Embed Size (px)
Citation preview

Die schließende Statistik befasst sich mit dem Rückschluss von einer Stichprobe auf die Grundgesamtheit (Population). Die Stichprobe muss repräsentativ für die Grundgesamtheit sein. Grundlage der schließenden Statistik ist die Wahrscheinlichkeitsrechnung.
Typische Fragestellungen sind:• Welche Zahnpasta ist für die Kariesprophylaxe zu empfehlen?• Kann Mukoviszidose mit einem Schnelltest frühzeitig diagnostiziert
werden?• Welche Therapie wirkt bei Kindern mit Asthma am besten?• Welche Faktoren beeinflussen die Heilungschancen von
Karzinompatienten?• Treten Mißbildungen bei Neugeborenen nach Tschernobyl
häufiger auf?• Die neue Therapie wirkt bei 85% aller Patienten.
Schließende Statistik

Typische Aufgabenstellungen sind:
• das Schätzen von Parametern, Angabe von Konfidenzintervallen
• das Testen von Hypothesen
Konfidenzintervalle dienen dem Zweck, die Genauigkeit von Zählungen und Messungen zu bestimmen. Testverfahren werden angewandt, um vermutete Sachverhalte (Hypothesen) anhand von Versuchen gegenüber täuschenden Zufallseffekten abzusichern.
Schließende Statistik

Das Bestimmen der Auftrittswahrscheinlichkeit eines beliebigen Ereignisses:
• theoretische Überlegungen: alle Elementarereignisse (nicht weiter aufteilbare Ereignisse: z.B. Würfeln einer 1) sind gleichwahrscheinlich – Würfel, Kartenspiel
P = (Anzahl der günstigen Fälle) / (Anzahl der möglichen Fälle)
• Empirie – relative Häufigkeiten: mit wachsender Anzahl von Versuchen d.h. einer langen Folge von unabhängigen Durchführungen des zugrundeliegenden Experiments nähert sich die relative Häufigkeit einem bestimmten Zahlenwert – der Wahrscheinlichkeit.
Wahrscheinlichkeit
Statistiker Münzwürfe (n) Wappen (k) k/nBuffon 4000 2048 0,5080Pearson 12000 6019 0,5016Pearson 24000 12012 0,5005

die Verteilung der Wahrscheinlichkeiten auf die verschiedenen Merkmalsausprägungen heißt Wahrscheinlichkeitsverteilung, kurz Verteilung
• Beispiel: Würfel Merkmalsausprägungen: xi = i; i = 1,2,...,6 Wahrscheinlichkeiten pi = 1/6 ⇒ diskrete Gleichverteilung
Die Wahrscheinlichkeitsfunktion ist das theoretische Gegenstück zur empirischen Häufigkeitsverteilung.
Wahrscheinlichkeitsverteilung

Wie bei Häufigkeitsverteilungen kann die in einer Wahrscheinlichkeitsverteilung enthaltene Information durch Kenngrößen (Parameter) beschrieben werden. Die Parameter der Grundgesamtheit werden meist mit griechischen Buchstaben bezeichnet: z.B. Populationsmittelwert (Erwartungswert) μ und Varianz σ2.
Die wichtigsten Wahrscheinlichkeitsverteilungen unter den diskreten sind die Binomialverteilung und die Poissonverteilung, unter den stetigen Verteilungen ist es die Normalverteilung.
Wahrscheinlichkeitsverteilung

