Embed Size (px)
Citation preview

QuantitativesRisikomanagement
Korrelation und Abhängigkeit im
Risikomanagement:
Eigenschaften und Irrtümer
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 1
von Jan Hahne und Wolfgang Tischer

Agenda
1. Einführung in die Themenstellung
2. Grundlagen: Copula
3. Konzepte der Abhängigkeitsmodellierung
4. Irrtümer bzgl. Korrelation und Abhängigkeit
5. Fazit
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 2

1. Einführung in dieThemenstellung
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 3

1. Einführung in die Themenstellung
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 4

2. Grundlagen: Copula
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 5

2.1 Definition der Copula
Grundsätzliche Idee: Modellierung der Abhängigkeit soll zurückgeführt
werden auf die gemeinsame Verteilungsfunktion.
• Gegeben seien: n Zufallsvariablen X1 , … , Xn sowie deren gemeinsame
Verteilungsfunktion F
• Dann gilt bekanntlich: F(x1 , … , xn) = P (X1 ≤ x1 , … , Xn ≤ xn)
• Um zur Copula zu gelangen wird der folgende Satz benötigt:
Satz 2.1: Sei X eine Zufallsvariable mit zugehöriger Verteilungsfunktion F. Sei
weiterhin F-1 die Quantilfunktion zu F, also: F-1(α) = inf { x |F(x) ≥ α }, wobei
α Є (0,1). Dann gilt:
1. Für jede standard-gleichverteilte Zufallsvariable U ~ U(0,1) ist F-1(U) ~ F.
2. Wenn F stetig ist, so ist die Zufallsvariable F(X) standard-gleichverteilt,also F(X) ~ U(0,1).
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 6

2.1 Definition der Copula
• Besitzen die X1 , … , Xn stetige Randverteilungsfunktionen, so kann derVektor X = (X1 , … , Xn)‘ nach Satz 2.1 derart transformiert werden, dassjede Komponente eine standard-gleichverteilte Randverteilung besitzt.
• Die benötigte Transformation T : ℝn → ℝn bildet (x1 , … , xn)‘ auf
(F1(x1) , … , Fn(xn))‘ ab, so dass:
F(x1 , … , xn) = P (F1(X1) ≤ F1(x1) , … , Fn(Xn) ≤ Fn(xn)) = C(F1(x1) , … , Fn(xn))
• C ist die gemeinsame Verteilungsfunktion des transformierten Vektors(F1(X1) , … , Fn(Xn))‘.
• Man nennt C die Copula des Zufallsvektors (X1 , … , Xn)‘.
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 7

2.1 Definition der Copula
Definition 2.1: Eine n-dimensionale Copula ist eine Verteilungsfunktion eines
Zufallsvektors X Є ℝn, deren Randverteilungen alle (0,1) – gleichverteilt sind.
Äquivalent zur obigen Definition kann eine Copula definiert werden als
Funktion C : [0,1]n→ [0,1] mit den drei Eigenschaften:
1. C(x1 , … , xn) ist monoton steigend in jeder Komponente xi .
2. C(1 , … , 1 , xi , 1 , … , 1) = xi für alle i Є [0,1].
3. Für alle (a1 , … , an), (b1 , … , bn) Є [0,1]n, mit ai ≤ bi gilt:
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 8
2
1
2
1
...
1
11
1 ,0),...,()1(...i i
ii
n
nnii
n xxC
mit xj1 = aj und xj2 = bj für alle j Є {1,…,n}. Die Summe kann interpretiert
werden als:
P(a1 ≤ X1 ≤ b1 , ... , an ≤ Xn ≤ bn) ≥ 0.

2.1 Definition der CopulaZusammenfassend kann also festgehalten werden:
• Die gemeinsame Verteilungsfunktion F enthält vollständigeInformationen über die gesamte Abhängigkeitsstruktur zwischenZufallsvariablen
• Idee bei Verwendung der Copula: Teile die gemeinsameVerteilungsfunktion F in zwei Komponenten auf.
Die eindimensionalen Randverteilungen F1 , … , Fn
Die Copula C
• Der Copula-Ansatz ermöglicht eine sehr flexible Modellierung:
die Verteilung der einzelnen Zufallsvariablen kanngetrennt von der Abhängigkeit zwischen denZufallsvariablen festgelegt werden.
Die Abhängigkeitsstruktur die zwischen denZufallsvariablen besteht wird alleine durch die Copulamodelliert.
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 9

2.2 Der Satz von Sklar
Der bedeutendste Satz in Bezug auf Copulas ist der Satz von Sklar.
Satz 2.2:
1. Sei F eine multivariate Verteilungsfunktion mit Randverteilungs-funktionen F1 , … , Fn. So existiert eine Copula C : [0,1]n→ [0,1], s.d. füralle x1 , … , xn Є ℝ gilt:
F(x1 , … , xn) = C(F1(x1) , … , Fn(xn)).
Die Herleitung wurde oben bereits gezeigt.
Falls F1 , … , Fn stetig sind, so ist die Copula C sogar eindeutig bestimmt.
2. Seien nun umgekehrt eine Copula C sowie die eindimensionalenVerteilungsfunktionen F1 , … , Fn gegeben, dann ist die durch:
F(x1 , … , xn) = C(F1(x1) , … , Fn(xn))
definierte Verteilungsfunktion F eine multivariate Verteilung mit denRandverteilungen F1 , … , Fn .
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 10
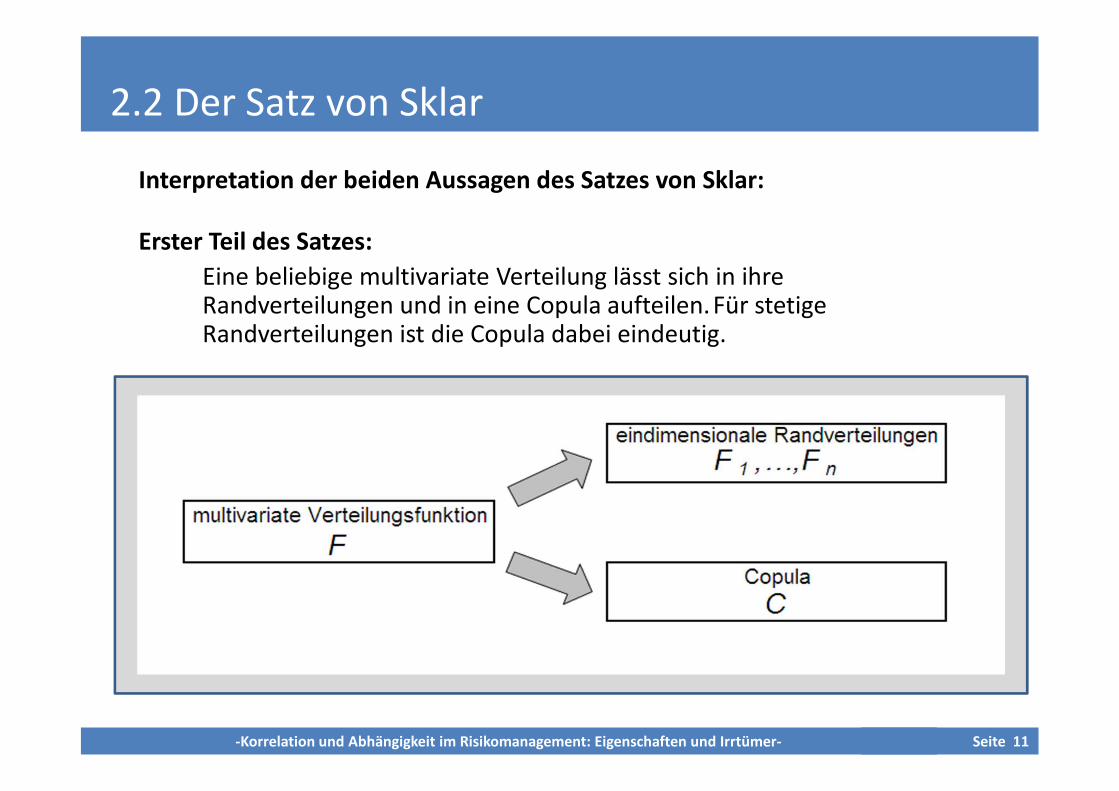
2.2 Der Satz von Sklar
Interpretation der beiden Aussagen des Satzes von Sklar:
Erster Teil des Satzes:
Eine beliebige multivariate Verteilung lässt sich in ihreRandverteilungen und in eine Copula aufteilen.Für stetigeRandverteilungen ist die Copula dabei eindeutig.
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 11

