Indexierung mehrdimensionaler Daten...............................................................3 3.3 SAMs und der R-Baum ........................................................................................................3
4 Konzepte für Indexstrukturen in metrischen Räumen ....................................................................5 4.1 Prinzipien metrischer Indexierung und Metrische Bäume .......................................................5
4.1.1 Ball Zerlegung ............................................................................................................5 4.1.2 Verallgemeinerte Hyperflächen-Zerlegung ....................................................................6 4.1.3 Metrische Bäume ........................................................................................................6
4.2 Der M-Baum.......................................................................................................................7 4.2.1 Struktur des M-Baums.................................................................................................7 4.2.2 Aufbauen des M-Baums ..............................................................................................8 4.2.3 Algorithmen des M-Baums...........................................................................................9 4.2.4 Experimentelle Ergebnisse...........................................................................................9
5 Konzepte für Indexstrukturen in hoch-dimensionalen Vektorräumen ............................................10 5.1 Der TV-Baum ...................................................................................................................10
5.1.1 Struktur des TV-Baums .............................................................................................10 5.1.2 Transformation des TV-Baums...................................................................................11 5.1.3 Algorithmen des TV-Baums .......................................................................................11 5.1.4 Experimentelle Ergebnisse.........................................................................................12
5.2 Der X-Baum .....................................................................................................................12 5.2.1 Struktur des X-Baums ...............................................................................................13 5.2.2 Algorithmen des X-Baums .........................................................................................13 5.2.3 Bestimmung der Teilung zur minimimalen Überlappung ..............................................14 5.2.4 Experimentelle Ergebnisse.........................................................................................14
6 Stärken und Schwächen der vorgestellten Konzepte....................................................................15 7 Zusammenfassung....................................................................................................................15 8 Literaturverzeichnis...................................................................................................................16

2 Seminar 1912 Multimedia-Datenbanken Thema: Indexing of Complex Data
2 Aufgabenstellung
Aufgrund der Mehrdimensionalität von Multimedia-Daten können die Indexstrukturen von klassischen Datenbanksystemen (z.B. B-Bäume) nicht für Multimedia-Daten verwendet werden. Bei diesem Thema sollen zwei Ansätze diskutiert werden, mit denen es möglich ist, mehrdimensionale Daten zu indexieren. [Uhl91] beschreibt die grundsätzliche Idee von Indexstrukturen in metrischen Räumen. Eine Umsetzung dieser Idee findet sich in [CPZ97]. Im Gegensatz dazu behandeln [LJF94] und [BKK96] Indexstrukturen für hoch-dimensionale Vektorräume. Ziel dieses Themas soll es nicht sein, alle Papiere im Detail darzustellen, sondern vielmehr einen Überblick über die Konzepte, ihre Stärken und Schwächen zu geben.
3 Einleitung
3.1 Gegenstand der Ausarbeitung In vielen Anwendungen ist die Indexierung mehrdimensionaler Daten wichtig. Typische Anwendungsbereiche sind CAD, Bilddatenbanken, medizinische Datenbanken, DNA-Datenbanken, Zeitfolgen-Datenbanken (z.B. zur Untersuchung von Aktien-/Wechselkursschwankungen), Adressdatenbanken und Multimedia-Datenbanken. Gegenstand der Ausarbeitung ist die Untersuchung zwei grundsätzlicher Ansätze mit denen es möglich ist, mehrdimensionale Daten effizient zu indexieren und zu verwalten, d.h. Indexstrukturen in metrischen Räumen und Indexstrukturen in hoch-dimensionalen Vektorräumen.
Zunächst werden Grund-Prinzipien zur Indexierung in metrischen Räumen, d.h. die Ball-Zerlegung (ball decomposition), die Verallgemeinerte Hyperflächen Zerlegung (Generalized Hyperplane Decomposition) und die metrischen Bäume sowie der R-Baum (Guttman1984) als Grundkonzept einer Vielzahl von weiterentwickelten Indexstrukturen eingeführt. Danach werden konkrete Konzepte, die im Prinzip alles Erweiterungen des R-Baum-Konzepts darstellen, d.h. der M-Baum (CPZ97) der TV-Baum (LJF94) der X-Baum (BKK96) zur Indexierung und Verwaltung mehrdimensionaler Daten vorgestellt. Schließlich werden die unterschiedlichen Konzepte im Hinblick auf Stärken und Schwächen gegenübergestellt und abschließend bewertet.

Seminar 1912 Multimedia-Datenbanken Thema: Indexing of Complex Data 3
3.2 Ansätze zur Indexierung mehrdimensionaler Daten Generell sind zwei Ansätze zur Indexierung (indicare [lat.] – anzeigen) mehrdimensionaler Daten zu unterscheiden. Einerseits lassen sich die mehrdimensionalen Daten in metrischen Räumen abbilden, andererseits in hoch-dimensionalen Vektorräumen.
Ein metrischer Raum ist formal gesehen ein Paar, M = (D, d), wobei D das Universum der Werte und d die Distanzfunktion ist. Für alle x, y, z ∈ D müssen die metrischen Axiome (Axiom [gr.] - Forderung; eine nicht beweisbare, aber einsichtige Aussage, aus der andere ableitbar sind) erfüllt werden, d.h. d(x, x) = 0 d(x, y) ≥ 0, d(x, y) = 0 ⇔ x = y (Positivität) d(x, y) = d (y, x) (Symmetrie) d(x,y) ≤ d(x,z) + d(z,y) (Dreiecksungleichung) Zur effizienten Indexierung von Objekten in metrischen Räumen nutzt man folgende Beobachtung: Echte Daten in hochdimensionalen Räumen stehen in enger Wechselwirkung zueinander und sind gruppiert, so dass die Daten nur Teile des hoch-dimensionalen Raumes belegen. Mehrdimensionale Daten werden in hoch-dimensionalen Vektorräumen mittels Eigenschafts-Vektoren der Objekte (Feature Vectors) abgebildet. Beispiele hierfür sind Farb-Histogramme, Formbeschreiber und Fourier Vektoren. [Vector [lat.] - Träger, Passagier, Seefahrer - Größe definiert durch 3 Zahlen -Vektorkomponenten - gedeutet als Koordinatendifferenzen, die jede gerichtete Strecke im Raum beschreiben). Dabei ergibt sich für multi-dimensionale Daten oftmals eine schlechte Performanz der Methoden in hoch-dimensionalen Räumen. Das Hauptproblem liegt darin, dass die Indexstrukturen für 2-3-dimensionale Probleme konstruiert und dann auf höher dimensionale Probleme übertragen wurden. Um dem "Fluch der hohen Dimensionen" in Vektorräumen zu begegnen, nutzt man die Beobachtung, dass in den meisten hochdimensionalen Datenmengen eine kleine Anzahl von Dimensionen die meisten Informationen beinhaltet.
3.3 SAMs und der R-Baum Grundsätzlich sind drei Klassen von Methoden -sogenannte SAMs – Spatial Access Method- zu unterscheiden, um auf Punkte bzw. Punktmengen im Raum zuzugreifen: Gridfiles Quadtrees R-Baum Idee des Gridfiles: Jeder Datensatz kann als Punkt in einem mehrdimensionalen Würfel verstanden werden, wobei die Anzahl der Dimensionen genau der Anzahl der einzelnen Attribute entspricht. Wenn sich die Attribute zweier Datensätze ähneln, dann liegen sie in diesem Modell räumlich nah beieinander. Um den Vorteil dieses Modells zu nutzen, wird der Datenraum, den man sich als mehrdimensionalen Würfel vorstellen kann, mit einem Gitter in mehrere konvexe Blöcke unterteilt. Dabei entstehen rechteckige Zellen bzw. Blöcke. Der Inhalt dieser Blöcke wird in sogenannten "buckets" gespeichert, die eine feste Größe haben. Ein Bucket enthält mindestens die Daten eines Blockes und kann, wenn der Speicherplatz ausreicht, noch die Datensätze von beliebig vielen anderen Blöcken speichern. Um den Zugriff zu den Buckets aus Performanzgründen vernünftig zu organisieren, muss eine Verbindung zwischen den Blöcken, in die der Würfel eingeteilt ist, und den zugehörgen Buckets organisiert werden. Diesem Zweck dient das Griddirectory. Das Griddirectory besteht aus zwei Komponenten: Den Skalen für die Einteilung der Wertemengen in den "grid blocks" und der directory matrix, in der Beziehungen zwischen der "grid blocks" zu den Buckets gespeichert sind. Diese Matrix enthält für jeden Block einen Eintrag, nämlich einen Zeiger auf den Bucket in dem die Datensätze des Blocks gespeichert sind.

4 Seminar 1912 Multimedia-Datenbanken Thema: Indexing of Complex Data
Idee des Quadtrees: Ein zwei-dimensionaler Datenraum kann mit zwei senkrecht aufeinander-stehenden Linien in vier Bereiche aufgeteilt werden. (NW-NorthWest, NE, SE, SW). Die Aufteilung wird dann rekursiv erweitert. Erweiterungen des Quadtrees für drei und mehr Dimensionen existieren, haben sich aber nicht durchgesetzt. Der R-Baum (Guttman, 1984) ist das Grundmodell vieler R-Baum-Varianten und Weiterentwicklungen (z.B. X-Baum, TV-Baum und M-Baum) zur Verwaltung mehrdimensionaler Daten und zeichnet sich durch nachstehende Eigenschaften aus: Mit Ausnahme der Wurzel enthält jeder innere Knoten und jeder Blattknoten zwischen m und 2 m
Einträgen für ein m ∈ |N. Für jeden Eintrag (I, Z) in einem inneren Knoten ist I die MBR (Minimum Bounding Region), die alle
Rechtecke des durch Zeiger Z referenzierten Knotens enthält. Für jeden Eintrag (I, Z) in einem Blatt-Knoten ist I die MBR (Minimum Bounding Region) des durch
Zeiger Z referenzierten geometrischen Objekts. Für alle Blätter ist die Länge des Pfades von der Wurzel gleich. Die Behälterregionen ergeben sich aufgrund der Reihenfolge und der Zuordnung beim Einfügen. Beim Überlauf des Blattknotens wird dieser geteilt, so dass möglichst gleichmäßig gefüllte
Behälterregionen entstehen. Bei der exakten Suche ist der Suchpfad aufgrund der Überlappung nicht immer eindeutig. Mit Hilfe eines k-dimensionalen Suchintervalls S wird rekursiv nach Einträgen (I, Z) gesucht, für die
I ∩ S ≠ ∅ ist.
A
B
C
ED
F I
HG
LK
J B CA
E FD H IG K LK LJ
...........................................................
A B C
D L
Rekursive bottom-up Aggregation von Objekten, die auf MBRs basieren.
Regionen ergeben sich aufgrund der Reihenfolge und Zuordnung beim Einfügen und können überlappen.
Jede Region kann bis C Einträge enthalten, jedoch nicht weniger als c ≤ 0,5 * C (ausgenommen ist die Wurzel).
Alle Blätter haben gleichlange Pfade bis zu Wurzel.
Bei der exakten Suche ist der Suchpfad aufgrund der Überlappung nicht immer eindeutig.
Zusammenfassend lässt sich für alle räumlichen Zugriffsmethoden -SAMs- feststellen, dass der Anwendungsbereich eingeschränkt wird, weil Objekte mittels Eigenschaftswerten im mehrdimensionalen Vektorraum repräsentiert werden, (Nicht-)Übereinstimmungen von Objekten auf der Distanz Funktion im metrischen Raum basieren, die
keine Korrelation zwischen Eigenschaftsvariablen ermöglichen, Schlüsselvergleiche als triviale Operationen im Vergleich zu Festplatten-Seitenzugriffen eingeschätzt
werden, was nicht generell für Multimedia Anwendungen gilt. Daher werden keine Anstrengungen unternommen, die Anzahl der Distanzberechnungen zu reduzieren.
Ferner erweist sich im R-Baum insbesondere die Überlappung der Verzeichnis-Knoten (MBRs) als problematisch je höher die Dimensionalität ist. Praktisch gilt, dass ab der fünften Dimension ca. 90% der MBRs überlappen. (Dimension 2 = 40%, Dimension 3 = 60%, Dimension 4 = 80%).

Seminar 1912 Multimedia-Datenbanken Thema: Indexing of Complex Data 5
v
rv
p
r
P1
P2
v
rv
p
r
P1
P2 • P1 und P2 enthalten je 8 Elemente
4 Konzepte für Indexstrukturen in metrischen Räumen
4.1 Prinzipien metrischer Indexierung und Metrische Bäume In metrischen Räumen ergibt sich als praktisches Problem der Mehrdimensionalität, unterschiedliche Anfragen, d.h. die Bereichsanfrage, die Enthaltseinsanfrage, die Suche nach dem nächsten Nachbarn und die Punktsuche, effizient durchzuführen. Dabei gilt es zu berücksichtigen, dass Anfragen nicht immer konvexe (convexus [lat.] – gewölbt, gerundet, gebündelt) Suchregionen definieren. Allen effizienten Anfrage-Algorithmen in metrischen Räumen ist jedoch gemeinsam, dass die Untersuchung jedes Punkts einer Menge vermieden wird. Daher wurden insbesondere Datenstrukturen entwickelt, die eine schnelle Näherungssuche unterstützen. Eine präzise Bedeutung von Näherung variiert jedoch von Fall zu Fall. Fast alle Datenstrukturen, die eine schnelle Näherungssuche unterstützen, basieren auf dem Paradigma (Paradigma [gr.] – Beispiel, Erfahrungsmuster) der rekursiven Hyperflächenzerlegung. Nach diesem Paradigma wird eine Fläche oder ein Raum rekursiv in kleinere Teile zerlegt und in einer Baumstruktur organisiert (Bsp. k-d-Baum). Um diese rekursive Zerlegung einer metrischen Datenmenge P ⊆ U (Universum) in zwei Teilmengen P1 und P2 durchzuführen, können zwei Prinzipien benutzt werden,
die Ball-Zerlegung (ball decomposition) und die Verallgemeinerte Hyperflächen Zerlegung (Generalized Hyperplane
Decomposition)
4.1.1 Ball Zerlegung
Mittels Ball-Zerlegung (ball decomposition) wird eine metrische Datenmenge P ⊆ U nachstehend zerlegt:
Suche einen Aussichtspunkt v aus der Datenmenge P aus.
Ermittle zu allen Punkten die Entfernung zum Aussichtspunkt v
Bilde zwei Teilmengen P1 und P2, wobei P1 = p : d(p,v) ≤ rv und P2 = p : d(p,v) > rv
Ist rv so gewählt, dass |P1| ≈ |P2| ≈ P/2, dann erhält man eine gleichmäßige Verteilung.
Insbesondere bei Bereichssuche bringt diese Vorgehensweise entscheidende Vorteile, da irrelevante Bereiche schnell abgeschnitten werden können.
Die Ball-Zerlegung ist interessant, weil nichts anderes als paarweise Entfernungen bekannt sein müssen. Das Prinzip der Ball-Zerlegung wird z.B. bei Routing-Problemen benutzt, um die minimalen Kosten von einem Punkt zum anderen ermitteln zu können.

6 Seminar 1912 Multimedia-Datenbanken Thema: Indexing of Complex Data
v1
rv
p
P1 P2
v2
q
rv1
rv
p
P1 P2
v1
rv
p
P1 P2
v2
q
r
4.1.2 Verallgemeinerte Hyperflächen-Zerlegung
Die verallgemeinerte Hyperflächen-Zerlegung ähnelt im Aufbau der Ball-Zerlegung. Im Unterschied zur Ball-Zerlegung wird jedoch eine Menge P in zwei Teilmengen P1 und P2 geteilt, indem zwei Aussichtspunkte v1 und v2 ausgewählt werden, von denen aus die Entfernungen zu den einzelnen Elementen der Menge ermittelt werden. Das Element wird dann jeweils der Menge zugeordnet, zu dessen Aussichtspunkt das Element näher liegt. Daher gilt:
P1 = p : d(p, v1) ≤ d(p, v2) und P2 = p : d(p,v2) < d(p, v1)
Der Algorithmus für Dynamisches Einfügen gemäß verallgemeinerter Hyperflächen-Zerlegung ist nachstehend definiert:
Punkt p wird in Baum H eingefügt Ist Baum H leer
• Erzeuge einen Knoten H mit Hx = p und Hy = nil , Hleft = nil, Hright = nil (Wobei Hx und Hy die Punkte sind, die die Teilung definieren)
Ist Hy = nil dann gebe H zurück mit Hy = p Ist d(p,Hx) <= d(p,Hy) dann gebe H zurück mit Hlinks = Einfügen (Hlinks, p) Gebe H zurück mit Hlinks = Einfügen (Hright, p)
Der Vorteil der verallgemeinerten Hyperflächen-Zerlegung gegenüber der Ball-Zerlegung liegt darin, dass diese weniger statisch ist. Als nachteilig erweist sich, dass es nicht generell möglich ist, eine Menge P in gleich große Mengen P1 und P2 aufzuteilen.
4.1.3 Metrische Bäume
Metrische Bäume sind Indexstrukturen, die ausschließlich über die Nutzung des relativen Abstands von Objekten aufgebaut und verwaltet werden. Ein metrischer Baum B konstruiert sich durch die Menge S von n Objekten mittels O(n log n) Entfernungsberechnungen. Beispielsweise wird ein metrischer Baum durch das Prinzip der Ball-Zerlegung durch den nachstehenden Algorithmus aufgebaut: Wenn die Mächtigkeit der Menge S (von Punkten) = 0
Dann erzeuge einen leeren Baum Sonst
Nimm ein zufälliges Objekt aus der Menge S. Suche eine mittlere Entfernung, so dass die Hälfte der Objekte innerhalb des metrischen Balls
mit dem Radius m und der Rest außerhalb liegt. Wiederhole den Vorgang solange rekursiv bis alle Objekte zufällig aber balanciert im Baum
eingeordnet sind. Metrische Bäume weiten das divide- and conquer-Paradigma für Suchprobleme auf metrische Räume aus. Sie sind wertvoll für Mustererkennung/Erinnerung und eine Vielzahl von Netzwerkoptimierungs-Anwendungen. Im Gegensatz zu SAMs wurde bei bekannten Arten von Metrischen Bäumen versucht, die Anzahl der Distanzberechnungen zu reduzieren. Metrische Bäume sind in der Regel effektiv, aber leiden an zu statischem Wesen.

Seminar 1912 Multimedia-Datenbanken Thema: Indexing of Complex Data 7
Leistungsfähiges Laufzeitverhalten kann jedoch nicht garantiert werden. Im Worstcase der Ball-Zerlegung liegen alle Punkte auf der Oberfläche des Balls und die Anfrage verlangt nach genau den Punkten, die knapp innerhalb des Balls liegen. In diesem Falle wird dann sowohl die Anfrage-Region als auch die Komplement-Region durchsucht.
4.2 Der M-Baum Insbesondere in Multimedia-Datenbanksystemen, die auf einheitliches Handling von Audio-, Video-, Bild-, Text- und Numerischen Daten abzielen, spielen inhaltsbasierte Suchvorgänge eine dominierende Rolle. Daher ist insbesondere die schnelle und effiziente Näherungssuche ein der wichtigsten Anforderungen an die ideale Indexstruktur für Multimedia-Daten. Der M-Baum (LPZ97) ist eine seitenbezogene metrische und balancierte Sekundärspeicherstruktur für die Indexierung von Datenmengen im metrischen Raum. Der M-Baum wurde explizit für die Integration mit anderen Zugriffsmethoden in Datenbanken entworfen und wurde als alternative Zugriffsmethode zu den SAMs entwickelt. Als Indexstruktur dient der M-Baum insbesondere zum Finden ähnlicher DB-Objekte. Daher wurden im Entwurf Prinzipien metrischer Bäume als auch Datenbank-Zugriffs-Methoden zur Optimierung der CPU- sowie der I/O-Kosten berücksichtigt. Zielstellung war es, dass der M-Baum - im Gegensatz zu SAMs - Dynamik als auch eine problemlose Skalierbarkeit bei wachsender Datenmenge gewährleistet. Die Grundidee des M-Baums liegt darin, die R-Baum-Prinzipien in metrischen Räumen ausschließlich mittels Distanzfunktionen zu realisieren.
4.2.1 Struktur des M-Baums
Die Knoten des M-Baums beinhalten ein Routing Objekt, bestehend aus dem Eigenschaftswert des Routing Objekts, einen Objekt Zeiger auf die Wurzel des Teilbaums, den abgedeckten Radius des Objekts und den Abstand zum Vater. Die Blätter des M-Baums beinhalten Daten-Objekte, bestehend aus dem Datenbank-Objekt selbst, der Objekt-ID und dem Abstand zum Vater.
A
D
C
F
E
B
Q Q1Q2
A B
C D E F

8 Seminar 1912 Multimedia-Datenbanken Thema: Indexing of Complex Data
4.2.2 Aufbauen des M-Baums
Der Aufbau-Algorithmus beinhaltet das Einfügen das Löschen den Überlauf eines Knotens den Unterlauf eines Knotens Beim Einfügen eines neuen Objekts steigt man den M-Baum rekursiv abwärts, um den best-
passenden Blatt-Knoten zu finden und ggf. zu teilen, wenn dieser voll ist. Best-passend ist das Blatt bzw. der Knoten, an dessen Pfad entlang keine Erweiterung des Radius erforderlich ist [D(Or, On) <= r(Or)]. Falls mehrere Knoten in Betracht kommen, wird der Teilbaum genommen, der am nächsten zum Objekt Q liegt. Falls kein passendes Routing-Objekt existiert, dann ist die Strategie, die Erweiterung des Radius möglichst gering zu halten. Die Bestimmung der Menge von Routing-Objekten, für die keine Radien-Erweiterung erforderlich ist, kann optimiert werden, indem Ergebnisse gesichert werden. Im Falle des Überlaufes eines Knotens wächst der M-Baum wie vergleichbare dynamisch balancierte Bäume, d.h. BOTTOM - UP. Das Einfügen eines neuen Knotens auf der Ebene von N wird durchgeführt indem die Einträge zwischen den Knoten geteilt werden und zwei Routing-Objekte zum Vaterknoten zur Referenzierung der beiden Knoten geschickt werden. Entgegen anderen metrischen Bäumen erlaubt der M-Baum die Durchführung unterschiedlicher Split-Policies (Spezifische Beförderungs- und Teilungsmethoden). Der Bedeutung der Radieneinhaltung muss jedoch bei allen Split Policies gewährleistet werden. Die ideale Split-Politik ermöglicht, dass die beiden neu erhaltenen Regionen minimales Volumen und minimale Überlappung verursachen. Dies steigert die Effizienz durch Vermeidung indexierten "toten Raumes". Für die Verteilung der Einträge einer Menge N in zwei Teilmengen sind grundsätzlich zwei Alternativen zu unterscheiden: Verallgemeinerte Hyperflächen-Zerlegung - Bestimme für jedes Objekt aus N, ob es näher zu
Mittelpunkt Vater1 oder Vater2 liegt und ordne entsprechend zu. Balancierte Zerlegung - Bestimme für die zu teilende Menge N jeweils abwechselnd den nächsten
Nachbarn zum Mittelpunkt der Routing-Objekte Vater1 oder Vater2. Entferne jeweils den nächsten Nachbarn des Routing-Objekts Vater1 bzw. Vater2 aus der Menge N und ordne jeweils diesen der Teilmenge N1 (Vater1) bzw. N2 (Vater2) zu. Wiederhole dies solange bis die Menge N leer ist.

Seminar 1912 Multimedia-Datenbanken Thema: Indexing of Complex Data 9
4.2.3 Algorithmen des M-Baums
Bei der Durchführung von Ähnlichkeitsanfragen liegen alle Informationen bezüglich der Entfernungen vorgerechnet in den Knoten vor. Bei der Bereichssuche liegt der Vorteil des M-Baums im schnellen Abschneiden irrelevanter Teilbäume.
Op
d(Or,Op)
Or
r(Or)
Qr(Q)
d(Op,Q)Op
d(Or,Op)
Or
r(Or)Or
r(Or)Or
r(Or)
Qr(Q)
Qr(Q)
Qr(Q)
d(Op,Q)
Sei Op das Vater(Routing)Objekt von Or
Kommen wir an den Eingang des Knotens Or, um zu entscheiden, ob dieser durchsuchtwerden muss, dann– wurde die Entfernung d(Op,Q) zwischen
Anfragepunkt und Vater(Routing)Objekt bereitsberechnet
– kennen wir die Entfernung zwischen d(Or,Op)
Durch die Dreieck-Ungleichheit gilt:d(Q,Or) ≥ |d(Op,Q) – d(Op,Qr)|
Gilt weiterhin, dass |d(Op,Q) – d(Op,Qr)|> r(Or) - r(Q)
Dann kann der irrelevante Teilbaum Or abgeschnitten werden. Bei der Suche nach k-Nächsten Nachbarn wird eine Verzweigungs- und Begrenzungstechnik, die dem des R-Baums ähnelt, eingesetzt. Genutzt werden zwei globale Strukturen
Prioritäten-Schlange, die Zeiger auf aktive Teilbäume enthalten und ein k-elementiger Array, der am Ende das Ergebnis beinhaltet.
4.2.4 Experimentelle Ergebnisse
Die Anfrageausführungen im M-Baum sind optimiert, um sowohl die Anzahl der Seitenzugriffe (I/O-Kosten) als auch die Anzahl der Entfernungsberechnungen (CPU-Kosten) zu minimieren. Experimentelle Ergebnisse bestätigen, dass die Balancierte Zerlegung zu einem erheblichen CPU Overhead und steigenden I/O-Kosten führt. So ist das Overhead-Volumen der Routing-Objekte einer balancierten Zerlegung um 4,6-mal höher als die der Verallgemeinerten Hyperflächen-Zerlegung. Steigt die Anzahl der Dimensionen für die Daten werden die I/O-Kosten vor allem durch reduzierte Seitenkapazität, die zu größeren Bäumen führen, erhöht. Experimentelle Ergebnisse zeigen, dass die Skalierbarkeit der Leistung des M-Baums mit wachsenden Datenmengen sowohl in Hinsicht auf I/O- als auch CPU-Kosten gegeben ist. Der Vergleich zwischen M-Baum und R*-Baum ergibt, dass der M-Baum sowohl beim Aufbau des Baumes (I/O-Kosten) als auch bei Bereichsabfragen schneller und effizienter als der R*-Baum ist. Insgesamt lässt sich zusammenfassen, dass der M-Baum die Vorteile von balancierten/dynamischen SAMs mit den Fähigkeiten metrischer Bäume kombiniert. Ferner ermöglicht der M-Baum eine anwendungs-spezifische Justierung zur Effizienzsteigerung je nach Split-Policy, da eine klare Trennung zwischen CPU- und I/O-Kosten gegeben ist.

10 Seminar 1912 Multimedia-Datenbanken Thema: Indexing of Complex Data
S1
S3
S2
S4
A
B
E
F
CD
G
H
SS1
SS2
SS1 SS2
S1 S3 S2 S4
E FA B G HC D
5 Konzepte für Indexstrukturen in hoch-dimensionalen Vektorräumen
5.1 Der TV-Baum Der Telescopic Vector-Baum (LJF94) ist ein seitenorientierter balancierter Baum, der zur Indexierung hoch-dimensionaler Daten. Verweise auf die Daten finden sich nur in den Blattknoten. Die Bezeichnung des TV-Baums resultiert aus der Ähnlichkeit seines Verhaltens zu einem Teleskop, das dynamisch zusammen- bzw. ausgezogen wird. Zielstellung beim Entwurf des TV-Baums war es, das Dimensionsproblem der SAMs zu lösen, d.h. die mit den Dimensionen exponentiell anwachsenden Zeit- und Speichplatzressourcen für Anfragen - bis hin zum sequentiellen Scan - zu vermeiden. So degeneriert beispielsweise der R-Baum und seine Varianten zu einer verketteten Liste, wenn ein einzelner Vektor mehr Platz als eine Datenseite fassen kann enthält. Die Grundidee des TV-Baumes ist es, sowenig Dimensionen wie möglich zu verwenden, um zwischen den Objekten unterscheiden zu können. Im TV-Baum wird eine variable Anzahl von Dimensionen für die Indexierung genutzt, in Abhängigkeit davon, wie viele Objekte indexiert werden müssen und auf welcher Ebene des Baumes man ist. Folglich haben die Knoten nah zur Wurzel einige wenige Dimensionen. Je weiter man "absteigt", desto mehr Dimensionen werden gebraucht. Der TV-Baum dehnt sich aus, wenn neue aktive Dimensionen eingeführt werden, was bei der Teilung oder dem Wiedereinfügen erfolgt. Er zieht sich zusammen, wenn Objekte eingefügt werden. Mit anderen Worten hat der TV-Baum die Fähigkeit Dimensionen dynamisch anzupassen, um zwischen zwei Objekten zu unterscheiden. Die Eigenschaftsvektoren werden also dynamisch zusammengezogen und ausgedehnt.
5.1.1 Struktur des TV-Baums
Der TV-Baum organisiert wie jeder andere Baum die Daten in einer hierarchischen Struktur bestehend aus Knoten und Blättern.
Jeder Knoten eines TV-Baum der Ordnung k hat zwischen k/2 und k Söhne oder Verweise auf die Daten und repräsentiert eine Minimum Bounding Region. Die MBR eines TV-Baumes werden mit TMBR bezeichnet. Die TMBRs (Telescopic Minimum Bounding Region) sowie deren Beschreibung befinden sich im Vaterknoten und sind als Kugeln realisiert, da nur Mittelpunkt und Radius bekannt sein müssen. Die Felder eines Knotens in einem TV-Baum der Dimension N sind: k Felder für Verweise auf eventuelle Sohnknoten Zentrum ist der Punkt, den der Knoten im N-
dimensionalen Raum darstellt Radius ist ein Wert, der die maximale Entfernung
zwischen Zentrum und einem Punkt im beschriebenen Suchraum bezeichnet.
Aktive Dimensionen bezeichnet die Anzahl der aktiven Dimensionen, die von diesem Knoten unterstützt werden (Aktive Dimensionen ≤ N)
Im Unterschied zu Bäumen mit fester Ordnung hat der TV-Baum eine größere Ausdehnung in der höchsten Ebene und ist damit kompakter und seichter. Er spart gegenüber Bäumen mit fester Ordnung Platz. Je mehr Objekte eingefügt werden, desto mehr Eigenschaften werden zur Unterscheidung erforderlich.

