Embed Size (px)
Citation preview

MATTHIAS GERDTS
Mathematik I
Universitat der Bundeswehr MunchenHerbsttrimester 2017

Addresse des Autors:
Matthias Gerdts
Institut fur Mathematik und Rechneranwendung
Universitat der Bundeswehr Munchen
Werner-Heisenberg-Weg 39
85577 Neubiberg
E-Mail: [email protected]
WWW: www.unibw.de/lrt1/gerdts
Vorlaufige Version: 24. Oktober 2017
Copyright c© 2017 by Matthias Gerdts

Inhaltsverzeichnis
1 Grundlagen 3
1.1 Aussagenlogik . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
1.2 Summen- und Produktzeichen . . . . . . . . . . . . . . . . . . . . . . . . . 12
1.3 Das Induktionsprinzip . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
1.4 Binomische Formeln . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
1.5 Mengen und Zahlen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
1.6 Komplexe Zahlen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
2 Vektoren und Matrizen 34
2.1 Vektoren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
2.1.1 Multiplikation mit Skalaren . . . . . . . . . . . . . . . . . . . . . . 36
2.1.2 Vektoraddition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
2.1.3 Lange eines Vektors . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
2.1.4 Ortsvektoren und Verbindungsvektoren . . . . . . . . . . . . . . . . 38
2.1.5 Skalarprodukt (Inneres Produkt) . . . . . . . . . . . . . . . . . . . 40
2.1.6 Kreuzprodukt (Vektorprodukt, Außeres Produkt) . . . . . . . . . . 45
2.1.7 Spatprodukt . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
2.1.8 Vektoren im Rn . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
2.2 Allgemeine Vektorraume . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
2.3 Matrizen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
2.4 Lineare Abbildungen und Matrizen . . . . . . . . . . . . . . . . . . . . . . 74
3 Lineare Gleichungssysteme 78
3.1 Lineare Gleichungssysteme . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
3.2 Existenz und Eindeutigkeit von Losungen . . . . . . . . . . . . . . . . . . . 80
3.3 Gauss’sches Eliminationsverfahren . . . . . . . . . . . . . . . . . . . . . . . 82
3.3.1 Die allgemeine Vorgehensweise . . . . . . . . . . . . . . . . . . . . . 83
3.3.2 Der n-dimensionale Fall . . . . . . . . . . . . . . . . . . . . . . . . 86
3.4 Determinanten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91
4 Eigenwertaufgaben 96
4.1 Eigenwerte und Eigenvektoren . . . . . . . . . . . . . . . . . . . . . . . . . 98
4.2 Eigenwerte, Krummung, Spur und Determinante . . . . . . . . . . . . . . . 115
ii

4.3 Eigenwertabschatzungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . 118
5 Funktionen 121
5.1 Affin-lineare Funktionen . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122
5.2 Quadratische Funktionen . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123
5.3 Polynome und rationale Funktionen . . . . . . . . . . . . . . . . . . . . . . 124
5.4 Trigonometrische Funktionen . . . . . . . . . . . . . . . . . . . . . . . . . 128
5.4.1 Sinus, Cosinus ( sin, cos) . . . . . . . . . . . . . . . . . . . . . . . . 128
5.4.2 Tangens, Cotangens (tan, cot) . . . . . . . . . . . . . . . . . . . . . 131
5.5 Exponentialfunktion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 132
5.6 Logarithmus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 135
5.7 Hyperbolische Funktionen . . . . . . . . . . . . . . . . . . . . . . . . . . . 137
Literaturverzeichnis 139

Vorwort
Diese Vorlesung basiert auf Vorlesungen von Prof. Dr. Marti, Prof. Dr. Gwinner, Prof. Dr.
Pesch und Prof. Dr. Apel, welche zuvor an der Universitat der Bundeswehr Munchen und
der Universitat Bayreuth gehalten wurden. Sie vermittelt Grundlagen der linearen Algebra
und richtet sich an Studierende im ersten Trimester in den Bachelor-Studiengangen Luft-
und Raumfahrttechnik (LRT), Bauingenieurwesen und Umweltwissenschaften (BAU) und
Elektrotechnik und Informationstechnik (EIT).
Die Vorlesung baut auf den Mathematikkenntnissen im Abitur auf und hat zum Ziel,
grundlegende Konzepte und Methoden der linearen Algebra zur mathematischen Beschrei-
bung naturwissenschaftlich-technischer Prozesse zu vermitteln und zu eigenstandigem lo-
gischen Denken anzuregen.
Als Erganzung stehen zum Selbststudium folgende Hilfsmittel zur Verfugung, um Wissen
aufzufrischen oder etwaige Wissenslucken zu schließen:
(a) Vorkurs Mathematik: Skript zur Auffrischung von Schulkenntnissen von Prof. Dr.
Gerdts.
(b) Mathematik – Vorwissen und Selbststudium: Skript von Prof. Dr. Apel.
(c) Das Lernsystem Mumie kann zum Uben und Wissensuberprufung verwendet wer-
den:
http://www.mumie.net/ .
Es stellt eine Benutzeroberflache zur Generierung von Aufgaben zur Verfugung, die
automatisch korrigiert werden. Eine Demoversion mit Gastzugangen ist unter
https://www.mumie-hosting.net/demo/public/index.html
verfugbar.
(d) Die Fakultat EIT bietet wochentliche Tutorien fur alle Teilnehmer der Vorlesung
an. Diese finden mittwochs ab 12:00 Uhr in Raum 3125 in Gebaude 41/100 statt.
Eine vorherige Anmeldung per Email ist notwendig.
Die Tutorien bieten die Moglichkeit, sich Inhalte der Vorlesung nochmals erklaren
zu lassen. Nutzen Sie dieses Angebot!
1

2
Allgemeine Tipps und Hinweise:
• Mathematische Inhalte erschließen sich nicht von selbst und in den seltensten Fallen
durch gelegentliches Uberfliegen des Vorlesungsskriptes, sondern sie erfordern ein
aktives Mitarbeiten und viel Ubung.
Arbeiten Sie deshalb die Vorlesungen (und Ubungen) nach!
Auch wenn die wochentlichen Ubungsaufgaben aus Kapazitatsgrunden nicht ein-
gesammelt und korrigiert werden konnen, so ist es zum Verstandnis des Stoffes
sehr wichtig, die Ubungsaufgaben regelmaßig und selbststandig zu bearbeiten.
Spatestens in der Klausur, aber insbesondere auch im weiteren Verlauf des Studi-
ums, ist eine gewisse Routine im Losen von Aufgaben notwendig. Diese erlangt man
nur durch eigenstandiges Losen von Aufgaben.
• Gehen Sie den Vorlesungsstoff und Ubungsaufgaben mit Kommilitonen durch. Er-
klaren und diskutieren Sie Definitionen und Satze in eigenen Worten! Fragen Sie
auch die Ubungsleiter und den Leiter der Veranstaltung bei Unklarheiten.
• Es ist keine gute Idee, sich erst kurz vor der Klausur mit dem Vorlesungsstoff zu
beschaftigen. Dann ist es zu spat und es bleibt nichts hangen. Die Inhalte der Vor-
lesung tauchen an verschiedenen Stellen im Studium immer wieder auf und werden
dann als bekannt vorausgesetzt.
• Wichtige Informationen zur Vorlesung, wie z.B. Ansprechpartner, Ubungsaufgaben
und Zusatzmaterial, finden sich auf der WWW-Seite
http://www.unibw.de/lrt1/gerdts/hm1
Diese Seite wird laufend aktualisiert, so dass sie regelmaßig besucht werden sollte.
• Nutzliche Webseiten mit Material zum Selbststudium sind
– http://www.mathe-online.at/
– http://www.geogebra.org/
– http://www.mumie.net/
c© 2011 by M. Gerdts

Kapitel 1
Grundlagen
Worum geht es in der Mathematik und warum muss ein Ingenieur Mathematikvorlesungen
horen?
In der Mathematik geht es um beweisbare Aussagen, die im Rahmen einer Theorie gultig
sind. Daruber hinaus ermoglicht die Mathematik die Modellierung von Vorgangen, etwa
technische oder naturwissenschaftliche Prozesse. Damit kann das Verhalten der Prozesse
auf Basis der Modellierungsannahmen vorhergesagt (simuliert) oder durch geeignete Wahl
von Modellparametern beeinflusst (optimiert) werden. Die Mathematik beschaftigt sich
auch mit der Analyse von Modellen im Hinblick auf qualitative Eigenschaften wie die
Abhangigkeit von Parametern, Stabilitat, Konvergenz und Grenzwertverhalten.
Beispiele:
• Statikberechnungen fur Gebaude und Brucken basieren auf einem mathematischen
Modell zur Berechnung der Lastkrafte und -momente. Diese Berechnungen sind
unerlasslich bei der Planung neuer Gebaude oder Brucken.
• Raumfahrtmissionen mussen vorab geplant, simuliert und optimiert werden. Hierzu
verwendet man mathematisch-physikalische Modelle der Raumfahrtmechanik, die
eine sehr prazise Vorhersage der Flugbahn erlauben.
3
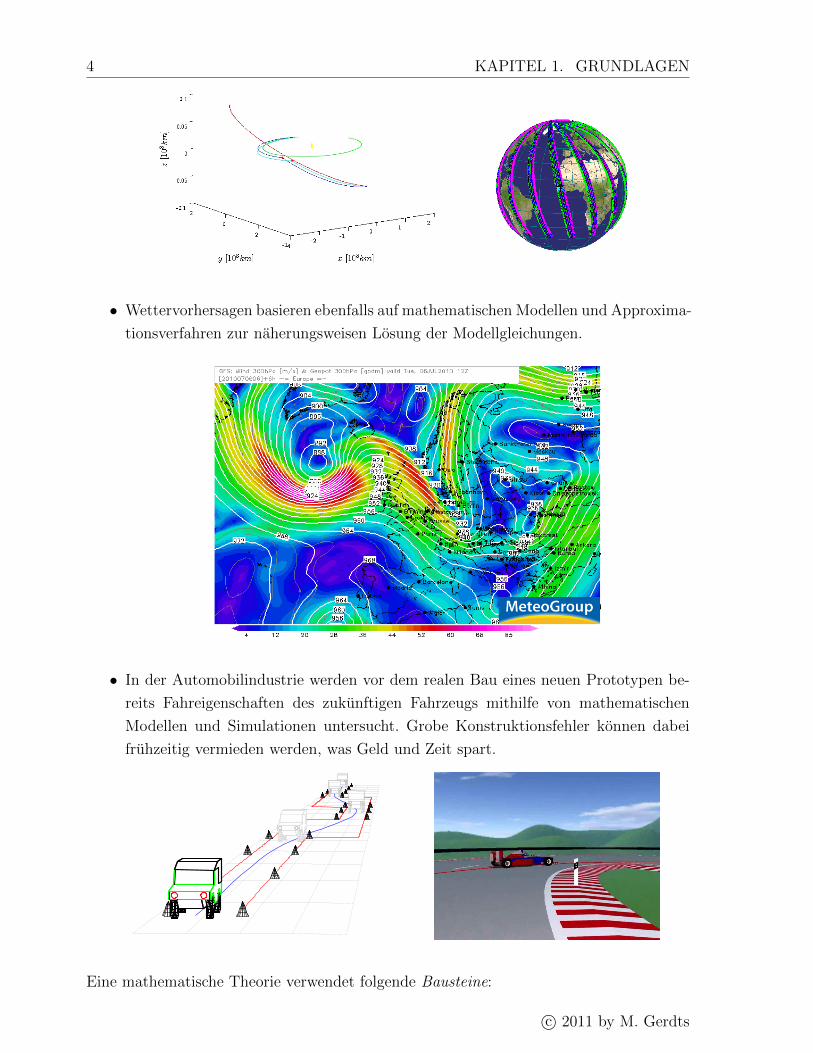
4 KAPITEL 1. GRUNDLAGEN
• Wettervorhersagen basieren ebenfalls auf mathematischen Modellen und Approxima-
tionsverfahren zur naherungsweisen Losung der Modellgleichungen.
• In der Automobilindustrie werden vor dem realen Bau eines neuen Prototypen be-
reits Fahreigenschaften des zukunftigen Fahrzeugs mithilfe von mathematischen
Modellen und Simulationen untersucht. Grobe Konstruktionsfehler konnen dabei
fruhzeitig vermieden werden, was Geld und Zeit spart.
Eine mathematische Theorie verwendet folgende Bausteine:
c© 2011 by M. Gerdts

5
Aussagen beschreiben einen Sachverhalt und sind entweder wahr oder falsch. Man sollte
allerdings beachten, dass nicht fur alle Aussagen entschieden werden kann, ob sie wahr
oder falsch sind.
Axiome sind grundlegende Annahmen bzw. Aussagen, die als wahr vorausgesetzt wer-
den und nicht bewiesen werden (konnen). Ein Axiomensystem darf keine Widerspruche
enthalten. Eine mathematische Theorie sollte auf moglichst wenigen Axiomen aufbauen.
Definitionen dienen zur exakten (!) Einfuhrung neuer Begriffe. Eine Definition muss
prazise sein und darf keinen Raum fur Zweideutigkeiten oder Interpretationsmoglichkeiten
lassen.
Satze (Theoreme) sind Aussagen, die durch logische Schlussfolgerungen aus Axiomen
hergeleitet werden. Den Vorgang der Herleitung nennt man Beweis. Damit sind Satze,
sobald sie bewiesen sind, fur immer gultig. Die einzelnen Schritte, die zum Beweis des
Satzes notig sind, mussen nachvollzogen werden konnen, allerdings benotigt man hierfur
in der Regel ein umfangreiches Wissen von weiteren Satzen, die im Beweis verwendet
werden.
Eine Folgerung ergibt sich aus einem Satz durch (einfache) logische Schlussfolgerungen.
Ein Lemma bzw. Hilfssatz ist ein Satz, der haufig grundlegende Sachverhalte bzw.
Zwischenresultate enthalt, die beim Beweis eines anderen Satzes verwendet werden.
Eine Vermutung ist eine Aussage, die noch nicht bewiesen oder widerlegt wurde. Es gibt
sehr beruhmte Vermutungen, mit denen man sogar Geld verdienen kann, wenn es gelingt,
sie zu beweisen oder zu widerlegen.
Beispiel 1.0.1 (Fermat’sche Vermutung)
Die beruhmte Fermat’sche Vermutung wurde 1637 vom franzosischen Mathematiker Fer-
mat wie folgt formuliert:
Es ist unmoglich, einen Kubus in zwei Kuben zu zerlegen, oder ein Biquadrat
in zwei Biquadrate, oder allgemein irgendeine Potenz großer als die zweite
in Potenzen gleichen Grades. Ich habe hierfur einen wahrhaft wunderbaren
Beweis gefunden, doch ist der Rand hier zu schmal, um ihn zu fassen.
c© 2011 by M. Gerdts

6 KAPITEL 1. GRUNDLAGEN
Mathematisch formuliert lautet die Vermutung:
Fur keine naturliche Zahl n ≥ 3 gibt es naturliche Zahlen a, b, c mit
an + bn = cn.
Diese Vermutung war sehr lange unbewiesen und konnte erst Anfang der 1990er Jahre
von Andrew Wiles und Richard Taylor bewiesen werden.
Beispiel 1.0.2 (Vermutung von Collatz)
Im Jahre 1937 vermutete Lothar Collatz, ein deutscher Mathematiker, der u.a. an der
Universitat Hamburg lehrte, dass die folgenden Zahlenfolgen fur beliebige Startwerte stets
bei 1 enden.
Die Zahlenfolgen werden dabei wie folgt konstruiert:
(i) Wahle eine beliebige naturliche Zahl N und setze a0 := N .
(ii) Definiere die Zahlen a1, a2, . . . solange fur n = 0, 1, 2, . . . durch die Vorschrift
an+1 :=
an2, falls an gerade ist,
3an + 1, falls an ungerade ist,
bis ak = 1 fur einen Index k gilt.
Beispiele:
N = 3 : a0 = 3, a1 = 10, a2 = 5, a3 = 16, a4 = 8, a5 = 4, a6 = 2, a7 = 1
N = 4 : a0 = 4, a1 = 2, a2 = 1,
N = 5 : a0 = 5, a1 = 16, a2 = 8, a3 = 4, a4 = 2, a5 = 1,
N = 6 : a0 = 6, a1 = 3, a2 = 10, a3 = 5, a4 = 16, a5 = 8, a6 = 4, a7 = 2, a8 = 1
Die Vermutung ist bis heute weder widerlegt noch bewiesen und kann auf
http://www.rzbt.haw-hamburg.de/dankert/spezmath/html/collatzproblem.html
getestet werden.
Beispiel 1.0.3 (Millennium Probleme)
Auf der Seite
http://www.claymath.org/millennium/
des Clay Mathematics Institute finden sich weitere Vermutungen, etwa die Riemannsche
Vermutung. Der Beweis oder die Widerlegung jeder dieser Vermutungen ist mit einer
Erfolgspramie von 1 Million Dollar dotiert.
Dieses Kapitel stellt das Handwerkszeug fur die nachfolgenden Kapitel bereit. Grundle-
gend ist dabei die Verwendung von Mengen und die Anwendung typischer Mengenope-
c© 2011 by M. Gerdts

1.1. AUSSAGENLOGIK 7
rationen, wie zum Beispiel Durchschnittsbildung, Vereinigung und Komplementbildung,
worauf wir in Abschnitt 1.5 eingehen.
Spezielle Mengen sind dabei die ublichen Zahlen, also die Menge der naturlichen, ganzen,
rationalen, reellen und komplexen Zahlen, die wir in den Abschnitten 1.5 und 1.6 einfuhren
werden.
Das Fuhren mathematischer Beweise basiert auf logischen Schlussen. Typische Schluss-
weisen werden in Abschnitt 1.1 vorgestellt.
In der Vorlesung werden viele Symbole als Variable verwendet, darunter auch griechische
Buchstaben (weil sie so schon sind und das deutsche Alphabet mitunter nicht ausreicht).
Hier sind die wichtigsten:
α alpha β beta γ,Γ gamma
δ,∆ delta ε, ε epsilon ι iota
µ mu ν nu ζ zeta
ω,Ω omega λ,Λ lambda η eta
κ kappa ξ,Ξ xi θ, ϑ,Θ theta
ρ, % rho σ,Σ sigma χ chi
τ tau
1.1 Aussagenlogik
Mathematische Beweise sind nichts anderes als die Aneinanderreihung von logisch kor-
rekten Schlussweisen. Daher kommt der Logik eine besondere Rolle in der Mathematik
zu.
In der Logik geht es um die Verknupfung von Aussagen. Zur Erinnerung: Aussagen be-
schreiben einen Sachverhalt und sind entweder wahr oder falsch. Man kann Aussagen
durch logische Operatoren miteinander verknupfen.
Die bekanntesten logischen Operatoren sind ∧ (logisches “und”) und ∨ (logisches “oder”).
Die verknupfte Aussage A∧B ist genau dann wahr, wenn sowohl A als auch B wahr sind.
Die verknupfte Aussage A ∨B ist genau dann wahr, wenn mindestens eine der Aussagen
A oder B wahr ist.
Beispiel 1.1.1
Wahre Aussagen:
• 3 ist kleiner als 5.
• Falls x < y ist, so ist x+ c < y + c fur alle Zahlen c.
• Die Gleichung x2 = 1 besitzt die reellen Losungen x = 1 und x = −1.
c© 2011 by M. Gerdts

8 KAPITEL 1. GRUNDLAGEN
• 5 ist kleiner als 3 oder 3 ist kleiner als 5.
Falsche Aussagen:
• 5 ist kleiner als 3.
• Aus c · x ≤ c · y folgt stets x ≤ y. (Gegenbeispiel: c = 0, x = 1, y = −1)
• Aus x2 = 1 folgt stets, dass x = 1 ist. (Gegenbeispiel: x = −1)
• 5 ist kleiner als 3 und 3 ist kleiner als 5.
Mochte man ausdrucken, dass aus der Aussage A die Aussage B folgt, so schreibt man
A =⇒ B (sprich: “Aus A folgt B.” bzw. “A impliziert B.”).
Beachte, dass die Aussage “A impliziert B” genau dann falsch ist, wenn A wahr und B
falsch ist. Man kann also aus einer wahren Aussage keine falsche Aussage folgern, wenn
man mathematisch korrekt schließt.
Gilt A =⇒ B, so sagt man auch:
• Die Aussage A ist hinreichend fur die Aussage B.
• Die Aussage B ist notwendig fur die Aussage A.
Die Negation (das Gegenteil) einer Aussage A wird mit ¬A bezeichnet.
Beispiel 1.1.2 (Notwendige und hinreichende Aussagen bei der Bestimmung
von Extrempunkten)
Sei f eine differenzierbare Funktion.
(a) Es gilt die folgende Implikation:
f hat lokales Minimum im Punkt x.︸ ︷︷ ︸Aussage A
=⇒ Es gilt f ′(x) = 0.︸ ︷︷ ︸Aussage B
Die Aussage “Es gilt f ′(x) = 0.” ist notwendig dafur, dass f in x ein lokales
Minimum besitzt. Die Negation dieser Aussage lautet “Es gilt f ′(x) 6= 0.”.
Aus der Aussage “Es gilt f ′(x) = 0.” kann man aber nicht schließen, dass f in x
ein Minimum besitzt (Gegenbeispiel: f(x) = −x2 und x = 0). Damit ist die Aussage
“Es gilt f ′(x) = 0.” nicht hinreichend dafur, dass f in x ein Minimum besitzt.
c© 2011 by M. Gerdts

1.1. AUSSAGENLOGIK 9
(b) Es gilt die folgende Implikation:
Fur x gilt f ′(x) = 0 und f ′′(x) > 0.︸ ︷︷ ︸Aussage A
=⇒ f besitzt in x ein lokales Minimum.︸ ︷︷ ︸Aussage B
Die Aussage “Fur x gilt f ′(x) = 0 und f ′′(x) > 0.” ist hinreichend dafur, dass f
in x ein lokales Minimum besitzt. Die Negation dieser Aussage lautet “Fur x gilt
f ′(x) 6= 0 oder f ′′(x) ≤ 0.”.
Aus der Aussage “f besitzt in x ein lokales Minimum.” kann man aber nicht schlie-
ßen, dass f ′(x) = 0 und f ′′(x) > 0 gelten (Gegenbeispiel: f(x) = x4 und x =
0).Damit ist die Aussage “f besitzt in x ein lokales Minimum.” nicht hinreichend
dafur, dass f ′(x) = 0 und f ′′(x) > 0 gelten.
Das folgende Beispiel zeigt, dass es sehr wohl moglich ist, aus einer falschen Aussage eine
wahre Aussage zu folgern. Solche Schlussweisen sind aber wertlos, da sie von einer falschen
Pramisse ausgehen.
Beispiel 1.1.3 (Beispiel fur Schlussfolgerung mit falscher Pramisse)
Die Aussage
“Jeden Tag gehen alle Menschen ins Schwimmbad, um zu schwimmen.”
ist falsch, da ich ein Mensch bin und z.B. am 16.7.2013 nicht im Schwimmbad war.
Da ich ein Mensch bin, impliziert diese Aussage jedoch die Aussage
“Ich war am 17.7.2013 im Schwimmbad, um zu schwimmen.”
Diese Aussage kann wahr sein, wenn ich tatsachlich am 17.7. im Schwimmbad war, um
zu schwimmen, oder sie kann falsch sein, wenn ich z.B. gar nicht schwimmen kann oder
am 17.7. nicht im Schwimmbad war, um zu schwimmen.
Mochte man ausdrucken, dass die Aussagen A und B gleichwertig (aquivalent) sind, so
schreibt man
A ⇐⇒ B (sprich: “A ist aquivalent zu B.” bzw. “A gilt genau dann, wenn B gilt.”).
Beachte, dass aquivalente Aussagen A und B entweder beide wahr oder beide falsch sind.
Beispiel 1.1.4
c© 2011 by M. Gerdts

10 KAPITEL 1. GRUNDLAGEN
(i) Die Aussage “Es gilt x + y = 1 mit reellen Zahlen x und y.” ist aquivalent zu der
Aussage “Es gilt x = 1−y mit reellen Zahlen x und y.”, da die Gleichungen x+y = 1
und x = 1− y dieselben reellen Losungen besitzen.
(ii) Gemaß der Rechenregeln fur reelle Zahlen sind die Aussagen “Fur c > 0 gilt 3c < 0.”
und “Es gilt 3 < 0.” aquivalent, weil man Ungleichungen immer mit positiven Zahlen
skalieren kann, ohne dass sich die Richtung der Ungleichung andert.
Beide Aussagen sind aber falsch.
Bei der Umformung von Formeln sollte man sich stets klar machen, ob man korrekt
schließt, d.h. ob man aquivalente Umformungen vornimmt oder Implikationen ableitet1.
Ein haufiger Fehler bei Umformungen ist, dass man Sonderfalle ubersieht und somit un-
terschlagt. Beispielsweise ist die Schlussweise
x2 = 1 =⇒ x = 1
nicht korrekt, da auch x = −1 eine Losung von x2 = 1 darstellt. Korrekt musste die
Folgerung
x2 = 1 =⇒ x = 1 oder x = −1
lauten. In diesem Fall sind beide Seiten sogar aquivalent:
x2 = 1 ⇐⇒ x = 1 oder x = −1 .
Die Schlussweise
x = −1 =⇒ x2 = 1
ist hingegen korrekt. Aquivalenz gilt hier aber nicht.
Mithilfe von sogenannten Wahrheitstabellen kann man folgende Aussagen beweisen:
1Im taglichen Leben findet man haufig auch ungerechtfertigte Schlussweisen, etwa wenn man von
Symptomen einer Krankheit auf die Krankheit selbst schließen mochte. Dies ist i.a. nicht gerechtfertigt,
da verschiedene Krankheiten dieselben Symptome haben konnen.
c© 2011 by M. Gerdts

1.1. AUSSAGENLOGIK 11
¬ (A =⇒ B) ⇐⇒ A ∧ (¬B)
¬(¬A) ⇐⇒ A
¬(A ∧B) ⇐⇒ (¬A) ∨ (¬B)
¬(A ∨B) ⇐⇒ (¬A) ∧ (¬B)
A =⇒ B ⇐⇒ (¬A) ∨BA =⇒ B ⇐⇒ (¬B) =⇒ (¬A)
A =⇒ B ⇐⇒ (A ∧ (¬B)) =⇒ (¬A) (Widerspruchsbeweis)
Hierin bezeichnen ∧ das logische “und” und ∨ das logische “oder”.
Diese Regeln konnen verwendet werden, um (verbale) Aussagen logisch richtig (!) umzu-
formen. 2
Bei der Formulierung von Aussagen greift man haufig auf die sogenannten Quantoren
zuruck:
Das Symbol ∀ ist eine Abkurzung fur”fur alle“.
Das Symbol ∃ ist eine Abkurzung fur”es existiert ein“.
Beispiel 1.1.5
• Die Aussage “Es gibt ein x ∈ R mit x > 0.” lasst sich mit Quantoren wie folgt
schreiben:
∃x ∈ R : x > 0
• Die Aussage “Fur alle x ∈ R gibt es ein y ∈ R mit x + y = 1.” lasst sich mit
Quantoren wie folgt schreiben:
∀x ∈ R ∃y ∈ R : x+ y = 1
Mochte man das Gegenteil einer Aussage, die Quantoren enthalt, ausdrucken, so ist dies
2Aufgabe: Formuliere die Negation der folgenden Aussage.
Aus |x− y| < δ folgt |f(x)− f(y)| < ε.
c© 2011 by M. Gerdts

12 KAPITEL 1. GRUNDLAGEN
einfach dadurch zu erreichen, dass man die Quantoren gegenseitig ausgetauscht und die
Eigenschaft negiert:
Sei E(x, y, z) ein Ausdruck, der von Parametern (x, y, z) abhange. Die Negation der Aus-
sage
∀x > 0 ∃y > 0 ∀z : E(x, y, z)
lautet
∃x > 0 ∀y > 0 ∃z : ¬E(x, y, z).
Mit anderen Worten: Um eine Aussage mit ∀ zu widerlegen, genugt es, ein Gegenbeispiel
zu finden (∃). Um eine Existenzaussage mit ∃ zu widerlegen, muss eine allgemeine Aussage
durch logisches Schließen bewiesen werden (∀) .
1.2 Summen- und Produktzeichen
Zur Summation von Zahlen wird haufig das Symbol Σ verwendet. Analog wird fur Pro-
dukte von Zahlen das Symbol∏
verwendet.
Beispiel 1.2.1 (Summenzeichen)
• Mochte man alle naturlichen Zahlen bis zur Zahl n ∈ N aufsummieren, so lasst sich
das mithilfe des Summenzeichens leicht schreiben als
n∑k=1
k = 1 + 2 + 3 + . . .+ n .
Schon Gauß hat erkannt, dass es fur diese Summe eine Berechnungsformel gibt,
namlichn∑k=1
k =n
2(n+ 1) .
(Begrundung?)
• Fur die Summe der Quadratzahlen
n∑k=1
k2 = 1 + 22 + 32 + . . .+ n2
gibt es ebenfalls eine geschlossene Formel, namlich
n∑k=1
k2 =1
6n(n+ 1)(2n+ 1) .
Diese Formel kann man formal mittels Induktion beweisen (siehe nachster Ab-
schnitt).
c© 2011 by M. Gerdts

1.2. SUMMEN- UND PRODUKTZEICHEN 13
• Die Zahlen ak seien fur k = 1, . . . , 100 definiert als ak = 1k+1
. Deren Summe lautet
dann
a1 + a2 + . . .+ a100 =100∑k=1
ak =100∑k=1
1
k + 1=
1
2+
1
3+ . . .+
1
101.
Beispiel 1.2.2 (Produktzeichen)
• Mochte man alle naturlichen Zahlen bis zur Zahl n ∈ N multiplizieren, so lasst sich
das mithilfe des Produktzeichens leicht schreiben alsn∏k=1
k = 1 · 2 · 3 · · ·n .
Diese Zahl hat einen speziellen Namen, namlich n! (sprich: n-Fakultat).
• Die Zahlen ak seien fur k = 1, . . . , 100 definiert als ak = 1k+1
. Deren Produkt lautet
dann
a1 · a2 · · · a100 =100∏k=1
ak =100∏k=1
1
k + 1=
1
2· 1
3· · · 1
101.
Gegeben seien n Zahlen a1, a2, . . . , an.
• Fur die Summe
a1 + a2 + . . .+ an
der Zahlen schreibt man abkurzend
n∑k=1
ak (= a1 + a2 + . . .+ an) .
Hierin ist k der Summationsindex, welcher von k = 1 bis n lauft.
• Fur das Produkt
a1 · a2 · · · an
der Zahlen schreibt man abkurzend
n∏k=1
ak (= a1 · a2 · · · an) .
Hierin ist k der Produktindex, welcher von k = 1 bis n lauft.
c© 2011 by M. Gerdts

14 KAPITEL 1. GRUNDLAGEN
Bemerkung 1.2.3
• Geht aus dem Kontext klar hervor, uber welchen Indexbereich die Summe bzw. das
Produkt gebildet werden soll, so schreibt man haufig auch abkurzend∑ak bzw.
∏ak .
• Naturlich kann man auch nur uber Teile der Zahlen summieren, indem der Bereich
des Summationsindex angepasst wird. Folgende Beschreibungen sind ublich:
n−3∑k=3
ak = a3 + a4 + . . .+ an−4 + an−3,
∑k=j
ak = aj + aj+1 + . . .+ a`−1 + a`, (fur 1 ≤ j ≤ ` ≤ n)
∑k=j
ak := 0, (Definition, falls ` < j)∑k∈4,5,6
ak = a4 + a5 + a6,∑j∈2k | k∈N,k<4
aj = a2 + a4 + a6.
Analog fur die Produktbildung.
1.3 Das Induktionsprinzip
Gegeben sei eine Aussage E(n), die von einer naturlichen Zahl abhangt.
Als Beispiel betrachten wir die Summation von Zahlen:
Aussage E(n) : Fur n ∈ N giltn∑k=1
k =n
2(n+ 1).
Ziel ist es, die Aussage E(n) fur alle n ∈ N (oder eine unendliche Teilmenge davon) zu
beweisen.
Die Aussage E(n) soll mit dem Induktionsprinzip bewiesen werden:
Induktionsprinzip:
• Induktionsanfang: Zeige, dass die Aussage E(n0) fur ein n0 ∈ N gilt (haufig ist
n0 = 1).
c© 2011 by M. Gerdts

1.3. DAS INDUKTIONSPRINZIP 15
• Induktionsschluss: Zeige fur ein beliebiges n ≥ n0, dass die Aussage E(n + 1)
gilt, wenn E(n) als wahr angenommen wird. Die Annahme, dass E(n) gelte, wird
als Induktionsannahme bezeichnet.
Induktionsanfang und Induktionsschluss zusammen zeigen, dass die Aussage E(n) fur
alle n ≥ n0 gilt. Das Induktionsprinzip arbeitet dabei nach dem Dominoprinzip: Der
Induktionsanfang entspricht dem Umkippen des ersten Steins. Der Induktionsschluss sorgt
dafur, dass der nachste Stein fallt, wenn der vorige gefallen ist.
Wir wenden das Induktionsprinzip auf das Beispiel an:
Induktionsanfang: Fur n = n0 = 1 gilt
n∑k=1
k =1∑
k=1
k = 1 =1
2(1 + 1)
√
Damit gilt die Aussage E(1).
Induktionsschluss: Die Aussage E(n) gelte nun fur ein beliebiges n ∈ N, d.h. es gelte
n∑k=1
k =n
2(n+ 1) (Induktionsannahme).
Wir mussen nun zeigen, dass auch E(n+ 1) gilt. Wir erhalten
n+1∑k=1
k = (n+ 1) +n∑j=1
j︸ ︷︷ ︸=n
2(n+1) nach Induktionsannahme
= (n+ 1) +n
2(n+ 1)
= (n+ 1)(
1 +n
2
)=
n+ 1
2(n+ 2) .
c© 2011 by M. Gerdts