Diese Verteilung hat in der Statistik eine zentrale Bedeutung: Eine Summe von vielen unabhängigen, beliebigen Zufallsvariablen ist angenähert normalverteilt; das bedeutet in der Praxis, dass viele Probleme unter Verwendung der Normalverteilungsannahme gelöst werden können -vorausgesetzt, die Stichprobe ist groß genug.
Sie wird häufig verwendet um die Lage und Streuung von Meßwerten zu beschreiben. Die Standardnormalverteilunghat einen Mittelwert von μ=0 und eine Standardabweichung von σ=1.
Normalverteilung
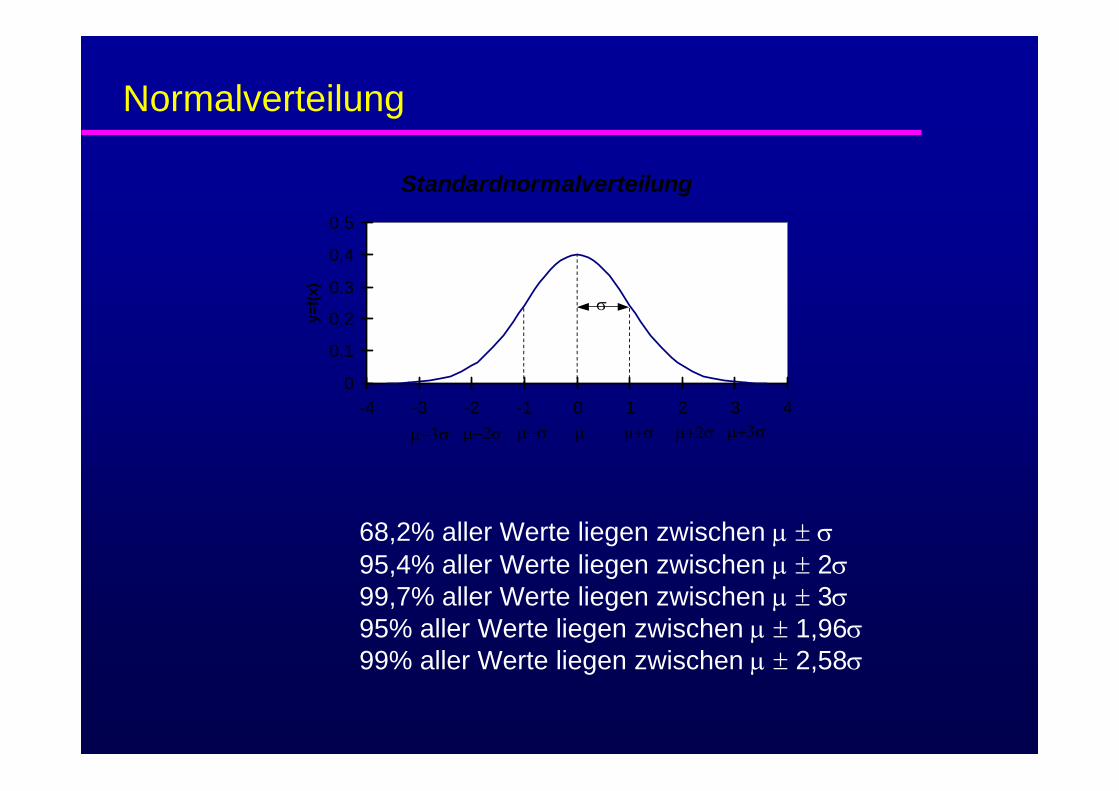
Normalverteilung
68,2% aller Werte liegen zwischen μ ± σ95,4% aller Werte liegen zwischen μ ± 2σ99,7% aller Werte liegen zwischen μ ± 3σ95% aller Werte liegen zwischen μ ± 1,96σ99% aller Werte liegen zwischen μ ± 2,58σ
Standardnormalverteilung
0
0,1
0,2
0,3
0,4
0,5
-4 -3 -2 -1 0 1 2 3 4
y=f(x
)
μ−3σ μ−2σ μ−σ μ μ+σ μ+2σ μ+3σ
σ