2.2 Der Satz von Sklar
Der Satz von Sklar gibt jedoch lediglich an, dass diese Überführung
möglich ist. Wie dies konkret umgesetzt werden kann wird nicht
deutlich.
Es ist aber folgendermaßen vorzugehen:
• Bei bekannter multivariater Verteilungsfunktion F könnendie eindimensionalen Randverteilungen F1 , … , Fn bestimmtwerden.
• Sind nun die Zufallsvariablen X1 , … , Xn mit zugehörigenVerteilungsfunktionen F1 , … , Fn bekannt. Sei weiterhin
ui = P(Xi ≤ xi) = Fi(xi) und daher ui Є [0,1] für alle i Є {1 , … , n},so folgt:
C(u1 , … , un) = F(F1-1(u1) , … , Fn
-1(un)).
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 12
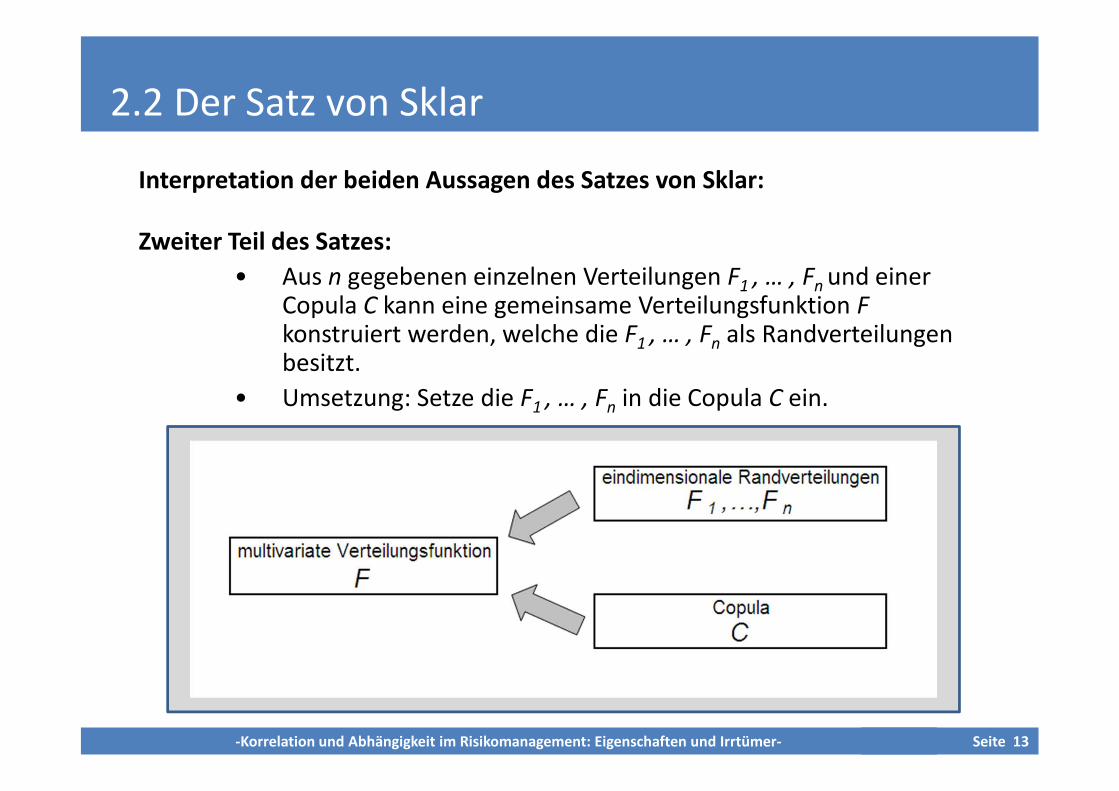
2.2 Der Satz von Sklar
Interpretation der beiden Aussagen des Satzes von Sklar:
Zweiter Teil des Satzes:
• Aus n gegebenen einzelnen Verteilungen F1 , … , Fn und einerCopula C kann eine gemeinsame Verteilungsfunktion Fkonstruiert werden, welche die F1 , … , Fn als Randverteilungenbesitzt.
• Umsetzung: Setze die F1 , … , Fn in die Copula C ein.
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 13

2.3 Invarianz unter streng monoton steigendenTransformationen
Copulas besitzen eine Eigenschaft, die für praktische Anwendungen
sehr nützlich ist:
Satz 2.3:
Sei C eine Copula zu (X1 , … , Xn)‘. Dann ist C für alle streng monotonsteigenden stetigen Transformationen T1 , … , Tn ebenfalls die Copula zu(T1(X1) , … , Tn(Xn))‘.
Erläuterung des Vorteils dieser Eigenschaft an einem Beispiel:
• Die Abhängigkeit von Verlusten mehrerer Einzelrisiken sind in der EinheitEuro durch eine Copula C modelliert.
• Übergang von Euro zu Dollar: streng monoton steigende Transformation.
• Das Modell in Dollar-Beträgen besitzt dieselbe Copula C wie das Euro-Modell.
• Achtung: Die Randverteilungen, die die Verteilungen der Einzelrisikenbeschreiben müssen in der Regel an die neuen Skalen angepasst werden.
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 14

2.4 Beispiele für Copulas
Hier werden zwei klassische Beispiele für Copulas vorgestelltwerden.
Betrachtung im 2-dimensionalen, d.h. gegeben sind:
• Zwei Zufallsvariablen X und Y mit Verteilungsfunktionen F1
und F2
• Sei u1 = P(X ≤ x1) = F1(x1) bzw. u2 = P(Y ≤ x2) = F2(x2), also u1,u2
Є [0,1].
• Wie oben gezeigt, gilt:
C(u1 , u2) = F(F1-1(u1) , F2
-1(u2)) (*)
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 15

• Randverteilungen F1 und F2 sind univariate Normalverteilungen. DieVerteilungsfunktionen werden mit φ bezeichnet.
• F ist Verteilungsfunktion der bivariaten Normalverteilung N2(0,ψ). Sie wird hier mit φρ bezeichnet.
• Gemäß (*) ergibt sich die Gauß-Copula als:
CρGa (u1 , u2) = φρ(φ -1(u1) , φ -1(u2))
• Sind anders herum die Gauß-Copula und die zwei normalverteiltenRisiken X und Y mit den Verteilungsfunktionen F1 und F2 undKorrelationskoeffizient ρ gegeben, ergibt sich:
F(x1 , x2) = CρGa (F1(x1) , F2(x2))
• Die Gauß-Copula ist genau diejenige Copula, die mehrere univariateNormalverteilungen zu einer multivariaten Normalverteilungzusammenführt.
2.4.1 Die Gauß-Copula
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 16

