Embed Size (px)
Citation preview

45
1.1.3. Die Repräsentation des Sprachsignals Bei der automatischen Erkennung gesprochenerSprache kommt es darauf an, im Sprachsignalbestimmte, für einzelne Laute (oder Laut-verbindungen) charakteristische Muster zufinden. Diese lassen sich sowohl verbal alsauch optisch/graphisch als auch elektronischbeschreiben. Letzteres bedeutet, daß man dieMuster elektronisch als Referenz für dieErkennung von Lauten realisieren kann.
Für die Sprachsynthese sind diese Repräsen-tationen als physikalische Eingabegrößen fürden akustischen Synthetisator unmittelbareinzusetzen. Allerdings kann man die Syn-these auch dadurch realisieren, daß dieLaute durch einen Sprecher erzeugt, dannentsprechend adaptiert (Übergänge in ver-schiedenen Varianten) und so gespeichertwerden.
Vokoide:Sie sind durch die Lage ihrer Formantengekennzeichnet. Diese können als konstanteFunktionen angenommen werden.
Kontoide:Sie sind durch den zeitabhängigen Verlaufihrer Formanten gekennzeichnet.

46
Für beide Klassen hat man die Übergänge zwi-schen den einzelnen Lauten zusätzlich zumodellieren. Bei Kontoiden (speziell Ver-schlußlauten) sind relativ kurze Veränderun-gen charakteristisch, bei denen die Forman-ten eine hohe Intensität haben.