Da man nicht die gesamte Population erfasst, sondern so gut wie immer auf Stichproben von begrenzten Umfang angewiesen ist, muß man sogenannte Schätzungen für die Populationsparameter angeben.
Die empirische Häufigkeitsverteilung ist eine Schätzung für die Wahrscheinlichkeitsverteilung
Die Kennzahlen, die wir in der deskriptiven Statistik kennengelernt haben, stellen Schätzungen für die Populationsparameter dar.
Im Falle der Normalverteilung (oder zumindest eingipfligen, symmetrischen Verteilung) sind das arithmetische Mittel und die Stichprobenvarianz s2 “gute” Schätzer für Erwartungswert μ und Varianz σ2 der Population.
Schätzen von Parametern

Die Punktschätzung liefert einen einzelnen Wert für den unbekannten Parameter.
Mehr Information bietet ein Schätzintervall (Konfidenzintervall), in dem der unbekannte (wahre) Parameter mit entsprechend hoher Wahrscheinlichkeit (z.B. 95%) enthalten ist.
Ein solches Schätzintervall ist deshalb von besonderer Bedeutung, weil seine Breite die Genauigkeit oder Ungenauigkeit der Schätzung repräsentiert. Die Grenzen werden aus der Stichprobe bestimmt.
Konfidenzintervall

Mit statistischen Testverfahren kann man prüfen, ob die erhobenen Daten für eine Hypothese sprechen oder ob sich die Daten auch durch zufallsbedingte Abweichungen erklären lassen
Der Hypothesentest ermittelt die Wahrscheinlichkeit, mit der das Untersuchungsergebnis ein reines Zufallsergebnis ist. Wenn diese Wahrscheinlickeit genügend klein ist (α=0.05), zeigt uns das an, dass das Untersuchungsergebnis nicht zufallsbedingt ist, sondern ein systematischer Effekt vorliegt. In diesem Fall spricht man von einem statistisch signifikantenErgebnis.
Testverfahren

Statistischer Test
Mit statistischen Testverfahren kann man überprüfen,
ob sich die beobachteten Daten durch zufallsbedingte Abweichungen erklären lassen - weichen nur zufällig von Null ab - Nullhypothese (H0)
oder
ob die erhobenen Daten für die Vermutung, dass es einen wahren Effekt gibt, sprechen - Alternativhypothese (H1)
objektive und nachvollziehbare Entscheidung

Ein Spieler hat den Verdacht, dass ein Würfel nicht in Ordnung ist. Er würfelt 12mal und zählt die Anzahl der 6er.
Nullhypothese (Würfel ist ideal) H0 : p = 1/6Alternativhypothese (Würfel ist nicht ideal) H1 : p ≠ 1/6
Unter der Nullhypothese – Annahme der Würfel ist ideal –Berechnung der Wahrscheinlichkeit für das Auftreten der Augenzahl 6 bei 12 Würfen (Binomialverteilung)
Einführungsbeispiel

Einführungsbeispiel
kritischer BereichEntscheidung für die Alternativhypothese
0,990,03<0,01
5>5
AnnahmebereichEntscheidung für die
Nullhypothese
0,110,380,680,870,96
0,110,270,300,200,09
01234
P (X ≤ k)P (X = k)k
k: Anzahl gewürfelter 6er
P(X = k): Wahrscheinlichkeit für k gewürfelte 6er

Entscheidungsregel:Falls 0≤k≤4, wird die Nullhypothese nicht abgelehntFalls k>4, entscheidet man sich für die AlternativhypotheseEs wird angenommen, dass das Ergebnis nicht allein auf zufällige Abweichungen zurückgeführt werden kann
Anmerkung:Falls die Nullhypothese richtig ist, wird mit einer Wahrscheinlichkeit von 96% eine richtige Entscheidung getroffen.Das Risiko einer Fehlentscheidung beträgt 4%.
Einführungsbeispiel

Fehlentscheidungen beim Testen
Fehler 1. Art (Signifikanzniveau):
das unberechtigte Ablehnen der Nullhypothese
P (Fehler 1. Art) = α
Fehler 2. Art: das unberechtigte Beibehalten der Nullhypothese
P (Fehler 2. Art) = β