2.4.2 Die Gumbel-Copula
•Gegeben ist ein Parameter Θ Є [0,1].
•Die Gumbel-Copula ist dann gegeben als:
CΘGu (u1 , u2) = exp ( - ( ( - log u1 )1/Θ + ( - log u2 )1/Θ ))Θ )
•Modelliert man Abhängigkeit zwischen Zufallsvariablen mit derGumbel-Copula kann durch den Parameter Θ jede positive Abhängigkeitsstruktur zwischen Unabhängigkeit (Θ = 1) und perfekter Abhängigkeit (Θ → 0) abgedeckt werden.
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 17

3. Konzepte derAbhängigkeitsmodellierung
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 18
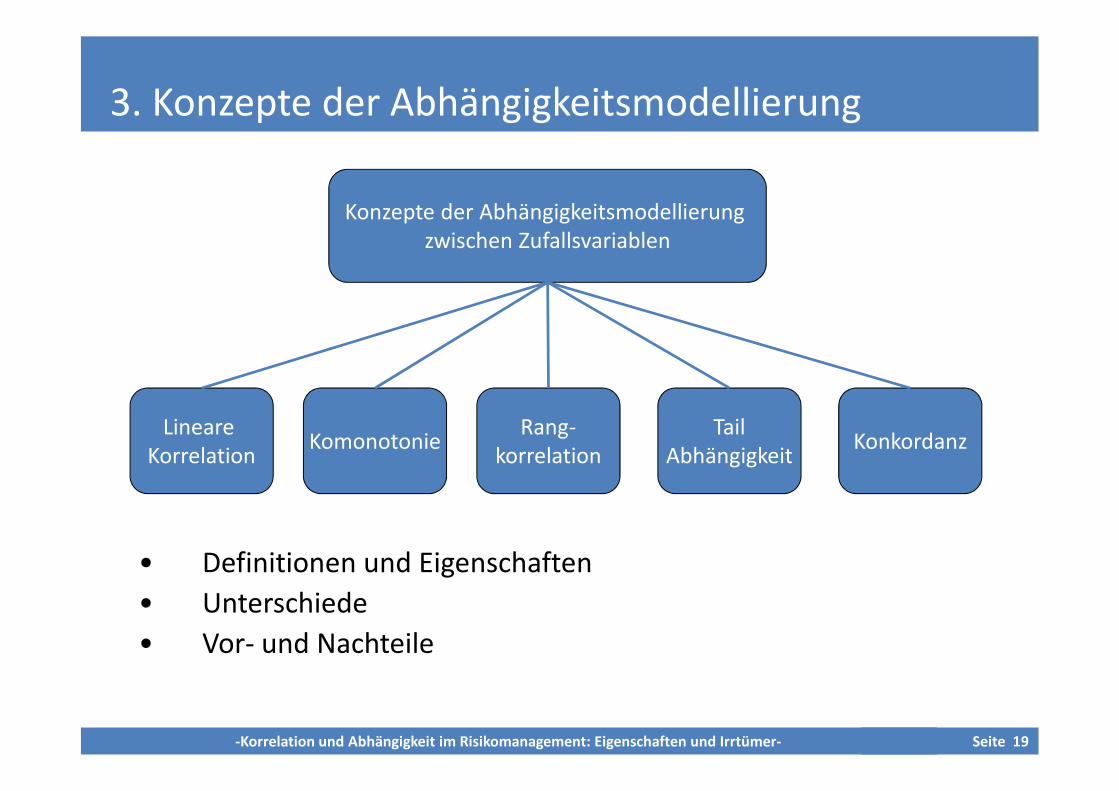
3. Konzepte der Abhängigkeitsmodellierung
• Definitionen und Eigenschaften
• Unterschiede
• Vor- und Nachteile
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 19
Konzepte der Abhängigkeitsmodellierungzwischen Zufallsvariablen
LineareKorrelation
KomonotonieRang-
korrelationTail
AbhängigkeitKonkordanz
3.1 Lineare Korrelation
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 20
Konzepte der Abhängigkeitsmodellierungzwischen Zufallsvariablen
LineareKorrelation
KomonotonieRang-
korrelationTail
AbhängigkeitKonkordanz

3.1.1 Definition der linearen Korrelation
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 21
Das am häufigsten verwendete Maß zur Modellierung von Abhängigkeiten.
Idee: Die Stärke des linearen Zusammenhangs zwischen zwei Zufallsvariablenin Form einer Maßzahl – dem linearen Korrelationskoeffizienten – ausdrücken.
Definition 3.1: Der Pearsonsche bzw. lineare Korrelationskoeffizient
zweier Zufallsvariablen X und Y (mit 0 < Var(X), Var(Y) <∞) ist definiert als:
ρ(X,Y) Є [-1,1]
ρ(X,Y) = 0: unkorrelierte Zufallsvariablen. Also kein linearerZusammenhang.
ρ(X,Y) = 1: perfekte lineare Abhängigkeit im positiven Sinn.
ρ(X,Y) = -1: perfekte lineare Abhängigkeit im negativen Sinn.
)()(
),(),(
YVarXVar
YXCovYX

3.1.2 Vor- und Nachteile der linearen Korrelation
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 22
Vorteile der linearen Korrelation:
• Einfach zu bestimmen (nur Berechnung zweiter Momente)
• Bestimmung der Korrelation von linear transformierten Zufallsvariablensehr elegant möglich, da für a,c Є \ {0} und b,d Є :
und daher:
D.h. insbesondere: lineare Korrelation invariant unter positiven affinenTransformationen.
• Für sphärische und elliptische Verteilungen kann die gesamteAbhängigkeitsstruktur zweier Zufallsvariablen über die Korrelationbeschrieben werden. Zu den elliptischen Verteilungen zählt auch dieNormalverteilung (daher viele Anwendungsgebiete wo die Benutzungder linearen Korrelation Sinn macht).
),(),( YXCovacdcYbaXCov
),(||||
),( YXc
c
a
adcYbaX