Beispiele für Vokoide:
Die Formanten der Vokoide hängen zusätzlichvon weiteren Faktoren ab, etwa dem Sprech-tempo und der Betonung (von dem phonolo-gischen Merkmal der Länge ohnehin, da diesgenerell mit Qualitätsunterschieden verbun-den ist).
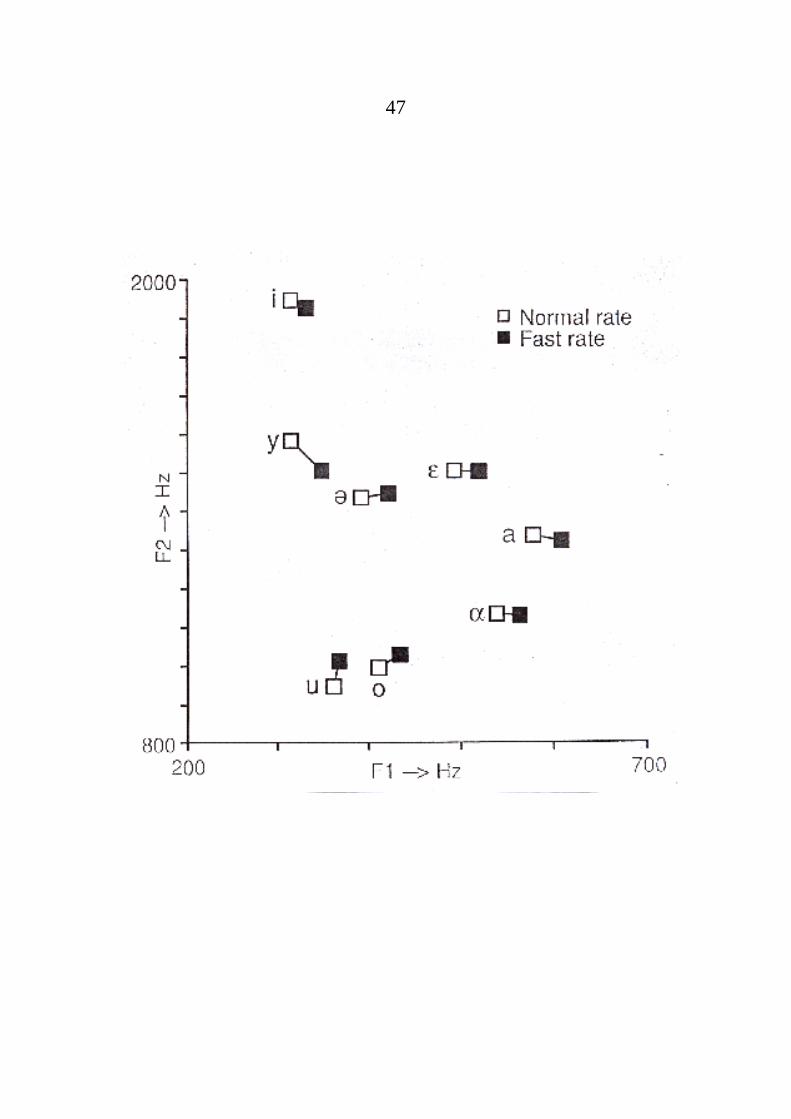
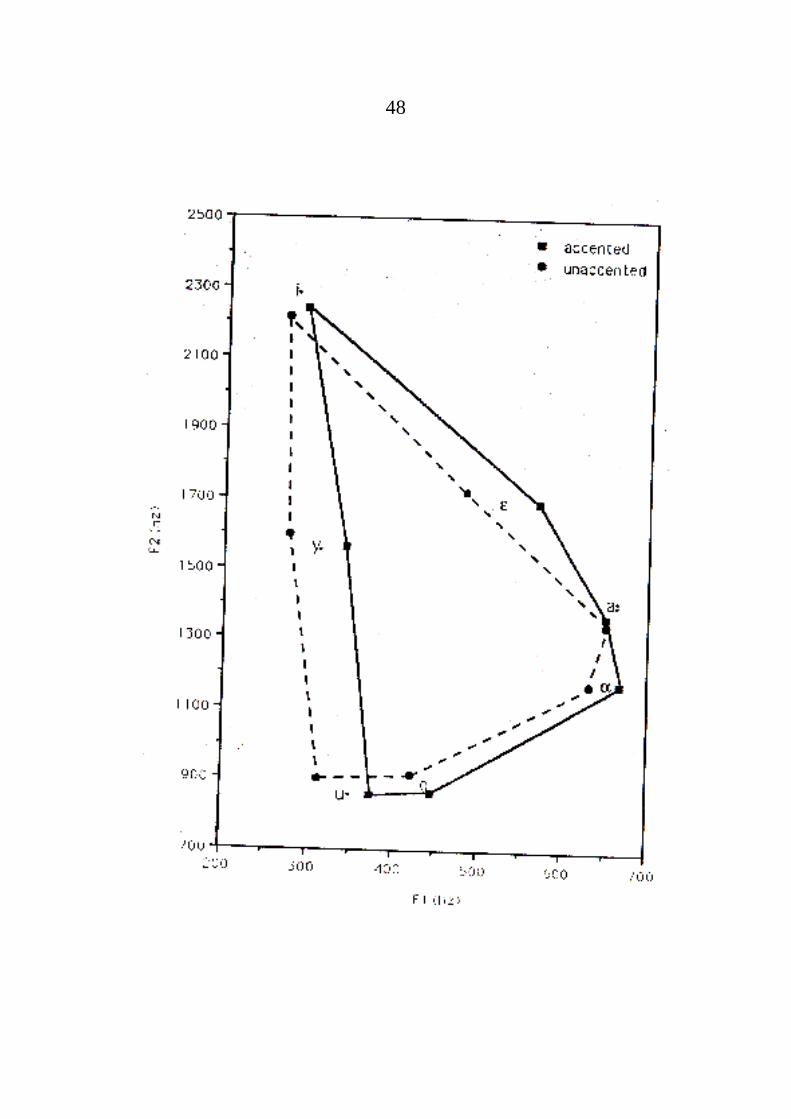
Die folgenden Seiten zeigen die Differenzen der Formanten F1 und F2 für die genanntenFaktoren (Phoneme des Engl.). Dabei zeigtsich (überraschenderweise?), daß schnellesSprechen die gleiche Tendenz wie Betonunghervorruft, nämlich einen höheren Wert fürF1. Die Tabellen stammen aus verschiedenenQuellen (s. die absoluten Werte!).
47
48

49

50
Beispiele für Vokoide:
Zur Darstellung für das engl. Phonem /r/ aufder vorangehenden Folie:
Die Spektraldarstellung beruht auf 54 Koef-fizienten, die das Intervall von 63 Hz bis6093 Hz abdecken. Jeder Koeffizient beziehtsich auf eine Bandbreite von 250 Hz, miteiner Überlappung von 125 Hz:
- - 125 Hz- - z z
- y - y
x - x
-n n+1 n+2 t
Ein besonderer Algorithmus `errät' die For-manten und ermittelt ihren Verlauf in derZeit (durchgezogene Linien).