16 KAPITEL 1. GRUNDLAGEN
Damit ist unter Verwendung der Induktionsannahme gezeigt, dass auch E(n+ 1) gilt.
Induktionsanfang und Induktionsschluss liefern zusammen die Behauptung.
1.4 Binomische Formeln
In den Anwendungen treten oft Ausdrucke der Form
(a+ b)2, (a− b)2, (a+ b)3, (a− b)3, (a+ b)4, (a− b)4, . . .
bzw. allgemein der Form
(a+ b)n (n ∈ N, a, b ∈ R)
auf.
Fur n = 2 erhalt man
(a+ b)2 = (a+ b)(a+ b) = a2 + 2ab+ b2 (1. binomische Formel),
(a− b)2 = (a− b)(a− b) = a2 − 2ab+ b2 (2. binomische Formel),
a2 − b2 = (a− b)(a+ b) (3. binomische Formel).
Des Weiteren berechnen sich die Ausdrucke (a+ b)n fur n = 1, 2, . . . , 5 wie folgt:
(a+ b)0 = 1
(a+ b)1 = 1a+ 1b
(a+ b)2 = 1a2 + 2ab+ 1b2
(a+ b)3 = 1a3 + 3a2b+ 3ab2 + 1b3
(a+ b)4 = 1a4 + 4a3b+ 6a2b2 + 4ab3 + 1b4
(a+ b)5 = 1a5 + 5a4b+ 10a3b2 + 10a2b3 + 5ab4 + 1b5
...
Schaut man sich die Koeffizienten vor den einzelnen Termen an, so kann man ein Mu-
ster erkennen, welches uns die Koeffizienten der Ergebnisse liefert. Es basiert auf dem
Pascal’schen Dreieck in der folgenden Abbildung 1.1:
c© 2011 by M. Gerdts

1.4. BINOMISCHE FORMELN 17
Abbildung 1.1: Pascal’sches Dreieck
In den Außendiagonalen steht immer eine 1. Die inneren Terme werden als Summe der
daruberliegenden Terme gebildet.
Diese Ergebnisse kann man in einer einzigen Formel zusammenfassen. Darin verwendet
man die sogenannten Binomialkoeffizienten:
Definition 1.4.1 (Binomialkoeffizienten)
Fur n, k ∈ N0 mit k ≤ n sind die Binomialkoeffizienten definiert als(n
k
):=
n!
(n− k)!k!(sprich: “n uber k”),
wobei die Konvention 0! = 1 verwendet wird.
Eigenschaften:
•(n
k
)=
n!
(n− k)!k!=
(n− k + 1)(n− k + 2) . . . (n− 2)(n− 1)n
1 · 2 · 3 . . . k
•(n
k
)=
(n
n− k
)
•(
n
k − 1
)+
(n
k
)=
(n+ 1
k
)Beispiel: (
7
4
)=
1 · 2 · 3 · 4 · 5 · 6 · 7(1 · 2 · 3 · 4)(1 · 2 · 3)
= 35.
Mithilfe der Binomialkoeffizienten kann man per Induktion den folgenden Satz beweisen:
c© 2011 by M. Gerdts

18 KAPITEL 1. GRUNDLAGEN
Satz 1.4.2 (Binomiallehrsatz)
Fur a, b ∈ R und n ∈ N0 gilt
(a+ b)n =n∑k=0
(n
k
)an−kbk
=
(n
0
)an +
(n
1
)an−1b+
(n
2
)an−2b2 + · · ·+
(n
n− 1
)abn−1 +
(n
n
)bn .
Beweis: Wir beweisen den Binomilallehrsatz mittels Induktion nach n.
Induktionsanfang: Fur n = 0 gilt (a+ b)0 = 1 und
0∑k=0
(0
k
)a0−kbk =
(0
0
)a0−0b0 = 1.
Damit stimmt die Behauptung fur n = 0.
Induktionsschritt: Die Aussage gelte fur ein beliebiges n ∈ N0. Damit erhalten wir fur
n+ 1:
(a+ b)n+1 = (a+ b)n(a+ b)
= (a+ b)n∑k=0
(n
k
)an−kbk
=n∑k=0
(n
k
)an−k+1bk +
n∑k=0
(n
k
)an−kbk+1
=n∑k=0
(n
k
)an+1−kbk +
n+1∑k=1
(n
k − 1
)an−(k−1)bk
=
(n
0
)︸︷︷︸=(n+1
0 )
an+1b0 +n∑k=1
((n
k
)+
(n
k − 1
))︸ ︷︷ ︸
=(n+1k )
an+1−kbk +
(n
n
)︸︷︷︸=(n+1
n+1)
a0bn+1
=n+1∑k=0
(n+ 1
k
)an+1−kbk.
Damit ist die Behauptung fur n + 1 bewiesen und das Induktionsprinzip liefert die Be-
hauptung.
1.5 Mengen und Zahlen
Mengen sind Grundbausteine der Mathematik. Sie dienen zum”Sammeln“ von Objekten
mit definierten Eigenschaften.
c© 2011 by M. Gerdts

1.5. MENGEN UND ZAHLEN 19
Definition 1.5.1 (Menge, Element)
(a) Eine Menge ist eine Sammlung von (realen oder gedachten) Objekten, ihren Ele-
menten. Dabei kann man fur jedes Objekt entscheiden, ob es zur Menge gehort oder
nicht.
(b) Gehort ein Objekt x zur Menge M , so schreiben wir x ∈M .
Gehort ein Objekt x nicht zur Menge M , so schreiben wir x 6∈M .
(c) Besitzt die Menge M nur endlich viele Elemente, so heißt sie endliche Menge,
andernfalls unendliche Menge.
(d) ∅ ist die leere Menge, sie enthalt kein Element.
Zwei MengenM undN werden als gleich betrachtet, wenn sie dieselben Elemente besitzen,
d.h.
M = N ⇐⇒ (x ∈M ⇔ x ∈ N) .
In diesem Sinne sind die Mengen 1, 2, 3 und 3, 2, 1 gleich, es kommt also nicht auf die
Reihenfolge der Elemente an. Zwei Mengen sind ungleich, wenn sie nicht gleich sind.
Beispiel 1.5.2
(i) −2, 4, 2, 8, 9, 123 ist eine endliche Menge mit 6 Elementen.
(ii) rot, grun, blau ist eine endliche Menge mit 3 Elementen. Sie ist eine Teilmenge
der Menge aller Farben.
(iii) 1, 3, 5, 7, 9, 11, . . . = 2k−1 | k ∈ N ist eine unendliche Menge, die die ungeraden
naturlichen Zahlen enthalt.
Beispiel 1.5.3
• Naturliche Zahlen: Die Menge der naturlichen Zahlen wird mit N bezeichnet und
lautet
N := 1, 2, 3, 4, . . . , n, n+ 1, . . ..
c© 2011 by M. Gerdts

20 KAPITEL 1. GRUNDLAGEN
Formal definiert man die Menge dadurch, dass man sagt 1 ist eine naturliche Zahl
und mit n ∈ N folgt, dass auch n+ 1 ∈ N ist.
Mit
N0 := 0, 1, 2, 3, 4, . . . , n, n+ 1, . . .
bezeichnen wir die Menge der naturlichen Zahlen einschließlich der Null.
• Ganze Zahlen: Die Menge der ganzen Zahlen wird mit Z bezeichnet. Sie enthalt
neben den naturlichen Zahlen und der Null auch deren negative Zahlen und lautet
Z := n | n ∈ N0 ∪ −n | n ∈ N= . . . ,−(n+ 1),−n, . . . ,−4,−3,−2,−1, 0, 1, 2, 3, 4, . . . , n, n+ 1, . . ..
• Rationale Zahlen: Die Menge der rationalen Zahlen wird mit Q bezeichnet. Sie
enthalt Bruchzahlen und ist definiert durch
Q :=mn
∣∣∣ m ∈ Z, n ∈ N.
Fur eine rationale Zahl q = mn
heißt m Zahler und n Nenner.
Man konnte den Eindruck gewinnen, dass die rationalen Zahlen bereits alle wichtigen
Zahlen enthalten. Dies ist nicht der Fall, da sich z.B.
√2,√
3, π, e
nicht als Bruchzahl darstellen lassen und somit keine rationalen Zahlen sind.
• Reelle Zahlen: Die Menge der reellen Zahlen wird mit R bezeichnet. Die reellen
Zahlen ergeben sich durch sogenannte Vervollstandigung der rationalen Zahlen,
indem”
Lucken“ in den rationalen Zahlen geschlossen werden. Dazu erganzt man
die rationalen Zahlen um Zahlen, die nicht als Bruchzahl dargestellt werden konnen,
also z.B. um√
2,√
3, π, e.
Eine formale Definition der reellen Zahlen lautet wie folgt:
R :=r∣∣∣ es gibt eine Folge von Zahlen rn ∈ Q, n ∈ N, mit lim
n→∞rn = r
.
• Die Mengen
R+ := r ∈ R | r > 0,R− := r ∈ R | r < 0
bezeichnen die Menge der positiven bzw. negativen reellen Zahlen. Die Mengen
R+0 := r ∈ R | r ≥ 0,
R−0 := r ∈ R | r ≤ 0
c© 2011 by M. Gerdts

1.5. MENGEN UND ZAHLEN 21
bezeichnet die Menge der positiven bzw. negativen reellen Zahlen einschließlich der
Null.
• Fur a, b ∈ R mit a < b sind die folgenden Intervalle definiert:
[a, b] := x ∈ R | a ≤ x ≤ b (abgeschlossenes Intervall),
(a, b) := x ∈ R | a < x < b (offenes Intervall),
[a, b) := x ∈ R | a ≤ x < b (halboffenes Intervall),
(a, b] := x ∈ R | a < x ≤ b (halboffenes Intervall).
Um auch unendliche Intervalle abbilden zu konnen, werden die Unendlichsymbole
+∞ und −∞ verwendet, welche aber nicht als reelle Zahlen angesehen werden:
(−∞, b] := x ∈ R | x ≤ b,(−∞, b) := x ∈ R | x < b,
[a,∞) := x ∈ R | a ≤ x,(a,∞) := x ∈ R | a < x,
(−∞,∞) := R.
• Die komplexen Zahlen C werden in Abschnitt 1.6 behandelt.
Den reellen Zahlen kommt eine besondere Bedeutung zu, da innerhalb der Menge der
reellen Zahlen die ublichen Rechenregeln gelten3:
Rechenregeln und Eigenschaften in den reellen Zahlen R:
(i) Die Gleichung
a+ x = b
besitzt stets die reelle Losung x = b− a fur alle a, b ∈ R.
(ii) Fur a, b ∈ R, a 6= 0, besitzt die Gleichung
a · x = b
stets die reelle Losung x = ba. Fur a = 0 besitzt die Gleichung nur dann eine Losung,
wenn b = 0 gilt. Fur a = b = 0 ist jede Zahl x ∈ R eine Losung.
3Aufgabe: Uberprufen Sie, welche der Eigenschaften in den Mengen N, Z, Q gelten bzw. welche Ei-
genschaften nicht gelten.
c© 2011 by M. Gerdts

22 KAPITEL 1. GRUNDLAGEN
(iii) Fur alle x, y, z ∈ R gelten die folgenden Rechenregeln fur die vier Grundrechenarten
+, −, ·, /:
Addition, Subtraktion:
A1 : x+ (y + z) = (x+ y) + z (Assoziativgesetz)
A2 : x+ y = y + x (Kommutativgesetz)
A3 : es gibt 0 ∈ R mit x+ 0 = x (Existenz des Nullelements 0)
A4 : zu jedem x ∈ R gibt es (−x) ∈ R (Existenz eines additiv inversen
mit x+ (−x) = 0 Elements)
Multiplikation, Division:
M1 : x · (y · z) = (x · y) · z (Assoziativgesetz)
M2 : x · y = y · x (Kommutativgesetz)
M3 : es gibt 1 ∈ R, 1 6= 0, mit 1 · x = x (Existenz des Einselements 1)
M4 : zu jedem x ∈ R, x 6= 0, gibt es (Existenz eines multiplikativ inversen
x−1 ∈ R mit x · x−1 = 1 Elements)
D : x · (y + z) = x · y + x · z (Distributivgesetz)
(iv) Die reellen Zahlen sind auf der Zahlengeraden angeordnet, d.h. man kann reelle
Zahlen bzgl. ihrer Große miteinander vergleichen. Fur alle a, b ∈ R gilt genau eine
der folgenden Alternativen: a < b, a = b, a > b.
Es gelten folgende Regeln fur a, b, c, d ∈ R:
a < b und b < c =⇒ a < c
a < b =⇒ a+ d < b+ d
a < b und c > 0 =⇒ a · c < b · ca < b und c < 0 =⇒ a · c > b · c
Definition 1.5.4
(a) Die Menge M heißt Teilmenge der Menge N , in Zeichen M ⊆ N , wenn jedes
c© 2011 by M. Gerdts

1.5. MENGEN UND ZAHLEN 23
Element von M auch Element von N ist, d.h. es gilt
x ∈M =⇒ x ∈ N.
Im Fall M ⊆ N und M 6= N heißt die Menge M echte Teilmenge der Menge N ,
in Zeichen M ⊂ N oder M ( N .
(b) Die Menge M heißt (echte) Obermenge der Menge N , wenn N (echte) Teilmenge
von M ist.
Beispiel 1.5.5
(i) Die leere Menge ∅ ist Teilmenge jeder Menge.
(ii) −1, 2, 3 ⊂ −1, 2, 3, 5
(iii) N ⊂ Z ⊂ Q ⊂ R
(iv) Die Menge 0, 1, 3 ist weder Teilmenge noch Obermenge von −1, 0, 1.
Ublicherwise werden die Elemente einer Menge durch Angabe von Eigenschaften beschrie-
ben, also etwa in der Form
M1 = x ∈ N | 3 ≤ x ≤ 7 = 3, 4, 5, 6, 7,M2 = x ∈ R | x2 ≥ 1 = x | x ∈ R, x2 ≥ 1,M3 = x ∈ N | es gibt eine Zahl q ∈ N mit x = 2q
= 2x | x ∈ N= 2, 4, 6, 8, 10, . . ..
Die Beispiele zeigen, dass dieselbe Menge unterschiedliche Beschreibungen ihrer Elemente
besitzen kann. Das Zeichen | bedeutet bei der Charakterisierung von Mengen”mit der
Eigenschaft“, d.h.
M = x | E(x)
bezeichnet die Menge aller x mit der Eigenschaft E(x).
Mithilfe von Mengenoperationen kann man mit Mengen rechnen.
c© 2011 by M. Gerdts

24 KAPITEL 1. GRUNDLAGEN
Definition 1.5.6
(a) Die Vereinigung zweier Mengen M und N ist definiert als die Menge
M ∪N := x | x ∈M oder x ∈ N.
(b) Der Durchschnitt zweier Mengen M und N ist definiert als die Menge
M ∩N := x | x ∈M und x ∈ N.
Zwei Mengen M und N heißen diskjunkt, wenn ihr Durchschnitt leer ist, d.h.
M ∩N = ∅.
(c) Die Differenz zweier Mengen M und N ist definiert als die Menge
M \N := x | x ∈M und x 6∈ N.
(d) Ist M ⊆ N , so ist das Komplement von M bzgl. N definiert als die Menge
M := N \M (Sprechweise: N ohne M).
(e) Das Produkt zweier Mengen M und N ist definiert als die Menge
M ×N := (x, y) | x ∈M und y ∈ N.
(f) Die Potenzmenge P (M) (oder 2M) der Menge M ist definiert als die Menge aller
Teilmengen von M .
Beispiel 1.5.7
1, 2 ∪ 2, 3, 4 = 1, 2, 3, 41, 2 ∩ 2, 3, 4 = 21, 2 \ 2, 3, 4 = 11, 2 × 2, 3, 4 = (1, 2), (1, 3), (1, 4), (2, 2), (2, 3), (2, 4)
P (2, 3, 4) = ∅, 2, 3, 4, 2, 3, 2, 4, 3, 4, 2, 3, 4R2 = R× R,
Rn = R× . . .× R (n-mal)
c© 2011 by M. Gerdts

1.6. KOMPLEXE ZAHLEN 25
1.6 Komplexe Zahlen
Die Menge der reellen Zahlen ist schon sehr machtig und umfasst die gesamte Zahlen-
gerade. Allerdings ist die Menge der reellen Zahlen fur bestimmte Aufgaben noch nicht
ausreichend. Mochte man z.B. die Gleichung
x2 + 1 = 0 (1.1)
uber den reellen Zahlen losen, so ist dies nicht moglich, da in R kein solches x existiert.
Solche Probleme treten z.B. bei der Bestimmung von sogenannten Eigenwerten auf, siehe
Kapitel 4 die u.a. bei der Stabilitatsanalyse von technischen Systemen und insbesondere
in der Regelungstechnik sehr wichtig sind.
Um auch Gleichung (1.1) losen zu konnen, fuhren wir eine neue”Zahl“ mit dem Symbol
i ein. Beachte allerdings, dass i keine Zahl im Sinne der reellen Zahlen ist, sondern ein
zusatzliches Objekt.4
Definition 1.6.1 (die imaginare Zahl i)
Die imaginare Zahl i ist definiert als Losung der Gleichung (1.1), d.h. sie erfullt
i2 = −1.
Die komplexen Zahlen erhalten wir nun durch Summen von reellen Zahlen und reellen
Vielfachen der imaginaren Zahl i.
Definition 1.6.2 (komplexe Zahlen)
Die komplexen Zahlen sind definiert als die Menge
C := a+ ib | a ∈ R, b ∈ R.
Fur eine komplexe Zahl z = a + ib heißt a der Realteil von z und b der Imaginarteil
von z. Wir schreiben Re(z) = a und Im(z) = b.
Mit z := a− ib wird die konjugiert komplexe Zahl von z bezeichnet.
Komplexe Zahlen der Form ib mit b ∈ R heißen imaginare Zahlen.
Da die imaginare Zahl i keine reelle Zahl ist, stellen wir uns die komplexen Zahlen in einer
Ebene, der sogenannten Gauss’schen Zahlenebene, vor, siehe Abbildung 1.2.
4Haufig findet man die Schreibweise i :=√−1, woraus allerdings −1 = i · i =
√−1 ·
√−1 =√
(−1) · (−1) =√
1 = 1 folgen wurde. Daher sollte diese Schreibweise vermieden werden.
c© 2011 by M. Gerdts
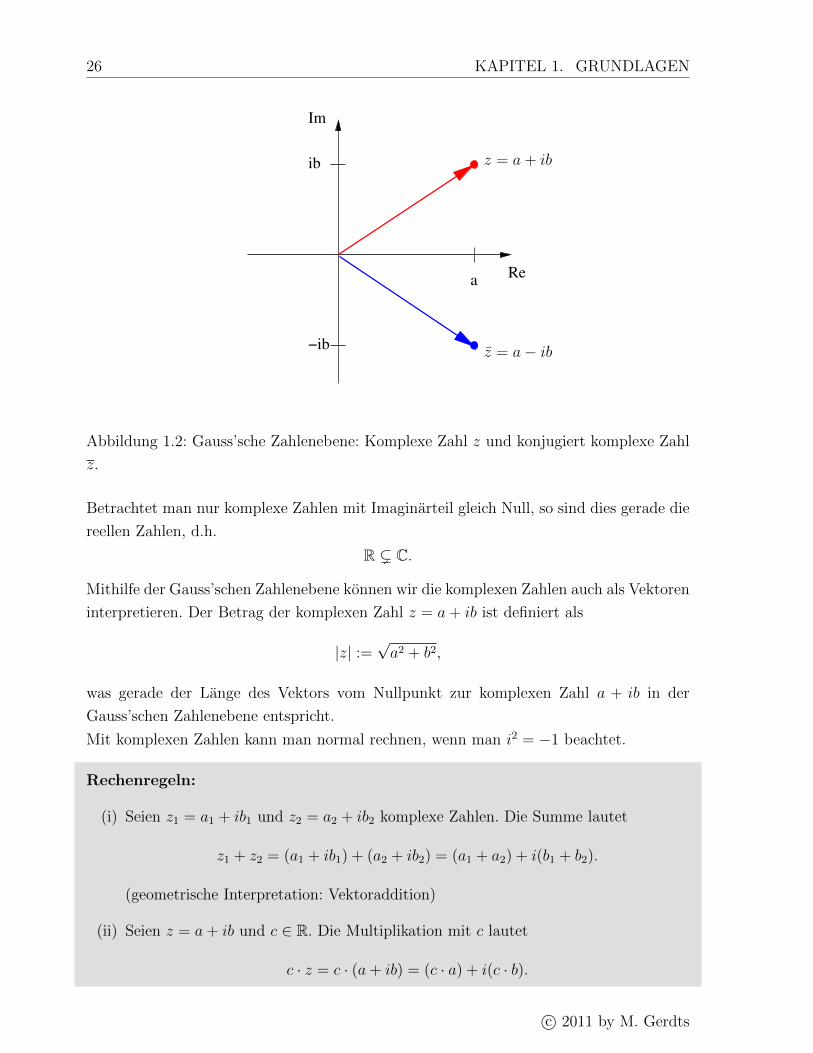
26 KAPITEL 1. GRUNDLAGEN
Im
Re
−ib
ib
a
z = a+ ib
z = a− ib
Abbildung 1.2: Gauss’sche Zahlenebene: Komplexe Zahl z und konjugiert komplexe Zahl
z.
Betrachtet man nur komplexe Zahlen mit Imaginarteil gleich Null, so sind dies gerade die
reellen Zahlen, d.h.
R ( C.
Mithilfe der Gauss’schen Zahlenebene konnen wir die komplexen Zahlen auch als Vektoren
interpretieren. Der Betrag der komplexen Zahl z = a+ ib ist definiert als
|z| :=√a2 + b2,
was gerade der Lange des Vektors vom Nullpunkt zur komplexen Zahl a + ib in der
Gauss’schen Zahlenebene entspricht.
Mit komplexen Zahlen kann man normal rechnen, wenn man i2 = −1 beachtet.
Rechenregeln:
(i) Seien z1 = a1 + ib1 und z2 = a2 + ib2 komplexe Zahlen. Die Summe lautet
z1 + z2 = (a1 + ib1) + (a2 + ib2) = (a1 + a2) + i(b1 + b2).
(geometrische Interpretation: Vektoraddition)
(ii) Seien z = a+ ib und c ∈ R. Die Multiplikation mit c lautet
c · z = c · (a+ ib) = (c · a) + i(c · b).
c© 2011 by M. Gerdts

1.6. KOMPLEXE ZAHLEN 27
(iii) Seien z1 = a1 + ib1 und z2 = a2 + ib2 komplexe Zahlen. Das Produkt der beiden
Zahlen lautet
z1 · z2 = (a1 + ib1) · (a2 + ib2)
= a1 · (a2 + ib2) + (ib1) · (a2 + ib2)
= a1a2 + ia1b2 + ib1a2 + i2b1b2
= (a1a2 − b1b2) + i(a1b2 + b1a2).
(iv) Sei z = a+ ib. Dann gilt nach (iii)
z · z = (a+ ib) · (a− ib) = a2 + b2 = |z|2.
(v) Seien z1 = a1 + ib1 und z2 = a2 + ib2 komplexe Zahlen mit z2 6= 0. Die Division der
Zahlen liefert
z1z2
=a1 + ib1a2 + ib2
=a1 + ib1a2 + ib2
· a2 − ib2a2 − ib2
=(a1a2 + b1b2) + i(b1a2 − a1b2)
|z2|2.
Bemerkung 1.6.3
Die komplexen Zahlen versehen mit der ublichen Addition + und der Multiplikation · bil-
den wie die reellen Zahlen wieder einen Korper (C,+, ·), d.h. Assoziativ-, Kommutativ-
und Distributivgesetz, Existenz von Null- und Einselement sowie Existenz von additiven
und multiplikativen inversen Elementen gelten analog.
Ubung: Weise die Regeln A1-A4, M1-M4 und D aus dem Abschnitt uber reelle Zahlen
nach.
Bemerkung 1.6.4
Die komplexen Zahlen sind nicht angeordnet, d.h. es gibt keine Ordnungsrelationen < oder
> zwischen zwei komplexen Zahlen.
Polarkoordinaten
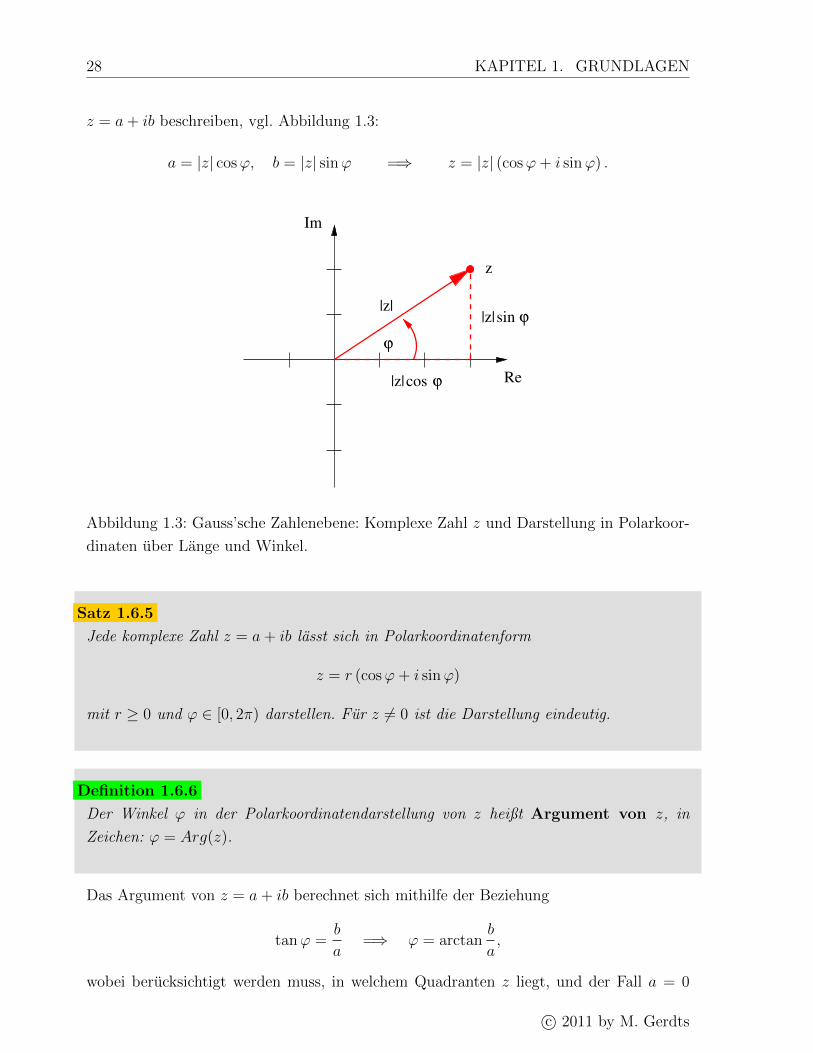
Man kann komplexe Zahlen auch in Polarkoordinaten durch ihre Lange und den Winkel
ϕ ∈ [0, 2π) zwischen der reellen Achse (Realteil) und dem Vektor vom Nullpunkt zur Zahl
c© 2011 by M. Gerdts
28 KAPITEL 1. GRUNDLAGEN
z = a+ ib beschreiben, vgl. Abbildung 1.3:
a = |z| cosϕ, b = |z| sinϕ =⇒ z = |z| (cosϕ+ i sinϕ) .
Im
Re
z
ϕ
|z||z|
|z|cos ϕ
sin ϕ
Abbildung 1.3: Gauss’sche Zahlenebene: Komplexe Zahl z und Darstellung in Polarkoor-
dinaten uber Lange und Winkel.
Satz 1.6.5
Jede komplexe Zahl z = a+ ib lasst sich in Polarkoordinatenform
z = r (cosϕ+ i sinϕ)
mit r ≥ 0 und ϕ ∈ [0, 2π) darstellen. Fur z 6= 0 ist die Darstellung eindeutig.
Definition 1.6.6
Der Winkel ϕ in der Polarkoordinatendarstellung von z heißt Argument von z, in
Zeichen: ϕ = Arg(z).
Das Argument von z = a+ ib berechnet sich mithilfe der Beziehung
tanϕ =b
a=⇒ ϕ = arctan
b
a,
wobei berucksichtigt werden muss, in welchem Quadranten z liegt, und der Fall a = 0
c© 2011 by M. Gerdts

1.6. KOMPLEXE ZAHLEN 29
muss gesondert betrachtet werden. Es ergibt sich
ϕ =
arctan ba, fur a > 0, b ≥ 0,
π2, fur a = 0, b > 0,
π + arctan ba, fur a < 0,
3π2, fur a = 0, b < 0,
2π + arctan ba, fur a > 0, b < 0.
Fur a = b = 0 ist das Argument nicht eindeutig definiert.
Beispiel 1.6.7
Die Zahl ib, b > 0, lautet in Polarkoordinatendarstellung
ib = b · (cosπ
2+ i sin
π
2).
Die Zahl −1− i lautet in Polarkoordinatendarstellung
−1− i =√
2 · (cos5π
4+ i sin
5π
4).
Mit der von Euler eingefuhrten
komplexen Exponentialfunktion
exp(z) = exp(a+ ib) := ea+ib := exp(a) (cos b+ i sin b) (z = a+ ib ∈ C)
ergibt sich speziell die Beziehung
exp(iϕ) = cosϕ+ i sinϕ.
Damit laßt sich z schreiben als
z = a+ bi = |z| exp(iϕ).
Damit laßt sich die Multiplikation zweier komplexer Zahlen z1 = |z1| exp(iϕ1) und z2 =
|z2| exp(iϕ2) sehr schon geometrisch darstellen. Das Ergebnis lautet (nachrechnen!)
z1 · z2 = |z1| · |z2| · exp(i(ϕ1 + ϕ2)),
d.h. das Produkt zweier komplexer Zahlen ist eine Drehstreckung mit der Lange |z1|·|z2|und dem Winkel ϕ1 + ϕ2, vgl. Abbildung 1.4.
c© 2011 by M. Gerdts

30 KAPITEL 1. GRUNDLAGEN
Re
Im
z1z2
|z1||z2|
ϕ1ϕ2
z1 · z2
|z1| · |z2|
ϕ1 + ϕ2
Abbildung 1.4: Gauss’sche Zahlenebene: Multiplikation komplexer Zahlen z1 und z2 als
Drehstreckung.
Mithilfe der Interpretation der Multiplikation zweier komplexer Zahlen als Drehstreckung
ergibt sich sofort der folgende Satz:
Satz 1.6.8 (Euler-Moivre Formel)
Sei z = r(cosϕ+ i sinϕ) gegeben. Dann gilt
zn = rn(cos(nϕ) + i sin(nϕ))
fur n ∈ N.
Die Euler-Moivre Formel ist nutzlich, um Additionstheoreme fur Sinus und Cosinus zu
gewinnen.
Beispiel 1.6.9
Aus z = cosϕ+ i sinϕ ergibt sich durch Ausmultiplizieren
z2 = (cosϕ+ i sinϕ)2 = (cos2 ϕ− sin2 ϕ) + i(2 sinϕ cosϕ).
c© 2011 by M. Gerdts

1.6. KOMPLEXE ZAHLEN 31
Die Euler-Moivre Formel liefert
z2 = cos(2ϕ) + i sin(2ϕ).
Vergleich von Real- und Imaginarteil liefert
cos(2ϕ) = cos2 ϕ− sin2 ϕ,
sin(2ϕ) = 2 sinϕ cosϕ.
Polynomnullstellen
Mithilfe der komplexen Zahlen lassen sich die Nullstellen quadratischer Polynome ange-
ben. Betrachte dazu die Polynomgleichung
ax2 + bx+ c = 0 mit a 6= 0.
Die Nullstellen x1 und x2 sind gegeben durch die bekannte Formel
x1,2 =−b±
√b2 − 4ac
2a,
die, wenn man komplexe Zahlen verwendet, auch fur b2 − 4ac < 0 verwendbar ist.
Beispiel 1.6.10
Fur
x2 − 4x+ 5 = 0
liefert die Formel die Nullstellen
x1,2 =4±√
16− 20
2= 2± 1
2
√−4 = 2±
√−1 = 2± i.
Damit besitzt die Gleichung die beiden komplexen Nullstellen 2 + i und dessen konjugiert
komplexe Zahl 2− i.
Es gilt folgender Satz:
Satz 1.6.11
Jedes quadratische Polynom ax2 + bx + c mit Koeffizienten a, b, c ∈ R, a 6= 0, hat genau
zwei Nullstellen x1, x2 ∈ C, die eventuell zusammenfallen. Es gilt ax2 + bx + c = a(x −x1)(x− x2).
Der Satz gilt analog auch fur allgemeine Polynome:
c© 2011 by M. Gerdts

32 KAPITEL 1. GRUNDLAGEN
Satz 1.6.12 (Fundamentalsatz der Algebra)
Jedes Polynom vom Grad n
pn(x) = anxn + an−1x
n−1 + . . .+ a1x+ a0
mit aj ∈ C, j = 0, 1, . . . , n, an 6= 0, besitzt uber C genau n Nullstellen x1, . . . , xn (mehr-
fache Nullstellen werden nach ihrer Vielfachheit gezahlt) und es gilt
pn(x) = an(x− x1) · · · (x− xn) = an
n∏j=1
(x− xj).
Nach dem Fundamentalsatz der Algebra hat ein Polynom n-ten Grades also hochstens n
reelle Nullstellen. Es gibt leider nur in Spezialfallen explizite Formeln zur Bestimmung
der Nullstellen.
Mithilfe der Euler-Moivre Formel konnen die Nullstellen von zn−w = 0 explizit berechnet
werden:
Beispiel 1.6.13
Fur w = `(cosα + i sinα) und n ∈ N betrachte die Gleichung zn = w. Nach dem Fun-
damentalsatz der Algebra gibt es n Losungen zk = rk(cosϕk + i sinϕk), k = 0, . . . , n− 1,
dieser Gleichung. Nach der Euler-Moivre Formel gilt
znk = rnk (cos(nϕk) + i sin(nϕk))
und |znk | = rnk = |w| = `, woraus
rk =n√`, k = 0, . . . , n− 1,
folgt. Somit liegen alle Losungen auf einem Kreis mit Radius n√`. Vergleich der Real- und
Imaginarteile von znk und w fuhren auf die Beziehungen
cosα = cos(nϕk) und sinα = sin(nϕk),
woraus
α + 2πj = nϕk bzw. ϕk =α + 2πj
nmit j ∈ Z folgt. Wahlt man speziell j = k = 0, 1, . . . , n − 1, so erhalt man verschiedene
Losungen
ϕk =α + 2πk
n, k = 0, 1, . . . , n− 1.
Damit haben wir genau n Nullstellen von zn − w = 0 gefunden:
zk =n√`
(cos
(α + 2πk
n
)+ i sin
(α + 2πk
n
)), k = 0, 1, . . . , n− 1.
c© 2011 by M. Gerdts