Seminar 1912 Multimedia-Datenbanken Thema: Indexing of Complex Data 11
Die Anzahl der aktiven Dimensionen eines TV-Baums entspricht der Anzahl der aktiven Dimensionen, die alle ihrer TMBRs haben (TV-1 bedeutet eine aktive Dimension; TV-2 bedeutet zwei aktive Dimensionen). Die Struktur des TV-Baums ähnelt der des R-Baums. Jeder Knoten enthält eine Menge von Verzweigungen. Jede Verzweigung wird durch eine TMBR repräsentiert, wobei TMBRs überlappen dürfen. Jeder Knoten belegt exakt eine Speicherseite. Auf jeder Stufe ist die Anzahl der aktiven Dimensionen einheitlich. Manchmal benutzt mehr als eine Ebene dieselbe Anzahl aktiver Dimensionen.
5.1.2 Transformation des TV-Baums
In den meisten Anwendungen ist es angemessen, den gegebenen Eigenschaftsvektor zu verändern, um eine gute Aufteilung zu erreichen. So werden mittels der K-L Transformation (Karhunen Loeve) z.B. für den 2-D-Raum zwei zusätzliche Vektoren zur Unterscheidung ermittelt, mit denen erreicht wird, dass die Eigenschaften nach Wichtigkeit geordnet sind. Die K-L Transformation ist gut für statische Datenmengen, die im Vorfeld bekannt sind. Die DCT (Discrete Cosine Transformation) andererseits eignet sich für dynamische Datenmengen und ist eine exzellente Wahl, wenn Grundzüge stark korrelieren (in Wechselbeziehung stehen). Dies gilt z.B. für 2-D-Bilder mit engen Bildpunkten mit sehr ähnlicher Farbe. Da eine passende Transformation orthogonal zum TV-Baum verläuft, beschleunigt diese das Auffinden von Objekten.
5.1.3 Algorithmen des TV-Baums
Die Suche beginnt an der Wurzel im TV-Baum und jeder Zweig, der die Suchregion schneidet, wird untersucht, indem man rekursiv den Zweigen folgt. Der Algorithmus arbeitet wie folgt: Ausgehend von einem Suchpunkt untersuche die Zweige auf oberster Ebene und errechne obere und
untere Grenzen für die Entfernungen. Steige den erfolgversprechendsten Zweig herunter und vernachlässige alle Zweige, die zu weit weg
sind. Der rekursive Algorithmus, der das Abschneiden zu weit von der Suchregion entfernter Teilbäume nutzt, kann wie beim M-Baum eingesetzt werden. Das Einfügen eines neuen Objekts erfolgt ähnlich der Suche, d.h. man sucht rekursiv jeweils die passensten Zweige aus bis man auf dem Blatt angekommen ist. Entscheidend im Einfüge-Algorithmus ist, den erfolgversprechensten Zweig auszuwählen. Daher werden insgesamt vier Kriterien in absteigender Prioritätenreihenfolge überprüft: Minimale Überlappung - Wähle die TMBR so aus, dass nach dem Einfügen die Anzahl der neuen
überlappenden Paare minimal ist. Minimale Verkleinerung der Dimensionalität - Wähle die TMBR so aus, dass für das neue
Objekt, so viele Koordinaten wie möglich übereinstimmen Minimale Erweiterung des Radius Minimale Entfernung vom Zentrum des TMBR zum Einfügepunkt Ziel der Teilung (Splitting) im Fall des Überlaufs ist es, die Menge der TMBRs so neu zu verteilen, dass künftige Operationen vereinfacht und eine hohe Speichernutzung sichergestellt werden. Es existieren einige Teilungs-Algorithmen, wie z.B. Teilung durch Gruppierung und durch Sortierung, die hier nicht näher behandelt werden. Bevor jedoch eine Teilung durchgeführt wird, kann beim erstmaligen Überlauf ein nochmaliges Einfügen der Objekte des Blattes ggf. den Split verhindern. Lässt sich die Teilung nicht vermeiden, werden nach Einfügen, Teilung und Wiedereinfügen der Objekte die TMBRs entlang des Pfades aktualisiert.

12 Seminar 1912 Multimedia-Datenbanken Thema: Indexing of Complex Data
Das Löschen erfolgt unkompliziert auch im Falle eines Unterlaufes. Die verbliebenen Zweige der Knoten werden gelöscht und neu eingefügt.
5.1.4 Experimentelle Ergebnisse
Experimentelle Ergebnisse zeigen, dass die beste Anzahl aktiver Dimensionen in Hinblick auf I/O- und CPU-Kosten zwei ist. Insbesondere mit wachsender Datenmenge ist der TV-Baum gegenüber dem R*-Baum wesentlich effektiver. So zeigt sich der TV-Baum im Vergleich zum R*-Baum überlegen, sowohl für den Indexaufbau - Anzahl Plattenzugriffe (Read+Write) als auch für die Durchführung der Suchoperationen - knapp 70% weniger Seitenzugriffe für
Punktsuche und knapp 40% weniger Seitenzugriffe für Bereichssuche. Schließlich hat der TV-Baum ca. 15-20% weniger Knoten als ein vergleichbarer R*-Baum und benötigt entsprechend weniger Speicherplatz.
5.2 Der X-Baum Der eXtended-Baum (BKK96) –nachstehend X-Baum- (extend [engl.] - ausbauen, ausstrecken, erweitern) ist eine Methode zur Indexierung großer Mengen von Punkt- und Raum-Daten. Der X-Baum ist eine Weiterentwicklung des R-Baums. Die Zielstellung beim Entwurf des X-Baums war es, im Unterschied zum R-Baum die problematische Überlappung von Behälterregionen (MBRs) zu vermeiden. Die Grundidee des X-Baums besteht darin, das Verzeichnis so hierarchisch wie möglich zu halten und zeitgleich zu vermeiden, dass durch Teilungen die Verzeichnisse stark überlappen. Dies wird durch das Konzept der Superknoten erreicht. Der X-Baum kann als Hybrid (hybrid [lat.] – von zweierlei Herkunft) gesehen werden, nämlich abgeleitet von
der Linearen Reihe in den Knoten, insbesondere in den Superknoten und dem R-Baum-Verzeichnis bezogen auf die Hierarchie der Einträge.
So wird das Überlappen der Behälterregionen (MBRs) in den Inhaltsverzeichnissen dadurch vermieden, dass Trennungen (Splits) nicht durchgeführt werden, die eine große Überlappung nach sich ziehen. Vielmehr werden die Verzeichnis-Knoten zu Superknoten, die größer als übliche Blöcke (Seiten) sind. Als problematisch bei dem Ansatz des X-Baums kann sich erweisen, dass die Super-Verzeichnisknoten sehr groß werden und dies eine lineare Suche bei Punkt- bzw. Bereichsanfragen verursachen könnte. Offensichtlich ist, dass die Reduktion der Dimensionalität zur Reduktion der problematischen Überlappung der Behälterregionen (MBRs) wichtig ist. So verschlechtert sich der R*-Baum zunehmend mit jeder weiteren Dimension. Beispielsweise überlappen im R*-Baum ab Dimensionalität 5 mehr als 90 % der Behälterregionen.

Seminar 1912 Multimedia-Datenbanken Thema: Indexing of Complex Data 13
5.2.1 Struktur des X-Baums
Normale Verzeichnisknoten
SuperknotenDaten-Knoten
Normale Verzeichnisknoten
SuperknotenDaten-KnotenSuperknotenDaten-Knoten
Superknoten sollen Aufteilungen(Splits) vermeiden, die eine ineffiziente Verzeichnisstruktur
verursachen Mit wachsender Dimensionalität wächst die Anzahl und Größe der Superknoten Die Höhe des X-Baums korrespondiert mit der Anzahl der erforderlichen Seitenzugriffe und fällt mit
wachsender Dimensionalität Um mehrere Seitenzugriffe bei Besuch eines Knotens zu vermeiden, sollten Superknoten im
Hauptspeicher gehalten werden. Zwei interessante Sonderfälle können sich in der Struktur eines X-Baums ergeben: Fall 1: Es gibt keinen Superknoten – Dann entspricht der X-Baum weitestgehend dem R-Baum. Fall 2: Die Wurzel selbst ist das Directory und ist ein großer Superknoten – Dann entspricht der X-
Baum einer linearen Liste.
5.2.2 Algorithmen des X-Baums
Der wichtigste Algorithmus des X-Baums ist das Einfügen eines neuen Objekts. Dieser wird nachstehend beschrieben:
Bestimme rekursiv zuerst die MBR, in die eingefügt wird. Ist keine Aufteilung erforderlich, aktualisiere lediglich die Größe der MBR. Ist eine Teilung des Subknotens erforderlich, muss eine zusätzliche MBR im laufenden Knoten
hinzugefügt werden, was einen Überlauf nach sich ziehen kann. Bei Überlauf ruft der aktuelle Knoten den Split-Algorithmus auf. Ist die Überlappung der neuen MBRs zu groß wird ein minimaler Überlappingssplit anhand der Split
History gesucht. Ist die Anzahl von MBRs in einer Partition unterhalb einer gegebenen Schwelle, endet der Split-
Algorithmus ohne eine Trennung zu verursachen. Es entsteht ein neuer Superknoten mit doppelter Blockgröße bzw. ein bestehender Superknoten wird
um einen Block erweitert, um die Schrumpfung des Baums und schlechte Speicherplatznutzung zu vermeiden.
Die Such-Anfrage-Algorithmen, d.h. Point- und Range-Queries und die Suche nach dem Nächsten Nachbarn, ähneln denen des R*-Baums. Auch die Lösch- und Update-Funktionen sind ebenfalls einfache Modifikationen der R*-Baum Algorithmen.

14 Seminar 1912 Multimedia-Datenbanken Thema: Indexing of Complex Data
5.2.3 Bestimmung der Teilung zur minimimalen Überlappung
Zur Bestimmung der besten Teilung eines Verzeichnisknotens mit minimaler Überlappung ist es erforderlich, die Überlappung der beiden Hyperrechtecke (MBRs) so gering wie möglich zu halten. Die Teilung ist überlappungs-minimal, wenn ||MBR(S1) ∩ MBR(S2)|| minimal ist. überlappungsfrei, wenn ||MBR(S1) ∩ MBR(S2)|| = ∅. balanciert, wenn -ε ≤ |S1| - |S2|≤ ε. Für die Teilung von MBRs gelten zwei Hilfssätze: Lemma1: Für gleichmäßig verteilte Punktdaten ist ein überlappungsfreier Split nur möglich, wenn alle
MBRs in einer Dimension vorher geteilt wurden. Generell gilt, dass die Dimension, in der alle MBRs geteilt werden, die Achse ist, die zur
Teilung des Wurzelknotens eingesetzt wird. Um eine überlappungsfreie Teilung zu ermöglichen, muss man daher in der Teilungshistorie
nachsehen, in welcher Dimension alle MBRs geteilt wurden. Zu beachten ist hierbei, dass eine Chance auf mehr als eine Splitdimension realistisch nur
vorhanden ist, wenn die Dimensionalität der Datenmenge kleiner als 4 ist. Lemma 2: Für Punkt Daten existiert immer ein überlappungsfreie Teilungsmöglichkeit. Insgesamt lässt sich zusammenfassen, dass die Chance die richtige Splitachse zufällig auszuwählen sehr gering ist. Daher ist die Historisierung der Teilungen in den Verzeichnisknoten sinnvoll. Dies umso mehr, da der Speicherplatz zur Historisierung der Teilungen nur wenige Bits erfordert.
5.2.4 Experimentelle Ergebnisse
Im Vergleich zum R*-Baum wächst der Vorteil des X-Baums enorm mit wachsender Anzahl von Dimensionen. So sind deutlich weniger Seitenzugriffe erforderlich und die CPU-Kosten sind wesentlich geringer. Experimentelle Ergebnisse zur Dimensionalität belegen, dass ein Beschleunigungsfaktor von 2 gegenüber dem R*-Baum ab 8 Dimensionen und ein Beschleunigungsfaktor von 8 gegenüber dem R*-Baum ab 16 Dimensionen realistisch ist. Bei großen Datenmengen mit Dimensionalität größer 2 ist der X-Baum bis zu 450-mal schneller als der R*-Baum und 4 bis 12-mal schneller als der TV-Baum.

Seminar 1912 Multimedia-Datenbanken Thema: Indexing of Complex Data 15
6 Stärken und Schwächen der vorgestellten Konzepte Unglücklicherweise ist durch das Fehlen eines klar definierten und allgemein akzeptierten "Benchmarks" ein qualifizierender bzw. quantifizierender Vergleich zwischen den drei vorgestellten Konzepten nicht möglich. Die Stärke des M-Baum liegt darin, dass es sich um eine dynamische, seitenbezogene und balancierte Indexstruktur handelt, die ausschließlich über Distanzfunktion strukturiert wird. Durch das schnelle Abschneiden zu weit entfernt liegender Regionen können schnell irrelevante Suchbereiche verlassen werden. Die Schwäche des M-Baums liegt in der Überlappung der Regionen sowie den aufwändigen Distanzberechnungen im Fall eines Splits (Overflow) bzw. Merge (Underflows). Die dynamische Veränderungsmöglichkeit der aktiven Dimensionen im TV-Baum erweist sich als Vorteil. Das Prinzip "Je tiefer man den Baum herabsteigt, desto mehr Dimensionen sind erforderlich" ermöglicht im Gegensatz zu Bäumen mit fester Ordnung Speicherplatz einzusparen. So werden ca. 15-20% weniger Knoten erforderlich, da in höchster Ebene eine größere Ausdehnung erreicht und somit der Baum seichter als vergleichbare Baumstrukturen wird. Darüber hinaus zeigt der TV-Baum insbesondere bei der Punkt- und Bereichssuche deutliche Performanzvorteile gegenüber dem vergleichbaren R*-Baum. Nachteilig ist wie beim M-Baum die Überlappung der Regionen. Darüber hinaus können sich im Fall nur einer aktiven Dimension sehr große Suchregionen ergeben. Die Stärke des X-Baums liegt insbesondere darin, dass durch "Superknoten" die Überlappung von Behälteregionen weitestgehend vermieden wird. Dies führt bei großen Datenmengen mit Dimensionalität größer zwei in der Regel zu deutlichen Performanzvorteilen gegenüber vergleichbaren Indexstrukturen (z.B. R*-Baum, TV-Baum). Der Vorteil der Nichtüberlappung durch Superknoten ist zeitgleich die Schwäche des X-Baums, da mit wachsender Anzahl von Dimensionen nicht auszuschließen ist, dass der Wurzelknoten selbst zu einem einzigen Superknoten degeneriert. Somit wird im schlechtesten Fall der X-Baum zu einer linearen Liste.
7 Zusammenfassung Alle drei vorgestellten Konzepte (M-Baum, TV-Baum, X-Baum) zur Beherrschung des "Fluchs der hohen Dimensionen" stellen Erweiterungen des R-Baums (Guttman, 1984) dar. Wenn gleich alle Konzepte im Hinblick auf CPU- und I/O-Kosten mit wachsender Dimensionalität der Daten deutliche Verbesserungen zum R-Baum-Konzept ermöglichen, ist die ideale Indexstruktur für dieses Problem noch lange nicht gefunden worden. Vielmehr ist die grundlegende Tatsache zu akzeptieren, dass egal wie clever die Indexstruktur zur Lösung des "Fluchs der hohen Dimensionen" entworfen ist, ein sequentieller Suchlauf in schlechten Konstellationen nicht zu vermeiden ist.

16 Seminar 1912 Multimedia-Datenbanken Thema: Indexing of Complex Data
8 Literaturverzeichnis
[Uhl91] Uhlmann, Jeffrey K.: Satisfying general proximity/similarity queries with metric trees; 1991
[CPZ97] Ciaccia, Patella, Zezula: M-tree: An Efficient Access Method for Similarity Search in Metric
Spaces; 1997
[LJF94]
Lin Jagadish, Faloutsos: The TV-tree – an index structure for high dimensional data; 1994
[BKK96] Berchtold, Keim, Kriegel: The X-tree: An Index Structure for High-Dimensional Data; 1996 [Guttman 1984]
Guttman, A., "R-trees: A Dynamic Index Structure for Spatial Searching," In Proc. Int'l Conf. on Management of Data, ACM SIGMOD, Boston, Massachusetts, pp. 47-57, June 1984.

FernUniversität in Hagen Fakultät für Mathematik und Informatik Praktische Informatik IV – Datenbanksysteme für neue Anwendungen
Seminar 1912: Multimedia-Datenbanken
Thema 3: Text Retrieval I
SS 2006
von
Maik Devrient

Thema 3: Text Retrieval 1 Maik Devrient Seite 1
Inhaltsverzeichnis
1. Einleitung....................................................................................................... 22. Zeichensuche in Texten ................................................................................ 2
2.1. Naiver Ansatz................................................................................................... 22.1.1. Verfahren............................................................................................................ 2 2.1.2. Laufzeit............................................................................................................... 3
2.2. Verfahren von Boyer und Moore ..................................................................... 32.2.1. Verfahren............................................................................................................ 3 2.2.2. Berechnung der Tabellen delta1 und delta2 ........................................................ 5 2.2.3. Beispiel............................................................................................................... 5 2.2.4. Laufzeit............................................................................................................... 6
3. Komprimierung von Texten ........................................................................ 73.1. Lempel-Ziv 77.................................................................................................. 7
3.1.1. Verfahren............................................................................................................ 7 3.1.2. Beispiel............................................................................................................... 8 3.1.3. Aufwand ........................................................................................................... 10
3.2. Lempel-Ziv 78................................................................................................ 103.2.1. Verfahren.......................................................................................................... 10 3.2.2. Beispiel............................................................................................................. 11 3.2.3. Aufwand ........................................................................................................... 13
4. Zeichensuche in komprimierten Texten................................................... 134.1. Der Algorithmus von Navarro und Tarhio..................................................... 14
4.1.1. Verfahren.......................................................................................................... 14 4.1.2. Beispiel............................................................................................................. 14 4.1.3. Aufwand ........................................................................................................... 16
5. Literaturverzeichnis ................................................................................... 17

Thema 3: Text Retrieval 1 Maik Devrient Seite 2
1. Einleitung
Die folgende Ausarbeitung beschäftigt sich zunächst mit der Problematik des Auffindens bestimmter Zeichen in einem gegebenen Text. Dabei wird ausgehend von einem naiven Ansatz ein verbessertes Verfahren von Boyer und Moore vorgestellt und mit dem naiven Ansatz verglichen. Anschließend wird der Aspekt der Komprimierung von Texten betrachtet und dabei näher auf das Verfahren von Lempel und Ziv eingegangen. Den Abschluss dieser Arbeit bildet schließlich ein Verfahren, dass diese beiden Techniken verbindet und damit in der Lage ist, direkt in komprimierten Texten zu suchen.
2. Zeichensuche in Texten
Die Suche nach bestimmten Zeichenketten (String-Matching) in einem vorgegebenen Text ist ein grundlegendes Problem beim Arbeiten mit und beim Bearbeiten von Texten. Praktische Bedeutung bekommt dieses Problem beispielsweise dann, wenn innerhalb einer Datenbank nach bestimmten Begriffen gesucht wird. Aufgrund der Größe vieler Datenbanksysteme die heutzutage viele Millionen Datensätze verwalten müssen, kommt dem Aspekt der Laufzeit eines solchen Verfahrens eine immense Bedeutung zu. Nachdem ein naiver Ansatz für die Suche in Texten vorgestellt wurde, soll deshalb anschließend auf ein Verfahren eingegangen werden, welches im best-case weitaus effizienter ist.
2.1. Naiver Ansatz
2.1.1. Verfahren
Gegeben seien ein Text T und ein Muster M. Ziel eines String-Matching Verfahrens ist es nun das erste Vorkommen von M in T zu finden. Ein naiver Ansatz wäre nun beispielsweise das Muster unter den Text zu legen und die jeweils untereinander stehenden Zeichen zu vergleichen. Die folgende Grafik verdeutlicht die Situation:
Text T a a b a c b a
Muster M a b c ↑
Index
Stimmt ein Zeichen des Musters mit dem korrespondierenden Zeichen des Textes überein, wird im Muster und im Text um jeweils ein Zeichen weitergegangen, d.h. der Index wird um eins erhöht. Sobald ein Zeichen in Text und Muster nicht mehr übereinstimmt, kann das Muster um 1 Position verschoben werden. Dieses Verfahren wird wiederholt, bis eine vollständige Übereinstimmung zwischen Text und Muster gefunden wurde oder das rechte Ende des Musters bis an das rechte Ende des Textes verschoben wurde.

Thema 3: Text Retrieval 1 Maik Devrient Seite 3
2.1.2. Laufzeit
Die Komplexität dieses Verfahrens bestimmt sich durch die Anzahl der nötigen Vergleiche um ein Muster zu finden bzw. festzustellen, dass das Muster nicht im Text enthalten ist. Der worst-case ergibt sich, wenn lange Präfixe des Musters oft im Text enthalten sind. Dabei müssen stets viele Vergleiche zwischen Text und Muster durchgeführt werden, bevor eine Abweichung festgestellt wird. Formal beschrieben müssen in diesem Fall i * Länge(M) Vergleiche durchgeführt werden. Die Funktion Länge gibt dabei die Anzahl der Zeichen des Musters an, während i die Anfangsposition des gefundenen Musters im Text bezeichnet. Im Gegensatz zur quadratischen Laufzeit im worst-case, hängt die Laufzeit für den average-case entscheidend von der Art des Textes ab, da beispielsweise in einem natürlich sprachlichen Text nur selten lange Präfixe wiederholt auftreten.
2.2. Verfahren von Boyer und Moore
Der Hauptnachteil des naiven Verfahrens besteht darin, dass die Informationen, die während des Vergleichens von Text und Muster gewonnen werden, nicht berücksichtigt werden, sobald das Muster um eine Position verschoben wird. Der Ansatz von Boyer und Moore besteht nun darin die Informationen die beim Vergleichen anfallen zu verwenden, um ein Muster bei einer Nichtübereinstimmung von Text und Muster um möglichst viele Stellen zu verschieben.
2.2.1. Verfahren
Ebenso wie beim naiven Verfahren, legt der Boyer-Moore Algorithmus zunächst das Muster unter den Text an. Der wesentliche Unterschied ist dabei jedoch, dass nun nicht mehr die ersten Zeichen von Text und Muster verglichen werden, sondern die letzten. Die grafische Darstellung ändert sich also wie folgt:
Text T a a b a c b a Muster M a b c ↑ Index
Beim Vergleich dieses Zeichens können nun nach Boyer-Moore folgende Situationen auftreten:
Fall 1: das verglichene Zeichen aus dem Text kommt im Muster nicht vor
Falls das aktuell verglichene Element des Textes im Muster überhaupt nicht vorkommt, kann das Muster um seine komplette Länge am Text verschoben werden, da es aufgrund des nicht vorhandenen Zeichens in diesem Teil des Textes keine Übereinstimmung mit dem Muster geben kann. Die folgende Darstellung beschreibt diesen Fall:

Thema 3: Text Retrieval 1 Maik Devrient Seite 4
Text T a a d a c b a Muster M a b c
Verschiebung: a b c ↑ Index
Fall 2: das verglichene Zeichen aus dem Text kommt im Muster vor
Falls das aktuell verglichene Element des Textes im Muster vorkommt, kann das Muster verschoben werden, bis das rechteste Vorkommen dieses Zeichens im Muster unter der aktuell betrachteten Textposition liegt. Das rechteste Vorkommen jedes Zeichens im Muster wird dabei zu Beginn des Algorithmus berechnet und in der Tabelle delta1 gespeichert. Auf die Berechnung dieser Tabelle wird in einem späteren Abschnitt eingegangen.
Text T a a a b c b a Muster M a b c
Verschiebung: a b c ↑ Index
Fall 3: nachdem mehrere Zeichen übereingestimmt haben, trifft das Verfahren auf eine Position die nicht übereinstimmt
Die folgende Darstellung verdeutlicht die Situation:
Text T a a a b c b a Muster M a b a b
↑ Index
Eine Möglichkeit wäre nun analog zu Fall 2 das Muster anhand der Informationen in Tabelle delta1 zu verschieben. Da in dieser Tabelle aber nur die Position des letzten Vorkommens eines Zeichens gespeichert ist, müsste im obigen Fall das Muster wieder nach links verschoben werden. Um diese unnötigen Linksverschiebungen zu verhindern, wird nur dann auf die Informationen in delta1 zurückgegriffen, wenn der Index sich rechts von der Position des letzten Vorkommens befindet. Anderenfalls wird das Muster um 1 Zeichen nach rechts verschoben. Die eben vorgestellte Strategie wird „bad character rule“ bezeichnet. Alternativ dazu wird von Boyer und Moore auch eine „good suffix rule“ vorgestellt. Diese betrachtet nicht das Zeichen das zu einer nicht Übereinstimmung geführt hat, sondern das Teilmuster das bisher mit dem Text übereingestimmt hat. Sollte dieses Teilmuster noch einmal im Muster auftreten, kann das Muster bis an diese Stelle verschoben werden. Ein Spezialfall ergibt sich, wenn das Ende des Submusters und der Anfang des eigentlichen Musters übereinstimmen. Die Anzahl der möglichen Verschiebungen für die Position im Muster bei der die Nichtübereinstimmung auftrat wird in einer Tabelle delta2 gespeichert und ebenso wie die Tabelle delta1 vor Beginn des eigentlichen Algorithmus berechnet.

Thema 3: Text Retrieval 1 Maik Devrient Seite 5
Wann immer der Algorithmus also in eine Situation analog zu Fall 3 kommt, kann anhand des Maximums aus delta1 und delta2 die größtmögliche Verschiebung ermittelt werden.
2.2.2. Berechnung der Tabellen delta1 und delta2
Delta1
Die Tabelle enthält einen Eintrag für jedes im Text vorkommende Zeichen. Initialisiert werden die Werte dieses Arrays mit der Länge des Suchmusters, da falls ein Zeichen des Textes nicht im Muster enthalten ist das Muster um seine gesamte Länge verschoben werden kann. Anschließend wird das Muster von links nach rechts durchlaufen und der Index des aktuellen Zeichens im entsprechenden Eintrag der Tabelle delta1 aktualisiert, so dass am Ende die rechteste Position jedes Zeichens des Musters in der Tabelle delta1 enthalten ist.
Delta2
Die Tabelle enthält für jede Position j des Musters die Anzahl der möglichen Verschiebungen anhand des Submusters rechts von j. Gesucht wird dabei im Muster eine Zeichenkette die mit dem Submuster identisch ist und sich im Zeichen vor dem Submuster von diesem unterscheidet. Die folgende Graphik verdeutlicht die Situation an einem Beispiel:
Muster 1 t e s t Muster 2 t e s t
Submuster
Gesucht wird hier im Muster „test“ ein weiteres Vorkommen des Submusters „est“ (j = 4). Es existiert zwar kein weiteres Vorkommen des Submusters, allerdings stimmt das Ende des Submusters mit dem Anfang des Musters überein, so dass das untere Muster über das linke Ende des oberen Musters hinaus verschoben wird, bis das Zeichen „t“ untereinander liegt. Daraus ergibt sich folgendes Bild:
Muster 1 t e s t Muster 2 t e s t
Submuster
Falls also eine Nichtübereinstimmung beim ersten (linken) „t“ des Musters auftritt, kann das Muster anhand der „good suffix rule“ um 3 Positionen verschoben werden.
2.2.3. Beispiel
Das vorgestellte Verfahren soll nun anhand eines Beispiels ausführlich erläutert werden.
Text d i e s i s t e i n b e i s p i e l t e x t . Muster s p i e l

Thema 3: Text Retrieval 1 Maik Devrient Seite 6
Die Initialisierung der Tabellen delta1 und delta2 liefert folgende Ergebnisse:
delta1:
Zeichen d i e s t n b p l x . Position 5 2 1 4 5 5 5 5 3 0 5 5
delta2:
j 5 4 3 2 1 0 Verschiebung 5 5 5 5 5 1
Der Ablauf des Boyer-Moore Verfahrens verläuft dann wie folgt:
Text d i e s i s t e I n b e i s p i e l t e x t . | | | | | | 1. Vergleich s p i e l | | | | | | | | | | 2. Vergleich s p i e l | | | | | | | | 3. Vergleich s p i e l | | | | | | 4. Vergleich s p i e l | | | | 5. Vergleich s p i e l | | 6. Vergleich s p i e l Ende s p i e l
Beim ersten Vergleich werden „l“ und „ “ verglichen. Da „ “ im Muster überhaupt nicht enthalten ist, wird nach delta1 das Muster um 5 Zeichen verschoben (Delta2 würde nur ein Verschieben von 1 Zeichen erlauben). Beim zweiten Vergleich stimmen „e“ und „l“ nicht überein, allerdings kann nun das Muster laut delta1 und delta2 nur um 1 Stelle verschoben werden. Das Verfahren benötigt insgesamt 5 Vergleiche um ein Vorkommen des Musters im Text zu finden und weitere 5 Vergleiche um das Muster zu verifizieren.
2.2.4. Laufzeit
Die Konstruktion der Tabellen delta1 und delta2 benötigt lediglich die Zeichen des Alphabets und das Muster M der Länge m. Beide Tabellen können deshalb unabhängig von der Länge des eigentlichen Textes n in O(m) konstruiert werden. Die Laufzeit des einfachen Boyer-Moore Verfahrens, welches nur auf die Daten der Tabelle delta1 zurückgreift beträgt im worst-case O(n*m). Dabei tritt eine Nichtübereinstimmung zwischen Muster und Text stets erst beim letzten (linken) Zeichen auf. Das Muster kann

Thema 3: Text Retrieval 1 Maik Devrient Seite 7
anschließend nur um 1 Stelle verschoben werden, so dass ebenso wie beim naiven Verfahren insgesamt O(n*m) Vergleiche notwendig sind. Bestenfalls erreicht das Verfahren eine Laufzeit O(n/m), falls nur jedes m-te Zeichen des Textes mit dem Muster verglichen werden muss und das Muster stets komplett verschoben werden kann. Vorraussetzung dafür sind allerdings relativ kleine Muster und große Alphabete. Die Konstruktion der Tabelle delta2 lohnt sich nur bei längeren Mustern in denen Submuster häufig wiederkehren. Ist außerdem das Alphabet klein, wird delta2 umso wichtiger, da die delta1 Tabelle häufig nur eine Verschiebung um eine Position ermöglicht. Unter Verwendung beider Tabellen wird insgesamt auch im worst-case eine Laufzeit von O(n+m) erreicht. Der Aufwand liegt also normalerweise deutlich unter dem des naiven Verfahrens.
3. Komprimierung von Texten
Die Komprimierung von Daten hat auch im Zeitalter immer größerer Bandbreiten und Speichermedien an Bedeutung nicht verloren, da die benötigten Datenmengen mindestens ebenso schnell steigen. Grundlegend kann dabei zwischen verlustfreien und verlustbehafteten Verfahren unterschieden werden. Verlustbehaftete Verfahren eignen sich beispielsweise bei Bildern, Musik- oder Videodateien, da hierbei zwar die Qualität der Information gemindert wird die Information an sich aber weiterhin erhalten bleibt. Für Textdateien eignen sich hingegen lediglich verlustfreie Verfahren, da hierbei Fehler inakzeptabel sind. Verlustfreie Verfahren versuchen dabei in erster Linie Redundanzen zu vermeiden bzw. zu verringern. Eine Möglichkeit Texte zu komprimieren bilden die wörterbuchbasierten Verfahren, diese werden grundsätzlich in Verfahren mit statischen oder dynamischen Wörterbüchern unterschieden. Statische Wörterbücher besitzen feste bereits vor der Bearbeitung eines Textes definierte Einträge, während dynamische Verfahren ihre Wörterbücher erst sukzessive mit der Bearbeitung des Textes aufbauen. Einen klassischen Vertreter für Verfahren mit dynamischen Wörterbüchern stellt dabei die Algorithmenfamilie von Abraham Lempel und Jacob Ziv dar. Im Folgenden sollen die beiden in den Jahren 1977 bzw. 1978 veröffentlichten Verfahren vorgestellt werden.
3.1. Lempel-Ziv 77
3.1.1. Verfahren
Der Kern des 1977 vorgestellten Verfahrens ist ein Datenfenster das sich während der Abarbeitung über den Text hinweg schiebt. Dabei wird dieses Fenster in zwei Bereiche unterteilt – einen Wörterbuchbereich mit dessen Hilfe die nächsten Zeichen kodiert werden und einen Vorschaubereich in dem sich die nächsten zu lesenden Zeichen befinden.
d i e s i s t e i n b e i s p i e l t e x t . Wörterbuchbereich Vorschaubereich
Die aktuelle Leseposition ist stets das erste Zeichen des Vorschaubereiches, in diesem Fall also „i“. Gesucht wird nun im Wörterbuchbereich die längste Zeichenkette die mit dem Anfang des Vorschaubereiches übereinstimmt. Wurde eine solche Position gefunden wird der

Thema 3: Text Retrieval 1 Maik Devrient Seite 8
Anfangsindex dieser Position, sowie die Länge der Übereinstimmung vom Algorithmus ausgegeben. Wurde keine Übereinstimmung gefunden werden für Position und Länge die Werte 0 ausgegeben. Zusätzlich wird vom Algorithmus das erste nicht übereinstimmende Zeichen innerhalb des Vorschaubereiches ausgegeben. Für den oberen Fall wäre also das Tripel (4, 1, e) ausgegeben worden, da die längste Übereinstimmung mit dem Vorschaubereich das einzelne Zeichen „i“ ist und das erste nicht übereinstimmende Zeichen ein „e“ ist. Anschließend werden die Leseposition und das Datenfenster, um 2 Zeichen nach rechts verschoben. Dieses Verfahren wiederholt sich bis die Leseposition das Ende des Textes erreicht hat. Die Größe des Vorschaubereiches beträgt normalerweise 10 - 100 Zeichen, während die Größe des Wörterbuchbereiches, welche entscheidend ist für den Komprimierungsgrad und die Komprimierungsgeschwindigkeit, durchaus mehrere 1000 Zeichen betragen kann.
3.1.2. Beispiel
Die Komprimierung und Dekomprimierung sollen nun anhand eines Beispiels erläutert werden. Auf die Festlegung einer Datenfenstergröße wurde verzichtet, so dass alle Zeichen links der Leseposition zum Wörterbuchbereich gehören und alle Zeichen rechts davon zum Vorschaubereich.
Komprimierung
In der Ausgangsposition befindet sich der Lesezeiger über dem ersten Zeichen, alle Zeichen gehören noch zum Vorschaubereich, während der Wörterbuchbereich noch leer ist. Da dieser leer ist kann auch keine Übereinstimmung mit dem Zeichen „a“ gefunden werden, so dass der Algorithmus (0, 0, a) ausgibt.
Wort a b a b c a a b Ausgabe: (0, 0, a) ↑
Leseposition
Anschließend wird das Zeichen „b“ gelesen. Da auch dieses nicht im Wörterbuch vorhanden ist erfolgt die zum ersten Schritt analoge Ausgabe (0, 0, b).
Wort a b a b c a a b Ausgabe: (0, 0, b) ↑
Leseposition
Als nächstes wird eine Übereinstimmung der Zeichenkette „ab“ mit dem Wörterbuchbereich festgestellt, so dass (1, 2, c) ausgegeben wird.
Wort a b a b c a a b Ausgabe: (1, 2, c) ↑
Leseposition
Für das Zeichen „a“ findet sich im Wörterbuch nur ein Eintrag der Länge 1 an Position ein, so dass das Tripel (1, 1, a) ausgegeben wird.