51
Für das ndl. Phonem \l\ in initialer Posi-tion werden z.B. folgende Parameter als`default specifications' zur Syntheseangenommen (VAN HEUVEN/POLS 1993: 166f.):
Gesamtdauer := 65 msDauer des Anfangsübergangs- für die meisten Parameter := 10 ms- für Formant F1 := 10 ms
Dauer des Schlußübergangs- für die meisten Parameter := 10 ms- für Formant F2 := 10 ms
/l/: ___/[+voc, +front, +unrounded]
F1: Frequenz F1: 300 HzBandbreite F1 := 120 Hz
F2: Frequenz F2 := 1700 HzBandbreite F2 := 120 Hz
F3: Frequenz F3 := 2500 HzBandbreite F3 := 200 Hz
F4: Frequenz F4 := 3300 HzBandbreite F4 := 400 Hz

52
Daraus wird abgeleitet:
/l/: ___/[+voc, +back]
F1: Frequenz F1: 300 HzBandbreite F1 := 120 Hz
F2: Frequenz F2 := 1500 HzBandbreite F2 := 120 Hz
F3: Frequenz F3 := 1700 HzBandbreite F3 := 200 Hz
F4: Frequenz F4 := 3300 HzBandbreite F4 := 400 Hz
/l/: ___/[+voc, +round]
F1: Frequenz F1: 300 HzBandbreite F1 := 120 Hz
F2: Frequenz F2 := 1500 HzBandbreite F2 := 120 Hz
F3: Frequenz F3 := 1700 HzBandbreite F3 := 200 Hz
F4: Frequenz F4 := 2500 HzBandbreite F4 := 400 Hz
Diese Allophone kann man als "Maschinen-

53
phoneme" auffassen.
Für das ndl. Phonem /l/ ergeben sich starkunterschiedliche Allophone je nach den umge-benden Vokalen, die durch Koartikulationbewirkt werden (VAN HEUVEN/POLS 1993: 303):

54
Fazit:
Das Sprachsignal ist physikalisch eine inder Zeit veränderliche Frequenz-Energie-Ver-teilung: Zu jedem Zeitpunkt t ist eine Ver-teilung von "Intensitäten" (physikalisch:Energien) auf die Frequenzen s gegeben: F(f,t) = ADie Frequenz f hat zum Zeitpunkt t die In-tensität A.
Die einzelnen Laute einer Sprache haben cha-rakteristische Verteilungsabläufe dieserArt. Eine mit dem Sprachsignal gegebeneFunktion F über einem Zeitintervall T istdaher in solche Abläufe zu zerlegen, wodurchman dann eine Lautkette erhalten kann. Dabeigilt jedoch:
1. Die Abläufe sind zeitlich relativ zu be-trachten, man muß eine Gummi-Zeitachse ver-wenden, damit man Sprachsignal und Abläufeaufeinander abbilden kann. Es ist notwendig,die Abläufe als Folgen von Zuständen darzu-stellen und die zeitlichen Verhältnissegroßzügiger zu handhaben. Die "vor-nach"-Be-ziehung bleibt natürlich bestehen. ImSprachsignal sind also gewisse Zustände zusuchen, die in gewisser Weise aufeinanderfolgen.

55
2. Die Funktion F braucht nur für einen Aus-schnitt des Frequenzbereichs betrachtet zuwerden (etwa bis 6 kHz). Außerdem wird die-ser Frequenzbereich in Bänder aufgeteilt,und die Intensität wird pro Band ermittelt.Ein Band ist noch keine Lokalisierung be-stimmter Abläufe, sie können je nach Spre-cherIn weiter oben oder unten (d.h. in ver-schiedenen Bändern) liegen. Außer den Band-filtern gibt es noch andere (mathematische)Verfahren zur Ermittlung der einzelnen Merk-male. Insgesamt wird die Frequenz-Energie-Verteilung durch einen Vektor erfaßt, deraus 10 bis 30 Zahlen besteht, und die Ver-änderung dieser Zahlen in der Zeit ist das,was vom Sprachsignal bleibt.
3. Die Funktion F kann natürlich auch nichtfür jedes einzelne t ermittelt werden. Manführt daher Abtastintervalle ein, die soklein sind, daß sich in jedem einzelnen vonihnen keine wesentliche Veränderung voll-zieht, die nicht auch bei Mittlung über die-se Intervalle erkennbar wäre. Es liegt somitein der Aufgabe angepaßtes Zeitraster vor.Als Länge dieser Intervalle wird etwa 10 msangenommen, d.h. pro Sekunde werden etwa 100Messungen durchgeführt.