Fehler 1. Art (Produzentenrisiko):das unberechtigte Ablehnen der NullhypotheseP (Fehler 1. Art) = α
Fehler 2. Art (Konsumentenrisiko): das unberechtigte Beibehalten der NullhypotheseP (Fehler 2. Art) = β
Fehlentscheidungen beim Testen
WirklichkeitEntscheidung des
TestsH0 wahr
(HA falsch)H0 falsch(HA wahr)
H0 abgelehnt(HA angenommen)
Fehler 1. Art(α)
Richtige Entschei-dung (Power)
(1 - β)
H0 beibehalten(HA abgelehnt)
Richtige Entscheidung(1 - α)
Fehler 2. Art(β)

Der p-Wert gibt die Wahrscheinlichkeit an, die vorliegenden oder extremere Studienergebnisse zu beobachten, wenn die Nullhypothese zutrifft.
Ein Testergebnis heißt statistisch signifikant, wenn der p-Wert unterhalb des vorgegebenen Fehlers 1. Art α (meist 0,05) liegt (p ≤ α).
Signifikant bedeutet also im statistischen Sinne, dass das betreffende Ergebnis nicht durch den Zufall allein erklärbar ist, allerdings unter dem Vorbehalt des Fehlers 1. Art.
p - Wert, signifikantes Ergebnis

Erkennen eines bedeutsamen Effektesd.h. Wahrscheinlichkeit für korrektes Verwerfen der Nullhypothese
Geplante Studie: FallzahlberechnungEin Effekt vorgegebener Größe soll, wenn er vorhanden ist z.B. mit einer Wahrscheinlichkeit von 90% als signifikant durch den Test beurteilt werden
Power der Studie

Merke:Vorliegende Signifikanz heißt nicht klinische Relevanz: bei großen Stichprobenumfängen wird auch jeder irrelevante Effekt signifikant.
Fehlende Signifikanz heißt nicht: kein Effekt.Bei kleinen Stichprobenumfängen kann auch der Nachweis eines tatsächlich vorhandenen relevanten Effektes misslingen.Die Signifikanz drückt lediglich das Vertrauen aus, dass man darin haben kann, dass ein Effekt nicht vom Zufall vorgegaukelt wird.
Signifikanz

Testablauf:Formulierung der Hypothesen
Nullhypothese - Alternativhypothese
Wahl des Signifikanzniveaus (Irrtumswahrscheinlichkeit)
Wahl des TestverfahrensAnzahl der Stichproben, abhängige oder unabhängige Stichproben, parametrische oder nicht-parametrische Testverfahren
Ausführung des Tests und Entscheidung
Testen von Hypothesen - statistische Signifikanztests