Thema 3: Text Retrieval 1 Maik Devrient Seite 9
Wort a b a b c a a b Ausgabe: (1, 1, a) ↑
Leseposition
An der letzen Position schließlich steht nur das Zeichen „b“, welches im Wörterbuch vorhanden an Position 2 vorhanden ist. Da keine Zeichen mehr im Vorschaubereich vorhanden sind, wird kein nicht übereinstimmendes Zeichen im Tripel angegeben.
Wort a b a b c a a b Ausgabe: (2, 1, ) ↑
Leseposition
Das Ergebnis der Komprimierung ist schließlich die Folge der Tripel:
(0, 0, a) (0, 0, b) (1, 2, c), (1, 1, a), (2, 1, )
Dekomprimierung
Die Dekomprimierung benötigt für die Rekonstruktion des Textes lediglich die Tripel und die Informationen über die Größen des Wörterbuch- und des Vorschaubereiches. Ein Wörterbuch muss nicht mit übertragen werden, da dies im Verlauf der Dekomprimierung mit aufgebaut wird.
Die Dekomprimierung liest zunächst das Tripel (0, 0, a). Da auf keinen Wörterbucheintrag verwiesen wird, wird lediglich das Zeichen a ausgegeben und gleichzeitig der Wörterbuchbereich mit einem „a“ angelegt
Eingabe: (0, 0, a) a Ausgabe: a
Als nächstes wird das Tripel (0, 0, b) verarbeitet. Da wiederum nicht auf das Wörterbuch verwiesen wird, erfolgt lediglich die Ausgabe des Zeichens.
Eingabe: (0, 0, b) a b Ausgabe: b
Anschließend wird das Tripel (1, 2, c) eingelesen. Dieses verweist auf die Position 1 des Wörterbuches und eine Zeichenfolge der Länge 2, d.h. „ab“ wird zusammen mit dem nicht übereinstimmenden Zeichen „c“ ausgegeben.
Eingabe: (1, 2, c) a b a b c Ausgabe: abc
Die Verarbeitung des Tripels (1, 1, a) hat nun die Ausgabe „aa“ zur Folge. Eingabe: (1, 1, a) a b a b c a a Ausgabe: aa
Schließlich wird das Tripel (2, 1, ) eingelesen und das Zeichen „b“ ausgegeben.

Thema 3: Text Retrieval 1 Maik Devrient Seite 10
Eingabe: (2, 1, ) a b a b c a a b Ausgabe: b
Am Ende ergibt sich damit wieder der ursprüngliche Text:
a b a b c a a b
3.1.3. Aufwand
Die Laufzeit und der Komprimierungsgrad stehen bei diesem Verfahren in engem Zusammenhang. Je größer der Wörterbuchbereich gewählt wird desto größer ist der Komprimierungsgrad, da die Möglichkeit ein möglichst langes Teilwort des Pufferbereiches innerhalb des Wörterbuchbereiches zu finden steigt. Andererseits steigt damit auch die Laufzeit des Algorithmus, da nun ein größeres Wörterbuch, beispielsweise mit Hilfe des Boyer-Moore Verfahrens, durchsucht werden muss. Das heißt, dass die größtmögliche Komprimierung gleichzeitig auch die langsamste ist. Der worst-case bei diesem Verfahren tritt auf, falls die Zeichen des Vorschaubereiches nicht im Wörterbuchbereich auftreten. Dies ist beispielsweise der Fall, wenn die 26 Buchstaben des Alphabets komprimiert werden sollen. Da jedes Zeichen des Textes nur einmal auftritt, sind alle 25 Suchen im Wörterbuch (Beim ersten Zeichen „a“ ist das Wörterbuch noch leer.) erfolglos. Da keine Übereinstimmung mit dem Wörterbuch gefunden wurde, muss also stets ein Tripel der Form (0, 0, $) ausgegeben werden, wobei $ für jeweils ein Zeichen des Alphabets steht. Bei diesem Beispiel kann auch ein zweiter Nachteil dieses Verfahrens beobachtet werden. Der ursprüngliche Text wurde nicht wie beabsichtigt komprimiert, sondern hat sich im Gegensatz dazu nun auch deutlich vergrößert. Jeder Buchstabe des Alphabets wird nun durch ein Tripel dargestellt, das neben den Buchstaben auch die (in diesem Falle unnötigen) Informationen über Position und Länge eines nicht vorhandenen Wörterbucheintrages enthält. Im Gegensatz zu diesen Problemen bei der Komprimierung ist die Dekomprimierung eines Textes relativ schnell, da hierbei keine Vergleichsoperationen durchgeführt werden müssen. Für jedes Tripel wird lediglich der eventuell vorhandene Teil des Wörterbuchbereiches ermittelt und das nicht übereinstimmende Zeichen angehängt.
3.2. Lempel-Ziv 78
Aufgrund der Probleme des ursprünglichen Verfahrens entstanden in den folgenden Jahren verschiedene Weiterentwicklungen des Algorithmus. Eine dieser Weiterentwicklungen wurde von Lempel und Ziv 1978 selbst vorgestellt.
3.2.1. Verfahren
Im Gegensatz zum ersten Verfahren verwendet dieser Algorithmus kein Datenfenster mit beschränktem Wörterbuch, sondern ein getrennt verwaltetes Wörterbuch. Das Wörterbuch kann dabei, unter Berücksichtigung des zur Verfügung stehenden Speichers, beliebig groß werden, so dass stets die maximalen möglichen Wörterbucheinträge gefunden werden. Das Verfahren beginnt indem ein leeres Wörterbuch angelegt wird und an Position 0 dieses Wörterbuches der Leerstring eingefügt wird. Anschließend wird das erste Zeichen eingelesen und das Wörterbuch wird nach diesem Zeichen durchsucht. Da das Zeichen nicht im

Thema 3: Text Retrieval 1 Maik Devrient Seite 11
Wörterbuch vorhanden ist, wird dieses an Position 1 des Wörterbuches gespeichert. Danach wird vom Algorithmus ein Paar der Form (0, $) ausgegeben. Die Zahl 0 steht für den referenzierten Wörterbucheintrag und $ für das erste nicht übereinstimmende Zeichen. Nun werden die nächsten Zeichen eingelesen und im Wörterbuch stets nach einem möglichst langen übereinstimmenden Eintrag für diese Zeichen gesucht. Dieses Vorgehen wiederholt sich bis der gesamte Text komprimiert wurde.
3.2.2. Beispiel
Das gesamte Verfahren soll nun anhand des bereits oben verwendeten Beispieltextes demonstriert werden.
Komprimierung
Das erste Zeichen „a“ wird eingelesen und da dieses im Wörterbuch nicht gefunden wird als Eintrag 1 zum Wörterbuch hinzugefügt. Ausgegeben wird das Paar (0, a), da die kodierten Zeichen aus dem Leerstring und einem „a“ bestehen.
Wörterbuch Pos. Eintrag a b a b c a a b Ausgabe: (0, a)
0 Leerstring ↑ 1 a Leseposition
Nach Einlesen des Zeichens „b“ verhält sich das Verfahren analog, d.h. das Zeichen b wird zum Wörterbuch hinzugefügt und das Paar (0, b) ausgegeben.
Wörterbuch Pos. Eintrag a b a b c a a b Ausgabe: (0, b)
0 Leerstring ↑ 1 a Leseposition 2 b
Beim Einlesen des Zeichens „a“ wird nun eine Übereinstimmung mit dem Wörterbucheintrag an Position 1 festgestellt. Dementsprechend wird nun bei der Ausgabe der Verweis auf diesen Eintrag ausgegeben. Zusätzlich werden die Zeichen „ab“ zum Wörterbuch hinzugefügt.
Wörterbuch Pos. Eintrag a b a b c a a b Ausgabe: (1, b)
0 Leerstring ↑ 1 a Leseposition 2 b 3 ab
Alle folgenden Schritte des Verfahrens ergeben sich analog, so dass sich am Ende das folgende Wörterbuch und die folgende Ausgabe ergeben:

Thema 3: Text Retrieval 1 Maik Devrient Seite 12
Wörterbuch Gesamte Ausgabe: Pos. Eintrag
0 Leerstring (0, a) 1 a (0, b) 2 b (1, b) 3 ab (0, c) 4 c (1, a) 5 aa (2, )
Dekomprimierung
Die Dekomprimierung benötigt ebenso wie beim Verfahren von 1977 keine Informationen des Wörterbuches, sondern baut dieses während der Komprimierung schrittweise auf.
Die Dekomprimierung legt ebenfalls ein Wörterbuch mit dem Leerstring an Position 0 an und liest dann das Paar (0, a). Aufgrund dieser Informationen kann das Zeichen „a“ ausgegeben werden. Im Wörterbuch wird analog zur Komprimierung ein Eintrag für das Zeichen „a“ hinzugefügt.
Wörterbuch Eingabe: (0, a) Pos. Eintrag Ausgabe: a 0 Leerstring 1 a
Für das Paar (0, b) verhält sich die Dekomprimierung analog, so dass das Zeichen „b“ ausgegeben und zum Wörterbuch hinzugefügt wird. Anschließend wird das Paar (1, b) eingelesen. Die Ausgabe setzt sich nun aus dem Eintrag an Position 1 und dem Zeichen „b“ zusammen, also „ab“. Diese Zeichenfolge wird wiederum zum Wörterbuch hinzugefügt.
Wörterbuch Eingabe: (0, b) Pos. Eintrag Ausgabe: b 0 Leerstring 1 a
Eingabe: (1, b) 2 b Ausgabe: ab 3 ab
Nachdem alle Paare eingelesen wurden, ergibt sich schließlich wieder das folgende Wörterbuch und der ursprüngliche Text.
Wörterbuch Gesamte Ausgabe: Pos. Eintrag
0 Leerstring a 1 a b 2 b ab 3 ab c 4 c aa 5 aa b

Thema 3: Text Retrieval 1 Maik Devrient Seite 13
3.2.3. Aufwand
Der Hauptaufwand bei diesem Verfahren ist die Suche nach einer Übereinstimmung mit dem Wörterbuch. Dies ist besonders kritisch, da die Größe des Wörterbuches nicht wie beim Algorithmus von 1977 beschränkt wird. Eine effiziente Suche innerhalb des Wörterbuches ist deshalb sowohl für die Komprimierung als auch die Dekomprimierung entscheidend. Als Datenstruktur würde sich beispielsweise ein Baum anbieten, indem jeder Sohn eines Knotens das nächste Zeichen eines Eintrages darstellt. Jeder Pfad von der Wurzel zu einem Knoten stellt dabei ein Wort des Wörterbuches dar, der sich durch die jeweilige Kantenbeschriftung ergibt. Für das oben verwendete Beispiel würde sich folgender Baum ergeben:
Der Grad des Baumes entspricht der Anzahl der Zeichen des zugrunde liegenden Alphabets. Für das Suchen eines Eintrages im Wörterbuch würden logd n Schritte benötigt, wobei d die Größe des Alphabets beschreibt und n die Anzahl der Einträge des Wörterbuches. Diese optimale Laufzeit setzt allerdings eine Gleichverteilung der Wörter innerhalb des Baumes voraus. Beispielsweise würde der Baum bei Zeichenketten wie „aaaaaaaa“ zu einer linearen Liste entarten, da der Baum stets ganz links um einen linken Sohn erweitert würde.Problematisch bei diesem Verfahren ist die Größe des zugrunde liegenden Alphabets und die damit zusammenhängende Verwaltung der Söhne jedes Knotens. Eine Möglichkeit wäre zum Beispiel die Verwendung eines Arrays pro Knoten bei dem der i-te Index stets dem i-ten Zeichen des Alphabets entspricht. Allerdings wird dabei Speicherplatz verschwendet, da viele Elemente dieser Arrays lediglich Null-Zeiger enthalten. Da bei diesem Verfahren das Wörterbuch nicht mitübertragen wird, muss dieses bei der Dekomprimierung schrittweise erzeugt werden. Für die Implementierung eignet sich hierbei aber eher eine Hashtabelle, da ein beliebiger Index des Wörterbuches möglichst schnell gefunden werden muss. Verglichen mit dem Verfahren von 1977 ist deshalb die Komprimierung schneller, während der Aufwand zum Dekomprimieren gewachsen ist.
4. Zeichensuche in komprimierten Texten
Eine Möglichkeit der Verknüpfung der oben vorgestellten Verfahren stellt die Suche in komprimierten Texten dar. Ziel ist es dabei direkt im komprimierten Text zu suchen und sich auf diese Weise den Aufwand für eine vollständige Dekomprimierung zu ersparen. Der im Folgenden vorgestellte Ansatz geht auf Gonzalo Navarro und Jorma Tarhio zurück und wurde von diesen im Jahr 2000 veröffentlicht.
ba
bca
0
2 4 1
3 5

Thema 3: Text Retrieval 1 Maik Devrient Seite 14
4.1. Der Algorithmus von Navarro und Tarhio
4.1.1. Verfahren
Die Grundidee des Verfahrens ist eine direkte Boyer-Moore Suche auf einem nach Lempel-Ziv Verfahren von 1978 komprimierten Text. Ebenso wie beim ursprünglichen Boyer-Moore Verfahren wird der gesuchte Begriff unter dem Text angelegt. Beim Anlegen des Musters wird jedes Paar (s, x) des komprimierten Textes durch eine Linie mit abschließenden Quadrat dargestellt. Das Quadrat steht für das explizite Zeichen x des Paares, während die Linie alle impliziten Zeichen s repräsentiert. Die impliziten Zeichen eines Blocks sind stets alle Zeichen eines weiter links stehenden Paares, so dass bei jedem Zugriff auf die Referenz der impliziten Zeichen ein weiteres Klartextzeichen ermittelt wird. Die folgende Darstellung verdeutlicht die Idee:
Beim Vergleich werden nun zunächst die expliziten Zeichen des Textes von links nach rechts mit dem Muster verglichen. Erst wenn diese alle übereinstimmen werden die nur implizit vorhandenen Zeichen berücksichtigt. Dabei werden die Blöcke von rechts nach links abgearbeitet, wobei mit dem Block links des letzten explizit vorhandenen Zeichens begonnen wird. Erst wenn alle diese Blöcke Übereinstimmungen liefern wird der Block rechts des letzten explizit vorhandenen Zeichens überprüft, da bei diesem Block normalerweise mehr Dereferenzierungen nötig sind, um die gewünschten Zeichen zu erhalten. Die Reihenfolge der Abarbeitung ergibt sich deshalb wie folgt:
Vor Beginn des eigentlichen Algorithmus wird analog zum ursprünglichen Boyer-Moore Verfahren eine Tabelle ermittelt die die maximal mögliche Verschiebung angibt. Dabei wird die folgende Formel verwendet:
B(i, c) = min( i U i – j, 1 ≤ j ≤ i Λ Pj = c )
Die Variable i beschreibt hierbei die Position innerhalb des Musters, c das Zeichen, das im Text der Position i des Musters gegenübersteht und Pj das j-te Zeichen des Musters (Pattern). Falls das Zeichen in Muster und Text übereinstimmt ist B(i, c) = 0.
4.1.2. Beispiel
Für die im Abschnitt 3.2.2. kodierte Folge, wird nun nach der Zeichenkette „aa“ gesucht:

Thema 3: Text Retrieval 1 Maik Devrient Seite 15
Zeichenfolge:
komprimierte Zeichenfolge: (0, a) (0, b) (1,b) (0, c) (1, a), (2, )
Die bei der Initialisierung berechnete Verschiebe-Tabelle ergibt folgende Werte:
B (i,c) 1 2 a 0 0 b 1 2 c 1 2
Der Algorithmus legt nun das Muster an den Text und überprüft von rechts nach links die expliziten Zeichen:
0 0 1 0 1 2 a b b c a
Text
Muster a a
Beim ersten Schritt werden das explizite Zeichen „b“ aus dem Text und das Zeichen „a“ aus dem Muster verglichen. Anhand der Verschiebe-Tabelle kann das Muster daraufhin um 2 Stellen verschoben werden.
0 0 1 0 1 2 a b b c a
Text
Muster a a
Beim Vergleich der Zeichen „b“ und „a“ verhält sich der Algorithmus gleich und verschiebt das Muster um zwei Zeichen.
0 0 1 0 1 2 a b b c a
Text
Muster a a
Betrachtet wird nun zuerst das explizit vorliegende Zeichen „c“ mit Zeichen „a“ an Position 1 des Musters. Laut Verschiebe-Tabelle kann das Muster um 1 Zeichen versetzt werden.
a b a b c a a b
Thema 3: Text Retrieval 1 Maik Devrient Seite 16
0 0 1 0 1 2 a b b c a
Text
Muster a a
Das explizite Zeichen „a“ stimmt mit dem Muster überein, so dass jetzt in der Referenzkette auf Block 1 zugegriffen wird. Dieser besitzt als explizites Zeichen wiederum ein „a“, so dass eine Übereinstimmung des Musters mit dem Text gefunden wurde.
4.1.3. Aufwand
Navarro und Tarhio schlagen eine leichte Verbesserung dieses Verfahrens vor, bei dem expliziten Zeichen von links nach rechts verglichen werden. Dadurch kann bei jedem lesen eines Blockes überprüft werden, ob eine Verschiebung möglich ist. Diese Variante wird als „BM-simple-opt“ bezeichnet, während die ursprüngliche Version mit „BM-simple“ bezeichnet wird. Die untere Grenze für dieses Verfahren liegt bei Ω(n), da jeder Block n der komprimierten Folge betrachtet werden muss. Entscheidend für den Umfang möglicher Verschiebungen ist die Größe des Alphabets. Je mehr Zeichen ein Alphabet beinhaltet, desto größere Verschiebungen sind möglich und desto schneller arbeitet der Algorithmus folglich. Eine von Navarro und Tarhio vorgestellt Variante betrachtet deshalb nicht einzelne Zeichen, sondern Blöcke von Zeichen. Das Alphabet wird dabei größer, da nun Kombinationen der einzelnen Zeichen als Grundlage dienen. Bezeichnet wird diese Variante als „BM-multichar“. Eine weitere Variante „BM-blocks“ berechnet die Verschiebungen ähnlich wie die Tabelle delta2 des ursprünglichen Verfahrens, indem die möglichen Verschiebungen für die Präfixe des Musters berechnet werden. Bei ihren Tests verglichen Navarro und Tarhio die beiden schnellsten Varianten „BM-simple opt“ und „BM-blocks“ mit einem von Navarro und Raffinot bereits 1999 vorgestellten Verfahren „Bit-parallel“ und zwei Varianten, die den Text zunächst dekomprimieren und anschließend durchsuchen.
Angegeben wird die Zeit für die Suche in Sekunden, für ein Muster der Länge m und einen 10 MB großen Text, der einmal aus dem Wallstreet Journal stammt und im zweiten Fall eine DNA Sequenz darstellt.

Thema 3: Text Retrieval 1 Maik Devrient Seite 17
Während die beiden BM-Varianten bis zu 22.2 MB/s unkomprimierten Text verarbeiten können, erreichen die beiden Verfahren die den Text dekomprimieren und anschließend durchsuchen lediglich 12 MB/s. Interessant ist, dass alle Algorithmen relativ schnell eine untere Grenze für m erreichen, bei der die Verfahren nicht mehr schneller werden, obwohl m größer wird. Dies ergibt sich durch die Notwendigkeit jeden Block des komprimierten Textes mindestens einmal zu lesen, egal wie lang das Muster ist. (NT, S.10)
5. Literaturverzeichnis
[BM] R.S. Boyer, J.S. Moore: A Fast String Searching Algorithm. Communications of the ACM, 20, Number 10, S. 762-772, 1977
[LZ] J. Ziv, A. Lempel: A universal algorithm for sequential data compression, IEEE Transactions on information theory, S. 337-343, 1977
[NT] G. Navarro, J. Tarhio: Boyer-Moore string matching over Ziv-Lempel compressed text, In R. Giancarlo and D. Sankoff, editors, Proceedings of the 11th Annual Symposium on Combinatorial Pattern Matching, number 1848, S. 166-180, Montreal, Canada, Springer Verlag, Berlin, 2000
[HWL] H. W. Lang: Boyer-Moore-Algorithmus, http://www.inf.fh-flensburg.de/lang/algorithmen/pattern/bm.htm, 2006 [OW] T. Ottmann, P. Widmayer: Algorithmen und Datenstrukturen, 3. Auflage, Spektrum
Akademischer Verlag, Heidelberg, 1996

Seminar 1912Multimedia-Datenbanken
Text Retrieval 2
Sylvia Zotz

Text Retrieval 2, Sylvia Zotz 1
Inhalt
1 Einleitung ................................................................................................................................2 2 Grundlagen des Text Retrievals ..............................................................................................2
2.1 Allgemeine Verfahren zur Indexierung von Text-Dokumenten .....................................3 2.2 Allgemeine Darstellung verschiedener Retrieval Modelle .............................................4
2.2.1 Boolesches Retrieval ...............................................................................................4 2.2.2 Retrieval mit Ranking .............................................................................................4 2.2.3 Vektorraum Modelle ...............................................................................................5
2.3 Probleme beim Text Retrieval.........................................................................................5 2.4 Qualitätsmaße zur Beurteilung von Text Retrieval Verfahren........................................6
3 Ausgewählte Ansätze von Indexierungsverfahren beim Text Retrieval .................................7 3.1 Ansatz von Moffat und Zobel: 'Self-Indexing Inverted Files'.........................................7
3.1.1 Definition und Aufbau invertierter Listen...............................................................7 3.1.2 Vorgehensweise bei der Verarbeitung von booleschen Suchanfragen ...................9 3.1.3 Vorgehensweise bei der Verarbeitung von Suchanfragen mit Ranking ...............10 3.1.4 Untersuchungsaufbau ............................................................................................11 3.1.5 Untersuchungsergebnisse ......................................................................................11
3.2 Ansatz von Deerwester, Dumais und Harshman: 'Indexing by Latent Semantic Analysis' ........................................................................................................................12
3.2.1 Konzept der latenten semantischen Strukturen .....................................................12 3.2.2 Umsetzung des Konzepts der latenten semantischen Strukturen mit Hilfe der Singulärwertzerlegung ..........................................................................................133.2.3 Vorgehensweise bei der Verarbeitung von Suchanfragen ....................................14 3.2.4 Untersuchungsaufbau ............................................................................................15 3.2.5 Untersuchungsergebnisse ......................................................................................15
4 Fazit .......................................................................................................................................16 5 Literatur.................................................................................................................................17 6 Abbildungsverzeichnis ..........................................................................................................17

Text Retrieval 2, Sylvia Zotz 2
1 Einleitung
Die Suche nach Text-Dokumenten spielt in verschiedensten Bereichen eine wichtige Rolle. So will beispielsweise ein Bibliotheksbenutzer aus der großen Zahl der vorhandenen Bücher und Zeitschriften solche auswählen, die sich mit dem Thema beschäftigen, das für ihn gerade von Interesse ist. Dazu wird er in das rechnergestützte Suchsystem der Bibliothek entsprechende Schlüsselwörter eingeben und hoffen, daß seine Abfrage möglichst viele sinnvolle Treffer erzielt. Damit aber eine Übereinstimmung zwischen Abfragebegriffen und Büchern bzw. Zeitschriftartikel möglich wird, muß auf den Textdokumenten eine Indexierung durchgeführt werden, welche deren Zuordnung zu bestimmten Themen erlaubt. Die Vorgehensweise, die bei einer solchen Indexierung gewählt wird, kann sehr unterschiedlich sein.In der vorliegenden Arbeit werden verschiedene Verfahren zur Indexierung von Text-Doku-menten dargestellt. Dabei sollen besonders das Konzept des 'Latent Semantic Indexing' von Deerwester et al. [1] und der Ansatz 'Self-Indexing Inverted Files' von Moffat und Zobel [2] behandelt werden. Außerdem wird auf Probleme eingegangen, die allgemein mit dem Thema Text Retrieval verbunden sind.
2 Grundlagen des Text Retrievals
Text Retrieval ist ein Teilbereich des Information Retrievals. Während Text Retrieval nur die textuelle Suche in Dokumenten beinhaltet, ist Information Retrieval weiter gefaßt und zielt ganz allgemein auf die inhaltsorientierte Suche in multimedialen Datenbeständen. In Mandl [4] heißt es dazu:
'Information Retrieval beschäftigt sich mit der Suche nach Information und mit der Repräsentation, Speicherung und Organisation von Wissen. Information Retrieval modelliert Informationsprozesse, in denen Benutzer aus einer großen Menge von Wissen die für ihre Problemstellung relevante Teilmenge suchen. Dabei entsteht Information, die im Gegensatz zum gespeicherten Wissen problembezogen und an den Kontext angepaßt ist.' (S. 7)
Die folgende Abbildung veranschaulicht den Information Retrieval Prozeß bezogen auf Text-Dokumente (vgl. (Mandl [4], Seite 8).
Abbildung 1 Text Retrieval Prozeß

Text Retrieval 2, Sylvia Zotz 3
Aus dieser Darstellung geht hervor, daß sowohl die einzelnen Dokumente des Datenbestandes als auch die Anfragen der Benutzer mittels eines Erschließungsverfahrens – meist auch als Indexierung bezeichnet – in eine interne Darstellung transformiert werden müssen, die den Inhalt des jeweiligen Dokuments bzw. der einzelnen Anfrage adäquat widerspiegelt. Wie diese interne Darstellung bzw. Repräsentation letztlich aussieht, ist von dem verwendeten Indexierungsansatz abhängig.Wichtig ist, daß erst mit Hilfe dieser Repräsentationen ein sinnvoller Ähnlichkeitsabgleich durchgeführt werden kann und es dadurch möglich wird, eine Übereinstimmung zwischen Dokumenten und Abfrage zu ermitteln. Diejenigen Dokumente, die gemäß dem Retrieval System der Anfrage des Informations-suchenden entsprechen, werden als Ergebnis ausgegeben. Der Benutzer muß dann entscheiden, welche der Ergebnisdokumente tatsächlich für ihn relevant sind, das heißt, einen Treffer darstellen. Natürlich ist auch die Trefferwahrscheinlichkeit abhängig von der internen Darstellung der Dokumente und der Anfrage und damit wiederum vom gewählten Indexierungsansatz.
2.1 Allgemeine Verfahren zur Indexierung von Text-Dokumenten
Um eine Textsuche auf einem Dokumentenbestand durchführen zu können, ist es – wie bereits oben angeführt – zunächst notwendig eine Indexierung vorzunehmen. Ganz allgemein ist darunter zu verstehen, daß Repräsentationen der Retrieval-Objekte erstellt werden. Bei Text-Dokumenten handelt es sich bei diesen Repräsentationen um eine Menge von Begriffen oder Termen. Wie die ein Dokument repräsentierenden Begriffe ausgewählt werden, hängt von der Indexierungsmethode ab. Mandl [4] unterscheidet dabei grundsätzlich zwei Arten von Indexierungsverfahren.Bei der intellektuellen (oder manuellen) Indexierung wird jedes Dokument, das in den Datenbestand aufgenommen werden soll, von einem menschlichen Indexierer überprüft und mit inhaltskennzeichnenden Schlagwörtern versehen. Diese Schlagwörter stammen zudem meist aus einem kontrollierten Vokabular. Beim automatischen (oder maschinellen) Indexieren hingegen extrahiert ein Algorithmus alle in einem Dokument vorkommenden Wörter, reduziert aber eventuell vorkommende morphologische Formen. Außerdem finden oftmals sogenannte Stoppwortlisten Verwendung, die dafür sorgen, daß sehr häufig gebrauchte Wörter und Funktionswörter wie Artikel und Präpositionen bei der Indexierung nicht berücksichtigt werden. Ist die zu einem Dokument gehörende Begriffsliste fertig, so wird zusätzlich die Vorkommenshäufigkeit der einzelnen Wörter abgespeichert. Diese Vorkommenshäufigkeiten werden später dazu verwendet, um als Zwischenergebnis die Häufigkeit der jeweiligen Begriffe im gesamten Datenbestand zu ermitteln. Die Begriffe, die dabei sehr oft vorkommen, erhalten eine geringere Gewichtung, da sie bei einer Suchabfrage meist nur zu mäßigen oder schlechten Resultaten führen. Das Ergebnis der automatischen Indexierung eines Dokuments ist somit eine Begriffsliste und für jeden Begriff eine, seiner in dem betreffenden Dokument und der gesamten Datenbasis Vorkommens-häufigkeit entsprechenden Gewichtung.Die wesentlichen Unterschiede zwischen den beiden skizzierten Indexierungsverfahren sind, daß zum einen die Anzahl der Terme, die bei der automatischen Indexierung zur Repräsentation eines Dokuments ausgewählt werden, wesentlich größer ist als bei der intellektuellen Indexierung. Zum anderen kommen die bei der intellektuellen Indexierung zugeordneten Schlagwörter nicht unbedingt in dem Dokument vor, da hier versucht wird, ein Dokument auch semantisch zu modellieren, d.h. die Bedeutung bzw. den Inhalt des Dokuments zu extrahieren.

