Embed Size (px)
Citation preview

Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 1
Einführung in die Mehrebenenanalyse
1. Die Entwicklung der Kontextanalyse in der Soziologie
Bereits Durkheim beschäftigte sich im Rahmen seiner Untersuchungen zu den sozialen Ursa-chen des Selbstmordes intensiv mit dem Kontext- bzw. Mehrebenenphänomen. Gestützt auf dieArbeiten der Moralstatistiker Wagner, Morselli und Prinzip stellte bei seiner Analyse derkonfessionsspezifischen Selbstmordraten der Jahre 1852 bis 1890 fest, daß „der Einfluß derKonfession ist also so mächtig, daß er über alles andere dominiert.“ (Durkheim 1983, S. 164)
„So stellen also überall ohne jede Ausnahme die Protestanten viel mehr Selbstmörder als dieGläubigen anderer Religionen. Der Unterschied schwankt zwischen einem Minimum von 20 bis30% und einem Maximum von 300%.“ (A.a.O.)
Durkheim führte dies darauf zurück, daß die protestantisch-lutheranische Kirche ihre Mitgliederin geringerem Maße integriere als die katholische Kirche dies tat. Diese Schwächung ihrerIntegrationsfunktion resultierte seines Erachtens daraus, daß der Protestantismus seinen Gläubi-gen seine Interpretation der Evangelien nicht dogmatisch aufzwang sondern sie zur eigenenGlaubenserfahrung ermutigte. „In weit höherem Grade ist der Protestant Schöpfer seineseigenen Glaubens. Man gibt ihm die Bibel in die Hand und es wird ihm keine bestimmteAuslegung aufgezwungen. Dieser religiöse Individualismus erklärt sich aus der Eigenart desreformierten Glaubens. ... Wir kommen also zu dem ersten Ergebnis, daß die Anfälligkeit desProtestantismus gegenüber dem Selbstmord mit dem diese Religion bestimmenden Geist derfreien Forschung zusammenhängt. ... Wir kommen also zu dem Schluß, daß der Grund für diegrößere Selbstmordanfälligkeit des Protestantismus darin zu suchen ist, daß er als Kircheweniger stark integriert als die katholische.“ (Durkheim 1983, S. 169ff.)
Durkheim untersuchte eben dieser generellen Integrationsfunktion der Religionsgemeinschaftebenfalls deren Abhängigkeit von der Mehrheits- oder Minderheitenrolle der jeweiligen Konfes-sion in Preußen, Bayern sowie Österreich. Hierbei stellte er als Kontexteffekt fest, daß indenjenigen Staaten, in denen die Katholiken bzw. Protestanten in der Minderheit waren, ihreSelbstmordraten im Vergleich zu den von ihnen dominierten Staaten deutlich sanken.
„In Preußen ist der Minderheitenstatus der Katholiken sehr ausgeprägt, denn sie stellen nuretwa ein Drittel der Bevölkerung. Dabei bringen sie sich dreimal weniger selbst um als dieProtestanten. Diese Spanne vermindert sich in Bayern, wo zwei Drittel der Bevölkerungkatholisch sind. Die Anzahl ihrer Selbstmorde verhält sich zu der der Protestanten wie 100:275oder auch wie 100:238, je nach der geprüften Periode. Dieses Verhältnis sinkt schließlich imkatholischen Österreich auf 155 protestantische Selbstmorde gegenüber 100 katholischen ab.Es scheint also, daß die Selbstmordanfälligkeit der Protestanten abnimmt, wenn sie zur Min-derheit werden.“ (A.a.O., S. 167)
Durkheim führte diese Zunahme der Schutzfunktion der protestantischen Kirchen darauf zurück,daß in der Diaspora die evangelischen Gemeinden aufgrund ihrer Minderheitenrolle sich in einerihnen feindlichen Umwelt befänden und daher ihr Zusammenhalt und damit ihre Integrationnach innen steige.

Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 2
1Weltz, Rainer (1974): Probleme der Mehrebenenanalyse. Zum Versuch der Verbindungvon Individual- Kollektivdaten. In: Soziale Welt, 25 (1974), 169-187
Einen ähnlichen Kontexteffekt beobachtete Durkheim bei seiner Analyse zum „anomischenSelbstmord“. Hierbei untersuchte Durkheim den Einfluß der familiären Desintegration auf dienationalen Selbstmordraten. Ihn interessierte, inwieweit die Scheidung oder Trennung von „Bettund Tisch“ zu einer Erhöhung der Selbstmordrate führte. Er stellte bei seinem Vergleich derScheidungs- und Selbstmordraten der schweizer Kantone und französischen Departments seinerZeit fest, daß je höher die Scheidungsrate war, desto höher fiel die jeweilige Selbstmordrate aus.Für einzelne Länder des deutschen Kaiserreichs wies er nach, daß die Selbstmordrate derGeschiedenen vereinzelt die doppelte Höhe derjenigen der Verwitweten erreichte. Im Vergleichzu den Verheirateten lag die Selbstmordrate der Geschiedenen drei- bis viermal so hoch. Desweiteren stellte Durkheim fest, daß mit der zunehmendenVerbreitung der Scheidung dieIntegrationsfunktion der Familie abnahm und die Selbstmordraten der Verheirateten im Ver-gleich zu den Ledigen deutlich anstiegen und diese sogar übertrafen. Weltz (1974, S. 182) faßtdiesen Kontexteffekt in der folgenden Grafik zusammen, wobei er die Geschiedenen mit X unddie Verheirateten mit � kennzeichnet.1
Abbildung1: Das Mehrebenenmodell des „anomischen Selbstmordes“ bei Durkheim (Weltz 1974, S. 182)

Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 3
2 Hummell, H.J. (1972): Probleme der Mehrebenenanalyse. Stuttgart: Teubner
3 Blau, Peter M. (1961): Structural Effects. In: American Sociological Review, 25,S.178-193
Diese Beobachtung Durkheims formalisierten Blau und Davis zu Beginn der 60er Jahre mit demBegriff der „Gruppenkompositionshypothese“, die drei verschiedene Variablentypen beinhaltet:
„1. Ein individuelles Merkmal Y als abhängige Variable (Durkheim-Beispiel: Selbstmord-wahrscheinlichkeit bzw. Dichotomie „Begeht Selbstmord / Begeht nicht Selbstmord“)
2. Ein individuelles Merkmal X als explikative Variable („Geschieden / Nicht geschie-den“). (Es sei darauf hingewiesen, daß weder X noch Y notwendigerweise Dichotomiensein müssen; insbesondere können sie auch von metrischer Struktur sein.)
3. Eine weitere explikative Variable P als kollektives Merkmal, welches definitorisch einemathematisch-analytische Funktion der Verteilung von X in den einzelnen Kollektivenist (Prozentsatz der Geschiedenen).“ (Hummell1972, S. 60)2
Beide Autoren gehen davon aus, daß im Falle einer Gruppenkompositionshypothese dieselbeEigenschaft sowohl als Individual- also auch als Kollektivmerkmal einen unterschiedlichenEffekt auf die abhängige Variable auf der Individual- und Kollektivebene ausüben kann.
Der strukturelle Effekt eines exogenen Merkmals auf der Kollektivebene tritt nach Blau (1961,S. 161)3 folgendermaßen in Erscheinung:
„The essential principle is that the relation-ship between the distribution of a given characteri-stic in various collectivities and an effect criterion is ascertained, while this characteristic is heldconstant for individuals. This procedure differentiates teh effect of social structures uponpatterns of action from the influences exerted by the characteristics of the acting individuals ortheir inter-personal relationships.“(A.a.O.)
Blau differenziert zwischen zwei Eigenschaften sozialer Kollektive, die sich grundlegend vonden individuellen unterscheiden und einen eigenen strukturellen Einfluß auf das individuelleHandeln ausüben. Hierzu gehören zu einem die Werte und Normen einer Subkultur bzw. Kulturund zum anderen die Netzwerke sozialer Beziehungen, „ in which processes of social inter-action become organized and through which social positions of individuals and subgroupsbecome differentiated“. (Blau 1961, S. 178)
Blau veranschaulicht die unabhängige Wirkung struktureller Effekte im Sinne kollektiverNormen und Werte am folgenden Beispiel. In einer Anzahl von Gemeinden erhob ein Forschermit Hilfe der von Adorno u. a. entwickelten F-Skala das Ausmaß der „autoritären Unterwürfig-keit“ der Bürger. Gleichzeitig maß er ihre Vorurteile gegenüber ethnischen Minoritäten. Um dieDominanz autoritärer Werte zu bestimmen, aggregierte er die individuellen Meßwerte durcheine Mittelwertsbildung auf der Gemeindeebene. Anschließend stellte er einen starken Zu-sammenhang zwischen einem autoritär geprägten Wertklima der Gemeinde und den Vorurteilenihrer Bürger fest. Dieser Zusammenhang zwischen bestimmten sozialen Werten bzw. Normenund der individuellen Einstellung läßt sich auf zweierlei Arten erklären: Zum einen prägen die

Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 4
4 Davis, J.A., Spaeth, J.L.& Huson, C. (1961): A Technique for Analyzing the Effects ofGroup Composition. In: American Sociological Review, 26, 215-25
5 Van den Eeden, P. (1988): A Two-step Procedure for Analysing Multi-level StructuredData. In: Saris, W.E. & Gallhofer, J.N. (Eds.): Sociometric Research, Vol. 2: Data Analysis.London: Macmillan Press, S. 180-199
autoritären Werte der Gemeinde die ethnischen Vorurteile ihrer Bürger. Zum anderen sindgerade Gemeinden mit autoritären Werten dadurch gekennzeichnet, daß in ihnen ein besondershoher Anteil von Personen mit autoritären Wertvorstellungen wohnt. Letztere tendieren auf-grund ihrer autoritären Persönlichkeitsstruktur zu besonders ausgeprägten Vorurteilen gegen-über ethnischen Minoritäten.
Für das Zusammenwirken des Individual- und Kollektiveffekts eines exogenen Merkmals habenDavis u.a. (1961)4 eine analytische Klassifikation entwickelt, die Van den Eeden (1988, S. 184)5
in Abbildung 2 zusammenfaßt. Sie umfaßt fünf analytische Typen, die jeweils von linearenEffekten ausgehen. Hierbei differenzieren die Autoren zwischen dem Individual-, demKollektiv- sowie dem Interaktionseffekt zwischen den beiden Erstgenannten. Idealtypischunterscheidet Davis beim Individualmerkmal X jediglich zwei Gruppen von Befragten, dieTräger des Merkmals X sind (X) und denjenigen, die es nicht sind (�).
Typus 0
Weder das individuelle Merkmal X noch der Prozentsatz der Mitglieder einer Gruppe, die dasMerkmal X aufweisen, übt einen Einfluß auf die individuelle Kriteriumsvariable Y aus.
Typus I
Nur der Besitz oder das Vorliegen des Individualmerkmals X übt einen Effekt auf Y aus, nichtaber das Kollektivmerkmal des Prozentsatzes der Personen, die das Merkmal X aufweisen.
Typus II
Das Individualmerkmal X übt keinen Einfluß auf Y aus. Ein Effekt ist nur auf der Ebene desKollektivmerkmals X - seinen Prozentsatz in der Gruppe - zu beobachten.
Typus III
Sowohl das Individualmerkmal X als auch das Kollektivmerkmal X üben unabhängig vonein-ander einen linearen Effekt auf die Kriteriumsvariable Y aus. In ihre gemeinsame Wirkungresultiert aus der Summe der Einzeleffekte.
Typus IV
Neben dem Individudal- und Kompositionaleffekt liegt ein Interaktionseffekt beider Einfluß-arten vor. Bei dieser speziellen Interaktion unterscheiden Davis, Spaeth und Huson zwei

Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 5
Varianten, erstens das „differential susceptibility“-Modell, bei dem sie annehmen, daß derGruppeneffekt von der jeweiligen Ausprägung des Individualmerkmals abhängt, und zweitensdas „conditional individual differences“-Modell, das von gruppenspezifischen Individual-effekten ausgeht. Bei letzteren hängt das Ausmaß und die Richtung des Individualeffekts vomNiveau der Kontextvariablen ab.
Abbildung2: Typologie der Kombinationen von individuellen undko l l ek t iven Effek ten au f e ine ind iv idue l l eKriteriumsvariable (Van den Eeden 1988, S. 184)

Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 6
Ein reiner Kontexteffekt im Sinne des Typus II liegt dann vor, wenn eine Merkmal auf derindividuellen Ebene zwar keinen Einfluß auf die abhängige Variable ausübt, aber dies auf demWege der Gruppenzusammensetzung erfolgt. Graphisch gesehen, ergibt sich dann eine für dasIndividual- und Kollektivmerkmal identische Gerade, deren Lage vom KollektivmerkmalsMittelwert oder Anteilswert von X abhängt. Hummell (1972, S. 66) veranschaulicht dies amBeispiel der Blauschen Gemeindestudie. „So könnte man im ersten Beispiel von Blau anneh-men, daß die Neigung zu antisemitischen Verhalten (Y) mit der Häufigkeit P der in einerGemeinde befindlichen autoritären Personen steigt. Dies gilt für nicht-autoritäre Personen .. ingleichem Maß wie für autorritäre.. . Zu erklären wäre dieses Phänomen dadurch, daß derAnteil der autoritären Personen das Gemeinde“klima“ bestimmt und dieses wiederum innormatives Weise auch Nicht-Autoritäre zu antisemitischen Aktivitäten zwingt.“ Bei Typus III unterscheiden Davis u.a. zwei Variaten, wobei ersterer von der Gleichgerichtetheitder Einflüsse auf des Individual- und Kollektivmerkmals ausgeht. Bei der zweiten Variantewirkt dasselbe Merkmal auf der Ebene des Individuums genau umgekehrt wie auf derjenigendes Kollektivs. Zu dieser paradox erscheinenden Erkenntnis gelangten die Sozialwissenschaftlerdes Forschungsverbund „American Soldier“ während des zweiten Weltkriegs. Sie untersuchten, inwieweit Beförderungen die subjektive Zufriedenheit der Soldaten erhöhen. „Innerhalb jederKampfeinheit waren die Beförderten mit dem Beförderungssystem weniger unzufrieden als dieNicht-Beförderten. Verglich man die jedoch die Unzufriedenheit (Y) über verschiedene Kampf-einheiten, so stellt man fest, daß mit dem Anteil der Beförderten (P) in einer Einheit sowohl dieUnzufriedenheit der Nicht-Beförderten .. als auch der Beförderten .. anstiegt und nicht absank.“(Hummell 1972, S. 67)
Den Typus IV, der von einer Interaktion zwischen dem Individual- und Kollektivmerkmalausgeht, veranschaulicht Hummell (1972, S.68) für die Variante C am folgenden Beispiel:
„Der Antisemitismus steigt mit dem Anteil der Juden (P) in bestimmten Gemeinden. Dies giltaber nur für die Kategorie der Nicht-Juden .. .Hier wirkt wiederum das kollektive Merkmalgenau umgekehrt wie das individuelle; weiterhin ist jedoch die Art der Wirkung variabel: inGemeinden mit wenig Juden ist der Unterschied des Antisemitismus von Juden und Nicht-Judengering, in Gemeinden mit relativ viel Juden ist der Unterschied im Antisemitismus relativgroß.“
Dieser Interaktionseffekt läßt sich aufgrund seiner Symmetrieeigenschaft alternativ inter-pretieren. Bei ersten Erklärungsansatz beeinflußt der Anteil P der exogenen Variablen X in derGruppe G die Kriteriumsvariable Y, aber dieser Einfluß fällt unterschiedlich aus, je nach demob die Befragten das Merkmal X aufweisen oder nicht. Im Blauschen Sinne weisen beideKategorien von Personen eine unterschiedliche Sensitivität gegenüber dem Kontextmerkmal auf(„differential susceptibility“). Personen, die Merkmalsträger sind, reagieren anders als diejeni-gen, die es nicht sind. Alternativ hierzu läßt sich dieses Phänomen im Sinne der „conditionalindividual differences“-Perspektive folgendermaßen erklären: Das Individualmerkmal übt einenEinfluß auf Y aus, aber seine Größe bzw. Richtung kovariiert mit dem Kollektivmerkmal P.D.h, daß die individuellen Unterschiede zwischen Merkmalsträgern und Nichtträgern abhängigsind von der jeweiligen Gruppenzusammensetzung.

Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 7
Die Typen II, III und IV, bei denen das Kontextmerkmal allein, additiv oder Interaktion mit demIndividualmerkmal X auf die Kriteriumsvariable Y wirkt, stellen Snijders&Bosker (1999, S. 11)jeweils als Pfaddiagramm dar:
Abbildung3: Die Struktur der Makro-Mikro-Beziehungen im Zweiebenenmodell
Zur terminologischen Abgrenzung der unterschiedlichen Erhebungs- und Analyseeinheiten imZweiebenenmodell haben Snijders&Bosker (1999, S.8) die folgende Tabelle zusammengestellt:

Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 8
6 Lazarsfeld, P.F. & Menzel, H. (1961): On the relation between individual andcollective properties. In: A.Etzioni (ed.): Complex Organizations: A Sociological Reader. NewYork: Holt, Rhinehart&Winston
In ihrer Tabelle 2.2 haben sie einige Beispiele für die Makro-Mikro-Ebene hierarchischerDatenstrukturen aufgeführt, für die die idealtypische Datenmatrix in Abbildung 5 charakteri-stisch ist. Hierfür sind zunächst alle Beobachtungen nach der Gruppen-/Kontextzugehörigkeitihrer Befragten sortiert worden. Anschließend wurde das Kontextmerkmal Z an die DatenmatrixDas Kontextmerkmal Z selbst variiert nur zwischen und nicht innerhalb der Gruppen.
Abbildung5: Beispiel für die hierarchische Datenstruktur der Mehrebenenanalyse
Dieser hierarchischen Variablenstruktur entspricht eine Typologie von Variablenarten, dieLazarsfeld&Menzel (1961)6 entwickelt haben. Bei der Mehrebenenanalyse lassen sich Variablenauf jeder Ebene der Hierarchie definieren. Einige dieser Merkmale können hierbei direkt aufihrer natürlichen Ebene erhoben werden. Beispielsweise läßt sich die Größe und die Träger-schaft direkt auf der Schuleebene messen. Hingegen erfolgt die Erhebung des Intelligenzquo-tienten und des Schulerfolgs direkt auf der Ebene des Schülers in seiner Schule. Zusätzlichlassen sich Merkmale durch Aggregation oder Disaggregation von einer Ebene zur anderenverschieben. Aggregation bedeutet hierbei, daß die auf der unteren Ebene gemessenen Varia-blen durch die Mittelwert- oder Anteilswertbildung auf die höhere Ebene transferiert werden.Beispielsweise läßt sich das Anspruchsniveau einer Schule dadurch bestimmen, daß der Mittel-wert der Intelligenzquotienten der ihr angehörenden Schüler berechnet und an die Individual-daten angehängt wird. Bei der Disaggregierung werden die Kontextmerkmale der Schule wie

Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 9
7 Hox, J.J. (1995): Applied Multilevel Analysis. Amsterdam: TT-Publikaties
ihre Trägerschaft oder Größe an die Individualdaten angehängt. Hox (1995)7 hat diese Arbeits-schritte im folgenden Diagramm dargestellt.
Abbildung6: Lazarsfeld&Menzels Typologie der Individual- und Kollektivmerkmale in derMehrebenenanalyse (Hox 1995, S. 2)
Die unterste Ebene bilden normalerweise die befragten Individuen. Im Rahmen von Längs-schnittsanalysen mit Messwiederholungen definiert Goldstein (1999, Chapter 6) die Messzeit-punkte als unterste Ebene, wobei der Befragte selbst die zweite Ebene darstellt. Auf jeder dieserEbenen existierenunterschiedliche Merkmalstypen. Globale oder absolute Variablen beziehensich nur auf die Ebene, für die sie definiert worden sind. Sie beziehen sich auf keine der anderenEbenen. Als absolute Variablen werden lediglich Merkmale bezeichnet, die auf der unterstenEbene erhoben worden sind. Beim Intelligenzquotienten des Schülers handelt es sich um einesolche globale oder absolute Variable. Relationale Variablen beziehen sich ebenfalls nur aufeine Ebene. Sie erfassen die Relationen der auf dieser Ebene angesiedelten Befragungseinheitenuntereinander. Soziometrische Indizes wie der Reziprozitäts- oder der Popularitätsindex sindsolche relationale Variablen. Analytische oder strukturelle Variablen beziehen sich auf dieVerteilung von Merkmalen in untergeordneten Einheiten. Analytische Merkmale beziehen sichhierbei auf die Verteilung eines absoluten Merkmals auf der unteren Ebene in Form ihresMittel- oder Anteilswerts. Hingegen basieren Strukturelle Variablen auf der Verteilung rela-tionaler Variablen auf der untergeordneten Ebene. Viele Netzwerkindizes gehören diesem Typan. Die Konstruktion von analytischen oder strukturellen Variablen erfordert stets eine Daten-aggregation, die in Abbildung 6 durch den Pfeil nach rechts (�) gekennzeichnet ist. Die auf derunteren Ebene erhobenen Daten werden auf eine kleinere Anzahl von Einheiten der höherenEbene transformiert. Kontextuelle Variablen beziehen sich hingegen auf übergeordnete Ein-heiten. Alle Einheiten der Mikroebene erhalten dieselben Werte wie die ihnen übergeordnete„superunit“, zu der sie auf der Makroebene gehören. Dieser Schritt wird als Disaggregationbezeichnet und durch einen Pfeil nach links (�) gekennzeichnet. Der Vorteil dieser Klassifikation besteht darin, daß der Forscher allen Variablentypen ihrenjeweiligen Ebenen eindeutig zu ordnen kann. Hieran anknüpfend definiert Hox (1995, S. 5f.)

Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 10
8 Robinson, W.S. (1950): Ecological correlations and the behavior of individuals. In:American Sociological Review, 15, 351-357
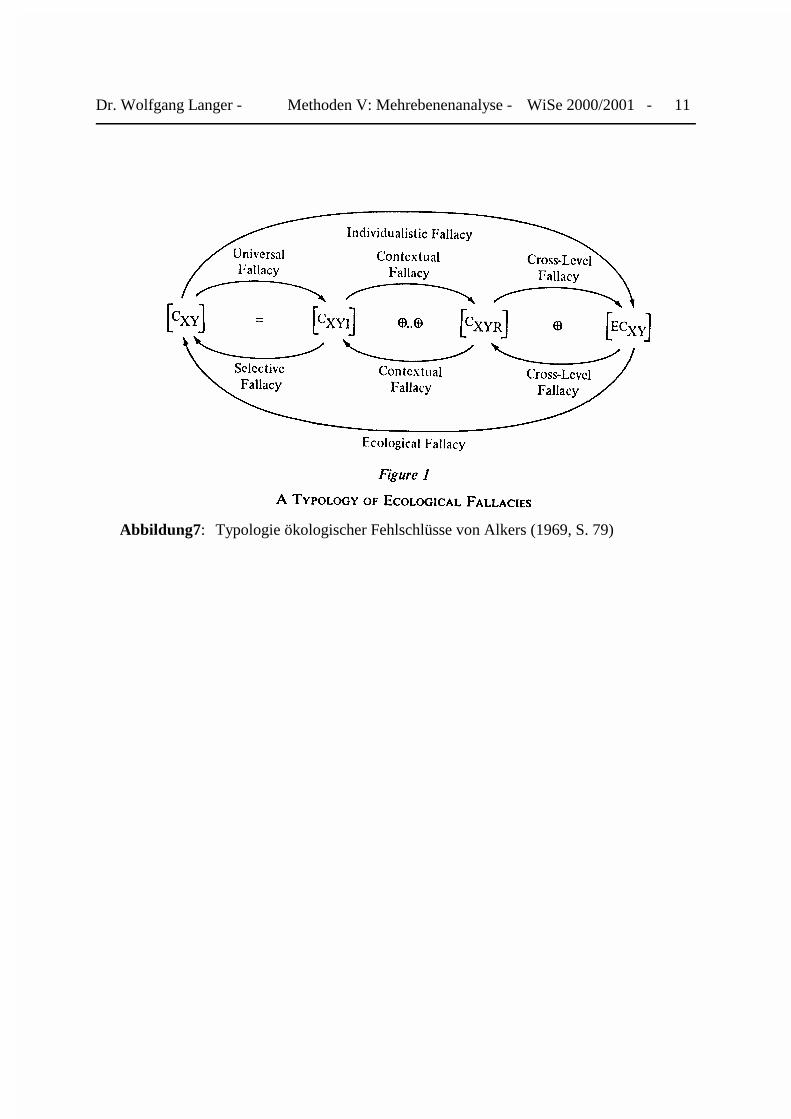
9 Alker, H.R. (1969): A Typology of Ecological Fallacies. In: M.Dogan& S.Rokkan(eds.): Quantitative Ecological Analysis in the Social Sciences. Cambridge, Mass: M.I.T. Press
das Ziel der Mehrebenenanalyse folgendermaßen:
„The goal of the analysis is to determine the direct effect of individual and group level ex-planatory variables, and to determine if the explanatory variables at the group level serve asmoderators of individual-level relationships. If group level variables moderate lower levelrelationships, this shows up as a statistical interaction between explanatory variables fromdifferent levels.“ (A.a.O.)
Ein weiterer Vorteil der Mehrebenenanalyse besteht darin, daß sie im Gegensatz zu „ökologi-schen Analysen“ gegen den von Robinson (1950)8 entdeckten „ökologischen Fehlschluß“ gefeitist. In seinem bahnbrechenden Aufsatz untersuchte Robinson die Stärke des Zusammenhangeszwischen dem Anteil der Farbigen und der Analphabetenrate auf unterschiedlichen regionalenEbenen mit Hilfe der amerikanischen Volkszählungsdaten von 1930. Hierbei stellte er auf derEbene der Bundesstaaten eine Korrelation von +0,95 fest. Hingegen erreichte die Korrelationauf der Ebene der befragten Bürger nur noch einen Wert von +0,20. Robinson schloß hieraus,daß die üblicherweise auf der ökologischen Ebene, der Makroebene, berechneten Korrelationennicht mit denjenigen der Mikroebene identisch seien. Schlußfolgerungen dieser Art führenseines Erachtens stets zu einem „ökologischen Fehlschluß“ (ecological fallacy). Umgekehrtkann die Verallgemeinerung von auf der Mikroebene beobachtet Korrelationen in Richtunghöherer Ebenen ebenfalls zu einem Fehlschluß, dem sogenannten „atomistic fallacy“ führen.Beispielsweise zeigen Wahlnachbefragungen stets, daß Arbeiter eher als Angehörige höhereSchichten sozialdemokratische oder sozialistische Parteien wählen. Hieraus könnte man auf derLänderebene ableiten, daß je höher der Arbeiteranteil eines Landes liegt, desto eher führt dorteine linke Regierung die Geschäfte. De facto zeigt sich aber, daß gerade in Industrienationen mithohem Arbeiteranteil konservative Regierungen vorherrschen. Alkers (1969)9 hat eine Ty-pologie von Fehlschlüssen entwickelte, die neben den bereits genannten zusätzlichen den„kontextuellen“ und „Cross-Level-Fallacy“ enthält. Erstere bezieht sich auf irrtümliche Verall-gemeinerung eines Befundes, der in einem selektiven Kontext erhoben worden, auf benachbarteKontexte. Beispielsweise läßt sich aus den Wahlergebnissen eines Stimmbezirkes, der sich seitJahrzehnten in SPD-Hand befindet, nicht schließen, daß die SPD in allen benachbarten Bezirkendie Wahl gewinnt. Bei Cross-Level-Fehlschuß erlag der Forscher der Versuchung, aus demBundestagswahl 1998, die Rot-Grün mit absoluter Mehrheit gewannen, die Wahlsiege von Rot-Grün bei den folgenden Landtagswahlen vorherzusagen. Die hessische Landtagswahl im Herbst1999, die eine CDU-FDP-Koalition gewann, offenbart diesen Fehlschluß.
Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 11
Abbildung7: Typologie ökologischer Fehlschlüsse von Alkers (1969, S. 79)

Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 12
10 Cronbach, L.J. & Webb, N. (1975): Between class and within class effects in areported aptitude x treatment interaction: A reanalysis of a study by G.L. Anderson. In: Journalof Educational Psychology, 67, 717-24
11 Boyd, L.H. & Iversen, G.R. (1979): Contextual Analysis: Concepts and StatisticalTechniques. Belmont, Ca.: Wadsworth
2. Die klassischen Verfahren der Kontextanalyse
Die wichtigsten Ansätze der „klassischen Mehrebenen- / Kontextanalyse“ werden im folgendenanhand eines Beispieldatensatzes aus der Schulforschung dargestellt, den Kreft und de Leeuwin ihrem Lehrbuch verwenden und unter der folgenden Internetadresse dem interessierten Leserzur Verfügung stellen:
http://www.stat.ucla.edu/~deleeuw/sagebook/
Zu diesen Verfahren der Kontextanalyse gehören die Realisierungen der ANOVA, der ANCO-VA ohne und mit kontextspezifischen Interaktionseffekten sowie die Ansätze von Cronbach&Webb (1975)10 bzw. Boyd&Iversen (1979)11. Alle Analysen werden mit der StandardsoftwareSPSSfWin Version 10.0 durchgeführt und als Befehls-/Syntaxdateien dokumentiert..
2.1 Die ANOVA als linearen Regressionsmodell
Im Rahmen der Natonal Education Longitudinal Study ließ das amerikanische Erziehungsmini-sterium im Frühjahr 1988 in einer landsweiten Studie die Mathematikleistungen von 21.580Schüler der achten Klasse in 1.003 Schulen untersuchen. 80% der Schulen wurden von denKommunen und 20% von privaten Trägern finanziert. Bei dieser Stichprobe handelt es sich umeine repräsentative Auswahl der Grundgesamtheit von rd. 3 Millionen Schülern in 38.000Schulen. Kreft und De Leeuw (1998) stellen zu den Beispielen ihres Einführungsbuch „In-troducing Multilevel Modeling“ drei Datensätze im Internet bereit, die jeweils 10, 23 oder alle1003 Schulen umfassen. Ihr primäres Forschungsinteresse gilt hierbei der Frage, inwieweit dieKontextmerkmale der Schule die Leistungsergebnisse der Schüler in einem standardisiertenMathematiktest beeinflussen. Hierbei gehen sie davon aus, daß einerseits auf der Mikroebenedie Testergebnisse der Schüler wesentlich davon abhängen, wieviel Zeit sie mit dem Lösen vonMathematikhausaufgaben verbringen. Anderseits erwarten sie auf der Makro- oder Schulebeneeinen deutlichen Leistungsunterschied zwischen Schülern, die private anstatt kommunaleSchulen besuchen. Ihren Forschungshypothesen liegen dem folgenden Pfaddiagramm in Abb.1 zugrunde, das einer einfachen Kovarianzanalyse entspricht:

Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 13
Level 1: XijWochen-stundenMathehaus-aufgaben(V5)
Level 2: Z.j
Oeffentlichevs. privateSchule(PUBLIC)
Punkte desMathematik-leistungstest:(V9) Yij
++
--
Abbildung8: Kovarianzmodell zur Erklärung derLeistungsunterschiede in Mathematik
Um die Kontextabhängigkeit der endogenen und exogenen Merkmale V9 und V4 zu untersu-chen, bieten zwei Möglichkeiten an. Erstens können wir mit Hilfe der von Tukey (1977)entwickelten Box&Wiskers-Plot prüfen, ob sich die Mediane der Mathematiktestergebnisse unddes wöchentlichen Zeitaufwands für Hausaufgaben über die Schulen hinweg unterscheiden.Gleichzeitig bilden diese Boxplots sehr genau die Binnenvarianz innerhalb der Schulen ab,wobei im jeweiligen „Kasten“ die beiden mittleren Quartile (25%-75%) der Fälle der jeweiligenSchule liegen. Bedauerlicherweise bietet selbst die Version 10.0 von SPSS nicht die Möglich-keit, sich zusätzlich die Konfidenzintervalle der Mediane einzeichnen zu lassen.
Hierfür benötigen wir die folgende SPSSfWin-Befehlssequenz:

Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 14
GET FILE='D:\multilev\nels10.sav'.EXECUTE .
* Recodierung der Variablen V6: Public vs. Private school.
recode v6 (1=1) (2 thru 4=0) into public.var labels public 'Kommunale vs. private Schulträger'.value labels public 1 'Kommunaler Träger' 0 ' Privater Träger'.
FREQUENCIES VARIABLES=public /ORDER= ANALYSIS .
* Graphische Exploration der Kontextabhängigkeit der Variablen V9 und V5.
EXAMINE VARIABLES=v9 BY v1 BY PUBLIC /PLOT=BOXPLOT/STATISTICS=NONE/NOTOTAL /MISSING=REPORT.EXAMINE VARIABLES=v5 BY v1 /PLOT=BOXPLOT/STATISTICS=NONE/NOTOTAL /MISSING=REPORT.
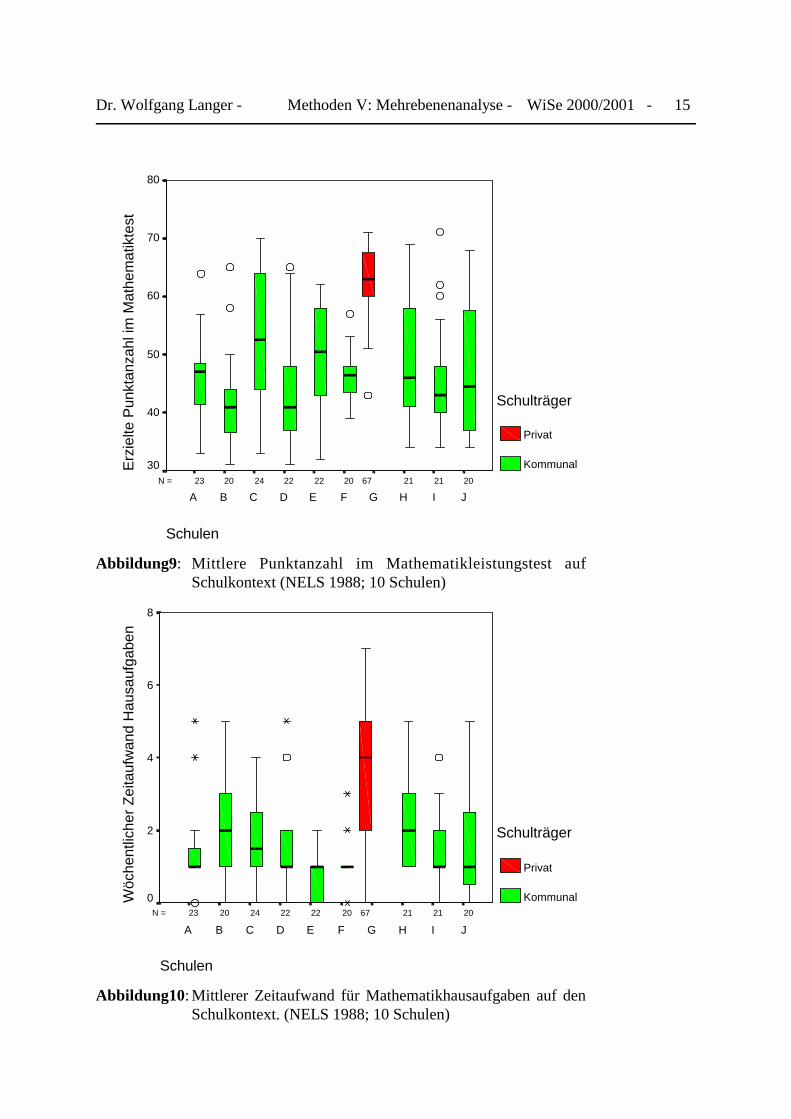
Für die beiden Variablen V9 und V5 erhalten wir die beiden folgenden Boxplot, die als Zusatz-information die Unterscheidung zwischen öffentlicher und privater Schulträgerschaft enthalten.In den Abbildungen 7 und 8 ist zweierlei deutlich erkennbar. Zum einen liegen deutlicheKontexteffekte sowohl bei den Mathematiktestergebnissen als auch beim wöchentlichenArbeitsaufwand für Mathematikhausaufgaben vor. Zum anderen läßt sich bei beiden Variableneine erhebliche innerschulische Varianz beobachten, wie die Länge der jeweiligen „Kästchen“veranschaulicht. Sowohl bei den Testergebnissen als auch bei den Hausaufgaben nimmt dieSchule G, die sich in privater Trägerschaft befindet, eine Spitzenstellung ein.
Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 15
202121202222242023 67N =
Schulen
JIHGFEDCBA
Erz
ielte
Pun
ktan
zahl
im M
athe
mat
ikte
st
80
70
60
50
40
30
Schulträger
Privat
Kommunal
Abbildung9: Mittlere Punktanzahl im Mathematikleistungstest aufSchulkontext (NELS 1988; 10 Schulen)
202121202222242023 67N =
Schulen
JIHGFEDCBA
Wöc
hent
liche
r Z
eita
ufw
and
Hau
sauf
gabe
n
8
6
4
2
0
Schulträger
Privat
Kommunal
Abbildung10: Mittlerer Zeitaufwand für Mathematikhausaufgaben auf denSchulkontext. (NELS 1988; 10 Schulen)

Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 16
Um die Stärke des jeweiligen Kontexteffektes nummerisch zu bestimmen, können wir entwederdas Kontingenzmaß �2 (ETA SQUARED) berechnen oder ein lineares Regressionsmodellschätzen, das neun Schuldummies als Prädiktoren enthält. Als Vergleichskategorie bietet sichdie Schule G an, die sich privat finanziert. Hierzu müssen wir zunächst die Schulidentifikations-variable V1 in 10 Dummy-Variablen zerlegen. Anschließend können wir dann für die VariablenV9 und V5 das entsprechende ANOVA-Modell schätzen. Dem Determinationskoeffizienten R2
entspricht dann exakt das �2 der Kontingenztafelanalyse. Dieser ANOVA oder Varianzanalyseentspricht das folgende Regressionsmodell:
Regressionsmodell mit Schuldummy�Variablen:
Vergleichskategorie: SCHOOL G (Privat)
Mathescoreij � b0 � b1�DSCHOOLA�b2�DSCHOOLB�b3�DSCHOOLC�b4�DSCHOOLD�b5�DSCHOOLE�b6�DSCHOOLF�b7�DSCHOOLH�b8�DSCHOOLI�b9�DSCHOOLJ � eij
Legende:i: Index des Schülers ij: Index der Schule jij: Schüler i in Schule j
Für seine Schätzung benötigen wir die folgenden SPSS-Befehle:

Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 17
recode v1 (7472=1) (ELSE=0) into dschoola.recode v1 (7829=1) (ELSE=0) into dschoolb.recode v1 (7930=1) (ELSE=0) into dschoolc.recode v1 (24725=1) (ELSE=0) into dschoold.recode v1 (25456=1) (ELSE=0) into dschoole.recode v1 (25642=1) (ELSE=0) into dschoolf.recode v1 (62821=1) (ELSE=0) into dschoolg.recode v1 (68448=1) (ELSE=0) into dschoolh.recode v1 (68493=1) (ELSE=0) into dschooli.recode v1 (72292=1) (ELSE=0) into dschoolj.
freq /variables=dschoola to dschoolj.
REGRESSION /MISSING LISTWISE /STATISTICS COEFF OUTS R ANOVA /CRITERIA=PIN(.05) POUT(.10) /NOORIGIN /DEPENDENT v9 /METHOD=ENTER dschoola dschoolb dschoolc dschoold dschoole dschoolf dschoolh dschooli dschoolj .
REGRESSION /MISSING LISTWISE /STATISTICS COEFF OUTS R ANOVA /CRITERIA=PIN(.05) POUT(.10) /NOORIGIN /DEPENDENT v5 /METHOD=ENTER dschoola dschoolb dschoolc dschoold dschoole dschoolf dschoolh dschooli dschoolj .
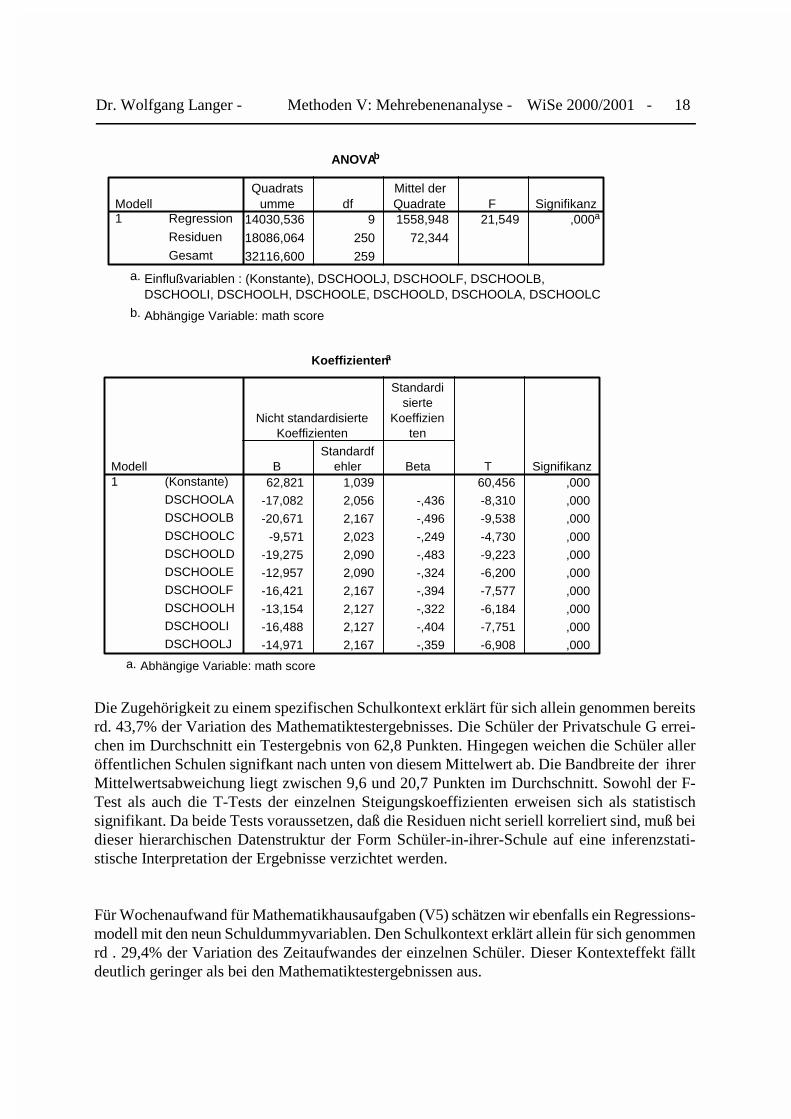
Für die Kriteriumsvariable V9 erhalten wir das folgende Ausgabeprotokoll mit der Modell-anpassung, der Zerlegung der Abweichungsquadrate sowie den Regressionkoeffizienten:
Modellzusammenfassung
,661a ,437 ,417 8,5055Modell1
R R-QuadratKorrigiertesR-Quadrat
Standardfehler desSchätzers
Einflußvariablen : (Konstante), DSCHOOLJ,DSCHOOLF, DSCHOOLB, DSCHOOLI, DSCHOOLH,DSCHOOLE, DSCHOOLD, DSCHOOLA, DSCHOOLC
a.
Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 18
ANOVAb
14030,536 9 1558,948 21,549 ,000a
18086,064 250 72,344
32116,600 259
Regression
Residuen
Gesamt
Modell1
Quadratsumme df
Mittel derQuadrate F Signifikanz
Einflußvariablen : (Konstante), DSCHOOLJ, DSCHOOLF, DSCHOOLB,DSCHOOLI, DSCHOOLH, DSCHOOLE, DSCHOOLD, DSCHOOLA, DSCHOOLC
a.
Abhängige Variable: math scoreb.
Koeffizientena
62,821 1,039 60,456 ,000
-17,082 2,056 -,436 -8,310 ,000
-20,671 2,167 -,496 -9,538 ,000
-9,571 2,023 -,249 -4,730 ,000
-19,275 2,090 -,483 -9,223 ,000
-12,957 2,090 -,324 -6,200 ,000
-16,421 2,167 -,394 -7,577 ,000
-13,154 2,127 -,322 -6,184 ,000
-16,488 2,127 -,404 -7,751 ,000
-14,971 2,167 -,359 -6,908 ,000
(Konstante)
DSCHOOLA
DSCHOOLB
DSCHOOLC
DSCHOOLD
DSCHOOLE
DSCHOOLF
DSCHOOLH
DSCHOOLI
DSCHOOLJ
Modell1
BStandardf
ehler
Nicht standardisierteKoeffizienten
Beta
Standardisierte
Koeffizienten
T Signifikanz
Abhängige Variable: math scorea.
Die Zugehörigkeit zu einem spezifischen Schulkontext erklärt für sich allein genommen bereitsrd. 43,7% der Variation des Mathematiktestergebnisses. Die Schüler der Privatschule G errei-chen im Durchschnitt ein Testergebnis von 62,8 Punkten. Hingegen weichen die Schüler alleröffentlichen Schulen signifkant nach unten von diesem Mittelwert ab. Die Bandbreite der ihrerMittelwertsabweichung liegt zwischen 9,6 und 20,7 Punkten im Durchschnitt. Sowohl der F-Test als auch die T-Tests der einzelnen Steigungskoeffizienten erweisen sich als statistischsignifikant. Da beide Tests voraussetzen, daß die Residuen nicht seriell korreliert sind, muß beidieser hierarchischen Datenstruktur der Form Schüler-in-ihrer-Schule auf eine inferenzstati-stische Interpretation der Ergebnisse verzichtet werden.
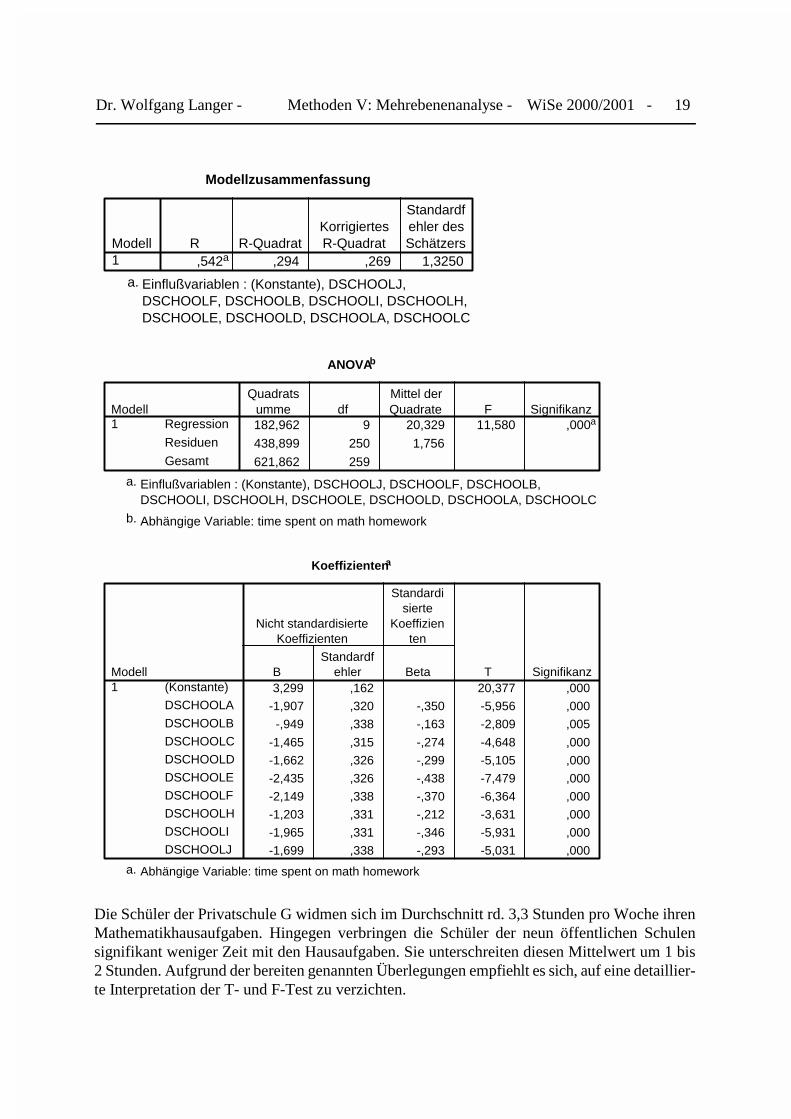
Für Wochenaufwand für Mathematikhausaufgaben (V5) schätzen wir ebenfalls ein Regressions-modell mit den neun Schuldummyvariablen. Den Schulkontext erklärt allein für sich genommenrd . 29,4% der Variation des Zeitaufwandes der einzelnen Schüler. Dieser Kontexteffekt fälltdeutlich geringer als bei den Mathematiktestergebnissen aus.
Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 19
Modellzusammenfassung
,542a ,294 ,269 1,3250Modell1
R R-QuadratKorrigiertesR-Quadrat
Standardfehler desSchätzers
Einflußvariablen : (Konstante), DSCHOOLJ,DSCHOOLF, DSCHOOLB, DSCHOOLI, DSCHOOLH,DSCHOOLE, DSCHOOLD, DSCHOOLA, DSCHOOLC
a.
ANOVAb
182,962 9 20,329 11,580 ,000a
438,899 250 1,756
621,862 259
Regression
Residuen
Gesamt
Modell1
Quadratsumme df
Mittel derQuadrate F Signifikanz
Einflußvariablen : (Konstante), DSCHOOLJ, DSCHOOLF, DSCHOOLB,DSCHOOLI, DSCHOOLH, DSCHOOLE, DSCHOOLD, DSCHOOLA, DSCHOOLC
a.
Abhängige Variable: time spent on math homeworkb.
Koeffizientena
3,299 ,162 20,377 ,000
-1,907 ,320 -,350 -5,956 ,000
-,949 ,338 -,163 -2,809 ,005
-1,465 ,315 -,274 -4,648 ,000
-1,662 ,326 -,299 -5,105 ,000
-2,435 ,326 -,438 -7,479 ,000
-2,149 ,338 -,370 -6,364 ,000
-1,203 ,331 -,212 -3,631 ,000
-1,965 ,331 -,346 -5,931 ,000
-1,699 ,338 -,293 -5,031 ,000
(Konstante)
DSCHOOLA
DSCHOOLB
DSCHOOLC
DSCHOOLD
DSCHOOLE
DSCHOOLF
DSCHOOLH
DSCHOOLI
DSCHOOLJ
Modell1
BStandardf
ehler
Nicht standardisierteKoeffizienten
Beta
Standardisierte
Koeffizienten
T Signifikanz
Abhängige Variable: time spent on math homeworka.
Die Schüler der Privatschule G widmen sich im Durchschnitt rd. 3,3 Stunden pro Woche ihrenMathematikhausaufgaben. Hingegen verbringen die Schüler der neun öffentlichen Schulensignifikant weniger Zeit mit den Hausaufgaben. Sie unterschreiten diesen Mittelwert um 1 bis2 Stunden. Aufgrund der bereiten genannten Überlegungen empfiehlt es sich, auf eine detaillier-te Interpretation der T- und F-Test zu verzichten.

Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 20
2.2 Das „gepoolte“ Regressionsmodell
Anschließend ist zu überprüfen, ob ein linearer Zusammenhang zwischen der Anzahl derWochenstunden die ein Schüler ij mit den Mathematikhausaufgaben verbracht hat und seinemTestergebnis in diesem Fach besteht. Dies läßt sich mit Hilfe eines einfachen linearen Regres-sionsmodells ermitteln, wobei zunächst unberücksichtigt bleibt, daß jeder Schüler einer be-stimmten Schule angehört. Diese Schüler-in-Schule-Hierarchie ignorieren wir erst einmal.Hierfür benötigen wir die folgenden SPSSfWin-Befehle:
Für die gepoolte Stichprobe ihrer 260 Schüler haben sie die folgende Modellanpassung und diezugehörigen Regressionskoeffizienten erhalten:
Modellzusammenfassung
,497a ,247 ,244 9,6815Modell1
R R-QuadratKorrigiertesR-Quadrat
Standardfehler desSchätzers
Einflußvariablen : (Konstante), time spent on mathhomework
a.
ANOVAb
7933,807 1 7933,807 84,644 ,000a
24182,793 258 93,732
32116,600 259
Regression
Residuen
Gesamt
Modell1
Quadratsumme df
Mittel derQuadrate F Signifikanz
Einflußvariablen : (Konstante), time spent on math homeworka.
Abhängige Variable: math scoreb.
REGRESSION /MISSING LISTWISE /STATISTICS COEFF OUTS R ANOVA /CRITERIA=PIN(.05) POUT(.10) /NOORIGIN /DEPENDENT v9 /METHOD=ENTER v5 /SAVE PRED(PYREG1).
GRAPH /SCATTERPLOT(BIVAR)=v5 WITH pyreg1 /MISSING=LISTWISE .
Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 21
Koeffizientena
44,074 ,989 44,580 ,000
3,572 ,388 ,497 9,200 ,000
(Konstante)
time spent onmath homework
Modell1
BStandardf
ehler
Nicht standardisierteKoeffizienten
Beta
Standardisierte
Koeffizienten
T Signifikanz
Abhängige Variable: math scorea.
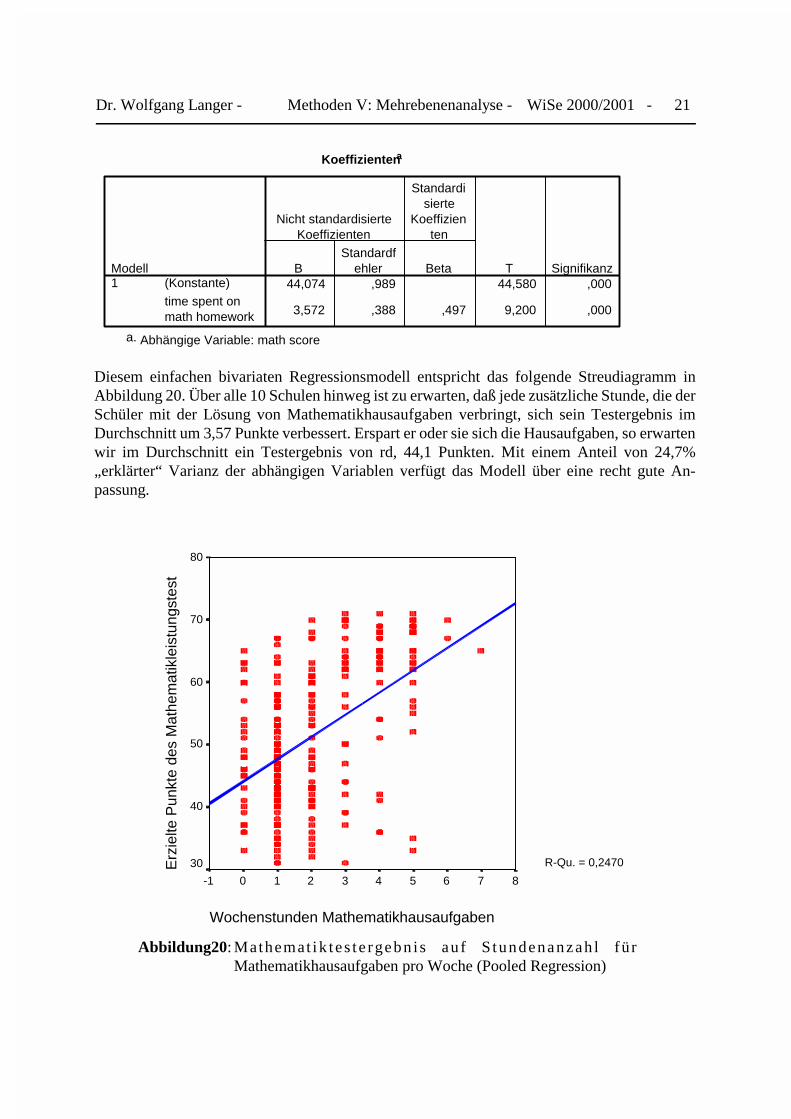
Diesem einfachen bivariaten Regressionsmodell entspricht das folgende Streudiagramm inAbbildung 20. Über alle 10 Schulen hinweg ist zu erwarten, daß jede zusätzliche Stunde, die derSchüler mit der Lösung von Mathematikhausaufgaben verbringt, sich sein Testergebnis imDurchschnitt um 3,57 Punkte verbessert. Erspart er oder sie sich die Hausaufgaben, so erwartenwir im Durchschnitt ein Testergebnis von rd, 44,1 Punkten. Mit einem Anteil von 24,7%„erklärter“ Varianz der abhängigen Variablen verfügt das Modell über eine recht gute An-passung.
Wochenstunden Mathematikhausaufgaben
876543210-1
Erz
ielte
Pun
kte
des
Mat
hem
atik
leis
tung
stes
t
80
70
60
50
40
30 R-Qu. = 0,2470
Abbildung20: Mathemat ik t e s t e rgebn i s au f S tundenanz ah l fü rMathematikhausaufgaben pro Woche (Pooled Regression)
Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 22
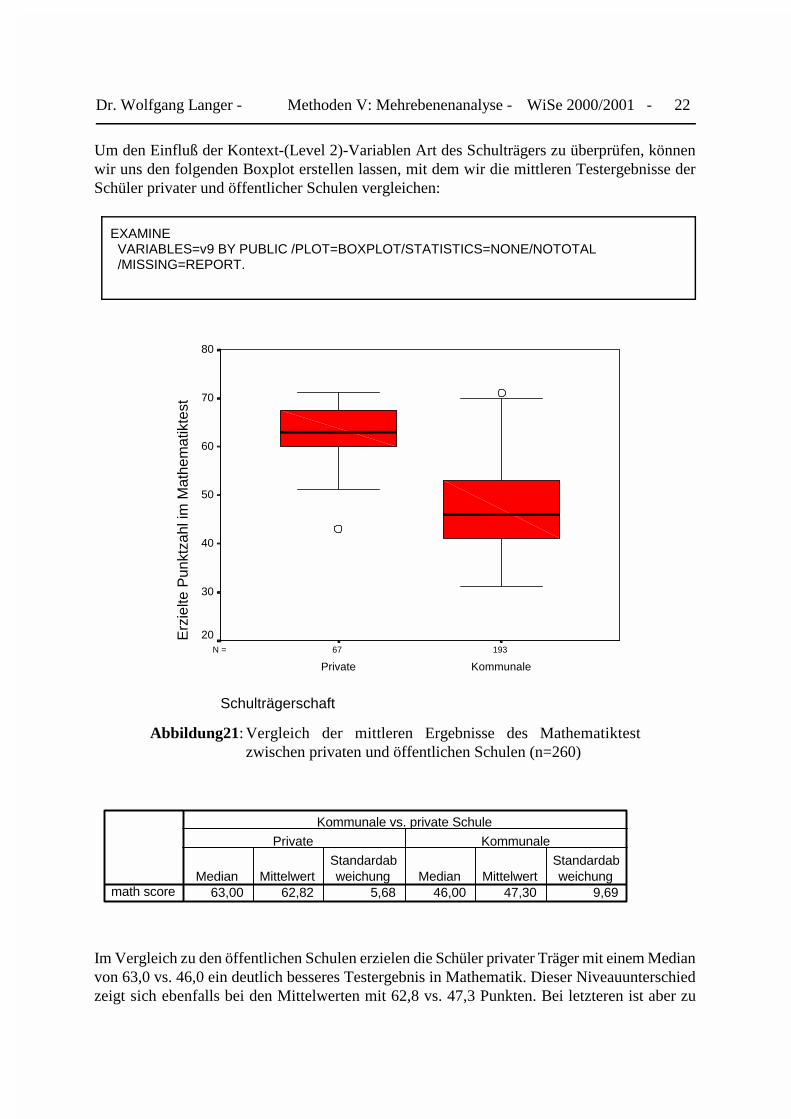
Um den Einfluß der Kontext-(Level 2)-Variablen Art des Schulträgers zu überprüfen, könnenwir uns den folgenden Boxplot erstellen lassen, mit dem wir die mittleren Testergebnisse derSchüler privater und öffentlicher Schulen vergleichen:
19367N =
Schulträgerschaft
KommunalePrivate
Erz
ielte
Pun
ktza
hl im
Mat
hem
atik
test
80
70
60
50
40
30
20
Abbildung21: Vergleich der mittleren Ergebnisse des Mathematiktestzwischen privaten und öffentlichen Schulen (n=260)
63,00 62,82 5,68 46,00 47,30 9,69math scoreMedian Mittelwert
Standardabweichung
Private
Median MittelwertStandardabweichung
Kommunale
Kommunale vs. private Schule
Im Vergleich zu den öffentlichen Schulen erzielen die Schüler privater Träger mit einem Medianvon 63,0 vs. 46,0 ein deutlich besseres Testergebnis in Mathematik. Dieser Niveauunterschiedzeigt sich ebenfalls bei den Mittelwerten mit 62,8 vs. 47,3 Punkten. Bei letzteren ist aber zu
EXAMINE VARIABLES=v9 BY PUBLIC /PLOT=BOXPLOT/STATISTICS=NONE/NOTOTAL /MISSING=REPORT.

Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 23
beachten, daß die Standardabweichung des Testergebnisses der öffentlichen Schulen fast doppeltso hoch ist wie bei den privaten Trägern. Dies weist auf erhebliche Unterschiede innerhalb deröffentlichen Schulen hin.
2.3 Das klassische Kovarianzmodell der Regressionsanalyse
Um die Effekt beider exogener Variablen zu ermitteln, schätzen wir zunächst einfaches Ko-varianzmodell, mit Hilfe dessen wir den Niveauunterschied zwischen öffentlichen und privatenSchulen unter Kontrolle des Zeitaufwands der Schüler für Mathematikhausaufgaben ermittelten.Dies entspricht folgender Modellgleichung:
Kovarianzmodell:
Mathescoreij � b0 � b1�PUBLIC.j � b2�HOMEWORKij � eij
Legende:i: Index des Schülers ij: Index der Schule jij: Schüler i in Schule j
Mit Hilfe von SPSS schätzen wir die Koeffizienten für dieses multiple lineare Regressions-modell, für das wir die folgenden Steuerbefehle benötigen:
Wir erhalten die folgende Modellanpassung, Zerlegung der Abweichungsquadrate sowie dieRegressionskoeffizienten:
REGRESSION /MISSING LISTWISE /STATISTICS COEFF OUTS R ANOVA /CRITERIA=PIN(.05) POUT(.10) /NOORIGIN /DEPENDENT v9 /METHOD=ENTER public v5 /SAVE PRED(PYREG2).
GRAPH /SCATTERPLOT(BIVAR)=v5 WITH pyreg2 /MISSING=LISTWISE .
Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 24
Modellzusammenfassungb
,652a ,426 ,421 8,4730Modell1
R R-QuadratKorrigiertesR-Quadrat
Standardfehler desSchätzers
Einflußvariablen : (Konstante), Kommunale vs. privateSchule, time spent on math homework
a.
Abhängige Variable: math scoreb.
ANOVAb
13666,137 2 6833,069 95,179 ,000a
18450,463 257 71,792
32116,600 259
Regression
Residuen
Gesamt
Modell1
Quadratsumme df
Mittel derQuadrate F Signifikanz
Einflußvariablen : (Konstante), Kommunale vs. private Schule, time spent on mathhomework
a.
Abhängige Variable: math scoreb.
Koeffizientena
56,607 1,648 34,349 ,000
1,884 ,389 ,262 4,846 ,000
-12,283 1,375 -,483 -8,936 ,000
(Konstante)
time spent onmath homework
Kommunale vs.private Schule
Modell1
BStandardf
ehler
Nicht standardisierteKoeffizienten
Beta
Standardisierte
Koeffizienten
T Signifikanz
Abhängige Variable: math scorea.
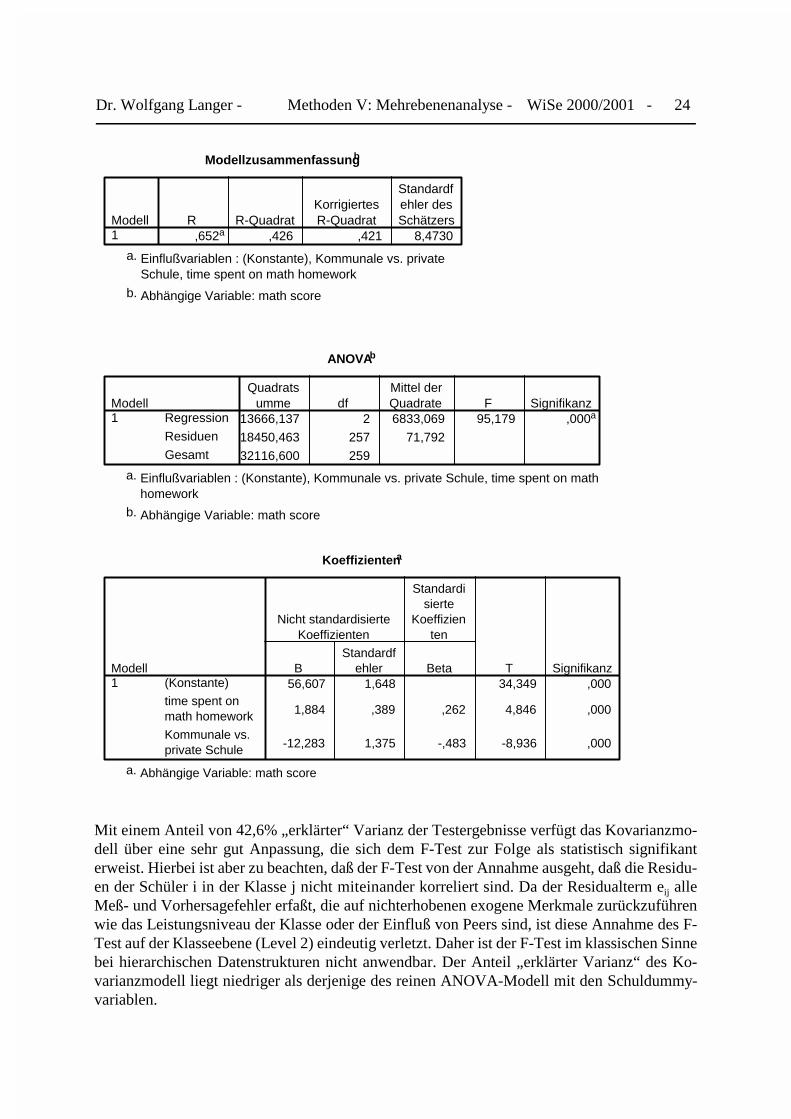
Mit einem Anteil von 42,6% „erklärter“ Varianz der Testergebnisse verfügt das Kovarianzmo-dell über eine sehr gut Anpassung, die sich dem F-Test zur Folge als statistisch signifikanterweist. Hierbei ist aber zu beachten, daß der F-Test von der Annahme ausgeht, daß die Residu-en der Schüler i in der Klasse j nicht miteinander korreliert sind. Da der Residualterm eij alleMeß- und Vorhersagefehler erfaßt, die auf nichterhobenen exogene Merkmale zurückzuführenwie das Leistungsniveau der Klasse oder der Einfluß von Peers sind, ist diese Annahme des F-Test auf der Klasseebene (Level 2) eindeutig verletzt. Daher ist der F-Test im klassischen Sinnebei hierarchischen Datenstrukturen nicht anwendbar. Der Anteil „erklärter Varianz“ des Ko-varianzmodell liegt niedriger als derjenige des reinen ANOVA-Modell mit den Schuldummy-variablen.
Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 25
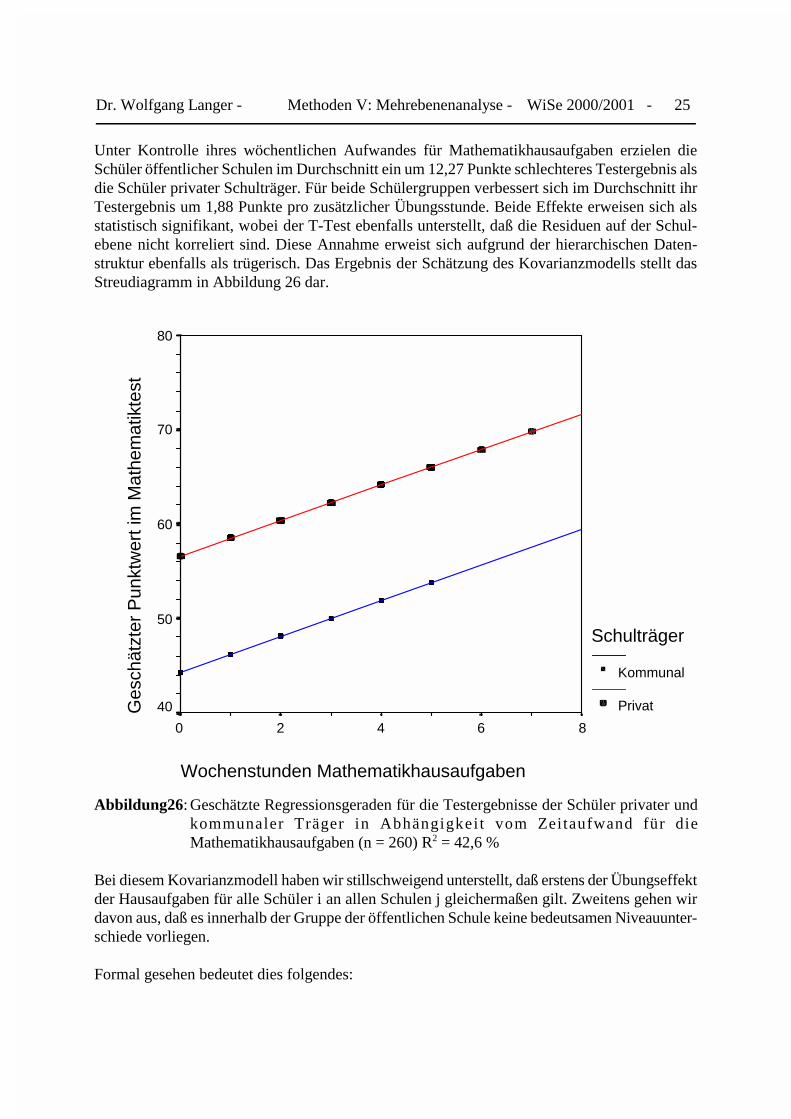
Unter Kontrolle ihres wöchentlichen Aufwandes für Mathematikhausaufgaben erzielen dieSchüler öffentlicher Schulen im Durchschnitt ein um 12,27 Punkte schlechteres Testergebnis alsdie Schüler privater Schulträger. Für beide Schülergruppen verbessert sich im Durchschnitt ihrTestergebnis um 1,88 Punkte pro zusätzlicher Übungsstunde. Beide Effekte erweisen sich alsstatistisch signifikant, wobei der T-Test ebenfalls unterstellt, daß die Residuen auf der Schul-ebene nicht korreliert sind. Diese Annahme erweist sich aufgrund der hierarchischen Daten-struktur ebenfalls als trügerisch. Das Ergebnis der Schätzung des Kovarianzmodells stellt dasStreudiagramm in Abbildung 26 dar.
Wochenstunden Mathematikhausaufgaben
86420
Ges
chät
zter
Pun
ktw
ert i
m M
athe
mat
ikte
st
80
70
60
50
40
Schulträger
Kommunal
Privat
Abbildung26: Geschätzte Regressionsgeraden für die Testergebnisse der Schüler privater undkommunaler Träger in Abhängigkei t vom Zeitaufwand für dieMathematikhausaufgaben (n = 260) R2 = 42,6 %
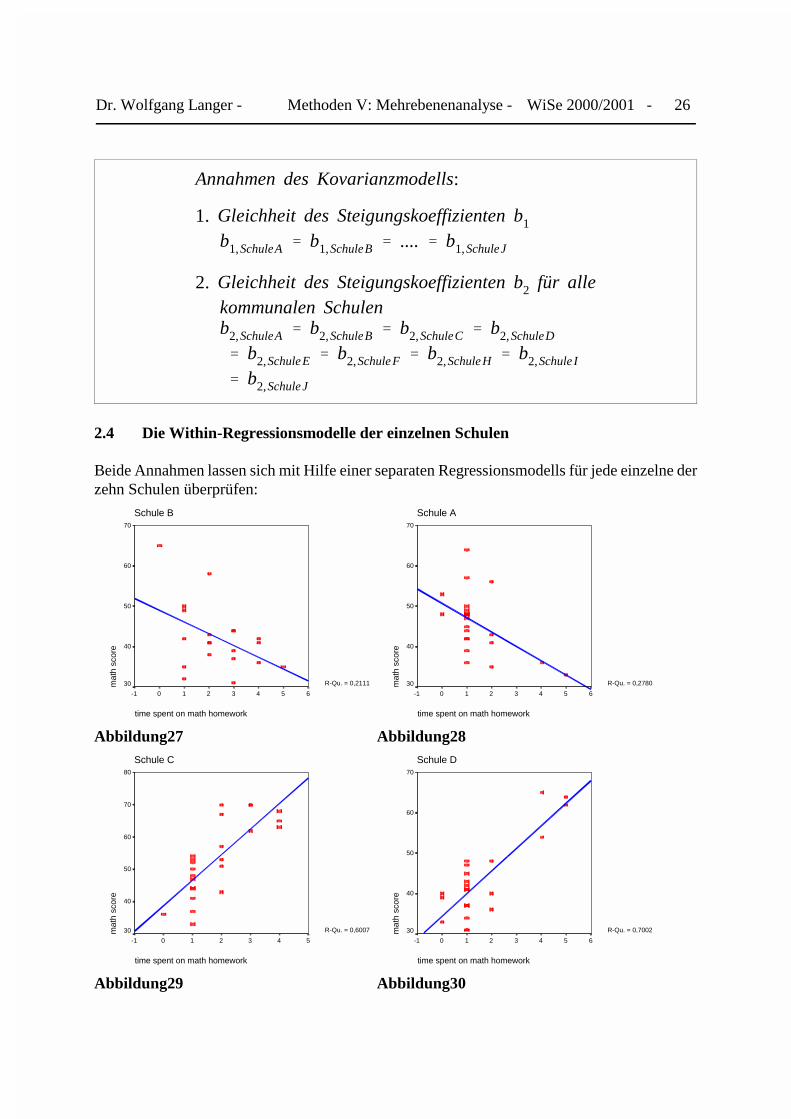
Bei diesem Kovarianzmodell haben wir stillschweigend unterstellt, daß erstens der Übungseffektder Hausaufgaben für alle Schüler i an allen Schulen j gleichermaßen gilt. Zweitens gehen wirdavon aus, daß es innerhalb der Gruppe der öffentlichen Schule keine bedeutsamen Niveauunter-schiede vorliegen.
Formal gesehen bedeutet dies folgendes:
Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 26
Annahmen des Kovarianzmodells:
1. Gleichheit des Steigungskoeffizienten b1
b1,SchuleA � b1,SchuleB � .... � b1,SchuleJ
2. Gleichheit des Steigungskoeffizienten b2 für allekommunalen Schulenb2,SchuleA � b2,SchuleB � b2,SchuleC � b2,SchuleD
� b2,SchuleE � b2,SchuleF � b2,SchuleH � b2,Schule I
� b2,SchuleJ
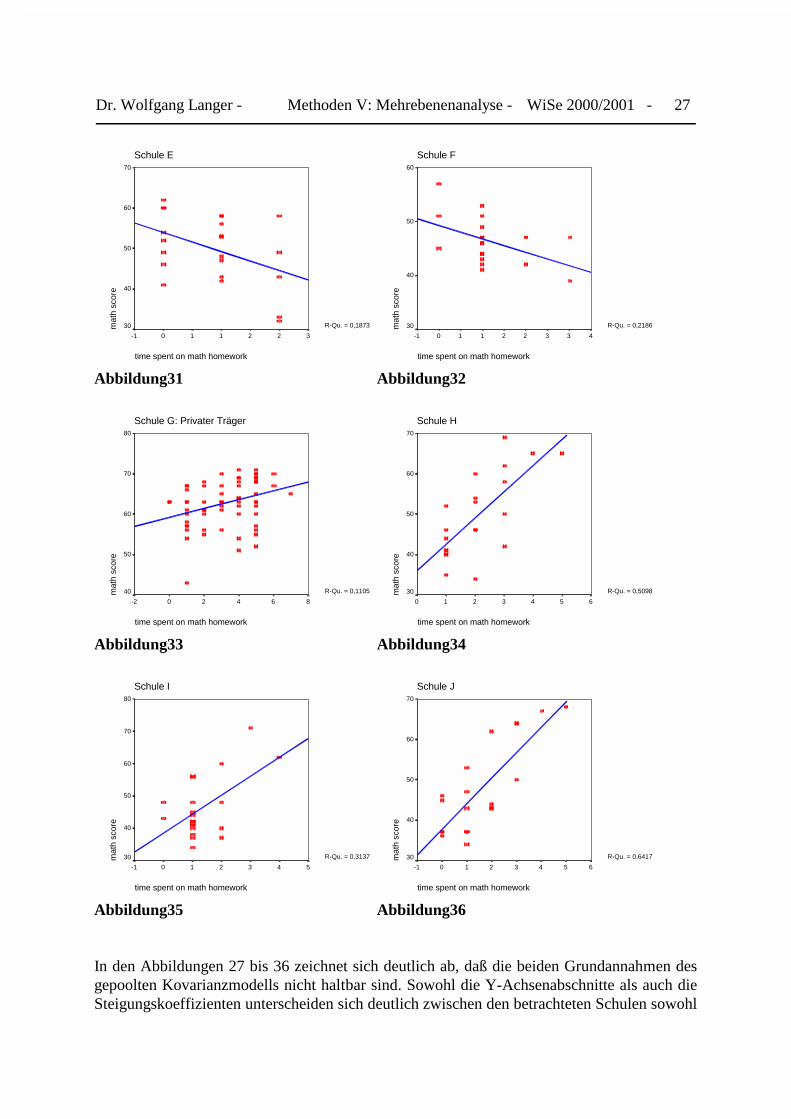
2.4 Die Within-Regressionsmodelle der einzelnen Schulen
Beide Annahmen lassen sich mit Hilfe einer separaten Regressionsmodells für jede einzelne derzehn Schulen überprüfen:
Schule B
time spent on math homework
6543210-1
mat
h sc
ore
70
60
50
40
30 R-Qu. = 0,2111
Abbildung27
Schule A
time spent on math homework
6543210-1
mat
h sc
ore
70
60
50
40
30 R-Qu. = 0,2780
Abbildung28Schule C
time spent on math homework
543210-1
mat
h sc
ore
80
70
60
50
40
30 R-Qu. = 0,6007
Abbildung29
Schule D
time spent on math homework
6543210-1
mat
h sc
ore
70
60
50
40
30 R-Qu. = 0,7002
Abbildung30
Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 27
Schule E
time spent on math homework
322110-1
mat
h sc
ore
70
60
50
40
30 R-Qu. = 0,1873
Abbildung31
Schule F
time spent on math homework
43322110-1
mat
h sc
ore
60
50
40
30 R-Qu. = 0,2186
Abbildung32
Schule G: Privater Träger
time spent on math homework
86420-2
mat
h sc
ore
80
70
60
50
40 R-Qu. = 0,1105
Abbildung33
Schule H
time spent on math homework
6543210
mat
h sc
ore
70
60
50
40
30 R-Qu. = 0,5098
Abbildung34
Schule I
time spent on math homework
543210-1
mat
h sc
ore
80
70
60
50
40
30 R-Qu. = 0,3137
Abbildung35
Schule J
time spent on math homework
6543210-1
mat
h sc
ore
70
60
50
40
30 R-Qu. = 0,6417
Abbildung36
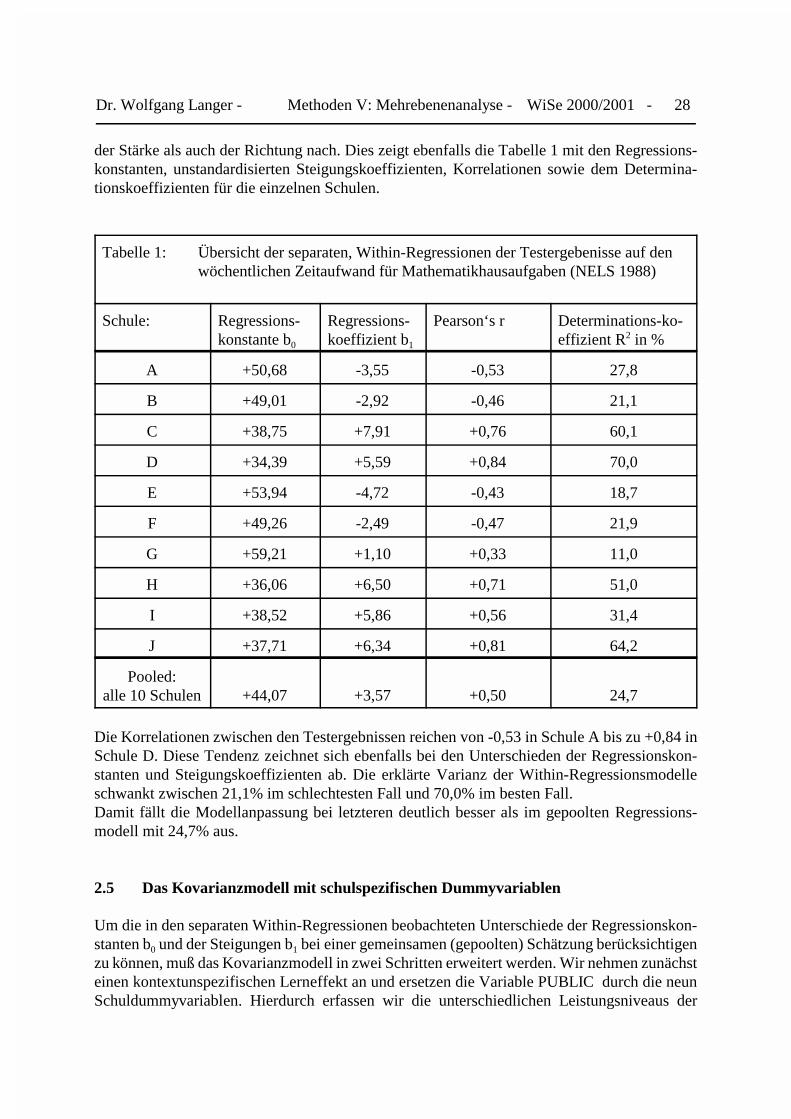
In den Abbildungen 27 bis 36 zeichnet sich deutlich ab, daß die beiden Grundannahmen desgepoolten Kovarianzmodells nicht haltbar sind. Sowohl die Y-Achsenabschnitte als auch dieSteigungskoeffizienten unterscheiden sich deutlich zwischen den betrachteten Schulen sowohl
Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 28
der Stärke als auch der Richtung nach. Dies zeigt ebenfalls die Tabelle 1 mit den Regressions-konstanten, unstandardisierten Steigungskoeffizienten, Korrelationen sowie dem Determina-tionskoeffizienten für die einzelnen Schulen.
Tabelle 1: Übersicht der separaten, Within-Regressionen der Testergebenisse auf denwöchentlichen Zeitaufwand für Mathematikhausaufgaben (NELS 1988)
Schule: Regressions-konstante b0
Regressions-koeffizient b1
Pearson‘s r Determinations-ko-effizient R2 in %
A +50,68 -3,55 -0,53 27,8
B +49,01 -2,92 -0,46 21,1
C +38,75 +7,91 +0,76 60,1
D +34,39 +5,59 +0,84 70,0
E +53,94 -4,72 -0,43 18,7
F +49,26 -2,49 -0,47 21,9
G +59,21 +1,10 +0,33 11,0
H +36,06 +6,50 +0,71 51,0
I +38,52 +5,86 +0,56 31,4
J +37,71 +6,34 +0,81 64,2
Pooled:alle 10 Schulen +44,07 +3,57 +0,50 24,7
Die Korrelationen zwischen den Testergebnissen reichen von -0,53 in Schule A bis zu +0,84 inSchule D. Diese Tendenz zeichnet sich ebenfalls bei den Unterschieden der Regressionskon-stanten und Steigungskoeffizienten ab. Die erklärte Varianz der Within-Regressionsmodelleschwankt zwischen 21,1% im schlechtesten Fall und 70,0% im besten Fall. Damit fällt die Modellanpassung bei letzteren deutlich besser als im gepoolten Regressions-modell mit 24,7% aus.
2.5 Das Kovarianzmodell mit schulspezifischen Dummyvariablen
Um die in den separaten Within-Regressionen beobachteten Unterschiede der Regressionskon-stanten b0 und der Steigungen b1 bei einer gemeinsamen (gepoolten) Schätzung berücksichtigenzu können, muß das Kovarianzmodell in zwei Schritten erweitert werden. Wir nehmen zunächsteinen kontextunspezifischen Lerneffekt an und ersetzen die Variable PUBLIC durch die neunSchuldummyvariablen. Hierdurch erfassen wir die unterschiedlichen Leistungsniveaus der

Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 29
Schulen unter Kontrolle des Lerneffekts. Anschließend führen wir zusätzlich in Form vonInteraktionseffekten einen schulspezifischen Lerneffekt ein.
Kovarianzmodell Schuldummy�Variablen:
Vergleichskategorie: SCHOOL G (Privat)
Mathescoreij � b0 � b1�HOMEWORKij
�b2�DSCHOOLA�b3�DSCHOOLB�b4�DSCHOOLC�b5�DSCHOOLD�b6�DSCHOOLE�b7�DSCHOOLF�b8�DSCHOOLH�b9�DSCHOOLI�b10�DSCHOOLJ � eij
Legende:i: Index des Schülers ij: Index der Schule jij: Schüler i in Schule j
Für die Schätzung der entsprechenden Regressionskoeffizienten der Haupt- und Interaktions-effekte müssen wir zunächst unsere Schulvariable in K-1 Dummy-Variablen zerlegen, wobeisich in privater Trägerschaft befindende Schule G als ausgelassene Vergleichskategorie anbietet.Wir benötigen hierzu die folgenden beiden SPSSfWin-Befehle:
REGRESSION /MISSING LISTWISE /STATISTICS COEFF OUTS R ANOVA /CRITERIA=PIN(.05) POUT(.10) /NOORIGIN /DEPENDENT v9 /METHOD=ENTER v5 dschoola dschoolb dschoolc dschoold dschoole dschoolf dschoolh dschooli dschoolj /SAVE PRED(PYREG3) .
GRAPH /SCATTERPLOT(BIVAR)=v5 WITH pyreg3 BY v1 /MISSING=LISTWISE .
Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 30
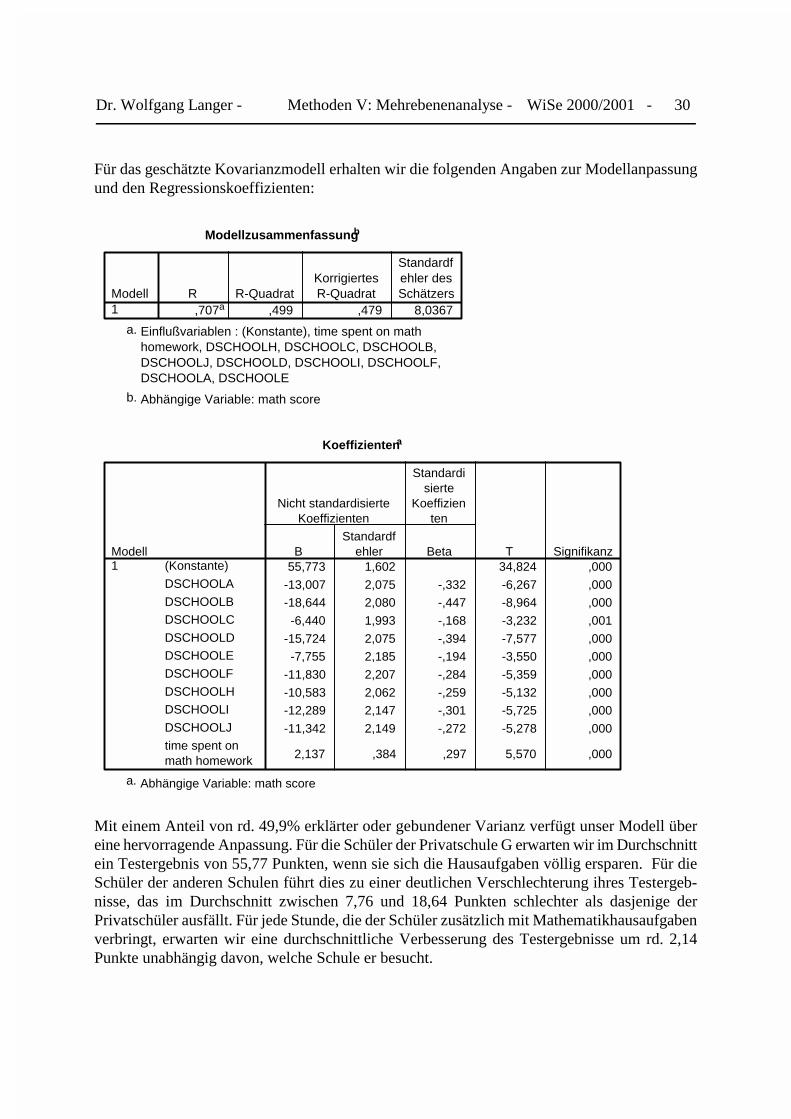
Für das geschätzte Kovarianzmodell erhalten wir die folgenden Angaben zur Modellanpassungund den Regressionskoeffizienten:
Modellzusammenfassungb
,707a ,499 ,479 8,0367Modell1
R R-QuadratKorrigiertesR-Quadrat
Standardfehler desSchätzers
Einflußvariablen : (Konstante), time spent on mathhomework, DSCHOOLH, DSCHOOLC, DSCHOOLB,DSCHOOLJ, DSCHOOLD, DSCHOOLI, DSCHOOLF,DSCHOOLA, DSCHOOLE
a.
Abhängige Variable: math scoreb.
Koeffizientena
55,773 1,602 34,824 ,000
-13,007 2,075 -,332 -6,267 ,000
-18,644 2,080 -,447 -8,964 ,000
-6,440 1,993 -,168 -3,232 ,001
-15,724 2,075 -,394 -7,577 ,000
-7,755 2,185 -,194 -3,550 ,000
-11,830 2,207 -,284 -5,359 ,000
-10,583 2,062 -,259 -5,132 ,000
-12,289 2,147 -,301 -5,725 ,000
-11,342 2,149 -,272 -5,278 ,000
2,137 ,384 ,297 5,570 ,000
(Konstante)
DSCHOOLA
DSCHOOLB
DSCHOOLC
DSCHOOLD
DSCHOOLE
DSCHOOLF
DSCHOOLH
DSCHOOLI
DSCHOOLJ
time spent onmath homework
Modell1
BStandardf
ehler
Nicht standardisierteKoeffizienten
Beta
Standardisierte
Koeffizienten
T Signifikanz
Abhängige Variable: math scorea.
Mit einem Anteil von rd. 49,9% erklärter oder gebundener Varianz verfügt unser Modell übereine hervorragende Anpassung. Für die Schüler der Privatschule G erwarten wir im Durchschnittein Testergebnis von 55,77 Punkten, wenn sie sich die Hausaufgaben völlig ersparen. Für dieSchüler der anderen Schulen führt dies zu einer deutlichen Verschlechterung ihres Testergeb-nisse, das im Durchschnitt zwischen 7,76 und 18,64 Punkten schlechter als dasjenige derPrivatschüler ausfällt. Für jede Stunde, die der Schüler zusätzlich mit Mathematikhausaufgabenverbringt, erwarten wir eine durchschnittliche Verbesserung des Testergebnisse um rd. 2,14Punkte unabhängig davon, welche Schule er besucht.
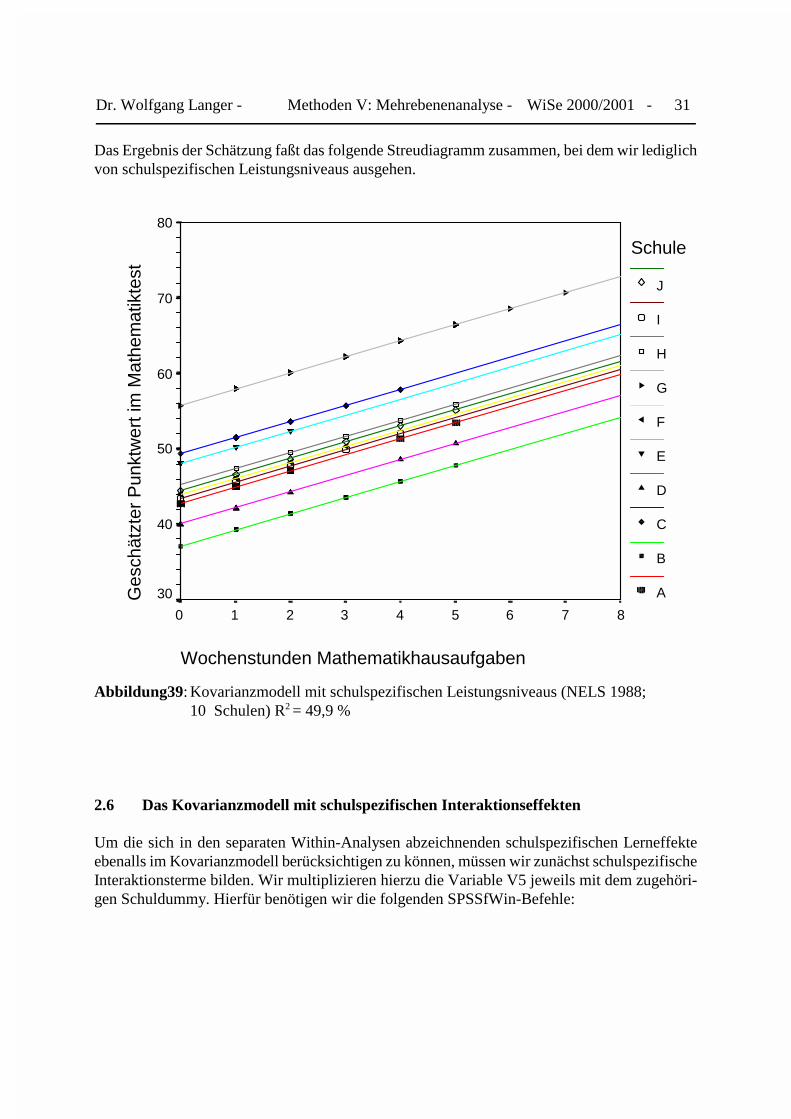
Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 31
Das Ergebnis der Schätzung faßt das folgende Streudiagramm zusammen, bei dem wir lediglichvon schulspezifischen Leistungsniveaus ausgehen.
Wochenstunden Mathematikhausaufgaben
876543210
Ges
chät
zter
Pun
ktw
ert i
m M
athe
mat
ikte
st
80
70
60
50
40
30
Schule
J
I
H
G
F
E
D
C
B
A
Abbildung39: Kovarianzmodell mit schulspezifischen Leistungsniveaus (NELS 1988;10 Schulen) R2 = 49,9 %
2.6 Das Kovarianzmodell mit schulspezifischen Interaktionseffekten
Um die sich in den separaten Within-Analysen abzeichnenden schulspezifischen Lerneffekteebenalls im Kovarianzmodell berücksichtigen zu können, müssen wir zunächst schulspezifischeInteraktionsterme bilden. Wir multiplizieren hierzu die Variable V5 jeweils mit dem zugehöri-gen Schuldummy. Hierfür benötigen wir die folgenden SPSSfWin-Befehle:

Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 32
Für das Kovarianzmodell mit schulspezifischen Leistungsniveaus und Lerneffekten benötigenwir die folgende Schätzgleichung:
Kovarianzmodell Schuldummy�Variablen:
Vergleichskategorie: SCHOOL G (Privat)
Mathescoreij � b0 � b1�HOMEWORKij
�b2�DSCHOOLA �b3�DSCHOOLB �b4�DSCHOOLC�b5�DSCHOOLD �b6�DSCHOOLE �b7�DSCHOOLF�b8�DSCHOOLH �b9�DSCHOOLI �b10�DSCHOOLJ�b11� (DSCHOOLA�HOMEWORKij )�b12� (DSCHOOLB�HOMEWORKij )�b13� (DSCHOOLC�HOMEWORKij )�b14� (DSCHOOLD�HOMEWORKij )�b15� (DSCHOOLE�HOMEWORKij )�b16� (DSCHOOLF�HOMEWORKij )�b17� (DSCHOOLH�HOMEWORKij )�b18� (DSCHOOLI�HOMEWORKij )�b19� (DSCHOOLJ�HOMEWORKij ) � eij
Legende:i: Index des Schülers ij: Index der Schule jij: Schüler i in Schule j
do repeat #dummy=dschoola,dschoolb,dschoolc,dschoold,dschoole,dschoolf,dschoolg,dschoolh,dschooli ,dschoolj/#interak=ischav5,ischbv5,ischcv5,ischdv5,ischev5,ischfv5,ischgv5,ischhv5,ischiv5,ischjv5.
+ compute #interak= #dummy*v5.
end repeat.
frequencies /variables=ischav5 to ischjv5.

Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 33
Bei der Schätzung des zugehörigen Regressionsmodells müssen wir zusätzlich die schulspezi-fischen Interaktionseffekte berücksichtigen. Für die Vergleichschule G ist kein Interaktionstermzu bilden, da ihr Effekt direkt von der Variablen V5 erfaßt wird. Bei ihrem Schätzer handelt essich um einen bedingten oder konditionalen Effekt, der den Einfluß des Zeitaufwandes unter derBedingung mißt, daß alle anderen Dummy-Variablen Null sind. Die Interaktionseffekte zwi-schen Schule K und dem Zeitaufwand ihrer Schüler für Mathematikhausaufgaben erfassenjeweils unmittelbar die Abweichung des Lerneffektes in der Schule K von demjenigen derVergleichsschule G.
Für die Schätzung dieses Regressionsmodells benötigen wir die folgenden SPSSfWin-Befehle:
REGRESSION /MISSING LISTWISE /STATISTICS COEFF OUTS R ANOVA /CRITERIA=PIN(.05) POUT(.10) /NOORIGIN /DEPENDENT v9 /METHOD=ENTER dschoola dschoolb dschoolc dschoold dschoole dschoolf dschoolh dschooli dschoolj v5 ischav5,ischbv5,ischcv5,ischdv5,ischev5,ischfv5,ischhv5,ischiv5,ischjv5 /SAVE PRED (PYREG4).
GRAPH /SCATTERPLOT(BIVAR)=v5 WITH pyreg4 BY V1 /MISSING=LISTWISE.
Zu dem geschätzten Regressionsmodell mit schulspezifischen Effekten erhalten wir folgendesSPSSfWin-Ausgabeprotokoll:
Modellzusammenfassungb
,823a ,678 ,652 6,5645Modell1
R R-QuadratKorrigiertesR-Quadrat
Standardfehler desSchätzers
Einflußvariablen : (Konstante), ISCHJV5, ISCHDV5,ISCHEV5, ISCHFV5, ISCHAV5, ISCHIV5, ISCHBV5,ISCHHV5, ISCHCV5, time spent on math homework,DSCHOOLD, DSCHOOLE, DSCHOOLJ, DSCHOOLA,DSCHOOLF, DSCHOOLI, DSCHOOLC, DSCHOOLB,DSCHOOLH
a.
Abhängige Variable: math scoreb.
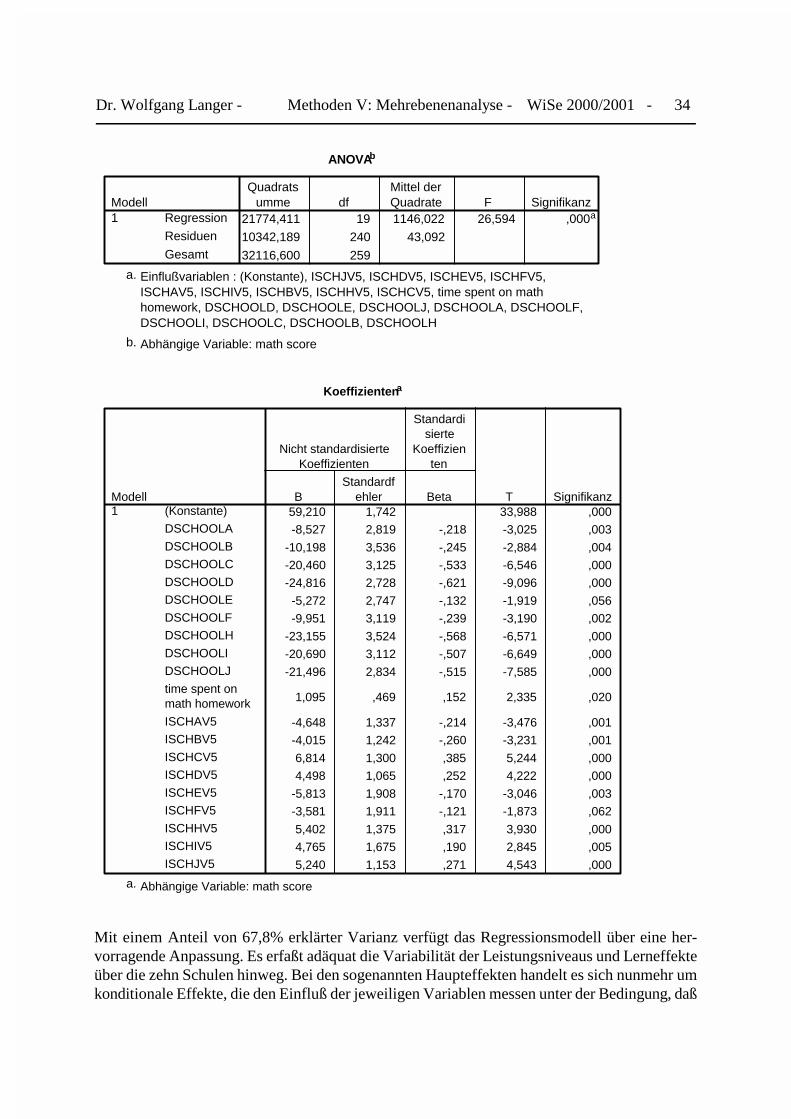
Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 34
ANOVAb
21774,411 19 1146,022 26,594 ,000a
10342,189 240 43,092
32116,600 259
Regression
Residuen
Gesamt
Modell1
Quadratsumme df
Mittel derQuadrate F Signifikanz
Einflußvariablen : (Konstante), ISCHJV5, ISCHDV5, ISCHEV5, ISCHFV5,ISCHAV5, ISCHIV5, ISCHBV5, ISCHHV5, ISCHCV5, time spent on mathhomework, DSCHOOLD, DSCHOOLE, DSCHOOLJ, DSCHOOLA, DSCHOOLF,DSCHOOLI, DSCHOOLC, DSCHOOLB, DSCHOOLH
a.
Abhängige Variable: math scoreb.
Koeffizientena
59,210 1,742 33,988 ,000
-8,527 2,819 -,218 -3,025 ,003
-10,198 3,536 -,245 -2,884 ,004
-20,460 3,125 -,533 -6,546 ,000
-24,816 2,728 -,621 -9,096 ,000
-5,272 2,747 -,132 -1,919 ,056
-9,951 3,119 -,239 -3,190 ,002
-23,155 3,524 -,568 -6,571 ,000
-20,690 3,112 -,507 -6,649 ,000
-21,496 2,834 -,515 -7,585 ,000
1,095 ,469 ,152 2,335 ,020
-4,648 1,337 -,214 -3,476 ,001
-4,015 1,242 -,260 -3,231 ,001
6,814 1,300 ,385 5,244 ,000
4,498 1,065 ,252 4,222 ,000
-5,813 1,908 -,170 -3,046 ,003
-3,581 1,911 -,121 -1,873 ,062
5,402 1,375 ,317 3,930 ,000
4,765 1,675 ,190 2,845 ,005
5,240 1,153 ,271 4,543 ,000
(Konstante)
DSCHOOLA
DSCHOOLB
DSCHOOLC
DSCHOOLD
DSCHOOLE
DSCHOOLF
DSCHOOLH
DSCHOOLI
DSCHOOLJ
time spent onmath homework
ISCHAV5
ISCHBV5
ISCHCV5
ISCHDV5
ISCHEV5
ISCHFV5
ISCHHV5
ISCHIV5
ISCHJV5
Modell1
BStandardf
ehler
Nicht standardisierteKoeffizienten
Beta
Standardisierte
Koeffizienten
T Signifikanz
Abhängige Variable: math scorea.
Mit einem Anteil von 67,8% erklärter Varianz verfügt das Regressionsmodell über eine her-vorragende Anpassung. Es erfaßt adäquat die Variabilität der Leistungsniveaus und Lerneffekteüber die zehn Schulen hinweg. Bei den sogenannten Haupteffekten handelt es sich nunmehr umkonditionale Effekte, die den Einfluß der jeweiligen Variablen messen unter der Bedingung, daß

Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 35
die anderen im Modell enthaltenen exogenen Merkmale jeweils den Wert Null aufweisen. DieRegressionskonstante erfaßt wiederum das Leistungsniveau der Schule G unter der Bedingung,daß ihre Schüler keine Mathematikhausaufgaben machen. Für sie erwarten wir im Durchschnittein Testergebnis von rd. 59,2 Punkten. Die Dummyvariablen der anderen Schulen erfassenunmittelbar die Abweichung des geschätzten Testmittelwerts der jeweiligen Schule unterderselben Bedingung. Ihre Testergebnisse fallen im Durchschnitt zwischen 5,27 in Schule E und24,8 Punkten D in Schule schlechter aus. Der Steigungskoeffizient der Variablen V5 (mathhomework) erfaßt nun den spezifischen Lerneffekt der Privatschule G. Für jede Stunde , die einSchüler dieser Schule mit Mathematikhausaufgaben verbringt, kann er im Durchschnitt eineVerbesserung seines Testergebnisse um rd. 1,1 Punkte erwarten. Die schulspezifischen Inter-aktionseffekte der Variablen V5 bilden jetzt direkt die Abweichung des Lerneffektes der be-trachteten Schule von demjenigen der Privatschule G ab. Hierbei zeichnet sich ein durchauswidersprüchliches Bild ab. Der Ertrag einer Stunde Mathematikhausaufgaben liegt in deröffentlichen Schule C um rd, 6,8 Punkte höher als in der Privatschule G. Im Gegensatz hierzufällt der Ertrag in der Schule E um rd. 5,8 Punkte niedriger als in der Vergleichsschule aus. MitHilfe elaborierterer Verfahren der Mehrebenenanalyse werden wir versuchen, diese differentiel-len Lerneffekte und ihre Paradoxien durch die Kontextmerkmale der Schulen selbst zu erklären.
Das Ergebnis der Schätzung des Kovarianzmodells mit Interaktionseffekten können wir mitHilfe des folgenden Streudiagramms darstellen, wobei die Regressionsgraden der einzelnenSchulen durch unterschiedliche Farben und Symbole gekennzeichnet werden. Hierbei ist klarersichtlich, daß sich die Schulen im Hinblick auf sowohl auf ihr Leistungsniveau als auch ihreLerneffekte bedeutsam voneinander unterscheiden. In der Abbildung 43 können wir drei Grup-pen von Schulen erkennen, die beim Y-Achsenabschnitt und der Steigung deutlich voneinanderabweichen. Zur ersten Gruppe gehören die Schulen C, D, H, I und J, die über einen niedrigen Y-Achsenabschnitt (unter 40 Punkte) und eine relativ starke positive Steigung verfügen. Die zweiteGruppe bilden die Schulen A, B, E und F, deren Y-Achsenabschnitt zwar über 50 Punkten liegt, sie aber jeweils eine negative Steigung aufweisen. Für ihre Schüler bedeutet dies, daß ihreBearbeitung der Mathematikhausaufgaben zu einer Verschlechterung ihres Testergebnissesführt. Die dritte Gruppe umfaßt allein die Privatschule G, deren Schüler mit 60 Punkten dasbeste Testergebnis ohne weitere Hausaufgaben erzielen. Ihr Übungseffekt fällt zwar positiv abersehr gering aus. Wenn wir die Regressionskonstanten und Steigungen der ersten beiden Gruppenmiteinander vergleichen, so scheinen die Regressionskonstanten mit den Steigungskoeffizientennegativ zu korrelieren. Hohe Y-Achsenabschnitte scheinen mit negativen Steigungen sowieniedrige Y-Achsenabschnitte mit positiven Steigungen zu korrelieren. Sowohl die Y-Achsen-abschnitte als auch die Steigungen weisen jeweils eine erhebliche Varianz über die Schulkon-texte hinweg auf.
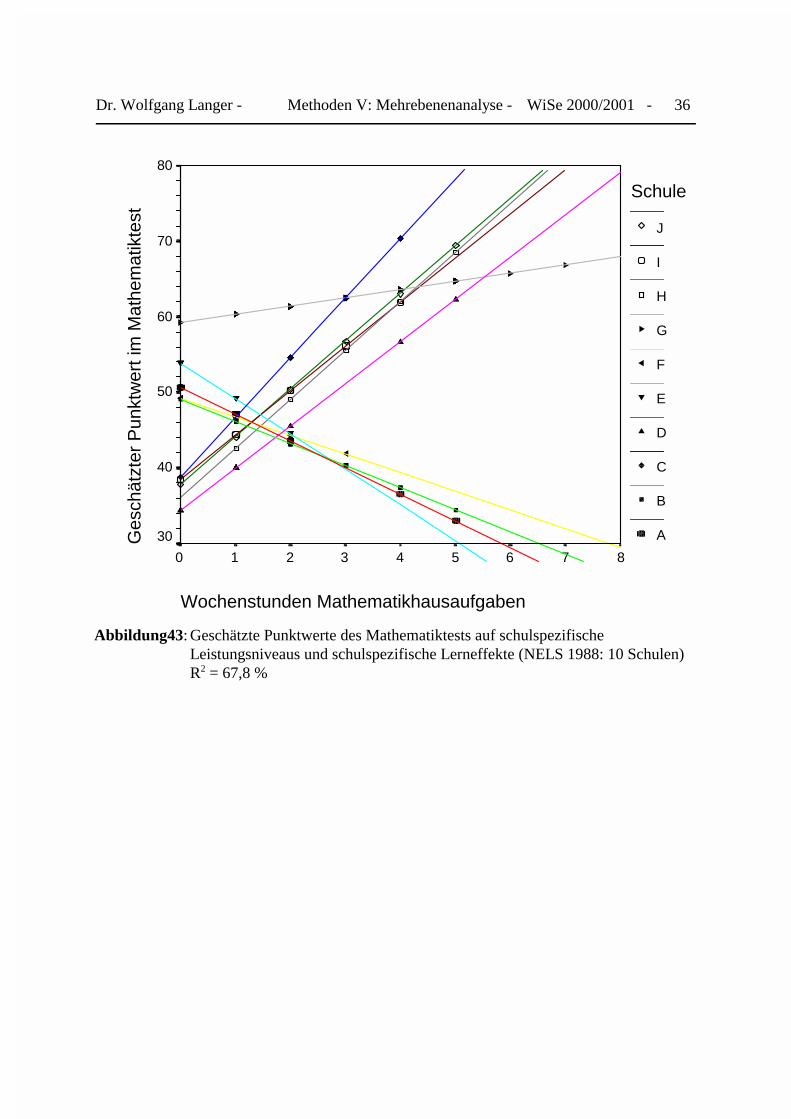
Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 36
Wochenstunden Mathematikhausaufgaben
876543210
Ges
chät
zter
Pun
ktw
ert i
m M
athe
mat
ikte
st
80
70
60
50
40
30
Schule
J
I
H
G
F
E
D
C
B
A
Abbildung43: Geschätzte Punktwerte des Mathematiktests auf schulspezifischeLeistungsniveaus und schulspezifische Lerneffekte (NELS 1988: 10 Schulen) R2 = 67,8 %

Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 37
2.7 Das Mehrebenenmodell von Cronbach und Webb
Bei dem von Cronbach & Webb (1975) vorgeschlagenen Modell handelt es sich um einen derersten Versuche, die Effekte exogener Individual- und Kontextmerkmale in ein und demselbenRegressionsmodell zu schätzen. Im Sinne Davis und Blaus gingen die Autoren davon aus, daßder individuelle Lerneffekt des Schüler i vom Leistungspensum seiner Schule j abhängig ist bzw.hierdurch moderiert wird. Dieses Leistungspensum operationalisierten die Autoren über denarithmetrischen Mittelwert der von Schülern der Schule j geleisteten Wochenstunden an Ma-thematikhausaufgaben. Ihm entspricht ihres Erachtens die soziale Leistungsnorm der Schule j.Im einfachsten Ansatz lassen sich die individuelle Wochenstundenzahl und das kollektiveAufgabenpensum zur Vorhersage der Mathematiktestergebnisse heranziehen. Hierbei stellt sichaber das Problem, daß sich der Schulmittelwert analytisch gesehen aus den individuellenMeßwerten der Schüler ergibt und daher beide hoch miteinander korrelieren. Dies führt zumbekannten Problem der Multikollinearität exogener Merkmale.
Regressionsmodell mit exogenen Mermalen auf der Individual�und Kollektivebene:
Matheescoreij � b0 � b1�HOMEWORKij
� b2�MEAN (HOMEWORK ).j � eij
Variablenbezeichnungen im Kreft&DeLeeuw Datensatz:
V9� b0 � b1�V5ij � b2�MEAN (V5 ).j � eij
Diese lineare Abhängigkeit der exogenen Individual- und Kollektivmerkmale führt dazu, daß beider Kleinsten-Quadrate-Schätzung die Steigungskoeffizienten und ihre zugehörigen Standard-fehler verzerrt ermittelt werden. Durch diesen Bias laufen wir Gefahr, falsche Schlüsse sowohlbei der Interpretation der Effektstärken also ihrer Generalisierbarkeit zu ziehen. Um die Multi-kollinearität zwischen exogenen Individual- und Kollektivmerkmalen zu beseitigen, schlagenCronbach&Webb (1975) eine getrennte Zentrierung beider Merkmalstypen vor. Erstens ziehensie vom Meßwert der Variablen X des Schülers i in der Schule j den Mittelwert X in der Schulej ab. Durch diese spezielle Form der Substraktion bereinigen Cronbach&Webb das Merkmal Xum seine Niveauunterschiede in den einzelnen Kontexten. Sie schließen hierdurch seine Varia-tion zwischen den Kontexten aus. Somit betrachten sie nur noch die Binnenvarianz des Merk-mals X innerhalb der Kontexte. Diese Form der Zentrierung am Gruppenmittelwert wird imEnglischen als „Group-Mean-Centering“ oder „Centering-Within-Context“ bezeichnet. ImSchulbeispiel von Kreft&De Leuuw führt die Zentrierung am jeweiligen Gruppenmittelwertdazu, daß sich die Interpretation des individuellen Lerneffektes der Hausaufgaben ändert. Durchdie Zentrierung nivellieren wir die Schulunterschiede des Leistungspensums und fragen uns überalle Schulen hinweg, um wieviel Punkte sich das Mathematiktestergebnis im Durchschnittverbessert, wenn der Schüler i der Schule j eine Stunde mehr in das Lösen seiner Mathematik-

Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 38
12 Cronbach, L.J. (1976): Research in classrooms and schools: Formulation of questions,designs and analysis. (Occational paper), Stanford, Ca.: Stanford Evaluation Consortium
hausaufgaben investiert als von ihm an seiner Schule j erwartet wird. Zweitens zentrierenCronbach&Webb die Schulmittelwerte der Wochenstunden am Gesamtmittelwert der in Ma-thematikhausaufgaben investierten Stunden aller Schüler i der Schulen j. Diese Form derZenterierung am Gesamtmittelwert wird im Englischen als „Grand-Mean-Centering“ bezeichnet.Hierdurch ändert sich die Interpretation des zugehörigen Steigungskoeffizienten ebenfalls. Ergibt nunmehr an, um wieviel sich das Testergebnis der Schüler der Schülers i im Durchschnittverbessert, wenn das Aufgabenpensum seiner Schule j eine Arbeitsstunde über dem Gesamt-mittelwert liegt, der die allgemeine Leistungsnorm definiert.
Das Mehrebenenmodell von Cronbach&Webb (1975) mit exogenenIndividual und Kollektivmerkmalen:
Yij � b0 � b1� (Xij � X̄. j ) � b2� ( X̄. j � X̄. . ) � eij
Legende:
Xij: Meßwert der Variablen X des Schülers i in Schule j
X̄. j: Mittelwert der Variablen X der Schule j
Xij � X̄. j: Zentrierung der Variablen X des Schülers i amMittelwert seiner Schule j
X̄. .: Mittelwert der Variablen X über alle Schüler i undSchulen j (Grand Mean)
X̄. j � X̄. .: Zentrierung des Schulmittelwertes von X am Grand Meanaller Schüler i in den Schulen j
ei j: Residuum des Schülers i in Schule j
Beide Zentrierungsarten hat Cronbach (1976)12 vorgeschlagen, um die Effekte auf derIndividual- und Kontextebene voneinander trennen zu können. Boyd&Iversen (1979) haben sieweiter entwickelt und im Rahmen ihrer Mehrebenenmodelle eingesetzt. Eine Besonderheit derZentrierung am Gruppenmittelwert besteht darin, daß sich erstens im Vergleich zum Ursprungs-modell der Steigungskoeffizient der zentrierten Variable nicht verändert. Lediglich ihr Mittel-wert wird auf ihren Nullpunkt verschoben. Dies führt zweitens dazu, daß die Regressionskon-stante den Erwartungswert für Y unter der Bedingung schätzt, daß das exogene Merkmal Xseinen eigenen Mittelwert annimmt. Die zugehörige Prognose der Kriteriumsvariablen beziehtsich nunmehr auf den „Durchschnittfall von X“. Boyd&Iversen (1979) veranschaulich dies mitHilfe der Abbildungen 44 und 45.
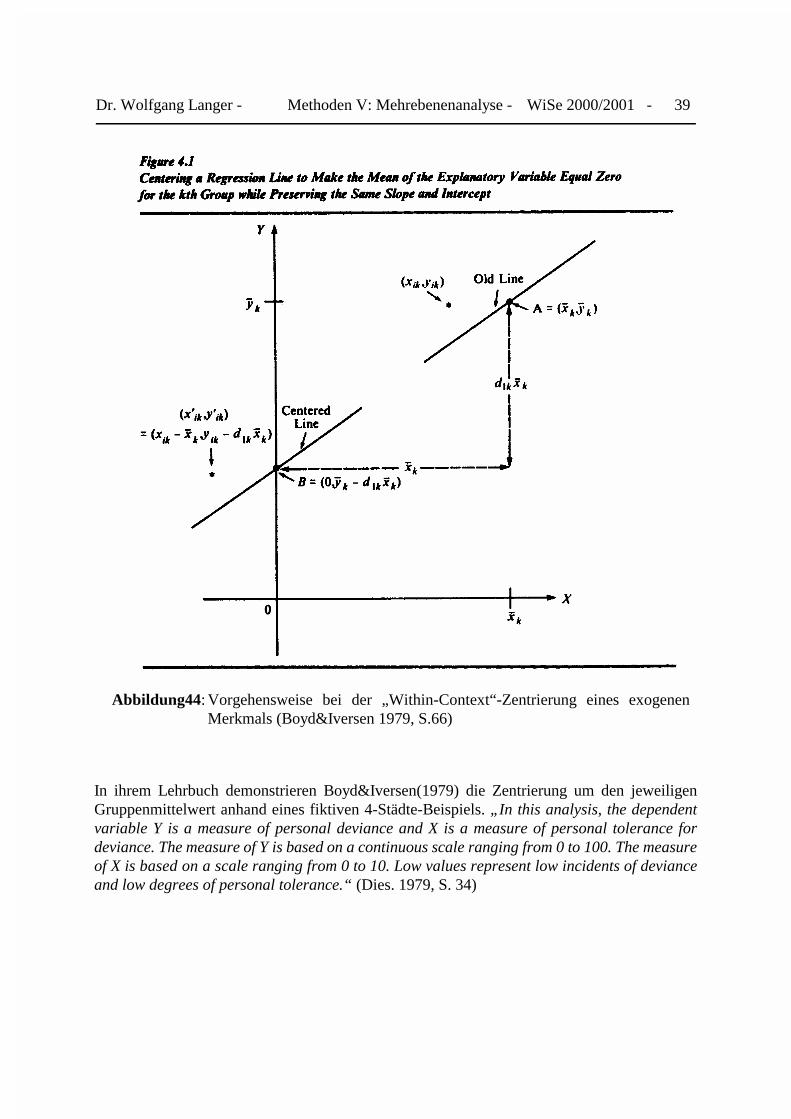
Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 39
Abbildung44: Vorgehensweise bei der „Within-Context“-Zentrierung eines exogenenMerkmals (Boyd&Iversen 1979, S.66)
In ihrem Lehrbuch demonstrieren Boyd&Iversen(1979) die Zentrierung um den jeweiligenGruppenmittelwert anhand eines fiktiven 4-Städte-Beispiels. „In this analysis, the dependentvariable Y is a measure of personal deviance and X is a measure of personal tolerance fordeviance. The measure of Y is based on a continuous scale ranging from 0 to 100. The measureof X is based on a scale ranging from 0 to 10. Low values represent low incidents of devianceand low degrees of personal tolerance.“ (Dies. 1979, S. 34)
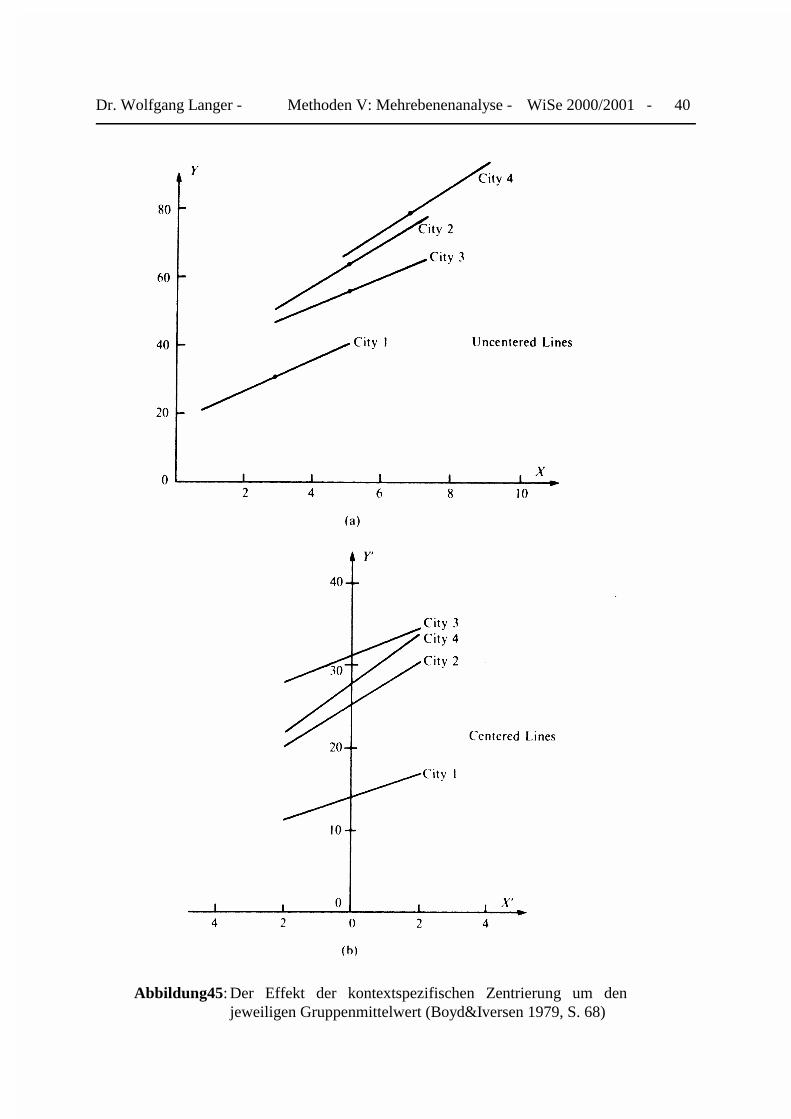
Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 40
Abbildung45: Der Effekt der kontextspezifischen Zentrierung um denjeweiligen Gruppenmittelwert (Boyd&Iversen 1979, S. 68)
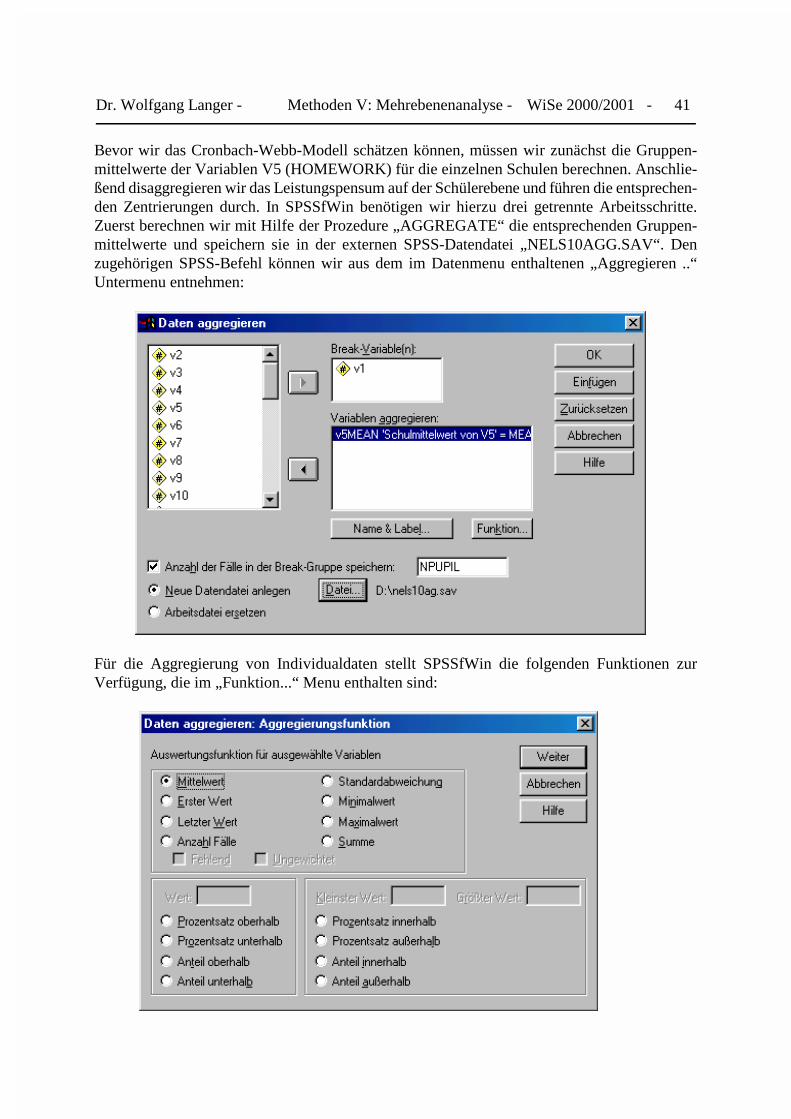
Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 41
Bevor wir das Cronbach-Webb-Modell schätzen können, müssen wir zunächst die Gruppen-mittelwerte der Variablen V5 (HOMEWORK) für die einzelnen Schulen berechnen. Anschlie-ßend disaggregieren wir das Leistungspensum auf der Schülerebene und führen die entsprechen-den Zentrierungen durch. In SPSSfWin benötigen wir hierzu drei getrennte Arbeitsschritte.Zuerst berechnen wir mit Hilfe der Prozedure „AGGREGATE“ die entsprechenden Gruppen-mittelwerte und speichern sie in der externen SPSS-Datendatei „NELS10AGG.SAV“. Denzugehörigen SPSS-Befehl können wir aus dem im Datenmenu enthaltenen „Aggregieren ..“Untermenu entnehmen:
Für die Aggregierung von Individualdaten stellt SPSSfWin die folgenden Funktionen zurVerfügung, die im „Funktion...“ Menu enthalten sind:

Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 42
Um später eine „ökologische Regression“ zwischen den Schulen schätzen zu können, benötigenwir ebenfalls den Mittelwert der abhängigen Variablen V9 (Punktanzahl im Mathematiktest) aufder Schulebene. Zusätzlich über nehmen wir die Unterscheidung zwischen privaten und öffentli-chen Schulen (PUBLIC), die für die Schüler ein und derselben Schule bereits ein Kontextmerk-mal darstellt. Der Wert dieser Dummyvariablen variiert nur zwischen den Schulen aber nichtinnerhalb der Schulen. Daher können wir einfach den ersten oder letzten Wert für die Ag-gregierung übernehmen. Zusätzlich speichert SPSSfWin die Kontextkennung (Break-Variable)V1 und die Anzahl der Schüler der jeweiligen Schule in der Variablen NPUPIL ab. Für dieAggregierung auf der Schulebene benötigen wir den folgenden SPSS-Befehl:
Um die aggregierten Kontextmerkmale wieder auf der Schülerebene zu disaggregieren, müssenwir die berechneten Schulmittelwerte auf der Ebene ihrer Schüler spiegeln. Hierzu ist es er-forderlich, die unterschiedlichen Datendateien der Schüler- und Schulebene dergestalt mitein-ander zu verknüpfen, daß die Mittelwerte der Schulen für ihre jeweiligen Schüler dupliziertwerden. Im Rahmen der Menusteuerung von SPSSfWin können Dateien nur auf derselbenAnalyseebene miteinander verknüpft werden. Den zugehörigen Befehl entnehmen wir aus der„Datei-Menugruppe“ Untermenu „Dateien zusammenfügen - Variablen hinzufügen“.
AGGREGATE /OUTFILE='D:\multilev\nels10agg.sav' /BREAK=v1 /v5mean 'Leistungsnorm für Hausaufgaben' = MEAN(v5) /v9mean 'Durchschnitt Mathematiktest' = MEAN(v9) /dpublic 'Öffentliche vs. Privatschule' = FIRST(public) /NPUPIL=N.
EXECUTE.

Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 43
Beide Dateien werden entsprechend der Schlüsselvariablen V1 zusammengefügt, die dieSchulkennziffer enthält. Zuvor müssen wir beide Dateien jeweils nach dieser Schlüsselvariablenin aufsteigender Reihenfolge sortieren. Wenn wir Schaltknopf „Einfügen“ drücken erhalten wirfolgenden SPSSfWin-Befehl:
Damit die Schulmittelwerte auf der Schülerebene dupliziert werden, müssen wir den Unterfehl„/FILE=“ durch die Angabe „/TABLE=“ ersetzen. SPSS spiegelt dann die aggregierten Kon-textmerkmale der Schule j auf der Ebene ihrer Schüler ij. Mit Hilfe der Option „/MAP“ fordernwir ein Protokoll der Dateiverknüpfung an.
Bevor wir das Cronbach-Webb-Modell schätzen können, müssen wir zunächst die Wochen-stunden für Mathematikhausaufgaben der Schüler auf der Schulebene zentrieren. Ebenso habenwir das geforderte Leistungspensum der Schule am Gesamtdurchschnitt zu zentrieren. Wirbenötigen hierzu die beiden folgenden „COMPUTE“-Befehle. Da SPSSfWin bei Datentrans-formationen nur zeilenorientiert arbeitet, kann es den Gesamtmittelwert nicht im Rahmen eines„COMPUTE“-Befehls berechnen. Wir müssen daher in einem Zwischenschritt zunächst dieGruppenmittelwerte sowie den Gesamtmittelwert für V5 und V9 berechnen.
MATCH FILES /FILE=* /FILE='D:\multilev\nels10agg.sav' /BY v1.EXECUTE.
MATCH FILES /FILE=* /TABLE='D:\multilev\nels10agg.sav' /BY v1 /MAP.EXECUTE.

Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 44
Wir benötigen hierzu die folgenden SPSSfWin-Befehle:
* Basic Tables.TABLES /FORMAT BLANK MISSING('.') /OBSERVATION v9 v5 /FTOTAL $t 'Gruppen-Gesamtwert' /TABLES (v1 > (v9 + v5) + $t ) BY (STATISTICS) /STATISTICS mean( (F5.2)) stddev((F5.2)) count( ( F5.0 )).
COMPUTE v5grc = v5-v5mean .VARIABLE LABELS v5grc 'V5 Gruppenzentriert (Schule)' .EXECUTE .
COMPUTE v5m_gmc = v5mean-2.02 .VARIABLE LABELS v5m_gmc 'V5 Schulnorm Grand Mean Centered' .EXECUTE .
* Schätzung des Cronbach&Webb-Modells.
REGRESSION /DESCRIPTIVES MEAN STDDEV CORR SIG N /MISSING LISTWISE /STATISTICS COEFF OUTS R ANOVA /CRITERIA=PIN(.05) POUT(.10) /NOORIGIN /DEPENDENT v9 /METHOD=ENTER v5grc v5m_gmc /SAVE PRED(PYREG5) .
* Grafiken unzentriert.
GRAPH /SCATTERPLOT(BIVAR)=v5mean WITH pyreg5 BY v1 /MISSING=LISTWISE .
GRAPH /SCATTERPLOT(BIVAR)=v5 WITH pyreg5 BY v1 /MISSING=LISTWISE .
* Grafiken zentriert.
GRAPH /SCATTERPLOT(BIVAR)=v5m_gmc WITH pyreg5 BY v1 /MISSING=LISTWISE .
GRAPH /SCATTERPLOT(BIVAR)=v5grc WITH pyreg5 BY v1 /MISSING=LISTWISE .
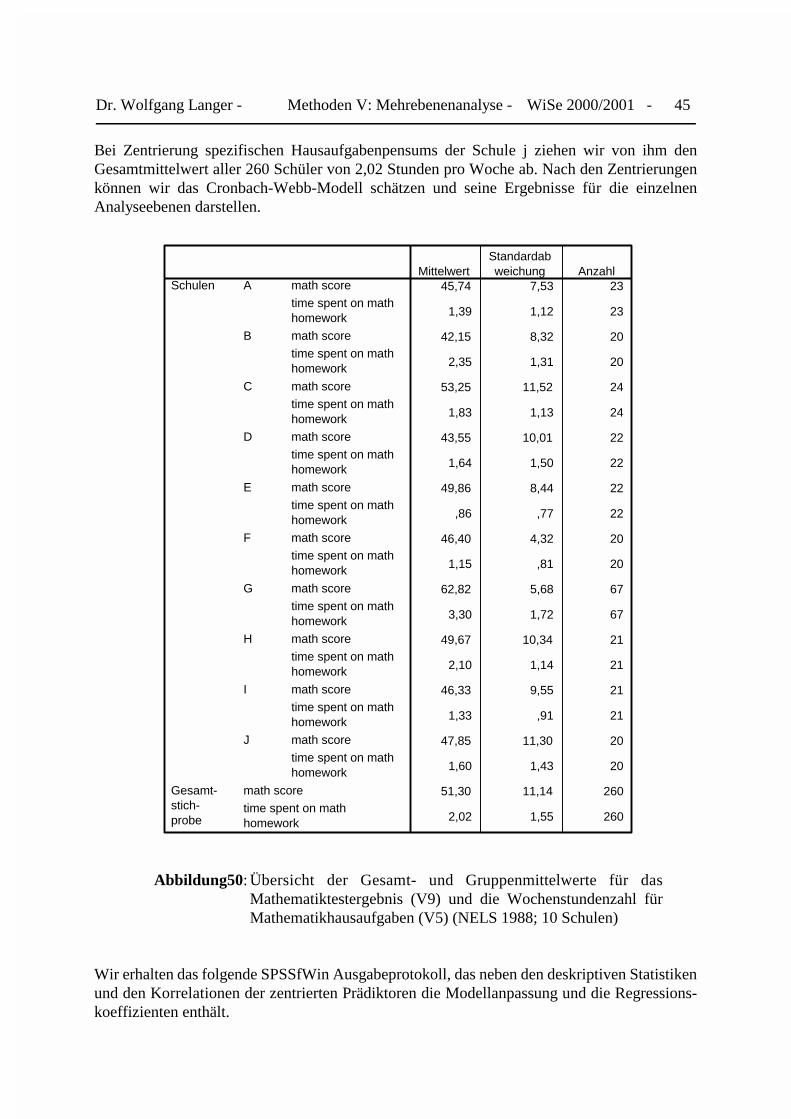
Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 45
Bei Zentrierung spezifischen Hausaufgabenpensums der Schule j ziehen wir von ihm denGesamtmittelwert aller 260 Schüler von 2,02 Stunden pro Woche ab. Nach den Zentrierungenkönnen wir das Cronbach-Webb-Modell schätzen und seine Ergebnisse für die einzelnenAnalyseebenen darstellen.
45,74 7,53 23
1,39 1,12 23
42,15 8,32 20
2,35 1,31 20
53,25 11,52 24
1,83 1,13 24
43,55 10,01 22
1,64 1,50 22
49,86 8,44 22
,86 ,77 22
46,40 4,32 20
1,15 ,81 20
62,82 5,68 67
3,30 1,72 67
49,67 10,34 21
2,10 1,14 21
46,33 9,55 21
1,33 ,91 21
47,85 11,30 20
1,60 1,43 20
51,30 11,14 260
2,02 1,55 260
math score
time spent on mathhomework
A
math score
time spent on mathhomework
B
math score
time spent on mathhomework
C
math score
time spent on mathhomework
D
math score
time spent on mathhomework
E
math score
time spent on mathhomework
F
math score
time spent on mathhomework
G
math score
time spent on mathhomework
H
math score
time spent on mathhomework
I
math score
time spent on mathhomework
J
Schulen
math score
time spent on mathhomework
Gesamt-stich- probe
MittelwertStandardabweichung Anzahl
Abbildung50: Übersicht der Gesamt- und Gruppenmittelwerte für dasMathematiktestergebnis (V9) und die Wochenstundenzahl fürMathematikhausaufgaben (V5) (NELS 1988; 10 Schulen)
Wir erhalten das folgende SPSSfWin Ausgabeprotokoll, das neben den deskriptiven Statistikenund den Korrelationen der zentrierten Prädiktoren die Modellanpassung und die Regressions-koeffizienten enthält.
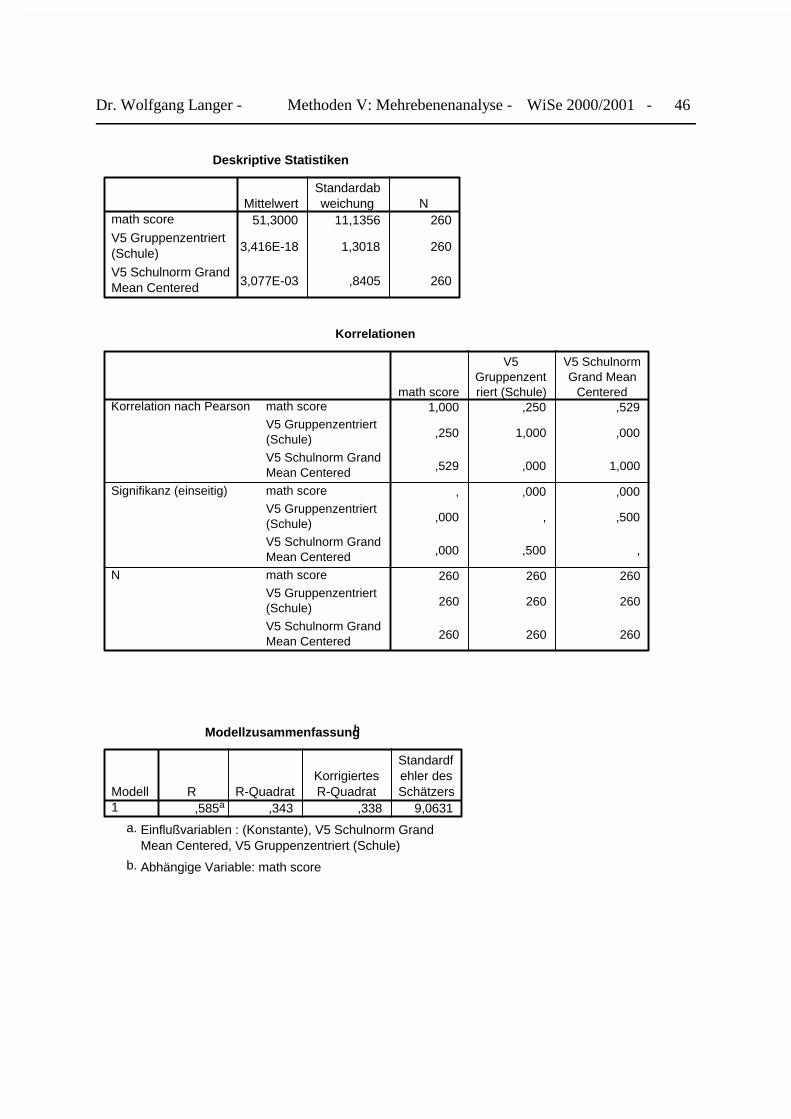
Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 46
Deskriptive Statistiken
51,3000 11,1356 260
3,416E-18 1,3018 260
3,077E-03 ,8405 260
math score
V5 Gruppenzentriert(Schule)
V5 Schulnorm GrandMean Centered
MittelwertStandardabweichung N
Korrelationen
1,000 ,250 ,529
,250 1,000 ,000
,529 ,000 1,000
, ,000 ,000
,000 , ,500
,000 ,500 ,
260 260 260
260 260 260
260 260 260
math score
V5 Gruppenzentriert(Schule)
V5 Schulnorm GrandMean Centered
math score
V5 Gruppenzentriert(Schule)
V5 Schulnorm GrandMean Centered
math score
V5 Gruppenzentriert(Schule)
V5 Schulnorm GrandMean Centered
Korrelation nach Pearson
Signifikanz (einseitig)
N
math score
V5Gruppenzentriert (Schule)
V5 SchulnormGrand Mean
Centered
Modellzusammenfassungb
,585a ,343 ,338 9,0631Modell1
R R-QuadratKorrigiertesR-Quadrat
Standardfehler desSchätzers
Einflußvariablen : (Konstante), V5 Schulnorm GrandMean Centered, V5 Gruppenzentriert (Schule)
a.
Abhängige Variable: math scoreb.
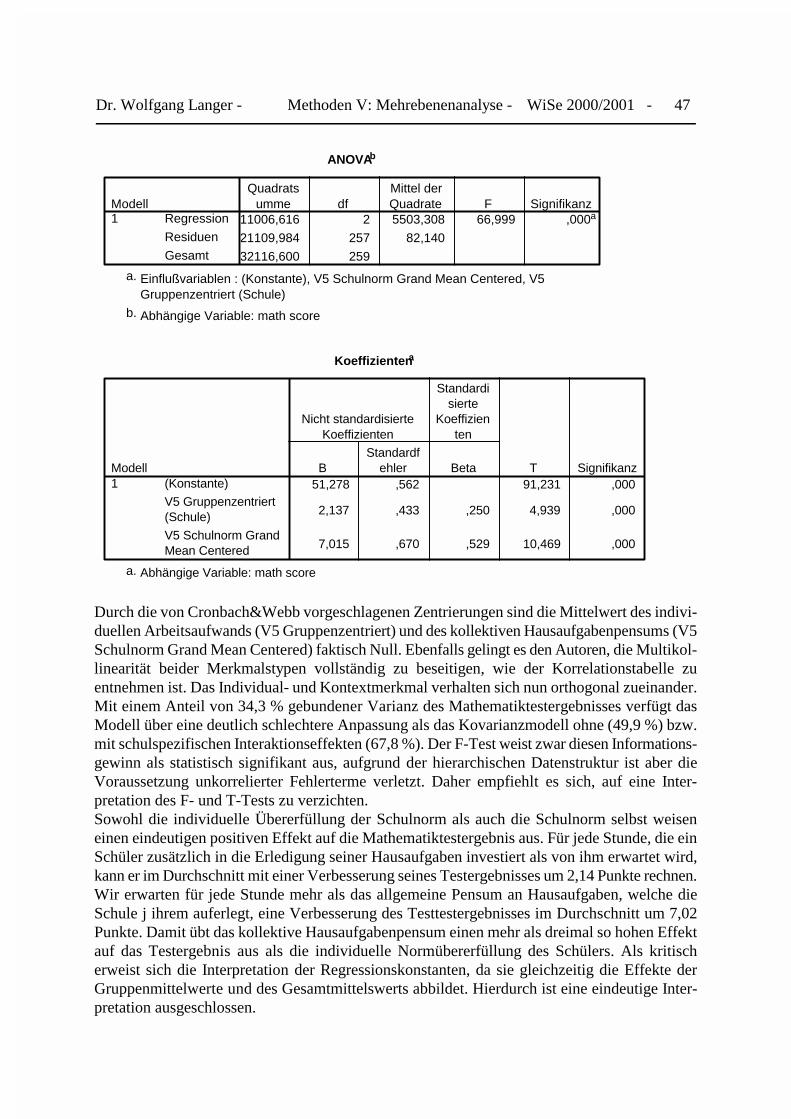
Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 47
ANOVAb
11006,616 2 5503,308 66,999 ,000a
21109,984 257 82,140
32116,600 259
Regression
Residuen
Gesamt
Modell1
Quadratsumme df
Mittel derQuadrate F Signifikanz
Einflußvariablen : (Konstante), V5 Schulnorm Grand Mean Centered, V5Gruppenzentriert (Schule)
a.
Abhängige Variable: math scoreb.
Koeffizientena
51,278 ,562 91,231 ,000
2,137 ,433 ,250 4,939 ,000
7,015 ,670 ,529 10,469 ,000
(Konstante)
V5 Gruppenzentriert(Schule)
V5 Schulnorm GrandMean Centered
Modell1
BStandardf
ehler
Nicht standardisierteKoeffizienten
Beta
Standardisierte
Koeffizienten
T Signifikanz
Abhängige Variable: math scorea.
Durch die von Cronbach&Webb vorgeschlagenen Zentrierungen sind die Mittelwert des indivi-duellen Arbeitsaufwands (V5 Gruppenzentriert) und des kollektiven Hausaufgabenpensums (V5Schulnorm Grand Mean Centered) faktisch Null. Ebenfalls gelingt es den Autoren, die Multikol-linearität beider Merkmalstypen vollständig zu beseitigen, wie der Korrelationstabelle zuentnehmen ist. Das Individual- und Kontextmerkmal verhalten sich nun orthogonal zueinander.Mit einem Anteil von 34,3 % gebundener Varianz des Mathematiktestergebnisses verfügt dasModell über eine deutlich schlechtere Anpassung als das Kovarianzmodell ohne (49,9 %) bzw.mit schulspezifischen Interaktionseffekten (67,8 %). Der F-Test weist zwar diesen Informations-gewinn als statistisch signifikant aus, aufgrund der hierarchischen Datenstruktur ist aber dieVoraussetzung unkorrelierter Fehlerterme verletzt. Daher empfiehlt es sich, auf eine Inter-pretation des F- und T-Tests zu verzichten.Sowohl die individuelle Übererfüllung der Schulnorm als auch die Schulnorm selbst weiseneinen eindeutigen positiven Effekt auf die Mathematiktestergebnis aus. Für jede Stunde, die einSchüler zusätzlich in die Erledigung seiner Hausaufgaben investiert als von ihm erwartet wird,kann er im Durchschnitt mit einer Verbesserung seines Testergebnisses um 2,14 Punkte rechnen.Wir erwarten für jede Stunde mehr als das allgemeine Pensum an Hausaufgaben, welche dieSchule j ihrem auferlegt, eine Verbesserung des Testtestergebnisses im Durchschnitt um 7,02Punkte. Damit übt das kollektive Hausaufgabenpensum einen mehr als dreimal so hohen Effektauf das Testergebnis aus als die individuelle Normübererfüllung des Schülers. Als kritischerweist sich die Interpretation der Regressionskonstanten, da sie gleichzeitig die Effekte derGruppenmittelwerte und des Gesamtmittelswerts abbildet. Hierdurch ist eine eindeutige Inter-pretation ausgeschlossen.
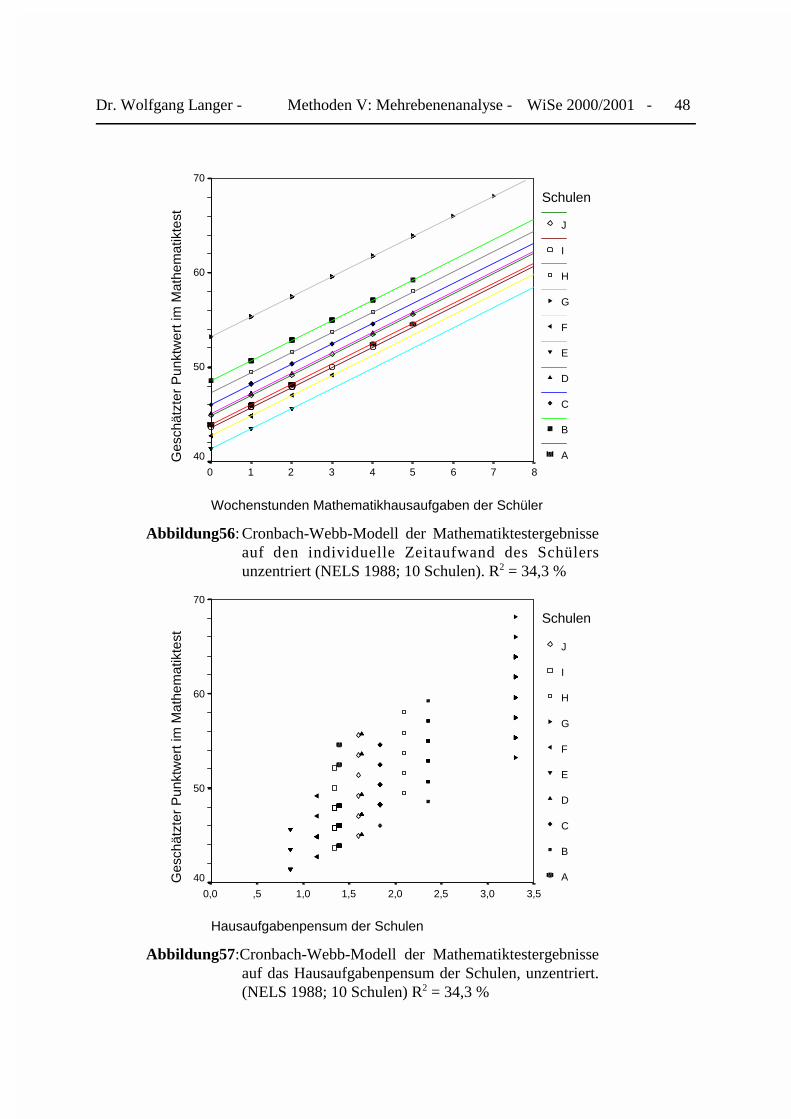
Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 48
Wochenstunden Mathematikhausaufgaben der Schüler
876543210
Ges
chät
zter
Pun
ktw
ert i
m M
athe
mat
ikte
st70
60
50
40
Schulen
J
I
H
G
F
E
D
C
B
A
Abbildung56: Cronbach-Webb-Modell der Mathematiktestergebnisseauf den individuelle Zeitaufwand des Schülersunzentriert (NELS 1988; 10 Schulen). R2 = 34,3 %
Hausaufgabenpensum der Schulen
3,53,02,52,01,51,0,50,0
Ges
chät
zter
Pun
ktw
ert i
m M
athe
mat
ikte
st
70
60
50
40
Schulen
J
I
H
G
F
E
D
C
B
A
Abbildung57:Cronbach-Webb-Modell der Mathematiktestergebnisseauf das Hausaufgabenpensum der Schulen, unzentriert.(NELS 1988; 10 Schulen) R2 = 34,3 %
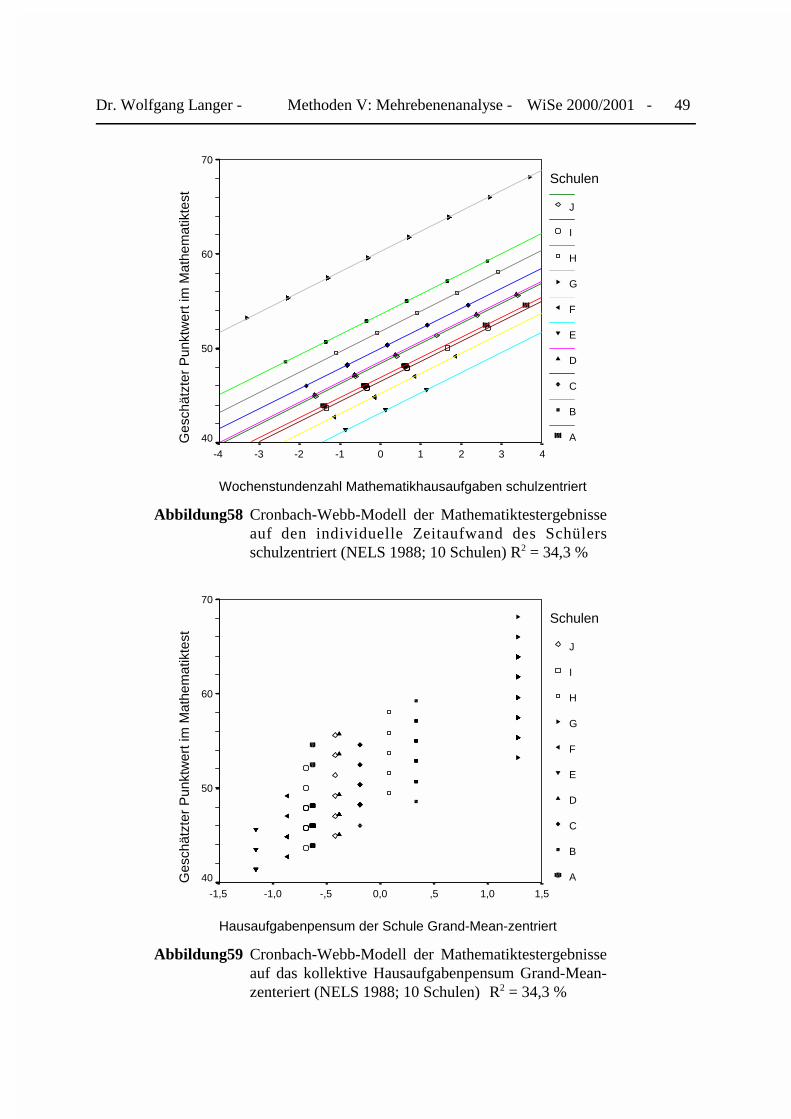
Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 49
Wochenstundenzahl Mathematikhausaufgaben schulzentriert
43210-1-2-3-4
Ges
chät
zter
Pun
ktw
ert i
m M
athe
mat
ikte
st
70
60
50
40
Schulen
J
I
H
G
F
E
D
C
B
A
Abbildung58 Cronbach-Webb-Modell der Mathematiktestergebnisseauf den individuelle Zeitaufwand des Schülersschulzentriert (NELS 1988; 10 Schulen) R2 = 34,3 %
Hausaufgabenpensum der Schule Grand-Mean-zentriert
1,51,0,50,0-,5-1,0-1,5
Ges
chät
zter
Pun
ktw
ert i
m M
athe
mat
ikte
st
70
60
50
40
Schulen
J
I
H
G
F
E
D
C
B
A
Abbildung59 Cronbach-Webb-Modell der Mathematiktestergebnisseauf das kollektive Hausaufgabenpensum Grand-Mean-zenteriert (NELS 1988; 10 Schulen) R2 = 34,3 %

Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 50
Die Abbildungen 56 und 57 sowie 58 und 59 stellen der Effekt des exogenen Individual- undKontextmerkmals wöchentlicher Hausaufgabenaufwand auf das erwartete Testergebnis in derursprünglichen Maßeinheit und ihrer jeweiligen Zentrierung jeweils getrennt dar. Wie denAbbildungen zu entnehmen ist, ändert sich durch die Zentrierung nicht die Steigung der Regres-sionsgeraden. Lediglich der gruppen- oder gesamtspezifische Mittelwert wird in den Nullpunktder X-Achse verschoben. Bei der Zentrierung am Gruppenmittelwert erfassen die Y-Achsen-abschnitte der einzelnen Schulen nunmehr unmittelbar für diejenigen Schüler, die genau dasHausaufgabenpensum ihrer Schule erledigen.
Das von Cronbach&Webb entwickelte Modell weist zwei entscheidende Nachteile aus. Esberücksichtigt erstens nicht adäquat die hierarchische Datenstruktur, wie sie in der Schüler-an-seiner-Schule-Relation empirisch gegen ist. Hierdurch berechnet SPSSfWin bei der Kleinsten-Quadrate-Schätzung Standardfehler für die Regressionsparameter, die zu gering ausfallen. Diesführt dazu, daß wir fälschlicherweise Effekte exogener Merkmale als statistisch signifikanteinstufen, die es in Wirklichkeit nicht sind. Diese Gefahr des Fehlschlusses wird durch dieAbhängigkeit der Vorhersagefehler auf der Ebene der Schüler ihrer Schule weiter verschärft.Zweitens berücksichtigen Cronbach&Webb nicht die Interaktion zwischen dem exogenenIndividual- und Kontextmerkmalen, wie sie Davis u.a. (1961) in seinem Typus IV A bis Cidealtypisch dargestellt hat. Von unseren Kovarianzanalysen wissen wir aber, daß solcheInteraktionen vorliegen und in einem Mehrebenenmodell adäquat zu berücksichtigen sind.

Dr. Wolfgang Langer - Methoden V: Mehrebenenanalyse - WiSe 2000/2001 - 51
2.8 Das Mehrebenenmodell von Boyd&Iversen