1.6. KOMPLEXE ZAHLEN 33
Zusammenfassend gelten folgende Mengenrelationen fur die besprochenen Zahlensysteme:
N ( N0 ( Z ( Q ( R ( C
c© 2011 by M. Gerdts

Kapitel 2
Vektoren und Matrizen
Das Ziel dieses Kapitels ist es, Vektoren und Matrizen einzufuhren und geometrisch zu
motivieren. Elementare Rechenregeln fur Matrizen und Vektoren werden dargestellt, wel-
che uns spater bei der allgemeineren Definition von Vektorraumen in Kapitel 3 wieder
begegnen werden.
Daruber hinaus werden Konstrukte wie Skalarprodukt, Kreuzprodukt und Spatprodukt
eingefuhrt, die in den Ingenieurwissenschaften haufig Anwendung finden.
2.1 Vektoren
Wir unterscheiden im Folgenden zwischen skalaren Großen und Vektoren. Skalare
Großen sind reelle Zahlen und beschreiben zum Beispiel die Zeit, die Dichte, die Lange,
die Temperatur, die potenzielle oder kinetische Energie eines Objektes. Skalare Großen
lassen sich auf der Zahlengeraden darstellen, sie enthalten jedoch keine Information uber
Richtungen. Damit sind skalare Großen geeignet, um zum Beispiel die Große einer auf
einen Korper einwirkenden Kraft anzugeben, aber sie sind nicht geeignet, um die Richtung
der einwirkenden Kraft anzugeben.
Hier kommen Vektoren ins Spiel, die in der Physik zum Beispiel eine auf einen Korper
wirkende Kraft, ein Drehmoment, eine Stromungsrichtung, eine Geschwindigkeitsrichtung
oder eine Beschleunigungsrichtung darstellen. Vektoren enthalten neben ihrer Lange ins-
besondere eine Richtungsinformation und wir stellen uns Vektoren geometrisch als ge-
richtete Pfeile in einem ebenen oder raumlichen kartesischen Koordinatensystem mit
Ursprung 0 vor, vgl. Abbildung 2.1. Zur geometrischen Veranschaulichung der Begriffe
beschranken wir uns zunachst auf den 2-dimensionalen (ebenen) Fall und verallgemeinern
den Vektorbegriff anschließend auf den n-dimensionalen Fall mit n ∈ N.
34
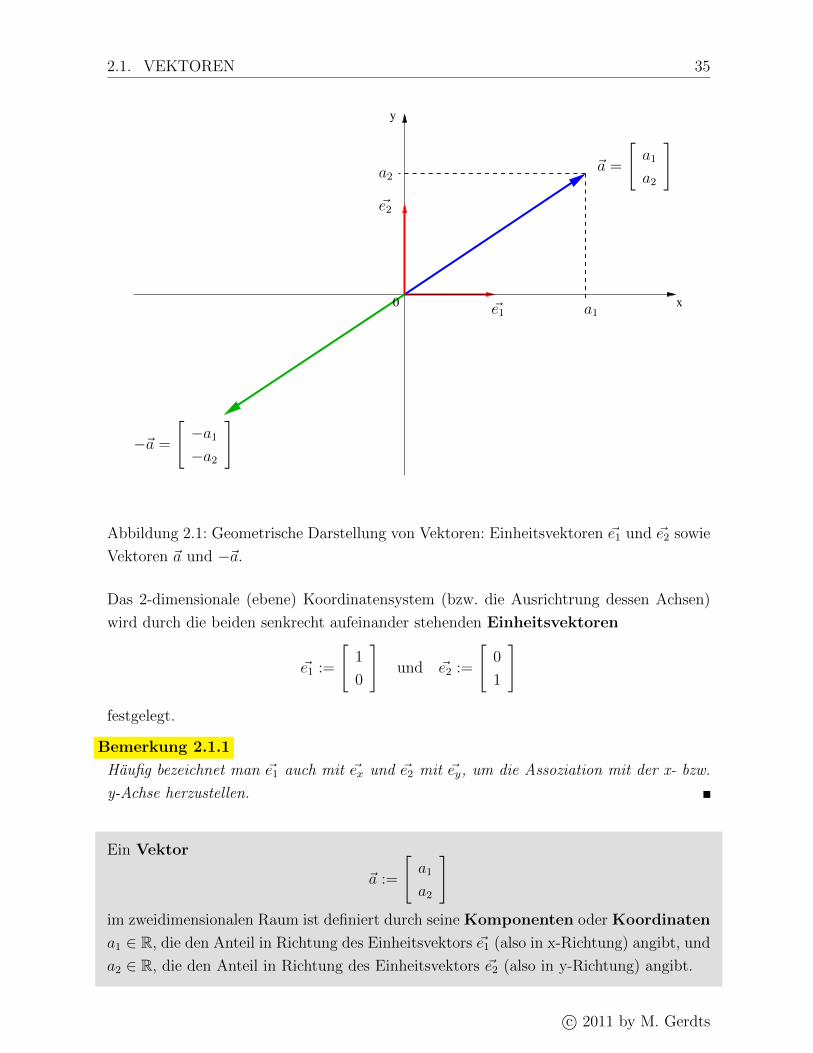
2.1. VEKTOREN 35
x
y
0 ~e1
~e2
a1
a2~a =
[a1
a2
]
−~a =
[−a1−a2
]
Abbildung 2.1: Geometrische Darstellung von Vektoren: Einheitsvektoren ~e1 und ~e2 sowie
Vektoren ~a und −~a.
Das 2-dimensionale (ebene) Koordinatensystem (bzw. die Ausrichtrung dessen Achsen)
wird durch die beiden senkrecht aufeinander stehenden Einheitsvektoren
~e1 :=
[1
0
]und ~e2 :=
[0
1
]
festgelegt.
Bemerkung 2.1.1
Haufig bezeichnet man ~e1 auch mit ~ex und ~e2 mit ~ey, um die Assoziation mit der x- bzw.
y-Achse herzustellen.
Ein Vektor
~a :=
[a1
a2
]im zweidimensionalen Raum ist definiert durch seine Komponenten oder Koordinaten
a1 ∈ R, die den Anteil in Richtung des Einheitsvektors ~e1 (also in x-Richtung) angibt, und
a2 ∈ R, die den Anteil in Richtung des Einheitsvektors ~e2 (also in y-Richtung) angibt.
c© 2011 by M. Gerdts

36 KAPITEL 2. VEKTOREN UND MATRIZEN
Der Nullvektor ist definiert als ~0 =
[0
0
].
Die komponentenweise Darstellung eines Vektors ~a mit Komponenten a1 ∈ R und a2 ∈ Rbezieht sich dabei immer auf das fest gewahlte Koordinatensystem, das bei uns immer
das bekannte kartesische (d.h. rechtwinklige) Koordinatensystem sein wird, welches durch
die Einheitsvektoren ~e1 und ~e2 aufgespannt wird.
Bemerkung 2.1.2
Durch Parallelverschiebung eines Vektors erhalten wir beliebig viele Vektoren mit derselben
Ausrichtung und derselben Lange, die lediglich in verschiedenen Punkten des Koordinaten-
systems starten. Alle diese Vektoren werden als gleich angesehen. Als Stellvertreter dieser
Klasse von Vektoren wahlt man den vom Ursprung 0 ausgehenden Vektor.
Zwei Vektoren ~a und ~b sind genau dann gleich, wenn ihre Komponenten gleich sind, d.h.[a1
a2
]=
[b1
b2
]⇐⇒ a1 = b1 und a2 = b2.
2.1.1 Multiplikation mit Skalaren
Sei ~a =
[a1
a2
]ein Vektor. Die Multiplikation mit einem Skalar λ ∈ R ist definiert als
λ · ~a = λ
[a1
a2
]:=
[λ · a1λ · a2
].
Geometrisch handelt es sich um eine Skalierung der Lange des Vektors, wobei die Richtung
des resultierenden Vektors im Fall λ > 0 gleich der von ~a und im Fall λ < 0 entgegengesetzt
zu ~a ist.
Satz 2.1.3 (Rechenregeln)
Seien ~a und ~b Vektoren und λ und µ reelle Zahlen. Dann gelten die folgenden Distribu-
tivgesetze:
(a) (λ+ µ)~a = λ~a+ µ~a
(b) λ(~a+~b) = λ~a+ λ~b
c© 2011 by M. Gerdts
2.1. VEKTOREN 37
2.1.2 Vektoraddition
Seien ~a =
[a1
a2
]und ~b =
[b1
b2
]Vektoren. Die Summe von ~a und ~b ist definiert als
~a+~b =
[a1
a2
]+
[b1
b2
]:=
[a1 + b1
a2 + b2
].
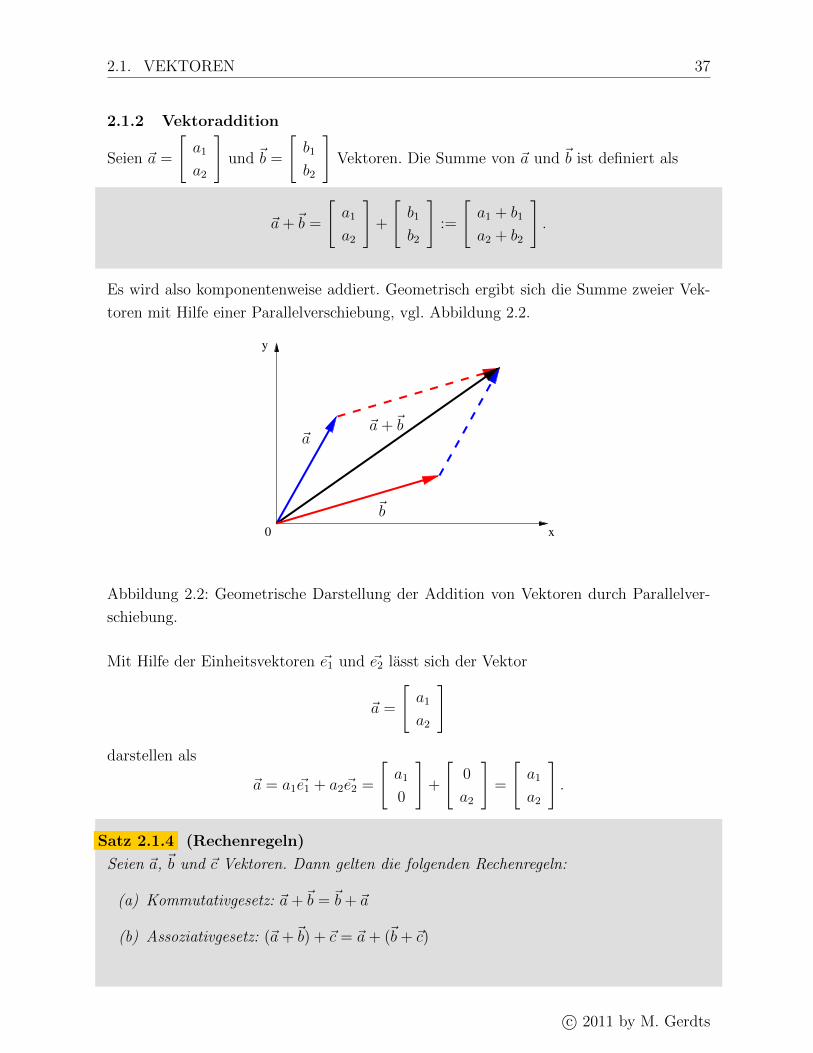
Es wird also komponentenweise addiert. Geometrisch ergibt sich die Summe zweier Vek-
toren mit Hilfe einer Parallelverschiebung, vgl. Abbildung 2.2.
x
y
0
~a
~b
~a+~b
Abbildung 2.2: Geometrische Darstellung der Addition von Vektoren durch Parallelver-
schiebung.
Mit Hilfe der Einheitsvektoren ~e1 und ~e2 lasst sich der Vektor
~a =
[a1
a2
]
darstellen als
~a = a1~e1 + a2~e2 =
[a1
0
]+
[0
a2
]=
[a1
a2
].
Satz 2.1.4 (Rechenregeln)
Seien ~a, ~b und ~c Vektoren. Dann gelten die folgenden Rechenregeln:
(a) Kommutativgesetz: ~a+~b = ~b+ ~a
(b) Assoziativgesetz: (~a+~b) + ~c = ~a+ (~b+ ~c)
c© 2011 by M. Gerdts

38 KAPITEL 2. VEKTOREN UND MATRIZEN
2.1.3 Lange eines Vektors
Die (euklidische) Lange des Vektors
~a =
[a1
a2
]
ist nach dem Satz von Pythagoras gegeben durch
‖~a‖ :=√a21 + a22.
Der Operator ‖ · ‖ (genannt Norm) ordnet hierbei jedem Vektor seine euklidische Lange
zu. Ein Vektor mit Lange 1 heißt normiert. Haufig schreibt man auch |~a| anstatt ‖~a‖.
Bemerkung 2.1.5
Man kann die Lange eines Vektors auch anders definieren, etwa durch ‖~a‖1 := |a1|+ |a2|(Manhattan-Abstand) oder durch ‖~a‖∞ := max|a1|, |a2|.
Satz 2.1.6 (Rechenregeln)
Seien ~a und ~b Vektoren und λ ∈ R. Dann gelten die folgenden Rechenregeln:
(a) Dreiecksungleichung: |‖~a‖ − ‖~b‖| ≤ ‖~a+~b‖ ≤ ‖~a‖+ ‖~b‖
(b) ‖λ~a‖ = |λ|‖~a‖
2.1.4 Ortsvektoren und Verbindungsvektoren
Der Vektor vom Koordinatenursprung zum Punkt P = (p1, p2) heißt Ortsvektor von P
und ist durch
~p =
[p1
p2
]gegeben.
Fur zwei gegebene Punkte P = (p1, p2) mit Ortsvektor ~p und Q = (q1, q2) mit Ortsvektor
~q heißt der Vektor
~q − ~p =
[q1 − p1q2 − p2
]Verbindungsvektor von P nach Q. Er hat die Lange
‖~q − ~p‖ =√
(q1 − p1)2 + (q2 − p2)2
c© 2011 by M. Gerdts

2.1. VEKTOREN 39
und gibt den Abstand der Punkte P und Q an.
Beispiel 2.1.7 (Parameterdarstellung einer Geraden)
Sei P ein gegebener Punkt mit Ortsvektor ~p und ~r 6= ~0 ein Richtungsvektor. Die durch die
Vektoren
~x(t) := ~p+ t~r, t ∈ R,
gegebenen Ortsvektoren liegen alle auf der Geraden
g := ~x(t) | t ∈ R
durch P mit Richtung ~r.
~p
P
~r
g
Abbildung 2.3: Darstellung einer Geraden.
Beispiel 2.1.8 (Parameterdarstellung einer Ebene)
Sei P ein gegebener Punkt mit Ortsvektor ~p und ~r1, ~r2 6= ~0 Richtungsvektoren, die nicht
parallel seien. Die durch die Vektoren
~x(t1, t2) := ~p+ t1~r1 + t2~r2, t1, t2 ∈ R,
gegebenen Ortsvektoren liegen alle auf der Ebene
E := ~x(t1, t2) | t1, t2 ∈ R.
c© 2011 by M. Gerdts

40 KAPITEL 2. VEKTOREN UND MATRIZEN
~p
~r1
~r2
E
Abbildung 2.4: Darstellung einer Ebene.
2.1.5 Skalarprodukt (Inneres Produkt)
Wir haben bereits gesehen, wie die Multiplikation eines Skalars mit einem Vektor aus-
sieht. Es stellt sich die Frage, ob auch Vektoren miteinander multipliziert werden konnen.
Dies kann auf verschiedene Arten erfolgen. Wir beginnen mit dem Skalarprodukt zweier
Vektoren und betrachten spater das Kreuzprodukt.
Definition 2.1.9 (Geometrische Definition des Skalarprodukts)
Das Skalarprodukt (auch Inneres Produkt genannt) 〈~a,~b〉 zweier Vektoren ~a und ~b
ist definiert als
〈~a,~b〉 := ‖~a‖ · ‖~b‖ · cosϕ,
wobei ϕ den zwischen ~a und ~b eingeschlossenen Winkel bezeichnet.
Bemerkung 2.1.10
Beachte, dass das Skalarprodukt zweier Vektoren eine reelle Zahl und nicht etwa ein Vektor
ist! Haufig findet man auch die Schreibweise ~a ·~b anstatt 〈~a,~b〉.
Stehen die Vektoren ~a und ~b senkrecht aufeinander, d.h. gilt ϕ = ±90, so gilt cosϕ = 0
und damit auch 〈~a,~b〉 = 0.
c© 2011 by M. Gerdts

2.1. VEKTOREN 41
Definition 2.1.11 (Orthogonalitat, Orthonormalitat, Normalenvektor)
(a) Zwei Vektoren ~a 6= ~0 und ~b 6= ~0 heißen orthogonal (in Zeichen ~a ⊥ ~b), wenn
〈~a,~b〉 = 0 gilt.
(b) Zwei Vektoren ~a 6= ~0 und ~b 6= ~0 heißen orthonormal, wenn 〈~a,~b〉 = 0 und ‖~a‖ =
‖~b‖ = 1 gelten.
(c) Ein Vektor ~n der Lange ‖~n‖ = 1, der senkrecht auf einer Geraden oder einer Ebene
steht, heißt Normalenvektor.
Satz 2.1.12 (Rechenregeln)
Seien ~a, ~b und ~c Vektoren. Dann gelten die folgenden Rechenregeln:
(a) Kommutativgesetz: 〈~a,~b〉 = 〈~b,~a〉
(b) Distributivgesetz: 〈~a,~b+ ~c〉 = 〈~a,~b〉+ 〈~a,~c〉
(c) Zusammenhang von Lange und Skalarprodukt: 〈~a,~a〉 = ‖~a‖2
Beweis: Teile (a) und (c) ergeben sich sofort aus der Definition.
Fur Teil (b) nutzt man folgende geometrische Betrachtung:
~a ~a
~b~b
b~a = ‖~b‖ cosϕ
ϕ
~c
~b+ ~c
b~a c~a
Im linken Bild ist b~a := ‖~b‖ cosϕ die Lange der Projektion des Vektors ~b auf den Vektor
~a. Fur das Skalarprodukt gilt dann
〈~a,~b〉 = ‖~a‖ · ‖~b‖ · cosϕ = ‖~a‖ · b~a.
Analog gilt fur ~c
〈~a,~c〉 = ‖~a‖ · c~a.
c© 2011 by M. Gerdts

42 KAPITEL 2. VEKTOREN UND MATRIZEN
und fur ~b+ ~c
〈~a,~b+ ~c〉 = ‖~a‖ · (b+ c)~a,
wobei (b+ c)~a die Lange der Projektion von ~b+ ~c auf ~a bezeichnet.
Aus dem rechten Bild ist ersichtlich, dass
b~a + c~a = (b+ c)~a
gilt. Damit folgt
〈~a,~b+ ~c〉 = ‖~a‖ · (b+ c)~a
= ‖~a‖ · (b~a + c~a)
= ‖~a‖ · b~a + ‖~a‖ · c~a= 〈~a,~b〉+ 〈~a,~c〉.
Beispiel 2.1.13 (Hesse’sche Normalform einer Geraden)
Sei ~n ∈ R2 ein Vektor mit ‖~n‖ = 1 und c ∈ R eine gegebene Zahl mit c ≥ 0. Die Menge
g = ~x ∈ R2 | 〈~n, ~x〉 = c
beschreibt eine Gerade im R2, welche in der sogenannten Hesse’schen Normalform
dargestellt ist. Die Gerade enthalt den Punkt c~n wegen
〈~n, c~n〉 = c‖~n‖ = c.
Desweiteren verlauft die Gerade g senkrecht zu ~n, denn fur beliebige ~x, ~y ∈ g gilt
〈~n, ~x− ~y〉 = 〈~n, ~x〉 − 〈~n, ~y〉 = c− c = 0.
~n
c~n
~x
~y
~y − ~x
g
Im dreidimensionelen Raum R3 konnen Ebenen in analoger Weise durch die Hesse’sche
Normalform beschrieben werden. Im m-dimensionalen Raum Rm beschreibt die Menge
~x ∈ Rm | 〈~n, ~x〉 = c
c© 2011 by M. Gerdts

2.1. VEKTOREN 43
eine sogenannte Hyperebene.
Das Skalarprodukt zweier Vektoren kann ohne den Cosinus berechnet werden. Seien dazu
~a = a1~e1 + a2~e2 =
[a1
a2
]und ~b = b1~e1 + b2~e2 =
[b1
b2
]
in Koordinatenform gegeben. Mit Hilfe der Einheitsvektoren, des Kommutativgesetzes
und des Distributivgesetzes folgt dann
〈~a,~b〉 = 〈a1~e1 + a2~e2, b1~e1 + b2~e2〉= 〈a1~e1 + a2~e2, b1~e1〉+ 〈a1~e1 + a2~e2, b2~e2〉= (a1b1) 〈~e1, ~e1〉︸ ︷︷ ︸
=1
+(a2b1) 〈~e2, ~e1〉︸ ︷︷ ︸=0
+(a1b2) 〈~e1, ~e2〉︸ ︷︷ ︸=0
+(a2b2) 〈~e2, ~e2〉︸ ︷︷ ︸=1
= a1b1 + a2b2.
Damit ist folgender Satz bewiesen, der analog auch fur allgemeine Vektordimensionen gilt:
Satz 2.1.14
Gegeben seien Vektoren
~a =
[a1
a2
]und ~b =
[b1
b2
].
Dann gilt
〈~a,~b〉 = ‖~a‖ · ‖~b‖ · cosϕ = a1b1 + a2b2.
Fur Abschatzungen ist der folgende beruhmte Satz nutzlich, der ebenfalls fur allgemeine
Vektordimensionen gilt:
Satz 2.1.15 (Cauchy-Schwarz’sche Ungleichung)
Fur Vektoren ~a und ~b gilt ∣∣∣〈~a,~b〉∣∣∣ ≤ ‖~a‖ · ‖~b‖bzw. in Koordinatenschreibweise
|a1b1 + a2b2| ≤√a21 + a22 ·
√b21 + b22.
c© 2011 by M. Gerdts

44 KAPITEL 2. VEKTOREN UND MATRIZEN
Mit Hilfe von Satz 2.1.14 kann das Skalarprodukt leicht berechnet werden. Definition 2.1.9
kann dann benutzt werden, um den Winkel zwischen zwei Vektoren gemaß
cosϕ =〈~a,~b〉‖~a‖ · ‖~b‖
zu bestimmen.
Beispiel 2.1.16 (Winkel zwischen Vektoren)
(a)
~a =
[1
0
],~b =
[1
1
]=⇒ cosϕ =
1 + 0
1 ·√
2=
1√2, ϕ =
π
4
(b)
~a =
[1
−1
],~b =
[1
1
]=⇒ cosϕ =
1− 1√2 ·√
2= 0, ϕ =
π
2
(c)
~a =
[−1
−1
],~b =
[1
1
]=⇒ cosϕ =
−1− 1√2 ·√
2= −1, ϕ = π
Beispiel 2.1.17 (Winkel zwischen Geraden und Ebenen)
(a) Sind ~r1 und ~r2 Richtungsvektoren von zwei Geraden g1 und g2, so erfullt der Winkel
ϕ zwischen den Geraden die Gleichung
cosϕ =〈~r1, ~r2〉‖~r1‖ · ‖~r2‖
.
(b) Sind ~n1 und ~n2 Normalenvektoren von zwei Ebenen E1 und E2, so erfullt der Winkel
ϕ zwischen den Ebenen die Gleichung
cosϕ =〈 ~n1, ~n2〉‖ ~n1‖ · ‖ ~n2‖
.
(c) Ist ~n ein Normalenvektor der Ebene E und ~r ein Richtungsvektor der Geraden g,
so erfullt der Winkel ϕ zwischen der Ebene und der Geraden die Gleichung
sinϕ = cos(π
2− ϕ
)=〈~n,~r〉‖~n‖ · ‖~r‖
.
c© 2011 by M. Gerdts

2.1. VEKTOREN 45
~n2
~n1ϕ
~r ~n
ϕ
Bei der Umkehrabbildung von cos zur Bestimmung von ϕ ist es in obigen Fallen ublich,
den kleineren Winkel zu wahlen, also ϕ aus [0, π/2] zu wahlen.
2.1.6 Kreuzprodukt (Vektorprodukt, Außeres Produkt)
Das Skalarprodukt ist nicht die einzige Moglichkeit, eine Multiplikation von Vektoren
gleicher Dimension zu definieren. Eine weitere Moglichkeit bietet das sogenannte Kreuz-
produkt zweier Vektoren im R3, welches als Resultat wieder einen Vektor im R3 liefert.
Das Kreuzprodukt wird haufig in der Mechanik zur Beschreibung von Momenten und
Winkelgeschwindigkeiten verwendet.
Definition 2.1.18 (Kreuzprodukt, Vektorprodukt, Außeres Produkt)
Seien
~a =
a1
a2
a3
, ~b =
b1
b2
b3
Vektoren im R3. Das Kreuzprodukt (Vektorprodukt, Außeres Produkt) ~a ×~b ist
definiert als
~a×~b :=
a2b3 − a3b2a3b1 − a1b3a1b2 − a2b1
.
Bemerkung 2.1.19
Spater werden wir Determinanten kennen lernen. Damit lasst sich das Kreuzprodukt for-
mal darstellen als
~a×~b =
∣∣∣∣∣∣∣~e1 ~e2 ~e3
a1 a2 a3
b1 b2 b3
∣∣∣∣∣∣∣ .c© 2011 by M. Gerdts

46 KAPITEL 2. VEKTOREN UND MATRIZEN
Satz 2.1.20 (Eigenschaften)
Das Kreuzprodukt ~c = ~a×~b zweier Vektoren ~a,~b ∈ R3 besitzt folgende Eigenschaften:
(a) ~c ist orthogonal zu ~a und ~b, d.h. es gilt 〈~c,~a〉 = 〈~c,~b〉 = 0.
(b) Die Vektoren ~a, ~b und ~c bilden ein Rechtssystem, d.h. wenn Daumen und Zeige-
finger der rechten Hand in Richtung ~a und ~b zeigen, dann zeigt ~c in Richtung des
angewinkelten Mittelfingers.
(c) Es gilt ‖~c‖ = ‖~a‖ ·‖~b‖ · sinϕ, wobei ϕ den zwischen ~a und ~b eingeschlossenen Winkel
bezeichnet. Damit gibt ‖~c‖ gerade den Flacheninhalt des von ~a und ~b aufgespannten
Parallelogramms an.
Beispiel 2.1.21 (Flacheninhalt eines Dreiecks)
Betrachte ein im Raum liegendes Dreieck, dessen Eckpunkte durch die Ortsvektoren ~u,~v, ~w ∈R3 beschrieben werden. Der Flacheninhalt ist dann gegeben durch
F =1
2‖(~u− ~w)× (~v − ~w)‖.
~u
~v
~w
Beispiel 2.1.22 (Drehmoment)
Greift eine Kraft ~F im Punkt ~r (gemessen vom Schwerpunkt des Korpers) an einem
drehbaren, starren Korper an, so ergibt sich das Drehmoment
~M = ~r × ~F ,
c© 2011 by M. Gerdts

2.1. VEKTOREN 47
vgl. Abbildung.
~M
~r ~F
Der Betrag des Drehmoments betragt ‖ ~M‖ = ‖~r‖ · ‖~F‖ · sinϕ, wobei ‖~F‖ · sinϕ gerade die
auf ~r senkrechte Kraftkomponente von ~F ist. Der Vektor ~r bzw. dessen Lange ‖~r‖ wird
auch als Hebelarm bezeichnet.
Beispiel 2.1.23 (Bahngeschwindigkeit)
Die Winkelgeschwindigkeit ~ω ist ein Vektor, der die Drehachse und Geschwindigkeit einer
Rotationsbewegung angibt. Die Richtung von ~ω ist dabei senkrecht zur Rotationsebene.
Bewegt sich ein Teilchen mit konstanter Winkelgeschwindigkeit auf einer Bahn mit Radi-
usvektor ~r, so ergibt sich dessen Bahngeschwindigkeit ~v aus
~v = ~ω × ~r,
siehe Abbildung (Quelle: Wikipedia).
Durch Nachrechnen (bitte machen!) ergeben sich folgende Ergebnisse fur die Einheitsvek-
c© 2011 by M. Gerdts

48 KAPITEL 2. VEKTOREN UND MATRIZEN
toren ~e1, ~e2 und ~e3:
~e1 × ~e1 = ~e2 × ~e2 = ~e3 × ~e3 = ~0,
~e1 × ~e2 = −(~e2 × ~e1) = ~e3,
~e1 × ~e3 = −(~e3 × ~e1) = −~e2,~e2 × ~e3 = −(~e3 × ~e2) = ~e1.
Diese Ergebnisse legen die Vermutung nahe, dass das Kreuzprodukt paralleler Vektoren
den Nullvektor ergibt. Desweiteren zeigt sich, dass das Kreuzprodukt nicht kommutativ
ist, sondern dass das Vertauschen der Reihenfolge der Vektoren zum entgegengesetzten
Kreuzprodukt-Vektor fuhrt. Diese Beobachtungen gelten allgemein:
Satz 2.1.24
Seien ~a, ~b und ~c Vektoren im R3. Dann gelten folgende Aussagen:
(a) Sind ~a und ~b parallel, d.h. es gibt λ ∈ R, λ 6= 0, mit ~a = λ~b, so gilt ~a×~b = ~0.
(b) Rechenregeln:
~a×~b = −(~b× ~a),
(λ~a)×~b = ~a× (λ~b) = λ(~a×~b),~a× (~b+ ~c) = ~a×~b+ ~a× ~c,(~a+~b)× ~c = ~a× ~c+~b× ~c.
(c) Das Kreuzprodukt ist nicht assoziativ, d.h. im Allgemeinen gilt
(~a×~b)× ~c 6= ~a× (~b× ~c).
(Finde ein Beispiel hierfur! Finde auch Spezialfalle, fur die Gleichheit gilt!)
Mit Hilfe des Kreuzprodukts kann die Hesse’sche Normalform einer Ebene leicht berechnet
werden.
Beispiel 2.1.25 (Berechnung der Hesse’schen Normalform einer Ebene aus der
Parameterdarstellung)
Gegeben sei ein Ortsvektor ~p ∈ R3 und zwei Richtungsvektoren ~r1, ~r2 ∈ R3, die die Ebene
E aufspannen. Ein Normalenvektor fur die Ebene ist dann durch
~n =~r1 × ~r2‖~r1 × ~r2‖
c© 2011 by M. Gerdts

2.1. VEKTOREN 49
gegeben. Eine Darstellung der Ebene in Hesse’scher Normalform lautet dann
E = ~x ∈ R3 | 〈~n, ~x− ~p〉 = 0,
wobei der Vektor ~n aus Konventionsgrunden noch mit −1 multipliziert werden muss, falls
〈~n, ~p〉 < 0 ist (Beachte, dass mit ~n auch −~n ein Normalenvektor ist!). Insbesondere ist
|〈~n, ~p〉| der Abstand der Ebene zum Ursprung.
Beispiel 2.1.26 (Richtung der Schnittgeraden zweier Ebenen)
Betrachte zwei sich schneidende Ebenen mit Normalenvektoren ~n1, ~n2 ∈ R3. Gesucht ist
die Richtung ~r der Schnittgeraden der Ebenen.
Offenbar ist ~r dann orthogonal zu ~n1 und ~n2, d.h. wir suchen einen Vektor, der senkrecht
auf beiden Normalenvektoren steht. Ein solcher Vektor ist gegeben durch
~r = ~n1 × ~n2.
Jedes Vielfache von ~r ist ebenfalls geeignet.
Beispiel 2.1.27 (Abstand eines Punktes von einer Geraden)
Die Gerade g liege in Parameterform
g = ~x ∈ R3 | ~x = ~p+ t~r, t ∈ R
mit Ortsvektor ~p und Richtungsvektor ~r 6= ~0 vor.
Gesucht ist der Abstand d des Punktes Q mit Ortsvektor ~q zur Gerade g.
Q
P
~q − ~p~r
d
ϕ
Es gilt
d = ‖~q − ~p‖ sinϕ,
‖(~q − ~p)× ~r‖ = ‖~q − ~p‖ · ‖~r‖ · sinϕ = d‖~r‖,
d =‖(~q − ~p)× ~r‖
‖~r‖.
c© 2011 by M. Gerdts

50 KAPITEL 2. VEKTOREN UND MATRIZEN
Beispiel 2.1.28 (Abstand windschiefer Geraden)
Gegeben seien die Geraden g1 und g2 in Parameterform
g1 = ~x ∈ R3 | ~x = ~p1 + t~r1, t ∈ R,g2 = ~x ∈ R3 | ~x = ~p2 + t~r2, t ∈ R,
wobei ~r1 und ~r2 nicht parallel seien.
Gesucht ist der Abstand d der Geraden.
E2
E1
~p2 − ~p1
d
ϕ~n
Wir betten die Gerade in parallele Ebenen
E1 = ~x ∈ R3 | ~x = ~p1 + t1~r1 + t2~r2, t1, t2 ∈ R,E2 = ~x ∈ R3 | ~x = ~p2 + t1~r1 + t2~r2, t1, t2 ∈ R
ein und bestimmen den Abstand der Ebenen.
Es gilt
d = ‖~p2 − ~p1‖ cosϕ,
~n = ±(~r1 × ~r2),
cosϕ =〈~p2 − ~p1, ~n〉‖~p2 − ~p1‖ · ‖~n‖
und damit
d =〈~p2 − ~p1, ~n〉‖~n‖
=±〈~p2 − ~p1, ~r1 × ~r2〉‖~r1 × ~r2‖
=|〈~p2 − ~p1, ~r1 × ~r2〉|‖~r1 × ~r2‖
.
Nicht parallele Geraden mit Abstand d > 0 heißen windschief.
c© 2011 by M. Gerdts