56
Die eigentliche Funktion F wird in dem Meß-verfahren durch eine andere Funktion appro-ximiert, bei der statt der Frequenzen Bänderund statt der Zeitpunkte kleine Intervalleauftreten. Auf dieser Funktion beruht danndie Berechnung der Vektoren. Insgesamt fin-det eine mehrfache Reduktion der Datenstatt.
Aus den Folgen der Vektoren werden die Merk-male gewonnen, die etwas über die akusti-schen Ereignisse in Folgen von Zeitinterval-len besagen. Diese werden dann mit gegebenenMustern verglichen, die die Merkmalsabläufefür bestimmte Einheiten repräsentieren(subword units). Dieser Prozeß (patternmatching oder pattern recognition) ist einganz wesentlicher Schritt bei der Sprach-erkennung, der über die Effektivität desGesamtverfahrens entscheidet. Insbesondereliegt hier ein Einsatzfeld für Lernalgorith-men über statistische Daten.
Wie man die skizzierten Gegebenheiten exaktbehandelt, wird bei den HMM's beschrieben.

57
1.1.4. Perzeptive (auditive) Phonetik
Im Gegensatz zur artikulatorischen Phonetikbeschäftigt sich die auditive Phonetik mitdem `Eindruck', den das Sprachsignal beimHörer hervorruft. Schon die dafür verwende-ten Termini (meist Metaphern) zeigen, daßdarauf aufbauende Klassifikationen nicht dasleisten, was die artikulatorische Beschrei-bung ermöglicht.
Engl. Beispiel: /l/ hat zwei Allophone:
auditiv: artikulatorisch:dunkel velarhell palatal
Wie grenzt man auditiv den ach-/ich-Laut ab?
Ziemlich hilflos ist man erst recht bei derauditiven Unterscheidung der Vokale.
Man kann daher die artikulatorische Klassi-fizierung nicht durch eine "ohrenphoneti-sche" ersetzen, zumal die Vorgänge in denHörorganen weit schlechter zugänglich sindals die der Artikulationsorgane, sie sindaußerdem nicht gesteuert/aktiv. Gelegentlich

58
kann man die auditiven Merkmale jedoch mitNutzen verwenden.
1.2. Einiges zur Phonologie
Während die Phonetik die Sprachlaute prinzi-piell unabhängig von den Einzelsprachenbetrachtet, geht es bei der Phonologie umdie einzelsprachenbezogene Untersuchung derLaute. Im ersten Fall wird auch von Phonengesprochen, während die sprachbezogene Klas-sifizierung der Laute zu Phonemen führt.
Der Begriff Phonem ist schon über 100 Jahrealt (Baudouin de Courtenay 1895: "psycholo-gisches Äquivalent des Sprachlautes", worinschon der trans-akustische Inhalt zum Aus-druck kommt). Die Phonologie in ihrer heuti-gen Ausprägung ist jünger (Prager Schule,etwa 1930; strukturalistische Ansätze, Chom-sky/Halle 1968). Nach moderner Auffassungwir das Phonem funktional definiert in demSinne, daß durch verschiedene Phoneme Bedeu-tungen (innerhalb einer Sprache) differen-ziert werden (s.u.). Eine artikulatorischeoder auditive Ähnlichkeit/Abgrenzung istdabei zunächst nicht im Spiel (abgesehen vonder scheinbaren Trivialität, das man rele-vante Unterschiede auch hören können muß,doch s.u.!).