Text Retrieval 2, Sylvia Zotz 4
2.2 Allgemeine Darstellung verschiedener Retrieval Modelle
Im folgenden sollen die grundlegenden Ansätze dargestellt werden, wie Informationen in Retrieval Systemen repräsentiert bzw. verarbeitet werden.
2.2.1 Boolesches Retrieval
Das Boolesche Retrieval Modell orientiert sich an den Vorstellungen der elementaren Mengenlehre. Eine elementare Menge ist gemäß diesem Modell eine Sammlung von Dokumenten, die alle denselben Begriff enthalten. Das heißt beispielsweise, daß alle Dokumente, die mit dem Wort 'A' indexiert sind, zur selben elementaren Menge gehören. Dabei ist es natürlich unumgänglich, daß ein Dokument mehreren elementaren Mengen gleichzeitig zugeordnet wird. In diesem System muß die Anzahl der elementaren Mengen mit der Zahl der bei der Indexierung des Datenbestands ermittelten Begriffe bzw. Terme übereinstimmen. Text Retrieval wird als eine Mengenoperation betrachtet, die das Ziel hat, aus einer Grundmenge von Dokumenten, welche den Datenbestand darstellen, diejenigen herauszufinden, die für die Abfrage eines Benutzers von Interesse sind. Dieses Modell basiert somit auf der Annahme, daß jede Abfrage als Ergebnis eine exakt anzugebende Menge an Dokumenten liefert. Bei den Suchabfragen sind dabei die klassischen Mengenoperationen Durchschnitt, Vereinigung und Komplement zugelassen. Die so zusammengesetzten Anfragen können dann als boolesche Suchanfragen bezeichnet werden. Folgende Abbildung aus Mandl [4] (S. 13) soll das Konzept des Booleschen Retrievals nochmals verdeutlichen.
Abbildung 2 Elementare Operationen im Booleschen Retrieval Modell
Der Nachteil Boolescher Retrieval Modelle besteht darin, daß eine Gewichtung der Indexbegriffe keine Berücksichtigung findet. Für den Benutzer bedeutet dies, daß er die Ergebnisdokumente ungeordnet ausgegeben bekommt und somit im Grunde alle diese Dokumente sichten muß, um festzustellen, welche am besten zu seiner Anfrage passen.
2.2.2 Retrieval mit Ranking
Ranking Modelle versuchen das Problem, den Benutzer nach einer Suchanfrage mit einer ungeordneten Menge von Ergebnisdokumenten zu überhäufen, in den Griff zu bekommen. Dazu wird bei einer Anfrage für jedes auszugebende Dokument seine Relevanz berechnet. So entsteht gewissermaßen eine Rangordnung auf den Antworten und die potentiell passendsten Dokumente stehen am Beginn der Ergebnisliste.

Text Retrieval 2, Sylvia Zotz 5
2.2.3 Vektorraum Modelle
Beim Vekorraum Modell spannen die einzelnen Begriffe, die bei der Indexierung des Datenbestands ermittelt worden sind, einen multidimensionalen Term-Raum auf. Sowohl die einzelnen Textdokumente als auch die Suchanfragen werden als Punkte bzw. Vektoren in diesem multidimensionalen Koordinatensystem aufgefaßt. Jedem Dokument und jeder Abfrage wird an den Term-Achsen das Gewicht für den entsprechenden Indexbegriff zugewiesen.Man muß sich bei diesem Modell also beispielsweise ein Dokument als Vektor vorstellen, dessen einzelne Komponenten die Gewichte zu den verschiedenen Indexbegriffen darstellen.Ob ein Dokument zu einer Suchanfrage paßt, ergibt sich aus der räumlichen Nähe zwischen den entsprechenden Dokumenten- und Abfragerepräsentation im Term-Raum. Da ein multidimensionaler Term-Raum nur schwer vorstellbar ist, soll das Prinzip des Vektorraum Modells anhand eines durch nur zwei Begriffe aufgespannten Term-Raums verdeutlicht werden (vgl. Mandl [4], S. 15).
Abbildung 3 Zweidimensionaler Term-Raum mit Suchanfrage und zwei Dokumenten
Gemäß dieser Abbildung werden die Anfrage und die Dokumente als zweidimensionale Vektoren dargestellt, deren erste Komponente der Wert für das Gewicht von Term A und die zweite Komponente den Wert für das Gewicht von Term B enthält. Da sich das Dokument 2 näher zur Position der Anfrage befindet, paßt es besser als das Dokument 1.
2.3 Probleme beim Text Retrieval
Wie die vorangegangene Darstellung der verschiedenen Retrieval Modelle gezeigt hat, baut Text Retrieval darauf auf, daß die bei der Indexierung der einzelnen Dokumente gewonnenen Terme mit den Wörter, die in einer Abfrage gewählt werden, zueinander passen. Das grundlegende Problem besteht nun aber darin, daß die von einem Benutzer verwendeten Begriffe oft nicht mit denjenigen übereinstimmen, mit denen die Textdokumente indexiert wurden. Wie Deerwester et al. [1] anmerkt, richten Benutzer ihre Abfragen gewöhnlich in Hinblick auf begriffliche Inhalte und Konzepte aus, wohingegen einzelne Wörter nur unzulängliche Hinweise auf die in einem Dokument behandelten Themen sind. Damit wird aber auch die Schwäche der üblichen Indexierungsverfahren offenbar, da einzelne Terme den Inhalt eines Textes nie auch nur annähernd adäquat widerspiegeln können [4]. Grundsätzlich führt Deerwester et al. [1] zwei Aspekte an, die beim Text Retrieval zu Schwierig-keiten führen. So erschwert zum einen das Vorhandensein synonymer Begriffe die Zuordnung

Text Retrieval 2, Sylvia Zotz 6
relevanter Dokumente zu einer Suchanfrage. Oftmals gibt es verschiedenste Möglichkeiten, einen Sachverhalt auszudrücken, und je nach Kontext, Erfahrung und sprachlichen Gewohnheiten des Benutzers wird eine entsprechende Formulierung gewählt. Zum anderen bereitet aber auch die Mehrdeutigkeit von Begriffen Probleme. Viele Wörter haben je nach Kontext mehr als eine eindeutige Bedeutung. Betrachtet man beispielsweise das Wort 'Schloß' so kann dieses zum einen die Verriegelungsvorrichtung einer Tür bezeichnen, zum anderen kann damit aber auch der herrschaftliche Wohnsitz eines Adeligen gemeint sein. Das hat aber zur Folge, daß die Verwendung eines bestimmten Begriffes in einer Suchabfrage noch nicht bedeutet, daß ein Dokument, das mit demselben Begriff indexiert ist, zur Anfrage paßt.
2.4 Qualitätsmaße zur Beurteilung von Text Retrieval Verfahren
Um ein Retrieval Verfahren beurteilen zu können, muß zunächst zwischen Effizienz und Effektivität unterschieden werden. Hierbei bezieht sich die Effizienz eines Verfahrens auf einen möglichst sparsamen Einsatz an Ressourcen. Bei diesen Ressourcen handelt es sich insbesondere um CPU-Zeit, Speicherplatz, Anzahl an I/O-Operationen und Antwortzeiten. Beim Begriff Effektivität steht hingegen das Kosten-Nutzen-Verhältnis, das sich bei der Verwendung eines bestimmten Verfahrens ergibt, im Vordergrund. Auf der Kostenseite werden dabei der vom Benutzer aufzubringende Zeitaufwand und seine mentale Belastung angeführt, die mit der Erzielung einer befriedigenden Lösung verbunden sind. Wobei die Lösung eines Text Retrieval Problems aus einer durch das entsprechende Verfahren ermittelten Menge an Ergebnisdoku-menten besteht. Dem gegenüber steht auf der Nutzenseite die Qualität der erzielten Lösung [6].Zur Bewertung der Qualität einer Lösung, wird meist auf das Konzept der Relevanz zurück-gegriffen [6]. Allerdings stellt dieses Konzept nur ein subjektives Kriterium dar, da es lediglich die Einschätzung eines Benutzers bezüglich der Übereinstimmung bzw. Eignung eines Ergebnisdokuments hinsichtlich einer zuvor formulierten Abfrage ausdrückt.Ausgehend vom Konzept der Relevanz können dann die drei weiteren Meßgrößen Precision,Recall und Fallout abgeleitet werden. Precision gibt dabei den Anteil der tatsächlich relevanten Dokumente innerhalb der Menge der Ergebnisdokumente wider. Dahingegen bezieht sich der Recall-Wert auf den Prozentsatz an relevanten Dokumenten, die sich mit Hilfe des Retrieval Verfahrens ermitteln haben lassen. Fallout bezeichnet schließlich den Anteil der gefundenen irrelevanten Dokumente in Hinblick auf die Gesamtmenge aller irrelevanten Dokumente des Datenbestands [6]. Da Text Retrieval Verfahren wohl kaum in der Lage sein werden, jemals alle zu einer Suchabfrage relevanten Dokumente zu ermitteln, und gleichzeitig es auch unumgänglich ist, daß sich irrelevante Dokumente unter den Ergebnisdokumenten befinden, stellen diese Meßgrößen sinnvolle Kennzahlen dar, um die Qualität verschiedener Text Retrieval Verfahren miteinander vergleichen zu können. Mandl [4] (S. 30) hat in einer graphischen Darstellung diesen Zusammenhang zwischen rele-vanten bzw. irrelevanten Dokumenten und den Kennziffern Precision und Recall wie folgt veranschaulicht.
Abbildung 4 Relevanz, Precision und Recall

Text Retrieval 2, Sylvia Zotz 7
Es ist wichtig darauf hinzuweisen, daß eine gleichzeitige Optimierung von Precision und Recall
nicht möglich ist. Während durch eine einfache Vergrößerung der Ergebnismenge der Recall-Wert verbessert werden kann, nimmt die Precision im Gegenzug ab. [4] Allerdings eignen sich diese Kennzahlen in ihrer so beschriebenen Form nur für Retrieval Modelle, die eine eindeutige Einteilung in relevante und irrelevante Dokumente zulassen. Während dies beim Booleschen Modell der Fall ist, findet bei Ranking Modellen eine graduelle Abstufung auf einer imaginären Skala statt, die die ermittelte Übereinstimmung zu einer Suchanfrage widerspiegelt. Eine scharfe Trennung zwischen relevanten und irrelevanten Dokumenten, wie es das obige Venn-Diagramm in der Abbildung 4 suggeriert, gibt es somit nicht. Der Benutzer arbeitet stattdessen die durch das Ranking Verfahren ausgegebene Dokumentenliste nach und nach ab, wobei sich mit jedem zusätzlichen Dokument, das er betrachtet, die Ergebnismenge vergrößert. Entsprechend lassen sich auch für jedes zusätzliche Dokument neue Werte für die Kennziffern Precision und Recall ermitteln, die in ein Koordinatensystem eingetragen werden können. Dabei entsteht dann der sogenannte Recall-Precision-Graph. Damit es aber auch bei Retrieval Verfahren die mit Ranking Modellen arbeiten, möglich wird, die verschiedenen Verfahren hinsichtlich ihrer Qualität miteinander zu vergleichen, wird zumeist die Precision auf neun Recall-Niveaus gemittelt (0.1 bis 0.9).
3 Ausgewählte Ansätze von Indexierungsverfahren beim Text Retrieval
3.1 Ansatz von Moffat und Zobel: 'Self-Indexing Inverted Files'
Moffat und Zobel [2] beschreiben in ihrem Ansatz ein Verfahren, das mit invertierten Listen arbeitet. Sie erweitern dabei aber die herkömmlichen, ebenfalls auf invertierten Listen basierenden Modelle, indem sie zusätzliche Informationen in die Listen einfügen und ein neues Komprimierungskonzept verwenden. Außerdem modifizieren sie die Vorgehensweise bei der Bearbeitung von Suchabfragen.Im folgenden wird zunächst eine Erklärung des Begriffs invertierte Listen vorgenommen und anschließend der Ansatz von Moffat und Zobel ausführlicher dargestellt.
3.1.1 Definition und Aufbau invertierter Listen
Invertierte Listen stellen eine Indexstruktur dar, die insbesondere bei der Verarbeitung von booleschen Suchanfragen häufig eingesetzt wird [2].Wie bereits ausgeführt, wird bei der Indexierung des Dokumentenbestands eine Menge an Begriffen ermittelt, welche oftmals auch als Vokabular bezeichnet wird. Jeder Eintrag dieses Vokabulars besitzt einen Zeiger auf eine sogenannte invertierte Liste, welche all diejenigen Dokumente enthält, in denen der entsprechende Begriff vorkommt. Das bedeutet, daß es für jeden Indexbegriff eine invertierte Liste gibt, und diese wenigstens ein Dokument enthalten muß. Die einzelnen Dokumente in den invertierten Listen werden dabei durch Nummern referenziert, die in aufsteigender Reihenfolge angeordnet werden.Die invertierte Liste zu dem Begriff 'index' könnte zum Beispiel so aussehen [4] ( S. 2):
I 'index' = <5, 8, 12, 13, 15, 18, 23, 28, 29, 40, 60>
Nimmt man alle invertierten Listen zusammen, so erhält man eine invertierte Datei (inverted
file), welche auf der Festplatte gespeichert wird.

Text Retrieval 2, Sylvia Zotz 8
Um eine Anfrage eines Benutzers zu verarbeiten, sind genau diejenigen invertierten Listen zu betrachten, die zu den Suchbegriffen der Anfrage passen. Je nach Formulierung der Benutzeranfrage muß dann die Schnittmengenbildung oder eine Vereinigung der betroffenen invertierten Listen erfolgen, um so die Ergebnisdokumente zu erhalten. Allerdings ist die Ermittlung der Ergebnisdokumente – insbesondere wenn dem verwendeten Retrieval Modell ein Ranking Konzept zugrunde liegt – mit sehr hohen Kosten hinsichtlich Speicherplatzbedarf und Rechenzeit verbunden, wenn mit diesen herkömmlichen invertiertenListen gearbeitet wird. Zwar führen Komprimierungsmaßnahmen zu einer deutlichen Reduzierung des Speicherplatzes, doch wird aufgrund der infolge notwendig werdenden Dekomprimierung gleichzeitig die Verarbeitungsgeschwindigkeit herabgesetzt.Um sowohl die Rechenzeit als auch den Speicherplatzbedarf zu verringern, nehmen Moffat und Zobel einige Modifikationen am Aufbau der invertierten Listen vor. Dazu wird zunächst jedem Indexbegriff t, das heißt jedem Vokabulareintrag, ein Parameter ft angefügt, der die Vorkom-menshäufigkeit des entsprechenden Begriffs in der gesamten Dokumentenbasis angibt. Außerdem wird in den invertierten Listen neben den Dokumentennummern zusätzlich jeweils die Vorkommenshäufigkeit des Begriffs innerhalb des einzelnen Dokuments d aufgenommen. Dieser Parameter wird mit ft,d bezeichnet und ermöglicht es, für jeden Begriff in jedem Dokument ein eigenes Gewicht zu berechnen [2]. Jeder Listeneintrag hat dann die folgende Form <d, ft,d > . Moffat und Zobel gehen des weiteren dazu über, nicht wirklich die Dokumentennummern in den invertierten Liste abzulegen, sondern lediglich die Differenzen zwischen aufeinanderfolgenden Dokumentennummern. Diese Differenzen werden d-gaps genannt. Eine Liste von Dokumenten wird mit Hilfe dieser Methode dann beispielsweise wie folgt abgespeichert:
5, 8, 12, 13, 15, 18, 23, 28, 29, 40, 60 ursprüngliche Liste
5, 3, 4, 1, 2, 3, 5, 5, 1, 11, 20 Liste mit d-gaps
Der Vorteil dieser Vorgehensweise besteht darin, daß damit insgesamt kleinere Werte in den Listen vorkommen. Diese Werte werden dann nicht wie üblich binär codiert, sondern es wird die sog. Colomb-Codierung verwendet, die es erlaubt, kleine Integerwerte sehr knapp darzustellen und damit Speicherplatz einzusparen. Werden auf den invertierten Listen nun die üblichen Komprimierungsverfahren angewendet, so ist es nicht möglich irgendwo inmitten einer dieser Listen hineinzuspringen. Statt dessen muß eine Dekodierung der gesamten Liste erfolgen, denn der Ausgangspunkt für eine Dekodierung ist immer der Listenanfang. Um eine Abfrage verarbeiten zu können, ist aber im Grunde nur der Vergleich mit einem Teil der Listeneinträge nötigt. Damit es also möglich wird auch an eine beliebige Stelle innerhalb der Liste zu springen, fügen Moffat und Zobel zusätzliche Synchronisationspunkte (sog. skips) ein, von denen aus ebenfalls eine Dekodierung möglich ist. Zur Veranschaulichung dieser Vorgehensweise kann folgende Abbildung betrachtet werden, die von einer Menge von Paaren <d, ft,d > ausgeht:
Abbildung 5 Self-Indexing Inverted File

Text Retrieval 2, Sylvia Zotz 9
Um also feststellen zu können, ob ein Dokument d0 in einer invertierten Liste enthalten ist, werden zunächst einmal nur die ersten beiden Synchronisationspunkt dekodiert. Daraufhin werden die in diesen Synchronisationspunkten abgespeicherten Dokumentennummern d1 und d2
betrachtet. Falls d1 d0 < d2 gilt, befindet sich das gesuchte Dokument im ersten Block – d.h. zwischen den ersten beiden Synchronisationspunkten – und es ist nur notwendig diesen Block zu dekodieren. Ist das gesuchte Dokument jedoch dort nicht enthalten, so ist eine Dekodierung dieses Blocks nicht notwendig und es wird zum dritten Synchronisationspunkt gesprungen. Dieser wird dann wiederum dekodiert und daraufhin überprüft, ob d0 < d3 ist. Ist dies der Fall, so wird lediglich der zweite Block in der invertierten Liste dekodiert und der nicht benötigte erste Abschnitt kann einfach übersprungen werden. In dieser Weise wird zunächst die Liste der Synchronisationspunkte abgearbeitet, bis schließlich der gesuchte Eintrag gefunden wurde. Anschließend wird nur der entsprechende Block in der invertierten Liste decodiert. [2] Durch die zusätzliche Liste an Synchronisationspunkte erhöht sich zwar der Speicherplatzbedarf und damit auch die Rechenzeit für das Einlesen der Daten in den Arbeitsspeicher. Es hat sich aber gezeigt, daß die Einsparungen, die sich durch die, – aufgrund der Synchronisationspunkte nur teilweise nötigen – Dekodierung der invertierten Listen ergeben, größer sind und nicht durch die zusätzlich nötige Einlesezeit überkompensiert werden. [2]
3.1.2 Vorgehensweise bei der Verarbeitung von booleschen Suchanfragen
Soll eine boolesche Suchanfrage bearbeitet werden, bei der die einzelnen Suchterme jeweils mit AND verbunden worden sind (Konjunktion der Suchterme), so müssen die entsprechenden Suchbegriffe zunächst im Vokabular gefunden werden. Anschließend werden sie aufsteigend gemäß ihrer Vorkommenshäufigkeit ft geordnet, und diejenige invertierte Liste, die zu dem Indexbegriff mit den wenigsten Dokumenteinträgen gehört, als erste in den Arbeitsspeicher geladen. Diese Liste stellt dann den Ausgangspunkt der Bearbeitung dar, da durch sie die Menge der Dokumente festgelegt wird, die letztendlich als Ergebnisdokumente in Frage kommen. Moffat und Zobel bezeichnen diese Dokumente deshalb auch als Kandidaten. Daraufhin wird die nächste invertierte Liste bearbeitet und für jeden Kandidaten wird überprüft, ob die entsprechen-de Dokumentennummer auch in ihr vorkommt. Ist dies nicht der Fall, so kann dieser Kandidat nicht zu den Ergebnisdokumenten gehören, wird verworfen und in den weiteren Listen nicht mehr gesucht. Sind alle invertierten Listen, die aufgrund der Suchbegriffe ausgewählt worden sind, auf diese Weise durchlaufen worden, so ergeben die am Ende noch verbleibenden Kandidaten die Menge der Ergebnisdokumente. Diese werden dann vom Retrieval System an den Benutzer ausgegeben. [2] Der Vorteil dieser Vorgehensweise besteht darin, daß zum einen von Anfang an möglichst wenige potentielle Ergebnisdokumente betrachtet werden müssen. Zum anderen nimmt aufgrund der beschriebenen Bearbeitungsreihenfolge die Zahl der Kandidaten kontinuierlich ab. Ist hingegen eine boolesche Suchanfrage zu verarbeiten, deren Suchterme jeweils mit OR verknüpft sind (Disjunktion von Suchtermen), so sind auch hier wiederum erst die entsprechenden Suchbegriffe im Vokabular zu suchen und die dazugehörigen invertierten Listen. Als Ergebnisdokumente werden dann all diejenigen Dokumente ausgegeben, die in irgendeiner dieser Listen referenziert worden sind.

Text Retrieval 2, Sylvia Zotz 10
3.1.3 Vorgehensweise bei der Verarbeitung von Suchanfragen mit Ranking
Beim Ranking wird jedem Dokument ein Wert zugewiesen, der seine Übereinstimmung mit der Suchanfrage ausdrückt. Diejenigen Dokumente, die dabei am besten abschneiden werden am Ende als Ergebnis ausgegeben. Moffat und Zobel verwenden bei der Bestimmung der Ähnlichkeit eines Dokuments d mit der Suchanfrage q das sog. Cosinus-Maß, das durch folgende Funktion ausgedrückt wird:
t tdt tq
t tdtq
ww
wwdqcosine
2,
2,
,,),(
Wobei wq,t bzw. wd,t das Gewicht des Begriffs t in der Suchanfrage q bzw. dem Dokument d
darstellt. Zur Berechnung dieser Gewichte wird der Parameter ft herangezogen, der die Vorkommenshäufigkeit des Begriffs t innerhalb der gesamt vorliegenden Dokumentenbasis angibt und der Parameter ft,d bzw. ft,q der die Vorkommenshäufigkeit des Begriffs t im einzelnen Dokument d oder der Suchanfrage q bezeichnet. Denjenigen Begriffen, die seltener vorkommen, wird dabei ein größeres Gewicht zugewiesen, da davon ausgegangen wird, daß sie einen stärker unterscheidungstragenden Charakter besitzen als häufiger auftretende Wörter. Und das gleichzeitige Vorkommen eines seltenen Begriffs sowohl in der Suchanfrage als auch in einem Dokument wird als ein relativ zuverlässiger Hinweis auf einen Treffer angesehen.Suchanfragen mit Ranking ähneln in gewisser Hinsicht booleschen Anfragen, bei denen die Suchterme durch Disjunktionen verknüpft sind, da auch hier im Grunde jedes Dokument in dem irgendeiner der Suchbegriffe vorkommt, als möglicher Kandidat für die Ergebnisausgabe angesehen werden kann. [2] Die einfachste Vorgehensweise bei Suchanfragen mit Ranking wäre es, jedem Dokument d, das sich in der Dokumentenbasis befindet, eine Akkumulatorvariable Ad zuzuweisen, welche zu Beginn der Verarbeitung mit den Wert 0 initialisiert würde. Anschließend wäre für jedes Paar <d, ft,d > in der invertierten Listen für einen Suchbegriff t ein Gewicht wq,t • wd,t zu berechnen und zum Akkumulator Ad zu addieren. Ist dieser Vorgang für alle Suchbegriffe der Benutzeranfrage wiederholt worden, müßten abschließend alle Akkummulatorwerte Ad nochdurch die Länge des jeweils zugehörigen Dokuments d dividiert werden, damit sie miteinander vergleichbar werden. Die so entstehenden Werte entsprechen dem oben beschriebenen Cosinus-Maß cosine(q,d). In einem letzten Schritt würden dann die Dokumente ausgegeben, welche die höchsten Cosinus-Maß-Werte besitzen. Dabei wird die Anzahl der Dokumente, die als Ergebnisdokumente zurückgeliefert werden sollen, bereits im voraus festgelegt. Der Nachteil dieser Vorgehensweise besteht darin, daß zum einen die Akkumulatoren sehr viel Platz im Arbeitsspeicher beanspruchen und zum anderen für deutlich mehr Dokumente das zuge-hörige Cosinus-Maß ermittelt werden muß, als letztendlich Ergebnisdokumente vorhanden sind. Um sowohl Rechenzeit als auch Speicherplatz zu sparen, wandeln Moffat und Zobel das eben dargestellte Verfahren leicht ab. Zur Reduzierung des Speicherbedarfs für die Akkumulatoren Ad
ordnen sie zunächst die Suchbegriffe nach absteigender Gewichtung an. Von Anfang an wird eine Obergrenze für die Anzahl an Akkumulatoren festgelegt. Dann werden die Paare <d, ft,d >des Suchterms mit der stärksten Gewichtung betrachtet und für die in dieser Liste referenzierten Dokumente die Akkumulatoren berechnet. Wird dabei die zuvor festgelegte Höchstgrenze an zulässigen Akkumulatoren noch nicht überschritten, wird zur nächsten invertierten Liste übergegangen und die dort abgelegten Einträge bearbeitet, indem entweder errechnete Gewichte zu bereits vorhandene zugehörige Akkumulatoren hinzuaddiert oder neue Akkumulatoren angelegt werden. Bei dieser Vorgehensweise gibt es also nicht für jedes Dokument, das in der Datenbasis vorhanden ist, einen Akkumulator, sondern nur für diejenigen Dokumente, die

Text Retrieval 2, Sylvia Zotz 11
tatsächlich für die Suchabfrage relevant sind. Zudem besteht die Einschränkung, daß keine weiteren Akkumulatoren mehr angelegt werden, wenn eine bestimmte Höchstzahl erreicht wurde, was bedeutet, daß die Anzahl an möglichen Kandidaten für die Ergebnisausgabe nicht mehr erweitert wird. Können keine weiteren Akkumulatoren mehr angelegt werden, weil die Obergrenze erreicht ist, so werden die invertierten Listen der noch verbleibenden Suchterme nach Dokumenten durchsucht, für die bereits im vorausgegangenen Schritt ein Akkumulator angelegt worden ist. Das Gewicht des entsprechenden Eintrags wird ermittelt, und der betroffene Akkumulator um diesen Wert erhöht. Sind alle invertierten Listen schließlich bearbeitet worden, wird wieder wie oben für jeden Akkumulator das zugehörige Cosinus-Maß berechnet und die Dokumente mit den größten Werten ausgegeben. Da die zulässige Anzahl von Akkumulatoren von Beginn an begrenzt war, muß das Cosinus-Maß nun für deutlich weniger Dokumente berechnet werden und entsprechend ist es möglich, Rechenzeit einzusparen. Das von Moffat und Zobel vorgeschlagene Verfahren ähnelt in seinem ersten Teil der Vorgehensweise bei der Verarbeitung von disjunktiven booleschen Suchanfragen. Ist die Höchstzahl an Akkumulatoren jedoch erreicht, erfolgt ein Wechsel zu einer eher der Behandlung konjunktiver boolescher Abfragen entsprechenden Verarbeitungsweise, da nun nur noch Dokumente betrachtet werden, die bereits als Einträge in den invertierten Listen höher gewichteter Suchterme vorkommen. [2]
3.1.4 Untersuchungsaufbau
Grundlage für die Analyse des von Moffat und Zobel beschriebenen Verfahrens ist eine von der TREC zusammengestellte Sammlung von Artikeln aus den Bereichen Finanzwesen, Wissen-schaft und Technologie. TREC steht dabei für Text REtrieval Converence – eine Veranstaltung, die seit 1992 mit dem Ziel durchgeführt wird, die Effektivität verschiedener Retrieval Systeme zu überprüfen. Die ausgewählten Artikel variieren dabei stark in ihrer Länge und bei einem maschinellen Indexierungsverfahren wurden fast 196 Millionen Indexterme ermittelt. Für die booleschen Suchanfragen wurden von Moffat und Zobel 25 Listen erstellt, die jeweils 50 Wörter enthielten. Bei diesen Listen handelt es sich um zufällige, aus der Dokumentenbasis ausgewählte Bestandteile von Seiten, aus denen mehrmals vorkommende Begriffe, Wörter mit demselben Stamm und Stopwörter entfernt wurden. Diese Vorgehensweise garantiert bei Suchabfragen zwischen 1 und 50 Begriffen, die aus ein und derselben Liste stammen, daß mindestens ein Treffer vorhanden sein muß, und die Verarbeitung einer Suchabfrage nicht abgebrochen wird, bevor nicht alle angegebenen Suchbegriffe abgearbeitet sind.Bei den Suchanfragen mit Ranking wurde auf eine standardisierte Sammlung von Anfragen zurückgegriffen, für die bereits bei der Text REtrieval Converence manuell eine Menge relevanter Dokumente bestimmt worden war. Für diese Suchanfragen lag also bereits eine entsprechende Relevanzbeurteilung vor. Dabei wurden zwei Durchläufe vorgenommen. Bei einem Durchlauf wurden die Stopwörter aus den Suchabfragen entfernt, beim anderen blieben sie enthalten.
3.1.5 Untersuchungsergebnisse
Eine Analyse mit Hilfe des oben beschriebenen Untersuchungsaufbaus zeigt, daß durch das von Moffat und Zobel entwickelten Retrieval Verfahren im Vergleich zu den üblichen Vorgehens-weisen beim Text Retrieval, sowohl der Speicherplatzbedarf deutlich gesenkt als auch die benötigte Rechenzeit erheblich reduziert werden kann. Zwar führt die Einführung von Synchronisationspunkten in den invertierten Listen zunächst zu einer Speicherplatzerhöhung von