2.1. VEKTOREN 51
2.1.7 Spatprodukt
Das Spatprodukt setzt sich aus Kreuz- und Skalarprodukt zusammen.
Definition 2.1.29 (Spatprodukt)
Fur gegebene Vektoren ~a,~b,~c ∈ R3 ist das Spatprodukt [~a,~b,~c] definiert durch
[~a,~b,~c] := 〈~a×~b,~c〉.
Fur
~a =
a1
a2
a3
, ~b =
b1
b2
b3
, ~c =
c1
c2
c3
ergibt sich durch Nachrechnen die Formel
[~a,~b,~c] = (a2b3 − a3b2)c1 + (a3b1 − a1b3)c2 + (a1b2 − a2b1)c3.
Bemerkung 2.1.30
Mit Hilfe der spater behandelten Determinanten kann das Spatprodukt geschrieben werden
als
[~a,~b,~c] =
∣∣∣∣∣∣∣a1 b1 c1
a2 b2 c2
a3 b3 c3
∣∣∣∣∣∣∣ .
Das Spatprodukt ist nutzlich, um Volumina von geometrischen Objekten zu berechnen.
Beispiel 2.1.31 (Volumen eines Parallelepipeds)
Gegeben sei ein durch die Vektoren ~a,~b,~c ∈ R3 aufgespanntes Parallelepiped (Spat), vgl.
Abbildung.
~a
~b
~c
~a×~b
ϕ
~c
h
Gesucht ist das Volumen V des Parallelepipeds. Es gilt
V = ‖~a×~b‖ · h
c© 2011 by M. Gerdts

52 KAPITEL 2. VEKTOREN UND MATRIZEN
mit h = ‖~c‖ · | cosϕ|. Mit Hilfe des Skalarprodukts folgt
cosϕ =〈~a×~b,~c〉‖~a×~b‖ · ‖~c‖
=⇒ h =
∣∣∣〈~a×~b,~c〉∣∣∣‖~a×~b‖
und damit
V = ‖~a×~b‖ · h =∣∣∣[~a,~b,~c]∣∣∣ .
Tetraeder spielen eine wichtige Rolle in der Finite Element Methode (FEM) zur numeri-
schen Losung partieller Differentialgleichungen, welche u.a. Stromungsvorgange, Aufhei-
zungsprozesse und Transportprozesse beschreiben.
Beispiel 2.1.32 (Volumen eines Tetraeders)
Gegeben sei ein durch die Vektoren ~a,~b,~c ∈ R3 aufgespannter Tetraeder, vgl. Abbildung.
~a
~b
~c
Das Volumen des Tetraeders betragt dann
V =1
6
∣∣∣[~a,~b,~c]∣∣∣ .
Satz 2.1.33 (Eigenschaften)
(a) Das Spatprodukt ist genau dann Null, wenn die drei Vektoren in einer Ebene liegen.
(b) Das Spatprodukt [~a,~b,~c] ist großer Null, wenn die ~a, ~b, ~c ein Rechtssystem bilden,
und kleiner Null, wenn sie ein Linkssystem bilden.
(c) Die Vektoren konnen zyklisch vertauscht werden, ohne den Wert des Spatprodukts
zu andern, d.h.
[~a,~b,~c] = [~c,~a,~b] = [~b,~c,~a].
(d) Werden die Vektoren antizyklisch vertauscht, so andert sich das Vorzeichen des
Spatprodukts, d.h.
[~a,~b,~c] = −[~c,~b,~a].
c© 2011 by M. Gerdts

2.1. VEKTOREN 53
2.1.8 Vektoren im Rn
Nachdem wir uns bisher auf den ebenen bzw. raumlichen Fall beschrankt haben, verall-
gemeinern wir den Vektorbegriff nun auf n ∈ N Dimensionen. Fur n > 3 versagt die
geometrische Vorstellungskraft, allerdings spricht mathematisch nichts dagegen, n Zahlen
in einem gemeinsamen Vektor der Dimension n zusammenzufassen und damit zu rechnen.
Definition 2.1.34 (Vektor, Dimension, Komponenten, Nullvektor, Skalar)
(a) Fur n ∈ N und n Zahlen x1, . . . , xn heißt
~x :=
x1
x2...
xn
(Spalten-)Vektor. n bezeichnet die Dimension des Vektors.
(b) Die Zahlen x1, . . . , xn heißen Komponenten des Vektors.
(c) Vektoren der Dimension n = 1 heißen Skalar.
(d) Ein Vektor, dessen Komponenten alle Null sind, heißt Nullvektor und wird mit ~0
bezeichnet.
(e) Werden die Komponenten x1, . . . , xn nebeneinander in der Form[x1 · · · xn
]geschrieben, so spricht man von einem Zeilenvektor.
(f) Die Vektoren
~e1 =
1
0...
0
, ~e2 =
0
1...
0
, . . . , ~en =
0...
0
1
heißen Einheitsvektoren des Rn.
c© 2011 by M. Gerdts

54 KAPITEL 2. VEKTOREN UND MATRIZEN
Bemerkung 2.1.35
Im Folgenden verstehen wir unter einem Vektor stets einen Spaltenvektor. Falls nichts an-
deres gesagt wird, sind die Komponenten eines Vektors stets reelle Zahlen. Wir schreiben
~x ∈ Rn fur einen n-dimensionalen Vektor mit reellen Komponenten. Alternative Schreib-
weisen in der Literatur sind x, x oder einfach x.
Zwei Vektoren ~x und ~y sind genau dann gleich, wenn ihre Komponenten gleich sind, d.h. x1...
xn
=
y1...
yn
⇐⇒ xi = yi fur i = 1, . . . , n.
Vektoren unterschiedlicher Dimension sind also niemals gleich!
Die Multiplikation eines Vektors mit einem Skalar und die Addition zweier Vek-
toren gleicher Dimension sind komponentenweise definiert:
λ
x1...
xn
:=
λx1...
λxn
, x1
...
xn
+
y1...
yn
:=
x1 + y1...
xn + yn
.Fur Vektoren unterschiedlicher Dimension ist die Addition nicht definiert!
Durch Nachrechnen ergibt sich
Satz 2.1.36 (Rechenregeln)
Seien ~a, ~b und ~c Vektoren gleicher Dimension und λ und µ Zahlen. Dann gelten folgende
Rechenregeln:
~a+~b = ~b+ ~a (Kommutativgesetz)
(~a+~b) + ~c = ~a+ (~b+ ~c) (Assoziativgesetz)
~a+~0 = ~a (Neutralitat des Nullvektors bzgl. Addition)
~a+ (−~a) = ~0 (Existenz eines additiv inversen Vektors)
λ(µ~a) = (λµ)~a (Assoziativitat bei Multiplikation mit Skalaren)
λ(~a+~b) = λ~a+ λ~b (Distributivgesetz I)
(λ+ µ)~a = λ~a+ µ~a (Distributivgesetz II).
c© 2011 by M. Gerdts

2.1. VEKTOREN 55
Spater werden wir den Spieß umdrehen und einen Vektorraum (also eine Menge von
Vektoren) dadurch definieren, dass in einem solchen Raum genau die Rechenregeln in
Satz 2.1.36 gelten. Dies kann auf sehr allgemeine Mengen fuhren, deren Elemente formal
als Vektoren bezeichnet werden, die aber nichts mehr mit der ublichen geometrischen
Vorstellung von Vektoren zu tun haben mussen. Dennoch kann man mit diesen Vektoren
wie in Satz 2.1.36 angegeben rechnen.
Die folgende Normdefinition gilt fur reelle und komplexe Vektoren:
Definition 2.1.37 (Norm (Lange) eines Vektors)
Die (euklidische) Norm (Lange) des Vektors
~x =
x1...
xn
ist definiert als
‖~x‖ :=√|x1|2 + . . .+ |xn|2.
Ein Vektor ~x mit ‖~x‖ = 1 heißt normiert.
Fur Vektoren ~x mit reellen Komponenten konnen die Betrage in den Termen |xk|2, k =
1, . . . , n, in Definition 2.1.37 auch weggelassen werden.
Die Normabbildung ‖ · ‖ besitzt folgende Eigenschaften:
Satz 2.1.38 (Normeigenschaften)
Seien ~x und ~y Vektoren gleicher Dimension und λ eine Zahl. Dann gelten:
‖λ~x‖ = |λ| · ‖~x‖‖~x+ ~y‖ ≤ ‖~x‖+ ‖~y‖ (Dreiecksungleichung)
‖~x+ ~y‖ ≥ |‖~x‖ − ‖~y‖|‖~x‖ = 0 ⇐⇒ ~x = ~0
Analog zu Satz 2.1.14 ist das Skalarprodukt auch fur n-dimensionale Vektoren definiert.
c© 2011 by M. Gerdts

56 KAPITEL 2. VEKTOREN UND MATRIZEN
Definition 2.1.39 (Skalarprodukt)
Fur reelle Vektoren
~x =
x1...
xn
und ~y =
y1...
yn
ist das Skalarprodukt 〈~x, ~y〉 definiert als
〈~x, ~y〉 :=n∑i=1
xiyi.
Satz 2.1.40 (Cauchy-Schwarz’sche Ungleichung)
Fur alle Vektoren ~x und ~y gleicher Dimension gilt
|〈~x, ~y〉| ≤ ‖~x‖ · ‖~y‖.
Bemerkung 2.1.41
(a) Die geometrische Definition des Skalarprodukts aus Definition 2.1.9 mit
〈~x, ~y〉 = ‖~x‖ · ‖~y‖ · cosϕ
gilt unverandert.
(b) Sind die Komponenten von ~x und ~y komplexe Zahlen, so muss die Definition des
Skalarprodukts modifiziert werden zu
〈~x, ~y〉 :=n∑i=1
xiyi,
um die wichtige Eigenschaft 〈~x, ~x〉 ≥ 0 zu erhalten.
2.2 Allgemeine Vektorraume
Mit Hilfe der Rechenregeln in Satz 2.1.36 lassen sich allgemeine Vektorraume definie-
ren. Deren Elemente – die Vektoren – genugen dann automatisch den Rechenregeln in
c© 2011 by M. Gerdts

2.2. ALLGEMEINE VEKTORRAUME 57
Satz 2.1.36. Die bisher betrachteten n-dimensionalen Vektoren des Rn bilden damit einen
speziellen Vektorraum.
Definition 2.2.1 (Vektorraum, linearer Raum)
Ein Vektorraum (V,+, ·) uber dem Skalarenkorper K = R oder K = C besteht aus einer
Menge V , auf der die Addition zweier Elemente und die Multiplikation mit einem Skalar
aus K mit den folgenden Eigenschaften definiert sind:
(a) Abgeschlossenheit: Mit x, y ∈ V ist auch x + y ∈ V . Mit x ∈ V und λ ∈ K ist
auch λx ∈ V .
(b) Kommutativgesetz: Fur alle x, y ∈ V gilt
x+ y = y + x.
(c) Assoziativgesetz: Fur alle x, y, z ∈ V gilt
x+ (y + z) = (x+ y) + z.
(d) Existenz eines Nullelements: Es existiert 0 ∈ V (Nullelement), so dass fur alle
x ∈ V gilt:
x+ 0 = x.
(e) Existenz eines additiv inversen Elements: Zu jedem x ∈ V gibt es genau ein
Element y ∈ V mit
x+ y = 0.
(f) Neutralitat der 1: Fur alle x ∈ V gilt
1 · x = x.
(g) Multiplikation mit Skalar: Fur alle x, y ∈ V und λ, µ ∈ K gelten
λ(µx) = (λµ)x,
(λ+ µ)x = λx+ µx,
λ(x+ y) = λx+ λy.
Man schreibt haufig V an Stelle von (V,+, ·), wenn klar ist, welche Addition und welche
Multiplikation gemeint ist. Die Elemente des Vektorraums V nennt man Vektoren.
c© 2011 by M. Gerdts

58 KAPITEL 2. VEKTOREN UND MATRIZEN
Beispiel 2.2.2
(a) Rn ist ein Vektorraum uber K = R und Cn ist ein Vektorraum uber K = C.
(b) Die Menge aller stetigen Funktionen auf dem Intervall [0, 1] versehen mit der punkt-
weisen Addition und Multiplikation ist ein Vektorraum.
(c) Die Menge aller Polynome vom Hochstgrad n definiert einen Vektorraum uber R(Zeige dies durch Nachprufen der Bedingungen (a)-(f)!).
(d) Die Gerade ~x(t) ∈ R2
∣∣∣ ~x(t) = t
[1
−1
], t ∈ R
definiert einen Vektorraum uber R.
(e) Die Gerade ~x(t) ∈ R2
∣∣∣ ~x(t) =
[1
0
]+ t
[1
−1
], t ∈ R
definiert keinen Vektorraum uber R (Warum nicht?).
Vektorraume konnen also sehr viel abstrakter aussehen als die bisher betrachteten geo-
metrischen Vektorraume, daher schreibt man fur die Elemente eines Vektorraums in der
Regel auch x (ohne Pfeil) anstatt ~x. Mit ~x verbinden wir stets die geometrischen Vek-
toren im Rn. Dennoch gelten stets dieselben Rechenregeln in allen Vektorraumen. Kann
man Aussagen fur allgemeine Vektorraume beweisen, so gelten diese somit auch fur alle
speziellen Vektorraume.
Definition 2.2.3 (Linearkombination)
Seien m ∈ N Vektoren x1, . . . , xm aus einem Vektorraum und Zahlen λ1, . . . , λm gegeben.
Dann heißt
λ1x1 + . . .+ λmxm =m∑i=1
λixi
eine Linearkombination der Vektoren x1, . . . , xm.
c© 2011 by M. Gerdts

2.2. ALLGEMEINE VEKTORRAUME 59
Beispiel 2.2.4
Wegen
x1...
xn
= x1
1
0...
0
+ . . .+ xn
0...
0
1
= x1~e1 + . . .+ xn ~en =n∑i=1
xi~ei
lasst sich jeder Vektor ~x ∈ Rn als Linearkombination der Einheitsvektoren darstellen.
Definition 2.2.5 (Lineare Unabhangigkeit, lineare Abhangigkeit)
Seien m ≥ 2 Vektoren x1, . . . , xm aus einem Vektorraum gegeben.
(a) Die Vektoren xk, k = 1, . . . ,m, sind linear unabhangig genau dann, wenn aus
der Darstellung
0 =m∑k=1
λkxk = λ1x1 + . . .+ λmxm
stets folgt
λ1 = . . . = λm = 0.
(b) Die Vektoren xk, k = 1, . . . ,m, sind linear abhangig genau dann, wenn es Zahlen
λk, k = 1, . . . ,m, gibt, die nicht alle Null sind und
0 =m∑k=1
λkxk = λ1x1 + . . .+ λmxm.
erfullen.
Beispiel 2.2.6
(a) Die Einheitsvektoren ~e1, . . . , ~en ∈ Rn sind linear unabhangig.
(b) Die Vektoren 1
1
0
, 1
−1
0
, 1
1
1
sind linear unabhangig.
c© 2011 by M. Gerdts

60 KAPITEL 2. VEKTOREN UND MATRIZEN
(c) Die Vektoren 1
1
0
, 0
0
−1
, 1
1
1
sind linear abhangig, denn es gilt
−
1
1
0
+
0
0
−1
+
1
1
1
= ~0.
Sind die Vektoren x1, . . . , xm linear abhangig, so laßt sich stets einer dieser Vektoren als
Linearkombination der ubrigen Vektoren darstellen, da es dann Zahlen λ1, . . . , λm gibt,
die nicht alle Null sind, mit
0 = λ1x1 + . . .+ λmxm.
Ist dann etwa λk 6= 0 fur k ∈ 1, . . . ,m, so folgt
xk = − 1
λk
m∑j=1
j 6=k
λjxj.
Eine solche Darstellung ist nicht moglich, wenn die Vektoren linear unabhangig sind.
Definition 2.2.7 (Basis, Dimension, Unterraum)
Sei V ein Vektorraum.
(a) Die Menge B ⊆ V heißt Basis von V , wenn sich jedes Element aus V eindeutig
als Linearkombination von Elementen aus B darstellen lasst. Die Elemente in B
heißen Basiselemente oder Basisvektoren.
(b) Die Dimension des Vektorraums V ist definiert als die Anzahl der Basiselemente
in B. Ist B endlich, so ist V ein endlichdimensionaler Vektorraum, andernfalls
ein unendlichdimensionaler Vektorraum.
(c) Eine Teilmenge U von V heißt Untervektorraum oder Teilraum von V , wenn
U selbst ein Vektorraum ist.
c© 2011 by M. Gerdts

2.2. ALLGEMEINE VEKTORRAUME 61
Beispiel 2.2.8
(a) B = ~e1, . . . , ~en ist eine Basis des Vektorraums Rn. Die Dimension von Rn ist n.
(b) B =
[1
0
],
[1
−1
]ist eine Basis des R2. Die Dimension ist 2.
(c) B =
[1
0
],
[1
−1
],
[0
1
]ist keine Basis des R2.
(d) Die Menge ~x(t) ∈ R2
∣∣∣ ~x(t) = t
[1
−1
], t ∈ R
definiert einen Untervektorraum des R2.
(e) Die Menge der elementaren Polynome
1, x, x2, . . . , xn
ist eine (n+1)-dimensionale Basis des Vektorraums der Polynome mit Hochstgrad
n.
Bemerkung 2.2.9
Die Basiselemente einer Basis B sind stets linear unabhangig im Sinne von Definiti-
on 2.2.5. Andernfalls konnten die Elemente eines Vektorraums durch verschiedene Line-
arkombinationen dargestellt werden, was per Definition einer Basis ausgeschlossen ist.
Da sich die in Vektorraumen gultigen Rechenregeln auf Teilmengen vererben, genugt es,
die Abgeschlossenheit einer Teilmenge zu uberprufen:
Satz 2.2.10
U ⊆ V , U 6= ∅, ist genau dann ein Untervektorraum von V , wenn U abgeschlossen ist,
d.h. wenn
x, y ∈ U =⇒ x+ y ∈ U,x ∈ U, λ ∈ K =⇒ λx ∈ U.
c© 2011 by M. Gerdts

62 KAPITEL 2. VEKTOREN UND MATRIZEN
Durch Vorgabe von endlich vielen Vektoren wird ein Vektorraum durch das Bilden aller
Linearkombinationen erzeugt:
Definition 2.2.11
Sei V ein Vektorraum und x1, . . . , xn ∈ V gegebene Vektoren. Dann heißt
U :=
x ∈ V
∣∣∣ x =n∑k=1
λkxk, λk ∈ R, k = 1, . . . , n
der von x1, . . . , xn erzeugte Vektorraum.
Man muss noch nachweisen, dass der von x1, . . . , xn erzeugte Vektorraum tatsachlich ein
Vektorraum ist. Dies gelingt am einfachsten mit Hilfe von Satz 2.2.10 durch Nachrechnen.
Die Dimension des von x1, . . . , xn erzeugten Vektorraums ist gleich der maximalen
Anzahl linear unabhangiger Vektoren in x1, . . . , xn.
Beispiel 2.2.12
Der durch
~a =
1
0
−1
und ~b =
1
1
0
erzeugte Vektorraum lautet
U =
λ1 + λ2
λ2
−λ1
∣∣∣ λ1, λ2 ∈ R
.
Dieser erzeugte Vektorraum ist eine Ebene durch den Ursprung:
c© 2011 by M. Gerdts
2.3. MATRIZEN 63
-2-1.5 -1-0.5 0 0.5 1 1.5 2 -1-0.5
0 0.5
1
-1
-0.5
0
0.5
1
Beachte, dass der Nullvektor ~0 stets im erzeugten Vektorraum enthalten ist. In diesem Bei-
spiel sind die Vektoren ~a und~b linear unabhangig und spannen daher einen 2-dimensionalen
Untervektorraum des R3 auf.
2.3 Matrizen
Eine Matrix ist ein mathematisches Objekt, welches u.a. eine effiziente Schreibweise fur die
in Kapitel 3 behandelten linearen Gleichungssysteme und lineare Abbildungen ermoglicht.
Matrizen entstehen, wenn man mehrere Spaltenvektoren gleicher Dimension hintereinan-
der schreibt und zusammenfasst. Vektoren sind dabei spezielle Matrizen mit nur einer
Spalte.
Definition 2.3.1 (Matrix)
(a) Fur m,n ∈ N und nm Zahlen aij, i = 1, . . . ,m, j = 1, . . . , n, heißt
A :=
a11 a12 · · · a1n
a21 a22 · · · a2n...
.... . .
...
am1 am2 . . . amn
eine m × n-Matrix mit m Zeilen und n Spalten. Man sagt, die Matrix hat die
c© 2011 by M. Gerdts

64 KAPITEL 2. VEKTOREN UND MATRIZEN
Dimension m× n. Als abkurzende Schreibweise wird
A = [aij] i=1,...,mj=1,...,n
verwendet.
(b) Die Zahlen aij, i = 1, . . . ,m, j = 1, . . . , n, heißen Elemente der Matrix A. Sind
alle Elemente reellwertig, so spricht man von einer reellen Matrix und schreibt
A ∈ Rm×n. Sind die Elemente komplexe Zahlen, so spricht man von einer komple-
xen Matrix und schreibt A ∈ Cm×n.
(c) Die m-dimensionalen Spaltenvektorena1j
a2j...
amj
, j = 1, . . . , n,
bezeichnen die Spalten von A und die n-dimensionalen Zeilenvektoren[ai1 ai2 . . . ain
], i = 1, . . . ,m,
bezeichnen die Zeilen von A.
(d) Im Fall m = n heißt die Matrix A quadratisch.
(e) Eine Matrix, deren Elemente alle Null sind, heißt Nullmatrix und wird mit 0
bezeichnet.
(f) Die Matrix
In :=
1. . .
1
∈ Rn×n,
die auf ihrer Hauptdiagonalen lauter Einsen und sonst nur Nullen enthalt, heißt
Einheitsmatrix. Es ist ublich, Nulleintrage wegzulassen.
Matrizen sind sehr nutzlich, um eine Vielzahl von Informationen kompakt zusammenzu-
fassen.
Beispiel 2.3.2 (Matrixspiel)
Gegeben seien zwei Spieler X und Y . Der Spieler X kann aus Zahlen 1, . . . ,m auswahlen
c© 2011 by M. Gerdts

2.3. MATRIZEN 65
und Spieler Y aus den Zahlen 1, . . . , n. Wahlt Spieler X die Zahl i ∈ 1, . . . ,m und
Spieler Y die Zahl j ∈ 1, . . . , n, so zahlt der Spieler Y einen vor Beginn des Spiels
festgelegten Betrag aij ∈ R an Spieler X. Negative Werte von aij bedeuten, dass Spieler
Y von Spieler X den Betrag |aij| bekommt. Dies definiert ein so genanntes Matrixspiel
mit der Auszahlungsmatrix A = [aij] i=1,...,mj=1,...,n
.
Ein konkretes Matrixspiel ist gegeben durch die Auszahlungsmatrix
A =
2 2 3 9
6 5 4 6
7 6 2 1
.Es stellt sich nun die Frage, welche Zeilen- bzw. Spaltenwahl fur Zeilen- und Spaltenspieler
moglichst gut sind. Der Zeilenspieler mochte seinen Gewinn maximieren, wahrend der
Spaltenspieler seinen Verlust minimieren mochte. Hier entsteht offenbar ein Konflikt. Was
soll gewahlt werden?
Was ergibt sich fur die Auszahlungsmatrix
B =
2 2 3 9
6 5 6 6
7 6 2 1
?
Definition 2.3.3
Zwei Matrizen
A = [aij] i=1,...,mj=1,...,n
und B = [bij] i=1,...,mj=1,...,n
gleicher Dimension heißen gleich, wenn ihre Elemente gleich sind, d.h. wenn
aij = bij ∀i = 1, . . . ,m, j = 1, . . . , n.
Addition und Multiplikation mit Skalaren ist wie bei Vektoren komponentenweise defi-
niert.
Definition 2.3.4 (Matrixaddition, Multiplikation mit Skalaren)
(a) Die Addition zweier Matrizen
A = [aij] i=1,...,mj=1,...,n
und B = [bij] i=1,...,mj=1,...,n
c© 2011 by M. Gerdts

66 KAPITEL 2. VEKTOREN UND MATRIZEN
gleicher Dimension ist definiert als
A+B :=
a11 + b11 · · · a1n + b1n...
. . ....
am1 + bm1 · · · amn + bmn
.Fur Matrizen unterschiedlicher Dimension ist die Matrixaddition nicht definiert.
(b) Die Multiplikation einer Matrix A = [aij] i=1,...,mj=1,...,n
mit einem Skalar λ ist definiert als
λA :=
λa11 · · · λa1n...
. . ....
λam1 · · · λamn
.
Durch Nachrechnen folgt
Satz 2.3.5 (Rechenregeln I)
Seien A, B und C Matrizen gleicher Dimension und λ und µ Zahlen. Dann gelten folgende
Rechenregeln:
A+B = B + A (Kommutativgesetz)
(A+B) + C = A+ (B + C) (Assoziativgesetz)
A+ 0 = A (Neutralitat der Nullmatrix bzgl. Addition)
A+ (−A) = 0 (Existenz einer additiv inversen Matrix)
λ(µA) = (λµ)A (Assoziativitat bei Multiplikation mit Skalaren)
λ(A+B) = λA+ λB (Distributivgesetz I)
(λ+ µ)A = λA+ µA (Distributivgesetz II).
Matrizen konnen miteinander multipliziert werden, wenn ihre Dimensionen passen. Das
Ergebnis ist wieder eine Matrix. Das Element ij des Matrixprodukts berechnet sich nach
dem Prinzip”Zeile i der ersten Matrix multipliziert mit der Spalte j der zweiten Matrix“,
wobei die Multiplikation im Sinne des Skalarprodukts erfolgt. Dieses Skalarprodukt ist
jedoch nur definiert, wenn die Anzahl der Spalten der ersten Matrix mit der Anzahl der
Zeilen der zweiten Matrix ubereinstimmt. Wir definieren diesen Vorgang zunachst formal
c© 2011 by M. Gerdts

2.3. MATRIZEN 67
und veranschaulichen ihn dann an Beispielen.
Definition 2.3.6 (Matrixmultiplikation)
Gegeben seien die m× n-Matrix A und die n× p-Matrix B gemaß
A =
a11 · · · a1n...
. . ....
am1 · · · amn
, B =
b11 · · · b1p...
. . ....
bn1 · · · bnp
.Das Matrixprodukt C = AB ist eine m×p-Matrix, deren Elemente cij fur i = 1, . . . ,m
und j = 1, . . . , p gegeben sind durch
cij =n∑k=1
aikbkj (Zeile i von A mal Spalte j von B).
Schema: “Zeile i mal Spalte j ergibt das Element ij”
...
......
ai1 · · · ain...
......
︸ ︷︷ ︸
m×n−Matrix
· · ·· · ·· · ·
b1j...
bnj
· · ·· · ·· · ·
︸ ︷︷ ︸
n×p−Matrix
=
...
......
· · ·n∑k=1
aikbkj · · ·
......
...
︸ ︷︷ ︸
m×p−Matrix
.
Bemerkung 2.3.7
Mit Hilfe des Skalarprodukts fur Vektoren kann die Matrixmultiplikation fur reelle Ma-
trizen wie folgt dargestellt werden. Bezeichnen ~ai ∈ Rn, i = 1, . . . ,m, die Zeilenvektoren
von A und ~bj ∈ Rn, j = 1, . . . , p, die Spaltenvektoren von B, so ist das Element cij von
C gegeben durch das Skalarprodukt
cij = 〈~ai, ~bj〉.
Beispiel 2.3.8
(a) [2 −1
0 4
][1 −1
2 3
]=
[0 −5
8 12
]
c© 2011 by M. Gerdts

68 KAPITEL 2. VEKTOREN UND MATRIZEN
(b) [2 −1
0 4
][1
−1
]=
[3
−4
](c) 5
−3
0
[ 1 −1 2]
=
5 −5 10
−3 3 −6
0 0 0
(d) [
1 −1 2] 5
−3
0
=[
8]
(e) Die Matrizen 5
−3
0
0
und
1 −7
−2 4
0 1
konnen nicht miteinander multipliziert werden.
(f) Wegen 1. . .
1
a11 · · · a1n
.... . .
...
an1 · · · ann
=
a11 · · · a1n...
. . ....
an1 · · · ann
=
a11 · · · a1n...
. . ....
an1 · · · ann
1
. . .
1
gilt fur alle m× n-Matrizen stets
ImA = AIn = A.
Wegen [2 −1
0 4
][1 −1
2 3
]=
[0 −5
8 12
]6=
[2 −5
4 10
]=
[1 −1
2 3
][2 −1
0 4
]ist die Matrixmultiplikation im Allgemeinen nicht kommutativ (!), d.h. es gilt im All-
gemeinen
AB 6= BA.
c© 2011 by M. Gerdts

2.3. MATRIZEN 69
Satz 2.3.9 (Rechenregeln II)
Seien A, B und C Matrizen passender Dimension. Dann gelten folgende Rechenregeln:
(AB)C = A(BC) (Assoziativgesetz)
A(B + C) = AB + AC (Distributivgesetz I)
(A+B)C = AC +BC (Distributivgesetz II).
Durch Spiegeln der Elemente an der Hauptdiagonalen entsteht die sogenannte transpo-
nierte Matrix. Aus der i-ten Zeile wird dann in der transponierten Matrix die i-te Spalte.
Definition 2.3.10 (Transponierte Matrix)
Die zur m× n-Matrix
A =
a11 a12 · · · a1n
a21 a22 · · · a2n...
. . ....
am1 am2 · · · amn
transponierte Matrix A> ist definiert als die n×m-Matrix
A> :=
a11 a21 · · · am1
a12 a22 · · · am2
.... . .
...
a1n a2n · · · amn
.
Matrizen mit A> = A heißen symmetrisch. Komplexe Matrizen mit A> = A heißen
hermitesch, wobei A die zu A konjugiert komplexe Matrix bezeichnet.
Beispiel 2.3.11
(a)
[2 −1
0 4
]>=
[2 0
−1 4
]
c© 2011 by M. Gerdts

70 KAPITEL 2. VEKTOREN UND MATRIZEN
(b) 5
−3
0
>
=[
5 −3 0]
(c) 1 −7
−2 4
0 1
>
=
[1 −2 0
−7 4 1
]
(d) Die Matrix 1 2 5
2 −3 7
5 7 1
ist symmetrisch.
(e) Die komplexe Matrix [1 4− 2i
4 + 2i 5
]ist hermitesch.
Symmetrische und hermitesche Matrizen haben besondere Eigenschaften in Bezug auf
ihre Eigenwerte. Dies wird in Kapitel 4 deutlich werden.
Satz 2.3.12 (Rechenregeln)
Seien A und B m× n-Matrizen, C eine n× k-Matrix und λ ein Skalar. Dann gelten die
folgenden Rechenregeln:
(A>)> = A,
(A+B)> = A> +B>,
(λA)> = λA>,
(BC)> = C>B>.
Beweis: Die ersten drei Eigenschaften kann man leicht nachrechnen. Die letzte Eigen-
schaft ergibt sie wie folgt. Zunachst bemerken wir, dass BC eine m×k-Matrix ist. Damit
c© 2011 by M. Gerdts

2.3. MATRIZEN 71
ist (BC)> eine k ×m-Matrix. Die Matrix C> ist eine k × n-Matrix und B> eine n×m-
Matrix. Das Produkt C>B> ist damit eine k×m-Matrix. Wir berechnen nun jeweils das
Element mit dem Index ij von (BC)> und C>B>.
Fur BC ergibt sich das Element
(BC)µν =n∑`=1
bµ`c`ν .
Damit lautet das Element ij von (BC)>
(BC)>ij =n∑`=1
bj`c`i.
Fur das Produkt C>B> ergibt sich das Element ij, indem die i-te Spalte von C mit der
j-ten Zeile von B multipliziert wird, d.h.
(C>B>)ij =n∑`=1
c`ibj`.
Folglich stimmen beide Darstellungen uberein.
Bemerkung 2.3.13
Das Skalarprodukt zweier Vektoren ~a ∈ Rn und ~b ∈ Rn kann mit der Transposition dar-
gestellt werden als
〈~a,~b〉 = ~a>~b =n∑i=1
aibi.
Beim Losen von linearen Gleichungssystemen spielt die Inverse einer Matrix eine entschei-
dende Rolle.
Definition 2.3.14 (Inverse einer Matrix)
Gegeben sei die n × n-Matrix A. Jede n × n-Matrix X heißt Inverse von A (inverse
Matrix von A) genau dann, wenn
AX = XA = In
gilt. Die Inverse von A wird mit A−1 bezeichnet.
Besitzt A eine inverse Matrix A−1, so heißt sie invertierbar, andernfalls singular.
Beispiel 2.3.15
Die Matrix
A =
[1 −1
1 1
]
c© 2011 by M. Gerdts

72 KAPITEL 2. VEKTOREN UND MATRIZEN
besitzt die Inverse
A−1 =
[12
12
−12
12
],
denn
AA−1 =
[1 −1
1 1
][12
12
−12
12
]=
[1 0
0 1
]=
[12
12
−12
12
][1 −1
1 1
]= A−1A.
Satz 2.3.16 (Eindeutigkeit)
Existiert die Inverse einer Matrix, so ist sie eindeutig.
Beweis: Annahme: Die n × n-Matrix A besitzt zwei Inverse X und Y mit X 6= Y .
Dann gilt AX = In = AY . Multiplikation von links mit X liefert
X = XIn = XAX = XAY = InY = Y.
Dies ist ein Widerspruch zur Annahme. Daher ist die Annahme falsch und die Aussage
bewiesen.
Nicht jede Matrix besitzt eine Inverse, wie das folgende Beispiel verdeutlicht.
Beispiel 2.3.17
Die Matrix
A =
[1 0
0 0
]besitzt keine Inverse, da
AX =
[1 0
0 0
][x11 x12
x21 x22
]=
[x11 x12
0 0
]6= I2,
fur alle 2× 2-Matrizen X.
Definition 2.3.18 (Lineares Gleichungssystem)
Seien A eine n× n-Matrix und ~b ein Vektor der Dimension n.
Die Gleichung
A~x = ~b
heißt lineares Gleichungssystem fur den Vektor ~x.
Jeder Vektor ~x mit A~x = ~b heißt Losung des linearen Gleichungssystems.
c© 2011 by M. Gerdts