59
Im Dt. sind [v] und [b] verschiedene Pho-neme, da es Paare wie Wein vs. Bein; Wall vs. Ball etc. gibt.
Im Span. dagegen spielt dieser Unterschiedkeine Rolle, das Auftreten von [â] (in etwa[v]) und [b] ist positionsbedingt:[â]: intervokalisch in Wort und Satz[b]: im absoluten Anlaut und nach NasalDie Schreibung v oder b ist irrelevant.[â] [b]noventaLa Habanay Barcelona en Barcelonay Valencia en Valencia
BarcelonaValencia
Somit gehören [â] und [b] zu einem Phonem.
Im Dt. gibt es das dunkle /l/ [»] höchstensin Dialekten, das Phonem wird durch dashelle [l] realisiert.
Im Russ. ergibt dieser Unterschied zweiPhoneme:[dal]: `Weite, Ferne' [da»]: `(er) gab'

60
Im Engl. handelt es sich um zwei positions-bedingte Varianten eines Phonems: [l]: prävokalisch (little)[»]: präkonsonantisch und final (colt, little)
Zungenspitzen-/r/ (gerollt oder ein Schlag)und Zäpfchen-/r/ bewirken im Dt. keinenBedeutungsunterschied, obwohl sie phonetischsehr verschieden sind. Es handelt sich nichtum positionsbedingte Varianten des Phonems/r/, wenngleich das gerollte /r/ im Anlauthäufiger vorkommen mag als sonst. Es liegenfakultative (oder freie) Varianten vor.
[x] und [ç] sind im Dt. positionsbedingteAllophone eines Phonems. Dieses Beispielzeigt auch, daß man die oben angedeuteteDefinition des Phonems präzisieren muß:Einerseits kann man die Bedingung für dieAuswahl zwischen [x] und [ç] nur unterBerücksichtigung der Morphemgrenzen zutref-fend formulieren, zum anderen soll sich diebedeutungsdifferenzierende Funktion auf diekleinsten bedeutungstragenden Einheiten -eben die Morpheme - beziehen.
Frau + ch en vs. fau ch + en d 6 * h 7 h d 6 d * 7 h
Die bisherigen dt. Beispiele sind nicht mit

61
einer Überschreitung der Phonemgrenze ver-bunden. Demgegenüber waren (z.B. bei denAssimilationen) auch Variationen angegebenworden, für die dies nicht gilt (u.a. Aus-lautverhärtung).
Wie bei der Phonetik schon gezeigt, könnendie Phone durch eine Reihe von Merkmalenbeschrieben werden. Durch den Phonembegriffstellt sich die Frage, welche dieser Merk-male in einer Einzelsprache relevant sind,um die Phoneme zu unterscheiden. Zur Klärungdessen verwendet man Oppositionen (PragerSchule), bei denen minimale Differenzierun-gen festgestellt werden. So kann man durch
Wein - fein [v] - [f]Bein - Pein [b] - [p]
zeigen daß stimmhaft/stimmlos und Frikativ/Plosiv distinktiv sind. Durch
Wein - sein
ergibt sich, daß auch der Artikulationsortunterscheidend wirkt. Auf diese Weise kommtman zu einem Inventar von Phonemen unddistinktiven Merkmalen für eine Einzel-sprache.

62
Diese Prozedur ist jedoch nicht so einfach,wie es auf den ersten Blick erscheint. Manbenötigt eine Reihe von Zusatzannahmen, diehier nicht behandelt werden können und mitdenen man der Auslautverhärtung oder derkomplementären Verteilung von [õ] und [h] imDt. (nicht ein Phonem!) beikommen kann.
Zur Illustration zwei Beispiele: 1. Bei vielen Sprechern ist kein Unterschiedzwischen scharrt und Schacht zu hören, dieRealisierung ist [÷]. Durch scharren undSchächte (Sprecherwissen!) ist jedoch klar,daß hier zwei Phoneme vorliegen, sie hättenjedoch (wenigstens) teilweise gleiche Reali-sierungen.
2. Durch vereisen (mit [?]) vs. verreisen(ohne [?]) könnte man auf die Idee kommen,[?] Phonemstatus zuzuweisen. In verheißenhat man [h]. [h] und [?] haben die gleicheDistribution (nicht final, keine Verbindungmit anderen Konsonanten innerhalb einesMorphems). Andererseits ist [?] vorhersagbar(nach dem Grundsatz "Wo nichts ist, ist[?]"). Wie löst man dieses Puzzle?

63
Für die Verarbeitung gesprochener Spracheist die Berücksichtigung der skizziertenPhänomene von größter Wichtigkeit, insbeson-dere gilt dies für die Bedingungen zur Aus-wahl der Allophone. Da bisher jedes Verfah-ren zur Generierung oder Erkennung für Ein-zelsprachen funktioniert, ist dies auch ohneweiteres möglich.