Text Retrieval 2, Sylvia Zotz 12
fast 20 %, doch kann diese durch das angewendete Komprimierungsverfahren kompensiert werden. Die Zeitersparnis, die dadurch zustande kommt, daß aufgrund der Synchronisations-punkte nicht mehr eine gesamte invertierte Liste dekomprimiert werden muß, sondern an einen beliebigen Punkt innerhalb der Liste gesprungen werden kann, ist beträchtlich. Im Vergleich zu Versuchen mit nicht komprimierten invertierten Listen ohne Synchronisationspunkte, ergeben sich bei den Suchanfragen mit Ranking dadurch Einsparungen von bis zu 50 % und bei den booleschen Anfragen sogar noch etwas größere.Einsparungen bezüglich des benötigten Speicherplatzes sind nicht nur durch das von Moffat und Zobel vorgeschlagene Komprimierungsverfahren bei den invertierten Listen zu erreichen, sondern v.a. auch aufgrund der Festlegung einer Obergrenze für die Anzahl der zu verwendenden Akkumulatoren bei der Bearbeitung von Suchanfragen mit Ranking. Unerwarteterweise ist bei dieser Vorgehensweise sogar eine verbesserte Retrieval Leistung zu vermerken, als bei der ursprünglichen Methode, bei der für jedes Dokument ein Akkumulator angelegt worden war. In einer Untersuchung konnten Moffat und Zobel nachweisen, daß die niedrig bis mittel gewichteten Suchbegriffe zwar einen wichtigen Beitrag für die Effektivität des Retrievals leisten, diese aber bei der Auswahl von Dokumenten nicht herangezogen werden sollten, wenn diese Dokumente nicht bereits auch höher gewichtete Suchbegriffe enthalten. Aufgrund der Anordnung der bei einer Anfrage zu bearbeitenden invertierten Listen nach abnehmender Gewichtung der zugehörigen Suchbegriffe, wird diese Bedingung erfüllt. Nur diejenigen Dokumente, die in den zuerst bearbeiteten invertierten Listen referenziert werden, erhalten einen Akkumulator. Als letztes wurde noch der Einfluß von Stopwörtern auf die Retrieval Leistung bei Suchanfragen mit Ranking überprüft. Dabei zeigt sich, daß durch die Entfernung von Stopwörtern keine Einbußen bezüglich der Effektivität des Retrieval Prozesses festzustellen sind, die Verarbei-tungszeit aber erheblich gesenkt werden kann.
3.2 Ansatz von Deerwester, Dumais und Harshman: 'Indexing by Latent Semantic Analysis'
Der von Deerwester et al. [1] entwickelte Text Retrieval Ansatz kann zu den in Abschnitt 2.2.3 beschriebenen Vektorraum Modellen gezählt werden. Allerdings werden bei den herkömmlichen Vektorraum Konzepten meist nur sehr spärlich besetzte Term-Räume erzeugt, was darauf zurückzuführen ist, daß die Dokumente in einer großen Datenbasis nur einen geringen Prozent-satz der Indexbegriffe enthalten, welche durch automatische Indexierungsverfahren ermittelt werden. Stellt man sich die Zuordnung von Indexbegriffen und Dokumenten als Dokument-Term-Matrix vor, so besitzen also nur wenige der Zellen einen Wert ungleich Null [4]. Um diesen Nachteil zu kompensieren, führen Deerwster et al. ein Verfahren ein, das die Dimensionalität des Term-Raums reduziert. Außerdem wollen sie mit ihrem Ansatz diejenigen Schwierigkeiten, die aufgrund mehrdeutiger bzw. synonymer Wörter entstehen, besser in den Griff bekommen.
3.2.1 Konzept der latenten semantischen Strukturen
Herkömmliche Retrieval Modelle stehen häufig vor dem Problem, daß versucht wird, eine Übereinstimmung zwischen Dokument und Suchanfrage darauf zurückzuführen, daß beide dieselben Begriffe enthalten müssen. Einzelne Begriffe sind aber nach Deerwester et al. unzulängliche Indikatoren für den Inhalt bzw. das in einem Dokument behandelte Thema, da es

Text Retrieval 2, Sylvia Zotz 13
unzählige Möglichkeiten gibt, ein und denselben Sachverhalt auszudrücken. Aus diesem Grunde entwickeln Deerwester et al. das Konzept der latenten semantischen Strukturen, welches sie bei der Vorverarbeitung von Suchanfragen heranziehen.Mit Hilfe der latenten semantischen Strukturen soll zum Ausdruck gebracht werden, daß ein Zusammenhang bzw. eine Verbindung zwischen verschiedenen Begriffen bestehen kann. Es soll vorhersagbar werden, welche Begriffe tatsächlich von einer Suchanfrage impliziert werden oder den Inhalt eines Dokuments am besten widerspiegeln. Das gehäufte Auftreten bestimmter Wortkombinationen wird dabei als wichtiger Hinweis angesehen, daß zwischen den verwendeten Begriffen eine Beziehung besteht. Die Stärke einer solchen Beziehung – bzw. die Höhe der entsprechenden Korrelation – wird unter Verwendung von statistischen Techniken ermittelt. Kommen in einer Dokumentendatenbasis beispielsweise zwei Begriffe in vielen Dokumenten vor und in den meisten von diesen auch gleichzeitig, so ist es sinnvoll anzunehmen, daß in denjenigen Dokumenten, in denen einer der beiden Begriffe fehlt, dies nur zufällig geschieht bzw. auf die sprachlichen Vorlieben des Autors zurückzuführen ist. Enthält also eine Suchabfrage den in manchen Dokumenten fehlenden Begriff, sollten trotzdem auch diese Dokumente als Ergebnis mitausgegeben werden. Die Auswahl eines Ergebnisdokuments erfolgt somit nicht mehr aufgrund gemeinsam vorkommender Begriffe in Suchanfrage und Dokumenten, sondern anhand latenter semantischer Strukturen, welche letztendlich eine Verdichtung der Bedeutung eines Begriffs oder des Inhalts eines Dokuments darstellen. Wie nun aber diese latenten semantischen Strukturen von Deerwester et al. ermittelt und für die Bearbeitung von Suchabfragen verwendet werden, wird im folgenden aufgezeigt.
3.2.2 Umsetzung des Konzepts der latenten semantischen Strukturen mit Hilfe der Singulärwertzerlegung
Ausgangspunkt der Umsetzung des Konzepts der latenten semantischen Strukturen ist eine Dokument-Term-Matrix, bei der in jeder Zelle die Häufigkeit vermerkt ist, mit der ein bestimmter Begriff in einem Dokument vorkommt. Welche Begriffe dabei zu berücksichtigen sind, wird mit einem der herkömmlichen Indexierungsverfahren festgelegt. Anschließend wird mit Hilfe des mathematischen Verfahrens der Singulärwertzerlegung bzw. Singular Value Decomposition (SVD) aus dieser ursprünglichen Matrix eine reduzierte Matrix gewonnen.Hintergrund von SVD ist, daß jede beliebige Rechtecksmatrix X so in drei andere Matrizen zerlegt werden kann, daß deren Produkt wieder die Ausgangsmatrix ergibt – also X = T0 S0 D0.Dabei stellen T0 und D0 orthogonale Spalten dar und S0 ist eine Diagonalmatrix, die die sog. Singulärwerte (Singular Values) enthält. Diese Sigular Values sind alle positiv und werden nach fallender Wertigkeit angeordnet. Die Größe des Wertes zeigt dabei an, wieviel der betreffende Singulärwert zur Erzeugung der ursprünglichen Matrix X beiträgt. Die Position in der Diagonalmatrix spiegelt also die Wichtigkeit des betreffenden Singulärwerts wieder. [4]
Abbildung 6 Reduktion der Ausgangsmatrix

Text Retrieval 2, Sylvia Zotz 14
Der Vorteil der Singulärwertzerlegung besteht nun darin, daß mit Hilfe dieses Verfahrens eine modifizierte Matrix X ' mit geringerer Dimensionalität geschaffen werden kann, welche jedoch trotzdem eine gute Annäherung an die Ausgangsmatrix X darstellt. Hierzu werden die k größten Werte der Diagonalmatrix ausgewählt und alle restlichen auf Null gesetzt. Multipliziert man anschließend die Matrizen T0, die abgeänderte Diagonalmatrix S0 ' und D0, so erhält man die Matrix X ' mit der Dimensionalität k. Im Grunde führt also das Verfahren der Singular Value
Decomposition zu einer Komprimierung der ursprünglichen Dokumenten-Term-Matrix. Die k Dimensionen der neuen Matrix, welche oftmals auch als LSI-Dimensionen bezeichnet werden, bilden die Grundlage des Konzepts von Deerwester et al. Sie lassen sich jedoch nicht inhaltlich interpretieren oder als einzelne Begriffe oder Gruppen von Begriffen deuten, sondern stehen letztlich für komplexe Kombinationen von Termen. Es handelt sich also um künstliche Konstrukte, welche sozusagen gemeinsame Bedeutungen repräsentieren, die aus verschiedenen Begriffen und Dokumenten herausgefiltert wurden. [1] Mit Hilfe der LSI-Dimensionen läßt sich ein k-dimensionaler Raum aufspannen, in dem jeder Begriff und jedes Dokument durch einen Vektor dargestellt werden kann. Die einzelnen Komponenten der Vektoren geben dabei die jeweilige Gewichtung für die verschiedenen LSI-Dimensionen wider. Die Singulärwertzerlegung kann somit als eine Technik verstanden werden, die es erlaubt, für das Text Retrieval unabhängige Indexvariablen – nämlich die LSI-Dimensionen – zu ermitteln. Aufgrund der Reduzierung der ursprünglichen Anzahl von Term-Dimensionen auf eine deutlich geringere Zahl von LSI-Dimensionen wird es jetzt möglich, daß Dokumente, die zwar das gleiche Thema behandeln, sich aber hinsichtlich der Begriffswahl unterscheiden, durch denselben Vektor dargestellt werden können. [1]
3.2.3 Vorgehensweise bei der Verarbeitung von Suchanfragen
Wie bereits oben angeführt, wird durch die LSI-Dimensionen ein k-dimensionaler Raum aufgespannt, in dem jeder Begriff und jedes Dokument durch einen Vektor repräsentiert wird. Auch eine Suchanfrage ist letztlich nichts anderes als eine Sammlung von Wörtern und kann aus diesem Grunde ebenso als Vektor dargestellt werden, dessen Komponenten die Gewichte für die jeweiligen LSI-Dimensionen angeben. Dazu wird die Suchanfrage im Mittelpunkt der Begriffe plaziert, aus denen sie sich zusammensetzt. Eine Suchanfrage ist somit eine Art Pseudo-Dokument, welches gleichzeitig mit den übrigen Dokumenten der Datenbasis in dem, durch die LSI-Dimensionen aufgespannten Raum eingetragen werden kann. Um einen Vergleich zwischen Suchanfrage und Dokumenten vorzunehmen, wird die Ähnlichkeit bzw. Nähe zwischen den entsprechenden Vektoren berechnet. Dabei stellt der Kosinus eine gute Möglichkeit dar, um diese Ähnlichkeit zu ermitteln. Diejenigen Dokumente, die der Anfrage am nächsten liegen, werden als Ergebnis zurückgeliefert. Üblicherweise wird jedoch eine konkrete Begrenzung für die Anzahl der auszugebenden Treffer angegeben. Entweder wird eine Obergrenze für die Ergebnisdokumente festgelegt, oder es wird ein Wert für die notwendige Nähe zwischen Abfrage und Dokument bestimmt. Dokumente, die hinsichtlich ihrer Nähe zur Suchanfrage weiter entfernt liegen, zählen dann nicht mehr zu den Ergebnisdokumenten.

Text Retrieval 2, Sylvia Zotz 15
3.2.4 Untersuchungsaufbau
Deerwester et al. verwenden zur Messung der Retrieval Leistung ihres Konzepts des Latent
Semantic Indexing (LSI) die beiden Dokumentensammlungen MED und CISI, für welche sowohl standardisierte Suchanfragen als auch eine Beurteilung hinsichtlich der Relevanz der ermittelten Ergebnisdokumente vorliegen. Die entsprechenden Dokumente bestehen jeweils aus einer Zusammenfassung und dem vollständigen Titel. MED ist dabei eine Menge von 1033 Abstracts aus dem Bereich der Medizin zu der 30 Suchanfragen gehören. Bei einer automatischen Indexierung wurden annähernd 6000 Indexbegriffe ermittelt, und die durchschnittliche Anzahl der zu verarbeitenden Wörter in einer Suchanfrage beträgt ungefähr 10.Bei CISI handelt es sich um eine Sammlung von 1460 Abstracts aus dem informationswissen-schaftlichen Bereich zusammen mit 35 Suchanfragen. Eine Suchanfrage besteht hier im Mittel aus ungefähr 8 zu verarbeitenden Begriffen. Mit dieser Dokumentenbasis wurden für die Analyse der Retrieval Leistung zwei Durchläufe vollzogen, die sich in den verwendeten automatischen Indexierungsverfahren unterschieden. Dabei betrug die Anzahl der erfaßten Indexbegriffe beim ersten Analysedurchlauf 5135. Im zweiten Durchlauf wurde diese Zahl auf 5019 gesenkt. Dies geschah dadurch, daß Wörter auf ihre Stammformen reduziert wurden, was zur Folge hatte, daß einige der vorherigen Indexbegriffe wegfielen.Gemäß Deerwester et al. [1] ist die CISI-Dokumentensammlung schon immer als schwierig für automatische Text Retrieval Verfahren eingeschätzt worden, da es sich um eine recht homogene Zusammenstellung von Dokumenten handelt, die auf der Basis von Abstracts nur schwer unterscheidbar sind. Außerdem sind die zugehörigen Suchanfragen nur recht allgemein gehalten. Um die Retrieval Leistungen, die bei der Anwendung des Verfahrens des Latent Semantic
Indexing erzielt wurden, beurteilen zu können, wird ein Vergleich mit zwei anderen Text Retrieval Systemen vorgenommen, deren Leistungen ebenfalls anhand der MED und der CISI Dokumentensammlung gemessen wurden.
3.2.5 Untersuchungsergebnisse
Die Ergebnisse der Analyse der Retrieval Leistungen des LSI-Modells erscheinen erfolg-versprechend.So zeigt das LSI-Konzept hinsichtlich des erzielten Precision-Wertes angewandt auf die MED Dokumentensammlung eine bessere Leistung als die beiden Vergleichsverfahren. Allerdings gilt dies nur für die höheren Recall-Level. Warum die gemessene Precision von LSI bei den niedrigen Recall-Stufen so gering ist, führen Deerwester et al. zum einen darauf zurück, daß der Wert für die Precision bei allen verwendeten Retrievalverfahren bereits sehr gut war und damit eine weitere Verbesserung kaum noch möglich erscheint. Zum anderen argumentieren sie, daß ihr Konzept vor allem darauf ausgerichtet ist, mit Schwierigkeiten umzugehen, die aufgrund der Benutzung von Synonymen entstehen. Synonyme Begriffe stellen aber auf den unteren Recall-Stufen kaum ein Problem dar, da im Grunde jede Übereinstimmung von Begriffen zur Ausgabe eines relevanten Dokuments führt. Damit kommen die Vorteile des LSI-Konzepts – so die Autoren – erst bei höheren Recall-Level zum tragen, was durch das Untersuchungsergebnis dann auch bestätig wird. Zudem hat sich bei der Verarbeitung von Suchanfragen aus der MED Dokumentenbasis herausgestellt, daß eine Reduzierung der ursprünglichen annähernd 6000 Term-Dimensionen auf 100 LSI-Dimensionen optimal erscheint. So steigt die Retrievalleistung kontinuierlich an, indem man ausgehend von 10 LSI-Dimensionen immer weitere hinzunimmt, und fällt dann ab 100 LSI-Dimensionen wieder ab.

Text Retrieval 2, Sylvia Zotz 16
Bei der CISI Dokumentensammlung schließen alle verwendeten Retrieval Verfahren mehr oder weniger gleich schlecht ab. Dabei ist das Ergebnis der LSI-Methode im ersten Durchlauf, bei dem keine Reduzierung der Indexbegriffe auf die Stammformen vorgenommen worden war, sogar etwas schlechter als bei einem der beiden Vergleichsverfahren. Um ausschließen zu können, daß die Minderleistungen des LSI-Ansatzes nicht lediglich auf Unterschiede bei der automatischen Indexierung zurückzuführen sind, wird in einem zweiten Durchlauf – wie bei den Vergleichsverfahren bereits auch zuvor – die Indexbegriffmenge um Wörter mit gleichem Stamm vermindert. Dadurch kann eine leichte Verbesserung der Retrieval Leistung des LSI-Modells beobachtet werden. Es schließt nun genauso gut ab, wie das Vergleichsverfahren, das im ersten Durchlauf noch leicht überlegen war. Eine darüber hinausreichende Verbesserung ist allerdings nicht zu beobachten. Bei der CISI Dokumentensammlung zeigt sich damit jedoch, daß die Anwendung der Singulärwertzerlegung hier nicht mehr Nutzen erbringt, als die Verwendung der ursprünglichen Dokument-Term-Matrix. [1] Insgesamt wird durch die Untersuchungsergebnisse deutlich, daß das Konzept des 'Latent
Semantic Indexing' die Schwierigkeiten, die in Verbindung mit synonymen Begriffen auftreten, sehr gut lösen kann. Im Umgang mit mehrdeutigen Begriffen scheitert es hingegen1.
4 Fazit
Die vorliegende Arbeit setzt sich mit dem Thema Text Retrieval auseinander. Um einen Überblick über den Themenbereich zu geben, wird zunächst auf grundlegende Indexierungs-verfahren und verschiedene allgemeine Retrieval Modelle eingegangen. Anschließend werden die Probleme, die bei der Verarbeitung von Suchanfragen zu bewältigen sind, kurz skizziert und einige Maße zur Beurteilung der Qualität von Retrieval Systemen betrachtet. Der Schwerpunkt der Arbeit liegt jedoch auf der Vorstellung der Retrieval Konzepte von Deerwester et al. und von Moffat und Zobel. Während der Ansatz Self-Indexing inverted Files von Moffat und Zobel ein vollständiges Retrieval System beschreibt, stellt das Latent Semantic Indexing Verfahren von Deerwester et al. nur eine Komponente eines Retrieval Modells dar, welche der Vorverarbeitung von Suchanfragen dient. Entsprechend verschieden umfassend fallen die Qualitätsbeurteilungen der beiden Verfahren aus. Deerwester et al. beschränken sich darauf, ihr Konzept v.a. hinsichtlich der erzielten Precision-Werte mit anderen Retrieval Verfahren zu vergleichen. Themen wie Speicherplatzbedarf und Verarbeitungszeit werden nur sehr kurz angeschnitten. Es wird lediglich allgemein darauf hingewiesen, daß aufgrund der Arbeit mit einer reduzierten Matrix, Speicherkapazität eingespart werden kann, diese Einsparungen aber durch die hohe Verarbeitungszeit, die beim Vergleich des Suchanfragevektors mit allen Dokumentenvektoren nötig wird, wieder zunichte gemacht werden könnten. Genauere Berechnungen hierzu werden allerdings nicht durchgeführt, sondern es erfolgt lediglich die Einschätzung, daß dadurch eine Verwendung des Latent Semanic Indexing Ansatzes in seiner oben beschriebenen Form für große Dokumentensammlungen eher als ungeeignet erscheint. Moffat und Zobel stellen hingegen neben einer kurzen Betrachtung des Precision-Qualitätsmaßes sehr ausführliche Untersuchungen zum Speicherplatz- und Rechenzeitbedarf ihres Verfahrens an, und kommen zu dem Schluß, daß ihr Konzept den üblichen Retrieval Ansätzen in jeder Hinsicht vorzuziehen ist.
1 Deerwester et al. führen die Schwierigkeiten, die bei der Verarbeitung von mehrdeutigen Begriffen darauf zurück, daß bei ihrem Konzept jeder Begriff als ein einziger Punkt dargestellt wird. Ein Begriff, der aber mehrere verschiedene Bedeutungen besitzt, wird im Mittelpunkt seiner Bedeutungen plaziert. Damit kann es passieren, daß keine der eigentlichen Bedeutungen mehr diesem Durchschnittswert entspricht.

Text Retrieval 2, Sylvia Zotz 17
Bei der Beurteilung der beiden skizzierten Ansätze wurde jedoch nicht auf dieselben Dokumentensammlungen zurückgegriffen, so daß eine abschließende Beurteilung hinsichtlich der Überlegenheit eines der beiden Verfahren noch aussteht.
5 Literatur
[1] Scott C. Deerwester, Susan T. Dumais, Thomas K. Landauer, George W. Furnas, and Richard A. Harshman. Indexing by latent semantic analysis. JASIS, 41(6):391-407, 1990.
[2] Alistair Moffat and Justin Zobel. Self-indexing inverted files for fast text retrieval. ACM
Transactions on Information Systems, 14(4):349-379, 1996.
[3] Reginald Ferber. Information Retrieval - Suchmodelle und Data-Mining-Verfahren für
Textsammlungen und das Web. Dpunkt Verlag, 2003.
[4] Thomas Mandl. Tolerantes Information Retrieval - Neuronale Netze zur Erhöhung der
Adaptivität und Flexibilität bei der Informationssuche. Schriften zur Informationswissen-
schaft 39, Herausgegeben vom Hochschulverband für Informationswissenschaft (HI) e.V. Konstanz, 2001.
[5] Landauer, T.K., Foltz, P.W., & Laham. Introduction to Latent Semantic Analysis.
Discourse Processes, 25, 259-284, 1998.
[6] Norbert Fuhr. Information Retrieval. Skriptum zur Vorlesung im SS 06.http://www.is.informatik.uni-duisburg.de/courses/ir_ss06/folien/irskall.pdf (am 03.05.2006).
6 Abbildungsverzeichnis
Abbildung 1 Text Retrieval Prozeß................................................................................................2 Abbildung 2 Elementare Operationen im Booleschen Retrieval Modell.......................................4 Abbildung 3 Zweidimensionaler Term-Raum mit Suchanfrage und zwei Dokumenten..............5 Abbildung 4 Relevanz, Precision und Recall.................................................................................6 Abbildung 5 Self-Indexing Inverted File .......................................................................................8Abbildung 6 Reduktion der Ausgangsmatrix...............................................................................13

Seminar 1912
Multimedia-Datenbanken
Content Based Image Retrieval 2
Karsten Mende

Content Based Image Retrieval 2 Karsten Mende Seite: 1
Inhaltsverzeichnis
1 Einführung Bilddatenbanken...................................................................................................22 Beispiel für die Ermittlung gleicher / ähnlicher Formen in einer Formen-DB (Jagadish)......2
2.1 Form-Darstellung ............................................................................................................2 2.2 Speicherungsstrukturen ...................................................................................................3 2.3 Indexstrukturen................................................................................................................5 2.4 Query-Arten ....................................................................................................................6
2.4.1 Full-Match...............................................................................................................62.4.2 Match with shift ......................................................................................................7 2.4.3 Match with Uniform Scaling...................................................................................7 2.4.4 Match with Independent Scaling.............................................................................7 2.4.5 Approximate Match.................................................................................................7
2.5 Spezialfälle ......................................................................................................................7 2.5.1 Vielfache Repräsentationen.....................................................................................7 2.5.2 Unterschiedliche Anzahl Dimensionen...................................................................8
2.6 Testergebnisse .................................................................................................................9 2.7 Empfindlichkeitsreduktion ............................................................................................10 2.8 Höhere Dimensionen.....................................................................................................10 2.9 Ausblick ........................................................................................................................11
3 Beispiel für Farb-Queries unter Verwendung von Farb-Histogrammen (QBIC) .................11 3.1 Farb-Darstellung mittels Farb-Histogramm..................................................................11 3.2 Abstandsberechnung .....................................................................................................12 3.3 Speicherungsstrukturen .................................................................................................14 3.4 Indexstrukturen..............................................................................................................14 3.5 Query-Arten ..................................................................................................................14
3.5.1 Direct Query..........................................................................................................15 3.5.2 Query by example .................................................................................................15
3.6 Testergebnisse ...............................................................................................................15 3.7 Laufzeit-Testergebnisse ................................................................................................16 3.8 Schlußfolgerungen ........................................................................................................16
4 Fazit .......................................................................................................................................17 5 Literaturliste ..........................................................................................................................17

Content Based Image Retrieval 2 Karsten Mende Seite: 2
1 Einführung Bilddatenbanken Im Zuge der Digitalisierung von Bildern und Fotos und der Weiterentwicklung von Datenbank-Technologien sind weltweit viele große Bilddatenbanken entstanden.Mit herkömmlichen Index- und Suchmethoden, bei denen den Bildern Schlüsselwörter zugeordnet werden, die den Inhalt (grob) beschreiben, ist nur eine grobe Suche, die sich an den vergebenen Schlüsselwörtern orientieren muß, möglich. Werden z.B. Strandbilder gesucht und den entsprechenden Bildern ist aber nicht das Schlüsselwort „Strand“ zugeordnet worden, muß möglicherweise die Abfrage auf eine Kategorie „Urlaub“ eingeschränkt werden und Strandbilder, die nicht während eines Urlaubes entstanden sind, werden nicht gefunden.
Speziell Bilddatenbanken und auch allgemein Multimedia-Datenbanken haben normalerweise u.a. folgende Eigenschaften [FBF+94]:Objekte können relativ groß sein und es gibt viele Objekte. Updates sind jedoch selten. Die Anzahl der Merkmale jedes Objektes kann hoch sein, z.B. um die 100. Abstandsfunktionen müssen nicht unbedingt euklidisch sein, es können Wechselbeziehungen zwischen den Merkmalen bestehen. Die Anwender- und Abfrage-Schnittstellen sollten so visuell und intuitiv wie möglich gestaltet sein. Die Laufzeit der Abfragen sollte kurz sein, da die Multimedia-Datenbanken interaktiv benutzt werden.
In den beiden nachfolgend aufgeführten Beispielen von Bilddatenbanken erfolgt die Suche nicht über den Bildern zugeordneten Text-Attributen sondern über aus den Bildern berechneten Merkmalen. Nach diesen vorberechneten Merkmalen sind die Bilder indiziert und auffindbar. Diese Merkmale untersützen gut die o.g. visuelle Schnittstelle des Programms zum Anwender, der z.B. Farbmerkmale mittels einer Farbpalette auswählen kann oder für eine Vorlageskizze für die Abfrage ein Zeichentool verwenden kann. Dies hat den Vorteil, daß auch nach „unerwarteten“ Fragestellungen gesucht werden kann und nicht nur nach vorgegebenen Überschriften wie z.B. „Urlaubsbild“, „Auto“ oder „Bild mit viel Blau“. „Unerwartete“ Fragestellungen sind z.B. solche wie „Finde alle Bilder die gleich oder ähnlich einem vorgegebenen Bild sind“ oder die eine ähnliche Form, Struktur oder einen ähnlichen Farbverlauf haben. Solch eine Suche ist mit Textattributen natürlich nicht möglich.
2 Beispiel für die Ermittlung gleicher / ähnlicher Formen in einer Formen-DB (Jagadish)
In diesem Beispiel, entnommen aus [Jag91], geht es um eine Datenbank, in der 16.000 ausschließlich Computer-generierte Formen enthalten sind. Jede Form ist aus jeweils 10 verschiedenen zufällig generierten Rechtecken erstellt. Im folgenden wird vorgestellt, wie man gleiche oder ähnliche Formen in solch einer großen Formen-Datenbank findet bzw. ermittelt. Ein verwandtes - hier allerdings nicht behandeltes - Problem ist das Auffinden einer (Teil-)Form in einem großen Bild.
2.1 Form-Darstellung
In der Datenbank sind nur geradlinige, 2-dimensionale rechtwinklige Formen enthalten. Da eine allgemeine Form mittels Treppenstufen, die fein genug abgestuft sind, sehr gut angenähert werden kann, sind die vorgenannten Beschränkungen nicht zu strikt. Jede Form in der Datenbank besteht aus einer bestimmten Folge von Rechtecken. Diese Folge muß erstellt und berechnet werden, bevor eine Form in den Index aufgenommen werden kann. Eine Form wird beschrieben mittels der relativen Positionen der Rechtecke.