3.1.2 Vor- und Nachteile der linearen Korrelation
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 23
Nachteile der linearen Korrelation:
• Korrelationskoeffizient ist nur definiert falls eine Verteilung mitendlicher Varianz vorliegt. (z.B. Probleme für heavy-tailedVerteilungen).
• Lediglich Messung der linearen Abhängigkeit.
• Zwar invariant unter positiven affinen Transformationen abernicht invariant unter streng monoton steigendenTransformationen T. D.h. ρ(X,Y) ≠ ρ(T(X),T(Y)).
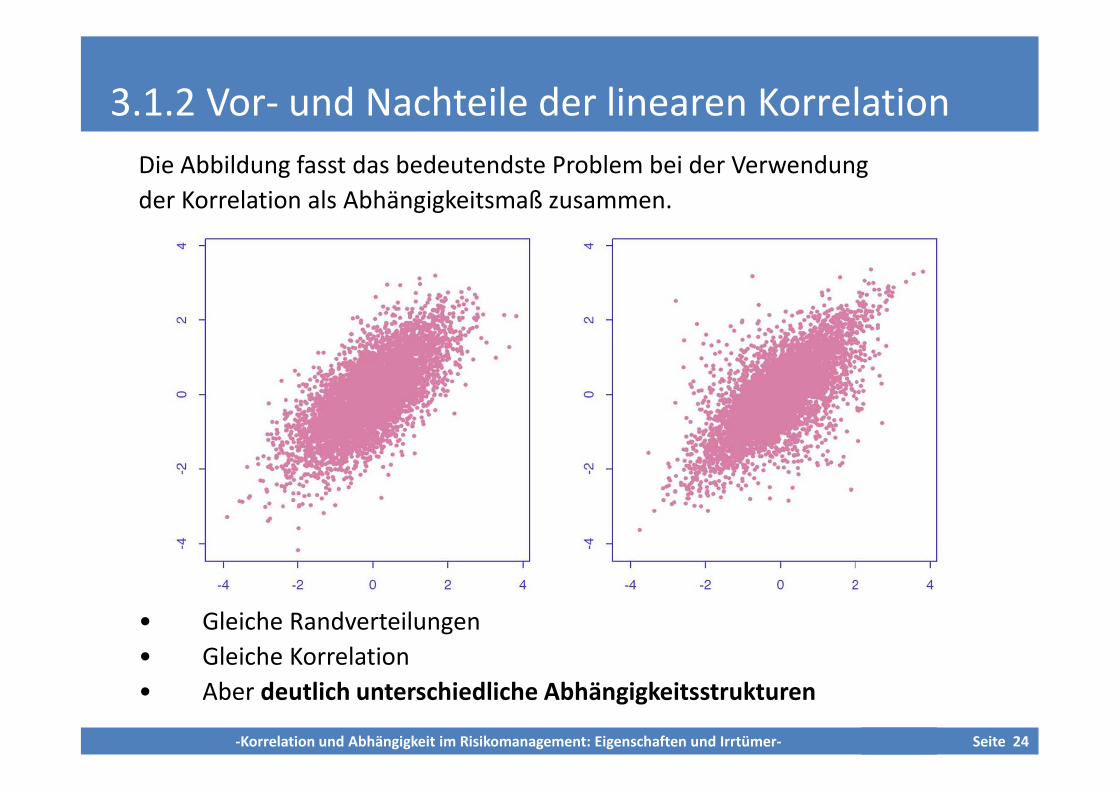
Die Abbildung fasst das bedeutendste Problem bei der Verwendung
der Korrelation als Abhängigkeitsmaß zusammen.
• Gleiche Randverteilungen
• Gleiche Korrelation
• Aber deutlich unterschiedliche Abhängigkeitsstrukturen
3.1.2 Vor- und Nachteile der linearen Korrelation
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 24

Exkurs: Sphärische und elliptischeVerteilungen
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 25

E.1 Sphärische Verteilungen
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 26
• Erweiterung der multivariaten Normalverteilung Nn(0,I).
• Klasse symmetrischer Verteilungen für unkorrelierte Zufalls-variablen mit Mittelwert 0.
Definition 3.2: Ein Zufallsvektor X = (X1 , … , Xn)‘ hat eine sphärischeVerteilung, wenn für jede orthogonale Matrix U Є n x n (also U’U =UU’ = In x n) die folgende Gleichung erfüllt ist:
UX =d X²
• A =d B bedeutet: ,,A besitzt dieselbe Verteilung wie B”.

E.1 Sphärische Verteilungen
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 27
Definition 3.3: Für alle t Є n ist die charakteristische Funktion φ : ℝ n →
einer n-dimensionalen Zufallsvariablen X definiert als:
φX(t) = E(exp(it‘X))
• Die charakteristische Funktion sphärischer Verteilungen nimmt einesehr einfache Form an, denn es existiert eine Funktion γ : 0
+ →
0+, sodass:
φ(t) = γ(t‘t) = γ(t1² + … + t2²).
• Die Funktion γ wird als charakteristischer Generator der sphärischen Verteilung bezeichnet. Man schreibt daher auch:
X ~ Sn(γ).

E.1 Sphärische Verteilungen
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 28
Bemerkungen zu sphärischen Verteilungen:
1. Sphärische Verteilungen sind i.A. Verteilungen unkorrelierter – nichtjedoch unabhängigker – Zufallsvariablen.
2. Die multivariate Normalverteilung ist die einzige Verteilung unter densphärischen Verteilungen, bei der die Zufallsvariablen auch unabhängigsind.
3. X ~ Sn(γ) ist äquivalent zu X =d RU, wobei U auf der Einheitskugel
Sn-1 = { x Є | x’x = 1 } gleichverteilt ist und R ≥ 0 eine von Uunabhängige Zuvallsvariable darstellt.
Die 3. Bemerkung ermöglicht eine Interpretation sphärischer Verteilungen als
n-dimensionale Gleichverteilung auf Umgebungen mit verschiedenen Radien.

E.2 Elliptische Verteilungen
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 29
• Erweiterung der multivariaten Normalverteilung Nn(μ,∑).
• Klasse symmetrischer Verteilungen mit Mittelwert μ und
Kovarianzmatrix ∑.
• Mathematisch gesehen: affine Transformationen sphärischerVerteilungen.
Definition 3.4: Sei eine affine Transformation T : n → n mit T(x) = Ax + μ, A Є n x n, μ Є n gegeben. Ein Zufallsvektor X Є n hat eine elliptischeVerteilung, falls X = T(Y), wobei Y ~ Sn(γ).
Die charakteristische Funktion ist gegeben als:
φ(t) = exp(it‘μ) γ(t‘ ∑ t),
mit ∑ = AA‘.
• Notation: X ~ En(μ , ∑ , γ)

E.2 Elliptische Verteilungen
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 30
Bemerkungen zu elliptischen Verteilungen:
1. Die Verteilung von X bestimmt nur μ ŝŶ�ĞŝŶĚĞƵƟŐĞƌ�t ĞŝƐĞ͘�є�ƵŶĚ�γ sindnur bis auf eine positive Konstante bestimmt.
2. Es ist möglich ∑ so zu wählen, dass sie die Kovarianzmatrix von Xdarstellt.
Insgesamt bedeutet dies:
Eine elliptische Verteilung ist eindeutig definiert durch:
• Mittelwert μ
• Kovarianzmatrix ∑
• Charakteristischer Generator γ
Insbesondere: Die Varianz einer elliptisch verteilten Zufallsvariablen ist
endlich der lineare Korrelationskoeffizient für solch eine Zufallsvariable ist
wohldefiniert.

Elliptische Verteilungen besitzen einige sehr nützliche Eigenschaften:
• Jede Linearkombination eines elliptisch verteilten Zufallsvektors ist selbst wiederelliptisch verteilt und besitzt sogar den selben charakteristischen Generator.
• Die Randverteilungen elliptischer Verteilungen sind ebenfalls elliptisch verteiltund besitzen den selben charakteristischen Generator.
• Sei die Kovarianzmatrix є�ĂůƐ�ƉŽƐŝƟǀ �ĚĞĮ Ŷŝƚ�ǀ ŽƌĂƵƐŐĞƐĞƚnjƚ͘ ��ĂŶŶ�ŝƐƚ�ĚŝĞ�ďĞĚŝŶŐƚĞ�Verteilung X1 unter X2 auch elliptisch verteilt – allerdings i.A. mit einem anderencharakteristischen Generator.
Alle Randverteilungen elliptisch Elliptische Verteilung eindeutig durch Mittelwert,
Kovarianzmatrix und Verteilungstypen bestimmt.
Anders ausgedrückt: Gesamte Abhängigkeitsstruktur stetiger, elliptischer Verteilungen
eindeutig festgelegt durch Korrelationsmatrix und Verteilungstypen.
Jegliche Form von Abhängigkeit wird für elliptisch verteilte
Zufallsvariablen komplett über den linearen
Korrelationskoeffizienten beschrieben.
E.3 Korrelation und Kovarianz als natürlicheAbhängigkeitsmaße in der Welt elliptischer Verteilungen
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 31