2.3. MATRIZEN 73
Kennt man die Inverse einer Matrix A, so ist die Losung ~x eines linearen Gleichungssy-
stems A~x = ~b durch
~x = A−1~b
gegeben, da A~x = AA−1~b = In~b = ~b. Leider ist es insbesondere fur hochdimensionale Ma-
trizen sehr aufwandig, die Inverse zu berechnen. Daher wird die Inverse einer Matrix in der
Regel nicht explizit berechnet, sondern es werden andere Techniken (Gauß-Algorithmus,
vgl. Abschnitt 3.1) zur Losung eines linearen Gleichungssystems verwendet. Als theoreti-
sches Hilfsmittel ist die Inverse aber unverzichtbar in der linearen Algebra.
Satz 2.3.19 (Eigenschaften der Inversen)
Seien A und B invertierbar. Dann gelten folgende Rechenregeln:
(A−1)−1 = A,
(AB)−1 = B−1A−1,
(A>)−1 = (A−1)>.
Beweis: Die erste Aussage folgt aus
A−1A = I = AA−1.
Die zweite folgt wegen
(AB)B−1A−1 = A(BB−1)A−1 = AA−1 = I
und
B−1A−1(AB) = B−1(A−1A)B = B−1B = I.
Die dritte Aussage folgt wie folgt. Transposition der Gleichung A−1A = I liefert
I = I> = (A−1A)> = A>(A−1)>
und Transposition der Gleichung AA−1 = I liefert
I = I> = (AA−1)> = (A−1)>A>.
Beide Gleichungen zusammen zeigen die Behauptung.
Definition 2.3.20 (Rang einer Matrix)
Sei A ∈ Rm×n eine Matrix.
c© 2011 by M. Gerdts

74 KAPITEL 2. VEKTOREN UND MATRIZEN
(a) Der Zeilenrang der Matrix A ist die maximale Anzahl von linear unabhangigen Zei-
len von A.
(b) Der Spaltenrang der Matrix A ist die maximale Anzahl von linear unabhangigen
Spalten von A.
Beispiel 2.3.21
(a) Die Matrix [1 −1 2 0
0 0 1 0
]hat Zeilenrang 2 und Spaltenrang 2.
(b) Die Matrix 1 −1 2
0 1 1
0 0 1
hat Zeilenrang 3 und Spaltenrang 3.
(c) Die Matrix 1 4 8
0 0 0
0 0 0
hat Zeilenrang 1 und Spaltenrang 1.
Bemerkung 2.3.22
Zeilen- und Spaltenrang einer Matrix A stimmen stets uberein. Daher spricht man auch
nur vom Rang von A und schreibt Rang(A) oder Rg(A).
2.4 Lineare Abbildungen und Matrizen
Im Folgenden wird der Zusammenhang zwischen linearen Abbildungen und Matrizen her-
gestellt.
c© 2011 by M. Gerdts

2.4. LINEARE ABBILDUNGEN UND MATRIZEN 75
Definition 2.4.1 (Lineare Abbildung)
Eine Abbildung T : Rn −→ Rm heißt lineare Abbildung, wenn
T (~x+ ~y) = T (~x) + T (~y),
T (λ~x) = λT (~x)
fur alle ~x, ~y ∈ Rn und alle λ ∈ R gilt.
Beispiel 2.4.2
Sei A ∈ Rm×n. Dann ist durch
T (~x) = A~x
eine lineare Abbildung T : Rn −→ Rm gegeben, denn fur ~x, ~y ∈ Rn und λ ∈ R gilt:
T (~x+ ~y) = A(~x+ ~y) = A~x+ A~y = T (~x) + T (~y),
T (λ~x) = A(λ~x) = λA~x = λT (~x).
Die Umkehrung in Beispiel 2.4.2 gilt ebenfalls: Jede lineare Abbildung kann durch eine
Matrix dargestellt werden:
Satz 2.4.3
Sei T : Rn −→ Rm eine lineare Abbildung. Dann gibt es eine Matrix A ∈ Rm×n mit
T (~x) = A~x fur alle ~x ∈ Rn.
Beweis: Sei
~x =n∑i=1
xi~ei
ein beliebiger Vektor. Aus der Linearitat von T folgt dann
T (~x) = T
(n∑i=1
xi~ei
)=
n∑i=1
xiT (~ei) = A~x,
wobei die Matrix A ∈ Rm×n sich aus den Spalten T (~ei) ∈ Rm, i = 1, . . . , n, zusammen-
setzt:
A :=[T (~e1) · · · T (~en)
].
c© 2011 by M. Gerdts

76 KAPITEL 2. VEKTOREN UND MATRIZEN
Definition 2.4.4 (Bild und Kern)
Sei A ∈ Rm×n eine Matrix und T : Rn −→ Rm die zugehorige durch T (~x) := A~x definierte
lineare Abbildung.
(a) Der Nullraum (oder Kern) von A bzw. T ist definiert als
Kern(A) := ~x ∈ Rn | A~x = ~0.
(b) Das Bild (engl. image) von A bzw. T ist definiert als
Bild(A) := ~y ∈ Rm | ~y = A~x, ~x ∈ Rn.
Der Kern von A ∈ Rm×n ist ein Untervektorraum des Rn und das Bild von A ist ein
Untervektorraum des Rm, wie man mit Hilfe von Satz 2.2.10 leicht nachpruft.
Beispiel 2.4.5
Fur
A =
[1 −1
0 0
]ist
Bild(A) =
[t
0
] ∣∣∣ t ∈ R
und Kern(A) =
t
[1
1
] ∣∣∣ t ∈ R
.
Wir fassen noch einige aus der linearen Algebra bekannte Resultate zusammen:
Satz 2.4.6
Sei A ∈ Rm×n. Dann gelten folgende Aussagen:
(a)
n = dim(Kern(A)) + dim(Bild(A))
m = dim(Kern(A>)) + Rang(A)
Kern(A) = Bild(A>)⊥,
Bild(A>) = Kern(A)⊥,
Kern(A) = Kern(A>A),
Bild(A>) = Bild(A>A).
c© 2011 by M. Gerdts

2.4. LINEARE ABBILDUNGEN UND MATRIZEN 77
Hierin bezeichnet V ⊥ = w ∈ Rn | 〈w, v〉 = 0 ∀v ∈ V das orthogonale Komplement
des Unterraums V ⊆ Rn.
(b) Im Fall n = m sind folgende Aussagen aquivalent:
– A ist regular (invertierbar)
– Kern(A) = ~0– Bild(A) = Rn
– Rang(A) = n
– A~x = ~0 ⇐⇒ ~x = ~0
– A~x = ~b hat fur jedes ~b genau eine Losung
c© 2011 by M. Gerdts

Kapitel 3
Lineare Gleichungssysteme
Nachdem wir in Kapitel 2 bereits gerlernt haben, mit Vektoren und Matrizen zu rechnen,
geht es in diesem Kapitel um das Losen von linearen Gleichungssystemen mit dem Gauss-
Algorithmus.
3.1 Lineare Gleichungssysteme
Als Motivation fur dieses Kapitel betrachten wir eine Aufgabe, die in nahezu allen An-
wendungen fruher oder spater auftritt: die Losung eines linearen Gleichungssystems.
Beispiel 3.1.1 (Elektrische Schaltkreise und Kirchhoffsches Gesetz)
Gegeben sei das folgende stationare elektronische Netzwerk mit gegebenen ohmschen Wi-
derstanden R1, . . . , R5 und gegebenem Eingangsstrom I0.
I0 I101 2
3
4
R4R4
R3
R5
R3
R2 R1
R2R1
I1 I8
I3 I9
I2I6
I4
I5
I7
Das erste Kirchhoffsche Gesetz (Knotensatz)
An jedem Knotenpunkt ist die Summe aller zu- (positiven) und abfließenden
(negativen) Strome unter Beachtung der durch die Pfeile angegebenen
Richtungen in jedem Zeitpunkt gleich Null
78

3.1. LINEARE GLEICHUNGSSYSTEME 79
liefert die Beziehungen
−I1 + I3 = −I0,I1 − I2 − I4 + I6 = 0,
I2 − I3 − I7 = 0,
I4 − I5 + I8 = 0,
I5 − I6 + I7 − I9 = 0,
−I8 + I9 − I10 = 0.
Aus dem Ohmschen Gesetz
U = R · I
und dem zweiten Kirchhoffschen Gesetz (Maschensatz)
In einer Masche ist die Summe aller Teilspannungen in jedem Zeitpunkt
gleich Null
folgen die Gleichungen
R1 · I1 +R4 · I2 +R2 · I3 = 0,
R2 · I8 +R4 · I5 +R1 · I9 = 0,
R4 · I2 +R5 · I6 +R3 · I7 = 0,
R3 · I4 +R4 · I5 +R5 · I6 = 0.
Diese 10 Gleichungen fur die Strome I1, . . . , I10 konnen als lineares Gleichungssystem
geschrieben werden:
−1 0 1 0 0 0 0 0 0 0
1 −1 0 −1 0 1 0 0 0 0
0 1 −1 0 0 0 −1 0 0 0
0 0 0 1 −1 0 0 1 0 0
0 0 0 0 1 −1 1 0 −1 0
0 0 0 0 0 0 0 −1 1 −1
R1 R4 R2 0 0 0 0 0 0 0
0 0 0 0 R4 0 0 R2 R1 0
0 R4 0 0 0 R5 R3 0 0 0
0 0 0 R3 R4 R5 0 0 0 0
·
I1
I2
I3
I4
I5
I6
I7
I8
I9
I10
=
−I00
0
0
0
0
0
0
0
0
.
Das Folgende gilt sowohl fur reellwertige als auch fur komplexwertige Vektoren und Ma-
trizen. Wir beschranken uns jedoch auf den reellen Fall.
c© 2011 by M. Gerdts

80 KAPITEL 3. LINEARE GLEICHUNGSSYSTEME
Problem 3.1.2 (Lineares Gleichungssystem)
Gesucht ist die Losung ~x ∈ Rn des linearen Gleichungssystems
a11x1 + a12x2 + . . .+ a1nxn = b1,
a21x1 + a22x2 + . . .+ a2nxn = b2,...
an1x1 + an2x2 + . . .+ annxn = bn,
(3.1)
wobei aij, i, j = 1, . . . , n, und bi, i = 1, . . . , n, gegebene Zahlen sind. Mit
A =
a11 a12 · · · a1n
a21 a22 · · · a2n...
.... . .
...
an1 an2 · · · ann
∈ Rn×n, ~b =
b1
b2...
bn
∈ Rn, ~x =
x1
x2...
xn
∈ Rn (3.2)
lautet das lineare Gleichungssystem in Matrixschreibweise
A~x = ~b. (3.3)
Lineare Gleichungssysteme treten in nahezu allen Anwendungen und Verfahren auf.
Unser Ziel ist es, Verfahren zur Bestimmung einer Losung ~x von (3.3) zu entwickeln und
zu analysieren.
3.2 Existenz und Eindeutigkeit von Losungen
Es stellt sich die Frage, welche Voraussetzungen an A und ~b gestellt werden mussen,
damit das lineare Gleichungssystem (3.3) uberhaupt eine Losung ~x besitzt. Zunachst ist
klar, dass das lineare Gleichungssystem genau eine Losung besitzt, falls die Matrix A
invertierbar (regular) ist. Die eindeutige Losung des Gleichungssystems ist dann durch
~x = A−1~b (3.4)
gegeben. Es kann aber auch der Fall eintreten, dass (3.3) mehrere Losungen oder gar keine
Losung besitzt. Offensichtlich kann die Matrix A dann nicht regular sein.
Beispiel 3.2.1
Das folgende lineare Gleichungssystem besitzt keine Losung:[1 0
0 0
][x1
x2
]=
[1
1
]
c© 2011 by M. Gerdts

3.2. EXISTENZ UND EINDEUTIGKEIT VON LOSUNGEN 81
Das folgende lineare Gleichungssystem besitzt genau eine Losung:[1 0
0 1
][x1
x2
]=
[1
1
]
Das folgende lineare Gleichungssystem besitzt unendlich viele Losungen:[1 0
0 0
][x1
x2
]=
[1
0
]
Es gilt das folgende Kriterium, welches die Frage der Losbarkeit von (3.3) abschließend
beantwortet.
Satz 3.2.2
Das lineare Gleichungssystem (3.3) besitzt genau dann mindestens eine Losung, falls
gilt:
Rang(A) = Rang(A|~b).
Unter (A|~b) wird die um die rechte Seite ~b erweiterte Matrix
(A|~b) =
a11 a12 · · · a1n b1
a21 a22 · · · a2n b2...
.... . .
......
an1 an2 · · · ann bn
verstanden.
Beweis: Offenbar besitzt das lineare Gleichungssystem genau dann eine Losung, wenn~b ∈ Bild(A) gilt.
Sei nun~b ∈ Bild(A). Dann gilt auch Bild(A) = Bild(A|~b) und somit Rang(A) = Rang(A|~b).Gilt nun Rang(A) = Rang(A|~b), so laßt sich ~b als Linearkombination der Spalten von A
schreiben. Also gilt ~b ∈ Bild(A) und somit besitzt das Gleichungssystem eine Losung.
Die Struktur der Losungsmenge eines linearen Gleichungssystems wird im folgenden Satz
behandelt.
Satz 3.2.3
Seien A ∈ Rn×n und ~b ∈ Rn gegeben. Sei ~z eine Losung von A~x = ~b. Die gesamte
Losungsmenge von A~x = ~b ist gegeben durch ~z + Kern(A).
c© 2011 by M. Gerdts

82 KAPITEL 3. LINEARE GLEICHUNGSSYSTEME
Beweis: Sei ~y ∈ Kern(A), d.h. A~y = ~0. Dann gilt A(~z + ~y) = A~z + A~y = ~b und ~z + ~y
ist Losung.
Sei ~x Losung. Dann gilt A(~x − ~z) = ~b − ~b = ~0 und somit ~x − ~z ∈ Kern(A) bzw. ~x ∈~z + Kern(A).
3.3 Gauss’sches Eliminationsverfahren
Zur Motivation betrachten wir ein System aus 3 linearen Gleichungen in den 3 Unbekann-
ten x, y, z:
6x− 2y + 2z = 12
12x− 8y + 6z = 34
3x− 13y + 9z = 28
⇐⇒
6 −2 2
12 −8 6
3 −13 9
︸ ︷︷ ︸
=A∈R3×3
x
y
z
︸ ︷︷ ︸=~x∈R3
=
12
34
28
︸ ︷︷ ︸=~b∈R3
Gesucht sind Werte fur x, y und z, die diese drei Gleichungen erfullen.
In der Schule geht man ublicherweise so vor, dass man eine der Gleichungen nach ei-
ner der Variablen auflost und letztere dann in den beiden ubrigen Gleichungen ersetzt.
Dieser Vorgang wird solange wiederholt, bis man fur eine Variable einen Wert ausrech-
nen kann und durch Einsetzen erhalt man dann schrittweise alle anderen Variable. Diese
Vorgehensweise fuhrt zwar auf das richtige Ergebnis, aber es ist etwas willkurlich.
Wir wollen einen systematischen Weg zur Losung des linearen Gleichungssystems kennen
lernen – das Gauß’sche Eliminationsverfahren (Gauß-Algorithmus). Die Idee des
Gauß’schen Eliminationsverfahrens besteht darin, die Koeffizienten im Gleichungssystem
durch elementare Zeilenumformungen schrittweise in obere Dreiecksform zu uberfuhren.
Dieses kann dann mittels Ruckwartssubstitution gelost werden. Wichtig ist hierbei, dass
die Losung des Ausgangsproblems mit der des transformierten Problems ubereinstimmt.
Dies ist bei der Verwendung elementarer Zeilenumformungen gewahrleistet. Elemen-
tare Zeilenumformungen sind
• die Multiplikation einer Zeile mit einem Wert ungleich Null,
• die Addition bzw. Subtraktion zweier Zeilen,
• sowie das Vertauschen zweier Zeilen.
Wir wenden den Gauß-Algorithmus auf unser Gleichungssystem
6x− 2y + 2z = 12
12x− 8y + 6z = 34
3x− 13y + 9z = 28
←→
6 −2 2 12
12 −8 6 34
3 −13 9 28
c© 2011 by M. Gerdts

3.3. GAUSS’SCHES ELIMINATIONSVERFAHREN 83
an und gehen schrittweise vor. Auf der rechten Seite fassen wir die Gleichungssysteme in
Kurzform zusammen, in der nur die Koeffizienten dargestellt sind.
Wir lassen die erste Zeile unverandert und subtrahieren das 126
-fache der ersten Zeile von
der zweiten Zeile und das 36-fache der ersten Zeile von der dritten Zeile und erhalten
6x− 2y + 2z = 12
−4y + 2z = 10
−12y + 8z = 22
←→
6 −2 2 12
0 −4 2 10
0 −12 8 22
Nun lassen wir die ersten beiden Zeilen unverandert und subtrahieren das −12−4 -fache der
zweiten Zeile von der dritten Zeile und erhalten
6x− 2y + 2z = 12,
−4y + 2z = 10,
2z = −8.
←→
6 −2 2 12
0 −4 2 10
0 0 2 −8
Dieses Gleichungssystem besitzt dieselbe Losung wie unser Ausgangssystem, da wir nur
elementare Zeilenumformungen verwendet haben. Es hat jedoch den Vorteil, dass es Drei-
ecksgestalt besitzt, so dass wir die letzte Zeile leicht nach z auflosen konnen:
z = −4.
Mit Kenntnis von z konnen wir nun die zweite Gleichung nach y auflosen und erhalten
y = −1
4(10− 2z) = −1
4(10 + 8) = −9
2.
Damit folgt aus der ersten Gleichung
x =1
6(12 + 2y − 2z) =
1
6(12− 9 + 8) =
11
6.
Die Losung des linearen Gleichungssystems lautet also
x =11
6, y = −9
2, z = −4.
3.3.1 Die allgemeine Vorgehensweise
Unser Gleichungssystem steht stellvertretend fur das folgende allgemeine lineare Glei-
chungssystem in den 3 Variablen x, y, z:
a11x+ a12y + a13z = b1
a21x+ a22y + a23z = b2
a31x+ a32y + a33z = b3
⇐⇒
a11 a12 a13
a21 a22 a23
a31 a32 a33
︸ ︷︷ ︸
=A∈R3×3
x
y
z
︸ ︷︷ ︸=~x∈R3
=
b1
b2
b3
︸ ︷︷ ︸=~b∈R3
mit gegenenen Koeffizienten aij, i, j = 1, 2, 3, und bi, i = 1, 2, 3.
Wir wiederholen dieselben Schritte wie in unserem konkreten Beispiel.
Schritt 1:
c© 2011 by M. Gerdts

84 KAPITEL 3. LINEARE GLEICHUNGSSYSTEME
• erste Zeile bleibt unverandert
• subtrahiere das a21a11
-fache der ersten Zeile von der zweiten Zeile, falls a11 6= 0
• subtrahiere das a31a11
-fache der ersten Zeile von der dritten Zeile, falls a11 6= 0
a11x+ a12y + a13z = b1(a22 −
a21a11
a12
)︸ ︷︷ ︸
=:a(1)22
y +
(a23 −
a21a11
a13
)︸ ︷︷ ︸
=:a(1)23
z = b2 −a21a11
b1︸ ︷︷ ︸=:b
(1)2(
a32 −a31a11
a12
)︸ ︷︷ ︸
=:a(1)32
y +
(a33 −
a31a11
a13
)︸ ︷︷ ︸
=:a(1)33
z = b3 −a31a11
b1︸ ︷︷ ︸=:b
(1)3
←→
a11 a12 a13 b1
0 a(1)22 a
(1)23 b
(1)2
0 a(1)32 a
(1)33 b
(1)3
Schritt 2:
• ersten beiden Zeilen bleiben unverandert
• subtrahiere dasa(1)32
a(1)22
-fache der zweiten Zeile von der dritten, falls a(1)22 6= 0
a11x+ a12y + a13z = b1
a(1)22 y + a
(1)23 z = b
(1)2(
a(1)33 −
a(1)32
a(1)22
a(1)23
)︸ ︷︷ ︸
=:a(2)33
z = b(1)3 −
a(1)32
a(1)22
b(1)2︸ ︷︷ ︸
=:b(2)3
←→
a11 a12 a13 b1
0 a(1)22 a
(1)23 b
(1)2
0 0 a(2)33 b
(2)3
Ruckwartssubstitution: Lose Gleichungssystem schrittweise auf:
z =b(2)3
a(2)33
(falls a(2)33 6= 0),
y =1
a(1)22
(b(1)2 − a
(1)23 z)
(falls a(1)22 6= 0),
x =1
a11(b1 − a12y − a13z) (falls a11 6= 0).
Naturlich funktioniert die obige Vorgehensweise nur, wenn die sogenannten Pivotelemente
a11, a(1)22 und a
(2)33 alle ungleich Null sind. Es kann aber sehr wohl der Fall eintreten, dass ei-
ner dieser Werte gleich Null ist. Was macht man dann? Nun, ublicherweise verwendet man
c© 2011 by M. Gerdts

3.3. GAUSS’SCHES ELIMINATIONSVERFAHREN 85
sogenannte Pivotstrategien bei denen man im einfachsten Fall zwei Zeilen miteinander
vertauscht.
Beispiel 3.3.1 (Pivoting)
Gegeben sei das lineare Gleichungssystem
−2y + 2z = 1
3x− 4y + 6z = 33
3x− 12y + 9z = 27
←→
0 −2 2 1
3 −4 6 33
3 −12 9 27
Rein formal konnen wir das Gauß-Verfahren nicht anwenden, da in der ersten Zeile der
Koeffizient 0 vor dem x steht. Da der Koeffizient in der zweiten Zeile vor x nicht Null
ist, vertauschen wir die erste und die zweite Zeile:
3x− 4y + 6z = 33
−2y + 2z = 1
3x− 12y + 9z = 27
←→
3 −4 6 33
0 −2 2 1
3 −12 9 27
Nun konnen wir das Gauß-Verfahren anwenden. Subtraktion des 3
3-fachen der ersten Zeile
von der dritten Zeile liefert
3x− 4y + 6z = 33
−2y + 2z = 1
−8y + 3z = −6
←→
3 −4 6 33
0 −2 2 1
0 −8 3 −6
Subtraktion des −8−2-fachen der zweiten Zeile von der dritten Zeile liefert
3x− 4y + 6z = 33
−2y + 2z = 1
−5z = −10
←→
3 −4 6 33
0 −2 2 1
0 0 −5 −10
Dieses System hat obere Dreiecksform und wir konnen auflosen:
z = 2,
y = −1
2(1− 2z) =
3
2,
x =1
3(33 + 4y − 6z) = 9.
Trotz Vertauschens zweier Zeilen kann es vorkommen, dass man den Gauß-Algorithmus
nicht fortsetzen kann. In diesem Fall besitzt das lineare Gleichungssystem jedoch keine
oder unendlich viele Losungen. Die Matrix enthalt in diesem Fall linear abhangige Zeilen
oder Spalten und besitzt keinen vollen Rang.
c© 2011 by M. Gerdts

86 KAPITEL 3. LINEARE GLEICHUNGSSYSTEME
Beispiel 3.3.2
Betrachte fur gegebenes b3 das folgende lineare Gleichungssystem
x− 2y + 2z = 1
3x− 4y + 6z = 33
2x− 2y + 4z = b3
←→
1 −2 2 1
3 −4 6 33
2 −2 4 b3
Anwendung des Gauß-Verfahrens liefert im ersten Schritt:
x− 2y + 2z = 1
2y = 30
2y = b3 − 2
←→
1 −2 2 1
0 2 0 30
0 2 0 b3 − 2
Der nachste Gauß-Schritt liefert
x− 2y + 2z = 1
2y = 30
0 = b3 − 32
←→
1 −2 2 1
0 2 0 30
0 0 0 b3 − 32
Die letzte Gleichung ist nur fur b3 = 32 losbar, andernfalls besitzt das Gleichungssystem
keine Losung.
Fur b3 = 32 ergibt sich aus der zweiten Gleichung y = 15. Die erste Gleichung liefert
dann
x = 1 + 2y − 2z = 31− 2z.
Hierin kann z ∈ R beliebig gewahlt werden, so dass es unendlich viele Losungen gibt.
Der Rang der Matrix ist 2, d.h. sie besitzt nur 2 linear unabhangige Zeilen oder Spalten.
3.3.2 Der n-dimensionale Fall
Die bisherige Vorgehensweise lasst sich leicht auf den n-dimensionalen Fall ubertragen.
Die Idee des Gauss’schen Eliminationsverfahrens besteht nun darin, die Matrix A durch
elementare Zeilenumformungen schrittweise in eine rechte obere Dreiecksmatrix R und
die rechte Seite ~b in einen Vektor ~c zu uberfuhren, so dass ein Gleichungssystem der Form
R~x = ~c (3.5)
fur ~x mit rechter oberer Dreiecksmatrix
R =
r11 r12 r13 · · · r1n
r22 r23 · · · r2n
r33. . .
.... . . rn−1,n
rnn
, rii 6= 0, i = 1, . . . , n,
c© 2011 by M. Gerdts

3.3. GAUSS’SCHES ELIMINATIONSVERFAHREN 87
entsteht. Dann kann man die Gleichungen
r11x1 + r12x2 + . . .+ r1nxn = c1,
r22x2 + . . .+ r2nxn = c2,...
rn−1,n−1xn−1 + rn−1,nxn = cn−1,
rnnxn = cn
beginnend mit der letzten Zeile nach xi, i = n, n− 1, . . . , 1, auflosen:
x1 = 1r11
(c1 − r12x2 − r13x3 − . . .− r1nxn) ,
x2 = 1r22
(c2 − r23x3 − . . .− r2nxn) ,...
xn−1 = 1rn−1,n−1
(cn−1 − rn−1,nxn) ,
xn = cnrnn
Diesen Vorgang nennt man Ruckwartssubstitution.
Schematisch lauft der Gauss’sche Eliminationsalgorithmus wie folgt ab.
Gauss’scher Eliminationsalgorithmus:
(i) Setze A(1) := A und ~b(1) := ~b.
(ii) Beginnend mit A(1)~x = ~b(1) fuhre n− 1 Transformationsschritte durch bis ein aqui-
valentes lineares Gleichungssystem mit oberer Dreiecksstruktur erreicht ist:
A(1)~x = ~b(1) ⇔ A(2)~x = ~b(2) ⇔ . . .⇔ A(n)~x = ~b(n)
(iii) Lose das lineare Gleichungssystem A(n)~x = ~b(n) durch Ruckwartssubstitution.
Beispiel 3.3.3
6 −2 2 4
12 −8 6 10
3 −13 9 3
−6 4 1 −18
︸ ︷︷ ︸
=A(1)
x1
x2
x3
x4
=
12
34
27
−38
︸ ︷︷ ︸
=~b(1)
Gauss’sche Elimination liefert folgendes Ergebnis:
c© 2011 by M. Gerdts

88 KAPITEL 3. LINEARE GLEICHUNGSSYSTEME
Start:
[A(1) ~b(1)
]=
6 −2 2 4 12
12 −8 6 10 34
3 −13 9 3 27
−6 4 1 −18 −38
Subtraktion des 2-fachen der 1. Zeile von der 2. Zeile und des 0.5-fachen der 1. Zeile von
der 3. Zeile und des −1-fachen der 1. Zeile von der 4. Zeile liefert:
[A(2) ~b(2)
]=
6 −2 2 4 12
0 −4 2 2 10
0 −12 8 1 21
0 2 3 −14 −26
Subtraktion des 3-fachen der 2. Zeile von der 3. Zeile und des −0.5-fachen der 2. Zeile
von der 4. Zeile liefert:
[A(3) ~b(3)
]=
6 −2 2 4 12
0 −4 2 2 10
0 0 2 −5 −9
0 0 4 −13 −21
Subtraktion des 2-fachen der 3. Zeile von der 4. Zeile liefert:
[A(4) ~b(4)
]=
6 −2 2 4 12
0 −4 2 2 10
0 0 2 −5 −9
0 0 0 −3 −3
Ruckwartssubstitution:
~x =
1
−3
−2
1
.
Im Folgenden wird der Schritt von i 7→ i+ 1 im Detail beschrieben. Der Algorithmus sei
c© 2011 by M. Gerdts

3.3. GAUSS’SCHES ELIMINATIONSVERFAHREN 89
bis zum i-ten Schritt fortgeschritten mit
A(i) =
a(i)11 · · · a
(i)1i . . . a
(i)1n
. . ....
. . ....
a(i)ii . . . a
(i)in
a(i)i+1,i . . . a
(i)i+1,n
.... . .
...
a(i)ni . . . a
(i)nn
, ~b(i) =
b(i)1...
b(i)i
b(i)i+1...
b(i)n
.
Ziel ist es, die Elemente a(i)ji , j = i + 1, . . . , n, durch elementare Zeilenumformungen zu
eliminieren. Es gelte a(i)ii 6= 0 fur das sogenannte Pivotelement. Die Matrix A(i+1) erhalt
man, indem dasa(i)ji
a(i)ii
-fache der i-ten Zeile von den Zeilen j = i+ 1, . . . , n subtrahiert wird:
A(i+1) =
a(i+1)11 · · · a
(i+1)1,i+1 . . . a
(i+1)1n
. . ....
. . ....
a(i+1)i+1,i+1 . . . a
(i+1)i+1,n
a(i+1)i+2,i+1 . . . a
(i+1)i+2,n
.... . .
...
a(i+1)n,i+1 . . . a
(i+1)nn
:=
a(i)11 · · · a
(i)1i . . . a
(i)1n
. . ....
. . ....
a(i)ii . . . a
(i)in
a(i)i+1,i −
a(i)i+1,i
a(i)ii
a(i)ii . . . a
(i)i+1,n −
a(i)i+1,i
a(i)ii
a(i)in
.... . .
...
a(i)ni −
a(i)ni
a(i)ii
a(i)ii . . . a
(i)nn − a
(i)ni
a(i)ii
a(i)in
.
Die Matrix A(i+1) hat formal dieselbe Struktur wie A(i) mit dem Unterschied, dass in A(i+1)
unterhalb der Hauptdiagonalen der i-ten Spalte, die in A(i) noch voll besetzt war, Nullen
erzeugt wurden. Im nachsten Schritt wurden dann die Elemente a(i+1)j,i+1 , j = i + 2, . . . , n
elimiert werden.
c© 2011 by M. Gerdts

90 KAPITEL 3. LINEARE GLEICHUNGSSYSTEME
Entsprechend muss der Vektor ~b(i) transformiert werden:
~b(i+1) =
b(i+1)1...
b(i+1)i
b(i+1)i+1...
b(i+1)n
:=
b(i)1...
b(i)i
b(i)i+1 −
a(i)i+1,i
a(i)ii
b(i)i
...
b(i)n − a
(i)ni
a(i)ii
b(i)i
.
Bemerkung 3.3.4 (Pivoting)
Der Gauss’sche Eliminationsalgorithmus ist durchfuhrbar, solange die Pivotelemente a(i)ii 6=
0, i = 1, . . . , n− 1, erfullen. Ist dies nicht der Fall, mussen ggf. Zeilen- oder Spaltenver-
tauschungen (Pivoting) durchgefuhrt werden, um den Algorithmus fortsetzen zu konnen.
Ist es trotz aller Zeilen- oder Spaltenvertauschungen nicht moglich, ein Pivotelement un-
gleich Null zu finden, so ist die Matrix A nicht invertierbar und es entsteht eine rechte
obere Dreiecksmatrix der Form
R =
[R ∗0 0
]
mit einer invertierbaren rechten oberen Dreiecksmatrix R der Dimension r× r mit r < n.
Der Rang der Matrix A ist dann gleich r, vgl. Beispiel 3.3.2.
Beispiel 3.3.5 (Berechnung der Inversen A−1)
Die Inverse X = A−1 einer invertierbaren Matrix A erfullt die Gleichung
A ·X = I.
Falls ~x(i) die i-te Spalte von X und ~ei den i-ten Einheitsvektor bezeichnen, mussen wir
zur Bestimmung von X die folgenden n linearen Gleichungssysteme losen:
A~x(i) = ~ei, i = 1, 2, . . . , n.
Dies konnen wir mit dem Gauß’schen Eliminationsverfahren simultan erledigen, indem
c© 2011 by M. Gerdts

3.4. DETERMINANTEN 91
wir die Transformationen auf jeden der Vektoren ~ei, i = 1, 2, . . . , n, anwenden:
A ·X = I ←→
1 2 0 1 0 0
2 4 1 0 1 0
2 1 0 0 0 1
←→
1 2 0 1 0 0
0 0 1 −2 1 0
0 −3 0 −2 0 1
←→
1 2 0 1 0 0
0 −3 0 −2 0 1
0 0 1 −2 1 0
Ruckwartssubstitution fur jede rechte Seite liefert die Inverse Matrix
A−1 = X =
−13
0 23
23
0 −13
−2 1 0
3.4 Determinanten
Determinanten sind nutzliche Hilfsmittel, mit deren Hilfe man z.B. die Invertierbarkeit
einer Matrix charakterisieren kann oder sogar die Losung eines linearen Gleichungssystems
mit Hilfe der Cramer’schen Regel angeben kann. Determinanten werden auch in Kapitel 4
eine wichtige Rolle spielen.
Definition 3.4.1 (Determinante)
Sei A ∈ Rn×n eine Matrix. Die Determinante von A,
detA =
∣∣∣∣∣∣∣∣∣∣a11 a12 · · · a1n
a21 a22 · · · a2n...
.... . .
...
an1 an2 · · · ann
∣∣∣∣∣∣∣∣∣∣,
ist rekursiv durch die folgenden Vorschriften definiert:
(a) Fur n = 1 mit A = [a] gilt detA = a.
(b) Fur n ≥ 2 gilt
detA = a11 detA11 − a12 detA12 ± . . .+ (−1)1+na1n detA1n
=n∑k=1
(−1)1+ka1k detA1k,
c© 2011 by M. Gerdts