Content Based Image Retrieval 2 Karsten Mende Seite: 3
Es gibt 2 Methoden, wie die Formen erstellt bzw. abgedeckt werden können:
1. Additive rechteckige ÜberdeckungenJedes neu dazu kommende Rechteck R muß neue Bereiche überdecken, die Überdeckung wird mit jedem Rechteck größer. Es darf kein Rechteck geben, welches durch schon existierende Rechtecke komplett überdeckt wird.
2. Allgemeine rechteckige ÜberdeckungenAllgemeine rechteckige Überdeckungen erlauben Addition und Subtraktion von Rechtecken, Subtraktion wird als pixelweise Mengen – Differenz ausgeführt.
Für beide Methoden gibt es eine Vielzahl von Lösungen je Form. Es werden allerdings nur Rechtecke minimaler Größe zugelassen, also die Rechtecke dürfen nicht größer sein als zur Darstellung der Überdeckung unbedingt notwendig.Die Beschreibung der Objektmerkmale erfolgt sequentiell, die wichtigsten Merkmale (größten Rechtecke) stehen vorne. Jeder Abbruch der Merkmalsfolge stellt eine gute Annäherung dar. Der Grundgedanke dieses Vorgehens ist es, eine sequentielle Merkmalsfolge zu erhalten und dann irgendwann abzuschneiden. Ein geringer Fehler wird beim Abschneiden immer bleiben, aber Störfaktoren wie Dreckflecken werden dafür ausgeschlossen. Allgemeine rechteckige Überdeckungen sind prägnanter:
Bild 1: (a) rechteckiger Rahmen, (b) allgemeine rechteckige Überdeckung (c) additive rechteckige Überdeckung
Im Beispiel des zu überdeckenden Rahmens (a) müssen bei der allgemeinen rechteckigen Überdeckung (b) nur 2 Rechtecke für die Beschreibung verwendet werden anstatt mindestens 4 bei einer additiven rechteckigen Überdeckung (c). Die Berechnung ist allerdings etwas aufwendiger als bei der additiven rechteckigen Überdeckung.
2.2 Speicherungsstrukturen
Jedes Rechteck kann identifiziert werden durch die beiden Ecken unten links (L-Corner) und oben rechts (U-Corner). Jede Ecke hat eine X- und eine Y-Koordinate , pro Rechteck sind also 4 Koordinaten zu seiner Bestimmung notwendig. Für K Rechtecke sind also 4K Koordinaten erforderlich. Es werden einige Transformationen vorgenommen: Die Position des Rechtecks wird ausgedrückt durch die Mittelwerte der X und Y-Koordinaten der L-Corner und U-Corner:
2,
2ULUL yyxx

Content Based Image Retrieval 2 Karsten Mende Seite: 4
Die Größe des Rechtecks wird ausgedrückt durch die Längen der Seiten:
LULU yyxx ,
Die Position des 1. Rechtecks wird zur Normalisierung der Positionen der anderen Rechtecke genommen: Der Mittelpunkt des 1. Rechtecks stellt den Ursprung im Koordinatensystem dar. Bei allen anderen Rechtecken wird von ihren Positionswerten der Wert des neuen Ursprungs (nach dem alten Koordinatensystem) abgezogen. Von jeder X- und jeder Y-Koordinate wird also jeweils eine Konstante abgezogen. Außerdem wird die Größe des 1. Rechtecks zur Normalisierung der Größen und Positionen der folgenden Rechtecke verwendet: deren X- und Y-Größen- und Positionswerte werden durch die X- und Y-Größenwerte des 1. Rechtecks dividiert. Auf die normalisierten Größenwerte wird noch der natürliche Logarithmus angewendet.Eine Form, beschrieben durch eine Menge von K Rechtecken, wird gespeichert durch folgende Faktoren:1. Ein Paar von Verschiebungs-Faktoren für die X- und Y-Koordinaten (shift factors) 2. Einen Bereichs-Skalierungsfaktor (X-Größenwert mal Y-Größenwert des 1. Rechteckes, area
scale factor) 3. Einen Verzerrungsfaktor (Y-Skalierung geteilt durch X- Skalierung, distortion factor)
sowie für die K-1 letzten Rechtecke: 4. Ein Paar X,Y-Koordinaten für den Rechteck-Mittelpunkt nach Verschiebung und Skalierung 5. Ein Paar für die X- und Y-Längen nach Skalierung und Logarithmierung
Da aufgrund der Normalisierung die Position des Mittelpunktes des 1. Rechtecks der neue Ursprung ist und seine Größe (1,1) beträgt, werden diese Werte des 1. Rechtecks nicht gespeichert. Da die ersten Rechtecke die größten Rechtecke sind, sind in ihnen gleichzeitig auch die wichtigsten Informationen enthalten. Erfahrungswerte mit allen möglichen Formen haben ergeben, daß bereits bei nur 2 bis 5 indizierten Rechtecken die Treffermenge sehr klein wird. Nachfolgend sind verschiedene Beschreibungen für die gleiche Form am Beispiel der Zahl 5 dargestellt:
Originäre Form: Berechnete Form, Rechtecke 1 - 5:
Bild 2: Originäre Form und „Zwischenstand“ der berechneten Form nach 5 Rechtecken
Die Verschiebungsfaktoren und die Skalierungsfaktoren, insbesondere der Bereichsskalierungsfaktor beziehen sich auf die hier im Dokument dargestellte Größe der Form. Der Wert für den X-Skalierungsfaktor beträgt 3.6, für den Y-Skalierungsfaktor 0.9. Damit ergibt sich ein Bereichs-Skalierungsfaktor von 3.24.
5
1
4
3
2

Content Based Image Retrieval 2 Karsten Mende Seite: 5
Der Verzerrungsfaktor ergibt sich aus den X- und Y-Skalierungsfaktoren, ist jedoch unabhängig von der Größe der Darstellung der Form, da ihr Verhältnis bei veränderten Maßstäben gleich bleibt.Die Positions- und Größenwerte des 1. Rechtecks werden wie o.a. nicht explizit gespeichert.
Query-Form-Beschreibung bestehend aus o.g. Faktoren und z.B. 3 Rechtecken: [(-1.8,-4.45),(3.24),(0.25)](-0.08,-4.83,-0.40,0.29)(0.33,-3.67,-1.11,0.51)
Index-Form-Beschreibung bestehend aus o.g. Faktoren und 4 Rechtecken: [(-1.8,-4.45),(3.24),(0.25)](-0.08,-4.83,-0.40,0.29)(0.33,-3.67,-1.11,0.51)(-0.38,-1.50,-1.39,0.69)
Daten-Form-Beschreibung bestehend aus o.g. Faktoren und 10 Rechtecken [(-1.8,-4.45),(3.24),(0.25)](-0.08,-4.83,-0.40,0.29)(0.33,-3.67,-1.11,0.51)(-0.38,-1.50,-1.39,0.69)(-0.08,-2.33,-1.11,0.00)(…)(…)(…)(…)(…)
Der im Index gespeicherte Datensatz zur Form ist also schon abgeschnitten gegenüber dem in der Datenbank gespeicherten kompletten Satz. Die Query-Beschreibung der gleichen Form kann nochmals kürzer als der Datensatz im Index sein. Die Form-Beschreibung wurde hiermit umgewandelt in eine Koordinatenmenge für Punkte im 4K-dimensionalen Raum.
2.3 Indexstrukturen
Nun können beliebige Indexmethoden für mehrdimensionale Punktmengen verwendet werden, z.B. Grid-Files, k-d-B-Bäume, buddy trees, holy-brick-trees, z-Kurven usw. Im folgenden möchte ich den k-d-B-Baum als eine Kombination der Datenstrukturen k-d-Baum und B-Baum vorstellen, siehe auch [Sch99]. Ein k-d-B-Baum unterteilt einen Raum mit k-Dimensionen. Der k-d-B-Baum ist ein Vielweg-Suchbaum. Da die inneren Knoten nur Separatorfunktion haben, ähnelt er dem B+-Baum. Jeder Knoten entspricht einer Seite im Arbeitsspeicher bzw. einem Block im Sekundärspeicher. Somit kann die in einem DBS vorgegebene Seitenstruktur gut auf den k-d-B-Baum abgebildet werden. Jeder innere Knoten entspricht einer Indexseite und bildet einen Teilbaum des k-d-B-Baumes ab, der nach mehreren Attributen hintereinander verzweigt Außerdem enthält jeder innere Knoten eine Anzahl von Einträgen der Form (I,Z). Dabei steht Z für einen Zeiger auf einen Nachfolgerknoten und I für ein k-dimensionales Intervall (I0, I1,…,IK-1), das alle k-dimensionalen Intervalle des inneren Knotens, auf den Z zeigt, als Vereinigung enthält. Das Intervall I entspricht einer Region. Jeder Blattknoten enthält Indexeinträge k*, wobei sich jeder Eintrag auf einen Punkt bezieht. Zeigt Z auf einen Blattknoten, so enthält I alle Punkte die in der Seite des Blattknotens gespeichert sind.Für alle Blätter ist die Länge des Pfades von der Wurzel zu einem Blatt gleich. Der Baum ist also balanciert. Läuft beim Einfügen die Behälterregion einer Blattseite über, wird diese an einer geeigneten Stelle geteilt, sodaß eine gute Verteilung der Punktobjekte gewährleistet ist. Ein Überlauf einer Blattseite kann sich nach oben fortsetzen, wenn die entsprechende Verzeichnisseite bereits voll ist und kein zusätzliches Intervall aufnehmen kann. Die Verzeichnisseite wird dann auch geteilt, und zwar so daß eine gute Verteilung der zu speichernden Regionen auf die beiden neu entstehenden Regionen erfolgt.Eine Bereichssuche auf einem k-d-B-Baum gestaltet sich sehr einfach. Mit Hilfe eines k-dimensionalen Suchintervalls S wird rekursiv nach Einträgen (I,Z) gesucht, für die I S Øgilt. Ist dies für ein I der Fall und zeigt Z auf einen inneren Knoten, so wird dort weitergesucht.
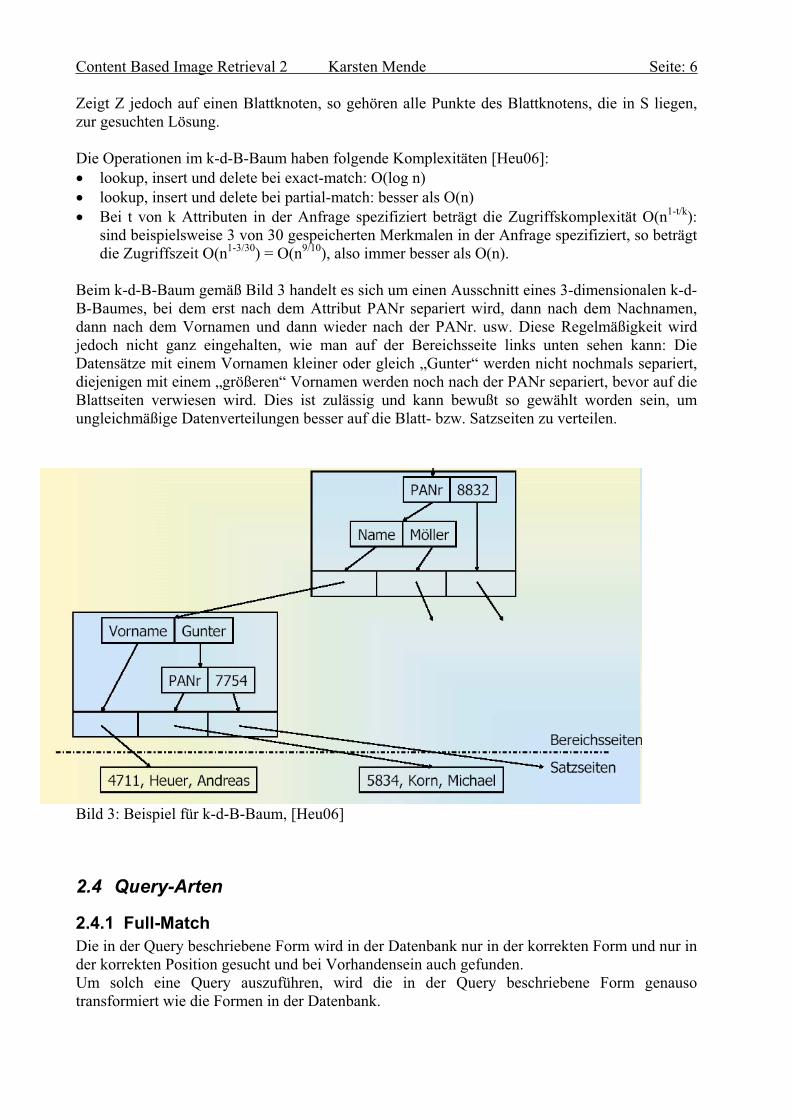
Content Based Image Retrieval 2 Karsten Mende Seite: 6
Zeigt Z jedoch auf einen Blattknoten, so gehören alle Punkte des Blattknotens, die in S liegen, zur gesuchten Lösung.
Die Operationen im k-d-B-Baum haben folgende Komplexitäten [Heu06]: lookup, insert und delete bei exact-match: O(log n) lookup, insert und delete bei partial-match: besser als O(n) Bei t von k Attributen in der Anfrage spezifiziert beträgt die Zugriffskomplexität O(n1-t/k):sind beispielsweise 3 von 30 gespeicherten Merkmalen in der Anfrage spezifiziert, so beträgt die Zugriffszeit O(n1-3/30) = O(n9/10), also immer besser als O(n).
Beim k-d-B-Baum gemäß Bild 3 handelt es sich um einen Ausschnitt eines 3-dimensionalen k-d-B-Baumes, bei dem erst nach dem Attribut PANr separiert wird, dann nach dem Nachnamen, dann nach dem Vornamen und dann wieder nach der PANr. usw. Diese Regelmäßigkeit wird jedoch nicht ganz eingehalten, wie man auf der Bereichsseite links unten sehen kann: Die Datensätze mit einem Vornamen kleiner oder gleich „Gunter“ werden nicht nochmals separiert, diejenigen mit einem „größeren“ Vornamen werden noch nach der PANr separiert, bevor auf die Blattseiten verwiesen wird. Dies ist zulässig und kann bewußt so gewählt worden sein, um ungleichmäßige Datenverteilungen besser auf die Blatt- bzw. Satzseiten zu verteilen.
Bild 3: Beispiel für k-d-B-Baum, [Heu06]
2.4 Query-Arten
2.4.1 Full-Match
Die in der Query beschriebene Form wird in der Datenbank nur in der korrekten Form und nur in der korrekten Position gesucht und bei Vorhandensein auch gefunden.Um solch eine Query auszuführen, wird die in der Query beschriebene Form genauso transformiert wie die Formen in der Datenbank.

Content Based Image Retrieval 2 Karsten Mende Seite: 7
2.4.2 Match with shift
Die gesuchte Form darf an jeder Position des Bildes sein: Die Shift-Faktor-Koordinaten – also eventuelle Verschiebungen - werden nicht berücksichtigt, die Query-Region wird auf ein unendliches Rechteck um den „Query-Point“ ausgeweitet.
2.4.3 Match with Uniform Scaling
Hier kommt es bei der Suche nur auf die vorgegebene Form an, Position und Größe sind egal.
2.4.4 Match with Independent Scaling
Hier wird zwar noch nach der vorgegebenen Form gesucht, aber neben beliebiger Position und Größe kann auch der Betrachtungswinkel beliebig sein.
2.4.5 Approximate Match
Um Objekte mit ähnlicher Form zu finden, muß man die Objekte suchen, die in allen Attributen (=Rechtecken) eine ähnliche Position und Größe haben. Hierfür kann man für jedes Attribut einen Bereich (um den durch die Query vorgegebenen Wert) festlegen.Je größer der Bereich, desto mehr wird natürlich das Suchkriterium aufgeweicht und desto größer ist die Treffermenge. In den meisten Anwendungen können hierfür globale Parameter spezifiziert werden, z.B. als eine vom Attributwert abhängige Funktion: hohe Attributwerte lassen höhere Bereiche / Abweichungen zu, niedrigere / kleinere Attributwerte entsprechend nur kleinere Abweichungen.
Eine andere Möglichkeit, ähnliche Formen zu selektieren ist folgende: Es werden nur die ersten x Rechtecke in der Query festgelegt, die übereinstimmen sollen. Hiermit kann man den Grad der Ähnlichkeit steuern.
Wann kann man das „Durchgehen“ durch die sequentielle Beschreibung und somit die Ähnlichkeitssuche beenden und ein Objekt als Treffer zählen? Hier gibt es 2 heuristische Verfahren:
1. Wenn die Error-Area klein genug wird, gemessen als Prozentsatz oder Teil von der gesamten Überdeckungsfläche bezogen von der Query-Form auf die gefundene Form.
2. Wenn das Fehlermaß, das vom nächsten hinzukommenden Rechteck korrigiert wird, klein genug ist, in bezug auf die gesamte Überdeckungsfläche oder wenn das nächste Rechteck selbst klein genug ist. Allerdings muß hierbei beachtet werden, daß es bei der allgemeinen Rechteck-Überdeckung möglich ist, daß der Fehler(grad) nicht monoton fällt!
2.5 Spezialfälle
2.5.1 Vielfache Repräsentationen
Ein Problem ergibt sich daraus, daß manche (ähnliche) Formen sehr verschiedene, sehr unterschiedliche sequentielle Beschreibungen haben können, die allerdings gleichwertig sind, beispielsweise bei den Buchstaben F und T, siehe Bild 4.
Das „T“ mit dem schmaleren senkrechten Balken (a) wird z.B. aus 2 additiven Rechtecken gebildet, wogegen das T mit dem breiten senkrechten Balken (b) aus 3 Rechtecken mittels allgemeiner rechteckiger Überdeckung gebildet wird: vom großen Quadrat (1.Rechteck) werden 2 schmale senkrechte Rechtecke abgezogen (2. und 3. Rechteck).

Content Based Image Retrieval 2 Karsten Mende Seite: 8
Auch die beiden ähnlichen „F“-Formen, einmal mit kürzerem unteren Balken (c) und einmal mit längerem unteren Balken (d) führen zu komplett unterschiedlichen Beschreibungen: (c) wird additiv aus 3 Rechtecken zusammengesetzt, (d) wird additiv und subtraktiv aus 4 ganz anderen Rechtecken zusammengesetzt.
Bild 4: Beispiele für ähnliche Formen mit sehr unterschiedlichen Beschreibungen
Eine „H“-Form ist noch problematischer: Der linke und rechte Balken sind normalerweise gleich groß. Welcher wird mit dem 1. Rechteck überdeckt und welcher mit dem zweiten? Glücklicherweise ist der noch bestehende Fehler bei beiden Beschreibungen gleich groß. Symmetrische Formen sind grundsätzlich problematisch: Die gleiche Form mit 2 verschiedenen sequentiellen Beschreibungen führt zu komplett unterschiedlichen Punkten im Attribut-Raum (4K-dimensionale Punkte) über den indiziert wird! Eine Lösung ist, alle verschiedenen Beschreibungen in der Datenbank , insbesondere im Index, zu behalten. Dies bläht natürlich die Datenbank auf. Eine bessere Lösung ist die, im ersten Schritt mehrere „gute“ sequentielle Bescheibungen zur gegebenen Query-Form zu erhalten, bzw. zu berechnen und im 2. Schritt eine Abfrage auf jede der erhaltenen Query-Beschreibungen auszuführen. Dies kann man z.B., indem man die Reihenfolge der Rechtecke der ersten Beschreibung so vertauscht, daß die Größen der Rechtecke immer noch eine annähernd monoton fallende Folge bilden. Hierbei erhöht sich zwar die Gesamt-Query-Laufzeit etwas, aber die Datenbank und ihre Index-Struktur muß nicht erweitert werden.
Darüberhinaus ist die Anzahl der verschiedenen sequentiellen Beschreibungen, die durchgerechnet und verglichen werden müssen, exponential zur Länge der Query-Beschreibung, die wahrscheinlich beträchtlich kürzer ist, als die Länge der vollen sequentiellen Beschreibung für die durch die Query vorgegebene Form und die Objekte in der Datenbank. In der Praxis ist die Anzahl typischerweise kleiner als der schon akzeptable worst case (bei der anfänglichen Berechnung nur auf Grundlage der kürzeren Query-Beschreibung).
2.5.2 Unterschiedliche Anzahl Dimensionen
Im allgemeinen muß die Anzahl der Dimensionen, also die Länge der sequentiellen Beschreibung eines gespeicherten Objektes nicht passen zur Anzahl der Dimensionen im Index. Wenn ein Objekt in der Datenbank eine längere Beschreibung hat, wird nur der erste Teil im Index genutzt. Das ist so üblich.

Content Based Image Retrieval 2 Karsten Mende Seite: 9
Es kann aber auch Ausnahmen geben, in denen die Anzahl der K gespeicherten Rechtecke der sequentiellen Beschreibung einer Form kleiner ist als die Anzahl k der im Index zu speichernden Rechtecke. Dann wird der entsprechende Index-Eintrag mit Dummy-Rechtecken aufgefüllt: Ein Größen-Parameter erhält den Wert 0, der andere Größenparameter wird als Bereich von – bis + , und die Positionsparameter als Bereiche von – bis + gespeichert, an Stelle von Einzelwerten.Folglich werden diese Objekte zu Hyper-Rechtecken im Attributraum und sind keine mehrdimensionalen Punkte mehr. Die meisten multi-dimensionalen Index-Strukturen können solche Hyper-Rechtecke zusätzlich zu mehrdimensionalen Punkten verwalten. Im Falle einer exakten Übereinstimmung funktioniert dies einwandfrei. Im Falle einer Ähnlichkeitsabfrage betrachten wir eine Query-Form, die einige zusätzliche Rechtecke hat: Wenn die Query-Form ähnlich dem betrachteten Objekt mit Dummy-Rechtecken aus der Datenbank ist, müssen diese zusätzlichen Rechtecke klein sein – sonst wäre ja keine Ähnlichkeit vorhanden – und deswegen muß für jedes zusätzliche Rechteck mindestens einer der beiden Größenparameter klein sein. Da bei der Ähnlichkeitssuche die Werte aufgeweicht und deren Bereiche erweitert werden, wird der kleinere Größenparameter jedes zusätzlichen Rechtecks auf einen Bereich zeigen, der Null enthält. Ohne Rücksicht auf den anderen Größenparameter und die Positionsparameter werden sie die Dummy-Rechtecke schneiden. Also funktioniert auch die Ähnlichkeitsabfrage mit den Dummy-Rechtecken.Umgekehrt kann die Methode mit den Dummy-Rechtecken auch bei kurzen Query-Formen verwendet werden um die Query-Form-Beschreibung zu verlängern. Alternativ könnten die anderen Attributachsen bzw. weiteren Rechtecke der Index-Beschreibung auch weggelassen werden, aber dann könnte man eine zu hohe Treffermenge bekommen. Wenn man die Query-Beschreibung mit Dummy-Rechtecken erweitert, stellt man ja sicher, daß in der Datenbank nur Beschreibungen gefunden werden, deren zusätzlichen Rechtecke klein sind und die damit ähnlich sind.
2.6 Testergebnisse
Für die folgenden Tests wurde eine Datenbank mit 16.000 synthetischen Objekten, jedes eine Mischung von 10 zufällig erstellten Rechtecken, aufgebaut. Für jede Form wurde eine sequentielle Beschreibung mittels additiver rechteckiger Überdeckungen erstellt und gespeichert. Folgende Ergebnisse wurden erzielt:
Wenn nach einer in der Datenbank gespeicherten Form gesucht wurde, wurde diese auch gefunden. Waren die Fehlertoleranzen klein eingestellt, so wurde auch nur diese eine gespeicherte Form gefunden. Wurde eine gespeicherte Form mit kleinen Störungen angefragt, so wurde diese ebenfalls gefunden. Waren hierbei die Fehlertoleranzen niedrig eingestellt, so wurde nur die gesuchte Form gefunden und keine weitere. Bei einer willkürlichen Form in der Query und niedrig eingestellten Fehlertoleranzen wurde nichts gefunden. Erst bei höher eingestellten Fehlertoleranzen stellten sich erste Treffer ein. Je mehr Parameter unberücksichtigt blieben, desto mehr Ähnlichkeits-Treffer erhielt man. Die willkürliche Form bestand aus 3 Rechtecken. Beim Versuch die Query aus 4 Rechtecken, also mit einem Dummy-Rechteck aufzubauen, wurden 3 von 4 Treffern wieder angezeigt.Tests mit 3 und 4 Rechtecken in der Anfrage haben ergeben, daß die meisten zurückgelieferten Formen gleich waren. Es besteht also keine Notwendigkeit, 4 Rechtecke in die Anfrage mit einzubeziehen.

Content Based Image Retrieval 2 Karsten Mende Seite: 10
Fazit:Die bei Ähnlichkeitsanfragen zurückgelieferten Formen waren tatsächlich in gewisser Weise ähnlich zur angefragten Form. Offen war jedoch, ob dies auch die am meisten ähnlichen Formen waren, die in der Datenbank enthalten waren. Dies bestätigte jedoch ein subjektiver Test: Zuerst wurden mit sehr lockeren Fehlertoleranzen die 40 „passendsten“ Formen zur o.g. willkürlichen Form herausgesucht. Dann suchte ein Mensch die 4 passendsten aus den 40 Formen heraus. Das waren die gleichen 4 Formen, die bei schärferen Fehlertoleranzen als Query-Ergebnisse geliefert wurden. Damit muß die Technik wohl auch erfolgreich aus den 16.000 Formen selektiert haben.
2.7 Empfindlichkeitsreduktion
Die bisher beschriebene Speicherungsstruktur berechnet die Größen und Positionen aller Rechtecke der Beschreibung mit Abstand zum 1. Rechteck. Folglich sind die gespeicherten Werte für Größen und Positionen eine Funktion der exakten Größe und Position des 1. Rechtecks.Wenn das 1. Rechteck einen großen Bereich überdeckt und das dominante Rechteck in der Beschreibung ist, ist diese Abhängigkeit akzeptabel und wünschenswert.Ist das 1. Rechteck jedoch lang und schmal, so können kleine Änderungen in der Breite dieses Rechtecks überproportional große Änderungen bei den gespeicherten Werten für Größe und Position der folgenden Rechtecke verursachen. Diese Empfindlichkeit kann unerwünscht sein.
Eine Lösung des Problems ist, die Größen und Positionen aller Rechtecke in bezug auf ein die ganze Form umgebendes Rechteck zu normalisieren. Vorteile dieser Lösung:
1. Die Empfindlichkeit von Änderungen mit Folgeänderungen ist aufgehoben 2. Man erhält eine natürliche Interpretation aller Größen und Positionswerte 3. Alle Rechtecke inklusive dem ersten werden in der gleichen Art behandelt, hieraus
resultiert eine Code-Vereinfachung Nachteile dieser Lösung:
1. Da nun auch die Werte für die ersten Rechtecke gespeichert werden müssen, wächst der Speicherplatzbedarf
2. Es entsteht ein höherer Indizierungsaufwand, da nun für gleiche Selektionsergebnisse 4 Dimensionen mehr berücksichtigt werden müssen
2.8 Höhere Dimensionen
Die bisher vorgestellten Techniken können auch auf 3 und mehr Dimensionen angewandt werden.Im 3-dimensionalen-Raum wird jedes Hyper-Rechteck (Quader) identifiziert durch 2 Eckpunkte, die 3-dimensional sind, also durch 6 Attribute pro Hyper-Rechteck. Das 1. Hyper-Rechteck (Größe X = 1, Größe Y = 1, Größe Z = 1, Position des Mittelpunktes im Ursprung) wird ersetzt durch:
- 3 Verschiebungsfaktoren - 1 Maßstabsfaktor - 2 Verzerrungsfaktoren (Y/X und Z/X – Verzerrungsrichtungen)
Jedes Folge-Rechteck wird beschrieben durch 3 Positionswerte (X, Y, Z) des Rechteck-Mittelpunktes und 3 Größen-Werte der Seitenlängen für jede Richtung, alle mit Abstand bzw. Beziehung zum 1. Rechteck.
Alle vorgestellten Ideen für den 2-dimensionalen Raum lassen sich mit geringen Änderungen auf den 3- oder mehrdimensionalen Raum übertragen.

Content Based Image Retrieval 2 Karsten Mende Seite: 11
2.9 Ausblick
Jagadish hat eine Index-Technik vorgestellt, mit der man aus einer Datenbank Formen ermitteln kann, die ähnlich oder gleich einer vorgegebenen Form sind. Mittels dieser Technik unter Benutzung angemessener Index-Strukturen kann der Prozeß auf einer Bild-Datenbank simuliert werden, wie ein Mensch ein Buch nach passenden vorgegebenen Bildern durchsucht. Auch bei Skalierungen und / oder Verschiebungen in einer oder mehreren Dimensionen funktioniert die Technik. Die Technik ist einfach und kann einfach „on top“ auf beliebige Standard Multi-Dimensions-Indizierungstechniken implementiert werden. Für Fließbandarbeiten und Anwendungen, in denen es nur darum geht, eine (Query-)Form gegen eine kleine Menge gespeicherter Formen zu testen, d.h. herauszufinden, ob die angefragte Form in der Menge enthalten ist, ist diese Technik zu aufwändig. In Anwendungen mit einer großen Anzahl von Bildern mit breit gefächerter Ausrichtung (Dimensionen) ist die vorgestellte Technik allerdings sehr wertvoll. Anwendungsbeispiele sind der Vergleich von Röntgenbildern ehemaliger Patienten mit dem Bild eines aktuellen Patienten oder Bildsuchen und Identifikationen in der Kriminalforschung.
3 Beispiel für Farb-Queries unter Verwendung von Farb-Histogrammen (QBIC)
Die QBIC-Studie [FBF+94] verbindet optische Anwendungen aus dem Bereich Muster-Erkennung mit Datenbank-Anwendungen. Sie ist beschränkt auf Bilddatenbanken. QBIC steht für „Query By Image Content.“ Die Ergebnisse, die die Suchtechniken liefern, sind den Vorgaben, d.h. den Query-Definitionen angenähert, liefern aber nicht nur exakte Treffer. Die QBIC-Techniken dienen also als Informationsfilter und reduzieren nur die Suche für den User, der aus der Treffermenge noch die falschen Kandidaten entfernen bzw. die richtigen auswählen muß. Im QBIC kann der User im Gegensatz zu den maschinellen optischen Anwendungen, bei denen nur zwischen einer kleinen Anzahl vordefinierter Objektklassen unterschieden werden kann, unendlich viele unvorhersehbare Queries stellen.Mögliche Anwendungsgebiete der QBIC-Techniken sind Edutainment (spielerisches Lernen), Journalismus, Katalogisierung in Museen, Medizin, Militär etc. Eine große Herausforderung ist die Bestimmung von Merkmalen, die gleichzeitig - den Inhalt eines Bildes beschreiben - ein Ähnlichkeitsmaß oder eine Metrik zulassen - die Basis eines Indexes für die Bildsammlung bilden können.
3.1 Farb-Darstellung mittels Farb-Histogramm
Mit den verwendeten Farb-Merkmalen und der verwendeten Abstandsfunktion wird versucht, die Art von Ähnlichkeit zu erzeugen, die auch ein Mensch wahrnimmt. Für jedes Objekt und jede Szene wird ein K-elementiges Farb-Histogramm berechnet. K kann theoretisch bis zu 16 Mio Farben haben, jede Farbe wird gekennzeichnet durch einen Punkt in einem 3-dimensionalen Farbraum. Ähnliche Farben werden geclustert und es wird eine repräsentative Farbe für jeden Behälter (color bin) ausgewählt. In den Experimenten wurden K = 256 und K = 64 Farbcluster getestet. Jede Komponente im Farbhistogramm ist der Prozentsatz an Pixeln, die am ähnlichsten der repräsentativen Cluster-Farbe sind. Jedes Histogramm wird repräsentiert durch einen K x 1 – Vektor.

Content Based Image Retrieval 2 Karsten Mende Seite: 12
3.2 Abstandsberechnung
Wenn die o.g. Histogramme berechnet sind, gibt es eine Vielzahl von Möglich-keiten, wie Ähnlichkeit zwischen 2 Farbhistogrammen berechnet werden kann.Eine Methode, den Abstand zwischen 2 Histogrammen x und y zu berechnen ist:
jjii
K
i
K
j
ij
t
hist yxyxayxAyxyxd ,2 (1)
Die Matrix A beschreibt mit ihren Einträgen aij die Ähnlichkeit zwischen den (Cluster-)Farben i und j. Der Einsatz dieser Formel bringt wünschenswerte Ergebnisse. So kann z.B. korrekt errechnet werden, daß orange Bilder ähnlich roten Bildern sind, aber daß zur Hälfte rot und zur Hälfte blaue Bilder sehr unterschiedlich von komplett lilafarbenen Bildern sind.Der euklidische Abstand ist ein Spezialfall des Abstandes der o.g. Formel, bei dem die Matrix A die identische Matrix (I) ist. Der Haupt-Unterschied zwischen dem Euklidischen Abstand und dem Abstand nach Gleichung (1) ist, daß Gleichung (1) die Wechselbeziehung zwischen 2 Farben ,wie z.B. orange und rot, berücksichtigt, und zwar indem auch gemischte Terme in die Berechung mit einfliessen: aij(xi-yi)(xj-yj) mit i j sind auch enthalten. Der euklidische Abstand enthält diese gemischten Terme nicht und berücksichtigt solche Wechselbeziehungen damit auch nicht. Im allgemeinen werden solche Phänomene jedoch nicht in Datenbanken berücksichtigt: Alle Multi-key-Index-Methoden gehen implizit von der Annahme aus, daß solche Wechselbeziehungen nicht bestehen und können daher für die Gleichung (1) nicht verwendet werden. Dies stellt ein großes Hindernis dar. Darüberhinaus ist die Berechnung von kompletten quadratischen Gleichungen inkl. der gemischten Glieder teurer als von Gleichungen wie beim euklidischen Abstand. Ein weiteres Problem ist, daß die Anzahl n der Merkmale sehr hoch werden kann, z.B. 64 oder sogar 256 Farb-Merkmale wurden getestet, und daß die meisten multi-dimensionalen Indexmethoden Speicherplatz und CPU-Rechenzeit benötigen, die exponential zu n steigen.
QBIC bietet Lösungen für alle vorgenannten Probleme an. Die Grundidee der Lösungen ist die Verwendung eines Filters, der „einige“ falsche Treffer erlaubt, aber keine echten Treffer
auslässt. Das Ziel ist also, eine Mapping-Funktion f mit )(' XfX zu finden, welche den
Merkmalsvektor X auf einen Vektor 'X abbildet, der eine niedrigere Dimension hat. Diese Mapping-Funktion f muß im Zusammenhang mit einer Abstandsfunktion D () stehen, die den
tatsächlichen Abstand „unterschätzt“ im Sinne von niedriger einschätzt:
YXDYXD ,','' (2)
Eine Operation, die bei Benutzung eines euklidischen Abstands solche Eigenschaften hat, ist z.B. die Projektion von 3-dimensionalen Punkten in die 2-dimensionale x-y-Ebene, durch Abschneiden (truncate) der z-Koordinate. Die obige Ungleichung soll Gültigkeit haben, damit eine Bereichsquery keine echten Treffer ausläßt. Mit der o.g. Ungleichung ist sichergestellt, dass
ein Merkmalsvektor X , der in einer -Umgebung von einem Anfrage-Vektor Q liegt, auch im
Filterungsschritt gefunden wird. Wenn eine Anfrage also lautet „Finde alle Merkmalsvektoren
X , die innerhalb einer -Umgebung vom Anfragevektor Q liegen“, dann läuft die Suche in
solch einem Fall wie folgt ab:
1. Die Funktion f muß alle Merkmalsvektoren X auf Merkmalsvektoren 'X mappen oder im
Rahmen von Vorabberechnungen bereits gemappt haben.
2. Es werden – in einem niedriger dimensionierten Raum - alle Merkmalsvektoren 'X gesucht,
die der Ungleichung ','' QXD genügen.