Elliptische Verteilungen begünstigen den Einsatz vieler mathematischer
Standard-Modelle. (Z.B. Markowitz-Modell und Value-at-Risk).
Konzentration auf Value-at-Risk (VaR):
• Gegeben sei ein elliptisch verteilter Zufallsvektor X = (X1 , … , Xn)‘,wobei Xi das Risiko i modelliert.
• Definiere die Menge linearer Portfolios, die aus diesen n Risikenbestehen als:
• Die Verteilungsfunktion von Portfolio Z ist gegeben durch FZ und derVaR zu vorgegebener Wahrscheinlichkeit α ist bekanntermaßen:
VaRα(Z) = FZ-1(α) = inf { z Є | FZ(z) ≥ α }
• VaR als Risikomaß besitzt für elliptische Verteilungen eine besondereEigenschaft.
E.4 Kovarianz und elliptische Verteilungen imRisikomanagement
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 32
}.R|{1
iii
n
i
XZ

E.4 Kovarianz und elliptische Verteilungen imRisikomanagement
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 33
Definition 3.5: Ein Risikomaß ist eine Funktion ξ mit: X ξ (X). D.h. ein Risikomaß ordnet jedem Risiko X eine reelle Zahl zu.
Definition 3.6: Ein kohärentes Risikomaß (nach Atzner, Delbaen, Eber undHeath) ist ein Risikomaß mit folgenden Eigenschaften:
1. Positivität: Für jedes X ≥ 0 ist: ξ(X) ≥ 0
2. Subadditivität: Für alle X und Y gilt: ξ(X + Y) ≤ ξ(X) + ξ(Y).
3. Positive Homogenität: Für jedes λ ≥ 0 ist: ξ(λX) = λξ(X).
4. Translationsinvarianz: Für jedes a Є gilt: ξ(X + a) = ξ(X) + a.
• Der VaR ist i.A. kein kohärentes Risikomaß, da er nicht subadditiv ist.
• Für elliptische Verteilungen erfüllt der VaR auch dieSubadditivitätseigenschaft und ist somit kohärent.
3.2 Alternative Abhängigkeitsmaße
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 34
Konzepte der Abhängigkeitsmodellierungzwischen Zufallsvariablen
LineareKorrelation
KomonotonieRang-
korrelationTail
AbhängigkeitKonkordanz
3.2.1 Komonotonie
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 35
Konzepte der Abhängigkeitsmodellierungzwischen Zufallsvariablen
LineareKorrelation
KomonotonieRang-
korrelationTail
AbhängigkeitKonkordanz

3.2.1 Komonotonie
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 36
Definition 3.7: Zwei Risiken X und Y werden komonoton genannt, wenn es eine
Zufallsvariable Z und zwei monoton steigende Funktionen f1 und f2 gibt, sodass:
X = f1(Z) und Y = f2(Z)
gilt. Wenn f1 eine monoton steigende Funktion ist und f2 monoton fällt, so spricht manvon kontramonotonen Zufallsvariablen.
• Die Entwicklung der beiden Risiken hängt komplett von einem einzigengemeinsamen Faktor ab.
• Komonotone Risiken können sich niemals ausgleichen extremste Formpositiver Abhängigkeit.
• Steigt das eine Risiko von zwei kontramonotonen Risiken, so sinkt das andereRisiko extremste Form negativer Abhängigkeit.
• Sind X und Y komonotone Zufallsvariablen, so gilt:
VaRα(X + Y) = VaRα(X) + VaRα(Y).

3.2.1.1 Fundamentale Copulas
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 37
Komonotonie und Kontramonotonie lassen sich – zumindest imZweidimensionalen – durch bestimmte Copulas modellieren. Zusammenmit der Unabhängigkeits-Copula bilden sie die fundamentalen Copulas.
Definition 3.8: Die Komonotonie-Copula Co wird für alle (u1,u2) Є [0,1]²definiert durch:
Co(u1,u2) = min(u1,u2).
Definition 3.9: Die Kontramonotonie-Copula Cu wird für alle (u1,u2) Є [0,1]²definiert durch:
Cu(u1,u2) = max(u1 + u2 -1 , 0).
Definition 3.10: Die Unabhängigkeits-Copula Cid wird für alle (u1,u2) Є [0,1]² definiert durch:
Cid(u1,u2) = u1 ∙ u2 .

3.2.1.2 Die Schranken von Fréchet
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 38
• Perfekte negative Abhängigkeit, Unabhängigkeit, perfekte positiveAbhängigkeit lassen sich mit fundamentalen Copulas darstellen.
• Sie stehen zu vielen anderen Copulas in einer interessanten Beziehung.(z.B. Gumbel-Copula: ,,interpoliert” zwischen Unabhängigkeits- undKomonotonie-copula).
Eine weitere wichtige Beziehung liefern die Fréchet-Schranken.
Satz 3.2: Für jede n-dimensionale Copula C(u1, … , un) gilt:
max {u1 + … + un + 1 – n , 0} ≤ C(u1, … , un) ≤ min {u1, … , un}.
• Im zweidimensionalen Fall gilt also genau: Cu ≤ C(u1, u2) ≤ Co.
• Für höhere Dimensionen sind die Schranken ähnlich zu interpretieren,aber die untere Schranke ist keine Copula mehr.
• Komonotonie ist eine sehr viel allgemeinere Definition vonAbhängigkeit als die lineare Korrelation. Sie erfasst nicht nur linearesondern jede Form von (perfekter) Abhängigkeit.
3.2.2 Rangkorrelation
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 39
Konzepte der Abhängigkeitsmodellierungzwischen Zufallsvariablen
LineareKorrelation
KomonotonieRang-
korrelationTail
AbhängigkeitKonkordanz

3.2.2 Rangkorrelation
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 40
Definition 3.11: Seien X und Y Zufallsvariablen mit den Randverteilungen F1
und F2 sowie F ihre gemeinsame Verteilungsfunktion. Der SpearmanscheRangkorrelationskoeffizient von X und Y ergibt sich als:
ρS(X,Y) = ρ(F1(X),F2(Y)) ,
wobei ρ den linearen Korrelationskoeffizienten bezeichnet.
Definition 3.12: Seien (X1,Y1)‘ und (X2,Y2)‘ zwei unabhängige Paare vonZufallsvariablen und F ihre gemeinsame Verteilungsfunktion. Der KendallscheRangkorrelationskoeffizient von X und Y ergibt sich als:
ρτ(X,Y) = P((X1 – X2)(Y1 – Y2) > 0) – P((X1 – X2)(Y1 – Y2) < 0) .
Sowohl der Spearmansche, als auch der KendallscheRangkorrelationskoeffizient messen den Grad monotoner Abhängigkeit.