92 KAPITEL 3. LINEARE GLEICHUNGSSYSTEME
wobei Aij fur 1 ≤ i, j ≤ n diejenige (n− 1)× (n− 1)-Matrix bezeichnet, die sich aus
A durch Streichen der i-ten Zeile und der j-ten Spalte ergibt.
Beispiel 3.4.2
(a) ∣∣∣∣∣ a11 a12
a21 a22
∣∣∣∣∣ = a11a22 − a12a21
Die Determinante einer 2x2-Matrix ist also gerade das Produkt aus den Diagonal-
elementen a11 · a22 minus dem Produkt der Nichtdiagonalelemente a12 · a21.
(b) ∣∣∣∣∣∣∣a11 a12 a13
a21 a22 a23
a31 a32 a33
∣∣∣∣∣∣∣ = a11
∣∣∣∣∣ a22 a23
a32 a33
∣∣∣∣∣− a12∣∣∣∣∣ a21 a23
a31 a33
∣∣∣∣∣+ a13
∣∣∣∣∣ a21 a22
a31 a32
∣∣∣∣∣= (a11a22a33 − a11a23a32)− (a12a21a33 − a12a23a31)
+ (a13a21a32 − a13a22a31)= a11a22a33 + a12a23a31 + a13a21a32
−a31a22a13 − a32a23a11 − a33a21a12.
Die letzte Formel kann man sich leicht mit dem folgenden Schema (Regel von
Sarrus) merken: ∣∣∣∣∣∣∣a11 a12 a13
a21 a22 a23
a31 a32 a33
∣∣∣∣∣∣∣a11 a12
a21 a22
a31 a32
Zur Berechnung der Determinante wird diagonal ausmultipliziert, wobei die Produkte
von links oben nach rechts unten (jeweils beginnend mit a11, a12, a13) positiv und
die Produkte von links unten nach rechts oben (jeweils beginnend mit a31, a32, a33)
negativ gewichtet werden.
(c) Die Determinante einer linken unteren Dreiecksmatrix berechnet sich zu∣∣∣∣∣∣∣∣∣∣a11
a21 a22...
.... . .
an1 an2 · · · ann
∣∣∣∣∣∣∣∣∣∣= a11
∣∣∣∣∣∣∣a22...
. . .
an2 · · · ann
∣∣∣∣∣∣∣ = . . . = a11a22 · · · ann.
c© 2011 by M. Gerdts

3.4. DETERMINANTEN 93
Bemerkung 3.4.3
Wir hatten in Kapitel 2 bereits erwahnt, dass sich das Kreuzprodukt zweier Vektoren
formal darstellen lasst als
~a×~b =
∣∣∣∣∣∣∣~e1 ~e2 ~e3
a1 a2 a3
b1 b2 b3
∣∣∣∣∣∣∣ ,und fur das Spatprodukt dreier Vektoren gilt
[~a,~b,~c] =
∣∣∣∣∣∣∣a1 b1 c1
a2 b2 c2
a3 b3 c3
∣∣∣∣∣∣∣ .
In Definition 3.4.1 (b) haben wir zur rekursiven Definition der Determinante die erste
Zeile der Matrix verwendet. Diese Wahl ist recht willkurlich und wir hatten auch andere
Zeilen oder Spalten verwenden konnen. Es gilt
Satz 3.4.4 (Determinantenentwicklungssatz)
Sei A = [aij]i,j=1,...,n eine n× n-Matrix. Dann gilt:
(a) Entwicklung nach der i-ten Zeile: Fur einen beliebigen, aber fest gewahlten
Zeilenindex i ∈ 1, . . . , n gilt
detA =n∑k=1
(−1)i+kaik detAik.
(b) Entwicklung nach der j-ten Spalte: Fur einen beliebigen, aber fest gewahlten
Spaltenindex j ∈ 1, . . . , n gilt
detA =n∑k=1
(−1)j+kakj detAkj.
Satz 3.4.5 (Eigenschaften)
Determinanten besitzen folgende Eigenschaften:
c© 2011 by M. Gerdts

94 KAPITEL 3. LINEARE GLEICHUNGSSYSTEME
(a) Es gilt detA = detA>.
(b) Werden zwei Zeilen in der Matrix A vertauscht, so andert die Determinante ihr
Vorzeichen.
(c) Wird eine Zeile oder Spalte von A mit einem Skalar λ multipliziert, so multipliziert
sich die Determinante mit λ.
(d) Addiert man zu einer Zeile (bzw. Spalte) ein Vielfaches einer anderen Zeile (bzw.
Spalte), so andert sich die Determinante nicht.
(e) Fur n× n-Matrizen A und B gilt
det(AB) = detA · detB.
Auf Grund der Eigenschaften (a), (b), (c) und (d) kann man Determinanten mit dem
Gauss-Algorithmus berechnen, da dieser lediglich Linearkombinationen von Zeilen und
ggf. Spaltenvertauschungen verwendet. Am Ende des Gauss-Algorithmus entsteht eine
rechte obere Dreiecksmatrix, welche dann bis auf das Vorzeichen dieselbe Determinante
wie die ursprungliche Matrix besitzt. Man uberlege sich hierzu, dass die Determinan-
te einer Dreiecksmatrix gegeben ist durch das Produkt ihrer Diagonalelemente. Daruber
hinaus ist die rechte obere Dreiecksmatrix invertierbar genau dann, wenn die ursprungli-
che Matrix invertierbar war. Aus diesem Zusammenhang zwischen Gauss-Verfahren und
Determinanten ergibt sich
Satz 3.4.6
Sei A eine n× n-Matrix. Dann sind folgende Aussagen aquivalent:
(a) detA 6= 0
(b) A ist invertierbar.
Im Umkehrschluss ergibt sich, dass die Determinante einer nicht invertierbaren Matrizen
stets Null ist.
Satz 3.4.7 (Cramer’sche Regel)
Sei A eine invertierbare n × n-Matrix und ~b ein Vektor der Dimension n. Dann besitzt
c© 2011 by M. Gerdts

3.4. DETERMINANTEN 95
das lineare Gleichungssystem A~x = ~b die eindeutige Losung
xk =detAkdetA
, k = 1, . . . , n.
Hierbei entsteht die Matrix Ak durch Ersetzen der k-ten Spalte in A durch ~b.
Beweis: Nach Satz 3.4.5 (c), (d) gilt
x1 det(A) =
∣∣∣∣∣∣∣a11x1 + . . .+ a1nxn a12 · · · a1n
......
. . ....
an1x1 + . . .+ annxn an1 · · · ann
∣∣∣∣∣∣∣ = det(A1)
und wegen det(A) 6= 0 folgt
x1 =det(A1)
det(A).
Fur x2, . . . , xn zeigt man die Behauptung analog.
Beispiel 3.4.8
Gegeben seien
A =
[1 2
0 −1
], ~b =
[1
1
].
Es gilt detA = −1 und die Cramer’sche Regel liefert
x1 =
∣∣∣∣∣ 1 2
1 −1
∣∣∣∣∣detA
=−3
−1= 3,
x2 =
∣∣∣∣∣ 1 1
0 1
∣∣∣∣∣detA
=1
−1= −1.
Die Cramer’sche Regel ist in der Regel nur von theoretischem Interesse, numerisch aufwandig
und anfallig fur Rundungsfehler. Zum Losen eines Gleichungssystems sollte stattdessen
die Gauss-Elimination verwendet werden.
c© 2011 by M. Gerdts

Kapitel 4
Eigenwertaufgaben
Eigenwerte spielen in vielen Anwendungen eine wichtige Rolle und geben zum Beispiel
Auskunft uber die Stabilitat von dynamischen Systemen (wichtig bei Reglerentwurf), das
Krummungsverhalten von Funktionen (wichtig in der Optimierung) oder Eigenfrequenzen
und Eigenschwingungen von Bauteilen (wichtig bei der Konstruktion von Bauwerken).
Beispiel 4.0.1
Betrachte fur k = 0, 1, 2, . . . und gegebene Zahlen λ1 und λ2 die folgende diskrete Dynamik:
~zk+1 =
[xk+1
yk+1
]=
[λ1 λ2 − λ10 λ2
][xk
yk
]= A~zk, ~z0 =
[1
1
]. (4.1)
Derartige Modelle werden haufig zur Beschreibung eines zeitabhangigen Vorgangs verwen-
det, wobei der Index k sich auf verschiedene Zeitpunkte bezieht. Der Zustandsvektor ~zk
beschreibt z.B. die Große einer Population mit zwei Spezies xk und yk zum Zeitpunkt k.
Man kann die Matrix A durch Multiplikation mit einer geeignet gewahlten Matrix T und
dessen Inversen T−1 diagonalisieren:
T−1AT =
[λ1
λ2
]=: Λ, T =
[1 1
0 1
], T−1 =
[1 −1
0 1
].
Setzt man diese Beziehung in Gleichung (4.1) ein, so erhalt man
T−1~zk+1 = T−1ATT−1~zk = ΛT−1~zk, k = 0, 1, 2, . . .
Mit der Substitution ~vk := T−1~zk folgt dann
~vk+1 = Λ~vk, k = 0, 1, 2, . . . .
Wiederholte Anwendung dieser Iterationsvorschrift liefert
~vk = Λk~v0, k = 0, 1, 2, . . .
bzw. in Koordinaten[v1kv2k
]=
[λk1
λk2
][v10v20
]=
[λk1v
10
λk2v20
], k = 0, 1, 2, . . . .
96

97
Die Werte λ1 und λ2 sind die sogenannten Eigenwerte der Matrix A. An Hand ihrer Werte
kann man ablesen, wie sich das dynamische System fur k −→ ∞ verhalt: Fur j = 1, 2
folgt
|λj| > 1 =⇒ |vjk| −→ ∞,|λj| < 1 =⇒ vjk −→ 0,
|λj| = 1 =⇒ |vjk| = |vj0|.
Im ersten Fall ist die Dynamik instabil (Teile der Population explodieren), im zweiten
Fall ist die Dynamik asymptotisch stabil (die Population stirbt aus), im dritten Fall ist
die Dynamik stabil. Beachte, dass hier nur Aussagen fur ~vk = T−1~zk getroffen wurden.
Man muss sich noch uberlegen, was dies fur ~zk = T~vk bedeutet.
Beispiel 4.0.2 (Eigenwerte und Schwingungen)
Eigenwertprobleme in einer allgemeineren Form treten auch in der Mechanik im Zusam-
menhang mit Schwingungen auf. Betrachte einen elastischen Balken der Lange L, der am
linken und rechten Rand eingespannt ist und schwingen kann, siehe Abbildung.
L
z
x
Ein Eigenwertproblem fur diesen Balken lautet wie folgt. Finde eine Eigenfrequenz ω
mit
z′′′′(x) = ω2 ρA
EIz(x),
z(0) = 0,
z′(0) = 0,
z(L) = 0,
z′′(L) = 0,
wobei die Massenbelegung ρA und die Biegesteifigkeit EI materialabhangige Konstanten
sind. Die zugehorigen”
Eigenvektoren“ z sind Losungen des Randwertproblems und somit
c© 2011 by M. Gerdts

98 KAPITEL 4. EIGENWERTAUFGABEN
Funktionen. Sie heißen Eigenschwingungen. Interessiert ist man hierbei insbesondere
an nichttrivialen Losungen z 6≡ 0.
Dass die Untersuchung von Eigenschwingungen und Eigenfrequenzen in Bezug auf Re-
sonanz wichtig bei der Konstruktion von z.B. Brucken ist, zeigt der Zusammensturz der
Tacoma Bridge, bei der Wind zur einer Anregung gefuhrt hat, was letztendlich in einem
Aufschaukeln der Anregung endete und zum Einsturz der Brucke fuhrte. Details finden
sich auf der WWW-Seite
http://de.wikipedia.org/wiki/Tacoma-Narrows-Br%C3%BCcke
4.1 Eigenwerte und Eigenvektoren
Die Definition eines Eigenwerts und eines zugehorigen Eigenvektors ist motiviert durch
die Aufgabe, Hauptrichtungen (Eigenvektoren) und Skalierungsfaktoren (Eigenwerte) bei
der Matrixmultiplikation zu finden.
Definition 4.1.1
Sei A ∈ Cn×n.
(a) Die Zahl λ ∈ C heißt Eigenwert der Matrix A, wenn
A~x = λ~x fur ein ~x 6= ~0
gilt. Ein Vektor ~0 6= ~x ∈ Cn mit A~x = λ~x heißt Eigenvektor zum Eigenwert λ.
(b) Die Menge aller Eigenwerte von A heißt Spektrum von A.
(c) Der Spektralradius von A ist definiert als
ρ(A) := max|λ| | λ ist Eigenwert von A.
Aus der Definition des Eigenwerts ergibt sich, dass λ genau dann Eigenwert von A ist,
wenn die Matrix A− λIn singular ist, da das homogene lineare Gleichungssystem
(A− λIn) ~x = ~0
eine nichttriviale Losung ~x 6= ~0 (namlich einen Eigenvektor zum Eigenwert λ) hat. Nach
Satz 3.4.6 ist die Singularitat von A− λIn aber gleichbedeutend mit
det(A− λIn) = 0.
c© 2011 by M. Gerdts

4.1. EIGENWERTE UND EIGENVEKTOREN 99
Die Eigenwerte einer Matrix A sind also durch die Nullstellen des sogenannten charakte-
ristischen Polynoms gegeben.
Definition 4.1.2 (charakteristisches Polynom)
Sei A ∈ Cn×n. Die Funktion
ϕA(µ) := det(A− µIn)
heißt charakteristisches Polynom von A und die Gleichung
ϕA(µ) = det(A− µIn) = 0
heißt charakteristische Gleichung.
Beispiel 4.1.3
Das charakteristische Polynom der rechten oberen Dreiecksmatrix
A =
a11 · · · a1n. . .
...
ann
lautet
ϕA(µ) = (a11 − µ)(a22 − µ) · · · (ann − µ).
Die Eigenwerte von A sind also gerade die Diagonalelemente aii, i = 1, . . . , n, von A.
Eine analoge Aussage gilt fur linke untere Dreiecksmatrizen.
Hat man einen Eigenwert λ einer Matrix A berechnet, so erhalt man einen zugehorigen
Eigenvektor ~x durch Losen des linearen Gleichungssystems (A− λI)~x = ~0. Hierbei muss
man allerdings berucksichtigen, dass die Matrix A−λI nicht invertierbar ist. Es gibt also
mehrere Losungen des Gleichungssystems.
Beispiel 4.1.4
Gegeben sei die Matrix
A =
[1 2
0 3
].
Das charakteristische Polynom lautet
ϕA(µ) = det(A− µI) =
∣∣∣∣∣ 1− µ 2
0 3− µ
∣∣∣∣∣ = (1− µ)(3− µ).
Die Eigenwerte von A sind gegeben durch die Nullstellen des charakteristischen Polynoms
und lauten
λ1 = 1, λ2 = 3.
c© 2011 by M. Gerdts

100 KAPITEL 4. EIGENWERTAUFGABEN
Wir bestimmen nun einen Eigenvektor zum Eigenwert λ1 = 1. Dazu mussen wir das
folgende Gleichungssystem losen:
(A− λ1I)~x =
[0 2
0 2
][x1
x2
]=
[0
0
].
Jeder Vektor der Form
~x =
[t
0
], t ∈ R
lost dieses Gleichungssystem und jeder solcher Vektor mit t 6= 0 ist daher auch Eigenvektor
zum Eigenwert λ1 = 1.
Wir bestimmen nun einen Eigenvektor zum Eigenwert λ2 = 3. Dazu mussen wir das
folgende Gleichungssystem losen:
(A− λ2I)~x =
[−2 2
0 0
][x1
x2
]=
[0
0
].
Jeder Vektor der Form
~x = t
[1
1
], t ∈ R
lost dieses Gleichungssystem und jeder solcher Vektor mit t 6= 0 ist daher auch Eigenvektor
zum Eigenwert λ2 = 3.
Mit Hilfe des Determinantenentwicklungssatzes lasst sich allgemein zeigen, dass ϕA ein
Polynom n-ten Grades der Form
ϕA(µ) = (−1)n(µn + αn−1µ
n−1 + . . .+ α0
)ist. Damit besitzt das charakteristische Polynom stets n Nullstellen uber C, die auch
komplex sein konnen, selbst wenn die Matrix A reell war.
Sind λi ∈ C, i = 1, . . . , k, die verschiedenen Nullstellen von ϕA mit Vielfachheit σi,
i = 1, . . . , k, so laßt sich ϕA in der Form
ϕA(µ) = (−1)n(µ− λ1)σ1(µ− λ2)σ2 · · · (µ− λk)σk
darstellen. Die Zahl σi wird auch als algebraische Vielfachheit des Eigenwerts λi
bezeichnet und wir bezeichnen mit σ diejenige Funktion, die einem Eigenwert λi dessen
algebraische Vielfachheit zuordnet, d.h. σ(λi) = σi.
Die Menge der Eigenvektoren (zzgl. des Nullvektors)
L(λ) := ~x ∈ Cn | (A− λIn)~x = ~0 = Kern(A− λIn)
c© 2011 by M. Gerdts

4.1. EIGENWERTE UND EIGENVEKTOREN 101
bildet einen Untervektorraum des Cn mit Dimension n − Rang(A − λIn). Dieser Unter-
vektorraum wird Eigenraum zum Eigenwert λ genannt. Insbesondere ist mit ~x und ~y
auch jede Linearkombination c1~x+ c2~y 6= ~0 mit c1, c2 ∈ C ein Eigenvektor zum Eigenwert
λ. Die Zahl %(λ) = dim(L(λ)) = n − Rang(A − λI) heißt geometrische Vielfachheit
des Eigenwerts λ und gibt die maximale Anzahl linear unabhangiger Eigenvektoren
zum Eigenwert λ an.
Im Allgemeinen sind die algebraische und geometrische Vielfachheit zum selben Eigenwert
verschieden.
Beispiel 4.1.5
Betrachte die Matrix (Jordankastchen)
J(λ) =
λ 1
λ. . .. . . 1
λ
∈ Cn×n.
Das charakteristische Polynom lautet ϕJ(λ)(µ) = (λ − µ)n und µ = λ ist der einzige
Eigenwert mit algebraischer Vielfachheit σ(λ) = n. Der Rang von J(λ) − λI ist jedoch
n− 1, so dass die geometrische Vielfachheit %(λ) = n− (n− 1) = 1 betragt.
Satz 4.1.6
Zwischen algebraischer und geometrischer Vielfachheit eines Eigenwerts λ besteht folgen-
der Zusammenhang:
1 ≤ %(λ) ≤ σ(λ) ≤ n.
Es stellt sich die Frage, welche Transformationen einer Matrix die Eigenwerte nicht verandern.
Insbesondere konnen solche Transformationen dann benutzt werden, um Matrizen auf ein-
fache Form zu bringen, ohne dabei die Eigenwerte zu andern. Eine solche Transformation
haben wir bereits in Beispiel 4.0.1 verwendet.
Definition 4.1.7
(a) Zwei Matrizen A,B ∈ Cn×n heißen ahnlich, wenn es eine regulare Matrix T ∈ Cn×n
gibt mit
B = T−1 · A · T.
(b) A heißt diagonalisierbar, wenn A ahnlich ist zu einer Diagonalmatrix.
c© 2011 by M. Gerdts

102 KAPITEL 4. EIGENWERTAUFGABEN
(c) A heißt normal, wenn A · A∗ = A∗ · A gilt, wobei A∗ := A>.
(d) A heißt hermitesch, wenn A∗ = A gilt.
(e) A heißt unitar, wenn A∗ = A−1 gilt. Ist A eine reelle Matrix, so heißt sie ortho-
gonal, falls A> = A−1 gilt.
Beispiel 4.1.8
(a) Symmetrische und hermitesche Matrizen sind normal. Eine symmetrische reelle Ma-
trix ist hermitesch.
(b) Die Drehmatrix 1 0 0
0 cosα − sinα
0 sinα cosα
ist orthogonal. Sie beschreibt eine Drehung um die x-Achse des R3 um den Winkel
α, wenn sie von links an einen Vektor multipliziert wird.
(c) Die Matrix
A =
[λ1 λ2 − λ10 λ2
]ist diagonalisierbar, denn es gilt
T−1AT =
[λ1
λ2
], T−1 =
[1 −1
0 1
], T =
[1 1
0 1
]
Der folgende Satz fasst zusammen, wie sich ubliche Matrixtransformationen, wie zum
Beispiel Ahnlichkeitstransformationen, Transponierung und Invertierung, auf Eigenwerte
auswirken.
Satz 4.1.9
Seien A,B ∈ Cn×n gegeben.
(a) Ist λ Eigenwert von A, so ist λ auch Eigenwert von A> und λ ist Eigenwert von
A∗.
c© 2011 by M. Gerdts

4.1. EIGENWERTE UND EIGENVEKTOREN 103
(b) Seien A und B ahnlich mit B = T−1AT . Dann besitzen A und B dieselben Eigen-
werte.
Ist ~x Eigenvektor von A zum Eigenwert λ, so ist T−1~x Eigenvektor von B zum
Eigenwert λ.
Ist ~y Eigenvektor von B zum Eigenwert λ, so ist T~y Eigenvektor von A zum Eigen-
wert λ.
(c) Ist A invertierbar, λ Eigenwert von A und ~x Eigenvektor von A zum Eigenwert λ,
so ist 1λ
Eigenwert von A−1 und ~x ist Eigenvektor zum Eigenwert 1λ
.
(d) Ist A orthogonal, so sind alle Eigenwerte betragsmaßig gleich eins und der Betrag
der Determinante ist eins. Daruber hinaus sind die Spalten von A paarweise ortho-
normale Vektoren.
Beweis:
(a) Folgt aus
det(A− λI) = det((A− λI)>) = det(A> − λI),
det(A∗ − λI) = det((A− λI)∗) = det (A− λI)> = det(A− λI).
(b) Seien A,B ahnlich, d.h. es gibt T invertierbar mit B = T−1 ·A · T . Sei λ Eigenwert
von A, d.h. A~x = λ~x fur ein ~x 6= 0. Dann gilt fur ~y = T−1~x:
B~y = BT−1~x = T−1ATT−1~x = T−1A~x = λT−1~x = λ~y.
Umgekehrt gilt fur einen Eigenwert λ von B mit zugehorigem Eigenvektor ~y und
~x = T~y:
A~x = AT~y = TBT−1T~y = TB~y = λT~y = λ~x.
(c) Ist A invertierbar, so ist λ 6= 0, da ansonsten A~x = ~0 fur ein ~x 6= ~0 erfullt ware,
woraus die Singularitat von A folgen wurde.
Der Rest folgt aus
A~x = λ~x =⇒ 1
λ~x = A−1~x.
(d) Sei A orthogonal, λ Eigenwert von A und ~x Eigenvektor zum Eigenwert λ. Dann
gilt
‖A~x‖2︸ ︷︷ ︸=~x>A>A~x=‖~x‖2
= |λ|2‖~x‖2 =⇒ |λ| = 1.
c© 2011 by M. Gerdts

104 KAPITEL 4. EIGENWERTAUFGABEN
Desweiteren folgt aus I = A>A, dass
1 = det(I) = det(A>A) = det(A>) det(A) = det(A)2
und somit | det(A)| = 1. Aus I = A>A folgt auch sofort, dass die Spalten von A
paarweise orthonormal sind.
2
Da ahnliche Matrizen dieselben Eigenwerte besitzen, liegt der Versuch nahe, eine Ma-
trix mittels Ahnlichkeitstransformationen auf rechte obere Dreiecksform, linke untere
Dreiecksform oder sogar Diagonalgestalt bringen zu wollen, da die Eigenwerte in die-
sen Fallen auf der Diagonalen stehen und damit leicht abzulesen sind. Wir beginnen mit
der Schur’schen Normalform, welche eine Ahnlichkeitstransformation auf rechte obere
Dreiecksform darstellt.
Satz 4.1.10 (Schur’sche Normalform)
Sei A ∈ Cn×n. Dann gibt es eine unitare Matrix T mit
T−1AT = Λ +R :=
λ1 r12 . . . r1n
. . . . . ....
λn−1 rn−1,n
λn
Insbesondere enthalt Λ := diag(λ1, . . . , λn) die Eigenwerte von A.
Bemerkung 4.1.11
Die Schur’sche Normalform einer Matrix kann numerisch mithilfe von sogenannten House-
holder-Transformationen berechnet werden.
Mit Hilfe der Schur’schen Normalform kann der folgende Satz zur Diagonalisierung von
Matrizen mittels unitarer Transformationen bewiesen werden:
Satz 4.1.12
(a) A ist genau dann normal, wenn es eine unitare Matrix T ∈ Cn×n gibt mit
T−1 · A · T = Λ :=
λ1. . .
λn
∈ Cn×n.
Man nennt diese Transformation auch Hauptachsentransformation.
c© 2011 by M. Gerdts

4.1. EIGENWERTE UND EIGENVEKTOREN 105
(b) A ist genau dann hermitesch, wenn es eine unitare Matrix T ∈ Cn×n gibt mit
T−1 · A · T = Λ :=
λ1. . .
λn
∈ Rn×n.
Die Eigenwerte einer hermiteschen Matrix sind insbesondere alle reell.
Satz 4.1.12 besagt, dass es genau die normalen Matrizen sind, die mittels unitarer Matri-
zen diagonalisierbar sind. Beachte, dass Ahnlichkeitstransformationen mit einer unitaren
Matrix T besonders angenehm sind, da T−1 = T ∗ gilt.
Schreibt man die Beziehung T−1AT = Λ in der Form
A · T = T · Λ ⇔ A~ti = λi~ti, i = 1, . . . , n,
wobei ~ti, i = 1, . . . , n, die Spaltenvektoren von
T =[~t1 · · · ~tn
]bezeichnet, so sieht man unmittelbar, dass der i-te Spaltenvektor ~ti gerade ein Eigenvektor
zum Eigenwert λi ist. Da T unitar ist, sind die Eigenvektoren ~t1, . . . ,~tn linear unabhangig
und orthogonal zueinander.
Die Spalten von T definieren also eine Basis des Cn aus orthogonalen Eigenvektoren
zu den Eigenwerten λ1, . . . , λn. Daruber hinaus stimmen geometrische und algebraische
Vielfachheit uberein. Wir fassen zusammen:
Folgerung 4.1.13
Sei A normal. Dann gelten folgende Aussagen:
(a) Alle Eigenwerte von A sind reell, falls A hermitesch ist.
(b) Eigenvektoren zu verschiedenen Eigenwerten sind orthogonal.
(c) Algebraische und geometrische Vielfachheit jedes Eigenwertes sind gleich.
Beispiel 4.1.14
Gegeben sei ein eingespannter elastischer Balken, der sich durch Krafteinwirkung ver-
formt, siehe Abbildung.
c© 2011 by M. Gerdts

106 KAPITEL 4. EIGENWERTAUFGABEN
Die mechanischen Spannungen an einem bestimmten Punkt des Balkens werden in einem
kartesischen Referenzkoordinatensystem durch den Spannungstensor
S =
σx τxy τxz
τyx σy τyz
τzx τzy σz
beschrieben, wobei σx, σy und σz Spannungen senkrecht zu den Schnittflachen eines sehr
kleinen Volumenelements bezeichnen (Normalspannungen) und τxy, τyx, τxz, τzx, τyz und
τzy Schubspannungen innerhalb der Schnittflachen darstellen, vgl. Abbildung (Quelle: Wi-
kipedia).
Durch eine Haupachsentransformation, d.h. durch Diagonalisierung der (symmetrischen)
Matrix S, kann man den Spannungszustand, der durch die Matrix S beschrieben wird,
in ein Koordinatensystem umrechnen, in dem die Schubspannungen verschwinden und
nur noch Normalspannungen auftreten, vgl. zur Verdeutlichung den ebenen Fall in der
folgenden Abbildung (Quelle: Wikipedia):
c© 2011 by M. Gerdts

4.1. EIGENWERTE UND EIGENVEKTOREN 107
Die Hauptspannungen σ1, σ2 (und im dreidimensionalen Fall σ3) sind dabei gerade die
Eigenwerte von S und die Hauptspannungsrichtungen sind durch die zugehorigen Eigen-
vektoren gegeben.
Es stellt sich jetzt noch die Frage, wie eine solche unitare Matrix T mit T−1AT = Λ
konstruiert werden kann? Hierzu beschranken wir uns auf den reellen Fall und gehen wir
wie folgt vor:
Algorithmus 4.1.15 (Bestimmung einer unitaren Matrix)
(0) Gegeben sei eine symmetrische Matrix A ∈ Rn×n.
(1) Berechne die Eigenwerte λ1, . . . , λn der Matrix.
(2) Bestimme linear unabhangige Eigenvektoren ~x1, . . . , ~xn. Treten mehrfache Eigen-
werte auf, so bestimme entsprechend ihrer Vielfachheit linear unabhangige Eigen-
vektoren fur jeden Eigenwert.
(3) Orthonormalisiere die Eigenvektoren ~x1, . . . , ~xn mit Hilfe des Gram-Schmidt’schen
Orthonormalisierungsverfahrens und berechne orthonormale Vektoren ~t1, . . . ,~tn.
(4) Definiere T :=[~t1 · · · ~tn
].
Zu klaren ist, wie die Orthonormalisierung in Schritt (3) erfolgen soll. Fur beliebige linear
unabhangige Vektoren ~x1, . . . , ~xn kann dies beispielsweise durch das Gram-Schmidtsche
Orthogonalisierungsverfahren bzgl. des Skalarprodukts 〈·, ·〉 erfolgen. Zur Konstruk-
c© 2011 by M. Gerdts

108 KAPITEL 4. EIGENWERTAUFGABEN
tion geht man iterativ wie folgt vor. Zunachst wird ~t1 := ~x1‖~x1‖ gesetzt. Sind dann bereits
orthonormale Vektoren ~t1, . . . ,~tk−1 bestimmt, so wird ~tk uber den Ansatz
~tk = ~xk −k−1∑j=1
αj~tj
mit noch zu bestimmenden Koeffizienten αj, j = 1, . . . , k − 1, gewahlt. Die Koeffizienten
αj, j = 1, . . . , k − 1, sind so zu bestimmen, dass 〈~t`,~tk〉 = 0 fur alle ` = 1, . . . , k − 1 gilt.
Daraus ergibt sich fur ` = 1, . . . , k−1 auf Grund der Orthonormalitat von ~t1, . . . ,~tk−1 die
Bedingung
0 = 〈~t`,~tk〉 = 〈~t`, ~xk〉 −k−1∑j=1
αj〈~t`,~tj〉 = 〈~t`, ~xk〉 − α`〈~t`,~t`〉 = 〈~t`, ~xk〉 − α`
und somit
α` = 〈~t`, ~xk〉, ` = 1, . . . , k − 1.
Normiert man die Vektoren noch, so erhalt man zusammenfassend
Algorithmus 4.1.16 (Gram-Schmidt’sches Orthonormalisierungsverfahren)
(0) Gegeben seien linear unabhangige Vektoren ~x1, . . . , ~xn.
(1) Setze ~t1 := ~x1‖~x1‖ .
(2) Fur k = 2, . . . , n berechne
~sk := ~xk −k−1∑j=1
〈~tj, ~xk〉~tj,
~tk :=~sk‖~sk‖
.
Wir demonstrieren die Konstruktion einer unitaren Ahnlichkeitstransformation an Hand
einer symmetrischen Matrix.
Beispiel 4.1.17
Gegeben sei die symmetrische Matrix
A =
−12
0 12
0 −1 012
0 −12
.c© 2011 by M. Gerdts

4.1. EIGENWERTE UND EIGENVEKTOREN 109
Die charakteristische Gleichung lautet
0 = det(A− λI) = (−1− λ)(−1
2− λ)2 − 1
4(−1− λ) = −λ(λ+ 1)2.
Also besitzt A die Eigenwerte λ1 = 0 und λ2 = −1 (doppelt).
Ein Eigenvektor zum Eigenwert λ1 = 0 lautet
~x1 =
1
0
1
.Zum Eigenwert λ2 = −1 gehoren die linear unabhangigen Eigenvektoren
~x2 =
0
1
0
, ~x3 =
1
1
−1
.Orthonormalisierung mit dem Gram-Schmidt-Verfahren liefert:
~t1 =1√2
1
0
1
,~t2 = ~x2 − 〈~t1, ~x2〉~t1 =
0
1
0
,
~s3 = ~x3 − 〈~t1, ~x3〉~t1 − 〈~t2, ~x3〉~t2 =
1
1
−1
− 0
1
0
=
1
0
−1
,~t3 =
1√2
1
0
−1
.Eine orthogonale Transformationsmatrix lautet daher
T =
1√2
0 1√2
0 1 01√2
0 − 1√2
.
Uberprufe, dass T>T = I und T>AT =
0
−1
−1
.
Beispiel 4.1.18
Wir interessieren uns fur sogenannte Quadriken (auch Hyperflachen 2. Ordnung
c© 2011 by M. Gerdts

110 KAPITEL 4. EIGENWERTAUFGABEN
genannt). Darunter versteht man die Losungen ~x ∈ Rn der quadratischen Gleichung
~x>A~x+ 2~b>~x+ c = 0,
wobei A ∈ Rn×n eine symmetrische Matrix, b ∈ Rn ein Vektor und c ∈ R eine Zahl sind.
Wir beschranken uns auf den zweidimensionalen Fall n = 2 und diskutieren einige Falle
(es gibt noch weitere Falle, die man untersuchen kann):
(a)
A =
[1a2
1b2
], ~b =
[0
0
], ~x =
[x1
x2
].
Die quadratische Gleichung lautet dann
x21a2
+x22b2
= −c.
Fur c > 0 besitzt die Gleichung offenbar keine relle Losung. Fur c ≤ 0 beschreibt sie
eine Ellipse mit Mittelpunkt (0, 0) und Radien |a|√|c| und |b|
√|c| (in der Abbildung
wurde a = 2, b = 1 und c = −1 gewahlt):
(b)
A =
[− 1a2
1b2
], ~b =
[0
0
], ~x =
[x1
x2
].
c© 2011 by M. Gerdts
4.1. EIGENWERTE UND EIGENVEKTOREN 111
Die quadratische Gleichung lautet dann
−x21
a2+x22b2
= −c.
Die Losungen sind hyperbolische Funktionen. Fur a = 2, b = 1 und c = −1 (Abb.
links) bzw. c = 1 (Abb. rechts) erhalt man die folgenden Abbildungen:
(c)
A =
[0
1b2
], ~b =
[0
0
], ~x =
[x1
x2
].
Die quadratische Gleichung lautet dann
x22b2
= −c.
Sie besitzt nur fur c ≤ 0 eine reelle Losung und man erhalt Geraden:
c© 2011 by M. Gerdts