Merkmalsart: quantitativ / qualitativ
Verteilungstyp: parametrisch (Normalverteilung)nicht-parametrisch
Anzahl der Stichproben: eine, zwei, mehrere
unabhängige oder abhängige (verbundene) Stichproben
!!! Testverfahren haben Voraussetzungen !!!
Auswahl der Testverfahren
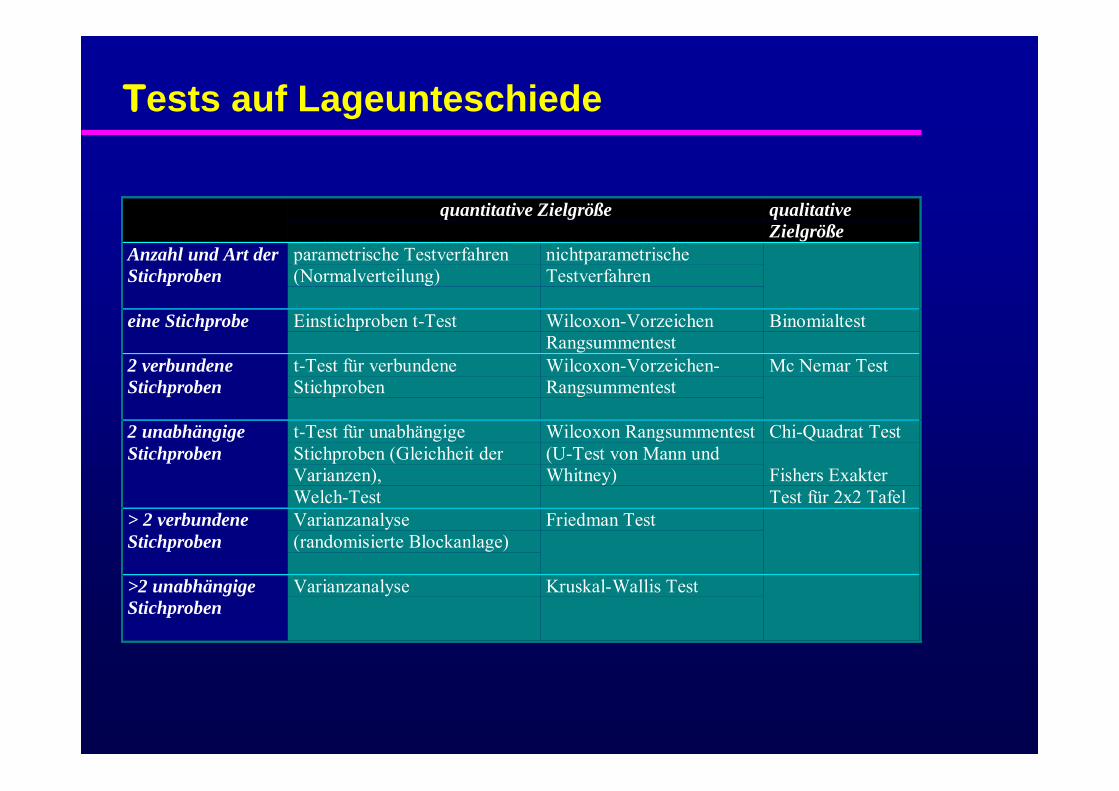
Tests auf Lageunteschiede
quantitative Zielgröße qualitativeZielgröße
Anzahl und Art derStichproben
parametrische Testverfahren(Normalverteilung)
nichtparametrischeTestverfahren
eine Stichprobe Einstichproben t-Test Wilcoxon-VorzeichenRangsummentest
Binomialtest
2 verbundeneStichproben
t-Test für verbundeneStichproben
Wilcoxon-Vorzeichen-Rangsummentest
Mc Nemar Test
2 unabhängigeStichproben
t-Test für unabhängigeStichproben (Gleichheit derVarianzen),Welch-Test
Wilcoxon Rangsummentest(U-Test von Mann undWhitney)
Chi-Quadrat Test
Fishers ExakterTest für 2x2 Tafel
> 2 verbundeneStichproben
Varianzanalyse(randomisierte Blockanlage)
Friedman Test
>2 unabhängigeStichproben
Varianzanalyse Kruskal-Wallis Test

t-Test für 2 unabhängige Stichproben:Hypothesen: H0: μ1 = μ2 H1: μ1 ≠ μ2
• Voraussetzungen:Die Beobachtungen der beiden Gruppen stammen aus unabhängigennormalverteilten Beobachtungen mit Mittelwerten µ1 und µ2 und die Standardabweichungen sind gleich σ1 = σ2, aber unbekannt.
SPSS Ausgabe (Menü Statistik, Mittelwerte vergleichen, Unabhängige-Stichproben T-Test)• Beschreibende Statistik der beiden Gruppen durch Anzahl, Mittelwert,
Standardabweichung, Standardfehler und Differenz der Mittelwerte• Test auf Gleichheit der Varianzen nach Levene H0: s1 = s2
• Ergebnis des t-Tests: Teststatistik, Freiheitsgrade, p-Wert, Konfidenzintervall
Tests auf Lageunteschiede