3.2.2 Rangkorrelation
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 41
Satz 3.3: Seien X und Y Zufallsvariablen
mit den Randverteilungen F1 und F2 ,
gemeinsamer Verteilungsfunktion F sowie
Copula C. Dann gilt:
1. ρS(X,Y) = ρS(Y,X) und ρτ(X,Y) = ρτ(Y,X)
2. X und Y unabhängig ρS(X,Y) = ρτ(X,Y) = 0
3. -1 ≤ ρS(X,Y) , ρτ(X,Y) ≤ +1
4.
5.
6. ρS und ρτ sind invariant unter streng
monotonen Transformationen T : → :
7. ρS(X,Y) = ρτ(X,Y) = 1 ⇔ C = Co
8. ρS(X,Y) = ρτ(X,Y) = -1 C = Cu
1. , 2. und 3. sind vom linearen
Korrelationskoeffizienten bekannt.
Die übrigen Punkte werden vom linearen
Korrelationskoeffizienten nicht erfüllt.
Größter Vorteil der Rangkorrelation
gegenüber linearer Korrelation:
Rangkorrelationskoeffizienten
hängen nur von der Copula ab (4.
und 5.) sie sind invariant unter
streng monotonen Transformationen.
Größter Nachteil der Rangkorrelationgegenüber linearer Korrelation:Keine momentbasierte Korrelation.
1
01),(),(4),( vudCvuCYXS
1
0)),((12),( dxdyyxyxCYXS
,
fallendTfalls),,(
steigendTfalls),,()),(( S
YX
YXYXT
3.2.3 Tail Abhängigkeit
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 42
Konzepte der Abhängigkeitsmodellierungzwischen Zufallsvariablen
LineareKorrelation
KomonotonieRang-
korrelationTail
AbhängigkeitKonkordanz
3.2.3 Tail Abhängigkeit
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 43
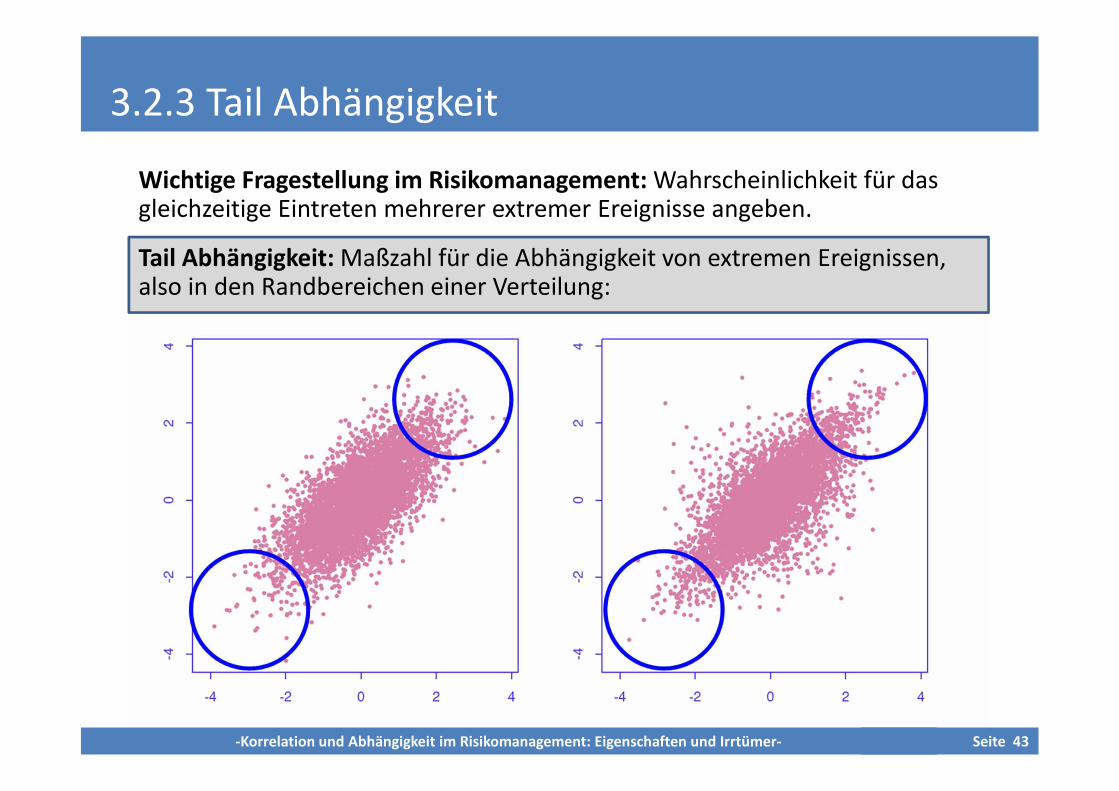
Wichtige Fragestellung im Risikomanagement: Wahrscheinlichkeit für dasgleichzeitige Eintreten mehrerer extremer Ereignisse angeben.
Tail Abhängigkeit: Maßzahl für die Abhängigkeit von extremen Ereignissen,also in den Randbereichen einer Verteilung:

3.2.3.1 Definition der Tail Abhängigkeit
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 44
Frage: „Wie hoch ist die bedingte Wahrscheinlichkeit, dass Risiko X höchstens zu einemVerlust von a führt, unter der Bedingung, dass Risiko Y höchstens einen Verlust von berleidet?“
Also:
Bei bekannter Copula C kann nach dem Satz von Sklar eine gemeinsame Verteilungs-funktion F gefunden werden, die F1 bzw. F2 als Randverteilungen hat:
O.B.d.A. treten die Ereignisse X ≤ a und Y ≤ b mit derselben Wahrscheinlichkeit α ein,also:
Und wegen der Stetigkeit der Randverteilungen gilt:
Es gilt also:
.)(
),()|(
bYP
bYaXPbYaXP
.)(
))(),(()|(
2
21
bF
bFaFCbYaXP
.)()(und)()(21
bFbYPaFaXP
).(und)( 1
2
1
1 FbFa
.),(
))((
)))(()),((()|(
122
122
111
C
FF
FFFFCbYaXP

3.2.3.1 Definition der Tail Abhängigkeit
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 45
Eine zweite interessante Frage lautet: „Wie hoch ist die bedingte Wahrscheinlichkeit,dass Risiko X einen sehr hohen Verlust erleidet (X > a), unter der Bedingung, dass auchRisiko Y einen sehr hohen Verlust verursacht hat (Y > b)?“ Also:
Äquivalent zu oben:
Sowie aufgrund der Stetigkeit der Randverteilungen:
Damit folgt in Copula-Schreibweise:
.)(1
),()()(1
)(
),()|(
bYP
bYaXPbYPaXP
bYP
bYaXPbYaXP
.)()(und)()(21
bFbYPaFaXP
).(und)( 1
2
1
1 FbFa
.)(1
),()()(1
)|(),(
bYP
bYaXPbYPaXP
bYaXPC

3.2.3.1 Definition der Tail Abhängigkeit
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 46
Definition 3.13 und Definition 3.14: Seien X und Y zwei stetige Zufallsvariablen. Beibekannter Copula C ergeben sich der untere Tail-Abhängigkeitskoeffizient λL bzw. derobere Tail-Abhängigkeitskoeffizient λU als:
wenn der Grenzwert existiert und λL , λU Є [0,1] ist.
λL = 0: asymptotische Unabhängigkeit im unteren Tail.
λU = 0: asymptotische Unabhängigkeit im oberen Tail.
λL Є (0,1]: Abhängigkeit im unteren Tail.
λU Є (0,1]: Abhängigkeit im oberen Tail.
Je größer λL (bzw. λU) ist, desto größer ist die Abhängigkeit im unteren (bzw.oberen) Tail.
Die Tail Abhängigkeit ist invariant unter streng monoton steigendenTransformationen.
Abhängigkeiten in den Tails werden durch unterschiedliche Copulasunterschiedlich modelliert. Bei Auswahl eines Copula-Modells wichtig.
1
),(21lim
),(lim
10
CCUL und
3.2.4 Konkordanz
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 47
Konzepte der Abhängigkeitsmodellierungzwischen Zufallsvariablen
LineareKorrelation
KomonotonieRang-
korrelationTail
AbhängigkeitKonkordanz