112 KAPITEL 4. EIGENWERTAUFGABEN
(d) Ist A keine Diagonalmatrix, so kann man die Form der Losungsmenge nicht di-
rekt ablesen. Aber man kann die Matrix mit Hilfe einer Hauptachsentransformation
diagonalisieren. Sei hierzu
A =
[32−1
2
−12
32
], ~b =
[0
0
], ~x =
[x1
x2
].
Das charakteristische Polynom von A berechnet sich zu
ϕA(λ) = λ2 − 3λ+ 2
und die Eigenwerte von A ergeben sich aus den Nullstellen zu λ1 = 1 und λ2 = 2.
Die Spalten der folgenden orthogonalen Matrix T enthalten zugehorige orthonormale
Eigenvektoren:
T :=
[12
√2 1
2
√2
12
√2 −1
2
√2
].
Es gilt T−1AT = Λ = diag(1, 2). Mit der Substitution ~y = T−1~x transformiert sich
die quadratische Gleichung in diesem Fall zu
0 = ~x>A~x+ c = (T~y)>AT~y+ c = ~y>T>AT~y+ c = ~y>
[1
2
]~y+ c = y21 + 2y22 + c.
Dies definiert wie in (a) eine Ellipse. Macht man die Transformation ~y = T−1~x
ruckgangig, so ergibt sich eine gedrehte Ellipse:
c© 2011 by M. Gerdts

4.1. EIGENWERTE UND EIGENVEKTOREN 113
Es gibt jedoch auch Matrizen, die nicht diagonalisierbar sind, z.B.[1 1
0 1
].
Immerhin kann man auch fur solche Matrizen noch eine weitere Normalform erreichen.
Es gilt:
Satz 4.1.19 (Jordan’sche Normalform)
Sei A ∈ Cn×n und λ1, . . . , λk ihre verschiedenen Eigenwerte. λi sei eine σi-fache Nullstelle
des charakteristischen Polynoms mit der geometrischen Vielfachheit %i, i = 1, . . . , k. Zu
jedem λi existieren dann %i eindeutig bestimmte Zahlen
ν(i)n ≥ ν(i)n−1 ≥ . . . ≥ ν
(i)n−%i+1 ∈ N
mitn∑
j=n−%i+1
ν(i)j = σi, i = 1, . . . , k,
sowie eine invertierbare Matrix T mit J = T−1AT , wobei
J =
Jν(1)n
(λ1). . .
Jν(1)n−%1+1
(λ1)
. . .
Jν(k)n
(λk). . .
Jν(k)n−%k+1
(λk)
c© 2011 by M. Gerdts

114 KAPITEL 4. EIGENWERTAUFGABEN
die Jordanmatrix und
Jν(i)j
(λi) =
λi 1
λi. . .. . . 1
λi
∈ Cν(i)j ×ν
(i)j
die Jordankastchen bezeichnen.
Aus der Jordan’schen Normalform kann man insbesondere ablesen, dass A genau dann
diagonalisierbar ist, wenn geometrische und algebraische Vielfachheit fur jeden Eigenwert
gleich sind.
Fur die Spalten t1, . . . , tν(1)n von T folgt aus T−1(A− λ1I)T = J − λ1I sofort
(A− λ1I)tm = tm−1, m = ν(1)n , ν(1)n − 1, . . . , 2,
und
(A− λ1I)t1 = 0.
Die Spalten tν(1)n , . . . , t1 bilden eine Hauptvektorkette zum Eigenwert λ1, wobei t1 ein
Eigenvektor zum Eigenwert λ1 ist. Die Vektoren tν(1)n , . . . , t2 heißen Hauptvektoren.
Analoge Bezeichnungen gelten fur die ubrigen Jordankastchen, so dass die Spalten von T
aus Eigen- und Hauptvektoren von A bestehen.
Die Schur’sche und Jordan’sche Normalform sind primar von theoretischem Interesse,
da man die Eigenwerte zur Bestimmung der Normalformen bereits kennen muss. Zur
Berechnung von Eigenwerten mussen andere Verfahren verwendet werden.
Verwendet man anstatt orthogonaler Matrizen in T>AT lediglich invertierbare Matrizen,
so bleiben die Eigenwerte in der Regel nicht mehr erhalten, allerdings gilt im reellen Fall
noch folgender
Satz 4.1.20 (Tragheitssatz von Sylvester)
Sei A ∈ Rn×n symmetrisch und T ∈ Rn×n invertierbar. Dann haben A und T>AT dieselbe
Anzahl positiver, negativer und Nulleigenwerte.
c© 2011 by M. Gerdts

4.2. EIGENWERTE, KRUMMUNG, SPUR UND DETERMINANTE 115
4.2 Eigenwerte, Krummung, Spur und Determinante
Definition 4.2.1
Sei A ∈ Cn×n hermitesch.
(a) A heißt positiv semidefinit, falls ~x∗A~x ≥ 0 fur alle ~x ∈ Cn gilt. Analog wird
negative Semidefinitheit definiert.
(b) A heißt positiv definit, falls ~x∗A~x > 0 fur alle ~x ∈ Cn, ~x 6= 0, gilt. Analog wird
negative Definitheit definiert.
(c) A heißt indefinit, falls A weder positiv noch negativ semidefinit ist.
Ist A positiv definit (bzw. positiv semidefinit), so sind die Diagonalelemente von A not-
wendigerweise positiv (bzw. ≥ 0). Desweiteren besteht der folgende Zusammenhang:
Satz 4.2.2
Sei A ∈ Cn×n hermitesch.
(a) A ist positiv semidefinit genau dann, wenn alle Eigenwerte von A großer oder gleich
Null sind. A ist negativ semidefinit genau dann, wenn alle Eigenwerte von A kleiner
oder gleich Null sind.
(b) A ist positiv definit genau dann, wenn alle Eigenwerte von A großer Null sind. A
ist negativ definit genau dann, wenn alle Eigenwerte von A kleiner Null sind.
(c) A ist genau dann positiv definit, wenn alle Hauptminoren von A positiv sind.
Entsprechend ist A negativ definit, falls alle Hauptminoren von −A positiv sind.
Unter den Hauptminoren einer n × n-Matrix A = [aij] versteht man dabei die
Determinanten
a11,
∣∣∣∣∣ a11 a12
a21 a22
∣∣∣∣∣ ,∣∣∣∣∣∣∣a11 a12 a13
a21 a22 a23
a31 a32 a33
∣∣∣∣∣∣∣ , . . . ,∣∣∣∣∣∣∣a11 . . . a1n...
. . ....
an1 · · · ann
∣∣∣∣∣∣∣ .
Beispiel 4.2.3 (Krummung und Eigenwerte)
Eigenwerte geben Auskunft uber das Krummungsverhalten von quadratischen Funktionen.
Wir veranschaulichen mogliche Falle im R2:
c© 2011 by M. Gerdts
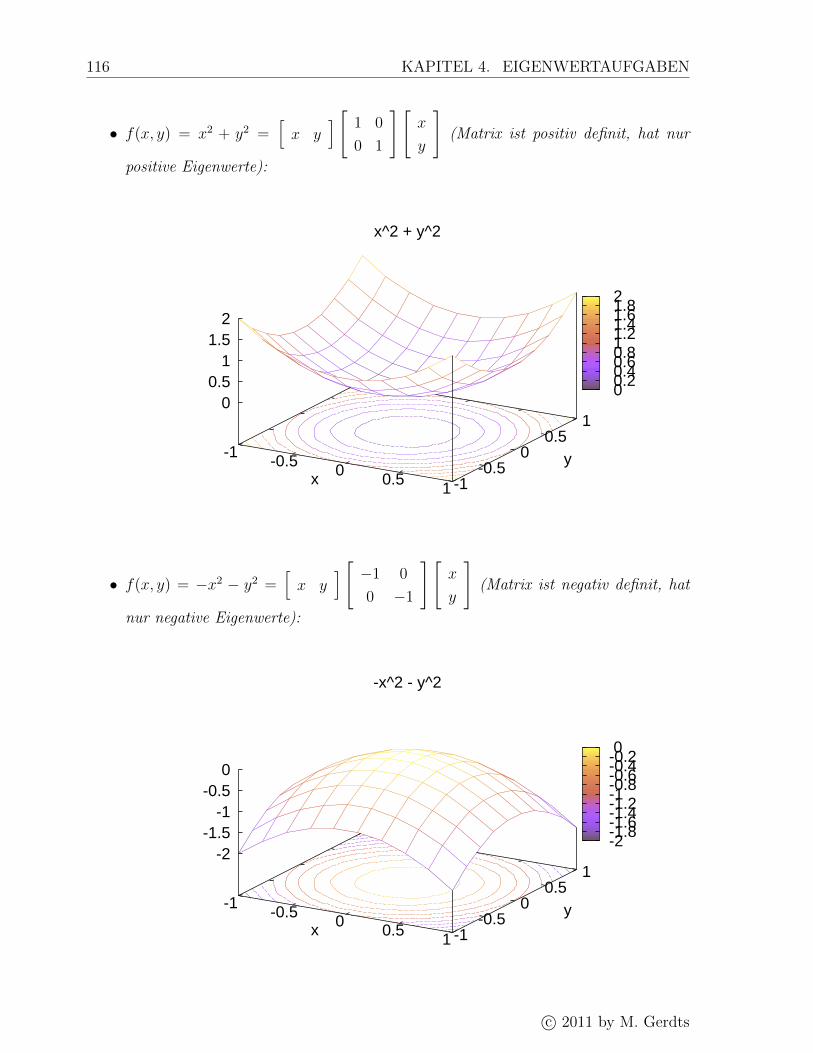
116 KAPITEL 4. EIGENWERTAUFGABEN
• f(x, y) = x2 + y2 =[x y
] [ 1 0
0 1
][x
y
](Matrix ist positiv definit, hat nur
positive Eigenwerte):
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2
x^2 + y^2
-1 -0.5 0 0.5 1x -1
-0.5 0
0.5 1
y
0 0.5
1 1.5
2
• f(x, y) = −x2 − y2 =[x y
] [ −1 0
0 −1
][x
y
](Matrix ist negativ definit, hat
nur negative Eigenwerte):
-2-1.8-1.6-1.4-1.2-1-0.8-0.6-0.4-0.2 0
-x^2 - y^2
-1 -0.5 0 0.5 1x -1
-0.5 0
0.5 1
y
-2-1.5
-1-0.5
0
c© 2011 by M. Gerdts
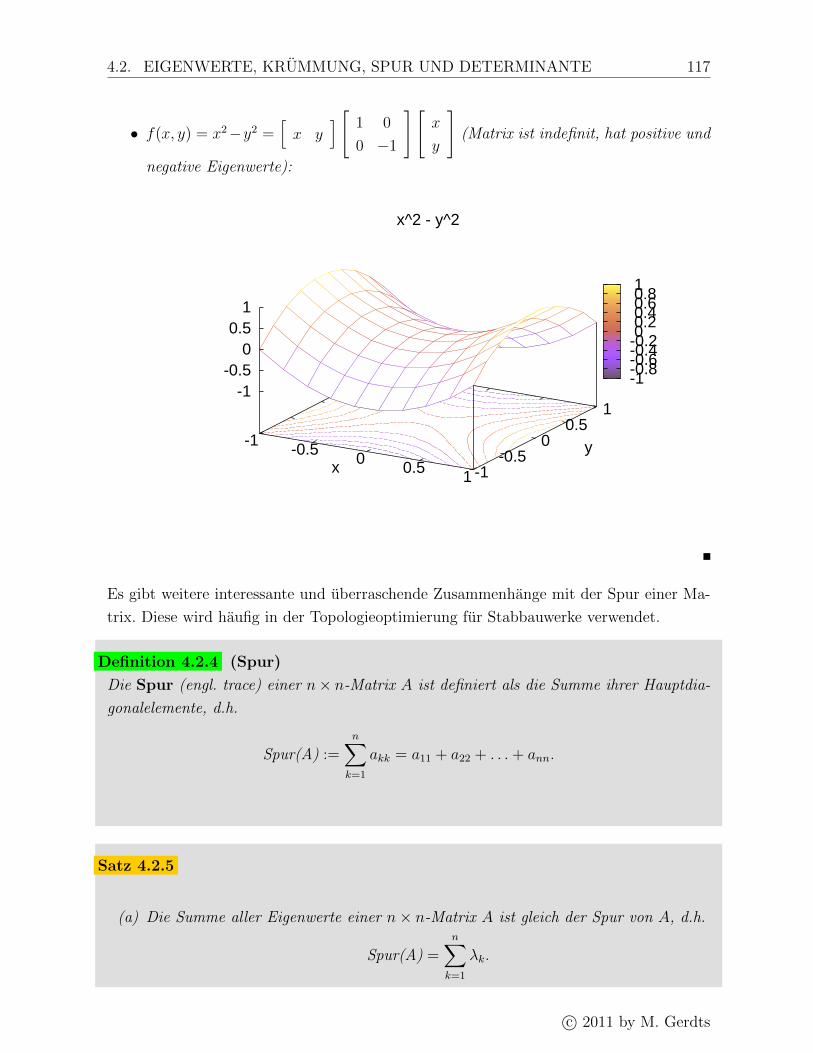
4.2. EIGENWERTE, KRUMMUNG, SPUR UND DETERMINANTE 117
• f(x, y) = x2−y2 =[x y
] [ 1 0
0 −1
][x
y
](Matrix ist indefinit, hat positive und
negative Eigenwerte):
-1-0.8-0.6-0.4-0.2 0 0.2 0.4 0.6 0.8 1
x^2 - y^2
-1 -0.5 0 0.5 1x -1
-0.5 0
0.5 1
y
-1-0.5
0 0.5
1
Es gibt weitere interessante und uberraschende Zusammenhange mit der Spur einer Ma-
trix. Diese wird haufig in der Topologieoptimierung fur Stabbauwerke verwendet.
Definition 4.2.4 (Spur)
Die Spur (engl. trace) einer n× n-Matrix A ist definiert als die Summe ihrer Hauptdia-
gonalelemente, d.h.
Spur(A) :=n∑k=1
akk = a11 + a22 + . . .+ ann.
Satz 4.2.5
(a) Die Summe aller Eigenwerte einer n× n-Matrix A ist gleich der Spur von A, d.h.
Spur(A) =n∑k=1
λk.
c© 2011 by M. Gerdts

118 KAPITEL 4. EIGENWERTAUFGABEN
(b) Das Produkt aller Eigenwerte ist gleich der Determinante einer n × n-Matrix A,
d.h.
det(A) =n∏k=1
λk.
(c) Die zu verschiedenen Eigenwerten gehorenden Eigenvektoren sind linear unabhangig.
4.3 Eigenwertabschatzungen
Ziel dieses Abschnitts ist die Abschatzung von Eigenwerten allein mit Hilfe der Matrix
A ∈ Cn×n.
Satz 4.3.1 (Gerschgorin)
Sei A ∈ Cn×n gegeben. Definiere Radien ri gemaß
ri =n∑
j=1,j 6=i
|aij|, i = 1, . . . , n,
und Kreisscheiben (Gerschgorin-Kreise) gemaß
Ki := z ∈ C | |z − aii| ≤ ri, i = 1, . . . , n.
Dann gelten folgende Aussagen.
(a) Fur jeden Eigenwert λ von A gilt
λ ∈n⋃i=1
Ki.
(b) Sei U1 die Vereinigung von m dieser Kreissscheiben und sei U2 die Vereinigung der
verbleibenden n−m Kreissscheiben. Gilt U1∩U2 = ∅, so enthalt U1 m Eigenwerte von
A und U2 n−m Eigenwerte von A (Eigenwerte und Kreisscheiben sind entsprechend
ihrer Vielfachheit zu zahlen.).
Mit Hilfe des Satzes von Gerschgorin erhalt man insbesondere dann einen guten Uberblick
uber die Lage der Eigenwerte, wenn samtliche Kreissscheiben paarweise disjunkt sind,
da dann in jeder Kreisscheibe genau ein Eigenwert liegt. Daruber hinaus konnen durch
Anwendung des Satzes auf A> (A und A> besitzen dieselben Eigenwerte!) mitunter bessere
c© 2011 by M. Gerdts

4.3. EIGENWERTABSCHATZUNGEN 119
Abschatzungen fur einige Eigenwerte erreicht werden. Ein Ansatz zum Erreichen besserer
Abschatzungen besteht darin, eine Ahnlichkeitstransformation D−1AD mit einer geeignet
gewahlten Diagonalmatrix D vor Anwendung des Satzes von Gerschgorin durchzufuhren.
D sollte idealerweise so gewahlt werden, dass die Radien kleiner werden, was haufig aber
nur fur einige Radien erreicht werden kann, wobei sich die ubrigen vergroßern.
Beispiel 4.3.2
Betrachte
A =
1 0.1 −0.1
0 2 0.4
−0.2 0 3
.Die Gerschgorin-Kreise
1 2 3
K1 = z ∈ C | |z − 1| ≤ 0.2,K2 = z ∈ C | |z − 2| ≤ 0.4,K3 = z ∈ C | |z − 3| ≤ 0.2
sind paarweise disjunkt, d.h. in jedem Kreis liegt genau ein Eigenwert von A.
Fur die symmetrische Matrix
B =
1 2 0
2 2 0.4
0 0.4 3
.uberschneiden sich die Gerschgorin-Kreise
1 2 30 4−1
c© 2011 by M. Gerdts

120 KAPITEL 4. EIGENWERTAUFGABEN
K1 = z ∈ C | |z − 1| ≤ 2,K2 = z ∈ C | |z − 2| ≤ 2.4,K3 = z ∈ C | |z − 3| ≤ 0.4,
so dass man aus dem Satz von Gerschgorin nur die Abschatzung
−1 ≤ λ ≤ 4.4
fur die Eigenwerte λ von B erhalt. Beachte, dass die Eigenwerte von B reell sind, da B
symmetrisch ist.
c© 2011 by M. Gerdts

Kapitel 5
Funktionen
Unter einer Funktion verstehen wir eine Abbildung von einem Definitionsbereich D ⊆R in einen Bildbereich, der bei uns immer R sein wird, d.h. wir betrachten Funktionen
f : D −→ R. Hierbei ordnet f jedem x ∈ D ein eindeutiges Element f(x) ∈ R zu.
Die Menge W := f(x) | x ∈ D bezeichnet den Wertebereich von f , also die Menge
aller Funktionswerte, die f auf dem Definitionsbereich annimmt.
Der Graph von f ist definiert als die Menge G := (x, f(x)) | x ∈ D.
Eine Funktion f : D −→ R ordnet jedem Element x ∈ D ein eindeutiges Element f(x) ∈ Rzu. Wahlt man umgekehrt ein beliebiges Element y ∈ R, so kann man die Urbildmenge
von y unter der Abbildung f
f−1(y) := x ∈ D | y = f(x)
betrachten. Es konnen mehrere Falle auftreten:
(i) Die Urbildmenge f−1(y) enthalt genau ein Element.
(ii) Die Urbildmenge f−1(y) ist leer.
(iii) Die Urbildmenge f−1(y) enthalt mindestens zwei verschiedene Elemente.
(Aufgabe: Uberlegen Sie sich Beispiele fur die drei Falle)
Falls der Fall (i) fur jedes Element y aus dem Wertebereich von f gilt, d.h. jedem y ∈ Wwird das eindeutige Element x = f−1(y) zugeordnet, so heißt die Abbildung f−1 : W −→D Umkehrfunktion oder inverse Funktion. Existiert die Umkehrfunktion f−1 von f ,
so nennt man f auch bijektiv. Die Umkehrfunktion hat die Eigenschaft
f(f−1(y)) = y (∀y ∈ W ) bzw. f−1(f(x)) = x (∀x ∈ D).
Wir stellen haufig vorkommende Funktionen kurz vor.
121
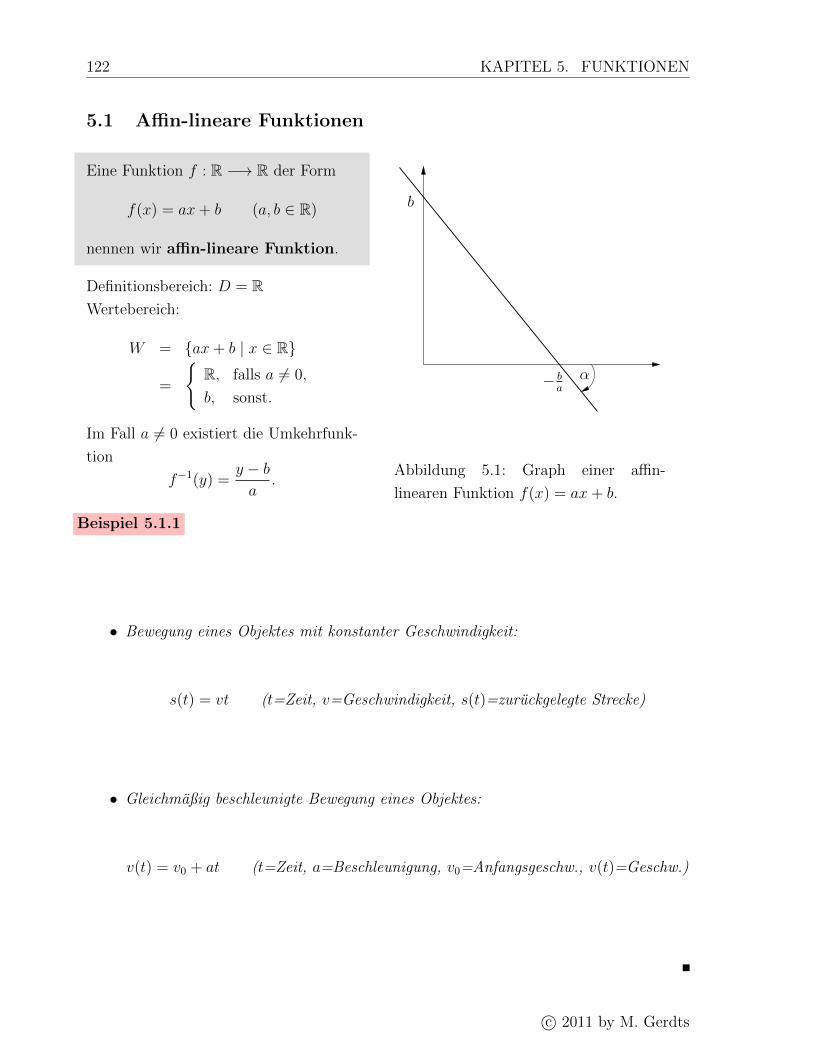
122 KAPITEL 5. FUNKTIONEN
5.1 Affin-lineare Funktionen
Eine Funktion f : R −→ R der Form
f(x) = ax+ b (a, b ∈ R)
nennen wir affin-lineare Funktion.
Definitionsbereich: D = RWertebereich:
W = ax+ b | x ∈ R
=
R, falls a 6= 0,
b, sonst.
Im Fall a 6= 0 existiert die Umkehrfunk-
tion
f−1(y) =y − ba
.
α− ba
b
Abbildung 5.1: Graph einer affin-
linearen Funktion f(x) = ax+ b.
Beispiel 5.1.1
• Bewegung eines Objektes mit konstanter Geschwindigkeit:
s(t) = vt (t=Zeit, v=Geschwindigkeit, s(t)=zuruckgelegte Strecke)
• Gleichmaßig beschleunigte Bewegung eines Objektes:
v(t) = v0 + at (t=Zeit, a=Beschleunigung, v0=Anfangsgeschw., v(t)=Geschw.)
c© 2011 by M. Gerdts

5.2. QUADRATISCHE FUNKTIONEN 123
Eigenschaften affin-linearer Funktionen1 (vgl. Abbildung 5.1):
• Der Graph von f ist eine Gerade.
• Die Gerade schneidet die y-Achse im Punkt (0, b).
• a gibt die Steigung der Geraden an:
– Im Fall a > 0 wachst die Gerade nach rechts an.
– Im Fall a < 0 fallt die Gerade nach rechts ab.
– Im Fall a = 0 verlauft die Gerade parallel zur x-Achse (f ist konstant).
• Fur a 6= 0 hat die Gerade genau eine Nullstelle im Punkt x = − ba.
• Der Neigungswinkel α der Geraden (=Winkel zwischen Gerade und x-Achse) erfullt
tanα = a.
5.2 Quadratische Funktionen
Eine Funktion f : R −→ R der Form
f(x) = ax2 + bx+ c (a, b, c ∈ R)
nennen wir quadratische Funktion
oder Parabel.
Definitionsbereich: D = RWertebereich:
– W = [fs,+∞), falls a > 0,
– W = (−∞, fs], falls a < 0.
xs = − b2a
fs = 4ac−b24a
x1 x2 x
y = f(x)
f(x) = ax2 + bx+ c
Abbildung 5.2: Graph einer quadrati-
schen Funktion f(x) = ax2 +bx+c (hier
a > 0, b2 − 4ac > 0).
Eigenschaften quadratischer Funktionen (vgl. Abbildung 5.2):
• Der Graph von f ist eine Parabel, die fur a > 0 nach oben und fur a < 0 nach unten
geoffnet ist.
1Haufig lasst man das Wort “affin” einfach weg. Streng genommen ist f nur im Fall b = 0 eine lineare
Funktion. Fur b 6= 0 erhalten wir eine verschobene lineare Funktion, daher der Name “affin-linear”. Eine
lineare Funktion erfullt f(x+ y) = f(x) + f(y) und f(cx) = cf(x) fur alle x, y, c ∈ R.
c© 2011 by M. Gerdts
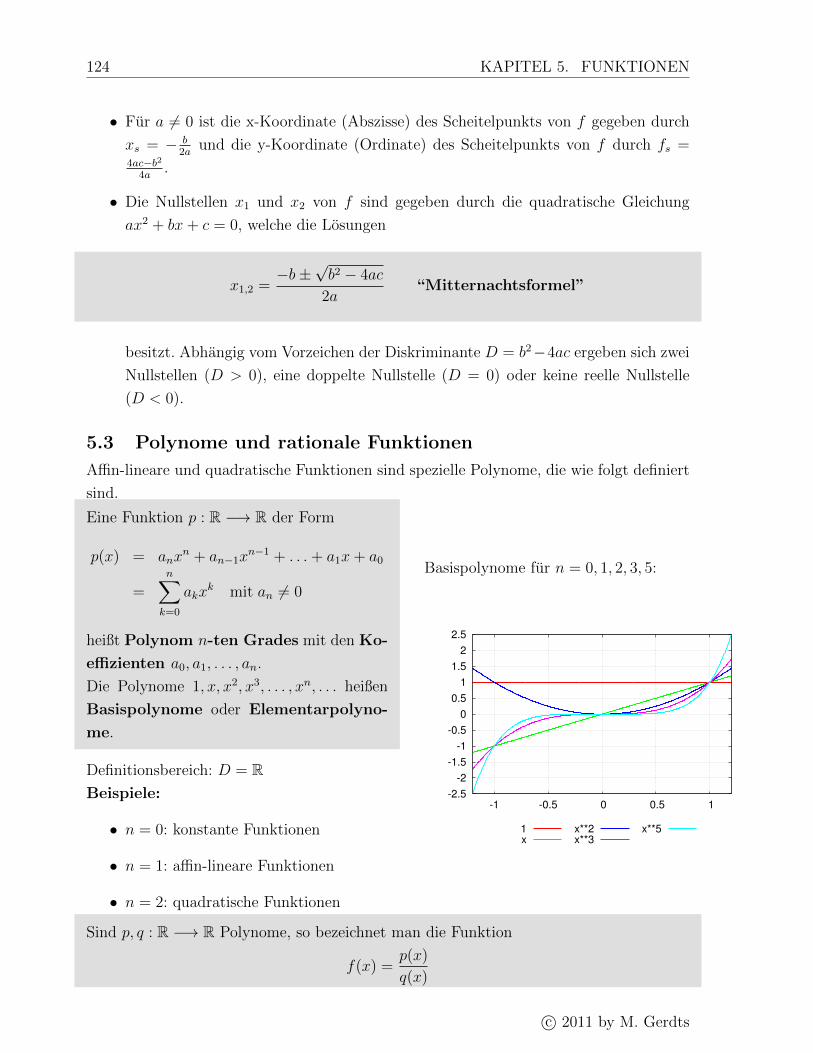
124 KAPITEL 5. FUNKTIONEN
• Fur a 6= 0 ist die x-Koordinate (Abszisse) des Scheitelpunkts von f gegeben durch
xs = − b2a
und die y-Koordinate (Ordinate) des Scheitelpunkts von f durch fs =4ac−b2
4a.
• Die Nullstellen x1 und x2 von f sind gegeben durch die quadratische Gleichung
ax2 + bx+ c = 0, welche die Losungen
x1,2 =−b±
√b2 − 4ac
2a“Mitternachtsformel”
besitzt. Abhangig vom Vorzeichen der Diskriminante D = b2−4ac ergeben sich zwei
Nullstellen (D > 0), eine doppelte Nullstelle (D = 0) oder keine reelle Nullstelle
(D < 0).
5.3 Polynome und rationale Funktionen
Affin-lineare und quadratische Funktionen sind spezielle Polynome, die wie folgt definiert
sind.
Eine Funktion p : R −→ R der Form
p(x) = anxn + an−1x
n−1 + . . .+ a1x+ a0
=n∑k=0
akxk mit an 6= 0
heißt Polynom n-ten Grades mit den Ko-
effizienten a0, a1, . . . , an.
Die Polynome 1, x, x2, x3, . . . , xn, . . . heißen
Basispolynome oder Elementarpolyno-
me.
Definitionsbereich: D = RBeispiele:
• n = 0: konstante Funktionen
• n = 1: affin-lineare Funktionen
• n = 2: quadratische Funktionen
Basispolynome fur n = 0, 1, 2, 3, 5:
-2.5
-2
-1.5
-1
-0.5
0
0.5
1
1.5
2
2.5
-1 -0.5 0 0.5 1
1
x
x**2
x**3
x**5
Sind p, q : R −→ R Polynome, so bezeichnet man die Funktion
f(x) =p(x)
q(x)
c© 2011 by M. Gerdts

5.3. POLYNOME UND RATIONALE FUNKTIONEN 125
als rationale Funktion.
Rationale Funktionen sind i.a. nicht fur alle reellen Argumente x definiert und konnen
Polstellen besitzen, namlich dort, wo q Nullstellen besitzt. Da q nur endlich viele Null-
stellen besitzt, gibt es auch nur endlich viele Polstellen.
Eine Polstelle xs von f zeichnet sich dadurch aus, dass die Funktion f bei Annaherung
an xs gegen +∞ oder gegen −∞ strebt.
Man spricht von einer hebbaren Polstelle, wenn xs Nullstelle von p mit Vielfachheit
mp und Nullstelle von q mit Vielfachheit mq ≤ mp ist. In diesem Fall kann man die zur
Nullstelle gehorenden Linearfaktoren kurzen, z.B.
f(x) =x3 + x2 − x− 1
x+ 1=
(x− 1)(x+ 1)2
x+ 1= (x− 1)(x+ 1) = x2 − 1.
Hier ist xs = −1 eine doppelte Nullstelle des Zahlers und einer einfache Nullstelle des
Nenners, so dass man den Term x+1 kurzen kann. Damit entfallt die potenzielle Polstelle
xs = −1.
Treten keine hebbaren Polstellen auf oder wurde bereits gekurzt, so ist die Ordnung der
Polstelle xs gegeben durch die Vielfachheit der Nullstelle xs in q. Ist die Ordnung gerade,
so liegt eine Polstelle ohne Vorzeichenwechsel vor. Ist die Ordnung ungerade, so liegt
eine Polstelle mit Vorzeichenwechsel vor.
Beispiel 5.3.1
(i) Die rationale Funktion f(x) = 1x2
besitzt in x = 0 eine Polstelle 2. Ordnung (ohne
Vorzeichenwechsel).
(ii) Die rationale Funktion f(x) = 1(x−2)3 besitzt in x = 2 eine Polstelle 3. Ordnung (mit
Vorzeichenwechsel).
(iii) Die rationale Funktion
f(x) =x+ 2
x3 + x2 − x− 1=
x+ 2
(x+ 1)2(x− 1)
besitzt in x = −1 eine Polstelle 2. Ordnung (ohne Vorzeichenwechsel) und in x = 1
eine Polstelle 1. Ordnung (mit Vorzeichenwechsel).
(iv) Die rationale Funktion
f(x) =x2 + 3x+ 2
x3 + x2 − x− 1=
(x+ 2)(x+ 1)
(x+ 1)2(x− 1)=
(x+ 2)
(x+ 1)(x− 1)
besitzt in x = −1 eine Polstelle 1. Ordnung (mit Vorzeichenwechsel) und in x = 1
eine Polstelle 1. Ordnung (mit Vorzeichenwechsel).
c© 2011 by M. Gerdts
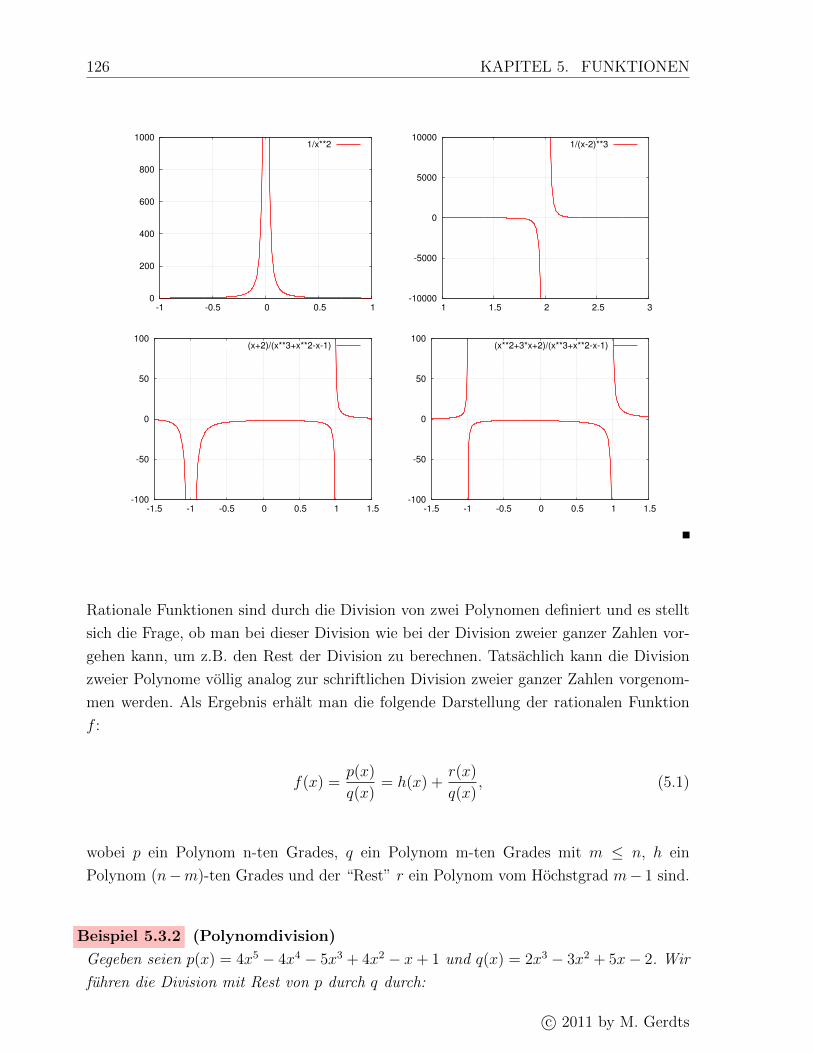
126 KAPITEL 5. FUNKTIONEN
0
200
400
600
800
1000
-1 -0.5 0 0.5 1
1/x**2
-10000
-5000
0
5000
10000
1 1.5 2 2.5 3
1/(x-2)**3
-100
-50
0
50
100
-1.5 -1 -0.5 0 0.5 1 1.5
(x+2)/(x**3+x**2-x-1)
-100
-50
0
50
100
-1.5 -1 -0.5 0 0.5 1 1.5
(x**2+3*x+2)/(x**3+x**2-x-1)
Rationale Funktionen sind durch die Division von zwei Polynomen definiert und es stellt
sich die Frage, ob man bei dieser Division wie bei der Division zweier ganzer Zahlen vor-
gehen kann, um z.B. den Rest der Division zu berechnen. Tatsachlich kann die Division
zweier Polynome vollig analog zur schriftlichen Division zweier ganzer Zahlen vorgenom-
men werden. Als Ergebnis erhalt man die folgende Darstellung der rationalen Funktion
f :
f(x) =p(x)
q(x)= h(x) +
r(x)
q(x), (5.1)
wobei p ein Polynom n-ten Grades, q ein Polynom m-ten Grades mit m ≤ n, h ein
Polynom (n−m)-ten Grades und der “Rest” r ein Polynom vom Hochstgrad m− 1 sind.
Beispiel 5.3.2 (Polynomdivision)
Gegeben seien p(x) = 4x5 − 4x4 − 5x3 + 4x2 − x+ 1 und q(x) = 2x3 − 3x2 + 5x− 2. Wir
fuhren die Division mit Rest von p durch q durch:
c© 2011 by M. Gerdts