Content Based Image Retrieval 2 Karsten Mende Seite: 13
3. Im letzten Schritt werden dann die unter 2. gefundenen Kandidaten 'X mit '1 Xf
„zurückgemappt“ auf Vektoren X , die mittels der quadratischen Abstandsberechnung aus Gleichung (1) überprüft werden und es werden die endgültigen Treffer festgestellt.
Das „Zurückmappen“ geschieht dadurch, daß die Vektoren 'X im Index auf die zugehörigen
Vektoren X in der Datenbank verweisen. Der Schlüssel für effizientes Suchen von (Farb-)Bildern, welches auf deren kompletten Farb-Histogrammen beruht, ist eine effiziente Annäherung an dhist, des Histogramm-Farbabstandes wie in Gleichung 1 definiert. Diese effiziente Annäherung wird im QBIC-Projekt berechnet durch eine Abschätzung nach unten durch
yxdavg ,
des durchschnittlichen Farbabstandes von zwei Objekten (Objekte im allgemeinen Sinne), und zwar einem Vielfachen davon. davg ist auf einem anderen wesentlich kleiner dimensionierten Farbmerkmal definiert als dhist des Farb-Histogramms, und zwar auf der Durchschnittsfarbe x eines Bildes, die sich aus den durchschnittlichen Rot-, Grün- und Blau-Farbanteilen aller Pixel des Bildes errechnet. Damit wird die Dimension von z.B. K=64 eines Farbhistogramms auf 3 für die zugehörige Durchschnittsfarbe gesenkt! Der durchschnittliche Farb-Vektor beispielsweise einer Szene mit 50% blauem Himmel und 50% grünem Rasen wäre als RGB-Vektor in Prozenten (0,50,50) oder als RGB-Vektor in Farbtiefendarstellung bei z.B. 8 bit (0,127,127). Wenn nun die Durchschnittsfarben x und y von 2 Bildern / Objekten errechnet sind, wird davg
als einfacher euklidischer Abstand zwischen den beiden 3-dimensionalen Vektoren der Durchschnittsfarben errechnet:
)(,2 yxyxyxdt
avg
Im Rahmen der Dokumentation des QBIC-Projektes wird mathematisch nachgewiesen, daß dhist k*davg gilt. Genauer:
2histd 1
2avgd
mit 1 als minimalem Eigenwert des verallgemeinertem Eigenwertproblems
zA~~zW~~
Hierbei ist A~
eine aus der Ähnlichkeitsmatrix A abgeleitete Matrix, W~
ist aus W abgeleitet, einer Matrix, die die Skalarprodukte der Clusterfarben der zu vergleichenden Objekte auf RGB-Basis enthält. Damit ist eine Unter-Schätzung gefunden, die die o.g. erwünschte Obermenge von Objekten liefert und damit auch die oben gesuchte Abstandsfunktion D (). Die davg-Funktion ist wesentlich billiger zu berechnen als dhist, sowohl in bezug auf die CPU-Zeit als auch auf die benötigten Festplatten-Zugriffe.Ganz entscheidend ist jedoch, daß davg als Skalarprodukt zweier Vektoren, bei dem keine Wechselwirkungen der unterschiedlichen Komponenten mit einfließen (nur Komponenten xiyi,aber nicht xiyj), die Verwendung von multidimensionalen-Indexmethoden ermöglicht.
Dies bedeutet, daß die Vektoren 'X indiziert werden müssen und nicht die Vektoren X ! Dies
wiederum bedeutet, daß ein Vektor X eines Farbhistogramms vor Indizierung auf den
entsprechenden Vektor 'X gemappt werden muß, der dann im Index enthalten ist und auf den
gespeicherten Vektor X des Farbhistogramms verweist.

Content Based Image Retrieval 2 Karsten Mende Seite: 14
3.3 Speicherungsstrukturen
Es wurden 2 neue Datentypen eingeführt: - Szene = komplettes Farbbild - Objekt = Teil einer Szene, z.B eine Person auf einem Strandbild
Die unter 3.2 beschriebenen Methoden erfordern, dass jedem Objekt und jeder Szene / Bild ein Merkmalsvektor zugeordnet wird. Diese (K x 1)-Merkmalsvektoren enthalten die gespeicherten Farb-Merkmale zu einer Szene bzw. zu einem Objekt mit den Clusterfarben des zugehörigen Farb-Histogramms. Um die Performance zu steigern, werden diese Merkmalsvektoren vorberechnet und gespeichert. Jeder Merkmalsvektor wird als ein Punkt im n-dimensionalen (bzw. hier: K-dimensionalen) Raum betrachtet.
Gleichfalls gespeichert werden müssen die korrespondierenden Vektoren 'X der Durchschnittsfarben, allerdings nur als 3-dimensionale Vektoren und nur in der zugehörigen Indexstruktur.
3.4 Indexstrukturen
Um multi-dimensionale Indexmethoden nutzen zu können, müssen die „Abstände“ zweier Objekte zum Euklidischen Abstand ihrer Punkte im Merkmalsraum korrespondieren / übereinstimmen. Außerdem muß die Dimensionalität des Merkmalsraums niedrig genug sein.
QBIC benötigt eine multidimensionale-Index-Methode, die maßgeblichen Methoden sind: - R*-Bäume bzw. R-Bäume - Linear quadtrees - Grid-files Bei linearen quadtrees und Grid files steigt der Aufwand exponentiell mit den Dimensionen.
Nur die R-Bäume sind robuster für höhere Dimensionen, vorausgesetzt, der Verzweigungsgrad der Knoten ist größer als 2. Experimente zeigen, daß R-Bäume bis mindestens 20 Dimensionen zuverlässig funktionieren. Die erfolgreichste, weil schnellste Variante ist der R*-Baum, der daher im QBIC-Projekt verwendet wird.
3.5 Query-Arten
Die User können für Szenen auf die Merkmale Farbe und Struktur, für Objekte auf die Merkmale Farbe, Form und Struktur abfragen. Kombinationen von Merkmalen in der Abfrage sind zulässig. QBIC unterstützt 2 Query-Arten, beide fragen auf Ähnlichkeit ab und liefern damit neben den gesuchten richtigen Treffern auch falsche Treffer. Nicht genauer in der QBIC-Studie beschrieben ist ein Ähnlichkeitsmaß, das wohl auch vom Anwender eingestellt werden kann und somit vorab die Anzahl der im Query-Ergebnis vorgeschlagenen Kandidaten einschränkt. Siehe dazu auch
Kapitel „3.2 Abstandsberechnung“: Berechnung aller Merkmalsvektoren X , die innerhalb einer
-Umgebung vom Anfragevektor Q liegen.

Content Based Image Retrieval 2 Karsten Mende Seite: 15
3.5.1 Direct Query
Der Anwender spezifiziert die gewünschte Farbverteilung, Form und Struktur direkt über Eingabemechanismen auf der grafischen Oberfläche, wie z.B. über einen multi-color-picker oder indem er eine Skizze mit der Maus zeichnet. Wenn der User beispielsweise ein Strandbild sucht, kann er in der Query eine Farbverteilung von 35% weißer und 65% blauer Bereichsüberdeckung angeben und zusätzlich noch sandigen Untergrund als Struktur beschreiben. Die Ergebnisse werden Bilder mit Strandszenen aber auch falsche Treffer sein, die eine entsprechende Farbverteilung und / oder Struktur haben. Im Normalfall ist es kein Problem für den Anwender, die falschen Treffer von den echten zu unterscheiden und auszusortieren, solange die Query nicht zu viele Treffer liefert.
3.5.2 Query by example
Der Anwender kann eins der aus der Datenbank angezeigten Bilder auswählen und die Datenbank nach ähnlichen Bildern anfragen.
Nicht in der QBIC-Studie erwähnt und wohl auch nicht getestet, ist eine Query, die ein Bild vorgibt und auf Enthaltensein des Bildes in der Datenbank abfragt.Für solch ein Bild müßte bei der Query-Ausführung das zugehörige Farbhistogrammm sowie der zugehörige Vektor der 3 RGB-Durchschnittsfarben errechnet werden. Außerdem würde der Farbabstand dhist auf 0 gesetzt. Ist das vorgegebene Bild enthalten, so wird es in jedem Fall gefunden. In seltenen Fällen würden auch noch weitere Bilder angezeigt werden, und zwar genau dann, wenn sie genau die gleichen Farbhistogramme hätten. Es können ja unterschiedliche Pixel-Formationen zu den gleichen prozentualen Verteilungen der K Clusterfarben führen.
3.6 Testergebnisse
Die verwendete Testdatenbank enthielt 1000 Farbbilder. Der Multicolor Farb-Picker enthält 64 Grundfarben. Eine Query kann bis zu 5 Farben enthalten, zusammen mit ihren relativen Prozentsätzen bezogen auf alle Pixel. Es wurden 10 Testbilder aus der Testdatenbank für 10 verschiedene Queries vorab von den Testern ausgewählt. Für jede Query wurden als Ergebnis 20 Bilder angezeigt. Für alle Queries galt: die meisten der relevanten Bilder – also mit ähnlichen Farbzusammensetzungen wie angefragt – wurden angezeigt und waren auch in vorderen Positionen in der Trefferliste. Insgesamt wurden nur 3 von 72 relevanten Bildern in den 10 Testqueries nicht angezeigt. Über alle Ergebnis-Positionen der relevanten Bilder in den Trefferlisten gemittelt, ergab sich ein durchschnittlicher Wert von 5,4 - also an der 6. Position - eines relevanten Bildes, da der ersten Position der Wert 0 zugeordnet wurde. Der optimale durchschnittliche Wert hätte bei 2,8 gelegen, also an der 4. Position. Die vorgegebenen Testbilder aus der Datenbank wurden alle gefunden und im Durchschnitt an der 2. Position (Durchschnittswert 1,1) angezeigt. Diese Testergebnisse zeigen, daß sowohl die Farbmerkmale als auch die Abstandsfunktion sehr effektiv sind. Ein weiteres Ergebnis war, daß der Multicolor Farb-Picker sehr einfach von den menschlichen Testern zu bedienen war und die Tester sehr einfach die falschen Treffer aus den 20 Ergebnissen der Trefferlisten aussortieren konnten.Bild-Datenbanken inkl. ihrer Tools sollten also für die menschliche Wahrnehmung optimiert werden, dann können sie von der menschlichen Fähigkeit profitieren, die schnell die angezeigten Bild-Treffermengen überfliegen und falsche Treffer aussortieren kann.

Content Based Image Retrieval 2 Karsten Mende Seite: 16
3.7 Laufzeit-Testergebnisse
Bei den Laufzeitexperimenten wurden 2 Methoden gegeneinander verglichen:
1. Eine einfache sequentielle Berechnung von dhist von allen Merkmalsvektoren in der
Datenbank zum Anfragevektor Q
2. Ein Filterungsschritt, der für alle Merkmals-Vektoren in der Datenbank davg zum
Anfragevektor Q berechnet und danach auf die besten x Prozent der gefundenen
Merkmalsvektoren dhist anwendet Es wurden absichtlich keine Indexmethoden verwendet, um so die Performance-Gewinne des Filterungsschrittes herauszustellen. Zuerst wurde die Selektivität des Filterungsschrittes getestet. Im Idealfall würde der Filterungsschritt nur bzw. genau die Vektoren ermitteln, die dhist erfüllen. Durch die Definition von davg ist sichergestellt, daß diese Vektoren auf jeden Fall alle gefunden werden, sowie auch noch weitere „falsche Treffer“. Die Testdatenbank enthielt 924 Farbbilder, zu denen 256 elementige Farbhistogramme errechnet wurden. Die Testergebnisse waren durchweg sehr positiv. Bei einer eingestellten Ziel-Treffermenge von 5% bezogen auf dhist, selektierte der Filterungsschritt 30% der Datensätze der Datenbank. Das bedeutete also, daß für 70% der Datensätze nicht die aufwendige Berechnung von dhist
durchgeführt werden mußte. Dies bedeutete erhebliche Laufzeitgewinne, denn selbst die Berechnung von dhist für nur wenige Vektoren ist sehr hoch verglichen mit dem auf die ganze Datenbank angewendeten Filterungsschritt. Bei (dem Testfall) einer eingestellten Ziel-Treffermenge von nur 1 % - welches ja einer typischen Query noch näher kommt - betrug die Selektivität sogar nur ca 11% aller Datensätze.
Im 2. Schritt wurden die relativen Kosten der beiden Berechnungsmethoden verglichen. Selbst bei worst case – Annahmen schlägt die 2. Methode mit dem Filterungsschritt klar die 1. Methode mit der sequentiellen Berechnung von dhist für alle Datensätze der Datenbank. Da die Laufzeit und auch die benötigte CPU-Zeit bei der sequentiellen Methode immer gleich (schlecht) sind, wachsen die Vorteile der Filterungsschritt-Methode mit kleiner werdender Treffermenge noch an. Doch selbst bei einer relativ hoch eingestellten Ziel-Treffermenge von 5% liegt die benötigte CPU-Zeit nur bei einem Viertel der sequentiellen Methode und auch die Query-Laufzeit beträgt nur gut 40% verglichen mit der sequentiellen Methode.
Diese Ergebnisse der Filterungsmethode sind umso herausragender, als daß die Vorteile eines möglichen indizierten Suchens noch gar nicht ausgeschöpft wurden.
3.8 Schlußfolgerungen
Das QBIC-Projekt hat sein Ziel erreicht, wirksame und leistungsfähige Abfragentechniken zu liefern, die sich auf den Inhalt von Bildern – und nicht ihnen zugeordneten Textattributen – in großen Bilddatenbanken beziehen.
Viele Merkmale und Ähnlichkeitsfunktionen aus dem Bereich der maschinellen Bildererkennung wurden mit schnellen Indexierungstechniken aus dem Datenbankbereich verknüpft. Hierin lag der Schlüssel des Erfolges. Die Antwortzeiten waren erheblich besser als die trivialer Methoden, außerdem können die Merkmale und Ähnlichkeitsfunktionen auch für noch größere Datenbanken gut skaliert bzw. erweitert werden, aufgrund der verwendeten multi-key-Indzierungstechniken.

Content Based Image Retrieval 2 Karsten Mende Seite: 17
4 Fazit Schon beim Aufbau einer Multimedia-DB muß man wissen, welche Kategorien von Daten wie z.B. Bilder, Zeichnungen, Formen, Videos, Sounds gespeichert werden sollen. Außerdem sollte bekannt sein, welche Arten von Anfragen an die gespeicherten Daten zukünftig gestellt werden, wie z.B „Finde alle Bilder, die eine ähnliche Farbzusammenstellung wie ein vorgegebenes Bild haben“. Nur so können für die gespeicherten Daten Merkmale festgestellt und berechnet werden, die dann den Merkmalen in der Query-Formulierung entsprechen. Diese Merkmale werden idealerweise vorab, z.B. zum Zeitpunkt der Speicherung der Daten, berechnet und nicht erst zur Laufzeit einer Query. Die berechneten Merkmale werden natürlich mit den Daten gespeichert. Sie sind auch Grundlage und Bestandteil für die zu verwendenden Indexstrukturen. Aus der Art der Indexstrukturen und der in ihnen gespeicherten Daten ergibt sich wiederum, wie die Anfragen intern umgeformt werden müssen. Die allumfassende beste Lösung gibt es nicht, es ist jeweils von den zu speichernden Daten, den zu erwartenden Anfragen und auch der Änderungshäufigkeit der Daten abhängig, wie die Daten gespeichert und indiziert werden sollten.Content-based-Image-Retrieval-Methoden bieten Abfragemöglichkeiten wie die Suche nach ganz bestimmten Bildern, die genau so oder so ähnlich wie ein vorgegebenes Bild aussehen. Dies ist für den Anwender sehr komfortabel und eine Funktionalität, die es bei der reinen Schlüsselwort-Zuordnung zu Bildern gar nicht gibt.Allerdings sind hierfür umfangreiche (Vor-)Berechnungen erforderlich. Bei Updates entsteht höherer Aufwand für die Anpassung eines Multi-key-Indexes als bei herkömmlichen Indizes. Der letzte Teilschritt einer Selektion muß ggf. durch den Anwender erfolgen: Entfernung falscher Treffer aus der Ergebnismenge. Eine Menge von Bildern / Szenen mit völlig unterschiedlichen Inhalten, die vielleicht aufgrund der zeitlichen Abfolge ihres Entstehens zusammengehören oder vom gleichen Maler oder Fotograf stammen, kann allerdings nicht über die o.g. berechneten inhaltsbasierten Merkmale gefunden werden: Für eine Abfrage nach einer Urlaubsfotoserie, zu der z.B. neben Strandbildern auch Bilder von Bauwerken oder Innenräumen mit komplett anderen Farbverläufen gehören können, wäre ein Textmerkmal „Urlaub2005“ o.ä. an den zugehörigen Bildern unabdingbar. Meiner Meinung nach ist eine Kombination aus vorberechneten Merkmalen – wie in den beiden Beispielen von Jagadish und dem QBIC-Experiment gezeigt – mit den Bildern zugeordneten Überschriften sinnvoll. Hiermit erreicht man eine hohe Anzahl verschiedenster Anfragemöglichkeiten, die meiner Meinung nach einen Aufbau verschiedener Indexstrukturen für vorberechnete Merkmale einerseits und für Überschriften und Schlagworte andererseits rechtfertigt. Geht man von annähernd statischen Datenbanken aus, ist der Aufwand für die Indexpflege minimal.
5 Literaturliste
[Jag91] H.V. Jagadish. A retrieval technique for similar shapes. In James Clifford and Roger King, editors, SIGMOD Conference, pages 208-217. ACM Press. 1991.
[FBF+94] Christos Faloutsos, Ron Barber, Myron Flickner, Jim Hafner , Wayne Niblack, Dragutin Petkovic and William Equitz. Efficient and effective querying by image content. J.Intell. Inf. Syst., 3(3/4): pages 231-262, 1994
[Sch99] Markus Schneider. Implementierungskonzepte für Datenbanksysteme, Kurs 1664, Kurseinheit 2, Seiten 91-93, FernUniversität Hagen 1999
[Heu06] Prof. Dr. Andreas Heurer, Lehrstuhl Datenbank- und Informationssysteme, Institut für Informatik, Universität Rostock, Vorlesung SS 2006, Kapitel 4, Folien 74-79

!

! "# $
$%&''( )* $$ $
$&'' $$' +
$(# +$* ,$ %-"% ,
$$() ,$$.)/ ,$$)/ 0$$$#) )& 0
+1#-)# 0+23- 0
+ #4# 0+(5-- #6 +$ ++75 +, "#-%
+(# +$ %8)#19% :++) :
++ #4# :++(5-- #6 ;++$ ;+++75 ;+, "#-% ;+0 -2% ;
,#-%=*-5 4#&? @,#-% @
,=* @,3 @
,A-B ,$&??-1 ,+ %&#-&- ,,)
0(-A3 $0# $0%- $0$B +0+-2% +0,)C-A3 ,
7 0

-&#- --#'#"-=5-& D##--8-"#-A5-#3 )5?##3E#"##-?"6=B3 -6-)34)#CFA?G--"#A-#4#?##6) )E E#3 1#A#C3-) )*A-AE##3---#)/
H-&##-3)6*)3-)-1--6-B3 )3--A #-#-5- 3-?)3--(#
2) 6-3-3-7-(#-#.3--I#-2 6-E5)*I #"-)"% 66#3-3-- )-)5-#-4#?A--3-2-"3-A#"-)5-FEG#--)"3'*#-&"* ##- )-3-)7"
& -#% 6-"%)3-A
#6--&J-3
75--#3#"--3
%--)#- #)3E-
C--2)3- E5-3- 6))I--3K)(A&# ##6-&J-33---4#3-

$
"$&#E#"##-*E#"#)-(3-)#3#*)""$*#?-#.-"$-)&#"##?)#C- )6
-!###* )#-?2"$3--)- 6)#-##- 6"*"-I-)-*)--.)5#3-E#-(#(# #%- --) )-#A-(-#-
!""#$ %&7#L##MN%#- /- 4#&''F&J%'"'#G-?*6 ))-F*#*G3-#-7-5- &##3-6*-7-#A#)3-
))-
H-"3-- #,& /-3--+@&'E#)#-3$-$@)3-*3--'F)$G0'--- -MN
!""
* &''#3-#-"--""#"&#))-*-A-3# #6-2"%&JF4G)3-3-- --"- #6&J5A# 6-3J3-#""3--- #-#""##"-3-*&'E#---)-26--B"-)&''6%#3-3-MN*D'"=-I#"-)-A-'"-"

+
))-
&''3-5C)-MN
*3- )""-&*-3-26-3-#/& #F#-G))?-"%3--(-E%)
& /-&3-&# ##- *-3--#&J#"#-#-&J-"-)5&J"--"--/3&J
*"3-#--"--755#
*3--E#"##A5FA+@G-5C-#--FA#&J--A5#6CG--*/A5
*E#"#-#-3-*##-'# ###*-3--!3(#-)'"E#3-3 )
"
& /-&5&'E#*3- - 52""?24#)-26C-(-A5-'1)-#)F?##G#-F?G-M$N8-&''!-#3-K)#A'3-)--!- 3--'---"-E#--23))--M$N?#-&3-0'MN
$
& /-7-3-)-"K))-C637-3-I-)-#4#-A53-

,
&
*A-)-# )*F#O*GM$N-- ------6#*)-/-)-)63---#-4-76
*)- #3
-
3 E#- 23-' -)-)
3-- -E)7)MN*23)#3-3--)--& --E# -K) #!93-)#
**3--)
' (
=-BC )" 3-*) ):@@@ --3-8-7-2D- -)--E )& /- 3--3#))))*3--)-37-A)7-3--D5 "% )
$ %
2-$))-37-))##C3--)-3 M)+N7-)#5*- )#?"--)#)
*)-)3-;-;&''- *)- 3#);&''-))
)%*+
*#)/)3A-#)/#-C- 3?##I )-5
7#-##3-- $?"-)M)+N& )7-3---"% )5,@-@7-- )" K)0@P- -"%"--7-A ?"-)--)3 )---5,7-)3@:-?")3)-

0
%*+
*)/3-4# - @5357--# %"%)3M)+$N*)3-+@,@P-"%7-5))57-+P*7- %#-@6)53
+%%!
H -#)-)-3-7-5 #)$@-75---)?@@P-&53--5-.-57- 7-M)+$N
, -(% ILA##L4LALI###M+N537#L##&'')/-#)----7-3#3-#-#) ))#- 3-
,./(
*1#----*---(#6C*)6* #353--66*3-*3-)3-- 3--3#*-(#-)"-))A #4# #65-75- "#-%8-7-3-+:2#H))-M+)N
*-7-3---"-)5#-)-1#---(# 1*)"*(#)35-) /- - 3-?&#-3---23)
,'0
*1#4#-&J"--/-A5-4#)--75 #-)-5-# # ),.3* 6#363-3--"-"-#H54#3---"-)&JF+@4)4G-E)3##-"M+)$N
*&J"-3-53&&'-&&# ##7- 3#

,$1(('2
D)-*- 63--#- --B-- #6)M+)$N
HA3-3- #-A6&&# ###*&J"--#-A63-H(3-0.)-/3$ 3--): #8----5-5# /-A#A(#-75$@0& -)A##)J#A(#**3-3---1#- #6B-)
,+
?2 6F3G-E5F 6G)25#--3-&J#(#-)--3"--!5C3*25# 6-E5---')3=-# -M+)$$N
H53-*&# ## --!#)##-&J)*-&J#-&#E#)-"--&J*A-E#3-----6CE##--75-7-*1#)---7---1
,,31
!#))-A3-75--)#75#-#7-))5*3-I)M+)$+N
C -75- 3--(5--33 )*-)175----)3C -B--753---75#
,4'(+
*)#-F-Q@-G&J)/.*3-4###- -))5- "#)-)3-5--!#))--#5C #M+)$,N
,$
D-1#- /- (##M+)N==3)---A5-(#-3--#-A#@@)@#8-7-3---#-!-#-

:
3-
*B337-3-4--)--
)
3#)
-E#"#-(#
) - 8-#5--7-
A))-D-- --57-7- )#HA3-)#)##)A35--)-)3-" #)-)))--1)--#5) )R/3--A))#--!3#*-6-E# )-1E#-)###.FS-GFT-7--T*#-(#G3--(3-#3---)## -) %-7)F3#H-G-)) #=-6-3"")6M+)+N
,' 56%-7
1#-B)3-8)#19%)-.3@@@ "$&#M+)+N*8"J%)-*-7--8?##- -)( *#-6-#'""#3-
*A -9%--8)#1- )A#-9%/-3-*D-3 -57-)C-)35-B##D)-3--(#5 ))A-35-D6
,,%
HA3--3-)- --)) -B)* 6#)/-B)3-)/*2%3- )-&5 )E##-)3M+),N
,,'0
*)#- -B)-#)(# 6)3- - ##-? )=-&J%#)7-) #A"2

;
,,$1(('2
*#)#-3E#-(#-)47-) #65-585D)5#----A--#3A)!#"-3#-#3--) - #65-5--=-3-7-#6
,,+
*)3#)--# #-7----2""#7--)-2""5-A3-)-%7-)-% 7-@82"" )*63---#--H)-*-#E#)#-
,,,31
4--)33 )-H755-3-##3)-)-=-#7-A#C--)5#--6A)-#--)7-)5-
,,4'(+
!#)--135-1#3- --@- /7-))3-F*3$-,UGH-=-1## -#C3& "##$:)"F)"G3-7-3@-,0)"5 )I--#! -B)-
,,8'(.
3--8)#1#-)3-#4--*3-)-3)A -- *-/3B3- )--#7---3-) ))3-$#)#)3?## )-&J5- "#-5 #65-*-(-7--E#5C/-#-!#--E# ) )3-
*3--'9-)& /-2)
T!#--
)7-3---T!#-7-

@
86C -#)3-7--23 *A#)-)-)5---/-*)I3--3 E-##-#3-*)-(5-&
4(9 :&+#9(1 0!9#L43(6M,N-(#3#)--3# ##-- H-*#3#D#)D#---"-#-57--3-#=-)3-"?-1%F&?G
4(9
H-%-(-#--7-&##-H-*?##-#"#3"$) 3A)-M,)+ND#-#"1-%&##-)?## )-#-5*3--*3-
4:&+
*!#'#-) - #65--#-H-8-#)- 66F="G5F*#3G#-))F"G3--"-A)-H5*-B-)3-&- ##- )"#"##B-23*-#-%---@8--3--##4--
4/
#L433-!#'#-#-?##M,)$N
*5- #65-3-)- #6(-(##3-#C=)3
H5 #63-?## )-H-#-#- #53H"*D###) )$A)73-D#5-#F7#G3 F#G-3F"G
?##%-#-3--)-D#--D#5"& /- #-#-3-#-DA--75HA -0 D#)

4; (<
H(#H1(##H53-K)--5K)-E-
2-K))--#)H))?(F-)-E3-H H-&3--#)G--E#!#F#-(3---%3(6G-A#%###- 3#43--###-H-&63#)
-5K))#H%-%H3--7#'##)J#)-75-5#3-35- #3H-M,)$N? %)3-5K)---7*)*3-41-#-."#F 76G-H-- )
4!9(-
=-)3--%?-13--5)#-5M,)+N
(# #33"#- ---*)3-?-1--#- )3-)--
*&?F&J%-?-1G3-#-535 I-345)#- 3--#--H--"-7--?-1#7-3-?-1-H57-)##-&?##-*)-3-
=--#-&?-3-3-#---&?" --?-133-A"33-#-5-?-1 -?-1 53-)#3-?-1 #-53K))-?-1"-)5-3-

4,' 5!(!(
))-$M,N%-)!#
* %&#-&-)*)@@@?*?*M,),N*# )'%-8"""& /- 3-*3 2 "#--#F=*H7H-D#-GV7"
*)#3))-$*#-3--##-"D#)3-?*?*"--%)5H---#-#-"5-3--?-1---*)-*"- 3--DH5-*)- )?##3 #-?"-3-
44%
#L43)51"--3#-A-3-(#75-H-A-?-1M,),$NI)),35-A#%###-)85-)#- -#3"-7-3--- -"5-*3#5--)I3)-(3--&?--A*)@@@7-)5-3#?-1A,---3(-3##?-1F-G
7-#A3-95- ) #-#-3-!#'#-)3-6

$
8$ (;/2--)#7#L##-#ILA##L4LALI##-)H)5-57-"$*#-)7-6C*)?2-#L43#D)#- -"-7--*)-*-H3 -()
8
3--&#"$--3-I!)35--&#-I5--?##-""$E#"# -#*& -*A8!?1#--#( M,),N-5-)"3-#-H)?2-)"$*)#3)#"-#-----*- (-"#)!--3"$)3-3-#I-) ?-H--63 7-956--/."#- "$*&--* )-=3)--*)-D-7----"$6 1---
89 (
*%-- 55#*#)A-#-3"$--23-2--&#*?-#7#L##-)-)-")35&'' -(#--1#)-#-%"3-A )--3E#?2-3ILA##L4LALI## )3)-- -A#---"-#---C-B--))6--- #-2-5)3-5#3-B"- 3- *-)-)- -*)--E- 3-#)/(363-/-#)-&5-!#-5#7-)--23-7-&''-)@# 00P-E#-)3)&-+@P&''#)-E#-
*%#-* )))-#-?--##-H-!#'#-#5)?33-3-!#'#-

+
)) 3-##L43-)A()F"-G-7-W45X)--)- 6-+@)7- 3#--!#'#-#-=*W45X )#-?##)-)))
8<
A---%5-#---B- 3-*&'' 3-0'-/3--"-E#--23))-)=-337-3---#O*)-#ILA##L4LALI##3-H)7-3--(#+:H*)-)# )--)-*4"-3-)-(-7#L###4#-A5-ILA##L4LALI##/3)--!-
?2--(#H-#"-K) #3-#-5B33H)3-& -!#)/-#-#3A#%##----( H53-#(#H)#L43---3-&??-1--))#)3-=-(#-D- A4----*-*)#-?-1-95-))
8,9 (.
*-6%-B3-/3 --) 3--))-.!#/3-D/8)#1F--)G33-*))**)6C3@@@-@@@ * -(3-#)-"#-35-1#A-3##"/-#% -H-( )#3"" -)*))-%)*3--3-7-353-#-#-#-D#)3- 36#D")3-A75- )-!%2#-3-) -*3--*)---)

,
849% =(;/
- A33-%-A--=---*6*)-5"$*6-)-"$*)3---#5?W6)X)3----H-## -4-#"$*#)--B-3-D -3) -2-)C--26C)-"$33D"))"3 ),#7-*#3#-?(-- *)3@@@@7--5H--)-526C" 3-*3- -B-A#-))--(53)))--*-23#")A"- "# 3-*23-"#7-,-3-)()--2#$P$:PC--D3--)-)#)#-D-#-*-(3-#&'')
*#--*-!#)--)-*-EJ5-."4#-/-# )-- -5-"$*)*-%)## "$*-*#3-&*-(3--&??-1#)@@@7-,-#?-1#@-A6C*)3--3#")3-H95-)#-"-)--)-D#D#)K)#---*)A)-W45X33 )-!#" -#-R 35#)63-H""
-#--"-5)--A?##)6

0
>3 MN A7#-##
%#)-#%@@
MN A7#&J%'"'###-
M$N Y)' #-72) #Z*# "#-=%;;:
M+N IDA##84#A-I##9%####%;;;
M,N #-843&F#-%-G3))-%?=E#I-#'##7D#'#"";;"@@$


Multimedia-Datenbanken
Music Retrieval 2
Ernst Jansen

Ernst Jansen Music Retrieval 2 Seite 2
Gliederung
1. Aufgabe 1 - Um was geht es ? - Ziele.....................................................................................3
2. Welche Schwierigkeiten ? - Lösungsansätze.........................................................................3
3. Datenhaltung der Orginal-Musik............................................................................................4
1. tone transition feature vector..............................................................................................5
2. partial tone transition feature vector...................................................................................5
3. tone distribution feature vector ..........................................................................................6
4. Aufbereitung des "Summens".................................................................................................6
5. Suchen und Finden..................................................................................................................7
6. Ergebniss-Beurteilung.............................................................................................................8
7. Aufgabe 2 - Codierung von Musikstücken durch Hashwerte.................................................9
8. Welche Schwierigkeiten ? - Lösungsansatz.........................................................................10
9. Herleitung der Hashwerte......................................................................................................10
10. Datenhaltung der Orginal-Musik........................................................................................11
11. Suchen und Finden..............................................................................................................12
12. Test-Ergebnisse...................................................................................................................13
13. Literatur...............................................................................................................................13

Ernst Jansen Music Retrieval 2 Seite 3
1. Aufgabe 1 - Um was geht es ? - Ziele
Ziel ist es, den Titel des Musikstückes festzustellen, aus dem eine Person ein Stückchen
summt [1]. Dabei sollte es nach Möglichkeit keine Rolle spielen, ob das Summen mit einem
Takt beginnt bzw. endet [2].
Das Summen soll über Mikrophon aufgenommen und einem einfachen PC zur
Weiterverarbeitung übermittelt werden [1].
In einer Datenbank ist eine Auswahl von Musikstücken gespeichert. Die Datenbank befindet
sich ebenfalls auf einem PC.
Die aufgenommenen und eventuell aufbereiteten Daten werden dazu benutzt, eine Abfrage auf
dieser Datenbank zu starten.
Das gesummte Stück wird mit den in der Datenbank gespeicherten Musikstücken verglichen.
Das Ergebnis der Abfrage sollte der Titel des Musikstückes sein, aus dem die Person ein
kleines Stück gesummt hat.
Die Lösung der Aufgabe sollte mit handelsüblicher Hardware realisiert werden. Die
Antwortzeiten sollten dabei wenige Sekunden betragen.
2. Welche Schwierigkeiten ? - Lösungsansätze
Eine große Schwierigkeit ist die mangelnde Reproduzierbarkeit des Summens. Eine Person
wird ein bestimmtes Stück wahrscheinlich jedesmal etwas anders summen. Verschiedene
Personen summen erst recht unterschiedlich. Hierbei ist besonders die Schwierigkeit, aus dem
Gedächtnis zu summen, zu nennen [1], aber auch die mehr oder weniger ausgebildete
Fähigkeit die richtige Tonlage zu treffen. Leicht kann es auch passieren, daß das Lied in einer
anderen Tonart angestimmt wird.
Absolute Fehler in Bezug auf die Qualität des Summens können bei Tempo, Takt und
Melodie auftreten [1][2].
Das Tempo kann z.B. nur halb so groß sein wie im Orginal. Dies passiert relativ häufig, wie
Untersuchungen gezeigt haben [2].
Noten können fehlen, falsch sein oder hinzugefügt worden sein.
Der Rythmus/Takt kann grundsätzlich falsch gewählt oder nicht gehalten worden sein.
Ein weiteres Problem besteht darin, daß ein beliebiger Teil aus einem Musikstück gesummt
können werden soll. D.h. das gesummte Stück kann auch mitten im Takt beginnen bzw.