3.2.4 Konkordanz
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 48
Hier: Nicht Stärke der Abhängigkeit zwischen Zufallsvariablen X und Y messensondern feststellen, ob die Abhängigkeit zwischen positiv ihnen (Konkordanz)oder negativ (Diskordanz) ist.
Zentrale Frage: „Wie ist positive (bzw. negative) Abhängigkeit definiert?“
1. Möglichkeit: Der Zusammenhang zwischen X und Y ist genau dannpositiv, wenn ρ(X,Y) > 0 (oder ρS(X,Y) > 0 bzw. ρτ(X,Y) > 0) ist.
In der Regel wird positive Abhängigkeit jedoch anders definiert!
2. Möglichkeit: Der Zusammenhang zwischen X und Y ist genau dannpositiv, wenn X und Y positiv quadrant abhängig (PQA) sind.
3. Möglichkeit: Der Zusammenhang zwischen X und Y ist genau dannpositiv, wenn X und Y positiv assoziiert (PA) sind.

Definition 3.15: Zwei Zufallsvariablen X und Y werden positiv quadrant abhängig (PQA)genannt, wenn für alle x,y Є gilt:
P(X ≤ x , Y ≤ y) ≥ P(X ≤ x) ∙ P(Y ≤ y).
• Positive quadrant Abhängigkeit ist geeignet um positive Abhängigkeit zwischen X und Yauszudrücken, da X und Y mit höherer Wahrscheinlichkeit beide große(bzw. kleine) Werte annehmen als im Falle der Unabhängigkeit zwischen X und Y.
• Wird die Ungleichung in Definition 3.15 umgekehrt, spricht man von negativquadrant abhängigen Zufallsvariablen.
Definition 3.16: Zwei Zufallsvariablen X und Y werden positiv assoziiert (PA) genannt,wenn für alle reellwertigen, messbaren Funktionen g1 und g2 , die monoton steigend inbeiden Komponenten sind und für die die nachfolgenden Erwartungswerte definiertsind, gilt:
E(g1(X,Y) ∙ g2(X,Y)) ≥ E(g1(X,Y)) ∙ E(g2(X,Y)).
3.2.4 Konkordanz
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 49

3.2.4 Konkordanz
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 50
Die obige Definition für (PA) ist äquivalent zu: Cov( g1((X,Y) , g2((X,Y) ) ≥ 0.Daran wird deutlich, warum die Positive Assoziation ein geeignetesKonzept ist, um positive Abhängigkeit zwischen X und Y zu beschreiben.
Wird die Ungleichung in Definition 3.16 umgekehrt, spricht man vonnegativ assoziierten Zufallsvariablen.
(PQA) und (PA) sind invariant unter streng monoton steigendenTransformationen.
(PQA) und (PA) sind stärkere Abhängigkeitsbedingungen als die dreibekannten Korrelationskoeffizienten. Folgende Darstellung verdeutlichtdies und zeigt gleichzeitig, dass Komonotonie die stärkste Form vonKonkordanz also positiver Abhängigkeit ist:
Komonotonie (PA) (PQA) ρ(X,Y) ≥ 0 , ρS(X,Y) ≥ 0 , ρτ(X,Y) ≥ 0

4. Irrtümer bzgl. Korrelation undAbhängigkeit
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 51

„Die gemeinsame Verteilungsfunktion F kann mithilfe derRandverteilungen F1 und F2 und der Korrelation zwischen denZufallsvariablen X und Y bestimmt werden.“
Die Aussage gilt für elliptische Verteilungen. Im Allgemeinen jedoch nicht!
Gegenbeispiel:
Betrachte zwei verschiedene gemeinsame Verteilungen mit Gamma(3,1)-Randverteilungen und derselben Korrelation ρ = 0,7. Dies ist sowohl mit derGauß- als auch mit der Gumbel-Copula konstruierbar.
Während die Gauß-Copula keine Tail-Abhängigkeiten aufweist, ist die Gumbel-Copula für θ < 1 asymptotisch abhängig.
4.1 Irrtum 1
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 52
))(),((),(und))(),((),( 1,31,31,31,3 yGxGCyxFyGxGCyxF GuGu
GaGa
.54,071,0 undmit

4.1 Irrtum 1
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 53
Um dies zu verdeutlichen betrachte für beide Modelle:
P(X > u | Y > u), mit u = VaR0,99(X) = VaR0,99(Y) = G3,1-1(0,99).
Empirische Schätzungen liefern:
PFGa
(X > u | Y > u) = 1/3 und PFGu
(X > u | Y > u) = 3/4
Gumbel-Modell: gemeinsame extrem hohe Verluste sind wahrscheinlicher alsim Gauß-Modell. weniger Diversifikation!
Analytische Aussage über den VaR der Summe X + Y unter den beiden Modellenzu treffen ist schwierig. Aber Simulationen belegen, dass das Gumbel-Modelleine höhere Anzahl an großen Resultaten für den VaR liefert.
Entscheidender Unterschied der Modelle bei Einschätzung extremer Verluste(der sich in den Randverteilungen und der Korrelation nicht bemerkbar macht).

4.2 Irrtum 2
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 54
“Seien F1 und F2 gegeben. Die lineare Korrelation zwischen X und Ykann – bei einer geeigneten Spezifikation von F – alle Korrelationenzwischen -1 und 1 annehmen.”
Diese Aussage ist falsch!
Gegenbeispiel:
• Betrachte: X ~ LN(0,1) und Y ~ LN(0,σ²), mit σ > 0.
• Was ist der minimale (ρmin) bzw. maximale (ρmax) Wert, den dieKorrelation bei diesen Randverteilungen annehmen kann?
• Da ρmin = ρ(eZ,e –σZ ) und ρmax = ρ(eZ,eσZ), mit Z ~ N(0,1) gilt, ist eineanalytische Lösung möglich:
)1()1(
1
)1()1(
122 maxmin
ee
e
ee
eund
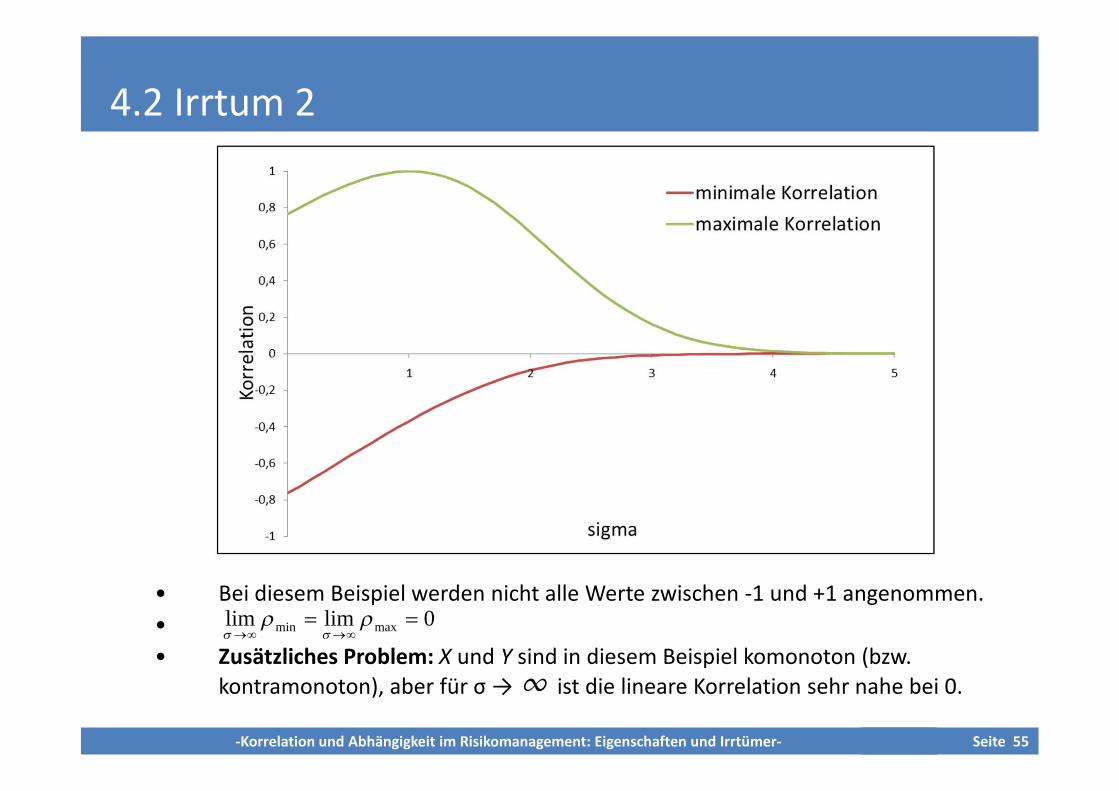
4.2 Irrtum 2
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 55
• Bei diesem Beispiel werden nicht alle Werte zwischen -1 und +1 angenommen.
•
• Zusätzliches Problem: X und Y sind in diesem Beispiel komonoton (bzw.kontramonoton), aber für σ → ∞ ist die lineare Korrelation sehr nahe bei 0.
0limlim maxmin