5.3. POLYNOME UND RATIONALE FUNKTIONEN 127
(4x5 −4x4 −5x3 +4x2 −x +1) : (2x3 − 3x2 + 5x− 2) = 2x2 + x− 6︸ ︷︷ ︸=h(x)
−(4x5 −6x4 +10x3 −4x2)
2x4 −15x3 +8x2 −x +1
−(2x4 −3x3 +5x2 −2x)
−12x3 +3x2 +x +1
−(−12x3 +18x2 −30x +12)
−15x2 +31x −11
︸ ︷︷ ︸=r(x)
Die Polynomdivision ist nutzlich, wenn man z.B. durch scharfes Hinsehen eine Nullstelle x1
des Polynoms p vom Grad n entdeckt hat und nun weitere Nullstellen berechnen mochte.
Dazu teilt man das Polynom p durch x − x1 und fuhrt eine Polynomdivision durch. Da
x1 eine Nullstelle ist, bleibt kein Rest ubrig und das Polynom h in der Darstellung (5.1)
besitzt den um eins reduzierten Polynomgrad n− 1, d.h. man erhalt die Darstellung
p(x)
x− x1= h(x) bzw. p(x) = (x− x1)h(x).
Fuhrt man dieses Prinzip fur h fort, so sieht man, dass ein Polynom n-ten Grades
hochstens n verschiedene reelle Nullstellen besitzen kann.
Beispiel 5.3.3
Betrachte das Polynom p(x) = x3 + x2 − x − 1. Durch hinsehen sieht man, dass x = 1
eine Nullstelle ist. Polynomdivision liefert:
(x3 +x2 −x −1) : (x− 1) = x2 + 2x+ 1
−(x3 −x2)2x2 −x −1
−(2x2 −2x )
x −1
−(x −1)
0
Man kann p also darstellen als p(x) = (x− 1)(x2 + 2x+ 1). Schaut man sich den zweiten
Faktor an und erkennt, dass x = −1 eine Nullstelle ist, so kann man fur x2 + 2x + 1
c© 2011 by M. Gerdts

128 KAPITEL 5. FUNKTIONEN
erneut die Polynomdivision durchfuhren:
(x2 +2x +1) : (x+ 1) = x+ 1
−(x2 +x)
x +1
−(x +1)
0
Somit gilt x2 + 2x + 1 = (x + 1)(x + 1) = (x + 1)2 und man kann p schreiben als
p(x) = (x− 1)(x+ 1)2.
5.4 Trigonometrische Funktionen
Wir untersuchen die wichtigsten trigonometrischen Funktion, u.a. Sinus, Cosinus, Tan-
gens. Diese Funktionen spielen eine wichtige Rolle bei der Beschreibung von periodischen
Vorgangen.
Definition 5.4.1 (periodische Funktion)
Eine Funktion f : R −→ R heißt periodisch mit Periode T > 0, falls
f(x+ T ) = f(x) fur alle x ∈ R
gilt.
Wegen der Periodizitat genugt es, eine periodische Funktion mit Periode T nur auf einem
Intervall der Lange T zu definieren.
5.4.1 Sinus, Cosinus (sin, cos)
Sinus und Kosinus konnen geometrisch oder analytisch definiert werden. Wir wahlen
zunachst die ubliche geometrische Definition mithilfe des Einheitskreises, vgl. Abbil-
dung 5.3. Dazu wahlen wir einen Punkt P auf dem Einheitskreis und bezeichnen den
Winkel zwischen der Verbindungslinie vom Ursprung zum Punkt P und der x-Achse
mit α. Der Sinus von α ist dann definiert als die y-Komponente des Punktes P (Ordina-
te) und der Cosinus von α ist definiert als die x-Komponente des Punktes P (Absizze),
also P = (cos(α), sin(α)).
c© 2011 by M. Gerdts

5.4. TRIGONOMETRISCHE FUNKTIONEN 129
1
α
cos(α)
sin(α)
P
x
y
Abbildung 5.3: Definition des Sinus und Cosinus am Einheitskreis mithilfe des Winkels.
Alternativ konnen Sinus und Cosinus auch uber die Bogenlange definiert werden. Hierzu
tragt man fur x ∈ R ausgehend vom Punkt (1, 0) auf dem Einheitskreis einen Bogen der
Lange |x| ab, wobei man fur x ≥ 0 im mathematisch positiven Sinne (also entgegen des
Uhrzeigersinns) und fur x < 0 im mathematisch negativen Sinne (also im Uhrzeigersinn)
entlang des Einheitskreises lauft. Dadurch wird ein Punkt Px auf dem Einheitskreis defi-
niert. Der Sinus von x ist dann definiert als die y-Komponente des Punktes Px (Ordinate)
und der Cosinus von x ist definiert als die x-Komponente des Punktes Px (Abszizze), also
Px = (cos(x), sin(x)), vgl. Abbildung 5.4.
In dieser Definition von sin und cos hat die Variable x die Bedeutung einer Bogenlange
auf dem Einheitskreis. Man sagt, x ist im Bogenmaß angegeben. Definiert man sin und
cos uber den Winkel α, so ist α im Gradmaß angegeben. Der Zusammenhang zwischen
den beiden Variablen x und α ist wie folgt:
x
2π=
α
360=⇒ x =
α
180· π bzw. α =
x
π· 180
Beispiel:
α = 30 =⇒ x =30
180· π =
π
6.
c© 2011 by M. Gerdts
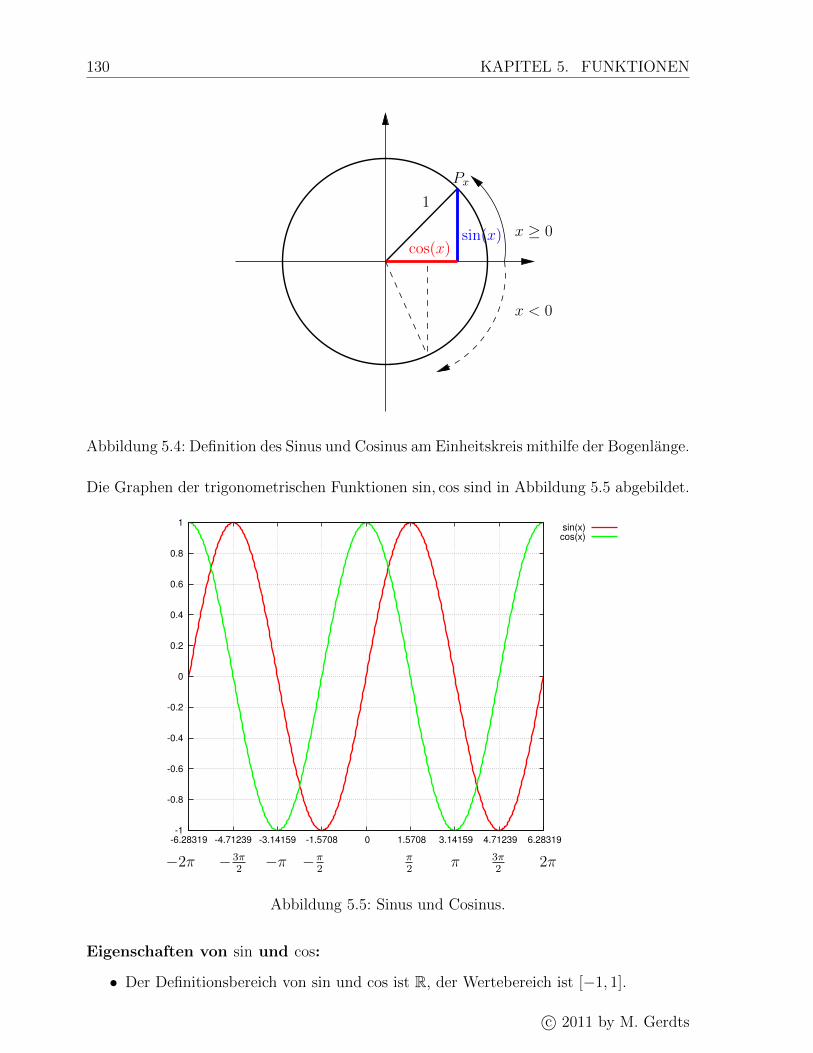
130 KAPITEL 5. FUNKTIONEN
1
cos(x)sin(x)
Px
x ≥ 0
x < 0
Abbildung 5.4: Definition des Sinus und Cosinus am Einheitskreis mithilfe der Bogenlange.
Die Graphen der trigonometrischen Funktionen sin, cos sind in Abbildung 5.5 abgebildet.
-1
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
1
-6.28319 -4.71239 -3.14159 -1.5708 0 1.5708 3.14159 4.71239 6.28319
sin(x)cos(x)
−2π −3π2−π −π
2π2
π 3π2
2π
Abbildung 5.5: Sinus und Cosinus.
Eigenschaften von sin und cos:
• Der Definitionsbereich von sin und cos ist R, der Wertebereich ist [−1, 1].
c© 2011 by M. Gerdts
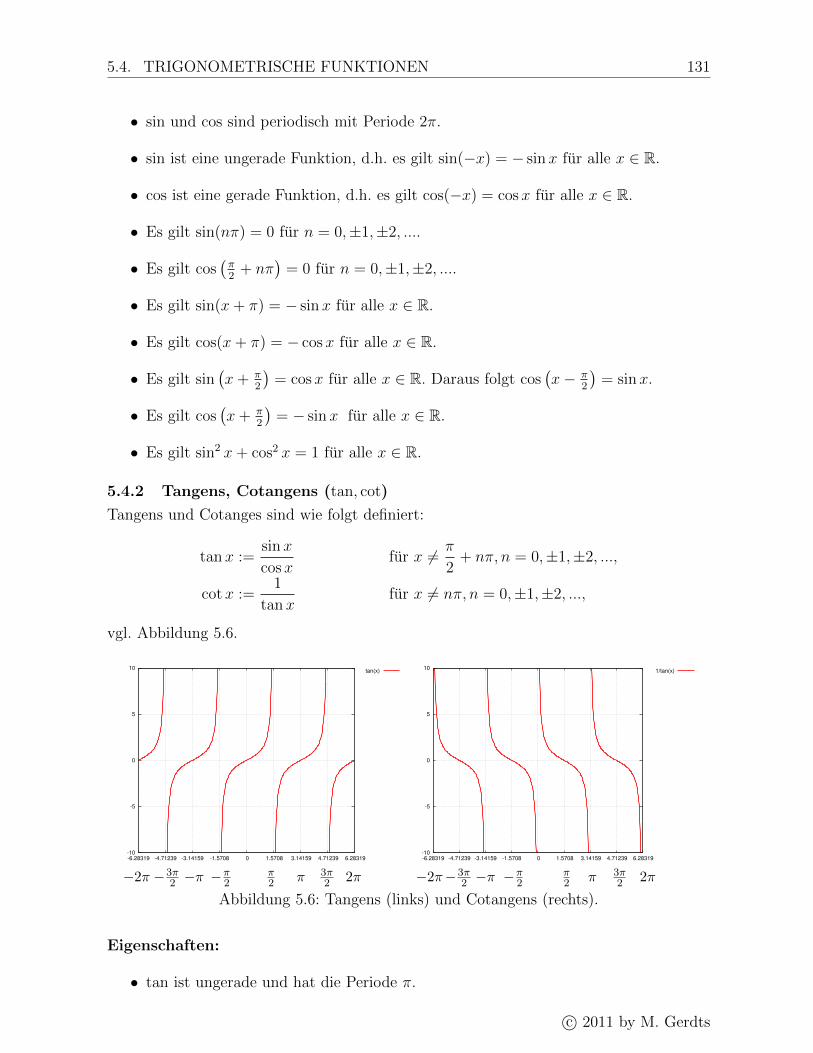
5.4. TRIGONOMETRISCHE FUNKTIONEN 131
• sin und cos sind periodisch mit Periode 2π.
• sin ist eine ungerade Funktion, d.h. es gilt sin(−x) = − sinx fur alle x ∈ R.
• cos ist eine gerade Funktion, d.h. es gilt cos(−x) = cos x fur alle x ∈ R.
• Es gilt sin(nπ) = 0 fur n = 0,±1,±2, ....
• Es gilt cos(π2
+ nπ)
= 0 fur n = 0,±1,±2, ....
• Es gilt sin(x+ π) = − sinx fur alle x ∈ R.
• Es gilt cos(x+ π) = − cosx fur alle x ∈ R.
• Es gilt sin(x+ π
2
)= cosx fur alle x ∈ R. Daraus folgt cos
(x− π
2
)= sinx.
• Es gilt cos(x+ π
2
)= − sinx fur alle x ∈ R.
• Es gilt sin2 x+ cos2 x = 1 fur alle x ∈ R.
5.4.2 Tangens, Cotangens (tan, cot)
Tangens und Cotanges sind wie folgt definiert:
tanx :=sinx
cosxfur x 6= π
2+ nπ, n = 0,±1,±2, ...,
cotx :=1
tanxfur x 6= nπ, n = 0,±1,±2, ...,
vgl. Abbildung 5.6.
-10
-5
0
5
10
-6.28319 -4.71239 -3.14159 -1.5708 0 1.5708 3.14159 4.71239 6.28319
tan(x)
-10
-5
0
5
10
-6.28319 -4.71239 -3.14159 -1.5708 0 1.5708 3.14159 4.71239 6.28319
1/tan(x)
−2π −3π2 −π −
π2
π2 π 3π
2 2π −2π−3π2 −π −
π2
π2 π 3π
2 2π
Abbildung 5.6: Tangens (links) und Cotangens (rechts).
Eigenschaften:
• tan ist ungerade und hat die Periode π.
c© 2011 by M. Gerdts

132 KAPITEL 5. FUNKTIONEN
• cot ist ungerade und hat die Periode π.
• Es gelten
tan(π
2− x)
=sin(π2− x)
cos(π2− x) =
cosx
sinx= cotx
und
cot(π
2− x)
= tanx.
Von manchen Winkeln kennen wir die exakten Sinus-(bzw. Kosinus-)werte, z.B.
x = 0 x = π/6 x = π/4 x = π/3 x = π/2
(0) (30) (45) (60) (90)
sin(x) 0 12
12
√2 1
2
√3 1
cos(x) 1 12
√3 1
2
√2 1
20
tan(x) 0 13
√3 1
√3 ∞
Satz 5.4.2 (Additionstheoreme)
Fur beliebige α, β ∈ R gelten
sin(α± β) = sinα cos β ± cosα sin β,
cos(α± β) = cosα cos β ∓ sinα sin β
5.5 Exponentialfunktion
Fur das Produkt
a · a · ... · a︸ ︷︷ ︸n mal
(a 6= 0)
schreibt man abgekurzt an. Speziell ist
a0 = 1, a1 = a, a2 = a · a.
Man nennt a die Basis und n den Exponenten. Beachte, dass der Ausdruck 00 nicht
definiert ist!
Rechengesetze: (m,n ∈ N0, a ∈ R, a 6= 0)
• am · an = am+n (laßt sich leicht unter Verwendung der Definition zeigen)
• a−n = a0 · a−n = 1an
• am · bm = (ab)m
c© 2011 by M. Gerdts
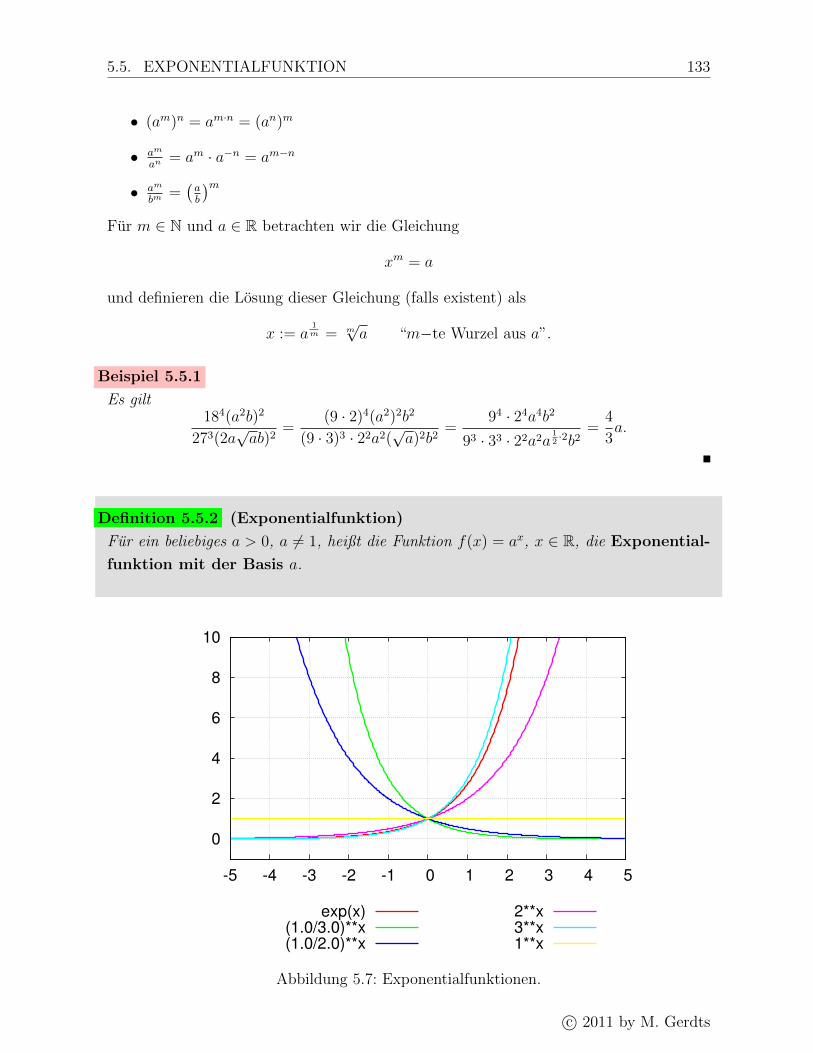
5.5. EXPONENTIALFUNKTION 133
• (am)n = am·n = (an)m
• am
an= am · a−n = am−n
• am
bm=(ab
)mFur m ∈ N und a ∈ R betrachten wir die Gleichung
xm = a
und definieren die Losung dieser Gleichung (falls existent) als
x := a1m = m
√a “m−te Wurzel aus a”.
Beispiel 5.5.1
Es gilt184(a2b)2
273(2a√ab)2
=(9 · 2)4(a2)2b2
(9 · 3)3 · 22a2(√a)2b2
=94 · 24a4b2
93 · 33 · 22a2a12·2b2
=4
3a.
Definition 5.5.2 (Exponentialfunktion)
Fur ein beliebiges a > 0, a 6= 1, heißt die Funktion f(x) = ax, x ∈ R, die Exponential-
funktion mit der Basis a.
0
2
4
6
8
10
-5 -4 -3 -2 -1 0 1 2 3 4 5
exp(x)(1.0/3.0)**x(1.0/2.0)**x
2**x3**x1**x
Abbildung 5.7: Exponentialfunktionen.
c© 2011 by M. Gerdts

134 KAPITEL 5. FUNKTIONEN
Die Exponentialfunktion f(x) = ax hat folgende Eigenschaften, vgl. Abbildung 5.7:
• f ist uberall definiert, d.h. der Definitionsbereich ist D = R.
• f nimmt nur positive Werte an, und zwar alle positive Werte, d.h. der Wertebereich
ist W = (0,∞).
• Wegen a0 = 1 hat jede solche Funktion an der Stelle x = 0 den Wert 1.
• Fur a > 1 ist f streng monoton steigend und nahert sich mit x→ −∞ asymptotisch
der x−Achse.
Fur 0 < a < 1 ist f streng monoton fallend und nahert sich mit x→∞ asymptotisch
der x−Achse.
• Vergleicht man zwei Exponentialfunktionen f1(x) = ax und f2(x) = bx mit a < b
miteinander, so stellt man fest:
Fur x > 0 gilt f1(x) < f2(x) und fur x < 0 gilt f1(x) > f2(x).
• Betrachte die Funktionen f1(x) = ax und f2(x) =(1a
)x. Wegen
f1(−x) = a−x = (a−1)x =
(1
a
)x= f2(x)
sind die Funktionen f1 und f2 an der y-Achse gespiegelt.
• Aus f(x1) = ax1 = ax2 = f(x2) folgt x1 = x2.
• Es gelten die Beziehungen
f(x+ y) = ax+y = ax · ay = f(x) · f(y),
f(x · y) = axy = (ax)y = f(x)y,
sowie
(ab)x = axbx.
In vielen technischen und wissenschaftlichen Anwendungen tritt eine ganz bestimmte Ex-
ponentialfunktion auf. Diese hat die Basis e, wobei e ≈ 2, 7182818284590 . . . die Euler-
sche Zahl bezeichnet. Diese spezielle Exponentialfunktion wird e-Funktion (oder auch
einfach Exponentialfunktion) genannt und man schreibt
f(x) = ex oder f(x) = exp(x).
Beispiel 5.5.3 (Anwendungen der e-Funktion)
Folgende Naturprozesse lassen sich durch diese Funktion modellieren:
c© 2011 by M. Gerdts

5.6. LOGARITHMUS 135
• Organisches Wachstum:
g(t) = g0 eλt
(g0 − Anfangsgroße,λ−Wachstumskonstante)
(der Zuwachs ist proportional dem vorhandenden Bestand)
• Zerfallsprozesse:
m(t) = m0 e−λt
(m0 − Anfangsgroße, λ− Zerfallskonstante)
• Gedampfte Schwingungen:
f(t) = e−Rt sin(ωt+ ϕ)
• Wahrscheinlichkeitsdichte:
f(x) =1
σ√
2πexp
(−1
2
(x− µσ
)2)
(“Gaußsche Glockenkurve”)
beschreibt die Wahrscheinlichkeitsdichte einer normalverteilten Zufallsvariablen X
mit Erwartungswert µ und Varianz σ2. Die Wahrscheinlichkeit, dass X im Bereich
[a, b] liegt, lautet dann
P (a ≤ X ≤ b) =
∫ b
a
f(x)dx.
5.6 Logarithmus
Die Umkehrfunktion der Exponentialfunktion heißt Logarithmus.
Definition 5.6.1 (Logarithmus)
Sei a > 0 gegeben. Fur x ∈ R, x > 0, heißt y ∈ R der Logarithmus von x zur Basis
a, wenn
ay = x
gilt. Man schreibt y = loga(x).
Die Funktion loga : R+ −→ R gemaß x 7→ loga(x) heißt Logarithmusfunktion zur
Basis a oder einfach Logarithmus zur Basis a.
c© 2011 by M. Gerdts
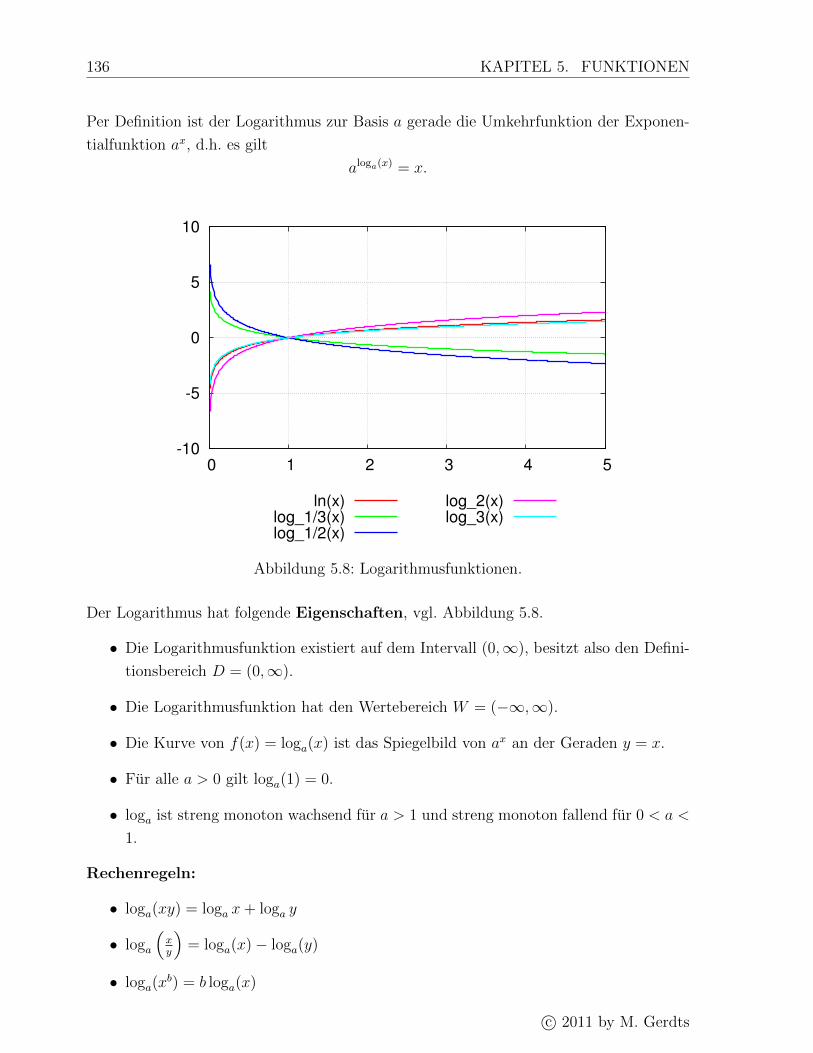
136 KAPITEL 5. FUNKTIONEN
Per Definition ist der Logarithmus zur Basis a gerade die Umkehrfunktion der Exponen-
tialfunktion ax, d.h. es gilt
aloga(x) = x.
-10
-5
0
5
10
0 1 2 3 4 5
ln(x)log_1/3(x)log_1/2(x)
log_2(x)log_3(x)
Abbildung 5.8: Logarithmusfunktionen.
Der Logarithmus hat folgende Eigenschaften, vgl. Abbildung 5.8.
• Die Logarithmusfunktion existiert auf dem Intervall (0,∞), besitzt also den Defini-
tionsbereich D = (0,∞).
• Die Logarithmusfunktion hat den Wertebereich W = (−∞,∞).
• Die Kurve von f(x) = loga(x) ist das Spiegelbild von ax an der Geraden y = x.
• Fur alle a > 0 gilt loga(1) = 0.
• loga ist streng monoton wachsend fur a > 1 und streng monoton fallend fur 0 < a <
1.
Rechenregeln:
• loga(xy) = loga x+ loga y
• loga
(xy
)= loga(x)− loga(y)
• loga(xb) = b loga(x)
c© 2011 by M. Gerdts
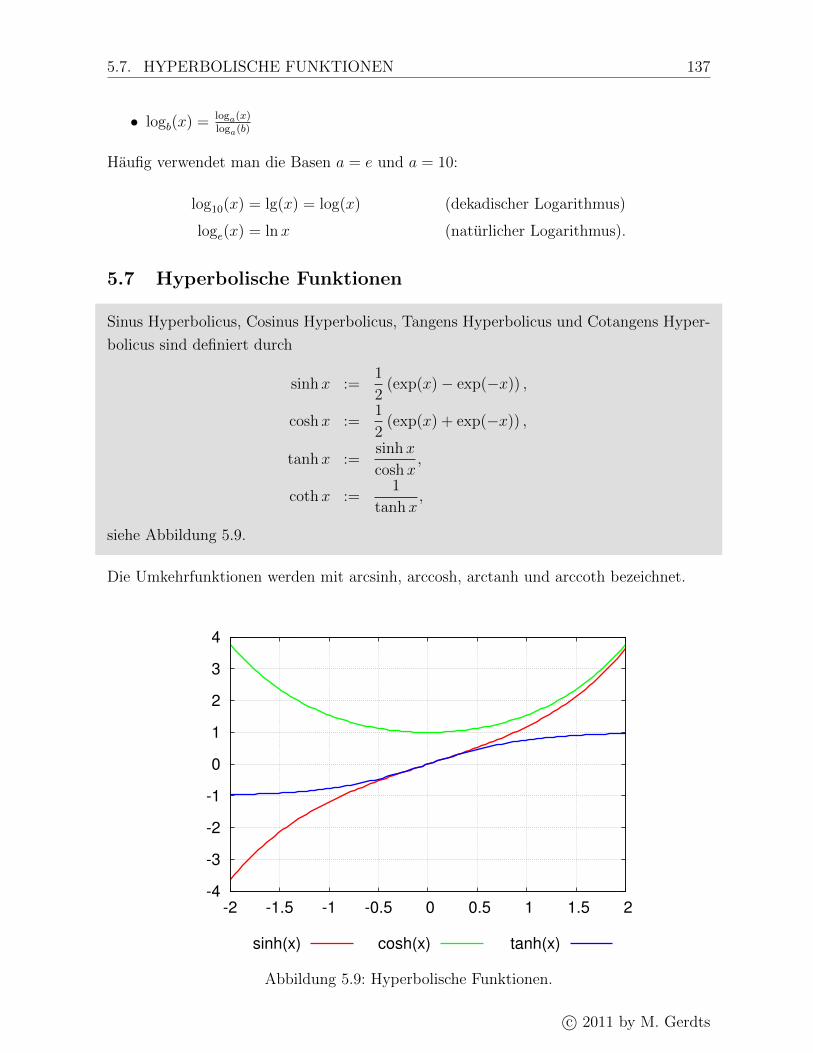
5.7. HYPERBOLISCHE FUNKTIONEN 137
• logb(x) = loga(x)loga(b)
Haufig verwendet man die Basen a = e und a = 10:
log10(x) = lg(x) = log(x) (dekadischer Logarithmus)
loge(x) = ln x (naturlicher Logarithmus).
5.7 Hyperbolische Funktionen
Sinus Hyperbolicus, Cosinus Hyperbolicus, Tangens Hyperbolicus und Cotangens Hyper-
bolicus sind definiert durch
sinhx :=1
2(exp(x)− exp(−x)) ,
coshx :=1
2(exp(x) + exp(−x)) ,
tanhx :=sinhx
coshx,
cothx :=1
tanhx,
siehe Abbildung 5.9.
Die Umkehrfunktionen werden mit arcsinh, arccosh, arctanh und arccoth bezeichnet.
-4
-3
-2
-1
0
1
2
3
4
-2 -1.5 -1 -0.5 0 0.5 1 1.5 2
sinh(x) cosh(x) tanh(x)
Abbildung 5.9: Hyperbolische Funktionen.
c© 2011 by M. Gerdts

138 KAPITEL 5. FUNKTIONEN
Eigenschaften:
• cosh2 x− sinh2 x = 1
• Additionstheoreme:
sinh(x± y) = sinh(x) cosh(y)± cosh(x) sinh(y),
cosh(x± y) = cosh(x) cosh(y)± sinh(x) sinh(y).
• Umkehrfunktionen:
arcsinh(x) = ln(x+√x2 + 1),
arccosh(x) = ln(x+√x2 − 1).
c© 2011 by M. Gerdts

Literaturverzeichnis
[BHW07] Burg, K., Haf, H. and Wille, F. Hohere Mathematik fur Ingenieure. Band II:
Lineare Algebra. Teubner, Stuttgart, 1987/2007.
[BS89] Bronstein, I. and Semendjaev, K. A., editors. Taschenbuch der Mathematik .
Verlag Harri Deutsch, Thun, 24th edition, 1989.
[MV93] Meyberg, K. and Vachenauer, P. Hohere Mathematik I-II . Springer, Berlin-
Heidelberg-New York, 2nd edition, 1993.
[Pap08] Papula, L. Mathematik fur Ingenieure und Naturwissenschaftler. Band 1-2 .
Vieweg+Teubner, Wiesbaden, 2008.
[Pap14] Papula, L. Mathematische Formelsammlung: Fr Ingenieure und Naturwissen-
schaftler . Springer Vieweg, Wiesbaden, 2014.
139





