Ernst Jansen Music Retrieval 2 Seite 4
aufhören. Phrasen und Takt stimmen also nicht immer überein [2].
Alle genannten Schwierigkeiten führen dazu, daß nur ein ungefähres Suchkriterium für die
Suche zur Verfügung steht. Trotzdem soll genau das eine gesuchte Lied ermittelt werden.
Dies kann naturgemäß nur näherungsweise erreicht werden.
Dazu werden die Stücke gesucht, die einen Teil beinhalten, der dem gesummten am nächsten
kommt. In einer Rangliste wird das Ergebnis nach Ähnlichkeit absteigend zusammengefasst.
Hierfür werden die Musikstücke, sowohl die Orginale als auch die gesummten, in kleine
Stücke gleicher Länge aufgeteilt, die dann miteinander verglichen werden können. Im
folgenden wird auf die Einzelheiten etwas näher eingegangen.
3. Datenhaltung der Orginal-Musik
Die Orginal-Musikstücke werden im MIDI-Format in der Datenbank abgelegt, da die Melodie
bei diesem Format in einem eigenem Kanal gespeichert werden kann [1]. Außerdem werden
in MIDI keine digitalisierten Tonaufnahmen gespeichert sondern Befehle für Instrumente, d.h.
der Klang, bzw. der erzeugte Ton, eines Instrumentes wird nicht in der MIDI-Datei
abgespeichert, sondern bei einer Wiedergabe neu erzeugt. Der Klang welches Instrumentes
auch immer, das für die Wiedergabe des Liedes verwendet wird, spielt für die Lösung der
Aufgabe hier keine Rolle.
Man beschränkt sich auf die Speicherung der Melodie, da nur die Melodie für die Suche
herangezogen wird. Weil die meisten Meschen ein Musikstück anhand seiner Melodie
erkennen, kann dieses Kriterium als ausreichend angenommen werden [1]. Dadurch wird der
Speicherplatzbedarf erheblich reduziert.
Bei sehr schnellen Liedern wird das Lied zusätzlich auch noch in einer Version, die nur halb
so schnell ist wie das Orginal, abgespeichert, da viele Leute bei solchen Liedern dazu neigen
sie nur in einem Tempo, das halb so schnell ist, zu summen [2].
Die Akkorde werden alle gelöscht. Behalten werden nur der erste bzw. der höchste Ton eines
Akkordes. Man kann beim Summen ("ta ta...") nicht zwei Töne gleichzeitig anschlagen [2].
Der Speicherplatzbedarf reduziert sich hierdurch weiter, außerdem wird die Verarbeitung
dadurch wesentlich vereinfacht.

Ernst Jansen Music Retrieval 2 Seite 5
Die Melodie wird nach der sliding window Methode nun in kleine, sich überschneidende
Stücke gleicher Länge zerlegt [2]. Die Größe des Fensters könnte z.B. der Taktlänge
entsprechen.
Dann wird die Information aus den Stücken gleicher Länge in verschiedenen
Merkmalsvektoren codiert [1]. Durch diese Aufteilung lassen sich später leicht Stücke
innerhalb von Liedern finden.
Die gewählte Auflösung von Achtel-Noten richtete sich nach Untersuchungen, die besagen,
daß Achtel-Noten bei weitem am häufigsten vorkommen [2].
Im folgenden wird näher auf verschiedenen Merkmalsvektoren eingegangen.
1. tone transition feature vector
Dieser Merkmalsvektor hat die Dimension des Fensters (z.B. des Taktes) in Schlägen, wobei
die Anzahl der Schläge sich nach der gewählten Auflösung richtet. In einem 4/4-Takt bei einer
Auflösung von 1/8-Noten hat der Vektor also die Dimension 8.
In den einzelnen Zellen des Vektors wird eine Nummer eingetragen, die den zu diesem
Zeitpunkt klingenden Ton identifiziert. Die Nummer des Tones ist die Nummer des Tones im
MIDI-Format.
Für den folgenden Takt z.B. ergibt sich
der tone transition vector zu (64, 64, 65, 65, 67, 67, 65, 65).
2. partial tone transition feature vector
Ein Schwierigkeit ist, daß gesummte Stücke und gespeicherte Stücke in ihrer Aufteilung nicht
immer deckungsgleich sind. Das liegt daran, daß der Summende nicht unbedingt mit dem
Takt anfängt, wie dies in der Datenbank der Fall ist, z.B. bei Auftakten.
Ein Lösungsansatz für diese Problem ist der partial tone trasition vector. Bei diesem
Merkmalsvektor stimmt die Dimension nicht mit den Fenstern (Stücken) in der Datenbank
bzw. den gesummten Liedern überein. Der Anfang des Vektors ist nicht konsistent mit dem
Anfang des Datenfensters aus der Aufteilung der Musikstücke. Stattdessen wird zum Vektor

Ernst Jansen Music Retrieval 2 Seite 6
der höchste Ton des vorherigen Fensters (z.B. Taktes) hinzugenommen.
Mit Hilfe der so entstehenden Merkmalsvektoren werden die Fehler durch unterschiedliche
Startpunkte (wegen Auftakte) von Orginal-Lied und gesummenten Lied reduziert. Da die
Wahrscheinlichkeit in der Datenbank einen Vektor, nämlich einen partial tone transition
vector, der den gleichen Startpunkt hat wie der, der aus den gesummten Daten hergeleitet
wurde, deutlich höher ist.
3. tone distribution feature vector
Dieser Vektor gibt an, wieviele Schläge ein Ton innerhalb des Datenfensters insgesamt klingt.
Die Dimension des Vektors entspricht der Anzahl der möglichen Töne zwischen dem
höchsten und tiefsten Ton, der im Datenfenster vorkommt.
Für das folgende Datenfenster erhält man somit den
tone distribution vector (2, 4, 0, 2).
Der so erhaltene Vektor ist unempfindlich für Tempovariationen, da nur die Gesamtzahl der
Schäge erfaßt wird, und auch gegenüber Tonlagen, da die Töne nur relativ zueinander
identifiziert werden.
Die so erhaltenen Merkmalsvektoren werden für die Indizierung herangezogen. Es werden
dazu verschiedene Indexe aufgebaut.
4. Aufbereitung des "Summens"
Für die Verarbeitung der Aufnahmen ist ein klare und deutliche Unterscheidung der Töne
vorteilhaft. Daher soll für das Summen nur die eine Silbe "ta, ta...." verwendet werden [2], so
wird gewährleistet, daß der Beginn jedes neuen Tones in immer gleicher Weise zu erkennen
ist.
Da viele Ungeübte Probleme haben, im richtigen Tempo zu summen, wird mit Hilfe eines bei
der Aufnahme laufenden Metronoms das Tempo synchronisiert [2]. Das Metronom kann in

Ernst Jansen Music Retrieval 2 Seite 7
seiner Einstellung den Möglichkeiten des Summenden angepaßt werden.
Wie die Orginal-Daten in der Datenbank wird das gesummte Stück nach der Aufnahme in das
MIDI-Format konvertiert.
Anschließend wird das Rauschen entfernt, Rauschen heißt hier Töne die zwar aufgezeichnet
wurden, aber nicht zum Summen gehören. So werden z.B. aufgezeichnete Noten direkt am
Beginn eines Stückes nach denen wieder eine längere Pause eintritt als fehlerhafte Töne
entfernt [2]. Da normalerweise der Unterschied in der Tonhöhe aufeinanderfolgender Töne
sich in einem gewissen Rahmen hält, werden solche Töne, die diesen Schwellwert im Abstand
zu den benachbarten Tönen übersteigen, ebenfalls als Rauschen interpretiert und gelöscht. Der
Schwellwert ist ein Konfigurationswert des Systems.
Fehlerhafte Oktavensprünge, die bei der Aufnahmeverarbeitung entstehen können, werden
verbessert. Erkannt werden sie wie oben bei der Entfernung des Rauschens an der Relation
des Tones in seiner Höhe zu der des nachfolgenden.
Dann wird das Stück wie die Orginale in der Datenbank in kleine sich überschneidende
Stücke gleicher Größe (Sliding-Window-Methode) aufgeteilt. Die Frame-Größe entspricht der
der Orginale in der Datenbank.
Das aufgenommene Summen wird genauso codiert wie die Orginaldaten. D.h. es werden die
verschiedenen Merkmalsvektoren gebildet, genau wie oben bei den Orginaldaten beschrieben.
Die erhaltenen Merkmalsvektoren dienen dann als Such-Schlüssel für die Suche über die
verschiedene Indexe in der Datenbank.
5. Suchen und Finden
Für die Suche werden die Merkmalsvektoren aus der Codierung des gesummten Stückes
herangezogen. Verglichen wird die Ähnlichkeit von Such-Vektor und Datenbank-(Index-)
Vektor mit Hilfe der Euklidischen Distanz. Hierbei werden aufgrund der drei verschiedenen
Merkmalsvektoren auch drei Suchläufe durchgeführt.
Das Ergebnis jedes Suchlaufes mit einem der verwendeten Merkmalsvektoren als
Suchschlüssel wird in einer Rangliste angegeben. Hierin sind die gefundenen Lieder von Rang
1 an der Ähnlichkeit nach abwärts aufgelistet, d.h. das gefundene Lied, das dem Gesuchten

Ernst Jansen Music Retrieval 2 Seite 8
am ähnlichsten ist, steht an Position bzw. Rang 1 [1][2].
Auf diese Weise erhält man drei Ranglisten, für jeden Suchschlüssel (Merkmalsvektor) eine.
Die drei erhaltenen Ranglisten stimmen nicht unbedingt überein.
Die verschiedenen Ranglisten lassen sich nun zu einer einzigen zusammenfassen, indem man
eine neue Rangliste aufstellt in der wiederum nach Ähnlichkeit sortiert die gefundenen Lieder
aufgelistet werden. Hierbei wird jeweils nach der größten vorhandenen Ähnlichkeit über alle
drei zuerst erhaltenen Ranglisten sortiert.
Beispiel:
d(hi, X) := Euklidische Distanz zwischen hi und X
mit
X = A, B, C, D, ... sind Lieder in der Datenbank
hi = h1, h2, h3 sind die drei Schlüssel (Merkmalsvektoren: tone transition, etc.)
es werden folgende Euklidischen Distanzen in aufsteigender Reihenfolge erhalten
Schlüssel Euklidische Distanzen
h1 d(h1, D) = 0,9 d(h1, B) = 1,5 d(h1, C) = 1,8 d(h1, A) = 5,8
h2 d(h2, A) = 0,3 d(h2, B) = 1,2 d(h2, C) = 2,0 d(h2, D) = 5,9
h3 d(h3, B) = 1,0 d(h3, C) = 1,2 d(h3, D) = 1,5 d(h3, A) = 6,0
es ergibt sich folgende Rangliste über alle 3 Schlüssel
d(h2, A) = 0,3 < d(h1, D) = 0,9 < d(h3, B) = 1,0 < d(h3, C) = 1,2
also: A - D - B - C
6. Ergebniss-Beurteilung
Bei der für die Tests verwendeten Datenbank von mehr als 10.000 Liedern ließ sich die Größe
um 38% reduzieren, wenn doppelte Informationen gelöscht werden [2].
Weiter wird den nachfolgenenden Beurteilungen die Suche nach 186 gesummten Stücken aus
Liedern in der Datenbank zu Grunde gelegt.
Eine Auflösung der Merkmalsvektoren von Achtel-Noten statt Viertel-Noten steigert die
Wahrscheinlichkeit, das richtige Ergebniss unter den ersten zwei in der Rangliste zu finden,
um ca. 10% [2].
Die Anwendung des partial tone transition vectors statt des tone transition vectors liefert ein

Ernst Jansen Music Retrieval 2 Seite 9
um etwa 7% besseres Ergebnis bis Rang 2.
Bei ausschließlicher Verwendung eines Feature-Vektors, eignet sich der tone transition vector
besser als der tone distribution vector [2].
Die besten Ergebnissen erzielt man durch die gleichzeitige Verwendung der verschiedenen
Feature-Vektoren, wie in der nachfolgende Abbildung deutlich wird.
Bei gleichzeitiger Verwendung von tone transition und tone distribution vector wird in
weniger als einer Sekunde das gesuchte Lied in der Rangliste unter den ersten fünf mit einer
Wahrscheinlichkeit von 75% erscheinen [2].
Eine weitere Verbesserung wird durch die Verknüpfung der verschiedenen Ergebnisse aller
drei Merkmalsvektoren erreicht. Hierdurch kann erreicht werden, daß in 74% der Fälle das
gesuchte Lied schlechtenfalls auf Platz 2 steht (siehe folgende Abbildung).
7. Aufgabe 2 - Codierung von Musikstücken durch Hashwerte
Es sollen Hashwerte zu Musikstücken für das Speichern und Wiederauffinden der
Musikstücke hergeleitet werden.
Mit Hilfe dieser Hashwerte sollen Lieder an Hand nur kleiner Auszüge identifiziert werden
können. Liegt z.B. ein kleiner Ausschnitt eines Liedes vor, evtl. in verschiedenen Daten-
Formaten (MP3, Real Media, etc.), so soll das zugehörige vollständige Lied in einer
Datenbank gefunden werden.
Dabei ist insbesondere darauf zu achten, daß verschiedene Interpretationen und
Aufnahmequalitäten zum gleichen Ergebnis führen.

Ernst Jansen Music Retrieval 2 Seite 10
8. Welche Schwierigkeiten ? - Lösungsansatz
Durch die möglichen Variationen in Aufnahmequalität und Interpretation der Lieder ergibt
sich hier wieder, wie in Aufgabe 1 der Näherungscharakter der Lösung. D.h. man kann unter
Umständen ein Ergebnis angeben, das dem gesuchten am nächsten liegt. Erreicht werden soll
dies unter anderem über die Bestimmung eines Abstandes zwischen dem Suchwert und den
Werten in der Datenbank. Wie sicher das richtige Ergebnis der Suche zurückgegeben wird, ist
dann von der Definition bzw. den Parametern der Abstandsfunktion abhängig.
Hashwerte sind üblicherweise äußerst empfindlich gegenüber auch nur bitweisen
Veränderungen der Ausgangsdaten [3]. D.h. eine kleine Änderung im Suchkriterium kann zu
völlig anderen Ergebnissen führen.
Es wird also ein Herleitungsverfahren für Hashwerte benötigt, das möglichst unempfindlich
ist gegenüber Qualitätsschwankungen (z.B. durch Packen der Daten in mp3-Format) oder
auch gegenüber Interpretationen (z.B. durch verschiedene Künstler).
Außerdem sollen aus benachbarten Ausgangswerten auch benachbarte Hashwerte erzeugt
werden. Dies gewährleistet Zusammenhang und Kontinuität der Musikstücke in der
Datenbank.
Ein solches Verfahren zur Herleitung solcher Hashwerte heißt "robust hash" und soll im
folgenden beschrieben werden.
9. Herleitung der Hashwerte

Ernst Jansen Music Retrieval 2 Seite 11
Zuerst werden die Audiodaten jedes einzelnen Liedes in Intervalle aufgeteilt aus denen dann
später die Hashwerte gebildet werden sollen. Diese Intervalle oder auch "frames" haben eine
Länge von 0.4s und überschneiden einander mit 31/32 ihrer Länge. Die Überlappung soll für
Kontinuität sorgen, d.h. aus zeitlich benachbarten Ausgangsdaten sollen benachbarte
Hashwerte gebildet werden [3].
Die Frames werden mittels Fourier-Transformation in eine Spektral-Darstellung überführt.
Anschließend werden die Daten der einzelnen Frames in 32 nicht überlappende
Frequenzbänder aufgeteilt [3].
Die Energie des Frequenzbandes m im Frame n wird bezeichnet mit EB(n,m). Sie hat sich in
verschiedenen Experimenten als robustes Kriterium erwiesen [3]
Das m-te Bit der Hashvariable wird dann bestimmt durch
1, falls EB(n,m) - EB(n,m+1) - (EB(n-1,m) - EB(n-1,m+1)) > 0
0, falls EB(n,m) - EB(n,m+1) - (EB(n-1,m) - EB(n-1,m+1)) 0
Jedes Frequenzband liefert ein Bit, so daß man für einen Frame einen 32-bit Hashwert erhält,
der dann für (0.4 * 31 / 32)s Audio-Signal steht. Die Hashwerte von 256 Frames werden zu
einem Hash-Block zusammengefaßt.
Werden zwei Hashblocks bitweise miteinander verglichen, erhält man die Bit-Error-Rate
(BER). Anders gesagt, die BER ist die XOR-Verknüpfung eines Hashblocks vom gesuchtem
Orginal mit einem zu vergleichenden Hashblock aus der Datenbank im Verhältnis zum
Orginal-Hashblock. Die BER kann somit als Maß für den Unterschied zwischen gesuchtem
Lied und dem Ergebnis der Suche herangezogen werden.
10. Datenhaltung der Orginal-Musik
Für jedes Lied werden die Hashwerte bzw. -blocks nach dem oben beschriebenen Verfahren
ermittelt und auf das Lied bezogen chronologisch in der Datenbank abgelegt.
Für alle möglichen Hashwerte wird ein lookup table (LUT) angelegt. Von jedem Eintrag im
LUT verweisen Zeiger auf die Stellen in den Liedern, wo dieser Eintrag bzw. Wert vorkommt.
Sind mehrere Zeiger vorhanden werden diese durch eine verkettete Liste verbunden.
H(n,m) =

Ernst Jansen Music Retrieval 2 Seite 12
11. Suchen und Finden
Zuerst werden die Hashblocks ermittelt, d.h. die Hashwerte werden nach oben beschriebenen
Verfahren hergeleitet und dann zu Blocks von je 256 Werte zusammengefaßt.
Zwei Hashblocks werden als gleich erkannt, wenn die Hamming-Distanz zwischen den beiden
Blocks kleiner ist als ein gewählter Schwellwert [3]. Der Schwellwert beeinflußt direkt das
Ergebnis, ein niedrigerer Schwellwert bedeutet, daß das Ergebnis mit größerer
Wahrscheinlichkeit richtig ist. Andererseits bedeutet er gleichzeitig auch, daß weniger
Übereinstimmungen gefunden werden, im Extremfall vielleicht sogar - z.B. aufgrund von
Qualitätsunterschieden - gar keine Übereinstimmung, obwohl es eine hätte geben müssen.
Mit jedem einzelnen Hashwert (der Reihe nach) des Hashblocks des gesuchten Liedes wird in
die LUT gegangen. Über die dort angegebenen Zeiger werden alle Lieder gefunden in denen
dieser Wert auftritt. Ist ein Kandidat für einen Hashwert gefunden, wird der ganze Block
verglichen [3]. Im Falle einer Ähnlichkeit (siehe 10), die nicht im Bereich des vorgegebenen
Schwellwertes liegt, wird der nächste Kandidat in der Liste bzw. der nächste Hashwert im
Block herangezogen.
Nun kann man wie bei der 1. Aufgabe eine Rangliste, sortiert nach der Ähnlichkeit, mit den
gefundenen Liedern aufstellen.

Ernst Jansen Music Retrieval 2 Seite 13
12. Test-Ergebnisse
Für den Test wurden 4 verschiedene Lieder herangezogen. Und ein Schwellwert von 0.25 zu
Grunde gelegt.
Trotz verschiedener Bearbeitung der Orginal-Stücke (z.B. Packen, Amplituden-Kompression,
etc.) bleiben die BER < 0.20. Bzgl. der Abstände der verschiedenen Lieder hingegen bleiben
die BER > 0.40. D.h. alle Lieder werden gefunden und korrekt zugeordnet.
13. Literatur
[1] Music Retrieval by Humming
Naoko Kosugi, Yuichi Nishihara, Seiichi Kon'ya,
Masashi Yamamuro, Kazuhiko Kushima
[2] A Practical Query-By-Humming System for a Large Music Database
Naoko Kosugi, Yuichi Nishihara, Tetsuo Sakata,
Masashi Yamamuro, Kazuhiko Kushima
[3] Robust Audio Hashing for Content Identifikation
Jaap Haitsma, Ton Kalker, Job Oostveen


Gesamtliteraturverzeichnis
• Edoardo Ardizzone and Marco La Cascia. Automatic video database indexing
and retrieval. Multimedia Tools Appl., 4(1):29–56, 1997.
• Sandra Barthel. jpg, 1999.
http://goethe.ira.uka.de/semibare/redundanz/vortrag11/ (2006).
• Stefan Berchtold, Daniel A. Keim, and Hans-Peter Kriegel. The x-tree: An
index structure for high-dimensional data. In T. M. Vijayaraman, Alejan-
dro P. Buchmann, C. Mohan, and Nandlal L. Sarda, editors, VLDB, pages
28–39. Morgan Kaufmann, 1996.
• Robert S. Boyer and J. Strother Moore. A fast string searching algorithm.
Commun. ACM, 20(10):762–772, 1977.
• Shih-Fu Chang, William Chen, Horace J. Meng, Hari Sundaram, and
Di Zhong. Videoq: An automated content based video search system using
visual cues. In ACM Multimedia, pages 313–324, 1997.
• Paolo Ciaccia, Marco Patella, and Pavel Zezula. M-tree: An efficient access
method for similarity search in metric spaces. In Matthias Jarke, Michael J.
Carey, Klaus R. Dittrich, Frederick H. Lochovsky, Pericles Loucopoulos, and
Manfred A. Jeusfeld, editors, VLDB, pages 426–435. Morgan Kaufmann, 1997.
• Scott C. Deerwester, Susan T. Dumais, Thomas K. Landauer, George W.
Furnas, and Richard A. Harshman. Indexing by latent semantic analysis.
JASIS, 41(6):391–407, 1990.
• Bjorn Eisert. Was ist MPEG?, 1995.
http://www.cybersite.de/german/service/Tutorial/mpeg/ (2006).
• Christos Faloutsos, Ron Barber, Myron Flickner, Jim Hafner, Wayne Niblack,
Dragutin Petkovic, and William Equitz. Efficient and eective querying by
image content. J. Intell. Inf. Syst., 3(3/4):231–262, 1994.
• Reginald Ferber. Information Retrieval - Suchmodelle und Data-Mining-Verfahren fur Textsammlungen und das Web. Dpunkt Verlag, 2003.
• Norbert Fuhr. Information Retrieval - Script zur Vorlesung.
http://is.informatik.uni-duisburg.de/courses/ir ss06/folien/ irskall.pdf (3006-
05-03).
• Didier Le Gall. Mpeg: A video compression standard for multimedia applica-
tions. Commun. ACM, 34(4):46–58, 1991.
• Venkat N. Gudivada and Vijay V. Raghavan. Design and evaluation of al-
gorithms for image retrieval by spatial similarity. ACM Trans. Inf. Syst.,13(2):115–144, 1995.
• Antonin Guttman. R-trees: A dynamic index structure for spatial searching.
In SIGMOD Conference, pages 47–57, 1984.
• Andreas Heurer. Datenbanken 2 - Script zur Vorlesung.
http://dbis.informatik.uni-rostock.de/ Studium/Lehrveranstaltungen/-
Sommersemester 2006/ Datenbanken II/Skripte/db2-2006-Kap4.pdf (2006).

• J. Haitsma, T. Kalker, and J. Oostveen. Robust audio hashing for content
identification. In Proceedings of the Content-Based Multimedia Indexing, pa-
ges 19–21, 2001.
• H.W.Lang. Boyer-Moore-Algorithmus.
http://inf.fh-flensburg.de/lang/algorithmen/pattern/bm.html, 2006.
• H. V. Jagadish. A retrieval technique for similar shapes. In James Cliord
and Roger King, editors, SIGMOD Conference, pages 208–217. ACM Press,
1991.
• Naoko Kosugi, Yuichi Nishihara, Tetsuo Sakata, Masashi Yamamuro, and
Kazuhiko Kushima. A practical query-by-humming system for a large music
database. In ACM Multimedia, pages 333–342, 2000.
• King-Ip Lin, H. V. Jagadish, and Christos Faloutsos. The tv-tree: An index
structure for high-dimensional data. VLDB J., 3(4):517–542, 1994.
• Beth Logan. Mel frequency cepstral coefficients for music modeling. In ISMIR,
2000.
• B. Logan and A. Salomon. A music similarity function based on signal analy-
sis. In Proceedings of the IEEE International Conference on Multimedia andExpo, pages 745–748, 2001.
• Thomas Mandl. Tolerantes Information Retrieval - Neuronale Netze zurErhohung der Adaptivitat und Flexibilitat bei der Informationssuche, volu-
me 39 of Schriften zur Informationswissenschaft. Hochschulverband fur In-
formationswissenschaft (HI) e.V. Konstanz, 2001.
• Alistair Moat and Justin Zobel. Self-indexing inverted files for fast text
retrieval. ACM Transactions on Information Systems, 14(4):349–379, 1996.
• S. Kon’ya N. Kosugi, Y. Nishimura, M. Yamamuro, and K. Kushima. Music
retrieval by humming. In PACRIM’99, pages 404–407, August 1999.
• G. Navarro and J. Tarhio. Boyer-Moore string matching over ziv-lempel com-
pressed text. In R. Giancarlo and D. Sanko, editors, Proceedings of the11thAnnual Symposium on Combinatorial Pattern Matching, volume 1848, pages
166–180, Montreal, Canada, 2000. Springer-Verlag, Berlin.
• Seung-Min Rho and Een-Jun Hwang. Fmf(fast melody finder): A web-based
music retrieval system. In Ue Kock Wiil, editor, CMMR, volume 2771 of
Lecture Notes in Computer Science, pages 179–192. Springer, 2003.
• Markus Schneider. Implementierungskonzepte fur Datenbanksysteme, Kurs
1664, 1999.
• Markus A. Stricker and Markus Orengo. Similarity of color images. In Storageand Retrieval for Image and Video Databases (SPIE), pages 381–392, 1995.
• T.Ottmann, P.Widmayer. Algorithmen und Datenstrukturen. Spektrum Aka-
demischer Verlag, Heidelberg, 1996. 2nd edition.

• Jerey K. Uhlmann. Satisfying general proximity/similarity queries with me-
tric trees. Inf. Process. Lett., 40(4):175–179, 1991.
• Gregory K. Wallace. The jpeg still picture compression standard. Commun.ACM, 34(4):30–44, 1991.
• M. Welsh, N. Borisov, J. Hill, R. von Behren, and A. Woo. Querying lar-
ge collections of music for similarity. Technical Report 1096, U.C. Berkeley
Computer Science Division, 1999.
• Wikipedia. Containerformat.
http://de.wikipedia.org/wiki/Containerformat
last changed: 22. Jun 2006.
• Wikipedia. Diskrete Kosinustransformation.
http://de.wikipedia.org/wiki/Diskrete Kosinustransformation
last changed: 14. Jun 2006.
• Wikipedia. Joint Photographic Experts Group.
http://de.wikipedia.org/wiki/JPEG
last changed: 22. Jun 2006.
• Wikipedia. Motion Compensation.
http://de.wikipedia.org/wiki/Motion Compensation
last changed: 21. Jun 2006.
• Wikipedia. Moving Picture Experts Group.
http://de.wikipedia.org/wiki/mpeg
last changed: 21. Jun 2006.
• Wikipedia. MPEG-1.
http://de.wikipedia.org/wiki/Mpeg-1
last changed: 26. Jun 2006.
• Wikipedia. MPEG-2.
http://de.wikipedia.org/wiki/Mpeg-2
last changed: 21. Jun 2006.
• Wikipedia. MPEG-4.
http://de.wikipedia.org/wiki/Mpeg-4
last changed: 21. Jun 2006.
• C.Tomasi Y.Rubner and L.Guibas. The earth mover’s distance as a metric
for image retrieval. Technical report, Stanford University, 1998.
• Jacob Ziv and Abraham Lempel. A universal algorithm for sequential da-
ta compression. IEEE Transactions on Information Theory, 23(3):337–343,
1977.