“Der Value-at-Risk eines linearen Portfolios X + Y wird am größten,wenn ρ(X,Y) maximal ist, also wenn X und Y komonoton sind.“
Wir wissen:
1. Für zwei komonotone Zufallsvariablen X und Y gilt:
VaRα(X + Y) = VaRα(X) + VaRα(Y).
2. Für elliptische Verteilungen erfüllt der VaR die Subadditiätseigenschaft, also
VaRα(X + Y) ≤ VaRα(X) + VaRα(Y).
3. Für nicht-elliptische Verteilungen erfüllt der VaR dieSubadditiätseigenschaft nicht, d.h. es existieren X und Y, s.d.
VaRα(X + Y) > VaRα(X) + VaRα(Y).
Die obige Aussage gilt also i.A. nicht, für elliptische Verteilungen ist sie jedochkorrekt.
4.3 Irrtum 3
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 56

4.3 Irrtum 3
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 57
Beispiel, bei dem sich der Value-at-Risk sehr interessant verhält:
• Betrachte zwei unabhängige Zufallsvariablen X und Y mit derselben Verteilung:
F1/2 = 1 – x -1/2, mit x ≥ 1.
• Hierbei handelt es sich um eine extreme heavy-tailed Verteilung ohne endlichenMittelwert.
• Betrachte nun die beiden Risiken: X + Y (unabhängig) sowie 2X (komomoton).
• Es lässt sich abschätzen, dass für z > 2 gilt:
• Damit folgt: VaRα(X + Y) > VaRα(2X) = VaRα(X) + VaRα(Y).
• Hier: aus Sicht des VaR Unabhängigkeit schlechter als perfekte positiveAbhängigkeit - ganz unabhängig von der Wahl von α.
keinerlei Diversifikationseffekt, sondern es ist sogar besser zwei „gleiche“Risiken einzugehen.
)2(12
1)( zXPz
zzYXP

5. Fazit
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 58
5. Fazit
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 59
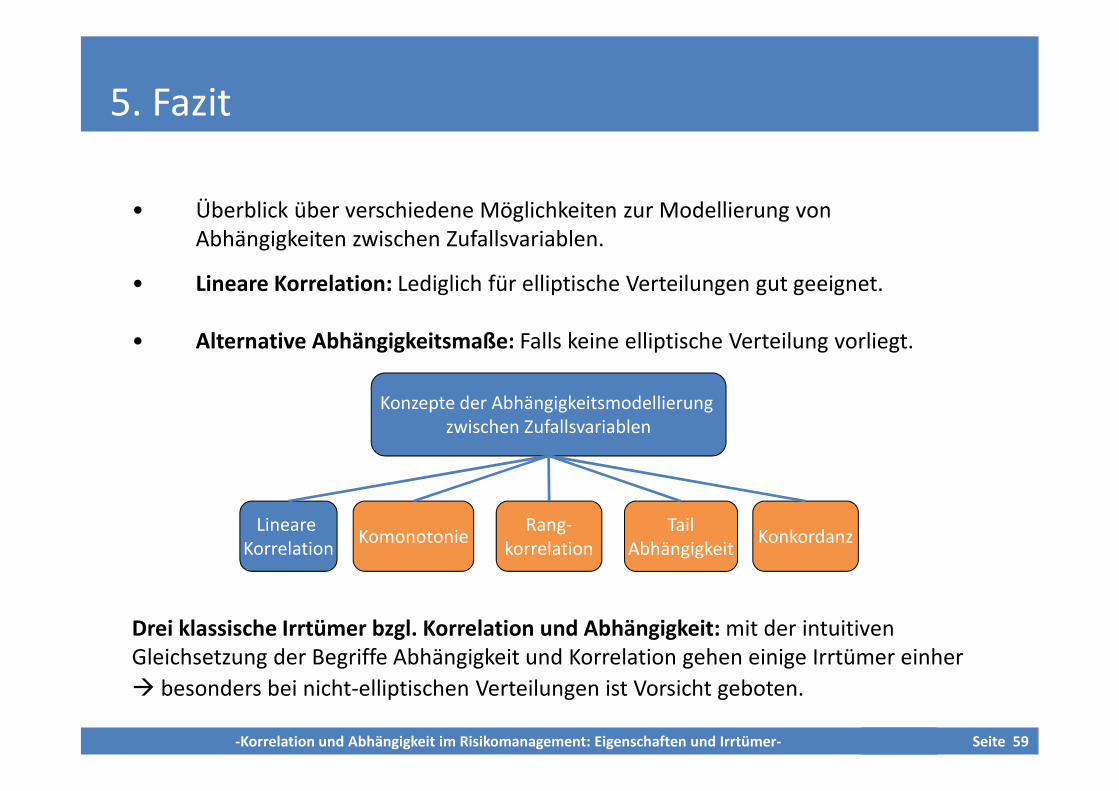
• Überblick über verschiedene Möglichkeiten zur Modellierung vonAbhängigkeiten zwischen Zufallsvariablen.
• Lineare Korrelation: Lediglich für elliptische Verteilungen gut geeignet.
• Alternative Abhängigkeitsmaße: Falls keine elliptische Verteilung vorliegt.
Drei klassische Irrtümer bzgl. Korrelation und Abhängigkeit: mit der intuitivenGleichsetzung der Begriffe Abhängigkeit und Korrelation gehen einige Irrtümer einher
besonders bei nicht-elliptischen Verteilungen ist Vorsicht geboten.
Konzepte der Abhängigkeitsmodellierungzwischen Zufallsvariablen
LineareKorrelation
KomonotonieRang-
korrelationTail
AbhängigkeitKonkordanz

Vielen Dank für IhreAufmerksamkeit!
-Korrelation und Abhängigkeit im Risikomanagement: Eigenschaften und Irrtümer- Seite 60





























